

A Generalized Deep Reinforcement Learning Model for Distribution Network Reconfiguration with Power Flow-Based Action-Space Sampling



Abstract
1. Introduction
1.1. Motivation and Literature Review
1.2. Related Work
1.3. Contributions
- Development of a novel method rooted in graph theory and power-flow analysis, aimed at reducing the size of the action space, which enhances the optimality and convergence of solutions generated by RL algorithms;
- Conducting a comprehensive sensitivity analysis of the action-space dimensions to demonstrate the substantial impact of action-space size on the performance of the RL agent;
- A thorough comparative analysis between the proposed method and conventional DNR methods in terms of execution speed and optimality of the obtained solutions, confirming the effectiveness of the proposed method.
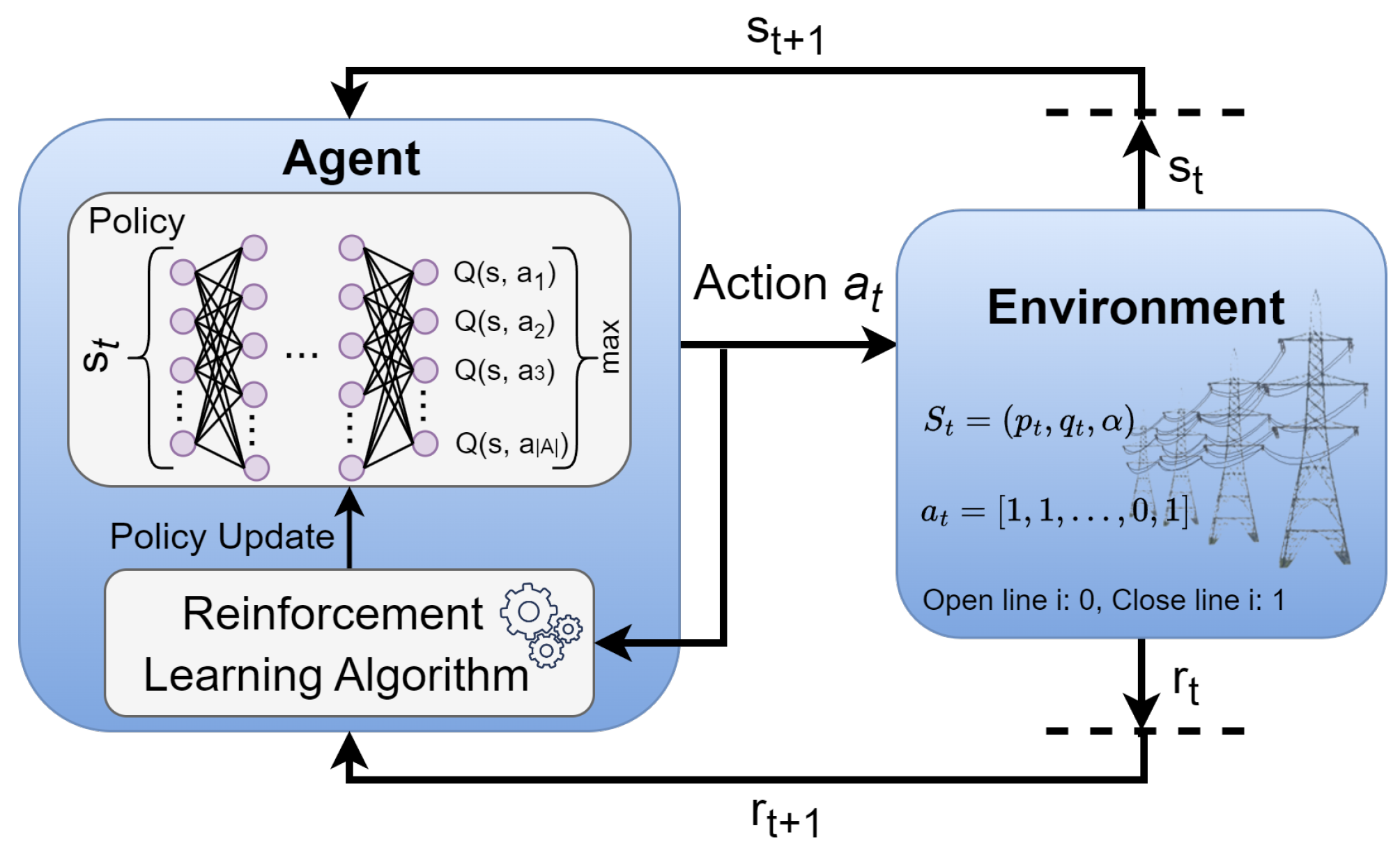
2. RL Foundations and Algorithms
2.1. RL Preliminaries
2.2. RL Algorithms
| Algorithm 1: RL Training Procedure |
 |
3. Problem Formulation
3.1. System Modeling
3.2. Action-Space Sampling
| Algorithm 2: Graph of Power-Flow Action Sampling |
 |
4. Simulation and Results
4.1. Experimental Setup and Data
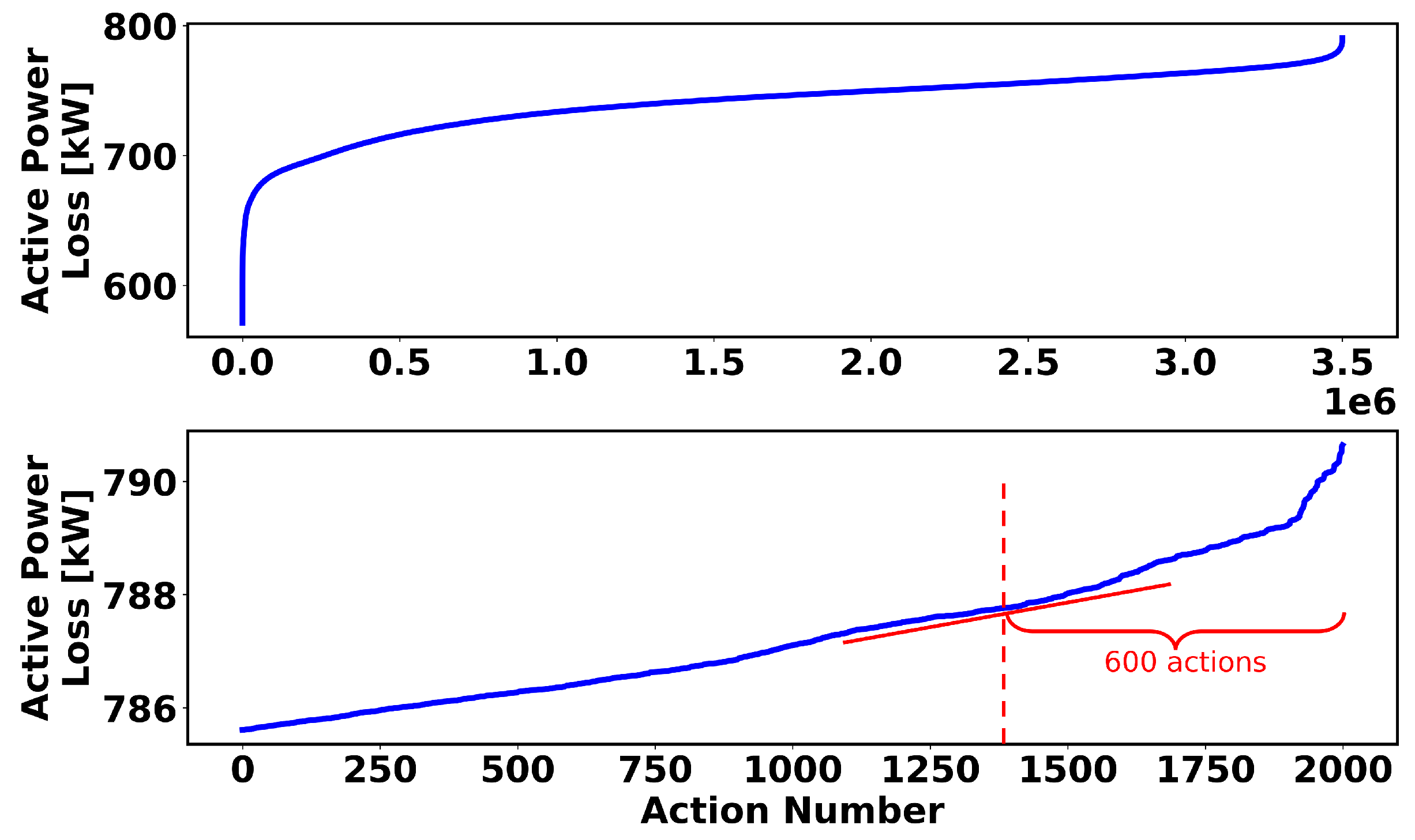
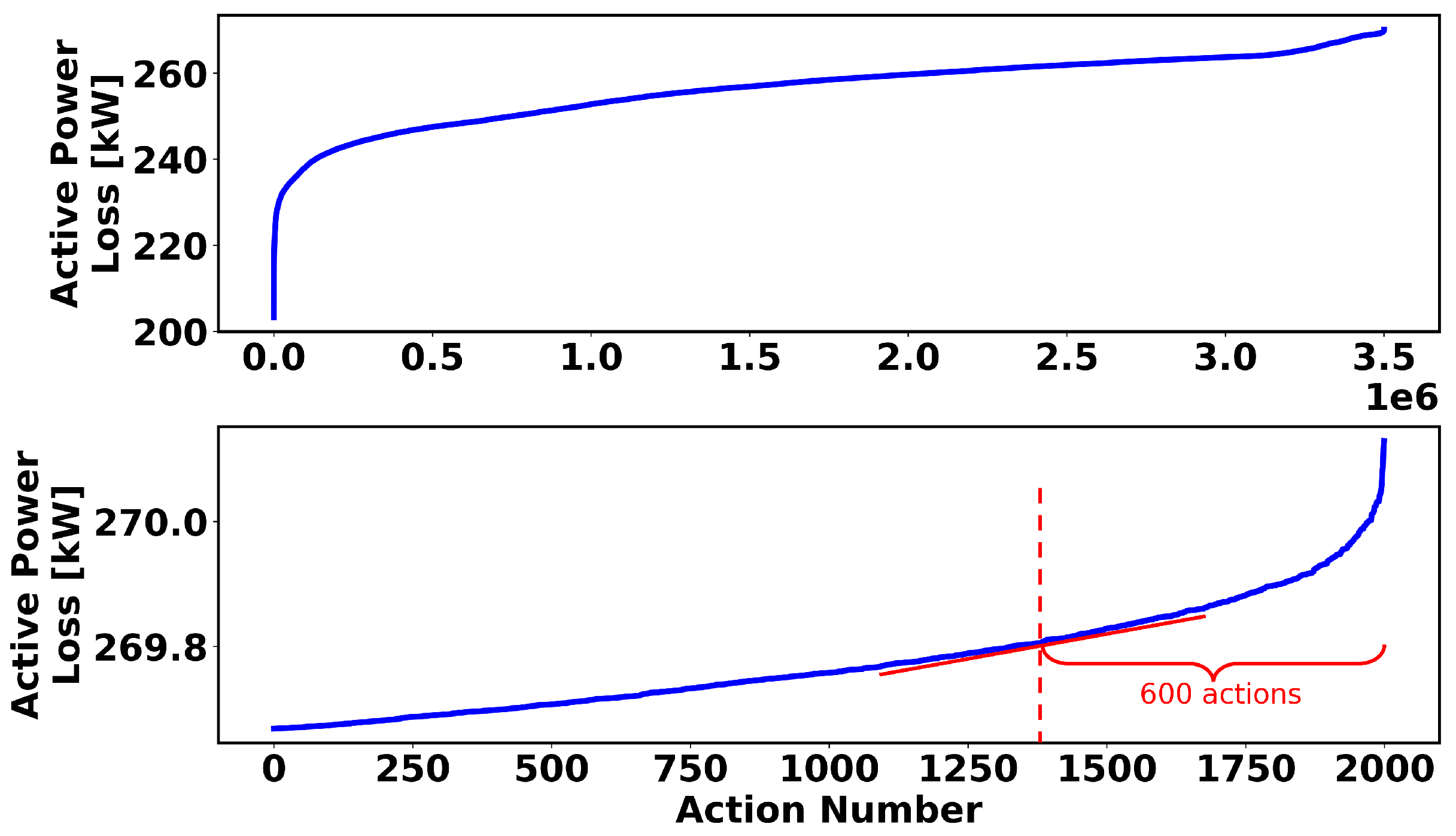
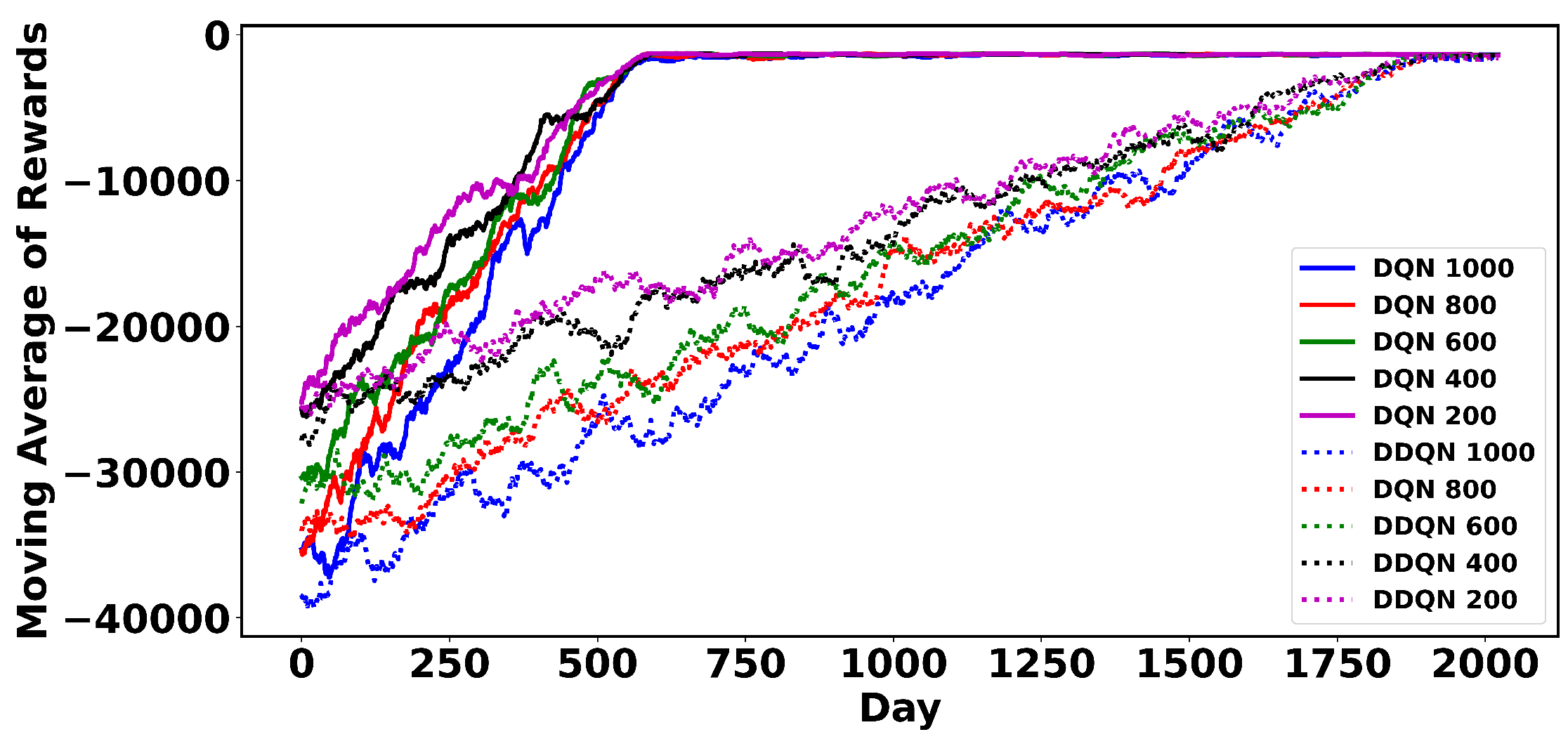
4.2. Action-Space Sampling
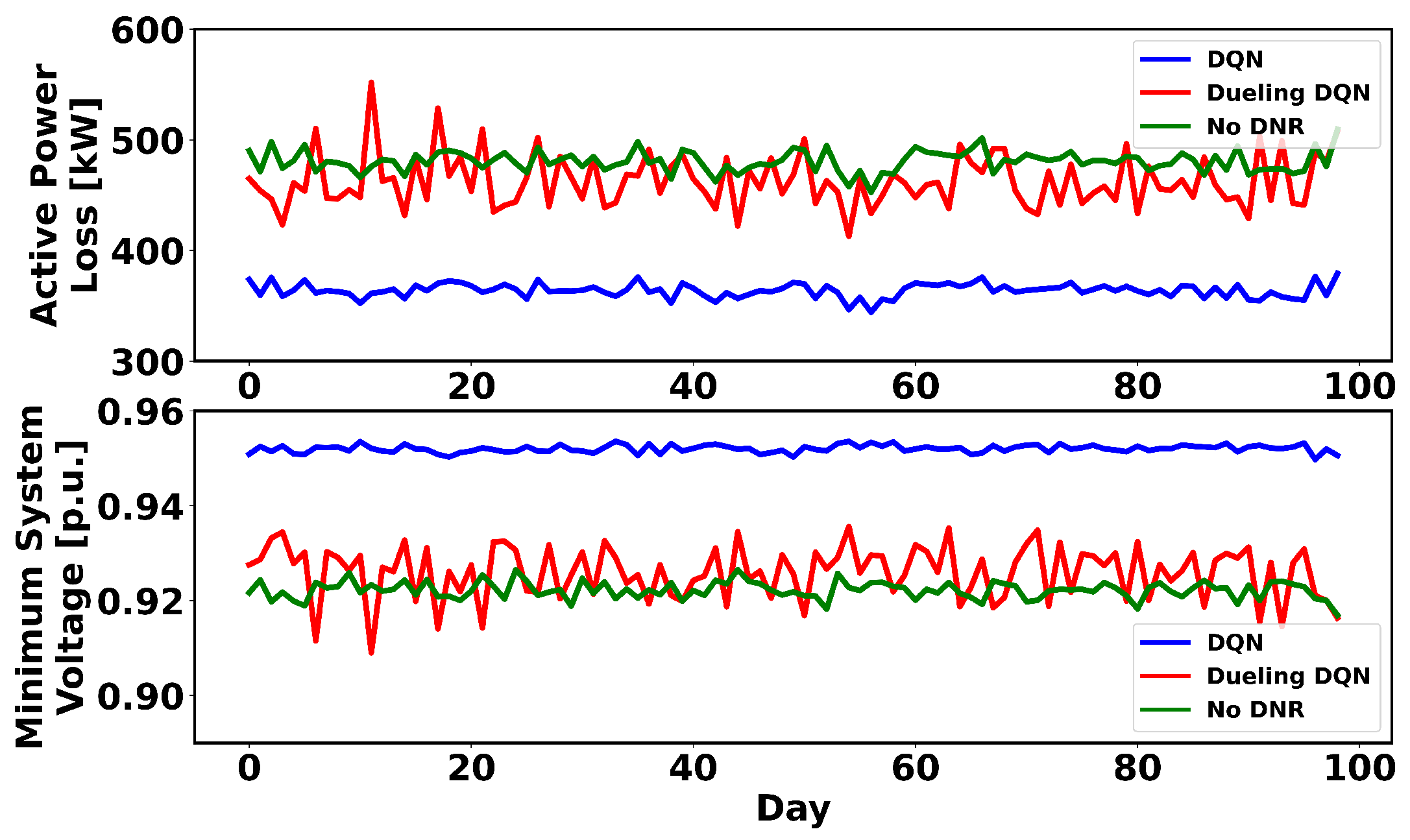
4.3. The 33-Node Test System
4.4. The 119-Node Test System
4.5. The 136-Node Test System
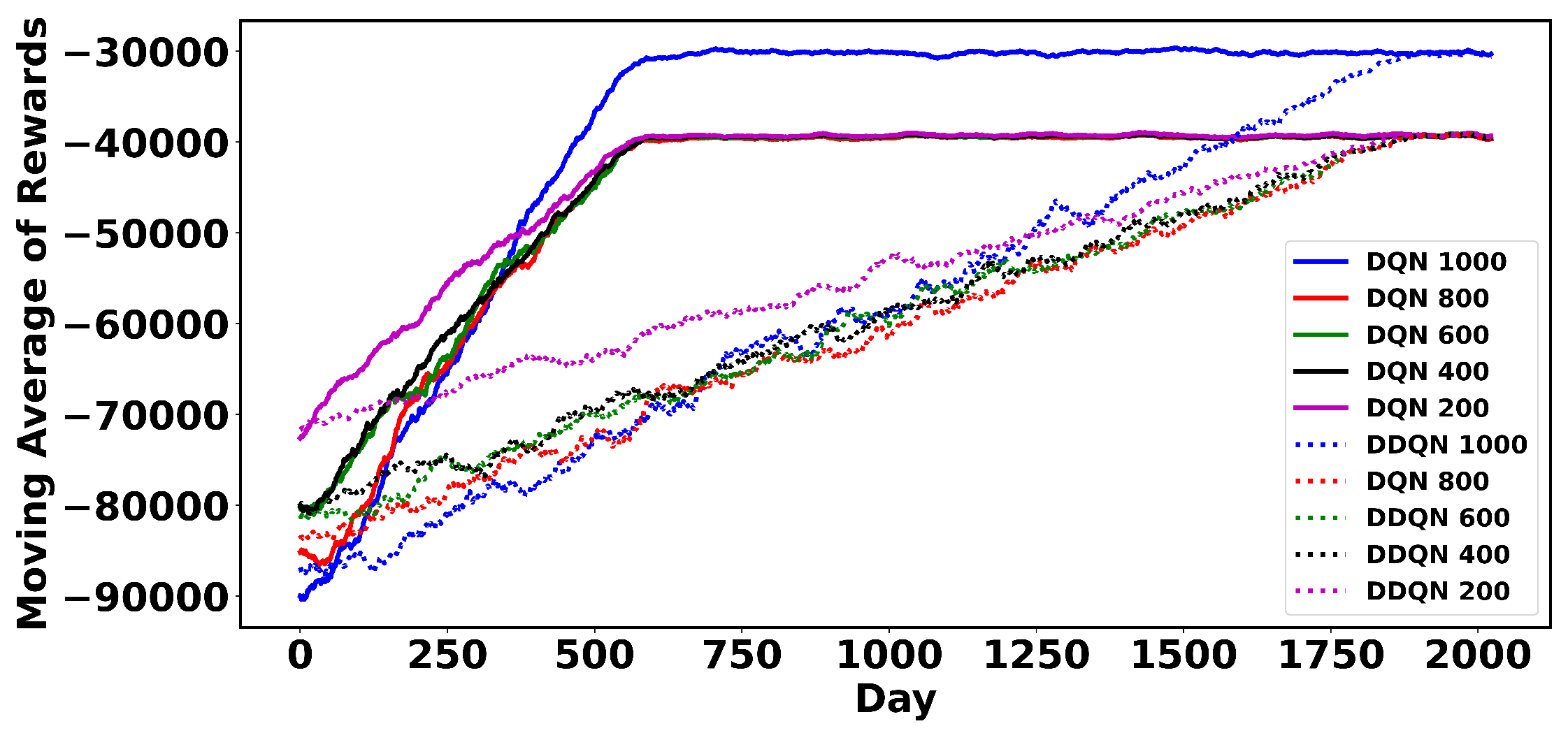
4.6. Sensitivity Analysis
4.7. Comparative Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pereira, E.C.; Barbosa, C.H.N.R.; Vasconcelos, J.A. Distribution Network Reconfiguration Using Iterative Branch Exchange and Clustering Technique. Energies 2023, 16, 2395. [Google Scholar] [CrossRef]
- Mahdavi, E.; Asadpour, S.; Macedo, L.H.; Romero, R. Reconfiguration of Distribution Networks with Simultaneous Allocation of Distributed Generation Using the Whale Optimization Algorithm. Energies 2023, 16, 4560. [Google Scholar] [CrossRef]
- Gao, H.; Ma, W.; Xiang, Y.; Tang, Z.; Xu, X.; Pan, H.; Zhang, F.; Liu, J. Multi-objective Dynamic Reconfiguration for Urban Distribution Network Considering Multi-level Switching Modes. J. Mod. Power Syst. Clean Energy 2022, 10, 1241–1255. [Google Scholar] [CrossRef]
- Hong, H.; Hu, Z.; Guo, R.; Ma, J.; Tian, J. Directed graph-based distribution network reconfiguration for operation mode adjustment and service restoration considering distributed generation. J. Mod. Power Syst. Clean Energy 2017, 5, 142–149. [Google Scholar] [CrossRef]
- Swarnkar, A.; Gupta, N.; Niazi, K. Adapted ant colony optimization for efficient reconfiguration of balanced and unbalanced distribution systems for loss minimization. Swarm Evol. Comput. 2011, 1, 129–137. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.; Wang, H.; Zuo, H. Dynamic Reconfiguration of Multiobjective Distribution Networks Considering DG and EVs Based on a Novel LDBAS Algorithm. IEEE Access 2020, 8, 216873–216893. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, W.; Wang, H.; Wu, J.; Li, X.; Lan, J. A Social Beetle Swarm Algorithm Based on Grey Target Decision-Making for a Multiobjective Distribution Network Reconfiguration Considering Partition of Time Intervals. IEEE Access 2020, 8, 204987–205013. [Google Scholar] [CrossRef]
- Muhammad, M.A.; Mokhlis, H.; Naidu, K.; Amin, A.; Franco, J.F.; Othman, M. Distribution Network Planning Enhancement via Network Reconfiguration and DG Integration Using Dataset Approach and Water Cycle Algorithm. J. Mod. Power Syst. Clean Energy 2020, 8, 86–93. [Google Scholar] [CrossRef]
- Peng, C.; Xu, L.; Gong, X.; Sun, H.; Pan, L. Molecular Evolution Based Dynamic Reconfiguration of Distribution Networks With DGs Considering Three-Phase Balance and Switching Times. IEEE Trans. Ind. Inform. 2019, 15, 1866–1876. [Google Scholar] [CrossRef]
- Helmi, A.M.; Carli, R.; Dotoli, M.; Ramadan, H.S. Efficient and Sustainable Reconfiguration of Distribution Networks via Metaheuristic Optimization. IEEE Trans. Autom. Sci. Eng. 2022, 19, 82–98. [Google Scholar] [CrossRef]
- Zhong, T.; Zhang, H.T.; Li, Y.; Liu, L.; Lu, R. Bayesian Learning-Based Multi-Objective Distribution Power Network Reconfiguration. IEEE Trans. Smart Grid 2021, 12, 1174–1184. [Google Scholar] [CrossRef]
- Fu, Y.Y.; Chiang, H.D. Toward Optimal Multiperiod Network Reconfiguration for Increasing the Hosting Capacity of Distribution Networks. IEEE Trans. Power Deliv. 2018, 33, 2294–2304. [Google Scholar] [CrossRef]
- Cebrian, J.C.; Kagan, N. Reconfiguration of distribution networks to minimize loss and disruption costs using genetic algorithms. Electr. Power Syst. Res. 2010, 80, 53–62. [Google Scholar] [CrossRef]
- Song, Y.; Zheng, Y.; Liu, T.; Lei, S.; Hill, D.J. A New Formulation of Distribution Network Reconfiguration for Reducing the Voltage Volatility Induced by Distributed Generation. IEEE Trans. Power Syst. 2020, 35, 496–507. [Google Scholar] [CrossRef]
- Ahmadi, H.; Martí, J.R. Distribution System Optimization Based on a Linear Power-Flow Formulation. IEEE Trans. Power Deliv. 2015, 30, 25–33. [Google Scholar] [CrossRef]
- Franco, J.F.; Rider, M.J.; Lavorato, M.; Romero, R. A mixed-integer LP model for the reconfiguration of radial electric distribution systems considering distributed generation. Electr. Power Syst. Res. 2013, 97, 51–60. [Google Scholar] [CrossRef]
- Tran, T.V.; Truong, B.H.; Nguyen, T.P.; Nguyen, T.A.; Duong, T.L.; Vo, D.N. Reconfiguration of Distribution Networks With Distributed Generations Using an Improved Neural Network Algorithm. IEEE Access 2021, 9, 165618–165647. [Google Scholar] [CrossRef]
- Liu, N.; Li, C.; Chen, L.; Wang, J. Hybrid Data-Driven and Model-Based Distribution Network Reconfiguration With Lossless Model Reduction. IEEE Trans. Ind. Inform. 2022, 18, 2943–2954. [Google Scholar] [CrossRef]
- Huang, W.; Zheng, W.; Hill, D.J. Distribution Network Reconfiguration for Short-Term Voltage Stability Enhancement: An Efficient Deep Learning Approach. IEEE Trans. Smart Grid 2021, 12, 5385–5395. [Google Scholar] [CrossRef]
- Zheng, W.; Huang, W.; Hill, D.J.; Hou, Y. An Adaptive Distributionally Robust Model for Three-Phase Distribution Network Reconfiguration. IEEE Trans. Smart Grid 2021, 12, 1224–1237. [Google Scholar] [CrossRef]
- Gao, Y.; Foggo, B.; Yu, N. A Physically Inspired Data-Driven Model for Electricity Theft Detection With Smart Meter Data. IEEE Trans. Ind. Inform. 2019, 15, 5076–5088. [Google Scholar] [CrossRef]
- Pegado, R.A.; Rodriguez, Y.P.M. Distribution Network Reconfiguration with the OpenDSS using Improved Binary Particle Swarm Optimization. IEEE Lat. Am. Trans. 2018, 16, 1677–1683. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, D.; Qiu, R.C. Deep reinforcement learning for power system applications: An overview. CSEE J. Power Energy Syst. 2020, 6, 213–225. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, W.; Shi, J.; Yu, N. Batch-Constrained Reinforcement Learning for Dynamic Distribution Network Reconfiguration. IEEE Trans. Smart Grid 2020, 11, 5357–5369. [Google Scholar] [CrossRef]
- Li, Y.; Hao, G.; Liu, Y.; Yu, Y.; Ni, Z.; Zhao, Y. Many-Objective Distribution Network Reconfiguration Via Deep Reinforcement Learning Assisted Optimization Algorithm. IEEE Trans. Power Deliv. 2022, 37, 2230–2244. [Google Scholar] [CrossRef]
- Wu, T.; Wang, J.; Lu, X.; Du, Y. AC/DC hybrid distribution network reconfiguration with microgrid formation using multi-agent soft actor-critic. Appl. Energy 2022, 307, 118189. [Google Scholar] [CrossRef]
- Jiang, S.; Gao, H.; Wang, X.; Liu, J.; Zuo, K. Deep reinforcement learning based multi-level dynamic reconfiguration for urban distribution network: A cloud-edge collaboration architecture. Glob. Energy Interconnect. 2023, 6, 1–14. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, S.; Zhao, Q. Sequential Reconfiguration of Unbalanced Distribution Network with Soft Open Points Based on Deep Reinforcement Learning. J. Mod. Power Syst. Clean Energy 2023, 11, 107–119. [Google Scholar] [CrossRef]
- Kundačina, O.B.; Vidović, P.M.; Petković, M.R. Solving dynamic distribution network reconfiguration using deep reinforcement learning. Electr. Eng. 2022, 104, 1487–1501. [Google Scholar] [CrossRef]
- Oh, S.H.; Yoon, Y.T.; Kim, S.W. Online reconfiguration scheme of self-sufficient distribution network based on a reinforcement learning approach. Appl. Energy 2020, 280, 115900. [Google Scholar] [CrossRef]
- Malekshah, S.; Rasouli, A.; Malekshah, Y.; Ramezani, A.; Malekshah, A. Reliability-driven distribution power network dynamic reconfiguration in presence of distributed generation by the deep reinforcement learning method. Alex. Eng. J. 2022, 61, 6541–6556. [Google Scholar] [CrossRef]
- Wang, B.; Zhu, H.; Xu, H.; Bao, Y.; Di, H. Distribution Network Reconfiguration Based on NoisyNet Deep Q-Learning Network. IEEE Access 2021, 9, 90358–90365. [Google Scholar] [CrossRef]
- Bui, V.H.; Su, W. Real-time operation of distribution network: A deep reinforcement learning-based reconfiguration approach. Sustain. Energy Technol. Assess. 2022, 50, 101841. [Google Scholar] [CrossRef]
- Yamada, T.; Kataoka, S.; Watanabe, K. Listing all the minimum spanning trees in an undirected graph. Int. J. Comput. Math. 2010, 87, 3175–3185. [Google Scholar] [CrossRef]
- Zhan, J.; Liu, W.; Chung, C.Y.; Yang, J. Switch Opening and Exchange Method for Stochastic Distribution Network Reconfiguration. IEEE Trans. Smart Grid 2020, 11, 2995–3007. [Google Scholar] [CrossRef]
- Tran, T.T.; Truong, K.H.; Vo, D.N. Stochastic fractal search algorithm for reconfiguration of distribution networks with distributed generations. Ain Shams Eng. J. 2020, 11, 389–407. [Google Scholar] [CrossRef]
- UNESP-FEIS Electrical Energy Systems Planning Laboratory Homepage, T.S. Available online: https://www.feis.unesp.br/#!/departamentos/engenharia-eletrica/pesquisas-e-projetos/lapsee/english/ (accessed on 10 February 2022).
- Landeros, A.; Koziel, S.; Abdel-Fattah, M.F. Distribution network reconfiguration using feasibility-preserving evolutionary optimization. J. Mod. Power Syst. Clean Energy 2019, 7, 589–598. [Google Scholar] [CrossRef]
- Harsh, P.; Das, D. A Simple and Fast Heuristic Approach for the Reconfiguration of Radial Distribution Networks. IEEE Trans. Power Syst. 2023, 38, 2939–2942. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Learning rate () | |
| Batch size (b) | 512 |
| Discount factor () | |
| Neural network structure | |
| Experience replay memory size |
| Algorithm | Tie Switches | System Loss [kW] |
|---|---|---|
| DQN | 7-8, 10-11, 14-15, 28-29, 32-33 | 140.71 |
| Dueling DQN | 7-8, 9-10, 14-15, 28-29, 32-33 | 139.98 |
| Algorithm | Tie Switches | System Loss [kW] |
|---|---|---|
| DQN | 23-24, 32-33, 72-73, 109-110, 46-27, | 1025.98 |
| 17-27, 54-43, 62-49, 37-62, 9-40, 58-96, | ||
| 88-75, 99-77, 108-83, 105-86 | ||
| Dueling DQN | 20-21, 34-35, 72-73, 109-110, 46-27, | 1015.04 |
| 17-27, 54-43, 62-49, 37-62, 9-40, | ||
| 58-96, 88-75, 99-77, 108-83, 105-86 |
| Algorithm | Tie Switches | System Loss [kW] |
|---|---|---|
| DQN | 47-62, 89-90, 105-106, 134-135, | 288.84 |
| 46-27, 7-73, 9-24, 15-83, 25-51, | ||
| 50-96, 55-98, 66-79, 79-131, 84-135, | ||
| 91-104, 90-129, 92-104, 92-132, | ||
| 96-120, 126-76, 128-77, 135-98 | ||
| Dueling DQN | 31-35, 48-51, 89-90, 106-107, | 294.33 |
| 7-73, 9-24, 15-83, 50-96, 55-98, | ||
| 62-120, 66-79, 79-131, 84-135, | ||
| 91-104, 90-129, 92-104, 92-132, | ||
| 96-120, 126-76, 128-77, 135-98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholizadeh, N.; Musilek, P. A Generalized Deep Reinforcement Learning Model for Distribution Network Reconfiguration with Power Flow-Based Action-Space Sampling. Energies 2024, 17, 5187. https://doi.org/10.3390/en17205187
Gholizadeh N, Musilek P. A Generalized Deep Reinforcement Learning Model for Distribution Network Reconfiguration with Power Flow-Based Action-Space Sampling. Energies. 2024; 17(20):5187. https://doi.org/10.3390/en17205187
Chicago/Turabian StyleGholizadeh, Nastaran, and Petr Musilek. 2024. "A Generalized Deep Reinforcement Learning Model for Distribution Network Reconfiguration with Power Flow-Based Action-Space Sampling" Energies 17, no. 20: 5187. https://doi.org/10.3390/en17205187
APA StyleGholizadeh, N., & Musilek, P. (2024). A Generalized Deep Reinforcement Learning Model for Distribution Network Reconfiguration with Power Flow-Based Action-Space Sampling. Energies, 17(20), 5187. https://doi.org/10.3390/en17205187