


PrOuD: Probabilistic Outlier Detection Solution for Time-Series Analysis of Real-World Photovoltaic Inverters


Abstract
:1. Introduction
- Imbalanced anomaly data: Anomalies are rare events. Therefore, in most cases, only limited amounts of labeled anomalous data and patterns are available in real-world datasets. The imbalance problem leads to difficulties in optimizing models and evaluating their performance comprehensively.
- Unknown generative process of anomalies: Without prior knowledge of physical systems, information about the generative process of anomalous patterns, such as generative functions and hyperparameters, is mostly inaccessible. Detection models are thus optimized based solely on existing anomalies, leading to overfitting and difficulty in handling unseen anomaly types.
- Suspicious detection results: Traditional detection methods, such as hypothesis tests based on comparing calculated errors with threshold values, offer deterministic results, i.e., it is either abnormal or not. However, these methods often fall short in convincing experts or aiding in root-cause analysis.
- Expensive annotation: Annotating anomalies in real-world data is consistently a temporally and financially expensive task, particularly when dealing with high-dimensional time-series data from complex physical systems. Expert analysis is essential for extracting critical information about anomalous sources, including their duration, influenced channels, and root causes. The absence of accurate annotations can lead to misclassifying abnormal data as regular, resulting in erroneous assessments.
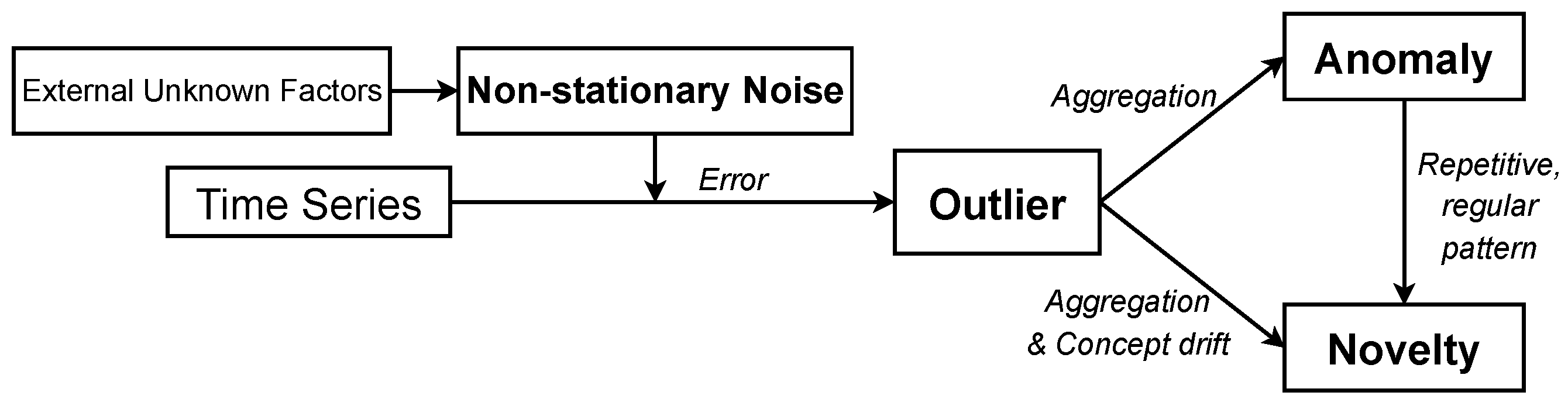
- We gave precise definitions of outlier, anomaly, novelty, and noise and mathematically analyzed their sources in multivariate time series from the perspective of Gaussian-distributed noise.
- We proposed generative methods for multivariate artificial time series and four anomalous patterns to address challenges to training and evaluating models when facing an insufficient number of samples.
- We proposed the PrOuD solution that describes a general workflow without being restricted to the specific application scenario or the neural network’s architecture. PrOuD is adaptive and can collaborate with various types of Bayesian neural networks. Compared with conventional probabilistic forecasting models and standalone detection models, PrOuD can provide domain experts with enhanced explanations and greater confidence in the detected results through an estimated outlier probability and the use of an explainable artificial intelligence technique. The experimental results on both artificial time series and real-world photovoltaic inverter data demonstrated high precision, fast detection, and interpretability of PrOuD.
- We published the code via (https://github.com/ies-research/probabilistic-outlier-detection-for-time-series (accessed on 5 November 2023)) for interested readers to generate artificial data and reimplement the experiments.
2. Related Work
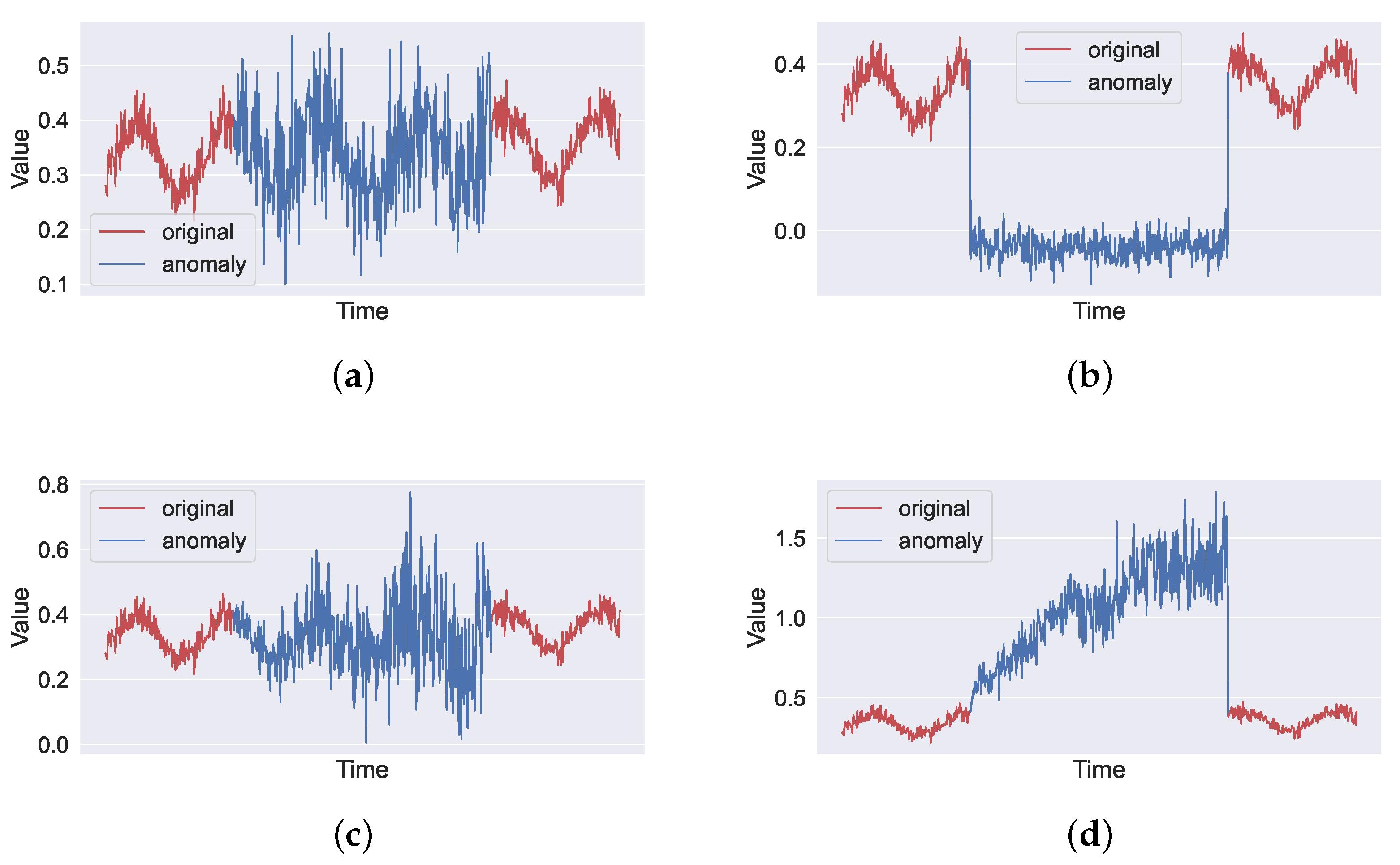
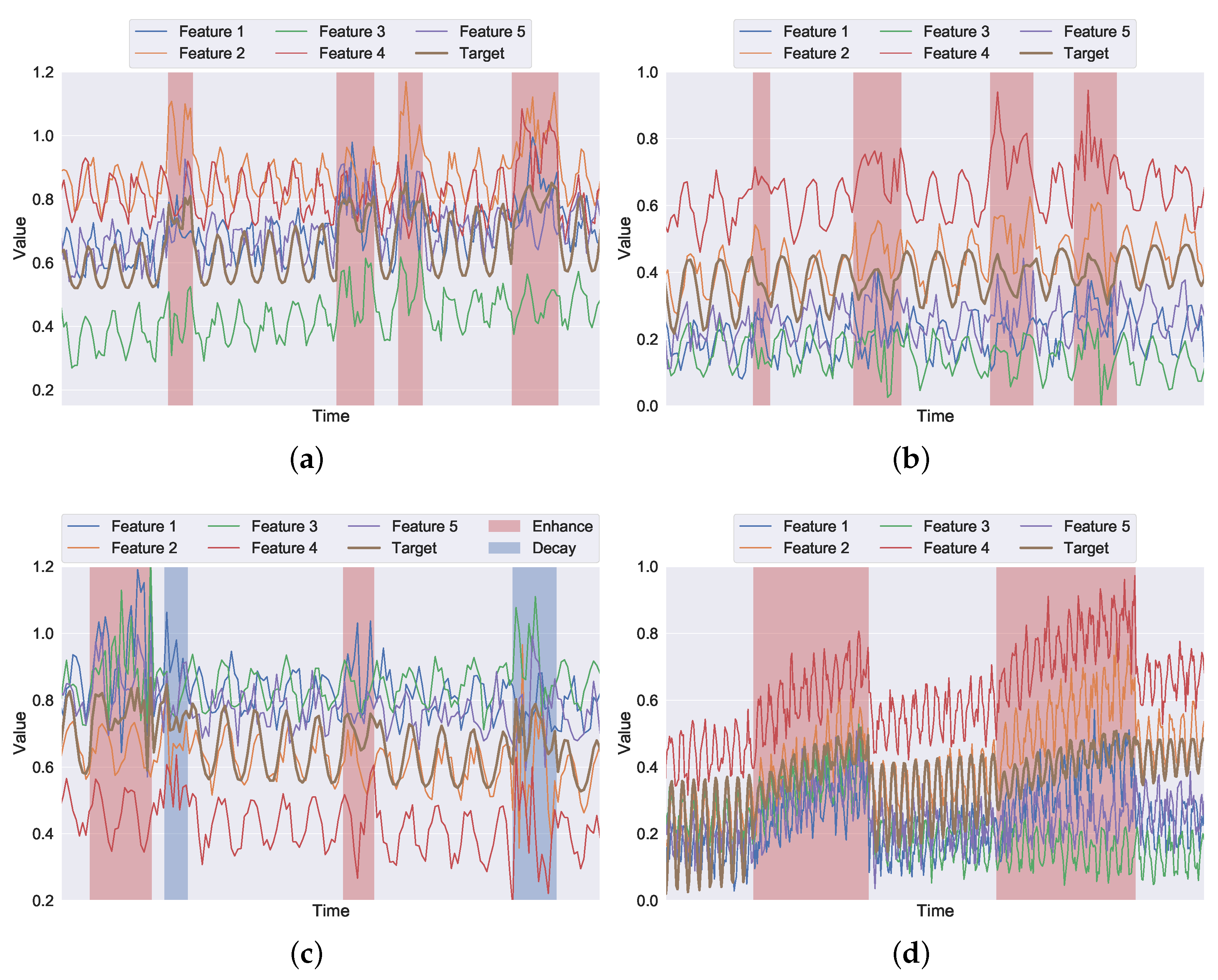
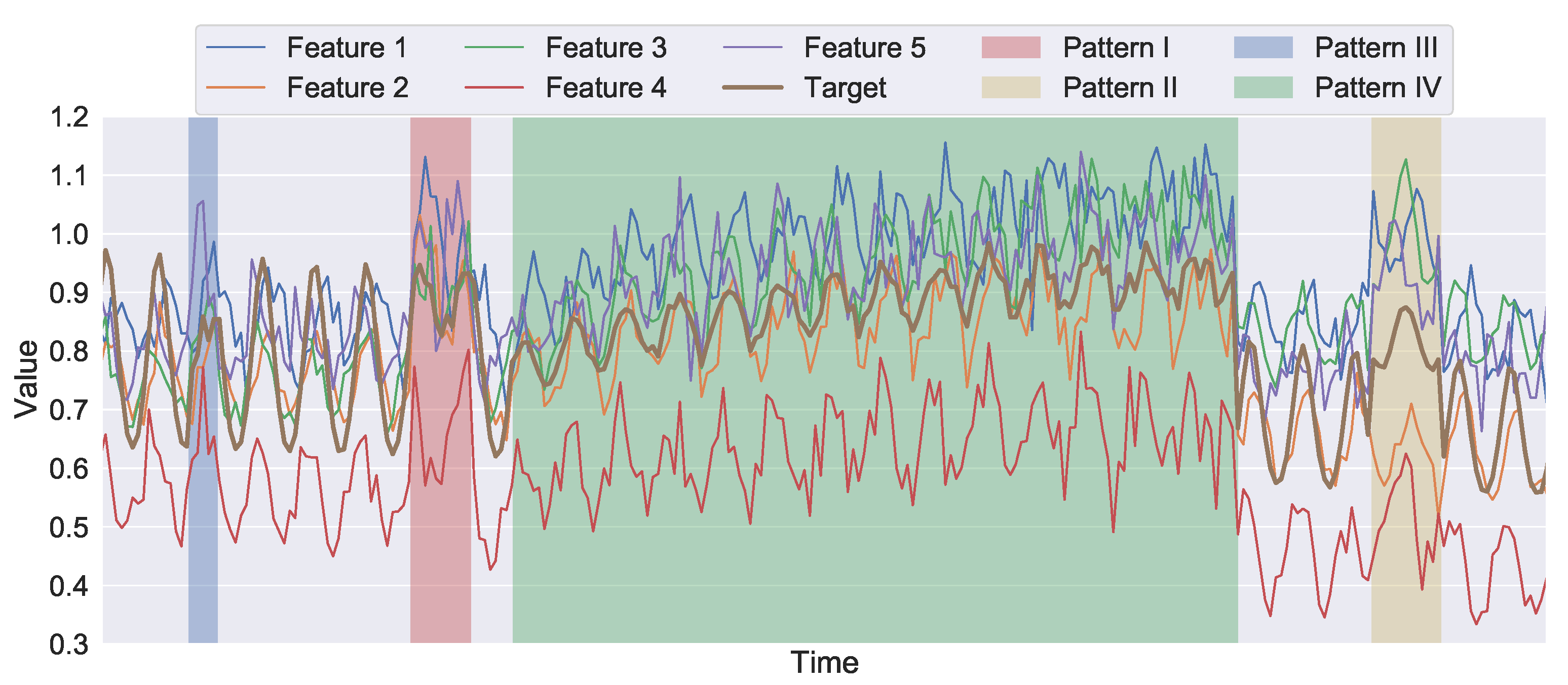
3. Artificial Time Series with Synthetic Anomalies
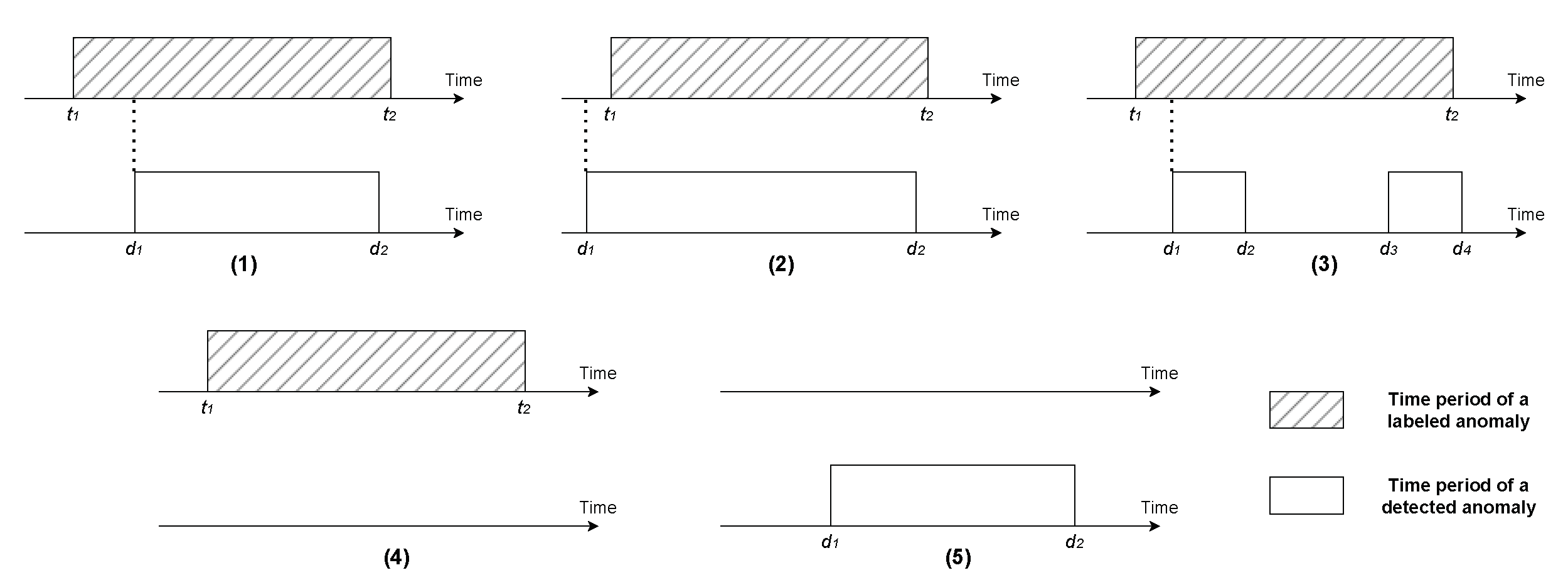
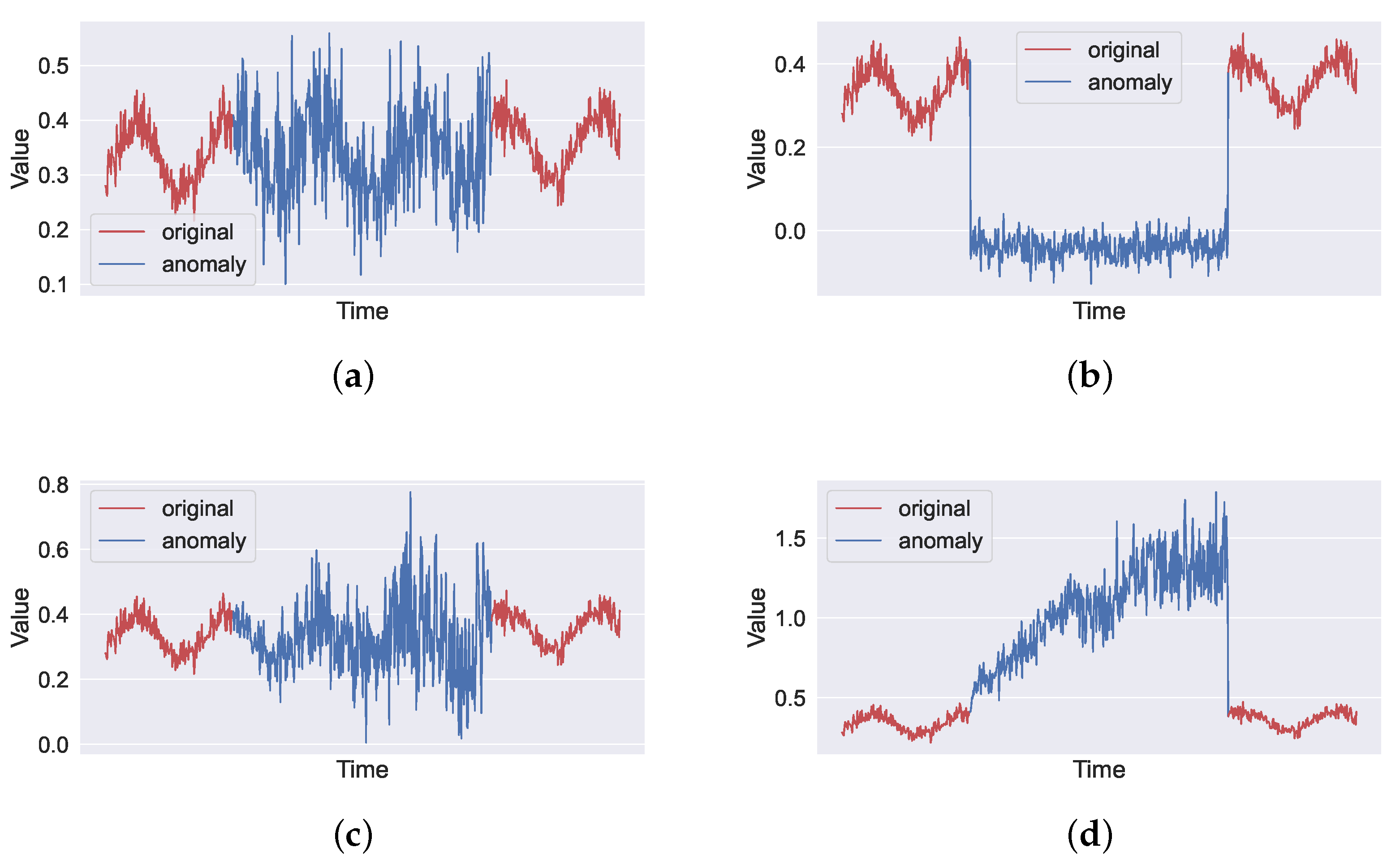
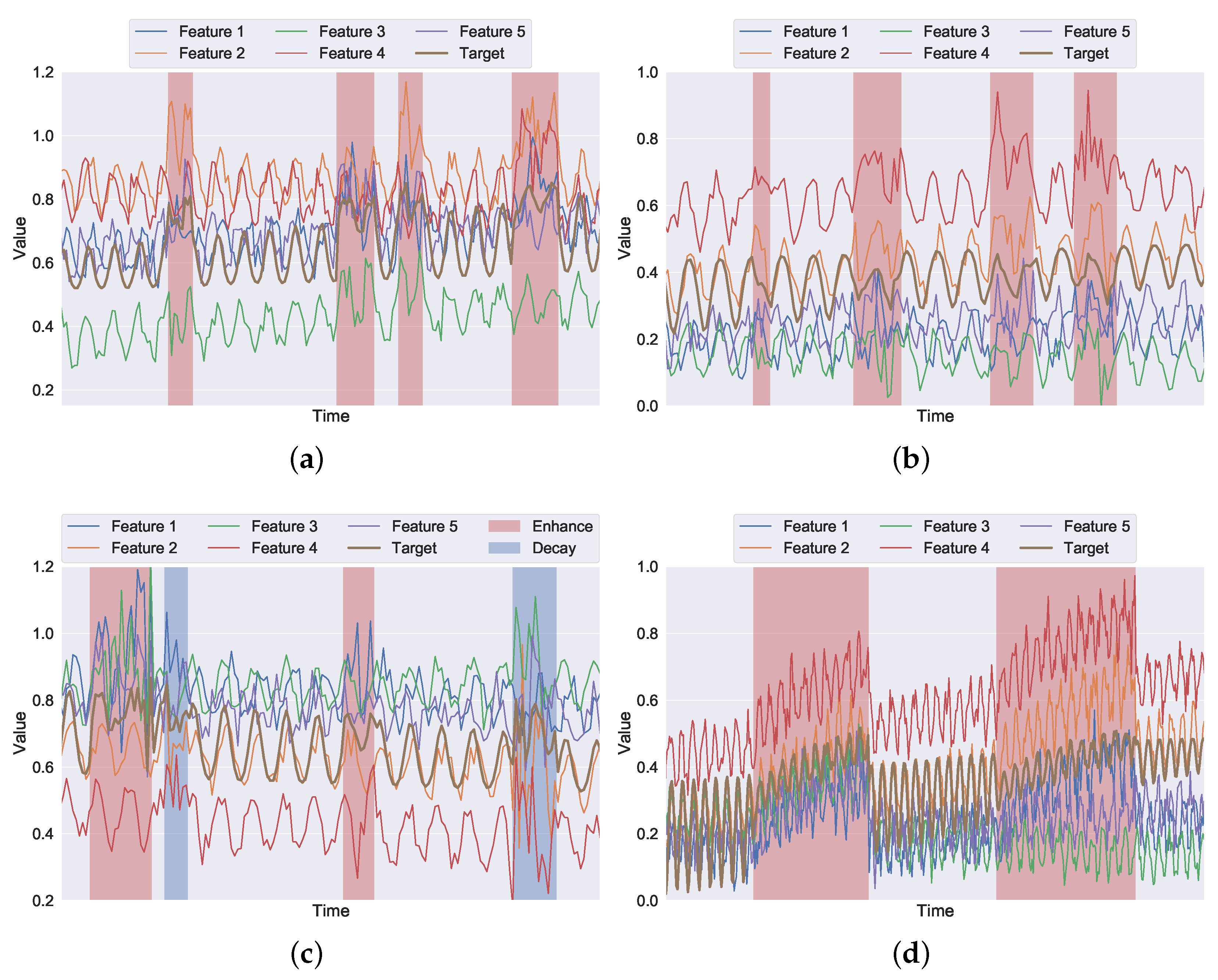
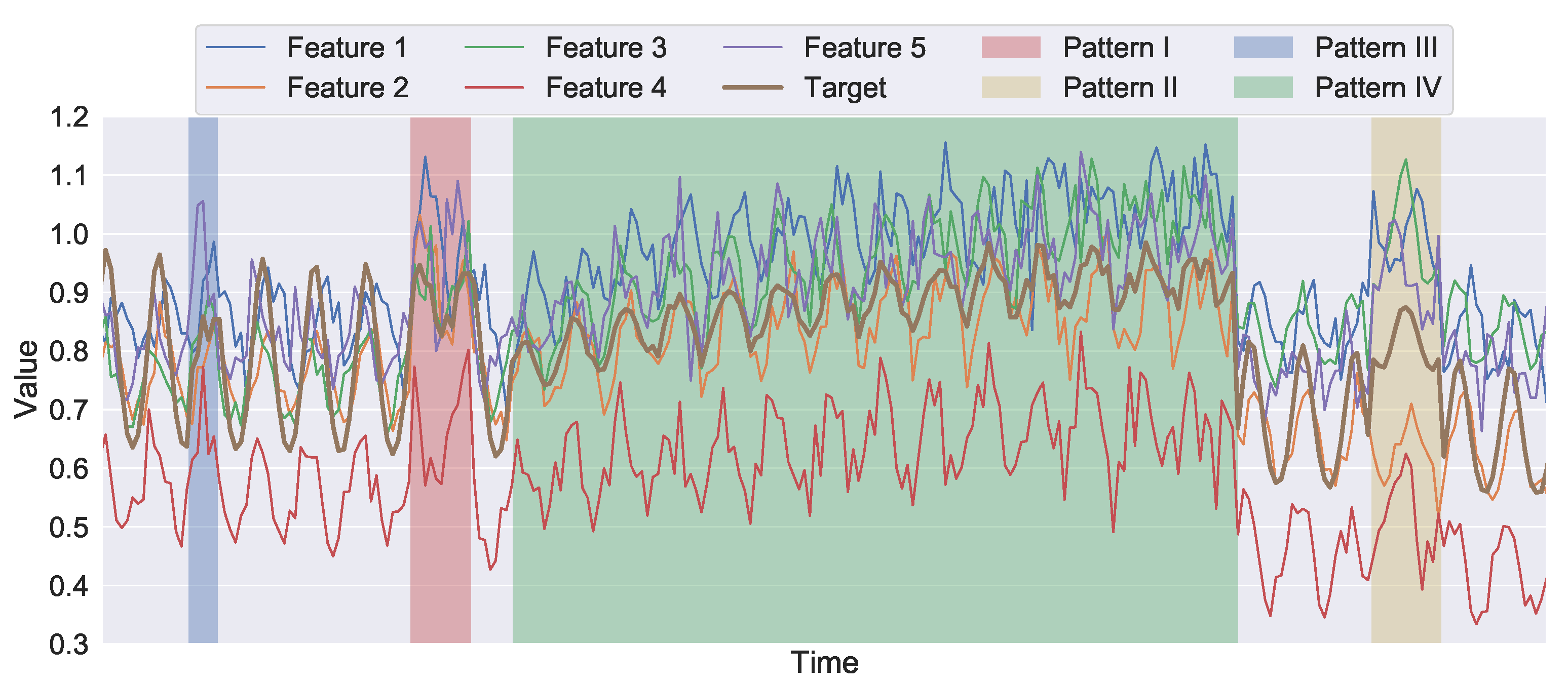
3.1. Terms and Definitions
3.2. Artificial Time Series with Synthetic Anomalies
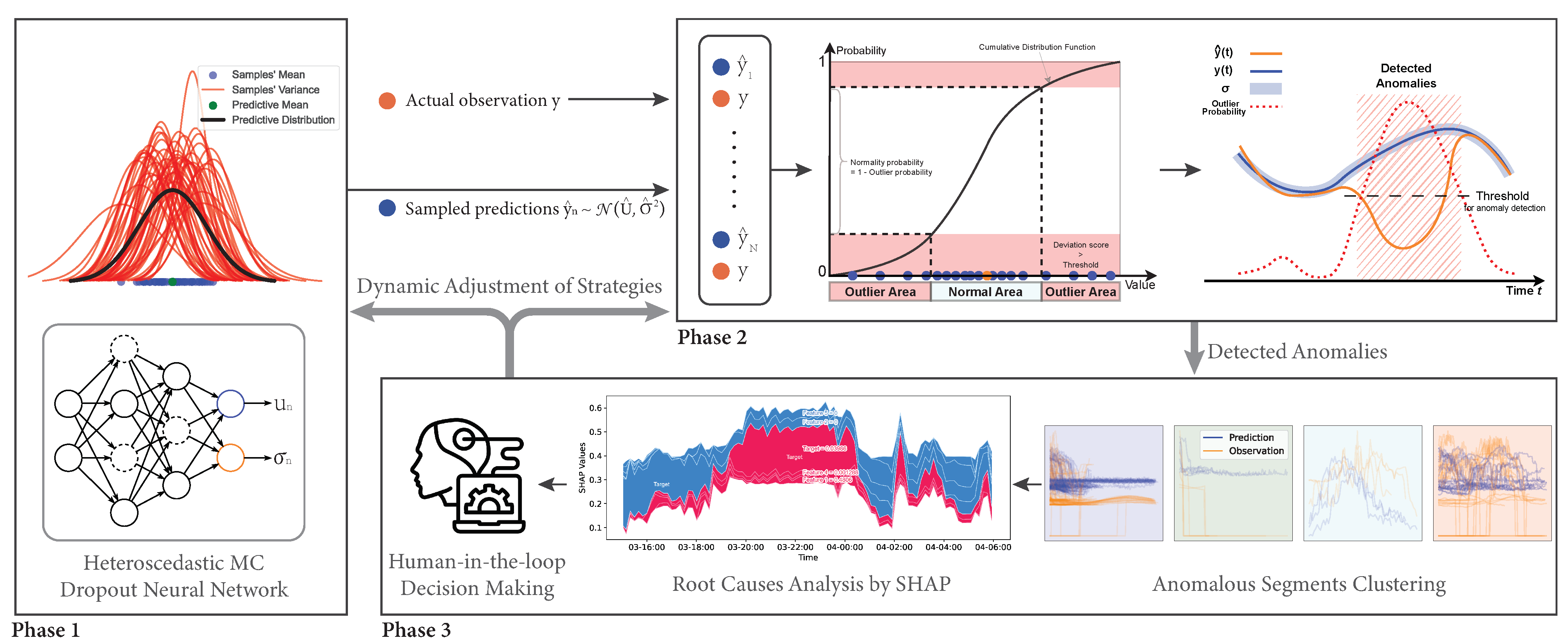
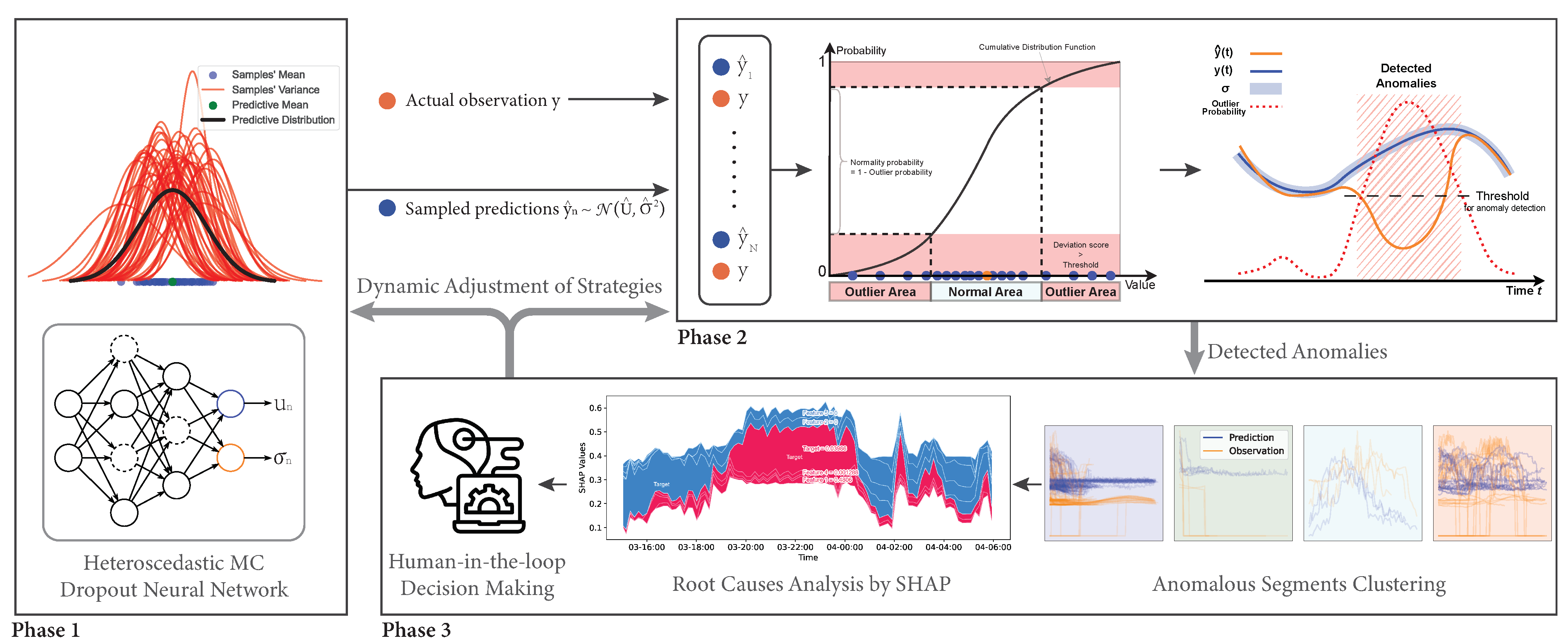
4. PrOuD: Probabilistic Outlier Detection Solution
4.1. Probabilistic Prediction Phase
4.2. Detection Phase
| Algorithm 1 Isolation Forest Algorithm |
|
| Algorithm 2 DBSCAN Algorithm |
|
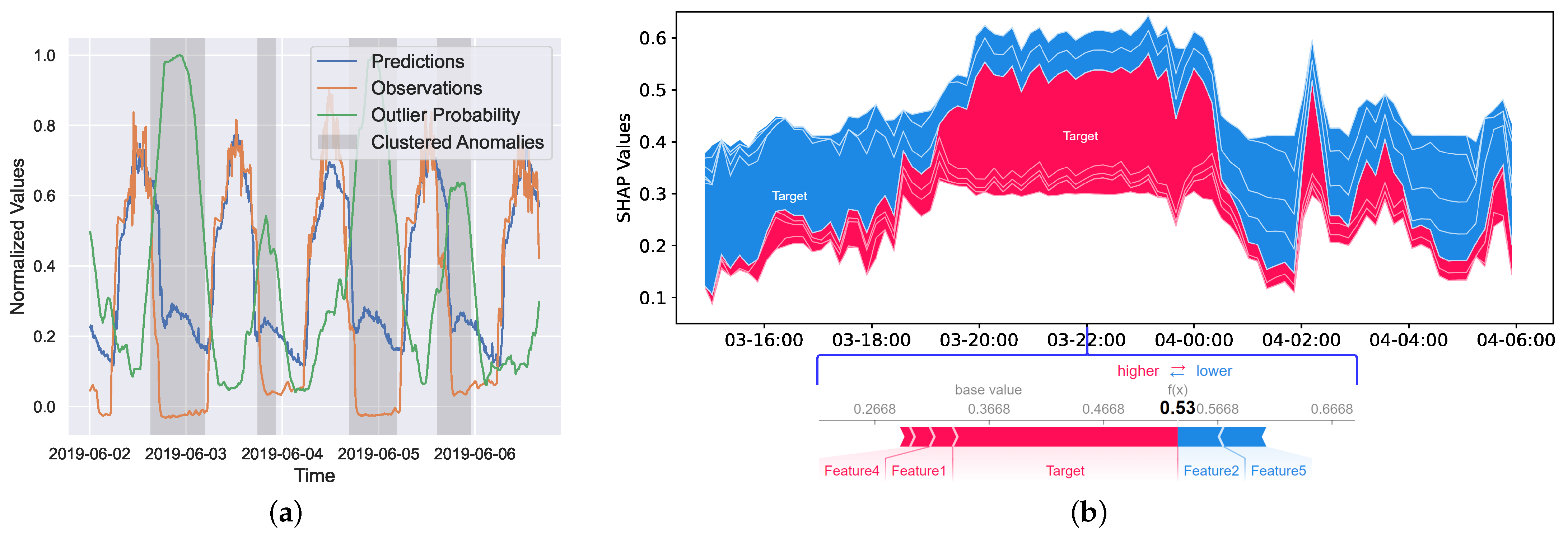
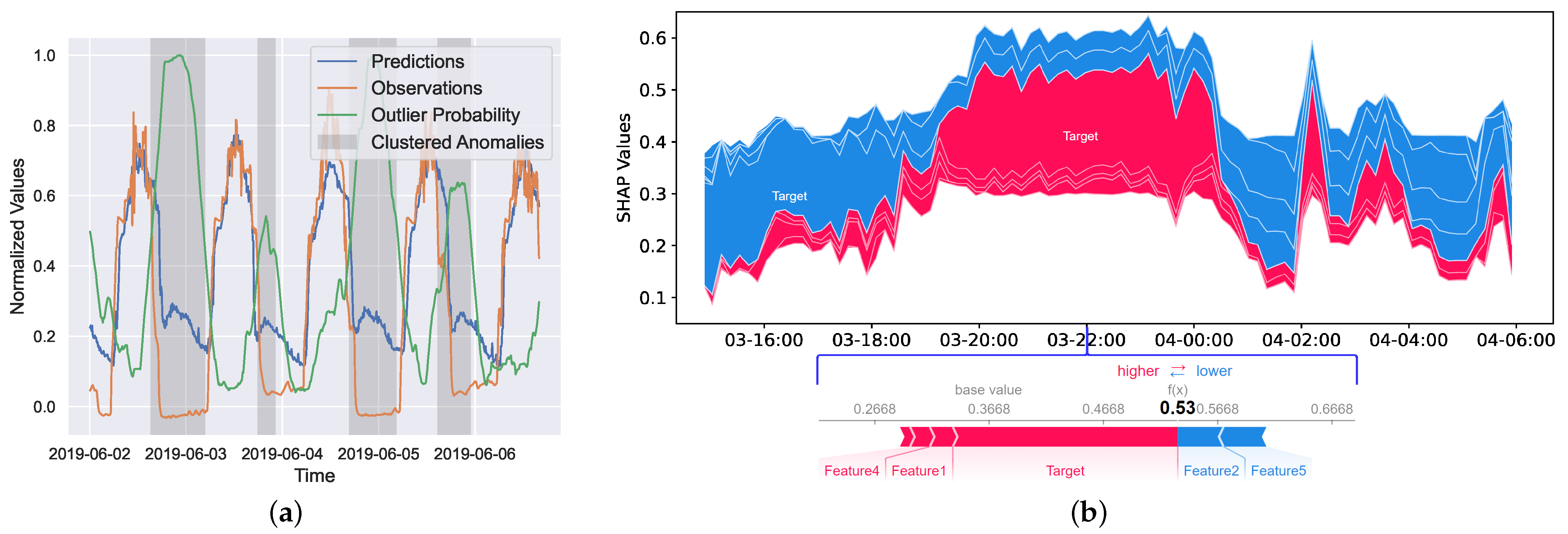
4.3. Explainable Interactive Learning Phase
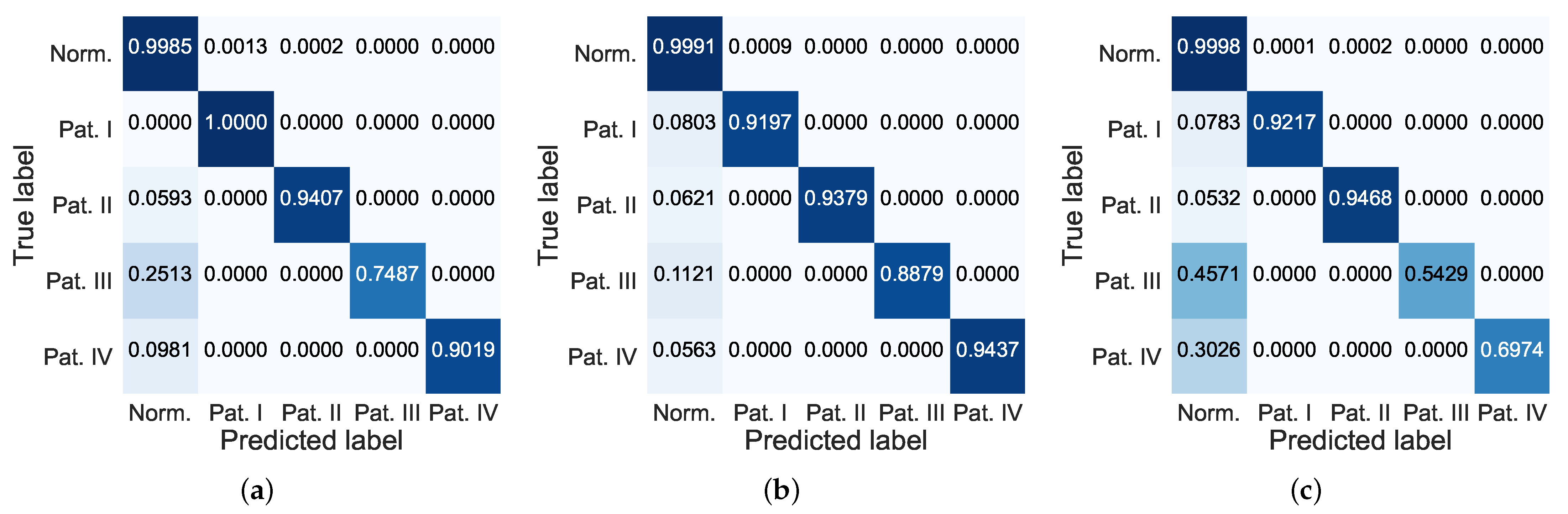
5. Experiments
5.1. Description of Datasets
5.2. Experimental Setups
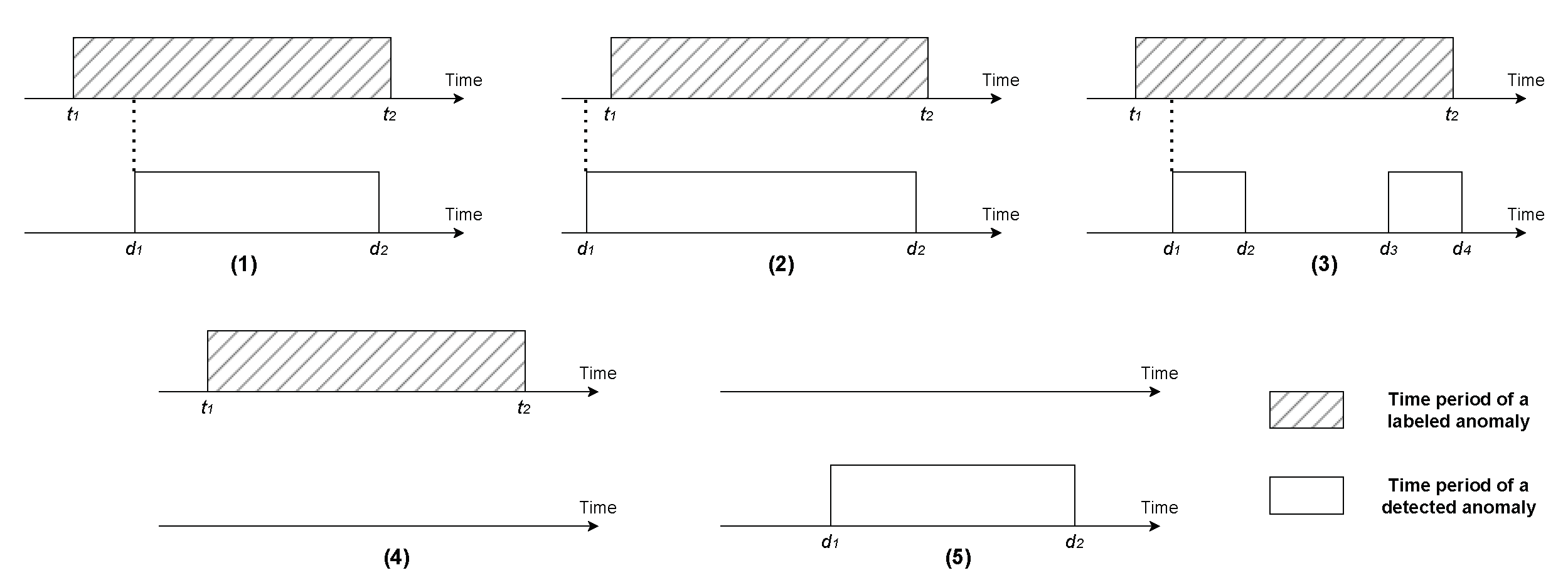
5.3. Evaluation Metrics
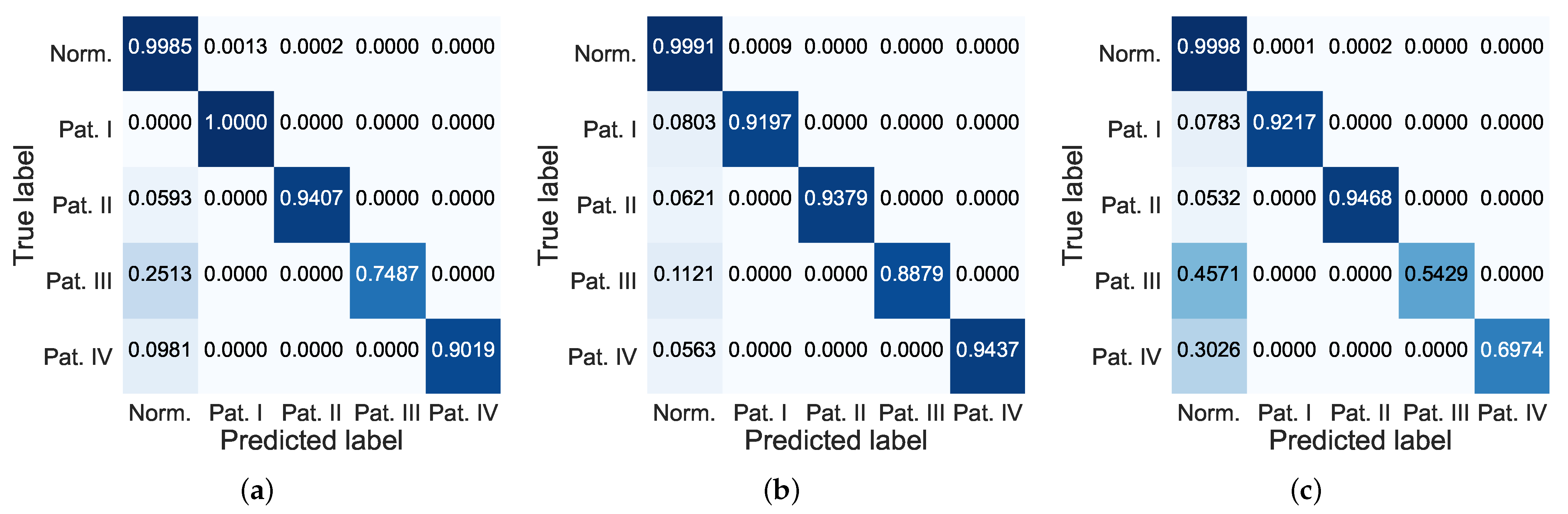
5.4. Results
6. Conclusions
6.1. Interpretation of Findings
6.2. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PrOuD | Probabilistic Outlier Detection |
| CNN | Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| GNN | Graphic Neural Network |
| MSE | Mean Square Error |
| HDNN | Heteroscedastic Deep Neural Network |
| MC dropout | Monte Carlo dropout |
| NLL | Negative Logarithm Likelihood |
| iForest | Isolation Forest |
| DBSCAN | Density-based Spatial Clustering of Applications with Noise |
| AUC | Area Under receiver operating characteristic Curve |
| MTTD | Mean Time To Detect |
| SHAP | SHapely Additive exPlanations |
| MCDHDNN | MC Dropout Heteroscedastic Deep Neural Network |
| VEHDNN | Voting Ensemble of Heteroscedastic Deep Neural Network |
| VEHLSTM | Voting Ensemble of Heteroscedastic Long Short-Term Memory |
Appendix A
Appendix A.1. MTTD Calculation
References
- Aggarwal, C.C. An introduction to outlier analysis. In Outlier Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–34. [Google Scholar]
- Miljković, D. Review of novelty detection methods. In Proceedings of the The 33rd International Convention MIPRO, Opatija, Croatia, 24–28 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 593–598. [Google Scholar]
- Choi, K.; Yi, J.; Park, C.; Yoon, S. Deep learning for anomaly detection in time-series data: Review, analysis, and guidelines. IEEE Access 2021, 9, 120043–120065. [Google Scholar] [CrossRef]
- He, Y.; Huang, Z.; Sick, B. Toward Application of Continuous Power Forecasts in a Regional Flexibility Market. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- He, Y.; Sick, B. CLeaR: An adaptive continual learning framework for regression tasks. AI Perspect. 2021, 3, 2. [Google Scholar] [CrossRef]
- Tsang, B.T.H.; Schultz, W.C. Deep neural network classifier for variable stars with novelty detection capability. Astrophys. J. Lett. 2019, 877, L14. [Google Scholar] [CrossRef]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Thill, M.; Konen, W.; Bäck, T. Time series encodings with temporal convolutional networks. In Proceedings of the Bioinspired Optimization Methods and Their Applications: 9th International Conference, BIOMA 2020, Brussels, Belgium, 19–20 November 2020; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2020; pp. 161–173. [Google Scholar]
- Zhang, Y.; Chen, Y.; Wang, J.; Pan, Z. Unsupervised deep anomaly detection for multi-sensor time-series signals. IEEE Trans. Knowl. Data Eng. 2021, 35, 2118–2132. [Google Scholar] [CrossRef]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data. In Proceedings of the AAAI conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1409–1416. [Google Scholar] [CrossRef]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Guerra, F. Novelty Detection with Autoencoders for System Health Monitoring in Industrial Environments. Appl. Sci. 2022, 12, 4931. [Google Scholar] [CrossRef]
- Yang, K.; Wang, Y.; Han, X.; Cheng, Y.; Guo, L.; Gong, J. Unsupervised Anomaly Detection for Time Series Data of Spacecraft Using Multi-Task Learning. Appl. Sci. 2022, 12, 6296. [Google Scholar] [CrossRef]
- Kim, H.; Lee, B.S.; Shin, W.Y.; Lim, S. Graph anomaly detection with graph neural networks: Current status and challenges. IEEE Access 2022, 10, 111820–111829. [Google Scholar] [CrossRef]
- Wu, Y.; Dai, H.N.; Tang, H. Graph neural networks for anomaly detection in industrial internet of things. IEEE Internet Things J. 2021, 9, 9214–9231. [Google Scholar] [CrossRef]
- Tang, J.; Li, J.; Gao, Z.; Li, J. Rethinking graph neural networks for anomaly detection. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 21076–21089. [Google Scholar]
- Buda, T.S.; Caglayan, B.; Assem, H. Deepad: A generic framework based on deep learning for time series anomaly detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 577–588. [Google Scholar] [CrossRef]
- Nguyen, V.Q.; Van Ma, L.; Kim, J.y.; Kim, K.; Kim, J. Applications of anomaly detection using deep learning on time series data. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 393–396. [Google Scholar] [CrossRef]
- Shen, L.; Li, Z.; Kwok, J. Timeseries Anomaly Detection using Temporal Hierarchical One-Class Network. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 13016–13026. [Google Scholar]
- Mathonsi, T.; Zyl, T.L.V. Multivariate anomaly detection based on prediction intervals constructed using deep learning. Neural Comput. Appl. 2022, 1–15. [Google Scholar] [CrossRef]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series. IEEE Access 2019, 7, 1991–2005. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph neural network-based anomaly detection in multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4027–4035. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, X.; Yuan, Z.; Cheng, X. Learning Graph Structures With Transformer for Multivariate Time-Series Anomaly Detection in IoT. IEEE Internet Things J. 2022, 9, 9179–9189. [Google Scholar] [CrossRef]
- He, Y.; Huang, Z.; Sick, B. Design of Explainability Module with Experts in the Loop for Visualization and Dynamic Adjustment of Continual Learning. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Vancouver, BC, Canada, 22 February–1 March 2022. Workshop on Interactive Machine Learning. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Depeweg, S. Modeling Epistemic and Aleatoric Uncertainty with Bayesian Neural Networks and Latent Variables. Ph.D. Thesis, Technische Universität München, Munich, Germany, 2019. [Google Scholar]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. Adv. Neural Inf. Process. Syst. 2017, 30, 6405–6416. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1050–1059. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Zhang, X.; Lin, Q.; Xu, Y.; Qin, S.; Zhang, H.; Qiao, B.; Dang, Y.; Yang, X.; Cheng, Q.; Chintalapati, M.; et al. Cross-dataset Time Series Anomaly Detection for Cloud Systems. In Proceedings of the USENIX Annual Technical Conference, Renton, WA, USA, 10–12 July 2019; pp. 1063–1076. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, Oregon, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Tan, S.C.; Ting, K.M.; Liu, T.F. Fast anomaly detection for streaming data. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Stationary Noise | Sum of Noise |
|---|---|
| Phase | Inputs | Operations | Outputs |
|---|---|---|---|
| 1 | Multivariate time series | Equations (20) and (21) | Predictive distribution |
| 2 | Equations (22)–(24) | Outlier probability and anomaly segments | |
| 3 | and anomaly segments | Equation (25) or other explanation methods | Anomaly clusters and visualization results |
| Pattern | Duration | Hyperparameters |
|---|---|---|
| I | 12–48 h | , , |
| II | 12–48 h | , , |
| III | 12–48 h | , , |
| IV | 10–15 days | , , |
| ID | MCDHDNN | VEHDNN | VEHLSTM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | |
| I-1 | 0.933 | 0.914 | 0.953 | 0.932 | 0.910 | 0.954 | 0.943 | ||
| I-2 | 0.944 | 0.927 | 0.910 | 0.925 | 0.939 | 0.912 | |||
| I-3 | 0.968 | 0.958 | 0.977 | 0.953 | 0.966 | 0.941 | |||
| I-4 | 0.967 | 0.962 | 0.967 | 0.891 | 0.950 | 0.840 | |||
| I-5 | 0.959 | 0.962 | 0.958 | 0.953 | 0.905 | 0.832 | |||
| AUC | MTTD | AUC | MTTD | AUC | MTTD | ||||
| I-1 | 13.5 | 0.971 | 14.2 | ||||||
| I-2 | 6.1 | 0.976 | 7.1 | ||||||
| I-3 | 27.3 | 0.980 | 41.9 | ||||||
| I-4 | 109.0 | 0.932 | 290.0 | ||||||
| I-5 | 26.3 | 0.972 | 51.8 | ||||||
| Model | F1 Score | Precision | Recall | AUC | MTTD | ||
|---|---|---|---|---|---|---|---|
| MCDHDNN | 0.700 () | () | 0.902 () | 0.974 () | 75.1 () | 0.002 () | 35.1 () |
| VEHDNN | () | 0.601 () | () | 0.972 () | () | () | 41.1 () |
| VEHLSTM | 0.547 () | 0.545 () | 0.632 () | 0.867 () | 183.2 () | 0.004 () | () |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Huang, Z.; Vogt, S.; Sick, B. PrOuD: Probabilistic Outlier Detection Solution for Time-Series Analysis of Real-World Photovoltaic Inverters. Energies 2024, 17, 64. https://doi.org/10.3390/en17010064
He Y, Huang Z, Vogt S, Sick B. PrOuD: Probabilistic Outlier Detection Solution for Time-Series Analysis of Real-World Photovoltaic Inverters. Energies. 2024; 17(1):64. https://doi.org/10.3390/en17010064
Chicago/Turabian StyleHe, Yujiang, Zhixin Huang, Stephan Vogt, and Bernhard Sick. 2024. "PrOuD: Probabilistic Outlier Detection Solution for Time-Series Analysis of Real-World Photovoltaic Inverters" Energies 17, no. 1: 64. https://doi.org/10.3390/en17010064
APA StyleHe, Y., Huang, Z., Vogt, S., & Sick, B. (2024). PrOuD: Probabilistic Outlier Detection Solution for Time-Series Analysis of Real-World Photovoltaic Inverters. Energies, 17(1), 64. https://doi.org/10.3390/en17010064