Probabilistic Wind Speed Forecasting for Wind Turbine Allocation in the Power Grid


Abstract
:1. Introduction
2. Materials and Methods
2.1. The Functional Time Series Concept
2.2. Quantile Regression Model When the Covariate Is a Function
2.2.1. Definition of the -th Conditional Quantile
2.2.2. Nadaraya–Watson-Type Estimator of
2.3. Interval Prediction for Nonstationary Processes
Clustering-Discrimination Kernel-Smoothed Approach (CD-KS)
- Step 1:
- unsupervised curve classification.
- Step 2:
- curve discrimination.
- Step 3:
- α-th conditional quantile estimation.
3. Results
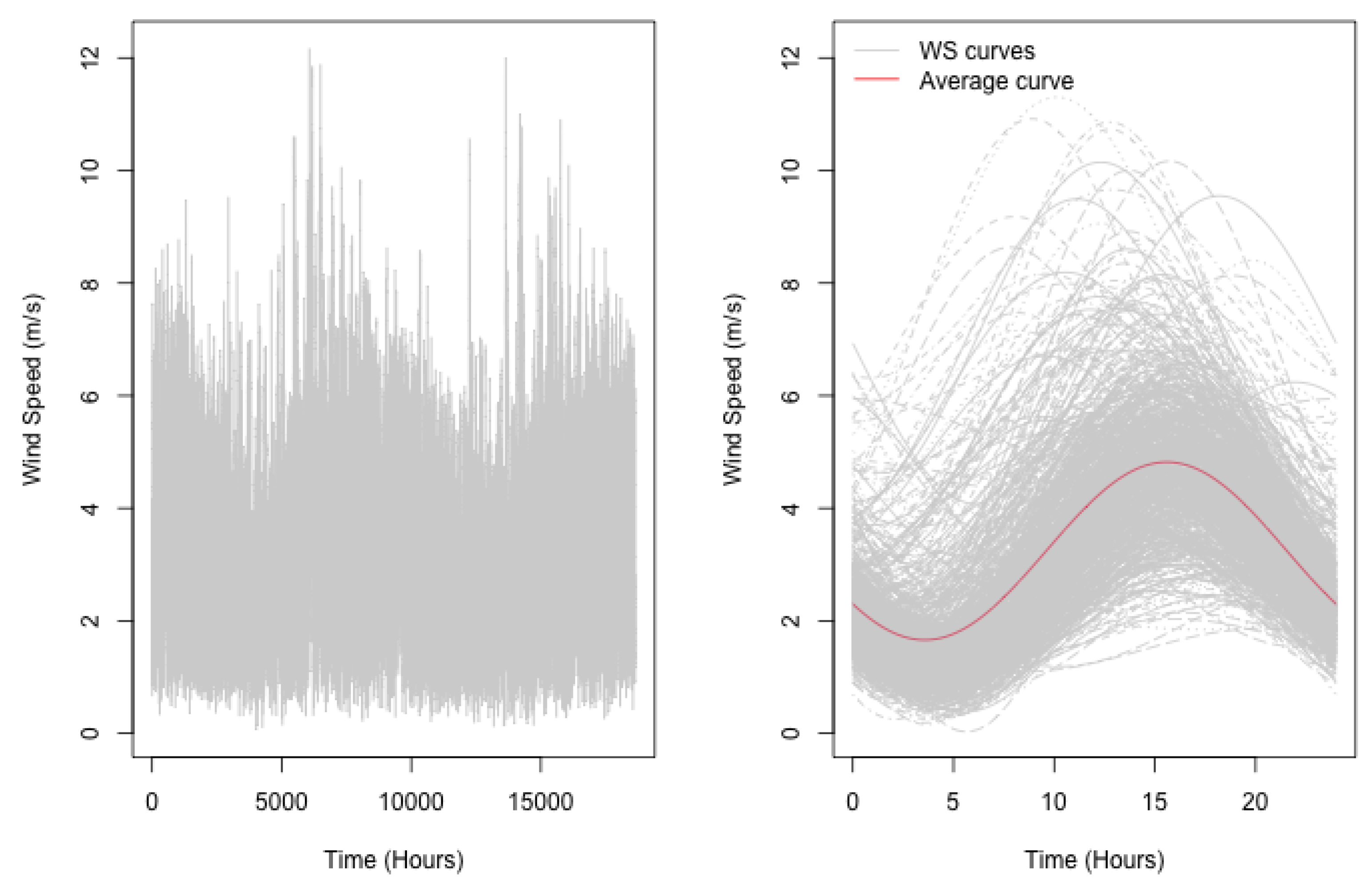
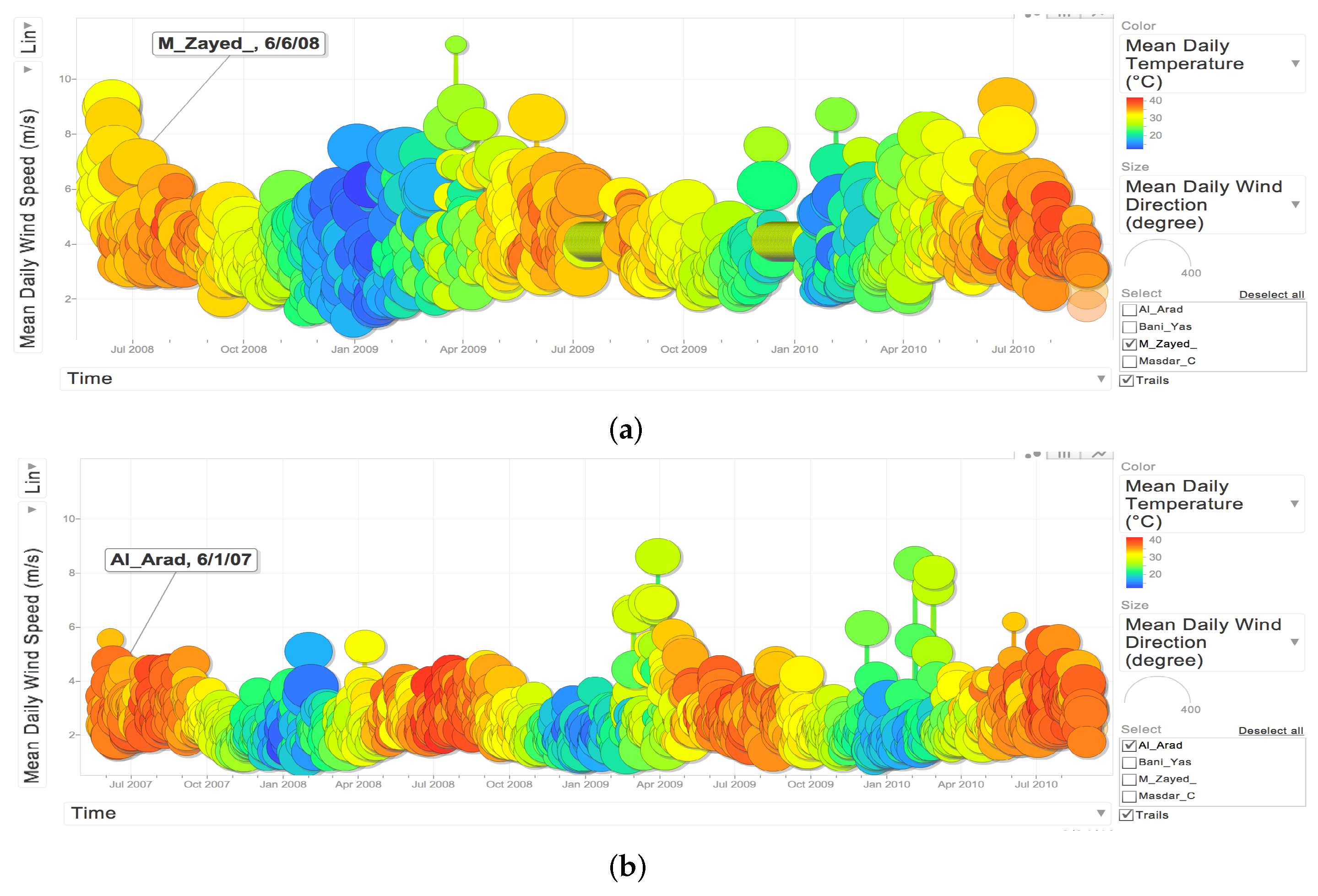
3.1. Data Description and Preliminary Analysis
- 6 June 2008 and 31 August 2010 in Madinat Zayed;
- 1 June 2007 and 31 August 2010 in Al Aradh.
3.2. An Illustrative Example for the Classification Step: Case of Madinat Zayed
3.3. Choice of the Tuning Parameters for KS and CD-KS Estimators
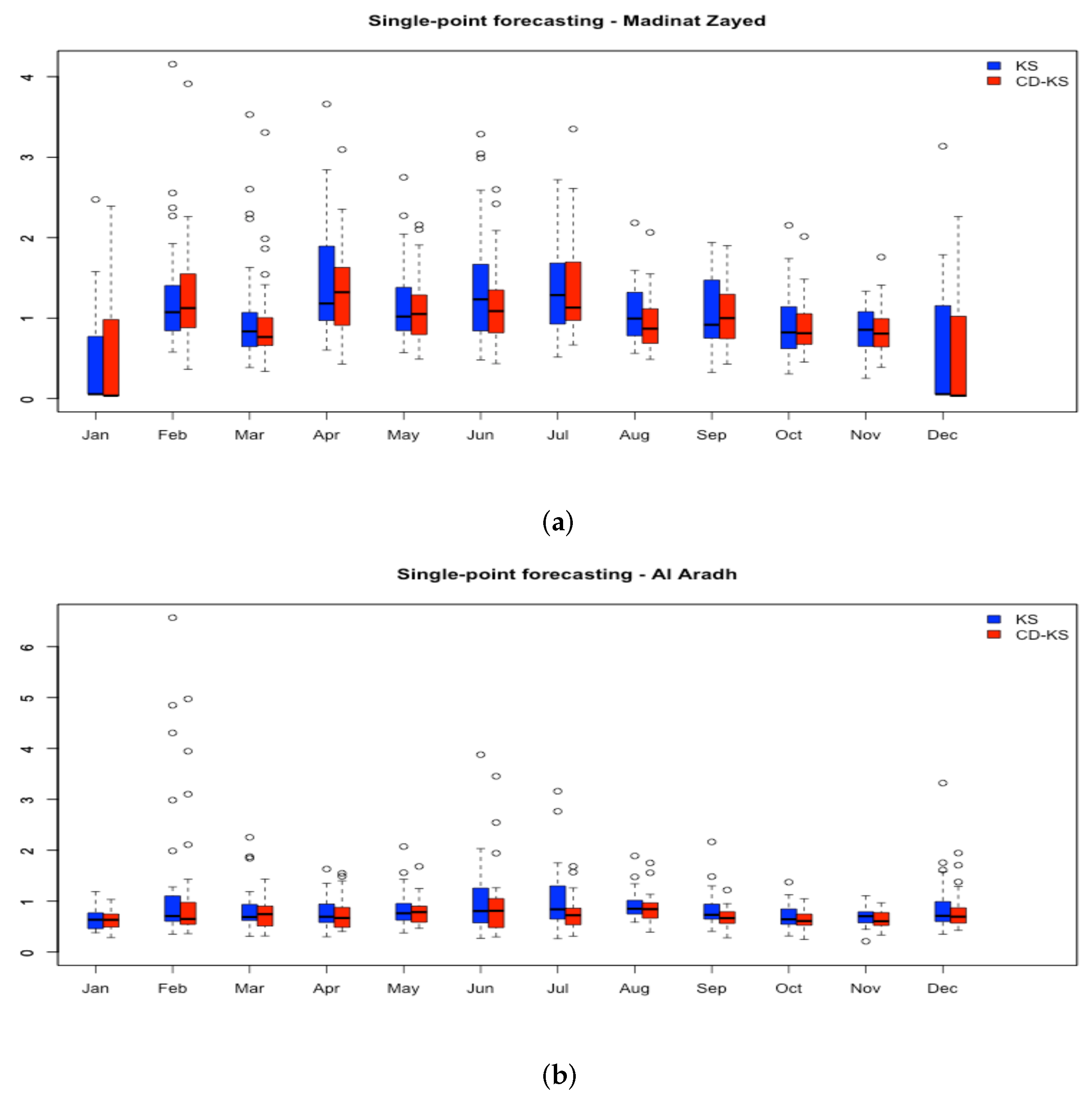
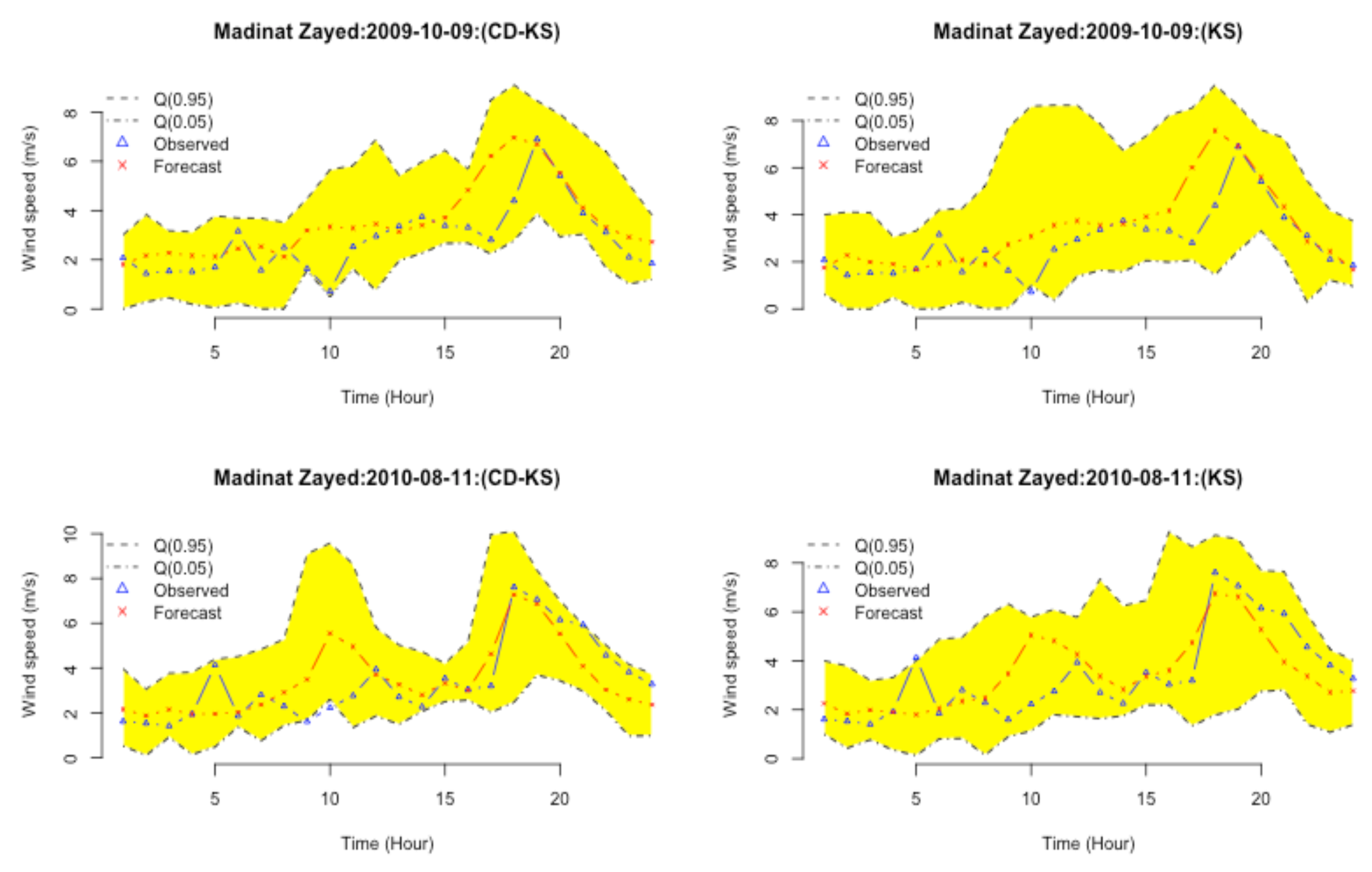
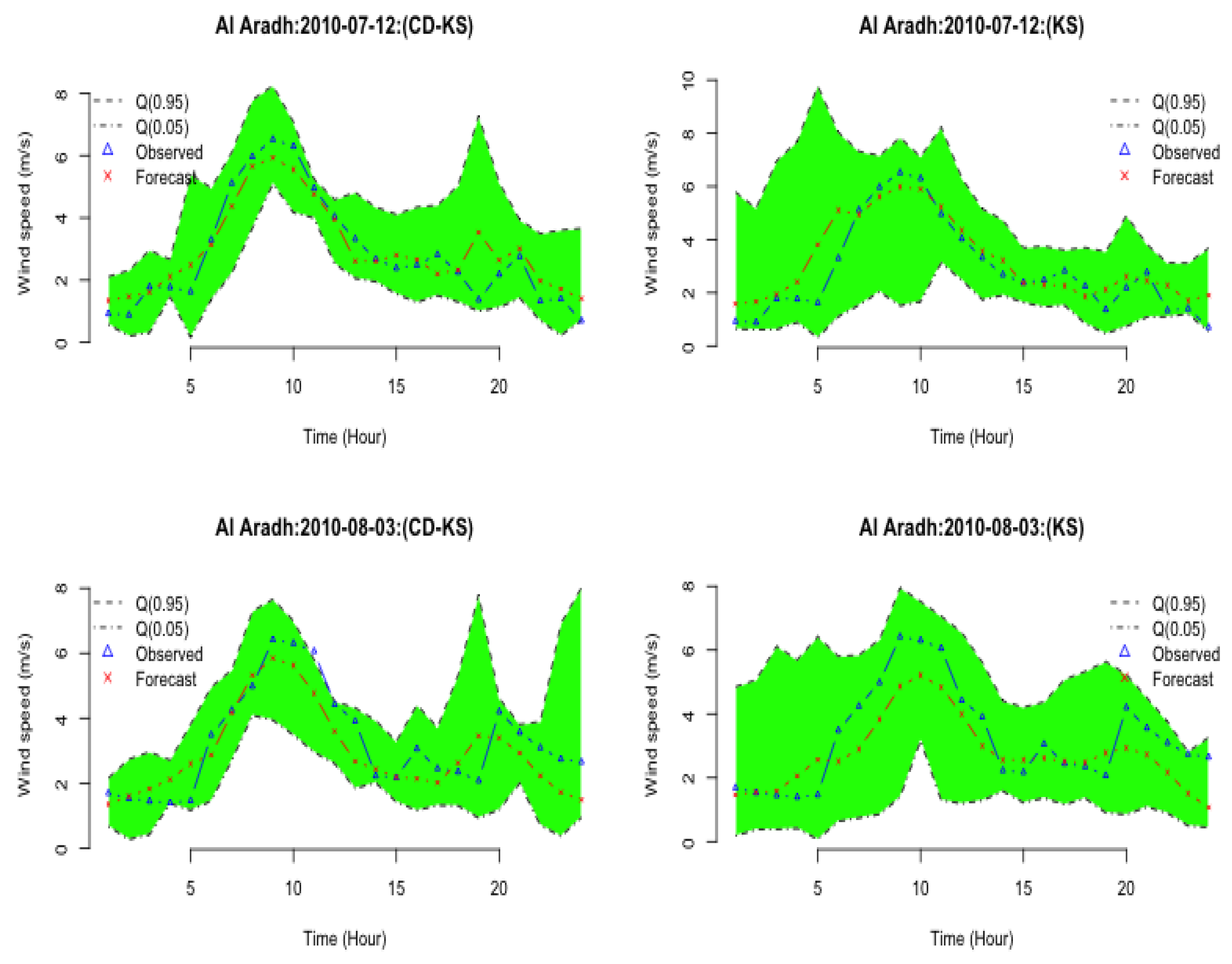
3.4. Validation Procedure and Accuracy Measurements
4. Discussion
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jeridi Bachellirie, I. Renewable Energy in the GCC Countries. Resources, Potential, and Prospects; Gulf Research Center: Dubai, United Arab Emirates, 2012. [Google Scholar]
- Sanchez, I. Short term prediction of wind energy production. Int. J. Forecast. 2006, 22, 43–56. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, J.; Xia, J.; Dai, Y.; Sheng, Y.; Yue, J. Performance evaluation and accuracy enhancement of a day-ahead wind power forecasting system in china. Renew. Energy 2012, 43, 234–241. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Pan, D.; Li, Y. Forecasting models of wind speed using wavelet, wavelet packet, time series and artificial neural networks. Appl. Energy 2013, 107, 191–208. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ortiz-Garcá, E.G.; Pérez-Bellido, Á.M.; Portilla-Figueras, A.; Piereto, L. Short term wind speed prediction based on evolutionary support vector regression algorithms. Expert Syst. Appl. 2006, 38, 4052–4057. [Google Scholar] [CrossRef]
- Poggi, P.; Muselli, M.; Notton, G.; Cristofari, C.; Louche, A. Forecasting and simulating wind speed in Corsica by using an autoregressive model. Energy Convers. Manag. 2003, 44, 3177–3196. [Google Scholar] [CrossRef]
- Kavasseri, R.; Seetharaman, G. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Ailliot, P.; Monbet, V.; Prevosto, M. An autoregressive model with time-varying coefficients for wind fields. Environmetrics 2006, 17, 107–117. [Google Scholar] [CrossRef]
- Hocaoglua, F.O.; Gerekb, Ö.N.; Kurbanb, M. A novel wind speed modeling approach using atmospheric pressure observations and hidden Markov models. J. Wind. Eng. Ind. Aerodyn. 2010, 98, 472–481. [Google Scholar] [CrossRef]
- D’Amico, G.; Petroni, F.; Prattico, F. Wind speed modeled as an indexed semi-Markov process. Environmetrics 2013, 24, 367–376. [Google Scholar] [CrossRef]
- Moldernik, A.; Bakker, V.; Bosman, M.; Hurink, J.; Smit, G. Management and control of domestic smart grid technology. IEEE Trans. Smart Grid 2010, 1, 109–119. [Google Scholar] [CrossRef]
- Ouammi, A.; Dagdougui, H.; Sacile, R. Optimal planning with technology selection for wind power plants in power distribution networks. IEEE Syst. J. 2019, 13, 3059–3069. [Google Scholar] [CrossRef]
- Ouammi, A.; Ghigliotti, V.; Robba, M.; Mimert, A.; Sacile, R. A decision support system for the optimal exploitation of wind energy on regional scale. Renew. Energy 2012, 37, 299–309. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2005. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Chaouch, M. Clustering-based improvement of nonparametric functional time series forecasting. Application to intraday household-level load curves. IEEE Trans. Smart Grid 2013, 99, 411–419. [Google Scholar] [CrossRef]
- Rice, J.A. Functional and longitudinal data analysis: Perspectives on smoothing. Stat. Sin. 2004, 14, 631–647. [Google Scholar]
- Yao, Q.; Tong, H. On prediction and chaos in stochastic systems. Philos. Trans. R. Soc. A 1994, 348, 357–369. [Google Scholar] [CrossRef]
- De Gooijer, J.G.; Gannoun, A. Nonparametric conditional predictive regions for time series. Comput. Stat. Data Anal. 2000, 33, 259–275. [Google Scholar] [CrossRef]
- Chaouch, M.; Khardani, S. Randomly censored quantile regression estimation using functional stationary ergodic data. J. Nonparametric Stat. 2015, 21, 65–87. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; Chapman & Hall: London, UK, 1995. [Google Scholar]
- Simonoff, J. Smoothing Methods in Statistics; Springer: New York, NY, USA, 1996. [Google Scholar]
- Cuesta-Albertos, J.; Fraiman, R. Impartial trimmed k-means and classification rules for functional data. Comput. Stat. Data Anal. 2007, 51, 4864–4877. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Ferraty, F.; Vieu, P. Mode estimation for functional random variable and its application for curves classification. Far East J. Theor. Stat. 2006, 18, 93–119. [Google Scholar]
- Ferraty, F.; Vieu, P. Curves discrimination: A nonparametric functional approach. Comput. Stat. Data Anal. 2003, 44, 161–173. [Google Scholar] [CrossRef]
- Lin, Y.; Qin, H.; Zhang, Z.; Pei, S.; Jiang, Z.; Feng, Z.; Zhou, J. Probabilistic spatiotemporal wind speed forecasting based on a variational bayesian deep learning model. Appl. Energy 2020, 260, 114259. [Google Scholar]
- Jiang, Y.; Zhao, N.; Peng, L.; Lin, S. A new hybrid framework for probabilistic wind speed prediction using deep feature selection and multi-error modification. Energy Convers. Manag. 2019, 199, 111981. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KS | CD-KS | |||||
|---|---|---|---|---|---|---|
| Jan. | 0.054 | 0.054 | 0.772 | 0.036 | 0.036 | 0.981 |
| Feb. | 0.846 | 1.073 | 1.388 | 0.884 | 1.125 | 1.497 |
| Mar. | 0.646 | 0.834 | 1.070 | 0.660 | 0.765 | 1.005 |
| Apr. | 0.982 | 1.182 | 1.877 | 0.912 | 1.322 | 1.623 |
| May | 0.844 | 1.020 | 1.381 | 0.795 | 1.051 | 1.288 |
| Jun. | 0.850 | 1.233 | 1.627 | 0.821 | 1.087 | 1.348 |
| Jul. | 0.926 | 1.286 | 1.684 | 0.972 | 1.131 | 1.696 |
| Aug. | 0.780 | 0.994 | 1.320 | 0.687 | 0.868 | 1.116 |
| Sep. | 0.753 | 0.917 | 1.414 | 0.745 | 0.999 | 1.291 |
| Oct. | 0.621 | 0.822 | 1.142 | 0.6753 | 0.812 | 1.055 |
| Nov. | 0.650 | 0.855 | 1.076 | 0.644 | 0.807 | 0.972 |
| Dec. | 0.054 | 0.054 | 1.155 | 0.027 | 0.036 | 1.023 |
| KS | CD-KS | |||||
|---|---|---|---|---|---|---|
| Jan. | 0.460 | 0.635 | 0.771 | 0.491 | 0.633 | 0.747 |
| Feb. | 0.612 | 0.707 | 1.078 | 0.549 | 0.651 | 0.931 |
| Mar. | 0.621 | 0.689 | 0.936 | 0.512 | 0.744 | 0.904 |
| Apr. | 0.583 | 0.694 | 0.933 | 0.505 | 0.669 | 0.866 |
| May | 0.626 | 0.762 | 0.954 | 0.586 | 0.784 | 0.902 |
| Jun. | 0.581 | 0.805 | 1.223 | 0.495 | 0.811 | 1.019 |
| Jul. | 0.649 | 0.840 | 1.300 | 0.538 | 0.723 | 0.862 |
| Aug. | 0.747 | 0.850 | 1.017 | 0.666 | 0.843 | 0.967 |
| Sep. | 0.656 | 0.732 | 0.931 | 0.566 | 0.666 | 0.787 |
| Oct. | 0.546 | 0.643 | 0.846 | 0.527 | 0.610 | 0.747 |
| Nov. | 0.579 | 0.704 | 0.784 | 0.527 | 0.606 | 0.763 |
| Dec. | 0.601 | 0.711 | 0.991 | 0.569 | 0.695 | 0.869 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaouch, M. Probabilistic Wind Speed Forecasting for Wind Turbine Allocation in the Power Grid. Energies 2023, 16, 7615. https://doi.org/10.3390/en16227615
Chaouch M. Probabilistic Wind Speed Forecasting for Wind Turbine Allocation in the Power Grid. Energies. 2023; 16(22):7615. https://doi.org/10.3390/en16227615
Chicago/Turabian StyleChaouch, Mohamed. 2023. "Probabilistic Wind Speed Forecasting for Wind Turbine Allocation in the Power Grid" Energies 16, no. 22: 7615. https://doi.org/10.3390/en16227615
APA StyleChaouch, M. (2023). Probabilistic Wind Speed Forecasting for Wind Turbine Allocation in the Power Grid. Energies, 16(22), 7615. https://doi.org/10.3390/en16227615