
Numerical Demonstration of Unsupervised-Learning-Based Noise Reduction in Two-Dimensional Rayleigh Imaging



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Numerical Analysis and Methodology
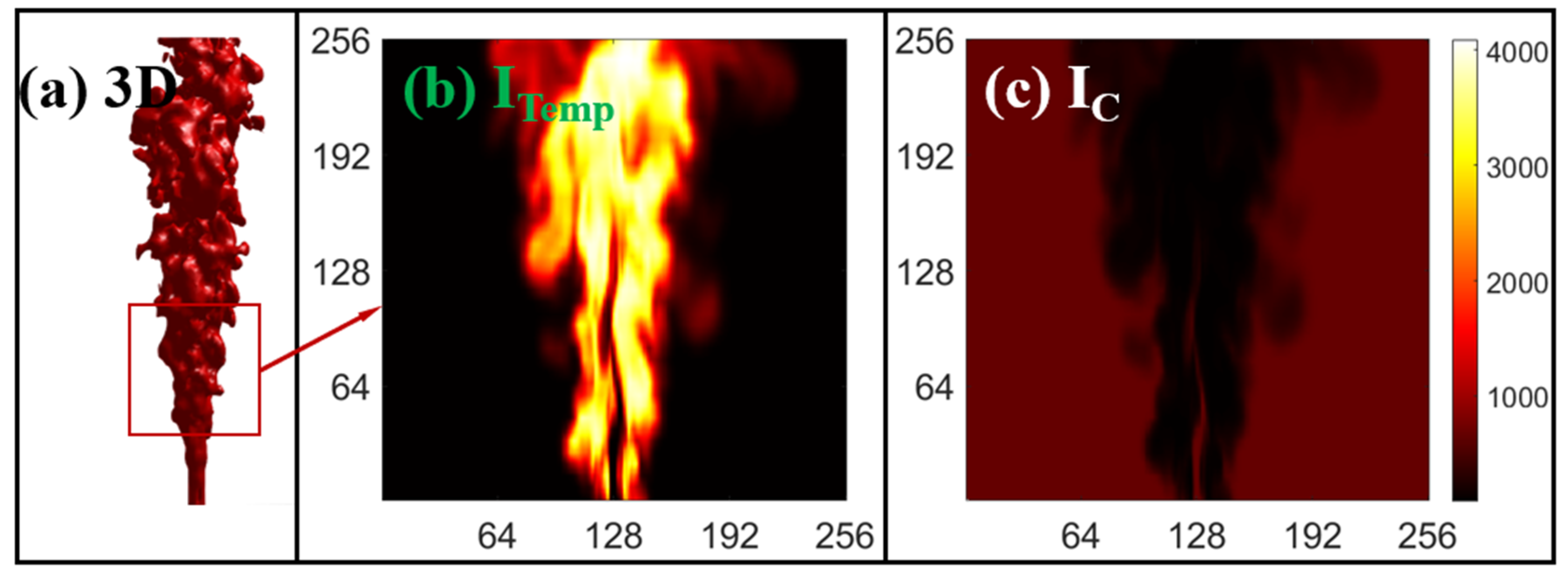
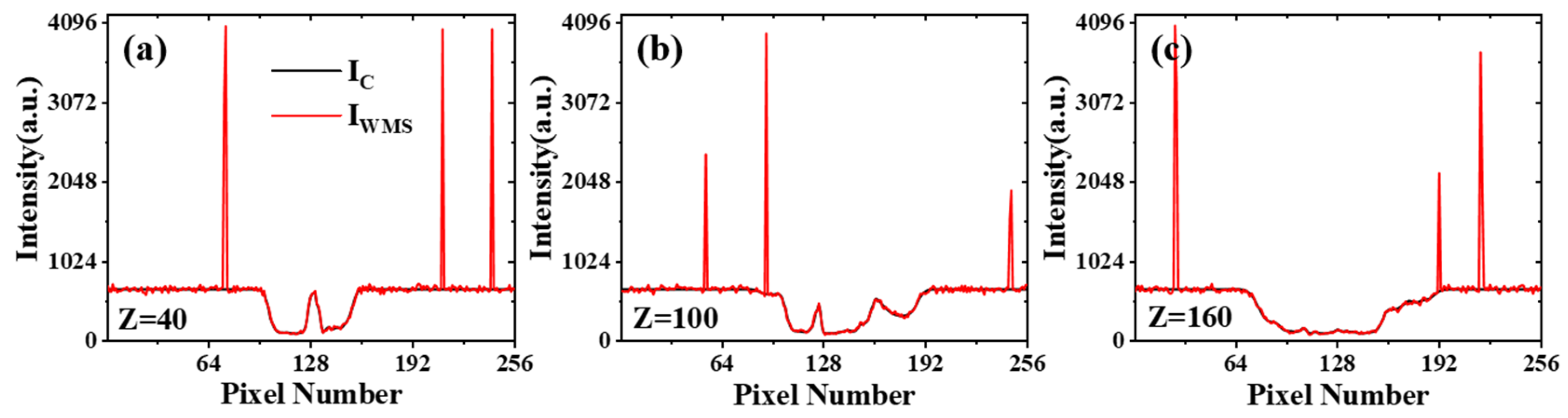
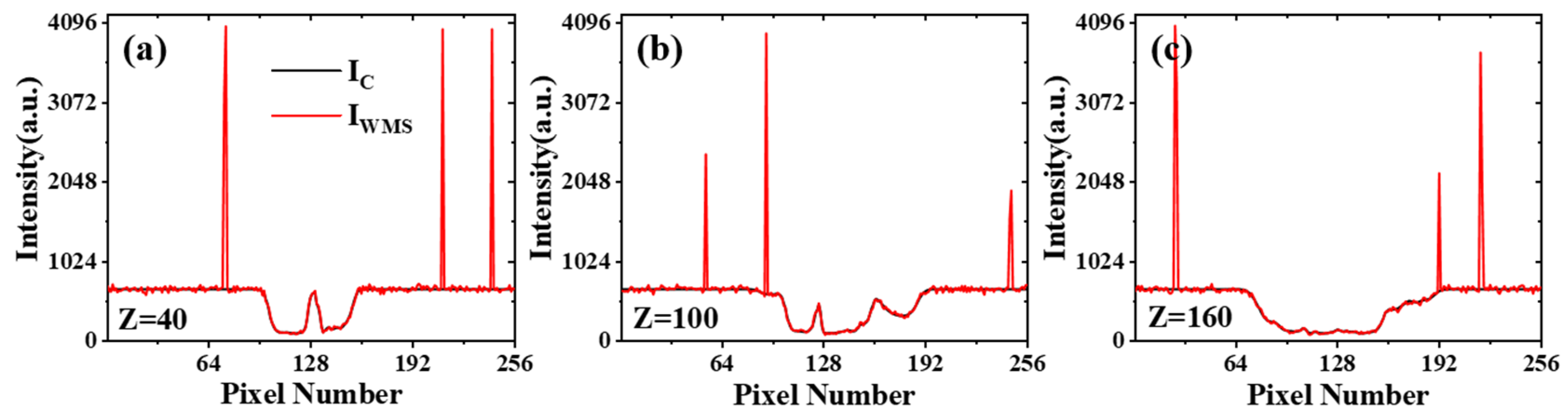
2.1. Data Generation
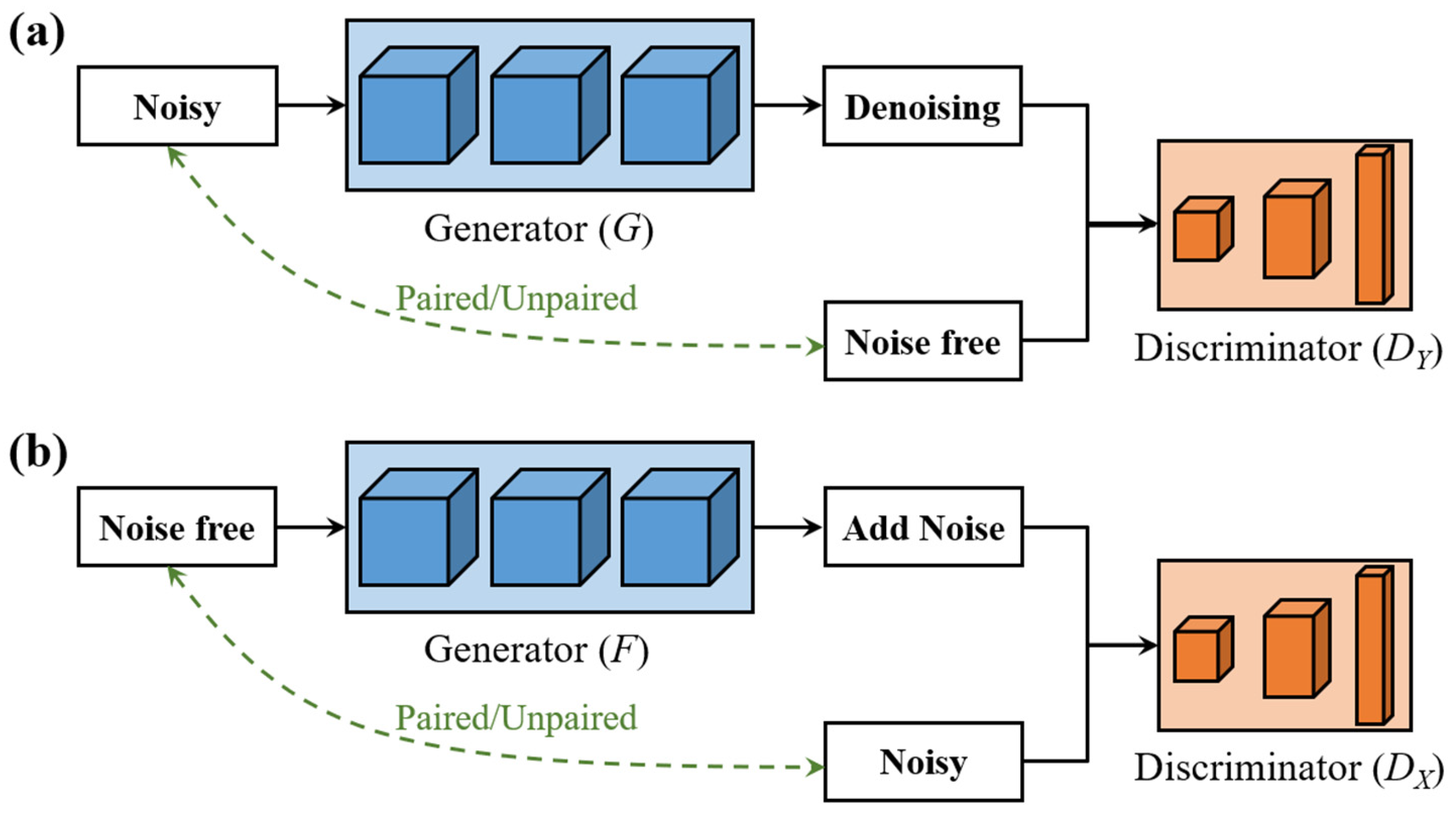
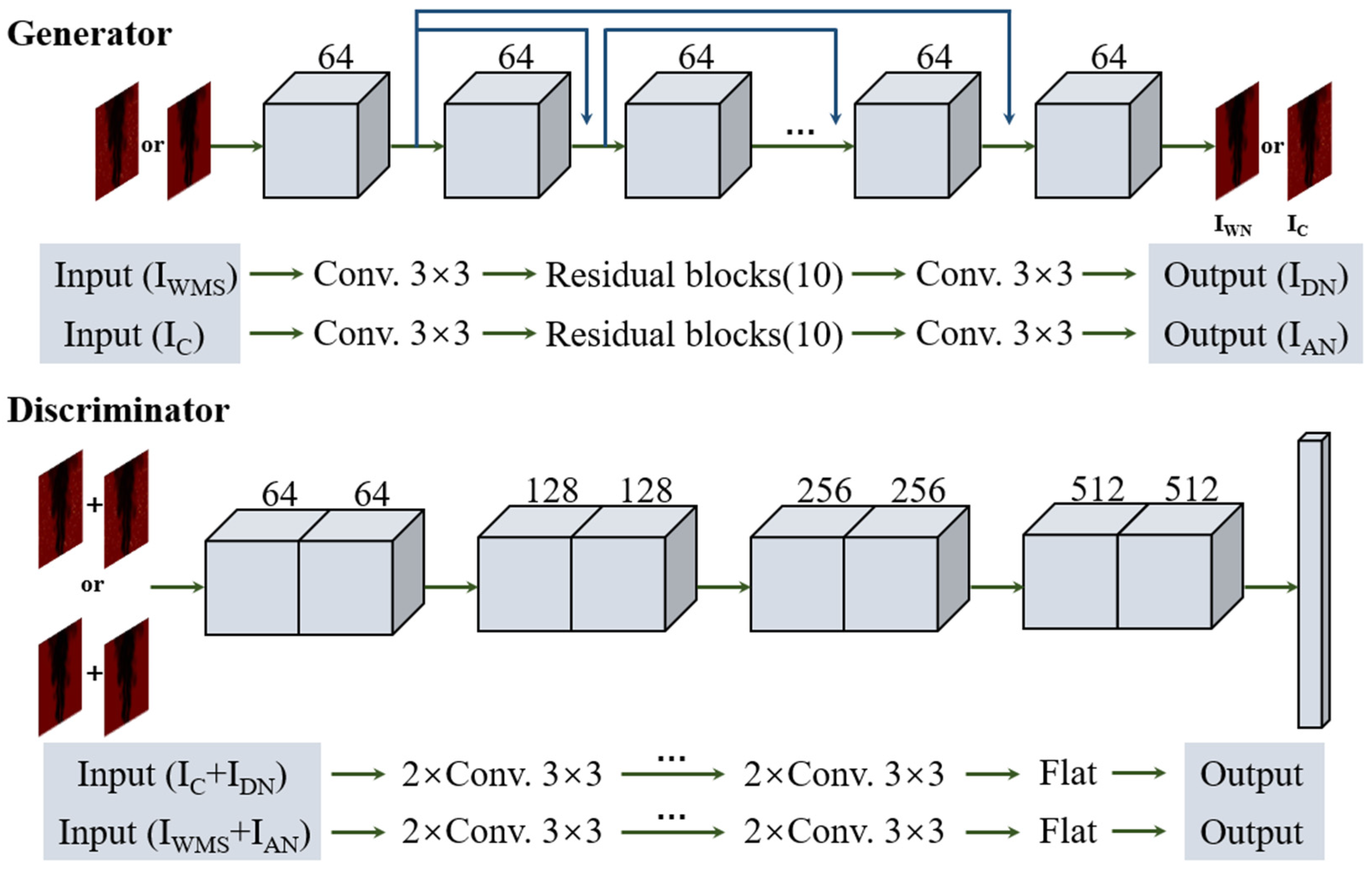
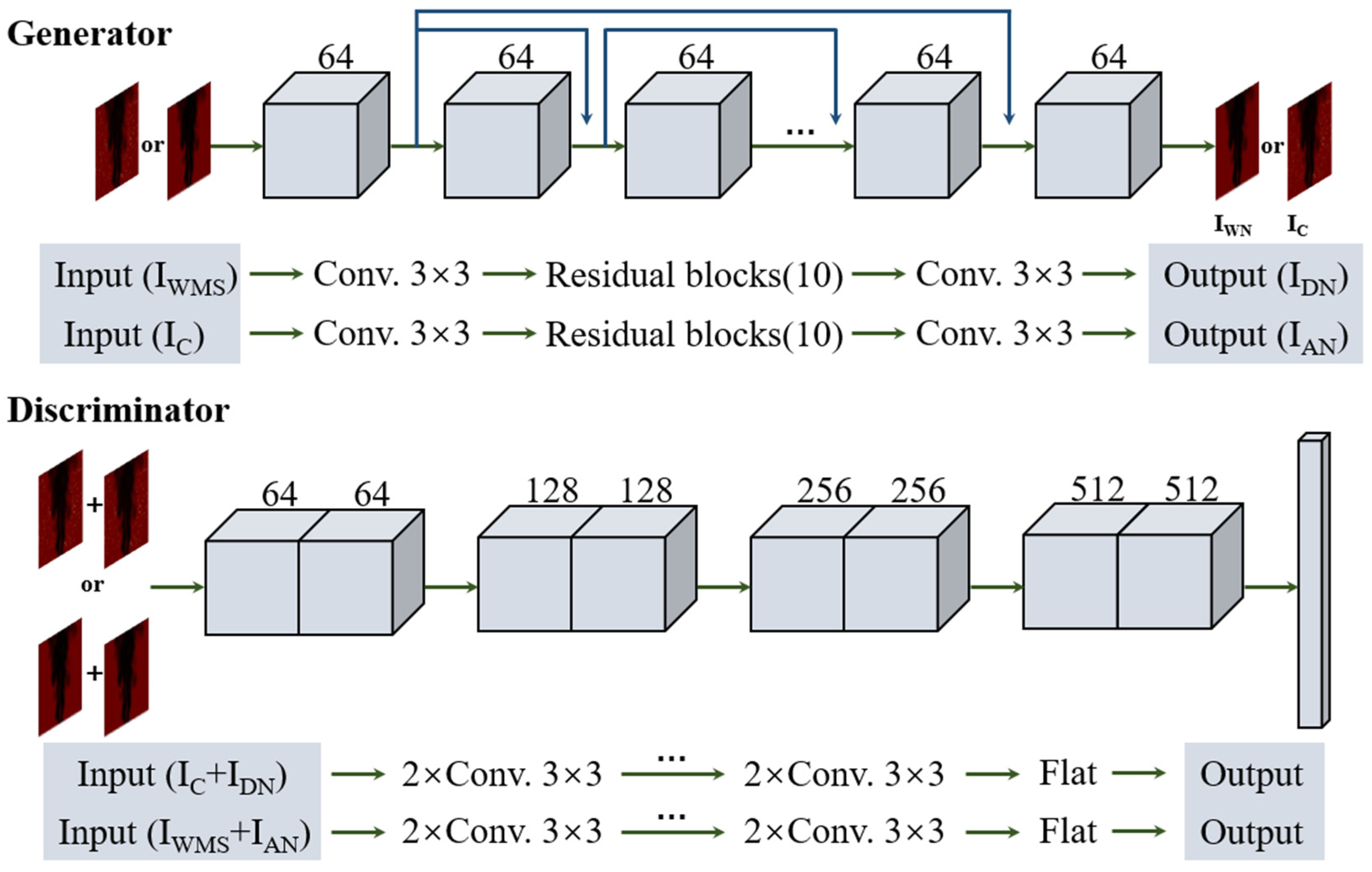
2.2. Denoising Model Architecture
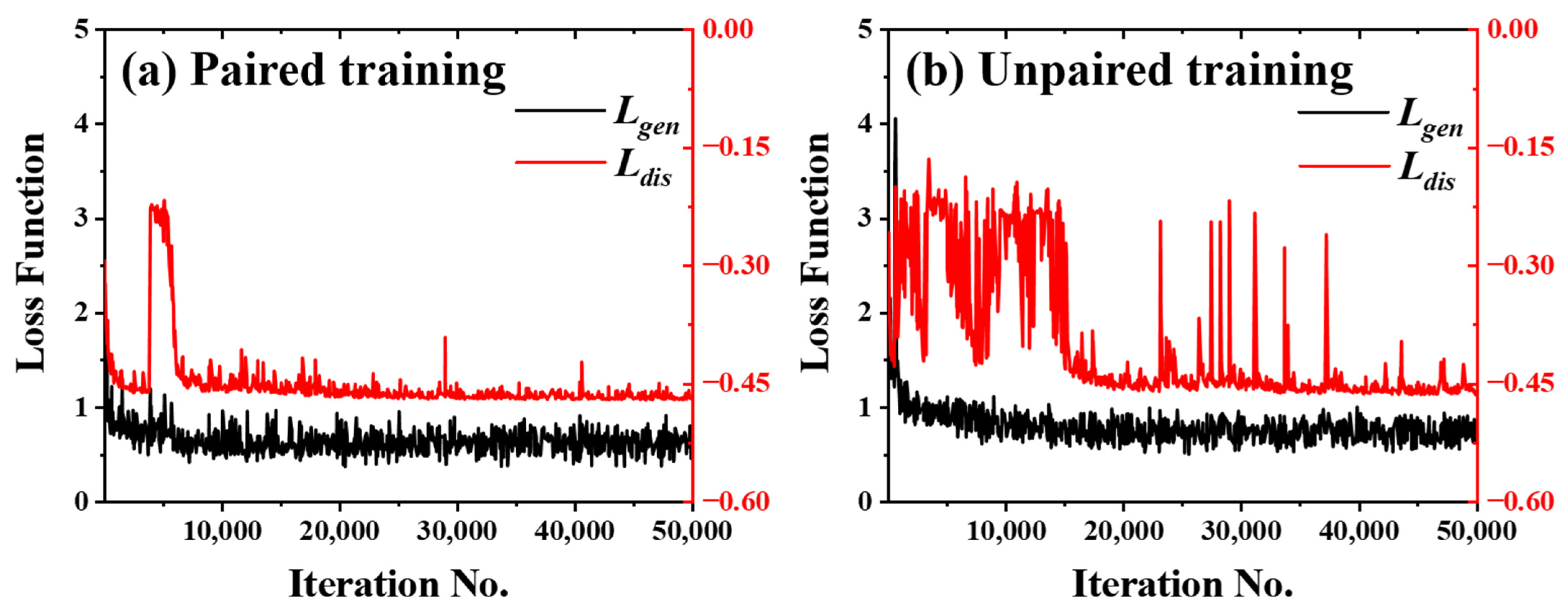
2.3. Model Training and Testing
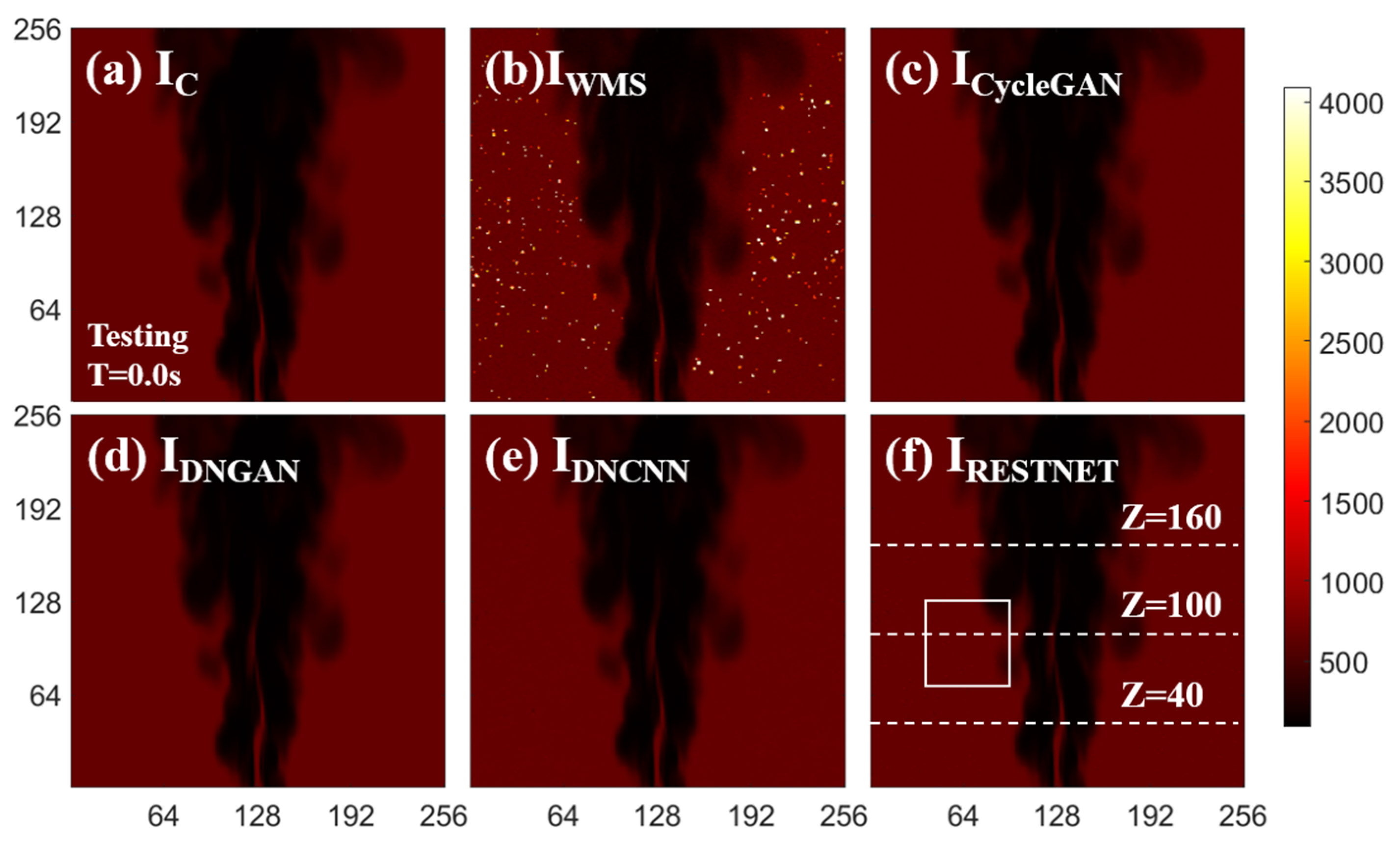
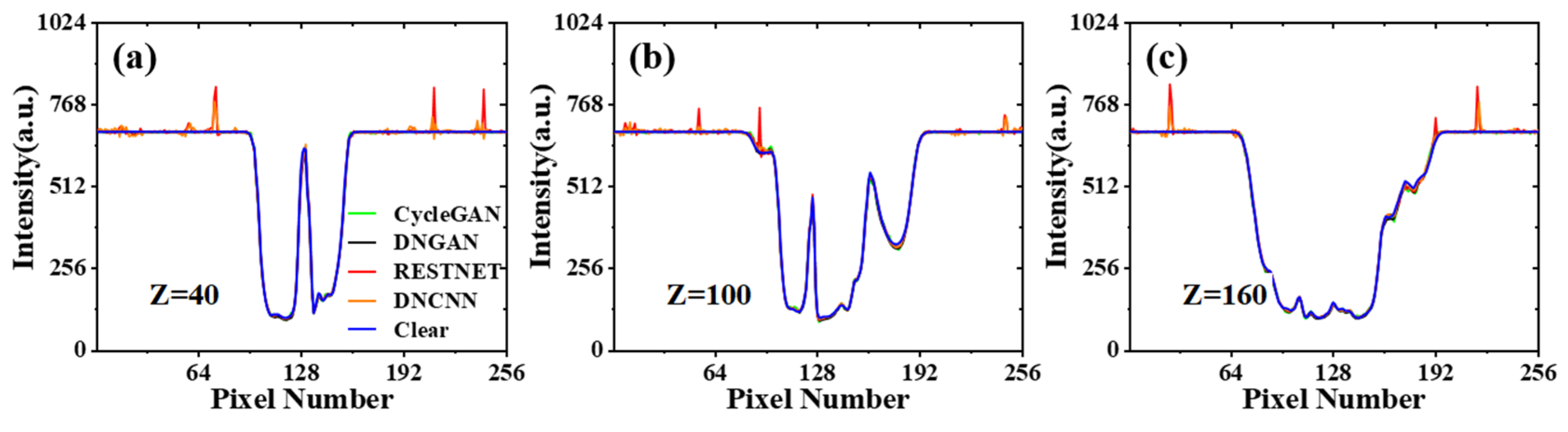
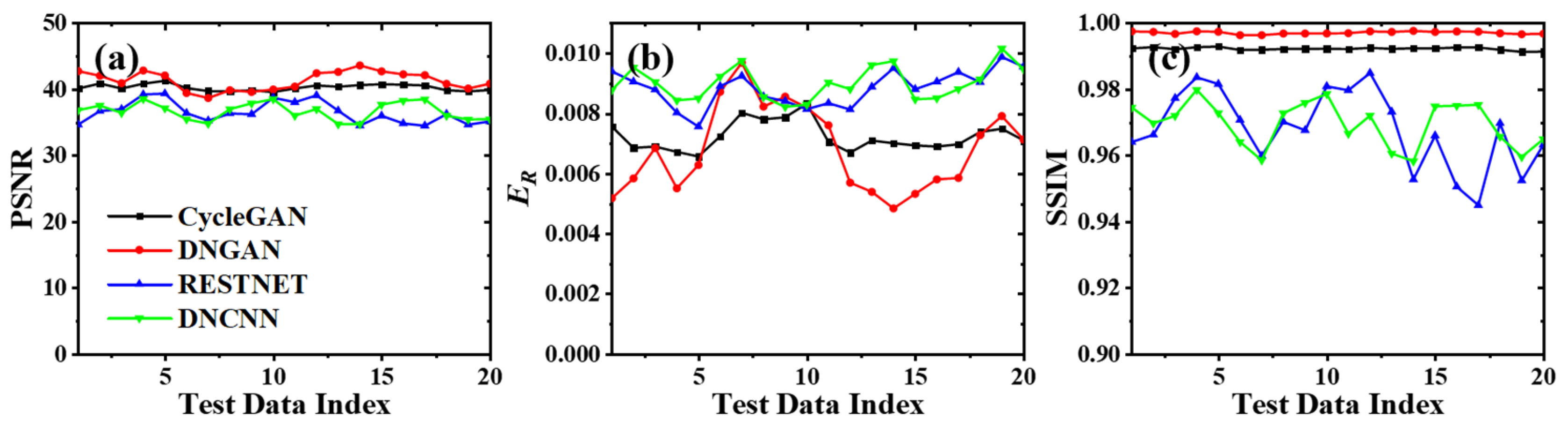
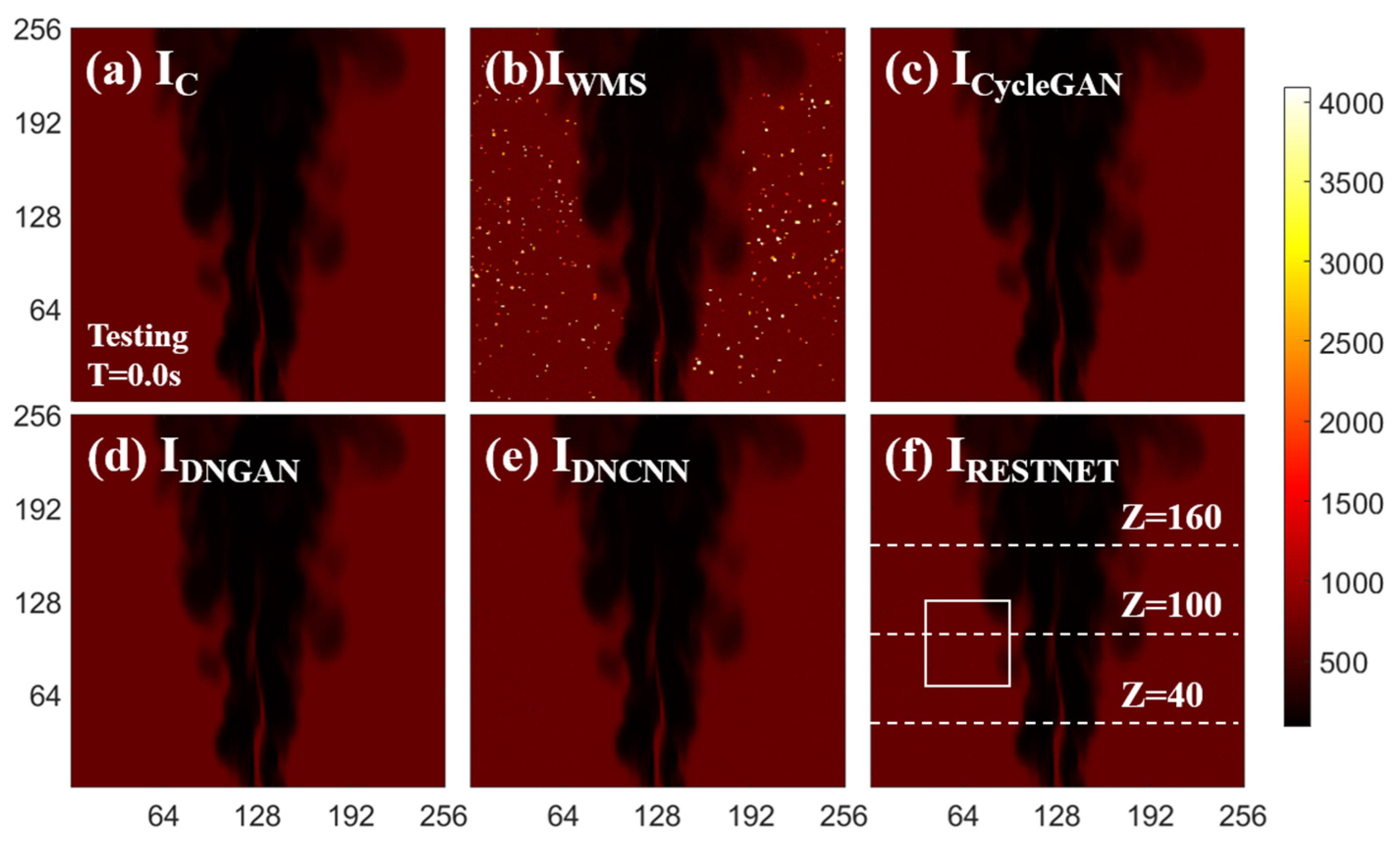
3. Results and Discussion
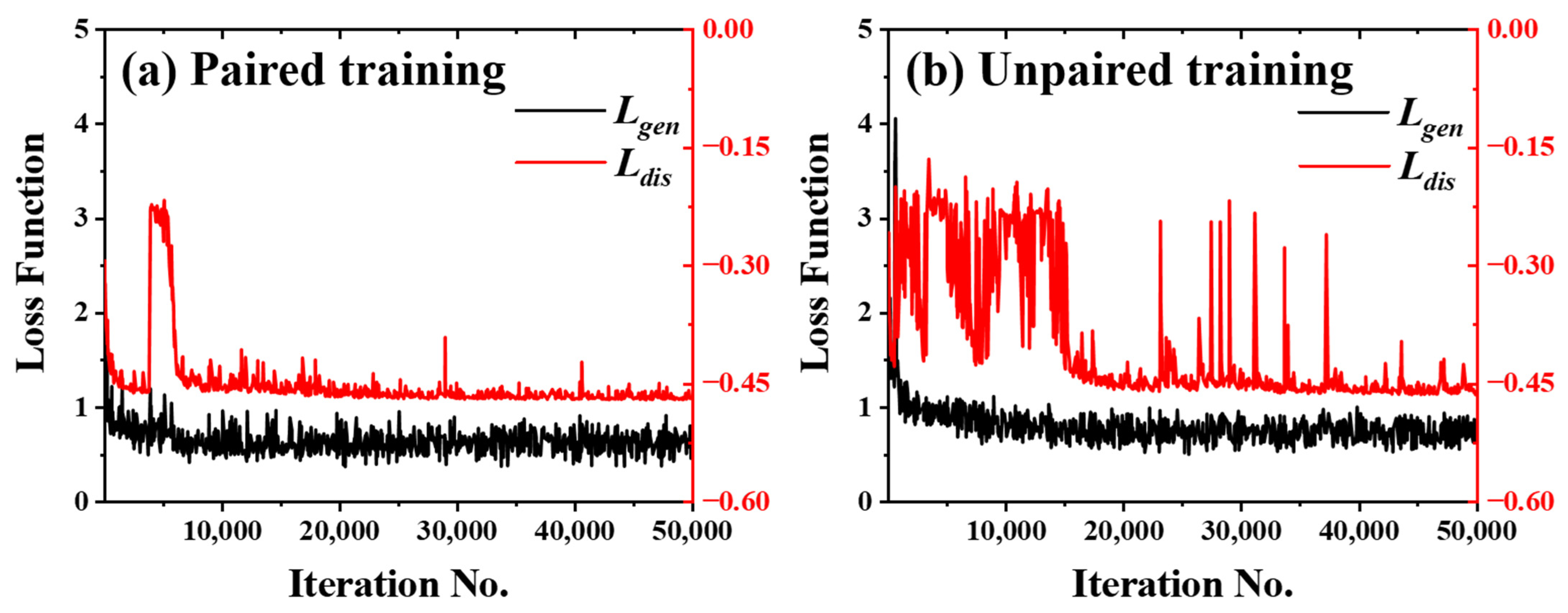
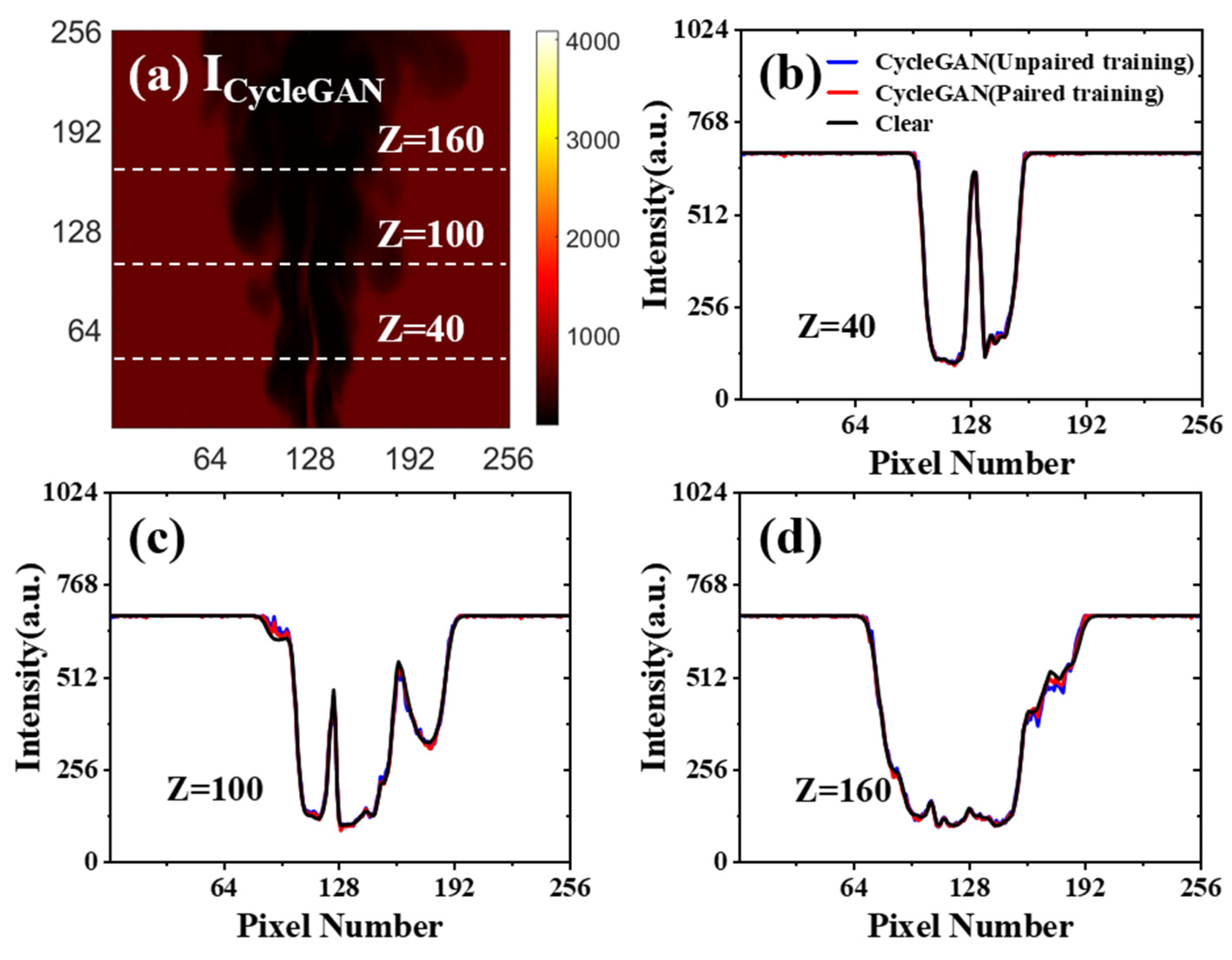
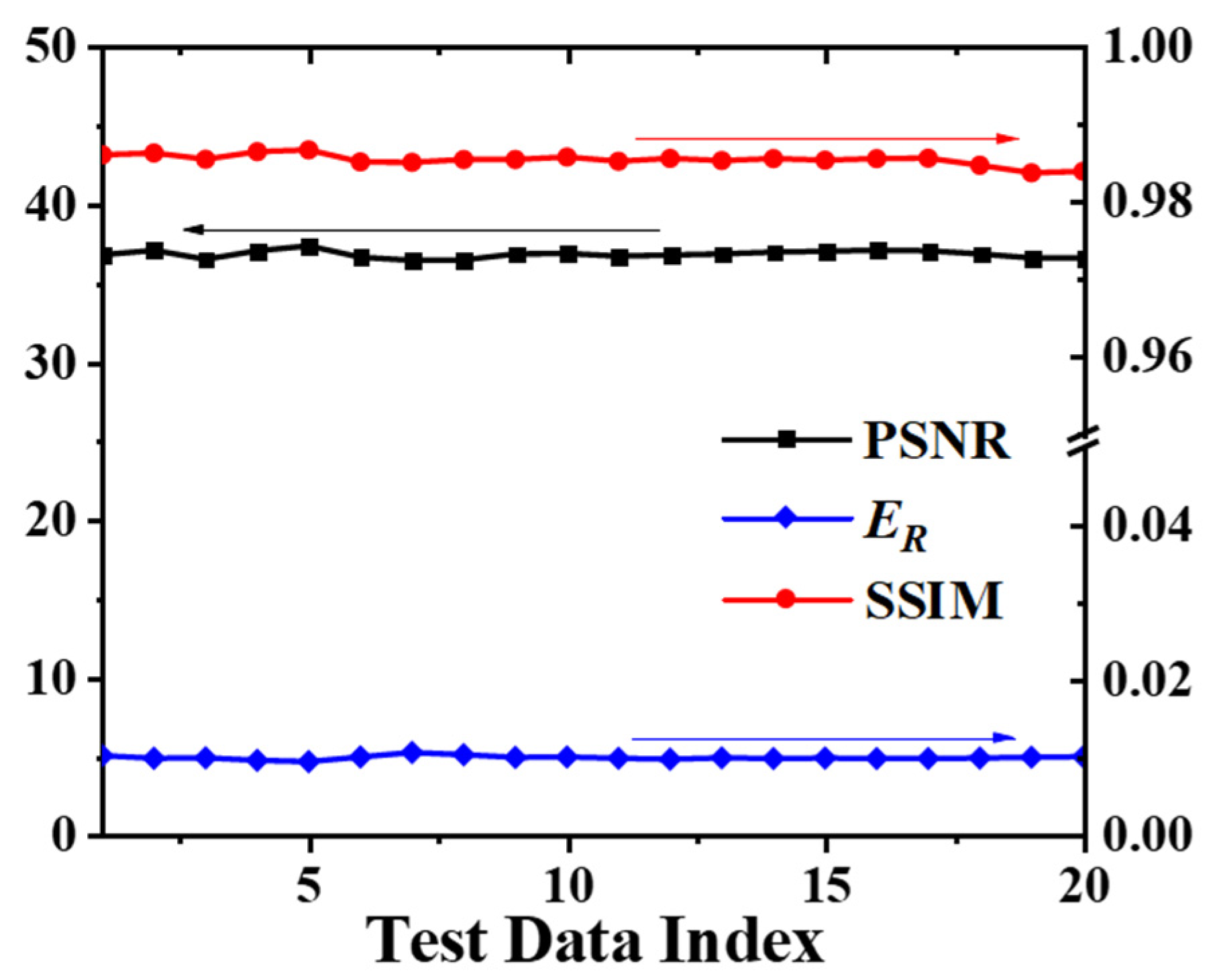
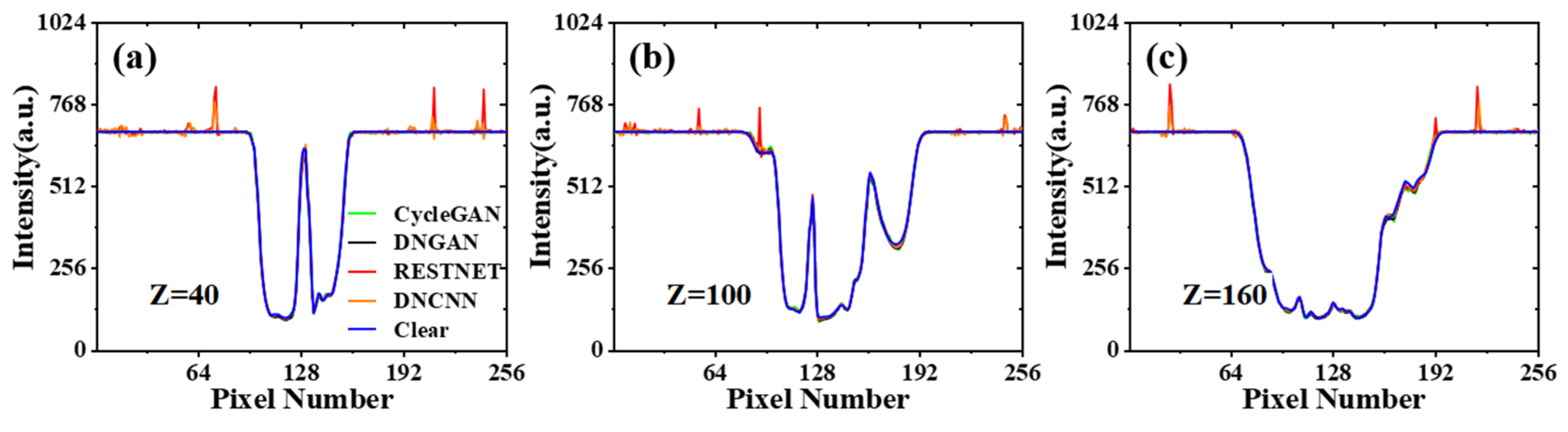
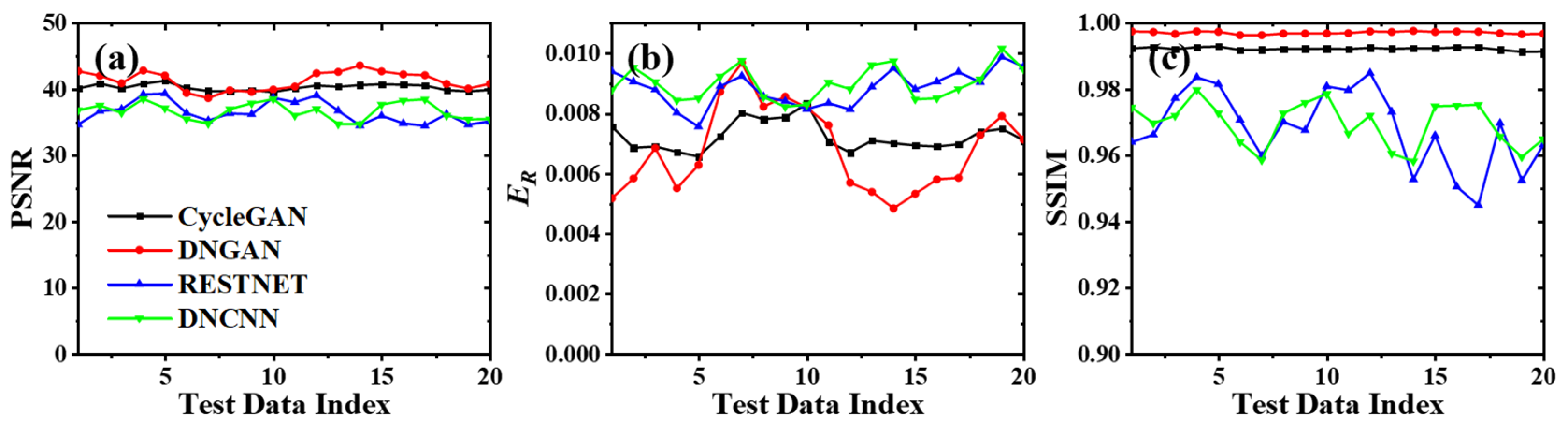
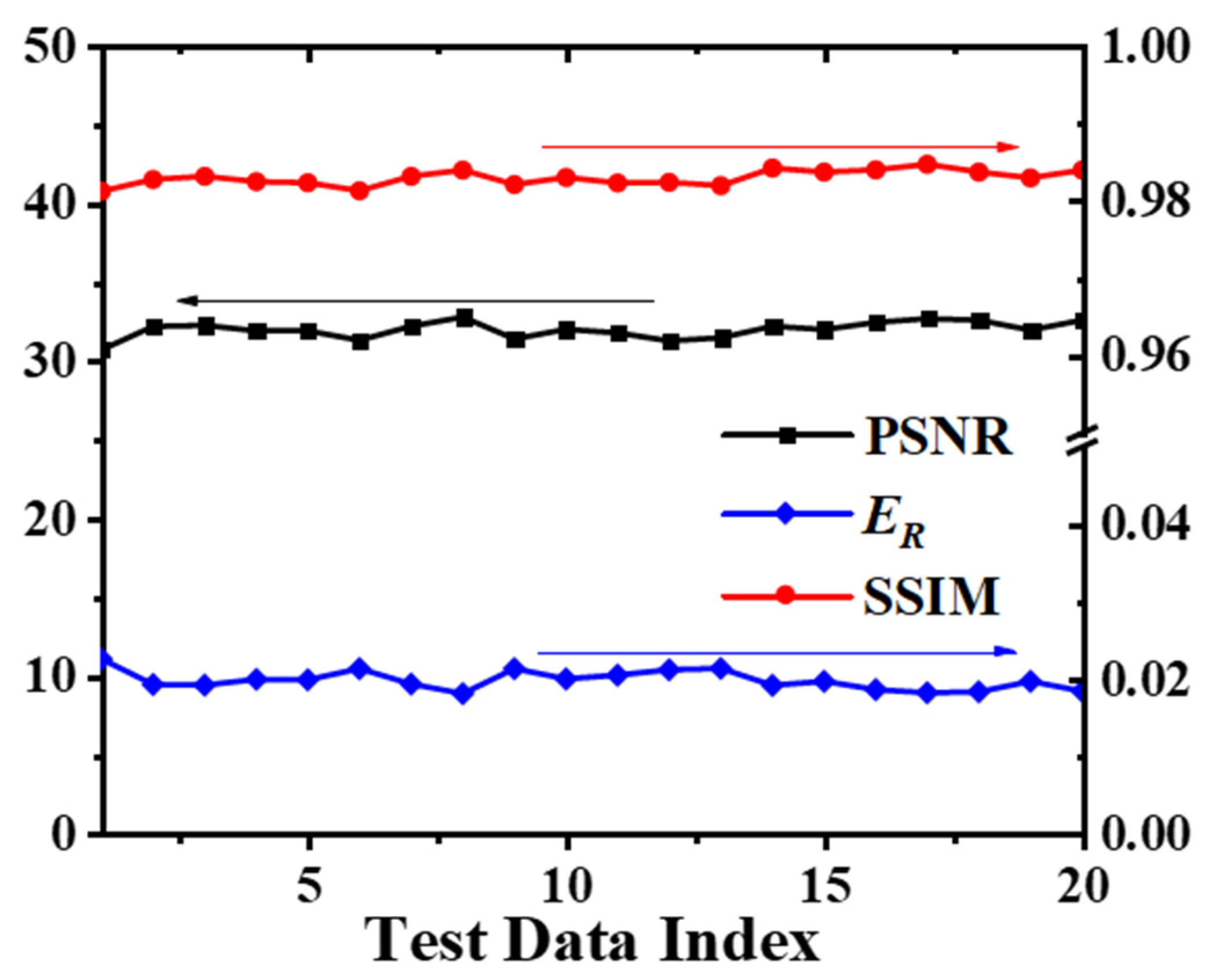
3.1. Network Performance Based on Feature-Paired Training
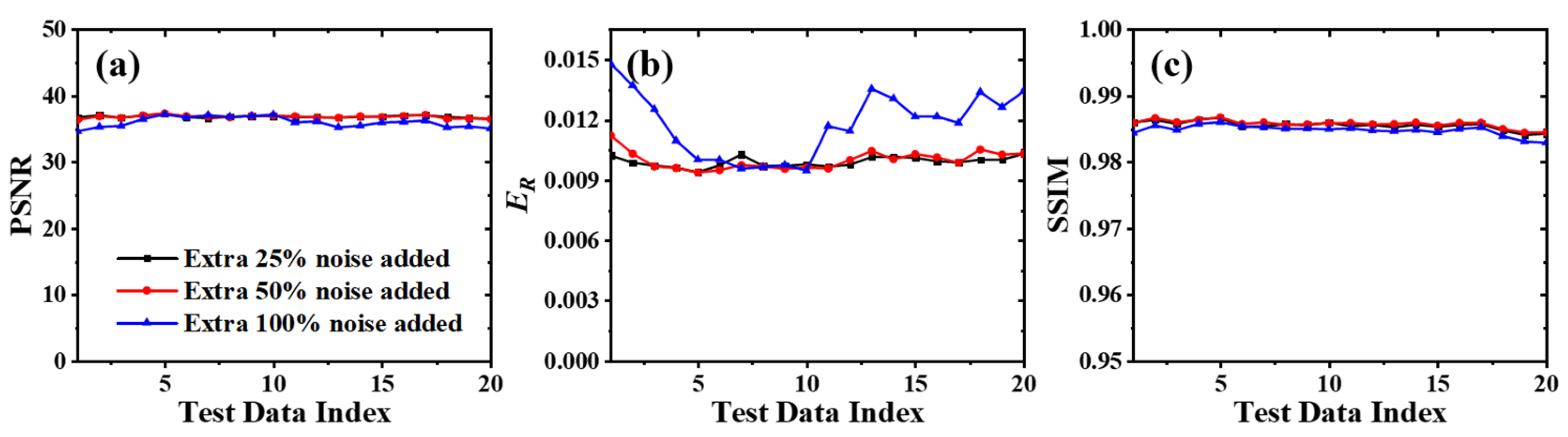
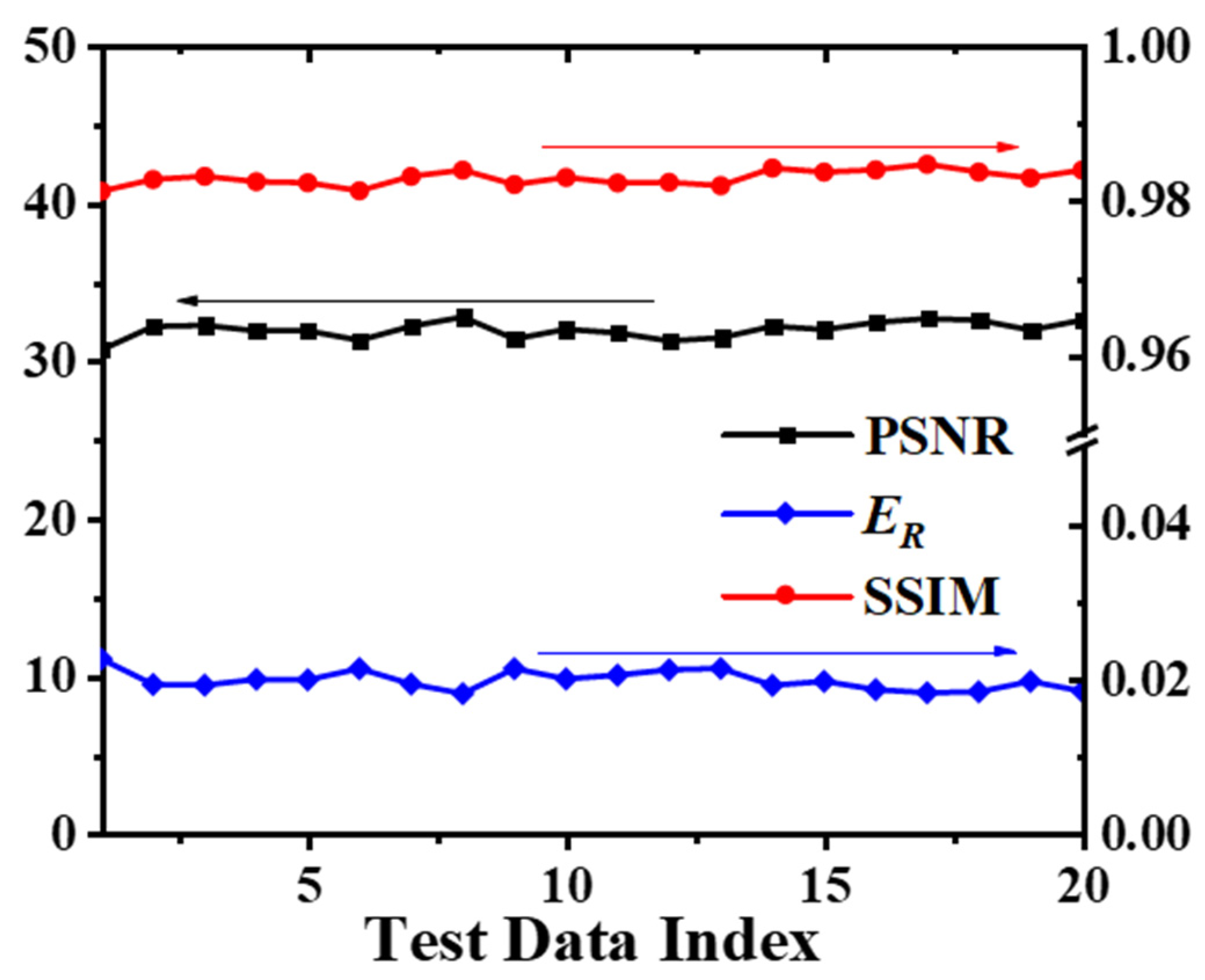
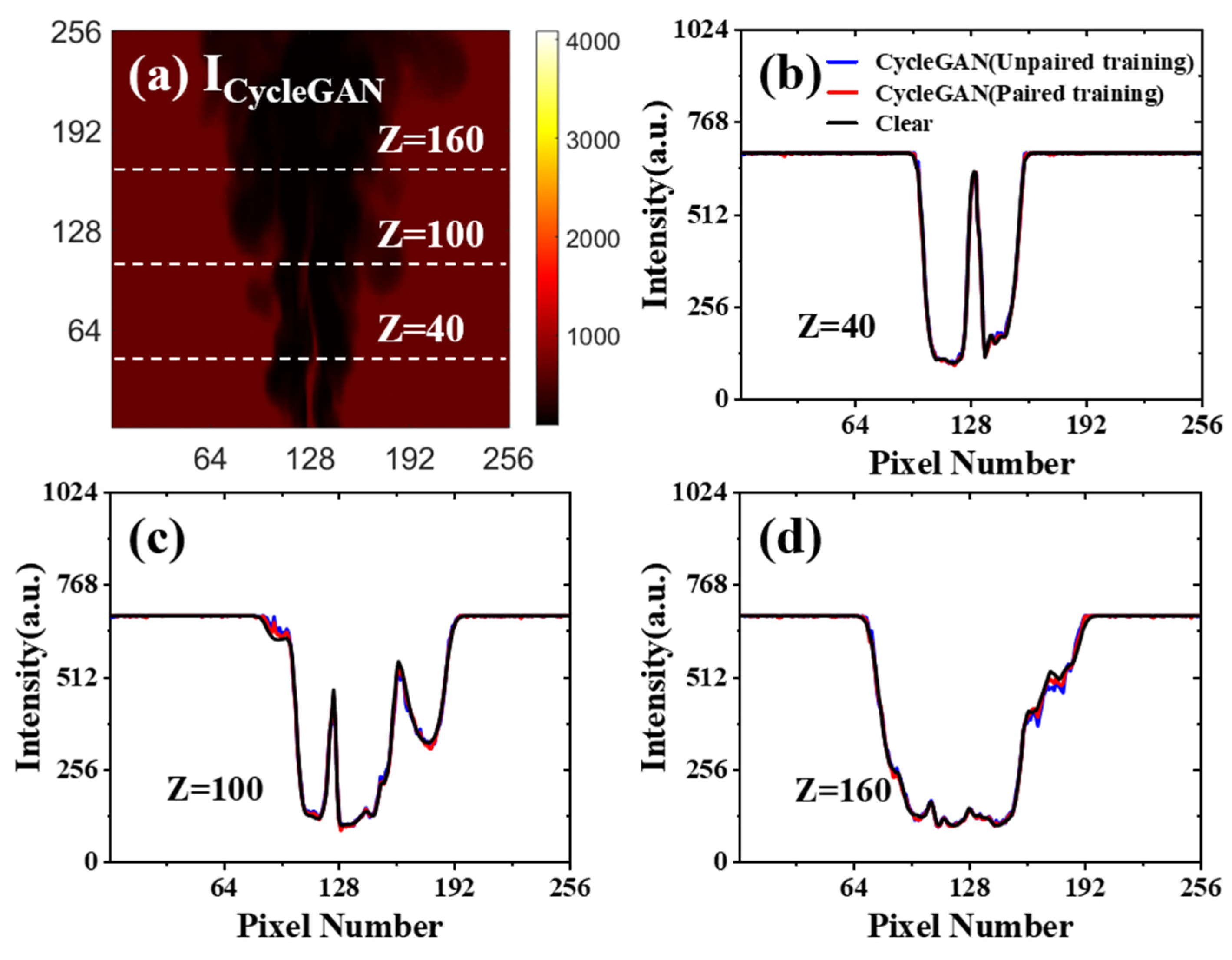
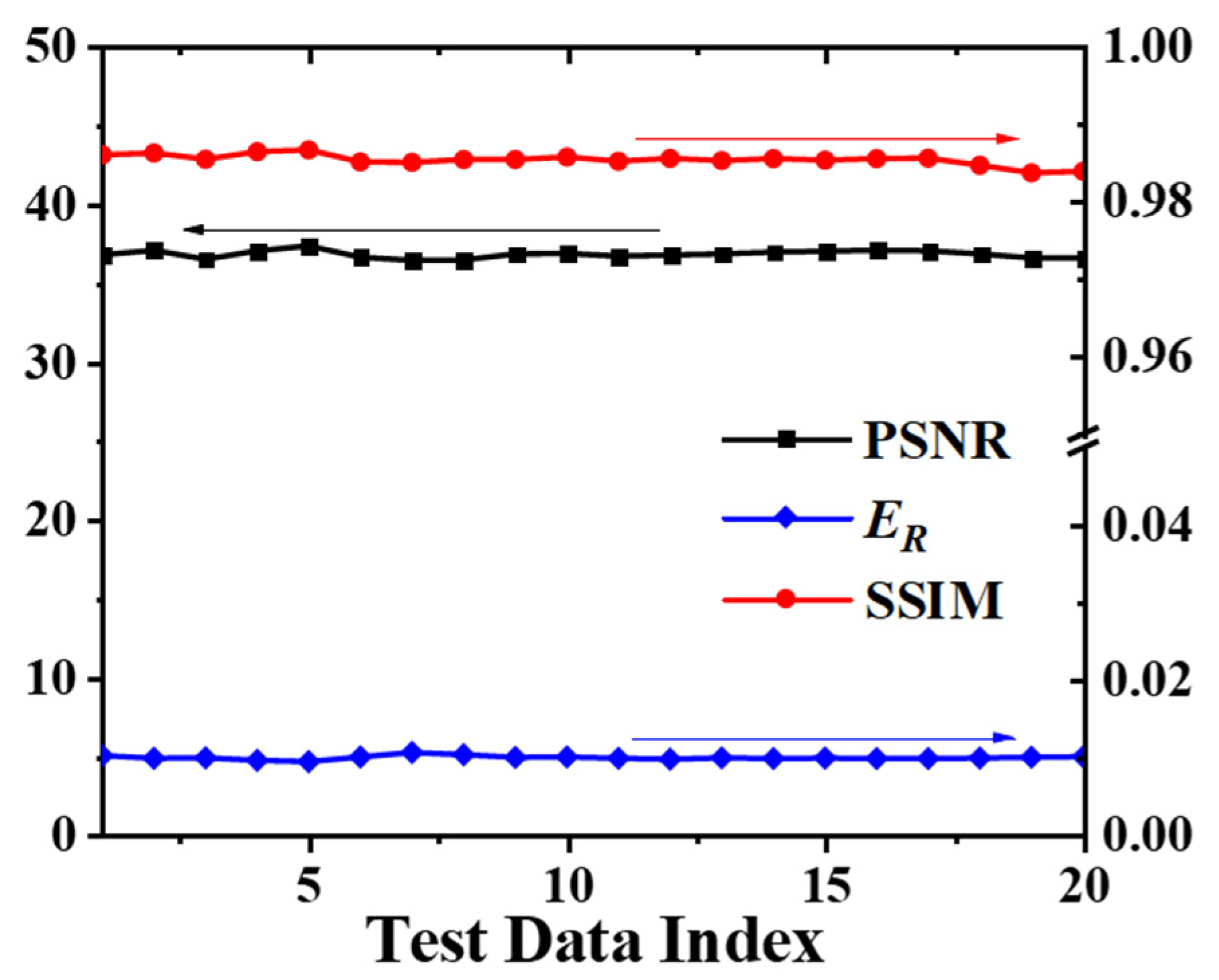
3.2. Network Performance Based on Feature-Unpaired Training
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pu, J.; Sutton, J.A. Quantitative 2D thermometry in turbulent sooting non-premixed flamesusing filtered Rayleigh scattering. Appl. Opt. 2021, 60, 5742–5751. [Google Scholar] [CrossRef] [PubMed]
- McManus, T.A.S.; Jeffrey, A. Quantitative planar temperature imaging in turbulent non-premixed flames using filtered Rayleigh scattering. Appl. Opt. 2019, 58, 2936–2947. [Google Scholar] [CrossRef]
- Patton, R.A.; Gabet, K.N.; Jiang, N.; Lempert, W.R.; Sutton, J.A. Multi-kHz mixture fraction imaging in turbulent jets using planar Rayleigh scattering. Appl. Phys. B 2012, 106, 457–471. [Google Scholar] [CrossRef]
- Espey, C.; Dec, J.E.; Litzinger, T.A.; Santavicca, D.A. Planar laser rayleigh scattering for quantitative vapor-fuel imaging in a diesel jet. Combust. Flame 1997, 109, 65–86. [Google Scholar] [CrossRef]
- Gustavsson, J.P.R.; Segal, C. Filtered Rayleigh scattering velocimetry—Accuracy investigation in a M = 2.2 axisymmetric jet. Exp. Fluids 2005, 38, 11–20. [Google Scholar] [CrossRef]
- Frank, J.H.; Kaiser, S.A. High-resolution imaging of dissipative structures in a turbulent jet flame with laser Rayleigh scattering. Exp. Fluids 2008, 44, 221–233. [Google Scholar] [CrossRef]
- Buch, K.A.; Dahm, W.J.A. Experimental study of the fine-scale structure of conserved scalar mixing in turbulent shear flows. Part 2. Sc ≈ 1. J. Fluid Mech. 1998, 364, 1–29. [Google Scholar] [CrossRef]
- Green, H.G. Developments in signal analysis for laser Rayleigh scattering. J. Phys. E Sci. Instrum. 1987, 20, 670–676. [Google Scholar] [CrossRef]
- Barat, R.B.; Longwell, J.P.; Sarofim, A.F.; Smith, S.P.; Bar-Ziv, E. Laser Rayleigh scattering for flame thermometry in a toroidal jet stirred combustor. Appl. Opt. 1991, 30, 3003–3010. [Google Scholar] [CrossRef] [PubMed]
- Miles, R.B.; Lempert, W.R.; Forkey, J. Instantaneous velocity fields and background suppression by filtered Rayleigh scattering. In Proceedings of the 29th AIAA Aerospace Sciences Meeting, Reno, NV, USA, 1 January 1991. [Google Scholar]
- Kempema, N.; Long, M. Quantitative Rayleigh thermometry for high background scattering applications with structured laser illumination planar imaging. Appl. Opt. 2014, 53, 6688–6697. [Google Scholar] [CrossRef]
- Kristensson, E.; Ehn, A.; Bood, J.; Aldén, M. Advancements in Rayleigh scattering thermometry by means of structured illumination. Proc. Combust. Inst. 2015, 35, 3689–3696. [Google Scholar] [CrossRef]
- Mehta, S.; Vajpai, J.; Mehta, S.; Vajpai, J. Directional Adaptive Multilevel Median Filter for Salt–and-Pepper Noise Reduction. J. Comput. Appl. 2014, 975, 8887. [Google Scholar]
- Song, Q.; Li, M.; Cao, J.; Xiao, H. Image Denoising Based on Mean Filter and Wavelet Transform. In Proceedings of the 2015 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Harbin, China, 21–23 August 2015. [Google Scholar]
- Zhao, R.; Li, X.; Sun, P. An improved windowed Fourier transform filter algorithm. Opt. Laser Technol. 2015, 74, 103–107. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image Blind Denoising with Generative Adversarial Network Based Noise Modeling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Xu, W.; Luo, W.; Wang, Y.; You, Y. Data-driven three-dimensional super-resolution imaging of a turbulent jet flame using a generative adversarial network. Appl. Opt. 2020, 59, 5729–5736. [Google Scholar] [CrossRef]
- Cai, M.; Luo, W.; Xu, W.; You, Y. Development of learning-based noise reduction and image reconstruction algorithm in two dimensional Rayleigh thermometry. Optik 2021, 248, 168082. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Won, S.; Lee, C. Unsupervised deep learning for super-resolution reconstruction of turbulence. J. Fluid Mech. 2021, 910, A29. [Google Scholar] [CrossRef]
- Xu, W.; Luo, W.; Chen, S.; You, Y. Numerical demonstration of 3D reduced order tomographic flame diagnostics without angle calibration. Optik 2020, 220, 165198. [Google Scholar] [CrossRef]
- Barlow, R.S.; Frank, J.H. Effects of turbulence on species mass fractions in methane/air jet flames. Symp. Int. Combust. 1998, 27, 1087–1095. [Google Scholar] [CrossRef]
- Jones, W.P.; Prasad, V.N. Large Eddy Simulation of the Sandia Flame Series (D–F) using the Eulerian stochastic field method. Combust. Flame 2010, 157, 1621–1636. [Google Scholar] [CrossRef]
- Yang, B.; Pope, S.B. An investigation of the accuracy of manifold methods and splitting schemes in the computational implementation of combustion chemistry. Combust. Flame 1998, 112, 16–32. [Google Scholar] [CrossRef]
- Xu, W.; Liu, N.; Ma, L. Super resolution PLIF demonstrated in turbulent jet flows seeded with I 2. Opt. Laser Technol. 2018, 101, 216–222. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, F.; Chen, J. Denoising Convolutional Neural Networkwith Mask for Salt and Pepper Noise. IET Image Process. 2019, 13, 2604–2613. [Google Scholar]
- Li, B.; Wei, W.; Ferreira, A.; Tan, S. ReST-Net: Diverse Activation Modules and Parallel Subnets-Based CNN for Spatial Image Steganalysis. IEEE Signal Process. Lett. 2018, 25, 650–654. [Google Scholar] [CrossRef]
- Yang, C.-Y.; Ma, C.; Yang, M.-H. Single-Image Super-Resolution: A Benchmark. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Xu, W.; Carter, C.D.; Hammack, S.; Ma, L. Analysis of 3D combustion measurements using CH-based tomographic VLIF (volumetric laser induced fluorescence). Combust. Flame 2017, 182, 179–189. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, M.; Jin, H.; Lin, B.; Xu, W.; You, Y. Numerical Demonstration of Unsupervised-Learning-Based Noise Reduction in Two-Dimensional Rayleigh Imaging. Energies 2022, 15, 5747. https://doi.org/10.3390/en15155747
Cai M, Jin H, Lin B, Xu W, You Y. Numerical Demonstration of Unsupervised-Learning-Based Noise Reduction in Two-Dimensional Rayleigh Imaging. Energies. 2022; 15(15):5747. https://doi.org/10.3390/en15155747
Chicago/Turabian StyleCai, Minnan, Hua Jin, Beichen Lin, Wenjiang Xu, and Yancheng You. 2022. "Numerical Demonstration of Unsupervised-Learning-Based Noise Reduction in Two-Dimensional Rayleigh Imaging" Energies 15, no. 15: 5747. https://doi.org/10.3390/en15155747
APA StyleCai, M., Jin, H., Lin, B., Xu, W., & You, Y. (2022). Numerical Demonstration of Unsupervised-Learning-Based Noise Reduction in Two-Dimensional Rayleigh Imaging. Energies, 15(15), 5747. https://doi.org/10.3390/en15155747