3.1. Feature Extraction
The total load of the power system
L can generally be decomposed into four components according to the type of influencing factors [
19], namely
where
Ln represents the normal trend of the load component, typically characterized by the load of typical historical days;
Lw is the power load component related to meteorological factors, primarily influenced by changes in various meteorological factors;
Ls is caused by special external factors such as holidays; and
Lr is a random component of the power load, which, while having a small proportion, is usually difficult to predict. Therefore, we focus on the first three key factors.
(1)
Temperature and humidity: Based on previous research experiences in power load forecasting [
20], the two meteorological factors of temperature and relative humidity have the strongest correlation with power system load. Thus, we construct their daily mean and variance into a vector,
where
K is the total number of observed days, and
tm(
k) and
tv(
k) refer to the daily mean and variance of the temperature
, and
hm(
k) and
hv(
k) those of the humidity. According to the range of annual temperature and humidity in the detection area, the ranges of the four variables can be determined. All the above vectors consist of a set
SH = {
Hk|
k = 1, 2, …,
K}.
(2)
Special days. The power loads are very different between working and non-working days, and particularly special days such as Spring Festival, Labor Day, and National Day. Each of them usually includes a group of continuous non-working days. Hence, a feature vector to represent any special day is constructed as follows,
where
q denotes the
qth special day,
m is the number of non-working days, and
Q is the total number of special days. All such vectors consist of a set,
SD = {
Dq|
q = 1, 2, …,
Q}.
(3)
Normal day. Owing to the cyclical and continuous changes, normal historical power loads from a week except special days are nearly repeated [
21]. Assume that the total number of normal days is
N; all normal days consist of a set,
SN = {
Dp|
p = 1, 2, …,
N}.
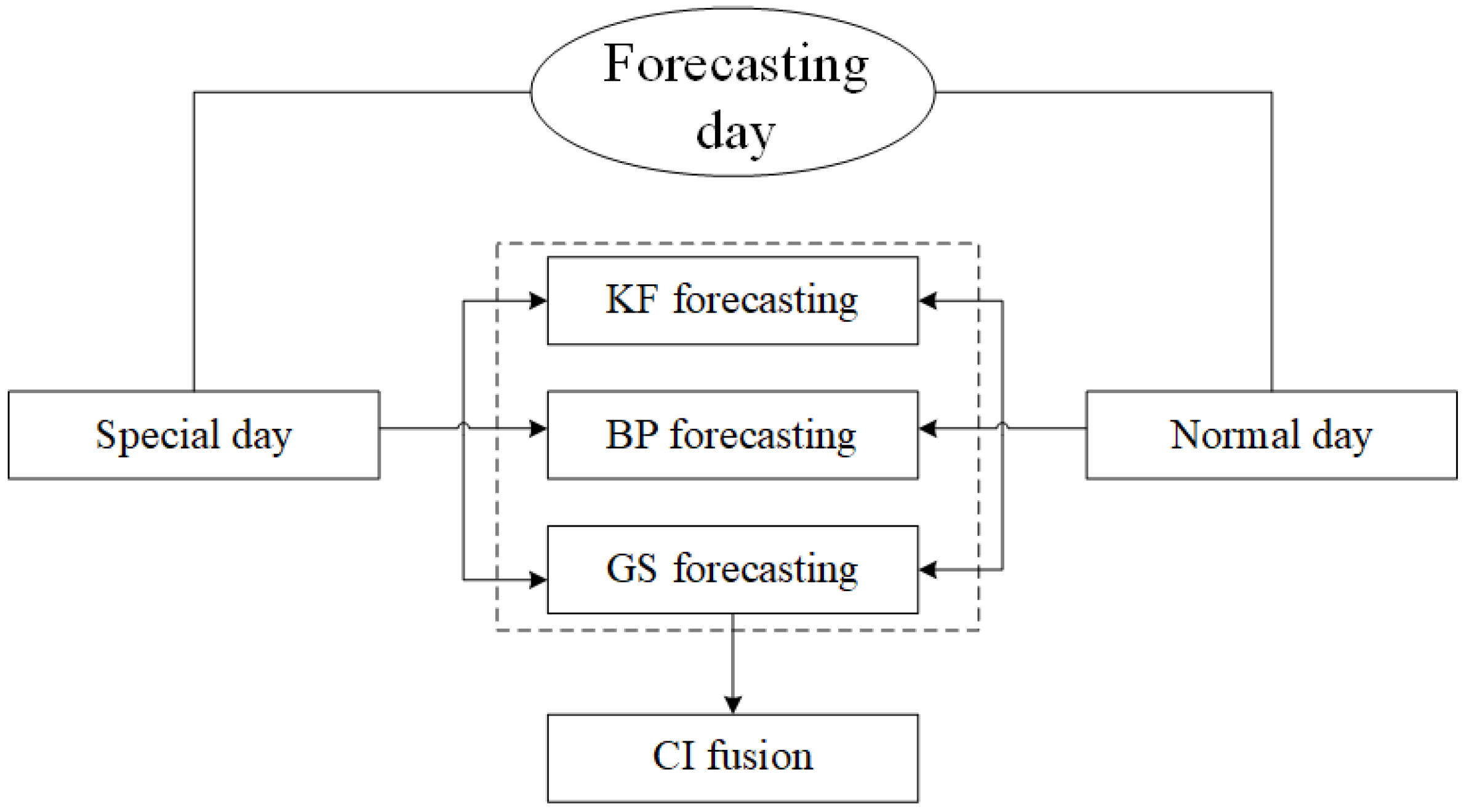
Therefore, the power load must be forecasted individually over special days and normal days after considering the influences of temperature and humidity. And any predicted power load firstly is distinguished by SD∪SH with relative power loads, and SN∪SH with relative power loads, respectively.
Let the forecasting model be
q = F(
H,
c), where
q is the power load and
c is the data type. We use KF, BP, and the GS to construct forecasting models to approximate
F(·,·) using historical data. For each predicted day, the three models provide power load forecastings, which are then integrated into the CI model to achieve a more accurate forecasting of power loads.
Figure 1 shows the flowchart of our proposed model.
3.2. Forecasting of the Three Existing Typical Methods
As an example, the historical load data used in this study consists of daily 24 h loads in a district in Tianjin from 1 July 2019 to 30 June 2021. The sampling unit is hours, and in total, 17,088 pieces of data are collected.
Table 1 shows their main features, such as their maximum, minimum, average, standard deviation, and variance. All data are partitioned into two groups, and the data in the first year are used to construct the forecasting model and the second year to evaluate the predicting accuracy of the model.
3.2.1. KF Forecasting
The KF forecasting method is developed using relative power loads from SD∪SH and SN∪SH in the first year. Denote the load data at time
k as
qk,
k = 1, 2, …,
n. Each piece of data is defined as a node, and the
kth node refers to a three-dimensional vector
, where
and
are defined as
They are the first-order and the second-order differences of
qk, and are recursively computed. The calculation process is shown in
Figure 2.
After recording the load every day along each regular interval (1 h), 24 daily sampling values are obtained, and the three-dimensional representation of the measurement nodes can be obtained,
. Hence, the KF matrix coefficient
A is determined as follows. Since
the coefficient matrix
A in the KF equation is obtained as
When there is no other available prior information, the measurement matrix Hk is taken as the identity matrix.
Using the following seven special days, such as New Year’s Day, Spring Festival, Tomb-Sweeping Day, Labor Day, the Long Boat Festival, Mid-Autumn Festival, and National Day, as dividing points, we divide the entire year from June 2019 to June 2020 into 7 stages to determine the parameters in each forecasting model. In the same way, the year from July 2020 to July 2021 is divided into 7 stages for load forecasting. In every stage, the forecasting is performed in every hour of all days. The KF forecasting accuracy is evaluated by a group of statistical quantities in each stage, such as maximal absolute error, average absolute relative error, average relative error, and standard error, as shown in
Table 2 as follows.
The following conclusions can be inferred from
Table 2.
(1) The minimum forecasting error occurs in the second stage, but the forecasting error tends to stabilize from the third stage onwards. This is because the KF method is advantageous as it is an adaptive process with a dynamic correction function. It updates the state variables using the estimated value from the previous moment and the observed value at the current moment to obtain the estimated value at this stage.
(2) The maximum absolute error ranges from 64.010 to 685.982 MW, the average absolute error ranges from 43.845 to 486.239 MW, the average relative error ranges from 15.6% to 38.6%, and the standard deviation ranges from 12.137 to 166.267, respectively. All error indicators are relatively high. This is because the parameters of the KF model significantly impact the forecasting results, with the state transition matrix having a particularly notable effect on the KF forecasting. Especially in the KF forecasting process, the state matrix is inferred based on the load information of the first two months of every two quarters, and its accuracy directly affects the forecasting results.
(3) Analysis of the measurement period reveals that the average relative error of load forecasting change during the National Day Golden Week is the smallest. Load value fluctuations are relatively small in summer and winter, while they are larger in spring and autumn. This indicates that seasonal variations impact the accuracy of the forecasting results.
3.2.2. BP Forecasting
The process of solving the BP network model is as follows:
- (1)
Input and output layer design: The inputs of the BP take the first-order and second-order difference of hourly loads, and the output is the load. Therefore, the number of nodes in the input layer is 2, and that in the output layer is 1.
- (2)
Hidden layer design: We use a multi-input–single-output BP network with three hidden layers for load forecasting. The determination of the number of hidden layer neurons is very important, and we thus refer to the empirical formula [
22]:
where
n is the number of input layer neurons,
m is the number of output layer neurons, and
a is a constant between the range [1, 10]. Therefore, the number of neurons in the BP network in each quarter can be calculated.
- (3)
Selection of incentive function: There are various transfer functions for BP neural networks. But with periodic data, using the tansig function for the transfer function has smaller errors and higher stability than the logsig function. Therefore, tansig is used, and the Purelin function is used as the transfer function in the output layer.
- (4)
Network parameter determination: Let the network parameters have 5000 epochs of network iterations and an expected error of 10
−5. The forecasting model established in the first two months of each quarter forecasts the third month by the BP neural network method; the experimental results are shown in
Table 3.
The results can be inferred from
Table 3 as follows.
(1) In some stages, there are individual points in the predicted results with significant forecasting errors, and some forecasting values deviate from the actual values. This may be due to the inherent drawback of local extremum points in the BP algorithm.
(2) The maximum absolute error is between 26.871 and 466.754 MW, the average absolute error ranges from 20.127 to 354.853 MW, the average relative error is between 3.8% and 23.4%, and the standard deviation is between 4.092 and 70.371.
(3) In the forecasting results of each quarter, the absolute and relative errors of the first, second, and fourth stages are relatively small, while the errors of other stages are relatively large, indicating that different stages each day have a certain impact on the accuracy.
3.2.3. GS Forecasting
When using the GS, both parameters
a and
u must be determined. We determined them through fitting the samples in the year from June 2019 to June 2020, as shown in
Table 4.
After taking these parameters into (13),
Table 5 shows the errors in all seven stages.
The following results can be inferred from
Table 5.
(1) The maximum absolute error predicted by the GS model is between 6.9329 and 109.3515 MW, the average absolute error ranges from 5.054 to 87.239 MW, the average relative error is between 1.62% and 18.57%, and the standard deviation is between 1.1782 and 43.5972. After evaluating these data, it was found that the GS forecasting results did not fluctuate up and down with the actual load value. The overall predicted trend manifests as exponential characteristics, which should be consistent with the actual situation in the short term. However, the general future load trend will not fully obey the exponential growth characteristics, which is the reason that the GS generates the larger error.
(2) The maximum absolute error, average relative error, and standard deviation of the predicted results outside the third and fifth stages are relatively small; especially, the absolute error of the forecasting in the second stage reaches small values, basically reaching the small error level that can be used for load forecasting. However, the GS has certain limitations and is only suitable for modeling and forecasting problems with relatively gentle data changes. It is not suitable for situations where the growth rate of data sequences is too fast or exhibits significant fluctuations.
3.3. Fusion Based on CI Model
Let
X = {
x1,
x2, …,
xn} be a set of
n inputs (components) and
P(
X) be the power set of
X. The set function
g on
X: P(
X)→[0, 1] is called a non-additive measure [
23], which represents the interrelation among the
n inputs, satisfying
- (1)
Boundary condition:
( is an empty set);
- (2)
Monotonicity condition: For any two sets A and B on X that satisfy
, .
Let
h:
X→
R be a normalized map on the measure
g, the discrete equation of CI is
where
are an ordering arrangement of
h(
x1),
h(
x2),…,
h(
xn), satisfying
,
. There is the relation with (23),
(24) shows that the CI can be formulated as a weighted average of the
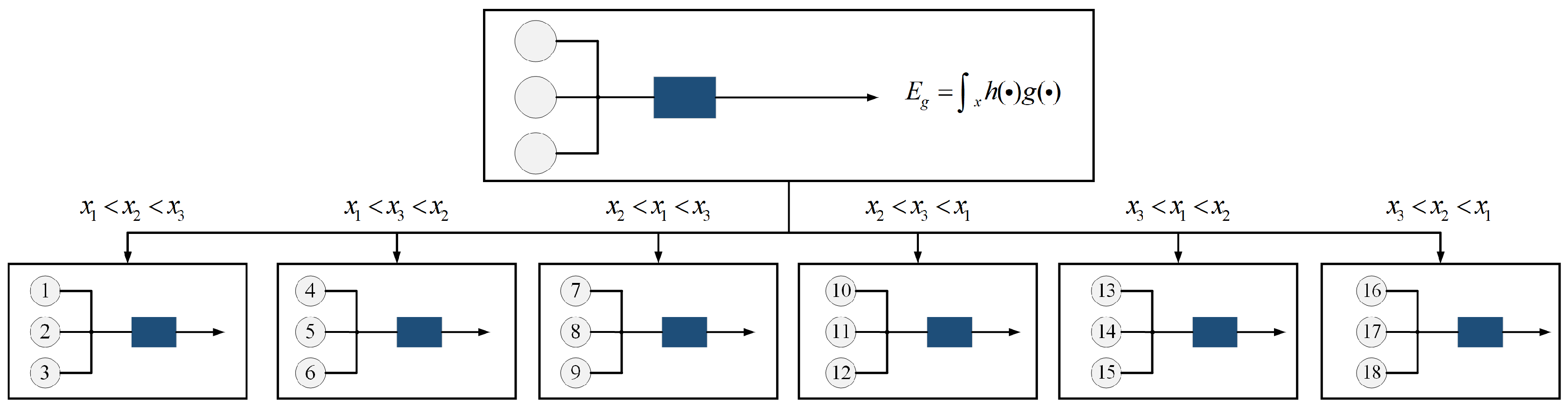
n inputs. However, each weighting value of the typical average formula is only relative to each input itself, while each in the CI is relative to all inputs. Therefore, the former is linear and the latter is nonlinear. Specially, the CI has a very strong generalization ability, and a CI with
n inputs is equivalent to
n! constrained feedforward neural networks. For example, when there are 3 inputs,
x1,
x2,
x3, the CI is equivalent to 6 feedforward neural networks, as shown in
Figure 3. The weights of each feedforward neural network consist of 3 relative measures. Therefore, the CI can act as a nonlinear classifier with a strong generalization ability and interpretability.
The parameter determination in the CI is a key step. For 2
n parameters from
n inputs, since there are additional constraints on the monotonicity conditions among these inputs, the solving method must be special. Currently, the typical and effective method to solve the CI parameter is the heuristic least mean square (HLMS) [
24]. After giving a set of
K training data pairs from the input
hk to output
Ek:
, the objective function of HLMS is formulated as
where
is the computed CI value of
.
To apply the CI to integrate the forecasting results from the KF, BP, and GS, we denote the variables x
1, x
2, and x
3 as their error from the real value. An HLMS algorithm can be performed to solve the parameter of the CI in the open-resource software Kappalab [
25]. For the set of training samples of three inputs relative to the three methods,
x1,
x2 and
x3,
Table 6 shows the solved parameter of the CI in Kappalab by HLMS after using the samples of each quarter in the entire year from June 2019 to June 2020.
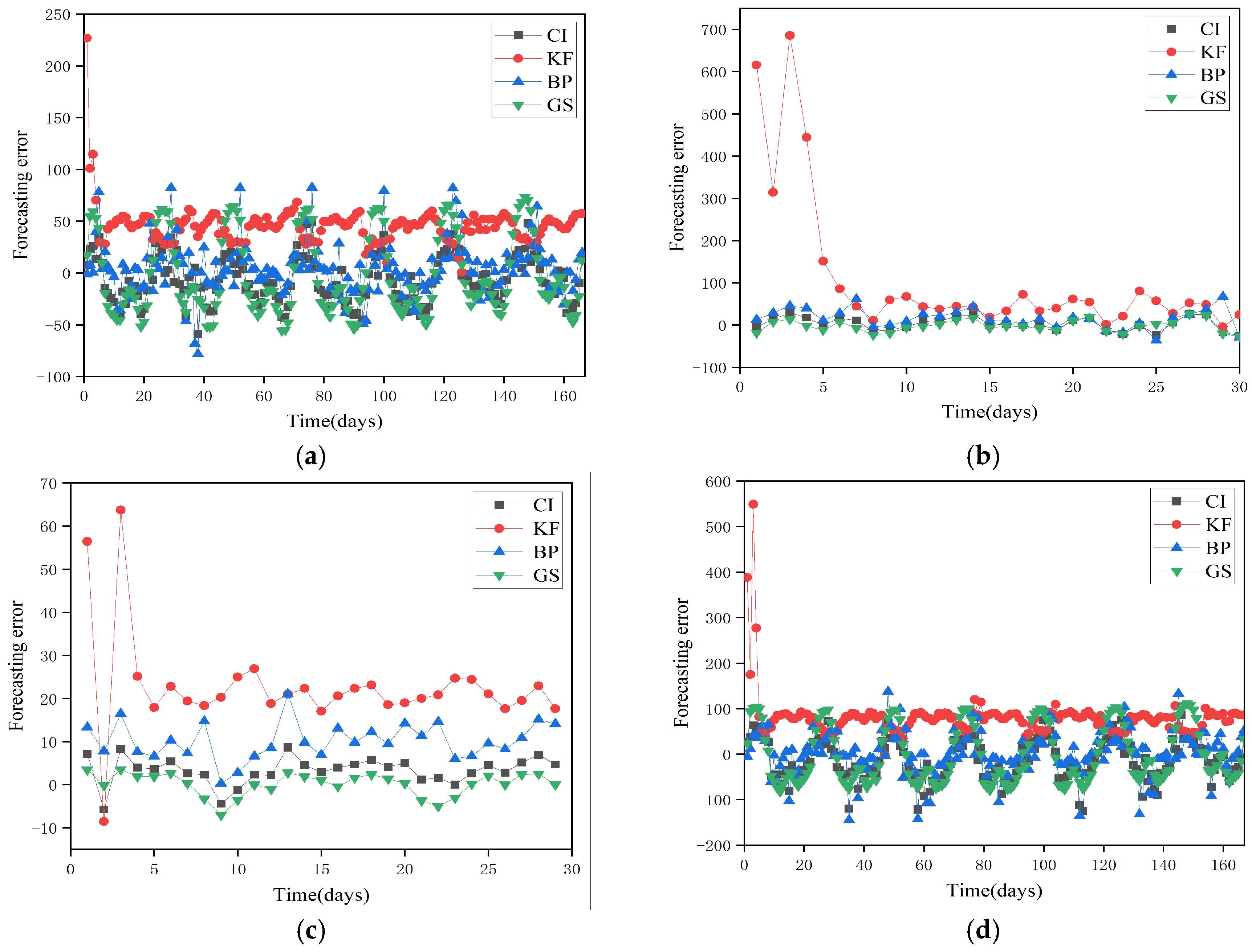
After substituting these parameters into (23) and using the MATLAB tool, the forecasting results by the CI for the entire year from July 2020 to July 2021 are presented by fusing the results from the three methods. Taking the four stages of the first quarter in the second year as an example, the forecasting results are shown in
Figure 4, where the forecasting results are evaluated by the error between each real load and the computed load.
The forecasting loads by the CI fusion method have reduced the problems of large errors in the first three sampling points of the KF, large errors in individual points of the BP method, and exponential changes in the forecasting values of the GS method. The forecasting errors of the proposed CI fusion for the four quarters are shown in
Table 7.
Compared with the respective forecasting results from the KF, BP, and GS, the fusion results by the CI from
Table 7 can be summarized as follows.
(1) The maximum forecasting error among the three methods occurs in the KF method. Although KF is a continuous iterative process, the errors at the initial points and the increase in subsequent errors can cancel each other out, and the subsequent filtering tends to stabilize. However, due to the significant errors at the first three points, the maximum errors still have a significant impact on the overall accuracy of load forecasting, resulting in various error indicators being less favorable compared to other methods.
(2) For stages 1 and 2, the GS forecasting results show the minimum average relative error, because this stage corresponds to the minimum fluctuation of the load value at the morning time of each day, and the GS model is well-suited for load forecasting with relatively flat data changes. The forecasting results of the CI fusion method are affected by the large forecasting error of the KF method, leading to inferior results compared to the GS in some stages. However, it weakens the instability and limitations of single forecasting results of both KF and the BP neural network.
(3) Comparing the errors of three single forecasting methods, the average relative error from the CI fusion forecasting results is the smallest, which overall reduces the instability and limitations of the single forecasting results of the other three methods in various stages. The advantages of the CI fusion method are obvious.






{kind=link}
{kind=link}
{kind=link}
{kind=link}