1. Introduction
Conventional control devices for volt/VAR control (VVC) in distribution systems are on-load tap changers (OLTC) and capacitor banks (CB) [
1]. Currently, distribution systems have more control functions to support the rapidly increasing penetration of renewable energy. For example, dynamic distribution network reconfiguration (DNR) that controls sectionalizing and tie switches reduces network power loss by changing power flow [
2,
3,
4]. It is a cost-effective method to increase the hosting capacity of solar photovoltaics (PV) [
5,
6]. The distribution system operator (DSO) controls these devices to maintain the voltage level in the normal operating range and operate the distribution system economically. Another important control entity is the smart inverter installed in the solar PV generator. The PV smart inverter (PVSI) is installed at the bus that suffers from the overvoltage problem, and it can absorb and provide reactive power. Therefore, VVC using PVSI shows a better performance than traditional VVC methods using OLTC or CB. Cooperative control schemes using both PVSI and dynamic DNR further improve the performance of voltage regulation and network power loss [
7].
Previous studies on VVC and dynamic DNR can be categorized into model-based and model-free algorithms. The optimization framework of model-based approaches is generally non-convex because of the non-linearity of the power system. Therefore, these non-convex optimization problems have been converted to those of convex optimization [
4,
8], mixed-integer linear programming (MILP) [
3,
9], mixed-integer quadratic programming (MIQP) [
10], and mixed-integer second-order cone programming (MISOCP) [
11,
12]. Because model-based approaches are based on an optimization framework, they have shown good performance. However, these approaches are difficult to apply to real distribution systems. This is because model-based approaches heavily depend on a specific model, which requires accurate distribution system parameters such as load, solar PV output, and impedance of power lines.
To overcome the limitations of model-based approaches, model-free algorithms, that is data-driven approaches, have been investigated [
13,
14,
15,
16,
17]. In [
13], the authors formulated dynamic DNR as a Markov decision process (MDP) and trained a deep
Q-network (DQN) based on historical operational datasets. They also proposed a data-augmentation method to generate synthetic training data using a Gaussian process. A two-stage deep reinforcement learning (DRL) method consisting of offline and online stages was proposed to improve the voltage profile using PVSIs [
16]. In our previous work [
18], we developed a DQN-based dynamic DNR algorithm for energy loss minimization.
Furthermore, model-free algorithms can control different devices in a coordinated manner using multi-agent reinforcement learning. In [
19], a multi-agent deep
Q-network based algorithm that controls CB, voltage regulators, and PVSIs by interacting with the distribution system was proposed. Different types of devices were modeled as independent agents. Through this mechanism, independent agents share the same state and reward. However, they also adopt a centralized control scheme that requires heavy communication to obtain global information between agents. In [
20], a centralized off-policy maximum entropy reinforcement learning algorithm was proposed using a voltage regulator, CB, and OLTC. Their proposed algorithm showed good voltage violation and power loss performance with limited communication among agents. However, communication between agents is still required, despite the reduced amount of communication.
Hybrid approaches that combine model-based and model-free methods have also been investigated [
12,
21]. In [
21], a two-timescale control algorithm was proposed. On a slow timescale, the operations of OLTC and CBs are determined using the MISOCP-based optimal power flow method. In contrast, a DRL algorithm is applied to control the reactive power of PVSIs locally on a fast timescale. Similarly, a two-timescale and a hybrid of model-based and model-free methods for VVC were proposed in [
12]. Their proposed algorithm controls shunt capacitors hourly using the DRL algorithm and PVSIs in seconds, using an optimization framework to improve the voltage profile. However, these approaches have the same limitations as model-based algorithms that involve optimization problems.
Most VVC control schemes operate in a centralized manner, even with a data-driven approach. Centralized control schemes require communication between the central control center and field devices, such as PVSIs, resulting in an increase in the amount of communication and computational complexity. In addition, DSO cannot fully control PVSIs when solar PVs are owned by PV generation companies. Therefore, centralized control schemes are not practical for the real operation of distribution systems.
In this paper, we propose a heterogeneous multiagent DRL (HMA-DRL) algorithm for voltage regulation and network loss minimization in distribution systems, which combines the central control of dynamic DNR and local control of PVSIs (Centralized VVC normally controls OLTC and CBs. However, recent research shows that dynamic DNR further improves the performance in terms of energy savings [
7]. Therefore, in this study, we chose dynamic DNR as the main control method for the DSO using a switch entity because dynamic DNR can be used on top of a traditional VVC using OLTC and CBs). We use DRL algorithms for central and local controls, but they have different states, actions, and rewards, that is, heterogeneous DRL, because their ownership types are different. Through a case study using a modified 33-bus distribution test feeder, the proposed HMA-DRL algorithm shows the best performance in terms of total power loss with no voltage violation among model-free methods. The total power loss is the sum of the curtailed energy, owing to voltage violations and network power loss. The main contribution of this work is the practical applicability of the proposed HMA-DRL algorithm. These are listed as follows:
Control authority: The two main control entities (switches and PVSIs) are owned by different parties in general. Typically, DSO and PV generation companies have switches and PVSIs, respectively. Therefore, in this study, we give their control authority to the owners. The agent located at the central control center (CCC) operates switches by the DSO, i.e., dynamic DNR, to mainly minimize network power loss. On the other hand, the agents located at PVSIs control the reactive power of the PVSIs to maintain the voltage level in the normal range by the PV generation companies.
Practical communication requirement: Each agent has different levels of information because of the different control authorities. The DSO can monitor PVSI’s active and reactive power output of solar PV as well as the overall status of the distribution system. Therefore, the agent at CCC can use this information. In contrast, agents at PVSIs can only observe their own buses. Therefore, the proposed HMA-DRL algorithm does not require a communication link for the control signal from CCC to PVSIs. Instead, it only requires a feedback link from PVSIs to CCC (a feedback link for reporting a simple measurement reading can use a public communication link with encryption; however, the communication link for the control signal requires a high level of security, such as private communication, owing to its importance) and the control signal from CCC to switches (We assume that a communication link between the CCC and switches already exists because the DSO owns switches and takes charge of its operation). Because the control signal to each PVSI requires a higher security level than simple status feedback, we believe that this assumption on communication requirements is practical for distribution systems.
Heterogeneous multi-agent DRL: A heterogeneous multi-agent DRL algorithm is applied for voltage regulation and dynamic DNR to remove the dependency of the distribution system parameters. We modeled the state, action, and reward of the MDP for each agent, the MDP of the dynamic DNR with the overall status of the distribution system, while the MDP of the voltage regulation at PVSI utilizes local measurements. In this manner, the agent at CCC and agents at PVSIs learn an optimal policy that complements each other because each reward results from their simultaneous combined action.
The remainder of this paper is organized as follows. In
Section 2, we first describe the system model and formulate the optimization problem. In
Section 3, the proposed HMA-DRL algorithm is described. After demonstrating the performance of the proposed algorithm in
Section 4, we conclude this paper in
Section 5.
2. System Model and Problem Formulation
2.1. System Model
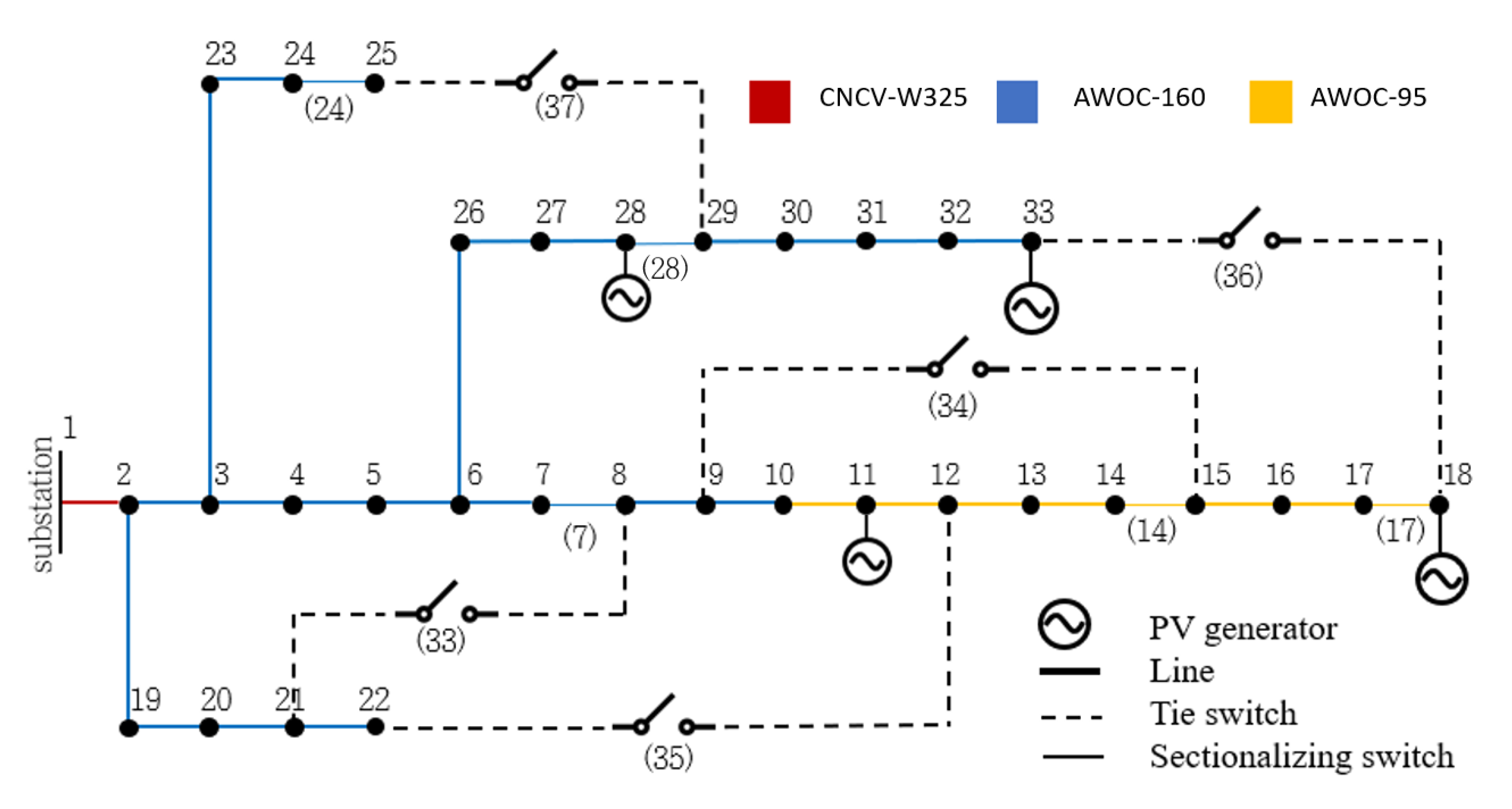
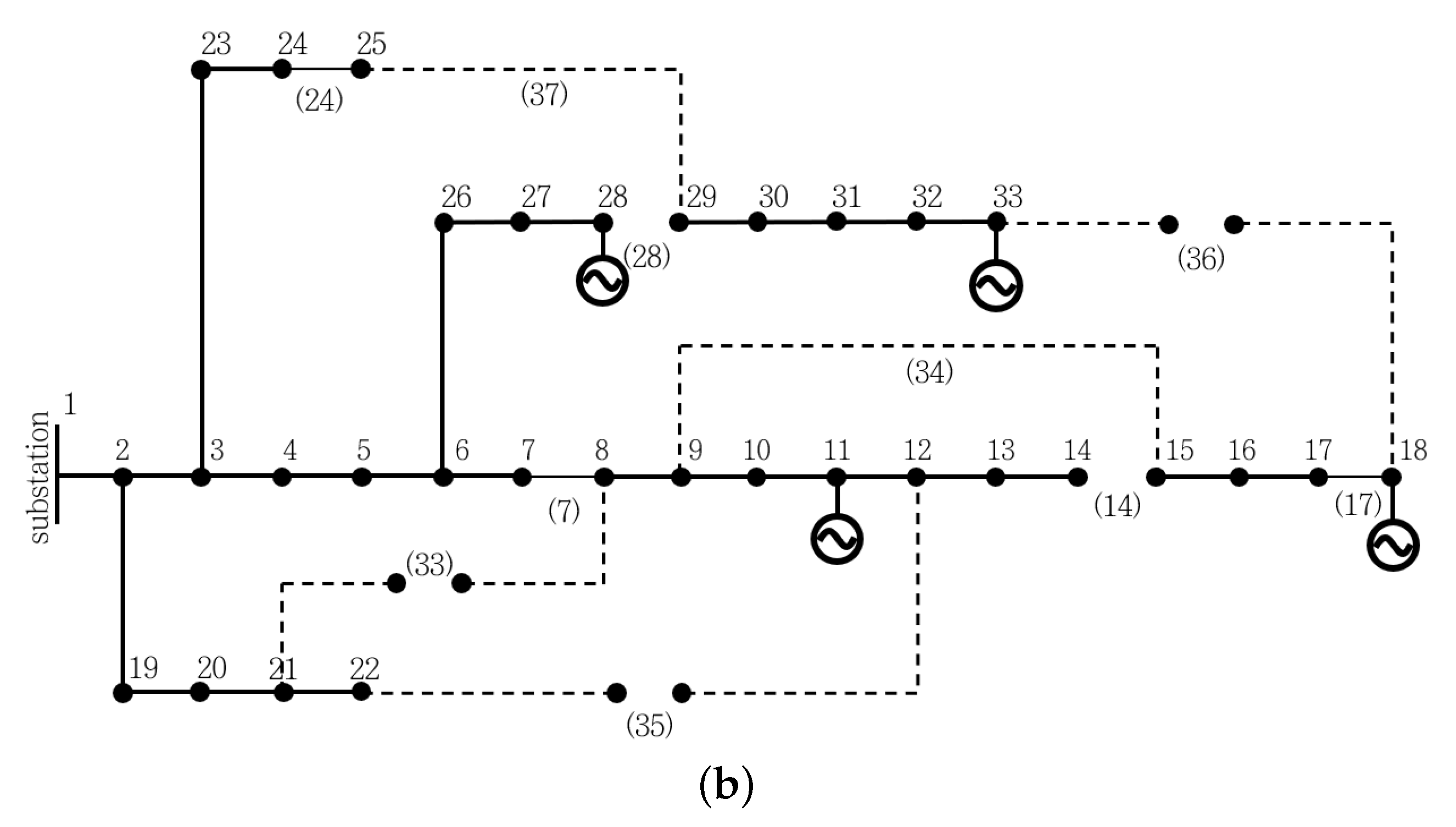
We consider a radial distribution system as shown in
Figure 1. The distribution system has several control units, such as sectionalizing and tie switches, OLTC, CBs, and solar PVs. Smart inverters operate all the solar PVs in this system. The control entities in this study are switches and PVSIs. The sets of buses and power lines are denoted as
and
, respectively. We assume that bus 1 is at the substation. We denote the set of buses with installed solar PV generators as
. Each day is divided by the control period and is denoted by a period set as
and the time index as
t. The phasor voltage and current in bus
n at time
t are
and
, respectively. Their magnitudes and phases angle are represented by
,
and
, respectively. The net active power and reactive power in bus
n at time
t are represented by
and
, respectively.
The voltage and current can be obtained by solving the power flow equations. At bus
n,
and
are computed as
The DSO accounts for the stable and reliable operation of the distribution system. In this study, the main control entity of the DSO is switches to operate the distribution system reliably. When a switch takes action, i.e., opens or closes, the topology of the distribution system changes, i.e., dynamic DNR. Therefore, we assume that the DSO centrally controls every switch, and the status information of the system is delivered to the control center. The DSO controls switches as long as the distribution system forms a radial network topology.
Another control entity is PVSIs, which have two control options: centralized and local. In centralized control of PVSIs, the DSO obtains information on the solar PV output and sends a control signal to the PVSI. This approach can achieve an optimal operation from a global perspective. However, this is not practical because solar PV owners should provide complete control to the DSO, and a reliable and secure communication channel is required between them. Therefore, in this study, we focus on the local control of PVSIs. We assume that a PVSI installed on bus k can only observe local information, i.e., , and , and take action by itself, which is a more practical assumption.
Note that a feedback link exists between the solar PV generators, and the CCC from solar PV generators to CCC exists. This link requires a low level of security because it only delivers the status of the PVSIs to the CCC. This link can be a public link, i.e., the Internet, with encryption, rather than a private link. This is a realistic assumption for a communication network in the distribution systems.
2.2. Centralized Optimization
In this section, we describe the role of the DSO as an optimization framework. Stable and reliable operation of the distribution system is the first requirement of a DSO. As long as this requirement is fulfilled, the DSO wants to operate the distribution system economically. The two control variables in this optimization framework are the switch status and the reactive power outputs of the PVSIs. Let
denote a binary variable representing the status of switch located in line
o at time
t. If the switch is closed, its value is one. Otherwise, it is 0. The reactive power output of the PVSI installed on bus
k at time
t is
. We formulate the optimization framework of the DSO as follows:
The objective function of the problem is to minimize the network loss in the distribution system while maintaining the distribution system constraints.
The distribution system constraints are given by Equations (
4a) and (
4b), respectively. In other words, the DSO should maintain all voltages and currents in the system within the regulation range (Power lines near the substation have more capacity than those at the end of feeders in the distribution system. Therefore, power lines located near the substation have a higher current flow limit. A detailed specification of power lines is given in
Section 4.1). One of the major constraints of dynamic DNR is that the distribution system remains to operate in a radial topology despite switching actions. Let
and
denote a vector of the switch status and a feasible set of switching actions that guarantees the radial topology of the distribution system, respectively. Therefore, Equation (
4c) describes the radial constraint of the distribution system. A feasible set for the radial constraint can be made using the spanning tree characteristics [
9]. When the topology created by
satisfies the following conditions,
is a member of
. That is
:
where
and
are the set of all buses directly connected to bus
n and a binary variable whose value is 1 if bus
m is the parent of bus
n and 0, otherwise, respectively.
Because switching actions reduce the lifespan of switches, we add a constraint of maximum switching numbers per day, as shown in Equation (
4d). The final constraint, that is, Equation (
4e), describes the reactive power output of a PVSI. Its maximum output is bounded by the capacity of the PVSI
and the current real power output of the PV
[
22].
The problem is not a convex optimization problem because of the non-linearity of the power flow equations and integer control variables. In addition, it requires a high level of security communication because the DSO sends control signals (reactive power output) to the PVSIs. Finally, the DSO can solve this problem by knowing the distribution system parameters, such as power line impedance, load, and solar PV output. Therefore, we propose using a model-free algorithm to overcome these limitations.
3. Heterogeneous Multi-Agent DRL Algorithm
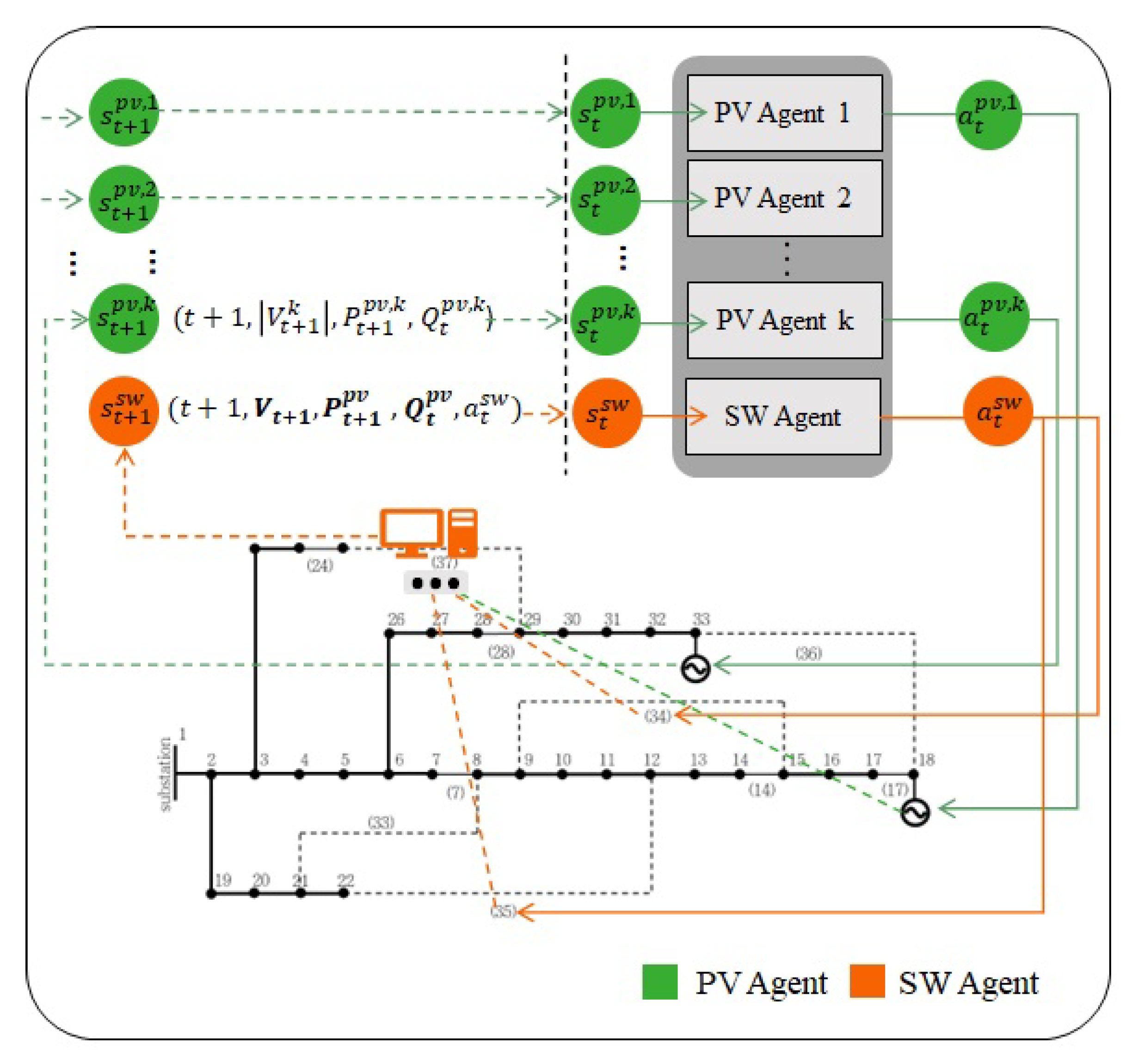
We propose a HMA-DRL algorithm for voltage regulation and network loss minimization in distribution systems that combines the central control of dynamic DNR and local control of PVSI.
Figure 2 shows the framework of the proposed HMA-DRL algorithm. The proposed HMA-DRL algorithm divides the control entities into two main parts: an agent at CCC (SW agent) and agents at PVSIs (PVSI agent). The two different agents operate independently. In central control, the DSO controls the switches to minimize network loss while maintaining the radial constraint. To this end, the DSO monitors the real power and reactive power of buses and obtains voltage and current through power flow calculations (Recent research has shown that machine learning-based models can approximate the power flow without distribution network parameters [
23,
24]). In local control, PVSIs control their reactive power output to avoid an overvoltage problem at the bus. The agents at PVSIs only know their own active power output and voltage level at the bus.
3.1. Multi-Agent Markov Decision Process
To train agents in a cooperative manner, we define a multi-task decision-making problem as a multi-agent MDP. The multi-agent system in this work is a heterogeneous multi-agent system that has different MDPs for different types of agents [
25]. The agent at CCC and agents at PVSIs have different types of agents because their ability to obtain information and control entities are different. Therefore, the agent at CCC and agents at PVSIs independently learn their policies, while other agents are regarded as part of the environment [
26]. The multi-agent MDP is composed of (
), where (i)
X and
x denote a set of agents and their indices, respectively. (ii)
is the joint space of state. (iii)
denotes the joint action space of the agents. (iv)
denotes the expected local reward of agent
x received after the state transition. (v)
is the state transition probability, and (vi)
is a discount factor.
Each agent takes an action moving to a new state and receives a reward. The process ends when the terminal state is reached. Through these processes, the sum of the discounted local reward
of agent
x at
t is calculated as follows:
The goal of MDP is to find a policy that maximizes . A policy is the probability of choosing an action in a given state . If the agents are the agent at CCC and agents at PVSIs, x is set as and , respectively.
3.2. MDP for Agent at CCC
The agent located at the CCC controls the open and close actions of switches, that is, dynamic DNR, because this action requires global information to maintain the radial topology of the distribution system. We define the state, action, and reward of this agent to minimize the sum of the network power losses in the distribution system while maintaining the voltage and current in the normal range.
3.2.1. State
We assume that the agent at the CCC can efficiently estimate the state of the distribution system, that is, the voltage of each bus, and obtain the output of PVSIs, including active and reactive power, through a feedback link (Each agent at PVSI sends its active and reactive power to the DSO every hour because the agent at DSO control switches status hourly. The latency requirement of this data is less than five seconds [
27]). The state of MDP at
t is defined as the time, voltages of all buses, real power outputs of PVSIs, reactive power outputs of PVSIs at
, which are previous actions of PVSIs, and switching status at
, that is, the previous action of the agent at the CCC. It is defined as
We put previous actions into the current state because the agent at CCC understands the other agents’ actions, resulting in a better choice of action at the current time.
3.2.2. Action
For the agent at CCC, an action at t is the opening and closing of each switch, that is, . After taking action, the topology of the distribution system changes. As the set of feasible actions is already defined, the agent takes action in the set. In this manner, the radial constraint of the optimization problem, that is, Equation (4c), is fulfilled by setting .
3.2.3. Reward
Because the MDP does not easily have constraints, we model the reward as a combination of the objective function and constraints of problem
. The reward consists of three parts: voltage violation and power loss
, current violation
, and penalty for frequent switching actions. That is
We select the first two reward terms,
and
as step functions to effectively train the agent. From the point of problem
view, we model
for the network loss minimization and voltage violation, that is, Equations (
3) and (
4a), and is given as
The agent at CCC obtains a positive reward when the network loss of the new topology is less than that of the initial topology without any voltage violation. The agent receives a negative reward for the voltage violation. Therefore, the agent preferentially avoids any voltage violation.
Next,
is modeled to imply a current violation, as shown in Equation (4b). It is
When a current violation occurs in the distribution system, the agent at CCC receives a highly negative reward. Note that the reason for the time index is that the agent receives a reward based on the outcome of its action at t. The last term corresponds directly to Equation (4d). Frequent switching action are not preferred. We put a negative reward per switching action and weight w on the hyperparameter adjusted by the DSO.
Note that the objective function and all the constraints in the problem are included in this MDP formulation except the reactive power constraint, that is, Equation (4e). This is because the DSO cannot control the reactive power of PVSIs. Therefore, the MDP formulation for PVSIs includes this constraint.
3.3. MDP for Agents at PVSIs
Agents located at PVSIs operate in a distributed manner because they have no global information. They control their reactive power using only the local information. The objective of these agents is to keep their bus voltage stable rather than minimizing the sum of network power losses. This is because obtaining the sum of network power losses is not possible without global information.
3.3.1. State
Considering the condition that PVSIs can observe only their generation profile, we define the state of agent
k as current time
t, voltage magnitude of the bus that PVSI installed as
, real power output of PVSI as
at the current time, and reactive power output of PVSI at the previous time as
. That is,
3.3.2. Action
The possible actions of the PVSI are its reactive power output. By controlling the reactive power, the curtailed energy of the active power output can be avoided, that is, by maintaining its voltage level in a stable range. The maximum reactive power output is bounded by the active power output and capacity of the inverter, as expressed in Equation (4e). For example, when the output of a PVSI is 0.9 p.u., the maximum reactive power output of the smart inverter is
p.u. Therefore, we set the control range of reactive power in this case study as
(In the case study, we use real solar PV output data from Yeongam, South Korea [
28]. These data show that the PV output peak of 0.93 p.u. occurred in March, so the PVSI can absorb reactive power up to
p.u. without over-sizing the PVSI. Therefore, the proposed HMA-DRL algorithm has almost no issue with this reactive power margin. However, in case of the PV output peak is 1 p.u., it is recommended to install a power conditioning system (PCS) with a 10% margin, i.e., 1.1 p.u., to use voltage regulation algorithms [
29]). We define action as the difference in reactive power outputs between
and
t in a discrete manner. That is,
Note that each action is constrained by reactive power limit as shown in Equation (4e).
3.3.3. Reward
Because the agents at PVSIs try to minimize the curtailed energy of their active power, the objective of agents at PVSIs is to maintain their bus voltage stable. In addition, when there is no voltage violation, PVSIs help reduce the network power loss. We define the reward as a penalty for the severity of voltage violation, in case of voltage violation. The reward in the no voltage violation condition is set as the negative of the square of the apparent power. Because the apparent power and current injection, i.e.,
), are directly proportional, this reward represents power loss near the bus. The reward function for the agent at the PVSIs is defined as
where
is a constant variable that adds an additional stage to the voltage violation. Because the reactive power control of PVSIs effectively mitigates the voltage violation problem more than dynamic DNR, we model the penalty for the voltage violation as more severe than that of the agent at CCC.
Although PV generation companies have no gain from reducing network power loss, they can help reduce network power loss. This is because the control of the extra reactive power of PVSIs does not negatively affect the PV generation companies. Other voltage regulation research using PVSIs also assumes that PV generation companies cooperate to improve the distribution system efficiency.
3.4. Multi-agent DRL Training Process
As an individual action–value function for the proposed multi-agent MDP, we adopted a DQN [
30], a representative value-based and off-policy DRL algorithm. It is because multi-agent DRL algorithms are generally difficult to train and achieve stable performance. Therefore, we limit the action space to a discrete set and then apply a value-based DRL algorithm. Each agent updates its action–value function
at
t via following the Bellman equation:
where
and
denote the learning rate and the discount factor, respectively. (In this paper, there are two meanings of notation
Q, i.e., action–value function and reactive power. The
Q variable without any sub- and super-script represents the action-value function, and all the other cases represent reactive power.) We use
-greedy policy to train the DQN. An agent performs action
with probability
, which is the best action thus far. On the other hand, it selects a random action with probability
to explore a better action than the current best action. For stable and efficient training, we set
as a function of time, which decreases over time.
After performing an action, the agent stores the experience tuple
in replay buffer
D, which is used to update the weights of the DQN. The target
Q function is defined as
. Then, the loss function of the DQN is the difference between the target and current
Q values as
where
is the parameter of DQN.
The training process of the proposed HMA-DRL algorithm is summarized in Algorithm 1. Note that we used a simulation environment with historical PV and load data, that is, offline training, to efficiently and safely train the heterogeneous DRL. In a simulation environment, agents are free to explore actions and states without considering any damage to the distribution system.
| Algorithm 1: Multi-agent DRL training process. |
- 1:
Initialize replay buffer - 2:
Initialize DQN parameter - 3:
for to do - 4:
Initialize state of all agents - 5:
for to T do - 6:
= random(); - 7:
if then - 8:
Choose random actions - 9:
else - 10:
Obtain actions and , - 11:
end if - 12:
Change topology according to - 13:
- 14:
Power flow calculation: observe - 15:
Power flow calculation at : observe - 16:
- 17:
Store transition in - 18:
Update and by Equation ( 15) - 19:
for all agents - 20:
end for - 21:
end for - 22:
return
|
5. Conclusions
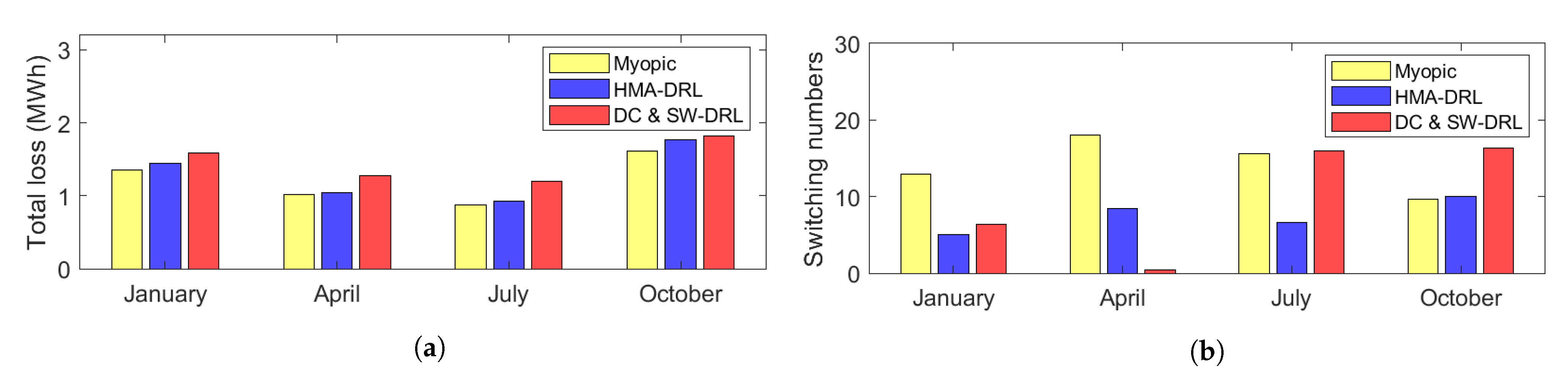
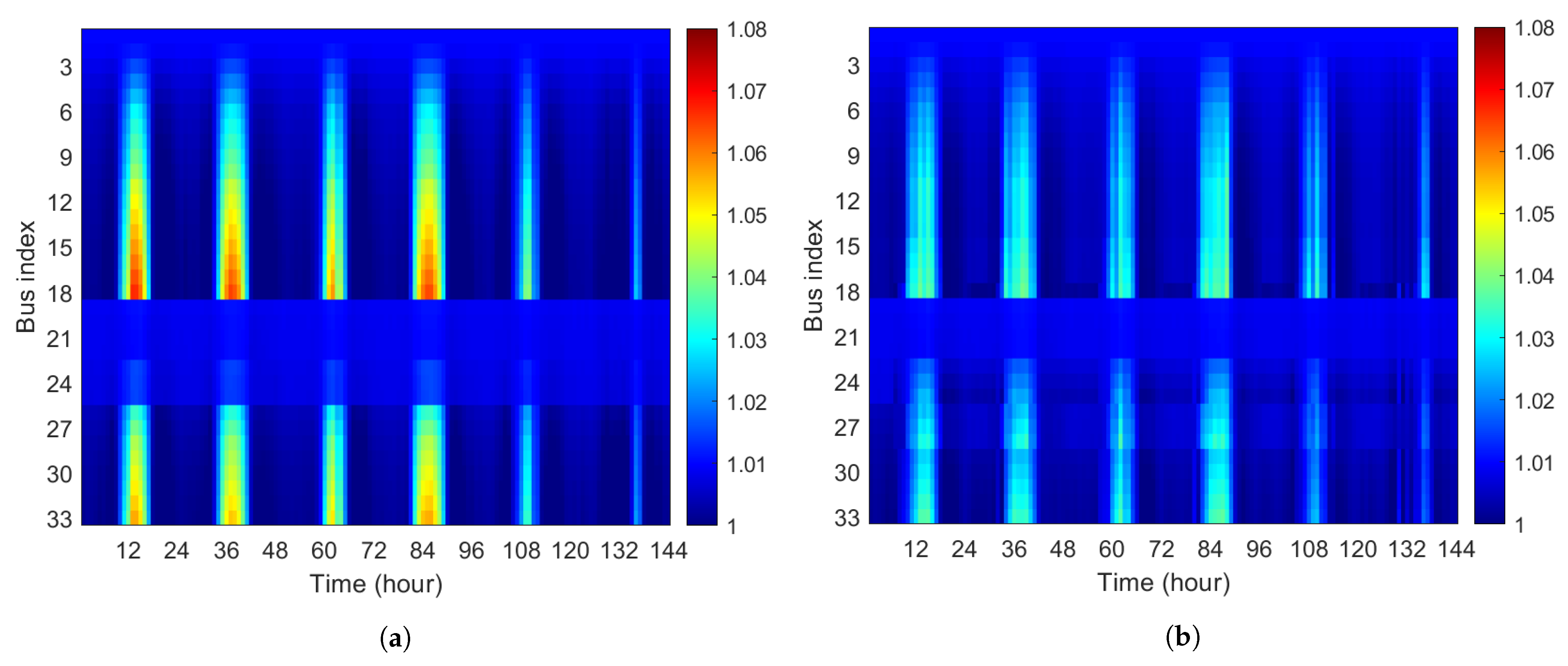
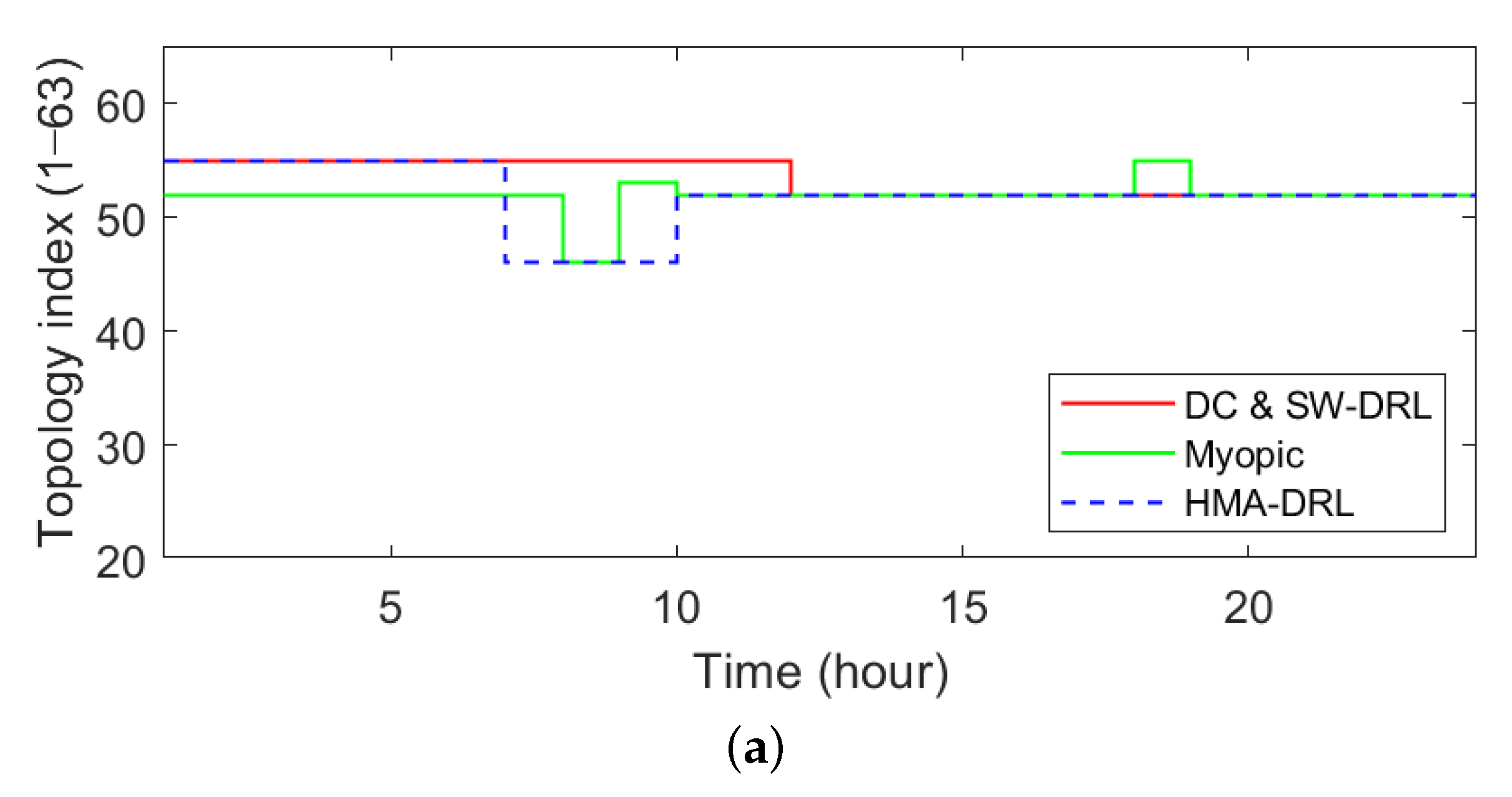
In this study, we propose a heterogeneous multi-agent deep reinforcement learning (HMA-DRL) algorithm to minimize network power loss while maintaining the voltage levels within the specified operational range. We considered two control entities: switches and solar PV smart inverters (PVSIs). Considering ownership of the two control entities, they are controlled by the DSO (centralized) and PV generation companies (distributed), respectively. In the proposed algorithm, the agent at the central control center operates switches, that is, the dynamic DNR, with complete information on the distribution system. It aims to minimize the power loss in the system while maintaining the voltage levels in the normal range. On the other hand, the agents at PVSIs take the action of reactive power output with local information. They do not require any information from neighbors or the DSO. The agents at PVSIs only aim to maintain their local voltage levels within the normal range. The heterogeneities of ownership, level of information acquisition, and actions make the proposed HMA-DRL algorithm practical for a real distribution system. Through case studies using the modified 33-bus distribution test feeder, the proposed HMA-DRL algorithm performs the best among model-free algorithms in terms of the total power loss in the distribution system. It shows a performance of 93.13% of Myopic, which can be regarded as the optimal solution. In addition, the proposed HMA-DRL algorithm shows stable and robust performance because it shows good performance throughout the year, and the standard deviation of its performance has the smallest value among the different schemes compared.
In future work, we plan to investigate a more robust approach using safe reinforcement learning (RL) to protect distribution networks from unexplainable actions [
36]. Additionally, energy storage systems can be considered to further improve system performance.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}