
SEiPV-Net: An Efficient Deep Learning Framework for Autonomous Multi-Defect Segmentation in Electroluminescence Images of Solar Photovoltaic Modules




Abstract
:1. Introduction
- Development of a deep learning-based framework for the automatic segmentation of 24 defects and features in EL images of solar PV modules.
- Emphasis on a lightweight segmentation system by optimizing the number of model parameters.
- Due to the coexistence of multiple defects and features in an image, various micro-defects occupy a trivial number of pixels in an image, consequently causing imbalanced classes. Three different loss functions are utilized by employing custom class weights. This comparison study aids in determining the most efficient loss function for the appropriate segmentation of 24 unique classes present in EL imagery.
2. Related Works
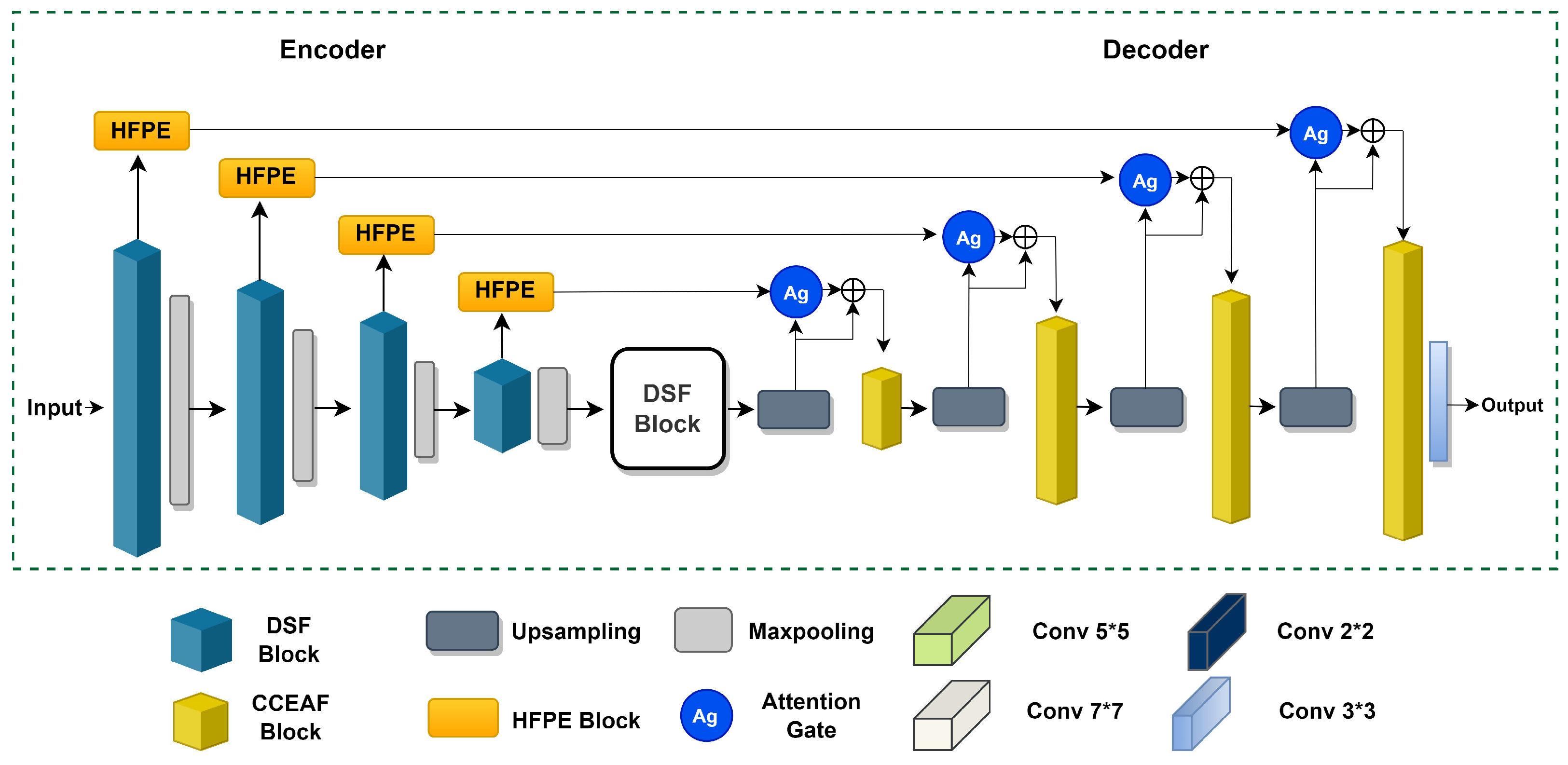
3. Proposed Network Architecture
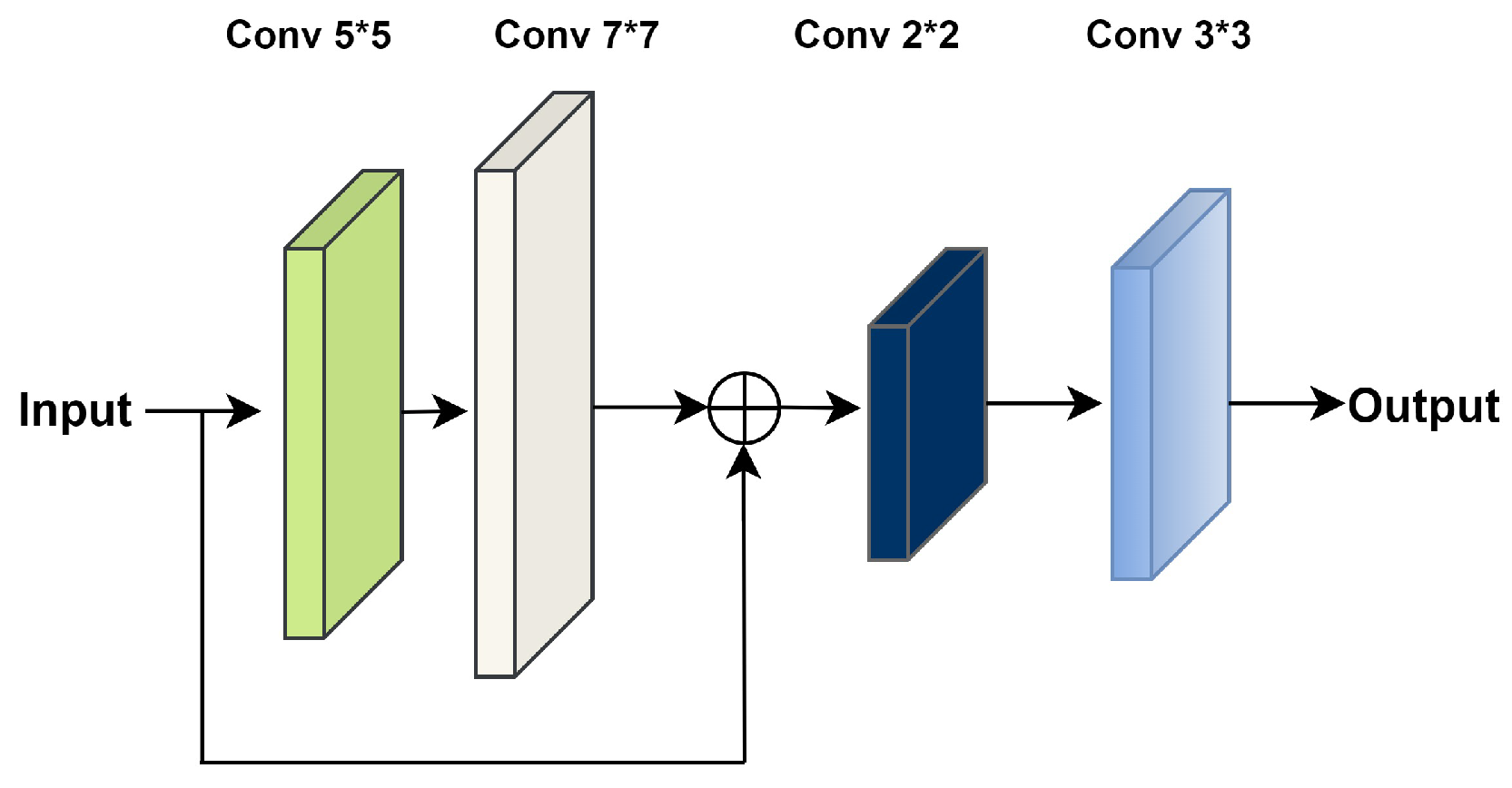
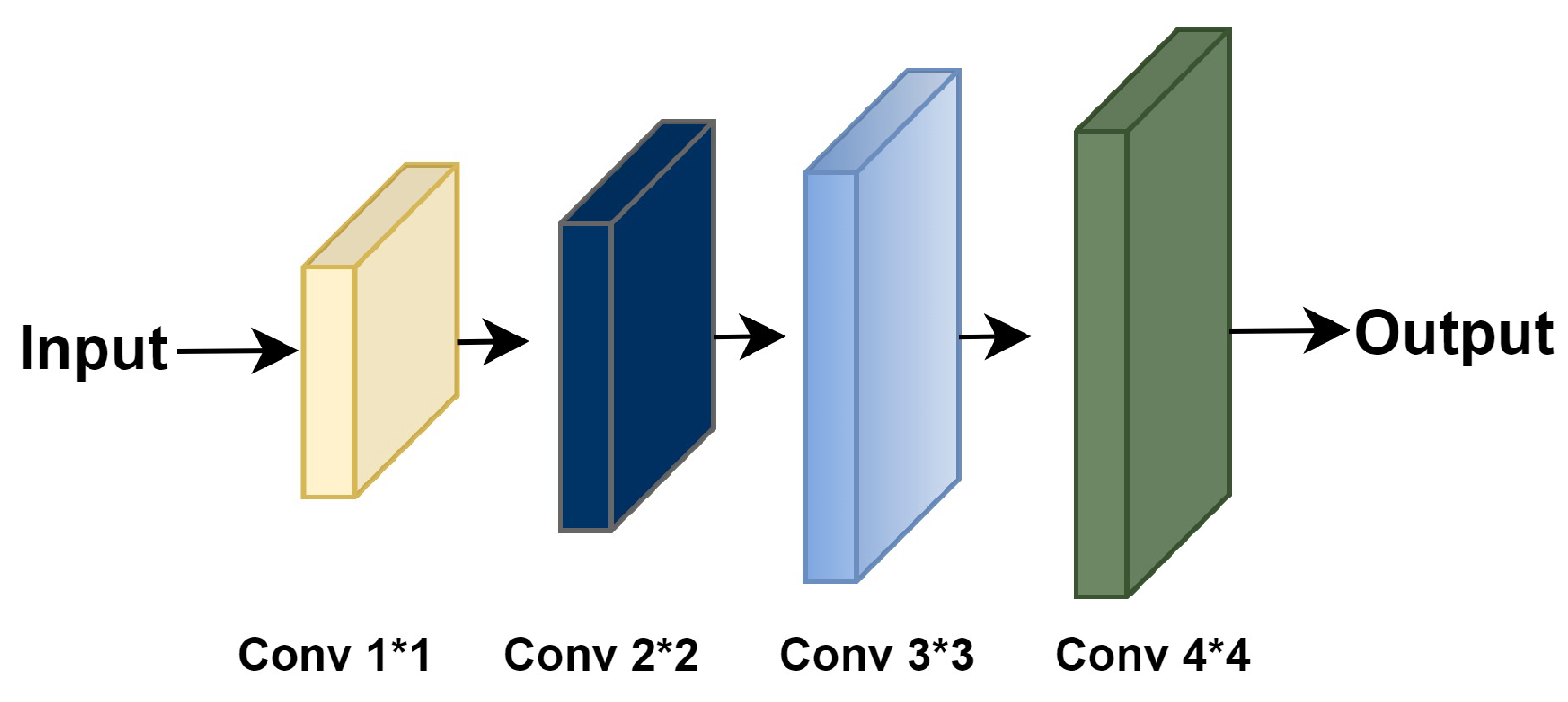
3.1. Dense and Successive Features (DSF) Block
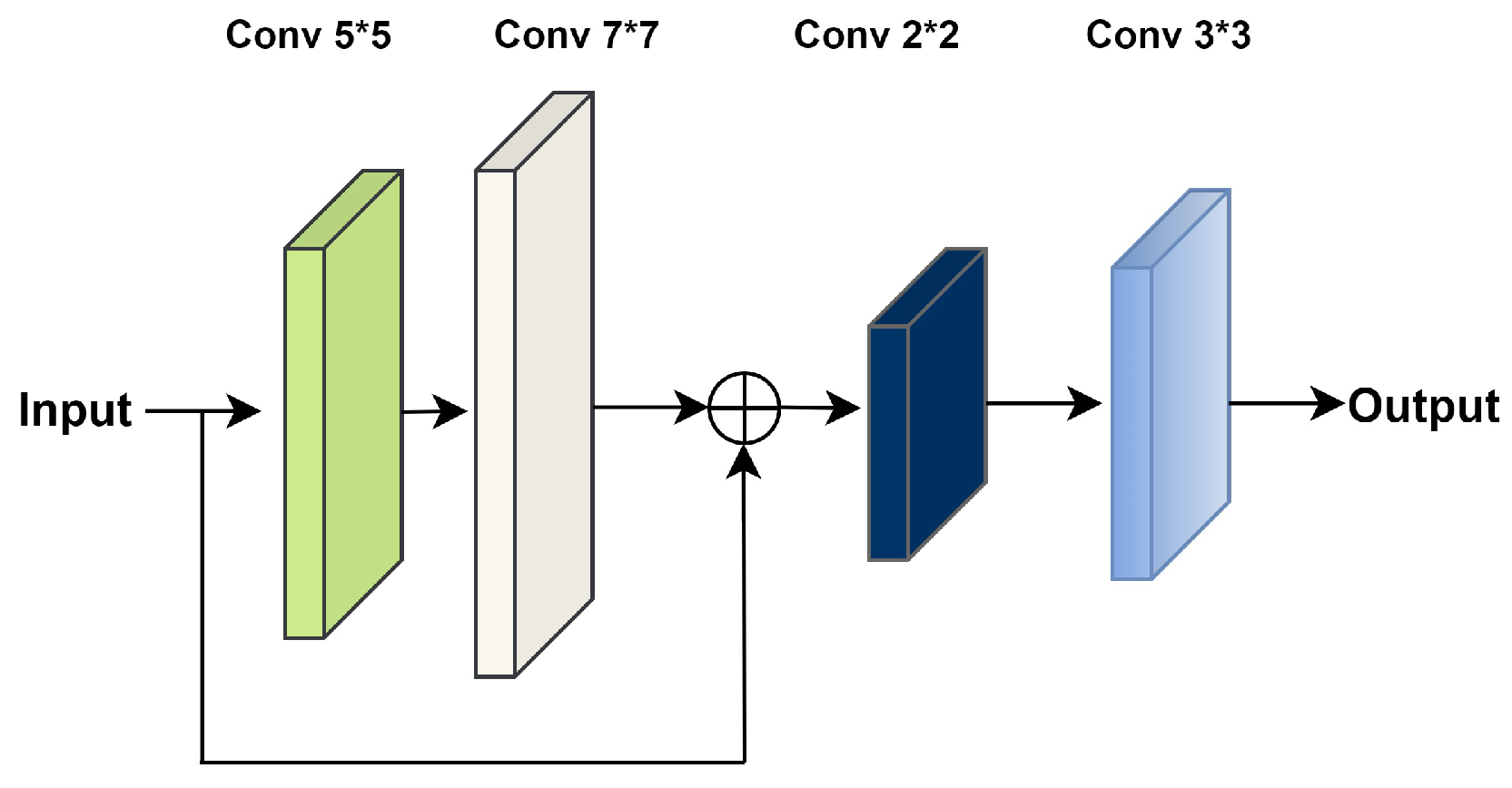
3.2. Hierarchical Feature Precision and Extraction (HFPE) Block
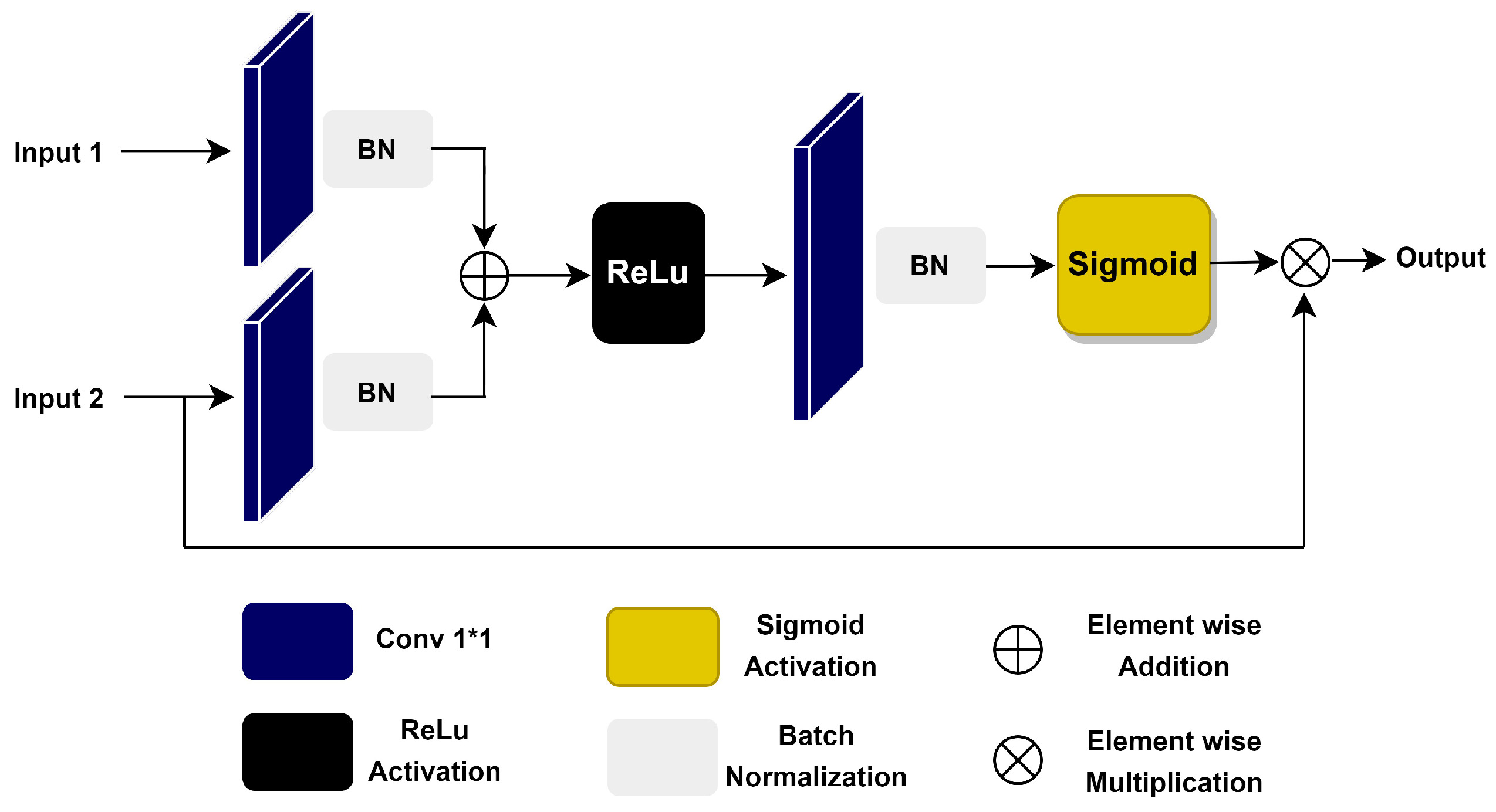
3.3. Attention Gate Block
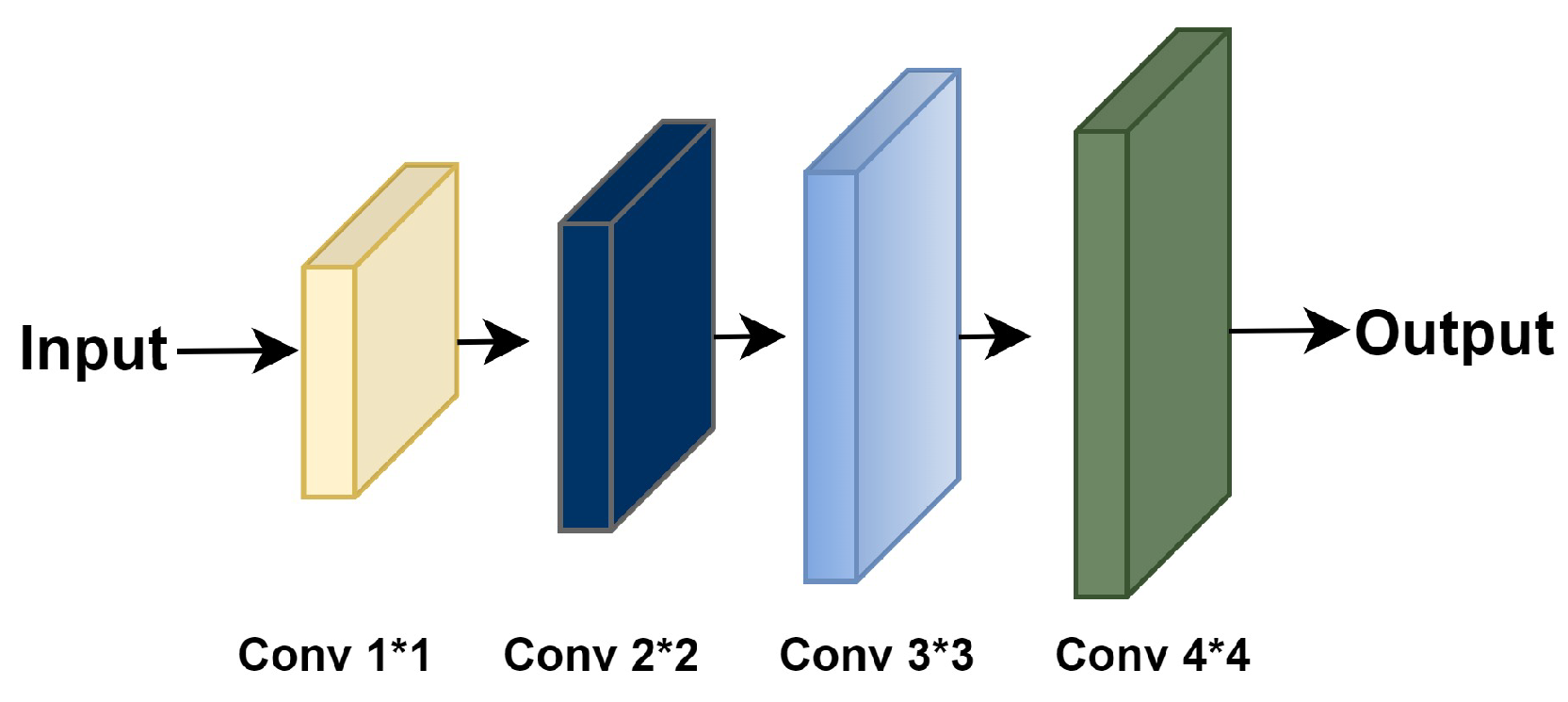
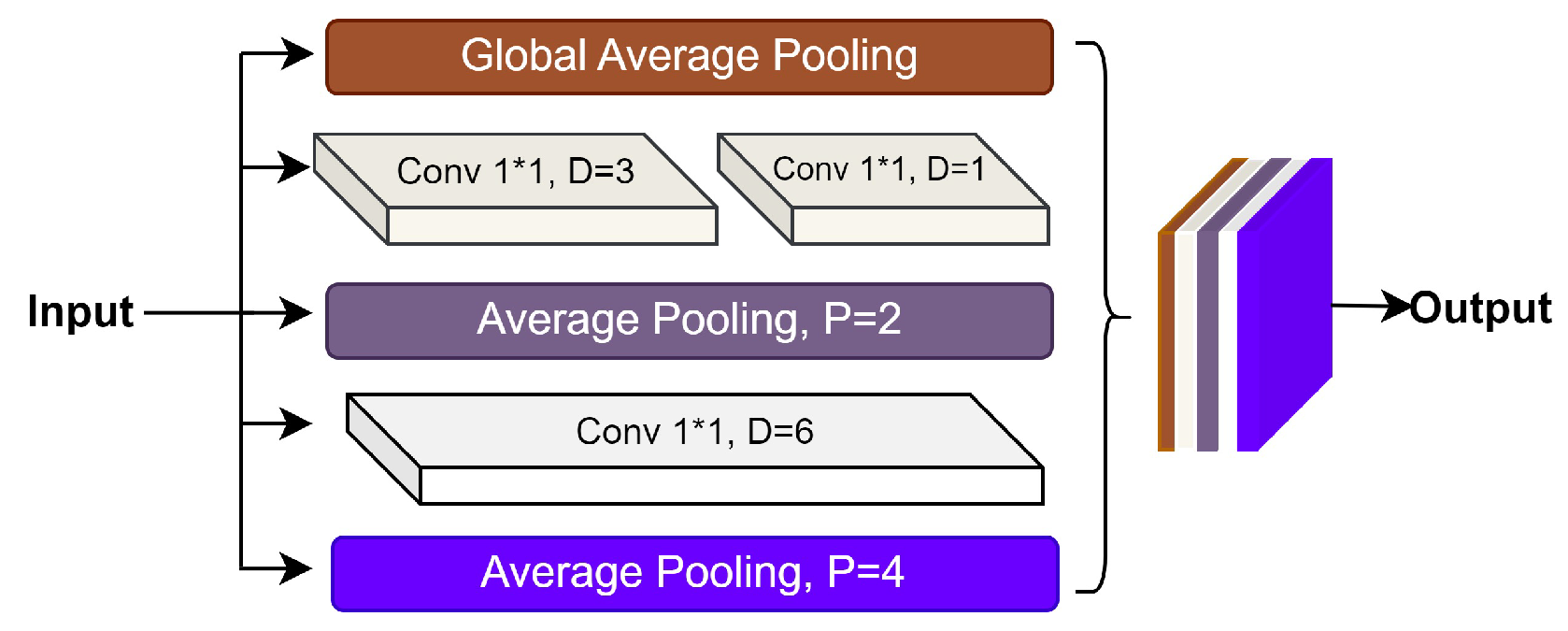
3.4. Contextual Characteristics Extraction and Attribute Fusion Block (CCEAF)
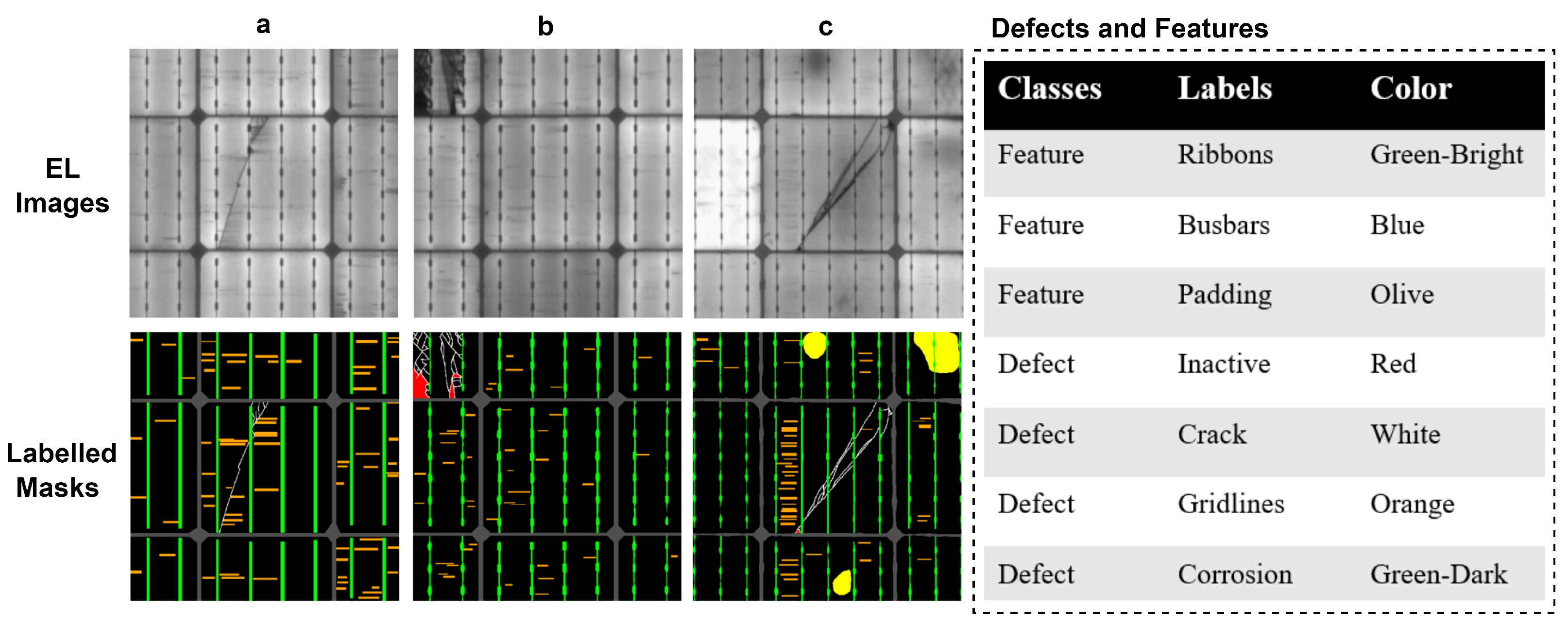
4. Dataset and Materials
Class Weights
5. Experimental Details
5.1. Performance Metrics
5.2. Implementation Details
6. Performance Evaluation and Discussion
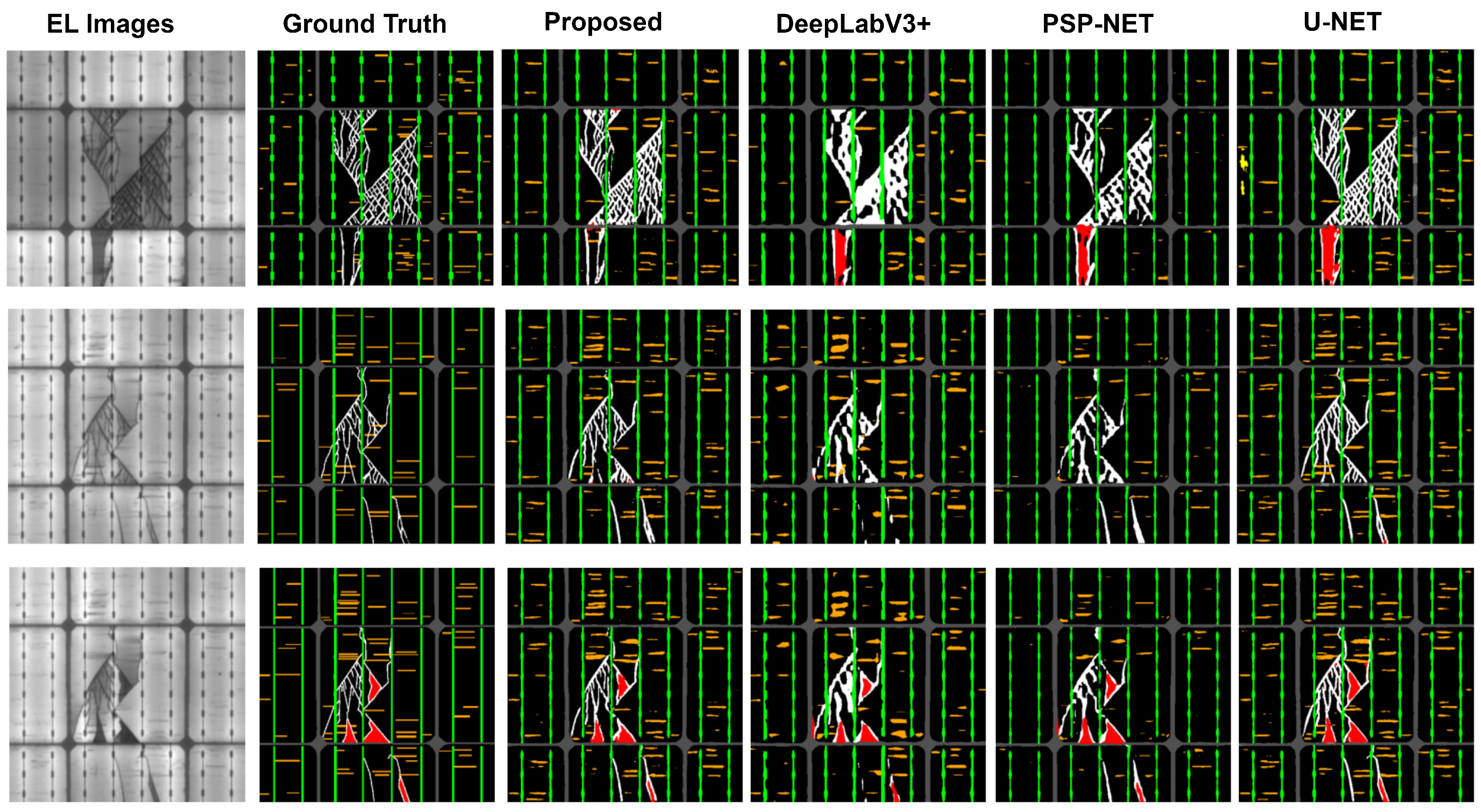
6.1. Comparison with Existing Techniques
6.2. Ablation Study
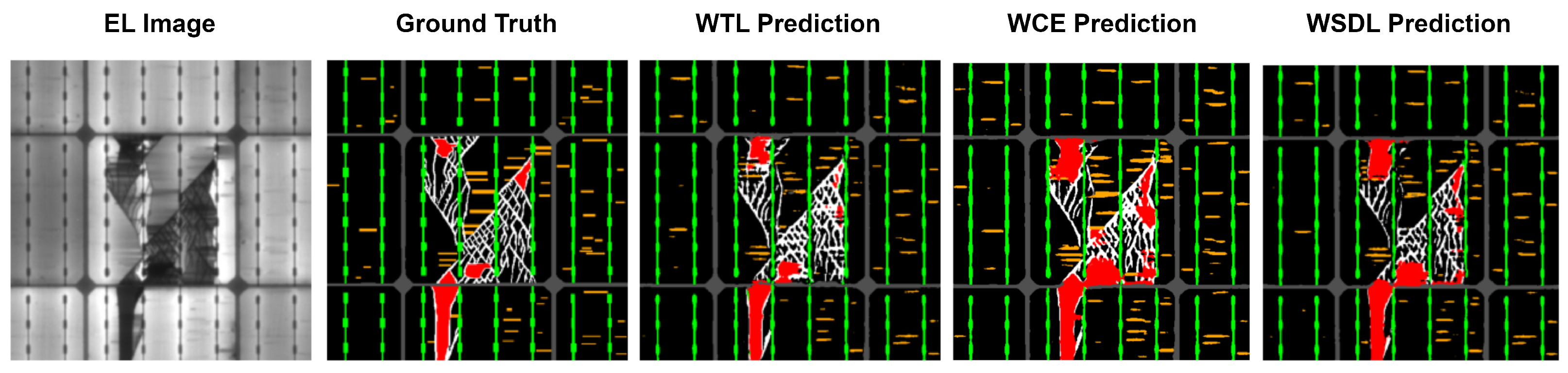
6.3. Comparative Analysis of Loss Functions
6.4. Comparative Analysis Based on Model Parameters
6.5. Implementation Challenges
6.6. Limiting Factors and Future Prospects
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tu, Q.; Mo, J.; Betz, R.; Cui, L.; Fan, Y.; Liu, Y. Achieving grid parity of solar PV power in China-The role of Tradable Green Certificate. Energy Policy 2020, 144, 111681. [Google Scholar] [CrossRef]
- Adams, S.; Nsiah, C. Reducing carbon dioxide emissions; Does renewable energy matter? Sci. Total. Environ. 2019, 693, 133288. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, M.; Liu, L.; Zhou, D. Can renewable energy investment reduce carbon dioxide emissions? Evidence from scale and structure. Energy Econ. 2022, 112, 106181. [Google Scholar] [CrossRef]
- Peike, C.; Hädrich, I.; Weiß, K.A.; Dürr, I.; Ise, F. Overview of PV module encapsulation materials. Photovoltaics Int. 2013, 19, 85–92. [Google Scholar]
- Makrides, G.; Theristis, M.; Bratcher, J.; Pratt, J.; Georghiou, G.E. Five-year performance and reliability analysis of monocrystalline photovoltaic modules with different backsheet materials. Sol. Energy 2018, 171, 491–499. [Google Scholar] [CrossRef]
- Haque, A.; Bharath, K.V.S.; Khan, M.A.; Khan, I.; Jaffery, Z.A. Fault diagnosis of photovoltaic modules. Energy Sci. Eng. 2019, 7, 622–644. [Google Scholar] [CrossRef]
- Gu, Q.; Li, S.; Gong, W.; Ning, B.; Hu, C.; Liao, Z. L-SHADE with parameter decomposition for photovoltaic modules parameter identification under different temperature and irradiance. Appl. Soft Comput. 2023, 143, 110386. [Google Scholar] [CrossRef]
- Makrides, G.; Zinsser, B.; Schubert, M.; Georghiou, G.E. Performance loss rate of twelve photovoltaic technologies under field conditions using statistical techniques. Sol. Energy 2014, 103, 28–42. [Google Scholar] [CrossRef]
- Buerhop, C.; Bommes, L.; Schlipf, J.; Pickel, T.; Fladung, A.; Peters, M. Infrared imaging of photovoltaic modules A review of the state of the art and future challenges facing gigawatt photovoltaic power stations. Prog. Energy 2022, 4, 042010. [Google Scholar] [CrossRef]
- Rahaman, S.A.; Urmee, T.; Parlevliet, D.A. PV system defects identification using Remotely Piloted Aircraft (RPA) based infrared (IR) imaging: A review. Sol. Energy 2020, 206, 579–595. [Google Scholar] [CrossRef]
- Fuyuki, T.; Tani, A. Photographic diagnosis of crystalline silicon solar cells by electroluminescence. In Experimental and Applied Mechanics, Volume 6: Proceedings of the 2010 Annual Conference on Experimental and Applied Mechanics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 159–162. [Google Scholar]
- Breitenstein, O.; Bauer, J.; Bothe, K.; Hinken, D.; Müller, J.; Kwapil, W.; Schubert, M.C.; Warta, W. Can luminescence imaging replace lock-in thermography on solar cells? IEEE J. Photovoltaics 2011, 1, 159–167. [Google Scholar] [CrossRef]
- Fuyuki, T.; Kondo, H.; Yamazaki, T.; Takahashi, Y.; Uraoka, Y. Photographic surveying of minority carrier diffusion length in polycrystalline silicon solar cells by electroluminescence. Appl. Phys. Lett. 2005, 86, 262108. [Google Scholar] [CrossRef]
- Fuyuki, T.; Kitiyanan, A. Photographic diagnosis of crystalline silicon solar cells utilizing electroluminescence. Appl. Phys. A 2009, 96, 189–196. [Google Scholar] [CrossRef]
- Deitsch, S.; Christlein, V.; Berger, S.; Buerhop-Lutz, C.; Maier, A.; Gallwitz, F.; Riess, C. Automatic classification of defective photovoltaic module cells in electroluminescence images. Sol. Energy 2019, 185, 455–468. [Google Scholar] [CrossRef]
- Shujaat, M.; Wahab, A.; Tayara, H.; Chong, K.T. pcPromoter-CNN: A CNN-based prediction and classification of promoters. Genes 2020, 11, 1529. [Google Scholar] [CrossRef]
- Karimi, A.M.; Fada, J.S.; Hossain, M.A.; Yang, S.; Peshek, T.J.; Braid, J.L.; French, R.H. Automated pipeline for photovoltaic module electroluminescence image processing and degradation feature classification. IEEE J. Photovoltaics 2019, 9, 1324–1335. [Google Scholar] [CrossRef]
- Tsai, D.M.; Wu, S.C.; Li, W.C. Defect detection of solar cells in electroluminescence images using Fourier image reconstruction. Sol. Energy Mater. Sol. Cells 2012, 99, 250–262. [Google Scholar] [CrossRef]
- Anwar, S.A.; Abdullah, M.Z. Micro-crack detection of multicrystalline solar cells featuring an improved anisotropic diffusion filter and image segmentation technique. Eurasip J. Image Video Process. 2014, 2014, 15. [Google Scholar] [CrossRef]
- Rehman, M.U.; Akhtar, S.; Zakwan, M.; Mahmood, M.H. Novel architecture with selected feature vector for effective classification of mitotic and non-mitotic cells in breast cancer histology images. Biomed. Signal Process. Control 2022, 71, 103212. [Google Scholar] [CrossRef]
- Rehman, M.U.; Ryu, J.; Nizami, I.F.; Chong, K.T. RAAGR2-Net: A brain tumor segmentation network using parallel processing of multiple spatial frames. Comput. Biol. Med. 2023, 152, 106426. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Rehman, M.U.; Cho, S.; Kim, J.; Chong, K.T. Brainseg-net: Brain tumor mr image segmentation via enhanced encoder–decoder network. Diagnostics 2021, 11, 169. [Google Scholar] [CrossRef] [PubMed]
- Rehman, M.U.; Cho, S.; Kim, J.H.; Chong, K.T. Bu-net: Brain tumor segmentation using modified u-net architecture. Electronics 2020, 9, 2203. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Cahall, D.E.; Rasool, G.; Bouaynaya, N.C.; Fathallah-Shaykh, H.M. Dilated inception U-net (DIU-net) for brain tumor segmentation. arXiv 2021, arXiv:2108.06772. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Ryu, J.; Rehman, M.U.; Nizami, I.F.; Chong, K.T. SegR-Net: A deep learning framework with multi-scale feature fusion for robust retinal vessel segmentation. Comput. Biol. Med. 2023, 163, 107132. [Google Scholar] [CrossRef]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Lewis, J.; Cha, Y.J.; Kim, J. Dual encoder–decoder-based deep polyp segmentation network for colonoscopy images. Sci. Rep. 2023, 13, 1183. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.J. SDDNet: Real-time crack segmentation. IEEE Trans. Ind. Electron. 2019, 67, 8016–8025. [Google Scholar] [CrossRef]
- Demirci, M.Y.; Beşli, N.; Gümüşçü, A. Efficient deep feature extraction and classification for identifying defective photovoltaic module cells in Electroluminescence images. Expert Syst. Appl. 2021, 175, 114810. [Google Scholar] [CrossRef]
- Tang, W.; Yang, Q.; Hu, X.; Yan, W. Convolution neural network based polycrystalline silicon photovoltaic cell linear defect diagnosis using electroluminescence images. Expert Syst. Appl. 2022, 202, 117087. [Google Scholar] [CrossRef]
- Rahman, M.R.U.; Chen, H. Defects inspection in polycrystalline solar cells electroluminescence images using deep learning. IEEE Access 2020, 8, 40547–40558. [Google Scholar] [CrossRef]
- Cheng, D.; Chen, L.; Lv, C.; Guo, L.; Kou, Q. Light-Guided and Cross-Fusion U-Net for Anti-Illumination Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8436–8449. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, H.; Han, D.; Liu, K. Accurate and robust crack detection using steerable evidence filtering in electroluminescence images of solar cells. Opt. Lasers Eng. 2019, 118, 22–33. [Google Scholar] [CrossRef]
- Cong, R.; Sheng, H.; Yang, D.; Cui, Z.; Chen, R. Exploiting Spatial and Angular Correlations with Deep Efficient Transformers for Light Field Image Super-Resolution. IEEE Trans. Multimed. 2023, 1–14. [Google Scholar] [CrossRef]
- Pratt, L.; Govender, D.; Klein, R. Defect detection and quantification in electroluminescence images of solar PV modules using U-net semantic segmentation. Renew. Energy 2021, 178, 1211–1222. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Pratt, L.; Mattheus, J.; Klein, R. A benchmark dataset for defect detection and classification in electroluminescence images of PV modules using semantic segmentation. Syst. Soft Comput. 2023, 5, 200048. [Google Scholar] [CrossRef]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, J.; Li, Y.; Zhang, H. Semantic segmentation with attention mechanism for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5403913. [Google Scholar] [CrossRef]
- Hou, G.; Qin, J.; Xiang, X.; Tan, Y.; Xiong, N.N. Af-net: A medical image segmentation network based on attention mechanism and feature fusion. Comput. Mater. Contin. 2021, 69, 1877–1891. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. 2022, 21, 2190–2205. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Cha, Y.J. Attention-based generative adversarial network with internal damage segmentation using thermography. Autom. Constr. 2022, 141, 104412. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Özdemir, Ö.; Sönmez, E.B. Weighted cross-entropy for unbalanced data with application on covid x-ray images. In Proceedings of the 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), Istanbul, Turkey, 15–17 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Images | Training Images Split | Total Classes | ||||||
|---|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | Image Size | EL Images | Multi-Crystalline | Mono-Crystalline | Features | Defects |
| 1912 | 54 | 50 | 512 × 512 | 593 | 1016 | 896 | 12 | 12 |
| Weights | Classes | |||||
|---|---|---|---|---|---|---|
| Background | Inactive | Crack | Ribbons | Gridline | Remaining Classes | |
| Equal Class Weights | 0.25 | 0.25 | 0.25 | 0.25 | 0.25 | 0.25 |
| Custom Class Weights | 0.15 | 0.40 | 0.45 | 0.30 | 0.35 | 0.25 |
| Class Weights | Method | Dice Coefficient | Precision | IoU | Recall | F1 Score | mIoU |
|---|---|---|---|---|---|---|---|
| Equal Class Weights | U-NET | 0.7957 | 0.9464 | 0.6633 | 0.9129 | 0.9290 | 0.8145 |
| PSP-NET | 0.8227 | 0.9314 | 0.7043 | 0.9169 | 0.9241 | 0.8516 | |
| DeepLabV3+ | 0.8363 | 0.9346 | 0.7198 | 0.9171 | 0.9258 | 0.8316 | |
| SEiPV-Net | 0.8531 | 0.9491 | 0.7447 | 0.9362 | 0.9426 | 0.8604 | |
| Custom Class Weights | U-NET | 0.7503 | 0.9436 | 0.6038 | 0.9028 | 0.9207 | 0.8065 |
| PSP-NET | 0.8009 | 0.9385 | 0.6714 | 0.9055 | 0.9210 | 0.8329 | |
| DeepLabV3+ | 0.8218 | 0.9325 | 0.6998 | 0.8960 | 0.9129 | 0.8457 | |
| SEiPV-Net | 0.8312 | 0.9463 | 0.7124 | 0.9290 | 0.9375 | 0.8573 |
| Ablation Study | Dice Coefficient | IoU | Precision | F1 Score | Recall | mIoU | Model Parameters |
|---|---|---|---|---|---|---|---|
| ConvE & ConvD + Ag | 0.7833 | 0.6440 | 0.9373 | 0.9216 | 0.9065 | 0.7881 | 235,140 |
| DSF & ConvD + Ag | 0.7982 | 0.6647 | 0.9471 | 0.9337 | 0.9208 | 0.8329 | 773,412 |
| DSF + HFPE & ConvD + Ag | 0.8216 | 0.6976 | 0.9484 | 0.9392 | 0.9302 | 0.8445 | 867,012 |
| ConvE & CCEAF + Ag | 0.8316 | 0.7126 | 0.9376 | 0.9305 | 0.9235 | 0.8441 | 221,280 |
| ConvE + HFPE & CCEAF + Ag | 0.8385 | 0.7227 | 0.9482 | 0.9395 | 0.9311 | 0.8542 | 314,880 |
| DSF & CCEAF + Ag | 0.8444 | 0.7308 | 0.9483 | 0.9415 | 0.9349 | 0.8539 | 759,552 |
| SEiPV-Net | 0.8531 | 0.7447 | 0.9491 | 0.9426 | 0.9362 | 0.8604 | 853,152 |
| Custom Class Weights | Dice Coefficient | Precision | IoU | Recall | F1 Score | mIoU |
|---|---|---|---|---|---|---|
| WCE | 0.9151 | 0.9447 | 0.8442 | 0.9361 | 0.9404 | 0.8600 |
| WSDL | 0.9253 | 0.9456 | 0.8616 | 0.9395 | 0.9426 | 0.8598 |
| WTL | 0.9275 | 0.9492 | 0.8651 | 0.9416 | 0.9453 | 0.8477 |
| Model | No. of Parameters | Average Inference Time |
|---|---|---|
| U-NET | 31,056,792 | 0.1048 s |
| PSP-NET | 1,711,384 | 0.0967 s |
| DeepLabV3+ | 37,709,568 | 0.0938 s |
| Proposed | 853,152 | 0.0931 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eesaar, H.; Joe, S.; Rehman, M.U.; Jang, Y.; Chong, K.T. SEiPV-Net: An Efficient Deep Learning Framework for Autonomous Multi-Defect Segmentation in Electroluminescence Images of Solar Photovoltaic Modules. Energies 2023, 16, 7726. https://doi.org/10.3390/en16237726
Eesaar H, Joe S, Rehman MU, Jang Y, Chong KT. SEiPV-Net: An Efficient Deep Learning Framework for Autonomous Multi-Defect Segmentation in Electroluminescence Images of Solar Photovoltaic Modules. Energies. 2023; 16(23):7726. https://doi.org/10.3390/en16237726
Chicago/Turabian StyleEesaar, Hassan, Sungjin Joe, Mobeen Ur Rehman, Yeongmin Jang, and Kil To Chong. 2023. "SEiPV-Net: An Efficient Deep Learning Framework for Autonomous Multi-Defect Segmentation in Electroluminescence Images of Solar Photovoltaic Modules" Energies 16, no. 23: 7726. https://doi.org/10.3390/en16237726
APA StyleEesaar, H., Joe, S., Rehman, M. U., Jang, Y., & Chong, K. T. (2023). SEiPV-Net: An Efficient Deep Learning Framework for Autonomous Multi-Defect Segmentation in Electroluminescence Images of Solar Photovoltaic Modules. Energies, 16(23), 7726. https://doi.org/10.3390/en16237726