4.1. Machine Learning-Based Predictions of Heat Transfer Characteristics
As mentioned earlier, machine-learning regression models were developed to predict the average Nusselt number in a lid-driven cavity with a rotating cylinder. Three different machine-learning models were applied: random forest regression, neural networks, and Gaussian process regression. Additionally, a conventional linear regression approach was employed for comparison purposes. The model’s predictive performance is demonstrated by the close agreement between the predicted and actual Nusselt number (Nu) values. In this study, the dataset was split into 70% for training and 30% for testing. The scatter plots (see
Figure 2), which compare the predicted versus actual Nu values for the test set, show a strong correlation, with most points closely aligned along the 45-degree line. This indicates a minimal deviation between the predicted and actual results for the tested ML models. In particular, the alignment is apparent for the random forest and neural network models, which exhibit a high predictive accuracy across a broad range of flow conditions.
Initial observations indicate that the performance of linear regression is limited in its ability to model the intricacies of the flow. While this baseline model achieves an acceptable
R2 score, its error metrics, particularly the mean absolute error (MAE), are considerably higher than those of more advanced machine-learning techniques. This disparity becomes evident as one moves to more sophisticated models, particularly random forest, which consistently exhibits a superior accuracy. As shown in the comparative performance metrics (as depicted in
Table 1), the random forest model achieves the highest
R2 and the lowest errors across all measures, clearly outperforming other models. This suggests its ability to handle the nonlinearity and high-dimensionality inherent in the fluid dynamics data, particularly when capturing the turbulent structures that significantly impact heat transfer.
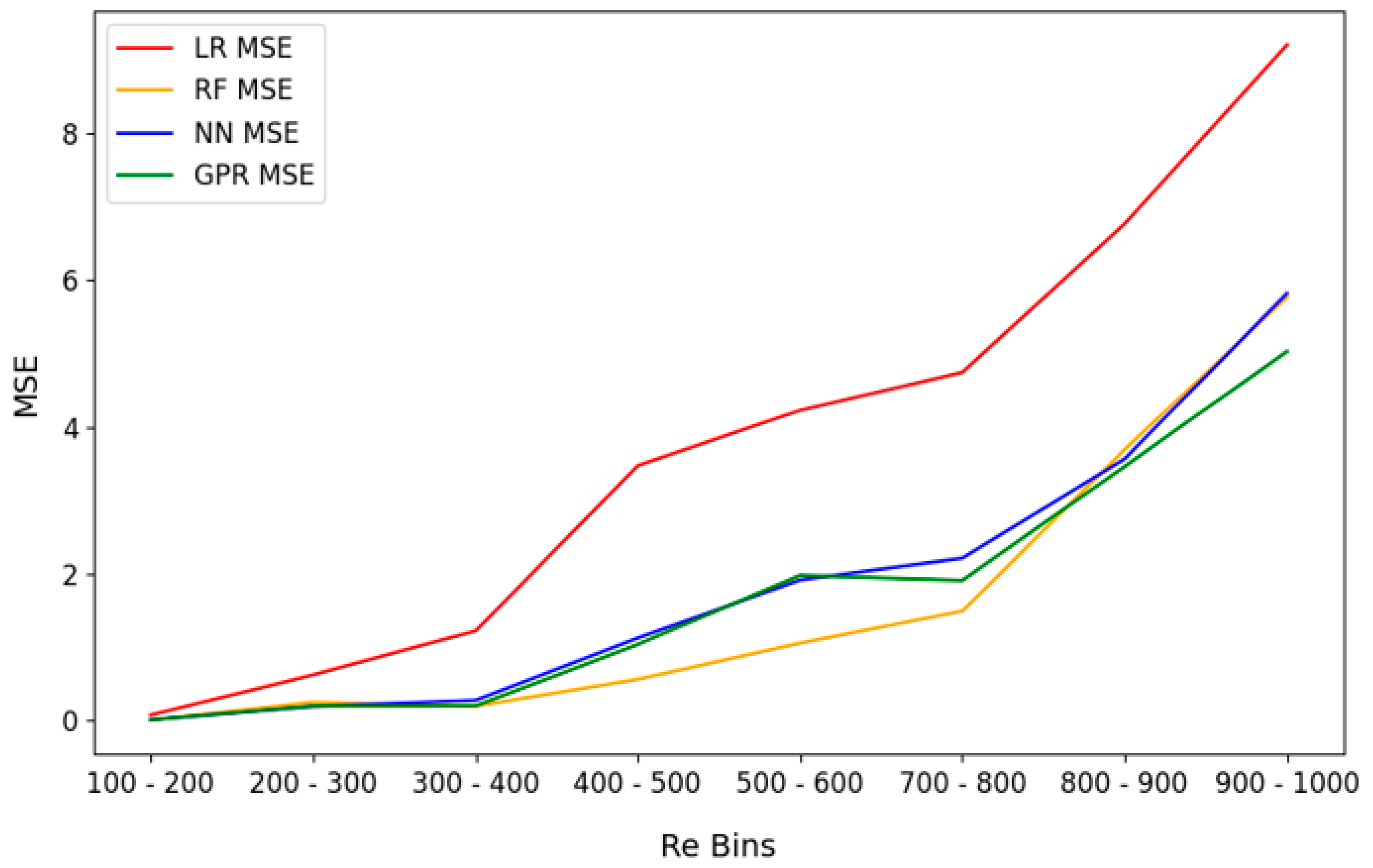
The neural network also performs well, closely trailing random forest in terms of accuracy. Although it shows slightly lower precision in predicting extreme conditions compared to random forest, its overall performance remains robust, especially when analyzing flow regimes characterized by moderate turbulence. These findings are further substantiated by the cross-validation results, where the mean squared error (MSE) of both random forest and neural network models remains consistently low across the entire range of Reynolds numbers, as illustrated in the cross-validation analysis observed in
Figure 3. Random forest, in particular, demonstrates notable stability in its predictive capacity, maintaining low errors even as the Reynolds number approaches higher, more turbulent values.
An important part of the model interpretation involves understanding the impact of the key flow parameters—Reynolds number (Re), Richardson number (Ri), and the rotational speed of the cylinder (ω)—on the prediction of the average Nusselt number. Feature importance analysis is performed using SHAP (Shapley additive explanations, Microsoft Research: Redmond, WA, USA) value analysis, a method derived from cooperative game theory that helps to interpret complex machine-learning models by quantifying the contribution of each feature to the model’s predictions. SHAP values attribute an individual contribution to each feature by comparing the model’s output with and without that feature. It can be seen that Re consistently emerges as the feature with the highest average impact on model predictions, as depicted in
Figure 4. This indicates the role of inertia in driving heat transfer within the cavity over the buoyancy and rotational effects.
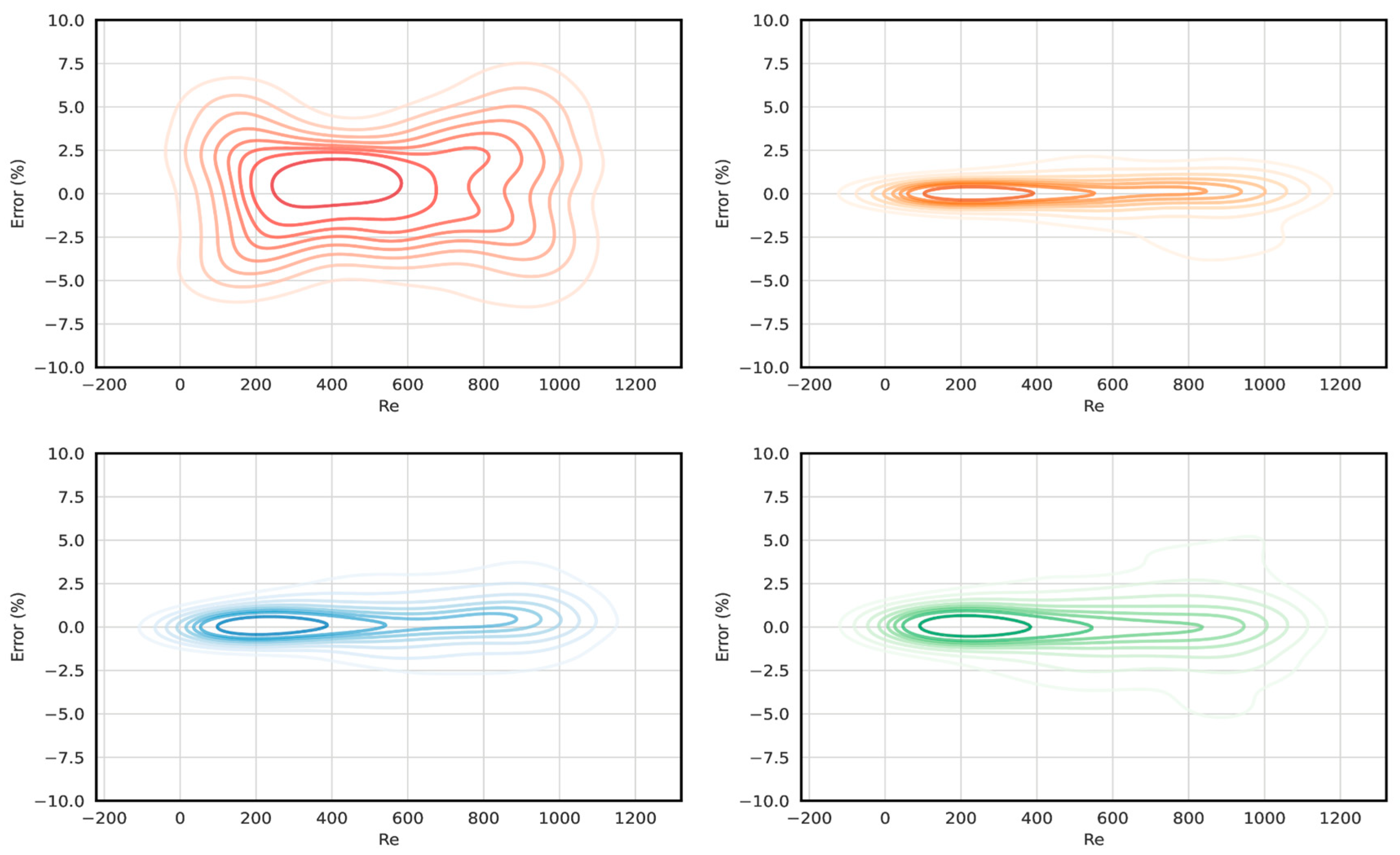
The error distribution across the different flow parameters is also tested to provide a better view into the strengths and weaknesses of the models. Among the key parameters affecting the predicted average Nusselt number (Nu), the Reynolds number (Re) consistently stands out as the most significant, as highlighted in the feature importance analysis. Given the dominant role of Re in the prediction process, we focus on the error contours for Re to examine the model’s accuracy under varying flow conditions.
Figure 5 illustrates the error contours for the Reynolds number across the tested ML models; the contours indicate that the random forest model (orange) and neural network (blue) show the lowest error values throughout the entire range of Re, demonstrating their ability to better capture the complex flow dynamics at higher Reynolds numbers. The Gaussian process regression model (green) follows closely, but with slightly higher errors in the upper Reynolds number range. Conversely, the linear regression model (red) exhibits the largest errors, particularly at higher Reynolds numbers, where the flow becomes more turbulent. This suggests that linear regression struggles to account for the nonlinear and chaotic nature of the flow at higher Re values, in contrast to more advanced models like random forest and neural network models, which manage to retain predictive accuracy even under these more challenging flow conditions.
4.2. Efficiency of Physics-Informed Neural Networks (PINN) in a Lid-Driven Cavity with a Rotating Cylinder
Physics-informed neural networks (PINNs) represent a groundbreaking approach that merges machine learning with physical laws to tackle complex problems. By embedding differential equations and boundary conditions directly into the training process, PINNs ensure that the solutions adhere to fundamental physical principles, such as the conservation of mass, momentum, and energy. This method is particularly advantageous in fields like flow and heat transfer. In fluid dynamics, PINNs can model intricate flow patterns by incorporating the Navier–Stokes equations, offering insights into phenomena ranging from aerodynamics to climate modeling. For heat transfer, PINNs solve problems related to temperature distribution and thermal conduction by integrating heat diffusion equations. The advantages of PINNs include their ability to handle complex and high-dimensional problems efficiently while ensuring physical consistency. They can significantly reduce the need for extensive data and computational resources, as the physical laws guide the learning process. However, the performance of PINNs is highly dependent on the choice of network architecture and hyperparameters, both of which play a crucial role in accurately capturing complex phenomena like flow dynamics. The architecture, including the number of layers, neurons, and activation functions, affects the network’s ability to model nonlinear behaviors, while the loss function must balance data-driven learning with the satisfaction of physical laws, such as conservation equations. Hyperparameters, such as the learning rate, batch size, and regularization, also significantly influence how well the model converges and generalizes. A poorly tuned learning rate can cause the model to oscillate or slow down convergence, while incorrect batch sizes or regularization terms may lead to overfitting or failure to capture critical flow features. Because PINNs must learn both from data and the governing physical equations, improper tuning can result in inaccurate representations of important flow dynamics, such as vortex formation or pressure gradients, especially in complex setups like a lid-driven cavity with a rotating cylinder. Therefore, optimizing the network architecture and hyperparameters is essential for the model to effectively generalize across different flow regimes, and failing to do so can lead to suboptimal or erroneous solutions.
In the study discussed, PINNs are tested on a heat transfer benchmark—specifically a buoyancy lid-driven thermal cavity with a rotating cylinder placed at the center of the cavity—to evaluate its performance. To the best knowledge of the present authors, this configuration never studied in the literature. As mentioned earlier, majority of the studies were focused on lid-driven flow and heat transfer inside a cavity. The fluid flow and thermal behavior inside a lid-driven cavity with a rotating cylinder are modeled using PINNs. The flow is analyzed for two Reynolds numbers,
Re = 100 and
Re = 1000, with comparisons made between actual data generated from computational fluid dynamics (CFD) simulations, PINN models trained with CFD data, and pure PINN models constructed without prior knowledge of data. The data-driven PINN model is constructed using pre-generated CFD data exported from Fluent, containing information on the velocity components u, v, pressure p, and temperature T fields at different Reynolds numbers. These data are used to train the neural network to predict flow and temperature fields with high accuracy. The neural network architecture consists of four hidden layers, each with 60 neurons, SiLU (sigmoid linear unit) is used as the activation function, which is known to improve convergence rates. The SiLU activation function is defined as follows:
where
σ(
x) is the sigmoid function. This choice of activation helps to capture the nonlinear dynamics of the system more effectively than the standard Tanh function. In this model, the loss function includes terms derived from the residuals of the continuity, momentum, and energy equations, which govern fluid flow and heat transfer. The training process involves optimizing the network parameters using the Adam optimizer, with the model trained for 10,000 epochs. PINNs combine data-based loss with the physics-informed loss by enforcing the residuals of the PDEs. A typical loss function,
L, for PINNs can be expressed in general form as follows:
where
Ldata is the mean squared error (MSE) loss based on the difference between predicted and observed data (if available).
Lphysicsi is a loss term associated with the residuals of each governing equation (e.g., continuity, momentum, and energy).
λi is a weighting factor for different physics terms.
Each residual loss term ensures that the model predictions satisfy the underlying physical laws:
The loss function for this model is a combination of the mean squared error (MSE) between the predicted and actual values for each field, as well as a penalty term to enforce adherence to the no-slip condition on the surface of the rotating cylinder. This no-slip boundary condition ensures that the fluid velocity on the cylinder’s surface equals the tangential velocity imposed by the rotation of the cylinder, calculated as follows:
vθ = −
ω ×
r, where
ω is the angular velocity and
r is the radial distance from the center of the cylinder. The total loss function is then expressed as follows:
where
Lu +
Lv +
Lp +
LT represent the MSE losses for the velocity components, pressure, and temperature fields, respectively, and L
boundary enforces the boundary conditions. The optimization process adjusts the neural network weights to minimize this loss over the specified number of epochs. Training data are interpolated onto a high-resolution grid, and a mask is applied to exclude points inside the rotating cylinder. In contrast to the data-driven approach, the second model employed a physics-based PINN method, often referred to as a purely physics-informed model. This approach does not rely on any pre-existing data but instead directly incorporates the governing Navier–Stokes and energy equations into the loss function, thus enforcing the physics of the system throughout the training process. The neural network architecture for this model consists of four layers with 50 neurons each, using the
SiLU activation function, similar to the data-driven PINN model. Automatic differentiation is used to compute the necessary spatial derivatives of the predicted fields, allowing the model to enforce these physical laws. Additionally, the boundary conditions for the top wall (driven by velocity), bottom wall (stationary but thermally active), side walls, and the rotating cylinder are included as constraints in the loss function. The training process is carried out for 50,000 epochs, using the Adam optimizer and the total loss function in this model is defined as follows:
where
Lcontinuity ensures mass conservation,
Lmomentum corresponds to the momentum equations, and
Lenergy enforces the energy equation. The boundary loss term
Lboundary is used for satisfying the boundary conditions at the walls and cylinder surface. The model is evaluated in the same Reynolds number regimes as the data-driven model.
The data-driven PINN model relies on the pre-existing CFD data to predict the flow and thermal fields. By training on actual data, the model implicitly learns to satisfy the governing equations and physical constraints, such as the continuity condition, without needing to explicitly compute the governing equations during training. This enables the model to focus on minimizing the error relative to the given data, which leads to faster training and more accurate predictions, particularly in cases where the flow behavior is intricate or nonlinear. On the other hand, the physics-based PINN model solves for the velocity components u, v, pressure p, temperature T, and stream function ψ by enforcing the governing Navier–Stokes and energy equations through automatic differentiation. The stream function ψ is used to ensure that the incompressibility condition ∇·u = 0 is automatically satisfied, simplifying the enforcement of the continuity equation. The momentum equations are expressed in terms of ψ, which governs the vorticity and streamlines of the flow, while the energy equation models the temperature distribution. The derivatives required for these equations are computed automatically through the network, and boundary conditions are applied as part of the loss function. This approach allows the physics-based PINN to predict flow behavior in situations where external data are unavailable, but it may become computationally more challenging when applied to more complex or turbulent flows, as it relies solely on the enforcement of physical laws through the loss function. The accuracy of PINNs is fundamentally tied to the precision of the embedded physical models. PINNs rely on the incorporation of governing physical laws, such as the Navier–Stokes equations for fluid flow or energy equation for thermal analysis, to guide the learning process alongside data. If these physical models are not accurately formulated or do not fully capture the complexities of the real-world system, the resulting predictions may deviate from actual behavior. This is particularly critical in complex flow scenarios, such as turbulent or multiphase flows, where even small inaccuracies in the representation of physical laws can lead to significant errors in the predicted velocity fields, temperature distributions, or pressure gradients. In cases involving complex geometries or boundary conditions, such as a lid-driven cavity with a rotating cylinder, any oversimplification or misrepresentation of the physical dynamics can cause the PINN to struggle in capturing phenomena like vortex formation or heat transfer patterns. Thus, the fidelity of the physical models embedded within PINNs directly constrains the network’s ability to make accurate and reliable predictions in real-world applications.
Both models are evaluated at the Reynolds numbers Re = 100 and Re = 1000, with the predictions for each field plotted and compared against the actual data generated from running the case using Fluent Ansys.
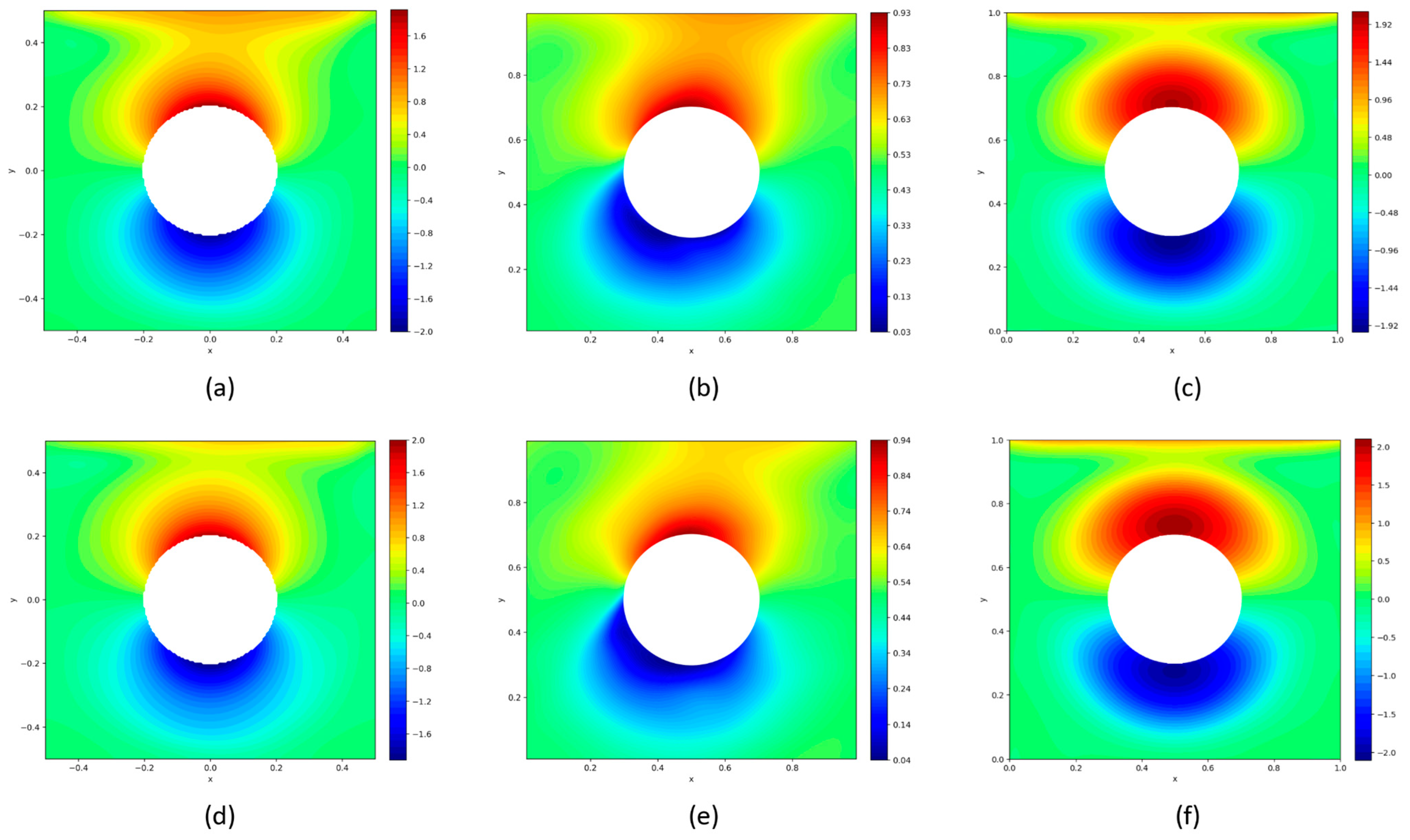
Figure 6 shows the contours of the u-velocity for the lid-driven cavity with a rotating cylinder at its center, comparing with the actual data, the data-driven PINN results, and the physics-based PINN results for
Re = 100 and
Re = 1000, respectively. The actual data for
Re = 100 and
Re = 1000 demonstrate the expected flow behavior. At
Re = 100 (
Figure 6a), the flow is smooth, laminar, and symmetric around the rotating cylinder. The regions of positive and negative u-velocity are well-defined, with a clear recirculation zone above the cylinder (positive
u) and a symmetric downward flow below (negative
u). As the Reynolds number increases to
Re = 1000 (
Figure 6d), the flow becomes highly nonlinear, and the gradients of the u-velocity field become sharper, particularly around the cylinder. The recirculation zones tighten, indicating increased shear due to higher inertia forces. The data-driven PINN model results for both
Re = 100 and
Re = 1000 depicted in
Figure 6b,e show a high degree of similarity to the actual data. At
Re = 100, the recirculation zones and velocity transitions are captured accurately, with smooth gradients and proper representation of the laminar flow characteristics. At
Re = 1000, the model continues to perform well in predicting the sharper gradients and tighter recirculation regions around the cylinder that arise due to the rotation of the cylinder. On the other hand, the results of the physics-based PINN model, shown in
Figure 6c,f, correctly capture the general flow pattern but tend to produce overly smooth results, especially at
Re = 1000. At
Re = 100, the flow structure is largely correct, but the contours show a lack of irregularities that are present in the actual data and the data-driven model. This is even more pronounced at
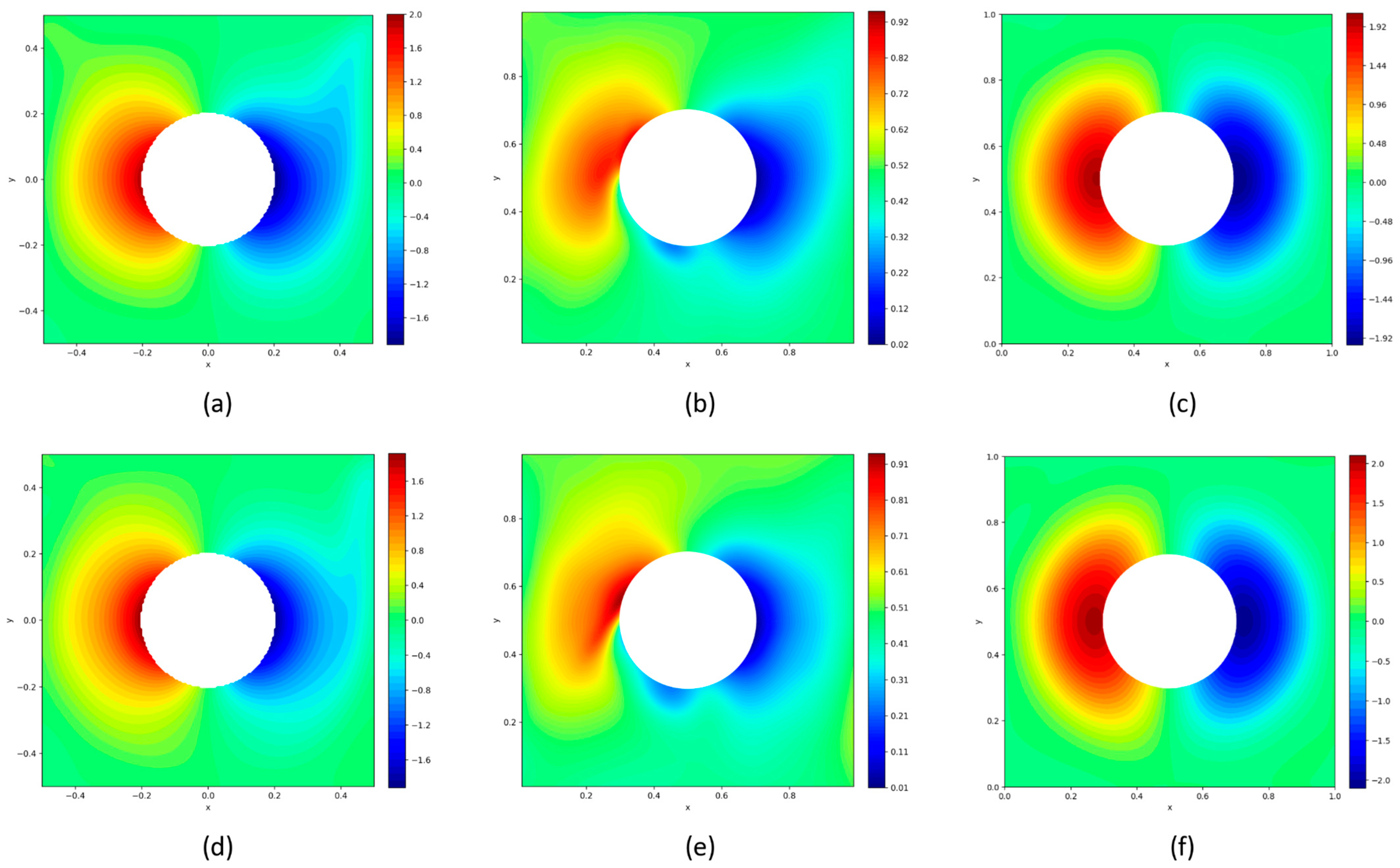
Re = 1000. This behavior can also be observed in the v-velocity analysis, as observed in
Figure 7.
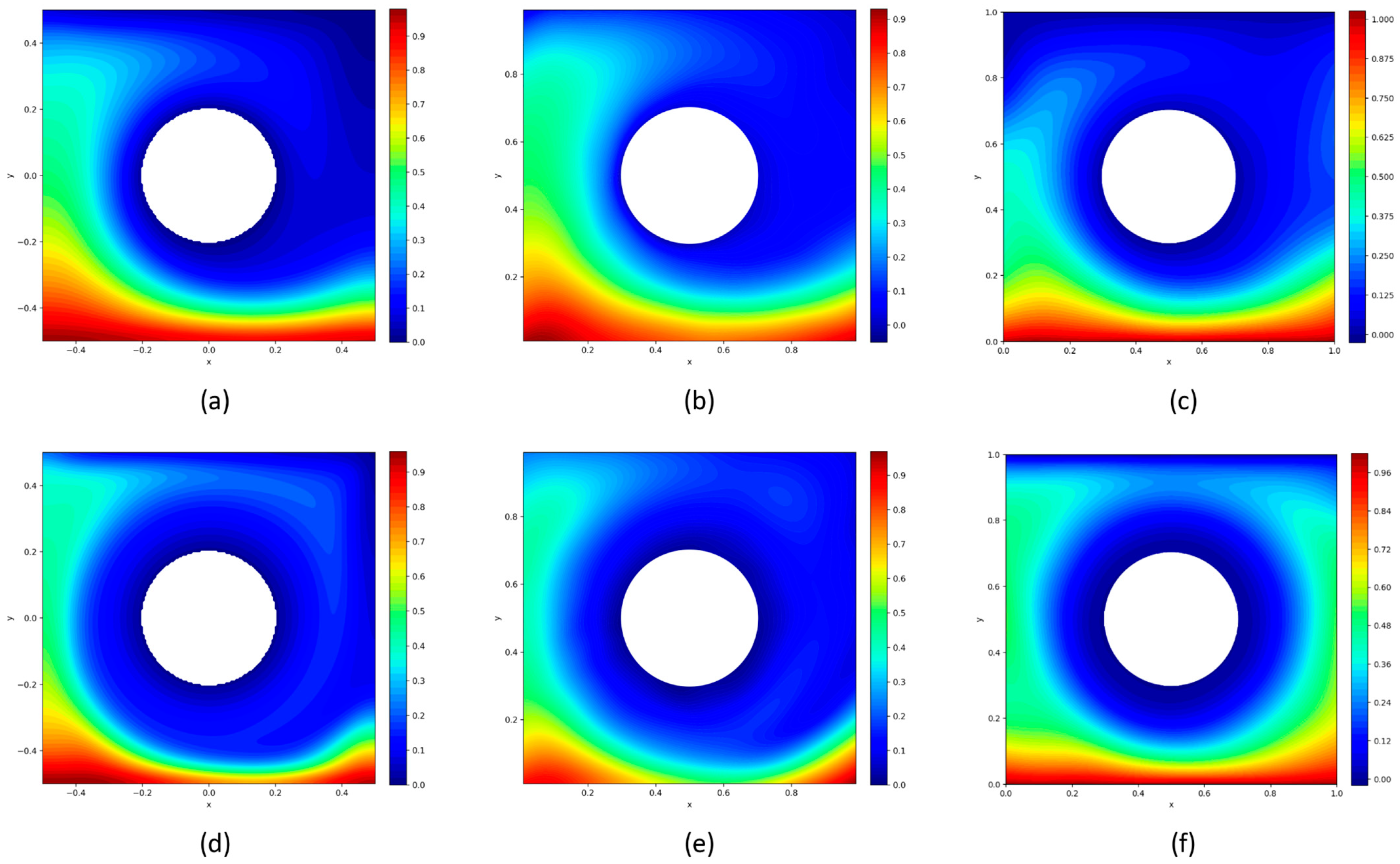
Figure 8 highlights the temperature distribution across the domain for both
Re = 100 and
Re = 1000, as previously mentioned, the lower wall is maintained at a hot temperature
Th = 1 and the upper wall at a cold temperature
Tc = 0. The presence of a rotating cylinder in the center induces convective effects that influence the temperature gradients. At
Re = 100, the actual data (
Figure 8a) show a smooth transition from hot at the bottom to cold at the top, with mild rotational influence around the cylinder. The data-driven PINN (
Figure 8b) accurately replicates this thermal behavior. The physics-based PINN (
Figure 8c), while generally following the same trend, produces a slightly smoother temperature field, indicating that it fails to capture the localized thermal effects of the rotation as precisely as the data-driven model. At
Re = 1000, the actual data (
Figure 8d) reveal sharper temperature gradients near the hot wall due to increased convection, with the rotating cylinder further disturbing the temperature field. The data-driven PINN (
Figure 8e) closely mimics these sharper gradients and rotational effects, effectively representing the complex convective flow. However, the physics-based PINN (
Figure 8f) once again produces a more uniform temperature field and struggles to accurately capture the enhanced convection and rotational disturbances.
This difference in performance can be further observed in the MAE and physics loss results shown in
Table 2. It is shown that the data-driven PINN achieves a significantly lower MAE at both Reynolds numbers, while the physics-based PINN exhibits much lower physics loss at both Reynolds numbers. This can be attributed to the model directly enforcing the governing equations through its loss function, which leads to higher adherence to physical laws. However, the higher MAE indicates that this strict adherence leads to less accurate predictions, particularly at higher Reynolds numbers, where the flow becomes more turbulent and difficult to resolve. In summary, the study emphasizes the challenges of achieving both convergence and stability during the training process, particularly when accounting for the expanded parameter space introduced by varying the rotation speeds, lid-driven speeds, and directions of the cylinder. As the complexity of the flow dynamics increases, it becomes more difficult for the model to generalize effectively. This increased complexity often results in overtraining, where the model fits the training data with high accuracy but fails to perform well on unseen or new data. The difficulty in balancing the learning process and ensuring the model adapts to a broad range of conditions without sacrificing predictive accuracy represents a critical limitation in machine-learning applications for complex flow and heat transfer problems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}