3.1. Multiple Regression Model
In the first step, during model construction, the dependent and independent variables used during the study were identified. The data were obtained from the OBD-II system. The quantitative variable fuel consumption (L/100 km) was identified as the dependent variable. Five continuous quantitative variables were selected as independent variables: slope (°), engine load (%), engine speed (rpm), speed (km/h), and acceleration (m/s
2), and one incremental variable: gear (1–6). Then, the basic descriptive statistics of the selected variables were calculated and the significance of their impact on the modeled dependent variable was assessed (
Table 3 and
Table 4). For this purpose, the correlation coefficient was assessed for continuous quantitative variables and the statistical Mann–Whitney U test was performed for the discrete variable gear. All continuous quantitative variables are related to the studied dependent variable. The correlation analysis showed a moderate or strong Influence on fuel consumption. In addition, it should be noted that slope and speed are destimulants, so fuel consumption decreases as they increase, while engine load, engine speed, and acceleration are stimulants.
However, the Mann–Whitney U test showed that for the calculated value, test statistic Z = 11.08, corresponding to p-value = 0.00. This means that the null hypothesis, that the values come from one population against the opposite alternative, should be rejected. Thus, there is a statistically significant impact of the variable gear on the dependent variable under study.
The next step was to build the model. The construction began by analyzing the distribution of independent variables and the relationships between them, with a particular emphasis on their linear course and the lack of relationships between individual predictors. Then, the parameters of the model were estimated and the type of influence of the predictors on the dependent variable was determined. All estimated parameters of the model turned out to be statistically significant, as evidenced by the calculated
p-value, which is lower than the designated significance level of 0.05, making the rejection of the null hypothesis in the parameter significance test against the alternative hypothesis that the parameter values are statistically significant not 0. The estimated values of the regression parameters are presented in
Table 5.
In addition, the calculated value of test statistic F (40.12) and the corresponding p = 0.00 proves that the regression equation is correct and statistically significant. The value of the model determination coefficient is 85%, which means that the examined independent variables explain 85% of the variability of fuel consumption.
The final equation for a multiple regression model that forecasts fuel consumption is as follows (4):
The final step in making predictions using a multiple regression model is model verification, which checks that the residual assumptions are met. In a properly constructed model, they should have a normal distribution as well as homoscedasticity and there should be no autocorrelation between them.
The random component normality test was performed based on the Shapiro–Wilk test. The value of the test statistic w was at the level of 0.085 and the corresponding probability level p = 0.01. This means that there is no basis to accept the null hypothesis that the distribution of residuals is close to the normal distribution. As a result, it should be concluded that there may still be dependencies in the model that have not been explained. This may be because fuel consumption is affected by many factors other than the technical parameters of the engine or the driver’s driving style, e.g., factors related to weather conditions. Nevertheless, with such high discrimination, including the data in the model could lead to difficulties in analyzing the impact of individual factors on the studied dependent variable.
Next, the fulfillment of the assumption concerning the homoscedasticity of residues was analyzed. For this purpose, the White test was used. The null hypothesis for this test says that the random term is heteroscedastic. The calculated value of the test statistic is 116.08, and the corresponding p-value is 0.00. As a result of this observation, the null hypothesis concerning the alternative hypothesis should be rejected, based on which it can be concluded that the model assumption regarding the constant value of the model residuals is satisfied.
Finally, the autocorrelation of model residuals was analyzed. For this purpose, the Durbin–Watson statistic was calculated at 1.97, proving that there is no correlation between the random components.
This means that the residuals of the model are random and there are no other dependencies that are not included in the model. The presented analysis, and in particular the estimated value of the determination coefficient, indicates that the constructed model can be considered satisfactory. In addition, the equation of the multiple regression model should be considered correct.
In the next step, the predictive ability of the model was tested by applying V-fold cross-evaluation, which consists of dividing the statistical sample into subsets, and then carrying out all analyses on some of them, the so-called training sets, then using the remaining ones, the so-called test sets, to confirm the reliability of the results. The V-fold cross-score fitting results were as follows:
Mean square error (MSE) = 3.19;
Mean absolute error (MAE) = 1.25;
Relative average deviation (MRAE) = 0.13.
The mean absolute error is 1.25 L, which leads to the conclusion that the model has good prognostic ability.
Finally, Ramsey’s regression specification error test (RESET) was carried out to confirm whether the linear functional form of the model is correct. For the calculated test statistic value of 240.89, the corresponding p-value is 0.00. This means that the model proposed for prediction is not the best possible solution. Therefore, in the next step for forecasting fuel consumption, a machine-learning model based on decision trees was proposed.
3.2. Decision Trees Model
In the next step, a machine learning model for forecasting fuel consumption was constructed. For this purpose, a traditional CART model and a random forest were built and compared. The CART decision tree model was the first to be built. Before starting the analysis, the boundary settings of the presented solution were defined as follows:
Stopping rule: prune on variance;
Minimum number of cases n = 100;
Maximum of nodes n = 1000;
V-fold cross-validation: v-value = 10.
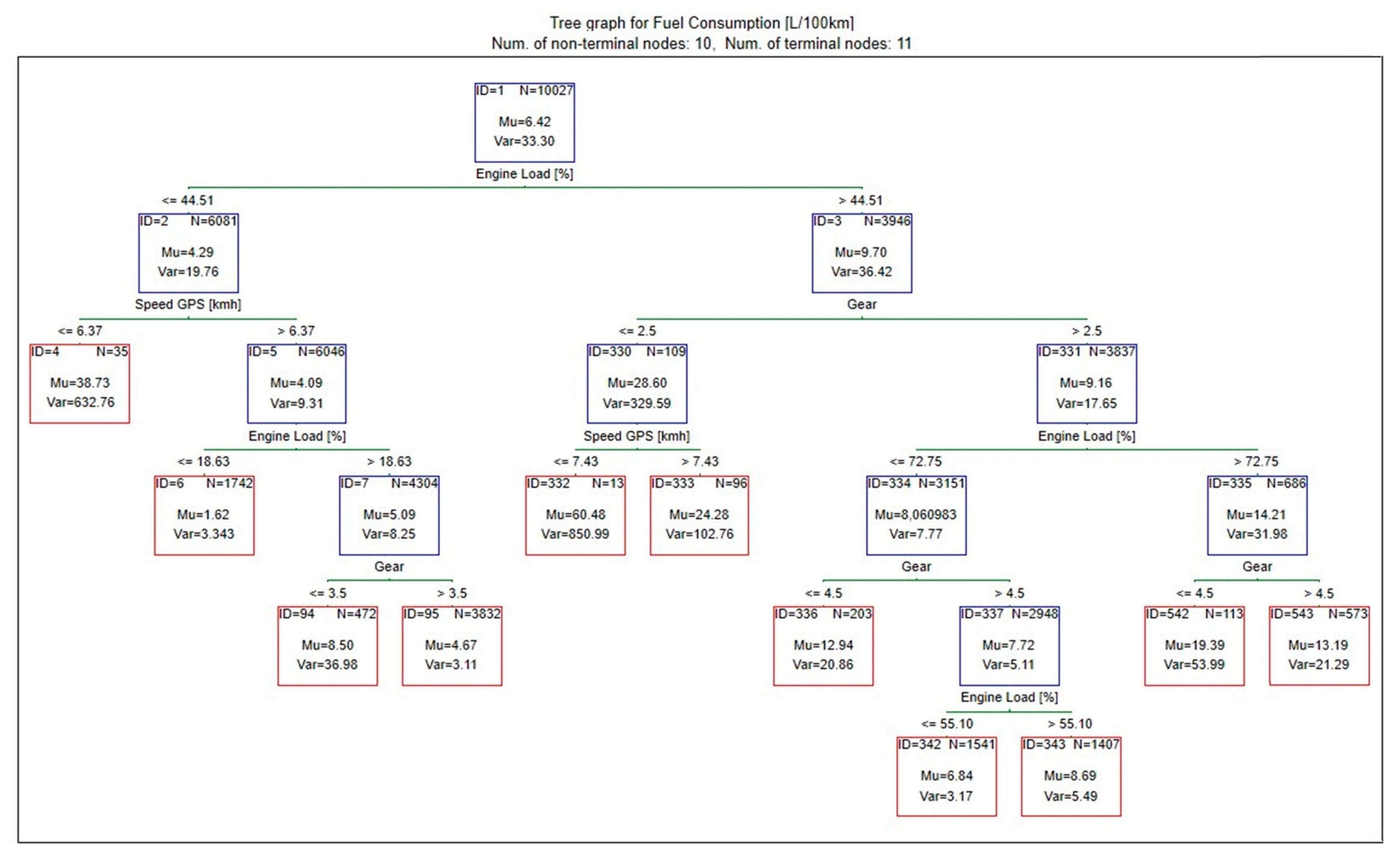
Based on the obtained results (
Figure 12), it can be concluded that the highest fuel consumption occurs when the predictor values belong to leaf 332, which show the following parameters: engine load > 44.5%; gear: 1 or 2; speed < 7.5 km/h. For these parameters, the median of instantaneous fuel consumption is over 60 L/100 km.
At the same time, a ranking of predictors that have the greatest impact on the modeled phenomenon was developed (
Table 6). According to the calculations, in the analyzed model, the variables gear, speed, and engine load have the greatest influence on fuel consumption.
Finally, an evaluation was performed using the cross-validation method with v-value = 10. For the developed model, the errors were at the following level:
MSE = 8.30;
MAE = 1.36;
MRAE = 0.22.
The second model was built using a random forest.
Before starting the analysis, the boundary settings of the presented solution were defined as follows:
Stopping rule: percentage decrease in training error, 5%;
Random test data proportion: 30%;
Number of trees = 20;
Minimum n in child node = 5;
Maximum n of levels n = 10;
Maximum n of nodes n = 1000.
In the next step, in order to properly assess the model’s goodness of fit, the sample was divided into two sets: training and testing. The training set was used to build the model and the test set to evaluate it.
During the construction of the model, the predictors were ranked again, indicating which had the greatest impact on the studied phenomenon (
Table 7). Again, the variables engine load, speed, and gear had the greatest impact on the examined phenomenon, but in a different configuration than in the CART model.
The developed model was saved in the form of PPLM code and then implemented based on the data contained in the test sample.
The model errors were at the following level:
MSE = 8.38;
MAE = 1.51;
MRAE = 0.25.
3.3. Neural Networks
Since the process of creating and teaching neural networks is experimental, it was decided to create approximately 750 networks in order to find the one with the fewest prediction errors. Input and output variables were adopted in accordance with the previous methodology.
The random sampling method was chosen with the following sizes: training sample, 80%; test sample, 10%; and validation sample, 10%. In order to force the identical learning process for each network, a fixed seed was chosen for all training networks.
MLP was chosen as the neural network due to its universality and ease of implementation. The number of hidden layers was limited to one, with 5 to 35 neurons in this layer. The activation functions used in the hidden layer were logistic, exponential, and hyperbolic tangent (tanh), and those in the output layer were identity, logistic, exponential, and tanh. Due to the large number of created neural networks, one learning algorithm was adopted, Broyden–Fletcher–Goldfarb–Shanno (BFGS), in order to allow the possibility of subsequent comparison of results. Finally, one error function was selected for all created neural networks, sum of squares (SOS).
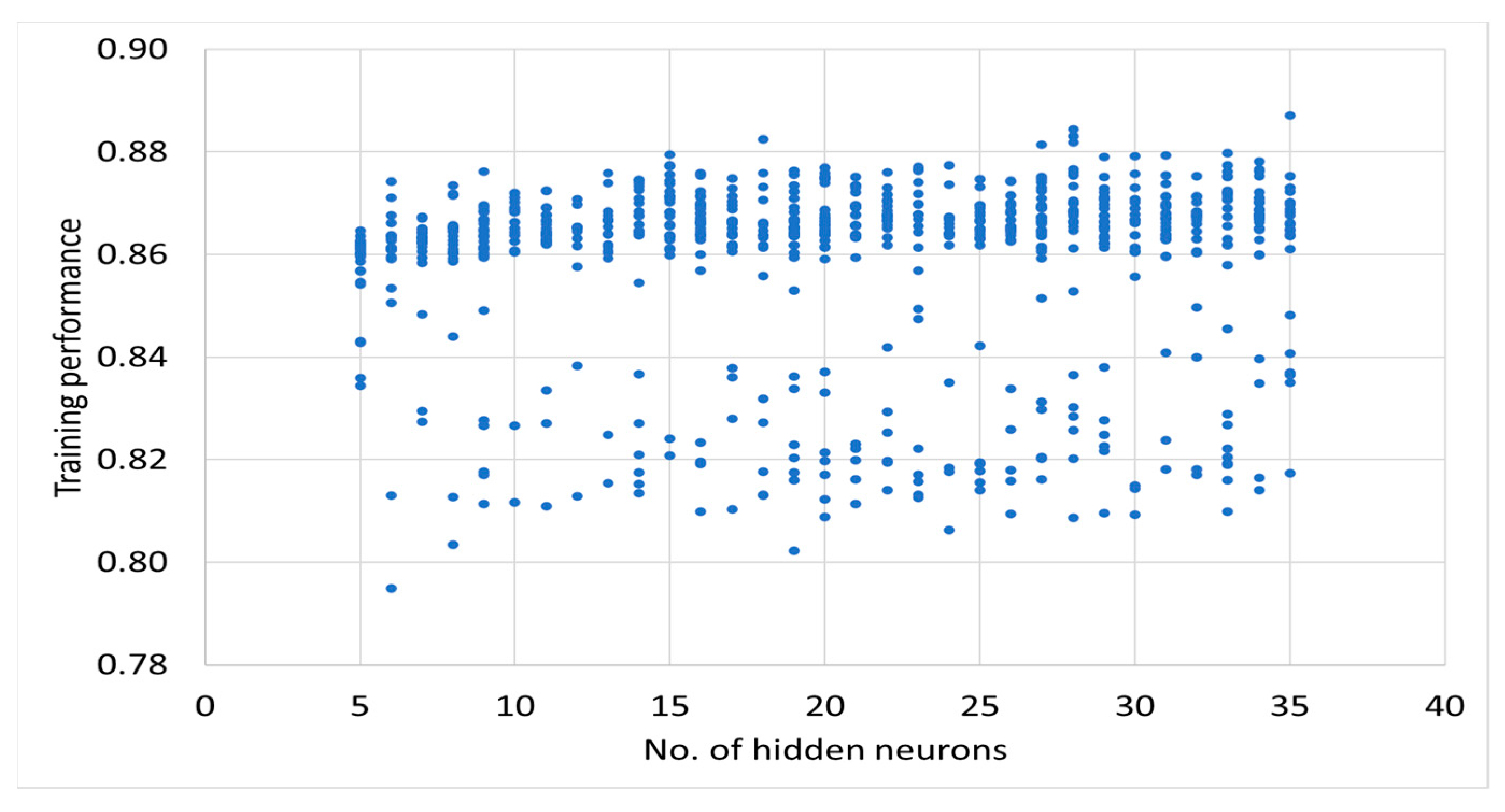
The results of teaching neural networks can be found in
Appendix A. The analysis of the results (
Figure A1 and
Figure A2) shows that there is no clear relationship (i.e., low correlation) between the number of neurons and the performance of the neural networks.
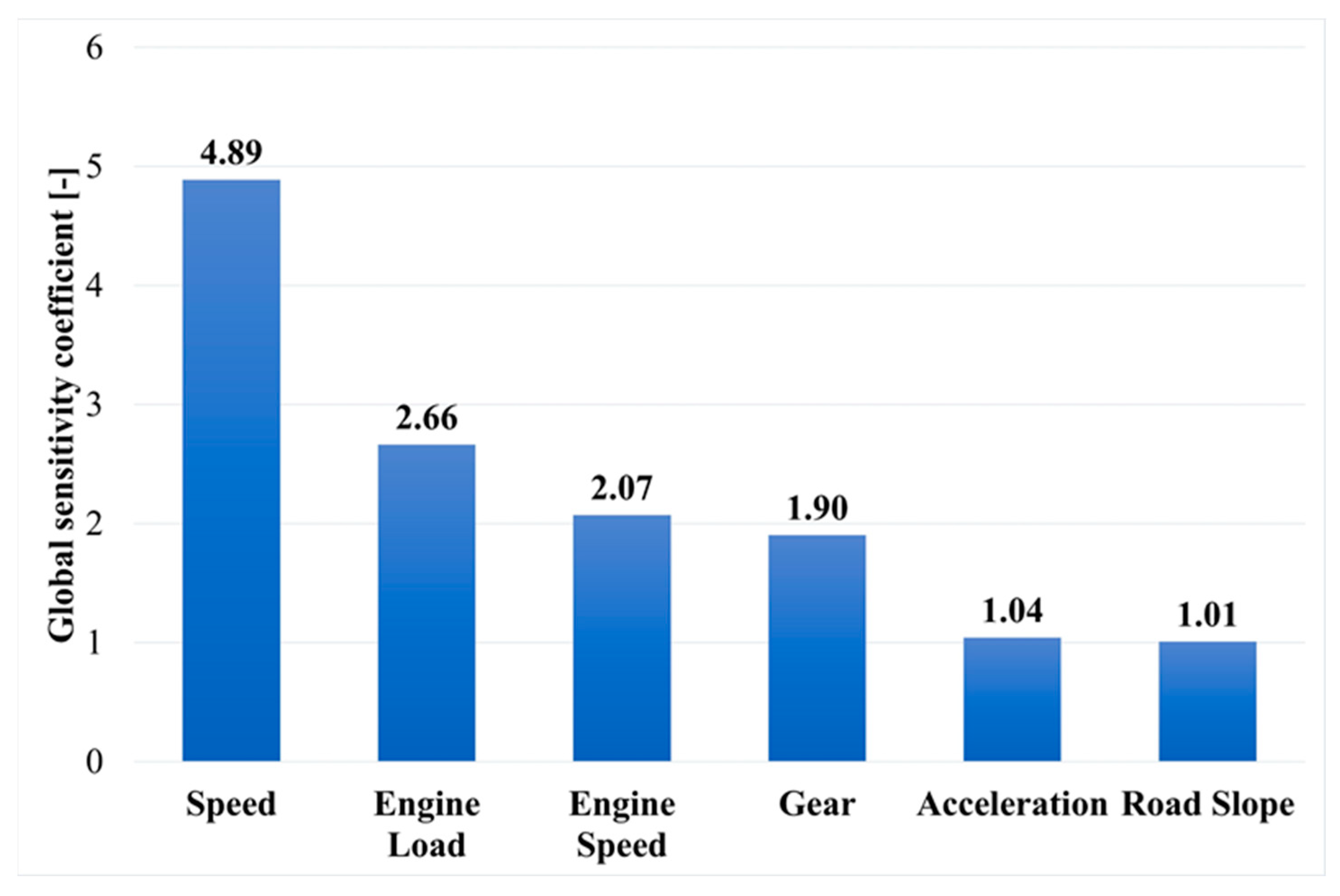
In the next stage of the analysis of the results, global sensitivity analysis was performed on 100 neural networks with the lowest error test performance values. This is a method for determining the validity of particular input variables of a neural network. For every network considered for the analysis, a coefficient for each input is calculated that describes the increase in error when the mentioned input variable is removed. If the value of the coefficient is equal to or less than 1, then the particular input variable can be removed without loss of quality of the neural network. However, if the value is greater than 1, it means that the network has a sensitivity to the variable proportional to the value. Cumulative averaged results of the global sensitivity analysis are presented In
Figure 13 [
43].
The sensitivity analysis shows that the variables with the greatest impact on fuel consumption (in descending order) are speed (4.89), engine load (2.66), engine speed (2.07), and gear (1.90). Acceleration and slope (with values close to 1) can be ignored or even removed without degrading network performance.
Among all created neural network models, one model was selected with the highest testing and learning performance. Details of the parameters of the created network are as follows:
Structure: MLP 6-35-1;
Training data sample performance (correlation): 0.88;
Test data sample performance (correlation): 0.89;
Validation data sample performance (correlation): 0.86;
Training data sample error: 3.75;
Test data sample error: 2.76;
Validation data sample error: 4.03;
Activation function of hidden layer: Tanh;
Activation function of output layer: Logistic.
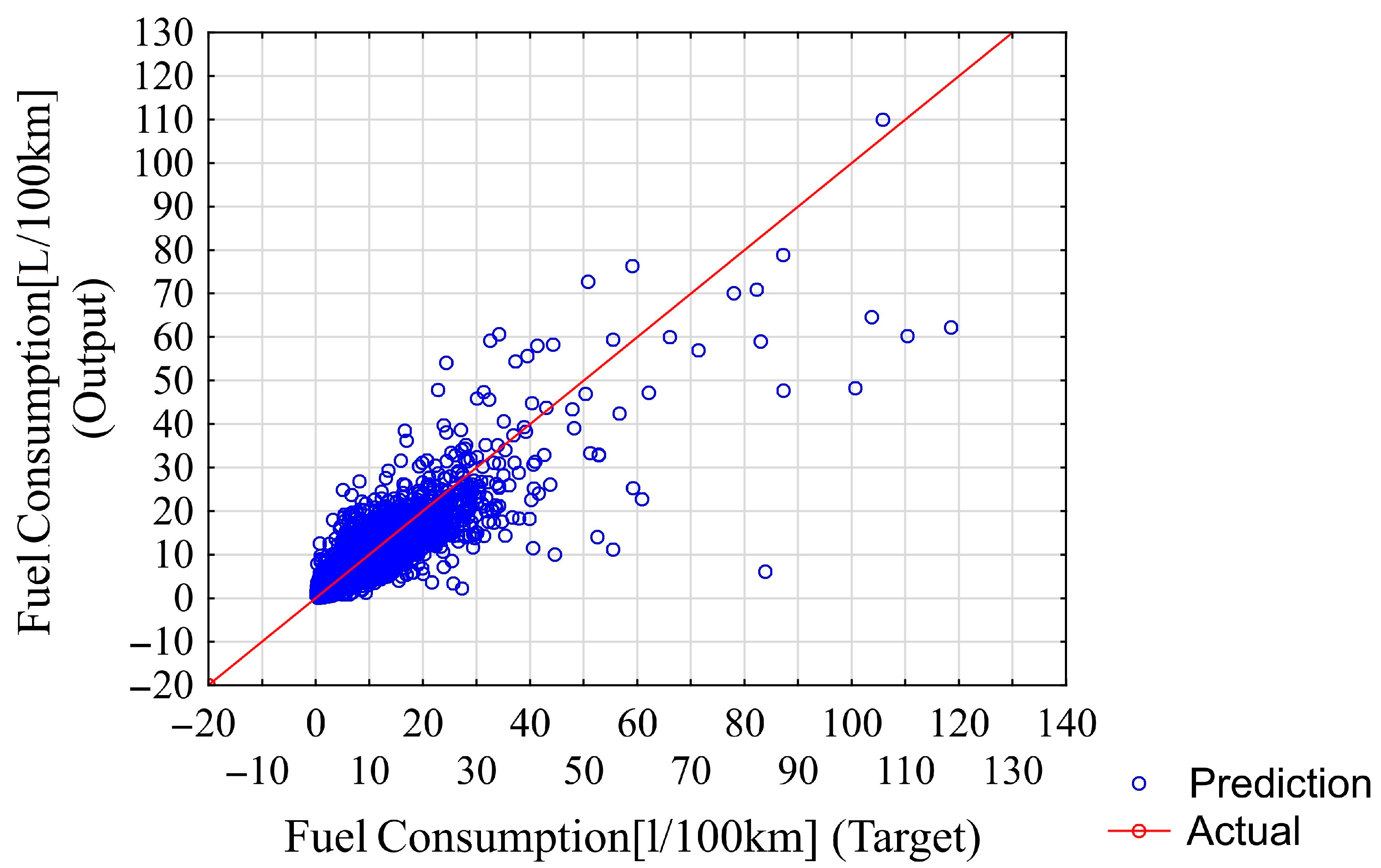
The fitting results of the chosen neural network for all data samples are shown in
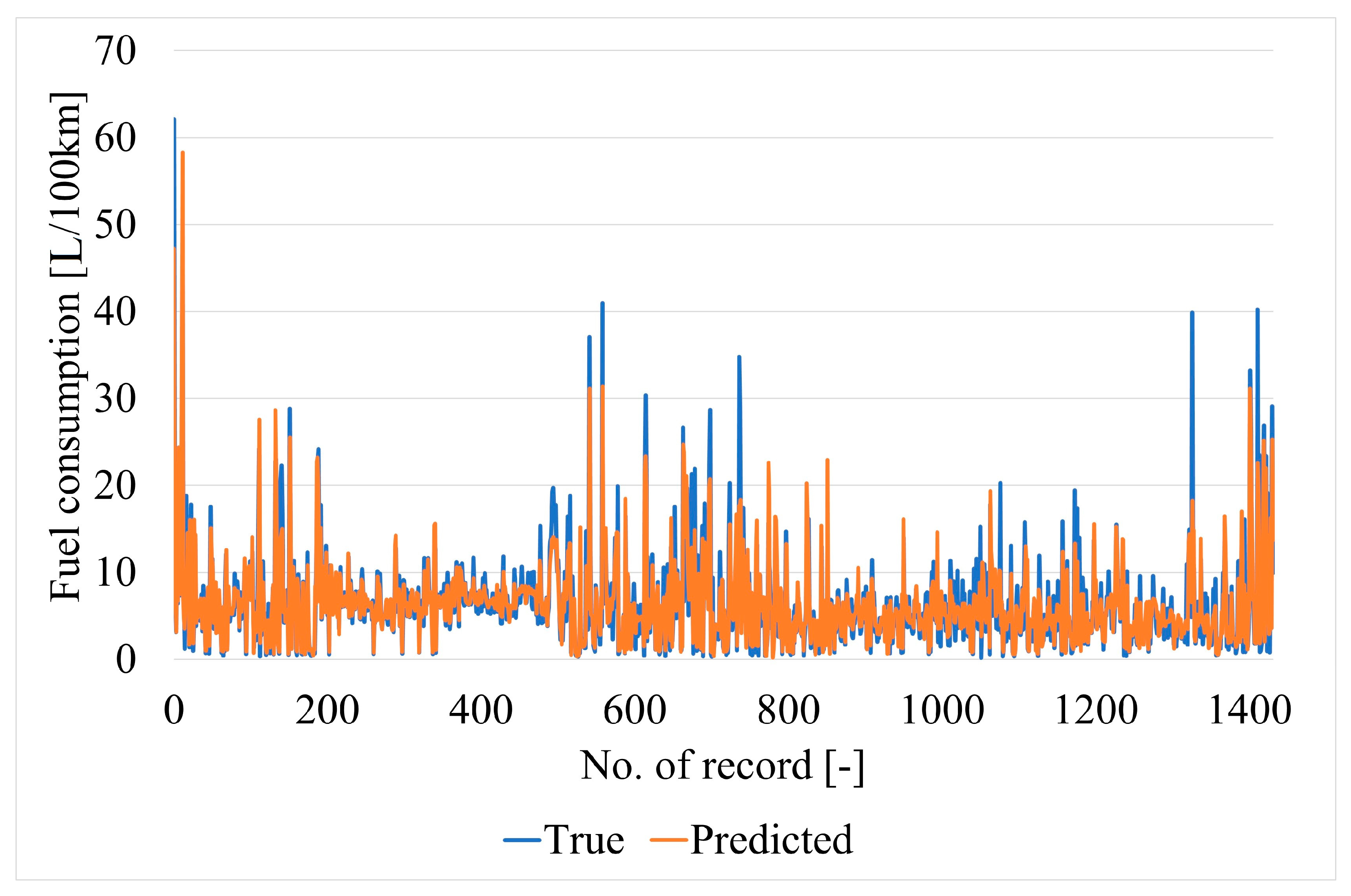
Figure 14. Neural network predictions and actual targets (for comparison) for the testing data samples are shown in
Figure 15.
The fitting results for the described neural network (test data samples) are as follows:
MSE = 5.51;
MAE = 1.37;
MRAE = 0.30.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}