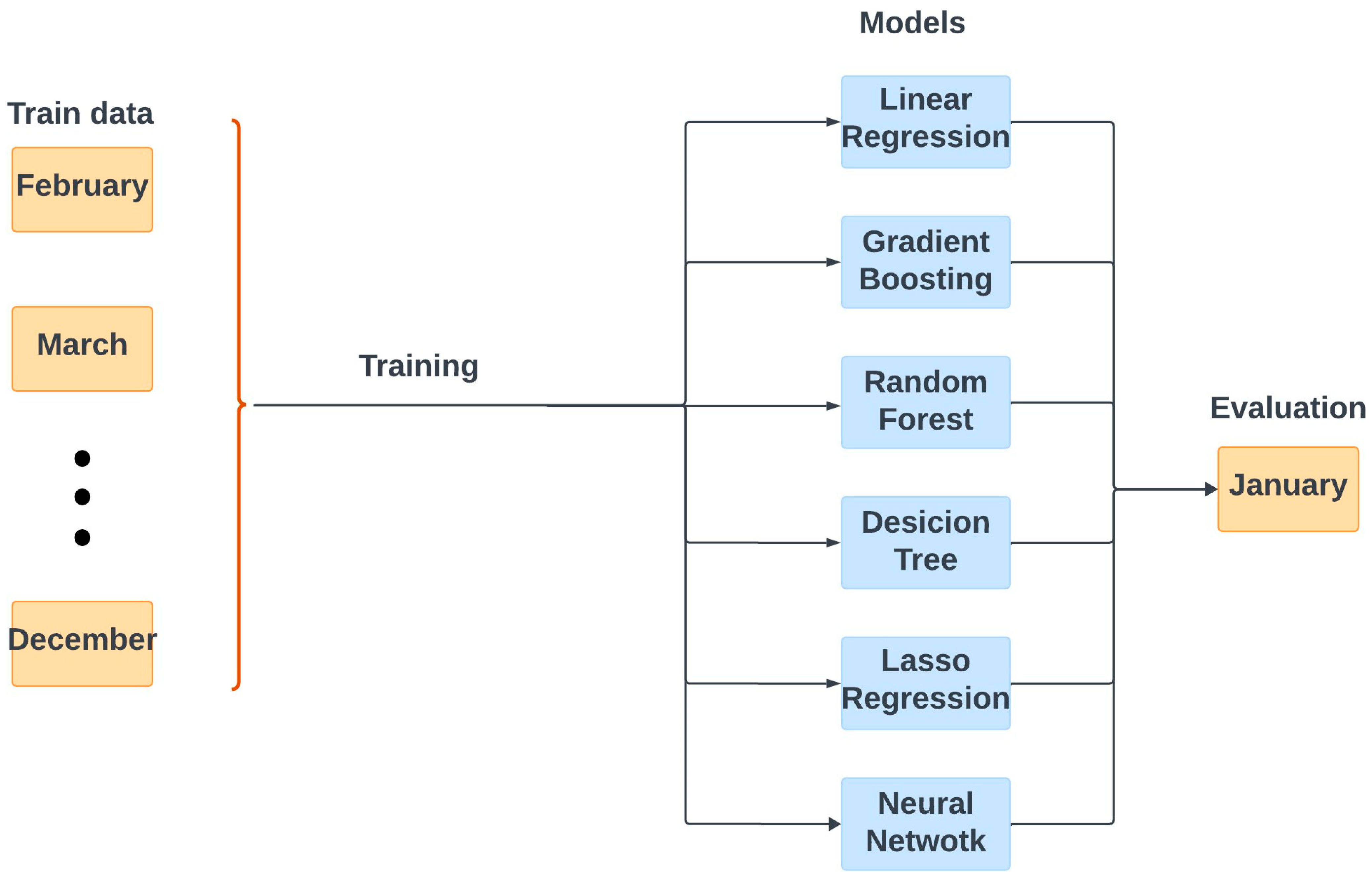
In this phase, various models were first implemented and tested individually. These included linear regression, lasso regression, neural networks, gradient boosting, decision trees, and random forest models. After evaluating the performance of each model across different months using the database of 153 buildings, the best-performing models were identified in order to develop a tree-based ensemble learning model and to optimize the performance by leveraging the strengths of each individual model.
3.2.1. Individual Model Development
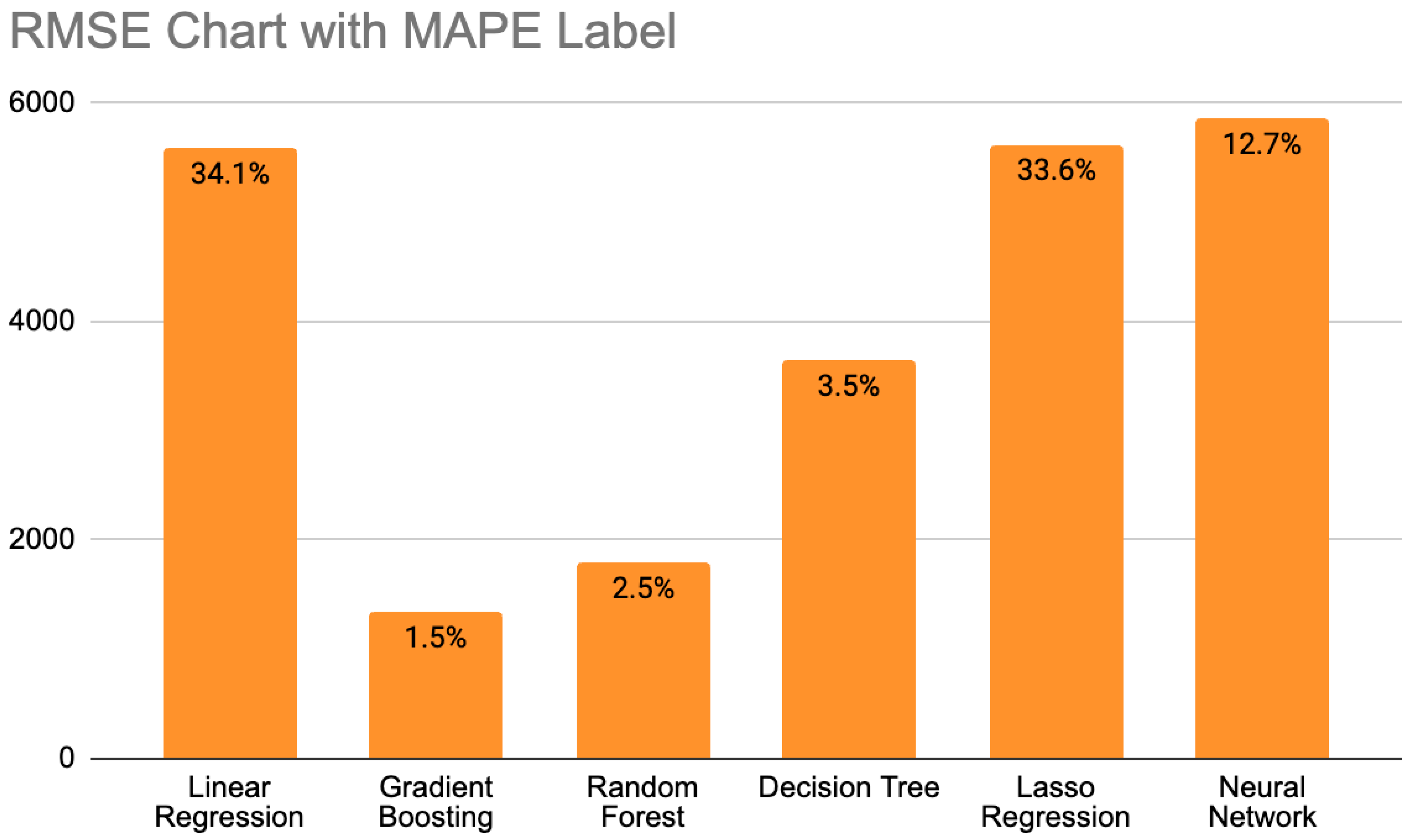
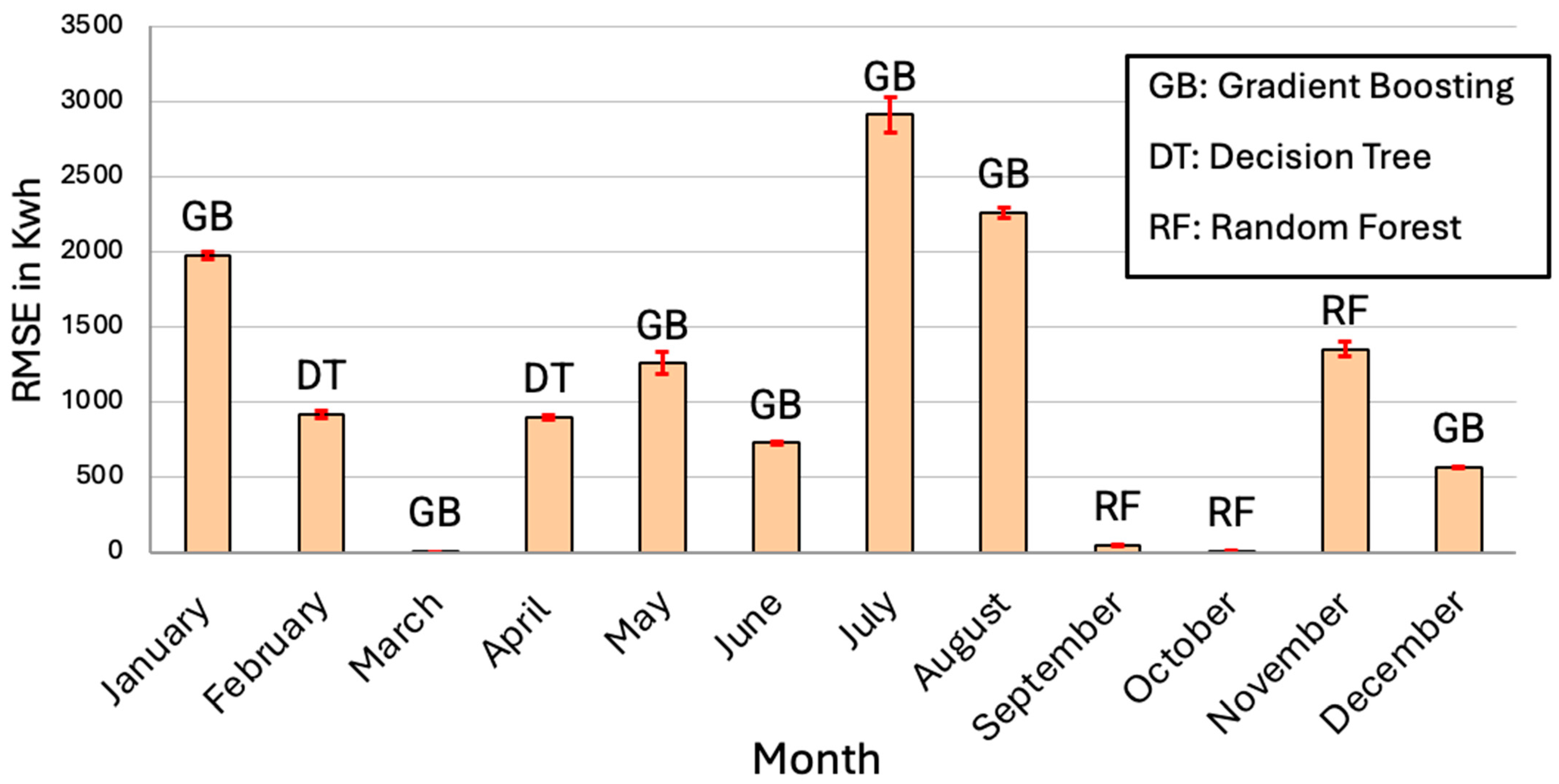
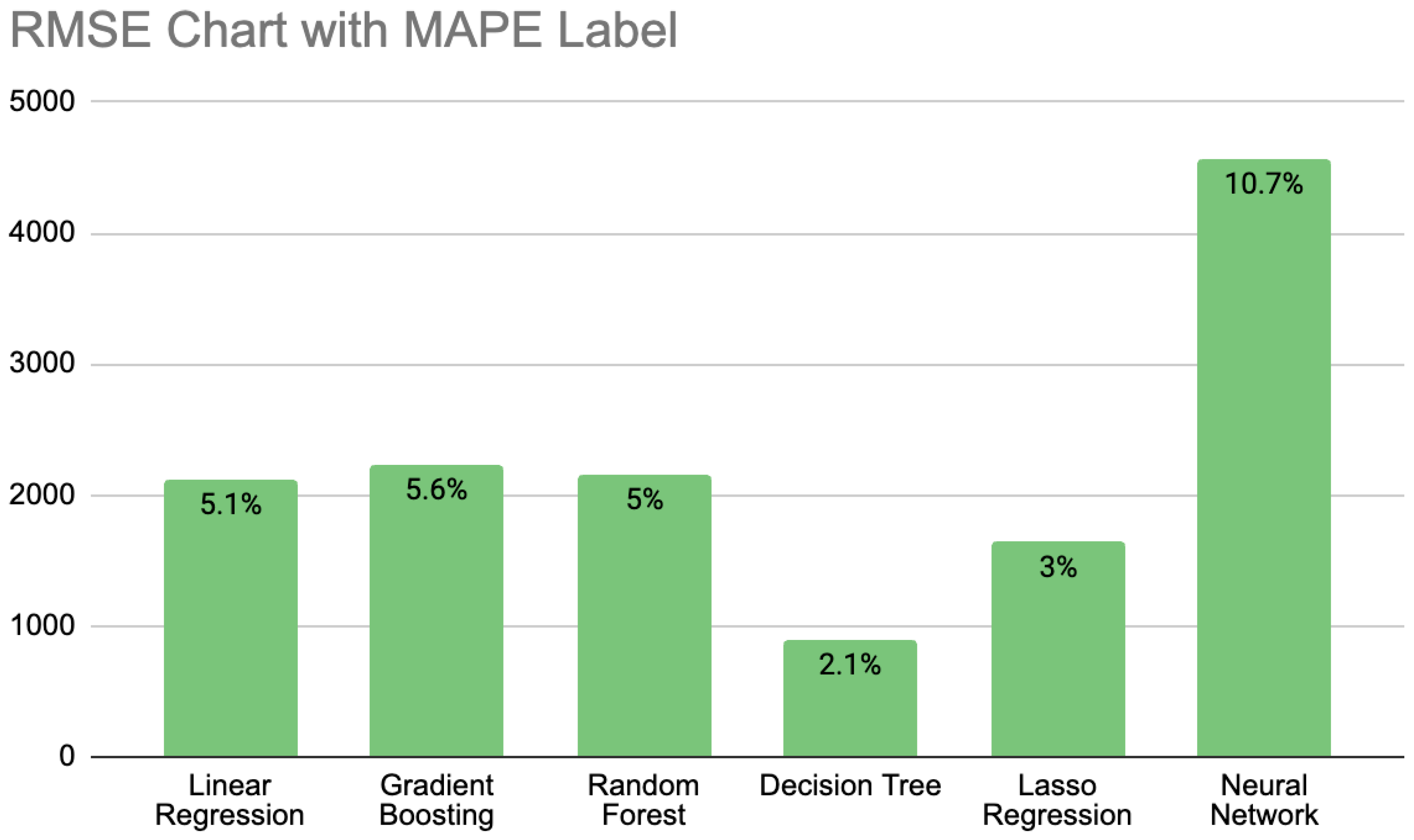
The first step of Phase II focused on implementing and evaluating various models, including linear regression, lasso regression, gradient boosting, random forest, decision tree, and neural networks, using the dataset prepared in Phase I. For each of the models, the best combination of features was studied to determine the optimal set. After training each individual model, including those listed above, the performance of each model was measured using root mean squared error (RMSE) and mean absolute percentage error (MAPE), shown in Equation (1) and Equation (2), respectively, which calculate the distance between the actual and predicted values.
where
represents the actual value,
represents the predicted value, and
n is the number of observations.
Linear regression is a statistical technique used to model the relationship between a dependent variable Y and one or more independent variables X. The primary objective of linear regression is to predict the value of Y based on the given values of X by fitting a “best line” through the data points. This technique assumes that the relationship between the variables is linear, meaning that changes in the independent variable X are associated with linearly proportional changes in the dependent variable Y.
The linear relationship can be expressed mathematically, as shown in Equation (3):
where
is the y-intercept and
is the slope of the regression line. These coefficients are estimated using methods such as the least squares estimator (LSE), which minimizes the sum of squared differences between observed and predicted values of
Y [
29].
Lasso regression, or “Least Absolute Shrinkage and Selection Operator”, improves ordinary least squares (OLS) by adding a penalty based on the absolute values of coefficients. This method addresses overfitting and enhances interpretability, particularly with many predictors. By shrinking some coefficients to zero, Lasso effectively performs variable selection while minimizing the residual sum of squares within a constraint. This results in a simpler and more interpretable model.
The mathematical formulation of lasso regression can be expressed as follows:
where
t is a tuning parameter that controls the strength of the penalty. This constraint allows lasso regression to shrink less important coefficients to exactly zero, which simplifies the model by reducing the number of predictors. This approach balances bias and variance and leads to models with better predictive performance and easier interpretation than those produced by OLS, particularly when high-dimensional data are involved [
30].
Gradient boosting is a powerful machine-learning technique that builds a predictive model by iteratively fitting weaker models to the residuals of previous iterations. The core idea is to minimize a loss function, L(y, F(x)), where F(x) is the model prediction and y is the true output. The process begins with an initial model, and in each iteration, the algorithm adds a new model that best reduces the loss function. This is achieved by fitting the new model to the negative gradient of the loss function with respect to the current model’s predictions. This approach can be formalized by solving the optimization problem , where the goal is to find the function F(x) that minimizes the expected loss.
In practice, gradient boosting involves constructing a model as a weighted linear combination of base learners, typically decision trees. The base learners are weak models that perform slightly better than random guessing. As described by the equation
where
represents the base learners, and each subsequent model in the sequence aims to correct the errors made by the previous ones. The algorithm determines the optimal parameters for these base learners using a steepest-descent approach. The gradient of the loss function guides the addition of new models. This iterative process continues until the model sufficiently reduces the loss function, leading to a strong predictive model [
31].
Random forests are an ensemble learning method that builds multiple decision trees during training and outputs the most common class (for classification) or average prediction (for regression). This method introduces randomness by randomly sampling training data (bagging) and selecting a subset of features for each tree split. This approach reduces model variance and helps prevent overfitting, particularly with noisy datasets. Each tree is trained independently, and the final prediction is an average of all trees’ predictions.
The generalization error of a random forest depends on the strength of the individual trees and the correlation between them. The margin function, which measures the extent to which the average number of votes for the correct class exceeds the votes for any other class, is a critical component in understanding the accuracy of the model. This can be mathematically expressed as
where ℎ(
X,
Θ) is the prediction of the tree classifier for a given input
X, and
Θ represents the random vector that governs the growth of each tree. A key insight provided by the analysis is that the generalization error decreases as the correlation between individual trees’ predictions decreases while maintaining a high strength for the individual trees [
32].
Decision trees are a widely used machine learning algorithm that recursively partitions a dataset into subsets based on the value of input features, ultimately aiming to improve the prediction accuracy of the target variable. The basic idea behind decision tree construction is to select the feature that best splits the data into subsets, where one class dominates. This selection is based on the concept of information gain, which measures how well a feature separates the classes. The information gain,
gain(
A) from using feature
A is calculated as the difference between the original entropy (a measure of uncertainty) and the weighted entropy after the split:
where
I(
p,
n) is the entropy of the entire dataset and
is the entropy of each subset created by the split on feature
A. Entropy is also defined as
where
is the probability of an arbitrary object belonging to class P and
refers to the probability of the same object belonging to class N.
The algorithm recursively splits data into subsets until they are “pure” (all members belong to a single class) or no further splits are meaningful. The ID3 algorithm prioritizes features with the highest information gain at each step, creating a tree structure where internal nodes represent features and branches represent feature values, with leaves indicating classification outcomes. While effective and interpretable, this method can be sensitive to noise and may lead to overly complex trees that overfit the data. Pruning strategies are used to remove less important branches, improving the model’s generalization to new data [
33].
Neural networks are computational systems inspired by the mammalian brain, designed to process data through layers of interconnected nodes, or “neurons.” These neurons receive inputs, process them via weighted connections, and use activation functions to produce outputs. The weights adjust during learning to minimize error. Neural networks excel in tasks like image recognition, machine translation, and pattern detection, making them powerful tools in machine learning and artificial intelligence [
34].
In the proposed neural network model, as shown in
Figure 3, two hidden layers with sizes of 64 and 32 neurons, respectively, are employed. The optimizer chosen for training the network is Adam, which stands for adaptive moment estimation. Adam combines the advantages of two other extensions of stochastic gradient descent: the ability to handle sparse gradients on noisy problems. The Adam optimizer updates the learning rate using the following formulas:
where
is the gradient of the objective function at time step t,
and
are the first and second moment estimates,
and
are the exponential decay rates for the moment estimates,
and
are bias-corrected moment estimates, η is the learning rate, and ϵ is a small constant to prevent division by zero [
35].
The activation function used in the hidden layers is the rectified linear unit (ReLU). ReLU is a widely used activation function in deep neural networks, known for its simplicity and efficiency. It works by outputting the input directly if it is positive and zero otherwise, making it a non-linear function. This function is mathematically defined as
where
x is the input. ReLU’s main advantage is that it introduces non-linearity without saturating the gradients, as is often the case with sigmoid or tanh functions. This helps avoid issues like the vanishing gradient problem during training. In practice, ReLU is applied to the output of neurons in hidden layers, allowing the network to model complex patterns. Its effectiveness has been demonstrated across various deep-learning tasks, such as image classification, natural language processing, and speech recognition [
36].
Parameter tuning was performed to optimize the model, including the selection of epochs, batch size, and other hyperparameters. Various configurations for the number of layers were also tested, with the best-performing architecture identified as a 2-layer model. Despite these efforts, the model consistently exhibited overfitting and did not demonstrate satisfactory performance, regardless of the parameter settings.
3.2.4. SHAP Analysis
SHAP (SHapley Additive exPlanations) is a method rooted in cooperative game theory that provides a unified approach to interpreting the predictions of machine learning models, particularly tree-based models. It calculates the contribution of each feature to the prediction by considering all possible feature combinations, ensuring that the explanations are both consistent and locally accurate. SHAP values uniquely satisfy properties of local accuracy, consistency, and missingness, making them ideal for understanding complex model behavior at both the local and global levels. This approach allows for detailed insights into how individual features interact to influence model predictions, offering a robust tool for model interpretability [
38]. SHAP enhances the decision-making processes, leading to more informed and reliable interpretability.
To improve model interpretability, SHAP analysis was performed individually for each tree-based model utilized in the ensemble learning approach: gradient boosting, decision tree, and random forest.
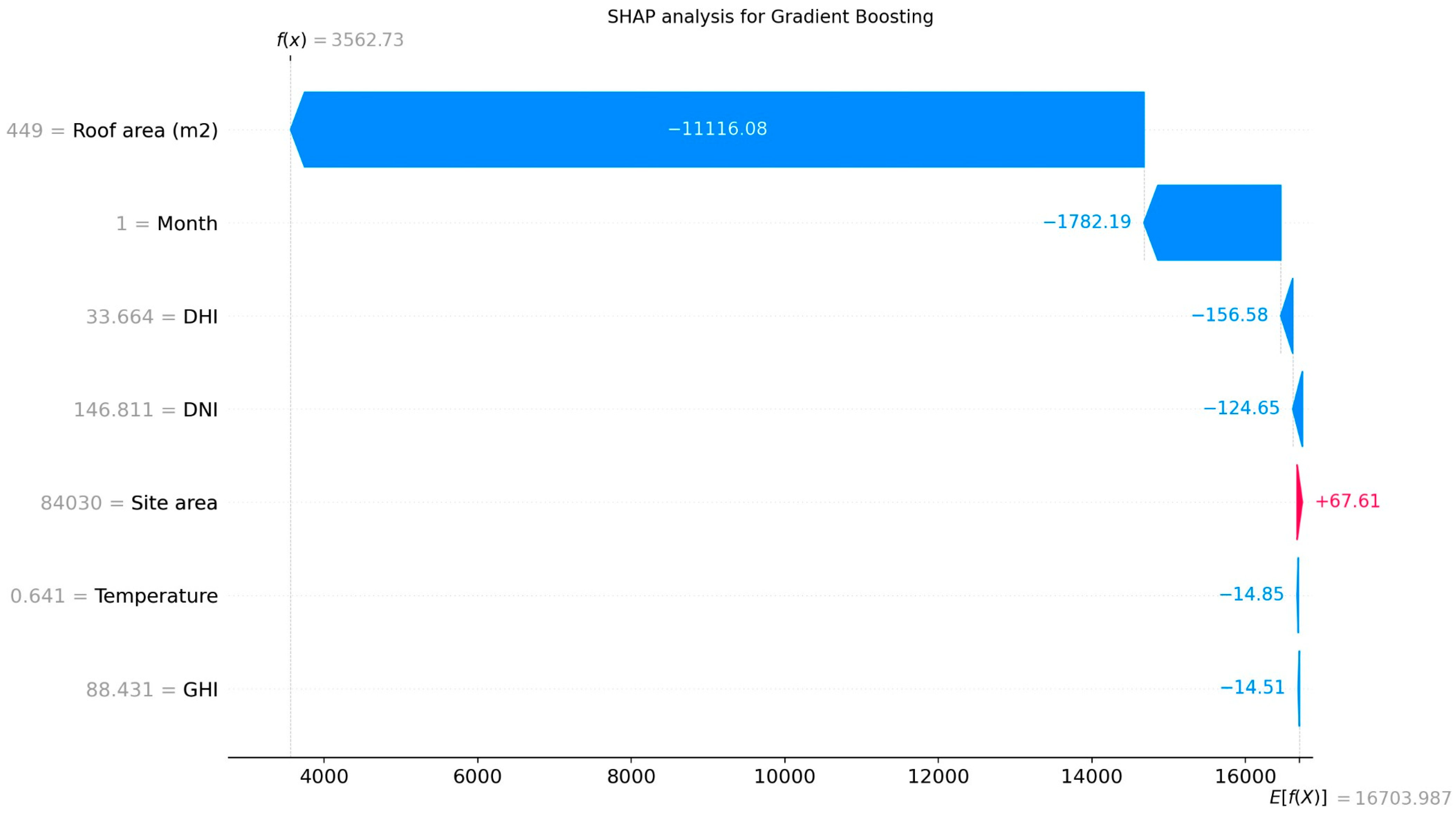
Figure 6 presents an example of SHAP results for the gradient boosting model and illustrates the contribution of each feature to the final prediction for a specific sample in the dataset.
For this purpose, we can take the mean SHAP values for each feature among all three tree-based models, as shown in
Table 1. The feature stability analysis across gradient boosting, random forest, and decision tree models reveals a high degree of consistency in SHAP values for most features. For instance, the SHAP values for the roof area (m
2) remain tightly clustered around 18,000 across all three models, indicating strong agreement regarding its contribution. Similarly, features like the month show stable SHAP values, ranging from 1787 to 2153, demonstrating consistent importance across models. While some features, such as DHI and DNI, exhibit slight variability in SHAP values, their contributions are relatively stable.
The statistical significance analysis of feature rankings, as shown in
Table 2, reveals notable variations across the decision tree, random forest, and gradient-boosting models. For all three models, the roof area (m
2) consistently emerges as the most significant predictor, with a
p-value of 0.000002 in the random forest model and 0.000029 in gradient boosting, indicating strong statistical significance. In contrast, the decision tree model shows a relatively higher
p-value of 0.072855 for this feature, suggesting marginal significance. Other features, such as the month and site area, demonstrate borderline significance in the random forest and gradient boosting models, but their
p-values remain above the conventional threshold of 0.05, particularly in the decision tree model. Features like Temperature, GHI, DNI, and DHI consistently exhibit high
p-values across all models, indicating they may not significantly contribute to the predictions. These results suggest that the random forest and gradient boosting models provide a more robust identification of key features with greater statistical confidence, while the decision tree’s rankings may be less stable or influenced by overfitting. This underscores the importance of considering multiple models to achieve a more reliable assessment of feature importance.
Several methods can be used to determine the feature importance threshold, with one practical approach being the setting of the threshold to the mean absolute value of SHAP values across all features. Using this threshold, the roof area is identified as the most significant feature, with an above-average SHAP value. This highlights the critical role of the roof area in the model’s predictions, a finding that is consistent across all three tree-based models employed in the analysis.
The addition of p-values provides insights into the statistical significance of the features in the proposed models, aiding in distinguishing between those with meaningful contributions and those that may not strongly relate to the model’s predictions. The standard threshold of 0.05 is used to assess statistical significance.
A p-value below 0.05 indicates a strong relationship between the feature and the model’s predictions, suggesting that the feature’s importance is consistent and unlikely due to random chance. For instance, the roof area (m2) consistently demonstrates very low p-values (0.000002 in random forest and 0.000029 in gradient boosting), emphasizing its statistical significance across both models. This result confirms that the roof area is a key feature in all models.
Conversely, a p-value above 0.05 suggests that the feature may not strongly relate to the model’s predictions. For example, the temperature, GHI, DHI, and DNI exhibit high p-values across all models, with values exceeding 0.05. The relatively low importance of features like GHI, DNI, and DHI can be attributed to the small geographic area of the University of Maryland, where weather and solar radiation conditions remain relatively uniform across the campus. Consequently, these features do not emerge as critical predictors due to their limited variability and impact on model performance.
Features such as the site area and month show borderline significance in some models but have p-values above 0.05, suggesting that their contributions may vary across different models.
p-values thus provide a statistical foundation for evaluating the reliability of feature importance rankings. Features with low p-values, such as the roof area, are strongly supported as key contributors, while features with higher p-values indicate weaker or more variable effects. This highlights the value of using multiple models for feature selection, as models like random forest and gradient boosting consistently identify important features, whereas models like decision trees.




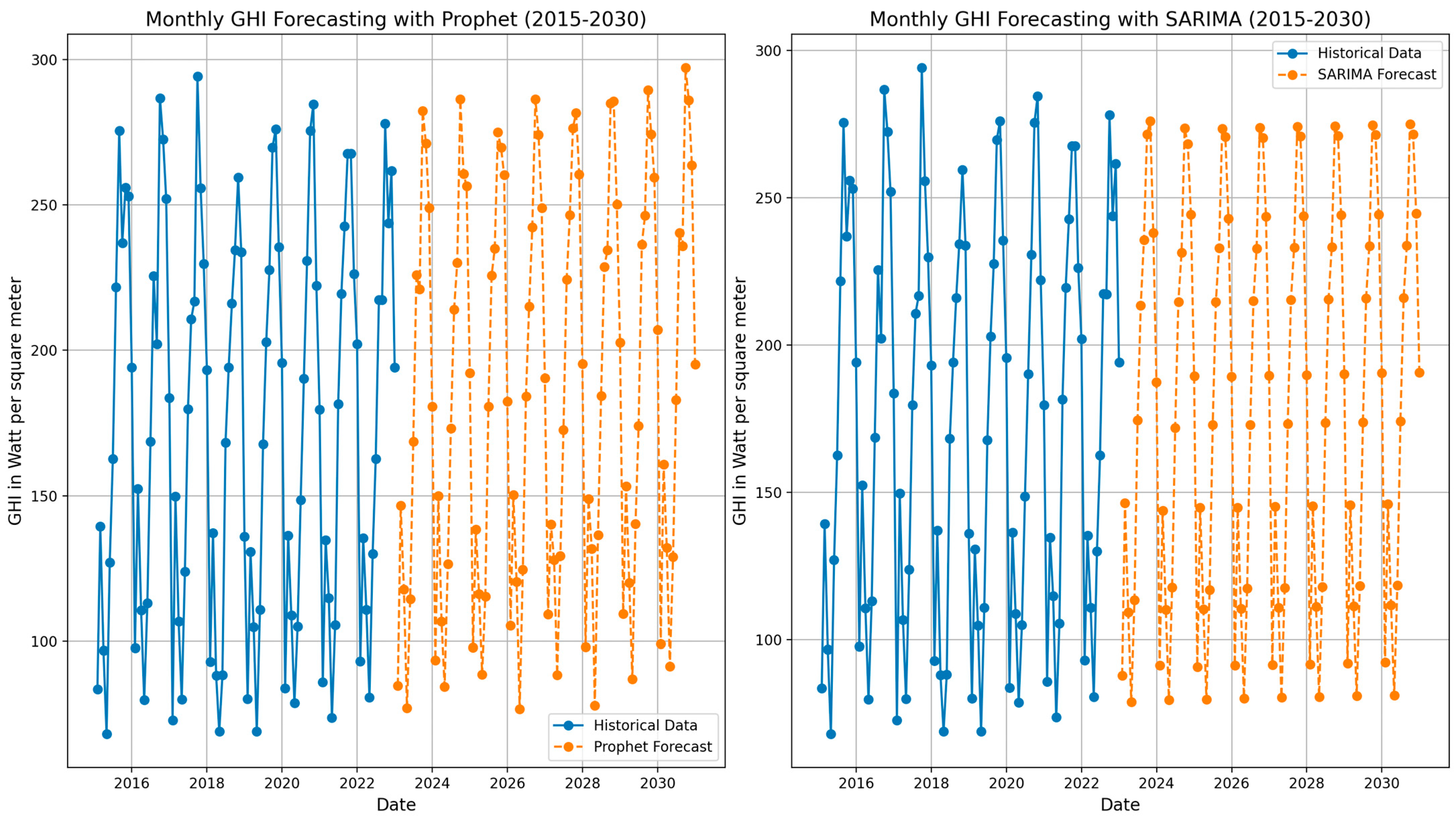
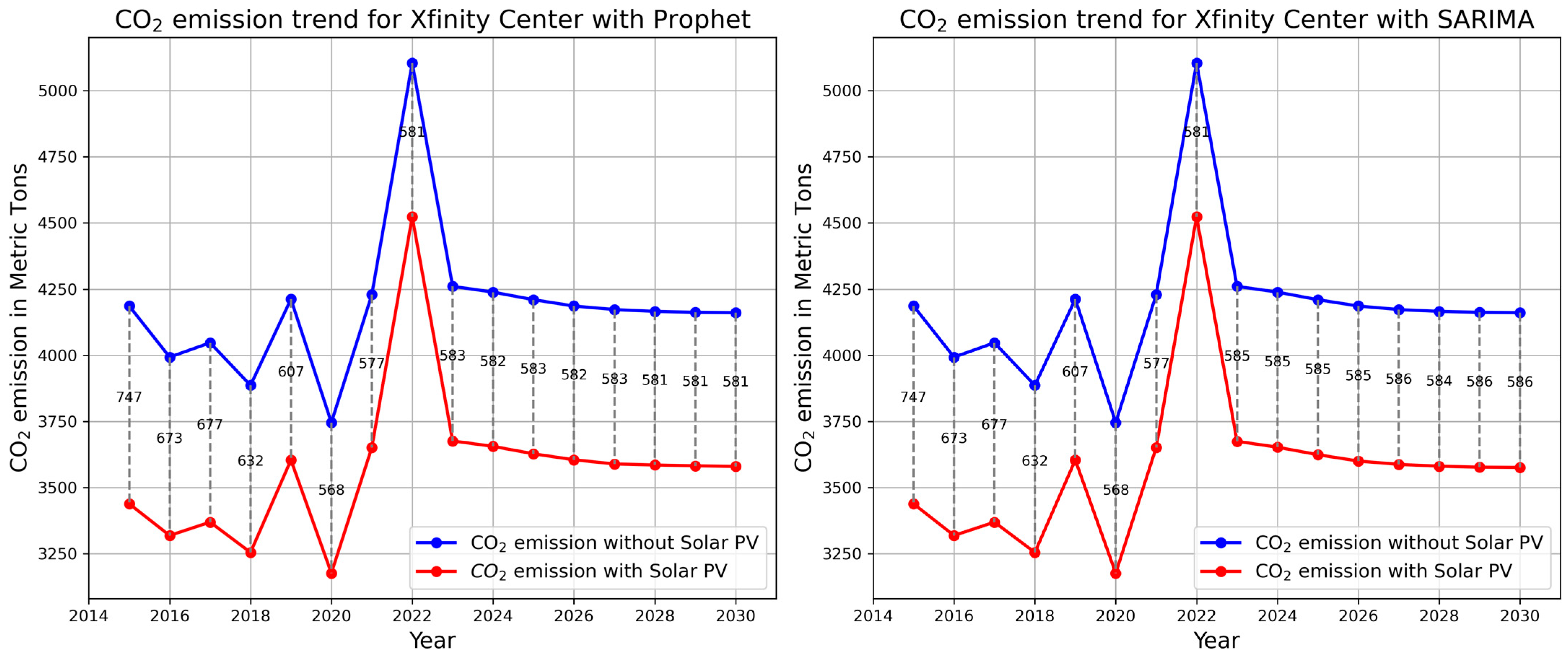

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}