In this section, the minimum and maximum daily outdoor temperatures from 37 weather stations (WS) will be used, in order to assess the impact of the trend component in the context of medium- or long-term estimations, as well as to compare exhaustively all the methods listed in
Table 1 and explained in previous sections. Furthermore, the best performing model will be finally selected, analysing the estimated temperature trends in Europe according to the selected model.
4.1. Data Description
First, the data used for the case study are described. All the data used in this paper come from the European Climate Assessment & Dataset project (ECA&D) [
30]. The dataset consists of thousands of weather stations, with quite complete daily temperature observations since 1980 for the main European cities. It should be noted that in spite of the fact that we have focused on the last forty years of data, the ECA&D dataset, depending on the weather station, has much more past information. As an example, the oldest (not-empty) available data point comes from Radcliffe Meteorological Station of Oxford University (ID 274 in ECA&D), from which there is information from December 1814. In this paper, we will select one reference time series for each country. A first pre-processing step to select that reference temperatures, remove outliers and fill their missing values was required before testing the different models. Regarding missing values, we have applied a hierarchical regression imputation method, based on neighbouring stations, that is detailed in
Appendix A.2. All the information regarding data pre-processing is detailed in
Appendix A, including the list of reference weather stations that have been selected.
Our dataset consists of the minimum (TMIN) and maximum (TMAX) daily outdoor temperatures recorded at the 37 weather stations of
Table A1, from January 1980 to December 2019. Thus, this case study consists of 74 daily time series of length 40 years (14,610 days). Furthermore, let us describe the different data partitions that have been used in this paper. The years 1980–2009 have been used as training data (in-sample, 10958 points), and years 2010–2019 have been used as test set (out-of-sample, 3652 points).
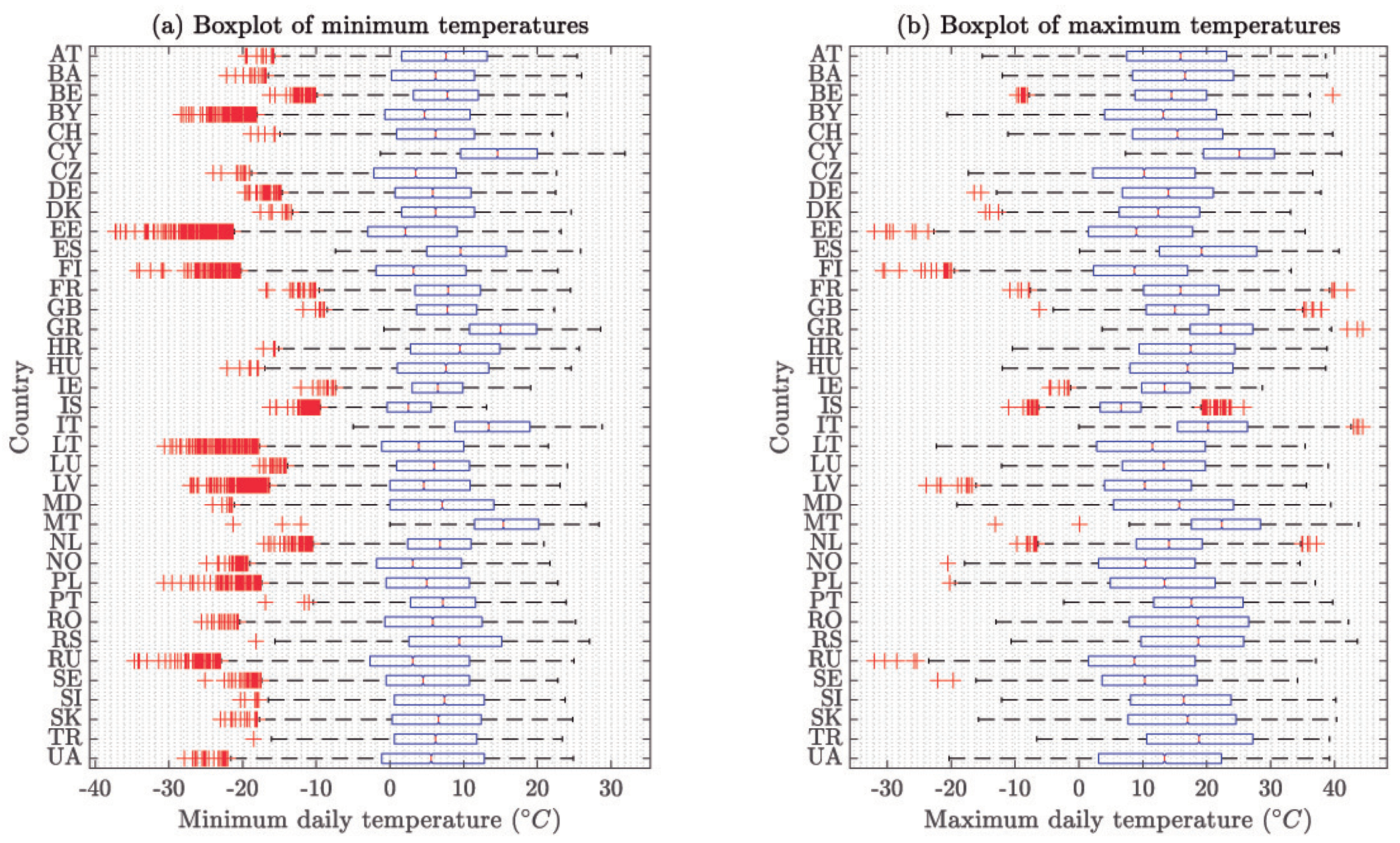
Figure 6 shows the boxplot of the minimum and maximum daily temperatures of the selected station for each country, once main outliers have been removed (see
Table A2). It is noticeable the clear differences between the Mediterranean countries, such as Malta (MT), Italy (IT), Greece (GR), Spain (ES) or Cyprus (CY), and the rest.
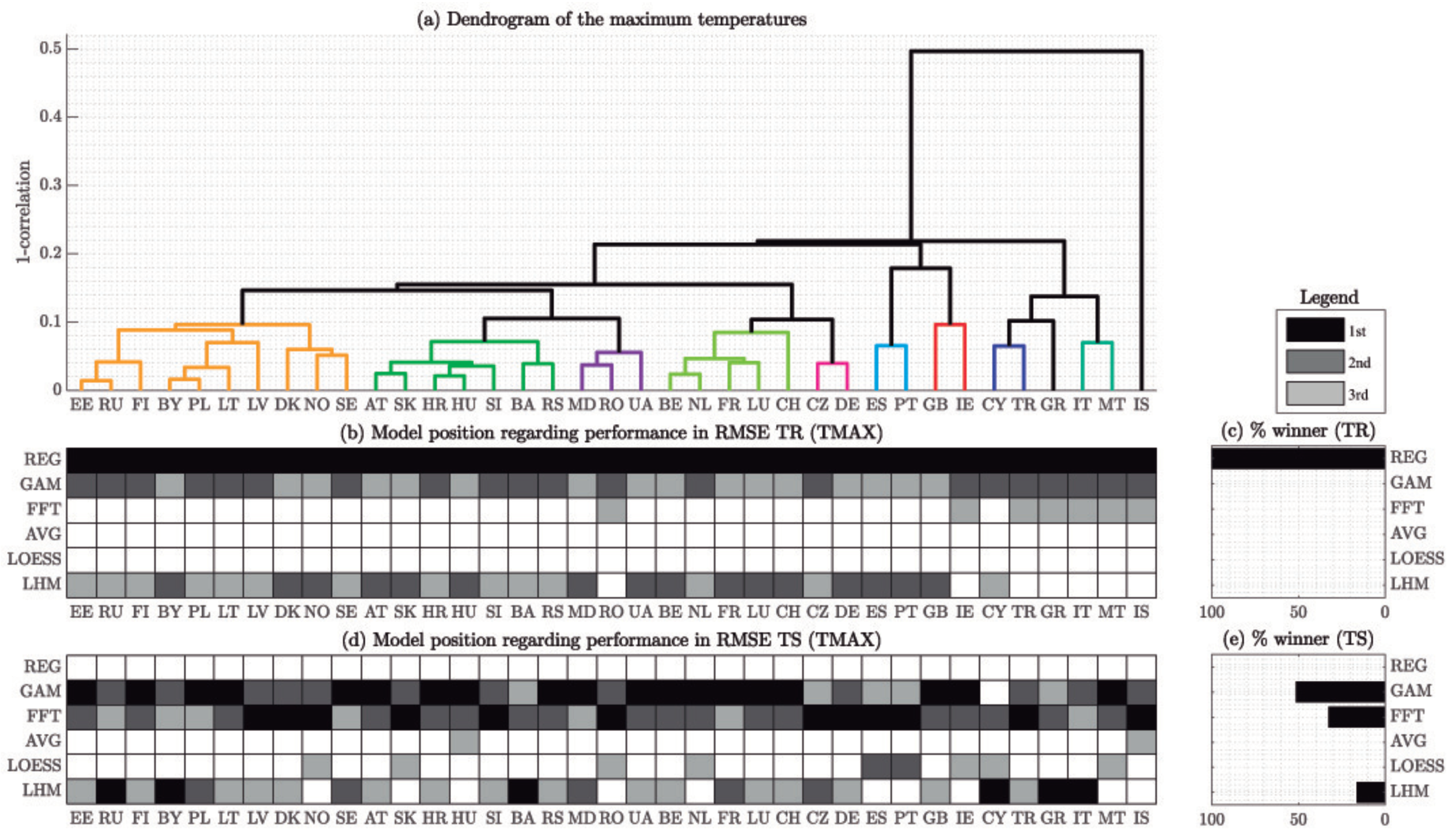
Dendrograms of
Figure 7 summarize the complex spatio-temporal correlations of the selected weather stations based on the minimum and maximum temperatures, respectively. It is remarkable that, considering a correlation threshold of 0.9, the clusters formed in both dendrograms are different. For example, according to the dendrogram of TMAX shown in
Figure 7a, Finland (FI) has similar maximum temperatures to Norway (NO), Denmark (DK) and Sweden (SE), whereas according to the one of TMIN (
bottom), FI is closer to Russia (RU) and Estonia (EE) in terms of minimum temperature.
Figure 8 shows the location of the selected weather stations. Each station has been coloured according to the identified clusters of the dendrogram of the maximum temperature (see
Figure 7a). Note that both latitude and longitude explain those clusters.
4.2. Importance of the Trend Component
This section aims to briefly analyze the effect of including the trend in all the methods described in
Section 2. To do that, two versions of each model have been fitted, one using linear trends as described in
Section 3, and other just using seasonal components and the level (i.e., mean value) of each time series.
Table 2 shows the out-of-sample error improvements obtained by including the trend in each case, calculated as the percentage improvement in RMSE of the model with linear trend, compared to the one using the mean.
First, it can be seen that results are systematic—the effect of including the trend in a particular time series (minimum or maximum from any country) provides similar error improvements regardless the model in use. Secondly, regarding trend significance, we have obtained
p-values lower than 0.05 in 73 of the 74 time series: the only exception is the minimum temperature from Romania (RO), with a
p-value of 0.112. Starting from this point, it can be clearly seen that including the trend improves model performance in nearly all the cases. In terms of minimum temperatures, excluding RO, 92% of the countries present out-of-sample error improvements, whereas in the case of TMAX, that rate rises to 97%. Finally, it can be seen that several countries, such as Cyprus (CY), Poland (PL), or Serbia (RS) present high error improvements. However, in the other side, one of the 74 analyzed time series has a surprising result: the trend of the minimum temperature from Ireland (IE), whose
p-value is 7.41
, and providing nearly an 1% of in-sample error improvement, causes an out-of-sample error increase of 6%. As it will be discussed in
Section 4.4, for all the models, the resulting trend in the minimum temperature of IE has been negative, and it seems not to be the behavior of the time series during the 10 years of test set. Ignoring that case, and as aforementioned, the trend has proved to improve model out-of-sample performance in most of series and countries.
4.3. Empirical Comparative Analysis
Having described the dataset to be used, and having confirmed the importance of the trend component in long-term temperature forecasting, this section aims to compare the performance of the different candidate models of
Table 1 in the selected 37 reference European stations (see
Table A1). As aforementioned, for those methods that require selecting model complexity (i.e., FFT, LOESS and AVG), their hyper-parameters have been estimated for each country by using repeated cross-validation, and are detailed in
Table A4. The estimated number of knots of the LHM for each country, which is automatically determined by its learning algorithm, can be also seen in
Table A4. The results provided by the six methods over the 37 reference weather stations, and for their minimum and maximum temperatures, are detailed below.
First, before presenting the R-squared and the in-sample and out-of-sample errors (RMSE) of all the methods,
Figure 9 and
Figure 10 show the relative position of the different methods when estimating the minimum and maximum temperatures, respectively, and in-sample and out-of-sample. It should be noted that in both figures, countries have been sorted attending to the clusters of
Figure 7 but there is not a best performing model for each group, and we have not found any relationship between that ordering and model performance.
The results obtained for the minimum and maximum temperatures are quite similar—the best performing models are the same in
Figure 9 and
Figure 10. First, it should be noted that regarding in-sample error, the REG method outperforms in all the countries all the other models. However, it can be seen that REG is never selected as one of the the top-3 models for out-of-sample performance. For that reason, we can conclude that it is clearly over-fitted. Ignoring REG, it can be seen that in both minimum and maximum temperatures, the second and third places regarding in-sample error belong to the GAM, and the LHM (the latter, beaten by the FFT in some countries).
On the other hand, in the out-of-sample set, there are three models that clearly outperform the others—GAM, FFT an LHM. The first one, that also was the second best in-sample performer after the over-fitted REG, has the lowest out-of-sample RMSE in most of the cases. As it can be seen in
Figure 9 and
Figure 10, GAM is the out-of-sample winner in almost 60% of the countries, both in the minimum and maximum temperatures. After the GAM, FFT provides the lowest error in approximately 25% of the countries, and LHM in the vast majority of remaining cases.
Before presenting the RMSE for all the methods and countries, and in order to check the goodness of the estimated deterministic (trend plus seasonal) components explaining temperature variance,
Table 3 and
Table 4 present the Adjusted R-squared (
) for the minimum and maximum temperatures, respectively. It can be seen that, in spite of the fact that the remainder has not been modelled and, therefore, forecasting performance can be improved, the obtained
are over 0.7 in the vast majority of cases. The average
for the minimum temperature and all the models and countries is of 0.731, for both in-sample and out-of-sample sets. Regarding maximum temperature, the average
is 0.777 and 0.776 respectively. The only cases where a weak
has been obtained (lower than 0.5 in average) are Ireland (IE), for its out-of-sample minimum temperature, and Iceland (IS), for its maximum temperature (both in- and out-of-sample).
Finally,
Table 5 and
Table 6 present the in-sample and out-of-sample errors (RMSE) of all the models, for the minimum and maximum temperatures respectively. As aforementioned, the GAM provides good in-sample results, is always in the top-3 models in terms of out-of sample performance, and beating all the others in almost 60% of cases. For that reason, in order to analyze long-term temperature trends in Europe, and their expected values in the following years
Section 4.4, the GAM will be the only method to use.
4.4. Analysis of the Long-Term Temperature Trends with the Best Performance Model
Once analysed the performance of all the different methods over the 37 European countries, and confirmed that the GAM is the model, this subsection aims to analyze the results provided by that model in all the countries to shed some light on potential future changes and better understand the behavior of European temperature trends. Furthermore, in order to exhaustively present the results of the GAM,
Appendix C presents the seasonal and trend components estimated by this method in all the countries. It should be noted that in spite of the fact that we will only analyze the results provided by the GAM in this section, we could extract the same conclusions, regarding the trend component, with all the tested methods, since their resulting trends are very similar. As an example, the average difference between the three best performing models (FFT, LHM and GAM) in the trends of the minimum temperatures is 9.43
°C/year.
It should be noted that this section presents the resulting trends of the GAM, using the reference weather stations from the ECA&D dataset presented in
Table A1. Although we have performed a systematic data pre-processing step, removing outliers and filling all the missing points (see
Appendix A), any data inconsistency in the original dataset can affect model results. As an example, the reference weather station from Estonia, presents a sudden temperature increase of around 1 °C during the last 13 years of our in-sample period for its minimum temperature. For that reason, its estimated trend may not be reflecting the actual behavior of that temperature.
Figure 11 shows the trends estimated by the GAM for the minimum and maximum temperatures and all the countries. First, it can be seen that most countries present positive temperature trends in both series, 0.02 to 0.08 °C/year. The only exceptions are Romania (RO), Ireland (IE) and Estonia (EE), regarding TMIN, and Malta (MT) and Croatia (HR) regarding TMAX. In the case of RO, its minimum temperature grows at a rate of 0.007 whereas its maximum does so at 0.06 °C/year. The case of IE is more surprising: although its maximum temperature is growing 0.04 °C each year, is the only country in which the GAM (and all the other models) has estimated a negative trend: its minimum temperature is decreasing 0.013 °C/year. At the far end, EE presents a very similar trend of TMAX to that of IE, but it is the country where the minimum temperature presents a higher growing rate: 0.102 °C/year. However, due to the aforementioned data issue, this result may be not representative.
On the other hand, in terms of maximum temperatures, Malta (MT) is growing slower than all the other countries (0.013 °C/year), and Croatia (HR), just in the other side, has the largest increases with 0.089 °C/year. In summary, the average temperature increase of the minimum temperatures of the 37 European countries is 0.0485 °C/year, whereas the average trend for the maximum temperatures is 0.0554 °C/year. To observe all the detail,
Table 7 shows the results of the GAM in all the different countries and for the minimum and maximum temperatures.
In order to find possible similar behaviors between countries,
Figure 12 presents the trends of
Table 7, separated in minimum and maximum, and coloured according to the clusters formed shown in
Figure 7. First, it can be seen that, once the countries have been sorted by cluster, several trend patterns can be appreciated.
Let us analyze several examples. Cluster number 5 of of maximum temperatures, formed by Baltic countries, Nordic countries (except Iceland), Belarus (BY), Poland (PL) and Russia (RU) presents trend values between 0.047 and 0.072 °C/year. Spain (ES) and Portugal (PT) form, for both minimum and maximum temperatures, the Iberian cluster with positive but low values of trend. Ireland (IE) is in the same cluster than the UK for the maximum temperatures and with similar values; however, they are in two separated clusters for TMIN (IE is the only country with negative trend for that variable). France (FR), Belgium (BE), Switzerland (CH) and the Netherlands (NL) have similar results in terms of maximum temperature, but regarding TMIN FR presents lower increases than all the other neighbours. Italy (IT) and Malta (MT) behaves similarly in TMAX (flat trends), but in TMIN, MT presents a higher value.
In order to check the geographical distribution of these trends,
Figure 13 shows the European map of minimum and maximum temperature trends. First, it can be seen that, in general terms, the minimum temperatures are increasing at a slower rhythm than maximum temperatures: 68% of countries present higher growing rates in its maximum temperature. Regarding maximum temperatures, fourteen countries present annual increases higher than 0.06 °C/year, leaded by Croatia (HR) with 0.089 °C/year. Only seven countries grow in minimum and maximum temperatures at a rate higher than 0.06 °C/year—the Czech Republic (CZ), Luxembourg (LU), Moldova (MD), Norway (NO), Serbia (RS), Sweden (SE) and Slovenia (SI). It should be noted that, Finland (FI) with trends of 0.052 and 0.063 °C/year for its minimum and maximum temperatures respectively, is not very far from that group, so Scandinavian countries present quite high grow rates for both variables.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















