1. Introduction
Cutting carbon emissions can benefit the natural environment and boost the rise in economic value for financial assets [
1]. Carbon emissions trading is an essential market tool and sustainable environmental policy tool [
2]. It can optimize the allocation of carbon emission resources and reduce the cost of emissions [
3]. In a sense, the carbon market can internalize the externality of greenhouse gas emissions so as to combat climate change [
4]. The BP statistical review of world energy states that China’s carbon dioxide emissions related to energy were about 10 billion tons in 2020 and 2021, making up nearly 31% of the carbon emissions worldwide. China is the largest carbon emitter [
5]. In order to actively address the issue of carbon emissions, China advocates the dialectical unity of letting the market play a decisive role in the allocation of resources, better embodying the function of the government. In this situation, China’s carbon emission reduction is driven by the government and the market instead of singly by the government. This country has formed an operational mode of coexistence between regional and national carbon markets. Additionally, regional carbon markets have made good progress in design, operation, and implementation in promoting the development and transformation of local energy [
6]. The national carbon market, whose coverage, system design, and market operation are immature, still needs the regional carbon markets to provide valuable reference [
7].
The price of carbon serves as a key indicator for pricing greenhouse gas emissions in the market [
8]. Reasonable carbon market prices can deliver a valid price incentive signal for businesses that reduce emissions [
9]. Nevertheless, the operation process of China’s carbon market suffers from greater uncertainty, resulting in severe fluctuations in the carbon price and increased trading risks in the carbon market. Violent fluctuations in carbon prices hinder the sustainable development of the market [
10]. Precise prediction of carbon prices not only contributes to risk aversion for participants in the carbon market but also provides investors with scientific decision-making tools. It can also encourage enterprises to optimize resource allocation to achieve maximum profit. At the same time, carbon price forecasting can further facilitate the formulation of economic and environmental integration policies under the goals of carbon peak and carbon neutrality. Consequently, it is essential to analyze and accurately predict the trend of the carbon price in order to act as a guide for investors to avoid risks and for regulators to formulate a scientific and reasonable mechanism.
In this study,
Section 2 is the literature review.
Section 3 outlines the theoretical methods and the framework of the forecasting model.
Section 4 introduces the empirical analysis. The main conclusions and future research are summarized in
Section 5.
2. Literature Review
The existing research for predicting carbon prices in China contains two kinds: single models and hybrid models. For single models, Ren and Lo (2017) [
11] utilized the generalized autoregressive conditional heteroscedasticity (GARCH) model to capture the carbon price. Zeng et al. (2017) [
12] adopted the structural vector autoregressive model to predict carbon prices. Using the E-GARCH model, Zhang et al. (2018) [
13] forecasted the price of carbon and argued that the carbon price returns contained memory. Song et al. (2019) [
14] utilized a fuzzy stochastic model to forecast the carbon price in Shanghai. Precisely forecasting the non-linear carbon price is particularly challenging because of the linear hypothesis of statistical models. Huang et al. (2019) [
15] pointed out that RBFNN outperformed BP in terms of forecasting carbon prices. Utilizing a long short-term memory (LSTM) framework, Xie et al. (2022) [
16] predicted the carbon price, illustrating the practicality of the model.
However, because fluctuations in the regional carbon prices exhibit nonlinear, irregular, and non-stationary characteristics [
17,
18,
19], a single model cannot adequately describe the intricate fluctuations in them. Signal decomposition technology can deeply explore the laws of carbon prices at various frequencies to reduce noise and better grasp the inherent characteristics of fluctuations in the carbon price [
20,
21,
22]. Under this background, prediction models based on signal decomposition technology have been extensively utilized in carbon price prediction. Empirical mode decomposition (EMD) is a classic decomposition method. Scholars adopted the EMD-GARCH model [
23] and the EMD-SVM model [
24] to forecast carbon price. Given that ensemble empirical mode decomposition (EEMD) performs slightly better than EMD in data decomposition, the EEMD-LSSVM model [
25] was proposed to capture carbon price. These single decomposition-based models reflect that data decomposition processing plays an irreplaceable role in improving the performance of carbon price prediction. However, EMD has mode aliasing, and EEMD still has residual noise [
26]. Yang et al. (2022) [
27] forecasted the pilot carbon prices based on a modified EEMD and LSTM models and concluded that the prediction effect of the combined model outperformed the LSTM model. CEEMDAN is an improvement over EEMD. To this end, Wang et al. (2021) [
28] proposed the CEEMDAN-LSTM model to predict carbon prices. Wang et al. (2023) [
29] combined CEEMDAN, BP, extreme learning machine (ELM), Elman, and LSTM to forecast the carbon price in Beijing and argued that the combined model is superior to a single model. Unfortunately, the modes generated by CEEMDAN have some residual noise [
30]. Sun and Zhang (2022) [
31] proposed a combined model that integrates local characteristic-scale decomposition and LSSVM to forecast carbon prices. Zhou and Chen (2021) [
32] decomposed the carbon price by the ICEEMDAN, utilized the ELM optimized by SSA to forecast carbon price, and concluded that carbon price subsequences generated by ICEEMDAN are more regular compared to that of CEEMDAN. Since KELM is an improvement on ELM, Hao and Tian (2020) [
33] put forward a blended model that incorporates ICEEMDAN and KELM to forecast carbon prices and proved the superiority of the ICEEMDAN-KELM model. Sun et al. (2021) [
34] combined VMD, SVM, and LSTM to forecast carbon prices and maintained that the decomposition effect of VMD is superior to that of EEMD. Li et al. (2022) [
35] developed a hybrid model based on VMD, ELM, and KELM to capture the carbon price series and demonstrated the superiority of VMD over EMD and CEEMDAN. Niu et al. (2021) [
36] combined VMD, the outlier robust ELM model, and an error-correction strategy to forecast the carbon price and suggested that the model using the error-correction strategy achieved good prediction results.
However, a single decomposition strategy cannot completely deal with random and irregular time series, resulting in large prediction errors for some decomposed series [
37]. In order to reduce the data complexity, the secondary decomposition strategy is widely used in carbon price decomposition. Namely, scholars have started attempting to combine two decomposition approaches to decompose the price of carbon in an effort to lessen the complexity of carbon price. Sun and Huang (2020) [
38] adopted VMD to decompose the highest frequency component generated by the EMD and used BP to forecast carbon price, maintaining that the EMD-VMD-BP model can predict carbon price more accurately than the EMD-based model. Zhou et al. (2021) [
39] employed VMD to further decompose the IMF1 obtained by EMD, used KELM optimized by SSA to forecast carbon price, and linearly superimposed the predictions of each subsequence to obtain the predicted carbon price. Zhou et al. (2022) [
40] employed VMD to further decompose the most complex subsequence of carbon prices obtained by CEEMDAN and utilized the LSTM to predict carbon price, proving that the secondary decomposition-based model is conducive to improving the forecasting levels of carbon prices. Li et al. (2022) [
41] decomposed carbon price by VMD; the modes with higher complexity were combined and decomposed by CEEMDAN; then, they employed the ELM model to capture carbon price and concluded that the decomposition effect of the VMD-CEEMDAN method is superior to the VMD or the CEEMDAN method. Regarding ELM, the hidden node number needs to be addressed and can be easily trapped in local optimum. Cheng and Hu (2022) [
42] utilized ICEEMDAN to decompose the residual term generated by VMD, used HKELM optimized by SSA to predict the carbon price, and acquired the final prediction results by linearly superposing the predictions of every subsequence. They found that the secondary decomposition strategy outperformed the traditional decomposition method, and the prediction effect of the HKELM on carbon prices is superior to the KELM.
In conclusion, there have been significant achievements in the current study of predicting the price of carbon. However, it still has shortcomings: (1) Previous research failed to appropriately take into account the choice of kernel function when using KELM to predict the price of carbon. The complicated properties of the carbon price may not be fully captured by the KELM with a single kernel function or the KELM with a combination of two kernel functions. Furthermore, for KELM, a bad kernel function could compromise the forecasting precision of the carbon price. (2) Most studies used EMD, CEEMDAN, or ICEEMDAN to decompose carbon residual sequences generated by VMD, which make it difficult to depict the time-varying properties of the residual signal. (3) The existing research on carbon price forecasting using the secondary decomposition technique ignores the impact of forecast error on the prediction result of carbon price.
The innovations of this paper are as follows: (1) It builds the MKELM model to forecast China’s regional carbon price. The wavelet kernel function has the advantages of wavelet signal local analysis and multi-resolution analysis. KELM containing wavelet kernel functions has never been used to predict carbon prices. Thus, MKELM is built to predict carbon prices, which contains a novel mixed kernel function. The kernel function is a combination of wavelet kernel, RBF kernel, and poly kernel functions. It can make the expression ability of China’s regional carbon price prediction model closer to reality. (2) TVFEMD, which can retain the time-varying characteristics of the signal, is innovatively used to decompose the carbon price residual term generated by VMD. The secondary decomposition strategy combining VMD and TVFEMD is utilized to better capture the characteristics of carbon price at various frequency levels. (3) The two-step nonlinear error-correction strategy is introduced to correct the initial prediction of the carbon price. This means that the error of the initial prediction is first predicted, and then, a non-linear correction of the error is performed to obtain the final prediction.
3. Methods
This section provides a detailed description of the methods and frameworks required to predict carbon prices.
3.1. VMD
Carbon prices are nonlinear and nonstationary, which increases the difficulty of their forecasting. To this end, it is critical for forecasting to reduce the impact of volatility and nonlinearity of the carbon price. The wavelet transform, EMD, and VMD models have been frequently utilized in finance to address the nonlinear problem for time series [
43]. However, the wavelet transform model suffers from problems including the choice of basis function and an inaccurate description of the frequency-to-time transformation [
44,
45]. Compared with wavelet transform models, VMD has fewer tuning parameters. VMD [
46] is a signal decomposition method with strong noise robustness and a rigorous mathematical theoretical framework. The noise or outliers in the data can be greatly removed via VMD [
47]. Compared with EMD, VMD can overcome mode aliasing [
48]. Hence, VMD is applied to extract the main characteristics of the carbon price.
For the raw carbon price
y, the VMD method can decompose it into several intrinsic mode functions, which are denoted by VMF components. Those VMFs contain the main information about the carbon price and are more regular and predictable. According to the theory of the VMD algorithm, the sum of all VMFs does not exactly match the raw carbon price. Particularly, the residual term can be calculated by subtracting the sum of VMFs from the raw carbon price. The process of VMD is realized by solving the following problem:
where
is the k-th VMF,
represents its central frequency,
K is the number of VMFs,
is the unit impulse function,
is the convolution operation symbol,
is an exponential term,
j is the imaginary unit,
t is the time indicator, and
is the partial derivative of
t.
By introducing the Lagrange multiplier λ, we can turn the above problem into the following problem:
where
α is the data-fidelity constraint. The alternative direction method of multipliers is applied to address the above equation. The following formulas are used to update the mode, its central frequency, and
λ:
where
is tolerance to noise.
The steps of the VMD are as follows:
Step 1: Define the initial , , and .
Step 2: Update and with Equations (3) and (4).
Step 3: Update the value of with Equation (5).
Step 4: If the condition , is satisfied, the process of VMD is over; otherwise, return to Step 2. The value of is set to 10−6.
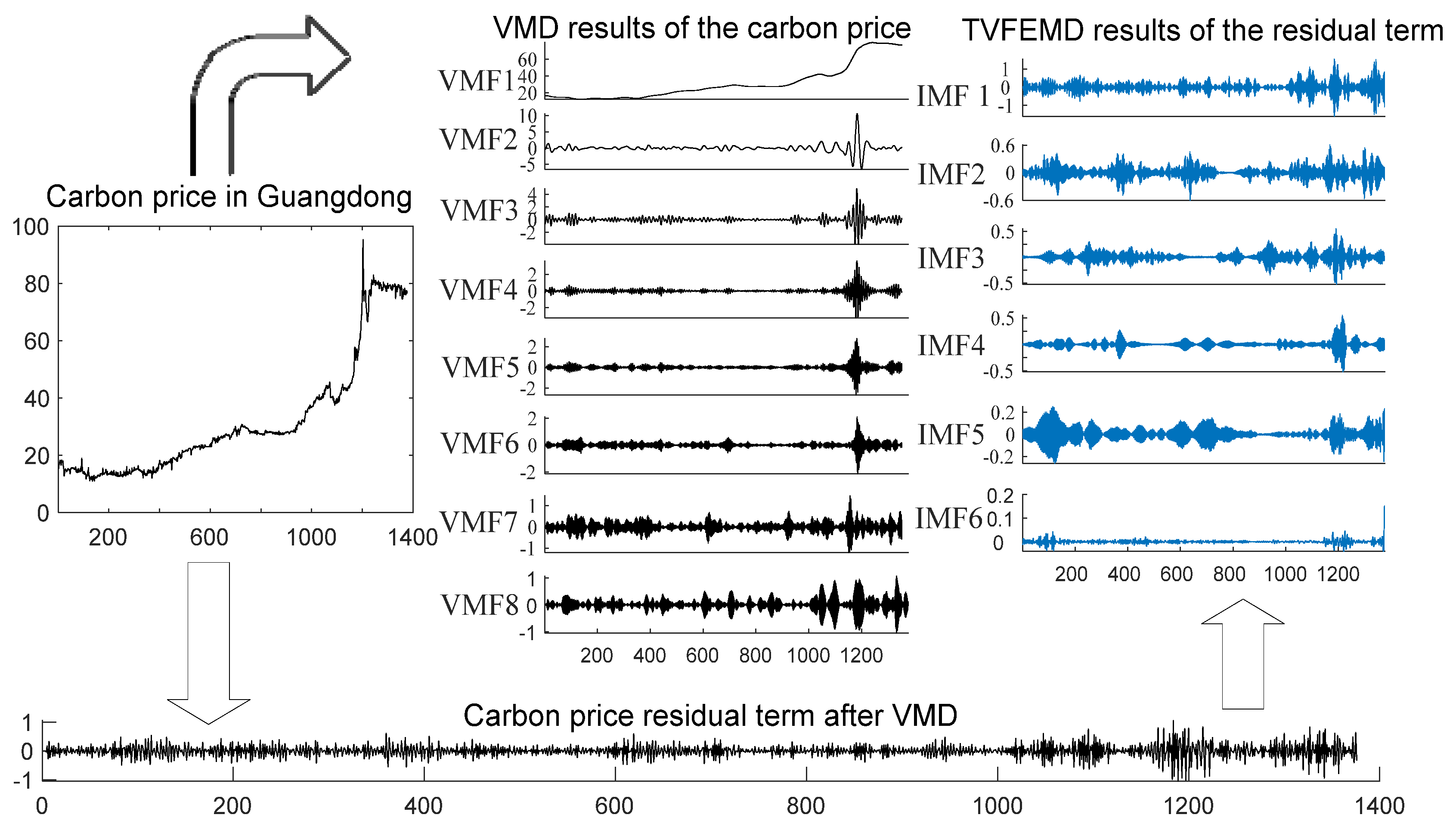
3.2. TVFEMD
The carbon price residual term generated by VMD fluctuates violently and lacks regularity. This study utilizes TVFEMD to weaken the prediction difficulty of the residual term. Li et al. (2017) [
49] proposed the TVFEMD. When compared to EMD, the TVFEMD method helps avoid mode aliasing and retain the time-varying characteristics of signals [
50]. The following are the main steps of the TVFEMD algorithm:
Step 1: Perform the Hilbert transform on the raw data series
S(
t), and the result is noted as
R(
t). Then, calculate
A(
t) and
λ(
t).
A(
t) is the instantaneous amplitude of the
S(
t).
λ(
t) is the instantaneous phase.
Step 2: Define the local maximum and local minimum of the
A(
t), recorded as
A({
tmax}) and
A({
tmin}). Then,
A({
tmax}) and
A({
tmin}) are interpolated to obtain
and
.
and
are calculated as below.
Step 3:
λ({t
min})
A2({
tmin}) and
λ({
tmax})
A2({
tmax}) are interpolated to obtain
β1(
t) and
β2(
t); then, calculate the instantaneous frequency component
,
.
Step 4: Define
, which is local cut-off frequency:
Step 5: Readjust to solve the intermittent problem.
Step 6: Define , where is employed to build the time-varying filter. B-spline interpolation is utilized to filter S(t), and the outcome of the approximation is given as m(t).
Step 7: When
is met,
S(
t) is determined as an IMF. Otherwise,
S(
t) =
S(
t) −
m(
t), repeat the previous steps.
where
is the stop condition,
is the weighted average of the instantaneous frequency, and
is the Loughlin instantaneous bandwidth. The value of
r is set to 0.1.
Eventually, several IMF components are acquired.
3.3. MKELM Optimized by SSA
3.3.1. Basic Theory of MKELM
As a novel feedforward neural network, ELM model has less parameter setting, a faster learning rate, stronger generalization ability, simplicity, and ease of use. However, the input weights and hidden layer thresholds of the ELM model are created randomly. Meanwhile, the number of hidden layer nodes of the ELM needs to be determined subjectively. These shortcomings will weaken its the stability. To alleviate the problem, Huang et al. (2012) [
51] developed the KELM. Compared with ELM, the regression result of KELM is more stable [
52]. In KELM, the kernel mapping replaces the random mapping. The generalization ability and stability of the KELM model is superior to ELM. However, different kernel functions have significantly different forecasting performance. Any base kernel may not be suitable for a variety of applications. Usually, the KELM with a single kernel function has limited representation capability and struggles to capture the complicated characteristics in carbon price. Compared with KELM, the MKELM has better generalization performance and learning ability and can enhance forecasting performance. Therefore, the MKELM is used to forecast carbon price.
For the training dataset
, the input included in the forecasting model is
, and
is its output. The standard KELM regression model can be displayed as follows:
In Equation (14), is a kernel matrix, is a unit diagonal matrix, represents a regularization coefficient, the addition of C can improve stability, and is the target output matrix.
The kernel function has an important influence on the prediction ability of KELM. The popular kernel functions used in the KELM model are RBF kernel, poly kernel, and wavelet kernel function. They are, respectively, expressed as , , and . The corresponding formulas of , , and are as follows:
- ①
- ②
- ③
where
d is the order of the
. While
has superior generalization capabilities,
has better learning capabilities [
53], and wavelet kernel function has the advantages of wavelet signal local analysis and multi-resolution analysis [
54]. Each single kernel function often has its own application field, making it challenging for them to maximize their capacity for representation. An unsuitable kernel function may have a negative impact on the predicted precision of the price of carbon [
55]. It is thus crucial for modeling and prediction to build a general multiple-kernel-based function for KELM. Based on Mercer’s theory, another kernel function can be created by linearly mixing different kernel functions. To combine the advantages of
,
, and
to their fullest extent, this paper constructs the following combined kernel function, which is made up of multiple kernel functions:
In Equation (15),
W1 is the weight of the corresponding RBF kernel function,
W2 represents the weight of the wavelet kernel function, and
is the weight of the poly kernel function. MKELM uses
Kcomb as the kernel function. When compared to KELM, MKELM, which utilizes a weighted combination of multiple kernel functions, can enhance prediction performance [
56]. MKELM is therefore utilized to forecast the price of carbon. It can be seen from Equations (14) and (15) that the stability and effectiveness of the MKELM model depend primarily on the regularization coefficient C; kernel function parameters
a,
b,
d,
g1,
g2, and
g3; and weights
W1 and
W2 in the model. These parameters need to be optimized to achieve greater predictive performance of the carbon price.
3.3.2. Sparrow Search Algorithm
As an optimization algorithm, SSA was proposed by Xue and Shen (2020) [
57]. Compared with PSO, it has faster convergence, stronger optimization ability, and stronger robustness [
58]. Therefore, the aforementioned parameters of the MKELM are selected by the SSA to effectively reduce the randomness of parameter selection.
In SSA, the results of optimization are obtained by simulating sparrows foraging and anti-predatory behavior. Based on the basic idea of SSA, the sparrow population is divided into three roles: discoverer, joiner, and vigilante.
The discoverers actively look for food sources. In general, the discoverers account for 10% to 20% of the total. The formula for position iteration of the discoverers is as follows:
where
is the maximum iterations;
i = 1,2,…,N, N is the number of sparrows;
and
represent random numbers;
t is the current times of iterations;
is a matrix whose all elements are 1, with a size of 1 ×
d;
[0.5, 1] represents a safe value; and
represents a warning value between [0, 1]. When
, the search environment is safe, there are no predators, and the discoverers will broaden the search area to obtain better fitness. When
, predators are found around the foraging location, and the population immediately adjusts the search strategy.
The joiners follow the discoverer for food. The position update formula of the joiners is as given below:
where
is the best position, and
represents the worst position.
Sparrows for early warning and reconnaissance usually occupy 10% to 20% of the entire population. These sparrows are called vigilantes. The position is updated as below:
where
is the globally optimal location, and
K [−1, 1] represents a random number.
is a minimal constant for avoiding the situation in which the denominator equals 0,
is the fitness value of the current sparrow,
is the global optimal, and
represents the worst fitness values.
β represents a random digit obeying standard normal distribution.
All in all, the sparrow population iterates based on the Equations (16)–(18). Once the conditions are met, the process of position updating of the sparrow population ends.
3.4. Error Correction Strategy of Carbon Price Prediction
Any prediction model will have a certain degree of prediction error. Critical information for carbon price forecasting is contained in the prediction error of carbon price. Hence, it is essential to fully utilize the effective information contained in the historical forecasting error. To further strengthen the prediction performance of the carbon price, the initial prediction error can be predicted to modify the prediction of the original carbon price, thereby weakening the inherent error of the combined model. The initial prediction error of carbon price in this paper is obtained by subtracting the initial prediction value of carbon price from the original carbon price. The choice of a correction strategy for the initial prediction error is the key to carbon price-prediction error correction. The current error-correction studies frequently employ the strategy of a simple addition of the error-prediction value and the initial prediction value to arrive at the final prediction result of the carbon price. However, the simple addition strategy has some limitations in capturing the impact of the error sequence and the initial prediction on the overall prediction result of the carbon price. To tackle carbon price forecasting with more precision, a nonlinear error-correction approach is required. Accordingly, based on SSA-MKELM, this research suggests a nonlinear correction technique. The following are the steps of the error-correction technique for predicting the price of carbon:
Step 1: Create the error-prediction model to predict the error.
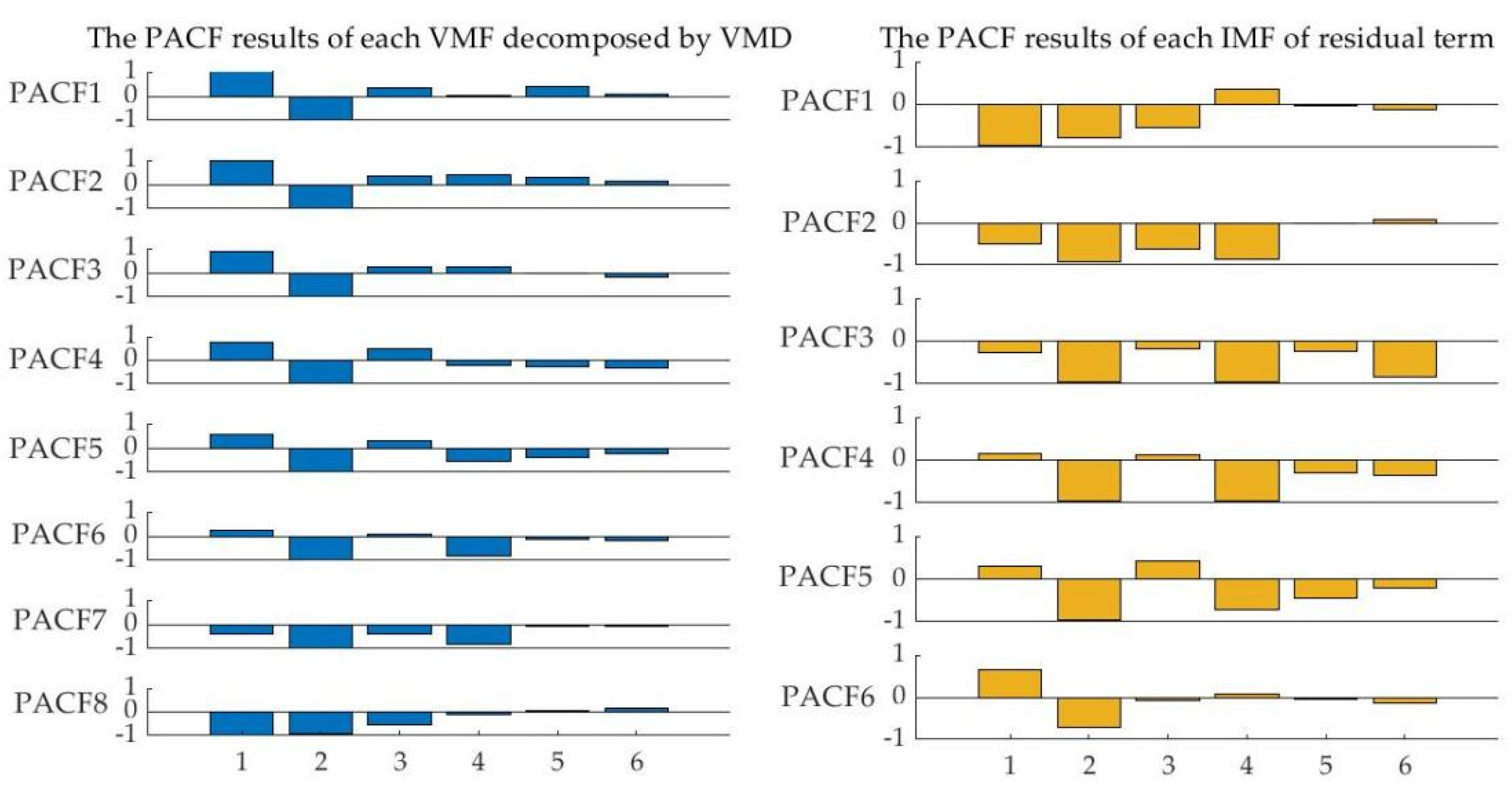
The initial prediction error of the carbon price is a set of time-series data. The autocorrelation of the error series is determined by PACF as the lag of the error series. Define Error(t) as the initial prediction error of the carbon price in period t. Using the historical data of Error (t) as the input term, the SSA-MKELM model is adopted to train and predict Error(t), and the predicted value of the error series in period t is obtained and recorded as EForecast(t).
Step 2: Carry out a non-linear correction to determine the final predicted results of the carbon price.
The performance of the forecast model of the carbon price can be increased by implementing an efficient error-correction approach. In this paper, a nonlinear error-correction strategy based on SSA-MKELM is proposed; that is, take the EForecast(t) and the initial prediction value of carbon price Forecast(t) as the input item of the MKELM model, take the actual price of carbon price in t period as the output item, build the mapping relationship between the input and the actual carbon price through sample training and learning, and then obtain the final prediction. The expression is as follows:
3.5. The Framework of the Proposed Model
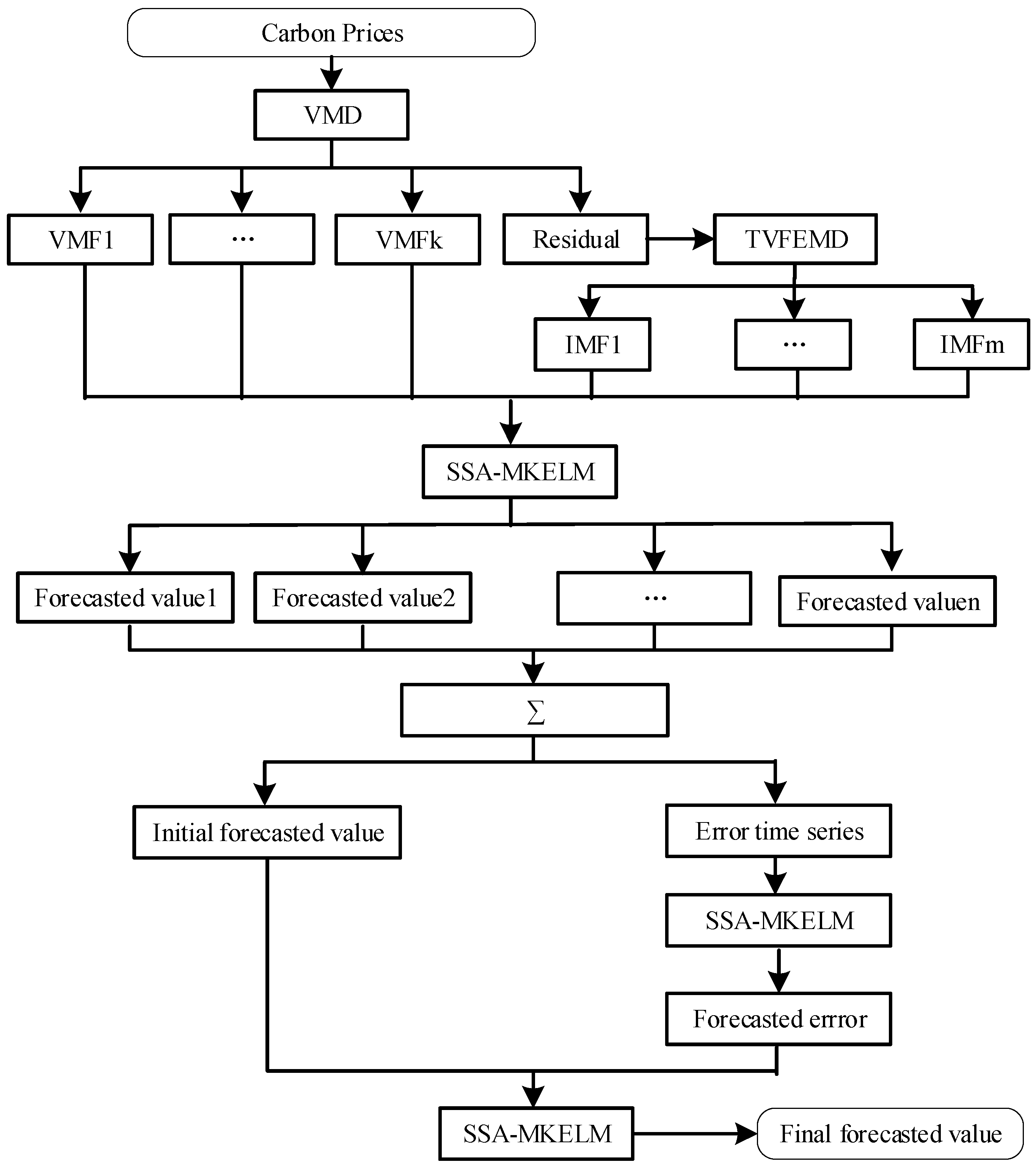
This study constructs a combined forecasting model for China’s regional carbon price based on secondary decomposition and a nonlinear error-correction strategy called the VMD-TVFEMD-SSA-MKELM-ENC model.
Figure 1 is the flowchart of the model. The following are the detailed modeling steps:
- (1)
Decomposition of the carbon price series: VMD is utilized to decompose the carbon price into several VMF components, which contain the main information of the carbon price. Subtract the sum of all VMF components from the carbon price to obtain a residual term. The residual term is a time series with irregular fluctuations. As an indispensable part of the carbon price, it offers valuable information for predicting the carbon price. Therefore, the residual term must be taken into account when predicting the price of carbon. The residual term is decomposed by TVFEMD to lessen its complexity. As a result, the residual term is divided into several IMFs;
- (2)
Initial prediction of the carbon price: Each subsequence, including each VMF and IMF, is predicted based on the SSA-MKELM model. The input of each subsequence of carbon price is identified by the PACF test. By adding the prediction values of each VMF and IMF, the initial prediction result for the price of carbon is obtained;
- (3)
Prediction of the initial prediction error: The initial prediction error is calculated by subtracting the initial prediction of carbon prices from the actual carbon prices. The SSA-MKELM model is further utilized to forecast the initial prediction error time series. Moreover, historical error data selected by PACF serve as the input;
- (4)
Integrated prediction of carbon price: The SSA-MKELM is utilized again to non-linearly integrate the initial prediction and error prediction. More specifically, the initial prediction of carbon price and the prediction value of the initial prediction error are employed as input variables of the SSA-MKELM model to produce the final prediction result for carbon price.
5. Conclusions
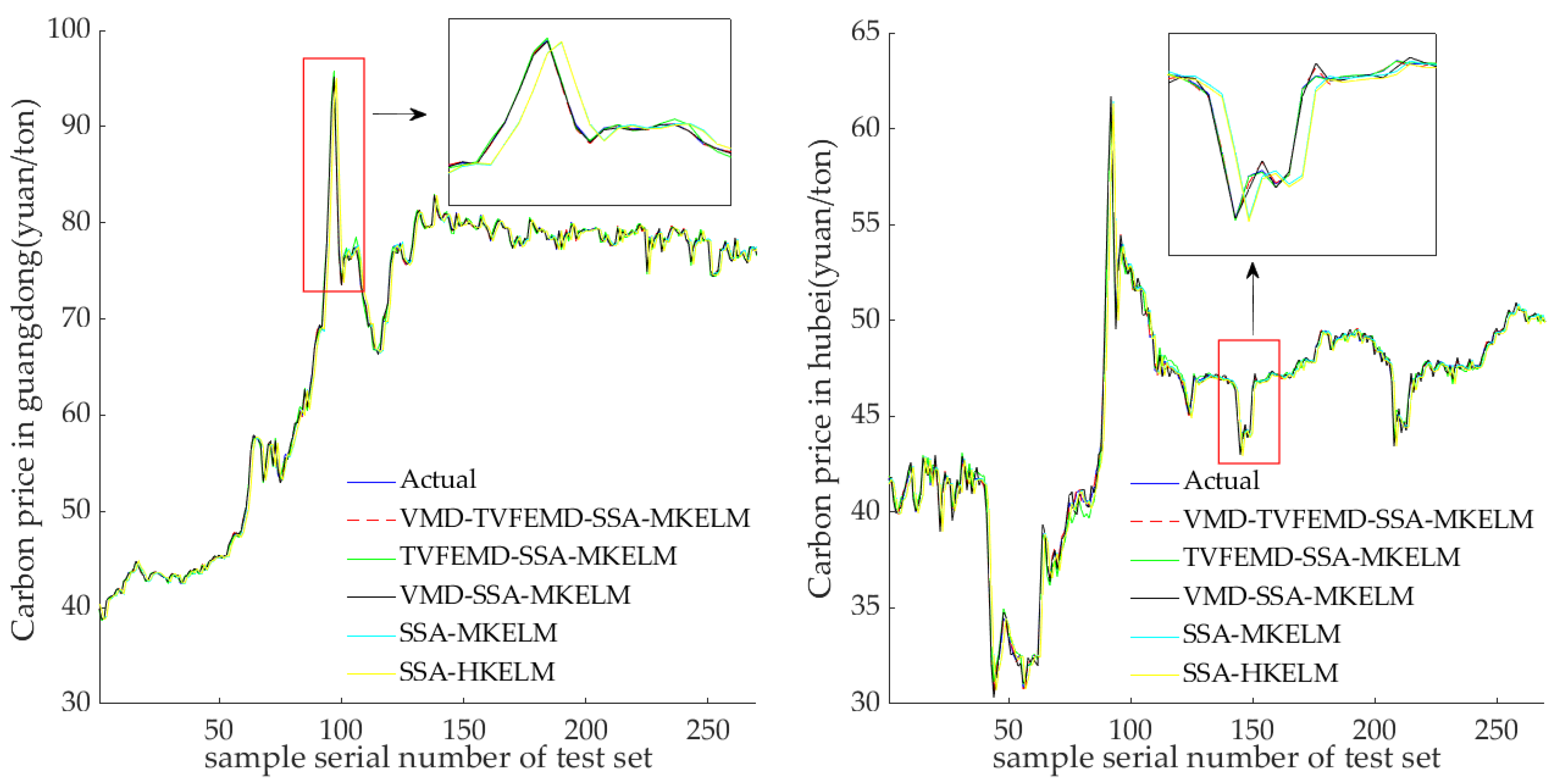
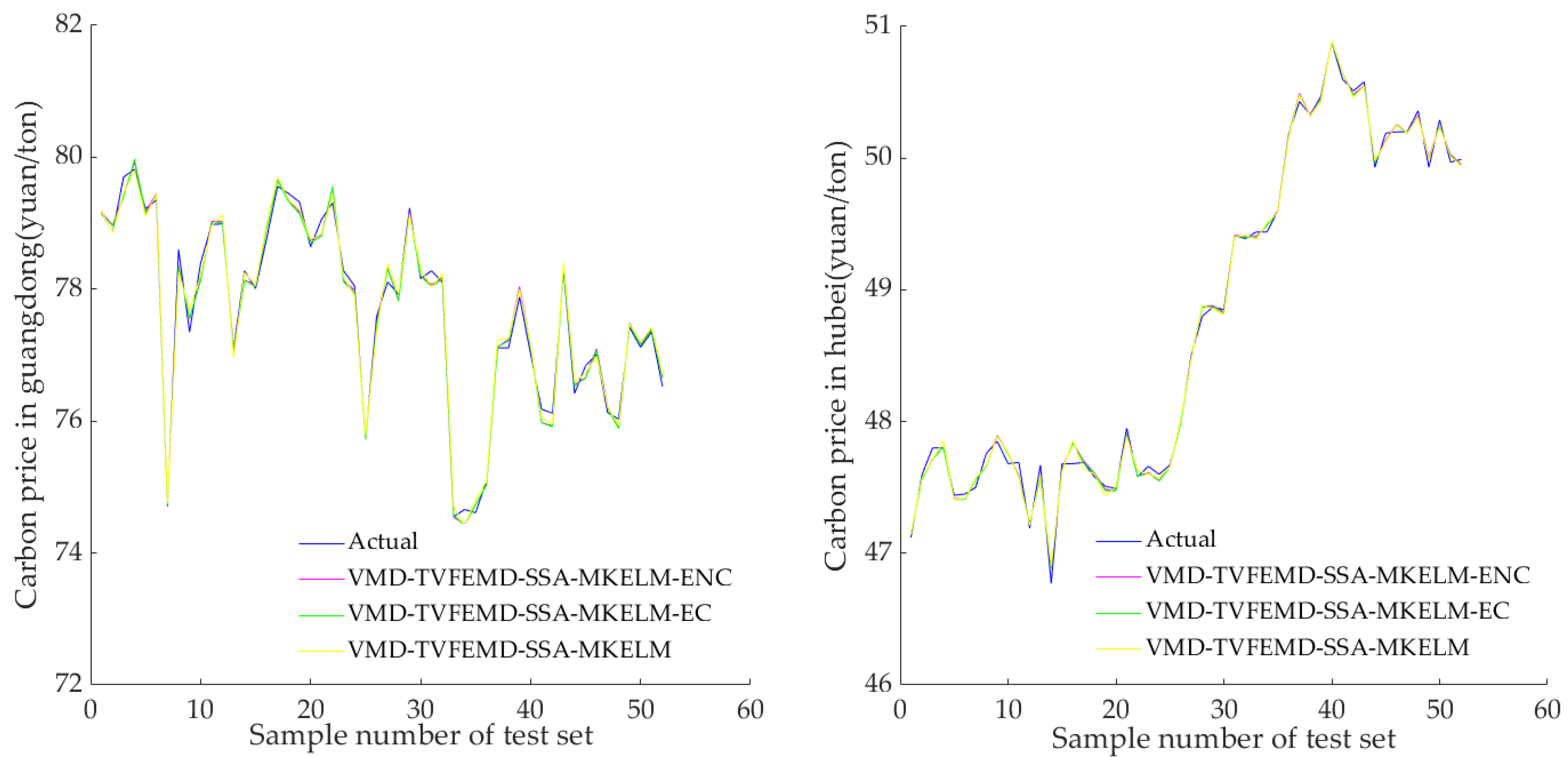
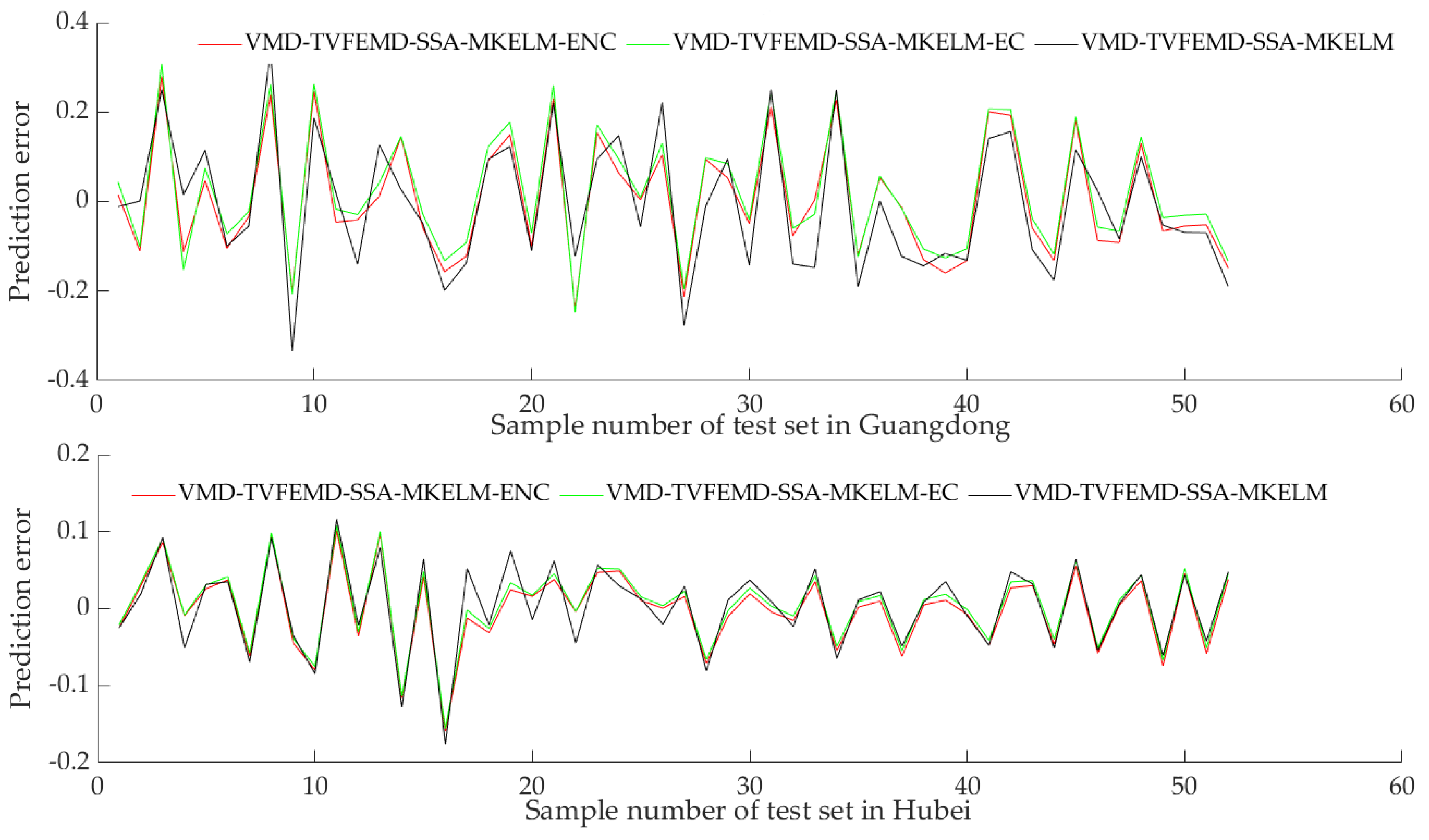
Carbon price prediction is among the crucial aspects of carbon financial market research. To address the problem in which previous studies on China’s regional carbon price forecasting based on secondary decomposition have ignored the effect of forecasting errors and only utilized HKELM models to capture the complex characteristics of regional carbon prices, the VMD-TVFEMD-SSA-MKELM-ENC model was created in this study to forecast the carbon prices in the marketplaces of Guangdong and Hubei. Firstly, the carbon prices were processed into several relatively smooth subsequences by the secondary decomposition process combining VMD and TVFEMD. Secondly, the SSA-MKELM model was constructed to forecast these subsequences of carbon price. The prediction results of these subsequences were added together to obtain the initial prediction value of the carbon price. Last but not least, a two-step nonlinear error-correction strategy was constructed to further enhance the prediction effect of the carbon price. The SSA-MKELM model was utilized to predict the initial prediction error of carbon price and was employed to nonlinearly integrate the initial prediction value and error-prediction value of carbon price to obtain the final prediction result of carbon price. The empirical results demonstrate that the proposed VMD-TVFEMD-SSA-MKELM-ENC model has superior prediction performance compared to the reference group models and that it is valid for predicting carbon prices.
The prediction model developed in this work boasts a few advantages over the existing prediction models of regional carbon prices in China: (1) The secondary decomposition method using the combination of VMD and TVFEMD can deeply explore the fluctuation characteristics and internal laws of different frequency series of carbon price, which is a feasible and effective carbon price decomposition processing method. (2) The MKELM model, which contains the multiple kernel function, is introduced to forecast the carbon price, which further improves the prediction accuracy. (3) The nonlinear error-correction strategy is innovatively introduced to correct the initial prediction results of the carbon price, which can distinguish the impact of the error series as well as the initial prediction results on the overall prediction results.
As a policy suggestion, the regional carbon prices are mainly affected by their own historical time series according to our analysis. The government can further improve the carbon price-management mechanism to avoid the risk caused by the drastic price fluctuations. Furthermore, China’s carbon market is still dominated by spot trading. Futures and options cannot be realized in these markets. Since diversified carbon financial trading tools can provide a more accurate price mechanism for carbon emissions trading, it is necessary to enrich carbon financial trading tools.
However, there are still some limitations in this study. Firstly, this analysis does not take into account how external influences may affect the price of carbon. Future work may attempt to incorporate external factors associated with the carbon price into the model to further enhance the prediction performance. Secondly, from the perspective of the optimization algorithm, the proposed prediction model only adopts single-objective optimization, and multi-objective optimization can be introduced into the proposed model in subsequent research. Finally, only the data from Guangdong and Hubei are considered, and the carbon prices of other pilots in China can be considered in the subsequent research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}