1. Introduction
The accelerated expansion of power system infrastructure has significantly increased the global demand for efficient power generation, transmission, and distribution. As a vital component in the power distribution network, the power transformer plays a critical role in maintaining the stability and security of the entire power system [
1]. Faults in transformers can result in severe equipment damage and, in extreme cases, may trigger cascading failures across the grid, posing significant risks to national economic stability. A major contributor to early transformer failure is the degradation of the insulating liquid. Studies have indicated that approximately 70–80% of transformer faults are incipient, highlighting the importance of early detection to prevent fault escalation. Timely diagnosis can mitigate fault progression and reduce the likelihood of grid-level failures. Accordingly, the development and implementation of advanced fault diagnosis technologies are essential for improving power system reliability [
2,
3]. Therefore, a range of diagnostic techniques has been developed to assess and monitor the operational condition of power transformers. Among various diagnostic techniques available, dissolved gas analysis (DGA) is one of the most established and widely adopted techniques for detecting incipient faults and assessing the operational status of power transformers [
3]. This technique involves detecting and monitoring the concentration of combustible and fault-related gases dissolved in the insulating liquid of transformers. These gases include hydrogen (H
2), methane (CH
4), ethylene (C
2H
4), ethane (C
2H
6), acetylene (C
2H
2), carbon monoxide (CO), and carbon dioxide (CO
2). Variation in these gas levels typically indicates the onset or progression of internal faults within the transformer [
2,
4]. Therefore, the type and the concentration of the dissolved gases are crucial in identifying and classifying specific types of faults. Gas chromatography is an analytical technique commonly used to separate and analyse these gases, relying on differences in their flow rates through a stationary phase [
3]. Based on this principle, several conventional diagnostic approaches have been developed, which are classified into three main categories. These categories are the key gas method, the gas generation rate method, and the gas ratio method [
2].
Conventional gas ratio techniques, such as the IEC ratio method (IRM), Rogers ratio method (RRM), Doernenburg ratio method (DRM), CIGRÉ method, and Duval triangle, have long been used in the industry for transformer fault diagnosis. However, despite their widespread adoption, these methods often suffer from limited diagnostic accuracy, particularly when multiple gases are involved or when the gas ratio falls near critical threshold boundaries. Also, the precision of fault analysis tends to decrease as the classification schemes become more granular, while overly broad classifications can obscure critical distinctions, thereby hindering effective fault identification. These challenges are exacerbated by the nonlinear behaviour of gas generated, which does not follow a simple relationship with transformer operating ageing indicators such as interfacial tension and acidity. Also, the imbalanced, insufficient, and overlapping state of gas-decomposed DGA datasets remains a significant limitation to the development and deployment of robust and accurate diagnostic approaches [
1,
5]. To address these challenges, machine learning (ML) has gained increasing attention for its ability to model complex, nonlinear relationships and generalize from historical DGA data. In many ML-based frameworks, conventional gas ratio schemes and graphical interpretations are used as input features, allowing the automated and data-driven classification of fault types [
1,
2]. A fault detection model based on the K-nearest neighbours (KNN) and decision tree (DT) was presented in [
6] using the New York Power Authority dataset. The model initially employs key gas methods to identify outliers, followed by the application of the basic gas ratio method for fault classification. The approach proposed achieved an accuracy of 88%, demonstrating its effectiveness in detecting transformer faults based on DGA data. The research in [
7] evaluates a hybrid diagnostic model that combines particle swarm optimization-tuned support vector machine (SVM) with the KNN framework. This model was integrated with the Duval Pentagon method to enhance transformer fault classification based on DGA. The proposed approach was tested against five distinct fault types detectable in insulating liquid and achieved a diagnostic accuracy of 88%. A diagnostic model was proposed in [
8] that integrated the SVM algorithm to assess the severity of transformer faults. This approach enhances traditional graphical analysis by incorporating gas concentration levels, gas generation rates, and standard DGA interpretation results into a unified diagnostic framework. The model demonstrated a diagnostic accuracy of 88%, indicating its effectiveness in providing a quantitative assessment of transformer fault conditions. In [
9], the authors proposed a hybrid fault diagnostic method based on the DGA dataset collected from the Agilent chemical laboratory. The approach integrates an SVM optimized using the Bat algorithm with Gaussian classifiers to enhance diagnostic performance. This coupled system aims to improve classification accuracy by combining the optimization capabilities of the Bat algorithm with the generalization strength of SVM and the probability modeling of Gaussian classifiers. The proposed model achieved a diagnostic accuracy of 93.75%, indicating a significant improvement over the conventional method.
In general, the recent systematic survey in [
1] revealed that the majority of research efforts on transformer fault classification using DGA predominantly employed ML algorithms such as SVM, Artificial Neural Network (ANN), and KNN, with usage rates of approximately 32%, 17%, and 12%, respectively. These algorithms demonstrated considerable effectiveness in identifying and classifying fault types based on gas concentration patterns, owing to their ability to model complex nonlinear relationships and generalize from limited datasets. However, each technique has inherent limitations. SVM often requires careful parameter tuning and may not scale efficiently with large datasets. ANN demands substantial computational resources and large volumes of labelled data for effective training, which may not always be available in practical cases. Similarly, the performance of KNN is highly sensitive to the choice of distance metric and the selection of the parameter
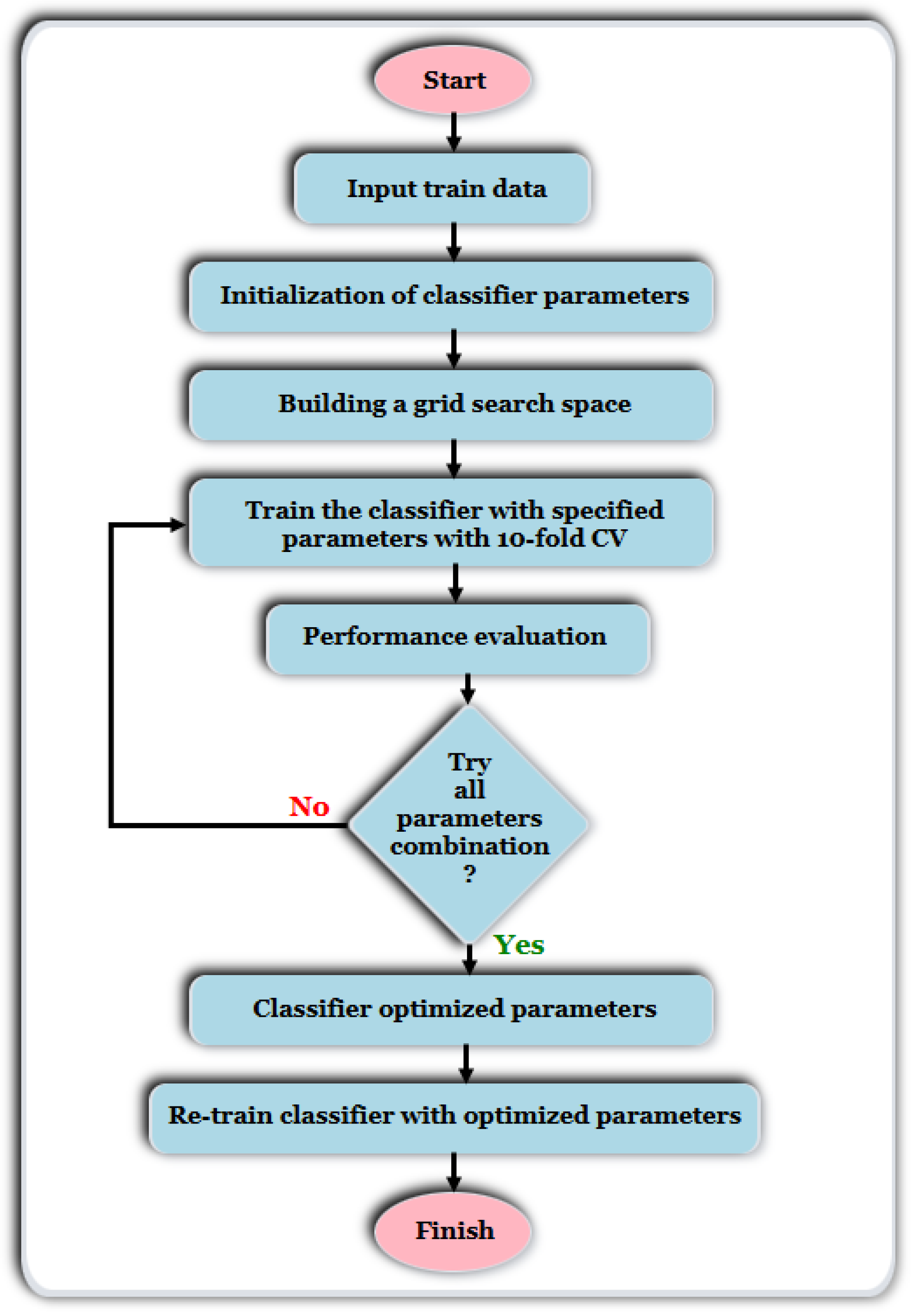
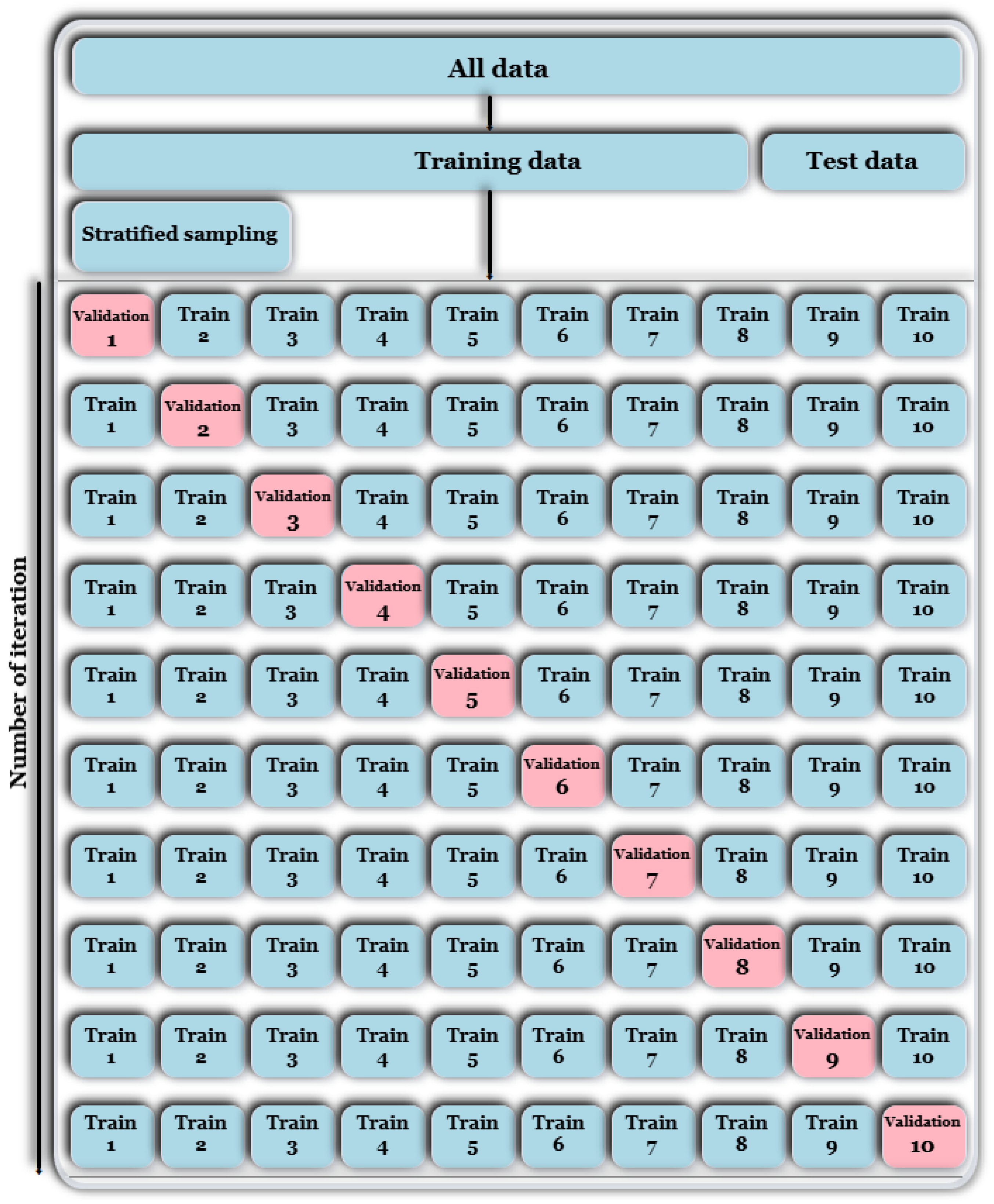
K. Also, its use can be computationally intensive during the prediction stage, as comparison with all training samples is required to determine the nearest neighbours. These drawbacks highlight the need for ongoing research into more advanced and efficient diagnostics frameworks. Therefore, beyond SVM and KNN, this study investigates the application of ensemble ML models across four widely accepted DGA diagnostic ratio schemes to enhance transformer fault classification performance. The performance of each model was evaluated using six key metrics to ensure a comprehensive assessment. In addition, to enhance the reliability and generalizability of the results, a 10-fold cross-validation strategy was employed with grid search optimization for hyperparameter tuning and optimal model selection. Comparative analysis was conducted to highlight the strengths and limitations of each model across different diagnostic schemes, providing valuable insights into their suitability for real-world deployment. Furthermore, key physicochemical and dielectric properties are incorporated to enable the more comprehensive interpretation of fault types beyond numerical classification. Therefore, this study not only compares model performance across different diagnostic schemes but also emphasizes the diagnostic significance of insulation liquid degradation trends and their correspondence with ML-based fault predictions.
2. Materials and Methodology
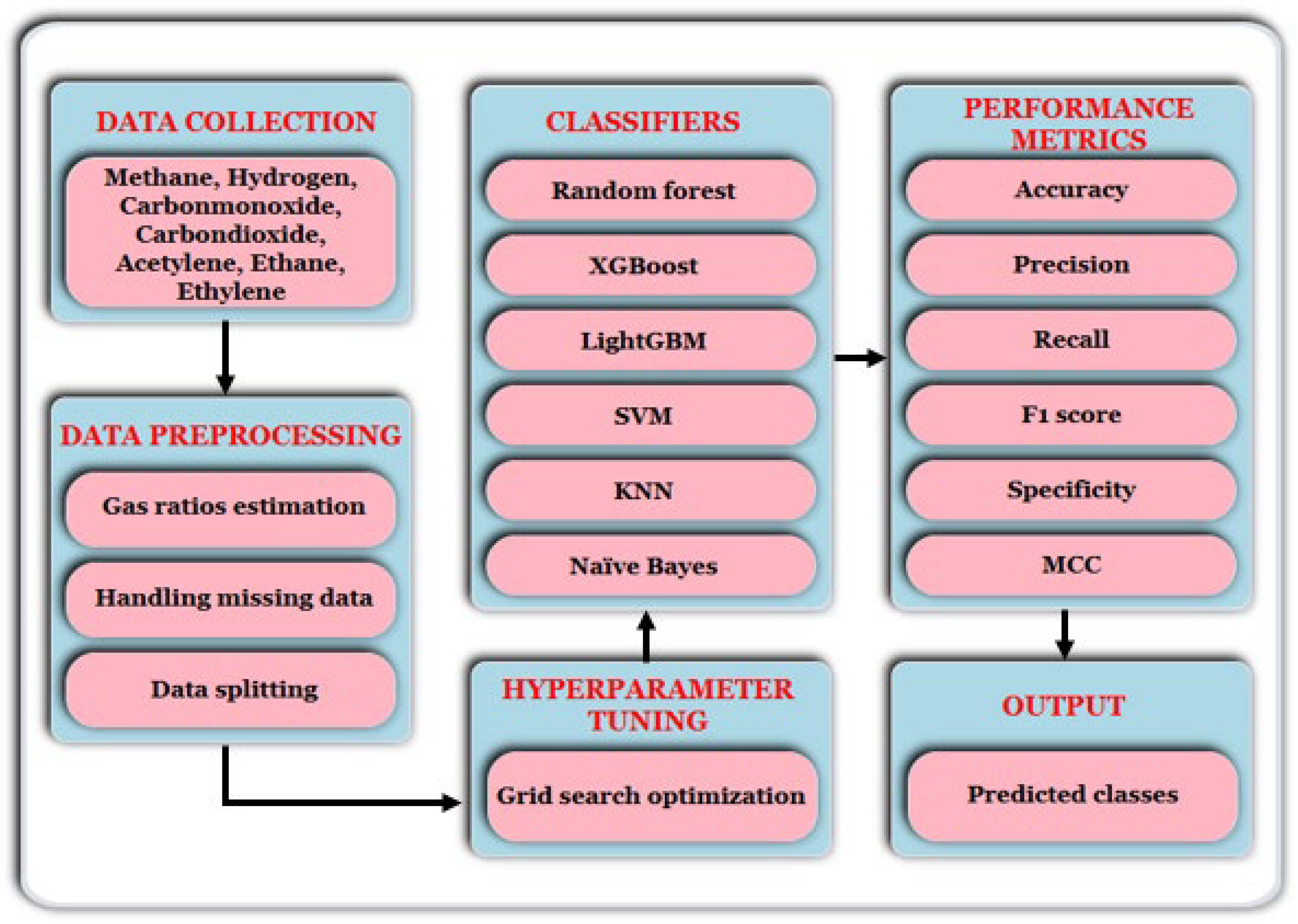
The DGA dataset employed in this study was collected from Rio Tinto, Saguenay, Canada, comprising 1702 records obtained between 2010 and 2024. The complete data entries were partitioned using an 80:20 train–test split, where 80% of the data was used for training and the remaining 20% was used for testing. This is a common and experimentally validated practice for ensuring robust model assessment. Simulations were conducted using six different ML models, and their performance was assessed based on standard evaluation metrics. Furthermore, to enable the ML models to process categorical output values, label encoding was applied to the multiclass target variable. This technique converts non-numerical forms of data by assigning each unique point a value between 0 and n_classes − 1, where n_classes represents the total number of distinct categories in the target variable. Also, the computational implementation was carried out on a system equipped with a Core i5 processor (1.8 GHz, 4 cores, 6 MB cache, 64-bit architecture, 8 GB RAM). It ran Windows 10 (64-bit) and utilized Python 3.9 libraries such as Scikit-learn, Pandas, NumPy, Matplotlib, and Seaborn.
Table 1 presents a sample of the DGA dataset, and a detailed flow diagram illustration of the methodology process is presented in
Figure 1.
In addition, a total of 50 power transformers, with some over 80 years old and originating from various manufacturers, were studied as part of a long-term condition monitoring initiative by the Canadian utility Rio Tinto. These transformers, rated between 13.8 kV and 173 kV, were originally installed and commissioned between 1930 and 2022. Over the years, insulating oil samples were periodically collected and analyzed to assess their electrical, chemical, and physical properties. This analysis, carried out from 1930 through to 2022, provides valuable insight into the ageing behaviour and operational condition of the service-aged transformer oils. The data include key physicochemical and dielectric parameters such as breakdown voltage (BDV), interfacial tension (IFT), acid value, moisture content, and CO2/CO ratio. For systematic analysis, the transformers were categorized into four voltage classes. The voltage classes are as follows: 13.8 kV with 11 units, 154 kV with 11 units, 161 kV with 22 units, and 173 kV with 6 units. The collected physicochemical and dielectric parameters data were subsequently compared with the diagnostic outputs of the best-performing ML classifier under each gas ratio scheme. This comparison is designed to systematically identify consistencies or discrepancies between the observed chemical degradation trends and fault types predicted by ML classifiers. Furthermore, this study presents practical insights gained from decades of operating ageing power equipment, with particular emphasis on units that have remained in continuous service for over 80 years.
2.1. Diagnostic Techniques
Several DGA interpretation methods have been developed to identify and classify faults in power transformers. Among the most widely employed are the ratio-based diagnostic methods, which analyse the relationship between specific dissolved gas concentrations to infer the presence and type of fault. In this study, four methods are considered, which are grounded in international standards and expert guidelines.
The Doernenburg ratio method (DRM) is based on the IEEE C57.104 standard and employs four key gas ratios to diagnose transformer faults. This method demonstrated the effectiveness of identifying various fault types, including thermal decomposition, partial discharge, and arcing, as illustrated in
Table 2 [
10,
11].
The Rogers ratio method (RRM), also derived from the IEEE C57.104 standard, relies on three specific gas ratios, as shown in
Table 3 [
10,
11]. These ratios were selected based on practical industry experience and their relevance in diagnosing common transformer fault scenarios. Unlike some diagnostic methods, RRM is applied when individual gas concentrations exceed prescribed thresholds and do not require predefined minimum limits for valid fault interpretation [
12].
The IEC ratio method (IRM) follows a similar approach to RRM as it utilizes three key gas ratios to diagnose transformer faults, as outlined in
Table 4 [
10,
11]. This method is particularly effective in identifying thermal faults across a range of temperature levels (300–700 °C), as well as four categories of electrical faults, which include normal ageing, partial discharges, and both low-energy and high-energy discharges [
12].
The CIGR
É method offers diagnostic criteria for interpreting DGA results based on expert knowledge and field experience. Unlike other methods, it employs five gas ratios to identify faults such as partial discharges, arcing, thermal faults, overheating in paper, and cellulosic degradation by electrical faults. The interpretation scheme for this method is presented in
Table 5 [
10,
11].
2.2. ML Frameworks
In this study, classical and ensemble machine learning algorithms were selected due to their proven accuracy, interpretability, and computational efficiency when applied to structured tabular data such as that derived from DGA. These models are well-suited for multiclass classification tasks, handle moderate-sized datasets effectively, and require neither extensive hardware nor a complex training procedure. Furthermore, ensemble models are more appropriate for deployment in practical, real-time fault detection systems given their speed, robustness, support for missing values, and ability to generate feature importance scores, thus aligning better with our goal of developing a high-performance, interpretable, and deployable diagnostic framework [
13].
2.2.1. Random Forest
Random forests (RFs), also known as random decision forests, are a robust ensemble learning technique that can be applied to both classification and regression tasks. They operate by constructing multiple independent decision trees during training, and for classification tasks, the final prediction is determined by aggregating the predictions of all the trees through majority voting. This approach effectively mitigates the overfitting commonly associated with single decision trees by introducing randomness in both feature selection and data sampling. Although random forests may not achieve the peak accuracy of more complex models like gradient boosting methods, they offer a strong balance of performance, interpretability, and efficiency. Due to their versatility and low pre-processing requirements, random forests are widely used in practice, often serving as reliable black box models that perform well across diverse datasets [
14]. In multiclass classification tasks, random forest evaluates all the classes simultaneously within each tree, rather than training separate trees for each class. The class prediction for a data sample is given by (1), and the model minimizes the objective function (2) during training:
where
denotes the predicted value,
is the actual value,
is the total number of decision trees, and
denotes the class predicted by the
-th tree.
2.2.2. XGBoost
Extreme gradient boosting (XGBoost) is a tree-based ML algorithm that has recently gained significant popularity for classification tasks due to its high effectiveness and scalability [
15]. It is an end-to-end gradient boosting framework designed to efficiently handle both classification and regression problems. The model is chosen for its numerous advantages, including the ability to learn from previous errors, fine-tune a wide range of hyperparameters, handle imbalanced datasets, and process missing values. As a boosting algorithm, XGBoost builds an ensemble of weak learners sequentially, with each new tree aiming to correct the errors of the previous ones. As a result, it enhances prediction accuracy by optimizing the gain from prior predictions. In multiclass classification tasks, XGBoost enhances decision-making by minimizing the log-loss function for each class, as defined in (3):
where
indicates whether the
-th instance belongs to class
, and
is the predicted probability of that instance belonging to class
.
2.2.3. LightGBM
The light gradient boosting machine (LightGBM) is an advanced gradient-boosting decision tree framework that supports parallel training, offering significant advantages in terms of computational speed, model stability, and low memory usage. It can efficiently handle large-scale and high-dimensional datasets. Unlike traditional gradient boosting methods, LightGBM is built on a histogram-based algorithm, which improves training speed and reduces memory consumption by grouping continuous feature values into discrete bins [
16]. In general, the key features of LightGBM include depth-constrained leaf-wise tree growth for improved accuracy, one-sided gradient sampling to reduce data complexity and accelerate training, and support for parallel and GPU-accelerated learning. Furthermore, the objective function in LightGBM combines the loss function, a regularization term, and an additional constant component, as shown in (4). The loss function is minimized iteratively by adjusting the weights of the training instances, allowing each subsequent tree to focus on the instances that were misclassified by the previous tree [
17].
where
is the loss function;
is the regularization term, penalizing model complexity; and
is a constant term.
2.2.4. SVM
Support vector machines (SVMs) are sparse, kernel-based classifiers that construct decision boundaries using only a subset of the training data, known as support vectors, which define the margins of the separating hyperplane. They operate based on the structural risk minimization principle to find the best hyperplane for separating two classes in the input space [
18]. Although the entire training set must be available during model fitting, only support vectors are retained for prediction, thereby reducing the computational complexity and storage requirements. The number of support vectors is data-dependent and reflects the underlying complexity of the dataset. SVMs solve a convex optimization problem regularized by a margin maximization constraint, which promotes better generalization by positioning the decision boundary at the maximum possible distance from the closest training samples of each class. For nonlinearly separable data, SVMs employ the kernel trick to project the input data into a higher-dimensional feature space, where a linear separator can effectively discriminate between classes. The choice of kernel function and its parameters is therefore critical to model performance as the effectiveness of SVM principally depends on the size and density of the kernel [
2,
19]. SVM determines the optimal hyperplane for class separation using (5).
where
is the output of the SVM decision function
is the weight vector that determines the orientation of the hyperplane,
is the input feature vector, and
is the bias term that adjusts the hyperplane (decision boundary) [
20].
2.2.5. KNN
K-nearest neighbour (KNN) is a versatile, non-parametric algorithm applicable to both classification and regression tasks [
15]. Unlike other conventional machine learning techniques that require training to build a predictive model, KNN operates in a model-free fashion. It makes a decision solely based on the relationships between data points. When a new data point needs to be classified, KNN calculates its distance to all existing samples in the training dataset. Based on these computations, it determines the k-nearest data points, those that exhibit the greatest similarity to the test instance, based on a chosen distance metric. The class label assigned to the test sample corresponds to the majority class among these
k-nearest neighbours. The algorithm’s performance principally depends on two factors, which are the value of
k and the distance metric. The value of k is typically selected through empirical testing. A small k can lead to overfitting, making the model too sensitive to noise in the data, while a large
k results in underfitting by smoothing out important local patterns and blurring class distinctions. The distance metric determines how similarity is quantified between data points. While several metrics, such as Euclidean, Minkowski, Manhattan, and Chebyshev, exist [
21], Euclidean is selected in this study. The Euclidean distance
between two samples
and
is computed as follows:
where
n is the number of features, and
and
represent the
-th feature values of the
-th and
-th data points, respectively [
20].
2.2.6. Naïve Bayes
The Naïve Bayes algorithm operates by calculating the probabilities of events occurring within a dataset to support decision-making [
3]. It evaluates the likelihood of each target attribute value in a data sample and classifies the sample, establishing the class with the highest probabilities. Furthermore, the algorithm assumes that all the features contribute equally and independently to the classification decision. While this assumption enhances computational efficiency, it can make Naïve Bayes less suitable for real-world problems where feature interdependencies exist [
22]. In addition, the Gaussian-type Naïve Bayes classifier, which minimizes variation within attributes, was employed in this study using the sklearn model modules.
5. Interdenpendence Analysis of Insulation Properties in Field Transformers
Comprehensive diagnostic analysis was conducted on 50 in-service transformers to investigate the interrelationship among their physicochemical and dielectric properties and to identify trends correlated with dissolved gas analysis. Furthermore, the RF classifier, identified as the top-performing classifier across all the diagnostic schemes, was employed to classify the transformer conditions and predict DGA-related outcomes based on observed parameter relationships.
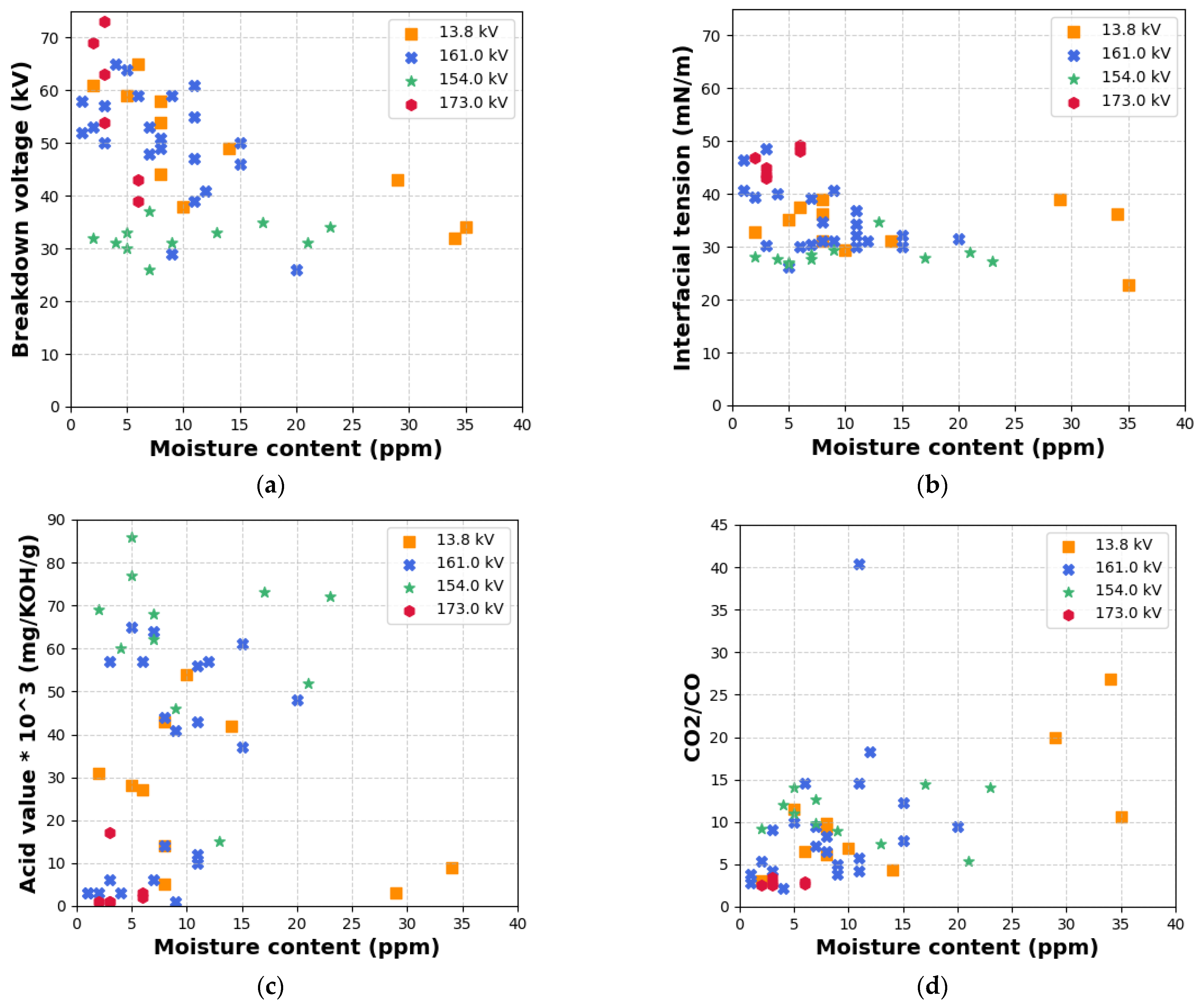
Figure 13a illustrates a consistently negative correlation between moisture content and BDV across all voltage classes. As moisture content increases, BDV values decrease correspondingly. This finding is consistent with the literature, which attributes dielectric strength deterioration to microbubble formation and explains that enhanced ionization is facilitated by elevated moisture levels under electric field stress [
26]. Furthermore, high-voltage units (particularly 154 kV and 161 kV) exhibited greater susceptibility to moisture-induced degradation compared to medium-voltage (13.8 kV) units. In
Figure 13b, a distinct inverse relationship between moisture content and IFT is observed. Higher moisture levels are associated with reduced IFT, which confirms the catalytic role of water in initiating hydrolysis and oxidation reactions. These reactions generate polar degradation products, the dissolution of which in the insulating liquid leads to a reduction in IFT.
Figure 13c reveals the positive correlation between moisture content and acidity, particularly within the 5–20 ppm moisture range. This indicates that the insulation of liquid acidity is predominantly governed by hydrolysis mechanisms, in which water functions as both a reactant and a catalyst, accelerating acid formation. A weak and scattered negative trend is evident in
Figure 13d, where the CO
2/CO ratio marginally decreases with increasing moisture content. This ratio is a known indicator of cellulose insulation degradation. The weak correlation implies that moisture alone does not directly influence this ratio, highlighting the role of other contributory factors such as thermal stress, oxidative degradation, and ageing duration in cellulose pyrolysis. As shown in
Figure 13e, there is a strong inverse relationship between acid value and BDV, indicating that increased acidity in the insulating fluid serves as a strong marker for declining dielectric strength and impending insulation failure.
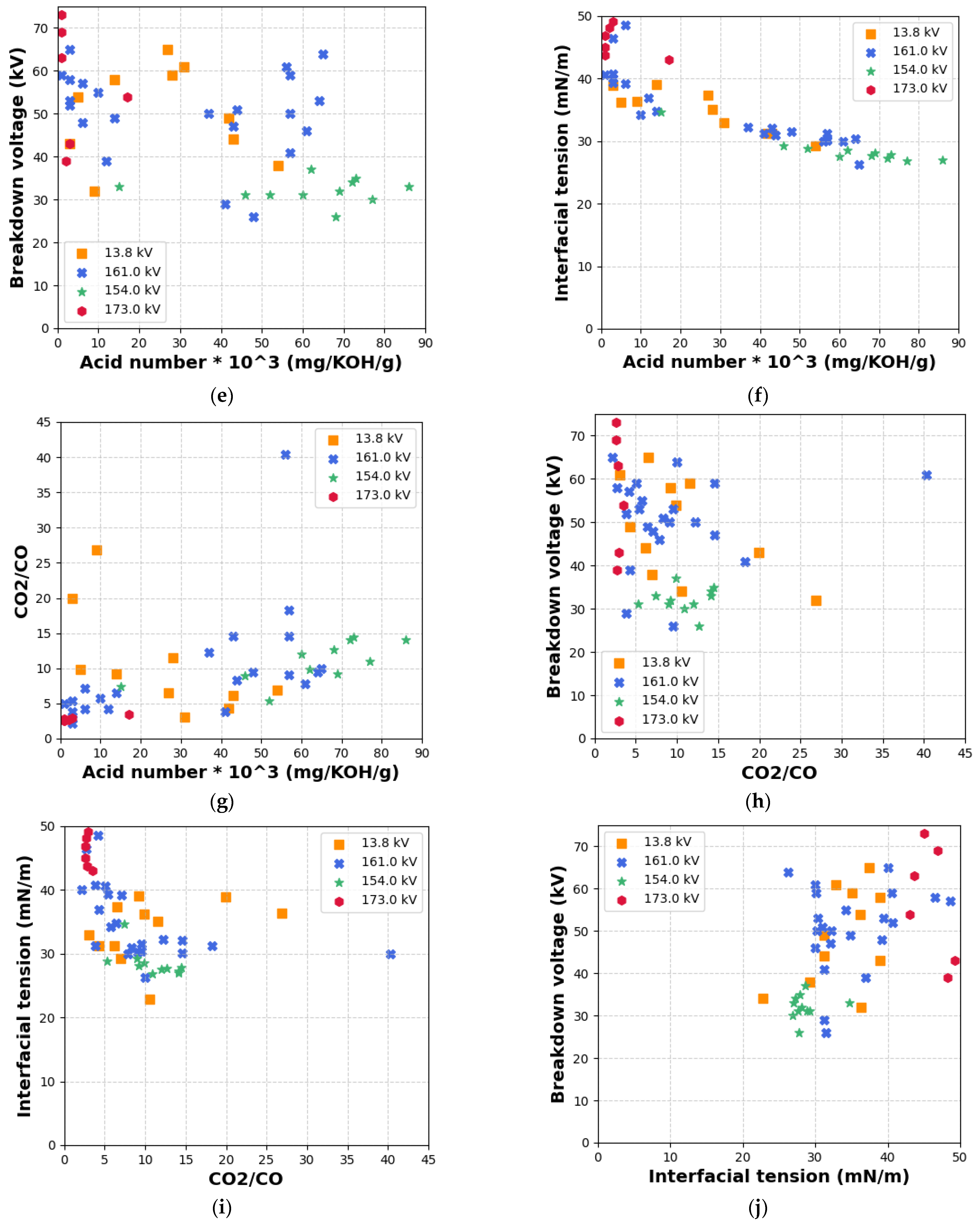
Similarly,
Figure 13f demonstrates the existence of a negative correlation between acid value and IFT. The reduction in IFT with increasing acid content supports the role of oxidation byproducts, particularly organic acids, in diminishing the surface activity of the insulating liquid. This reinforces the acid value and IFT as coupled indicators for transformer condition assessment. In
Figure 13g, a moderate positive correlation is observed between acid value and the CO
2/CO ratio. This relationship suggests that oxidative ageing, as reflected by elevated acid values, often coincides with cellulose decomposition, which releases CO and CO
2 gases [
27]. Nonetheless, the scattered distribution of data points indicates that the relationship is not perfectly synchronous, and that parallel degradation processes may also influence gas evolution.
Figure 13h presents the weak inverse correlation between BDV and the CO
2/CO ratio, suggesting that while gas ratios provide insight into paper insulation degradation, BDV is more directly affected by moisture and acidity than gas composition alone. In
Figure 13i, a negative trend is noted between the CO
2/CO ratio and IFT, implying that increased gas evolution due to cellulose ageing corresponds to a decline in IFT. This observation further supports the coupling of gas evolution indicators with surface-active degradation parameters [
28,
29]. Finally,
Figure 13j shows the strong positive relationship between IFT and BDV, where higher IFT values align with higher BDV values. This correlation confirms that reduced IFT is indicative of surface-active contaminants in the insulating fluid, which impair dielectric performance.
Furthermore, the comprehensive integration of transformer fault classification schemes employed in this study, emphasizing key physicochemical and dielectric properties, offers a multi-dimensional perspective on insulation health. Evaluation using an RF classifier underscores both congruence and divergence among diagnostic outcomes. Notably, 90% of the units satisfied the BDV threshold, and 98% fell within acceptable moisture content limits, indicating robust dielectric strength and moisture control in the majority of units. However, IFT emerged as a critical indicator of insulating liquid degradation, with only 26% of units maintaining values above the standard 40 mN/m benchmark. In addition, this chemical degradation is corroborated by the high incidence of thermal faults predicted by the RF classifier under the CIGRÉ diagnostic scheme, which classified 93.18% of the transformers as thermally stressed. In comparison, RRM and IRM identified thermal faults in 28.6% and 27.9% of units, respectively, offering more stratified fault gradation. While DRM categorized 66.67% of units as normal and 33.33% as thermally decomposed, its classification components lack the granularity necessary for nuanced diagnostic interpretation. Conversely, the tiered temperature-based classification in RRM and IRM provided enhanced alignment with the physicochemical deterioration observed, notably in terms of IFT and acid value. Further substantiating these insights is the CO2/CO ratio, a proxy for paper degradation severity. Only 58% of the samples exhibited values within the recommended range of 3–10, implying a combination of early-stage and long-term cellulose deterioration across the units. The elevated CO2/CO ratios observed in a subset of units are consistent with the thermal stress signals flagged by the CIGRÉ method, reinforcing its diagnostic sensitivity. Collectively, these results suggest that although the dielectric strength of most transformers remains functionally stable, there are pervasive chemical indicators of incipient or latent thermal degradation. The complementary roles of advanced classification schemes and physicochemical markers provide critical early-warning capabilities. In particular, CIGRÉ’s aggressive fault detection profile mirrors the widespread suboptimal IFT results, highlighting its utility in proactive insulation health monitoring.
In general, the results across all 13 figures demonstrate that moisture content exhibits a strong inverse relationship with both BDV and IFT, with this degradation trend being most pronounced in the 173 kV and 161 kV transformers. In these higher-voltage units, moisture levels exceeding 15 ppm consistently correspond to a marked decrease in BDV and IFT. Although a similar downward trend is observed in the 138 kV and 154 kV transformers, the decline in BDV and IFT with increasing moisture content is comparatively less severe, reflecting greater insulation stability at a lower voltage stress. As moisture content increases, both the acid number and the CO2/CO ratio increase across all voltage levels, with the most elevated values recorded in the 173 kV and 161 kV units, suggesting that both insulating liquid oxidation and cellulose degradation are accelerated under high-voltage operating conditions. The relationship between acid number and BDV reveals a consistent decrease in dielectric strength as acidity increases. This is again more significant in the 173 kV and 161 kV transformers, which confirms that acidic byproducts degrade insulating liquids more rapidly under elevated electrical and thermal stress conditions. Similarly, IFT decreases with the increasing acid number, with the steepest decrease evident in 173 kV systems. A clear positive correlation is also observed between acid number and the CO2/CO ratio, particularly in the 161 kV and 173 kV units, further supporting the interdependence of chemical ageing processes. As the CO2/CO ratio increases, both BDV and IFT continue to decrease, with the most severe degradation again seen in the 173 kV transformers. Finally, IFT shows a strong positive correlation with BDV across all voltage classes, though this relationship is especially critical in the 173 kV and 161 kV units, where decreases in IFT are closely aligned with dielectric failure. These results suggest that insulation-ageing mechanisms, driven by moisture ingress, acid formation, and paper decomposition, are highly voltage-dependent, with the 173 kV transformers exhibiting the most advanced stages of deterioration.
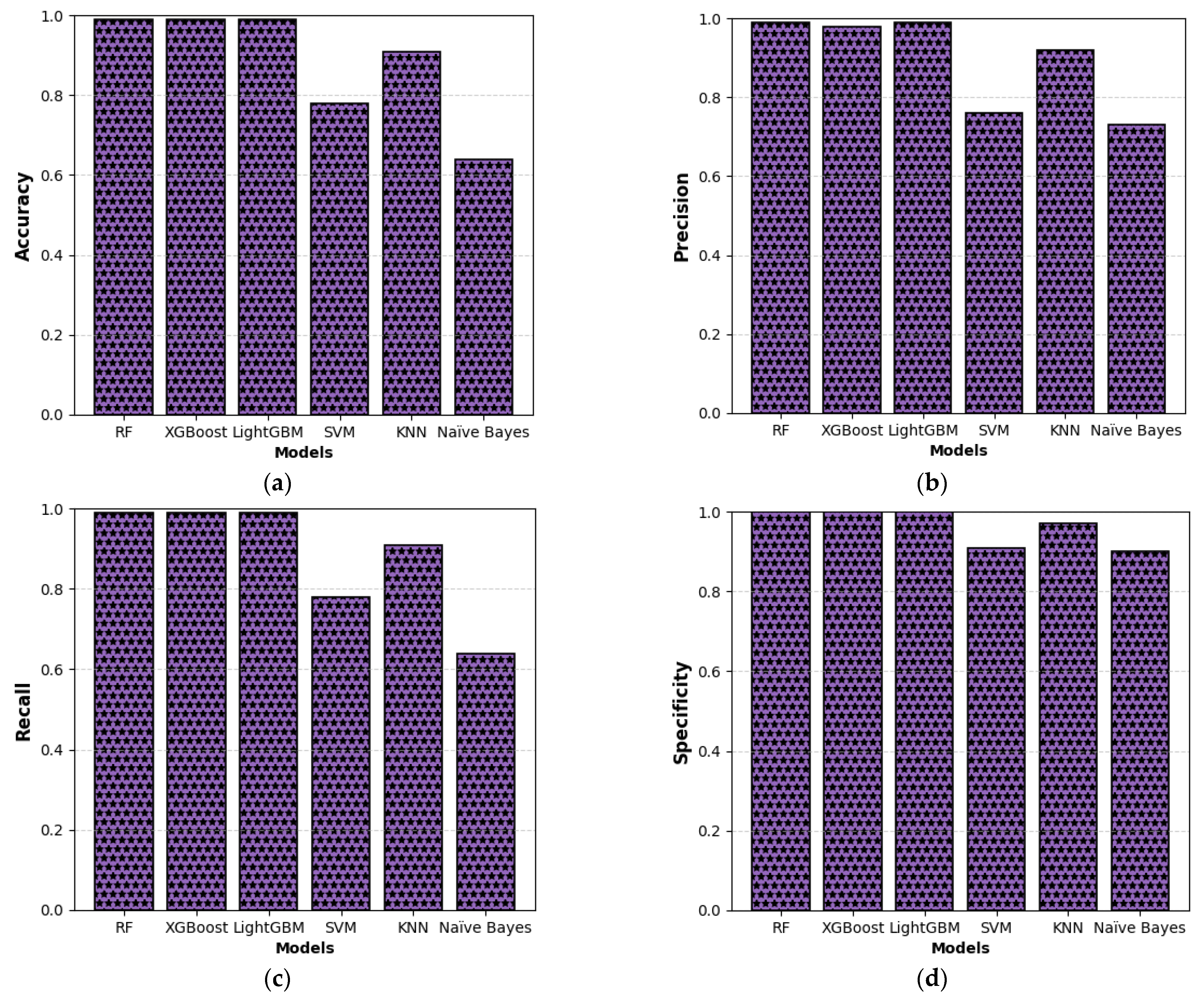
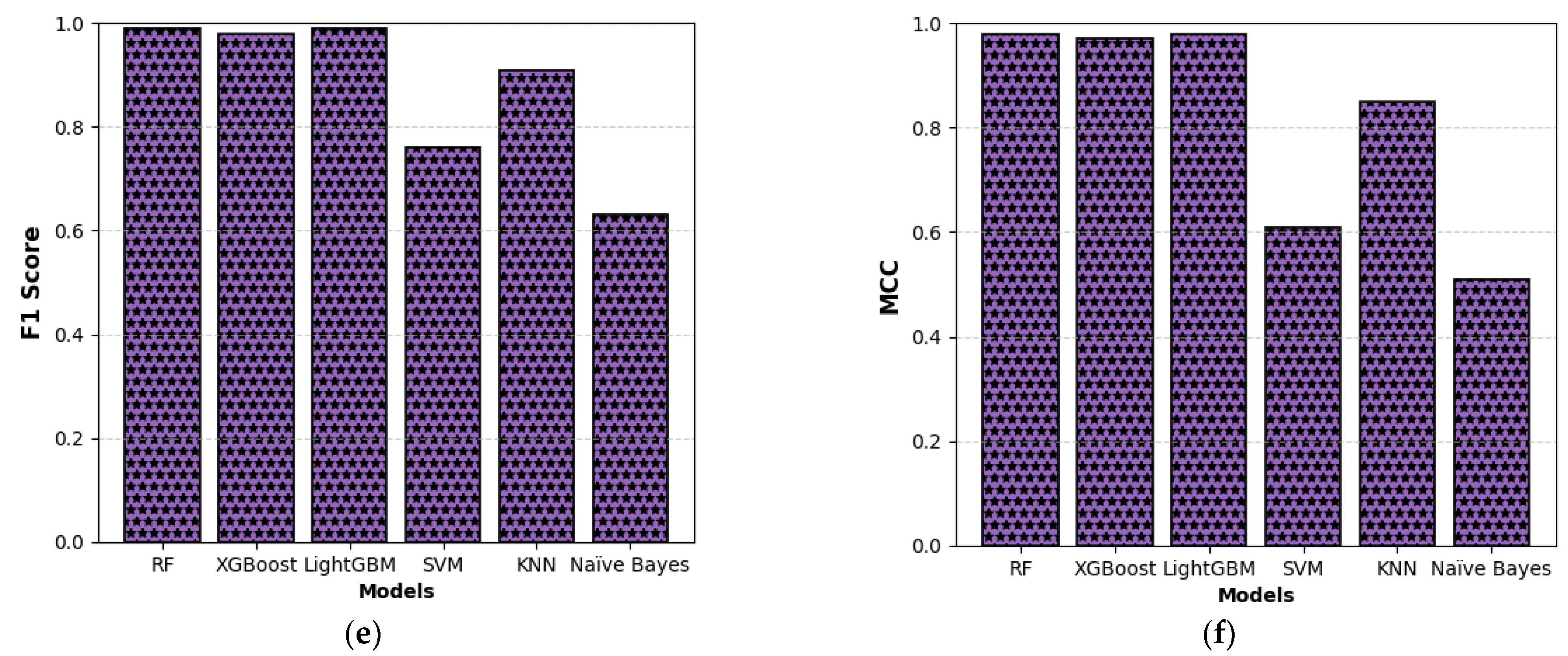
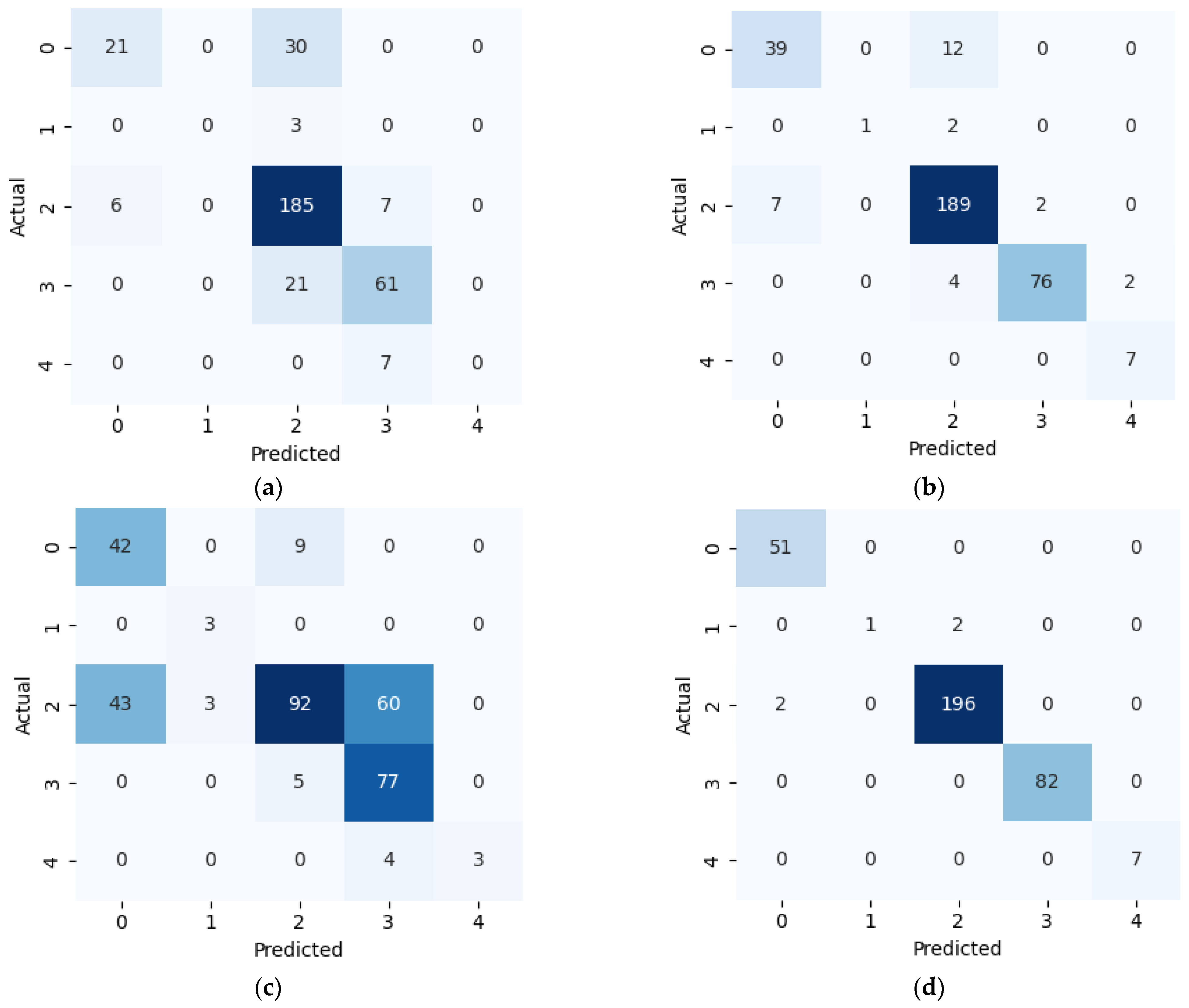
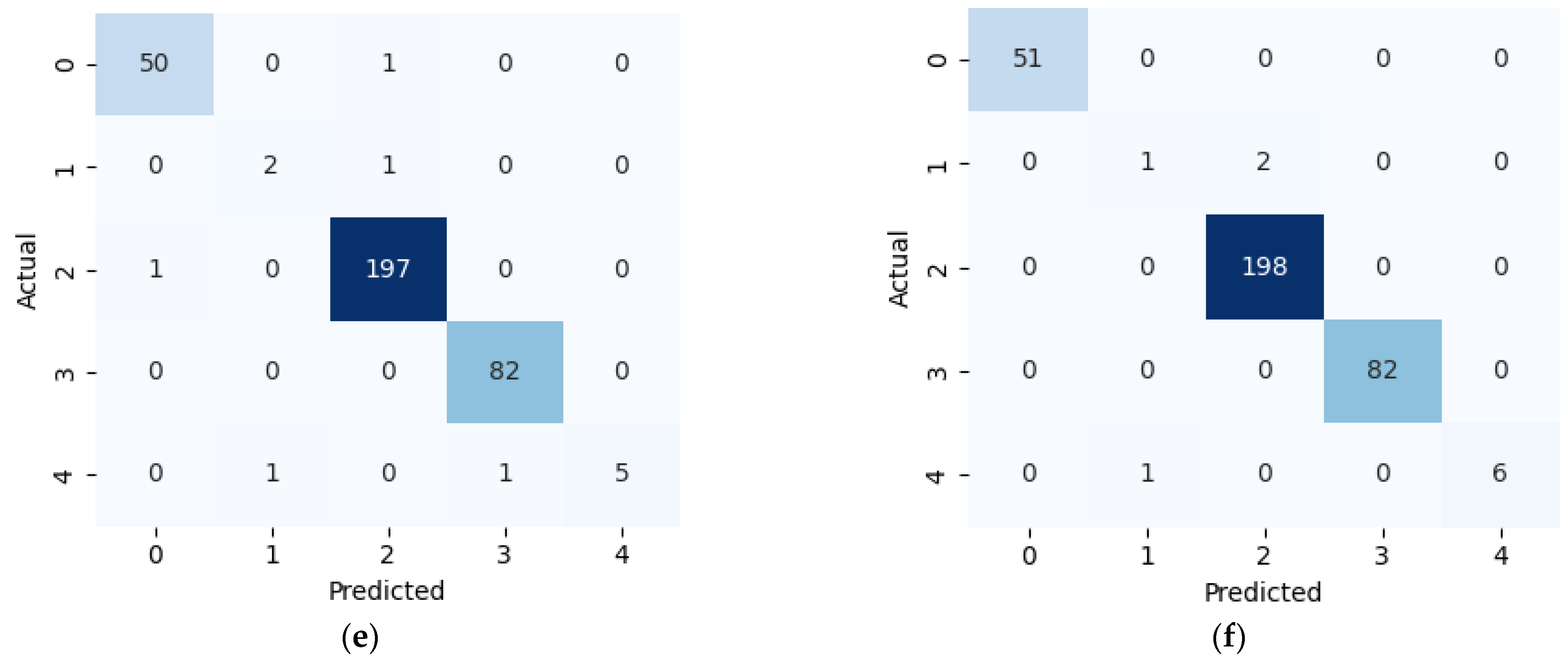
6. Conclusions
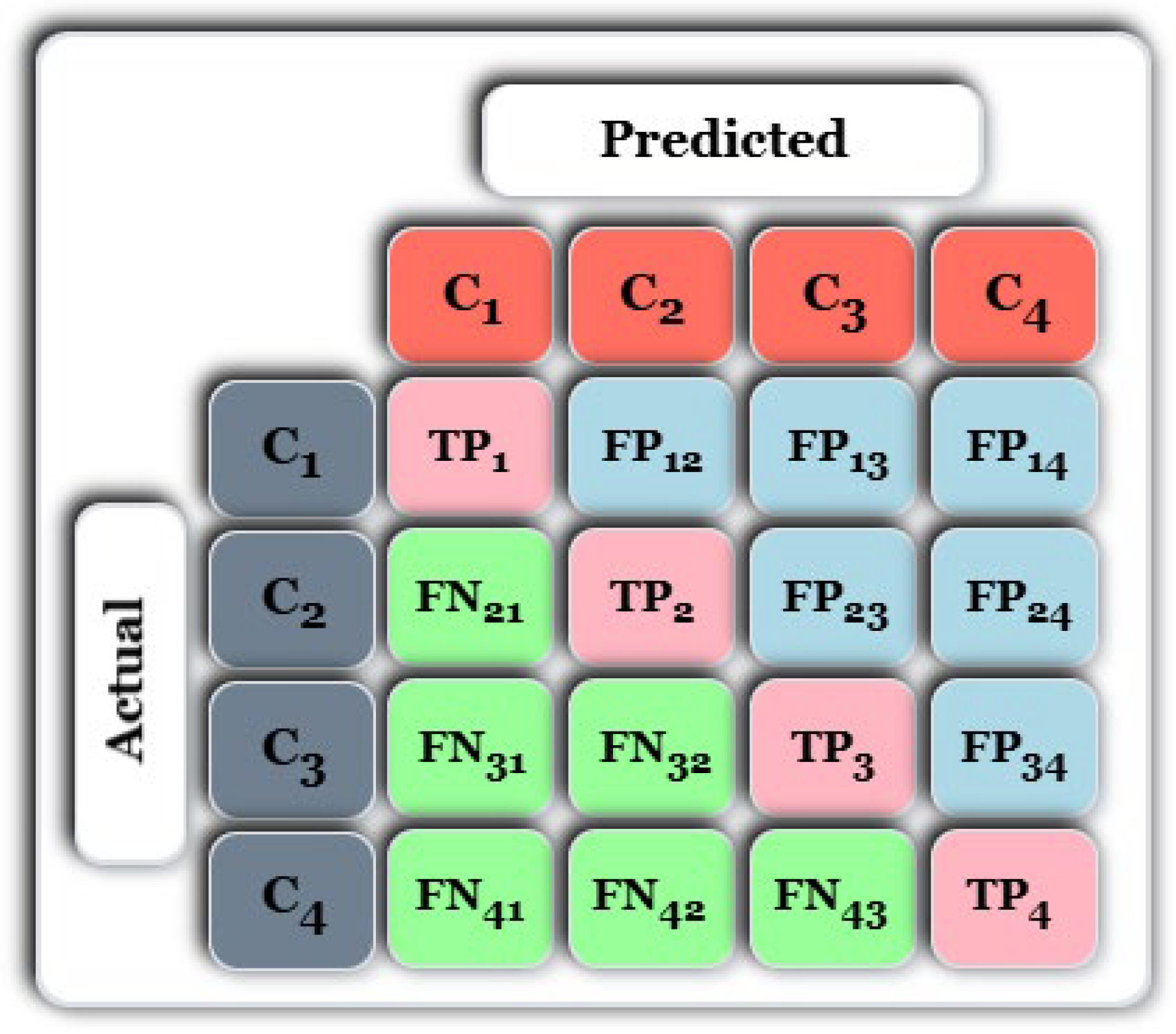
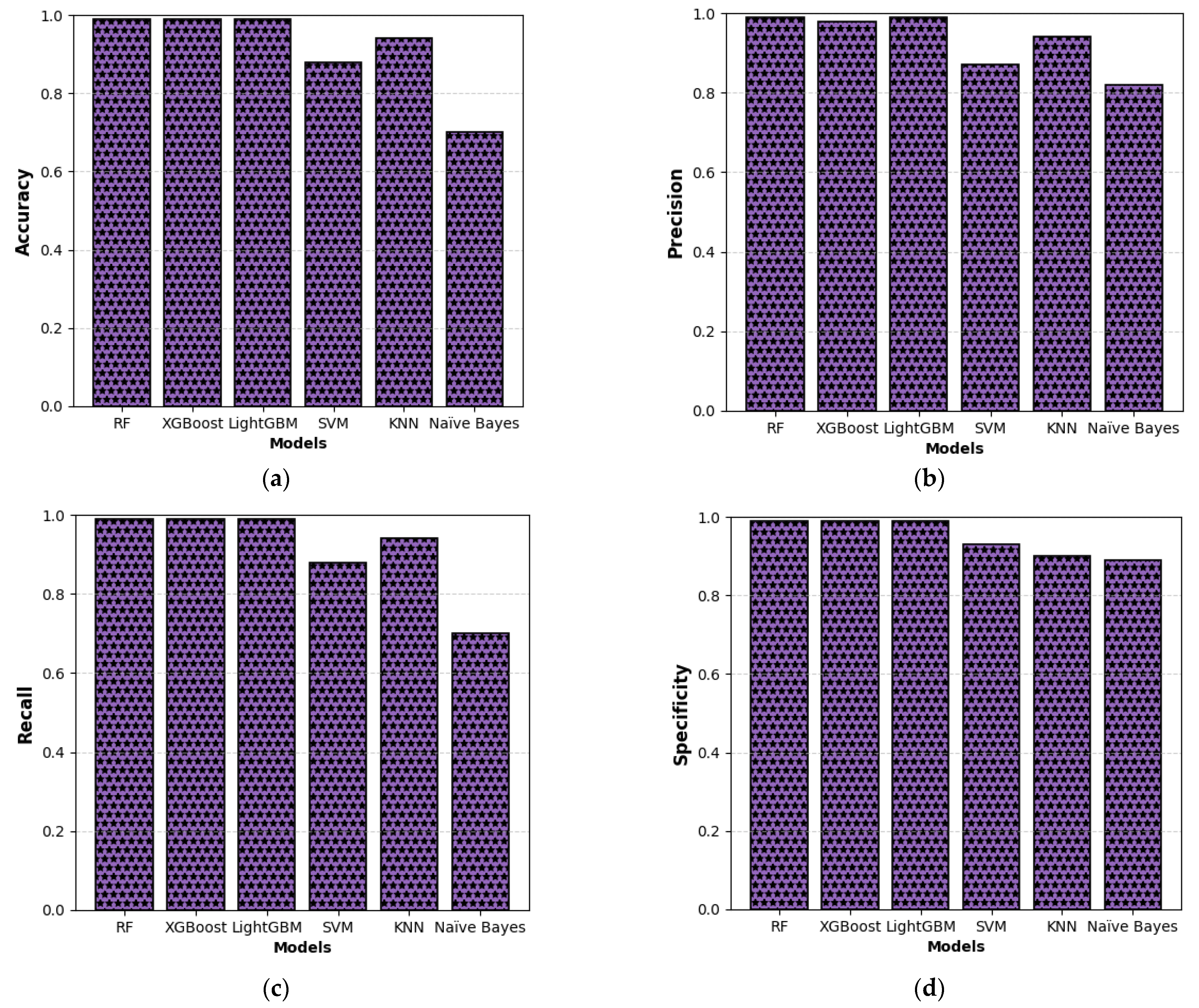
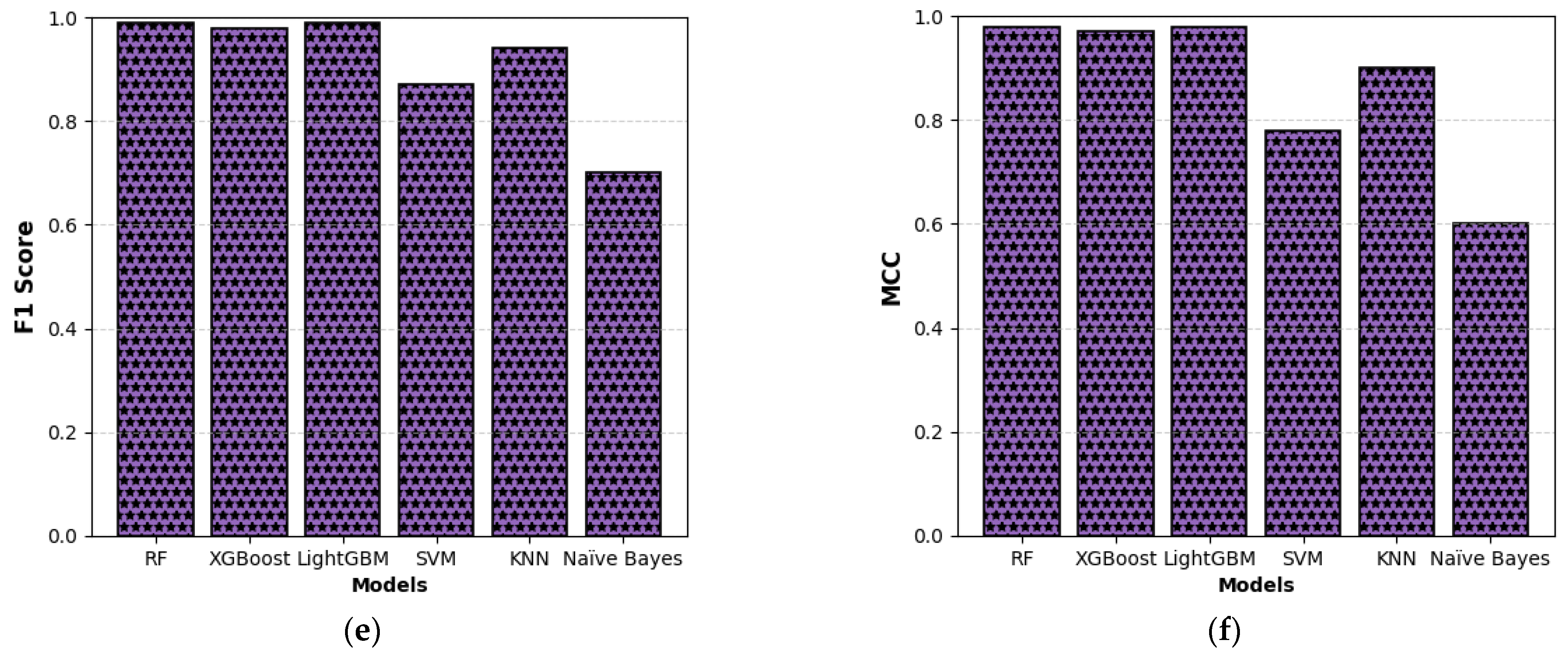
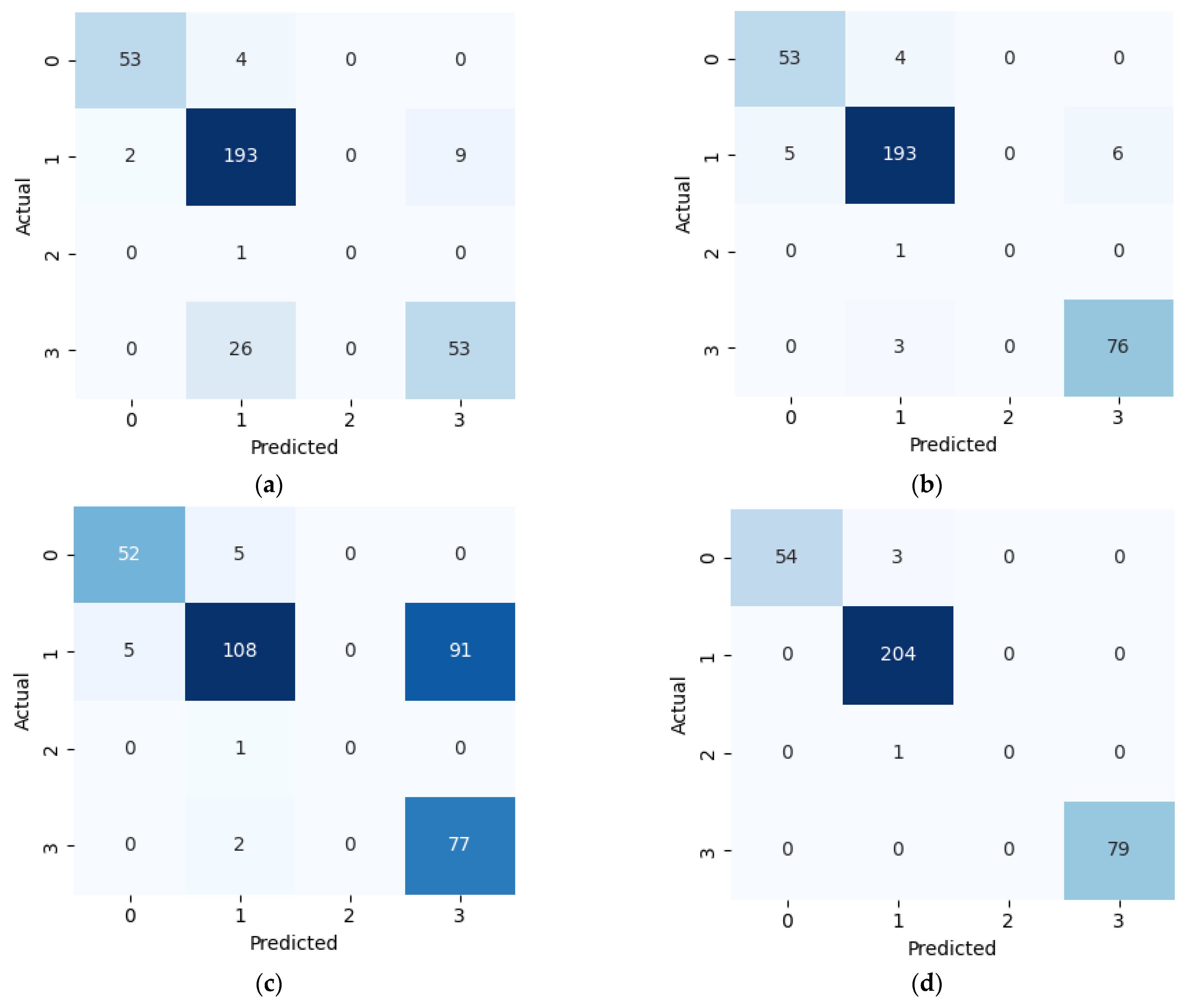
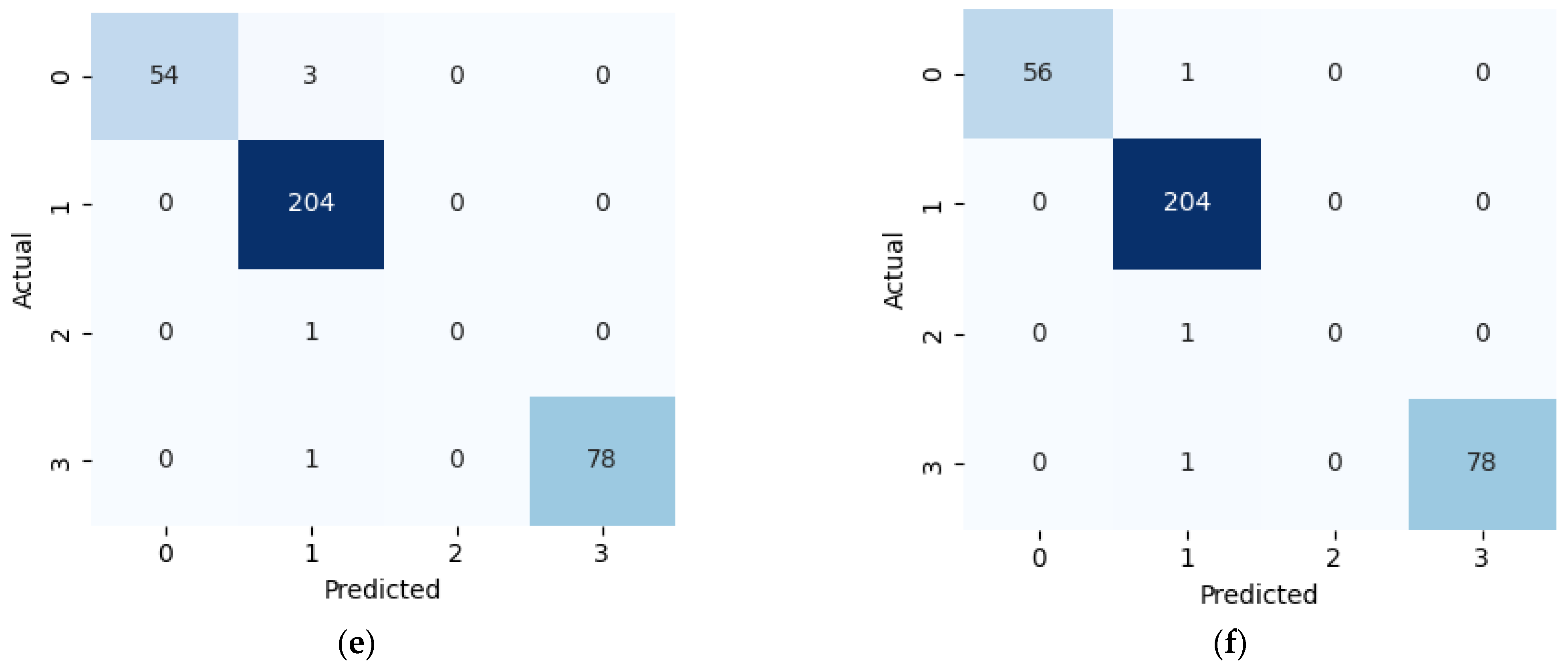
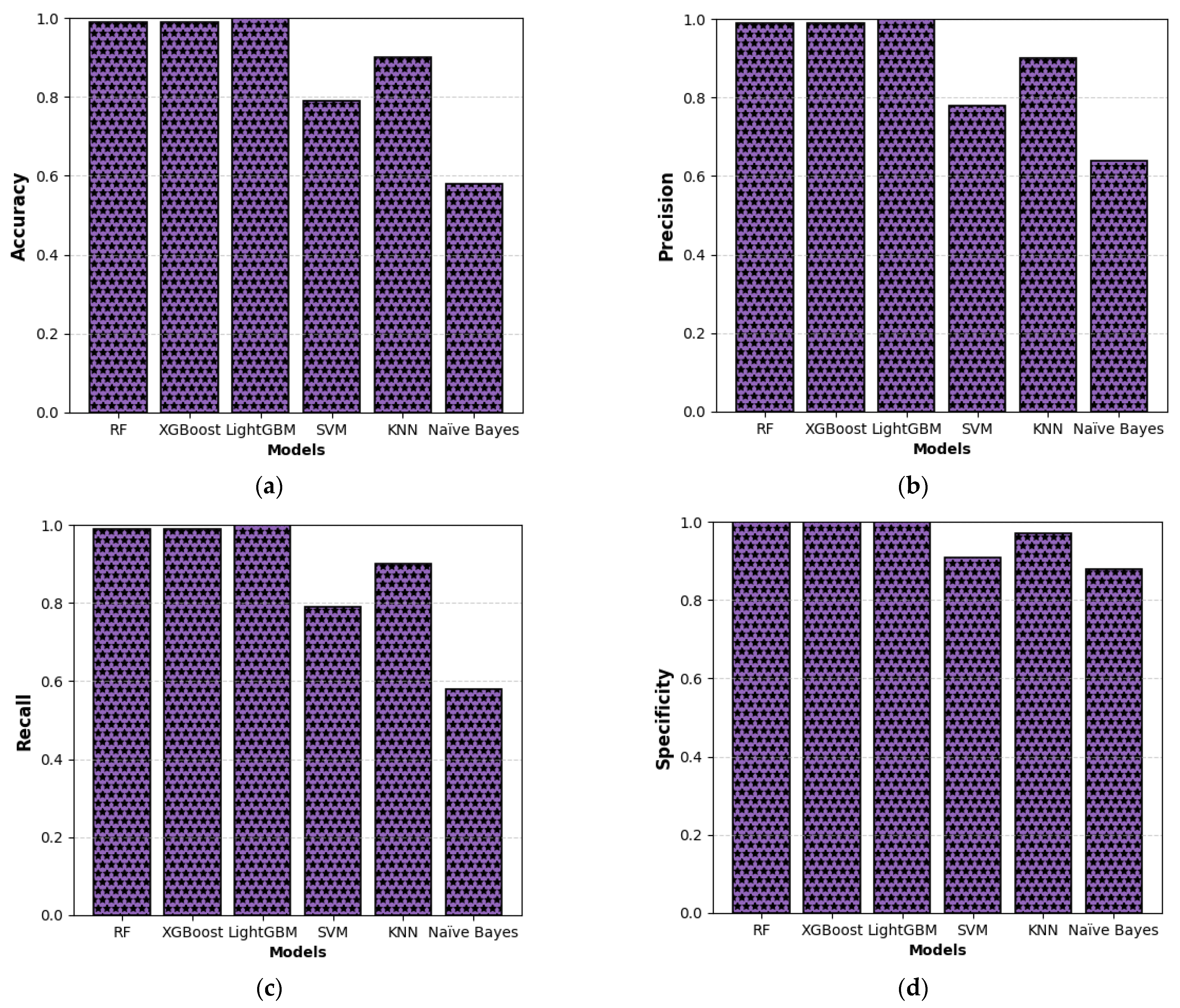
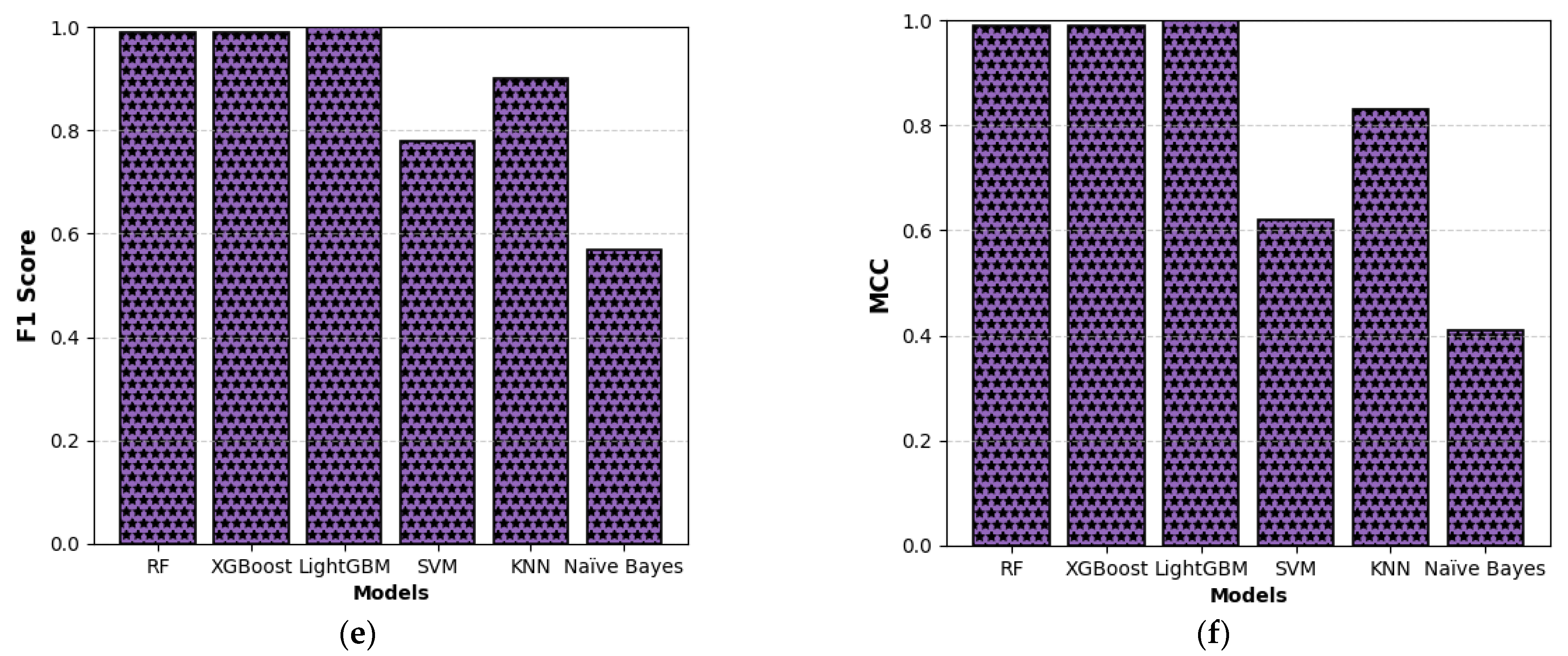
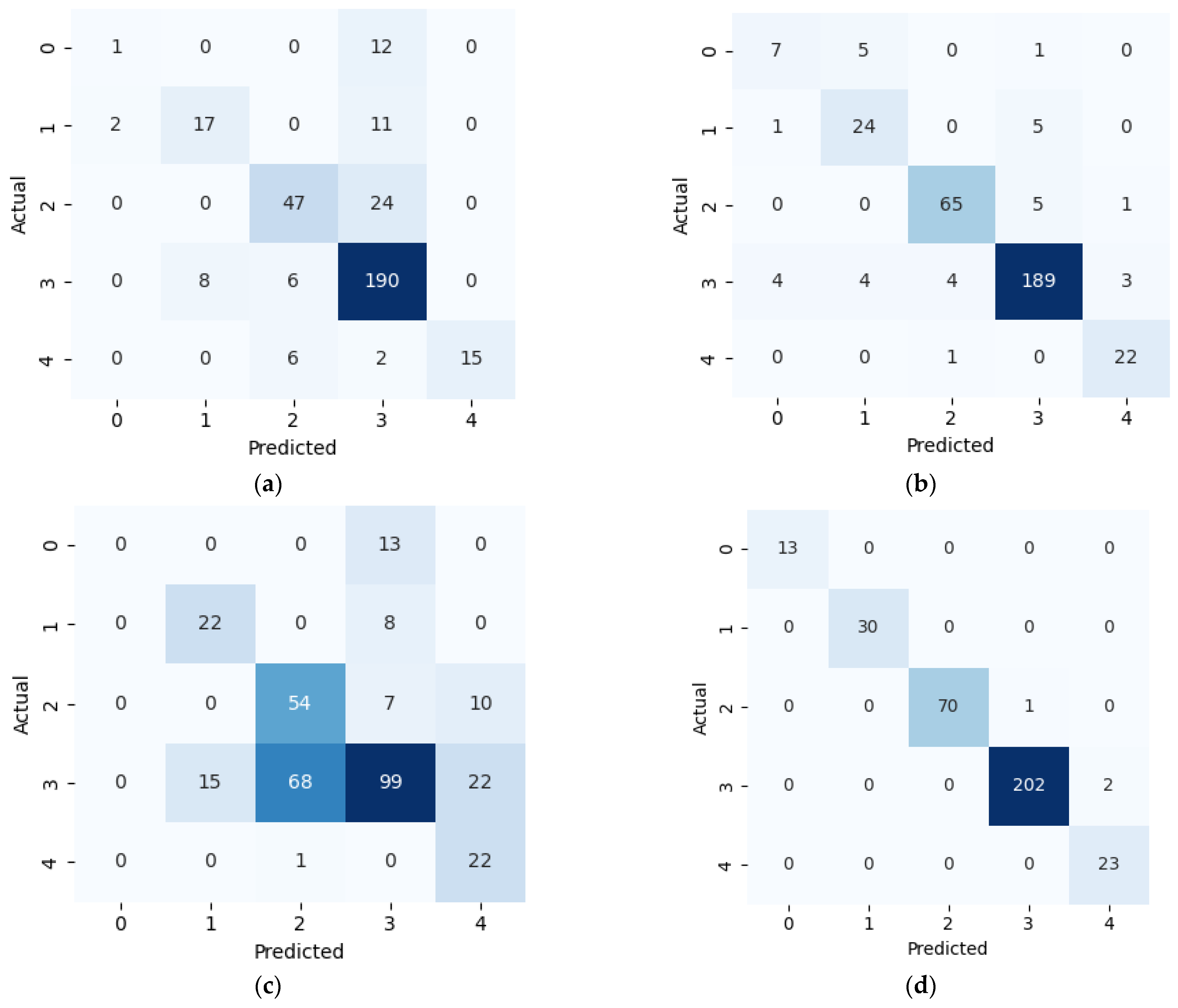
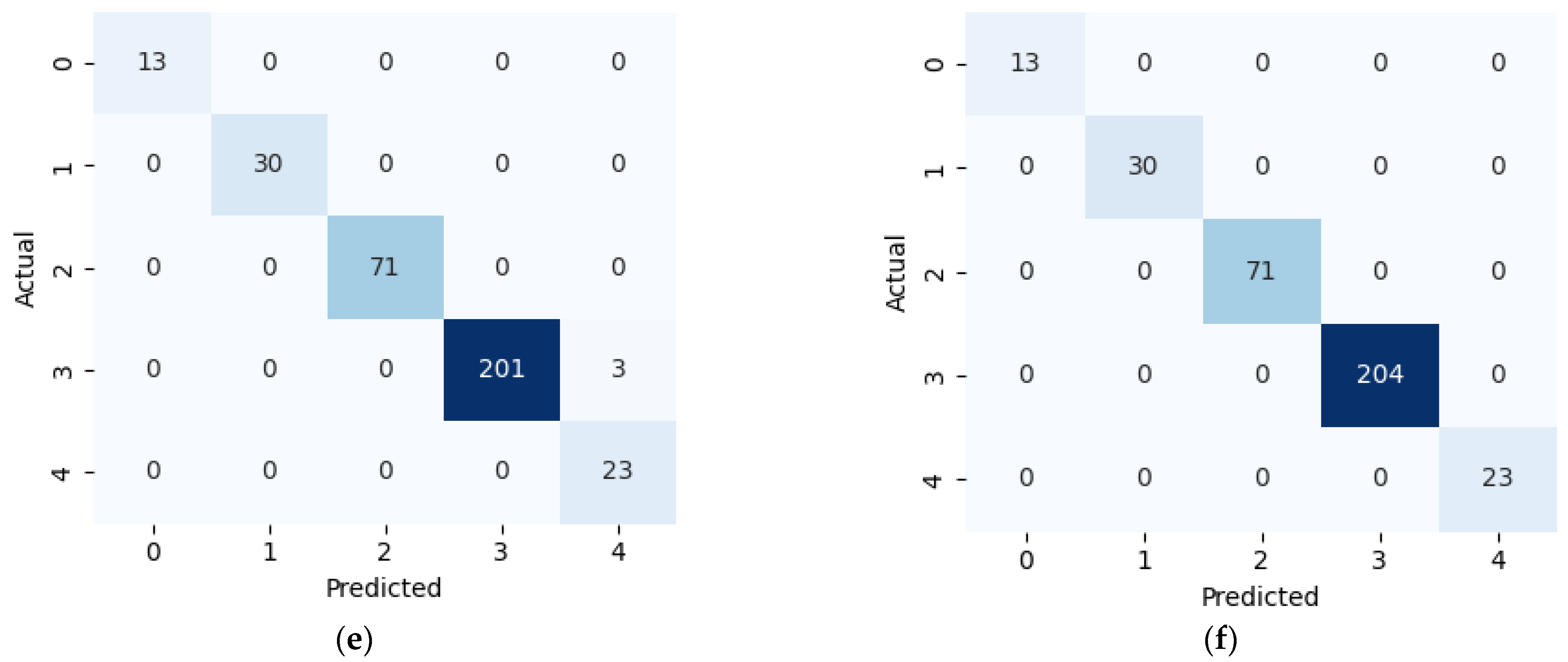
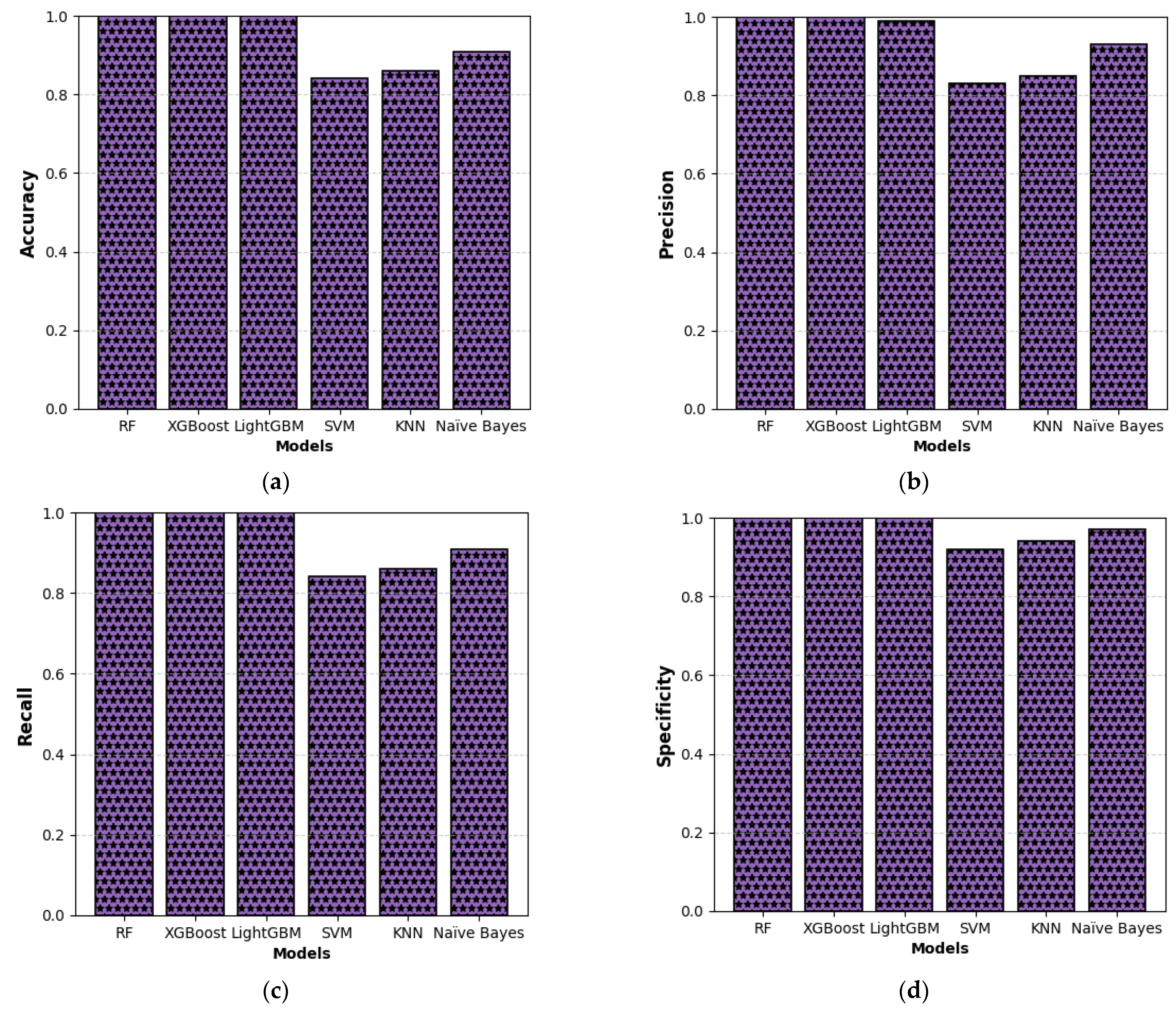
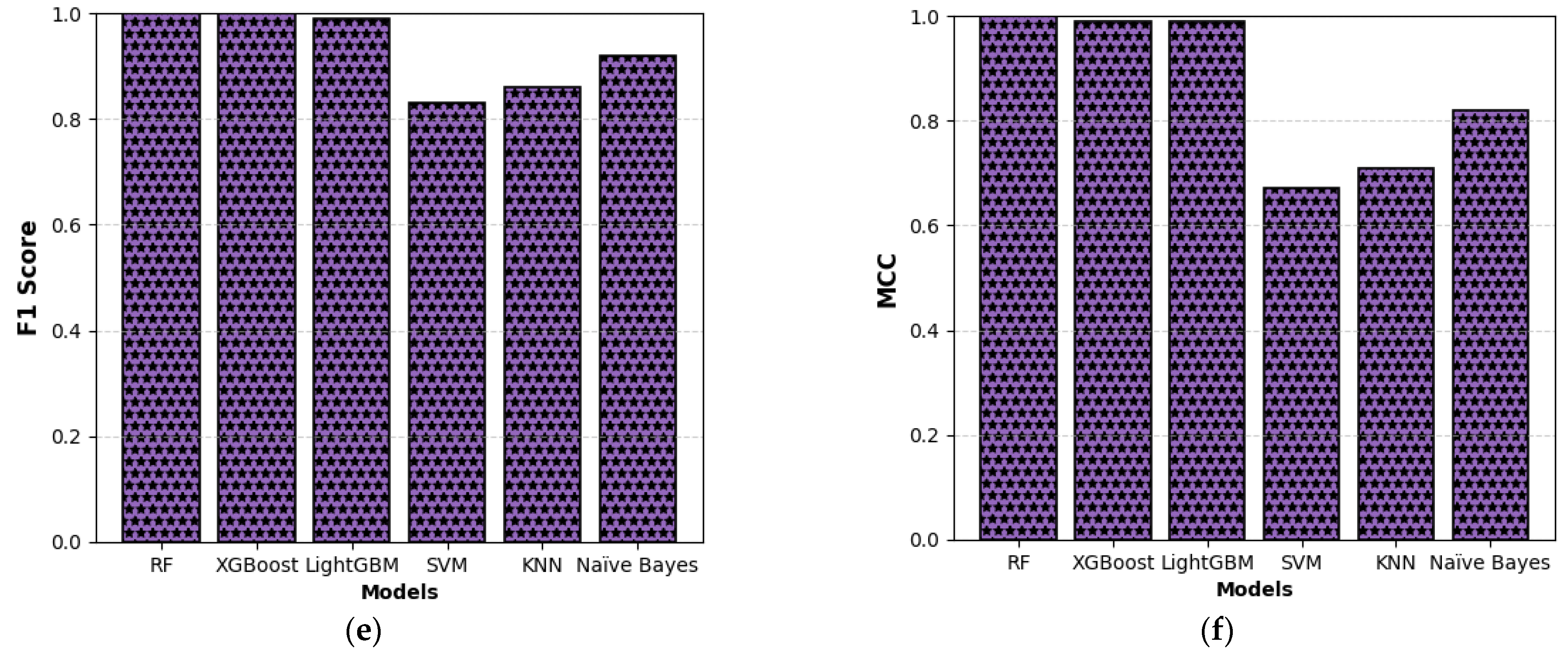
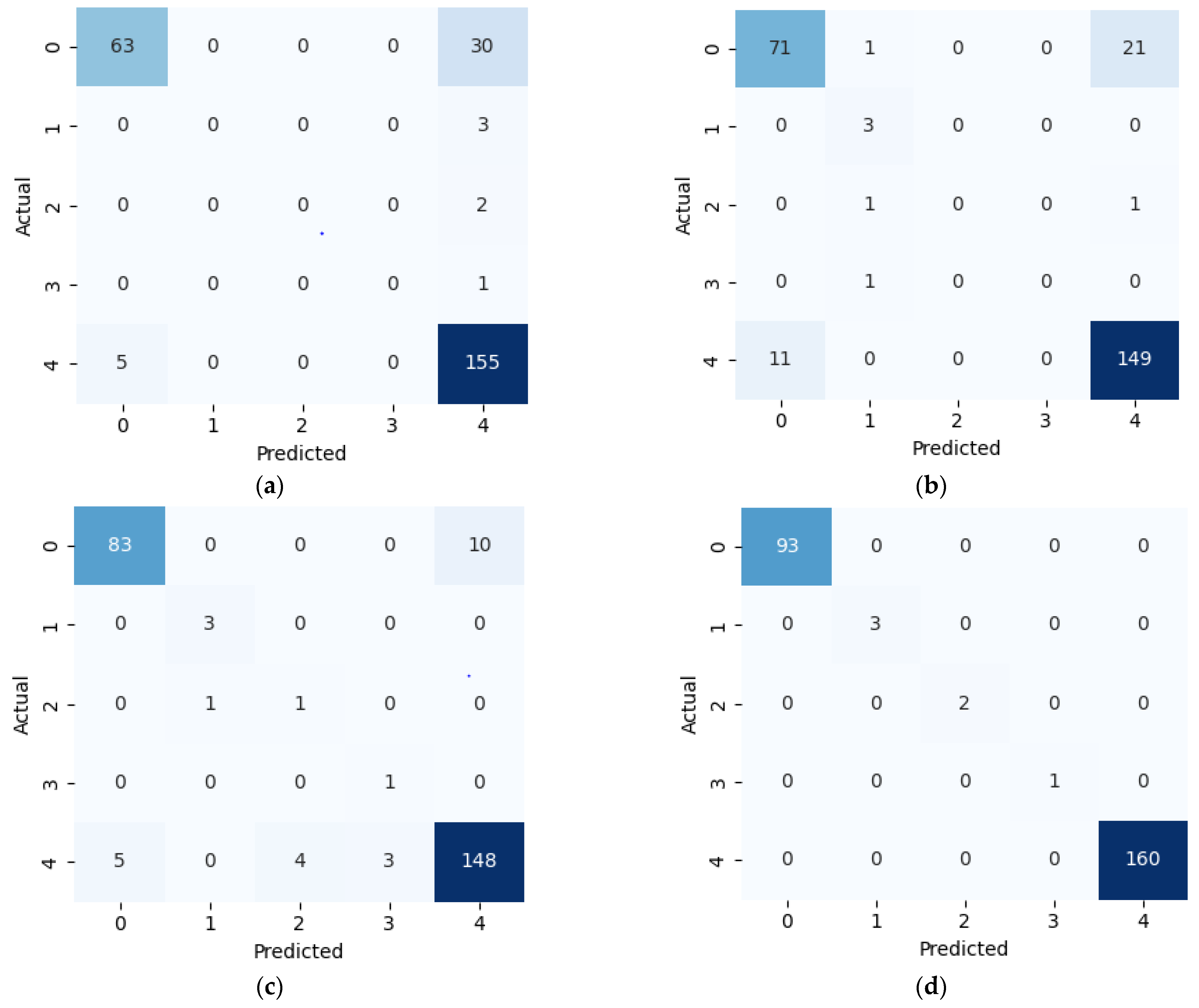
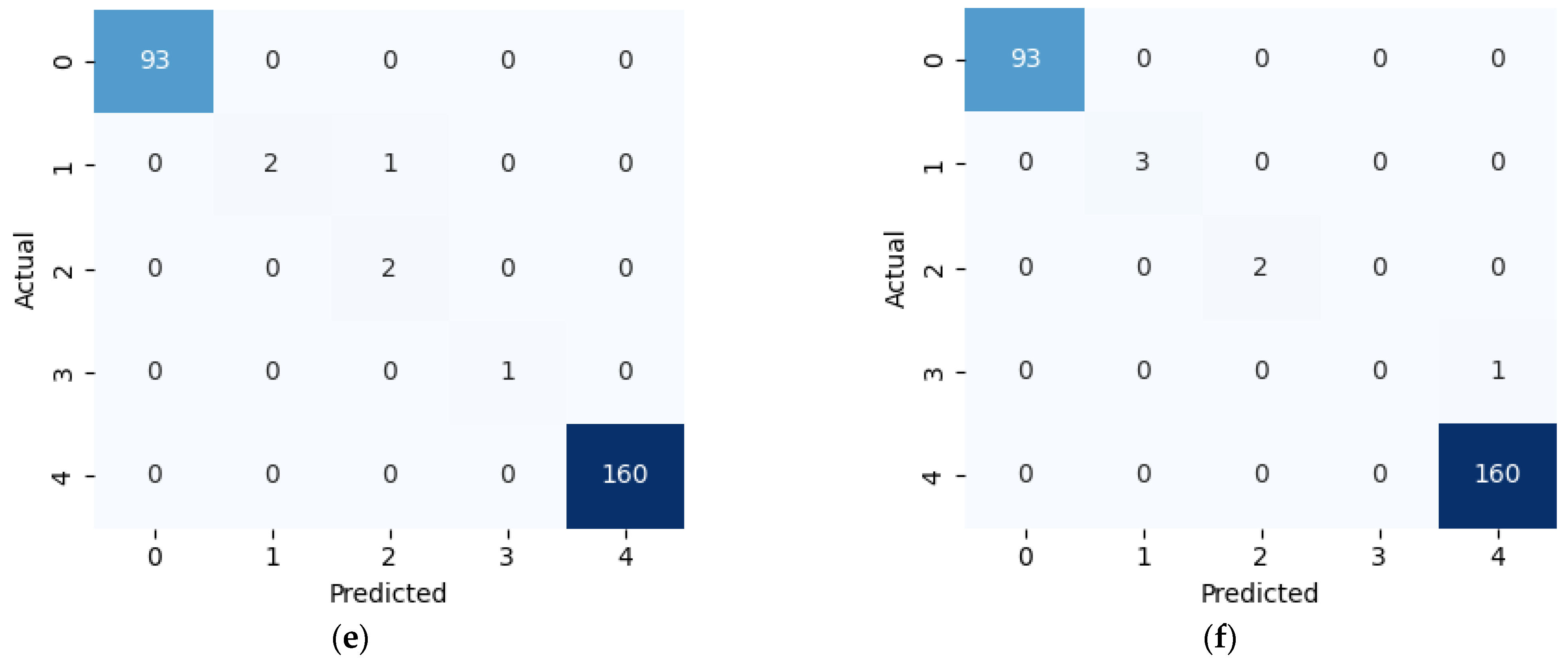
This study presents a comprehensive multiclass classification framework for automated power transformer fault diagnosis using DGA data. Four conventional gas ratio schemes, which are DRM, RRM, IRM, and CIGRÉ, were employed as feature generators, while six supervised ML classifiers were evaluated. The classifiers employed are RF, XGBoost, LightGBM, KNN, SVM, and Naïve Bayes. The results demonstrate that ensemble models, particularly RF and LightGBM, consistently outperform others across all diagnostic schemes. Furthermore, among the non-ensemble models, KNN showed moderate but consistent accuracy, while SVM displayed model instability and degraded performance on fault classes with overlapping features. Naïve Bayes, although weakest under DRM, RRM, and IRM, showed marked improvement under the CIGRÉ diagnostic scheme, suggesting its potential when fault classes are well-separated. The extensive confusion matrix analysis confirmed the high classification reliability of ensemble models, with RF and LightGBM achieving near-perfect diagonal dominance. The findings suggest that ensemble models are the best suited for multiclass DGA-based transformer fault classification. Their ability to generalize well across different diagnostic techniques and maintain high predictive performance under class imbalances makes them ideal for real-world deployment. The study underscores the importance of grid search optimization and 10-fold cross-validation in building reliable fault diagnosis models. In addition, the analysis conducted on the 50 in-service transformers underscores the interconnected degradation mechanisms affecting transformer insulation systems and reinforces the importance of multi-parameter condition monitoring for accurate fault diagnosis and predictive maintenance strategies. Generally, moisture content and acid value emerge as the dominant factors accelerating the degradation of insulating liquids, exerting a direct and measurable influence on both IFT and BDV. Among all the parameters analysed, IFT demonstrates the most consistent and robust correlation with key degradation indicators, positioning it as a reliable standalone diagnostic parameter. In contrast, while the CO2/CO ratio is a widely recognized marker for assessing paper insulation ageing, its weaker correlation with liquid-phase parameters suggests it should be interpreted in combination with other indicators to provide a comprehensive ageing assessment for insulating liquid. Notably, when data is grouped by voltage class, transformers rated at 13.8 kV exhibit greater variability in measured values. This dispersion reflects less rigorous operational control compared to higher-voltage units, which underscores the need for targeted monitoring strategies in distribution-class assets.
In future studies, the diagnostic framework developed in this work will be applied to real-time, autonomous fault detection by integrating ML models with Internet of Things (IoT) platforms and digital twin technologies. This future direction is expected to significantly enhance transformer health monitoring by enabling continuous data acquisition and intelligent analysis of DGA inputs through embedded sensor networks. Lightweight and scalable ML models will be adapted for deployment on resource-constrained hardware platforms such as ARM Cortex-M microcontrollers, Raspberry Pi, and NVIDIA Jetson Nano. These implementations will aim to support predictive maintenance and early fault identification at the edge. To facilitate this, further research will investigate optimization techniques such as model pruning, quantization, and conversion to formats like TensorFlow Lite or ONNX (open neural network exchange) to reduce memory and processing overhead. Real-time deployment will also require the development of low-latency data pipelines and the adoption of industrial communication protocols such as Modbus, message queuing telemetry transport (MQTT), and controller area network (CAN), which will be explored to ensure seamless integration with supervisory control and data acquisition (SCADA) systems and centralized condition monitoring dashboards. Moreover, future work will explore the creation of a digital twin for power transformers, a dynamic virtual model that mirrors the physical asset by integrating real-time sensor data, historical DGA trends, and ML-driven diagnostic outputs. This digital twin will be used to provide continuous health assessment, predict degradation trajectories, simulate fault scenarios, and inform maintenance decision-making. Such an approach will mark a significant step toward the realization of intelligent, self-monitoring transformer systems within modern smart grid infrastructure.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}