
Predicting Electric Vehicle Charging Station Availability Using Ensemble Machine Learning



Abstract
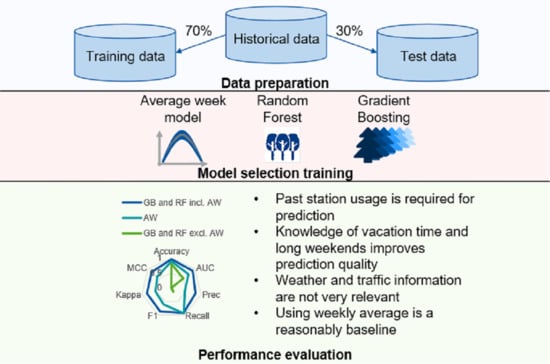
:
1. Introduction
1.1. Literature Review
1.2. Improvements of This Paper in the Context of the Literature
2. Materials
2.1. 2019 vs. 2021 Dataset
2.2. CS Usage Data
- Status changes of the EVSEs as defined by the Open Charge Point Protocol [36];
- Location of the charging infrastructure;
- Grouping of EVSEs into charging stations.
2.3. Public Holidays and School Holidays
2.4. Weather Data
2.5. Traffic Data
3. Methods
3.1. Data Merging
3.2. Data Preprocessing
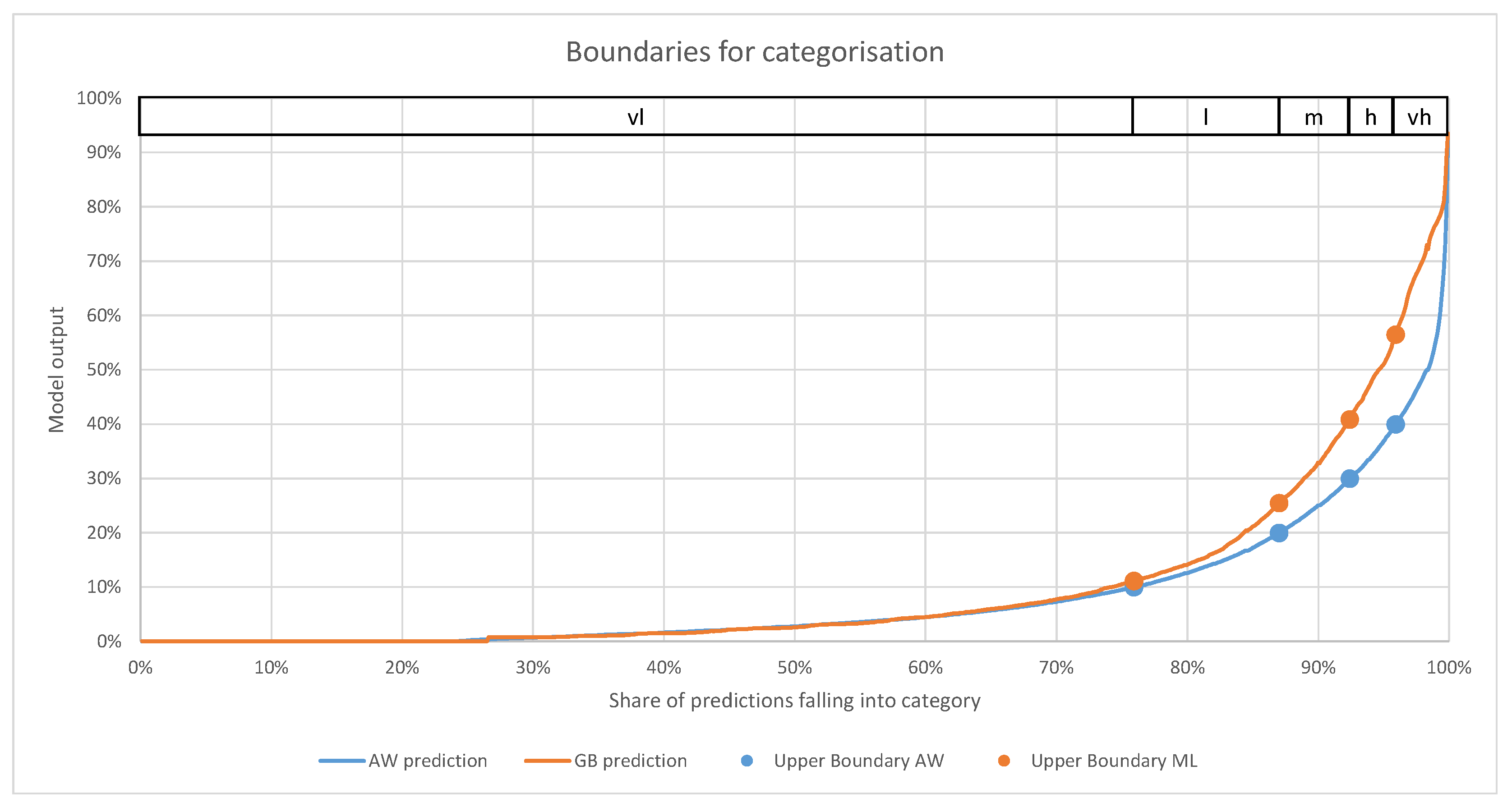
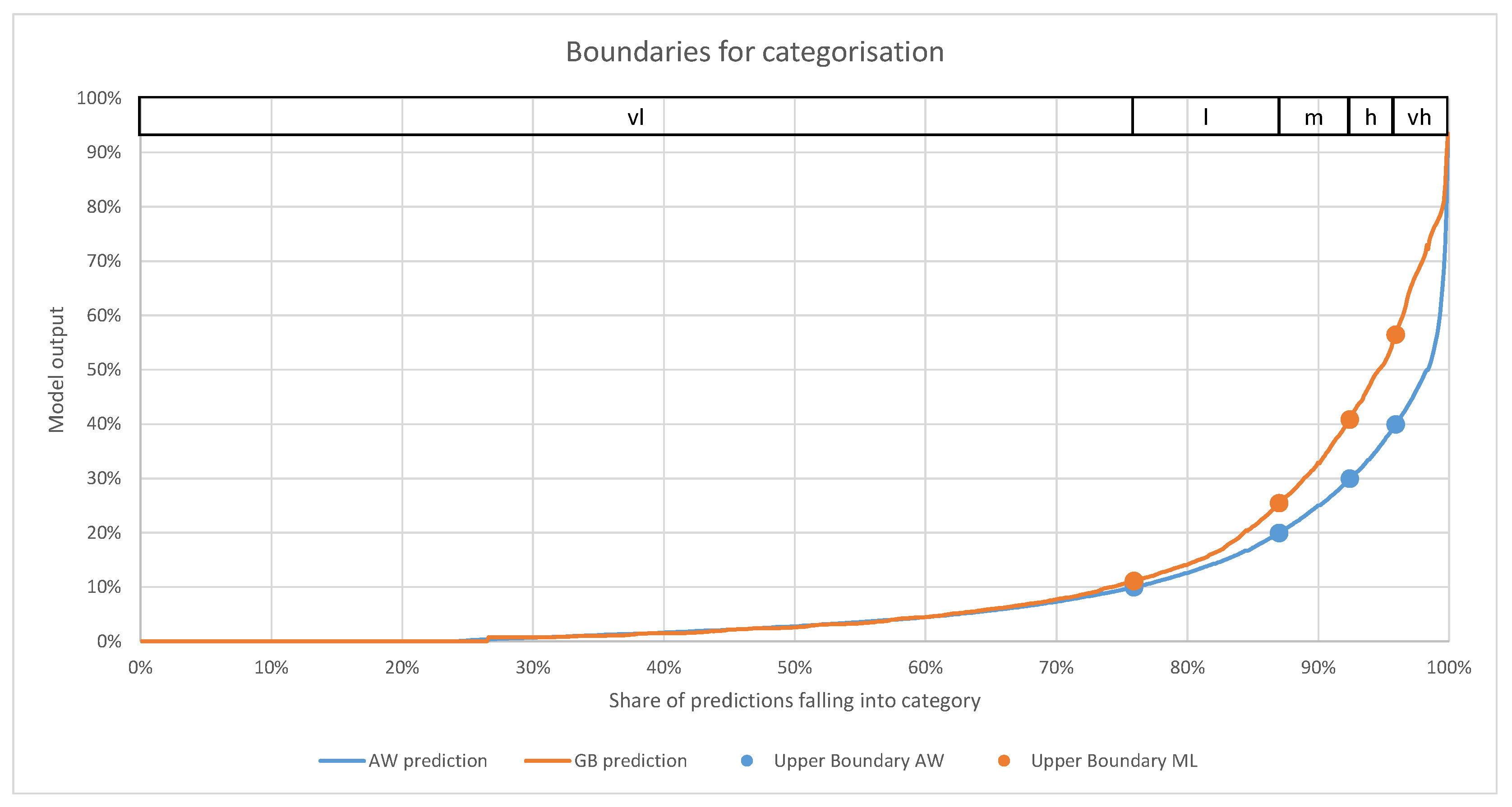
3.2.1. Feature Categorisation
3.2.2. Train–Test Split
3.3. Model Selection
3.4. Chosen Prediction Models
3.4.1. Average Week Model (AW)
3.4.2. Gradient Boosting Classifier Model
- max_depth: 5
- min_samples_leaf: 0.01%
3.4.3. Random Forest Classifier Model
- max_samples: 0.1%
- min_samples_leaf: 0.1%
4. Results
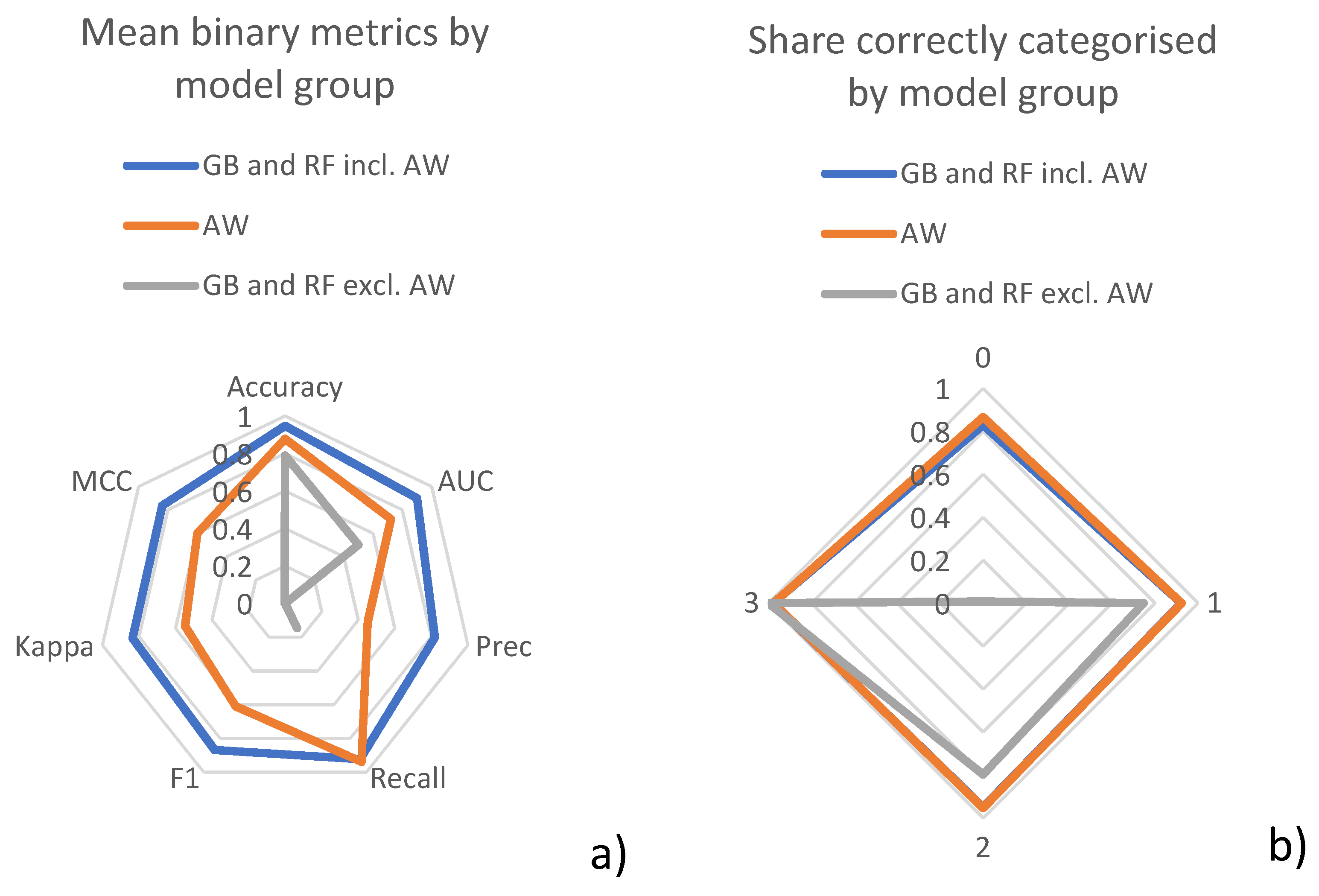
4.1. Model Comparison
4.2. Prediction Performance
- “Model” (column 1)The model used as explained in the Section 3.4 “Chosen Prediction Models”
- “Dataset”—“Include traffic” (columns 2–5)The columns contain the datasets used as outlined in the section “Data”. TRUE indicates that the dataset was used in training and prediction and FALSE indicates that it was not used.
- Share correctly categorised (columns 6–9)These columns contain the share of predictions that matched the real value. The numbers in the second title row of Table 4 indicate how far removed a category was allowed to be in order to be still considered correct. The column with the heading “0” consequently contains the share of correctly assigned categories. Column “1” allows for neighbouring categories (e.g., if “low” was predicted, “very low” and “medium” were still considered correct) to be correct. Columns 2 and 3 follow the same pattern, but allow further removed neighbours to be correct. Table 5 shows an example of how the confusion matrix translates into the values shown in Table 4.
- Binary metrics (columns 10–16)The binary metrics columns contain typically applied metrics in binary classification problems. These are, in order of appearance, accuracy, area under the receiver operating characteristic curve (AUC), recall, precision (Prec), F1 score (F1), Cohen’s kappa score (Kappa), and Matthews correlation coefficient (MCC). As these are standard metrics in machine learning, a detailed explanation of each is omitted at this point and the reader is referred to the Appendix A.1 of this paper. Further information can be found in the documentation of the used methods in the model evaluation package of sklearn [44] or other literature.
4.3. Feature Importance
5. Discussion
5.1. Model Choice
5.2. 2019 and 2021 Dataset
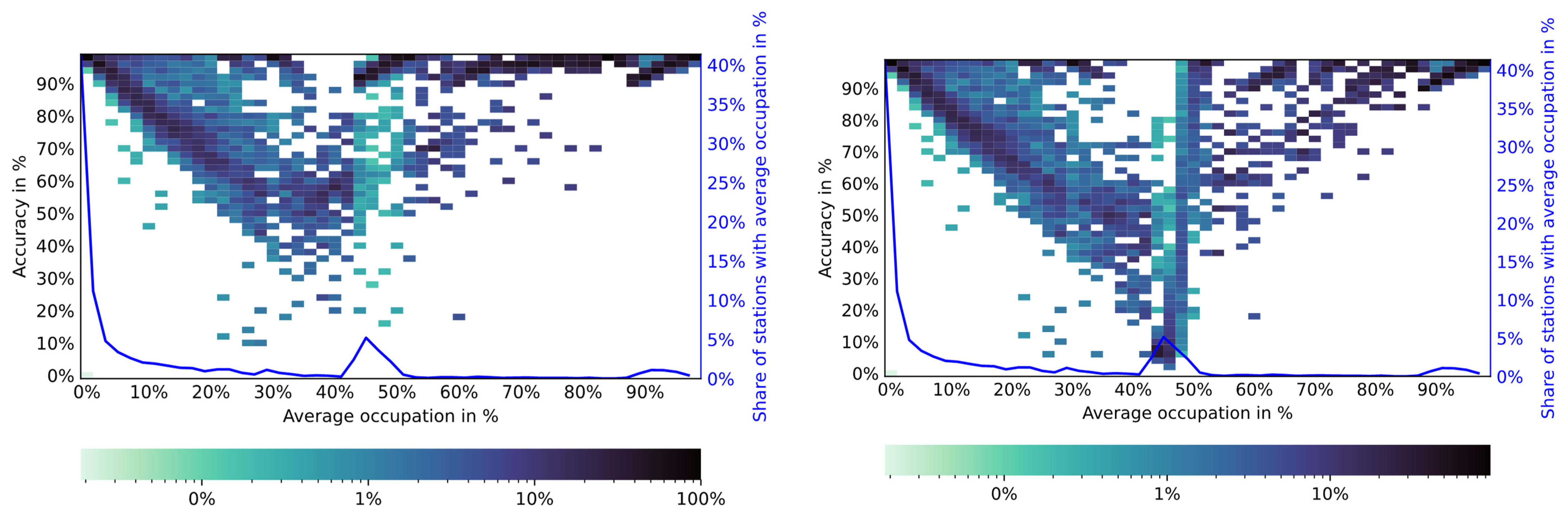
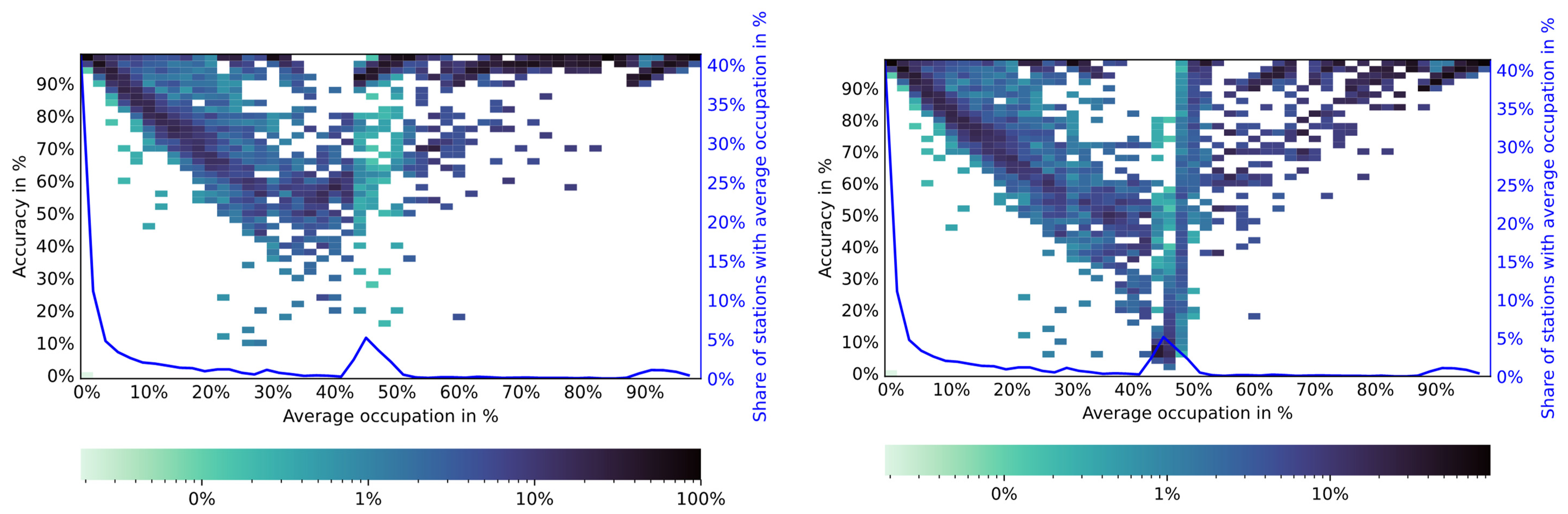
5.3. Predicting Half-Occupancy
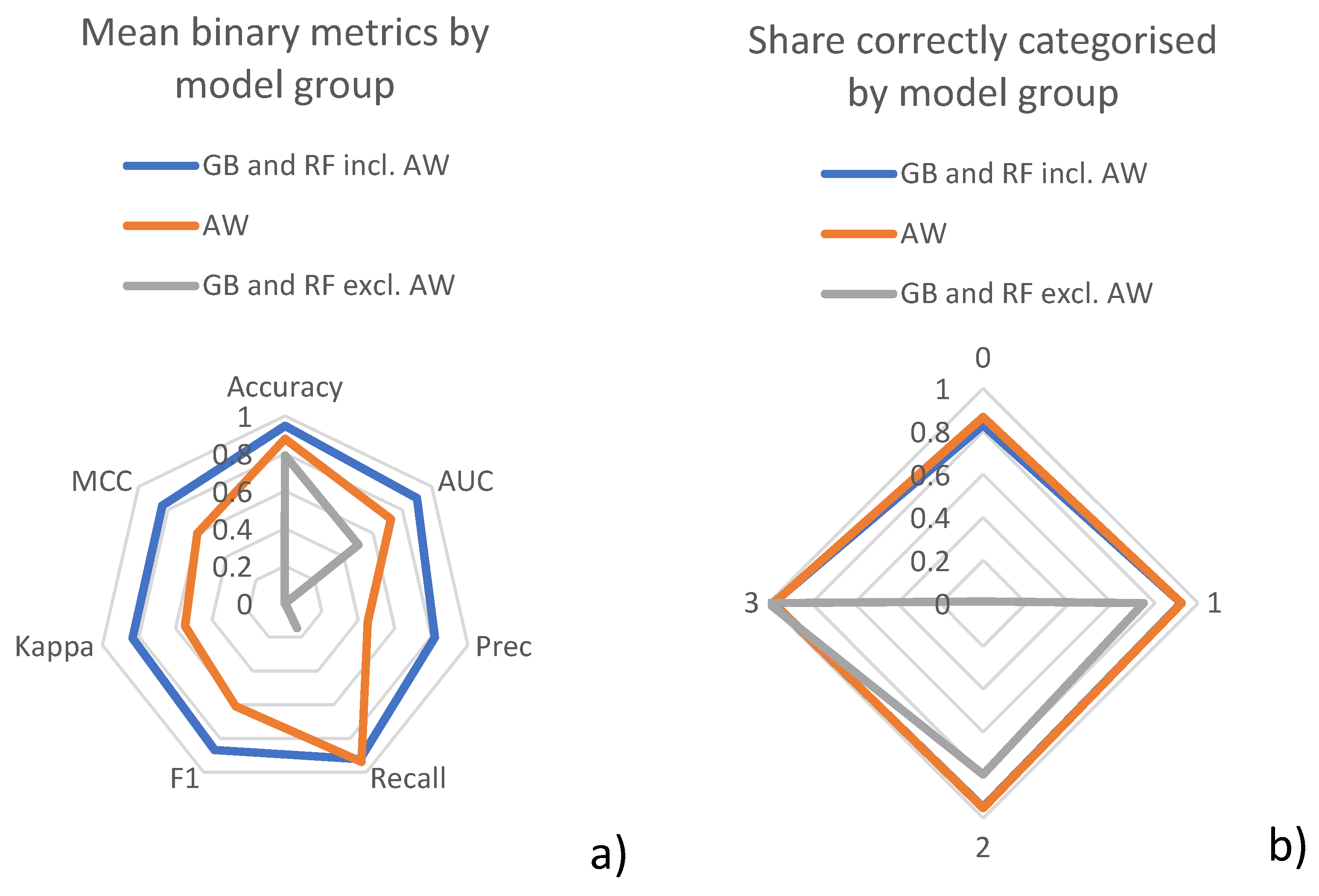
- GB and RF unaware of average weekly dataAll GB and RF models that are unaware of the average weekly data perform very poorly. Besides a seemingly reasonable accuracy of around 0.78, the MCC is 0 and AUC 0.5. The latter two indicate that the model has no predictive value. The reason for this is that the provided input features are an insufficient basis to predict a CS occupation of above 50% since the average occupation is too low and features are not unique enough.
- Average week modelThe average week model reaches a reasonable score in all major metrics. The relatively low recall, however, tells us that the model is unable to identify high CS occupation and earns most of its accuracy score by correctly predicting labels with low occupation rates. Given the goal of predicting usage spikes, this is clearly not ideal. This behaviour can be explained by the fact that only stations with an extremely high usage rate over the entire observed period during certain hours of the week would be correctly predicted as having a high occupation rate.
- GB and RF aware of average weekly dataOnce GB and RF are aware of the average weekly data, the prediction performance becomes much better. While there are small improvements in predictive quality if weather and traffic information is available, they do not make a strong contribution to station occupation. This occurs despite the fact that, individually, they show a strong correlation with station occupation. A reason for this could be that there are strong collinearities present. Traffic and station occupation, for instance, both show a similar pattern over the course of the day when using aggregated data. The results show that this effect holds true even when training detailed models.
5.4. Predicting Categorised Values
5.5. Feature Importance
5.6. Limitations
- Market developmentThe EV market has undergone tremendous changes in the studied period. The number of vehicles increased from approximately 150,000 vehicles in early 2019 to one million in 2021. Similar trends could be observed with respect to the number of CSs. At the same, vehicle range has increased significantly over time [9] and travel within Germany is now comfortably possible [48]. It seems probable that all these changes had an effect on infrastructure usage. Consequently, training and test data might in part be outdated, which the results in Table 4, including the 2019 dataset, also show.
- COVID-19 pandemicThe COVID-19 pandemic has had an immense and lasting impact on mobility and travel patterns in Germany and worldwide. These developments are a second highly dynamic factor that the used models may not be able to reflect in detail.
- Availability of datasetsOne can think of various other aspects that probably increase prediction accuracy but for which we could not obtain datasets in this study. Examples of such data are events taking place (where visitors require recharging opportunities), hotel bookings (assuming that people need more public infrastructure if they are not at home), etc. If a reliable and quantifiable dataset can be obtained for these tasks, the prediction accuracy would likely increase further.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Availability of Software
Abbreviations/Nomenclature
| Abbreviation | Meaning |
| AW | Average week model |
| CS | Charging station (for electric vehicles) |
| CI | Charging infrastructure (for electric vehicles) |
| EV | Electric vehicle |
| EVSE | Electric vehicle supply equipment |
| GB | Gradient Boosting Classifier |
| MCC | Matthews correlation coefficient |
| RF | Random Forest Classifier |
Appendix A
Appendix A.1. Metric Descriptions
Appendix A.2. Feature Importance of the Selected Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Include Average Week | Include Weather | Include Traffic | Feature Importance Based on Mean Decrease in Impurity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vacation | Long Weekend | Traffic | Traffic Relative | Weekday | Hour | Average Occupation | Temperature | Precipitation | |||||
| GB | 2021 | TRUE | TRUE | TRUE | 0.3% | 0.0% | 0.2% | 0.0% | 0.0% | 0.1% | 98.1% | 1.3% | 0.0% |
| GB | 2021 | TRUE | FALSE | TRUE | 0.3% | 0.0% | 0.1% | 0.0% | 0.0% | 0.0% | 99.5% | ||
| RF | 2021 | TRUE | TRUE | TRUE | 0.1% | 0.0% | 0.6% | 0.1% | 0.0% | 0.1% | 98.4% | 0.8% | 0.0% |
| RF | 2021 | TRUE | TRUE | FALSE | 0.1% | 0.0% | 0.0% | 0.1% | 99.2% | 0.7% | 0.0% | ||
| GB | 2021 | TRUE | FALSE | FALSE | 0.3% | 0.0% | 0.0% | 0.0% | 99.6% | ||||
| RF | 2021 | TRUE | FALSE | FALSE | 0.1% | 0.0% | 0.0% | 0.0% | 99.9% | ||||
| RF | 2021 | TRUE | FALSE | TRUE | 0.1% | 0.0% | 0.7% | 0.1% | 0.0% | 0.0% | 99.1% | ||
| GB | 2021 | TRUE | TRUE | FALSE | 0.3% | 0.0% | 0.0% | 0.1% | 98.2% | 1.3% | 0.0% | ||
| GB | 2021 | FALSE | FALSE | TRUE | 0.9% | 0.3% | 77.5% | 19.1% | 0.8% | 1.5% | |||
| GB | 2021 | FALSE | TRUE | TRUE | 1.0% | 0.4% | 75.5% | 18.7% | 0.7% | 1.3% | 2.4% | 0.0% | |
| RF | 2021 | FALSE | FALSE | FALSE | 36.9% | 4.9% | 10.8% | 47.5% | |||||
| GB | 2021 | FALSE | FALSE | FALSE | 37.1% | 6.9% | 13.2% | 42.8% | |||||
| RF | 2021 | FALSE | TRUE | TRUE | 1.4% | 0.2% | 82.2% | 11.1% | 0.7% | 1.9% | 2.6% | 0.1% | |
| RF | 2021 | FALSE | FALSE | TRUE | 1.4% | 0.2% | 83.0% | 12.8% | 0.7% | 2.0% | |||
| GB | 2021 | FALSE | TRUE | FALSE | 19.1% | 12.5% | 11.9% | 26.5% | 27.5% | 2.4% | |||
| RF | 2021 | FALSE | TRUE | FALSE | 19.0% | 4.1% | 10.7% | 33.3% | 30.7% | 2.2% | |||
| GB | 2019 | TRUE | TRUE | FALSE | 0.1% | 0.0% | 0.0% | 0.2% | 99.3% | 0.3% | 0.0% | ||
| GB | 2019 | TRUE | FALSE | FALSE | 0.1% | 0.0% | 0.0% | 0.1% | 99.7% | ||||
| RF | 2019 | TRUE | FALSE | FALSE | 0.0% | 0.0% | 0.0% | 0.1% | 99.8% | ||||
| RF | 2019 | TRUE | TRUE | FALSE | 0.1% | 0.0% | 0.0% | 0.2% | 99.5% | 0.2% | 0.0% | ||
| GB | 2019 | FALSE | FALSE | FALSE | 14.8% | 14.5% | 17.4% | 53.3% | |||||
| RF | 2019 | FALSE | FALSE | FALSE | 14.2% | 12.0% | 16.0% | 57.8% | |||||
| RF | 2019 | FALSE | TRUE | FALSE | 10.4% | 4.9% | 9.0% | 30.6% | 43.8% | 1.2% | |||
| GB | 2019 | FALSE | TRUE | FALSE | 13.1% | 6.8% | 10.6% | 28.2% | 39.8% | 1.5% | |||
References
- IEA. Global EV Outlook 2021; IEA: Paris, France. Available online: https://www.iea.org/reports/global-ev-outlook-2021 (accessed on 13 September 2021).
- Gorner, M.; Paoli, L. How Global Electric Car Sales Defied COVID-19 in 2020. Available online: https://www.iea.org/commentaries/how-global-electric-car-sales-defied-covid-19-in-2020 (accessed on 15 November 2021).
- Bundesregierung. Erstmals Rollen Eine Million Elektrofahrzeuge auf Deutschen Straßen: Mehr als 50 Prozent Dieser Elektrofahrzeuge Sind Rein Batteriebetrieben. Available online: https://www.bmwi.de/Redaktion/DE/Pressemitteilungen/2021/08/20210802-erstmals-rollen-eine-million-elektrofahrzeuge-auf-deutschen-strassen.html (accessed on 13 September 2021).
- Rogers, E.M. Diffusion of Innovations, 5th ed.; Riverside; Free Press: Amsterdam, The Netherlands, 2003; Available online: https://ebookcentral.proquest.com/lib/gbv/detail.action?docID=4935198 (accessed on 13 September 2021).
- Giansoldati, M.; Monte, A.; Scorrano, M. Barriers to the adoption of electric cars: Evidence from an Italian survey. Energy Policy 2020, 146, 111812. [Google Scholar] [CrossRef]
- She, Z.-Y.; Sun, Q.; Ma, J.-J.; Xie, B.-C. What are the barriers to widespread adoption of battery electric vehicles? A survey of public perception in Tianjin, China. Transp. Policy 2017, 56, 29–40. [Google Scholar] [CrossRef]
- ZLing, Z.; Cherry, C.R.; Wen, Y. Determining the Factors That Influence Electric Vehicle Adoption: A Stated Preference Survey Study in Beijing, China. Sustainability 2021, 13, 11719. [Google Scholar] [CrossRef]
- Hecht, C.; Das, S.; Bussar, C.; Sauer, D.U. Representative, empirical, real-world charging station usage characteristics and data in Germany. eTransportation 2020, 6, 100079. [Google Scholar] [CrossRef]
- Hecht, C.; Figgener, J.; Sauer, D.U. ISEAview—Elektromobilität; ISEA Insitute, RWTH Aachen: Aachen, Germany, 2021; Available online: https://www.doi.org/10.13140/RG.2.2.29327.51368 (accessed on 22 March 2021).
- Follmer, R.; Gruschwitz, D. Mobilität in Deutschland—MiD Kurzreport. Ausgabe 4.0; Studie von infas, DLR, IVT und infas 360 im Auftrag des Bundesministers für Verkehr und Digitale Infrastruktur: Bonn, Germany, 2019; Available online: http://www.mobilitaet-in-deutschland.de/pdf/infas_Mobilitaet_in_Deutschland_2017_Kurzreport.pdf (accessed on 22 June 2020).
- Figgener, J.; Tepe, B.; Rücker, F.; Schoeneberger, I.; Hecht, C.; Jossen, A.; Sauer, D.U. The Influence of Frequency Containment Reserve Flexibilization on the Economics of Electric Vehicle Fleet Operation. arXiv 2021, arXiv:2107.03489. [Google Scholar]
- Hecht, C. BeNutz LaSA: Bessere Nutzung von Ladeinfrastruktur durch Smarte Anreizsysteme. Available online: https://benutzlasa.de/ (accessed on 19 March 2021).
- Straka, M.; De Falco, P.; Ferruzzi, G.; Proto, D.; Van Der Poel, G.; Khormali, S.; Buzna, L. Predicting Popularity of Electric Vehicle Charging Infrastructure in Urban Context. IEEE Access 2020, 8, 11315–11327. [Google Scholar] [CrossRef]
- Viswanathan, S.; Appel, J.; Chang, L.; Man, I.V.; Saba, R.; Gamel, A. Development of an assessment model for predicting public electric vehicle charging stations. Eur. Transp. Res. Rev. 2018, 10, 1287. [Google Scholar] [CrossRef]
- Bi, R.; Xiao, J.; Viswanathan, V.; Knoll, A. Influence of Charging Behaviour Given Charging Station Placement at Existing Petrol Stations and Residential Car Park Locations in Singapore. Procedia Comput. Sci. 2016, 80, 335–344. [Google Scholar] [CrossRef] [Green Version]
- Ramachandran, A.; Balakrishna, A.; Kundzicz, P.; Neti, A. Predicting Electric Vehicle Charging Station Usage: Using Machine Learning to Estimate Individual Station Statistics from Physical Configurations of Charging Station Networks. arXiv 2018, arXiv:1804.00714. [Google Scholar]
- Bryden, T.S.; Hilton, G.; Cruden, A.; Holton, T. Electric vehicle fast charging station usage and power requirements. Energy 2018, 152, 322–332. [Google Scholar] [CrossRef]
- Majidpour, M. Time Series Prediction for Electric Vehicle Charging Load and Solar Power Generation in the Context of Smart Grid. Ph.D Thesis, University of California, Los Angeles, CA, USA, 2016. Available online: https://escholarship.org/uc/item/5gc4h0wh (accessed on 22 March 2021).
- Motz, M.; Huber, J.; Weinhardt, C. Forecasting BEV charging station occupancy at work places. INFORMATIK 2021, 2020, 771–781. [Google Scholar]
- Tian, Z.; Jung, T.; Wang, Y.; Zhang, F.; Tu, L.; Xu, C.; Tian, C.; Li, X.-Y. Real-Time Charging Station Recommendation System for Electric-Vehicle Taxis. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3098–3109. [Google Scholar] [CrossRef]
- Panahi, D.; Deilami, S.; Masoum, M.A.S.; Islam, S. Forecasting plug-in electric vehicles load profile using artificial neural networks. In Proceedings of the 2015 Australasian Universities Power Engineering Conference (AUPEC), Wollongong, NSW, Australia, 27–30 September 2015; pp. 1–6. [Google Scholar]
- AlMaghrebi, A.; AlJuheshi, F.; Rafaie, M.; James, K.; Alahmad, M. Data-Driven Charging Demand Prediction at Public Charging Stations Using Supervised Machine Learning Regression Methods. Energies 2020, 13, 4231. [Google Scholar] [CrossRef]
- Frendo, O.; Graf, J.; Gaertner, N.; Stuckenschmidt, H. Data-driven smart charging for heterogeneous electric vehicle fleets. Energy AI 2020, 1, 100007. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Zahid, M.; Jamal, A. Electric vehicle energy consumption prediction using stacked generalization: An ensemble learning approach. Int. J. Green Energy 2021, 18, 896–909. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Al Mamlook, R.E.; Jamal, A. A comparative performance of machine learning algorithm to predict electric vehicles energy consumption: A path towards sustainability. Energy Environ. 2021. [Google Scholar] [CrossRef]
- Dias, G.M.; Bellalta, B.; Oechsner, S. Predicting occupancy trends in Barcelona’s bicycle service stations using open data. In Proceedings of the 2015 SAI Intelligent Systems Conference (IntelliSys), London, UK, 10–11 November 2015; pp. 439–445. [Google Scholar]
- Yoshida, A.; Yatsushiro, Y.; Hata, N.; Higurashi, T.; Tateiwa, N.; Wakamatsu, T.; Tanaka, A.; Nagamatsu, K.; Fujisawa, K. Practical End-to-End Repositioning Algorithm for Managing Bike-Sharing System. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1251–1258. [Google Scholar]
- Sohrabi, S.; Paleti, R.; Balan, L.; Cetin, M. Real-time prediction of public bike sharing system demand using generalized extreme value count model. Transp. Res. Part A Policy Pract. 2020, 133, 325–336. [Google Scholar] [CrossRef]
- Almannaa, M.H.; Elhenawy, M.; Rakha, H.A. Dynamic linear models to predict bike availability in a bike sharing system. Int. J. Sustain. Transp. 2020, 14, 232–242. [Google Scholar] [CrossRef]
- Chen, B.; Pinelli, F.; Sinn, M.; Botea, A.; Calabrese, F. Uncertainty in urban mobility: Predicting waiting times for shared bicycles and parking lots. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 53–58. [Google Scholar]
- Liu, D.; Dong, H.; Li, T.; Corcoran, J.; Ji, S. Vehicle scheduling approach and its practice to optimise public bicycle redistribution in Hangzhou. IET Intell. Transp. Syst. 2018, 12, 976–985. [Google Scholar] [CrossRef]
- Hua, M.; Chen, J.; Chen, X.; Gan, Z.; Wang, P.; Zhao, D. Forecasting usage and bike distribution of dockless bike-sharing using journey data. IET Intell. Transp. Syst. 2020, 14, 1647–1656. [Google Scholar] [CrossRef]
- Cagliero, L.; Cerquitelli, T.; Chiusano, S.; Garza, P.; Xiao, X. Predicting critical conditions in bicycle sharing systems. Computing 2017, 99, 39–57. [Google Scholar] [CrossRef]
- Lozano, A.; De Paz, J.F.; González, G.V.; De La Iglesia, D.H.; Bajo, J. Multi-Agent System for Demand Prediction and Trip Visualization in Bike Sharing Systems. Appl. Sci. 2018, 8, 67. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Hu, J.; Shu, Y.; Cheng, P.; Chen, J.; Moscibroda, T. Mobility Modeling and Prediction in Bike-Sharing Systems. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 14–18 June 2010; ACM Press: New York, NY, USA, 2016; Volume 06202016, pp. 165–178. [Google Scholar]
- OpenChargeAlliance. Open Charge Alliance—Global Platform for Open Protocols. Available online: https://www.openchargealliance.org/ (accessed on 19 March 2021).
- Ryanss and Dr-Prodigy. Holidays—PyPI. Available online: https://pypi.org/project/holidays (accessed on 19 March 2021).
- Freiling Digital GmbH. Kalenderdaten als ICS Datei Download—Ferienwiki. Available online: https://www.ferienwiki.de/exports/de (accessed on 19 March 2021).
- DWD Climate Data Center (CDC). Historical Hourly Station Observations of 2 m Air Temperature and Humidity for Germany, Version v006. Available online: https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/air_temperature/ (accessed on 7 May 2021).
- DWD Climate Data Center (CDC). Historical Hourly Station Observations of Precipitation for Germany, Version v006. Available online: https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/precipitation/ (accessed on 7 May 2021).
- ADAC Service GmbH. ADAC B2B. Available online: https://adac-b2b.com/ (accessed on 17 September 2021).
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ali, M. PyCaret: An Open Source, Low-Code Machine Learning Library in Python. Online: PyCaret. 2020. Available online: https://pycaret.org/ (accessed on 15 September 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kraftfahrtbundesamt. FZ 1: Bestand an Kraftfahrzeugen und Kraftfahrzeuganhängern nach Zulassungsbezirken; Kraftfahrtbundesamt: Flensburg, Germany, 2020. [Google Scholar]
- Lund, S.; Madgavkar, A.; Manyika, J.; Smit, S.; Ellingrud, K.; Robinson, O. The future of work after COVID-19. McKinsey Global Institute. February 2021. Available online: https://www.mckinsey.com/featured-insights/future-of-work/the-future-of-work-after-covid-19 (accessed on 13 September 2021).
- Olk, C.; Trunschke, M.; Bussar, C.; Sauer, D.U. Empirical Study of Electric Vehicle Charging Infrastructure Usage in Ireland. In Proceedings of the 2019 4th IEEE Workshop on the Electronic Grid (eGRID), Xiamen, China, 11–14 November 2019; pp. 1–8. [Google Scholar]
- Hecht, C.; Victor, K.; Zurmühlen, S.; Sauer, D.U. Electric vehicle route planning using real-world charging infrastructure in Germany. eTransportation 2021, 10, 100143. [Google Scholar] [CrossRef]
| Tile x-Coordinate | Tile y-Coordinate | Date and Time | Number of Vehicles |
|---|---|---|---|
| 8653 | 5276 | 2021-01-05 06:00 | 353 |
| 8662 | 5293 | 2021-01-05 08:00 | 214 |
| 8660 | 5288 | 2021-01-08 01:00 | 166 |
| Occupation | Vacation | Long Weekend | Temperature | Precipitation | Number of Vehicles | Relative # Vehicles | Weekday | Hour |
|---|---|---|---|---|---|---|---|---|
| [0,1] | TRUE/FALSE | TRUE/FALSE | °C | # | % | [0–6] | [0–23] | |
| 0.000 | 1 | 0 | 15 | 1 | 166 | 150% | 1 | 14 |
| 0.667 | 1 | 0 | 15 | 0 | 130 | 83% | 3 | 0 |
| 0.932 | 0 | 1 | 5 | 0 | 202 | 216% | 0 | 12 |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC |
|---|---|---|---|---|---|---|---|
| Light Gradient Boosting Machine | 0.9435 | 0.9765 | 0.8099 | 0.9146 | 0.8591 | 0.8239 | 0.8263 |
| Gradient Boosting Classifier | 0.9432 | 0.9747 | 0.811 | 0.9121 | 0.8586 | 0.8232 | 0.8254 |
| Ada Boost Classifier | 0.9431 | 0.9697 | 0.8093 | 0.9132 | 0.8581 | 0.8227 | 0.825 |
| Ridge Classifier | 0.9429 | 0 | 0.8181 | 0.9043 | 0.8591 | 0.8234 | 0.825 |
| Linear Discriminant Analysis | 0.9421 | 0.9688 | 0.8244 | 0.8949 | 0.8582 | 0.8219 | 0.823 |
| Logistic Regression | 0.9407 | 0.9682 | 0.8297 | 0.8841 | 0.856 | 0.8187 | 0.8194 |
| Random Forest Classifier | 0.9404 | 0.9702 | 0.81 | 0.8998 | 0.8526 | 0.8154 | 0.8172 |
| Extra Trees Classifier | 0.9368 | 0.9634 | 0.8095 | 0.8834 | 0.8448 | 0.8052 | 0.8064 |
| SVM— Linear Kernel | 0.9248 | 0 | 0.797 | 0.8482 | 0.8181 | 0.771 | 0.7742 |
| Naive Bayes | 0.9218 | 0.9529 | 0.843 | 0.8001 | 0.821 | 0.7711 | 0.7715 |
| Decision Tree Classifier | 0.914 | 0.8755 | 0.7952 | 0.7994 | 0.7973 | 0.7428 | 0.7428 |
| K Neighbours Classifier | 0.8284 | 0.7782 | 0.3238 | 0.712 | 0.4451 | 0.3601 | 0.3993 |
| Quadratic Discriminant Analysis | 0.6291 | 0.4999 | 0.2752 | 0.212 | 0.2047 | −0.0001 | −0.0003 |
| Model | Dataset | Include Average Week | Include Weather | Include Traffic | Share Correctly Categorised by the Number of Allowed Neighbour Category | Metrics of Binary Classification | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | Accuracy | AUC | Recall | Prec | F1 | Kappa | MCC | |||||
| GB | 2021 | TRUE | TRUE | TRUE | 83% | 92% | 95% | 98% | 0.948 | 0.900 | 0.819 | 0.924 | 0.868 | 0.836 | 0.838 |
| GB | 2021 | TRUE | FALSE | TRUE | 84% | 92% | 95% | 98% | 0.948 | 0.901 | 0.821 | 0.922 | 0.868 | 0.836 | 0.838 |
| RF | 2021 | TRUE | TRUE | TRUE | 82% | 92% | 95% | 98% | 0.948 | 0.901 | 0.820 | 0.922 | 0.868 | 0.835 | 0.838 |
| RF | 2021 | TRUE | TRUE | FALSE | 82% | 93% | 95% | 98% | 0.948 | 0.900 | 0.819 | 0.923 | 0.868 | 0.835 | 0.838 |
| GB | 2021 | TRUE | FALSE | FALSE | 84% | 92% | 95% | 98% | 0.947 | 0.900 | 0.819 | 0.923 | 0.868 | 0.835 | 0.837 |
| RF | 2021 | TRUE | FALSE | FALSE | 84% | 92% | 95% | 98% | 0.947 | 0.901 | 0.820 | 0.922 | 0.868 | 0.835 | 0.837 |
| RF | 2021 | TRUE | FALSE | TRUE | 84% | 92% | 95% | 98% | 0.947 | 0.901 | 0.821 | 0.921 | 0.868 | 0.835 | 0.837 |
| GB | 2021 | TRUE | TRUE | FALSE | 82% | 92% | 95% | 98% | 0.947 | 0.899 | 0.816 | 0.924 | 0.867 | 0.834 | 0.837 |
| AW | 2021 | TRUE | FALSE | FALSE | 87% | 92% | 95% | 97% | 0.878 | 0.722 | 0.451 | 0.939 | 0.610 | 0.548 | 0.599 |
| GB | 2021 | FALSE | FALSE | TRUE | 1% | 73% | 80% | 100% | 0.790 | 0.500 | 0.001 | 0.609 | 0.002 | 0.001 | 0.019 |
| GB | 2021 | FALSE | TRUE | TRUE | 1% | 73% | 80% | 100% | 0.790 | 0.500 | 0.001 | 0.562 | 0.002 | 0.001 | 0.015 |
| RF | 2021 | FALSE | FALSE | TRUE | 1% | 72% | 81% | 100% | 0.789 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| RF | 2021 | FALSE | TRUE | TRUE | 1% | 73% | 81% | 100% | 0.790 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GB | 2021 | FALSE | TRUE | FALSE | 1% | 76% | 79% | 100% | 0.790 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| RF | 2021 | FALSE | TRUE | FALSE | 1% | 77% | 79% | 100% | 0.790 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GB | 2021 | FALSE | FALSE | FALSE | 1% | 77% | 79% | 100% | 0.789 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| RF | 2021 | FALSE | FALSE | FALSE | 1% | 77% | 79% | 100% | 0.789 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GB | 2019 | TRUE | TRUE | FALSE | 52% | 75% | 87% | 95% | 0.832 | 0.676 | 0.404 | 0.670 | 0.505 | 0.411 | 0.430 |
| GB | 2019 | TRUE | FALSE | FALSE | 52% | 75% | 87% | 95% | 0.832 | 0.675 | 0.404 | 0.671 | 0.504 | 0.411 | 0.430 |
| RF | 2019 | TRUE | FALSE | FALSE | 52% | 76% | 86% | 95% | 0.832 | 0.672 | 0.396 | 0.675 | 0.499 | 0.406 | 0.427 |
| RF | 2019 | TRUE | TRUE | FALSE | 53% | 78% | 85% | 95% | 0.831 | 0.660 | 0.363 | 0.693 | 0.476 | 0.387 | 0.416 |
| AW | 2019 | TRUE | FALSE | FALSE | 55% | 75% | 87% | 95% | 0.814 | 0.577 | 0.168 | 0.773 | 0.276 | 0.216 | 0.301 |
| RF | 2019 | FALSE | TRUE | FALSE | 1% | 75% | 79% | 100% | 0.789 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GB | 2019 | FALSE | TRUE | FALSE | 1% | 75% | 79% | 100% | 0.789 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GB | 2019 | FALSE | FALSE | FALSE | 1% | 76% | 78% | 100% | 0.788 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| RF | 2019 | FALSE | FALSE | FALSE | 1% | 76% | 78% | 100% | 0.788 | 0.500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Predicted | ||||||
|---|---|---|---|---|---|---|
| vl | l | m | h | vh | ||
| Real | vl | 1.0E+08 | 4.1E+07 | 1.0E+07 | 1.0E+07 | 4.9E+06 |
| l | 9.8E+05 | 1.2E+06 | 3.1E+05 | 2.9E+05 | 1.6E+05 | |
| m | 1.0E+06 | 1.9E+06 | 8.6E+05 | 9.0E+05 | 3.0E+05 | |
| h | 1.5E+06 | 1.8E+06 | 6.2E+05 | 1.0E+06 | 4.6E+05 | |
| vh | 6.0E+06 | 1.1E+07 | 6.4E+06 | 1.2E+07 | 1.6E+07 | |
| Correctly assigned | Correctly assigned incl. 1 neighbour | |||||
| Correctly assigned incl. 2 neighbour | Correctly assigned incl. 2 neighbour | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hecht, C.; Figgener, J.; Sauer, D.U. Predicting Electric Vehicle Charging Station Availability Using Ensemble Machine Learning. Energies 2021, 14, 7834. https://doi.org/10.3390/en14237834
Hecht C, Figgener J, Sauer DU. Predicting Electric Vehicle Charging Station Availability Using Ensemble Machine Learning. Energies. 2021; 14(23):7834. https://doi.org/10.3390/en14237834
Chicago/Turabian StyleHecht, Christopher, Jan Figgener, and Dirk Uwe Sauer. 2021. "Predicting Electric Vehicle Charging Station Availability Using Ensemble Machine Learning" Energies 14, no. 23: 7834. https://doi.org/10.3390/en14237834
APA StyleHecht, C., Figgener, J., & Sauer, D. U. (2021). Predicting Electric Vehicle Charging Station Availability Using Ensemble Machine Learning. Energies, 14(23), 7834. https://doi.org/10.3390/en14237834