Evaluating the Causal Relations between the Kaya Identity Index and ODIAC-Based Fossil Fuel CO2 Flux




Abstract
1. Introduction
2. Materials
2.1. Countries Included in the Study
2.2. ODIAC-Based CO2 Emission Data
2.3. Kaya Identity—An Introduction to the Methodology and a Description of Our Data Set
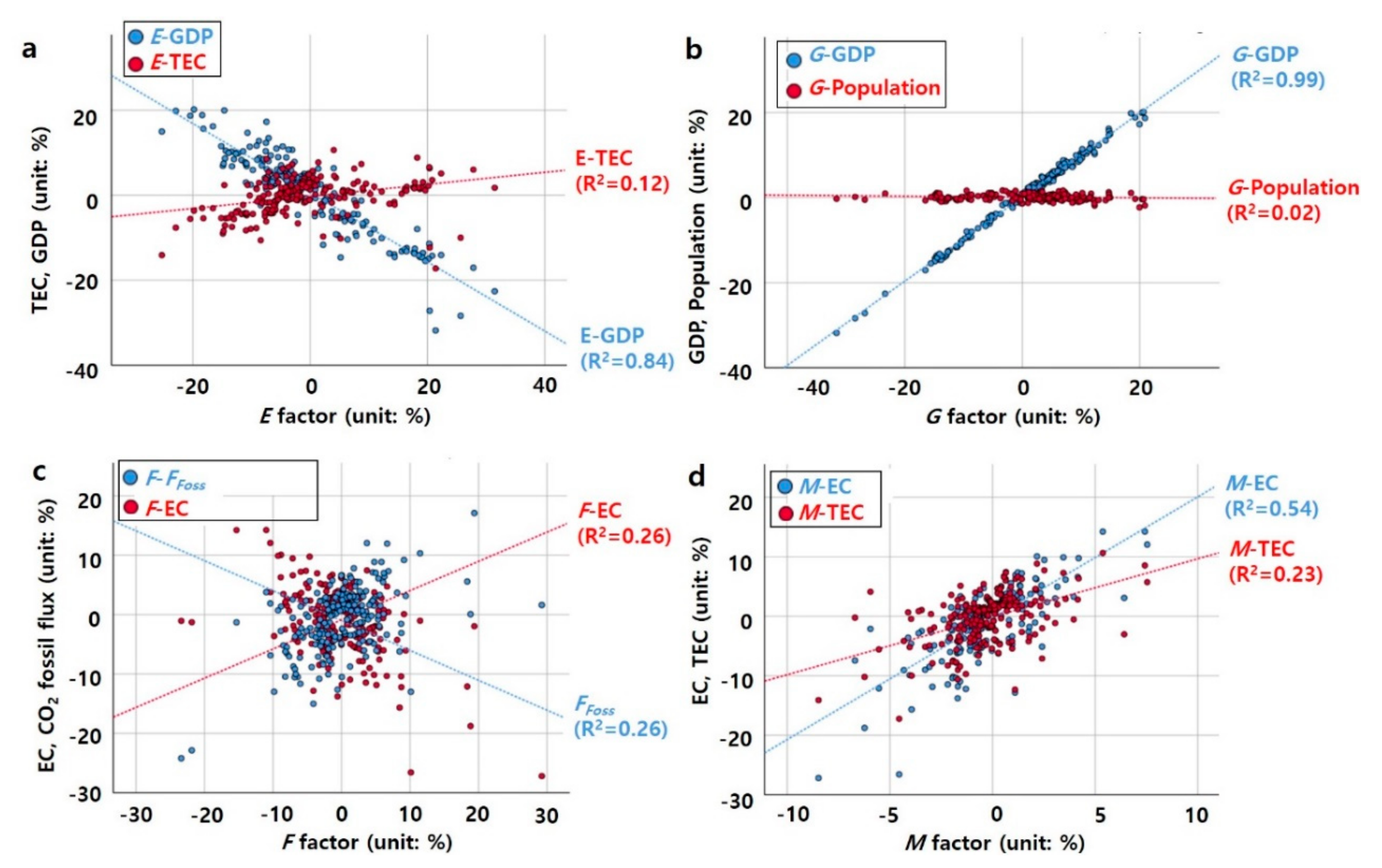
2.3.1. Kaya Identity—The Concept
2.3.2. Kaya Identity—The Data Sets
3. Methodology
3.1. Multiple Regression Models
3.2. Mediation Analysis–Introduction and Research Design
4. Results
4.1. Two Multiple Linear Regression Models for the Fossil Fuel CO2 Flux-Based CO2 Emissions
4.2. Interactions between the Decomposed Variables and Kaya Identity Factors and the ODIAC-Based Fossil Fuel CO2 Flux Detected through Mediation Analysis
4.2.1. Indirect Effects Among the Decomposed Variables on the Fossil Fuel CO2 Flux-Based CO2 Emissions
4.2.2. Indirect Effects between the Decomposed Variables and Kaya Identity Factors on ODIAC-Based Fossil Fuel CO2 Flux
5. Discussion
5.1. Consequences of Multicollinearity
5.2. Kaya Identity in the Context of Contemporary Literature
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CARMA | Carbon Monitoring for Action |
| CDIAC | Carbon Dioxide Information Analysis Center |
| CV | Coefficient of variation |
| EC | Fossil-fuel based energy consumption |
| E | CO2 emissions/EC |
| EKC | Environmental Kuznets curve |
| F | CO2 flux/EC |
| ODIAC-based fossil fuel CO2 flux | |
| G | GDP/P |
| GDP | Gross domestic product |
| GOSAT | Japan Aerospace Exploration Agency Greenhouse Gases Observing Satellite |
| I | TEC/GDP |
| IEA | International Energy Agency |
| M | EC/TEC |
| NDCs | Nationally determined contributions |
| LMDI | Logarithmic Mean Divisia Index |
| ODIAC | Open-Source Data Inventory of Anthropogenic CO2 emissions |
| P | Population size |
| STIRPAT | Stochastic Impacts by Regression on Population, Affluence and Technology |
| TEC | Total energy consumptions |
| UNFCCC | United Nations Framework Convention on Climate Change |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kaya Identity Factor | Decomposed Variables | Dataset |
|---|---|---|
| P factor | Population | Population data from the World Bank data |
| G factor (GDP/Population) | GDP | GDP (constant 2010 US$) from World Bank |
| Population | Population data from the World Bank data | |
| E factor (TEC/GDP) | TEC | Total final consumption from the IEA energy balance |
| GDP | GDP (constant 2010 US$) from the World Bank | |
| M factor (EC/TEC) | EC | Fossil fuel consumptions (coal, crude oil, oil products, natural gas) from the IEA energy balance |
| TEC | Total final consumption from the IEA energy balance | |
| F factor (CO2 flux/EC) | CO2 flux | ODIAC-based fossil fuel CO2 flux |
| EC | Fossil fuel consumptions (coal, crude oil, oil products, natural gas) from the IEA energy balance |
References
- Wang, J.; Hu, M.; Tukker, A.; Rodrigues, J.F.D. The impact of regional convergence in energy-intensive industries on China’s CO2 emissions and emission goals. Energy Econ. 2019, 80, 512–523. [Google Scholar] [CrossRef]
- IPCC. Special Report on Emissions Scenarios; IPCC: Cambridge, UK, 2000.
- Aye, G.C.; Edoja, P.E. Effect of economic growth on CO2 emission in developing countries: Evidence from a dynamic panel threshold model. Cogent Econ. Financ. 2017, 5, 1379239. [Google Scholar] [CrossRef]
- Tavakoli, A. A journey among top ten emitter country, decomposition of “Kaya Identity”. Sustain. Cities Soc. 2018, 38, 254–264. [Google Scholar] [CrossRef]
- UNFCCC. Synthesis Report on the Aggregate Effect of the Intended Nationally Determined Contributions; UNFCCC: Bonn, Germany, 2015. [Google Scholar]
- IEA. Renewables Information 2019; IEA: Paris, France, 2019. [Google Scholar]
- Aguir Bargaoui, S.; Liouane, N.; Nouri, F.Z. Environmental Impact Determinants: An Empirical Analysis based on the STIRPAT Model. Procedia Soc. Behav. Sci. 2014, 109, 449–458. [Google Scholar] [CrossRef]
- Maliszewska, M.; Mattoo, A.; van der Mensbrugghe, D. The Potential Impact of COVID-19 on GDP and Trade: A Preliminary Assessment; World Bank: Washington, DC, USA, 2020. [Google Scholar]
- OECD. Real GDP Forecast (Indicator); OECD Data; OECD: Paris, France, 2020. [Google Scholar] [CrossRef]
- Le Quéré, C.; Jackson, R.B.; Jones, M.W.; Smith, A.J.P.; Abernethy, S.; Andrew, R.M.; De-Gol, A.J.; Willis, D.R.; Shan, Y.; Canadell, J.G.; et al. Temporary reduction in daily global CO2 emissions during the COVID-19 forced confinement. Nat. Clim. Chang. 2020, 10, 647–653. [Google Scholar] [CrossRef]
- Jung, S.; An, K.-J.; Dodbiba, G.; Fujita, T. Regional energy-related carbon emission characteristics and potential mitigation in eco-industrial parks in South Korea: Logarithmic mean Divisia index analysis based on the Kaya identity. Energy 2012, 46, 231–241. [Google Scholar] [CrossRef]
- Chontanawat, J. Driving Forces of Energy-Related CO2 Emissions Based on Expanded IPAT Decomposition Analysis: Evidence from ASEAN and Four Selected Countries. Energies 2019, 12, 764. [Google Scholar] [CrossRef]
- Kim, S. LMDI Decomposition Analysis of Energy Consumption in the Korean Manufacturing Sector. Sustainability 2017, 9, 202. [Google Scholar] [CrossRef]
- Meng, Z.; Wang, H.; Wang, B. Empirical Analysis of Carbon Emission Accounting and Influencing Factors of Energy Consumption in China. Int. J. Environ. Res. Public Health 2018, 15, 2467. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, T.; Zheng, H.; Hu, J. The STIRPAT Analysis on Carbon Emission in Chinese Cities: An Asymmetric Laplace Distribution Mixture Model. Sustainability 2017, 9, 2237. [Google Scholar] [CrossRef]
- McGee, J.A.; Clement, M.T.; Besek, J.F. The impacts of technology: A re-evaluation of the STIRPAT model. Environ. Sociol. 2015, 1, 81–91. [Google Scholar] [CrossRef]
- Han, J.; Du, T.; Zhang, C.; Qian, X. Correlation analysis of CO2 emissions, material stocks and economic growth nexus: Evidence from Chinese provinces. J. Clean. Prod. 2018, 180, 395–406. [Google Scholar] [CrossRef]
- Duro, J.A.; Padilla, E. International inequalities in per capita CO2 emissions: A decomposition methodology by Kaya factors. Energy Econ. 2006, 28, 170–187. [Google Scholar] [CrossRef]
- Hwang, Y.; Um, J.-S.; Schlüter, S. Evaluating the Mutual Relationship between IPAT/Kaya Identity Index and ODIAC-Based GOSAT Fossil-Fuel CO2 Flux: Potential and Constraints in Utilizing Decomposed Variables. Int. J. Environ. Res. Public Health 2020, 17, 5976. [Google Scholar] [CrossRef]
- National Research Council. Verifying Greenhouse Gas Emissions: Methods to Support International Climate Agreements; The National Academies Press: Washington, DC, USA, 2010; p. 124. [Google Scholar]
- Zaleski, P.; Yash, C. Circular Economy in Poland: Profitability Analysis for Two Methods of Waste Processing in Small Municipalities. Energies 2020, 13, 5166. [Google Scholar] [CrossRef]
- Andrejiová, M.; Grincova, A.; Marasová, D. Study of the Percentage of Greenhouse Gas Emissions from Aviation in the EU-27 Countries by Applying Multiple-Criteria Statistical Methods. Int. J. Environ. Res. Public Health 2020, 17, 3759. [Google Scholar] [CrossRef]
- European Commission. Communication from the Commission to the European Parliament, the European Council, the Counfil, The European Economic and Social Committee and the Committee of the Regions-The European Green Deal; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Sadik-Zada, E.R.; Gatto, A. Energy Security Pathways in South East Europe: Diversification of the Natural Gas Supplies, Energy Transition, and Energy Futures. In From Economic to Energy Transition; Springer: Berlin, Germany, 2020; pp. 491–514. [Google Scholar]
- Mahony, T.O. Decomposition of Ireland’s carbon emissions from 1990 to 2010: An extended Kaya identity. Energy Policy 2013, 59, 573–581. [Google Scholar] [CrossRef]
- Wang, W.; Kuang, Y.; Huang, N.; Zhao, D. Empirical research on decoupling relationship between energy-related carbon emission and economic growth in Guangdong province based on extended Kaya identity. Sci. World J. 2014, 2014, 782750. [Google Scholar] [CrossRef]
- Ziemele, J.; Gravelsins, A.; Blumberga, D. Decomposition Analysis of District Heating System based on Complemented Kaya Identity. Energy Procedia 2015, 75, 1229–1234. [Google Scholar] [CrossRef][Green Version]
- Hwang, Y.; Um, J.-S. Performance evaluation of OCO-2 XCO2 signatures in exploring casual relationship between CO2 emission and land cover. Spat. Inf. Res. 2016, 24, 451–461. [Google Scholar] [CrossRef]
- Van Amstel, A.; Olivier, J.; Janssen, L. Analysis of Differences between National Inventories and an Emissions Database for Global Atmospheric Research (EDGAR). Environ. Sci. Policy 1999, 2, 275–293. [Google Scholar] [CrossRef]
- Hwang, Y.-S.; Lee, J.-J.; Park, S.-I.; Um, J.-S. Exploring Explainable Range of In-situ Portable CO2 Sensor Signatures for Carbon Stock Estimated in Forestry Carbon Project. Sens. Mater. 2019, 31, 3773. [Google Scholar] [CrossRef]
- Hwang, Y.; Um, J.-S. Comparative evaluation of OCO-2 XCO2 signature between REDD+ project area and nearby leakage belt. Spat. Inf. Res. 2017, 25, 693–700. [Google Scholar] [CrossRef]
- Li, Z.; Fu, J.; Lin, G.; Jiang, D.; Liu, K.; Wang, Y. Multi-Scenario Analysis of Energy Consumption and Carbon Emissions: The Case of Hebei Province in China. Energies 2019, 12, 624. [Google Scholar] [CrossRef]
- Yokota, T.; Yoshida, Y.; Eguchi, N.; Ota, Y.; Tanaka, T.; Watanabe, H.; Maksyutov, S. Global Concentrations of CO2 and CH4 Retrieved from GOSAT: First Preliminary Results. SOLA 2009, 5, 160–163. [Google Scholar] [CrossRef]
- Takagi, H.; Saeki, T.; Oda, T.; Saito, M.; Valsala, V.; Belikov, D.; Saito, R.; Yoshida, Y.; Morino, I.; Uchino, O.; et al. On the Benefit of GOSAT Observations to the Estimation of Regional CO2 Fluxes. SOLA 2011, 7, 161–164. [Google Scholar] [CrossRef]
- Maksyutov, S.; Takagi, H.; Valsala, V.K.; Saito, M.; Oda, T.; Saeki, T.; Belikov, D.A.; Saito, R.; Ito, A.; Yoshida, Y.; et al. Regional CO2 flux estimates for 2009–2010 based on GOSAT and ground-based CO2 observations. Atmos. Chem. Phys. 2013, 13, 9351–9373. [Google Scholar] [CrossRef]
- Oda, T.; Maksyutov, S.; Andres, R.J. The Open-source Data Inventory for Anthropogenic CO2, version 2016 (ODIAC2016): A global monthly fossil fuel CO2 gridded emissions data product for tracer transport simulations and surface flux inversions. Earth Syst. Sci. Data 2018, 10, 87–107. [Google Scholar] [CrossRef]
- Oda, T.; Maksyutov, S. A very high-resolution (1 km × 1 km) global fossil fuel CO2 emission inventory derived using a point source database and satellite observations of nighttime lights. Atmos. Chem. Phys. 2011, 11, 543–556. [Google Scholar] [CrossRef]
- Oda, T.; Bun, R.; Kinakh, V.; Topylko, P.; Halushchak, M.; Marland, G.; Lauvaux, T.; Jonas, M.; Maksyutov, S.; Nahorski, Z.; et al. Errors and uncertainties in a gridded carbon dioxide emissions inventory. Mitig. Adapt. Strateg. Glob. Chang. 2019, 24, 1007–1050. [Google Scholar] [CrossRef]
- Hwang, Y.; Um, J.-S. Exploring causal relationship between landforms and ground level CO2 in Dalseong forestry carbon project site of South Korea. Spat. Inf. Res. 2017, 25, 361–370. [Google Scholar] [CrossRef]
- Park, S.-I.; Hwang, Y.; Um, J.-S. Utilizing OCO-2 satellite transect in comparing XCO2 concentrations among administrative regions in Northeast Asia. Spat. Inf. Res. 2017, 25, 459–466. [Google Scholar] [CrossRef]
- Hwang, Y.; Um, J.-S. Evaluating co-relationship between OCO-2 XCO2 and in situ CO2 measured with portable equipment in Seoul. Spat. Inf. Res. 2016, 24, 565–575. [Google Scholar] [CrossRef]
- Park, A.-R.; Joo, S.-M.; Hwang, Y.; Um, J.-S. Evaluating seasonal CH4 flow tracked by GOSAT in Northeast Asia. Spat. Inf. Res. 2018, 26, 295–304. [Google Scholar] [CrossRef]
- GOSAT Project (GOSAT Data Archive Service). Available online: https://data2.gosat.nies.go.jp/index_en.html (accessed on 3 November 2020).
- Kaya, Y.; Yokobori, K. Environment, Energy, and Economy: Strategies for Sustainability; United Nations University Press Tokyo: Tokyo, Japan, 1997. [Google Scholar]
- Ma, M.; Cai, W. What drives the carbon mitigation in Chinese commercial building sector? Evidence from decomposing an extended Kaya identity. Sci. Total Environ. 2018, 634, 884–899. [Google Scholar] [CrossRef]
- Raupach, M.R.; Marland, G.; Ciais, P.; Le Quéré, C.; Canadell, J.G.; Klepper, G.; Field, C.B. Global and regional drivers of accelerating CO2 emissions. Proc. Natl. Acad. Sci. USA 2007, 104, 10288. [Google Scholar] [CrossRef]
- Raupach, M.R.; Canadell, J.G.; Le Quéré, C. Anthropogenic and biophysical contributions to increasing atmospheric CO2 growth rate and airborne fraction. Biogeosciences 2008, 5, 1601–1613. [Google Scholar] [CrossRef]
- Le Quéré, C.; Andrew, R.M.; Friedlingstein, P.; Sitch, S.; Pongratz, J.; Manning, A.C.; Korsbakken, J.I.; Peters, G.P.; Canadell, J.G.; Jackson, R.B.; et al. Global Carbon Budget 2017. Earth Syst. Sci. Data 2018, 10, 405–448. [Google Scholar] [CrossRef]
- Peters, G.P.; Andrew, R.M.; Canadell, J.G.; Fuss, S.; Jackson, R.B.; Korsbakken, J.I.; Le Quéré, C.; Nakicenovic, N. Key indicators to track current progress and future ambition of the Paris Agreement. Nat. Clim. Chang. 2017, 7, 118–122. [Google Scholar] [CrossRef]
- IEA. Energy Statistics of OECD Countries 2015; IEA: Paris, France, 2015. [Google Scholar]
- IEA. Energy Statistics of Non-OECD Countries 2015; IEA: Paris, France, 2015. [Google Scholar]
- MacKinnon, D.P.; Fairchild, A.J.; Fritz, M.S. Mediation analysis. Annu. Rev. Psychol. 2007, 58, 593–614. [Google Scholar] [CrossRef]
- Namazi, M.; Namazi, N. Conceptual Analysis of Moderator and Mediator Variables in Business Research. Procedia Econ. Financ. 2016, 36, 540–554. [Google Scholar] [CrossRef]
- MacKinnon, D.P. Introduction to Statistical Mediation Analysis; Routledge: Abingdon, UK, 2008. [Google Scholar]
- Hayes, A.F. Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach; Guilford Publications: New York, NY, USA, 2017. [Google Scholar]
- Demming, C.; Jahn, S.; Boztug, Y. Conducting Mediation Analysis in Marketing Research. Mark. ZFP 2017, 39, 76–98. [Google Scholar] [CrossRef]
- Preacher, K.J.; Hayes, A.F. SPSS and SAS procedures for estimating indirect effects in simple mediation models. Behav. Res. Methods Instrum. Comput. 2004, 36, 717–731. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Lynch, J.G.; Chen, Q.; Deighton, J. served as editor and Fitzsimons, G. served as associate editor for this article. Reconsidering Baron and Kenny: Myths and Truths about Mediation Analysis. J. Consum. Res. 2010, 37, 197–206. [Google Scholar] [CrossRef]
- Purcel, A.-A. New insights into the environmental Kuznets curve hypothesis in developing and transition economies: A literature survey. Environ. Econ. Policy Stud. 2020, 22, 585–631. [Google Scholar] [CrossRef]
- Georgiev, E.; Mihaylov, E. Economic growth and the environment: Reassessing the environmental Kuznets Curve for air pollution emissions in OECD countries. Lett. Spat. Resour. Sci. 2015, 8, 29–47. [Google Scholar] [CrossRef]
- Choi, E.; Heshmati, A.; Cho, Y. An empirical study of the relationships between CO2 emissions, economic growth and openness. J. Environ. Policy 2010, 10. [Google Scholar] [CrossRef]
- Robalino-López, A.; Mena-Nieto, Á.; García-Ramos, J.-E.; Golpe, A.A. Studying the relationship between economic growth, CO2 emissions, and the environmental Kuznets curve in Venezuela (1980–2025). Renew. Sustain. Energy Rev. 2015, 41, 602–614. [Google Scholar] [CrossRef]
- Graham, M.H. Confronting multicollinearity in ecological multiple regression. Ecology 2003, 84, 2809–2815. [Google Scholar] [CrossRef]
- Sadik-Zada, E.R. Drivers of CO2-Emissions in Fossil Fuel Abundant Settings: (Pooled) Mean Group and Nonparametric Panel Analyses. Energies 2020, 13, 3956. [Google Scholar] [CrossRef]
- Wooldridge, J.M. Introduction to Econometrics: Europe, Middle East and Africa Edition; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Roos, M.W.M. Endogenous Economic Growth, Climate Change and Societal Values: A Conceptual Model. Comput. Econ. 2018, 52, 995–1028. [Google Scholar] [CrossRef]
- Fischer-Kowalski, M.; Amann, C. Beyond IPAT and Kuznets Curves: Globalization as a Vital Factor in Analysing the Environmental Impact of Socio-Economic Metabolism. Popul. Environ. 2001, 23, 7–47. [Google Scholar] [CrossRef]
- Ahi, P.; Searcy, C. A comparative literature analysis of definitions of green and sustainable supply chain management. J. Clean. Prod. 2013, 52, 329–341. [Google Scholar] [CrossRef]
- Gong, R.; Xue, J.; Zhao, L.; Zolotova, O.; Ji, X.; Xu, Y. A Bibliometric Analysis of Green Supply Chain Management Based on the Web of Science (WOS) Platform. Sustainability 2019, 11, 3459. [Google Scholar] [CrossRef]
- Zimon, D.; Tyan, J.; Sroufe, R. Implementing Sustainable Supply Chain Management: Reactive, Cooperative, and Dynamic Models. Sustainability 2019, 11, 7227. [Google Scholar] [CrossRef]
- Sadik-Zada, E.R.; Gatto, A. The puzzle of greenhouse gas footprints of oil abundance. Socio-Econ. Plan. Sci. 2020, 100936. [Google Scholar] [CrossRef]
- Karl, H.; Ranné, O. European environmental policy between decentralisation and uniformity. Intereconomics 1997, 32, 159–169. [Google Scholar] [CrossRef]
- Sadik-Zada, E.R.; Ferrari, M. Environmental Policy Stringency, Technical Progress and Pollution Haven Hypothesis. Sustainability 2020, 12, 3880. [Google Scholar] [CrossRef]
- Scarpato, D.; Civero, G.; Rusciano, V.; Risitano, M. Sustainable strategies and corporate social responsibility in the Italian fisheries companies. Corp. Soc. Responsib. Environ. Manag. 2020, 27, 2983–2990. [Google Scholar] [CrossRef]




| Category | Min | Max | Mean | STDEV | CV (%) | |
|---|---|---|---|---|---|---|
| Kaya identity factors | E (ktoe/MM U.S. $) | 0.03 | 0.56 | 0.11 | 0.09 | 80.55 |
| G (1000 U.S. $/person) | 2.02 | 102.91 | 31.71 | 22.25 | 70.18 | |
| P (MM person) | 1.31 | 82.66 | 21.67 | 24.50 | 113.03 | |
| F (Kt CO2-Equation/ktoe) | 2.24 | 13.28 | 5.21 | 2.17 | 41.64 | |
| M (ktoe) | 0.33 | 0.80 | 0.6 | 0.11 | 18.23 | |
| E = TEC/GDP, G = GDP/Population, P = population size, F = FFoss/EC, and M = EC/TEC. | ||||||
| Decomposed variables of Kaya identity factors | GDP (100 billion U.S. $) | 0.20 | 38.84 | 6.53 | 9.05 | 138.53 |
| Population (MM person) | 1.31 | 82.66 | 21.67 | 24.50 | 113.03 | |
| TEC (Mtoe) | 2.84 | 228.90 | 44.99 | 51.62 | 114.73 | |
| EC (Mtoe) | 1.29 | 158.23 | 30.10 | 36.62 | 121.64 | |
| FFoss (10 Mt CO2-Equation yr−1) | 7.14 | 827.82 | 138.79 | 172.65 | 124.40 | |
| Category | Standardized Coefficient | t-Statistics | p-Value | Variance Inflation Factor (VIF) | |
|---|---|---|---|---|---|
| Decomposed variables of five factors in Kaya identity | Population | −0.11 | −2.31 | 0.22 | 9.30 |
| GDP | −0.43 | −7.98 | 0.00 | 12.79 | |
| TEC | 0.73 | 4.69 | 0.00 | 108.62 | |
| EC | 0.74 | 4.58 | 0.00 | 116.37 | |
| (a) R: 0.973 R2: 0.947 Durbin-Watson: 2.11 F-value (p-value): 1055.64 (0.00) | |||||
| Kaya identity factors | E | 0.02 | 0.54 | 0.59 | 1.63 |
| G | 0.18 | 4.97 | 0.00 | 2.05 | |
| P | 0.93 | 31.76 | 0.00 | 1.32 | |
| F | 0.19 | 6.05 | 0.00 | 1.50 | |
| M | 0.06 | 1.97 | 0.05 | 1.34 | |
| (b) R: 0.921 R2: 0.849 Durbin-Watson: 1.849 F-value (p-value): 263.31 (0.00) | |||||
| Category | Standardized Coefficient | t-Statistics | p-Value | VIF |
|---|---|---|---|---|
| Population | 0.56 | 13.34 | 0.00 | 3.28 |
| GDP | 0.41 | 9.88 | 0.00 | 3.28 |
| R: 0.93 R2: 0.87 Durbin-Watson: 2.13 F-value (p-value): 811.81 (0.00) | ||||
| Population | 0.08 | 1.75 | 0.08 | 7.14 |
| TEC | 0.89 | 19.58 | 0.00 | 7.14 |
| R: 0.97 R2: 0.93 Durbin-Watson: 1.99 F-value (p-value): 1606.50 (0.00) | ||||
| Population | 0.06 | 1.24 | 0.22 | 7.50 |
| EC | 0.91 | 19.45 | 0.00 | 7.50 |
| R: 0.97 R2: 0.93 Durbin-Watson: 2.12 F-value (p-value): 1591.92 (0.00) | ||||
| Population | −0.08 | −1.74 | 0.08 | 9.19 |
| GDP | −0.38 | −6.90 | 0.00 | 12.30 |
| EC | 1.40 | 16.90 | 0.00 | 28.11 |
| R: 0.97 R2: 0.94 Durbin-Watson: 2.06 F-value (p-value): 1285.93 (0.00) | ||||
| Population | −0.04 | −0.95 | 0.34 | 8.48 |
| GDP | −0.37 | −6.80 | 0.00 | 12.05 |
| TEC | 1.35 | 16.95 | 0.00 | 26.23 |
| R: 0.97 R2: 0.94 Durbin-Watson: 2.06 F-value (p-value): 1291.13 (0.00) | ||||
| Population | 0.06 | 1.19 | 0.24 | 7.50 |
| TEC | 0.49 | 2.82 | 0.01 | 104.41 |
| EC | 0.43 | 2.43 | 0.02 | 109.60 |
| R: 0.97 R2: 0.93 Durbin-Watson: 2.05 F-value (p-value): 1095.20 (0.00) | ||||
| Category | Decomposed Variables | Kaya Identity Factors | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Population | GDP | TEC | EC | E | G | P | F | M | ||
| Population | 1 | 0.83 ** | 0.93 ** | 0.931 ** | 0.91 ** | −0.01 | −0.063 | 1.00 ** | −0.18 ** | 0.47 ** |
| GDP | - | 1 | 0.95 ** | 0.95 ** | 0.88 ** | −0.34 ** | 0.286 ** | 0.83 ** | −0.29 ** | 0.38 ** |
| TEC | - | - | 1 | 0.99 ** | 0.97 ** | −0.14 * | 0.115 | 0.93 ** | −0.23 ** | 0.42 ** |
| EC | - | - | - | 1 | 0.97 ** | −0.15 * | 0.097 | 0.93 ** | −0.22 ** | 0.48 ** |
| - | - | - | - | 1 | −0.04 | 0.008 | 0.91 ** | −0.08 | 0.44 ** | |
| E | - | - | - | - | - | 1 | −0.61 ** | 0.01 | 0.37 ** | −0.08 |
| G | - | - | - | - | - | - | 1 | −0.06 | −0.52 ** | −0.09 |
| P | - | - | - | - | - | - | - | 1 | −0.18 ** | 0.47 ** |
| F | - | - | - | - | - | - | - | - | 1 | −0.16 * |
| M | - | - | - | - | - | - | - | - | - | 1 |
| Category | Mediator | R | R2 | p-Value | Coeff. | Std. Coeff. | Indirect Effect | ||
|---|---|---|---|---|---|---|---|---|---|
| Indirect (%) | LLCI | ULCI | |||||||
| Population | GDP | 0.83 | 0.70 | 0.00 | 0.31 | 0.83 | −39.36 | −3.50 | −1.69 |
| TEC | 0.93 | 0.86 | 0.00 | 1.95 | 0.93 | 74.92 | 2.33 | 7.76 | |
| EC | 0.94 | 0.87 | 0.00 | 1.39 | 0.93 | 76.10 | 1.90 | 8.10 | |
| 0.91 | 0.82 | 0.00 | 6.38 | 0.91 | - | - | - | ||
| Total effect (p-value): 6.38 (0.00) Direct effect (p-value): −0.74 (0.12) | |||||||||
| GDP | Population | 0.83 | 0.70 | 0.00 | 2.26 | 0.83 | −9.99 | −3.96 | 0.64 |
| TEC | 0.95 | 0.90 | 0.00 | 5.42 | 0.95 | 78.81 | 6.22 | 21.19 | |
| EC | 0.95 | 0.90 | 0.00 | 3.84 | 0.95 | 79.69 | 5.20 | 22.04 | |
| 0.88 | 0.78 | 0.78 | 16.83 | 0.58 | - | - | - | ||
| Total effect (p-value): 16.82 (0.00) Direct effect (p-value): −8.16 (0.00) | |||||||||
| TEC | Population | 0.93 | 0.86 | 0.00 | 0.44 | 0.93 | −10.15 | −0.76 | 0.13 |
| GDP | 0.95 | 0.90 | 0.00 | 0.17 | 0.95 | −42.09 | −1.84 | −0.95 | |
| EC | 1.00 | 0.99 | 0.00 | 0.71 | 1.00 | 76.38 | 0.98 | 4.06 | |
| 0.97 | 0.93 | 0.93 | 3.23 | 0.97 | - | - | - | ||
| Total effect (p-value): 3.23 (0.00) Direct effect (p-value): 2.45 (0.00) | |||||||||
| EC | Population | 0.93 | 0.87 | 0.00 | 0.62 | 0.93 | −10.19 | −0.76 | 0.13 |
| GDP | 0.95 | 0.90 | 0.00 | 0.23 | 0.95 | −42.06 | −1.84 | −0.95 | |
| TEC | 1.00 | 0.99 | 0.00 | 1.40 | 1.00 | 75.50 | 0.98 | 4.06 | |
| 0.97 | 0.93 | 0.00 | 4.55 | 0.97 | - | - | - | ||
| Total effect (p-value): 4.55 (0.00) Direct effect (p-value): 3.49 (0.00) | |||||||||
| Population | 0.91 | 0.82 | 0.00 | 0.13 | 0.91 | - | - | - | |
| GDP | 0.88 | 0.78 | 0.00 | 0.05 | 0.88 | - | - | - | |
| TEC | 0.97 | 0.93 | 0.00 | 0.29 | 0.97 | - | - | - | |
| EC | 0.97 | 0.93 | 0.00 | 0.21 | 0.97 | - | - | - | |
| Total effect (p-value): 1.00 (0.00) Direct effect (p-value): 1.00 (0.00) | |||||||||
| Category | Mediator | R | R2 | p-Value | Coeff. | Std. Coeff. | Indirect Effect | ||
|---|---|---|---|---|---|---|---|---|---|
| Indirect (%) | LLCI | ULCI | |||||||
| Population | E | 0.01 | 0.00 | 0.85 | 0.00 | −0.01 | −0.02 | −0.06 | 0.01 |
| G | 0.06 | 0.00 | 0.23 | −0.06 | −0.06 | −1.25 | −0.21 | 0.05 | |
| F | 0.18 | 0.03 | 0.00 | −0.02 | −0.18 | −3.83 | −0.35 | −0.14 | |
| M | 0.45 | 0.22 | 0.00 | 0.00 | 0.47 | 2.99 | 0.08 | 0.31 | |
| Total effect (p-value): 6.38 (0.00) Direct effect (p-value): 6.52 (0.00) | |||||||||
| GDP | E | 0.34 | 0.11 | 0.00 | 0.00 | −0.34 | −5.26 | −1.17 | −0.61 |
| G | 0.29 | 0.08 | 0.00 | 0.70 | 0.29 | 0.87 | −0.02 | 0.34 | |
| F | 0.29 | 0.09 | 0.00 | −0.07 | −0.29 | −4.86 | −1.11 | −0.59 | |
| M | 0.38 | 0.14 | 0.00 | 0.00 | 0.38 | 2.65 | 0.26 | 0.67 | |
| P | 0.83 | 0.70 | 0.00 | 2.26 | 0.83 | 38.29 | 5.08 | 8.10 | |
| Total effect (p-value): 16.82 (0.00) Direct effect (p-value): 11.49 (0.00) | |||||||||
| TEC | E | 0.14 | 0.02 | 0.00 | 0.00 | −0.14 | −0.83 | −0.04 | −0.01 |
| G | 0.12 | 0.01 | 0.00 | 0.05 | 0.12 | 0.04 | −0.01 | 0.01 | |
| F | 0.23 | 0.05 | 0.00 | −0.01 | −0.23 | −3.31 | −0.15 | −0.07 | |
| M | 0.42 | 0.17 | 0.00 | 0.00 | 0.42 | 2.80 | 0.06 | 0.13 | |
| P | 0.93 | 0.86 | 0.00 | 0.44 | 0.93 | −3.07 | −0.43 | 0.24 | |
| Total effect (p-value): 3.23 (0.00) Direct effect (p-value): 3.37 (0.00) | |||||||||
| EC | E | 0.15 | 0.02 | 0.00 | 0.00 | −0.15 | −1.12 | −0.08 | −0.03 |
| G | 0.10 | 0.01 | 0.01 | 0.06 | 0.10 | 0.18 | −0.08 | −0.03 | |
| F | 0.22 | 0.05 | 0.00 | −0.01 | −0.22 | −2.94 | −0.19 | −0.08 | |
| M | 0.48 | 0.23 | 0.00 | 0.00 | 0.48 | −0.87 | −0.10 | 0.02 | |
| P | 0.93 | 0.87 | 0.00 | 0.62 | 0.93 | −1.11 | −0.52 | 0.46 | |
| Total effect (p-value): 4.55 (0.00) Direct effect (p-value): 4.81 (0.00) | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, Y.; Um, J.-S.; Hwang, J.; Schlüter, S. Evaluating the Causal Relations between the Kaya Identity Index and ODIAC-Based Fossil Fuel CO2 Flux. Energies 2020, 13, 6009. https://doi.org/10.3390/en13226009
Hwang Y, Um J-S, Hwang J, Schlüter S. Evaluating the Causal Relations between the Kaya Identity Index and ODIAC-Based Fossil Fuel CO2 Flux. Energies. 2020; 13(22):6009. https://doi.org/10.3390/en13226009
Chicago/Turabian StyleHwang, YoungSeok, Jung-Sup Um, JunHwa Hwang, and Stephan Schlüter. 2020. "Evaluating the Causal Relations between the Kaya Identity Index and ODIAC-Based Fossil Fuel CO2 Flux" Energies 13, no. 22: 6009. https://doi.org/10.3390/en13226009
APA StyleHwang, Y., Um, J.-S., Hwang, J., & Schlüter, S. (2020). Evaluating the Causal Relations between the Kaya Identity Index and ODIAC-Based Fossil Fuel CO2 Flux. Energies, 13(22), 6009. https://doi.org/10.3390/en13226009