
Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles


Abstract
:1. Introduction
2. HEV Model and Problem Description
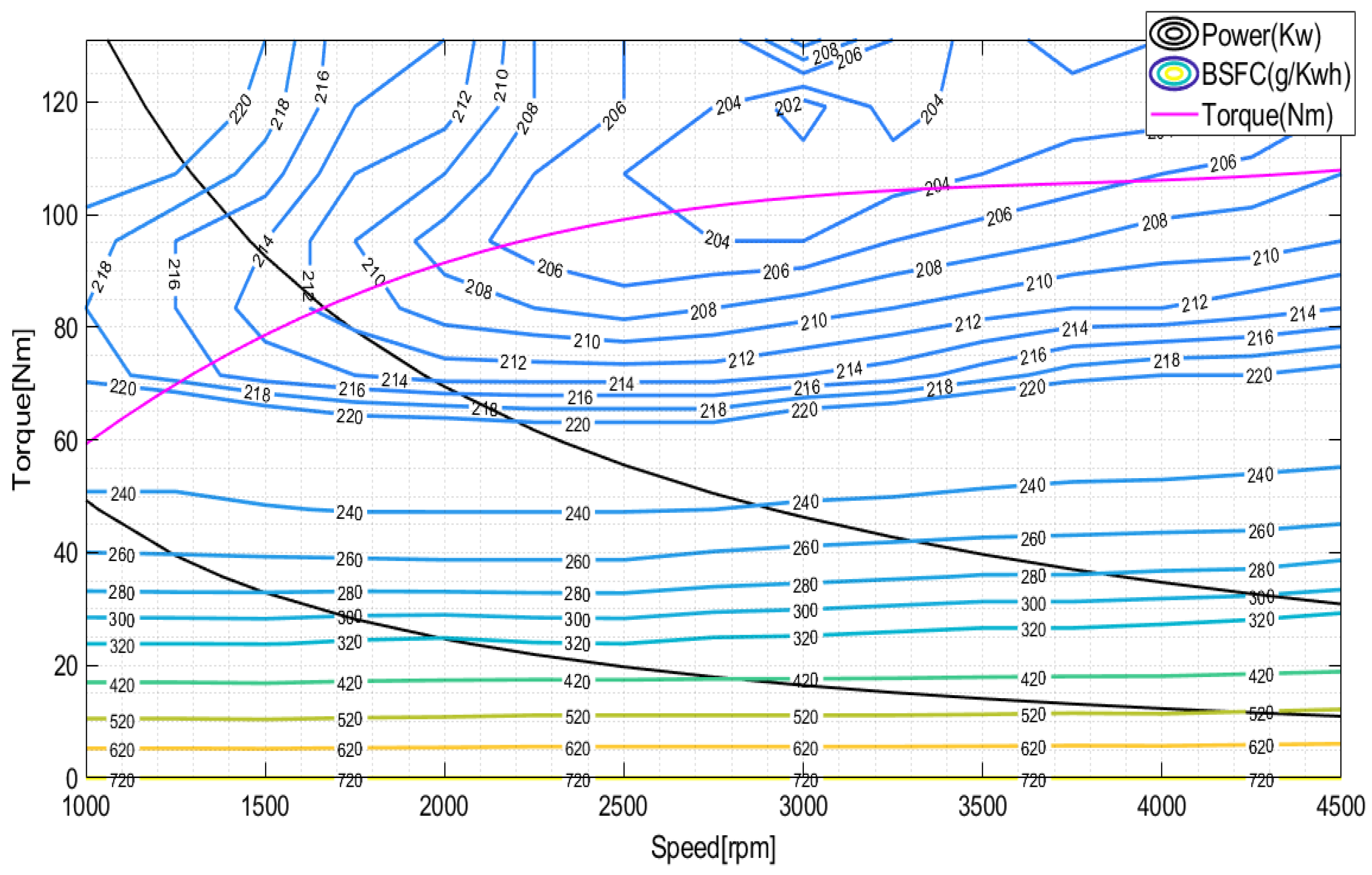
2.1. Powertrain Model
2.2. Battery Model
2.3. Energy Management Optimization Problem
3. Design of DHP-Based Real-Time EMS
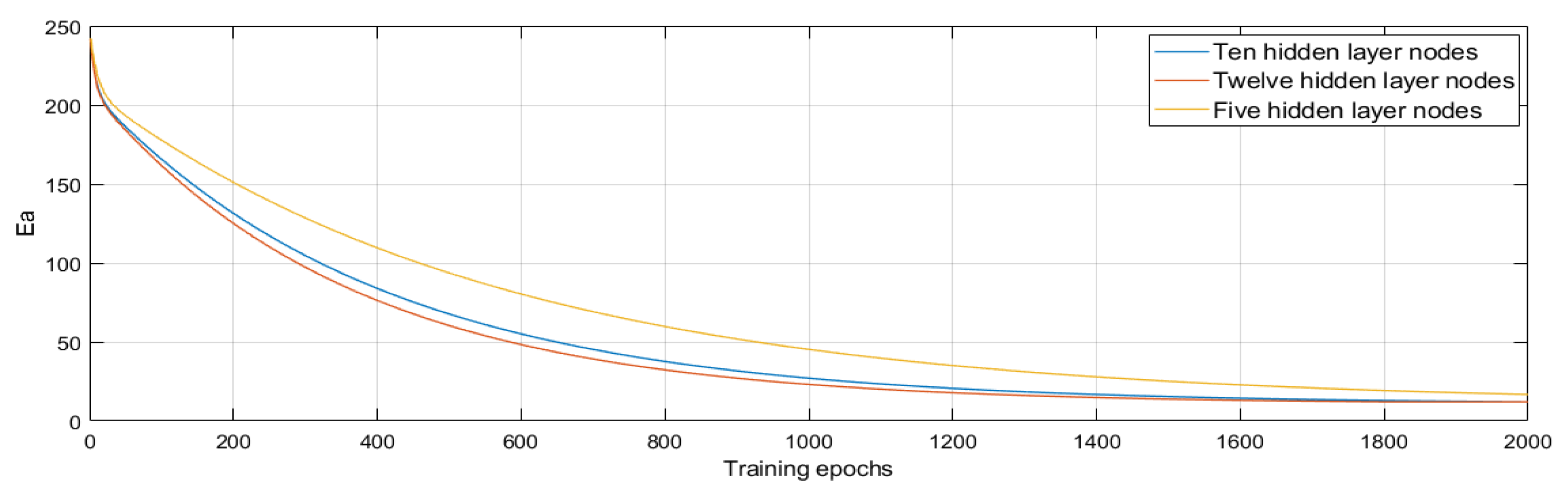
3.1. Speed Prediction Model
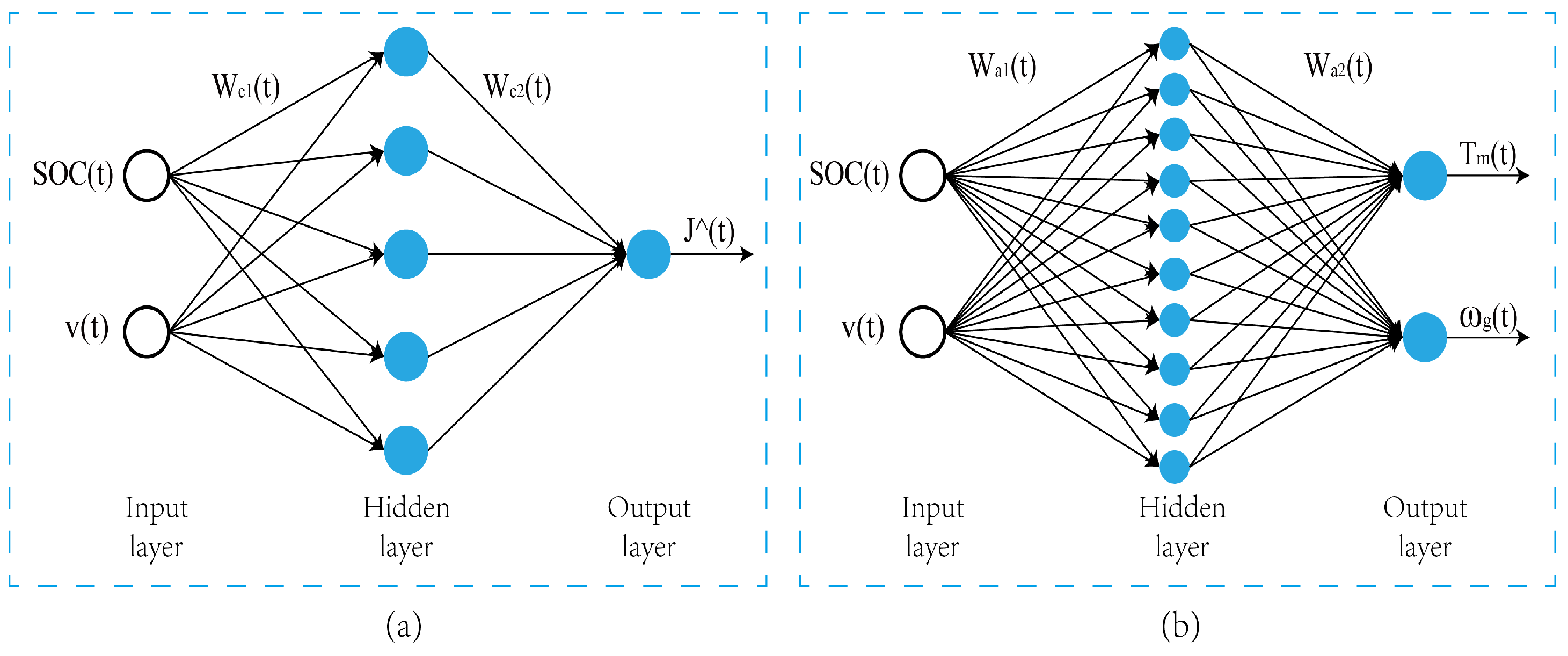
3.2. Design of Critic Network
3.3. Design of Actor Network
3.4. DHP-Based Real-Time EMS
| Algorithm 1: Online learning algorithm of HEV with DHP. |
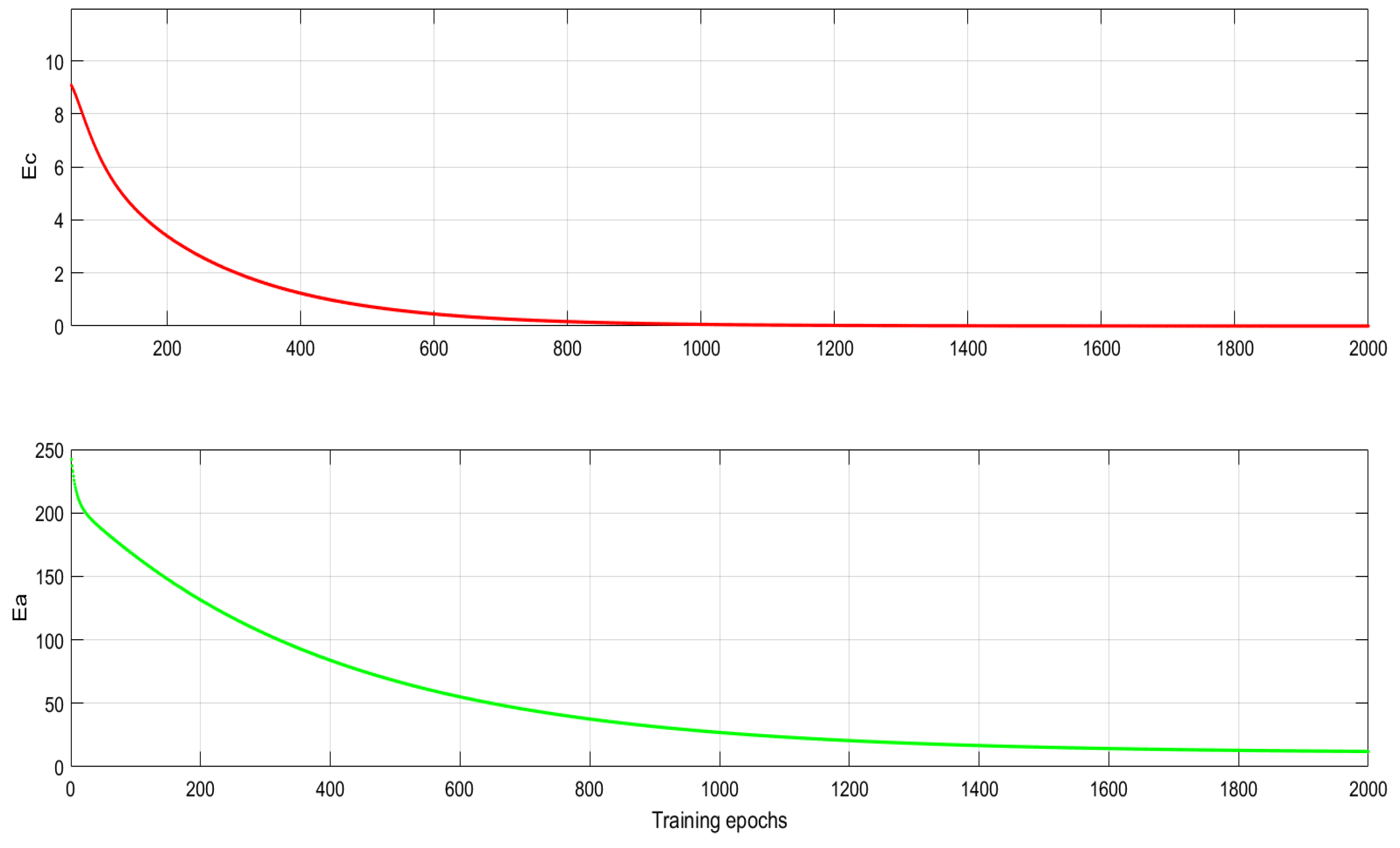
Parameters initialization State variable: SOC, v; Discount factor: ; Weights in CN: , ; Weights in AN: , ; Learning factor of CN and AN: , ; error value: , ; for Speed prediction and demand torque determination Getting the current speed from HEV; Running the speed prediction model to abtain ; Using PID controller to get ; Estimating and CN1: ; AN: ; ; Calculating and ; ; Calculating and CN2: ; ; ; ; Optimal control judgement while and Weights update ; ; ; ; Estimating and CN1: ; AN: ; ; Calculating and ; ; Calculating and CN2: ; ; ; ; end while end for |
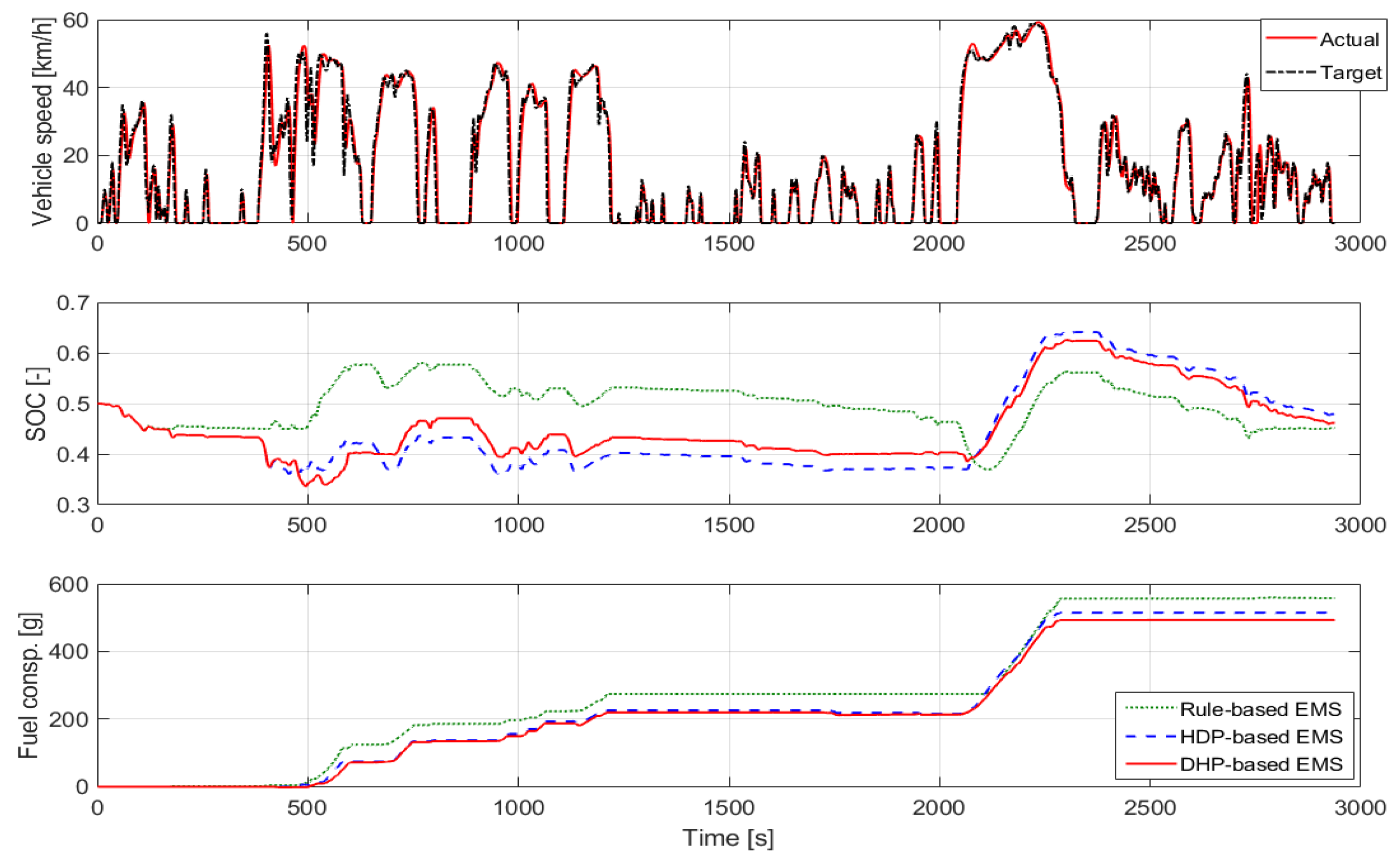
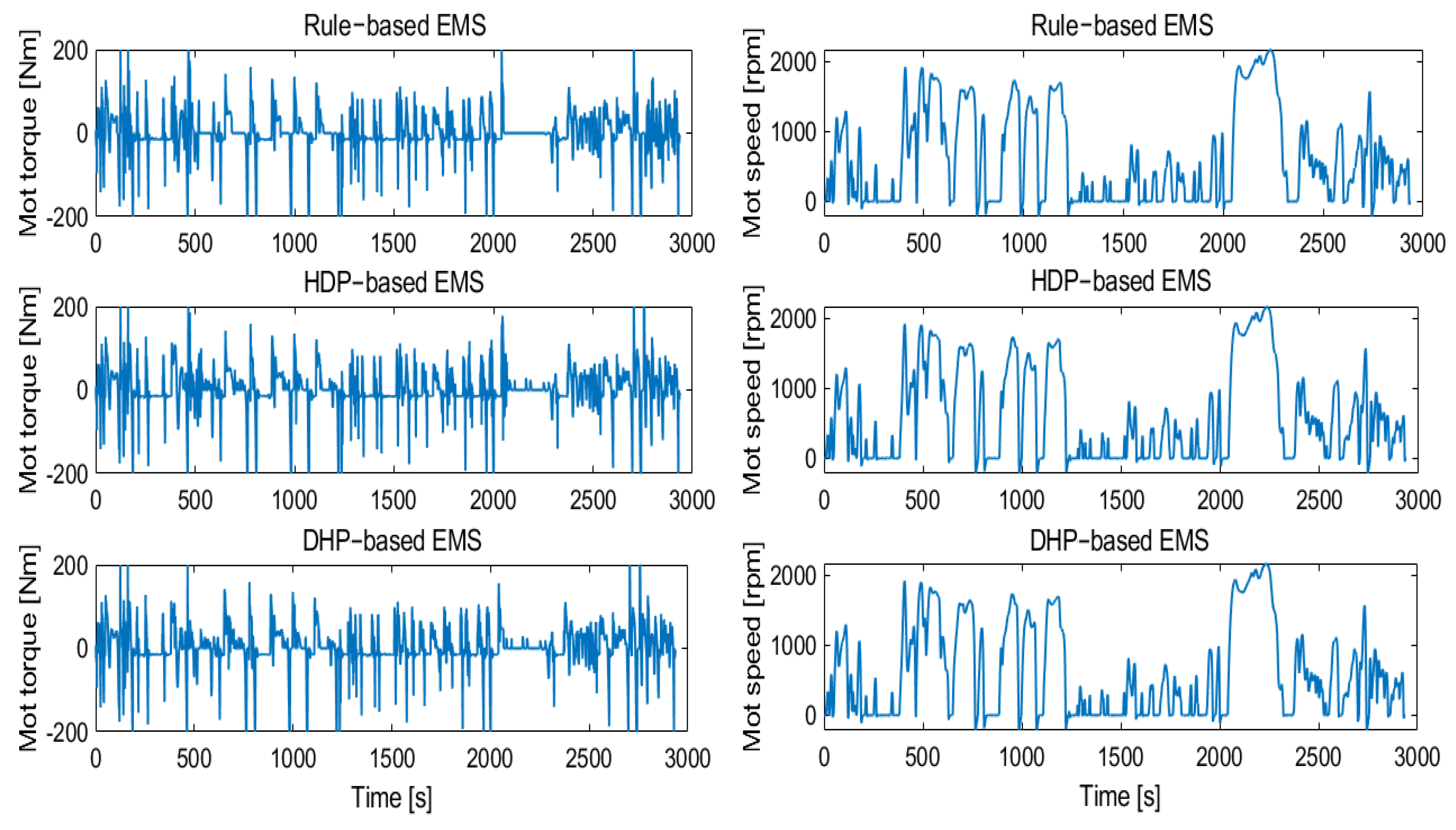
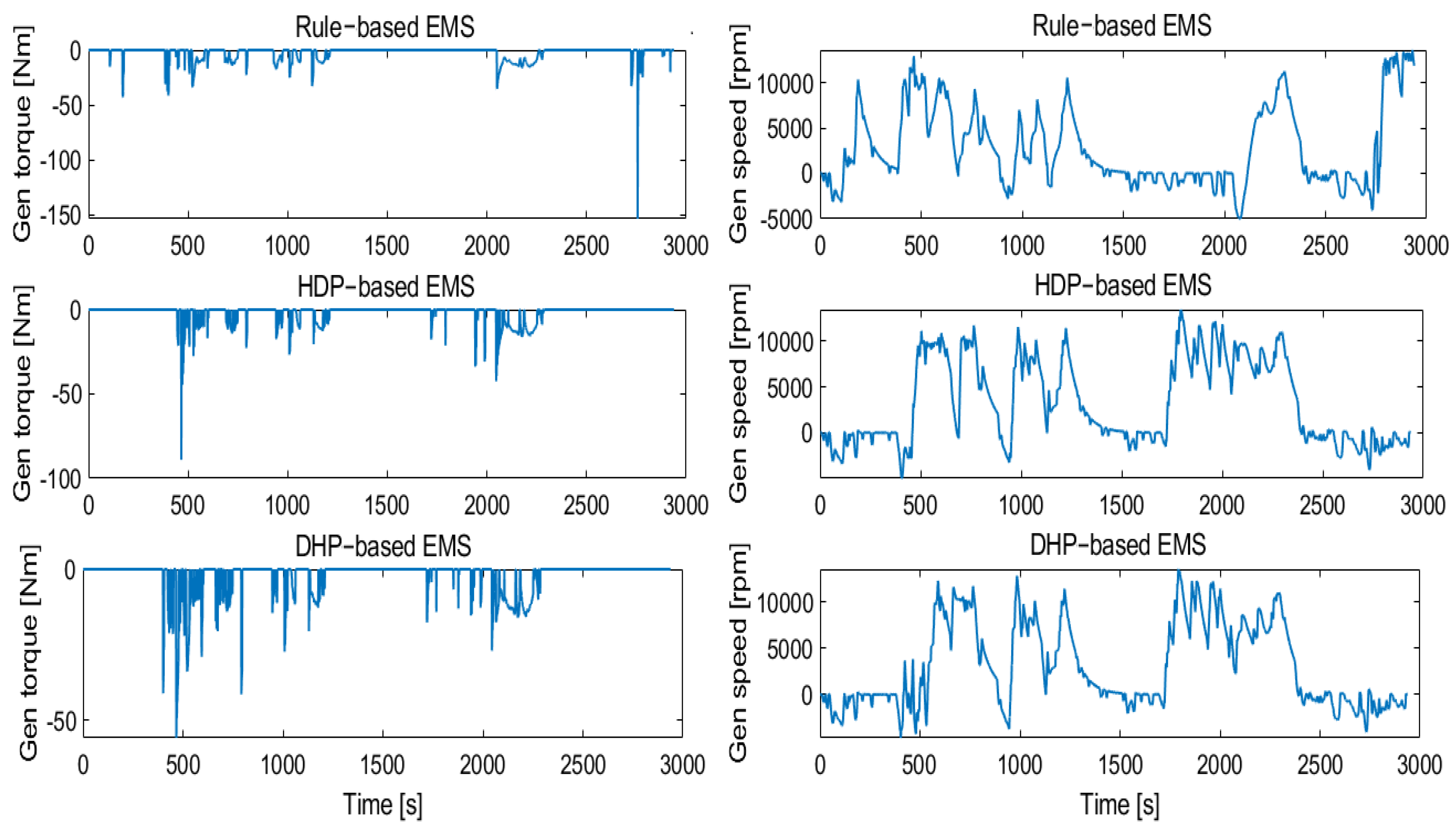
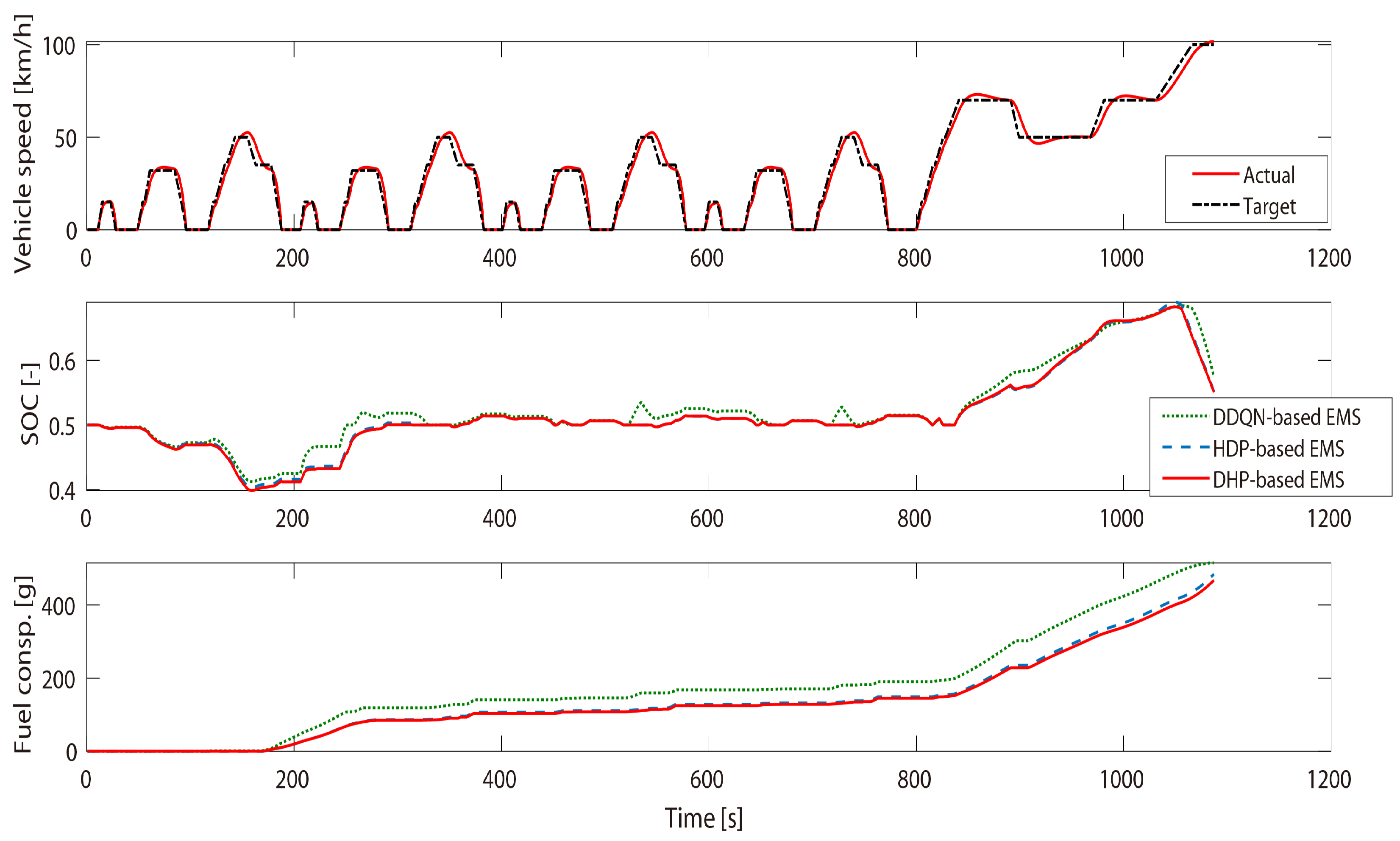
4. Simulation Verification and Results Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salmasi, F.R. Control strategies for hybrid electric vehicles: Evolution, classification, comparison, and future trends. IEEE Trans. Veh. Technol. 2007, 56, 2393–2404. [Google Scholar] [CrossRef]
- Caiazzo, B.; Coppola, A.; Petrillo, A.; Santini, S. Distributed nonlinear model predictive control for connected autonomous electric vehicles platoon with distance-dependent air drag formulation. Energies 2021, 14, 5122. [Google Scholar] [CrossRef]
- Tran, D.D.; Vafaeipour, M.; Baghdadi, M.E.; Barrero, R.; Van Mierlo, J.; Hegazy, O. Thorough state-of-the-art analysis of electric and hybrid vehicle powertrains: Topologies and integrated energy management strategies. Renew. Sustain. Energy Rev. 2020, 119, 109596. [Google Scholar] [CrossRef]
- Lekshmi, S.; Lal Priya, P.S. Mathematical modeling of electric vehicles—A survey. Control Eng. Pract. 2019, 92, 104138. [Google Scholar]
- Enang, W.; Bannister, C. Modelling and control of hybrid electric vehicles (A comprehensive review). Renew. Sustain. Energy Rev. 2017, 74, 1210–1239. [Google Scholar] [CrossRef] [Green Version]
- Wirasingha, S.G.; Emadi, A. Classification and review of control strategies for plug-in hybrid electric vehicles. IEEE Trans. Veh. Technol. 2010, 60, 111–122. [Google Scholar] [CrossRef]
- Anbaran, S.A.; Idris, N.R.N.; Jannati, M.; Aziz, M.J.; Alsofyani, I. Rule-based supervisory control of split-parallel hybrid electric vehicle. In Proceedings of the 2014 IEEE Conference on Energy Conversion (CENCON), Johor Bahru, Malaysia, 13–14 October 2014; pp. 7–12. [Google Scholar]
- Peng, J.; He, H.; Xiong, R. Rule based energy management strategy for a series–parallel plug-in hybrid electric bus optimized by dynamic programming. Appl. Energy 2017, 185, 1633–1643. [Google Scholar] [CrossRef]
- Yang, C.; Liu, K.; Jiao, X.; Wang, W.; Chen, R.; You, S. An adaptive firework algorithm optimization-based intelligent energy management strategy for plug-in hybrid electric vehicles. Energy 2022, 239, 122120. [Google Scholar] [CrossRef]
- Zhu, C.; Lu, F.; Zhang, H.; Sun, J.; Mi, C. A real-time battery thermal management strategy for connected and automated hybrid electric vehicles (CAHEVs) based on iterative dynamic programming. IEEE Trans. Veh. Technol. 2018, 67, 8077–8084. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Li, W.; Shang, F.; Zhan, J. Hybrid-trip-model-based energy management of a PHEV with computation-optimized dynamic programming. IEEE Trans. Veh. Technol. 2017, 67, 338–353. [Google Scholar] [CrossRef]
- Zheng, C.; Cha, S.W. Real-time application of Pontryagins Minimum Principle to fuel cell hybrid buses based on driving characteristics of buses. Int. J. Precis. Eng.-Manuf.-Green Technol. 2017, 4, 199–209. [Google Scholar] [CrossRef]
- Wang, Y.; Jiao, X. Multi-objective energy management for PHEV via Pontryagin’s Minimum Principle and PSO onlin. Sci. China Inf. Sci. 2021, 64, 119204. [Google Scholar] [CrossRef]
- Jiao, X.; Shen, T. SDP policy iteration-based energy management strategy using traffic information for commuter hybrid electric vehicles. Energies 2014, 7, 4648–4675. [Google Scholar] [CrossRef] [Green Version]
- Onori, S.; Tribioli, L. Adaptive Pontryagins Minimum Principle supervisory controller design for the plug-in hybrid GM Chevrolet Volt. Appl. Energy 2015, 147, 224–234. [Google Scholar] [CrossRef]
- Han, L.; Jiao, X.; Jing, Y. Recurrent-neural-network-based adaptive energy management control strategy of plug-in hybrid electric vehicles considering battery aging. Energies 2020, 13, 202. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Hu, X.; Qi, S.; Lang, K. An artificial neural network-enhanced energy management strategy for plug-in hybrid electric vehicles. Energy 2018, 163, 837–848. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Wang, H.; Khajepour, A.; He, H.; Ji, J. Model predictive control power management strategies for HEVs: A review. J. Power Sources 2017, 341, 91–106. [Google Scholar] [CrossRef]
- Shen, P.; Zhao, Z.; Zhan, X.; Li, J.; Guo, Q. Optimal energy management strategy for a plug-in hybrid electric commercial vehicle based on velocity prediction. Energy 2018, 155, 838–852. [Google Scholar] [CrossRef]
- Guo, J.; He, H.; Peng, J.; Zhou, N.T. A novel MPC-based adaptive energy management strategy in plug-in hybrid electric vehicles. Energy 2019, 175, 378–392. [Google Scholar]
- Chen, Z.; Hu, H.; Wu, Y.; Zhang, Y.; Li, G.; Liu, Y. Stochastic model predictive control for energy management of power-split plug-in hybrid electric vehicles based on reinforcement learning. Energy 2020, 211, 118931. [Google Scholar] [CrossRef]
- Xie, S.; Hu, X.; Xin, Z.; Brighton, J. Pontryagins minimum principle based model predictive control of energy management for a plug-in hybrid electric bus. Appl. Energy 2019, 236, 893–905. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Han, L.; Liu, H.; Wang, W.; Xiang, C. Real-time optimal energy management strategy for a dual-mode power-split hybrid electric vehicle based on an explicit model predictive control algorithm. Energy 2019, 172, 1161–1178. [Google Scholar] [CrossRef]
- Li, T.; Liu, H.; Wang, H.; Yao, Y. Hierarchical predictive control-based economic energy management for fuel cell hybrid construction vehicles. Energy 2020, 198, 117327. [Google Scholar] [CrossRef]
- Park, J.; Chen, Z.; Murphey, Y.L. Intelligent vehicle power management through neural learning. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–7. [Google Scholar]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement learning Cbased energy management strategy for a hybrid electric tracked vehicle. Energies 2015, 8, 7243–7260. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Hu, X.; Li, E.S.; Cao, D. Reinforcement learning optimized look-ahead energy management of a parallel hybrid electric vehicle. IEEE/ASME Trans. Mechatron. 2017, 22, 1497–1507. [Google Scholar] [CrossRef]
- Inuzuka, S.; Zhang, B.; Shen, T. Real-time HEV energy management strategy considering road congestion based on deep reinforcement learning. Energies 2021, 14, 5270. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Peng, J.; Wang, H. Deep reinforcement learning-based energy management for a series hybrid electric vehicle enabled by history cumulative trip information. IEEE Trans. Veh. Technol. 2019, 68, 7416–7430. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Peng, J.; Zhang, H. Power management for a plug-in hybrid electric vehicle based on reinforcement learning with continuous state and action spaces. Energy Procedia 2017, 142, 2270–2275. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Lewis, F.L.; Liu, D. Reinforcement Learning and Approximate Dynamic Programming for Feedback Control, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012; pp. 452–473. [Google Scholar]
- Buşoniu, L.; De Schutter, B.; Babuška, R. Chapter of Interactive Collaborative Information Systems. In Approximate Dynamic Programming and Reinforcement Learning; Babuška, R., Groen, F.C.A., Eds.; SCI281; Springer: Berlin/Heidelberg, Germany, 2010; pp. 3–44. [Google Scholar]
- Sedighizadeh, M.; Mohammadpour, A.; Alavi, S. A daytime optimal stochastic energy management for EV commercial parking lots by using approximate dynamic programming and hybrid big bang big crunch algorithm. Sustain. Cities Soc. 2019, 45, 486–498. [Google Scholar] [CrossRef]
- Wu, Y.; Ravey, A.; Chrenko, D.; Miraoui, A. Demand side energy management of EV charging stations by approximate dynamic programming. Energy Convers. Manag. 2019, 196, 878–890. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Chen, Y.; Zhan, J.; Shang, F. Heuristic dynamic programming based online energy management strategy for plug-in hybrid electric vehicles. IEEE Trans. Veh. Technol. 2019, 68, 4479–4493. [Google Scholar] [CrossRef]
- Li, G.; Göerges, D. Fuel-efficient gear shift and power split strategy for parallel HEVs based on heuristic dynamic programming and neural networks. IEEE Trans. Veh. Technol. 2019, 68, 9519–9528. [Google Scholar] [CrossRef]
- Li, G.; Göerges, D. Ecological adaptive cruise control and energy management strategy for hybrid electric vehicles based on heuristic dynamic programming. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3526–3535. [Google Scholar] [CrossRef]
- Wang, Y.; Jiao, X.; Sun, Z.; Li, P. Energy management strategy in consideration of battery health for PHEV via stochastic control and particle swarm optimization algorithm. Energies 2017, 10, 1894. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Hu, X.; Liu, T.; Qi, S.; Lang, K.; Li, H. Predictive vehicle-following power management for plug-in hybrid electric vehicles. Energy 2019, 166, 701–714. [Google Scholar] [CrossRef]
- Yasui, Y. JSAE-SICE benchmark problem2: Fuel consumption optimization of commuter vehicle using hybrid powertrain. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012. [Google Scholar]
- Zhang, J.; Jiao, X.; Yang, C. A Ddqn-based energy management strategy for hybrid electric vehicles under variable driving cycles. Energy Technol. 2021, 2000770. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter [Symbol] | Specification | Unit |
|---|---|---|
| Gross vehicle weight [M] | 1460 | [kg] |
| Tire radius [] | 0.2982 | [m] |
| Frontal area [A] | 3.8 | [] |
| air density [] | 1.293 | [] |
| drag coefficient [] | 0.33 | [-] |
| coefficient of rolling resistance [] | 0.015 | [-] |
| transmission efficiency of differential gear [] | 0.97 | [-] |
| Max power | 51 | [kW ] |
| Motor max power | 50 | [kW] |
| Generator max power | 30 | [kW] |
| Final differential gear ratio | 4.113 | [-] |
| Sun gear teeth number [] | 30 | [-] |
| Ring gear teeth number [] | 78 | [-] |
| Max charge capacity [] | 6.5 | [Ah] |
| Hidden Layer Nodes | Iterations | Training Time (s) |
|---|---|---|
| 5 | 2800 | 13,725 |
| 10 | 2000 | 12,680 |
| 12 | 1800 | 14,500 |
| 3.819 4.204 4.274 −5.009 −4.597 | |
| 8.426 8.100 8.331 −8.080 −4.597 | |
| 0.234 1.582 0.471 −1.693 0.520 | |
| 0.168 0.881 −0.245 0.039 −0.387 −0.158 0.640 0.133 0.164 0.114 | |
| 0.975 0.358 −0.050 0.555 0.115 0.257 0.205 0.368 0.628 0.544 | |
| −0.384 0.004 0.486 0.250 −0.084 0.541 0.448 0.085 −0.035 0.037 | |
| 0.287 0.141 0.645 0.820 0.886 0.776 0.147 0.718 0.476 0.332 |
| Algorithm | Final SOC | Equival. Fuel Consump. (g) | Reduction (%) |
|---|---|---|---|
| RB | 0.452 | 557.8 | − |
| HDP | 0.479 | 514.9 | 7.69 |
| DHP | 0.462 | 492.9 | 11.63 |
| Algorithm | Final SOC | Equival. Fuel Consump. (g) | Reduction (%) |
|---|---|---|---|
| DDQN | 0.359 | 574.1 | − |
| HDP | 0.391 | 552.6 | 3.74 |
| DHP | 0.395 | 519.1 | 9.58 |
| Algorithm | Final SOC | Equival. Fuel Consump. (g) | Reduction (%) |
|---|---|---|---|
| DDQN | 0.574 | 515.0 | − |
| HDP | 0.552 | 488.3 | 5.18 |
| DHP | 0.551 | 480.5 | 6.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jiao, X. Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles. Energies 2022, 15, 3235. https://doi.org/10.3390/en15093235
Wang Y, Jiao X. Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles. Energies. 2022; 15(9):3235. https://doi.org/10.3390/en15093235
Chicago/Turabian StyleWang, Yaqian, and Xiaohong Jiao. 2022. "Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles" Energies 15, no. 9: 3235. https://doi.org/10.3390/en15093235
APA StyleWang, Y., & Jiao, X. (2022). Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles. Energies, 15(9), 3235. https://doi.org/10.3390/en15093235