1. Introduction
Photovoltaic (PV) array modeling is crucial in many fields, including the prediction of energy production [
1], the design, the control [
2] and the diagnosis [
3]. The increase of the PV cells would be desirable, in a context where many types of technologies have been developing, although 90%–95% of the market is still dominated by mono-crystalline and poly-crystalline silicon technologies [
4]. The mono-crystalline PV commercial modules reach efficiencies between 15% and 22%; meanwhile, poly-crystalline technology goes up to the efficiency range of 14%–20%. The economies of scale of its main material, silicon, make crystalline silicon cells more affordable and highly efficient compared to other materials [
5]. Other technologies derived from crystalline silicon technologies have been gaining importance in the research and commercial fields, such as half-cell, double glass and bifacial [
4]. On the other hand, thin film technologies, e.g., amorphous silicon, CdS/CdTe and CIS, represent close to 5%–10% of the market [
4]. Emerging technologies, e.g., organic and perovskite ones, offer interesting perspectives in terms of efficiency [
6], but some barriers still need to be overcome, especially durability and price [
5]. The approach proposed in this paper refers to PV generators based on crystalline silicon cells, which represent the largest part of the market. Different models have been studied in the scientific publications to represent PV modules based on crystalline silicon cells. The single diode model (SDM) offers a reasonable trade-off between accuracy and degree of non linearity, such that it is widely used in literature. It involves five parameters, which are related to the photo-induced current, the P-N junction and the losses. These parameters are in turn dependent on other ones related to the cell material and the environmental conditions—the irradiance and the temperature; see [
7,
8]. The double diode model (DDM) allows one to model the dark current losses and the effect of pair generation—recombination in the space charge region [
9], but at the cost of an increase in the number of parameters, increasing from five for the SDM, to seven. A more complicated model can be used in a case where the PV cells’ behavior at negative voltage values has to be accounted for. A further generator is included in this model [
10], so that the parameters required become eight.
In this paper, the SDM is preferred to the DDM because of the features mentioned above and also because the PV array working conditions considered are uniform; thus, the model proposed in [
10] becomes superfluous. A key operation for an accurate SDM-based simulation of the PV array is the identification of the five model parameters. This is very often done by employing data that are provided by the PV module manufacturer through the data sheet. These experimental measurements refer to a specific operating conditions of the cells, called standard test conditions (STC).
In the literature, parametric identification is done by using analytical methods or fitting techniques [
11]. In
Table 1 a comparison among such approaches is given by referring to the implementation complexity, the convergence speed, the robustness when noisy data are considered, the impact of the initial conditions and the requirements of algorithmic setting. Analytical approaches are based on a set of simplified equations leading to explicit formulas allowing one to calculate the five parameters of the SDM without using any iterative method [
12]. Some approaches consider the SDM lossless model, or scale down the order of the SDM by considering an infinite value of the shunt resistance or by neglecting the series resistance [
13]. The most common simplification consists of supposing that the short-circuit current (
) value is equal to the photo-induced current (
) [
14]. A set of equations is derived at the main points of the current vs. voltage (I-V) curve: at the maximum power point (MPP), at the short circuit operating point through
and in open circuit conditions through
. Noisy I-V data may have a significant effect on parameters values. This is the case, for instance, for a series and for the shunt resistances whose values are related to the slopes of the I-V curve in an open circuit and in short circuit conditions, respectively. Additionally, the so called
translation equations have been considered in some papers to relate the I-V curve in non-standard conditions to the five SDM parameters that are scaled according to the irradiance and temperature conditions the I-V curve refers to [
14,
15,
16,
17,
18]. Simplified and direct equations make the implementation of the method suitable, even for an embedded processor, at the cost of a reduced accuracy.
Many other approaches to the SDM parametric identification are based on optimization methods, which are usually aimed at the root mean square error (RMSE) between the simulated I-V curve and the experimental curve minimization. The convergence of the algorithm depends on factors such as the guess condition, the objective function and the algorithm itself. Three main approaches are proposed: the one using non-linear minimization algorithms [
19,
20], the one using heuristics approaches [
21,
22,
23,
24] and the adoption of hybrid methods [
25]. The non-linear algorithms are computationally expensive [
19,
20], but that allows for solving numerically, the set of non-linear equations of SDM. In [
20],
Matlab embedded Levenberg–Marquardt and Gauss-Newton nonlinear equation solvers were used to manage the SDM equations. The parameters in STC were obtained from modules’ data sheets, and
translation equations [
15,
16] were used to obtain the SDM model in other operating conditions. Noisy data affect the confidence intervals of the solutions achieved by these algorithms. The termination conditions and the related parameters have to be chosen in order to have a trade-off between computation time and accuracy. Low values of the convergence thresholds and high values assigned to the maximum number of iterations are compatible with off-line identification purposes. Moreover, the iterative methods, such as Newton methods, are less complex, but they might be trapped in local optima and show a high dependency from the guess solution used. For instance, in [
26]
is neglected, so that four equations to determine four SDM parameters are proposed, the series resistance value being fitted by calculating the power error between the SDM and the experimental measurements in a iterative way. Nonlinear minimization algorithms are often used to fit I-V experimental curves, the objective function to minimize being the error between the model and experimental data. Trust-region and Levenberg-Marquardt methods are widely used, but they require a good guess solution. Simulation platforms, e.g.,
Matlab and
Mathematica, provide curve fitting tools to perform offline parametric identification. Recently, soft computing methods, such as artificial neural networks [
21,
22], genetic algorithms [
23] and particle swarm optimization (PSO) [
23], among others, have been employed more and more frequently. Such approaches are not suitable for online operation because of the computational complexity of the stochastic algorithms. The approaches introduced in [
21,
22] operate on suitable sets of I-V curves, related to a specific module’s operation, to train neural networks. To determine the amount of training data and the numbers of layers and neurons is a challenging task. In genetic algorithms [
23], fixing selection, reproduction and mutation operators and values of the related parameters is challenging as well. Settings such as population size, iteration number and mutation rate, among others, have to be well adjusted to prevent the algorithm from stalling. Therefore, in terms of setting of the heuristic algorithms, several initial guess values have to be designed by an expert and/or through a trial and error procedure. By combining different techniques, some weaknesses are reduced. For example, in [
25] the global exploration capabilities of the soft computing algorithm artificial bee colony (ABC) allowed it to reduce the space for exploring solutions, and local searching was done by the trust-region reflective algorithm, thereby improving accuracy, convergence and reliability. Unfortunately, there is not a consensus about the improvement of the computation time achieved by hybrid approaches.
The difficulty of the parametric identification comes from the high non linearity of the SDM and from the fact that the values of the parameters have very different orders of magnitude. With respect to the identification performed on the basis of the STC experimental data that are usually available in PV modules data sheets, the parametric identification using data acquired while the PV module is working in outdoor conditions show different features. Indeed, the whole I-V curve is usually available and irradiance (G) and temperature (T) values at which the PV module is working might be also given.
Interval arithmetic (IA) is a mathematical approach that is used in many contexts for evaluating the propagation of the uncertainty affecting input data on the output of a given system. Moreover, it has been used for tolerance analysis and design in the context of electrical and electronic engineering; e.g., in [
27,
28,
29]. By IA, parameters assume values that are not real numbers, but intervals limited by a lower and an upper bound: in an interval the parameter may assume any value with the same probability. In [
28] an evolutionary approach to worst case tolerance design of magnetic devices is presented. The algorithm improves on the classical nominal design, accounting for parameter variations and tolerances, so that the system performance does not exceed upper and lower specifications imposed in advance by the designer. In [
27], IA is used to perform tolerance analysis and design and to evaluate the production yield. In [
29], an IA based estimation state in power distribution networks with high penetration of photovoltaic generators is proposed. In this case, IA is adopted to deal with measurement uncertainty. The proposed method allows one to determine the upper and lower bounds of state variables, which is helpful for providing operators the confidence that the actual value variable is not exceeding the voltage security constraint, thereby improving the network operation for the case of uncertain inputs.
IA-based parametric identification has never been used in the outdoor PV context, but it can be helpful for designing an algorithm profiting from IA features, thereby giving a reliable result with little computational effort. The IA based approach presented in this paper starts from a large volume in the parameter search space and contracts it by means of a divide-and-conquer () strategy up to converge to a tight hyper-rectangle including the experimental measurements in the I-V plane. The proposed IA based algorithm requires the user to fix the initial intervals for the five SDM parameters and two thresholds for the feasibility and the termination conditions respectively. The initial intervals, which define the search parameters’ space, are contracted towards the identified set, if they are included in the search space. Otherwise, the IA based algorithm informs the user about the guaranteed infeasibility of the whole search space. To fix the search space is obviously easier for a not-so-skilled user than to provide a guess solution that is quite close to the final one, as is required by gradient-based minimization approaches. This feature is very helpful, especially for some parameters, e.g., saturation current and thermal voltage, that greatly depend on cells material and on operating conditions. As for the feasibility condition, the desired amount of experimental data contained in the IA computed I-V boundaries depends on the application, and it can be fixed as greater than 85%. In the same way, the threshold to fix in the termination condition is chosen as the desired resolution of the interval solution. strategy allows one to evaluate solutions separately, so parallel computing is suitable to decrease the computation time without sacrificing the size of search space. This is a distinctive feature compared to the other approaches, which in general have to make a compromise between accuracy and computation time.
The paper is organized as follows: In the first section an introduction of SDM is done. Then, IA theory is briefly recalled and it is applied to the SDM. Later on,
algorithm is presented. In
Section 4, the proposed method using IA and
algorithm is detailed. In
Section 5, the results obtained to estimate
,
,
,
B and
parameters of the SDM model are analyzed. The sixth section proposes a discussion about the results presented in the paper and closes with the conclusions.
2. Photovoltaic Generator Single Diode Model
Figure 1 shows the SDM circuit: it includes the photoinduced current generator
, which models the photovoltaic effect; a diode D modeling the P-N junction; and the resistances
and
representing the ohmic losses and the recombination losses respectively. Thus, the following five parameters appear in the model:
: saturation current in the P-N junction;
: photo-induced current;
: series resistance;
: parallel resistance;
B: it includes the ideality factor n, which is the fifth parameter to be identified. It is: , where is the number of series connected cells, T is the cells operating temperature, k is the Boltzmann constant and q is the electron charge.
It is worth noting that the five parameters mentioned above show some dependencies from physical parameters that are typical of the semiconducting material used for the cells’ fabrication and also from irradiance G and temperature T. As in the majority of the literature concerning I-V curve based parametric identification, in this paper also, the identification focuses on the five parameters mentioned above, thereby neglecting their dependencies on other physical parameters. This further correlation, and the dependency on G and T especially, can be exploited after having identified the set to the aim of having, in turn, the values of the physical parameters, including G and T.
The output current
I of the PV array is obtained by combining the Kirchhoff voltage and current laws and the characteristic equations of the components appearing in the SDM.
In [
30] it is shown that the resulting function expressing the relationship between the current
I and the voltage
V at the PV generator terminals is implicit, but the Lambert
W-function is useful for achieving an explicit non-linear relation between
I and
V, which is given in (
5).
wherein:
.
Later on, without loss of generality, the discussion is referred to one PV module. The set of unknown five parameters is .
In
Figure 2 a PV module I-V curve is shown by blue marks: it has been obtained by placing the values listed in
Table 2 into Equation (
5). The parameters in
Table 2 refer to a 140 W PV Yingli solar panel working in STC, which have been obtained by the method proposed in [
31] in STC. This PV module consists of 36 polycrystalline solar cells connected in series. In the same figure, the I-V curves corresponding to 30% variations of the parameters
,
,
and
B are also shown in magenta, cyan, red and black respectively. The I-V curve exhibits a significant sensibility with respect to variations of
B and
in proximity to the MPP and a dependency on
in the high voltage range. The parameter
depends on, almost directly, irradiance, and its value is usually assumed to be equal to the short-circuit current [
2].
In the literature, SDM parametric identification of the parameters has been often addressed by minimization algorithms, which are aimed at fitting the experimental I-V curve with the one generated by the SDM. The result is a set of five real values, one for each of the five parameters in the SDM (
Table 2). IA, instead, should be used to identify the parameters by starting from the I-V curve, and by exploiting the IA properties, guaranteeing that the I-V ranges correspond to the set of parameters bound to the experimental measurements. Later on, the main IA features and properties are recalled in order to appreciate how they are suitably exploited in the PV parametric identification context.
3. Interval Arithmetic for I-V Curve Representation
The basic mathematical entity used in IA is the interval. Thus, the parameters appearing in the model can be treated as intervals
instead of real numbers
X. The approach consists of treating parameters or variables as having ranges of values, instead of discrete values. The bounds of the interval
, using the nomenclature proposed in the IEEE Std 1788.1 [
32], are called
and
. Thus,
=
,
; it is defined by
. Basic arithmetic operations among interval variables are well defined in the IA foundations [
33]. The operation among two intervals results in an interval too, having the property that it contains all the possible results obtained by the combination of all the values included in the intervals corresponding to the operands. The values in the intervals are assumed to have the same probability of occurring, so that the probabilities of the values are uniform. This means that all the values in
are equi-probable. IA theory also shows that the simple representation of the operands, which consists of the lower and of the upper bound of the intervals thereof, does not allow one to take into account any correlation among the variables. As a consequence of this, the IA result is an over-estimation of the true range of the result. This means that the IA result is guaranteed to contain all the possible results of the operation, but the over-estimation might be too much wider than the real interval. In order to reduce this IA drawback, the number of occurrences of the same parameter in the IA-based operations must be minimized. For instance, in the Equation (
5), which allows one to calculate the PV generator current,
includes the computation of an equivalent resistance resulting from the parallel between
and
; thus,
. This expression involves two occurrences of each one of the resistances. By using the ranges
and
, the IA gives the result
. By using the real arithmetic, obviously the equivalent expression
gives the same results, but this is not true if IA is used. Indeed, a reduced number of variables’ occurrences results in
. Therefore, the lower the number of occurrences of the interval valued parameters in (
5), the more accurate the IA-based evaluation of the result. As widely shown in [
33], this is not the only cause of overestimation of the interval of variation of the result of an operation by using IA, because the non linearity of the function operating over interval valued parameters and variables contributes to widening the resulting range.
In the PV-oriented problem treated in this paper, the PV current given by the SDM (
5) is the explicit function
where
is the interval valued vector of the parameters to identify and
V is the real value of the voltage at which the current is evaluated. In case the set of interval values parameters is limited to two only, with the others being real values, the domain and co-domain of
is qualitatively depicted as in
Figure 3. In the bi-dimensional plane representing the domain,
is a initial square region in gray resulting from the two interval parameters
and
. This corresponds to the co-domain
. A contraction of the domain, which is represented by a smaller rectangle resulting from the sets
and
, corresponds to the co-domain
. If performed through the classical real valued analysis, e.g., by a Monte Carlo approach, the computations of the gray and the red envelopes in the I-V plane should require the selection of a high number of samples in the gray and the red rectangles in the parameters domain, and thus, a high number of Monte Carlo trials. The higher the number of
couples, the more accurate the evaluation of the corresponding envelope in the I-V plane, which is obtained by merging all the curves obtained, and the voltage value by voltage value, by taking the maximum and the minimum
I values. Such a computation should be able to reveal whether the experimental I-V curve is included or not in the envelope, and thus whether the corresponding sets
or
are feasible. A reliable evaluation of the envelopes, if performed by using the classical real numbers, thus, through a Monte Carlo method, should be more time consuming the more significant the non-linearity and non-monotonicity of the function
I are with respect to the parameters. Instead, IA is a tool that allows one to evaluate the envelopes corresponding to each set
and
by a single computation. Thanks to the IA properties, the result will be guaranteed to bound the true
I range.
In the next section, on the basis of such conclusions, the proposed IA parametric identification method is shown: it starts from a large rectangle in the parameters domain exemplified by the gray rectangle in the qualitative example of
Figure 3, and contracts it in order to bound as much as possible the experimental points, which are marked in blue in
Figure 3, in the I-V domain.
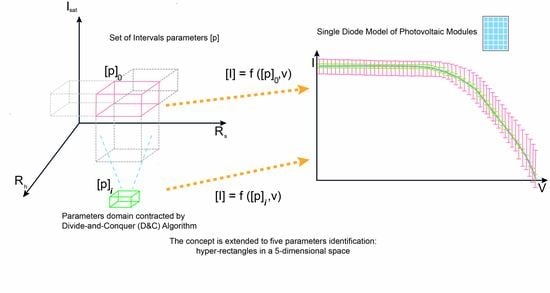
4. Parametric Identification by the IA-Based Divide-and-Conquer () Algorithm
In this paper, the identification of all the five parameters in (
5) is considered. As a consequence, the rectangles shown in
Figure 3 have to be considered hyper-rectangles in a 5-dimensional space. Iteration by iteration, the initial intervals
are contracted in order to contract the
around the experimental data. The iterations end when a termination condition fixed by the user is fulfilled. The divide-and-conquer (
) algorithm is an algorithm design paradigm for discrete and combinatorial optimization problems. The algorithm starts evaluating the largest candidate set of parameters assigned by the user, which is named
in
Figure 4. If the
bounds include the experimental I-V samples
, then all the five parameters intervals of
are halved, so that
sub-intervals are generated.
For each of the sub-intervals the I-V boundary is calculated by using IA. If the experimental points are not included in the boundaries, the corresponding subset is marked as infeasible and it is not partitioned into smaller subsets anymore. On the contrary, the subset is partitioned by halving again the intervals it is made of and these ones are analyzed at the next iteration level. Thus, the algorithm continues with the next dividing level until a termination condition fixed by the user is fulfilled.
In summary, the proposed
algorithm consists of the following main elements appearing in
Figure 4.
Dividing Level (i): it is identified by the sub-index i. At each level, the parameters’ intervals sets that fulfill the feasibility condition are halved, so that new sub-intervals are generated. Thus, in case all the intervals are feasible, at the dividing level i a number is generated and its feasibility has to be tested. Each interval in the subset takes a new sub-index , so that a particular set of parameters is called . For instance, at the branching level , each element in the interval is halved, and all the combinations of these sub-intervals, which are called: , have to be tested through the feasibility condition.
Feasibility condition: at the
i-th branching level, the subset of intervals
is substituted in (
5) for each voltage value
of the experimental data set. A current interval
results at each voltage value and it is verified that the
all the
experimental points fall within the calculated intervals:
Parameters’ sub-intervals that do not fulfill the feasibility condition are not divided anymore and are not transferred to the next algorithm iteration.
It is worth noting that the infeasibility of these sub-intervals is guaranteed by the use of IA. Indeed, IA properties recalled in
Section 3 ensure that the co-domain
evaluated over a set of parameters
is an overestimation of the true range spanned by the current
I for that domain
. As a consequence of the overestimation, if the range
does not fulfill the feasibility condition, namely, does not include all the experimental I-V samples, then it is guaranteed to be infeasible. The same guarantee would be achieved by classical methods, e.g., Monte Carlo, only at a very high cost, even tending towards an infinite computational cost, thanks to the trials in the Monte Carlo approach. This represents a relevant advantage of the proposed IA based approach.
Termination condition: Feasible intervals
falling below a minimum width, which is
wid, fixed by the user, are not divided further. Thus:
where
represents the midpoint of
. When the termination condition imposes that no more feasible intervals have to be partitioned further, then the union of the feasible intervals achieved by the algorithm represents the final result. The proposed IA-based
algorithm is presented in Algorithm 1.
| Algorithm 1: IA-based algorithm. |
 |
5. Identification of the Parameters , and through the IA-based Method
The identification of the SDM parameters almost consists of identifying
,
and
. Indeed, the
parameter is assumed as equal to the short-circuit current [
2], whose value is experimentally measured. On the other hand, once having measured the cells’ temperature and by assuming that the number of series connected cells in the module is known, the value of the parameter
B is fixed if, as it is quite common in literature, (see [
8,
34,
35]),
n assumes a value between 1 and 2. Typical values are below 1.5, but the search range has been extended up to 2 in order to account for more extreme cases documented in literature [
36]. It has to be kept in mind that the range is subjected to the contraction due to the IA based approach proposed in this paper. Thus, a smaller upper limit would not affect the final result of the identification process, but its rate of convergence. With those assumptions, the identification process limited to the three parameters
,
and
is of practical interest and allows one to demonstrate the performance of the proposed
algorithm on a reduced scale case. The algorithm in this case is tested by using I-V samples that are obtained by using the parameters in
Table 2 in the SDM (
5). Samples are calculated at a fixed voltage step
, so that the
I-V samples shown in
Figure 5 are considered.
The
algorithm has run on the following search space:
. The nominal values for
B and
given in
Table 2 have been also used.
has been used for settling the termination condition.
The algorithm has created the number of dividing levels shown in
Table 3. The third column of
Table 3 reveals the effectiveness of the proposed IA approach. Indeed, as pointed out before, the main advantage of applying IA to the feasibility condition is the immediate and guaranteed classification of the infeasible sets of the search space. It is evident that, for this example, just at the first dividing level, 50% of the search space is immediately classified as infeasible. The same result would require a number of Monte Carlo trials instead of four IA based computations. The fourth column of
Table 3 gives a measure of the volume of each subset at the corresponding dividing level. The solution is reached at the tenth dividing level, at which two sets of interval solutions have been identified. The union of those two intervals is shown in
Table 4. It reveals that the interval set solution contains the values of parameters
,
and
used to generate the I-V samples. This is the expected result, so that the convergence property of the
algorithm is confirmed. A personal computer (PC) equipped with a Corei7-3632QM processor @ 2.20 GHz, four cores and 8 GB of RAM memory is used. The executable file, produced by starting from the C++ source, was run on a PC. With this software and hardware, the algorithm reaches the solution in 1.02 s after 360 iterations.
Figure 5 puts into evidence that all the I-V samples fall inside of interval current
determined by the IA based method.
This first test has been done by identifying the parameters by using I-V samples obtained through the same model, the SDM, adopted for the identification thereof. In this way, the process has not been affected by inaccuracies of the SDM in fitting experimental data and by inaccuracies and noise over I-V measurements. These effects will be more evident in the next sections wherein experimental I-V data are used.
7. Discussion of the Results
Some aspects concerning the results presented in the previous examples deserve further comments. The first one concerns the way in which the initial interval set of parameters, and thus the search space, is chosen. The proposed IA-based algorithm was run on an initial interval set that was generally very large, just in order to test the convergence and contraction capabilities of the approach. In the first example, which referred to the identification of the values of three parameters only and used I-V data generated by the same model used for the identification thereof, a large initial interval set was used. The initial intervals for the two resistances were set to include typical values; thus, they were in the order of magnitude of hundreds of m and hundreds of for series and parallel resistances respectively. Such initial intervals might also include values corresponding to a degraded PV module. The initial interval of has been chosen across the short-circuit current value .
By using the I-V experimental measurements around the MPP, the
is settled at values that are close to the MPP current
; thus, an initial interval across
is used. The initial ranges of
B and
have been determined by keeping account of some physical relationships. The parameter
B depends on temperature
T and
n: it has been assumed that
T has been measured with a known accuracy and that the ideality factor, as can be deduced from the literature referring to silicon cells, assumes values ranging from
up to
. The larger the uncertainty affecting the measure of the temperature, the wider the initial interval
. As for
, it has been assumed that, for new PV modules, it assumes values of the order of
while
is used for aged modules. The
width affects the convergence features of the approach significantly. The proposed examples show the convergence capability of the
algorithm even using a
that is four orders of magnitude and has
n ranging up to 2, instead of stopping at 1.3, as can be deduced by reading some papers; e.g., [
35]. However, a better trade-off between accuracy and computation time should be reached by having a more accurate estimation of the initial range of the parameters.
The second aspect deserving further comments concerns the selection of the value
involved in the termination condition (
7), because it affects the accuracy of the result and the computation time required by the algorithm. In the case a low noise level affecting the I-V samples, a tiny termination condition does not affect the computation time significantly, as in the first example. Indeed, any relaxation of the inclusion property is required and a small number of feasible intervals at each dividing level is obtained. In the case of I-V experimental data exhibiting a significant noise level, a trade-off between accuracy and computation time needs to be achieved. Some relaxation of the inclusion property and a higher value of
help to achieve the convergence. It is worth noting that the number of feasible subsets obtained at the end of each algorithm run depends on both the ability of the SDM to fit the experimental curve and on the chosen
value. The additional step using the RMSE calculation discussed in some examples presented in
Section 5 and
Section 6 helps to improve the accuracy of the IA solution.
The third remark concerns the size of interval current
, as it is shown in
Figure 8,
Figure 10 and
Figure 12. In the SDM solution shown in
Figure 8 and
Table 6, the relative width of the interval parameters’ solution (
), is calculated by
. The results are
,
,
,
and
.
Figure 12 shows the I-V curve boundaries corresponding to the same interval solution, by neglecting the range of
. In this case, the relative width is 0.5143; thus, the important effect of the
interval on
becomes evident. By using the RMSE calculation in
Table 7, the relative interval sizes are reduced to the following values:
,
,
,
and
. The significant effect of this contraction on the range
is evident by looking at
Figure 10. The contraction is close to one order of magnitude for all the parameters, but not for
.
Figure 2 shows that
and
have significant effects on the
width.
Figure 13 shows that the true range of
is overestimated because of the use of IA, especially at high voltage. The overestimation is evident by comparing the IA results with those ones obtained by means of a Monte Carlo run over 2000 random trials. The corresponding I-V curves are shown in black color, which have been generated by randomly choosing sets of parameters in the ranges shown in
Table 7. It is worth noting that the Monte Carlo method giving a narrower range with respect to the IA method does not mean that the former result is more accurate than the latter one. Indeed, only if both of them are taken into account, exact information about the true range spanned by
I at the different voltages is obtained. Indeed, the Monte Carlo range would approach the true one by running an infinite number of trials; otherwise it gives an underestimation of the true range of
I. The IA overestimation is reduced by reducing the width of the interval parameters [
33]. The true range is placed in the middle, bounded by the Monte Carlo range, which is an underestimation of the true range, and the IA range, which is an overestimation of the true range.
An additional advantage of the proposed IA-based
algorithm can be put into evidence by referring to the results shown in
Table 10. The
Matlab Fit APP tool has been used to identify the five parameters of SDM. It minimizes the root mean square error between the experimental I-V data and I-V curve obtained through the SDM with the identified values of the parameters. The trust-region method has been selected, the function tolerance value has been settled at 1e-5 and the maximum number of iterations has been fixed at 400. In the second column the results achieved by this tool are given. The initial interval of the parameters has been set equal to the initial interval used in the proposed IA-based
algorithm; thus, the one given in the second column of
Table 6. The third column of
Table 10 shows the result when the initial search space used in
Matlab Fit APP is the union of the feasible intervals obtained by the the proposed IA-based
algorithm; thus, the one in the third column of
Table 6. It is evident that the proposed IA based approach has contracted the initial search space towards the solution in an effective way, so that the
Matlab Fit APP converges to the identified set by a number of iterations and function evaluations that is 80% lower than the one required if the search is started from the wider search space used by the IA
method. Moreover, the step size is reduced by four orders of magnitude, so that a higher accuracy in the parameter identification is achieved. This result reveals that the feasible intervals obtained by the proposed IA-based
algorithm are reliable guess solutions for gradient based minimization methods. The cascade of the methods thus allows one to improve the convergence and the accuracy of the result. The RMSE value obtained by
Matlab Fit APP is equal to 0.0587, which is close to the one obtained by the proposed analysis procedure of the feasible sub-intervals (
shown in
Table 7), which is 0.0659. The
IA-based method uses a simple partitioning of the intervals and feasibility test, and thus, any gradient or minimization method, also guaranteeing the infeasibility of the discarded intervals.
As a further comment concerning the implementation of the IA-based algorithm, it has to be evidenced that it might profit significantly from a parallel implementation of the IA operations. Indeed, in any IA operation, the computations of the lower bound and of the upper bound of the result can be done in parallel, because these two computations are independent. Moreover, the computation tree derived from the proposed method is also prone to a parallel computation. Consequently, the proposed algorithm, which has been already developed in C++ by means of a suitable library including all the IA operations, can be implemented in embedded devices including multi-core processors or field programmable gate arrays (FPGAs).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}