1. Introduction
Electric load forecasting, especially short-term electric load forecasting, holds paramount importance for the optimization of the power system′s operations and its significance to participants in the electricity market. Accurate electric load forecasts serve as valuable tools in assisting power system operation planning, electricity price structuring, and energy transactions, thereby enhancing the system’s efficiency and economic benefits [
1,
2]. However, the rapid proliferation of distributed energy sources, electric vehicles, and demand response introduces a growing level of uncertainty into load forecasting, making precise short-term load predictions an increasingly formidable endeavor [
3].
In contrast to traditional statistical forecasting methods, artificial intelligence techniques exhibit enhanced nonlinear fitting capabilities and superior generalization, thereby facilitating the acquisition of more precise forecasting results. The application of deep learning in load forecasting dates back to the 1990s [
4,
5,
6]. Currently, prevalent deep learning models employed in load forecasting predominantly encompass long short-term memory (LSTM) [
7,
8], temporal convolutional network (TCN) [
9,
10,
11], and their counterparts. These methodologies predominantly emphasize temporal correlations within user load sequences, often neglecting the latent connections among individual users. Nevertheless, users residing in geographically proximate locations experience similar influences from weather conditions and holiday patterns. Similarly, users situated in non-adjacent geographic locations might exhibit analogous load patterns due to shared electrical equipment or consumption habits. Thus, it is imperative to consider the interrelations among users in load forecasting.
In load forecasting, the methods that consider the relationships between users mainly include those based on convolutional neural network (CNN) [
12,
13], graph convolutional networks (GCNs) [
14,
15,
16,
17], and Transformer [
18,
19]. CNN-based methods are adept at capturing spatial correlations within regular Euclidean spaces, making them useful for extracting features from grid-like, spatially distributed user data. However, they might fall short when it comes to capturing complex relationships between users that do not conform to such regular, structured grids. This limitation makes CNN less suitable for describing the intricate interconnections among users that often occur in non-Euclidean spaces. In contrast, GCNs are specifically designed to operate on graph-structured data, where relationships between users can be more irregular and complex. GCN excel at extracting both node-specific information and the latent connections among users in these non-Euclidean spaces, thereby enhancing forecasting accuracy by considering the interdependencies between geographically or behaviorally similar users. Transformers, initially introduced for natural language processing tasks, have also shown promise in load forecasting. Transformers are particularly strong when it comes to capturing long-range dependencies within data, making them well suited for forecasting tasks that require an understanding of both temporal sequences and the underlying relationships between users. However, their global self-attention mechanism, while powerful, can lead to unnecessary computational complexity and efficiency issues in short-term forecasting tasks, especially in scenarios where spatial relationships change frequently. This characteristic may make Transformers less efficient compared to other models when dealing with rapidly changing or localized data, where the complexity of the attention mechanism does not necessarily translate to a better predictive performance [
20].
Table 1 summarizes the current load forecasting methods.
Aggregate load refers to the integration of the loads from multiple users or devices into a unified energy load, facilitating centralized control and management. In contrast to load forecasts at the user level, aggregate load forecasts exhibit reduced uncertainty due to the amalgamation of diverse user load behaviors. The collective behaviors of numerous users often offset each other’s uncertainties relatively smoothly, thereby resulting in higher forecast precision [
21]. Aggregate load forecasting holds paramount significance in demand response [
22,
23], power system planning [
24], and the development of electricity markets [
25]. Moreover, within cross-market transactions, the consideration of correlations among multiple aggregate loads assists market participants in understanding load correlations between different markets, facilitating a better balance of load demands and the formulation of suitable trading strategies.
Considering the limitations of CNNs, which are adept at capturing spatial correlations within regular Euclidean spaces but struggle with irregular and non-Euclidean relationships among loads, and the potential inefficiencies of Transformers, which may introduce unnecessary computational complexity in short-term forecasting tasks due to their global self-attention mechanisms, this paper proposes the application of deep learning to aggregate load forecasting by employing a GCN. The GCN is utilized to explore and leverage the correlations among aggregate loads, thereby enhancing predictive accuracy. However, we confront two primary challenges:
Data quality: Deep learning is a data-driven model, and high-quality data are indispensable for precise load forecasting. Issues such as sensor malfunctions, communication instability, and susceptibility to network attacks can compromise data quality, leading to incomplete load data.
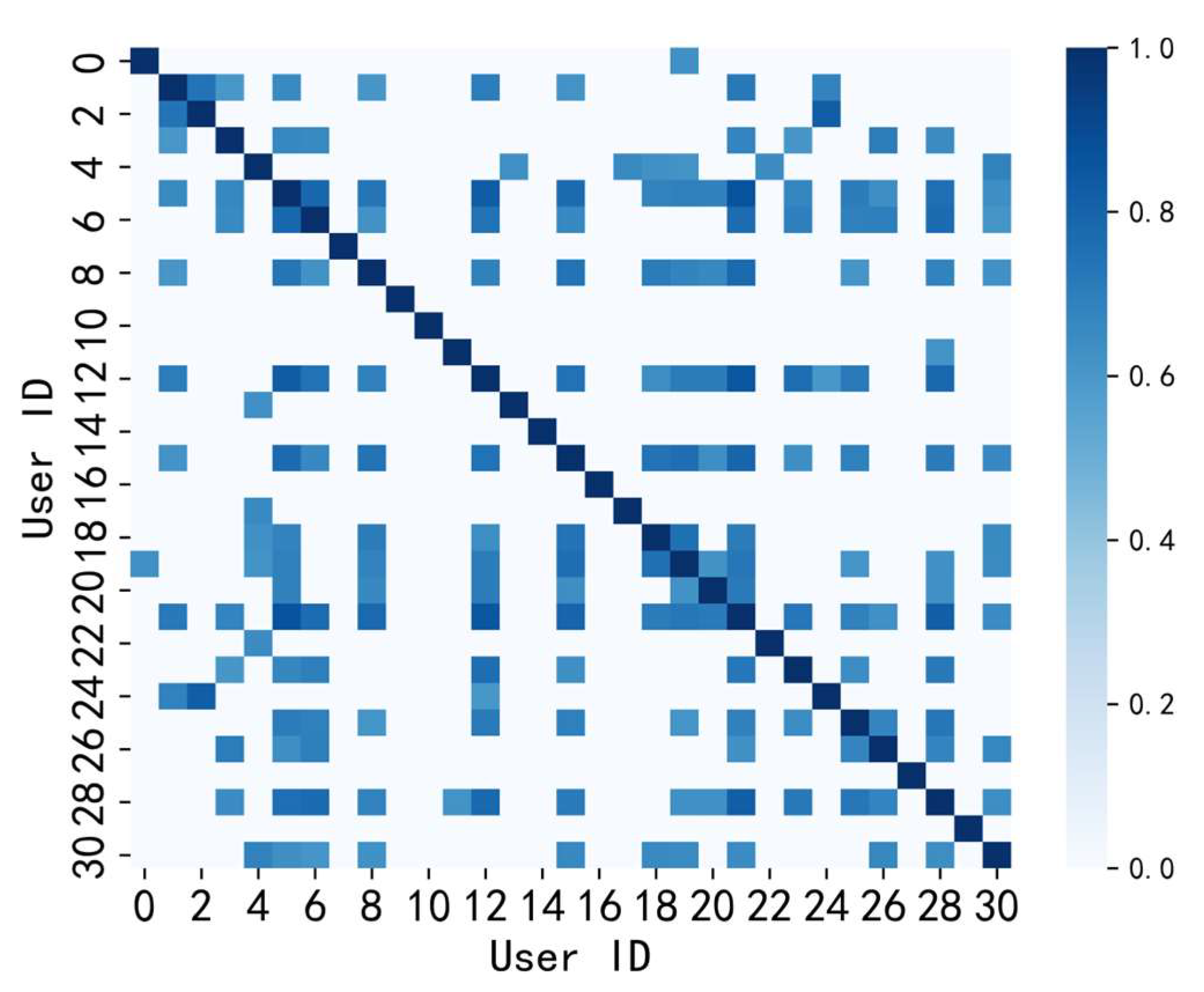
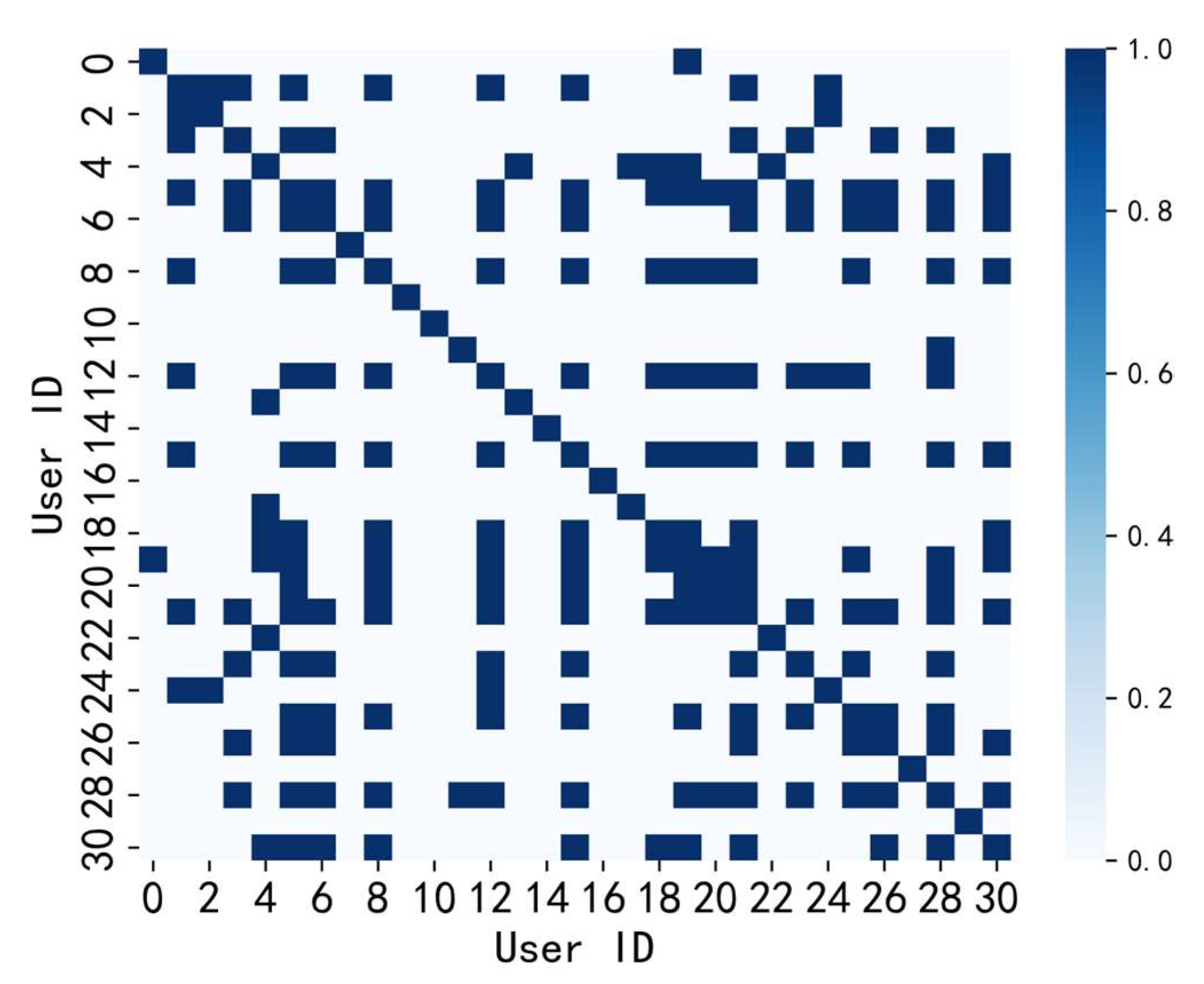
Adjacency matrix: In the utilization of GCN for user load prediction, relationships among users are represented as a graph structure through the adjacency matrix. Currently, a prevalent approach constructs the adjacency matrix based on the geographic distance between users, necessitating the predefinition of the graph structure [
26]. However, for entities like aggregate loads that lack distinct spatial geographic positions, the usage of distance-based methods to construct an adjacency matrix is impractical. Consequently, an approach is required that can derive an adjacency matrix without the need for predefining the graph structure.
Regarding issue 1, the current approaches for handling missing data can be categorized into direct deletion and imputation methods. Direct deletion, while simple, is suitable only for cases where the proportion of missing values is small. When missing values are prevalent, this method leads to a loss of crucial information, resulting in poor model performance or even training failure. Imputation methods can be divided into two categories. The first category is based on inferring missing values from similar data points, including methods such as using simple statistics (e.g., mean, median) [
27] and K-nearest neighbors (KNN) [
28]. The second category involves establishing a global model based on the entire dataset for imputation, including multiple imputation and generative adversarial networks (GANs). Refs. [
29,
30] employ a KNN-based imputation method, which is straightforward but is limited to modeling similarities between data points, lacking the construction of a global model and resulting in lower imputation accuracy. Ref. [
31] introduces a multiple imputation by chained equations (MICE) method, which iteratively traverses the entire dataset to obtain data association rules and utilizes these rules for imputation, making it a popular imputation method. Deep learning, with its multi-layered nonlinear structures, offers advantages in capturing complex data correlations and building global models. GANs, as a class of deep learning generative models, are capable of generating samples similar to the original data and adhering to the same probability distribution, thus improving data quality when the original dataset is of low quality [
32]. Refs. [
33,
34,
35] utilize GANs for the reconstruction of missing data in power system measurements, achieving favorable results. While methods based on similar data points are straightforward, they are limited by local similarity and lack global dataset information. On the other hand, methods based on global models can utilize features and distribution information from the entire dataset but come with higher computational complexity and sensitivity to extreme data points. As a result, this paper proposes an imputation method that simultaneously considers both local and global aspects. It initially uses a GCN to uncover potential connections between similar data points, constructing a local imputation model. Then, it employs a GAN to build a global imputation model. The combination of these two approaches enhances imputation accuracy [
36].
Table 2 summarizes the current imputation methods.
Regarding issue 2, the current methods for constructing adjacency matrices for users without explicit geographical locations primarily include correlation coefficient-based adjacency matrices and binary adjacency matrices. Both of these methods calculate the adjacency matrix by computing the correlation coefficients between different user load sequences. The latter, a binary adjacency matrix, is derived from the correlation coefficient matrix by applying a threshold. The advantages of these two adjacency matrix construction methods lie in their simplicity and computational efficiency. However, their drawback is that correlation coefficients can only reflect linear relationships between user sequences and cannot capture complex nonlinear relationships. Therefore, this paper proposes a learnable adjacency matrix, which can adaptively learn the interrelationships between different sequences to obtain the adjacency matrix. Compared to correlation coefficients, this approach can better capture the intricate relationships between user sequences. It can automatically adjust the strength of connections based on the data’s characteristics, thus accommodating different data distributions and features. This method proves effective for obtaining the adjacency matrix when the graph structure cannot be predefined.
Hence, in response to the issues outlined in the realm of user load forecasting, this paper’s contributions can be summarized as follows:
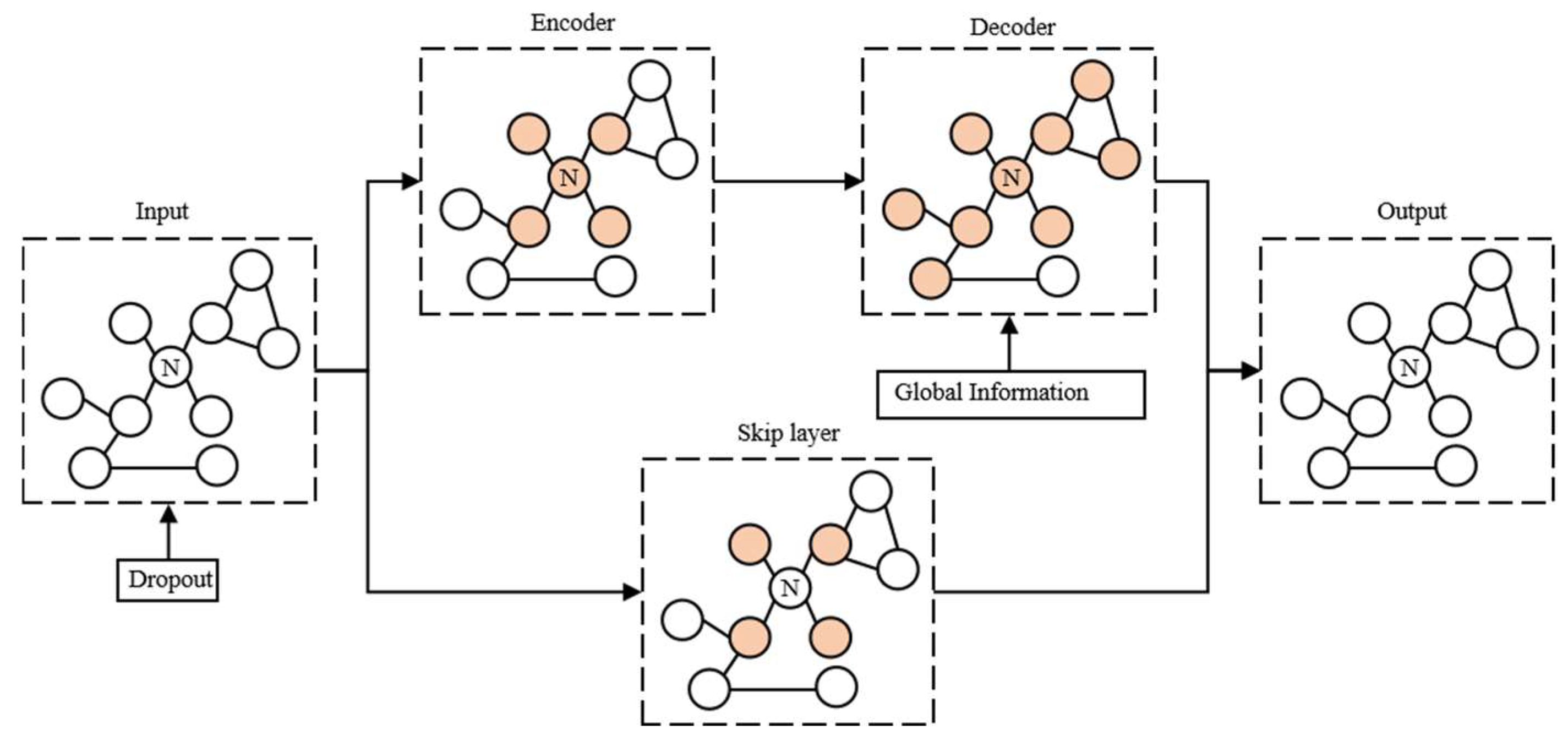
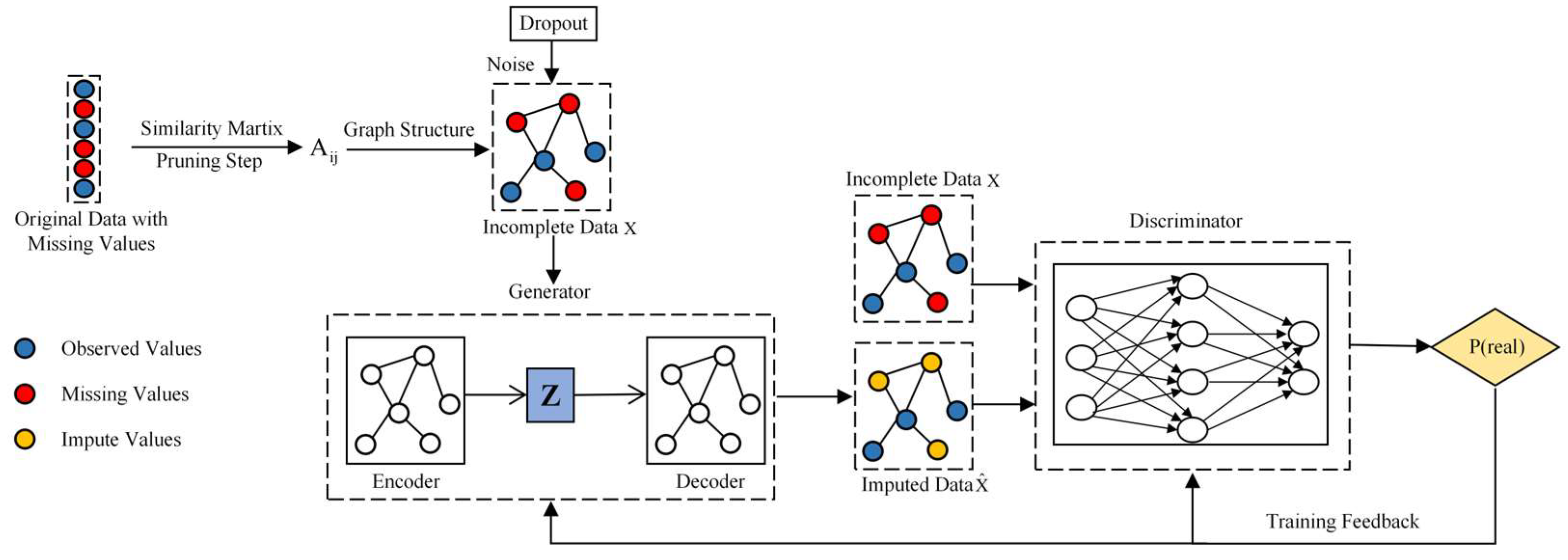
(1) We introduce an adversarial training-based graph convolutional imputation neural network that simultaneously considers both local and global correlations during the imputation process, aiming to enhance imputation accuracy. This involves the initial establishment of a local imputation model using GCN autoencoders, followed by the construction of a global imputation model through GAN-based adversarial training. Empirical evidence has solidly confirmed the effectiveness of this imputation model.
(2) We propose a method for the adaptive construction of an adjacency matrix through active learning of inter-sequence correlations. This method effectively addresses the limitations of traditional approaches, which lack flexibility and depend on spatial information, as demonstrated through empirical validation. The result is an improvement in prediction accuracy.
The remainder of the paper is organized as follows. In
Section 2, the framework for load imputation and prediction is introduced. In
Section 3, the experiments are introduced. In
Section 4, extended experiments on a public dataset are conducted. Finally,
Section 5 provides the conclusions.
5. Conclusions
To address the issues of data quality in aggregated load forecasting and the construction of adjacency matrices to capture correlations, this paper presents a graph convolution-based load data restoration and short-term load forecasting approach with a learnable adjacency matrix. The following summary is provided:
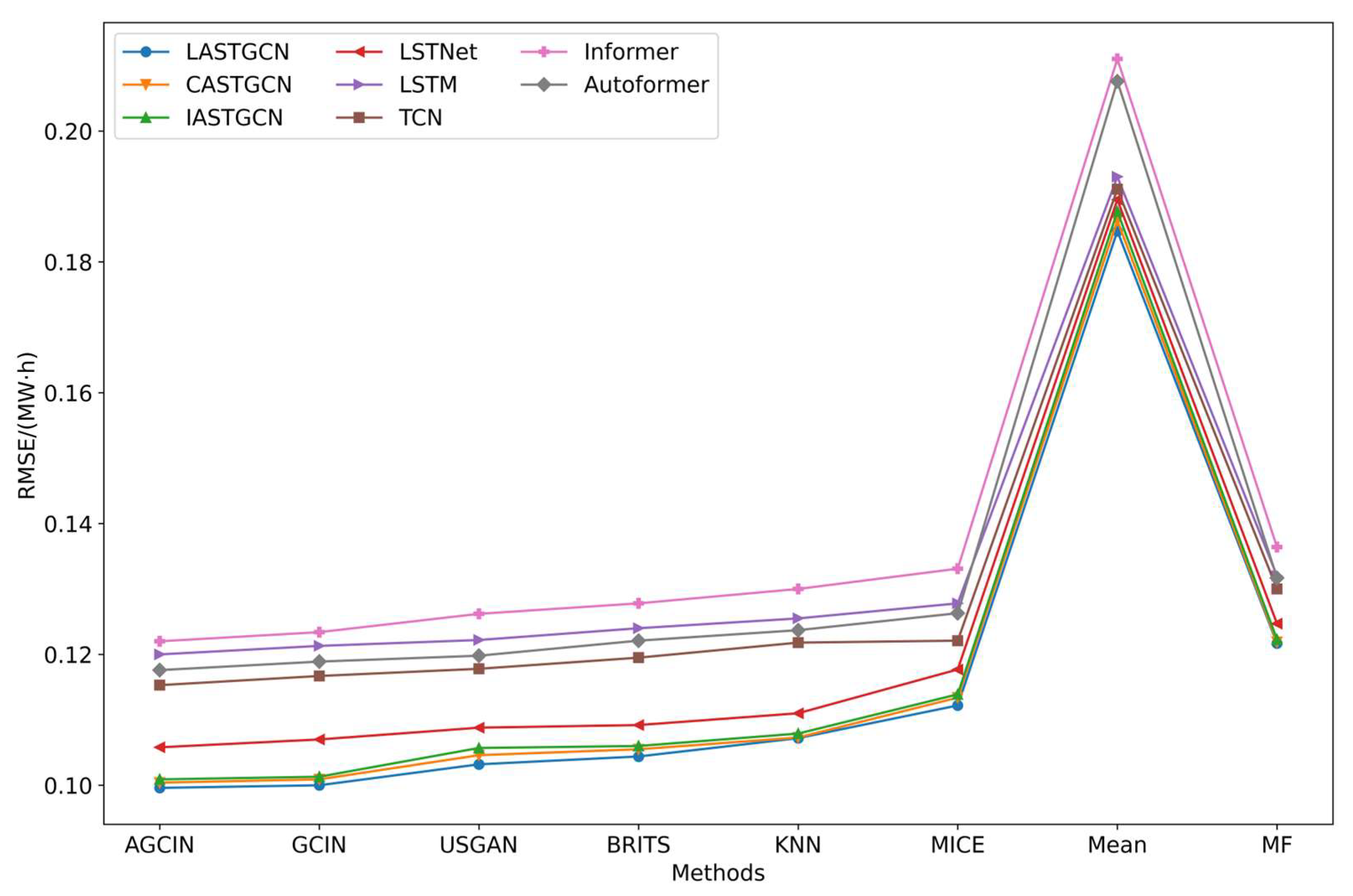
To tackle the data quality problem arising from missing load data, this paper introduces the AGCIN model. It represents data as nodes on a graph, employs GCN to capture local correlations between nodes, establishes a local imputation model, and then introduces GAN through adversarial training to create a global imputation model. Experimental verification demonstrates that the combination of local and global imputation enhances imputation accuracy and improves load data quality. The experimental results demonstrate that in random missing scenarios, with a missing rate ranging from 10% to 60%, the RMSE of the AGCIN model ranges from 0.0463 to 0.1465, outperforming other models. In the case of segment missing scenarios, with continuous missing data from 1 day to 9 days, the AGCIN model’s RMSE ranges from 0.0095 to 0.0411, consistently surpassing other models. This proves that combining local and global imputation can enhance imputation accuracy and improve load data quality.
In the context of an aggregated load where specific geographical locations are absent, it becomes challenging to construct an adjacency matrix based on geographical distance for spatio-temporal load forecasting. To address this issue, the paper presents the LASTGCN model. This model considers both temporal and spatial correlations and can adaptively learn interrelationships between different sequences from time series data, obtaining an adjacency matrix. This approach proves effective when predefined graph structures are unattainable. The experimental results show that the prediction errors of LASTGCN in terms of MAE, RMSE, and R2 are 0.0316, 0.0570, and 0.9528, respectively, outperforming other prediction models across all three metrics. This indicates that the learnable adjacency matrix provides a flexible and effective method with which to capture the spatial relationships between users. Furthermore, results from various GCN-based prediction models demonstrate that GCN exhibits strong spatial modeling capabilities, and accounting for spatial relationships between users can significantly enhance the accuracy of load forecasting.
Lastly, we must acknowledge some limitations of the current work. Firstly, while data privacy is a significant concern in aggregated load data, particularly as some users may be unwilling to share their data, this manuscript does not address these concerns in depth. The issue of data privacy is crucial because it directly impacts the willingness of users to participate in data collection and sharing, which in turn affects the accuracy and reliability of aggregated load forecasting. In future work, we plan to explore methods such as federated learning and differential privacy to mitigate these concerns. Federated learning, for example, allows for the training of models across decentralized devices or servers holding local data samples without exchanging them, thereby preserving user privacy. Similarly, differential privacy techniques can ensure that the output of the model does not reveal specific information about individual users, even if the data are aggregated.
Secondly, the scale of the data is an issue. For deep learning, larger datasets (both temporally and spatially) are beneficial for model training and validation of generalization. Therefore, in future efforts, we will consider using larger-scale datasets.
Moreover, we are committed to developing a more versatile imputation–prediction framework and extending it to a broader range of potential application scenarios, including the forecasting of other types of loads, such as wind and solar renewable energy. Extending our framework to these domains will allow us to assess its effectiveness in predicting the highly variable and weather-dependent nature of renewable energy sources.
By addressing data privacy concerns through advanced methodologies like federated learning and differential privacy, we believe our future work will make significant strides in both protecting user data and improving the robustness and applicability of our forecasting models. These advancements will be crucial for ensuring that our models can be widely adopted in practical applications, including renewable energy forecasting, while maintaining the trust and participation of users.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}