
Long Short-Term Renewable Energy Sources Prediction for Grid-Management Systems Based on Stacking Ensemble Model


Abstract
1. Introduction
- 1.
- Our primary focus tackles the crucial need for developing independent or hybrid forecasting models specifically for PV and wind energy prediction. Reliable forecasts enable grid operators to integrate these PV and Wind energy effectively, minimizing the need for costly backup power generation. Additionally, accurate forecasts support efficient energy market operations, inform policymakers about optimal resource allocation, enhance grid stability, and contribute to cost reduction in energy production and distribution.
- 2.
- Our second interest relies on developing cost-effective solutions for scheduling the utilization of PV, wind, and grid energies. This study acknowledges the complex relationship between predictions, power costs, and environmental elements in maximizing energy efficiency. An analysis of several solutions entails a comprehensive approach, taking into account real-time energy expenses, grid requirements, and weather predictions. Developing an adaptive scheduling pipeline that aims to optimize cost savings, decrease the carbon footprint, and emphasize the system’s capacity to react dynamically to different grid situations.
2. Renewable Energies (RE) Forecasting Models
2.1. Forecasting Model
2.1.1. Time Series Models
- Weighted Moving Averages (WMA): The decision to implement the WMA model for RE forecasting was made based on its suitability for capturing short-term fluctuations and its simplicity. However, it became evident that the model struggled to generalize effectively for the broader range of predictions required. While WMA excels at emphasizing recent data points, its simplistic approach may not adequately capture underlying trends or structural shifts in the data, particularly over longer timeframes. Consequently, the model’s limitations in generalization compromised its ability to provide accurate forecasts beyond short-term horizons, highlighting the need for alternative or supplementary forecasting algorithms that can better address the complexities of PV energy production patterns across various timescales [10].
- AutoRegressive Integrated Moving Average (ARIMA): ARIMA is a powerful technique for forecasting time series data. It combines autoregression, differencing, and moving averages seamlessly. The main advantage of this is its ability to effectively capture both immediate changes and long-term patterns in renewable energy data. The application of ARIMA involves a rigorous procedure of determining the most suitable order of differencing, autoregressive components, and moving average components through comprehensive statistical analysis [11].
2.1.2. Machine Learning (ML) Models
2.1.3. Deep Learning (DL) Algorithms
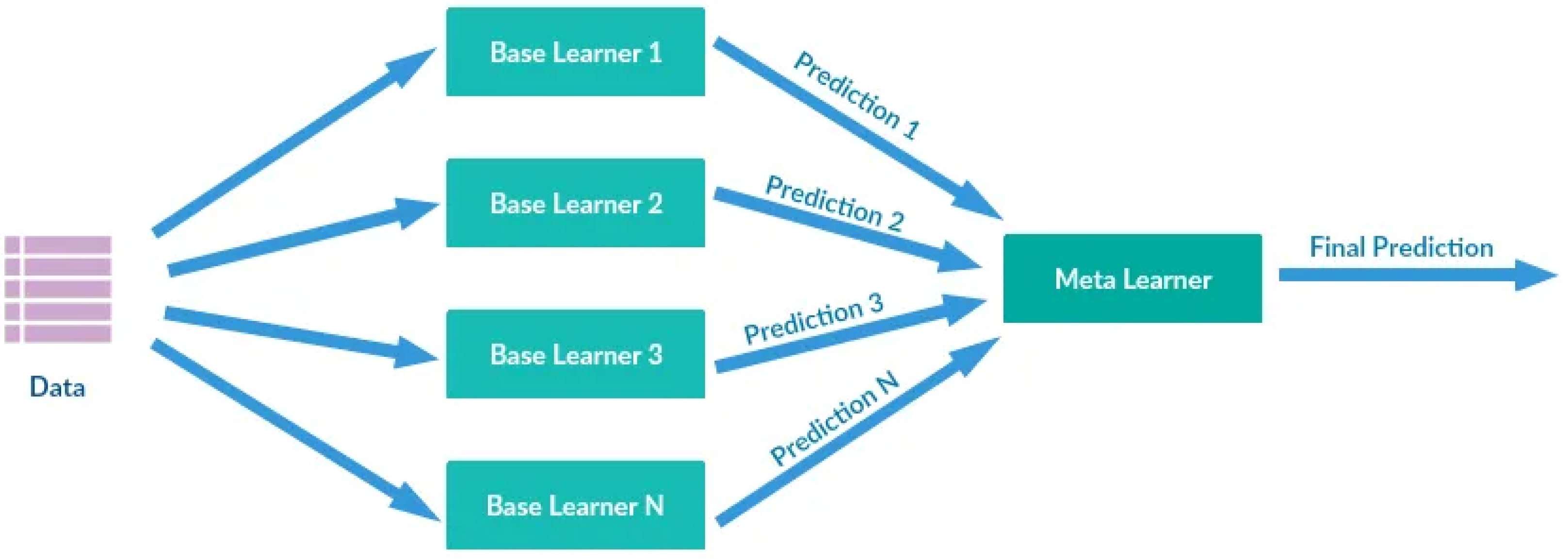
2.1.4. Stacking Algorithm
3. PV Power Forecasting
3.1. PV Dataset
3.1.1. Description
3.1.2. PV Dataset Features
- 1.
- Timestamp: This feature is dedicated to displaying the exact date and time of each recorded data point in the collection.
- 2.
- Power: This critical feature captures the measured values of the PV system, which is the major variable of importance in our analysis. The ‘Power’ entries use a quantitative approach, representing the quantitative components of energy generation and providing insights into the system’s performance.
- 3.
- Status: The ‘Status’ column indicates the operational status of the PV system at each date. This category data enables a thorough understanding of the system’s operation across time, assisting in the detection of patterns and abnormalities that may impact energy generation.
3.2. Meteorological Dataset
3.2.1. Description
3.2.2. Meteorological Features
- Sky Coverage and Precipitation: The sky coverage degree percent indicates cloud cover, while precipitation quantity in millimeters informs about rainfall.
- Solar Radiation and Sunshine Duration: The sum of radiation measurements (atmospheric, diffuse, and global) provides cumulative data on different types of radiation. Meanwhile, the sum of sunshine minutes quantifies the duration of sunshine in 15-min intervals, offering insights into sunlight patterns. Additionally, the sun angle indicates solar exposure by describing the angle of the sun.
- Temperature and Humidity: The temperature air degree Celsius measures air temperature, crucial for assessing PV system performance. Meanwhile, humidity percent indicates the level of humidity, affecting overall atmospheric conditions.
- Wind Information: Wind speed, measured at 15-min intervals, provides crucial data for analyzing environmental conditions. Additionally, wind direction indicates the origin of the wind flow, offering insights into atmospheric dynamics.
3.2.3. Dataset Integration Strategy
3.2.4. Preprocessing Strategies for the Integrated PV and Weather Dataset
- Date/time Transformation: The Date column is transformed regarding a standardized date/time format to ensure the establishment of a consistent temporal framework adapted to time series analysis.
- Temporal Feature Extraction: Extracting temporal components from the Date column, such as the day of the week, month, and hour of measurement, allows for a more sophisticated understanding of energy trends across time dimensions.
- Introduction of Interaction Terms: The generation of interaction terms, as illustrated by ‘Interaction1’ which signifies the product of ‘QUANTITY_IN_MM’ and ‘TEMPERATURE_AIR_DEGREE_CELSIUS’, is intended to document interdependent relationships that exist within the dataset.
- Domain-Informed Feature Engineering: Domain-specific knowledge informs the development of supplementary attributes, such as the binary ‘Raining_Category’, and the square of TEMPERATURE_AIR_DEGREE_CELSIUS’ which contribute to a more intricate depiction of environmental conditions.
- Temporal Lag Features and Rolling Mean: By including latency features (‘Power_i’) and a rolling mean of the ‘Power’ variable, the temporal context of the dataset is expanded, enabling the capture of historical patterns and trends.
- Handling Missing Values: To ensure data integrity, rigorous steps are implemented to address missing values caused by the introduction of lag characteristics. This is achieved by carefully removing the related rows.
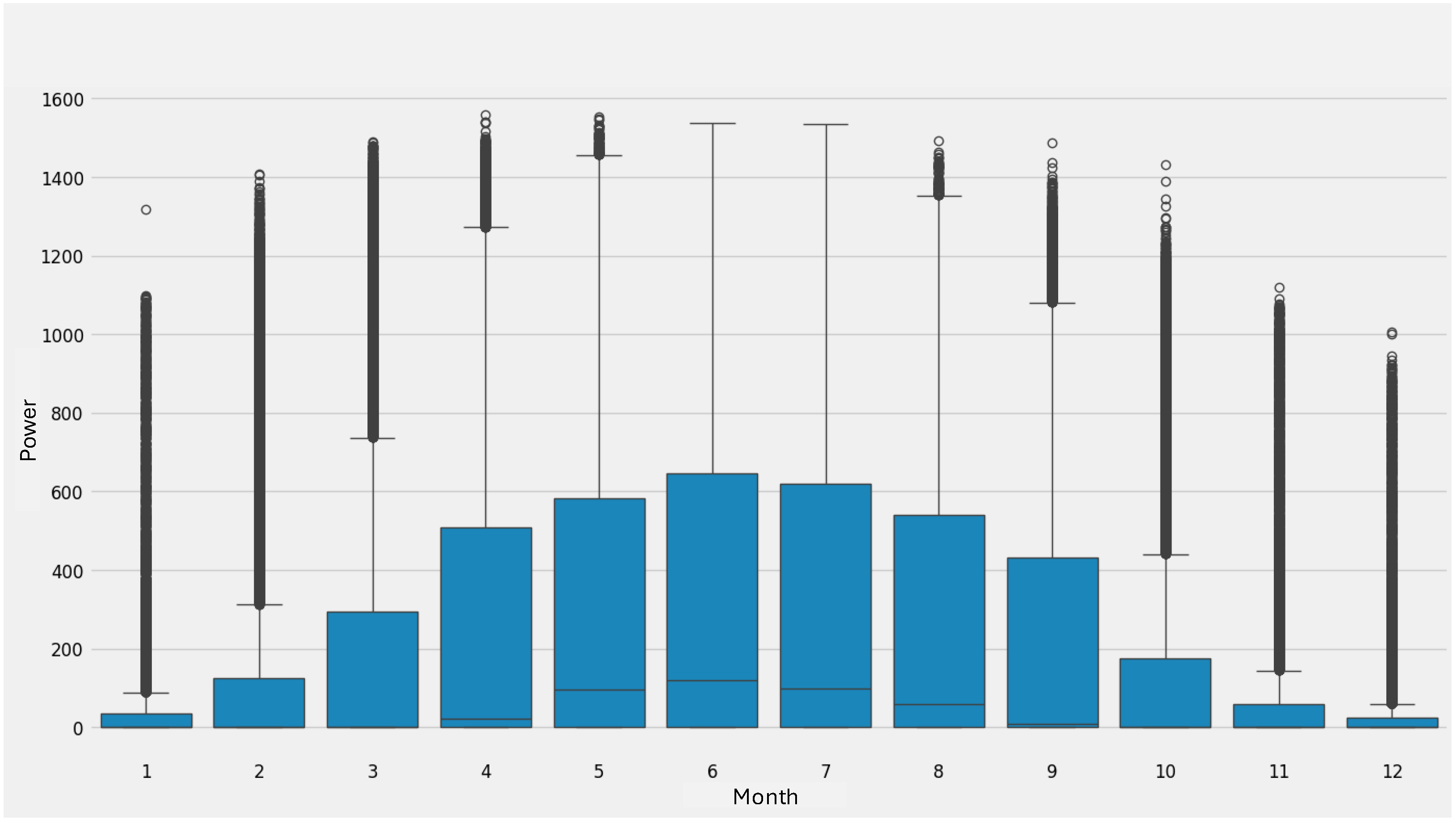
3.3. Exploratory Data Analysis (EDA)
3.3.1. Base Description and Descriptive Statistics
3.3.2. Stationary Test
3.3.3. PV Dataset Decomposition
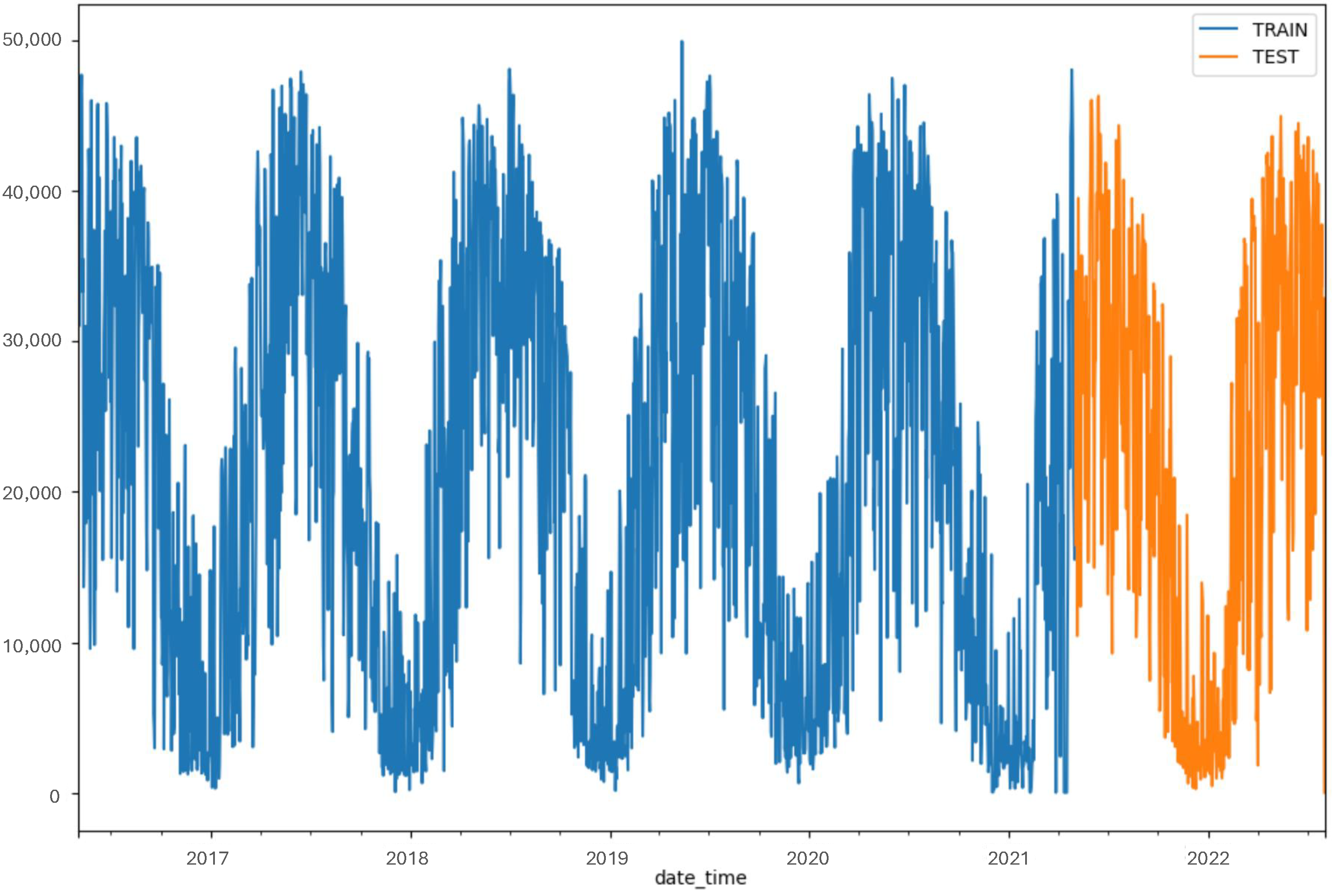
3.4. Data Partitioning and Model Evaluation Strategy
3.5. Forecasting Models
3.5.1. Single Model
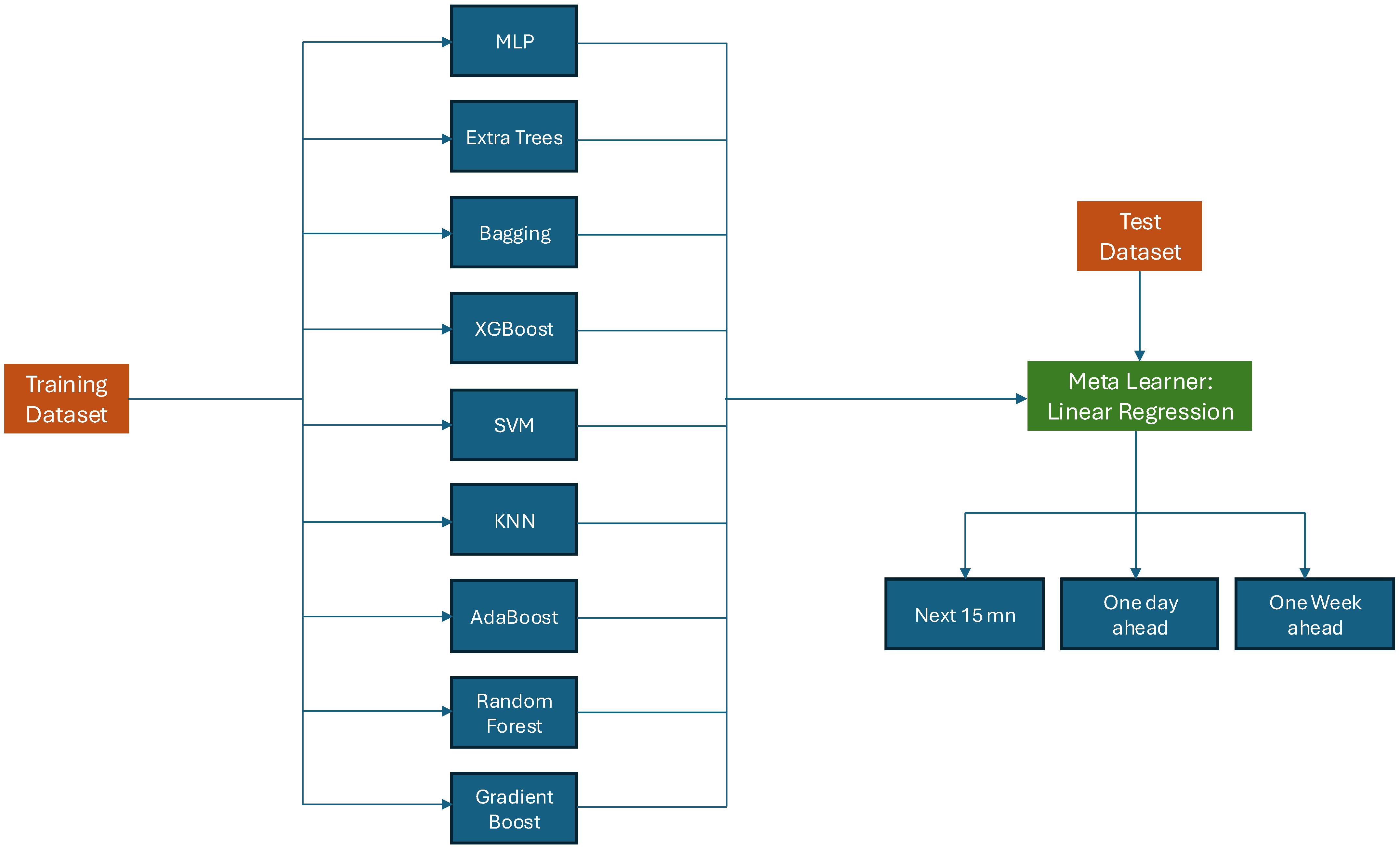
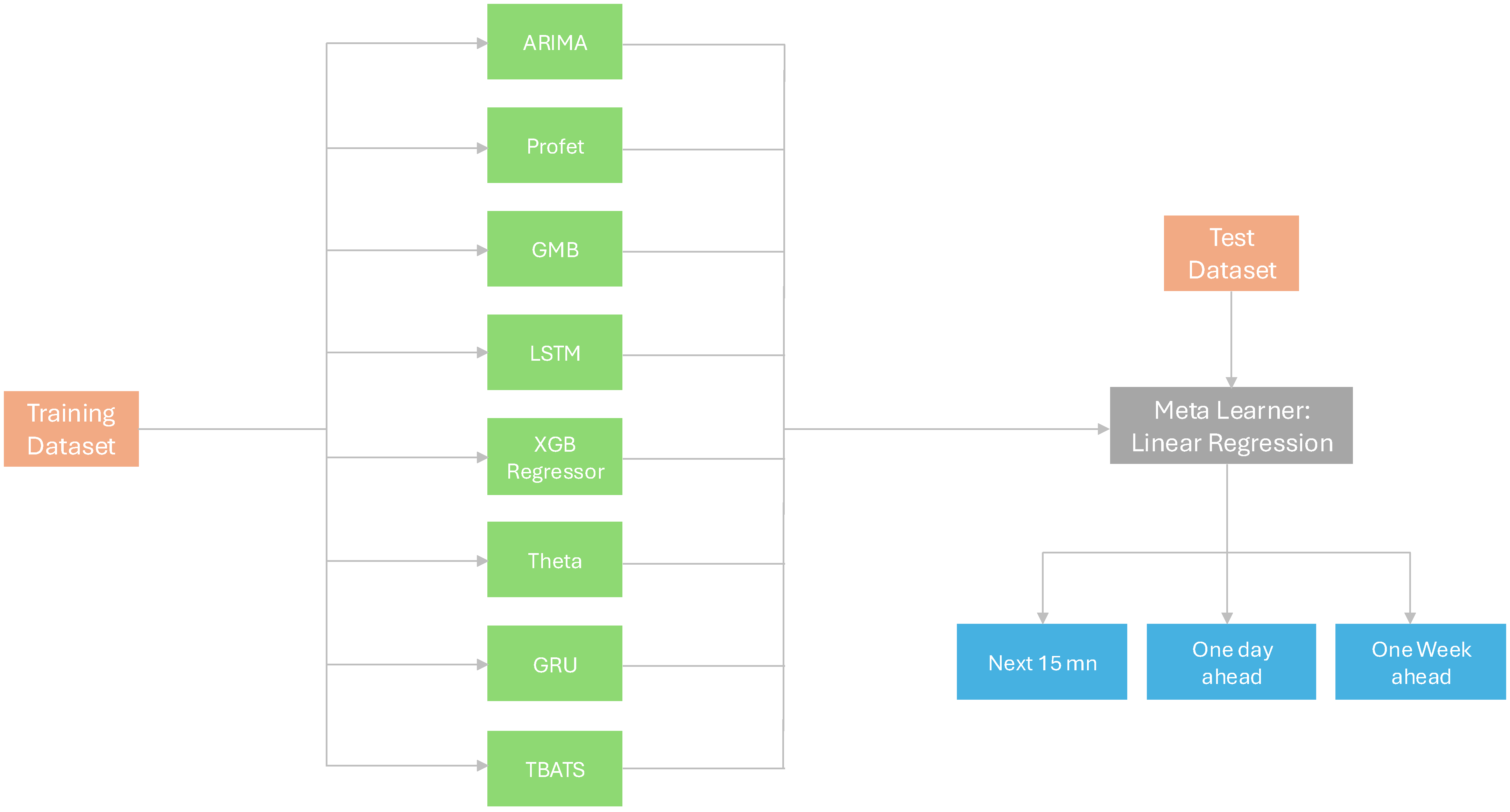
3.5.2. Stacking Model Architecture
- Base Models: For the base models, we have used different regression capabilities. For instance, in this example, some of the models are Gradient Boosting, Random Forest, AdaBoost, Linear Regression, K-Neighbors, SVM, XGBoost, Bagging, Extra Trees MLP Neural Network and optionally others.
- StackingRegressor: The models are then brought together in a single ensemble model, which is StackingRegressor. Every base model becomes a learner contributing to the prediction at the overall level.
- Final Estimator (Linear Regression in this case): A linear regression final estimator or something simple is most suitable for combining model predictions. This last estimator fine-tunes and improves forecasts made by many basic models.
- Training and Prediction: The training dataset is used for training the StackingRegressor (X_train and y_train). Both train and test datasets are predicated upon.
- Evaluation: To evaluate the performance of our algorithm on both train and test datasets we calculate RMSE as well as MAPE for StackingRegressor.
- GPU: NVIDIA Tesla V100.
- CPU: Intel Xeon E5-2698 v4.
3.6. Results
One Single Forecasting Model
- Next 15 min Prediction: The complete assessment of different predictive models has been done in the Next 15 min Prediction task and the results show informative performance measures. Significantly, AdaBoost Models are among the best predictors with a minimum RMSE of 8.3 which shows their efficiency in capturing and utilizing intricate patterns in dataset. The latter comes out as being particularly strong within this predictive environment, implying that they are good at capturing temporal dependencies and using historical information for accurate forecasting. Otherwise, RNN, Random Forest and XGBoost models give a comparable outcome but it fails to beat AdaBoost Model. Therefore, this study not only provides insights into predictions but also offers useful suggestions for the improvement of other similar future prediction cases.
- One Day Ahead Prediction: Various models were carefully examined for one day ahead forecast and among them, GRU model proved to be the best. The GRU model is reported to have the lowest RMSE value of 18.5 when compared to other models. This suggests that it captures very well short-term temporal dependencies and patterns embedded in the data thereby increasing its forecasting ability for one day ahead. It is important to note that over this time frame, the GRU model performs better than Gradient Boosting and XGBoost among others. This simply means that with regard to how intricately it can put together such information from all sources at its disposal, few models can compete with GRU’s predictive abilities.
- One Week Ahead Prediction: Various models’ evaluation of their performance in the context of one-week ahead predictions show that the LSTM model is the most accurate as manifested by its least RMSE among those considered. Specifically, the LSTM model records an impressive RMSE value of 39.6.
- One Month Ahead Prediction: When considering forecasts made one month ahead, it can be seen that the LSTM model had the lowest RMSE of all other models reviewed showing its accuracy at that time period. The LSTM model achieved a further low value of RMSE equal to 160.2 which underlines more its exactitude.
3.7. Stacking Model Prediction
3.8. Discussion
4. Wind Power Forecasting
4.1. Wind Dataset
4.1.1. Description
4.1.2. Wind Dataset Features
- Date and Time: Timestamps indicating when the wind measurements were recorded, facilitating temporal analysis and model validation.
- Wind Speed: The magnitude of wind motion at a specific location, usually measured in meters per second (m/s) or kilometers per hour (km/h).
- Wind Direction: The compass direction from which the wind is blowing, often reported in degrees relative to true north.
- Power Generation (if applicable): For wind farms, the amount of electrical power generated by wind turbines, is measured in kilowatts (kW) or megawatts (MW).
- Temperature: Ambient air temperature at the time of measurement, influencing wind behavior and atmospheric stability.
- Status: Indicators of data quality or instrument operation, such as error codes or sensor malfunctions.
4.2. Data Partitioning and Model Evaluation Strategy
4.3. Forecasting Models
4.3.1. One Single Model
4.3.2. Stacking Algorithm Architecture
4.4. Results
4.4.1. One Single Forecasting Model
- Next 15 min Prediction: Significantly, the Profet Model exhibits exceptional predictive capabilities, as evidenced by their RMSE value of 7.4. This underscores their efficacy in discerning and applying intricate patterns present in the dataset. Although alternative models achieve comparable outcomes, they fall short in comparison to the Profet Model.
- One Day Ahead Prediction: Upon evaluating different models for one-day ahead predictions, a comprehensive analysis reveals that the Gatboost model stands out as the most precise predictor. Among its peers, the Catboost model demonstrates the RMSE, showcasing a value of 17.2. This outcome underscores the effectiveness of RNN and LSTM architecture in capturing short-term temporal relationships and inherent patterns within the dataset, thus improving its predictive accuracy for the designated one-day forecasting period. Significantly, this superiority implies that the Catboost model excels in identifying and utilizing intricate data patterns, resulting in enhanced predictive abilities compared to alternative models.
- One Week Ahead Prediction: The assessment of different models for forecasting one week indicates that the CNN Regressor model emerges as the most precise for week-ahead predictions, evidenced by its lowest RMSE compared and its highest accuracy (see Table 2 and Table 3) to the other models examined. Specifically, the CNN Regressor model achieves a commendable RMSE value of 38.2.
- One Month Ahead Prediction: The evaluation of various models designed to forecast one month in advance reveals that the LSTM model exhibits the highest level of precision, as indicated by its lowest RMSE, in comparison to the other models that were assessed. More precisely, the RMSE value attained by the LSTM model is a praiseworthy 155.1.
4.4.2. Stacking Model across Different Forecasting Horizons
4.4.3. Discussion
5. Scheduling Pipeline Based on Mixed Integer Programming (MIP) Algorithm
5.1. Problem Statement
- Strategy 1: Minimize Cost with Cheapest Energy FirstThe primary objective is to ascertain the most efficient distribution of energy from various sources such as PV, Wind, and the Grid at each timestamp to fulfill the demand while reducing the total cost. Put simply, our objective is to identify the optimal blend of energy sources for each time interval to meet the energy requirements while minimizing expenses.
- Strategy 2: Prioritize Renewable Energy with Cost MinimizationThe second objective places a higher importance on utilizing renewable energy sources such as PV and wind power instead of relying on the traditional power infrastructure. The objective is to reduce the total cost by initially utilizing renewable energy sources. If the combined output of PV and wind power is insufficient to meet the need, the remaining demand is fulfilled by drawing electricity from the grid.
5.2. Scheduling Algorithm
- Objective Function: The objective function specifies the desired outcome of the optimization process. It is a mathematical expression that requires optimization, either by maximizing or minimizing it. Within the framework of MIP, this particular function can encompass both continuous and discrete variables, hence encompassing the entire purpose of the issue at hand.
- Decision Variables: MIP issues include decision variables that can have values that are both continuous and integer. Continuous variables encompass the whole range of real numbers, whereas integer variables are limited to whole integers. The incorporation of these diverse variable types enables a more authentic portrayal of decision-making in different applications.
- Constraints: Constraints are defined as circumstances that impose limitations on the possible solutions of an optimization problem. These can comprise linear equations or inequalities that involve both continuous and integer variables. Constraints are restrictions or conditions placed on the decision variables to ensure that the answer meets particular criteria.
5.3. Main Objective Function
- denotes the proportion of PV power used at a specific time t and it is expressed in kW.
- denotes the proportion of Wind power used at a specific time t and it is expressed in kW.
- denotes the proportion of Grid energy used at a specific time t and it is expressed in kWh.
5.3.1. Constraints of Strategy 1
- Energy Usage Percentage Constraint: This constraint ensures that the sum of the energy consumption percentages for each timestamp is equal to 1, showing that the whole energy demand is fully satisfied and is given as follows:
- Demand Satisfaction Constraint: This constraint guarantees that the chosen combination of energy sources meets the energy requirement at every timestamp and is given by the expression below:
5.3.2. Constraints of Strategy 2
- Energy Sum Constraint: This constraint guarantees that the sum of the energy consumption percentages is equal to 1 at each epoch, indicating that the entire energy demand is fulfilled.
- Renewable Priority Constraint: This constraint determines whether the combined wind and PV energy is adequate to meet demand. If so, the grid remains unused (). This constraint is formulated as follows:
- Grid Usage Constraint: This restriction is triggered when the total energy generated by both PV and wind sources is not enough to satisfy the energy requirement. In this scenario, it is necessary to utilize either PV or Wind energy, or both (), while the grid is employed to fulfill the remaining energy requirements. This constraint is expressed by Equations (6) and (7):
5.4. Results
- Strategy 1 is based on maximizing economic efficiency. This technique focuses on reducing expenses by strategically prioritizing the use of the most financially feasible energy sources. Practically speaking, this implies that the system will initially utilize the most cost-effective energy source before exploring other options. The scheduling algorithm using Strategy 1 has yielded a 60% improvement in cost savings compared to random scheduling methods.
- Strategy 2 heavily focuses on promoting environmental sustainability through the use of renewable energy sources. The idea behind this strategy is to use renewable energy sources like solar and wind as the main energy source and conventional energy systems as a backup. Second, it follows the global trend of reducing energy consumption’s negative effects on the environment and reducing carbon footprints. The use of renewable energy sources indicates a commitment to eco-friendly policies and practices. The scheduling algorithm using Strategy 2 has yielded a 40% reduction in carbon emissions compared to conventional energy scheduling practices.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Erdogan, G.; Fekih Hassen, W. Charging Scheduling of Hybrid Energy Storage Systems for EV Charging Stations. Energies 2023, 16, 6656. [Google Scholar] [CrossRef]
- Bouzerdoum, M.; Mellit, A.; Pavan, A.M. A hybrid model (SARIMA–SVM) for short-term power forecasting of a small-scale grid-connected photovoltaic plant. Sol. Energy 2013, 98, 226–235. [Google Scholar] [CrossRef]
- Chen, C.; Duan, S.; Cai, T.; Liu, B. Online 24-h solar power forecasting based on weather type classification using artificial neural network. Sol. Energy 2011, 85, 2856–2870. [Google Scholar] [CrossRef]
- An, G.; Jiang, Z.; Cao, X.; Liang, Y.; Zhao, Y.; Li, Z.; Dong, W.; Sun, H. Short-term wind power prediction based on particle swarm optimization-extreme learning machine model combined with AdaBoost algorithm. IEEE Access 2021, 9, 94040–94052. [Google Scholar] [CrossRef]
- Yu, L.; Meng, G.; Pau, G.; Wu, Y.; Tang, Y. Research on Hierarchical Control Strategy of ESS in Distribution Based on GA-SVR Wind Power Forecasting. Energies 2023, 16, 2079. [Google Scholar] [CrossRef]
- Yu, Y.; Han, X.; Yang, M.; Yang, J. Probabilistic prediction of regional wind power based on spatiotemporal quantile regression. In Proceedings of the 2019 IEEE Industry Applications Society Annual Meeting, Baltimore, MD, USA, 29 September–3 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–16. [Google Scholar]
- Liu, Y.; Wang, J. Transfer learning based multi-layer extreme learning machine for probabilistic wind power forecasting. Appl. Energy 2022, 312, 118729. [Google Scholar] [CrossRef]
- Moreira, M.; Balestrassi, P.; Paiva, A.; Ribeiro, P.; Bonatto, B. Design of experiments using artificial neural network ensemble for photovoltaic generation forecasting. Renew. Sustain. Energy Rev. 2021, 135, 110450. [Google Scholar] [CrossRef]
- Louzazni, M.; Mosalam, H.; Khouya, A.; Amechnoue, K. A non-linear auto-regressive exogenous method to forecast the photovoltaic power output. Sustain. Energy Technol. Assess. 2020, 38, 100670. [Google Scholar] [CrossRef]
- Nerlove, M.; Diebold, F.X. Autoregressive and moving-average time-series processes. In Time Series and Statistics; Springer: Berlin/Heidelberg, Germany, 1990; pp. 25–35. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S.; Shumway, R.H.; Stoffer, D.S. ARIMA models. In Time Series Analysis and Its Applications: With R Examples; Springer: New York, NY, USA, 2017; pp. 75–163. [Google Scholar]
- Li, C. A Gentle Introduction to Gradient Boosting. 2016. Available online: https://www.khoury.northeastern.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf (accessed on 1 December 2023).
- Kramer, O.; Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Rigatti, S.J. Random forest. J. Insur. Med. 2017, 47, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Schapire, R.E. Explaining adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Dietterich, T.G. Ensemble learning. Handb. Brain Theory Neural Netw. 2002, 2, 110–125. [Google Scholar]
- Setunga, S. Stacking in Machine Learning, 02.01.2023.
- Tsai, W.C.; Tu, C.S.; Hong, C.M.; Lin, W.M. A review of state-of-the-art and short-term forecasting models for solar pv power generation. Energies 2023, 16, 5436. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Kramer, O.; Gieseke, F. Short-term wind energy forecasting using support vector regression. In Soft Computing Models in Industrial and Environmental Applications, Proceedings of the 6th International Conference SOCO 2011, Salamanca, Spain, 6–8 April 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 271–280. [Google Scholar]
- Colak, I.; Sagiroglu, S.; Yesilbudak, M. Data mining and wind power prediction: A literature review. Renew. Energy 2012, 46, 241–247. [Google Scholar] [CrossRef]
- Dong, L.; Wang, L.; Khahro, S.F.; Gao, S.; Liao, X. Wind power day-ahead prediction with cluster analysis of NWP. Renew. Sustain. Energy Rev. 2016, 60, 1206–1212. [Google Scholar] [CrossRef]
- Kiplangat, D.C.; Asokan, K.; Kumar, K.S. Improved week-ahead predictions of wind speed using simple linear models with wavelet decomposition. Renew. Energy 2016, 93, 38–44. [Google Scholar] [CrossRef]
- Dantzig, G.B. Linear programming. Oper. Res. 2002, 50, 42–47. [Google Scholar] [CrossRef]
- Dorn, W. Non-linear programming—A survey. Manag. Sci. 1963, 9, 171–208. [Google Scholar] [CrossRef]
- Smith, J.C.; Taskin, Z.C. A tutorial guide to mixed-integer programming models and solution techniques. In Optimization in Medicine and Biology; Routledge: London, UK, 2008; pp. 521–548. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE Next 15 min | RMSE One Day Ahead | RMSE One Week Ahead | RMSE One Month Ahead |
|---|---|---|---|---|
| Autoregressive Models | 15.2 | 25.7 | 90.2 | 200.5 |
| Weighted Moving Averages | 12.3 | 21.3 | 70.4 | 180.2 |
| Simple Exponential Smoothing | 18.4 | 27.3 | 120.6 | 230.9 |
| Holt-Winters | 22.1 | 28.9 | 95.4 | 210.3 |
| ARMA | 20.2 | 32.5 | 140.6 | 250.1 |
| ARIMA | 17.6 | 23.6 | 103.1 | 220.8 |
| Gradient Boosting | 12.4 | 19.5 | 78.6 | 190.7 |
| Random Forest | 9.4 | 17.3 | 54.6 | 160.4 |
| AdaBoost | 8.3 | 18.3 | 56.4 | 165.2 |
| K-Neighbors | 16.2 | 34.5 | 76.9 | 200.9 |
| SVM | 11.7 | 26.3 | 56.8 | 175.6 |
| XGBoost | 9.6 | 17.7 | 48.8 | 150.3 |
| Bagging | 10.5 | 28.6 | 55.2 | 170.1 |
| Extra Trees | 13.8 | 25.3 | 78.2 | 205.8 |
| MLP Neural Network | 14.7 | 23.5 | 69.4 | 195.6 |
| RNN | 11.3 | 20.8 | 62.6 | 185.4 |
| LSTM | 13.2 | 23.5 | 39.6 | 160.2 |
| CNN | 9.4 | 24.9 | 70 | 175.8 |
| GRU | 9.7 | 18.5 | 58.2 | 170.6 |
| Stacking Model | 0.000001 | 0.0000287 | 0.0000492 | 0.000331 |
| Model | RMSE Next 15 min | RMSE 1 Day Ahead | RMSE 1 Week Ahead | RMSE 1 Month Ahead |
|---|---|---|---|---|
| Autoregressive Models | 14.8 | 24.9 | 88.7 | 197.5 |
| Weighted Moving Averages | 11.9 | 20.5 | 68.9 | 177.2 |
| Simple Exponential Smoothing | 17.6 | 26.3 | 119.1 | 228.1 |
| Holt-Winters | 21.0 | 37.5 | 93.8 | 207.8 |
| RNN | 19.2 | 31.0 | 138.1 | 247.1 |
| ARIMA | 16.8 | 29.6 | 101.5 | 218.7 |
| Gradient Boosting | 11.9 | 18.6 | 76.0 | 186.7 |
| CatBoost | 10.8 | 17.2 | 53.0 | 161.9 |
| AdaBoost | 15.5 | 33.0 | 74.0 | 197.8 |
| CNN | 11.2 | 25.0 | 38.2 | 171.7 |
| K-Neighbors | 19.2 | 36.9 | 67.0 | 166.8 |
| GRU | 10.1 | 27.4 | 52.8 | 166.6 |
| SVM | 13.3 | 24.4 | 75.4 | 201.3 |
| XGBoost | 14.2 | 22.7 | 67.5 | 190.0 |
| TBATS | 11.9 | 20.0 | 60.0 | 179.1 |
| Theta | 13.7 | 22.7 | 38.2 | 170.3 |
| LSTM | 12.9 | 23.6 | 66 | 155.1 |
| Profet | 7.4 | 27.6 | 55.4 | 165.0 |
| Stacking Model | 0.00003 | 0.00009 | 0.0002 | 0.000331 |
| Model | CNN Accuracy | RNN Accuracy | LSTM Accuracy | |
|---|---|---|---|---|
| Iteration | ||||
| 1 | 0.65 | 0.60 | 0.62 | |
| 10 | 0.70 | 0.65 | 0.66 | |
| 20 | 0.73 | 0.68 | 0.70 | |
| 30 | 0.75 | 0.70 | 0.73 | |
| 40 | 0.76 | 0.72 | 0.75 | |
| 50 | 0.77 | 0.73 | 0.76 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fekih Hassen, W.; Challouf, M. Long Short-Term Renewable Energy Sources Prediction for Grid-Management Systems Based on Stacking Ensemble Model. Energies 2024, 17, 3145. https://doi.org/10.3390/en17133145
Fekih Hassen W, Challouf M. Long Short-Term Renewable Energy Sources Prediction for Grid-Management Systems Based on Stacking Ensemble Model. Energies. 2024; 17(13):3145. https://doi.org/10.3390/en17133145
Chicago/Turabian StyleFekih Hassen, Wiem, and Maher Challouf. 2024. "Long Short-Term Renewable Energy Sources Prediction for Grid-Management Systems Based on Stacking Ensemble Model" Energies 17, no. 13: 3145. https://doi.org/10.3390/en17133145
APA StyleFekih Hassen, W., & Challouf, M. (2024). Long Short-Term Renewable Energy Sources Prediction for Grid-Management Systems Based on Stacking Ensemble Model. Energies, 17(13), 3145. https://doi.org/10.3390/en17133145