Laminar Burning Velocity Model Based on Deep Neural Network for Hydrogen and Propane with Air



Abstract
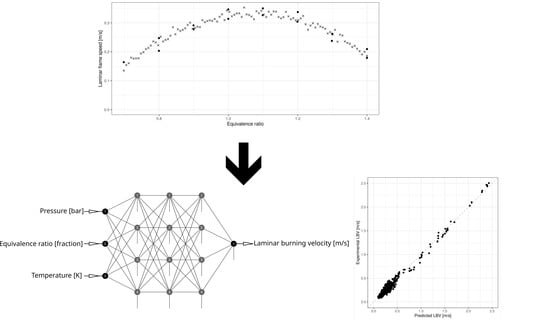
1. Introduction and Motivation
2. Experimental Data Sources
2.1. Hydrogen–Air
2.2. Propane–Air
3. Data Preprocessing
- Removal of the outliers and using linear interpolation to fill those values;
- Rounding of data (precision of 10 for temperature (K), 0.01 for pressure (bar) and 0.01 for equivalence ratio (fraction));
- Approximation of experimental data (over each variable separately);
- Approximation of the standard deviation of experimental data (over each variable separately);
- Data simulation (over each variable separately).
4. Model Construction, Tuning, and Training
- Initial conditions: 1 atm, 300 K;
- Three inputs: pressure (bar), temperature (K), and equivalence ratio (fractional form);
- One output: LBV (m/s);
- Hidden layers activation functions: hyperbolic tangent;
- Output layer activation function: identity.
- The number of hidden layers ranging from 1 to 4;
- The number of nodes (equal in every hidden layer) between 2 and 5;
- The regularization parameter: , , , , , or 0.
5. Model Validation
| —LBV of hydrogen–air mixture in reference conditions; | |
| —mass fraction of hydrogen in the mixture; | |
| —LBV of hydrogen–air mixture in given conditions; | |
| —reference temperature, 298 K; | |
| —reference pressure, Pa; | |
| p | —pressure the LBV is calculated for (Pa); |
| T | —temperature the LBV is calculated for (K); |
| —mixture-specific constant, ; | |
| —mixture-specific constant, ; |
| —LBV of hydrogen–air mixture in reference conditions; | |
| —equivalence ratio of propane–air mixture; | |
| —LBV of hydrogen–air mixture in given conditions; | |
| —reference temperature, 298 K; | |
| —reference pressure, Pa; | |
| p | —pressure the LBV is calculated for (Pa); |
| T | —temperature the LBV is calculated for (K); |
| —mixture-specific constant, ; | |
| —mixture-specific constant, . |
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- von Karman, T.; Penner, S. Fundamental approach to laminar flame propagation. In Selected Combustion Problems; Butterworths Scientific: London, UK, 1954. [Google Scholar]
- Gibbs, G.J.; Calcote, H.F. Effect of Molecular Structure on Burning Velocity. J. Chem. Eng. Data 1959, 4, 226–237. [Google Scholar] [CrossRef]
- Rallis, C.J.; Garforth, A.M. The determination of laminar burning velocity. Prog. Energy Combust. Sci. 1980, 6, 303–329. [Google Scholar] [CrossRef]
- Farrell, J.T.; Johnston, R.J.; Androulakis, I.P. Molecular Structure Effects on Laminar Burning Velocities at Elevated Temperature and Pressure; SAE Technical Paper Series; SAE International: Warrendale, PA, USA, 2004. [Google Scholar] [CrossRef]
- Ballal, D.; Lefebvre, A. The structure and propagation of turbulent flames. Proc. R. Soc. Lond. A Math. Phys. Sci. 1975, 344, 217–234. [Google Scholar]
- Wacks, D.H.; Chakraborty, N. Flame Structure and Propagation in Turbulent Flame-Droplet Interaction: A Direct Numerical Simulation Analysis. Flow Turbul. Combust. 2016, 96, 1053–1081. [Google Scholar] [CrossRef]
- Ravi, S.; Sikes, T.; Morones, A.; Keesee, C.; Petersen, E. Comparative study on the laminar flame speed enhancement of methane with ethane and ethylene addition. Proc. Combust. Inst. 2015, 35, 679–686. [Google Scholar] [CrossRef]
- Poinsot, T.; Veynante, D. Theoretical and Numerical Combustion; R.T. Edwards, Inc.: Flourtown, PA, USA, 2005; Volume 28. [Google Scholar]
- White, B.W.; Rosenblatt, F. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. Am. J. Psychol. 1963, 76, 705. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Tompson, J.; Schlachter, K.; Sprechmann, P.; Perlin, K. Accelerating Eulerian Fluid Simulation with Convolutional Networks. arXiv 2016, arXiv:1607.03597. [Google Scholar]
- Shang, Z. Application of artificial intelligence CFD based on neural network in vapor–water two-phase flow. Eng. Appl. Artif. Intell. 2005, 18, 663–671. [Google Scholar] [CrossRef]
- Elkamel, A.; Al-Ajmi, A.; Fahim, M. Modeling the hydrocracking process using artificial neural networks. Pet. Sci. Technol. 1999, 17, 931–954. [Google Scholar] [CrossRef]
- Ibargüengoytia, P.H.; Delgadillo, M.A.; García, U.A.; Reyes, A. Viscosity virtual sensor to control combustion in fossil fuel power plants. Eng. Appl. Artif. Intell. 2013, 26, 2153–2163. [Google Scholar] [CrossRef]
- Pearl, J. Bayesian networks: A model of self-activated memory for evidential reasoning. In Proceedings of the 7th Conference of the Cognitive Science Society, University of California, Irvine, CA, USA, 15–17 August 1985; pp. 15–17. [Google Scholar]
- Duer, S. Assessment of the Operation Process of Wind Power Plant’s Equipment with the Use of an Artificial Neural Network. Energies 2020, 13, 2437. [Google Scholar] [CrossRef]
- Amirante, R.; Distaso, E.; Tamburrano, P.; Reitz, R. Analytical Correlations for Modeling the Laminar Flame Speed of Natural Gas Surrogate Mixtures. Energy Procedia 2017, 126, 850–857. [Google Scholar] [CrossRef]
- Wallesten, J.; Lipatnikov, A.; Chomiak, J. Modeling of stratified combustion in a direct-ignition, spark-ignition engine accounting for complex chemistry. Proc. Combust. Inst. 2002, 29, 703–709. [Google Scholar] [CrossRef]
- Gülder, Ö.L. Correlations of Laminar Combustion Data for Alternative S.I. Engine Fuels; SAE Technical Paper Series; SAE International: Warrendale, PA, USA, 1984. [Google Scholar] [CrossRef]
- Burning Velocities of Ethanol-Air and Ethanol-Water-Air Mixtures. In Dynamics of Flames and Reactive Systems; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 1985; pp. 181–197. [CrossRef]
- Liao, S.; Jiang, D.; Cheng, Q. Determination of laminar burning velocities for natural gas. Fuel 2004, 83, 1247–1250. [Google Scholar] [CrossRef]
- Müller, U.; Bollig, M.; Peters, N. Approximations for burning velocities and markstein numbers for lean hydrocarbon and methanol flames. Combust. Flame 1997, 108, 349–356. [Google Scholar] [CrossRef]
- Hu, E.; Li, X.; Meng, X.; Chen, Y.; Cheng, Y.; Xie, Y.; Huang, Z. Laminar flame speeds and ignition delay times of methane–air mixtures at elevated temperatures and pressures. Fuel 2015, 158, 1–10. [Google Scholar] [CrossRef]
- Dirrenberger, P.; Gall, H.L.; Bounaceur, R.; Herbinet, O.; Glaude, P.A.; Konnov, A.; Battin-Leclerc, F. Measurements of Laminar Flame Velocity for Components of Natural Gas. Energy Fuels 2011, 25, 3875–3884. [Google Scholar] [CrossRef]
- Coppens, F.; Deruyck, J.; Konnov, A. The effects of composition on burning velocity and nitric oxide formation in laminar premixed flames of CH4 + H2 + O2 + N2. Combust. Flame 2007, 149, 409–417. [Google Scholar] [CrossRef]
- Jach, A.; Zbikowski, M.; Malik, K.; Żbikowski, M.; Adamski, K.; Cieślak, I.; Teodorczyk, A. Methane-air laminar burning velocity predictions with machine learning algorithms. In Proceedings of the 23rd International Symposium On Combustion Processes, Rynia, Poland, 3–6 September 2017. [Google Scholar] [CrossRef]
- Jach, A.; Żbikowski, M.; Teodorczyk, A. Laminar Burning Velocity Predictions of Single-Fuel Mixtures of C1-C7 Normal Hydrocarbon and Air. J. KONES 2018, 25, 227–235. [Google Scholar]
- Mehra, R.; Duan, H.; Ma, F. Laminar burning velocity of hydrogen and carbon-monoxide enriched natural gas (HyCONG): An experimental and artificial neural network study. Fuel 2019, 246, 476–490. [Google Scholar] [CrossRef]
- Walter, G.; Wang, H.; Kanz, A.; Kolbasseff, A.; Xu, X.; Haidn, O.; Slavinskaya, N. Experimental error assessment of laminar flame speed measurements for digital chemical kinetics databases. Fuel 2020, 266, 117012. [Google Scholar] [CrossRef]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Csáji, B.C. Approximation with artificial neural networks. Fac. Sci. Etvs Lornd Univ. Hung. 2001, 24, 7. [Google Scholar]
- Dahoe, A. Laminar burning velocities of hydrogen–air mixtures from closed vessel gas explosions. J. Loss Prev. Process Ind. 2005, 18, 152–166. [Google Scholar] [CrossRef]
- Tse, S.; Zhu, D.; Law, C. Morphology and burning rates of expanding spherical flames in H2/O2/inert mixtures up to 60 atmospheres. Proc. Combust. Inst. 2000, 28, 1793–1800. [Google Scholar] [CrossRef]
- Dowdy, D.R.; Smith, D.B.; Taylor, S.C.; Williams, A. The use of expanding spherical flames to determine burning velocities and stretch effects in hydrogen/air mixtures. Symp. (Int.) Combust. 1991, 23, 325–332. [Google Scholar] [CrossRef]
- Egolfopoulos, F.; Law, C. An experimental and computational study of the burning rates of ultra-lean to moderately-rich H2/O2/N2 laminar flames with pressure variations. Symp. (Int.) Combust. 1991, 23, 333–340. [Google Scholar] [CrossRef]
- Aung, K.; Hassan, M.; Faeth, G. Flame stretch interactions of laminar premixed hydrogen/air flames at normal temperature and pressure. Combust. Flame 1997, 109, 1–24. [Google Scholar] [CrossRef]
- Kwon, O.; Faeth, G. Flame/stretch interactions of premixed hydrogen-fueled flames: Measurements and predictions. Combust. Flame 2001, 124, 590–610. [Google Scholar] [CrossRef]
- Kuznetsov, M.; Czerniak, M.; Jordan, T.; Grune, J. Effect of temperature on laminar flame velocity for hydrogen-air mixtures at reduced pressures. In Proceedings of the International Conference on Hydrogen Safety (ICHS 2013), Brussels, Belgium, 9–11 September 2013; p. 231. [Google Scholar]
- Pareja, J.; Burbano, H.J.; Ogami, Y. Measurements of the laminar burning velocity of hydrogen–air premixed flames. Int. J. Hydrog. Energy 2010, 35, 1812–1818. [Google Scholar] [CrossRef]
- Ebaid, M.S.; Al-Khishali, K.J. Measurements of the laminar burning velocity for propane: Air mixtures. Adv. Mech. Eng. 2016, 8, 168781401664882. [Google Scholar] [CrossRef]
- Vagelopoulos, C.; Egolfopoulos, F.; Law, C. Further considerations on the determination of laminar flame speeds with the counterflow twin-flame technique. Symp. (Int.) Combust. 1994, 25, 1341–1347. [Google Scholar] [CrossRef]
- Vagelopoulos, C.M.; Egolfopoulos, F.N. Direct experimental determination of laminar flame speeds. Symp. (Int.) Combust. 1998, 27, 513–519. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 18 April 2020).
- Husson, F.; Josse, J.; Narasimhan, B.; Robin, G. Imputation of mixed data with multilevel singular value decomposition. J. Comput. Graph. Stat. 2019, 28, 552–566. [Google Scholar] [CrossRef]
- Beretta, L.; Santaniello, A. Nearest neighbor imputation algorithms: A critical evaluation. BMC Med. Informatics Decis. Mak. 2016, 16. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.L.; Zheng, H.; Gevaert, O. A deep learning framework for imputing missing values in genomic data. bioRxiv 2018. [Google Scholar] [CrossRef]
- Triola, M.F. Elementary Statistics, 13th ed.; Pearson: Boston, MA, USA, 2017. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems 24 (NIPS 2011); Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Neural Information Processing Systems Foundation: Granada, Spain, 2011; Volume 24. [Google Scholar]
- Klima, G. FCNN4R: Fast Compressed Neural Networks for R, R Package Version 0.6.2; 2016. Available online: https://www.rdocumentation.org/packages/FCNN4R/versions/0.6.2 (accessed on 18 April 2020).
- Browne, M.W. Cross-Validation Methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef]
- Riedmiller, M. Rprop—Description and Implementation Details: Technical Report; Inst. f. Logik, Komplexität u. Deduktionssysteme: Karlsruhe, Germany, 1994. [Google Scholar]
- Miles, J. R Squared, Adjusted R Squared. In Wiley StatsRef: Statistics Reference Online; American Cancer Society: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Ettner, F.; Vollmer, K.G.; Sattelmayer, T. Numerical Simulation of the Deflagration-to-Detonation Transition in Inhomogeneous Mixtures. J. Combust. 2014, 2014, 1–15. [Google Scholar] [CrossRef]
- Weller, H.G.; Tabor, G.; Jasak, H.; Fureby, C. A tensorial approach to computational continuum mechanics using object-oriented techniques. Comput. Phys. 1998, 12, 620–631. [Google Scholar] [CrossRef]
- Ardey, N. Struktur und Beschleunigung Turbulenter Wasserstoff-Luft-Flammen in Räumen mit Hindernissen; NA: München, Germany, 1998. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Absolute Error (m/s) | Mean Absolute Percentage Error (%) | R-Squared | |
|---|---|---|---|
| ANN H2—air | 0.3023 | 15.69 | 0.9192 |
| Analytical formula H2—air | 1.5118 | 34.78 | 0.7014 |
| ANN C3H8—air | 0.047 | 15.89 | 0.9755 |
| Analytical formula C3H8—air | 0.0641 | 14.71 | 0.9089 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, K.; Żbikowski, M.; Teodorczyk, A. Laminar Burning Velocity Model Based on Deep Neural Network for Hydrogen and Propane with Air. Energies 2020, 13, 3381. https://doi.org/10.3390/en13133381
Malik K, Żbikowski M, Teodorczyk A. Laminar Burning Velocity Model Based on Deep Neural Network for Hydrogen and Propane with Air. Energies. 2020; 13(13):3381. https://doi.org/10.3390/en13133381
Chicago/Turabian StyleMalik, Konrad, Mateusz Żbikowski, and Andrzej Teodorczyk. 2020. "Laminar Burning Velocity Model Based on Deep Neural Network for Hydrogen and Propane with Air" Energies 13, no. 13: 3381. https://doi.org/10.3390/en13133381
APA StyleMalik, K., Żbikowski, M., & Teodorczyk, A. (2020). Laminar Burning Velocity Model Based on Deep Neural Network for Hydrogen and Propane with Air. Energies, 13(13), 3381. https://doi.org/10.3390/en13133381