
Self-Attention-Based Short-Term Load Forecasting Considering Demand-Side Management

Abstract
:1. Introduction
1.1. Related Work and Motivation
1.2. Paper Contribution
- (1)
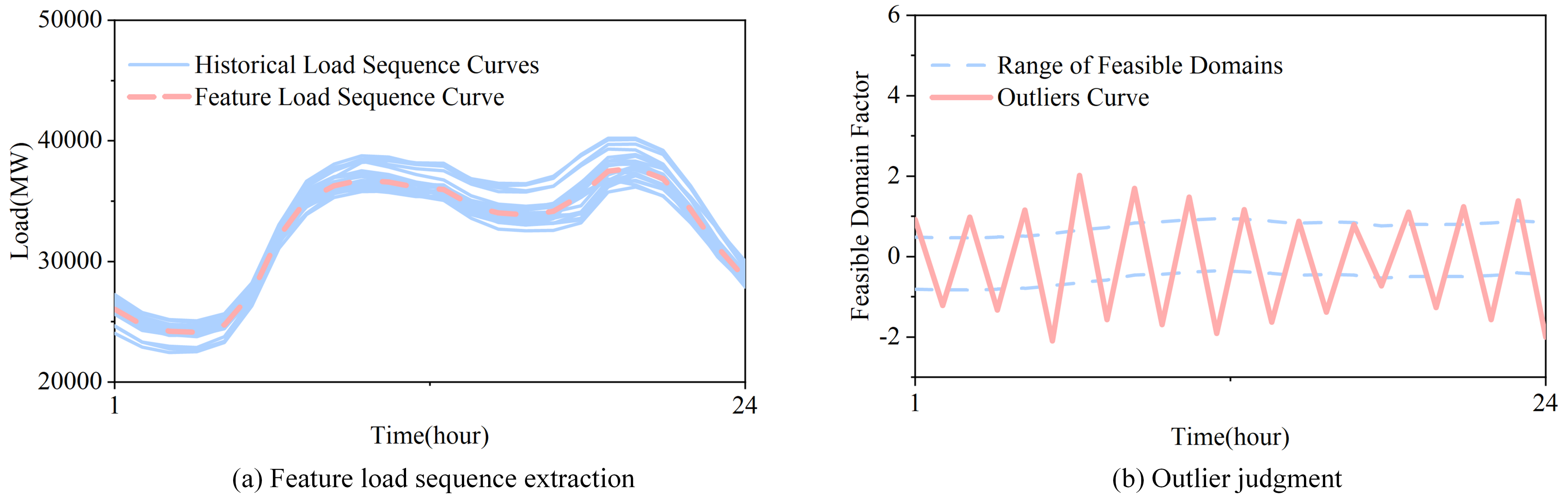
- A novel outlier determination method is proposed. In order to cope with inevitable dead numbers and abnormal sensitivity of smart meters and sensors, which lead to missing values and outliers in the transmission process, a data anomaly detection method based on non-parametric Gaussian kernel density estimation is proposed. Using the historical load data to construct the feature curve of customers’ electricity-consumption behavior, the upper and lower limits of the feasible domain are set to determine the anomaly.
- (2)
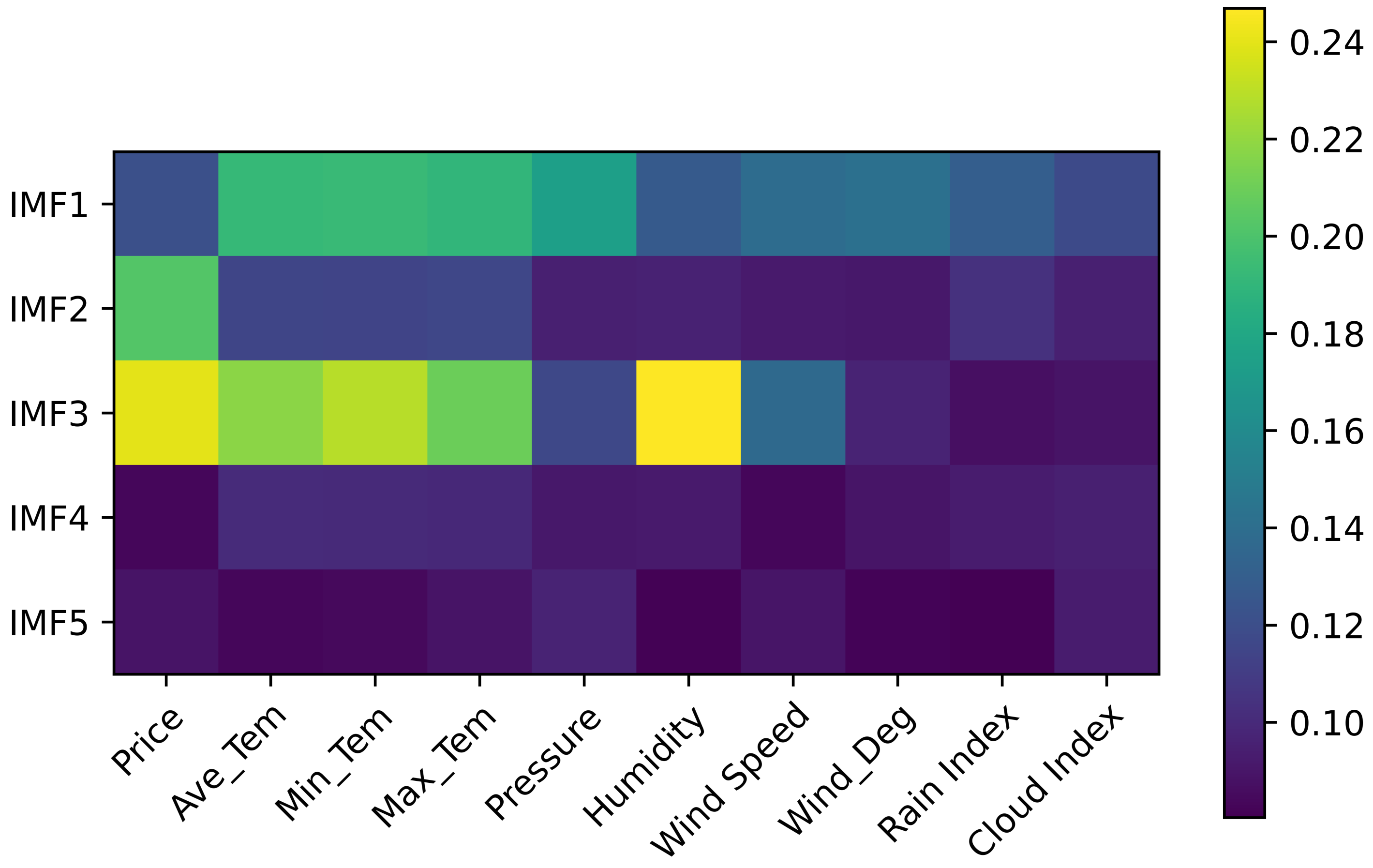
- A relatively novel feature-selection method is proposed. The original load signal is decomposed into several IMFs components by VMD. The maximal information coefficient (MIC) is used to find out the non-linear correlation between each IMF and the features, which contain meteorological, geographical, policy and other factors.
- (3)
- Abandoning the traditional recurrent neural network structure, this paper uses a novel improved self-attention Informer-based model to predict and reconstruct an IMF input matrix. The model is optimized using AdaBelief, which improves the accuracy and operational efficiency of the model operation.
- (4)
- The strengths and weaknesses of the model are analyzed in depth by comparing other single models with hybrid models and combining several statistical parameters’ evaluation indexes. The accuracy of the model was verified by cross-sectional and longitudinal experiments on a regional-level load dataset in Spain.
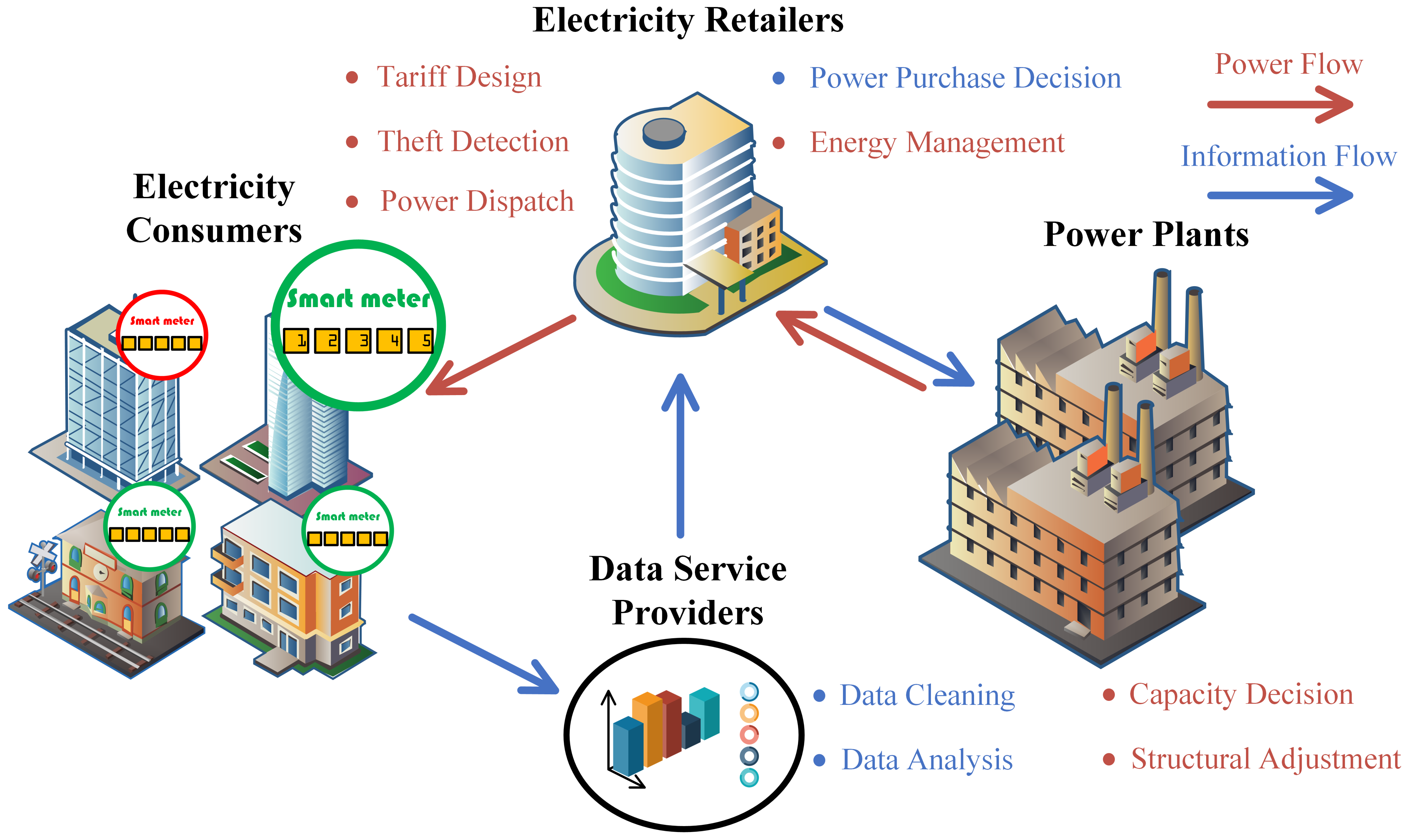
2. Data Preparation
- (1)
- Meteorological data include mean temperature, maximum temperature, minimum temperature, barometric pressure, humidity, wind speed, wind degree, cloud index and rain index.
- (2)
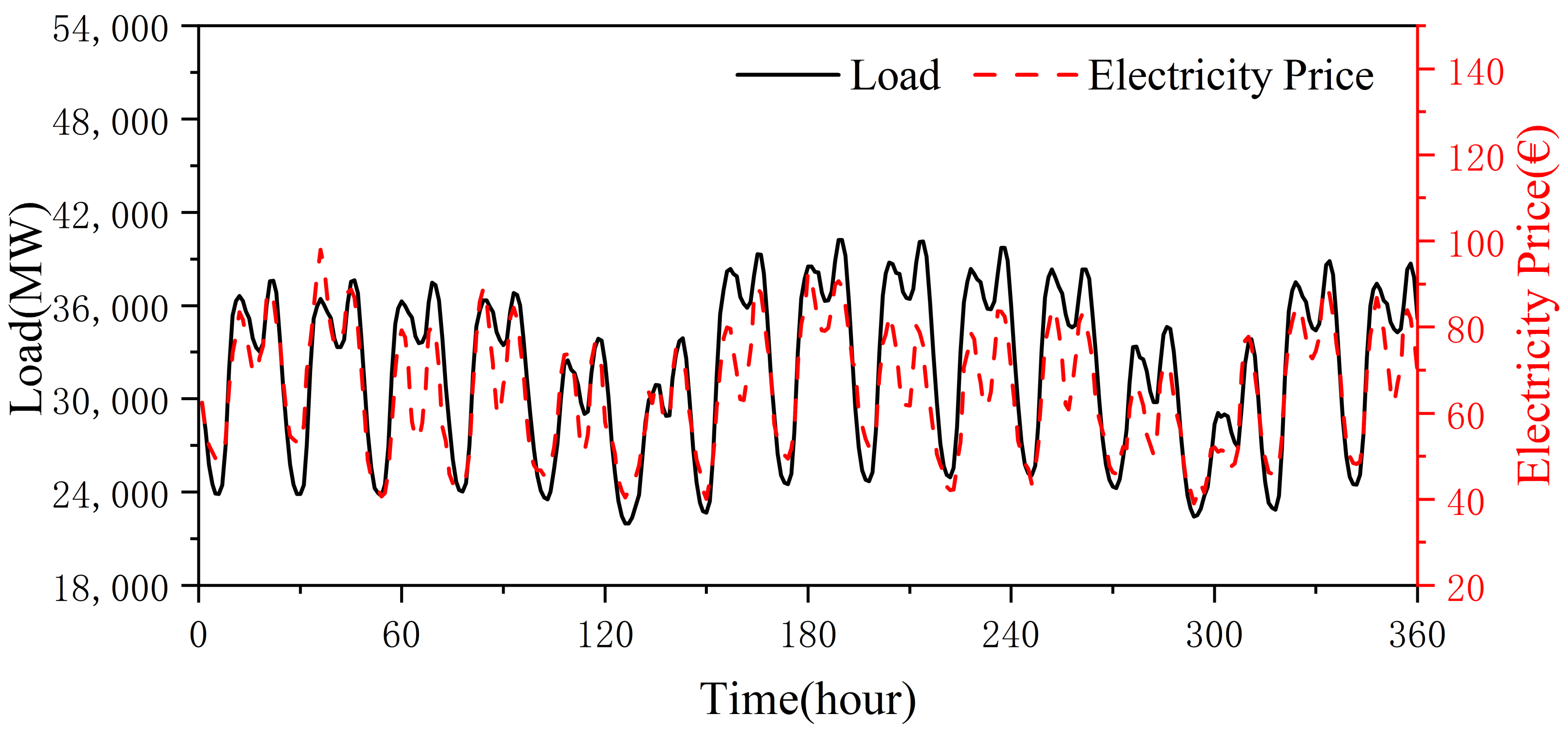
- DSM data. Electricity price and load belong to mutual causality, and it can be intuitively seen from Figure 2 that there is a certain correlation between electricity price and load, so electricity price is selected as DSM data.
- (3)
- The historical load data were divided into a training set, a validation set and a test set in the ratio of 8:1:1. The specific dataset division is shown in Table 1.
3. STLF Model
3.1. Outlier Processing
3.1.1. Feature Curves Construction
3.1.2. Feasible Domain Construction
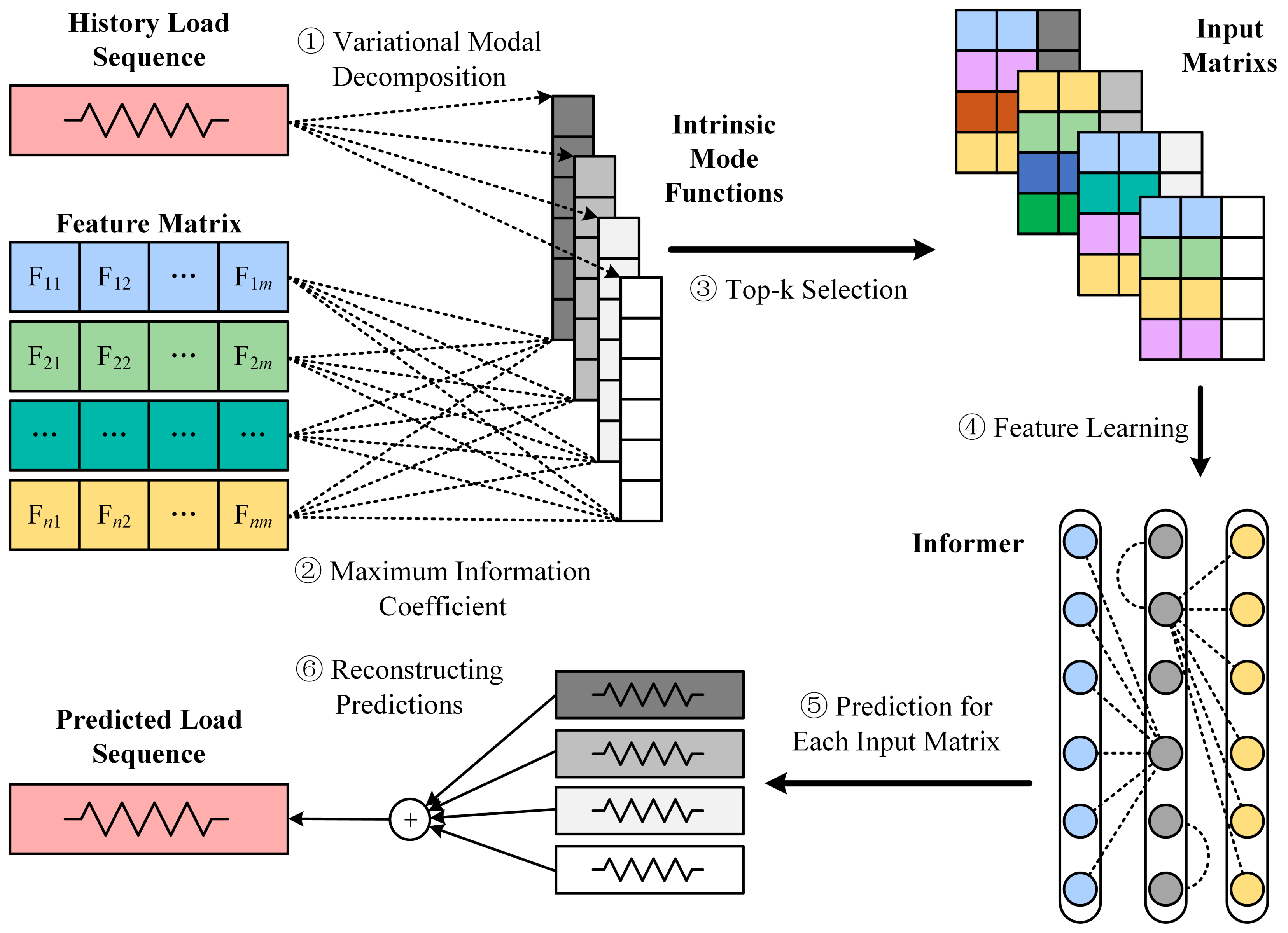
3.2. Feature Selection
3.2.1. VMD
| Algorithm 1 VMD |
|
1:Intialize , 2:Update 3:Update 4:Update until convergence |
3.2.2. MIC
3.3. Model Training
3.3.1. Informer
3.3.2. AdaBelief
| Algorithm 2 Adam |
|
1:Intialize , , , 2:While is not converged: , , , 3:Update |
| Algorithm 3 AdaBelief |
|
1:Intialize , , , 2:While is not converged: , , , 3:Update |
4. Simulation Environment and Experimental Results
4.1. Experimental Environment and Evaluation Metrics
4.2. Experimental Results
4.2.1. Experiment I: Outlier Detection
4.2.2. Experiment II: STLF Cross-Sectional Experiment
4.2.3. Experiment III: STLF Longitudinal Experiments
- (1)
- The proposed model.
- (2)
- VMD-Informer. The load was decomposed using VMD according to the same parameters as in the cross-sectional experiment. The MIC correlation analysis module was abandoned and all features were entered in the construction of the input matrix for prediction.
- (3)
- MIC-Informer. Correlation analysis was performed using MIC for loads only, and Top-k features were selected for detection.
- (4)
- Simple Informer. We dissolved all the modules and kept only the original Informer for load forecasting. We retained all features in the prediction.
4.2.4. Experiment IV: AdaBelief Optimization Experiment
5. Conclusions
- (1)
- The method uses a non-parametric Gaussian kernel density estimate to fit the user load feature curve. Outliers are identified by setting upper and lower limits on the feasible domain for the load.
- (2)
- The VMD-MIC feature filtering method optimizes the input feature dimension. After ablation experiments, it is proved that the prediction accuracy of the combined model is higher than that of the ablated single model.
- (3)
- Cross-sectional and longitudinal experiments are conducted on a regional-level load dataset set in Spain. The experimental results prove that the proposed method is superior to other methods.
- (4)
- Optimizing the proposed model using AdaBelief can significantly improve the prediction accuracy, but will reduce the convergence speed.
- (5)
- With the development of DSM, our work will focus on the study of more types and scales of customer electricity-consumption data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| STLF | Short-term Load Forecasting. |
| ER | Electricicty Retailer. |
| DSM | Demand-side Management. |
| DR | Demand Response. |
| IES | Integrated Energy System. |
| IMF | Intrinsic Mode Function. |
| EMD | Empirical Mode Decomposition. |
| VMD | Variational Modal Decomposition. |
| MIC | Maximal Information Coefficient. |
| MAPE | Mean Absolute Percentage Error. |
| RMSE | Root Mean Square Error. |
| EMA | Exponential Moving Average. |
| TCN | Temporal Convolutional Network. |
| CNN | Convolutional Neural Network. |
| LSTM | Long And Short-term Memory. |
| GRU | Gated Recurrent Unit. |
| RNN | Recurrent Neural Network. |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction | Evaluation | Predicted Length | |||
|---|---|---|---|---|---|
| Models | Metrics | 1 | 2 | 3 | 4 |
| Proposed | MAPE(%) | 0.98 | 1.54 | 1.79 | 2.03 |
| RMSE(MW) | 330.89 | 469.26 | 621.84 | 752.66 | |
| TCN-LSTM | MAPE(%) | 1.68 | 2.11 | 2.56 | 5.43 |
| RMSE(MW) | 522.96 | 790.05 | 965.15 | 1764.69 | |
| TCN-GRU | MAPE(%) | 1.31 | 1.79 | 2.31 | 2.64 |
| RMSE(MW) | 465.32 | 631.02 | 840.72 | 938.61 | |
| CNN-LSTM | MAPE(%) | 2.86 | 3.05 | 3.67 | 4.85 |
| RMSE(MW) | 963.61 | 1024.65 | 1495.35 | 1653.74 | |
| CNN-GRU | MAPE(%) | 2.51 | 3.79 | 4.32 | 4.15 |
| RMSE(MW) | 876.52 | 1480.62 | 1534.59 | 1493.51 | |
| VMD-Informer | MAPE(%) | 1.31 | 1.89 | 3.03 | 3.23 |
| RMSE(MW) | 426.917 | 735.71 | 1035.68 | 1076.44 | |
| MIC-Informer | MAPE(%) | 1.66 | 2.25 | 3.47 | 4.02 |
| RMSE(MW) | 575.41 | 935.67 | 1511.59 | 1406.51 | |
| Informer | MAPE(%) | 1.74 | 1.98 | 3.23 | 4.62 |
| RMSE(MW) | 621.33 | 702.08 | 963.51 | 1542.34 | |
| Prediction | Evaluation | Predicted Length | |||
|---|---|---|---|---|---|
| Models | Metrics | 1 | 2 | 3 | 4 |
| Proposed | MAPE(%) | 0.98 | 1.54 | 1.79 | 2.03 |
| RMSE(MW) | 330.89 | 469.26 | 621.84 | 752.66 | |
| XGBoost | MAPE(%) | 5.32 | 6.34 | 9.55 | 10.39 |
| RMSE(MW) | 1752.01 | 2231.84 | 2634.15 | 2963.45 | |
| GRU | MAPE(%) | 1.86 | 2.51 | 2.64 | 4.78 |
| RMSE(MW) | 658.31 | 883.15 | 925.37 | 1684.84 | |
| LSTM | MAPE(%) | 3.23 | 4.24 | 4.91 | 5.05 |
| RMSE(MW) | 1211.65 | 1563.54 | 1697.62 | 1732.41 | |
| TCN | MAPE(%) | 4.02 | 4.61 | 7.32 | 7.45 |
| RMSE(MW) | 1496.84 | 1602.89 | 2236.45 | 2311.54 | |
| SVR | MAPE(%) | 6.31 | 6.45 | 6.93 | 8.99 |
| RMSE(MW) | 2130.53 | 2201.34 | 2263.21 | 2632.84 | |
| MLP | MAPE(%) | 6.55 | 8.45 | 9.87 | 9.86 |
| RMSE(MW) | 2205.62 | 2597.32 | 2794.33 | 2763.45 | |
| CNN | MAPE(%) | 4.41 | 5.79 | 5.05 | 7.64 |
| RMSE(MW) | 1522.63 | 1822.49 | 2002.55 | 2469.84 | |
| Models | Parameters |
|---|---|
| Proposed | The learning rate is 0.01, the input sequence length is 96, the prediction sequence length is 1, the number of head is 8, the number of encoder is 2, the number of decoder is 1, the dropout rate is 0.05, the activation function is “GELU”. |
| XGBoost | The learning rate is 0.01, the max depth of trees is 6, iteration is 100, colsample is 0.95, alpha is 0.1, lambda is 0.15, gamma is 0.1, min child weight is 0.1. |
| CNN | The learning rate is 0.001, the nunber of convolution layers is 1, the number of filters in convolution layer is 48, the kernel size is 2, the strides is 1, the number of fully connected layers is 2, the number of neurons in fully connected layers is set 48/1,the activation function is “ReLU”. |
| TCN | The learning rate is 0.001, the nunber of convolution layers is 1, the number of filters in convolution layer is 64, the kernel size is 2, the strides is 1, the dilations are (1,2,4,8,16,32), the dropout rate is 0.2, the number of fully connected layers is 2, the number of neurons in fully connected layers is set 64/1,the activation function is “ReLU”. |
| GRU | The learning rate is 0.001, the number of hidden layers is 1, the number of nodes in hidden layer is 128, the dropout rate is 0.1, the number of fully connected layers is 2, the number of neurons in fully connected layers is set 128/1, the activation function is “tanh”. |
| LSTM | The learning rate is 0.001, the number of hidden layers is 1, the number of nodes in hidden layer is 128, the dropout rate is 0.1, the number of fully connected layers is 2, the number of neurons in fully connected layers is set 128/1, the activation function is “tanh”. |
| MLP | The learning rate is 0.001, the number of hidden layers is 4, the number of nodes in hidden layer are (256,128,64,32), the dropout rate is 0.2, the number of fully connected layers is 2, the number of neurons in fully connected layers is set 32/1, the activation function is “ReLU”. |
| SVR | The kernel is “rbf”, all other parameters are default parameters. |
References
- Kong, X.; Li, C.; Zheng, F.; Wang, C. Improved deep belief network for short-term load forecasting considering demand-side management. IEEE Trans. Power Syst. 2019, 35, 1531–1538. [Google Scholar] [CrossRef]
- Wang, H.; Ruan, J.; Wang, G.; Zhou, B.; Liu, Y.; Fu, X.; Peng, J. Deep learning-based interval state estimation of AC smart grids against sparse cyber attacks. IEEE Trans. Ind. Inform. 2018, 14, 4766–4778. [Google Scholar] [CrossRef]
- Arora, S.; Taylor, J.W. Short-term forecasting of anomalous load using rule-based triple seasonal methods. IEEE Trans. Power Syst. 2013, 28, 3235–3242. [Google Scholar] [CrossRef] [Green Version]
- Massaoudi, M.; Refaat, S.; Abu-Rub, H.; Chihi, I.; Oueslati, F.S. PLS-CNN-BiLSTM: An end-to-end algorithm-based Savitzky–Golay smoothing and evolution strategy for load forecasting. Energies 2020, 13, 5464. [Google Scholar] [CrossRef]
- Alonso, A.M.; Nogales, F.J.; Ruiz, C. A single scalable LSTM model for short-term forecasting of massive electricity time series. Energies 2020, 13, 5328. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Zhang, N.; Wang, Y. Conditional residual modeling for probabilistic load forecasting. IEEE Trans. Power Syst. 2018, 33, 7327–7330. [Google Scholar] [CrossRef]
- Browell, J.; Fasiolo, M. Probabilistic Forecasting of Regional Net-load with Conditional Extremes and Gridded NWP. IEEE Trans. Smart Grid 2021, 12, 5011–5019. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Hill, D.J.; Luo, F.; Xu, Y. Short-term residential load forecasting based on resident behaviour learning. IEEE Trans. Power Syst. 2017, 33, 1087–1088. [Google Scholar] [CrossRef]
- Xie, J.; Hong, T. Variable selection methods for probabilistic load forecasting: Empirical evidence from seven states of the united states. IEEE Trans. Smart Grid 2017, 9, 6039–6046. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, J.; Chen, X.; Zeng, X.; Kong, Y.; Sun, S.; Guo, Y.; Liu, Y. Short-term load forecasting for industrial customers based on TCN-LightGBM. IEEE Trans. Power Syst. 2020, 36, 1984–1997. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, Z.; Ji, W.; Gao, X.; Li, X. A short-term power load forecasting method based on attention mechanism of CNN-GRU. Power Syst. Technol. 2019, 43, 4370–4376. [Google Scholar]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM model for short-term individual household load forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- Xu, J.H.; Wang, X.W.; Yang, J.J. Short-term Load Density Prediction Based on CNN-QRLightGBM. Power Syst. Technol. 2020, 44, 3409–3416. [Google Scholar]
- Yao, C.W.; Yang, P.; Liu, Z.J. Load forecasting method based on CNN-GRU hybrid neural network. Power Syst. Technol. 2020, 44, 3416–3424. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI, Virtual, 2–9 February 2021. [Google Scholar]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Chen, H.; Wang, J.; Tang, B.; Xiao, K.; Li, J. An integrated approach to planetary gearbox fault diagnosis using deep belief networks. Meas. Sci. Technol. 2016, 28, 025010. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Li, W.; Quan, C.; Wang, X.; Zhang, S. Short-Term Power Load Forecasting Based on a Combination of VMD and ELM. Pol. J. Environ. Stud. 2018, 27, 2143–2154. [Google Scholar] [CrossRef]
- Shi, H.; Wang, L.; Scherer, R.; Woźniak, M.; Zhang, P.; Wei, W. Short-Term Load Forecasting Based on Adabelief Optimized Temporal Convolutional Network and Gated Recurrent Unit Hybrid Neural Network. IEEE Access 2021, 9, 66965–66981. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; Mcvean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Adv. Neural Inf. Process. Syst. 2020, 33, 18795–18806. [Google Scholar]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the 19th COMPSTAT, Paris, France, 22–27 August 2010. [Google Scholar]






| Dataset | Count | Max (MW) | Min (MW) | Mean (MW) | Median (MW) | Std (MW) |
|---|---|---|---|---|---|---|
| Overall | 35,064 | 41,015 | 18,041 | 28,697.99 | 28,902.5 | 4576.07 |
| Training | 28,052 | 41,015 | 18,041 | 28,657.25 | 28,876.5 | 4589.24 |
| Validation | 3506 | 40,693 | 19,706 | 28,813.13 | 28,971 | 4447.79 |
| Test | 3506 | 39,780 | 18,179 | 28908.79 | 29,031 | 4588.56 |
| Optimizer | MAPE (%) | RMSE (MW) | Convergence Epoch |
|---|---|---|---|
| AdaBelief | 0.98 | 330.89 | 12 |
| Adam | 2.56 | 969.05 | 3 |
| SGD | 1.39 | 478.68 | 18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, F.; Wang, L.; Jiang, Q.; Yan, Q.; Qiao, S. Self-Attention-Based Short-Term Load Forecasting Considering Demand-Side Management. Energies 2022, 15, 4198. https://doi.org/10.3390/en15124198
Yu F, Wang L, Jiang Q, Yan Q, Qiao S. Self-Attention-Based Short-Term Load Forecasting Considering Demand-Side Management. Energies. 2022; 15(12):4198. https://doi.org/10.3390/en15124198
Chicago/Turabian StyleYu, Fan, Lei Wang, Qiaoyong Jiang, Qunmin Yan, and Shi Qiao. 2022. "Self-Attention-Based Short-Term Load Forecasting Considering Demand-Side Management" Energies 15, no. 12: 4198. https://doi.org/10.3390/en15124198
APA StyleYu, F., Wang, L., Jiang, Q., Yan, Q., & Qiao, S. (2022). Self-Attention-Based Short-Term Load Forecasting Considering Demand-Side Management. Energies, 15(12), 4198. https://doi.org/10.3390/en15124198