
An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting



Abstract
1. Introduction
- Aiming at the problem that the CNN-BiGRU-Attention model cannot capture adequate information in the spatial dimension, the CBAM is implemented to boost the model’s capacity to capture positional information.
- Considering that WOA has the shortcomings of being sensitive to parameters, dependent on the initial solution, and easily falling into local optimal solutions, an improved WOA is proposed, which, by introducing good point sets, improved convergence factors, and mutation mechanisms, boosts the optimization potential of WOA.
- Through experiments, this study presents a model that achieves high levels of prediction accuracy and high training efficiency. Compared with models such as BiLSTM, RMSE and MAE decreased by 291.9470 and 219.9830, respectively, and R2 improved by 0.06941.
2. Related Work
3. Model and Methodology
3.1. CNN-BiGRU-CBAM
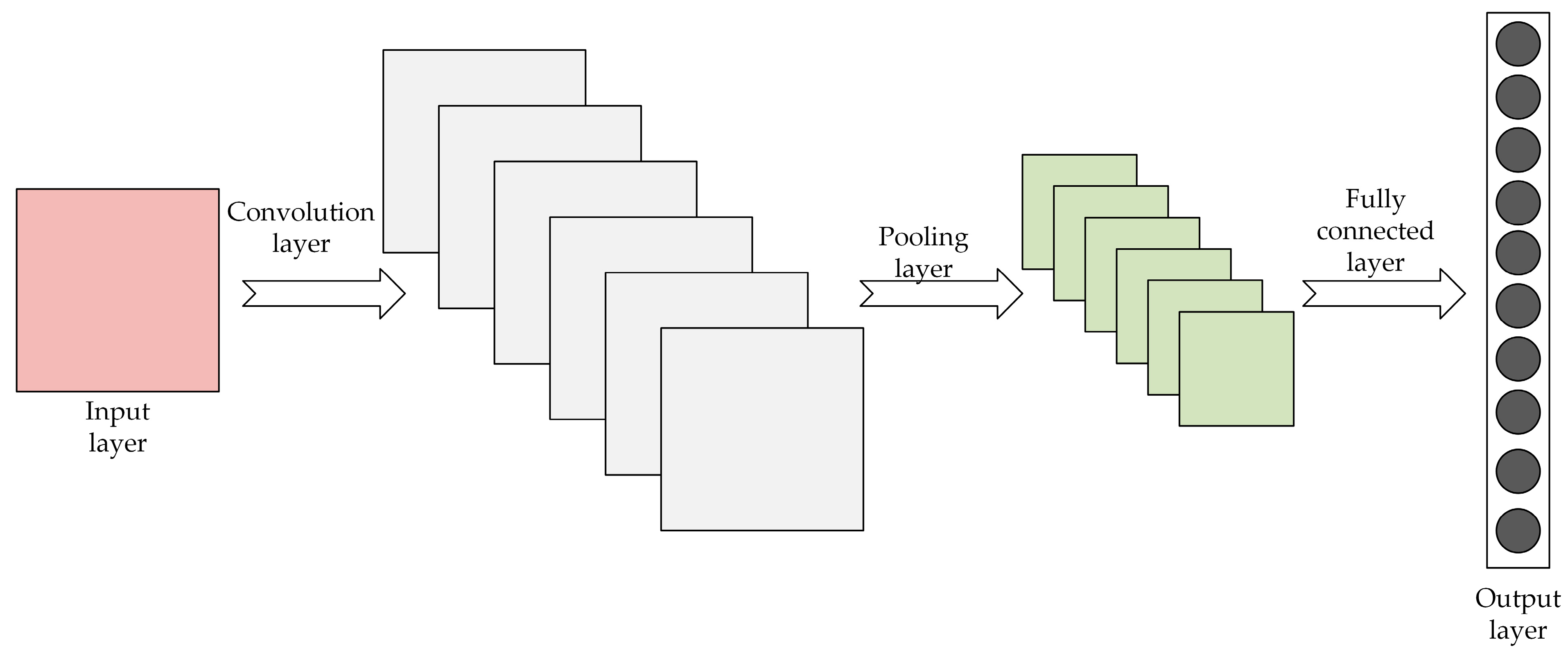
3.1.1. CNN
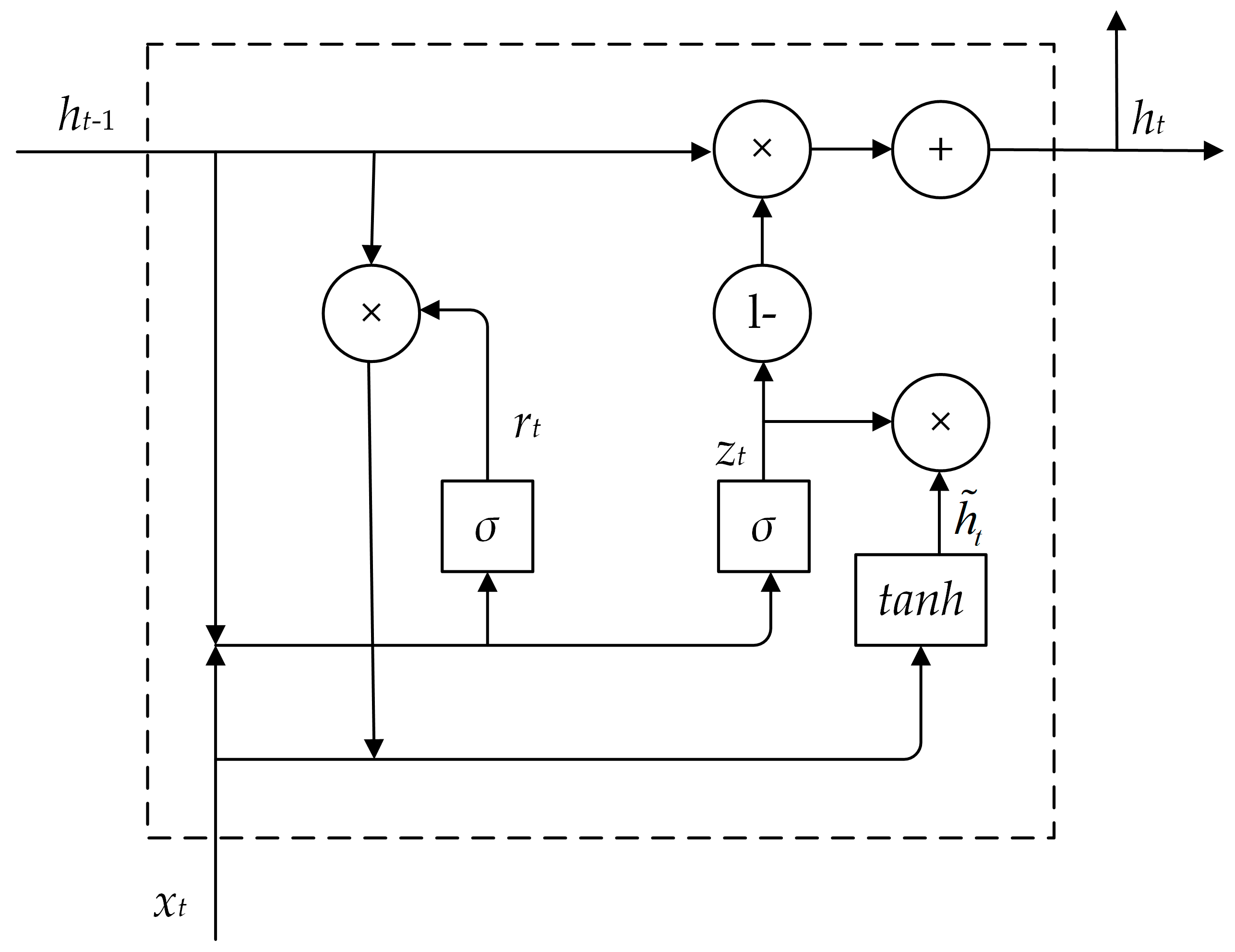
3.1.2. BiGRU
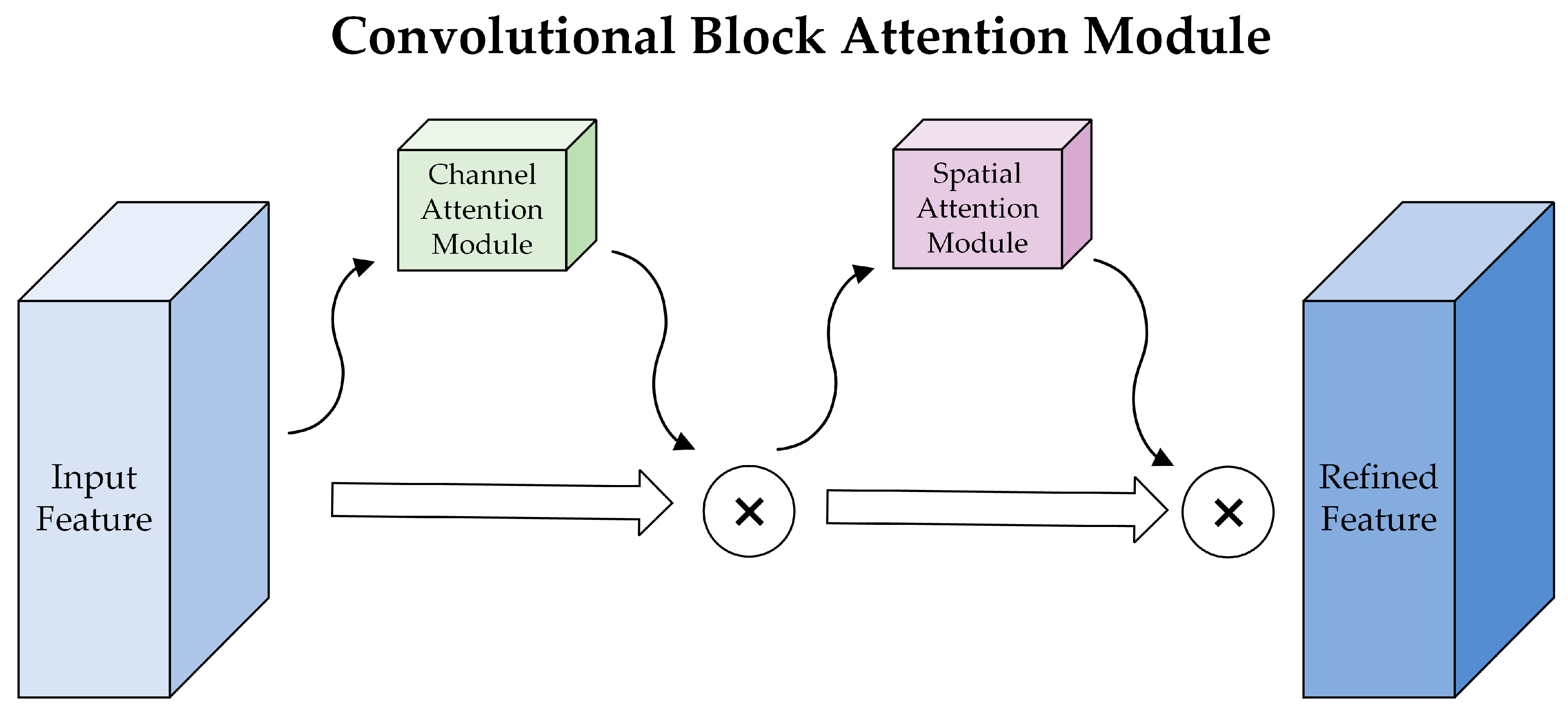
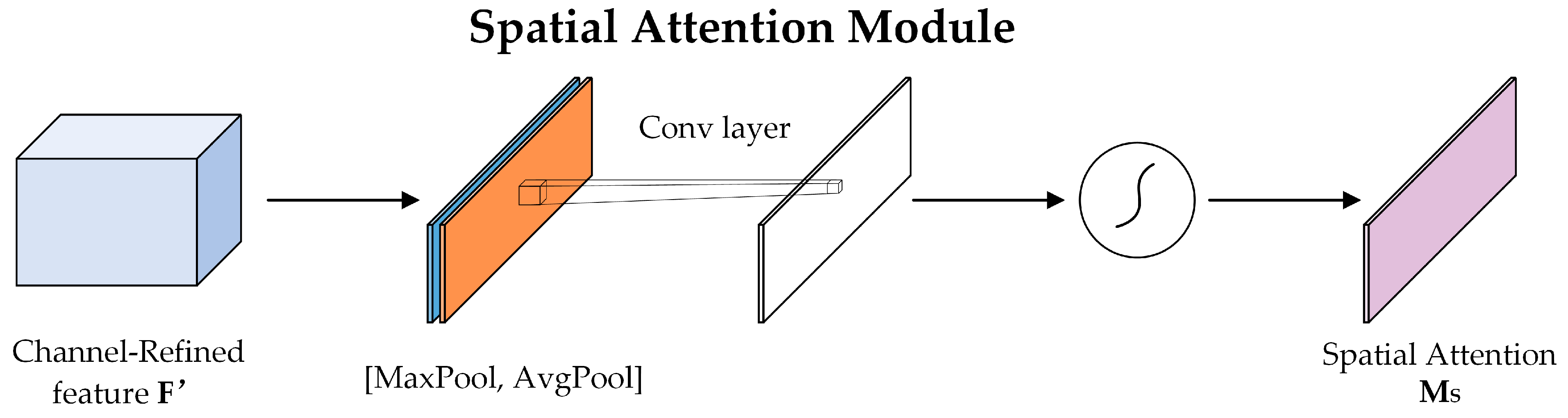
3.1.3. CBAM (Convolutional Block Attention Module)
3.2. Improved Whale Optimization Algorithm (IWOA)
3.2.1. WOA
- 1.
- Rounding up prey
- 2.
- Bubble netting
- 3.
- Searching for prey
3.2.2. Improvement of the Initial Population
3.2.3. Convergence Factors
3.2.4. Mechanisms for Friend Variation
- Good point set method for initializing populations;
- When , the encircling prey behaviour is performed; otherwise, the bubble-net behaviour is performed, the individual is updated, and the fitness value is calculated;
- Individuals were updated using Equation (21), and fitness values were calculated;
- Individuals in the population were updated using Equation (22);
- The convergence factor is updated;
- Determine whether the iteration end condition is reached. If so, the optimum solution will be ended and output. If not, jump back to step 2 to continue the loop.
| Algorithm 1: Pseudocode of the IWOA. |
| Input: Number of search agents: N, Dim, tmax. Output: Optimal fitness value. Generate the search agent’s initial position by using the good point set method. Calculate each search agent’s fitness value. The search agent with the best fitness was selected as the lead whale. While t < tmax Calculate parameter a, by Equation (18). Calculate parameters A and C by Equations (9) and (10): If p < 0.5 If |A| < 1 Apply Equation (8) to update the current search agent’s position. Else Apply Equation (16) to update the current search agent’s position. End if Else Apply Equation (12) to update the current search agent’s position. End if Calculate the fitness value named Fit1 for current search agents. Calculate the friends radius for current search agents by Equation (19). Determine friends of every current search agent using Equation (20). Update the current search agent’s new position named XFri using Equation (21). Calculate the fitness value named Fit2 of XFri. Update the current search agent’s position using Equation (22). Should a better solution emerge, update X*. t = t + 1 End while Return X* and optimal fitness value. |
4. Experiments and Analyses
4.1. Data Sources, Environmental Configuration, and Evaluation Indicators
4.2. Model Validation
4.3. Validation of IWOA
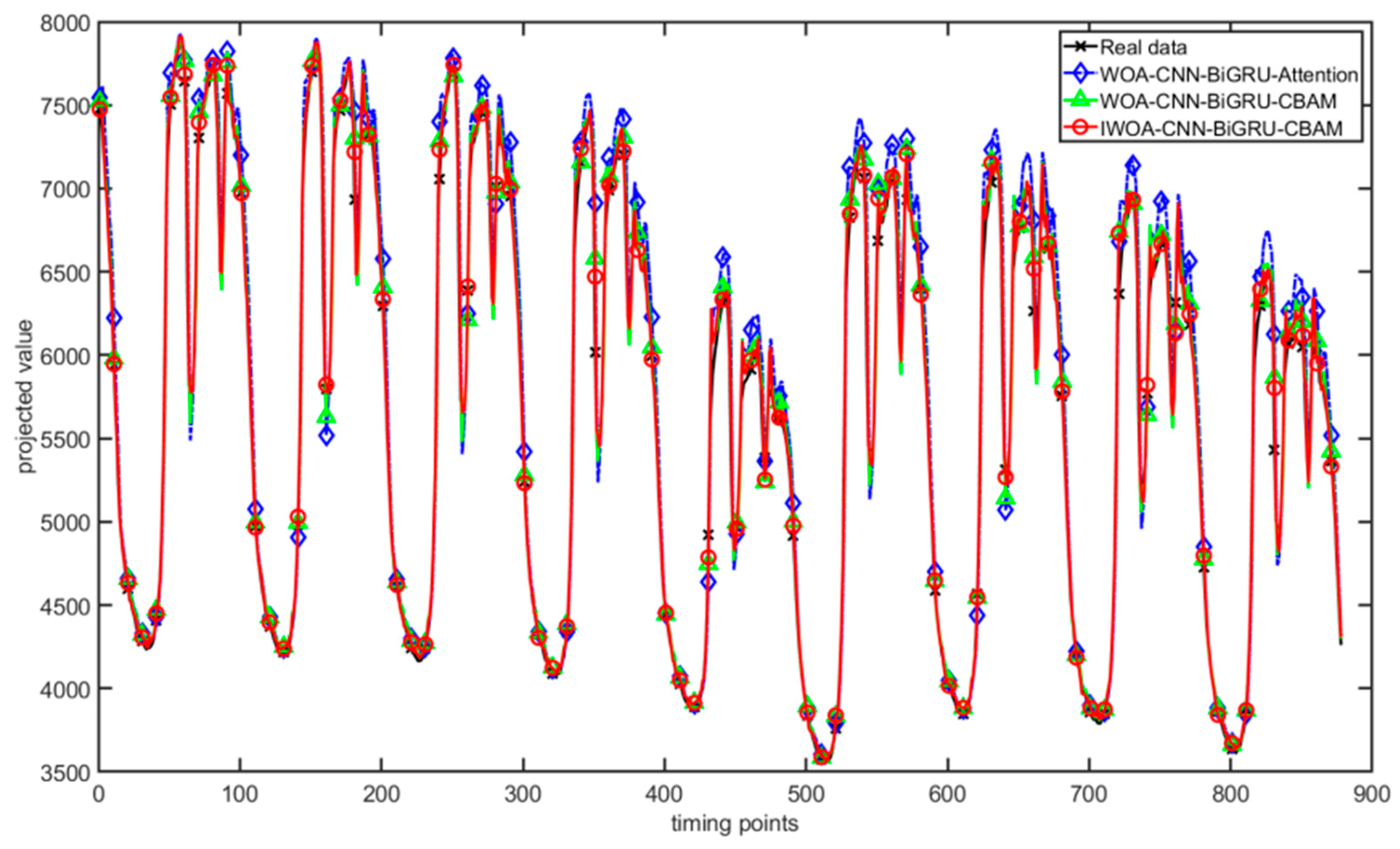
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Adam | Adaptive Moment Estimation |
| AI | Artificial intelligence |
| ANN | Artificial Neural Networks |
| ARIMA | Autoregressive Integrated Moving Average |
| BiLSTM | Bidirectional Long Short-Term Memory |
| BiGRU | Bidirectional Gated Recurrent Unit |
| BiGRU-SENet | Bidirectional Gated Recurrent Units and Squeeze-and-Excitation Networks |
| BP | Back Propagation |
| CBAM | Convolutional Block Attention Module |
| CEEMDAN | Complete Ensemble Empirical Mode Decomposition with Adaptive Noise |
| CNN | Convolutional Neural Network |
| CNN-BiGRU | Convolutional Neural Network-Bidirectional Gated Recurrent Unit |
| CNN-BiGRU-Attention | Convolutional Neural Network-Bidirectional Gated Recurrent Unit-Squeeze-and-Excitation Block |
| CNN-BiGRU-CBAM | Convolutional Neural Network-Bidirectional Gated Recurrent Unit-Convolutional Block Attention Module |
| CS | Cuckoo Search |
| ECA | Enhanced Clustering Algorithm |
| FARIMA | Fractional Autoregressive Integral Moving Average |
| GM | Grey Model |
| GRU | Gated Recurrent Unit |
| GWO | Grey Wolf Optimizer |
| IWOA | Improved Whale Optimization Algorithm |
| LSTM | Long Short-Term Memory |
| MFOA | Moth-Flame Optimization Algorithm |
| mPSO | Modified Particle Swarm Optimization |
| mSCA | Modified Sine Cosine Algorithm |
| msWOA | Multi-Strategy Whale Optimization Algorithm |
| MVO | Multiverse Optimization |
| PSO | Particle Swarm Optimization |
| PV | Photovoltaic |
| RAdam | Rectified Adaptive Moment Estimation |
| RBFNN | Radial Basis Function Neural Network |
| SE | Squeeze-and-Excitation |
| SENet | Squeeze-and-Excitation Networks |
| STLF | Short-term power load forecasting |
| SVM | Support Vector Machine |
| VMD | Variational Mode Decomposition |
| WOA | Whale Optimization Algorithm |
| WT | Wavelet Transform |
| XGBOOST | eXtreme Gradient Boosting |
| An intermediate feature map | |
| Average-pooled features | |
| Max-pooled features | |
| A convolution operation with the filter size of 7 × 7 | |
| A 1D channel attention map | |
| A 2D spatial attention map | |
| MAE | Mean Absolute Error |
| R2 | Coefficient of Determination |
| RMSE | Root Mean Squared Error |
| The sigmoid function |
References
- Sheng, Z.; An, Z.; Wang, H.; Chen, G.; Tian, K. Residual LSTM based short-term load forecasting. Appl. Soft Comput. J. 2023, 144, 110461. [Google Scholar] [CrossRef]
- Anh, N.N.; Dat, D.T.; Elena, V.; Vijender, K.S. Short-term forecasting electricity load by long short-term memory and reinforcement learning for optimization of hyper-parameters. Evol. Intell. 2023, 16, 1729–1746. [Google Scholar]
- Kim, D.; Lee, D.; Nam, H.; Joo, S.K. Short-Term Load Forecasting for Commercial Building Using Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) Network with Similar Day Selection Model. J. Electr. Eng. Technol. 2023, 18, 4001–4009. [Google Scholar] [CrossRef]
- Dima, A.; Mark, L. Short-term load forecasting in smart meters with sliding window-based ARIMA algorithms. Vietnam J. Comput. Sci. 2018, 5, 241–249. [Google Scholar]
- Mi, J.; Fan, L.; Duan, X.; Qiu, Y. Short-Term Power Load Forecasting Method Based on Improved Exponential Smoothing Grey Model. Math. Probl. Eng. 2018, 2018, 3894723. [Google Scholar] [CrossRef]
- Shalini, S.; Angshul, M.; Victor, E.; Emilie, C. Blind Kalman Filtering for Short-Term Load Forecasting. IEEE Trans. Power Syst. 2020, 35, 4916–4919. [Google Scholar]
- Pang, X.; Sun, W.; Li, H.; Wang, Y.; Luan, C. Short-term power load forecasting based on gray relational analysis and support vector machine optimized by artificial bee colony algorithm. Peer J. Comput. Sci. 2022, 8, e1108. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Guo, H.; Wang, J.; Song, A. A Hybrid System Based on LSTM for Short-Term Power Load Forecasting. Energies 2020, 13, 6241. [Google Scholar] [CrossRef]
- Zhao, H.; Zhou, Z.; Zhang, P. Forecasting of the Short-Term Electricity Load Based on WOA-BILSTM. Int. J. Pattern Recognit. Artif. Intell. 2023, 37, 272–286. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef]
- Ji, X.; Liu, D.; Xiong, P. Multi-model fusion short-term power load forecasting based on improved WOA optimization. Math. Biosci. Eng. 2022, 19, 13399–13420. [Google Scholar] [CrossRef] [PubMed]
- Chu, Z.; Tian, P.; Shahzad, N.M. A novel integrated photovoltaic power forecasting model based on variational mode decomposition and CNN-BiGRU considering meteorological variables. Electr. Power Syst. Res. 2022, 213, 108796. [Google Scholar]
- Dao, F.; Zeng, Y.; Qian, J. Fault diagnosis of hydro-turbine via the incorporation of bayesian algorithm optimized CNN-LSTM neural network. Energy 2024, 290, 2901–2916. [Google Scholar] [CrossRef]
- Li, D.; Wang, X.; Sun, J.; Feng, Y. Radial Basis Function Neural Network Model for Dissolved Oxygen Concentration Prediction Based on an Enhanced Clustering Algorithm and Adam. IEEE Access 2021, 9, 44521–44533. [Google Scholar] [CrossRef]
- Ge, L.; Xian, Y.; Wang, Z.; Gao, B.; Chi, F.; Sun, K. A GWO-GRNN based model for short-term load forecasting of regional distribution network. CSEE J. Power Energy Syst. 2020, 7, 1093–1101. [Google Scholar]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Wu, F.; Cattani, C.; Song, W.; Zio, E. Fractional ARIMA with an improved cuckoo search optimization for the efficient Short-term power load forecasting. Alex. Eng. J. 2020, 59, 3111–3118. [Google Scholar] [CrossRef]
- Bahrami, S.; Hooshmand, R.-A.; Parastegari, M. Short term electric load forecasting by wavelet transform and grey model improved by PSO (particle swarm optimization) algorithm. Energy 2014, 72, 434–442. [Google Scholar] [CrossRef]
- Abu-Shikhah, N.; Elkarmi, F.; Aloquili, O.M. Medium-Term Electric Load Forecasting Using Multivariable Linear and Non-Linear Regression. Smart Grid Renew. Energy 2011, 2, 126–135. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhang, K. Short-term electric load forecasting based on singular spectrum analysis and support vector machine optimized by Cuckoo search algorithm. Electr. Power Syst. Res. 2017, 146, 270–285. [Google Scholar] [CrossRef]
- Liu, T.; Fan, D.; Chen, Y.; Dai, Y.; Jiao, Y.; Cui, P.; Wang, Y.; Zhu, Z. Prediction of CO2 solubility in ionic liquids via convolutional autoencoder based on molecular structure encoding. AIChE J. 2023, 69, e18182. [Google Scholar] [CrossRef]
- Fan, D.; Xue, K.; Zhang, R.; Zhu, W.; Zhang, H.; Qi, J.; Zhu, Z.; Wang, Y.; Cui, P. Application of interpretable machine learning models to improve the prediction performance of ionic liquids toxicity. Sci. Total Environ. 2023, 908, 168168. [Google Scholar] [CrossRef] [PubMed]
- Bian, H.; Zhong, Y.; Sun, J.; Shi, F. Study on power consumption load forecast based on K-means clustering and FCM–BP model. Energy Rep. 2020, 6, 693–700. [Google Scholar] [CrossRef]
- Lin, W.; Zhang, B.; Li, H.; Lu, R. Short-term load forecasting based on EEMD-Adaboost-BP. Syst. Sci. Control Eng. 2022, 10, 846–853. [Google Scholar] [CrossRef]
- Liu, T.; Chu, X.; Fan, D.; Ma, Z.; Dai, Y.; Zhu, Z.; Wang, Y.; Gao, J. Intelligent prediction model of ammonia solubility in designable green solvents based on microstructure group contribution. Mol. Phys. 2022, 120, e2124203. [Google Scholar] [CrossRef]
- Mu, Y.; Wang, M.; Zheng, X.; Gao, H. An improved LSTM-Seq2Seq-based forecasting method for electricity load. Front. Energy Res. 2023, 10, 1093667. [Google Scholar] [CrossRef]
- Liu, F.; Liang, C. Short-term power load forecasting based on AC-BiLSTM model. Energy Rep. 2024, 11, 1570–1579. [Google Scholar] [CrossRef]
- Wu, K.; Wu, J.; Feng, L.; Yang, B.; Liang, R.; Yang, S.; Zhao, R. An attention-based CNN-LSTM-BiLSTM model for short-term electric load forecasting in integrated energy system. Int. Trans. Electr. Energy Syst. 2020, 31, 576–583. [Google Scholar] [CrossRef]
- Jia, T.; Yao, L.; Yang, G.; He, Q. A Short-Term Power Load Forecasting Method of Based on the CEEMDAN-MVO-GRU. Sustainability 2022, 14, 16460. [Google Scholar] [CrossRef]
- Liang, R.; Chang, X.; Jia, P.; Xu, C. Mine Gas Concentration Forecasting Model Based on an Optimized BiGRU Network. ACS Omega 2020, 5, 28579–28586. [Google Scholar] [CrossRef]
- Meng, Y.; Chang, C.; Huo, J.; Zhang, Y.; Al-Neshmi, H.M.M.; Xu, J.; Xie, T. Research on Ultra-Short-Term Prediction Model of Wind Power Based on Attention Mechanism and CNN-BiGRU Combined. Front. Energy Res. 2022, 10, 920835. [Google Scholar] [CrossRef]
- Xu, Y.; Jiang, X. Short-term power load forecasting based on BiGRU-Attention-SENet model. Energy Sources Part A Recovery Util. Environ. Eff. 2022, 44, 973–985. [Google Scholar] [CrossRef]
- Yang, B.; Wang, Y.; Zhan, Y. Lithium Battery State-of-Charge Estimation Based on a Bayesian Optimization Bidirectional Long Short-Term Memory Neural Network. Energies 2022, 15, 4670. [Google Scholar] [CrossRef]
- Feng, M.; Duan, Y.; Wang, X.; Zhang, J.; Ma, L. Carbon price prediction based on decomposition technique and extreme gradient boosting optimized by the grey wolf optimizer algorithm. Sci. Rep. 2023, 13, 18447. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Chen, C.; Wen, H.; Cai, G.; Liu, Y. Prediction model of goaf coal temperature based on PSO-GRU deep neural network. Case Stud. Therm. Eng. 2024, 53, 103813. [Google Scholar] [CrossRef]
- Xiao, M.; Luo, R.; Chen, Y.; Ge, X. Prediction model of asphalt pavement functional and structural performance using PSO-BPNN algorithm. Constr. Build. Mater. 2023, 407, 133534. [Google Scholar] [CrossRef]
- Luo, J.; Gong, Y. Air pollutant prediction based on ARIMA-WOA-LSTM model. Atmos. Pollut. Res. 2023, 14, 101761. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, J.; Yu, Z.; Liu, Z.; Yin, P. WOA (Whale Optimization Algorithm) Optimizes Elman Neural Network Model to Predict Porosity Value in Well Logging Curve. Energies 2022, 15, 4456. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Mansour, A.A.; Tilioua, A.; Touzani, M. Bi-LSTM, GRU and 1D-CNN models for short-term photovoltaic panel efficiency forecasting case amorphous silicon grid-connected PV system. Results Eng. 2024, 21, 101886. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Yang, W.; Xia, K.; Fan, S.; Wang, L.; Li, T.; Zhang, J.; Feng, Y. A Multi-Strategy Whale Optimization Algorithm and Its Application. Eng. Appl. Artif. Intell. 2022, 108, 104558. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Zhou, H.; Pang, J.; Chen, P.-K.; Chou, F.-D. A modified particle swarm optimization algorithm for a batch-processing machine scheduling problem with arbitrary release times and non-identical job sizes. Comput. Ind. Eng. 2018, 123, 67–81. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. A hybrid self-adaptive sine cosine algorithm with opposition based learning. Expert Syst. Appl. 2019, 119, 210–230. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| CNN | 2 convolutional layers 2 pooling layers |
| Convolution kernel size | 3 × 1 |
| Initial learn rate | 0.01 |
| Batch size | 128 |
| Epochs | 500 |
| The hidden neurons of BiGRU | 8 + 8 |
| The hidden neurons of BiLSTM | 8 + 8 |
| Model | RMSE/kw | Var | R2 | MAE | Var |
|---|---|---|---|---|---|
| WOA-CNN-BiGRU-Attention | 119.5528 | 83.5879 | 0.99099 | 94.8737 | 81.6412 |
| WOA-CNN-BiGRU-CBAM | 105.008 | 61.5237 | 0.99305 | 81.9422 | 65.8345 |
| IWOA-CNN-BiGRU-CBAM | 86.4299 | 25.4416 | 0.99529 | 56.0482 | 21.5276 |
| (a) F1–F6 | |||||||
| Function | IWOA | WOA | msWOA | mFOA | mPSO | mSCA | |
| F1 | best | 300 | 300 | 300 | 300 | 300.0001 | 300.0001 |
| worst | 300 | 300 | 300.0294 | 300 | 300.3384 | 300.0524 | |
| mean | 300 | 300 | 300.0035 | 300 | 300.0486 | 300.0133 | |
| std | 2.27 × 10−12 | 7.54 × 10−8 | 0.004477 | 0 | 0.058025 | 0.0128 | |
| F2 | best | 400.2777 | 401.6992 | 413.2647 | 403.3437 | 408.3338 | 421.0018 |
| worst | 479.3967 | 717.1292 | 1183.94 | 748.6179 | 857.7683 | 502.4041 | |
| mean | 422.1213 | 458.1891 | 612.9995 | 475.8902 | 496.6692 | 455.5791 | |
| std | 24.36634 | 61.39288 | 171.0077 | 73.62923 | 103.6627 | 16.61971 | |
| F3 | best | 600 | 600 | 600.0087 | 600 | 600.0081 | 600.0409 |
| worst | 600.003 | 600.1573 | 600.9438 | 600.0976 | 600.855 | 601.2707 | |
| mean | 600.0001 | 600.0202 | 600.2592 | 600.0023 | 600.2633 | 600.4247 | |
| std | 0.000322 | 0.037195 | 0.171672 | 0.011841 | 0.173438 | 0.238818 | |
| F4 | best | 812.9351 | 812.3129 | 812.4637 | 809.7649 | 820.047 | 822.6616 |
| worst | 876.6685 | 900.7113 | 868.3376 | 853.5478 | 863.1018 | 853.6567 | |
| mean | 843.9564 | 838.2078 | 839.1272 | 825.2598 | 838.2995 | 839.0441 | |
| std | 20.24485 | 14.55806 | 12.25264 | 9.418728 | 7.613952 | 6.627878 | |
| F5 | best | 900 | 900 | 900 | 900 | 900 | 900 |
| worst | 900 | 900 | 900.0076 | 900 | 900.0735 | 900.0028 | |
| mean | 900 | 900 | 900.0006 | 900 | 900.0067 | 900.0004 | |
| std | 1.37 × 10−11 | 1.81 × 10−7 | 0.001221 | 0 | 0.009845 | 0.000393 | |
| F6 | best | 1883.559 | 1891.493 | 6177.15 | 1842.683 | 15,077.6 | 41,854.58 |
| worst | 8135.544 | 42,432.68 | 530,264.3 | 2,982,948 | 1,494,901 | 10,471,639 | |
| mean | 3500.321 | 4691.582 | 110,153.8 | 81,266.17 | 446,976.4 | 1,507,792 | |
| std | 1631.162 | 4312.319 | 99,805.16 | 365,816 | 346,708 | 1,588,267 | |
| (b) F7–F12 | |||||||
| Function | IWOA | WOA | msWOA | mFOA | mPSO | mSCA | |
| F7 | best | 2089.897 | 2077.67 | 2103.471 | 2075.351 | 2073.808 | 2105.105 |
| worst | 2384.001 | 2482.748 | 2338.527 | 2348.3 | 2292.895 | 2240.146 | |
| mean | 2204.2 | 2214.59 | 2187.575 | 2178.615 | 2160.963 | 2164.61 | |
| std | 63.97263 | 70.09778 | 48.44177 | 57.09852 | 45.1093 | 24.47191 | |
| F8 | best | 2208.254 | 2222.903 | 2230.031 | 2218.175 | 2221.917 | 2220.173 |
| worst | 2247.829 | 2285.338 | 2374.429 | 2257.819 | 2414.043 | 2239.526 | |
| mean | 2232.685 | 2236.215 | 2261.016 | 2230.435 | 2242.665 | 2232.556 | |
| std | 5.452965 | 11.42288 | 46.94911 | 6.241747 | 28.48983 | 3.501958 | |
| F9 | best | 2300 | 2300 | 2300.055 | 2300 | 2300.342 | 2300.031 |
| worst | 2500 | 2300.031 | 2500.089 | 2500.304 | 2306.865 | 2303.564 | |
| mean | 2304 | 2300.006 | 2323.26 | 2351.198 | 2302.544 | 2301.311 | |
| std | 28.14106 | 0.006375 | 62.57088 | 84.78268 | 1.550569 | 0.760773 | |
| F10 | best | 2500.174 | 2500.291 | 2500.566 | 2500.385 | 2500.862 | 2500.655 |
| worst | 2501.906 | 3740.123 | 2502.508 | 2669.412 | 3943.525 | 2649.952 | |
| mean | 2500.704 | 2600.032 | 2501.291 | 2540.491 | 2607.37 | 2511.309 | |
| std | 0.252649 | 227.4614 | 0.418806 | 63.03421 | 231.2993 | 36.14797 | |
| F11 | best | 2600.182 | 2625.687 | 2735.615 | 3010.665 | 2775.496 | 2758.747 |
| worst | 4654.493 | 4679.533 | 4620.619 | 11652.84 | 3780.67 | 2883.853 | |
| mean | 2940.107 | 2986.62 | 3154.811 | 5540.764 | 3101.457 | 2785.171 | |
| std | 327.2382 | 270.581 | 275.6916 | 1545.086 | 328.7328 | 19.76031 | |
| F12 | best | 2861.531 | 2864.334 | 2896.135 | 2860.835 | 2862.535 | 2864.759 |
| worst | 2887.873 | 3094.582 | 2961.506 | 3070.876 | 3043.66 | 2879.305 | |
| mean | 2867.674 | 2902.119 | 2952.313 | 2902.824 | 2892.679 | 2870.294 | |
| std | 4.905309 | 43.53633 | 5.842151 | 38.01212 | 32.24627 | 2.236951 | |
| Algorithm | Ordinal Mean |
|---|---|
| IWOA | 2.87 |
| WOA | 4.15 |
| msWOA | 5.77 |
| mFOA | 3.98 |
| mPSO | 5.97 |
| mSCA | 4.15 |
| Model | RMSE/kw | R2 | MAE |
|---|---|---|---|
| IWOA-BiGRU | 183.9619 | 0.9789 | 124.1239 |
| IWOA-CNN-BiGRU | 158.6322 | 0.98431 | 115.6731 |
| IWOA-CNN-BiGRU-Attention | 111.2914 | 0.99225 | 85.4261 |
| IWOA-CNN-BiGRU-CBAM | 86.4299 | 0.99529 | 56.0482 |
| Model | RMSE/kw | R2 | MAE |
|---|---|---|---|
| IWOA-CNN-BiGRU-CBAM | 86.4299 | 0.99529 | 56.0482 |
| WOA-CNN-BiGRU-CBAM | 105.008 | 0.99305 | 81.9422 |
| msWOA-CNN-BiGRU-CBAM | 101.7268 | 0.99348 | 77.2248 |
| mFOA-CNN-BiGRU-CBAM | 300.6814 | 0.94303 | 239.2391 |
| mPSO-CNN-BiGRU-CBAM | 116.3347 | 0.99147 | 88.6592 |
| mSCA-CNN-BiGRU-CBAM | 102.1971 | 0.99342 | 69.5965 |
| Model | RMSE/kw | R2 | MAE |
|---|---|---|---|
| BiLSTM | 387.3769 | 0.92588 | 276.0312 |
| IWOA-CNN-BiLSTM-Attention | 185.1584 | 0.96124 | 162.2335 |
| IWOA-CNN-BiLSTM-CBAM | 154.6835 | 0.97247 | 137.2238 |
| IWOA-CNN-BiGRU-CBAM | 86.4299 | 0.99529 | 56.0482 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, L.; Wang, H. An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting. Energies 2024, 17, 2559. https://doi.org/10.3390/en17112559
Dai L, Wang H. An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting. Energies. 2024; 17(11):2559. https://doi.org/10.3390/en17112559
Chicago/Turabian StyleDai, Lei, and Haiying Wang. 2024. "An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting" Energies 17, no. 11: 2559. https://doi.org/10.3390/en17112559
APA StyleDai, L., & Wang, H. (2024). An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting. Energies, 17(11), 2559. https://doi.org/10.3390/en17112559