Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources

 ,
,  ,
, 
Abstract
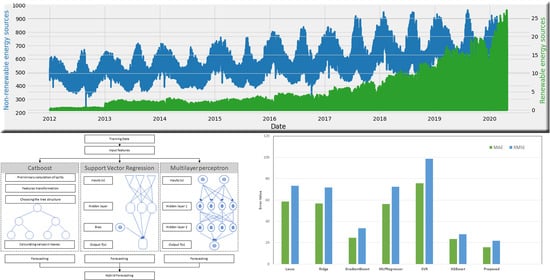
1. Introduction
- the data analysis of power consumption from renewable energy sources and nonrenewable energy sources;
- to propose a novel hybrid approach for energy consumption forecasting;
- to compare the proposed model with prediction algorithms.
2. Related Works
3. Machine Learning-Based Energy Load Forecasting
Power Sources
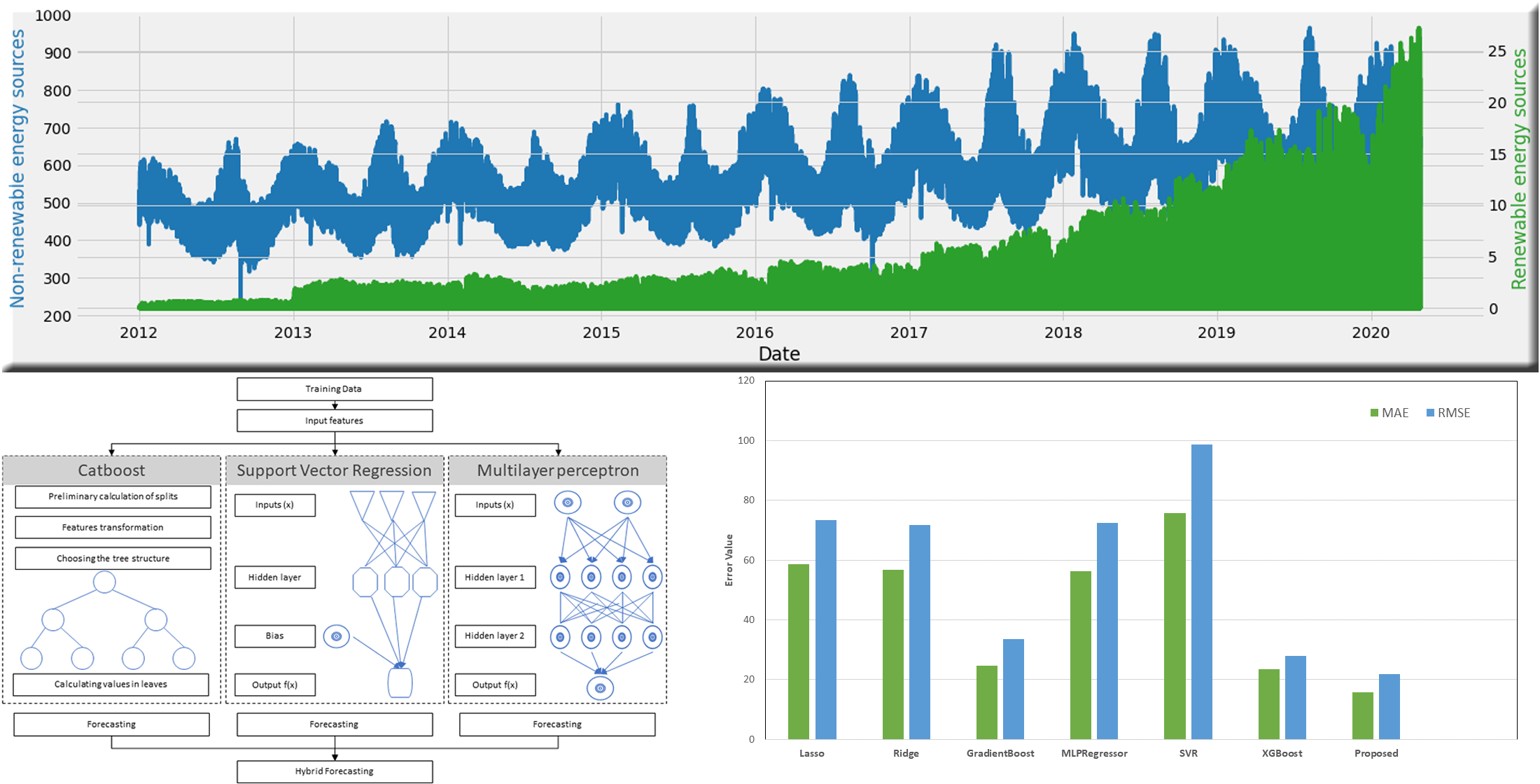
4. Proposed Hybrid Ensemble Model
4.1. CatBoost
4.2. Support Vector Regression
4.3. Multilayer Perceptron
5. Forecasting
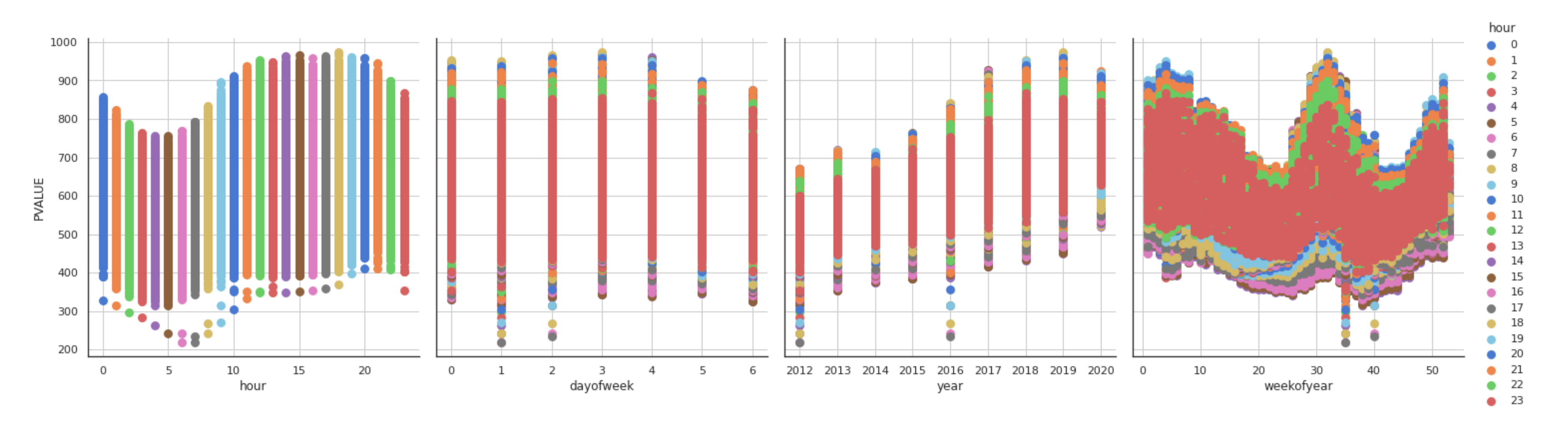
5.1. Exploratory Data Analysis
5.2. Pre-Processing
5.3. Training
5.4. Train-And-Test Split
6. Experimental Results and Discussion
6.1. Feature Importance Analysis
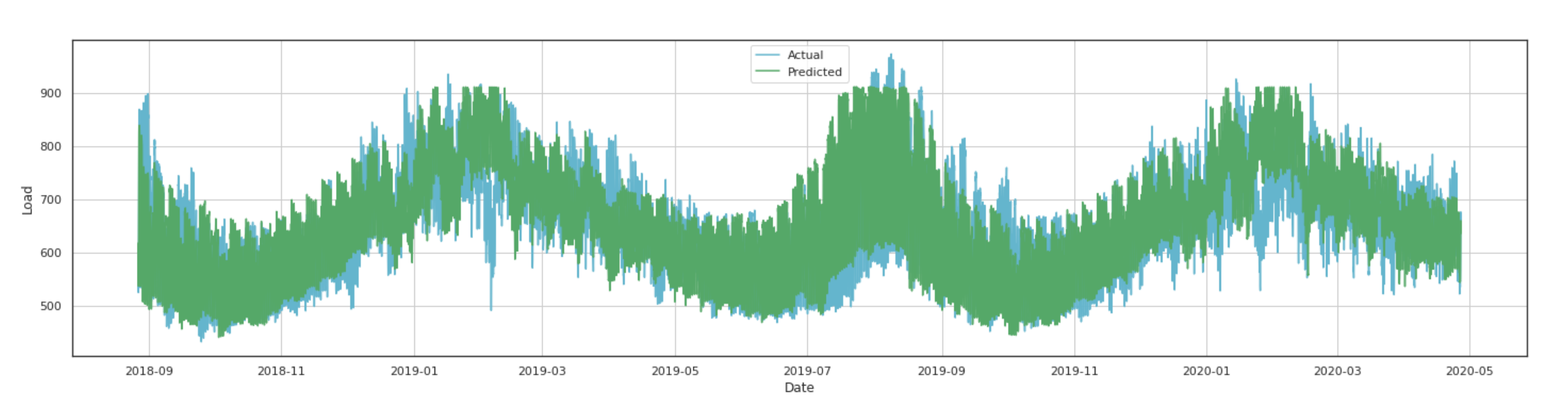
6.2. Forecasting Results
6.3. Model Goodness Inspection
6.3.1. Mean Absolute Error
6.3.2. Mean Squared Error
6.3.3. Root Mean Squared Logarithmic Error
6.3.4. Mean Absolute Percent Error
6.3.5. Comparison with Existing Models
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SVR | Support vector regression |
| JEC | Jeju Energy Corporation |
| MLP | Multilayer perceptron |
| ANN | Artificial neural network |
| FF | Fossil fuel |
| BTM | Behind the meter |
| PV | Photovoltaic |
| WP | Wind power |
| EDA | Exploratory data analysis |
| KEPCO | Korea Electric Power Corporation |
| KPX | Korea Power Exchange |
| PPA | Power purchase agreement |
| RMSE | Root mean squared error |
| EEMD | Ensemble empirical mode decomposition |
| ELM | Extreme learning machine |
| MAE | Mean absolute error |
| MSE | Mean squared error |
| RMSLE | Root mean squared logarithmic error |
| MAPE | Mean absolute percent error |
References
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Apergis, N.; Payne, J.E. Renewable and non-renewable energy consumption-growth nexus: Evidence from a panel error correction model. Energy Econ. 2012, 34, 733–738. [Google Scholar] [CrossRef]
- Pérez-Ortiz, M.; Jiménez-Fernández, S.; Gutiérrez, P.A.; Alexandre, E.; Hervás-Martínez, C.; Salcedo-Sanz, S. A review of classification problems and algorithms in renewable energy applications. Energies 2016, 9, 607. [Google Scholar]
- Marczinkowski, H.M.; Alberg Østergaard, P.; Roth Djørup, S. Transitioning island energy systems—Local conditions, development phases, and renewable energy integration. Energies 2019, 12, 3484. [Google Scholar] [CrossRef]
- Badal, F.R.; Das, P.; Sarker, S.K.; Das, S.K. A survey on control issues in renewable energy integration and microgrid. Prot. Control. Mod. Power Syst. 2019, 4, 8. [Google Scholar] [CrossRef]
- 100-Percent. 100% Renewable Energy Atlas Practical Steps Towards a Sustainable World. 2019. Available online: https://www.100-percent.org/tag/work-in-progress/page/5/ (accessed on 7 May 2020).
- Jeju Weekly. Jeju to Be Carbon Free by 2030. 2012. Available online: http://www.jejuweekly.com/news/articleView.html?idxno=2679 (accessed on 3 June 2020).
- Asrari, A.; Wu, T.X.; Ramos, B. A hybrid algorithm for short-term solar power prediction—Sunshine state case study. IEEE Trans. Sustain. Energy 2016, 8, 582–591. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Zeng, G. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Ahmad, A.; Hassan, M.; Abdullah, M.; Rahman, H.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Wang, R.; Li, J.; Wang, J.; Gao, C. Research and application of a hybrid wind energy forecasting system based on data processing and an optimized extreme learning machine. Energies 2018, 11, 1712. [Google Scholar] [CrossRef]
- Mendonça de Paiva, G.; Pires Pimentel, S.; Pinheiro Alvarenga, B.; Gonçalves Marra, E.; Mussetta, M.; Leva, S. Multiple Site Intraday Solar Irradiance Forecasting by Machine Learning Algorithms: MGGP and MLP Neural Networks. Energies 2020, 13, 3005. [Google Scholar]
- Ju, C.; Wang, P.; Goel, L.; Xu, Y. A two-layer energy management system for microgrids with hybrid energy storage considering degradation costs. IEEE Trans. Smart Grid 2017, 9, 6047–6057. [Google Scholar] [CrossRef]
- Diao, L.; Niu, D.; Zang, Z.; Chen, C. Short-term Weather Forecast Based on Wavelet Denoising and Catboost. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3760–3764. [Google Scholar]
- Catalao, J.; Pousinho, H.; Mendes, V. Hybrid wavelet-PSO-ANFIS approach for short-term wind power forecasting in Portugal. IEEE Trans. Sustain. Energy 2010, 2, 50–59. [Google Scholar] [CrossRef]
- Yu, J.; Park, J.H.; Kim, S. A New Input Selection Algorithm Using the Group Method of Data Handling and Bootstrap Method for Support Vector Regression Based Hourly Load Forecasting. Energies 2018, 11, 2870. [Google Scholar] [CrossRef]
- Cao, Z.; Wan, C.; Zhang, Z.; Li, F.; Song, Y. Hybrid ensemble deep learning for deterministic and probabilistic low-voltage load forecasting. IEEE Trans. Power Syst. 2019, 35, 1881–1897. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C.; Lee, S.J.; Park, N. Machine Learning Based Hybrid System for Imputation and Efficient Energy Demand Forecasting. Energies 2020, 13, 2681. [Google Scholar]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–34. [Google Scholar]
- Zhang, F.; Fleyeh, H. Short Term Electricity Spot Price Forecasting Using CatBoost and Bidirectional Long Short Term Memory Neural Network. In Proceedings of the 2019 16th International Conference on the European Energy Market (EEM), Ljubljana, Slovenia, 18–20 September 2019; pp. 1–6. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Hernández-Lobato, J.M.; Adams, R. Probabilistic backpropagation for scalable learning of bayesian neural networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1861–1869. [Google Scholar]
- Morin, F.; Bengio, Y. Hierarchical probabilistic neural network language model. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; pp. 246–252. [Google Scholar]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote. Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Tsoi, A.C.; Back, A. Discrete time recurrent neural network architectures: A unifying review. Neurocomputing 1997, 15, 183–223. [Google Scholar] [CrossRef]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.B. Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 809–821. [Google Scholar] [CrossRef] [PubMed]
- Almeshaiei, E.; Soltan, H. A methodology for electric power load forecasting. Alex. Eng. J. 2011, 50, 137–144. [Google Scholar] [CrossRef]
- Korea Legislation Government. The Act on The Promotion of the Development, Use and Diffusion of New and Renewable Energy. 2014. Available online: http://www.law.go.kr/lsInfoP.do?lsiSeq=150378#J12:3 (accessed on 22 July 2020).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count | Mean | Std | Min | Max | |
|---|---|---|---|---|---|
| FF | 72,936 | 574.00 | 105.53 | 219.20 | 965.50 |
| WP | 72,936 | 0.0240 | 0.0266 | 0.00 | 0.1619 |
| BTM | 72,936 | 0.9311 | 2.5194 | 0.00 | 25.443 |
| PV | 72,936 | 0.7877 | 2.3340 | 0.00 | 27.198 |
| Total | 291,744 | 143.93 | 253.85 | 0.00 | 965.50 |
| Model Name | MAE | MSE | RMSE | RMSLE |
|---|---|---|---|---|
| Lasso | 58.69445 | 5373.682 | 73.30541 | 0.128073 |
| Ridge | 56.65012 | 5151.027 | 71.77066 | 0.125468 |
| GradientBoost | 24.76477 | 1119.649 | 33.46116 | 0.056788 |
| MLPRegressor | 56.22875 | 5250.298 | 72.45894 | 0.123721 |
| SVR | 75.8136 | 9753.185 | 98.75822 | 0.171825 |
| XGBoost | 23.51242 | 777.4753 | 27.88325 | 0.049442 |
| Proposed | 15.72754 | 472.9644 | 21.74774 | 0.037885 |
| Name | Min Error % | Max Error % | Over all MAPE % |
|---|---|---|---|
| Lasso | 0.000076 | 48.09446 | 10.3914 |
| Ridge | 0.000773 | 47.81702 | 10.41394 |
| GradientBoost | 0.000039 | 39.00609 | 6.864313 |
| MLPRegressor | 0.001636 | 57.7405 | 19.52188 |
| SVR | 0.007006 | 80.19327 | 21.61039 |
| XGBoost | 0.00018 | 42.21712 | 5.769542 |
| Proposed | 0.001388 | 35.26321 | 4.294916 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, P.W.; Byun, Y.-C.; Lee, S.-J.; Kang, D.-H.; Kang, J.-Y.; Park, H.-S. Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources. Energies 2020, 13, 4870. https://doi.org/10.3390/en13184870
Khan PW, Byun Y-C, Lee S-J, Kang D-H, Kang J-Y, Park H-S. Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources. Energies. 2020; 13(18):4870. https://doi.org/10.3390/en13184870
Chicago/Turabian StyleKhan, Prince Waqas, Yung-Cheol Byun, Sang-Joon Lee, Dong-Ho Kang, Jin-Young Kang, and Hae-Su Park. 2020. "Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources" Energies 13, no. 18: 4870. https://doi.org/10.3390/en13184870
APA StyleKhan, P. W., Byun, Y.-C., Lee, S.-J., Kang, D.-H., Kang, J.-Y., & Park, H.-S. (2020). Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources. Energies, 13(18), 4870. https://doi.org/10.3390/en13184870