
A Bayesian Network Approach to Predicting Severity Status in Nuclear Reactor Accidents with Resilience to Missing Data


Abstract
1. Introduction
2. Materials and Methods
2.1. Data
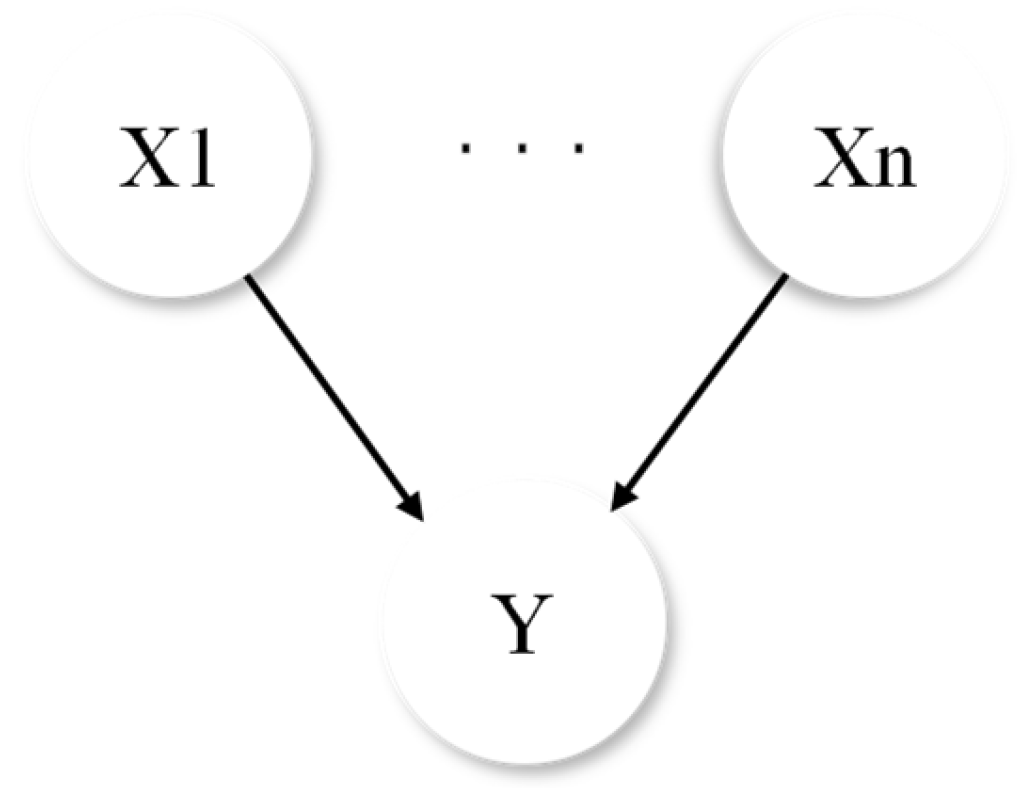
2.2. Bayesian Model
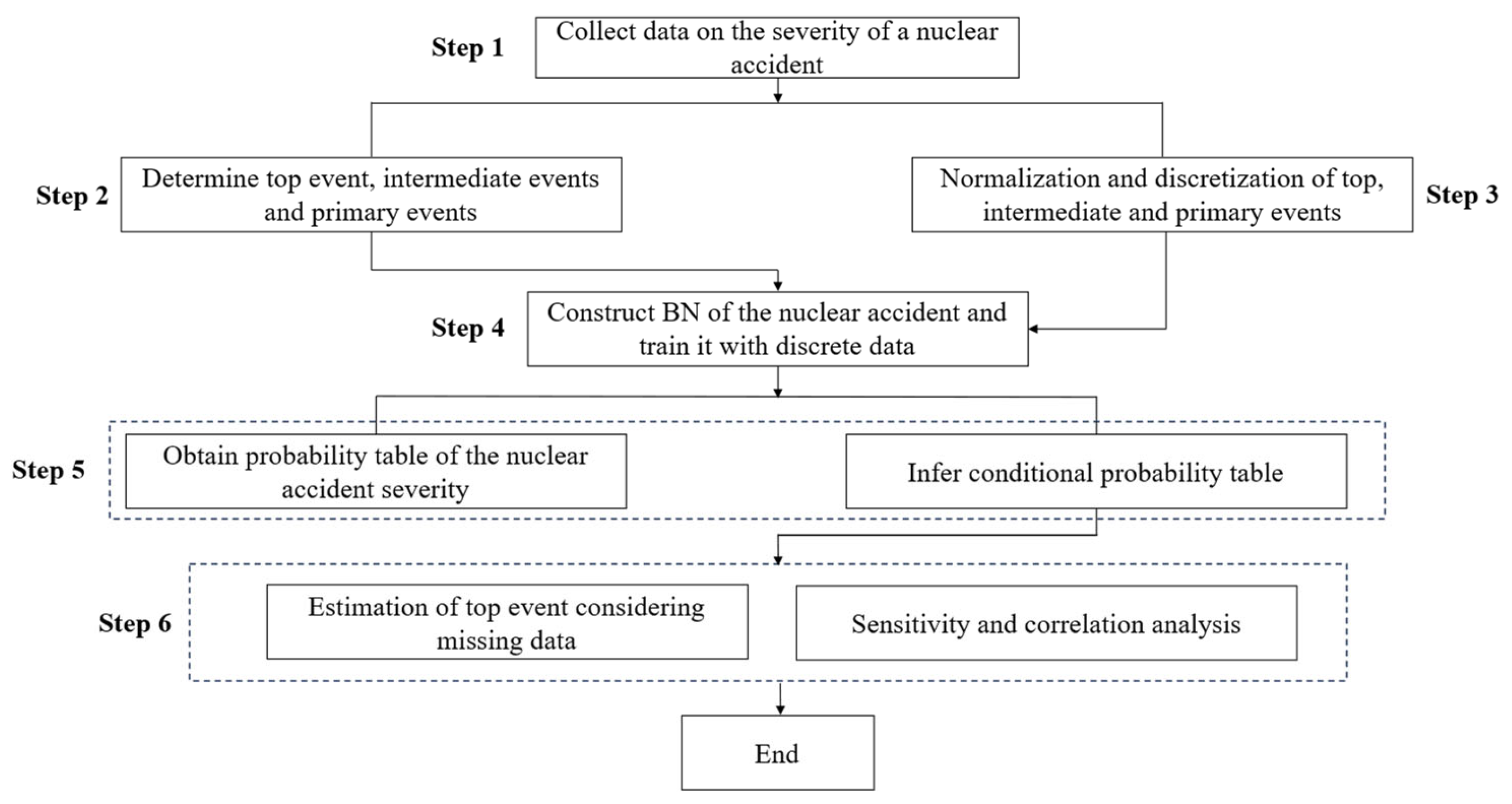
2.3. Analysis Steps of the Bayesian Network
2.4. Case Studies
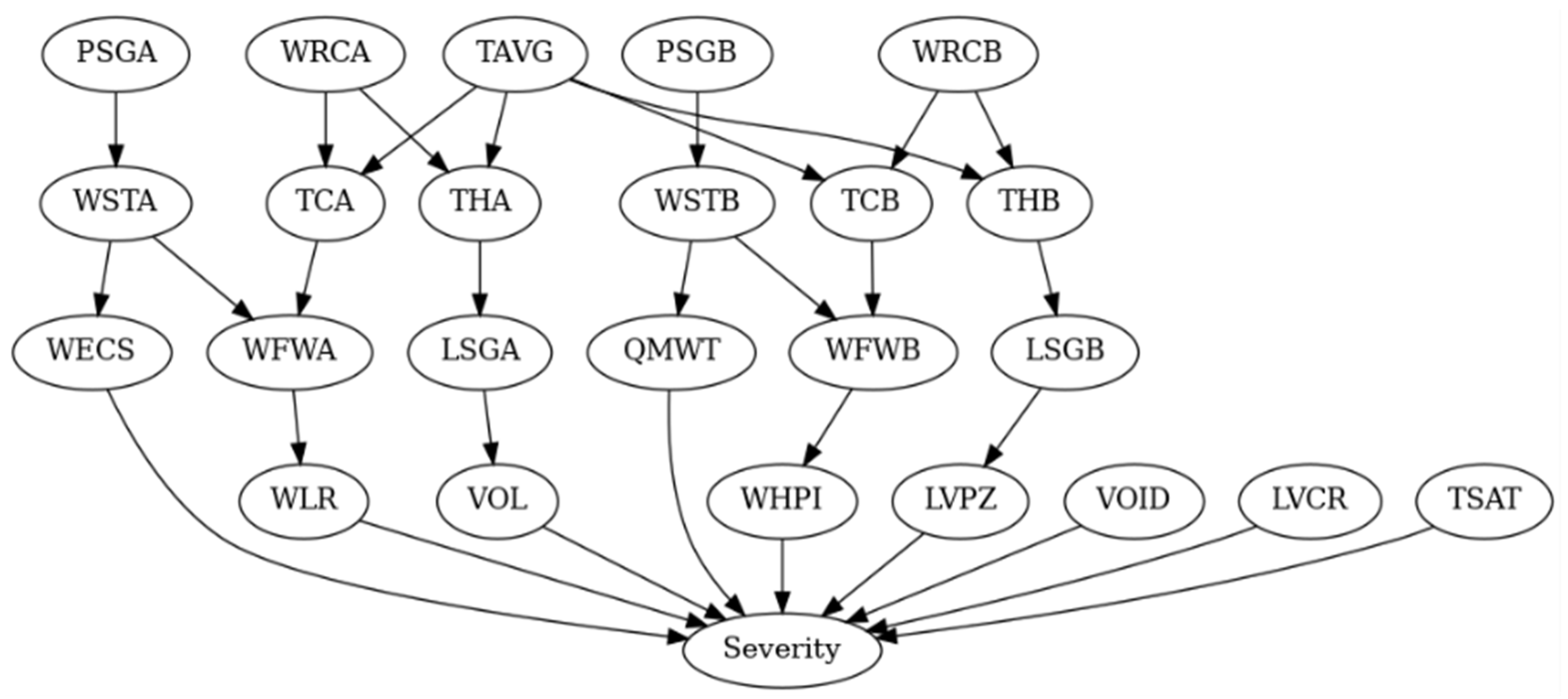
2.4.1. The Bayesian Network Structure for the LOCA
2.4.2. The Bayesian Network Structure for an SLBIC
3. Results and Discussion
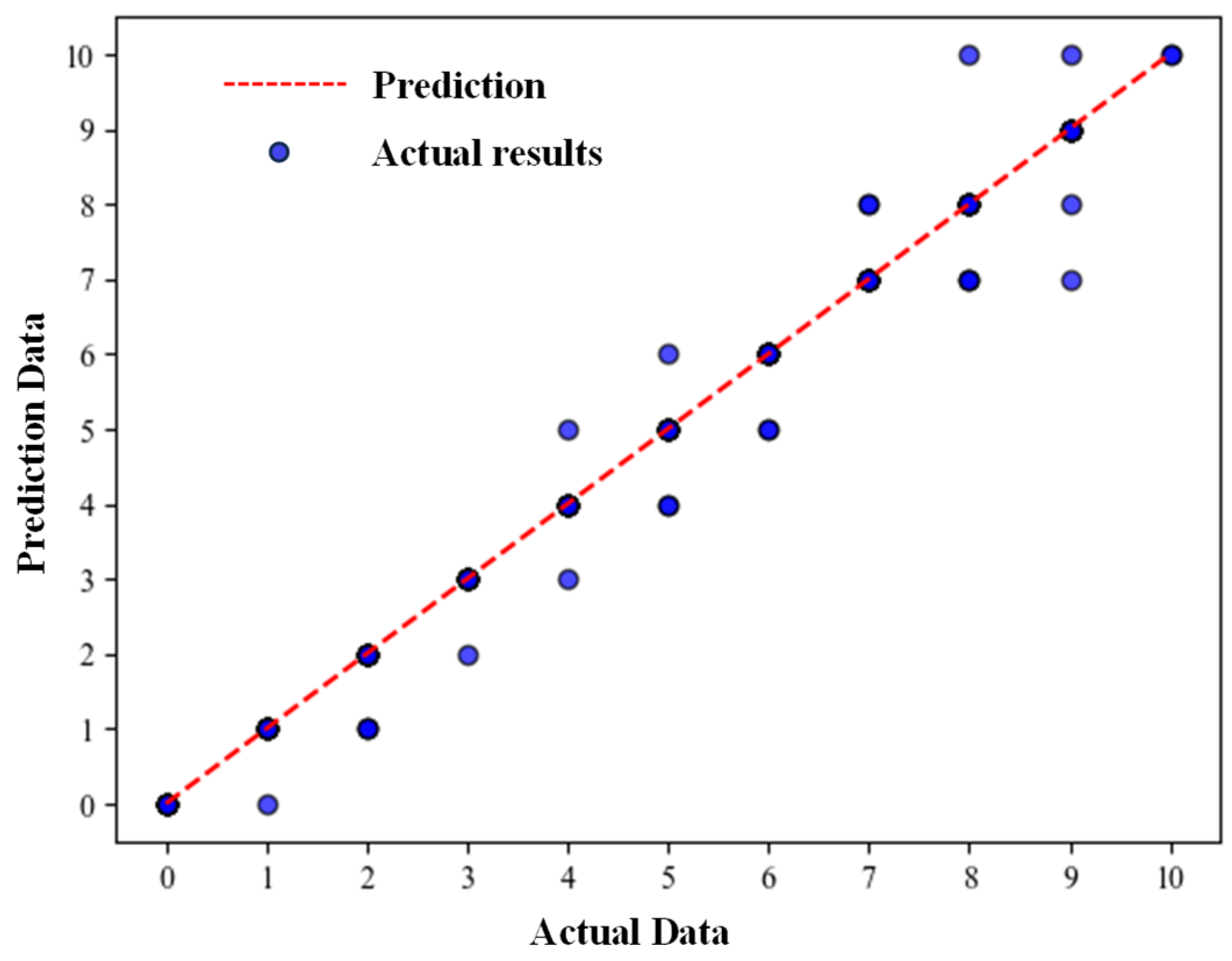
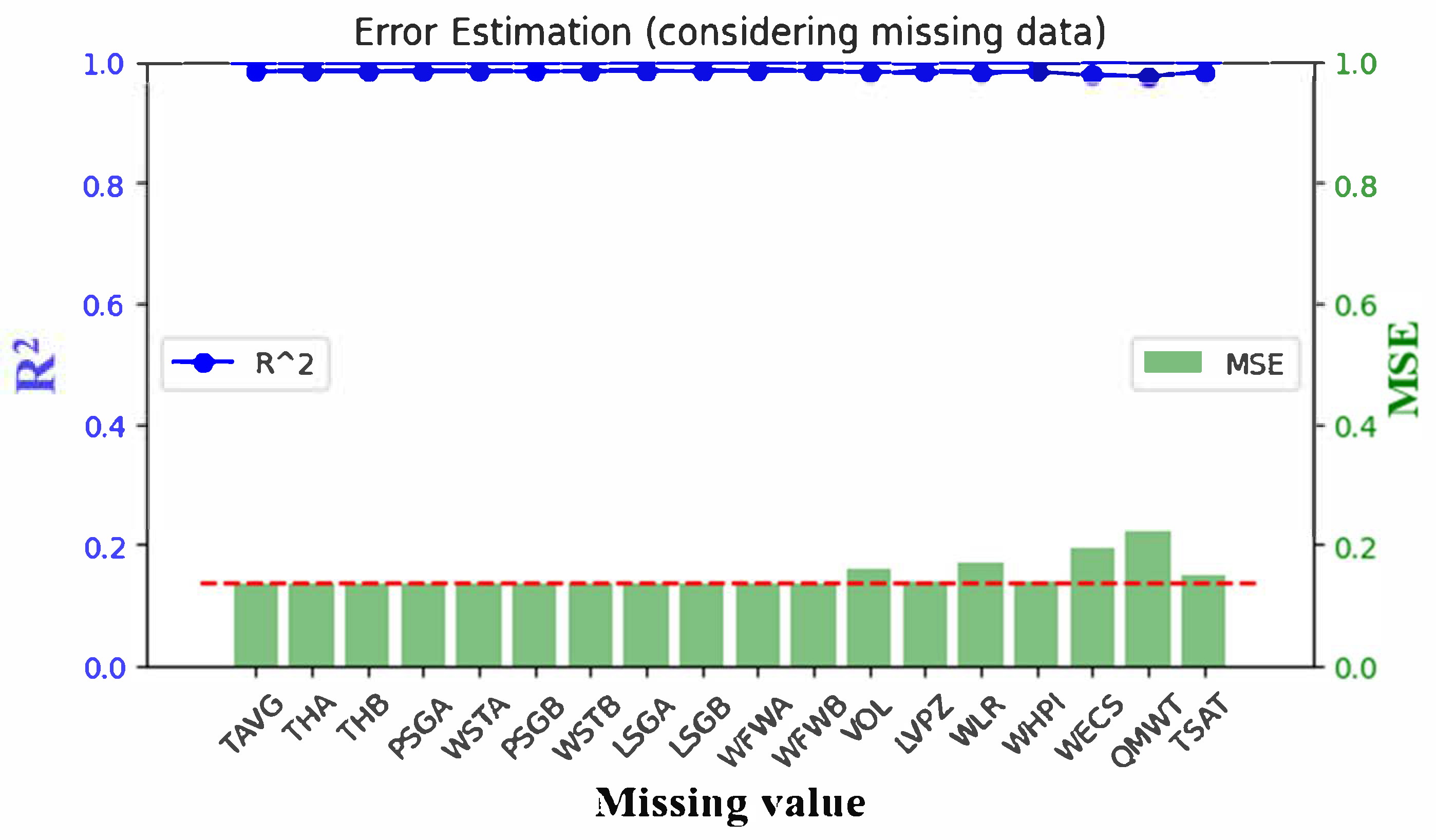
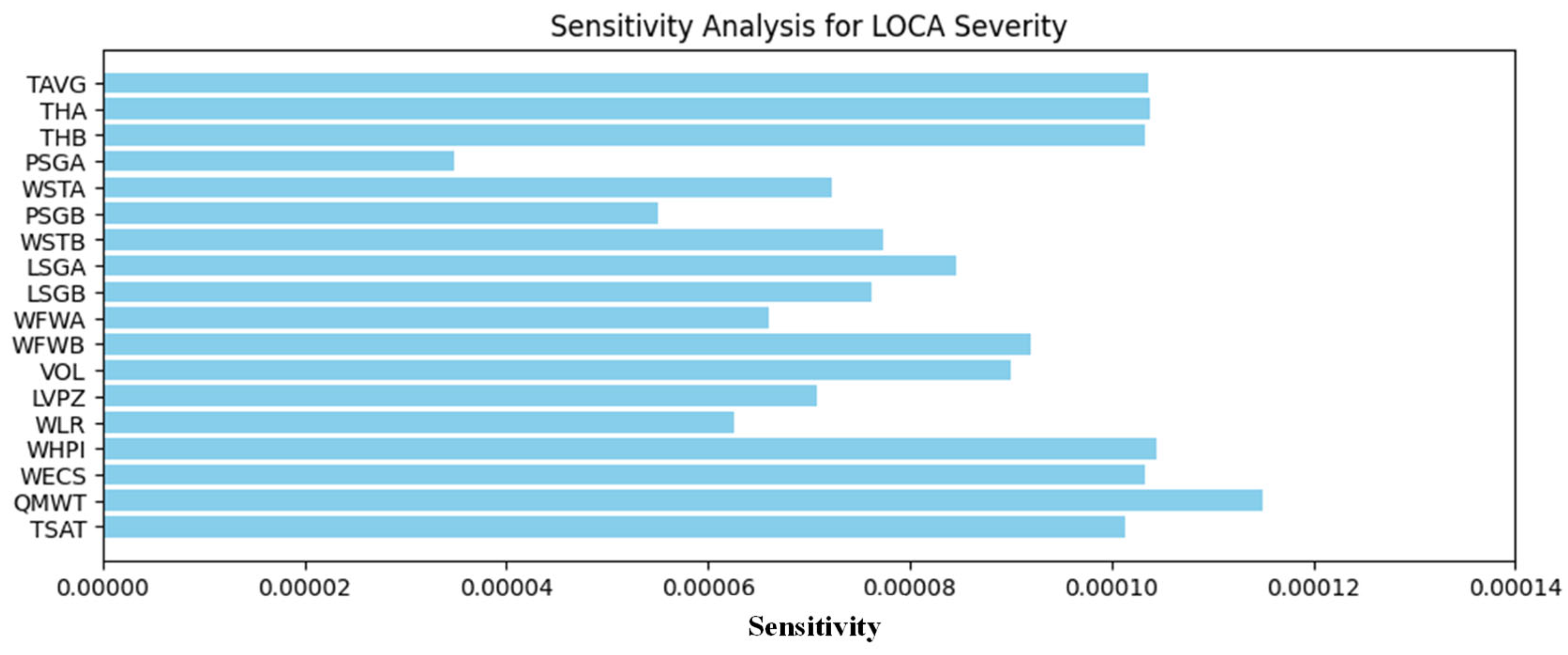
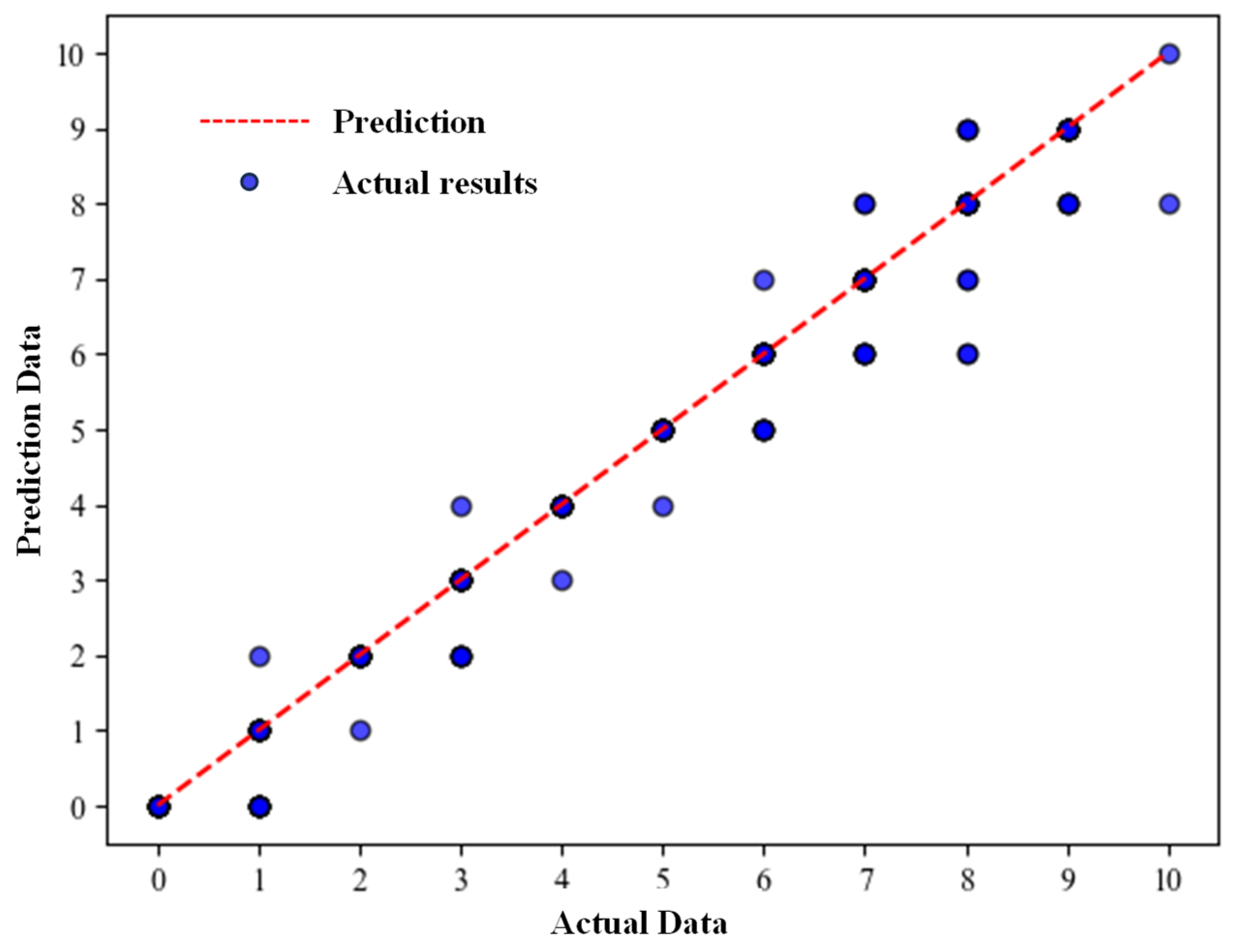
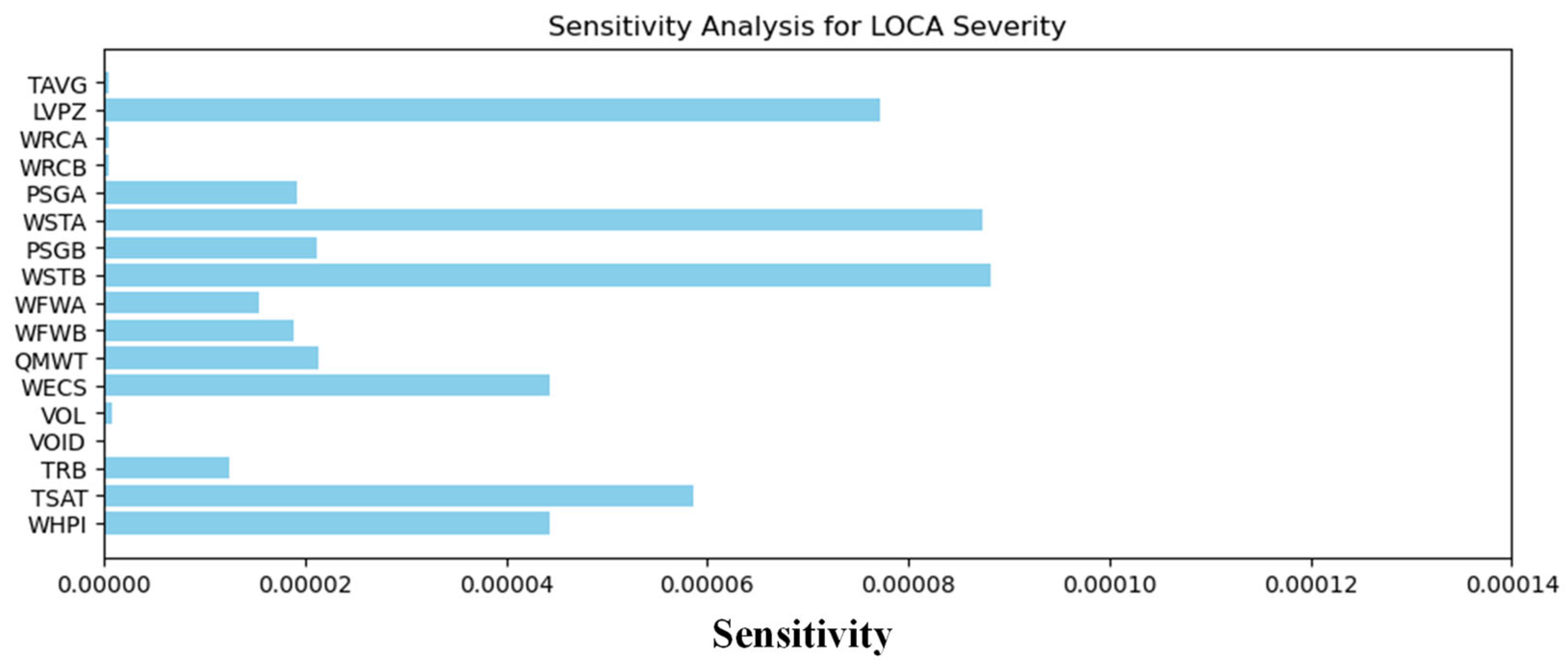
3.1. Results for the LOCA
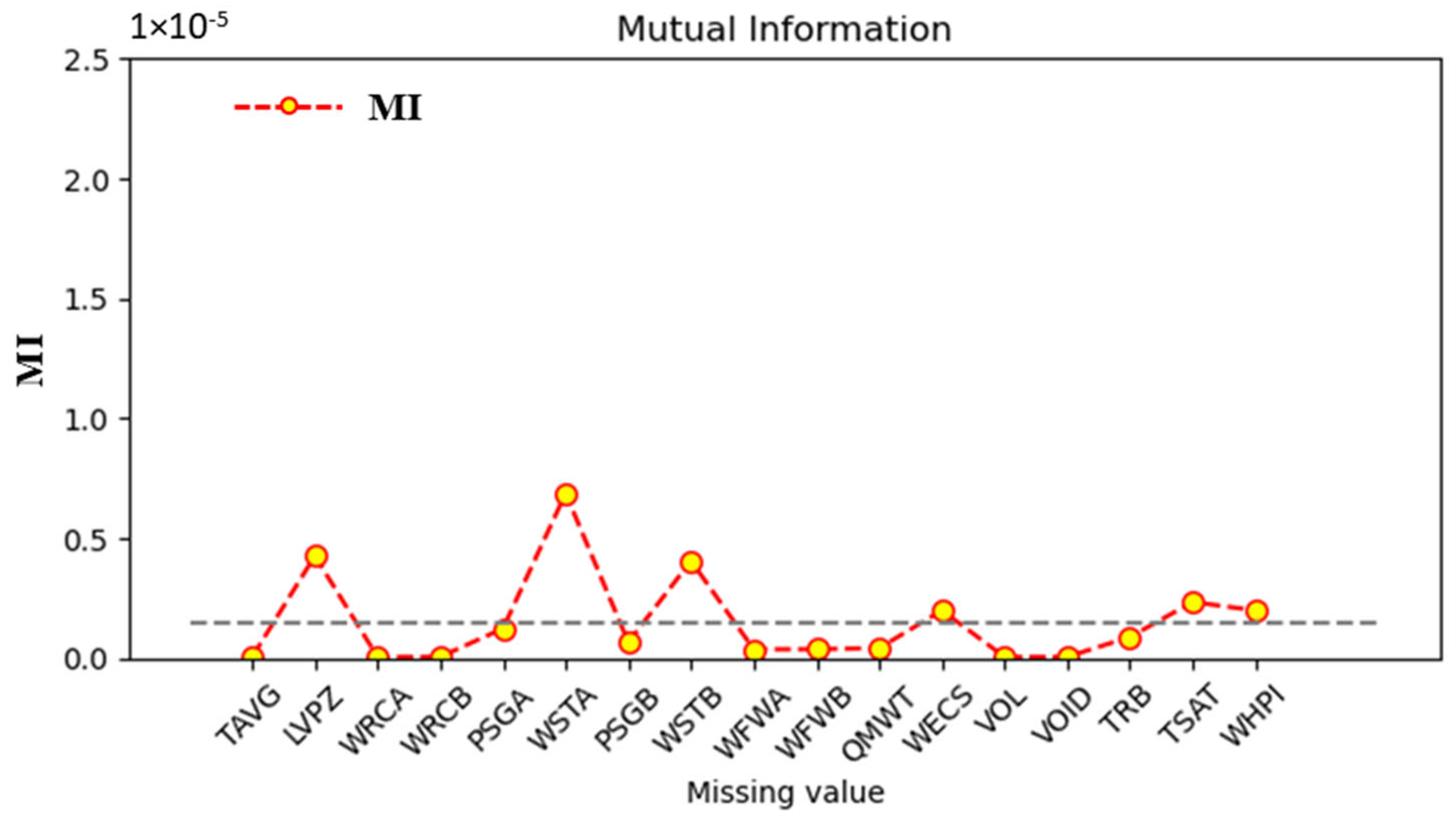
3.2. Results for the SLBIC
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Na, M.G.; Shin, S.H.; Lee, S.M.; Jung, D.W.; Kim, S.P.; Jeong, J.H.; Lee, B.C. Prediction of major transient scenarios for severe accidents of nuclear power plants. IEEE Trans. Nucl. Sci. 2004, 51, 313–321. [Google Scholar] [CrossRef]
- Sun, J.; Shi, X.; Lin, S.; Wang, H. Research on hydrogen risk prediction in probability safety analysis for severe accidents of nuclear power plants. Nucl. Eng. Des. 2024, 417, 112798. [Google Scholar] [CrossRef]
- Chabook, M.; Tashakor, S. Design of emergency solar energy system adjacent the nuclear power plant to prevent nuclear accidents and increase safety. Microelectron. J. 2024, 3, 100092. [Google Scholar] [CrossRef]
- Alhamadi, F.; An, B.; Yi, Y.; Alameri, S.A.; Choi, D. Evaluation of high-temperature oxidation behaviour of ATF claddings during severe accidents in nuclear power plants. Nucl. Eng. Des. 2024, 426, 113388. [Google Scholar] [CrossRef]
- Brandt, T.; Lestinen, V.; Toppila, T.; Kaehkoenen, J.; Timperi, A.; Paettikangas, T.; Karppinen, I. Fluid-structure interaction analysis of large-break loss of coolant accident. Nucl. Eng. Des. 2010, 240, 2365–2374. [Google Scholar] [CrossRef]
- Macdonald, P.E.; Shah, V.N.; Ward, L.W.; Ellison, P.G. Steam Generator Tube Failures; NUREG/CR—6365; Nuclear Regulatory Commission: Washington, DC, USA, 2017. [Google Scholar]
- Fagerlind, H.; Heinig, I.; Matias, V. Analysis of accident data for test scenario definition in the ASSESS project. In Proceedings of the 4th International Conference ESAR—Expert Symposium on Accident Research, Hannover, Germany, 16–18 September 2010. [Google Scholar]
- Fichot, F.; Adroguer, B.; Volchek, A.; Zvonarev, Y. Advanced treatment of zircaloy cladding high-temperature oxidation in severe accident code calculations: Part III. Verification against representative transient tests. Nucl. Eng. Des. 2004, 232, 97–109. [Google Scholar] [CrossRef]
- Saltbones, J.; Foss, A.; Bartnicki, J. Severe Nuclear Accident Program (SNAP)—A Real Time Model for Accidental Releases. In Air Pollution Modeling and Its Application XI; Air & Waste Management Association: Pittsburgh, PA, USA, 1996. [Google Scholar]
- D’Auria, F.; Gabaraev, B.; Soloviev, S.; Novoselsky, O.; Moskalev, A.; Uspuras, E.; Galassi, G.M.; Parisi, C.; Petrov, A.; Radkevich, V. Deterministic accident analysis for RBMK. Nucl. Eng. Des. 2008, 238, 975–1001. [Google Scholar] [CrossRef]
- Haruyuki, O.; Takeshi, I.; Takatoshi, H. Verification of screening level for decontamination implemented after Fukushima nuclear accident. Radiat. Prot. Dosim. 2012, 151, 36–42. [Google Scholar] [CrossRef]
- Doytchev, D.E.; Szwillus, G. Combining task analysis and fault tree analysis for accident and incident analysis: A case study from Bulgaria. Accid. Anal. Prev. 2009, 41, 1172–1179. [Google Scholar] [CrossRef] [PubMed]
- Kohda, T.; Inoue, K. Fault-tree analysis considering latency of basic events. In Proceedings of the Annual Reliability and Maintainability Symposium. 2001 Proceedings. International Symposium on Product Quality and Integrity, Philadelphia, PA, USA, 22–25 January 2001. [Google Scholar] [CrossRef]
- Zubair, M.; Zhang, Z.; Aamir, M. A Review: Advancement in Probabilistic Safety Assessment and Living Probabilistic Safety Assessment. In Proceedings of the Power & Energy Engineering Conference, Chengdu, China, 28–31 March 2010. [Google Scholar] [CrossRef]
- Siu, N.; Marksberry, D.; Cooper, S.; Coyne, K.; Stutzke, M. PSA technology challenges revealed by the Great East Japan Earthquake. In Proceedings of the PSAM Topical Conference in Light of the Fukushima Dai-Ichi Accident, Tokyo, Japan, 15–17 April 2013. [Google Scholar]
- Hayashi, Y.; Hayashi, K.; Segawa, S.; Sekine, K.; Matsuoka, S. Research on Consequence Analysis Method for Probabilistic Safety Assessment of Nuclear Fuel Cycle Facilities (VI). J. At. Energy Soc. Jpn. 2010, 9, 339–346. [Google Scholar] [CrossRef]
- Wood, D.; O’Riordain, S. Monte Carlo Simulation Methods Applied to Accident Reconstruction and Avoidance Analysis. SAE Trans. 1994, 103, 893–901. [Google Scholar] [CrossRef]
- Marseguerra, M.; Zio, E.; Devooght, J.; Labeau, P.E. A concept paper on dynamic reliability via Monte Carlo simulation. Math. Comput. Simul. 1998, 47, 371–382. [Google Scholar] [CrossRef]
- Clairand, I.; Trompier, F.; Bottollier-Depois, J.F.; Gourmelon, P. Gourmelon EX vivo ESR measurements associated with Monte Carlo calculations for accident dosimetry: Application to the 2001 Georgian accident. Radiat. Prot. Dosim. 2006, 119, 500–505. [Google Scholar] [CrossRef]
- Chow, T.C.; Oliver, R.M.; Vignaux, G.A. A Bayesian Escalation Model to Predict Nuclear Accidents and Risk. Oper. Res. 1990, 38, 265–277. [Google Scholar] [CrossRef]
- Abbess, C.; Jarrett, D.; Wright, C.C. Bayesian Methods Applied to Road Accident Blackspot Studies. J. R. Stat. Soc. Ser. Stat. 1983, 32, 181. [Google Scholar] [CrossRef]
- Pyy, P. An analysis of maintenance failures at a nuclear power plant. Reliab. Eng. Syst. Saf. 2001, 72, 293–302. [Google Scholar] [CrossRef]
- Friedman, N.; Koller, D. Being Bayesian About Network Structure. A Bayesian Approach to Structure Discovery in Bayesian Networks. Mach. Learn. 2003, 50, 95–125. [Google Scholar] [CrossRef]
- Zhang, Z.; Dong, F. Fault detection and diagnosis for missing data systems with a three time-slice dynamic Bayesian network approach. Chemom. Intell. Lab. Syst. 2014, 138, 30–40. [Google Scholar] [CrossRef]
- Ruggieri, A.; Stranieri, F.; Stella, F.; Scutari, M. Hard and Soft EM in Bayesian Network Learning from Incomplete Data. Algorithms 2020, 13, 329. [Google Scholar] [CrossRef]
- Qi, B.; Xiao, X.; Liang, J.; Po, L.C.; Zhang, L.; Tong, J. An open time-series simulated dataset covering various accidents for nuclear power plants. Sci. Data 2022, 9, 766. [Google Scholar] [CrossRef]
- Ninng, L.; Yu, X. Fault diagnosis in TE process based on feature selection via second order mutual information. J. Chem. Ind. Eng. Soc. China 2009, 60, 2252. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Name | Description |
|---|---|---|---|
| TAVG | Temp RCS Average | LSGA | Level Steam Generator A |
| THA | Thermal Hydraulic Analyzer A | LSGB | Level Steam Generator B |
| THB | Thermal Hydraulic Analyzer B | WFWA | Flow SG A Feedwater |
| PSGA | Pressure Steam Generator A | WFWB | Flow SG B Feedwater |
| PSGB | Pressure Steam Generator B | VOL | Volume RCS Liquid |
| WSTA | Flow SG A Steam | LVPZ | Level Pressurizer |
| WSTB | Flow SG B Steam | WLR | Flow RCS Leak |
| WHPI | Flow High-Pressure Injection | WECS | Flow Emergency Cooling System |
| QMWT | Power Total Megawatt Thermal | TSAT | Temp Przr Saturation |
| WRCB | Flow Reactor coolant loop B | TCA | Temp Cold leg A |
| VOID | Void of RCS | TCB | Temp Cold leg B |
| LVCR | Level Core water | TSAT | Temp Przr saturation |
| Name | Description | Name | Description |
|---|---|---|---|
| TAVG | Temp RCS average | VOID | Void of RCS |
| WRCA | Flow Reactor Coolant Loop A | TRB | Temp Reactor Building |
| WRCB | Flow Reactor Coolant Loop B | LVPZ | Level Pressurizer |
| PSGA | Pressure Steam Generator A | WSTA | Flow SG A Steam |
| PSGB | Pressure Steam Generator B | WSTB | Flow SG B Steam |
| WFWA | Flow SG A Feedwater | WECS | Flow Total ECCS |
| WFWB | Flow SG B Feedwater | TSAT | Temp Przr Saturation |
| QMWT | Power Total Megawatt Thermal | WHPI | Flow High-Pressure Injection |
| VOL | Volume RCS Liquid |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Chen, L.; Cai, X.; Xu, C.; Lu, Y.; Luo, S.; Wang, W.; Jiang, L.; Wu, G. A Bayesian Network Approach to Predicting Severity Status in Nuclear Reactor Accidents with Resilience to Missing Data. Energies 2025, 18, 2684. https://doi.org/10.3390/en18112684
Li K, Chen L, Cai X, Xu C, Lu Y, Luo S, Wang W, Jiang L, Wu G. A Bayesian Network Approach to Predicting Severity Status in Nuclear Reactor Accidents with Resilience to Missing Data. Energies. 2025; 18(11):2684. https://doi.org/10.3390/en18112684
Chicago/Turabian StyleLi, Kaiyu, Ling Chen, Xinxin Cai, Cai Xu, Yuncheng Lu, Shengfeng Luo, Wenlin Wang, Lizhi Jiang, and Guohua Wu. 2025. "A Bayesian Network Approach to Predicting Severity Status in Nuclear Reactor Accidents with Resilience to Missing Data" Energies 18, no. 11: 2684. https://doi.org/10.3390/en18112684
APA StyleLi, K., Chen, L., Cai, X., Xu, C., Lu, Y., Luo, S., Wang, W., Jiang, L., & Wu, G. (2025). A Bayesian Network Approach to Predicting Severity Status in Nuclear Reactor Accidents with Resilience to Missing Data. Energies, 18(11), 2684. https://doi.org/10.3390/en18112684