
Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal


Abstract
1. Introduction
2. Materials and Methods
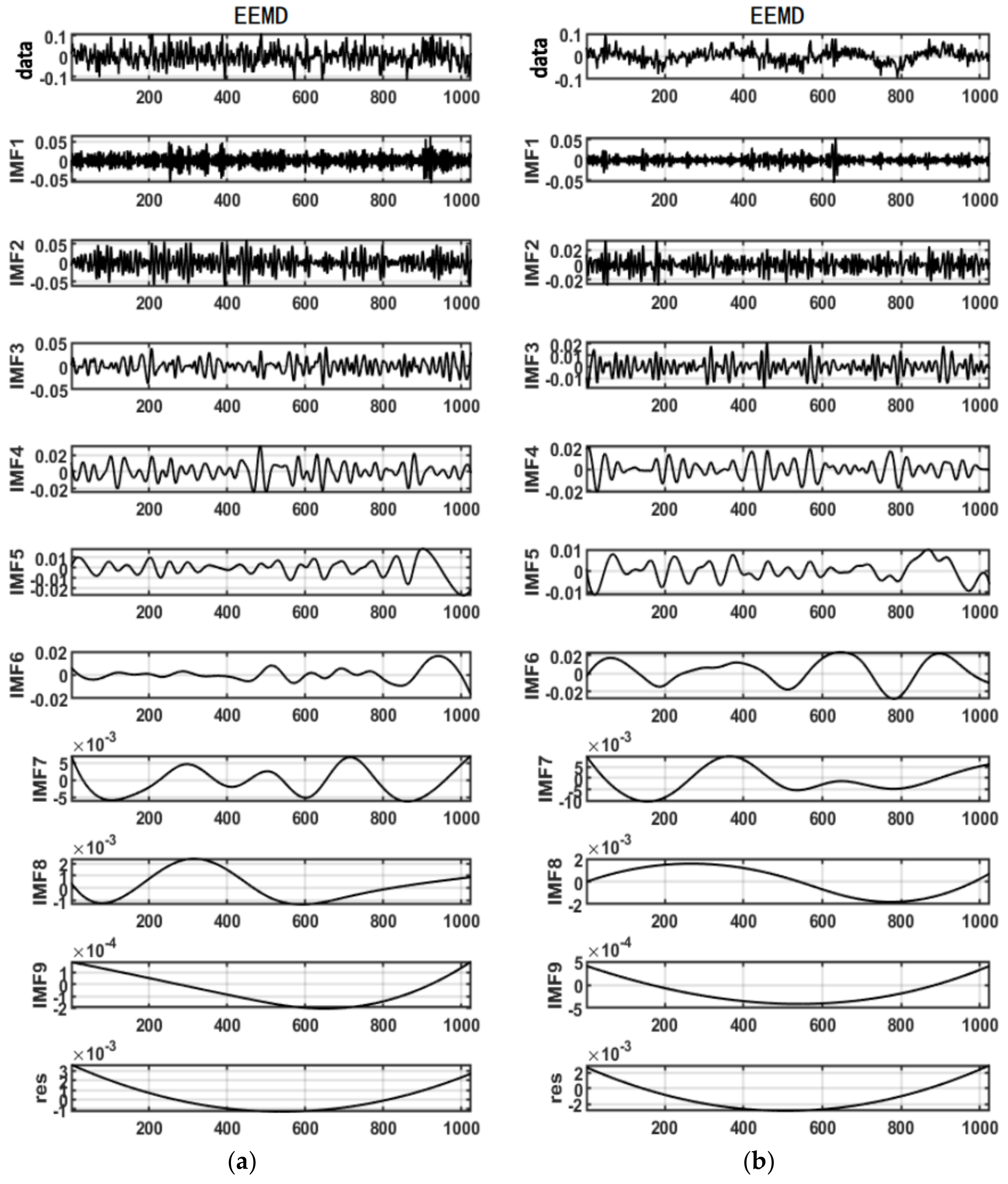
2.1. Ensemble Empirical Mode Decomposition
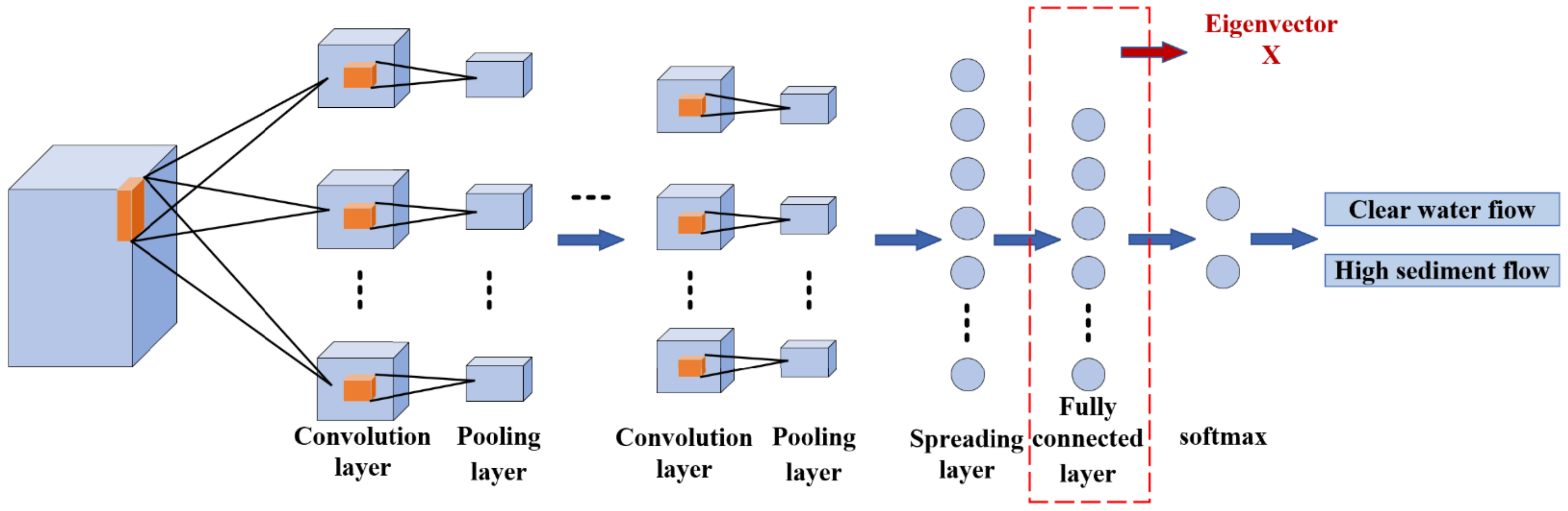
2.2. Convolutional Neural Networks
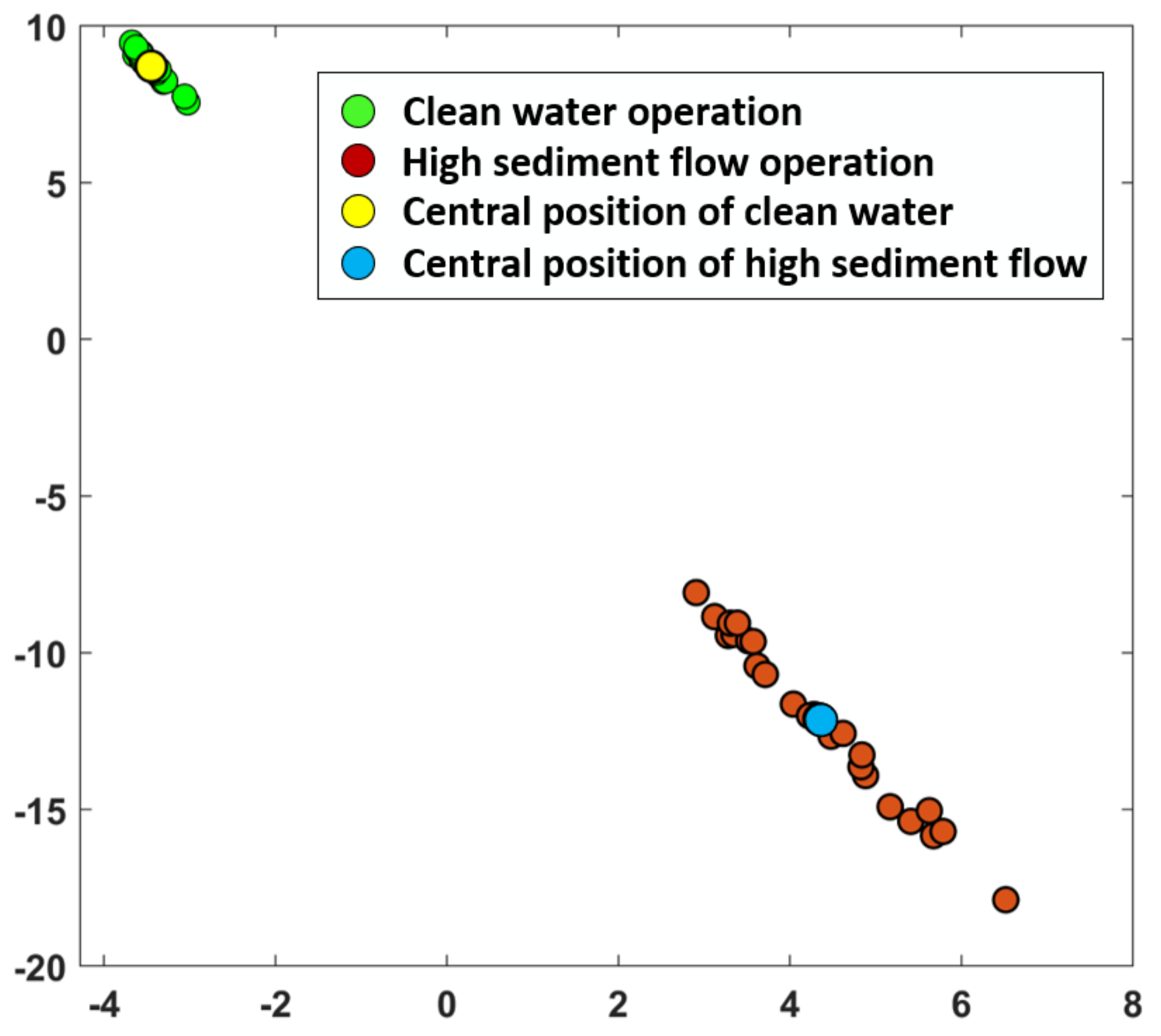
2.3. K-Means Clustering Algorithm
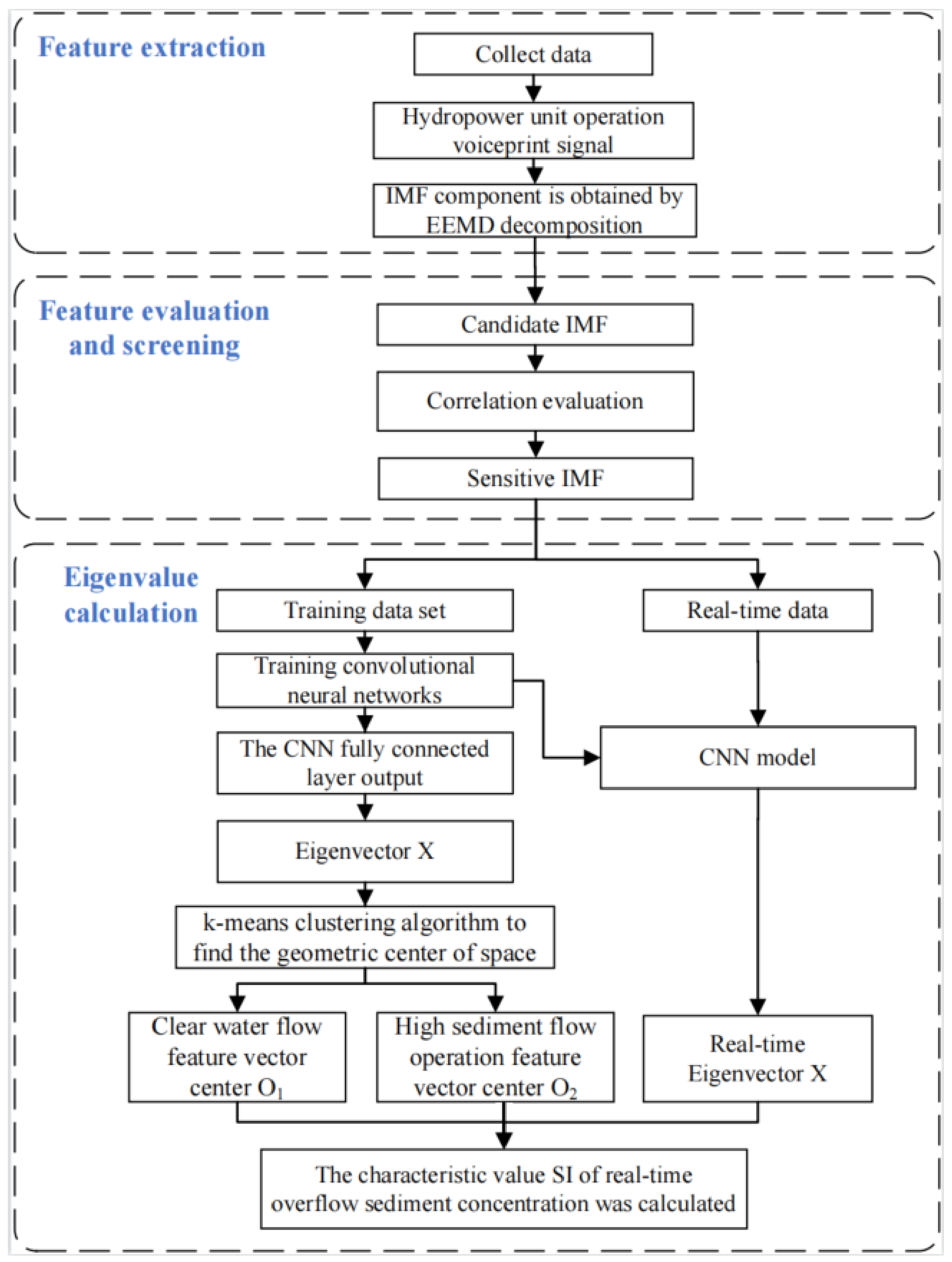
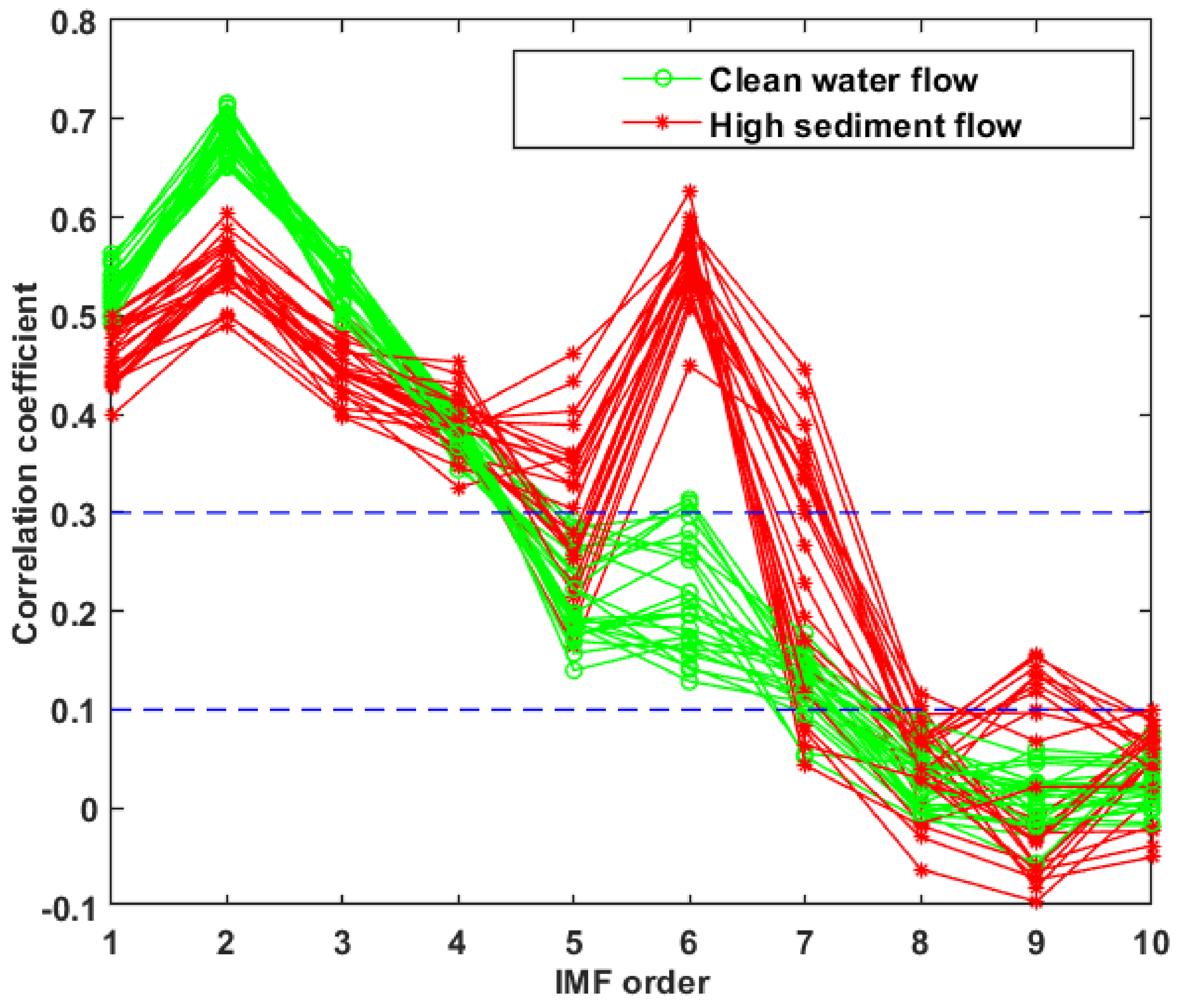
3. Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal
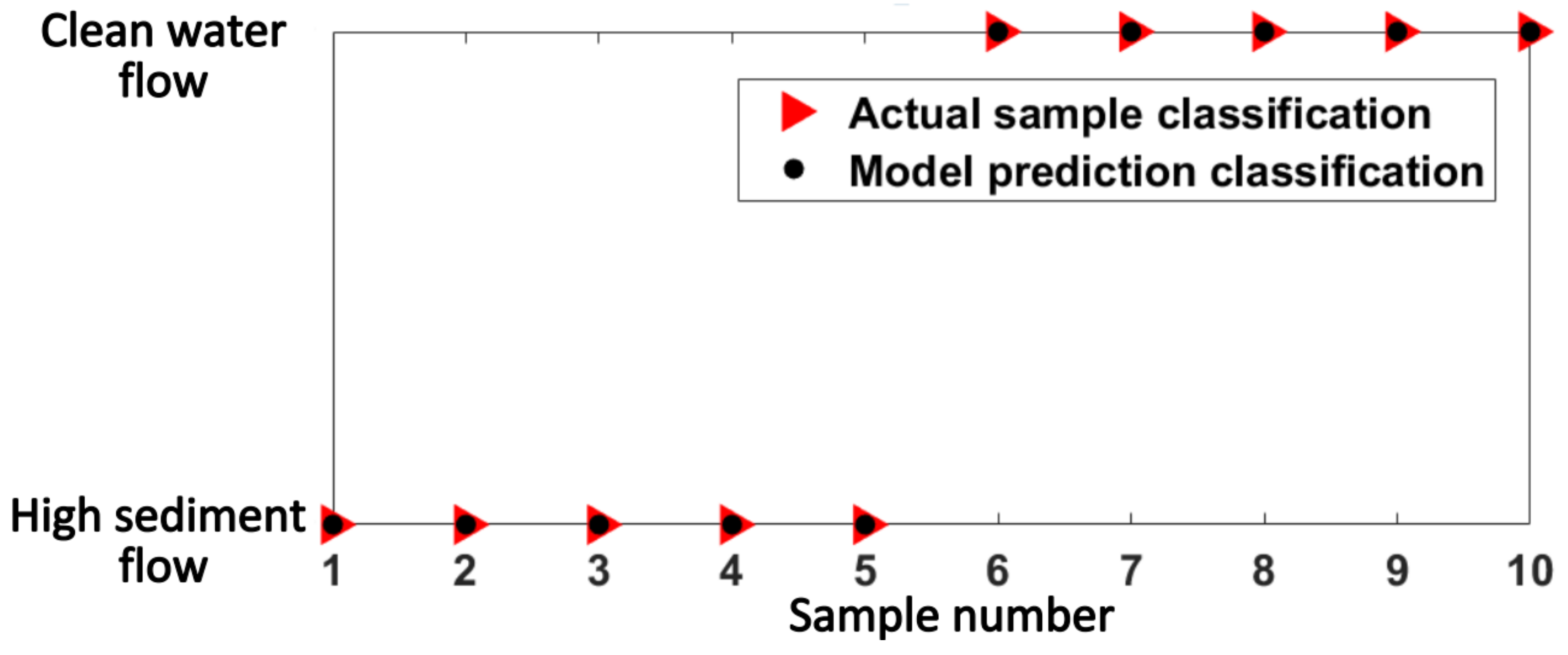
4. Test Results and Analysis
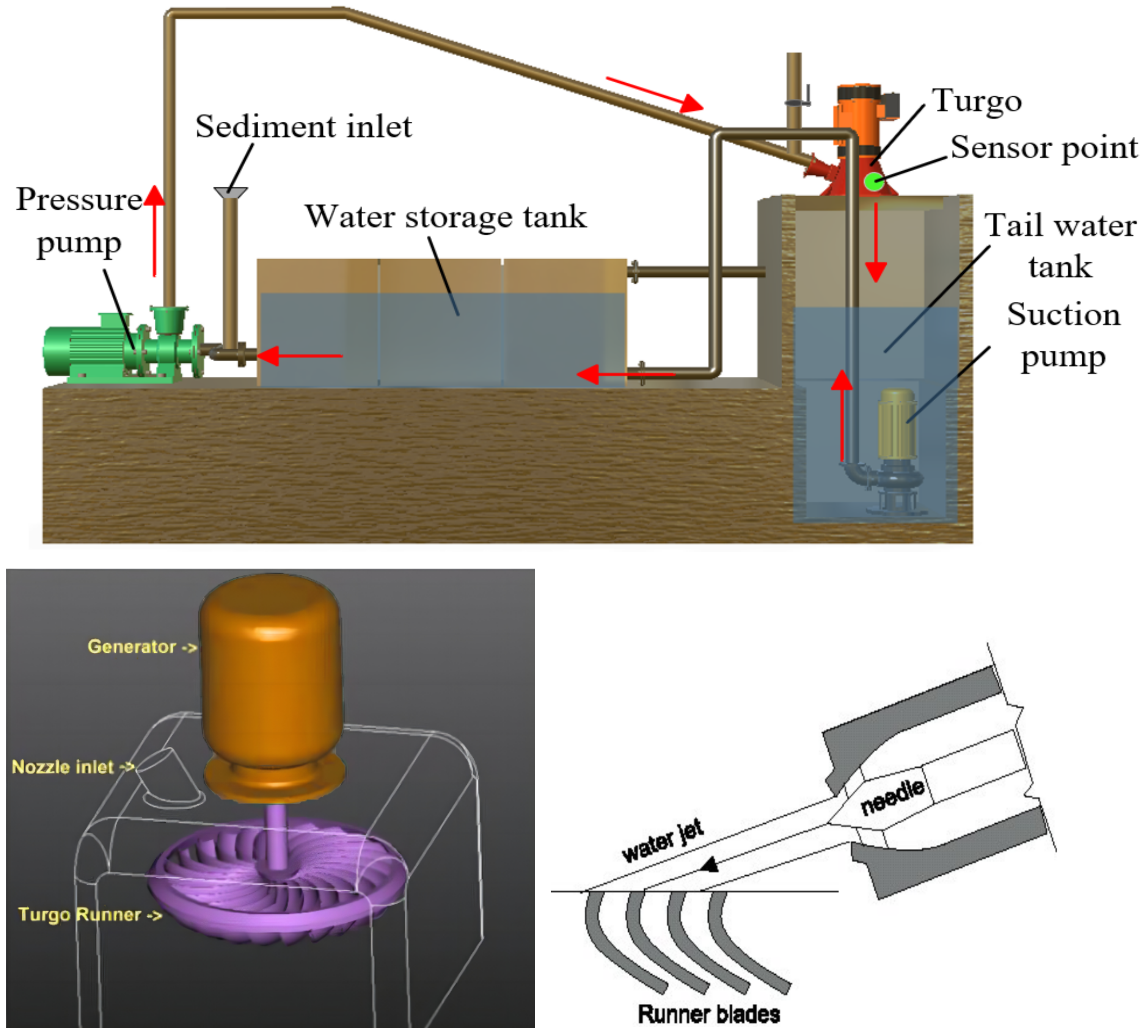
4.1. Test Bench
4.2. Data Collection
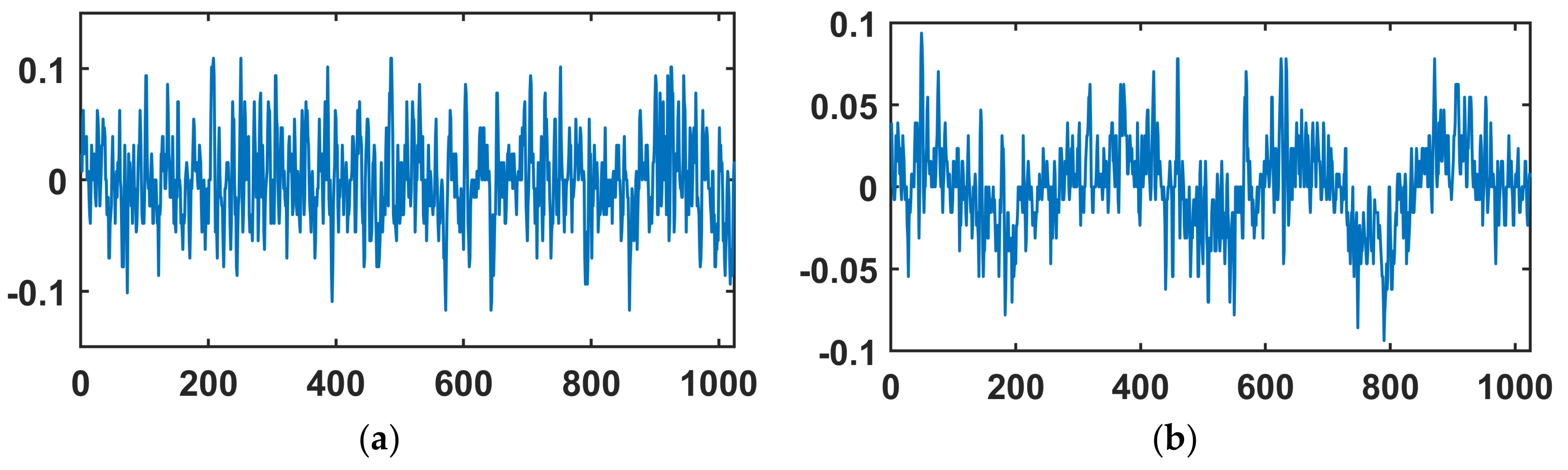
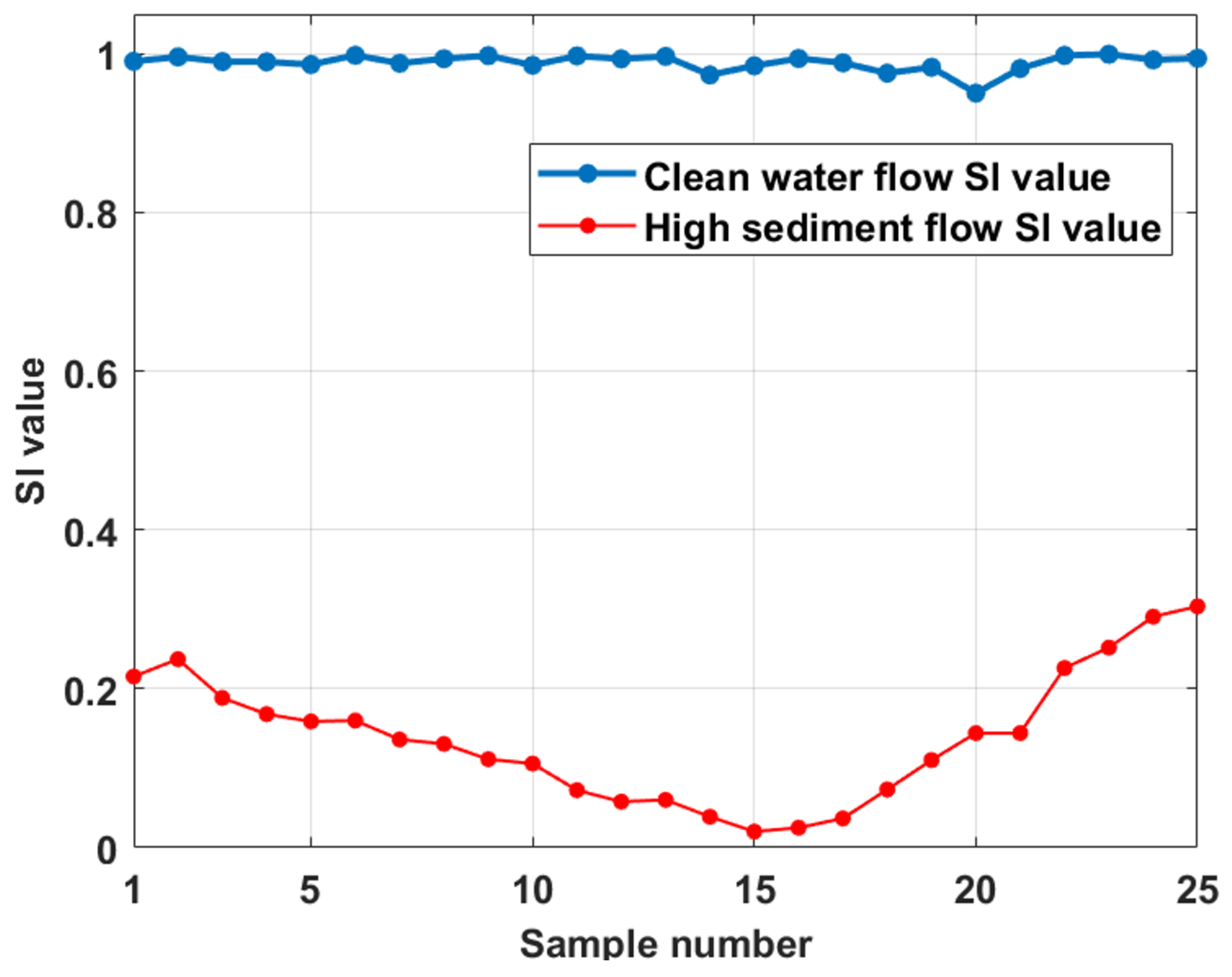
4.3. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Zhu, Y.; Xiao, Y. Numerical analysis of bucket hydro-abrasive erosion in a Impulse turbines on sediment season. J. Hydroelectr. Eng. 2024, 2, 1–8. [Google Scholar]
- Padhy, M.K.; Saini, R.P. A review on silt erosion in hydro turbines. Renew. Sustain. Energy Rev. 2008, 12, 1974–1987. [Google Scholar] [CrossRef]
- Khurana, S.; Varun Kumar, A. Effect of silt particles on erosion of Turgo impulse turbine blades. Int. J. Ambient Energy 2014, 35, 155–162. [Google Scholar] [CrossRef]
- Rai, A.K.; Kumar, A. Continuous measurement of suspended sediment concentration: Technological advancement and future outlook. Measurement 2015, 76, 209–227. [Google Scholar] [CrossRef]
- Rai, A.K.; Kumar, A.; Staubli, T. Effect of concentration and size of sediments on hydro-abrasive erosion of Pelton turbine. Renew. Energy 2020, 145, 893–902. [Google Scholar] [CrossRef]
- Rai, A.K.; Kumar, A. Sediment monitoring for hydro-abrasive erosion: A field study from Himalayas, India. International. J. Fluid Mach. Syst. 2017, 10, 146–153. [Google Scholar] [CrossRef]
- Zhou, X. Design of equipment fault diagnosis system based on audio analysis technology. J. Phys. Conf. Ser. 2023, 2433, 012033. [Google Scholar] [CrossRef]
- Huang, X.; Su, Z.; Sgu, S.; Rao, Z.; Hua, H. Vibroacoustic radiation of pump-.Jet hull coupling system under distributed pulsating pressure excitation. J. Vib. Shock 2021, 40, 1–9. [Google Scholar]
- Tang, Y.J.; Zhou, X.J.; Zhang, F. Application of noise analysis in fault diagnosis of hydropower units. J. China Rural. Water Hydropower 2017, 8, 206–208. [Google Scholar]
- Ni, J.; Hu, C.; Zhao, M. A ship radiation noise identification method based on VMD and improved CNN. J. Vib. Shock 2023, 42, 74–82. [Google Scholar]
- Zhou, S.; Hong, J.; Huang, C.J. Research on On-line Monitoring of tool wear State based on Acoustic emission Signal analysis. J. Tool Technol. 2022, 56, 51–55. [Google Scholar]
- Weng, Z.; Ll, N.; Yuan, J.; Liu, H.; Sun, X.; Hao, M.; Si, J. Friction state recognition of liquid film seal based on acoustic emission time-frequencyanalysis and convolution neural network. J. Lubr. Eng. 2023, 48, 136–141. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and nonstationary time series analysis. Proc. R. Soc. Lond. Ser. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.H.; Huang, N.E. Ensemble Empirical Mode Decomposition: A noise-assisted DATA analysis method. J. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- He, K.D.; Jia, C.H.E.N.; Yan, J.I.N.; Jiang, W.J.; Xiao, Z.H. Application of EEMD multi-scale entropy and ELM in feature extraction of vibration signal of hydropowerunit. J. China Rural. Water Hydropower 2021, 176, 187. (In Chinese) [Google Scholar]
- Yang, S.S.; Kim, Y.G.; Choi, H. Vehicle identification using discrete spectrums in wireless sensor networks. J. Netw. 2008, 3, 51–63. [Google Scholar] [CrossRef]
- Sun, Z.; Machlev, R.; Wang, Q.; Belikov, J.; Levron, Y.; Baimel, D. A public data-set for synchronous motor electrical faults diagnosis with CNN and LSTM reference classifiers. J. Energy AI 2023, 14, 100274. [Google Scholar] [CrossRef]
- Jasim, H.A.; Ahmed, S.R.; Ibrahim, A.A.; Duru, A.D. Classify bird species audio by augment convolutional neural network. In Proceedings of the 2022 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 9–11 June 2022; pp. 1–6. [Google Scholar]
- Chen, G.; Zhang, X.; Zhang, J.; Li, F.; Duan, S. A novel brain-computer interface based on audio-assisted visual evoked EEG and spatial-temporal attention CNN. J. Front. Neurorobotics 2022, 16, 995552. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J.; Yu, L. Signal processing of photoelectric weapon RF test based on EEMD. J. Artill. Launch Control 2023, 44, 19–23. [Google Scholar]
- Xiao, J.; Jin, J.; Li, C.; Xu, Z.; Luo, S. Fault diagnosis of wind turbine gearboxes based on deep learning. J. Sol. Energy 2023, 44, 302–309. [Google Scholar]
- Ksibi, A.; Hakami, N.A.; Alturki, N.; Asiri, M.M.; Zakariah, M.; Ayadi, M. Voice pathology detection using a two-level classifier based on combined CNN–RNN architecture. Sustainability 2023, 15, 3204. [Google Scholar] [CrossRef]
- Yan, R.; Lin, C.; Song, W.; Gao, S.; Zhong, L.; Zhang, W. Research on circuit breaker fault diagnosis based on EEMD and convolutional neural network. J. High Volt. Appar. 2022, 58, 213–220. [Google Scholar]
- Wang, H.; Zhu, J.; He, Z. Multivariable water level prediction model based on convolution radial basis network. J. Hydroelectr. Eng. 2023, 42, 70–81. [Google Scholar]
- Chen, Y.; Yang, L.; Li, S. Traffic congestion prediction algorithm based on CS-BiLSTM framework. J. Sci. Technol. Eng. 2022, 22, 12917–12926. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Runner Diameter/cm | Number of Runner Blades | Nozzle Diameter/mm | Distance from Nozzle to Blade/cm | Pipe Diamter/cm | Flow Rate/m3·h−1 | Pressure Pump Head/m | Rated Speed /rpm |
|---|---|---|---|---|---|---|---|
| 25 | 16 | 28 | 12 | 15 | 120 | 15 | 1500 |
| Parameter Name | Specification |
|---|---|
| Sampling rate | 48 kHz |
| Measurement frequency range | 10~20,000 Hz |
| Standard measuring range | 25~130 dBA |
| Measurement dynamic range | 110 dBA |
| Communication interface | USB Audio + USB SID |
| Structure | Parameter Configuration | Data Dimension | Structure | Parameter Configuration | Data Dimension |
|---|---|---|---|---|---|
| Input layer | — | 1 × 6 × 1024 | Activation layer 2 | ReLu | 16 × 7 × 516 |
| Convolution layer 1 | In channel = 1 | 8 × 8 × 1026 | Pooling layer 2 | MaxPool2d | 16 × 3 × 258 |
| Out channel = 8 | Convolution layer 3 | In channel = 16 | 32 × 6 × 264 | ||
| Kernel size = 3 | Out channel = 32 | ||||
| Stride = 1 | Kernel size = 3 | ||||
| Padding = 2 | Stride = 1 | ||||
| Activation layer 1 | ReLu | 8 × 8 × 1026 | Padding = 2 | ||
| Pooling layer 1 | MaxPool2d | 8 × 4 × 513 | Activation layer 3 | ReLu | 32 × 6 × 264 |
| Convolution layer 2 | In channel = 8 | 16 × 7 × 516 | Pooling layer 3 | MaxPool2d | 32 × 3 × 132 |
| Out channel = 16 | Fully connected layer 1 | 32 × 3 × 132, 6 | 6 | ||
| Kernel size = 2 | Fully connected layer 2 | 6 | 2 | ||
| Stride = 1 | classifier | Softmax | — | ||
| Padding = 2 | — | — | — |
| Sample Number | Dimension 1 | Dimension 2 | Dimension 3 | Dimension 4 | Dimension 5 | Dimension 6 | |
|---|---|---|---|---|---|---|---|
| Clean water flow | 15 | −9.0093 | 6.4762 | 8.0257 | −7.9252 | −6.6284 | 5.4979 |
| 16 | −9.8645 | 7.3514 | 8.93 | −8.8102 | −7.505 | 4.675 | |
| 17 | −10.0583 | 7.6418 | 9.1117 | −9.0261 | −7.7321 | 4.2243 | |
| 18 | −9.0093 | 6.4762 | 8.0257 | −7.9252 | −6.6284 | 5.4979 | |
| 19 | −10.2709 | 7.7413 | 9.3238 | −9.2237 | −7.8838 | 4.3558 | |
| High sediment flow | 35 | 16.4597 | −18.2944 | −17.3323 | 17.2836 | 18.2946 | 28.5648 |
| 36 | 26.8568 | −27.8913 | −27.5007 | 27.6373 | 27.875 | 35.9686 | |
| 37 | 20.1545 | −21.8032 | −20.9024 | 21.0477 | 21.6961 | 30.4255 | |
| 38 | 23.1942 | −24.5938 | −23.9545 | 24.0666 | 24.5519 | 33.6247 | |
| 39 | 24.7757 | −25.7658 | −25.3686 | 25.4017 | 25.6819 | 33.5591 |
| Dumped Sediment Mass | Pour Time | Theoretical Maximum Sediment Content | |
| Method 1 | 10 kg | 2 s | 1.492 × 105 mg/L |
| Method 2 | 10 kg | 3 s | 1 × 105 mg/L |
| Method 3 | 5 + 5 kg | 1 s + 1 s (interval) + 1 s | 1.492 × 105 mg/L |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, B.; Zeng, Y.; Hu, W.; Cheng, Y. Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal. Energies 2024, 17, 1041. https://doi.org/10.3390/en17051041
Xiao B, Zeng Y, Hu W, Cheng Y. Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal. Energies. 2024; 17(5):1041. https://doi.org/10.3390/en17051041
Chicago/Turabian StyleXiao, Boyi, Yun Zeng, Wenqing Hu, and Yuesong Cheng. 2024. "Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal" Energies 17, no. 5: 1041. https://doi.org/10.3390/en17051041
APA StyleXiao, B., Zeng, Y., Hu, W., & Cheng, Y. (2024). Feature Extraction of Flow Sediment Content of Hydropower Unit Based on Voiceprint Signal. Energies, 17(5), 1041. https://doi.org/10.3390/en17051041