1. Introduction
The concept of the Internet of Things (IoT) penetrates in many areas of life and technology [
1,
2,
3]. Combining it with other concepts such as machine learning, fuzzy logic, and others can be very successful. In particular, machine learning and neural networks are often applied for data processing and more effective control of processes [
3,
4], especially for forecasting [
5,
6].
One of the most pressing problems of modern industrial production is the need for using the latest information technology to improve performance. The Industrial Internet of Things (IIoT) represents a production system in the form of a set of intelligent end devices capable of collecting and analyzing data as well as central control algorithms. Because devices in the IIoT system are often located at a great distance from each other and are also low power, wireless communication is used to communicate between them. Special coding and error detection algorithms should be used to ensure the reliability of data processing and transmission for protecting terminal and control devices from external interference. The process of processing data coming from different devices is complex and requires the use of machine learning methods and artificial intelligence [
7].
A smart grid is an electrical network containing many smart end devices that collect and analyze data. In this way, it is possible to flexibly and efficiently distribute power system resources. The smart grid can also be used for efficient electricity distribution in industrial systems. Such grids also use a large number of end devices involved in data acquisition and decentralized system management. The development of industrial systems involves the use of new smart devices in production. These devices are more mobile, preferably perform specific functions, such as collect data from the environment, and analyze and transmit to the central control node [
8]. As a result of this approach, it is possible to expand the functionality of industrial production and reduce human intervention in the production process. The information collected from different devices is growing, is unstructured, and requires the use of Big Data processing techniques. Not all data collected from industrial devices are of equal practical value for anomaly detection algorithms or the prediction of possible emergencies. It is necessary to use methods to identify the most valuable information and reduce redundancy. Thus, it is possible to reduce the time of data processing from devices and provide real-time analysis [
9].
Detection of anomalies in the behavior of smart grid systems allows improving the efficiency of their operation and preventing accidents. Changes in the environmental parameters that capture end devices, such as sensors, may indicate a possible failure of a particular device, improper operation, or a threat to personnel. It is reasonable to constantly monitor the state of an industrial production system and respond as soon as possible to threats that could cause significant losses. For achieving this goal, special algorithms are used to search for anomalous values in the data stream. These algorithms have a strategy for selecting the information needed for analysis. The exchange of information about the detected anomalies between different industrial subsystems allows improving the efficiency of their prediction and elimination [
10,
11].
Industry 4.0 is now gaining momentum, and 5G is also actively used [
1]. Such technologies integrated into industrial production contribute to the use of the IoT and smart grid as an opportunity to use a variety of end devices that can partially or completely control themselves and process data from the environment. The architecture of the IIoT involves the use of a large number of low-power data collection devices. As the transfer of information from all of them creates a significant burden on communication channels, and thus the threat to the confidentiality of private information is growing, it is necessary to look for improved ways to analyze information. Federated machine learning is a subtype of machine learning that can improve the reliability of data processing from distributed industrial devices. Federated learning involves the use of local learning models directly on end devices, using private information. The learning outcomes are then sent to a global machine learning model, which is updated based on them and sent to other end devices. This approach can reduce the amount of information transmitted through communication channels and reduce the risk of damage, loss, or interception of private data during transmission [
12,
13].
Special machine learning algorithms and statistical methods should be used to process Big Data in the IIoT and smart grid systems. One of the most popular is the Singular Data Decomposition algorithm. With this algorithm, one can determine the most important information for further analysis and reduce redundancy, which significantly speeds up data processing. The Singular Value Decomposition algorithm (SVD) also allows us to find the relationship between data collected from sensors and events that occur during the production process. Because the Singular Decomposition algorithm in an IIoT system must constantly collect and transmit data, this leads to a critical increase in network traffic. The confidentiality of data from end devices is also at stake. Therefore, it is proposed to use the integration of the SVD algorithm and federated learning to solve these problems [
14]. This paper proposes the improvement of the SVD algorithm due to its decentralization. This approach allows the process of information to work faster as well as to find anomalies in IIoT systems and protect data from unauthorized access. The proposed method differs from the existing ones, as it allows maintaining the reliability and accuracy of FedSVD calculations by optimizing their duration. This approach is important for distributed industrial systems that constantly process Big Data and use algorithms to provide recommendations to users. The remainder of the paper is organized as follows. In
Section 2, we review the existing research on this topic and identify issues that are still relevant. Then, we identify the main issues of Big Data processing in the smart grid systems in
Section 3. We consider in detail the work of the algorithms for singular data scheduling in
Section 4.
Section 5 discusses the results and how they can be interpreted in future studies. Finally, we conclude the paper in
Section 6.
2. Related Works
In this section, we analyze the current research on selected topics. Many authors have studied the subject of Big Data processing in industrial systems. Naufan Raharya et al. [
7] consider the problems of data processing in IIoT systems. In particular, they propose using deep learning for distributed computing. Wang, X. et al. [
9] suggest using the distributed tensor-train (ADTT) decomposition method for Big Data processing in industrial systems. Y. Yang et al. investigate intrusion detection and propose their advanced ASTREAM method, which has high accuracy [
10]. Liu Y. et al. [
11] consider the distributed architecture of IIoT systems and the need to use federated machine learning for anomaly detection. The paper also proposes the AMCNN-LSTM model to increase the accuracy. In [
12], Peiying Zhang et al. proposed the use of federated learning in wireless industrial systems along with deep reinforcement learning to more accurately select the nodes where the training will take place.
We also analyzed research related to data processing methods in IIoT systems. The work of Peiying Zhang et al. [
13] covers the issue of edge computing in the IIoT, in particular the use of transfer learning to achieve training accuracy. Xiao Guo et al. [
14] consider the integration of SVD and the federated learning algorithm and propose the FedPower method, which provides better reliability and confidentiality. However, it is not considered what will be the result of the proposed method in large-scale IIoT systems. Y. Chi et al. [
15] and H. Chen and J. J. Rodrigues et al. [
16] consider the features of the architecture of IIoT systems and determine the need to use the distributed algorithms for data processing, as well as for wireless and cloud data processing technologies. C. Ma et al. offer a special in-network computation-oriented node placement (INP) algorithm for efficient distributed data processing in the IIoT [
17]. M. Kaur et al. [
18] investigate the use of blockchain and 5G technologies to provide flexibility and reliability in the management of large-scale IIoT systems.
Since in our study we used and modified the SVD algorithm, we considered the corresponding works of the authors. N. Hashemipour et al. [
19] proposed the use of the SVD algorithm to optimize data in smart grid systems. However, the distributed SVD algorithm was not considered. In [
20], Adnan Anwar et al. considered the prevention of injection attacks in the IIoT and smart grids. Venkata Venugopal Rao Gudlur Saigopal and Valliappan Raju [
21] address security issues when processing information from a large number of devices, and R. Huo et al. also consider a blockchain framework in the IIoT to improve system reliability [
22]. Y. Lee et al. [
23] propose to integrate a private blockchain into edge computing server systems to simplify transactions in industrial systems. K. Al-Gumaei et al. [
24] offer to use cloud technologies for Big Data processing in IIoT systems. Also, to solve the problem of Big Data processing L. Ren et al. offer a combination of cloud technologies and artificial intelligence [
25]. Y. Jaradat et al. [
26] determine the importance of using the SVD algorithm in processing and reducing the dimensionality of Big Data, and B. S. Reddy et al. investigated the use of SVD for information processing in healthcare systems [
27].
Analyzing the methods of matrix transformation of data, we considered the following articles. J. Lee et al. in [
28] proposed a new low-rank matrix approximation based on the assumption that the matrix is locally low rank. In [
29], Huang T et al. developed an efficient initialization method for the SVD algorithms using a general neural embedding initialization framework. S. Sedhain proposed a novel autoencoder framework for collaborative filtering (CF) [
30]. However, the processing of Big Data in recommender systems was not investigated in these works. In [
31], Y. Zheng et al. proposed a neural autoregressive architecture for collaborative filtering (CF-NADE). The authors used MovieLens 1M, MovieLens 10M, and Netflix datasets. In [
32], Q. Li et al. proposed a generic recommender framework called NCAE (neural collaborative autoencoder) for performing CF. However, the peculiarities of their operation in industrial systems are not considered in these methods. Thus, the issue of optimizing the operation of IIoT systems and ensuring their reliability and the confidentiality of data processing is quite relevant today. However, the issue of optimization and intelligent data retrieval in the IIoT is still open. Therefore, we considered the modification of the existing FedSVD algorithm to ensure more efficient operation of search algorithms and data optimization in IIoT systems.
3. Features of IIoT and Smart Grid Systems
The IIoT is a collection of many smart devices that process data from the environment and are located in different areas of production. The IIoT assumes that the use of data collection and analysis algorithms makes the industrial production system more automatically controlled, i.e., it can make decisions on troubleshooting, dynamic allocation of resources, emergency calls to staff, need for calibration [
33], etc. This approach allows speeding up the data processing and increasing the productivity of industrial production. However, there are also some difficulties in the IIoT systems. In particular, it is necessary to constantly monitor the state of the distributed production units to identify possible malfunctions, which leads to the constant analysis of large amounts of data. For solving the problems of information processing it is necessary to use the special algorithms for data analysis, the detection of anomalies, and machine learning. Because IIoT systems are distributed, data analysis algorithms must be adapted to certain types of systems. Therefore, it is necessary to provide effective data collection from different nodes, confidentiality, protection against external interference, and reliable communication between end and control devices [
15,
16].
The smart grid is a system of intelligent electricity supply through the use of information technology. For ensuring the efficient allocation of resources and the detection of critical occupations of system parameters and individual devices, a significant number of end devices that receive data from the environment are used. These data are then used to control a smart system on the control device. The smart grid management hierarchy allows monitoring edge devices and making decisions on central ones. System control allows us to quickly find possible places of electricity loss, damaged communication channels, equipment failures, etc. The integration of the IIoT and the smart grid allows using the complex infrastructure of the data protection system to ensure the optimal distribution of electricity according to user needs. In this work, we consider the peculiarities of using smart grids specifically in the industry sector, although they are successfully implemented in various sectors.
Distributed information systems are used for more flexible and efficient data processing. Such systems consist of many computing devices that work on the same tasks. Distributed calculations allow the distribution of large tasks into several smaller ones, and they are performed simultaneously on several computing devices. For implementing this, the central control node determines the set of nodes available to work with a particular type of task. Then, the information to be processed is distributed between the defined devices. After the calculations are completed, the results are returned to the central device, which combines them and receives the final result. This approach speeds up the calculation of large amounts of data and reduces the load on one computing node. For effectively organizing distributed computing in the systems of the IIoT, it is reasonable to use special algorithms that allow determining the nodes available for computing, dynamically redirecting data, and ensuring communication between them. With the help of machine learning algorithms, it is possible to analyze data from various devices of the industrial system. Federated machine learning allows working in distributed systems and learning directly on the end devices, which reduces the risk of confidentiality in the transmission of information and allows sharing learning outcomes with other devices [
17].
The IIoT allows modifying existing industrial production. The latest industrial systems are more scalable, flexible, and productive. The use of intelligent end devices can solve new problems that were not yet available, for example, the automatic control of individual devices or entire units in the case of the detection or threat of emergencies. However, the standard centralized architecture of computer systems is inefficient for the IoT because it puts too much strain on the central node and information transmission channels. The confidentiality of transmitted data is also vulnerable. Therefore, the decentralized computer system architecture and blockchain technology are widely used in the IIoT to protect private data. It is also reasonable to use 5G technology, which allows organizing reliable and efficient wireless communication in a decentralized industrial system. Such modern technologies in combination with the IIoT system allow creating modern intelligent production [
18,
19]. Due to the development of distributed information systems and the need to ensure data security, blockchain technology is used. It is a distributed database organization that can be shared by multiple nodes. Unlike traditional databases, blockchain data are collected in blocks. Then, the blocks are assembled into continuous chains [
20,
21]. The integration of the IIoT and blockchain creates a new model of data processing that uses smart devices and can achieve business goals. Improving the reliability of transactions between nodes provides an opportunity to involve users’ devices in the processes taking place in the enterprise [
15,
16].
The rapid growth of information in modern infocommunication systems is caused by several factors. First, the number of nodes that perform tasks has increased in computer systems. Also, the architecture of information systems is often distributed, and devices in it work on the same tasks and constantly exchange data. The number of services provided to their users has also increased. These factors determine the constant exchange of data between system users and data processing and storage devices. For analyzing all traffic in smart grid systems, it is necessary to use Big Data processing algorithms. The problems of Big Data processing in the smart grid and the IIoT are relevant and constantly being researched to identify new algorithms and improve the existing ones. For speeding up access to data from different devices, cloud resources are used, the number of which can also be quickly increased or decreased depending on the needs of a particular industrial system [
24]. Extracting the most important information from Big Data requires the process of further processing. By identifying patterns of process behavior in the IIoT and smart grid systems, it is possible not only to prevent negative situations, such as accidents and downtime, but also to make the most efficient use of available resources. The involvement of cloud computing power allows organizing a flexible data processing system. If a large amount of information needs to be processed in an industrial system, additional cloud resources can be used immediately. When the number of tasks to process is small, resources for data processing can be transferred to other systems. This approach allows much more efficient use of computing power. The architecture of the industrial smart grid cloud system is shown in
Figure 1.
When using traditional physical data processing devices, the system often cannot handle a heavy load. During low load, some of the calculated resources are idle, which is economically unprofitable. Cloud computing can be performed quickly, which is necessary for data analysis in industrial systems. The integration of artificial intelligence and cloud computing is also used to improve the efficiency of smart grid systems [
25].
Machine learning in the IIoT is another approach. For small-scale information systems, it is quite simple to perform data processing and rapid analysis. With the growing number of devices in the IIoT, there is a need to use advanced computational methods. Machine learning is a subspecies of artificial intelligence that allows computing devices to improve the results of their work and achieve their goals based on the data obtained. Because different infocommunication systems have different characteristics and features, machine learning methods are also modified to achieve maximum efficiency. IIoT systems have features such as the following:
Distributed architecture;
A large number of data collection devices;
The data collected are often redundant and difficult to process;
The transfer of information between nodes puts a strain on communication channels and increases the risk of privacy of private data;
The need to rapidly analyze data and make a decision.
The above features of the IIoT and smart grids require consideration when using machine learning methods. It is reasonable to separate the stages of preliminary data processing and further analysis. To begin with, after receiving data from various sources, it is reasonable to determine the most important data for further processing. One of the most commonly used methods of statistical data analysis in machine learning is SVD. This method allows decomposing data matrices collected from different sources, and on this basis to determine the most important of them with a given accuracy. If it needs to analyze the data extremely accurately, it can discard a small amount of information. If a certain error is allowed that does not significantly affect the result of further data analysis, but it is important to provide the result very quickly, it cannot take more information into account in the calculations. The features of the SVD algorithm are described in more detail in the next section. One of the problems with the use of machine learning methods in general and the SVD algorithm in the IIoT or smart grid systems is the need to take into account the peculiarities of the distributed architecture. Collecting data from a large number of devices requires additional communication and data protection algorithms [
26].
4. Singular Decomposition Algorithm for Big Data Analysis
To quickly and efficiently analyze data from different devices and nodes of the IIoT, we should use methods that can select data by certain characteristics and find relationships between them. One of the most commonly used is SVD. This algorithm decomposes the data array into three smaller matrices and then determines their characteristics. The following is an explanation of the SVD algorithm.
The input matrix
can be represented as the product of three matrices:
where
is a complex unitary matrix,
is a rectangular diagonal matrix with non-negative real numbers on the diagonal,
is a complex unitary matrix, and
is the conjugate transpose of
.
To represent the data, we used a square on a plane based on two vectors. It can be modified in a certain way: move, stretch, rotate, etc. (
Figure 2).
To ensure the linear transformation of data, the following rule should be followed: the initial diagonal line of the square should remain straight after the transformation (
Figure 3).
To avoid a nonlinear change in the square, it should be rotated to a certain angle before the transformation (
Figure 4).
Thus, we see the explanation of the geometric representation of the SVD algorithm. The square can be changed linearly, but it must be rotated, i.e., placed in a new plane. The width and height of the square are the singular values, which indicate the relationship between the data.
Now let us consider the algebraic explanation of the algorithm based on the above considerations. Let us call the sides of a square as vectors
та
. Then, after the application of matrix transformations
we obtain vectors
та
(
Figure 5).
Let us define vectors
and
as unitary vectors
та
, multiplied by coefficients
та
. We can write
Any vector can be described as a linear combination:
Thus, the matrix
can be described as
where
For larger matrices, the following statement is true:
As we can see, (12) confirms (1) [
27].
Federated SVD Algorithm for Use in Industrial Smart Grid Systems
Because IIoT systems are distributed and consist of a large number of computing devices, the implementation of Big Data processing algorithms causes some difficulties. Data from industrial system devices are collected from end devices, as they are located at a considerable distance from each other. Transferring their data to a central computing device requires significant communication resources and load communication channels. Another important issue is the confidentiality of the transmitted information. The methods of federated machine learning allow working with distributed systems and performing tasks. One of the modifications of the SVD algorithm for use in distributed systems is the FedSVD algorithm. FedSVD is quite simple to implement and allows us to optimize Big Data for the distributed recommender systems [
28,
29,
30,
31,
32].
Based on the FedSVD algorithm, the data matrix is decomposed according to the classic SVD algorithm:
where
However, data are collected from different devices:
where
are local data;
and
are matrices used to encrypt data from the few edge nodes, and
is a special number that each edge node generates to encrypt the data.
Therefore, matrix
is as follows:
where
The result is represented as
This section defines the mathematical fundamentals of the SVD and FedSVD algorithms. Based on these definitions, the FedSVD algorithm proposes a distributed architecture of the SVD algorithm, which consists of a separate server that generates matrices
and
for multiple nodes. In this paper, we proposed to transfer the server functions directly to the edge devices and create a modified FedSVD in the industrial smart grid system (
Figure 6).
As we can see from
Figure 6, the modification of the FedSVD algorithm solves the problem of data confidentiality, as it significantly reduces the risk of external factors interfering with the process of generating matrices. In the traditional FedSVD, it is reasonable to avoid the risks of connecting untested sources. However, it is not always possible to reliably protect an external server and transmission channels from external interference. Additional time is also required to check the safety and transport the matrices to the end devices. The proposed modified FedSVD algorithm reduces the processing time of masks and improves the reliability and confidentiality of data. However, it should be noted that not all nodes in the IIoT can generate matrices independently, as they do not always have enough computing power. This modification is offered primarily for systems with high privacy requirements, as all or part of the devices can perform additional functions of generating masks themselves. The following section compares the effectiveness of the proposed FedSVD method with the traditional ones.
5. Research of Smart Grid System Efficiency in Data Processing
The following tasks are set in this work:
To reduce the dimensionality of data in the smart grid for further processing;
To determine anomalous values in the messages collected from the end devices of the industrial system, which may indicate the interference of external factors in its work.
We used the SVD algorithm to solve both problems because, as described in the previous section, it allows us to reduce redundant information and find relationships between data. A software model in the Python language was created, which calculates an array of data with information about temperature on network devices. For convenience, only numeric data were processed. The task of bringing different data to one view is beyond the scope of this study. We used data for the calculations from the MovieLens 10M database. At the same time, the work stages were as follows:
Preprocessing of data received from MovieLens 10M. Since we used different sizes of data to study the algorithm’s performance, we prepared them in advance by choosing appropriate samples. We did not remove redundant data from the dataset or fill in missing values in advance, as the SVD algorithm performs this function itself. Therefore, we could compare the efficiency of data processing by different modifications of this algorithm. We also converted all forms of the data presentation into numerical ones for the convenience of processing. For the study of the federated SVD algorithm, the data should be divided between conditional groups of users.
Importing Python built-in libraries:
NumPy for convenient processing of data presented in matrix form.
PyTorch for implementing communication between nodes in the FedSVD algorithm.
SciPy for algebraic equations and their optimization.
Calculation of the standard SVD algorithm using the NumPy library and its built-in functions.
Calculation of FedSVD. Each node receives its own set of data and performs local calculations. Then, the obtained matrices and are aggregated on the central computing device to obtain the global . Then, the differences between the obtained data and the initial data are compared.
Calculation of the modified FedSVD, which uses a local generator of matrices and on the edge devices.
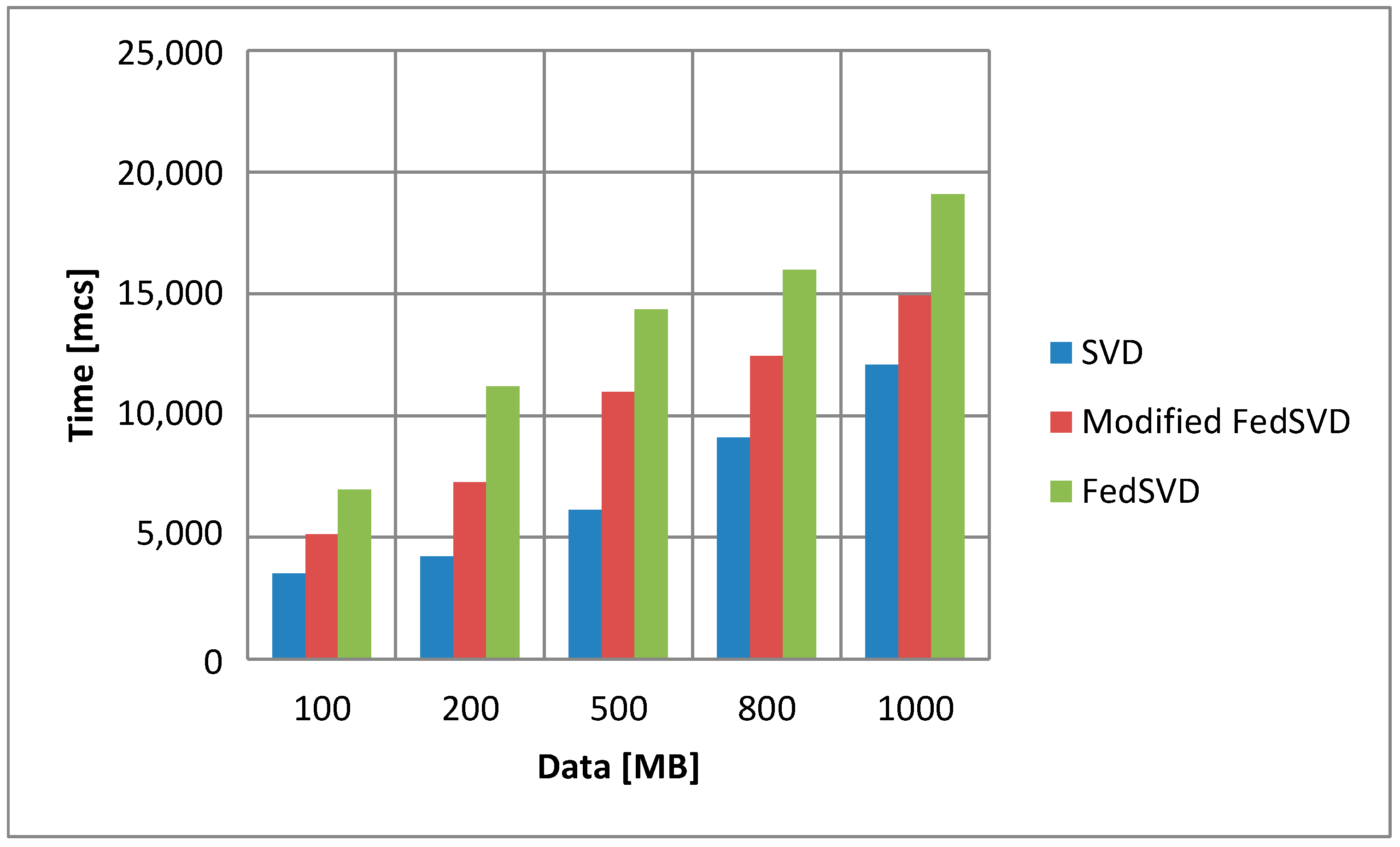
An experiment was performed using three algorithms: SVD, FedSVD, and modified FedSVD. Firstly, we compare the duration of calculations for these algorithms (
Figure 7).
As we can see from
Figure 7, the SVD algorithm is calculated as the fastest and FedSVD is the longest. The modified FedSVD algorithm is calculated 5 ms faster on average than the traditional one. Its use is appropriate in data processing systems that require rapid information processing and decision making. Now, let us compare the efficiency of anomaly detection in the data for all of the algorithms (
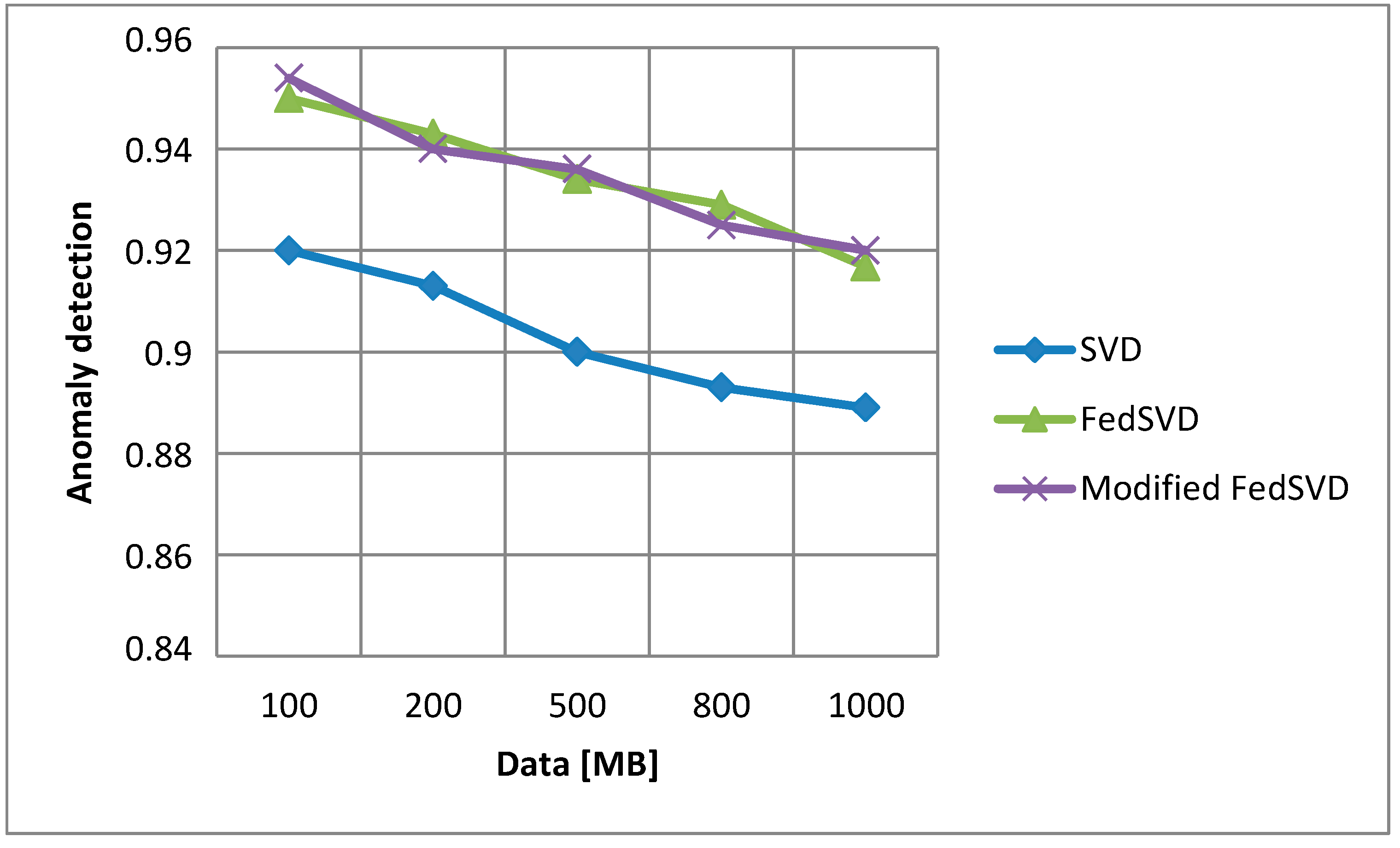
Figure 8).
As we can see from
Figure 8, the most accurate results are those of the modified and traditional FedSVD algorithms. The SVD algorithm is inferior in accuracy of this task. Therefore, if one needs to perform data analysis in IIoT systems with high accuracy, it is reasonable to use either the FedSVD or modified FedSVD algorithm. These FedSVD algorithms demonstrate higher calculation accuracies by an average of 3% in comparison to SVD.
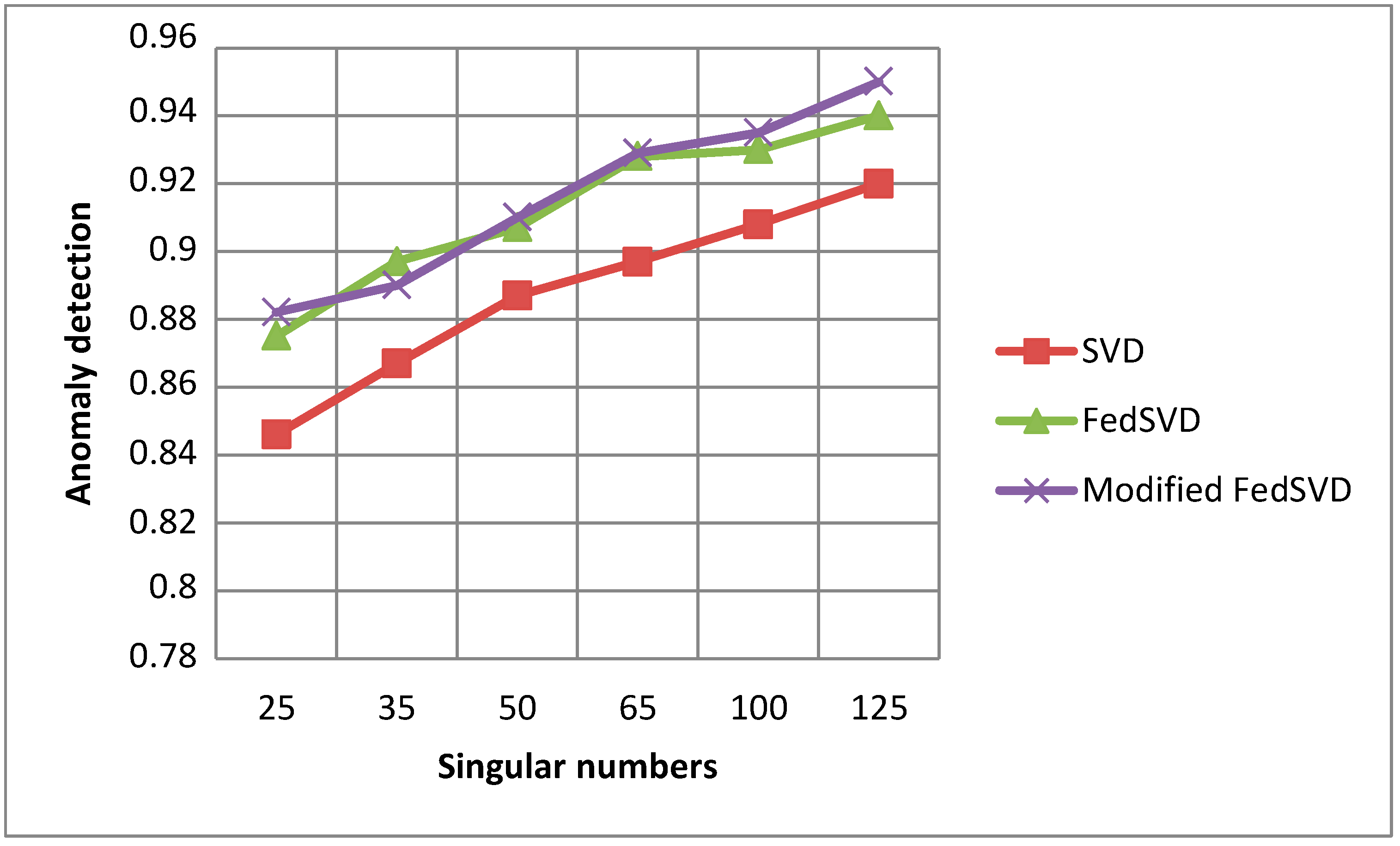
Now, we study the effectiveness of data dimensionality reduction using the SVD algorithm. According to (9), the matrix
consists of diagonal elements (singular numbers) arranged in ascending order. Having determined
, the largest singular numbers, we can discard the others and leave in the matrices
,
, and
only in the first
rows. This reduces the dimension of the data matrix. Changing the number of singular numbers also affects the accuracy of calculations and the level of anomaly detection. The relationship between singular numbers of the SVD algorithms and the ratio of anomaly detection is shown in
Figure 9.
Figure 9 shows that changing the singular numbers allows improving the accuracy of anomaly detection by an average of 3%. The modified and traditional FedSVD algorithms are better in comparison to SVD in anomaly detection for all the singular numbers they use (by 4% on average). The modified FedSVD algorithm shows a 1% better anomaly detection using the maximum singular numbers when compared with the traditional one.
The conducted experiments open the prospect of further research on the problem of Big Data processing in smart grid systems. The SVD algorithm is a powerful mathematical method for reducing the dimensionality of data and finding relationships between data. The proposed modification of FedSVD allows increasing reliability of the SVD algorithm and reducing computation time in distributed smart grid systems and the IIoT. This approach allows us to quickly make the necessary decisions for managing the system, i.e., automating the production process. Using the existing methods, we modified them for the possibility of use in industrial systems with high requirements for the speed and accuracy of calculations.
6. Conclusions
Currently, the smart grid and IIoT are the most promising industries. As almost any large-scale system requires the use of effective information acquisition methods, personal data protection, scalability, and noise immunity, it is reasonable to consider the concept of the IIoT. Smart grids are used for the efficient and flexible distribution of electricity in industrial systems. Despite the high efficiency of modernized industrial systems, the smart grid and IIoT also have some problems. These are threats to confidentiality, interference by outsiders, system overload, irrational use of resources, etc.
This paper considers the problem of anomaly detection of data sent by smart grid devices to the central server. Using the SVD algorithm allows analyzing Big Data. However, the distributed architecture of smart grid systems complicates the work of the SVD algorithm. The proposed modification of FedSVD allows collecting data from various devices in the industrial system while adding a special mask that protects data during transmission. The paper proposes the modified FedSVD algorithm that, unlike the traditional FedSVD algorithm, contains random-value generators for masking data directly on each edge device, rather than on a remote server. The proposed method improves reliability and reduces data processing time. The modified FedSVD algorithm is calculated 5 ms faster on average than the traditional one. Also, the modified FedSVD algorithm demonstrates higher calculation accuracy by an average of 3% when compared to SVD.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}