Comparative Risk Assessment for Fossil Energy Chains Using Bayesian Model Averaging †



Abstract
1. Introduction
2. Data
2.1. ENSAD
2.2. Country Groups
2.3. Frequency and Fatality Distributions
2.4. Normalization
3. Method
4. Results and Discussions
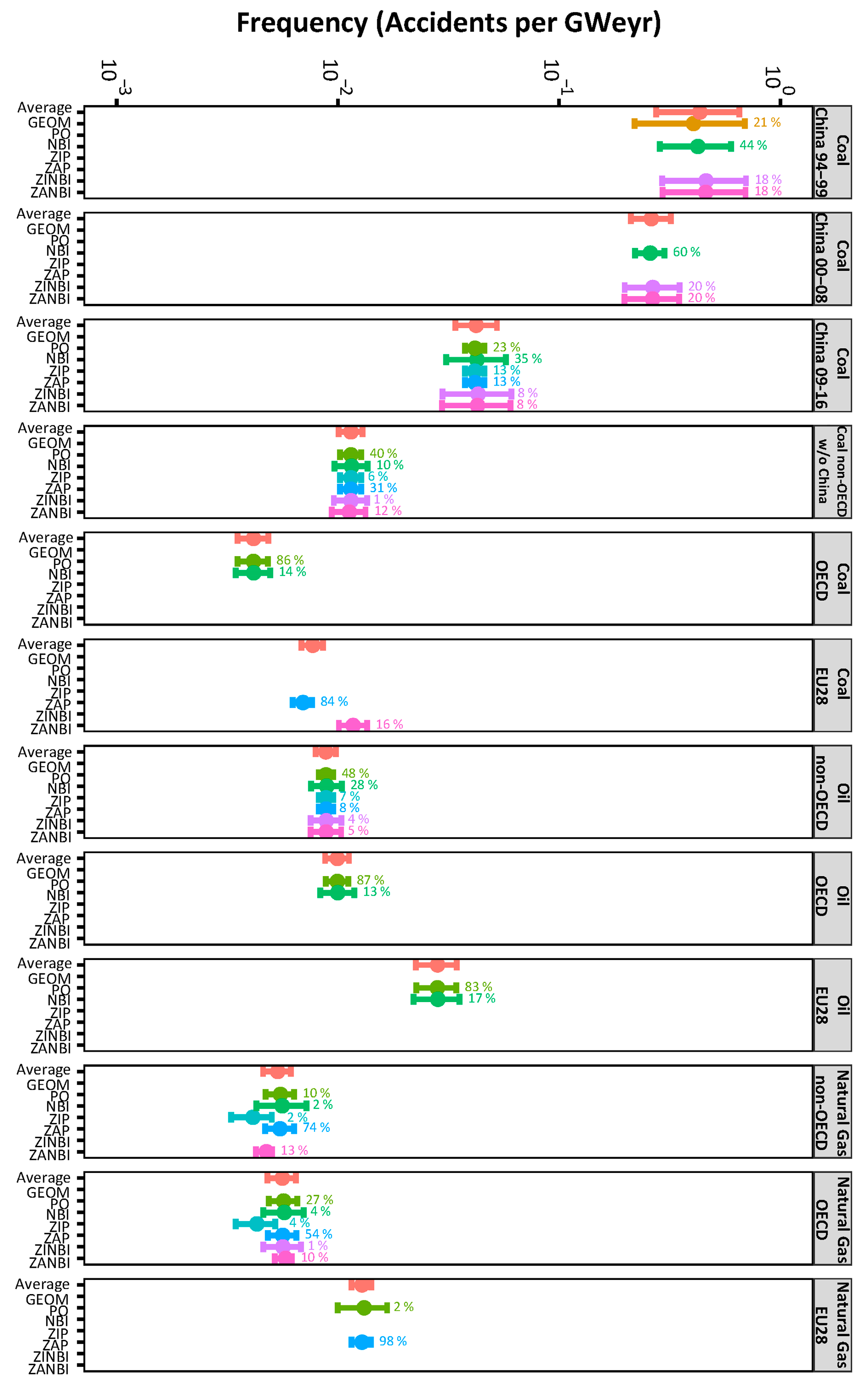
4.1. Frequency Distributions
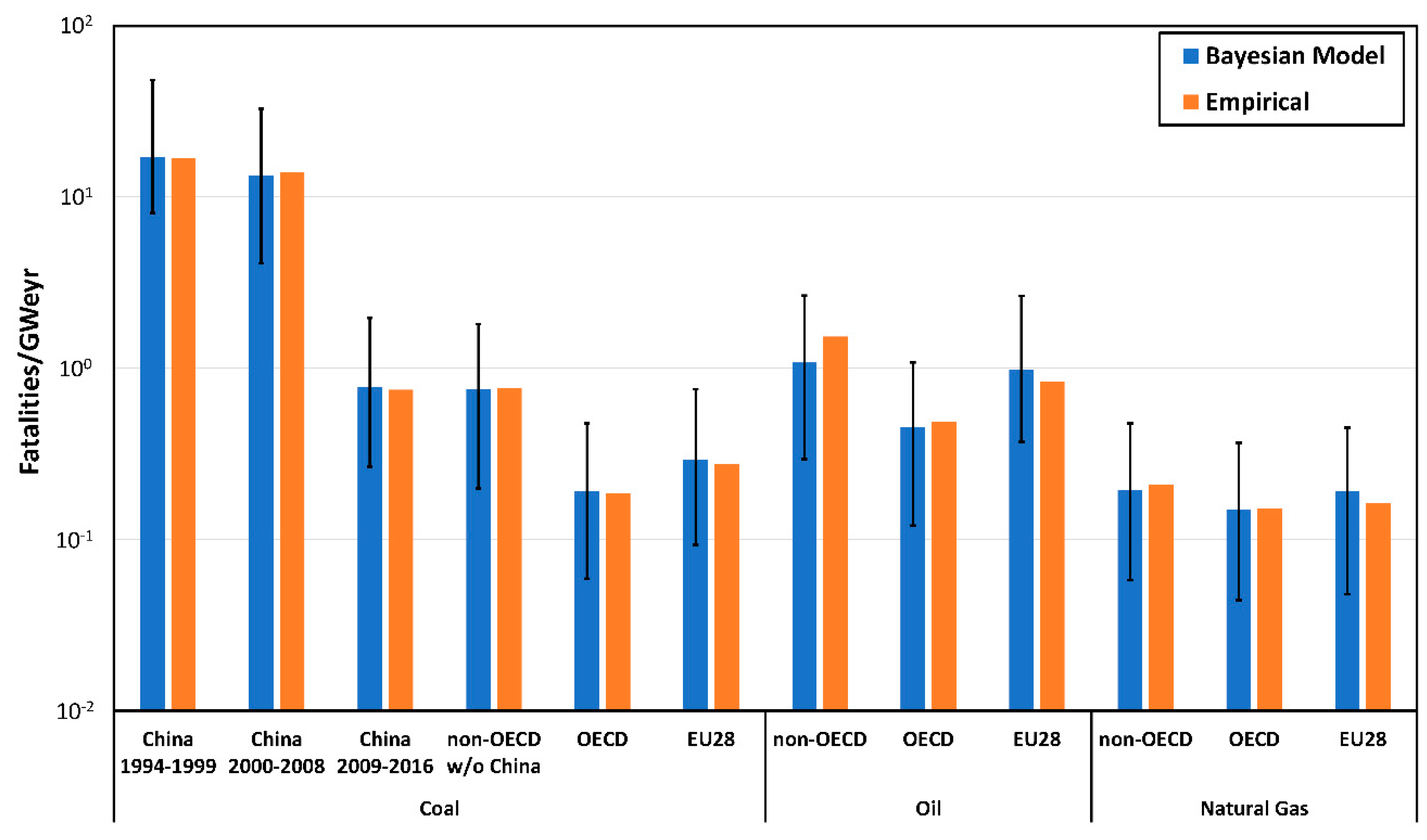
4.2. Fatality Distributions
4.3. Risk Assessment for Expected and “Extreme” Scenarios
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Roth, S.; Hirschberg, S.; Bauer, C.; Burgherr, P.; Dones, R.; Heck, T.; Schenler, W. Sustainability of electricity supply technology portfolio. Ann. Nucl. Energy 2009, 36, 409–416. [Google Scholar] [CrossRef]
- Rosner, R.; Burgherr, P.; Spada, M.; Lordan, R. Resilient Energy Infrastructures: Energy Security and Sustainability Implications. In Proceedings of the 6th International Disaster and Risk Conference (IDRC), Davos, Switzerland, 28 August–1 September 2016; pp. 532–535. [Google Scholar]
- Zio, E. The Future of Risk Assessment. Reliab. Eng. Syst. Saf. 2018, 177, 176–190. [Google Scholar] [CrossRef]
- Cinelli, M.; Spada, M.; Kadziński, M.; Miebs, G.; Burgherr, P. Advancing Hazard Assessment of Energy Accidents in the Natural Gas Sector with Rough Set Theory and Decision Rules. Energies 2019, 12, 4178. [Google Scholar] [CrossRef]
- Burgherr, P.; Eckle, P.; Hirschberg, S. Comparative assessment of severe accident risks in the coal, oil and natural gas chains. Reliab. Eng. Syst. Saf. 2012, 105, 97–103. [Google Scholar] [CrossRef]
- Burgherr, P.; Eckle, P.; Hirschberg, S. Severe accidents in the context of energy security and critical infrastructure protection. In Reliability, Risk and Safety—Back to the Future; Ale, B.J.M., Papazoglou, I.A., Zio, E., Eds.; Taylor & Francis Group: London, UK, 2010; pp. 456–464. [Google Scholar]
- Burgherr, P.; Hirschberg, S.; Spada, M. Comparative Assessment of Accident Risks in the Energy Sector. In Handbook of Risk Management in Energy Production and Trading; Kovacevic, R.M., Pflug, G.C., Vespucci, M.T., Eds.; Springer: New York, NY, USA, 2013; Volume 199, pp. 475–501. [Google Scholar]
- Spada, M.; Paraschiv, F.; Burgherr, P. A comparison of risk measures for accidents in the energy sector and their implications on decision-making strategies. Energy 2018, 154, 277–288. [Google Scholar] [CrossRef]
- Burgherr, P.; Spada, M.; Kalinina, A.; Vandepaer, L.; Lustenberger, P.; Kim, W. Comparative Risk Assessment of Accidents in the Energy Sector within Different Long-Term Scenarios and Marginal Electricity Supply Mixes. In Proceedings of the 29th European Safety and Reliability Conference, Hannover, Germany, 22–26 September 2019; Beer, M., Zio, E., Eds.; Research Publishing: Hannover, Germany, 2019; pp. 1525–1532. [Google Scholar]
- Edjossan-Sossou, A.M.; Deck, O.; Al Hleib, M.; Verdel, T. A decision-support methodology for assessing the sustainability of natural risk management strategies in urban areas. Nat. Hazards Earth Syst. Sci. 2014, 14, 3207–3230. [Google Scholar] [CrossRef]
- Novelo-Casanova, D.A.; Suárez, G. Estimation of the Risk Management Index (RMI) using statistical analysis. Nat. Hazards 2015, 77, 1501–1514. [Google Scholar] [CrossRef]
- Lambrechts, D.; Blomquist, L.B. Political–security risk in the oil and gas industry: The impact of terrorism on risk management and mitigation. J. Risk Res. 2017, 20, 1320–1337. [Google Scholar] [CrossRef]
- Spada, M.; Ferretti, V. Toward the integration of uncertainty and probabilities in spatial multi-criteria risk analysis: An application to tanker oil spills. In Safety and Reliability—Safe Societies in a Changing World; Haugen, S., Barros, A., Gulijk, C.V., Kongsvik, T., Vinnem, J., Eds.; CRC Press: London, UK, 2018. [Google Scholar]
- Renn, O. Concepts of Risk: An Interdisciplinary Review. Part 2: Integrative Approaches. GAIA 2008, 17, 196–204. [Google Scholar] [CrossRef]
- Riddel, M. Uncertainty and measurement error in welfare models for risk changes. J. Environ. Econ. Manag. 2011, 61, 341–354. [Google Scholar] [CrossRef]
- Cox, L.A., Jr. Confronting Deep Uncertainties in Risk Analysis. Risk Anal. 2012, 32, 1607–1629. [Google Scholar] [CrossRef]
- Aven, T. On Funtowicz and Ravetz’s “Decision Stake-System Uncertainties” Structure and Recently Developed Risk Perspectives. Risk Anal. 2013, 33, 270–280. [Google Scholar] [CrossRef]
- Bier, V.M.; Lin, S.-W. On the Treatment of Uncertainty and Variability in Making Decisions About Risk. Risk Anal. 2013, 33, 1899–1907. [Google Scholar] [CrossRef]
- Pasman, H.; Rogers, W. The bumpy road to better risk control A Tour d’Horizon of new concepts and ideas. J. Loss Prev. Process Ind. 2015, 35, 366–376. [Google Scholar] [CrossRef]
- Burgherr, P.; Hirschberg, S. Comparative risk assessment of severe accidents in the energy sector. Energy Policy 2014, 74 (Suppl. 1), S45–S56. [Google Scholar] [CrossRef]
- Härtler, G. Statistische Methoden für die Zuverlässigkeitsanalyse; VEB Verlag Technik: Berlin, Germany, 1983; p. 230. [Google Scholar]
- Cox, L.A., Jr. Risk Analysis of Complex and Uncertain Systems; Springer: New York, UA, USA, 2009; Volume 129, p. 453. [Google Scholar]
- Eckle, P.; Burgherr, P. Bayesian Data Analysis of Severe Fatal Accident Risk in the Oil Chain. Risk Anal. 2013, 33, 146–160. [Google Scholar] [CrossRef]
- Spada, M.; Burgherr, P.; Hirschberg, S. Comparative Assessment of Severe Accidents Risk in the Energy Sector: Uncertainty Estimation Using a Combination of Weighting Tree and Bayesian Hierarchical Models. In Proceedings of the 12th Probabilistic Safety Assessment and Management (PSAM12), Honolulu, HI, USA, 22–27 June 2014. [Google Scholar]
- Kalinina, A.; Spada, M.; Burgherr, P. Application of a Bayesian hierarchical modeling for risk assessment of accidents at hydropower dams. Saf. Sci. 2018, 110, 164–177. [Google Scholar] [CrossRef]
- Koch, K.-R. Introduction to Bayesian Statistics; Springer: Berlin, Germany, 2010; p. 250. [Google Scholar]
- Birrell, P.J.; Ketsetzis, G.; Gay, N.J.; Cooper, B.S.; Presanis, A.M.; Harris, R.J.; Charlett, A.; Zhang, X.S.; White, P.J.; Pebody, R.G.; et al. Bayesian modeling to unmask and predict influenza A/H1N1pdm dynamics in London. Proc. Natl. Acad. Sci. USA 2011, 108, 18238–18243. [Google Scholar] [CrossRef]
- Apputhurai, P.; Stephenson, A.G. Accounting for uncertainty in extremal dependence modeling using Bayesian model averaging techniques. J. Stat. Plan. Inference 2011, 141, 1800–1807. [Google Scholar] [CrossRef]
- Leamer, E.E. Specification Searches: Ad Hoc Inference with Nonexperimental Data; John Wiley & Sons Inc.: New York, NY, USA, 1978; p. 370. [Google Scholar]
- Fragoso, T.M.; Bertoli, W.; Louzada, F. Bayesian Model Averaging: A Systematic Review and Conceptual Classification. Int. Stat. Rev. 2018, 86, 1–28. [Google Scholar] [CrossRef]
- Shao, K.; Gift, J.S. Model Uncertainty and Bayesian Model Averaged Benchmark Dose Estimation for Continuous Data. Risk Anal. 2013, 34, 101–120. [Google Scholar] [CrossRef]
- Rios Insua, D.; Banks, D.; Rios, J. Modeling Opponents in Adversarial Risk Analysis. Risk Anal. 2015, 36, 742–755. [Google Scholar] [CrossRef]
- Dormann, C.F.; Calabrese, J.M.; Guillera-Arroita, G.; Matechou, E.; Bahn, V.; Bartoń, K.; Beale, C.M.; Ciuti, S.; Elith, J.; Gerstner, K.; et al. Model averaging in ecology: A review of Bayesian, information-theoretic, and tactical approaches for predictive inference. Ecol. Monogr. 2018. [Google Scholar] [CrossRef]
- Raftery, A.E. Bayesian model selection in social research. Sociol. Methodol. 1995, 25, 111–163. [Google Scholar] [CrossRef]
- Bottolo, L.; Consonni, G.; Dellaportas, P.; Lijoi, A. Bayesian Analysis of Extreme Values by Mixture Modeling. Extremes 2003, 6, 25–47. [Google Scholar] [CrossRef]
- Bhat, K.S.; Haran, M.; Terando, A.; Keller, K. Climate Projections Using Bayesian Model Averaging and Space–Time Dependence. J. Agric. Biol. Environ. Stat. 2011, 16, 606–628. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, J. Forecasting natural gas consumption in China by Bayesian Model Averaging. Energy Rep. 2015, 1, 216–220. [Google Scholar] [CrossRef]
- Zou, Y.; Lord, D.; Zhang, Y.; Peng, Y. Application of the Bayesian Model Averaging in Predicting Motor Vehicle Crashes; Bureau of Transportation Statistics: College Station, TX, USA, 2017.
- Tsai, F.T.C. Bayesian model averaging assessment on groundwater management under model structure uncertainty. Stoch. Environ. Res. Risk Assess. 2010, 24, 845–861. [Google Scholar] [CrossRef]
- Jia, W.; McPherson, B.; Pan, F.; Dai, Z.; Xiao, T. Uncertainty quantification of CO2 storage using Bayesian model averaging and polynomial chaos expansion. Int. J. Greenh. Gas Control 2018, 71, 104–115. [Google Scholar] [CrossRef]
- Dearmon, J.; Smith, T.E. Gaussian Process Regression and Bayesian Model Averaging: An Alternative Approach to Modeling Spatial Phenomena. Geogr. Anal. 2016, 48, 82–111. [Google Scholar] [CrossRef]
- Reis, D.S., Jr.; Stedinger, J.R. Bayesian MCMC flood frequency analysis with historical information. J. Hydrol. 2005, 313, 97–116. [Google Scholar] [CrossRef]
- Bailer, A.J.; Noble, R.B.; Wheeler, M.W. Model uncertainty and risk estimation for experimental studies of quantal responses. Risk Anal. 2005, 25, 291–299. [Google Scholar] [CrossRef] [PubMed]
- Ridout, M.; Demetrio, C.G.B.; Hinde, J. Models for Count Data with Many Zeros. International Biometric Conference; The International Biometric Society: Cape Town, South Africa, 1998; p. 13. [Google Scholar]
- Parent, E.; Bernier, J. Bayesian POT modeling for historical data. J. Hydrol. 2003, 274, 95–108. [Google Scholar] [CrossRef]
- Hirschberg, S.; Spiekerman, G.; Dones, R. Severe Accidents in the Energy Sector; Paul Scherrer Institut: Villigen, Switzerland, 1998; p. 340. [Google Scholar]
- Burgherr, P.; Spada, M.; Kalinina, A.; Hirschberg, S.; Kim, W.; Gasser, P.; Lustenberger, P. The Energy-related Severe Accident Database (ENSAD) for comparative risk assessment of accidents in the energy sector. In Safety and Reliability Theory and Applications; Čepin, M., Bris, R., Eds.; CRC Press: Portoroz, Slovenia, 2017; p. 205. [Google Scholar]
- Kim, W.; Burgherr, P.; Spada, M.; Lustenberger, P.; Kalinina, A.; Hirschberg, S. Energy-related Severe Accident Database (ENSAD): Cloud-based geospatial platform. Big Earth Data 2018, 2, 368–394. [Google Scholar] [CrossRef]
- Spada, M.; Burgherr, P.; Boutinard Rouelle, P. Comparative risk assessment with focus on hydrogen and selected fuel cells: Application to Europe. Int. J. Hydrogen Energy 2018, 43, 9470–9481. [Google Scholar] [CrossRef]
- Burgherr, P.; Hirschberg, S. Assessment of severe accident risks in the Chinese coal chain. Int. J. Risk Assess. Manag. 2007, 7, 1157–1175. [Google Scholar] [CrossRef]
- Aven, T. The risk concept—Historical and recent development trends. Reliab. Eng. Syst. Saf. 2012, 99, 33–44. [Google Scholar] [CrossRef]
- British Petroleum Company (BP). BP Statistical Review of World Energy; BP: London, UK, 2018. [Google Scholar]
- Brooks, S.; Gelman, A.; Jones, G.L.; Meng, X.L. Handbook of Markov Chain Monte Carlo; Chapman & Hall/CRC: Boca Raton, FL, USA, 2011; pp. 1–600. [Google Scholar]
- Yao, Y.; Vehtari, A.; Simpson, D.; Gelman, A. Using Stacking to Average Bayesian Predictive Distributions (with Discussion). Bayesian Anal. 2018, 13, 917–1007. [Google Scholar] [CrossRef]
- Wang, C.-P.; Ghosh, M. A Kullback-Leibler Divergence for Bayesian Model Diagnostics. Open J. Stat. 2011, 1, 172–184. [Google Scholar] [CrossRef]
- Piironen, J.; Vehtari, A. Comparison of Bayesian predictive methods for model selection. Stat. Comput. 2016, 27, 711–735. [Google Scholar] [CrossRef]
- Watanabe, S. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- Wasserman, L. Bayesian Model Selection and Model Averaging. J. Math. Psychol. 2000, 44, 92–107. [Google Scholar] [CrossRef]
- Andrieu, C.; de Freitas, N.; Doucet, A.; Jordan, M.I. An introduction to MCMC for machine learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D.B. Inference from Iterative Simulation Using Multiple Sequences. Stat. Sci. 1992, 7, 457–511. [Google Scholar] [CrossRef]
- Srivastava, R.C. On Some Characterizations of the Geometric Distribution. In Statistical Distributions in Scientific Work; Taillie, C., Patil, G.P., Baldessari, B.A., Eds.; NATO Advanced Study Institutes Series (Series C: Mathematical and Physical Sciences); Springer: Dordrecht, The Netherlands, 1981; pp. 349–355. [Google Scholar]
- Wu, L.; Jiang, Z.; Cheng, W.; Zuo, X.; Lv, D.; Yao, Y. Major accident analysis and prevention of coal mines in China from the year of 1949 to 2009. Min. Sci. Technol. (China) 2011, 21, 693–699. [Google Scholar] [CrossRef]
- Geng, F.; Saleh, J.H. Challenging the emerging narrative: Critical examination of coalmining safety in China, and recommendations for tackling mining hazards. Saf. Sci. 2015, 75, 36–48. [Google Scholar] [CrossRef]
- Trigui, I.; Laourine, A.; Affes, S.; Stephenne, A. The Inverse Gaussian Distribution in Wireless Channels: Second-Order Statistics and Channel Capacity. IEEE Trans. Commun. 2012, 60, 3167–3173. [Google Scholar] [CrossRef]
- Chhikara, R.S.; Folks, J.L. The Inverse Gaussian Distribution as a Lifetime Model. Technometrics 1977, 19, 461–468. [Google Scholar] [CrossRef]
- International Energy Agency (IEA). Energy Statistics of Non-OECD Countries; IEA: Paris, France, 2015; p. 771. [Google Scholar]
- Maiti, J.; Khanzode, V.V.; Ray, P.K. Severity analysis of Indian coal mine accidents—A retrospective study for 100 years. Saf. Sci. 2009, 47, 1033–1042. [Google Scholar] [CrossRef]
- Thelwall, M. The precision of the arithmetic mean, geometric mean and percentiles for citation data: An experimental simulation modelling approach. J. Informetr. 2016, 10, 110–123. [Google Scholar] [CrossRef]
- Volkart, K.; Weidmann, N.; Bauer, C.; Hirschberg, S. Multi-criteria decision analysis of energy system transformation pathways: A case study for Switzerland. Energy Policy 2017, 106, 155–168. [Google Scholar] [CrossRef]
- Gasser, P.; Suter, J.; Cinelli, M.; Spada, M.; Burgherr, P.; Hirschberg, S.; Kadziński, M.; Stojadinovic, B. Comprehensive resilience assessment of electricity supply security for 140 countries. Ecol. Ind. 2020, 110, 105731. [Google Scholar] [CrossRef]
- Spada, M.; Burgherr, P.; Hohl, M. Toward the validation of a National Risk Assessment against historical observations using a Bayesian approach: Application to the Swiss case. J. Risk Res. 2018, 22, 1323–1342. [Google Scholar] [CrossRef]
- Federal Office for Civil Protection (FOCP). Disasters and Emergencies in Switzerland: Risk Report 2015; Federal Office for Civil Protection (FOCP): Bern, Switzerland, 2015. [Google Scholar]
- Burgherr, P.; Cinelli, M.; Spada, M.; Blaszczynski, J.; Słowiński, R.; Pannatier, Y. Risk assessment of worldwide refinery accidents using advanced classification methods: Effects of refinery configuration and geographic location on outcome risk levels. In Safety and Reliability—Safe Societies in a Changing World; Haugen, S., Barros, A., Gulijk, C.V., Kongsvik, T., Vinnem, J., Eds.; CRC Press: London, UK, 2018. [Google Scholar]
- Burgherr, P.; Spada, M.; Kalinina, A.; Page, P. Regionalized risk assessment of accidental oil spills using worldwide data. In Safety and Reliability of Complex Engineered Systems: ESREL 2015; Podofilini, L., Sudret, B., Stojadinovic, B., Zio, E., Kröger, W., Eds.; CRC Press: Zurich, Switzerland, 2015. [Google Scholar]
- Spada, M.; Burgherr, P. An aftermath analysis of the 2014 coal mine accident in Soma, Turkey: Use of risk performance indicators based on historical experience. Accid. Anal. Prev. 2016, 87, 134–140. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Energy Chain | Country Group | Number of Accidents | Number of Fatalities |
|---|---|---|---|
| Coal | OECD | 110 | 2927 |
| non-OECD w/o China | 222 | 6143 | |
| EU28 | 50 | 1360 | |
| China 1994–1999 | 817 | 11,059 | |
| China 2000–2008 | 1182 | 14,662 | |
| China 2009–2016 | 275 | 2435 | |
| Oil | OECD | 199 | 3780 |
| non-OECD | 494 | 17,832 | |
| EU28 | 167 | 1186 | |
| Natural Gas | OECD | 124 | 1420 |
| non-OECD | 123 | 2127 | |
| EU28 | 41 | 411 |
| Energy Chain | Country Group | Total Production (GWeyr) | Average Annual Production (GWeyr) |
|---|---|---|---|
| Coal | OECD | 21,853 | 465 |
| non-OECD w/o China | 19,377 | 412 | |
| EU28 | 6799 | 145 | |
| China 1994–1999 | 1877 | 313 | |
| China 2000–2008 | 4559 | 507 | |
| China 2009–2016 | 6600 | 825 | |
| Oil | OECD | 19,383 | 412 |
| non-OECD | 53,968 | 1148 | |
| EU28 | 2488 | 53 | |
| Natural Gas | OECD | 17,707 | 377 |
| non-OECD | 22,220 | 473 | |
| EU28 | 3667 | 78 |
| Energy Chain | Country Group | Results | Distributions | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GEOM | PO | NBI | ZIP | ZAP | ZINBI | ZANBI | |||
| Coal | China 1994–1999 | BIC | 74 | 323 | 73 | 324 | 324 | 75 | 75 |
| Weight | 0.21 | 0.00 | 0.44 | 0.00 | 0.00 | 0.18 | 0.18 | ||
| China 2000–2008 | BIC | 110 | 137 | 94 | 139 | 139 | 97 | 97 | |
| Weight | 0.00 | 0.00 | 0.60 | 0.00 | 0.00 | 0.20 | 0.20 | ||
| China 2009–2016 | BIC | 75 | 59 | 58 | 60 | 60 | 61 | 61 | |
| Weight | 0.00 | 0.23 | 0.35 | 0.13 | 0.13 | 0.08 | 0.08 | ||
| non-OECD w/o China | BIC | 242 | 207 | 211 | 212 | 208 | 214 | 210 | |
| Weight | 0.00 | 0.40 | 0.10 | 0.06 | 0.31 | 0.01 | 0.12 | ||
| OECD | BIC | 322 | 266 | 270 | 620 | 490 | 630 | 513 | |
| Weight | 0.00 | 0.86 | 0.14 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| EU28 | BIC | 115 | 88 | 92 | 92 | 77 | 95 | 81 | |
| Weight | 0.00 | 0.00 | 0.00 | 0.00 | 0.84 | 0.00 | 0.16 | ||
| Oil | non-OECD | BIC | 313 | 258 | 259 | 262 | 262 | 263 | 263 |
| Weight | 0.00 | 0.48 | 0.28 | 0.07 | 0.08 | 0.04 | 0.05 | ||
| OECD | BIC | 386 | 312 | 315 | 473 | 572 | 501 | 590 | |
| Weight | 0.00 | 0.87 | 0.13 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| EU28 | BIC | 178 | 147 | 150 | 254 | 310 | 366 | 371 | |
| Weight | 0.00 | 0.83 | 0.17 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| Natural Gas | non-OECD | BIC | 164 | 131 | 134 | 134 | 127 | 138 | 130 |
| Weight | 0.00 | 0.10 | 0.02 | 0.02 | 0.74 | 0.00 | 0.13 | ||
| OECD | BIC | 192 | 161 | 165 | 165 | 160 | 169 | 163 | |
| Weight | 0.00 | 0.27 | 0.04 | 0.04 | 0.54 | 0.01 | 0.10 | ||
| EU28 | BIC | 90 | 74 | 1763 | 77 | 66 | 2304 | 1973 | |
| Weight | 0.00 | 0.02 | 0.00 | 0.00 | 0.98 | 0.00 | 0.00 | ||
| Energy Chain | Country Group | Results | Distributions | |||||
|---|---|---|---|---|---|---|---|---|
| IG | LO | RG | GP | LOGNO | WEI | |||
| Coal | China 1994–1999 | BIC | 335 | 497 | 473 | 341 | 328 | 336 |
| Weight | 0.03 | 0.00 | 0.00 | 0.00 | 0.95 | 0.02 | ||
| China 2000–2008 | BIC | 381 | 582 | 549 | 396 | 387 | 403 | |
| Weight | 0.95 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | ||
| China 2009–2016 | BIC | 144 | 199 | 188 | 165 | 140 | 142 | |
| Weight | 0.12 | 0.00 | 0.00 | 0.00 | 0.68 | 0.20 | ||
| non-OECD w/o China | BIC | 245 | 354 | 322 | 274 | 253 | 274 | |
| Weight | 0.97 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | ||
| OECD | BIC | 160 | 213 | 190 | 188 | 163 | 181 | |
| Weight | 0.85 | 0.00 | 0.00 | 0.00 | 0.15 | 0.00 | ||
| EU28 | BIC | 76 | 95 | 85 | 102 | 78 | 87 | |
| Weight | 0.68 | 0.00 | 0.00 | 0.00 | 0.32 | 0.00 | ||
| Oil | non-OECD | BIC | 418 | 570 | 528 | 443 | 428 | 454 |
| Weight | 0.99 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | ||
| OECD | BIC | 200 | 288 | 264 | 219 | 205 | 220 | |
| Weight | 0.93 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | ||
| EU28 | BIC | 86 | 114 | 105 | 101 | 89 | 94 | |
| Weight | 0.93 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | ||
| Natural Gas | non-OECD | BIC | 143 | 204 | 186 | 159 | 148 | 160 |
| Weight | 0.89 | 0.00 | 0.00 | 0.00 | 0.11 | 0.00 | ||
| OECD | BIC | 116 | 174 | 162 | 127 | 121 | 127 | |
| Weight | 0.92 | 0.00 | 0.00 | 0.00 | 0.08 | 0.00 | ||
| EU28 | BIC | 46 | 65 | 63 | 62 | 49 | 47 | |
| Weight | 0.93 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spada, M.; Burgherr, P. Comparative Risk Assessment for Fossil Energy Chains Using Bayesian Model Averaging. Energies 2020, 13, 295. https://doi.org/10.3390/en13020295
Spada M, Burgherr P. Comparative Risk Assessment for Fossil Energy Chains Using Bayesian Model Averaging. Energies. 2020; 13(2):295. https://doi.org/10.3390/en13020295
Chicago/Turabian StyleSpada, Matteo, and Peter Burgherr. 2020. "Comparative Risk Assessment for Fossil Energy Chains Using Bayesian Model Averaging" Energies 13, no. 2: 295. https://doi.org/10.3390/en13020295
APA StyleSpada, M., & Burgherr, P. (2020). Comparative Risk Assessment for Fossil Energy Chains Using Bayesian Model Averaging. Energies, 13(2), 295. https://doi.org/10.3390/en13020295