
Identification of Critical Components in the Complex Technical Infrastructure of the Large Hadron Collider Using Relief Feature Ranking and Support Vector Machines




Abstract
1. Introduction
- (i)
- the development of a method for the identification of critical components in CTIs that relies fully on data and, thus, unlike most of the existing methods of CTI analysis, it does not require detailed knowledge of the CTI;
- (ii)
- the application of the method to the real and complex CTI of the CERN LHC, on the basis of a large amount of monitoring data collected over one year of operation, in contrast to most existing methods of CTI analysis, which investigate simplified and theoretical cases of CTIs.
2. Problem Statement
3. Methodology
- sorting the monitoring signals according to their importance/relevance to the CTI state using the Relief-based feature ranking algorithm (Section 3.1);
- identifying the best performing features subset, , by the quantification of the information content (Section 3.2);
- identifying as critical components those whose states are monitored by the best feature subset .
3.1. Relief-Based Feature Ranking
3.2. Quantification of the Information Content of the Top-Ranked Feature Subsets
3.3. Classifier
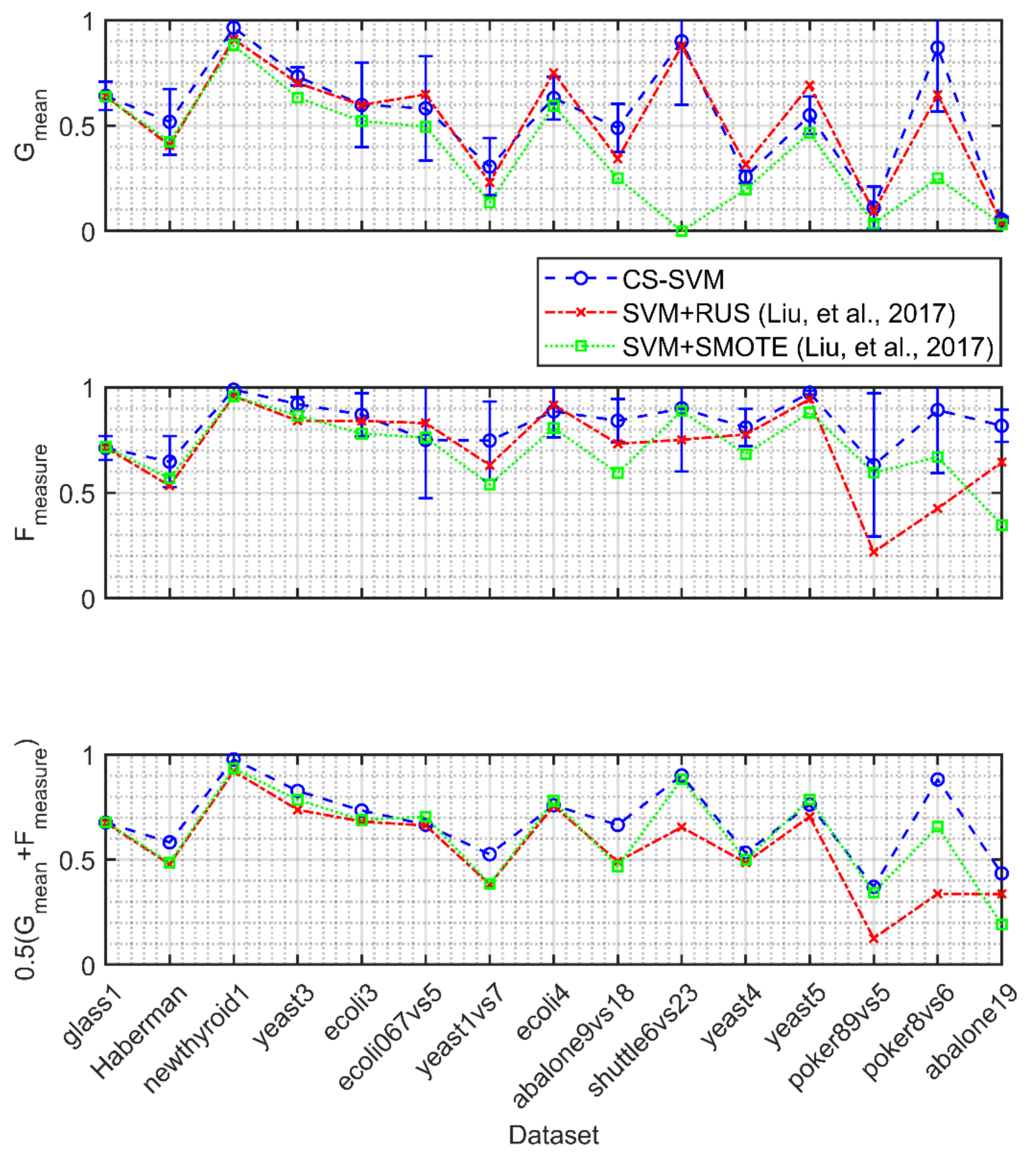
4. Validation of Proposed Method on Benchmark Datasets
4.1. Validation of the CS-SVM Classifier
4.2. Validation of the Relief Feature Ranking
4.3. Analysis of the Relief Robustness
4.4. Validation of the Information Content Quantification Procedure
5. Case Study: The CERN LHC Electrical Network
5.1. Feature Selection and Informativeness Quantification
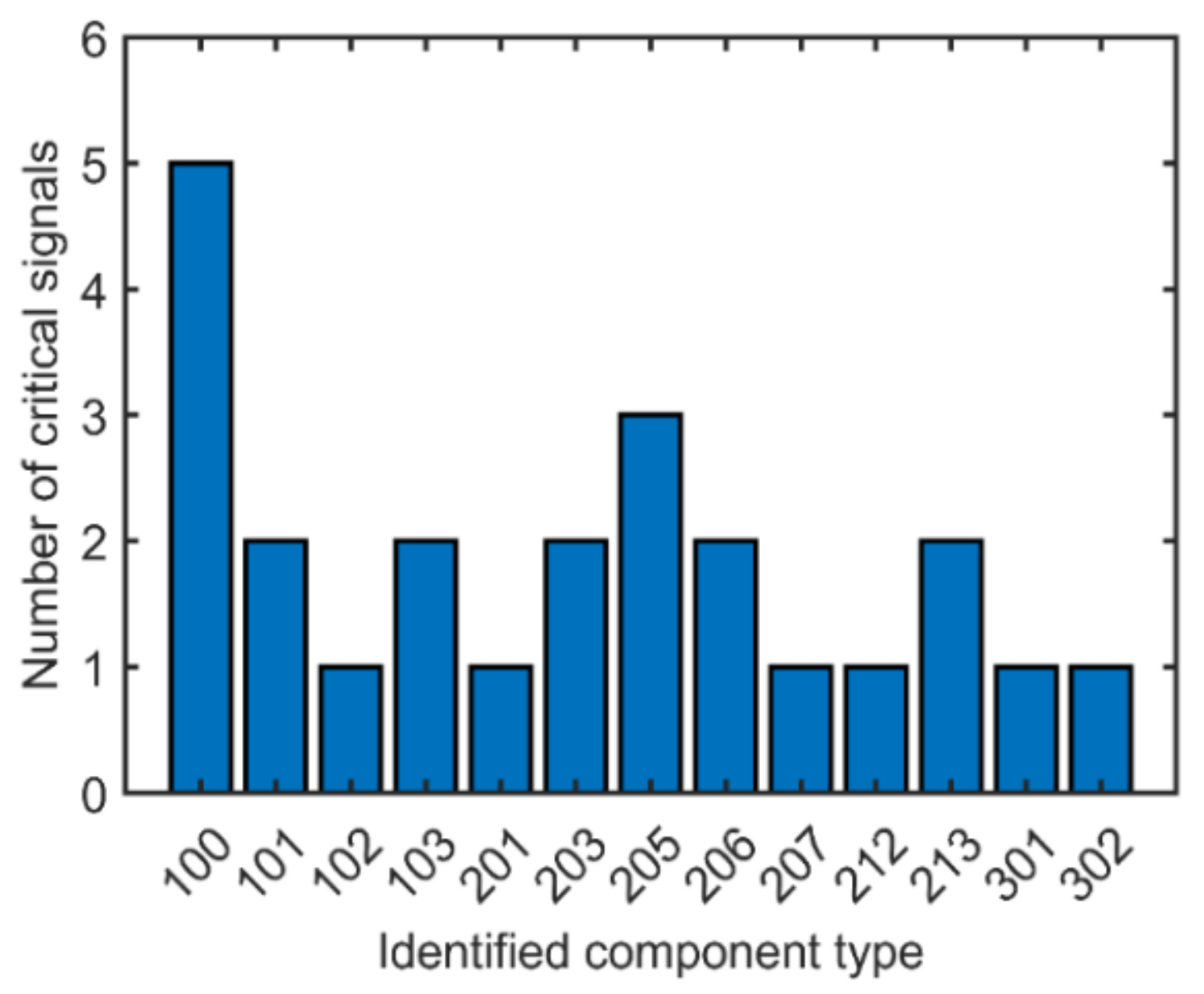
5.2. Engineering Analysis of the Best Features Subset
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zio, E. Challenges in the vulnerability and risk analysis of critical infrastructures. Reliab. Eng. Syst. Saf. 2016, 152, 137–150. [Google Scholar] [CrossRef]
- Antonello, F.; Baraldi, P.; Shokry, A.; Zio, E.; Gentile, U.; Serio, L. A Novel Association Rule Mining Method for the Identification of Rare Functional Dependencies in Complex Technical Infrastructures from Alarm Data. Expert Syst. Appl. 2021, 170, 114560. [Google Scholar] [CrossRef]
- Tian, D.; Zhao, C.; Wang, B.; Zhou, M. A Memcif-In method for safety risk assessment in oil and gas industry based on interval numbers and risk attitudes. Eng. Appl. Artif. Intell. 2019, 85, 269–283. [Google Scholar] [CrossRef]
- Bisht, S.; Kumar, A.; Goyal, N.; Ram, M.; Klochkov, Y. Analysis of Network Reliability Characteristics and Importance of Components in a Communication Network. Mathematics 2021, 9, 1347. [Google Scholar] [CrossRef]
- Zio, E.; Sansavini, G. Vulnerability of Smart Grids With Variable Generation and Consumption: A System of Systems Perspective. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 477–487. [Google Scholar] [CrossRef]
- Ahmed, H.; La, H.M.; Gucunski, N. Review of Non-Destructive Civil Infrastructure Evaluation for Bridges: State-of-the-Art Robotic Platforms, Sensors and Algorithms. Sensors 2020, 20, 3954. [Google Scholar] [CrossRef]
- Johansson, J.; Hassel, H.; Zio, E. Reliability and vulnerability analyses of critical infrastructures: Comparing two approaches in the context of power systems. Reliab. Eng. Syst. Saf. 2013, 120, 27–38. [Google Scholar] [CrossRef]
- Shokry, A.; Baraldi, P.; Castellano, A.; Gentile, U.; Serio, L.; Zio, E. A Methodology for the Identification of the Critical Components of the Electrical Distribution Network of CERN’s Large Hadron Collider. In Proceedings of the 30th European Safety and Reliability Conference—ESREL2020, Venice, Italy, 1–5 November 2020. [Google Scholar]
- Antonello, F.; Baraldi, P.; Shokry, A.; Zio, E.; Gentile, U.; Serio, L. Association rules extraction for the identification of functional dependencies in complex technical infrastructures. Reliab. Eng. Syst. Saf. 2020, 209, 107305. [Google Scholar] [CrossRef]
- Hausken, K. Defence and attack of complex interdependent systems. J. Oper. Res. Soc. 2013, 70, 364–376. [Google Scholar] [CrossRef]
- Wu, B.; Tang, A.; Wu, J. Modeling cascading failures in interdependent infrastructures under terrorist attacks. Reliab. Eng. Syst. Saf. 2016, 147, 1–8. [Google Scholar] [CrossRef]
- Chopra, S.S.; Khanna, V. Interconnectedness and interdependencies of critical infrastructures in the US economy: Implications for resilience. Phys. A Stat. Mech. Appl. 2015, 436, 865–877. [Google Scholar] [CrossRef]
- Zio, E.; Ferrario, E. A framework for the system-of-systems analysis of the risk for a safety-critical plant exposed to external events. Reliab. Eng. Syst. Saf. 2013, 114, 114–125. [Google Scholar] [CrossRef][Green Version]
- Genge, B.; Kiss, I.; Haller, P. A system dynamics approach for assessing the impact of cyber attacks on critical infrastructures. Int. J. Crit. Infrastruct. Prot. 2015, 10, 3–17. [Google Scholar] [CrossRef]
- Patterson, S.; Apostolakis, G. Identification of Critical Locations Across Multiple Infrastructures for Terrorist Actions. Reliab. Eng. Syst. Saf. 2007, 92, 1183–1203. [Google Scholar] [CrossRef]
- Baraldi, P.; Castellano, A.; Shokry, A.; Gentile, U.; Serio, L.; Zio, E. A Feature Selection-Based Approach for the Identification of Critical Components in Complex Technical Infrastructures: Application to the CERN Large Hadron Collider. Reliab. Eng. Syst. Saf. 2020, 201, 106974. [Google Scholar] [CrossRef]
- Lu, X.; Baraldi, P.; Zio, E. A data-driven framework for identifying important components in complex systems. Reliab. Eng. Syst. Saf. 2020, 204, 107197. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; LaCava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Gao, X. A filter-based feature construction and feature selection approach for classification using Genetic Programming. Knowl.-Based Syst. 2020, 196, 105806. [Google Scholar] [CrossRef]
- Jovic, A.; Brkić, K.; Bogunovic, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015. [Google Scholar]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Pourpanah, F.; Shi, Y.; Lim, C.P.; Hao, Q.; Tan, C.J. Feature selection based on brain storm optimization for data classification. Appl. Soft Comput. 2019, 80, 761–775. [Google Scholar] [CrossRef]
- Liu, X.; Liang, Y.; Wang, S.; Yang, Z.; Ye, H. A Hybrid Genetic Algorithm with Wrapper-Embedded Approaches for Feature Selection. IEEE Access 2018, 6, 22863–22874. [Google Scholar] [CrossRef]
- Le, T.T.; Urbanowicz, R.J.; Moore, J.H.; McKinney, B.A. STatistical Inference Relief (STIR) feature selection. Bioinformatics 2019, 35, 1358–1365. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Li, Y.F.; Zio, E. A SVM framework for fault detection of the braking system in a high speed train. Mech. Syst. Signal Process. 2017, 87, 401–409. [Google Scholar] [CrossRef]
- Liu, J.; Zio, E. Integration of feature vector selection and support vector machine for classification of imbalanced data. Appl. Soft Comput. 2019, 75, 702–711. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; López, S.G.; Hilario, A.F.; Martín, J.; Velázquez, I.; Rus, J.; Morales, V.; Muñoz, J. KEEL: Knowledge Extraction based on Evolutionary Learning. 2005. Available online: http://sci2s.ugr.es/keel/datasets.php (accessed on 30 January 2020).
- Brüning, O.; Burkhardt, H.; Myers, S. The Large Hadron Collider. Prog. Part. Nucl. Phys. 2012, 67, 705–734. [Google Scholar] [CrossRef]
- Nielsen, J.; Serio, L. Technical Services: Unavailability Root Causes, Strategy and Limitations. In Proceedings of the 7th Evian Workshop on LHC Beam Operation, Evian Les Bains, France, 13–15 December 2016. [Google Scholar]
- Osman, M.; Abu-Mahfouz, A.M.; Page, P.R. A Survey on Data Imputation Techniques: Water Distribution System as a Use Case. IEEE Access 2018, 6, 63279–63291. [Google Scholar] [CrossRef]
- Loyola-Fuentes, J.; Smith, R. Data reconciliation and gross error detection in crude oil preheat trains undergoing shellside and tubeside fouling deposition. Energy 2019, 183, 368–384. [Google Scholar] [CrossRef]
- Xie, R.; Jan, N.M.; Hao, K.; Chen, L.; Huang, B. Supervised Variational Autoencoders for Soft Sensor Modeling With Missing Data. IEEE Trans. Ind. Inform. 2020, 16, 2820–2828. [Google Scholar] [CrossRef]
- Albuquerque, J.; Biegler, L. Data reconciliation and gross error detection for dynamic systems. AIChE J. 1996, 42, 2841–2856. [Google Scholar] [CrossRef]
- Behroozsarand, A.; Afshari, S. Data reconciliation of an industrial petrochemical plant case study: Olefin plant (Hot section). Comput. Chem. Eng. 2020, 137, 106803. [Google Scholar] [CrossRef]
- Xiao, H.; Cao, M.; Peng, R. Artificial neural network based software fault detection and correction prediction models considering testing effort. Appl. Soft Comput. 2020, 94, 106491. [Google Scholar] [CrossRef]
- Khumprom, P.; Yodo, N. A Data-Driven Predictive Prognostic Model for Lithium-ion Batteries based on a Deep Learning Algorithm. Energies 2019, 12, 660. [Google Scholar] [CrossRef]
- Itania, S.; Lecron, F.; Fortemps, P. A one-class classification decision tree based on kernel density estimation. Appl. Soft Comput. 2020, 91, 106250. [Google Scholar] [CrossRef]
- Liu, X.; Li, Q.; Li, T.; Chen, D. Differentially private classification with decision tree ensemble. Appl. Soft Comput. 2018, 62, 807–816. [Google Scholar] [CrossRef]
- Lu, J.; Qian, W.; Li, S.; Cui, R. Enhanced K-Nearest Neighbor for Intelligent Fault Diagnosis of Rotating Machinery. Appl. Sci. 2021, 11, 919. [Google Scholar] [CrossRef]
- Mathew, J.; Pang, C.K.; Luo, M.; Leong, W.H. Classification of Imbalanced Data by Oversampling in Kernel Space of Support Vector Machines. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4065–4076. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Zhou, H.; Chen, J. CNC internal data based incremental cost-sensitive support vector machine method for tool breakage monitoring in end milling. Eng. Appl. Artif. Intell. 2018, 74, 90–103. [Google Scholar] [CrossRef]
- Mathworks. Matlab. 2019. Available online: https://www.mathworks.com/products/matlab.html (accessed on 1 September 2019).
- CERN. LHC Brochure; CERN: Geneva, Switzerland, 2016. [Google Scholar]
- Wielgosz, M.; Mertik, M.; Skoczeń, A.; De-Matteis, E. The model of an anomaly detector for HiLumi LHC magnets based on Recurrent Neural Networks and adaptive quantization. Eng. Appl. Artifi-cial Intell. 2018, 74, 166–185. [Google Scholar] [CrossRef]
- Gentile, U.; Serio, L. A Machine-learning based methodology for performance analysis in particles accelerator facilities. In Proceedings of the 2017 European Conference on Electrical Engineering and Computer Science (EECS), Bern, Switzerland, 17–19 November 2017. [Google Scholar]
- Todd, B.; Ponce, L.; Apollonio, A.; Walsh, D.J. LHC Availability 2017: Standard Proton Physics; Rep. CERN-ACC.NOTE-2017-0063; CERN: Geneva, Switzerland, 2017. [Google Scholar]
- Kahle, K. Proceedings of the CAS–CERN Accelerator School: Power Converters, Baden, Switzerland, 7–14 May 2014. arXiv 2016, arXiv:1607.028682015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Signals | Number of Instances | Number of Minority Class Instances | Imbalance Ratio |
|---|---|---|---|---|
| glass1 | 9 | 214 | 76 | 1.82 |
| Haberman | 3 | 306 | 81 | 2.78 |
| newthyroid1 | 5 | 215 | 35 | 5.14 |
| yeast3 | 8 | 1484 | 163 | 8.1 |
| ecoli3 | 7 | 336 | 35 | 8.6 |
| ecoli067vs5 | 6 | 220 | 20 | 10 |
| yeast1vs7 | 7 | 459 | 30 | 14.3 |
| ecoli4 | 7 | 336 | 20 | 15.8 |
| abalone9vs18 | 8 | 731 | 42 | 16.4 |
| shuttle6vs23 | 9 | 230 | 10 | 22 |
| yeast4 | 8 | 1484 | 51 | 28.1 |
| yeast5 | 8 | 1484 | 44 | 32.73 |
| poker89vs5 | 10 | 2075 | 25 | 82 |
| poker8vs6 | 10 | 1477 | 17 | 85.88 |
| abalone19 | 8 | 4174 | 32 | 129.44 |
| Combination | |||||
|---|---|---|---|---|---|
| * | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 |
| % | 20 | 30 | 40 | 50 | 60 |
| Rank | Signal | Weight |
|---|---|---|
| 1 | A | 0.215 |
| 2 | G | 0.210 |
| 3 | C | 0.207 |
| 4 | E | 0.200 |
| 5 | I | 0.189 |
| 6 | G_0.2_0.1 | 0.144 |
| 7 | A_0.2_0.1 | 0.134 |
| 8 | E_0.2_0.1 | 0.133 |
| 9 | I_0.2_0.1 | 0.132 |
| 10 | C_0.2_0.1 | 0.129 |
| 11 | C_0.3_0.2 | 0.105 |
| 12 | G_0.4_0.3 | 0.101 |
| 13 | B | 0.096 |
| 14 | I_0.3_0.2 | 0.092 |
| 15 | A_0.3_0.2 | 0.091 |
| 16 | E_0.3_0.2 | 0.090 |
| 17 | F | 0.087 |
| 18 | G_0.3_0.2 | 0.086 |
| 19 | H | 0.085 |
| 20 | J | 0.084 |
| Signal Rank | Signal Tag | Relief Weight | Network Line | Signal Type | Component Number | LHC Geographic Zone |
|---|---|---|---|---|---|---|
| 1 | EMD205_SLASH_5E_PM10_STAR_ | 0.249 | 18 kV | power | 205 | Point 5 |
| 2 | EMD212_SLASH_5E_PM10_STAR_ | 0.233 | 18 kV | power | 212 | Point 5 |
| 3 | EHD100_SLASH_4E_Q10_DASH_ | 0.227 | 66 kV | power | 100 | Point 4 |
| 4 | EMD302_SLASH_1E_PM10_STAR_ | 0.224 | 18 kV | power | 302 | Point 1 |
| 5 | EMD203_SLASH_1E_PM10_STAR_ | 0.222 | 18 kV | power | 203 | Point 1 |
| 6 | EMD213_SLASH_5E_PM10_STAR_ | 0.209 | 18 kV | power | 213 | Point 5 |
| 7 | EMD101_SLASH_4E_PM10_STAR_ | 0.205 | 18 kV | power | 101 | Point 4 |
| 8 | EMD213_SLASH_5E_Q_STAR_ | 0.203 | 18 kV | power | 213 | Point5 |
| 9 | EMD205_SLASH_1E_PM10_STAR_ | 0.202 | 18 kV | power | 205 | Point 1 |
| 10 | EMD203_SLASH_1E_Q_STAR_ | 0.189 | 18 kV | power | 203 | Point 1 |
| 11 | EMD205_SLASH_6E_S_STAR_ | 0.188 | 18 kV | current | 205 | Point 6 |
| 12 | EMD206_SLASH_4E_EA+ | 0.184 | 18 kV | power | 206 | Point 4 |
| 13 | EMD206_SLASH_2E_PM10_STAR_ | 0.180 | 18 kV | power | 206 | Point 2 |
| 14 | EMD101_SLASH_2E_PM10_STAR_ | 0.163 | 18 kV | power | 101 | Point 2 |
| 15 | EHD100_SLASH_6E_P10+ | 0.160 | 66 kV | power | 100 | Point 6 |
| 16 | EHD100_SLASH_6E_MPD | 0.158 | 66 kV | current | 100 | Point 6 |
| 17 | EMD103_SLASH_2E_QM | 0.157 | 18 kV | power | 103 | Point 2 |
| 18 | EMD102_SLASH_2E_PM10_STAR_ | 0.157 | 18 kV | power | 102 | Point 2 |
| 19 | EMD103_SLASH_2E_PMAX+ | 0.157 | 18 kV | power | 103 | Point 2 |
| 20 | EMD207_SLASH_1E_Q_STAR_ | 0.156 | 18 kV | power | 207 | Point 1 |
| 21 | EHD100_SLASH_4E_MQD | 0.156 | 66 kV | current | 100 | Point 4 |
| 22 | EMD201_SLASH_4E_Q_STAR_ | 0.154 | 18 kV | power | 201 | Point 4 |
| 23 | EMD301_SLASH_5E_PM | 0.150 | 18 kV | power | 301 | Point 5 |
| 24 | EHD100_SLASH_6E_P | 0.141 | 66 kV | power | 100 | Point 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shokry, A.; Baraldi, P.; Castellano, A.; Serio, L.; Zio, E. Identification of Critical Components in the Complex Technical Infrastructure of the Large Hadron Collider Using Relief Feature Ranking and Support Vector Machines. Energies 2021, 14, 6000. https://doi.org/10.3390/en14186000
Shokry A, Baraldi P, Castellano A, Serio L, Zio E. Identification of Critical Components in the Complex Technical Infrastructure of the Large Hadron Collider Using Relief Feature Ranking and Support Vector Machines. Energies. 2021; 14(18):6000. https://doi.org/10.3390/en14186000
Chicago/Turabian StyleShokry, Ahmed, Piero Baraldi, Andrea Castellano, Luigi Serio, and Enrico Zio. 2021. "Identification of Critical Components in the Complex Technical Infrastructure of the Large Hadron Collider Using Relief Feature Ranking and Support Vector Machines" Energies 14, no. 18: 6000. https://doi.org/10.3390/en14186000
APA StyleShokry, A., Baraldi, P., Castellano, A., Serio, L., & Zio, E. (2021). Identification of Critical Components in the Complex Technical Infrastructure of the Large Hadron Collider Using Relief Feature Ranking and Support Vector Machines. Energies, 14(18), 6000. https://doi.org/10.3390/en14186000