SMART Computational Solutions for the Optimization of Selected Technology Processes as an Innovation and Progress in Improving Energy Efficiency of Smart Cities—A Case Study



Abstract
:1. Introduction
- Process optimization.
- Enhanced biogas yield.
- Efficient on-site combined heat and power (CHP) generation.
- Co-digestion of sludge with food waste as a option to increase the biogas output.
- SMART Computational Solutions for the optimization of solid waste fuel production from separate combustible fractions—a polymorphic model of multi-threaded optimization of the production process of fuel components from combustible municipal waste fractions,
- Thread A—optimization of the light fraction production process with preset physicochemical, combustion and emission properties.
- Thread B—optimization of the production process of hybrid fuel components, by mixing the light fraction with fossil fuels, while fulfilling the objective function (Wd-calorific value) and constraints imposed on decision-making optimization tasks.
- SMART Wastewater Treatment Plant Computational Solutions-a model for optimizing the biological process of wastewater treatment using a multi-threaded hierarchical adaptive control algorithm, including:
- Thread A—a model for automatic control of the nitrification and denitrification process, while monitoring the value of total nitrogen in the treated wastewater,
- Thread B—a model for the optimization of internal and external recirculation processes of the bioreactor.
- SMART Waste Management Computational Solution,
- SMART Wastewater Treatment Plant Computational Solution.
2. Advanced Soft Computing Applications and Industrial Automation in Selected SMART Sectors
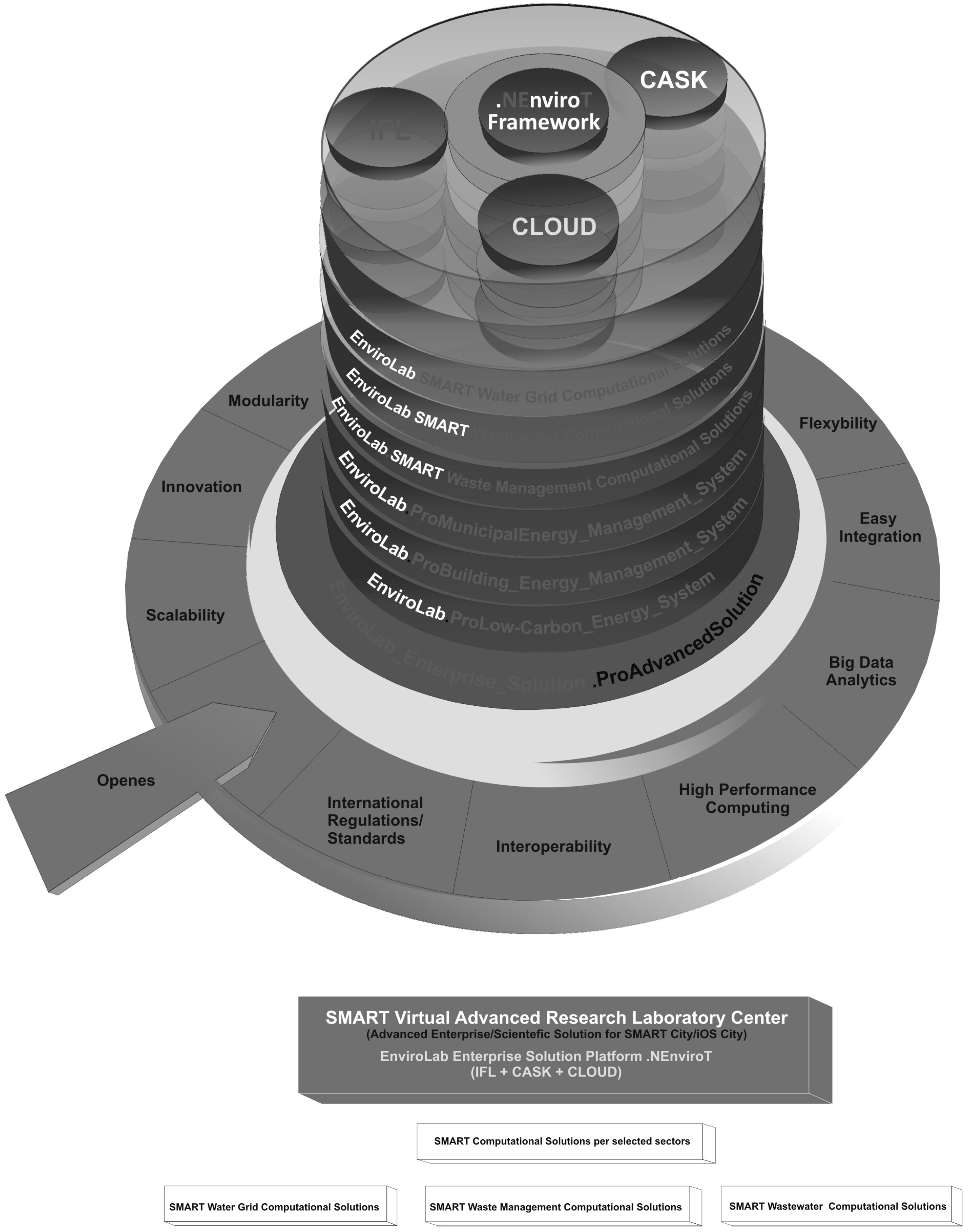
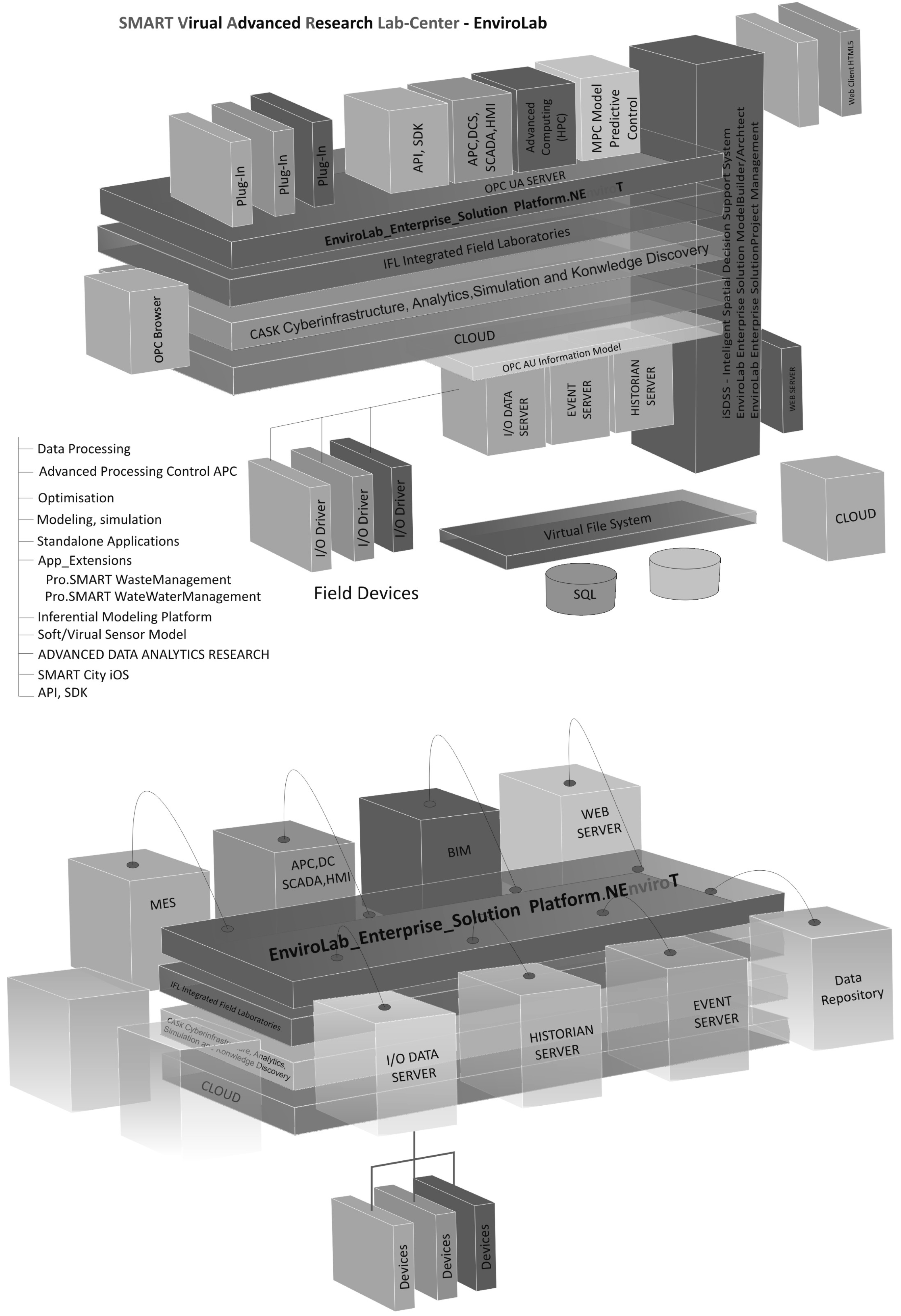
- IFL—Integrated Field Laboratories
- An advanced model of a virtualized laboratory space [12]. The IFL supporting the process of building and updating the knowledge base of an expert system (in the CASK layer).
- CASK—Cyberinfrastructure, Analytics, Simulation and Knowledge Discovery [12] (The expert system in the CASK layer includes the following functional specialized modules:
- EnviroLab.AdvancedProcessControl (an integrated package of diagnostic and optimization tools and advanced process control APC, predictive process control MPC),
- EnviroLab.EnvironmentalMonitoring (an advanced solution of HPC class, enabling simulation of pollution propagation and the optimization of technological process parameters in order to reduce the negative impact on the environment),
- EnviroLab.EnterpriseSolutions (an open and scalable platform based on .NET technology, using the latest IT technologies and modular plug-in solutions). The dedicated standard—EnviroLab.NEnviroT—provides SDK, API and many other tools—whereby it is possible to modify or expand applications, standard models etc.
- Cloud-GRID—technology [12]
- Preparation of a simulation model.
- Compilation of the project in the dedicated card containing analog/digital input/output interfaces.
- Development of a target hardware module, e.g., using the systems ASIC, FPGA, microcontrollers.
3. Materials and Methods
- Section 3.1—SMART Waste Management Computational Solution,
- Section 3.2—Computational Solution of SMART Wastewater Treatment Plant.
3.1. SMART Waste Management Computational Solution
- Optimal calorific value (enthalpy of devaluation).
- Appropriate fractional, elemental composition, fuel properties (moisture content, combustible content, non-combustible content, volatile content, aggressive content.
- Suitable ash softening and melting temperature, flash point, combustion temperature), as well as relevant material properties (shape, porosity).
- Substances included in fuels have identified chemical properties and composition.
- The combustion process involving molded fuels is known.
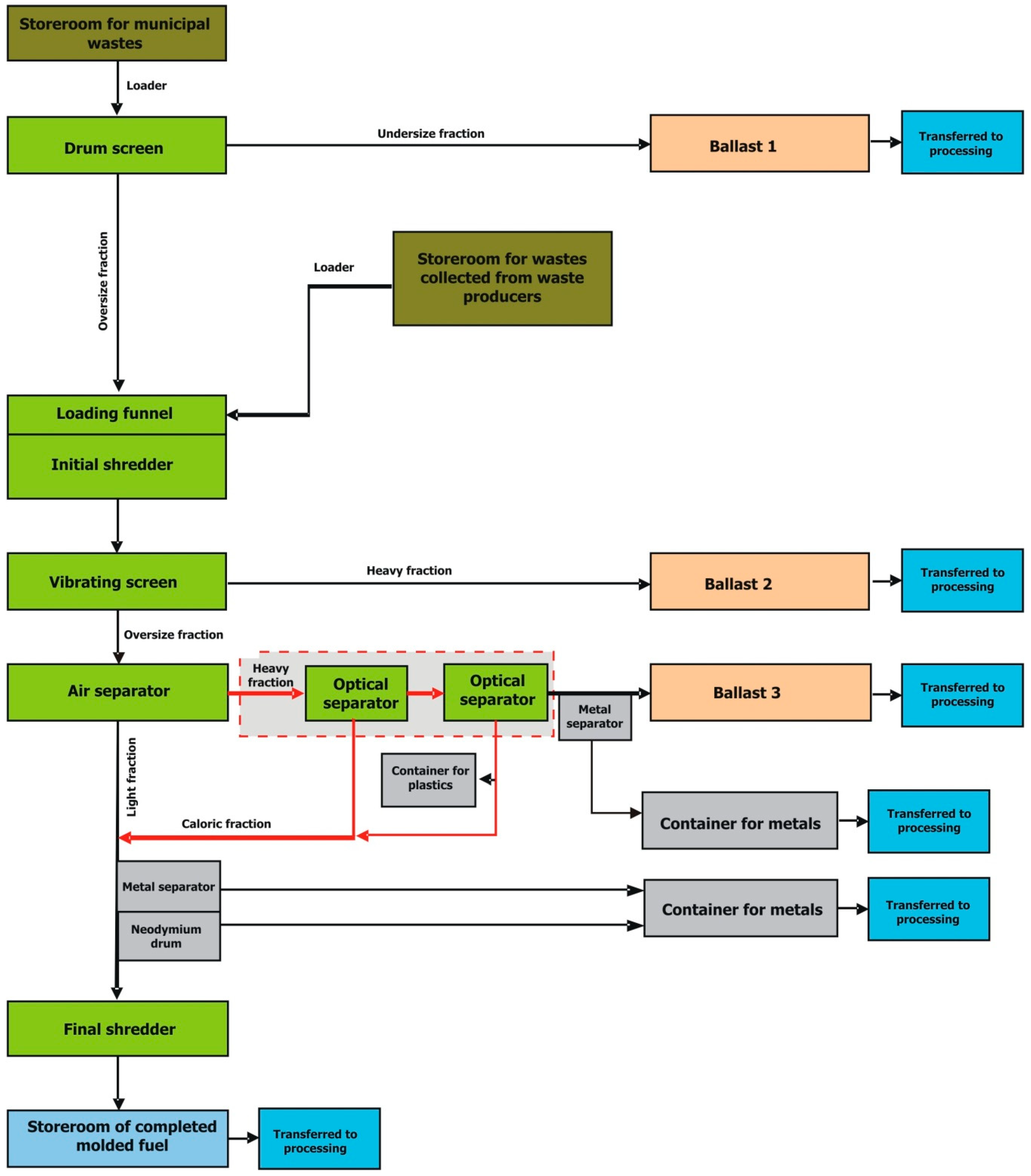
3.1.1. Algorithmic Model of Multi-Threaded Optimization of the Manufacturing Process of Fuel components
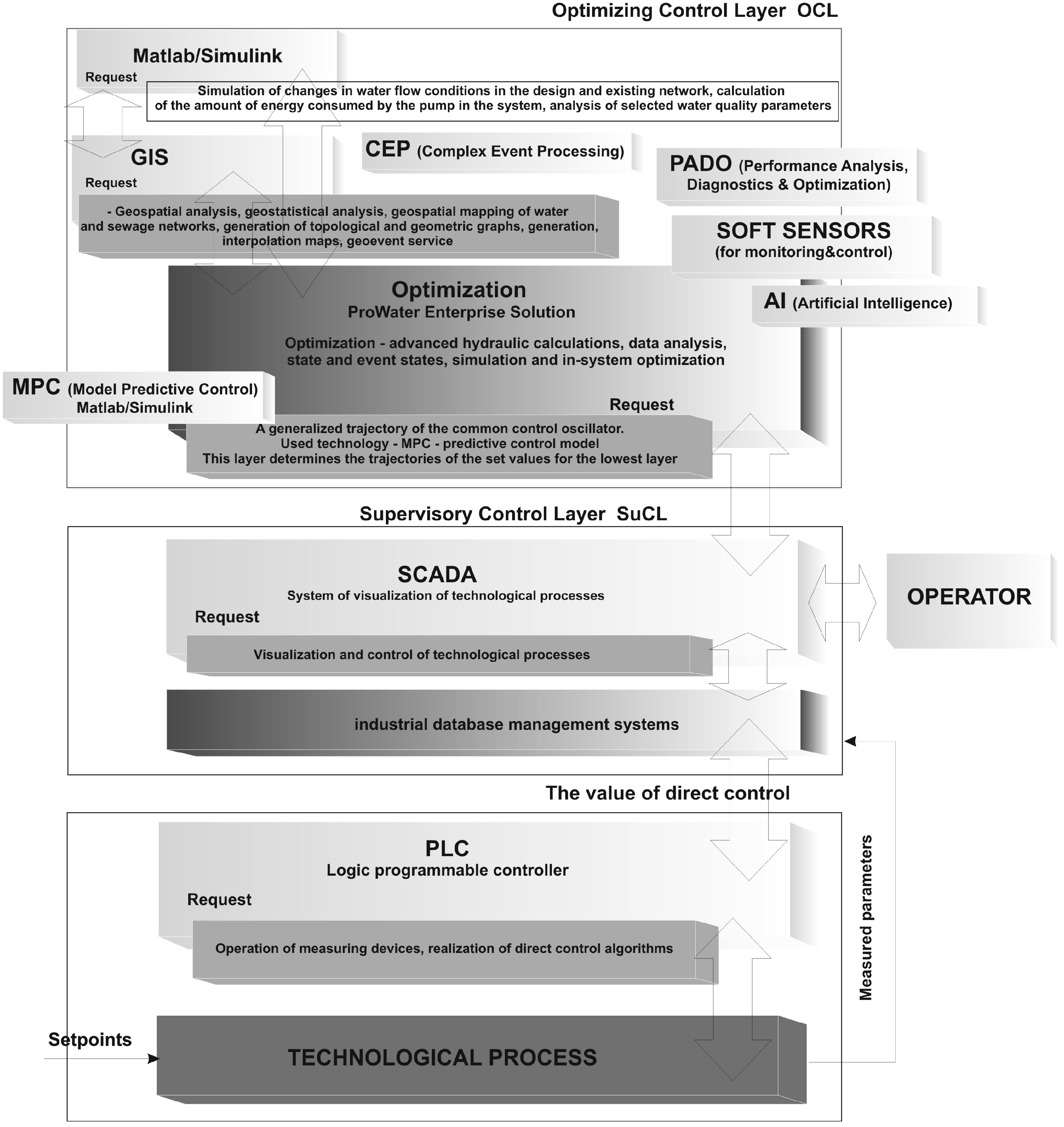
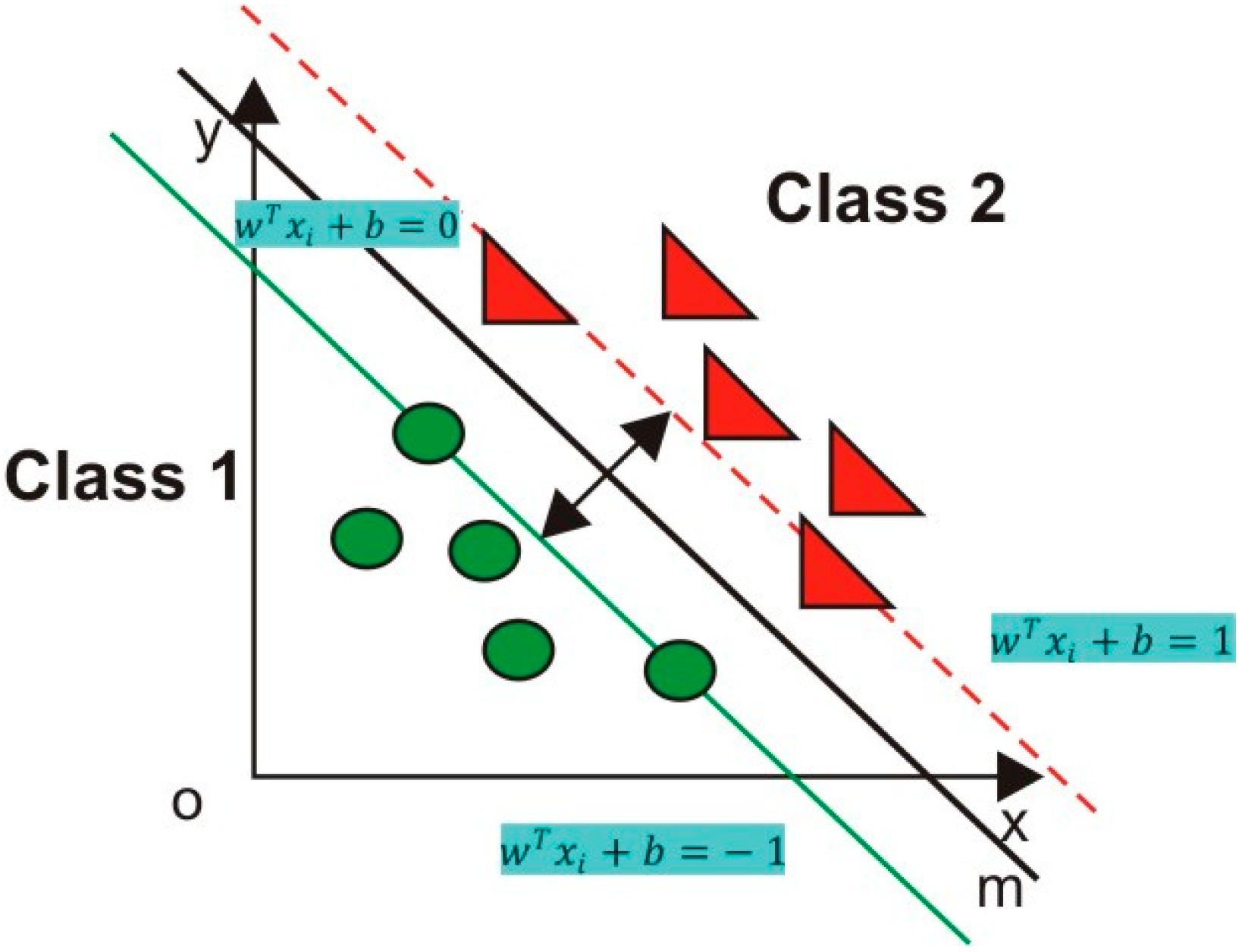
- optimization of the light fraction production process-consisting in separating (in the optical separator/s) from the heavy oversize fraction of waste stream- non-metallic components with high calorific value Wd, exceeding 38 MJ/kg in the case of PE using the advanced MPC predictive control algorithm (based on a Multi Class Vector Support Machine algorithm model) implemented in the optimizing control layer of the SCADA system,
- optimization of the production process of hybrid fuel components-consisting in mixing the light fraction (obtained as a result of the optimization of the optical separation process-thread A) with fossil fuels, while fulfilling the objective function, i.e., its maximizing while meeting the constraints imposed on decision variables of the optimization task, determined by the parameters of the realized technological processes. The optimization of the process is carried out by the modified simplex algorithm.
3.1.1.1. Algorithmic Subsystem Model for the Optimization of the Light-Caloric Fraction Production Process—Thread A
- NIR (near infrared)
- VIS (visible light)
- X-ray (high resolution x-ray)
- AAS (atomic spectrometry).
- 1
- 2
- 3
- while
- 4
- to select , which is maximizing
- 5
- 6
- 7
- return
| Algorithm 1 MCSVM |
| 1: Input: Category N, input for training samples; testing sample T. |
| 2: Output: Categories of T. |
| 3: Algorithm: |
| 4: // training section |
| 5: for n = 1 to N |
| 6: Positive Sample ← , Negative Sample ← other samples except |
| 7: Store the data of classifier |
| 8: end for |
| 9: // testing section |
| 10: for n = 1 to N |
| 11: Use classifier to calculate the value of |
| 12: end for |
| 13: Compare all , output the n corresponding to the maximum of |
Algorithmic Model for the Optimization of the Production Process of Hybrid Fuel Components—Thread B
- There is one constrained solution (the objective function takes the smallest value at one vertex of the set of permissible solutions).
- There is an unrestricted solution (when the objective function can adopt any small value while not violating the constraints).
- There are infinitely many solutions (there are at least two vertices of the set of permissible solutions at which the function assumes the same minimum value).
- There is no solution, i.e., the set of permissible solutions is an empty set.
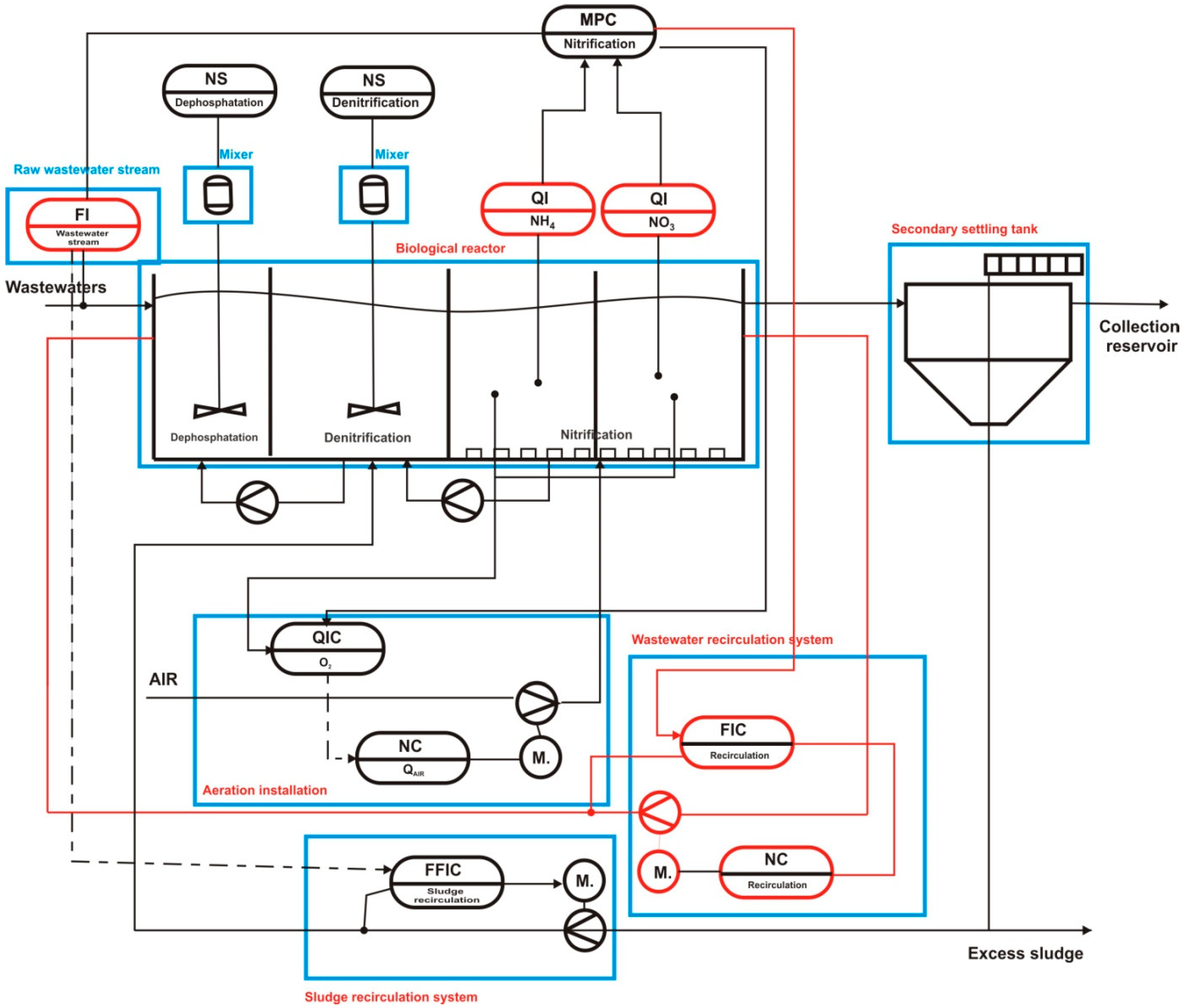
3.2. SMART Wastewater Treatment Plant Computational Solution
- Automatic control of the nitrification and denitrification process, with simultaneous control of total nitrogen in the treated wastewater.
- Elimination of situations related to the overload of activated sludge chambers at the time when the inflow of the load of ammonium nitrogen in raw sewage was lower, and related to it disturbance of the denitrification process.
- Optimization of the internal and external recirculation processes of the bioreactor.
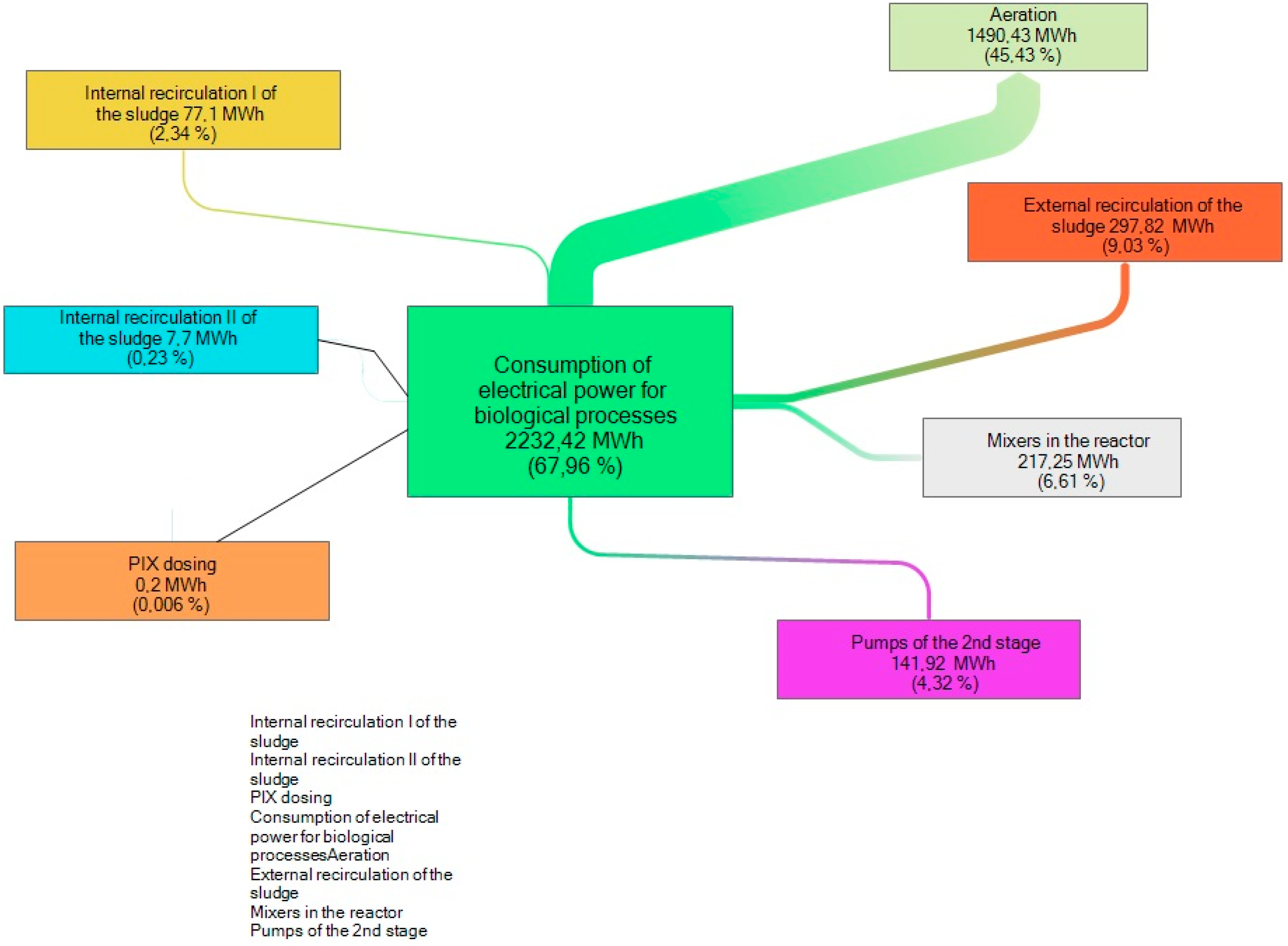
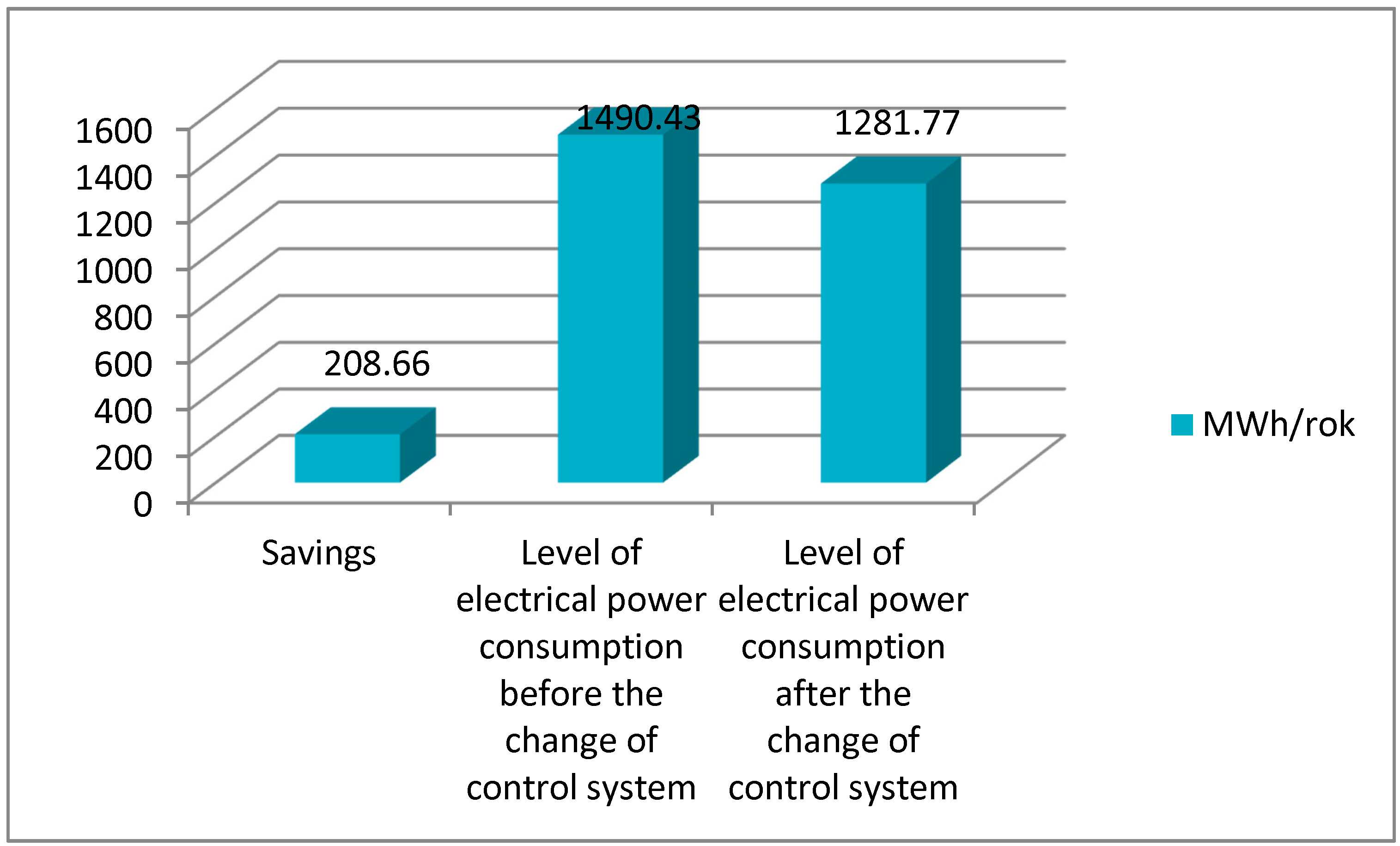
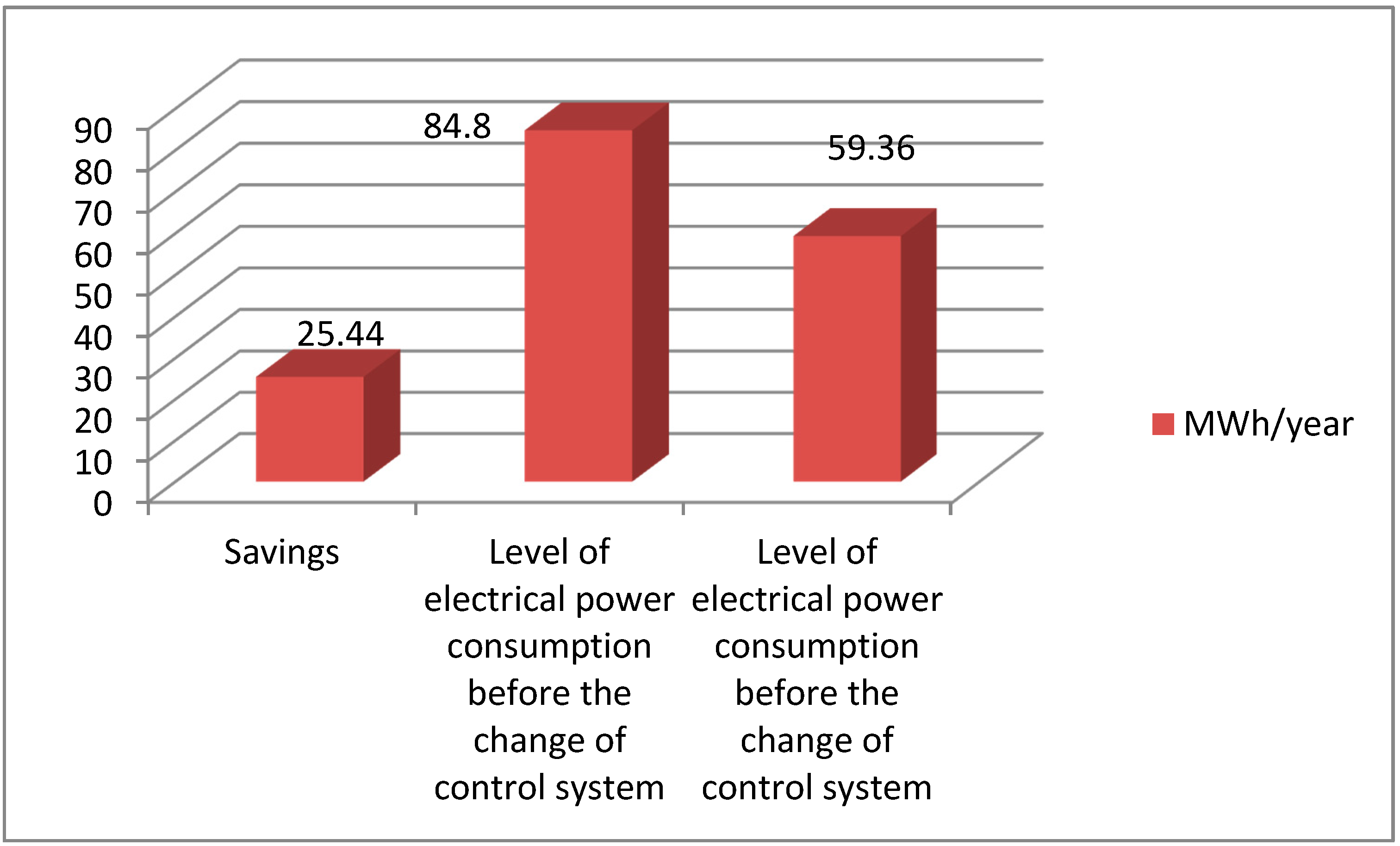
- Reduction of electricity consumption in the aeration and recirculation processes.
3.2.1. Multi-Threaded Optimization of Electricity Consumption in the Biological Wastewater Treatment Process
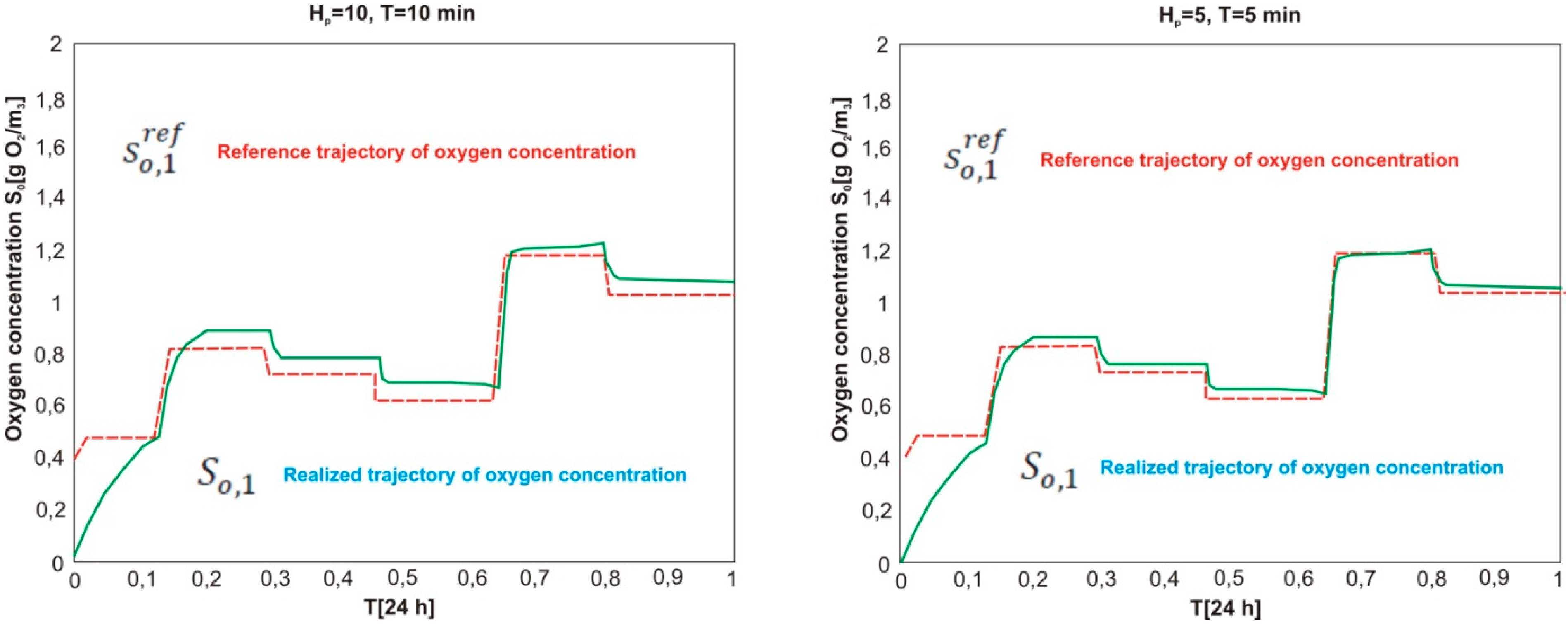
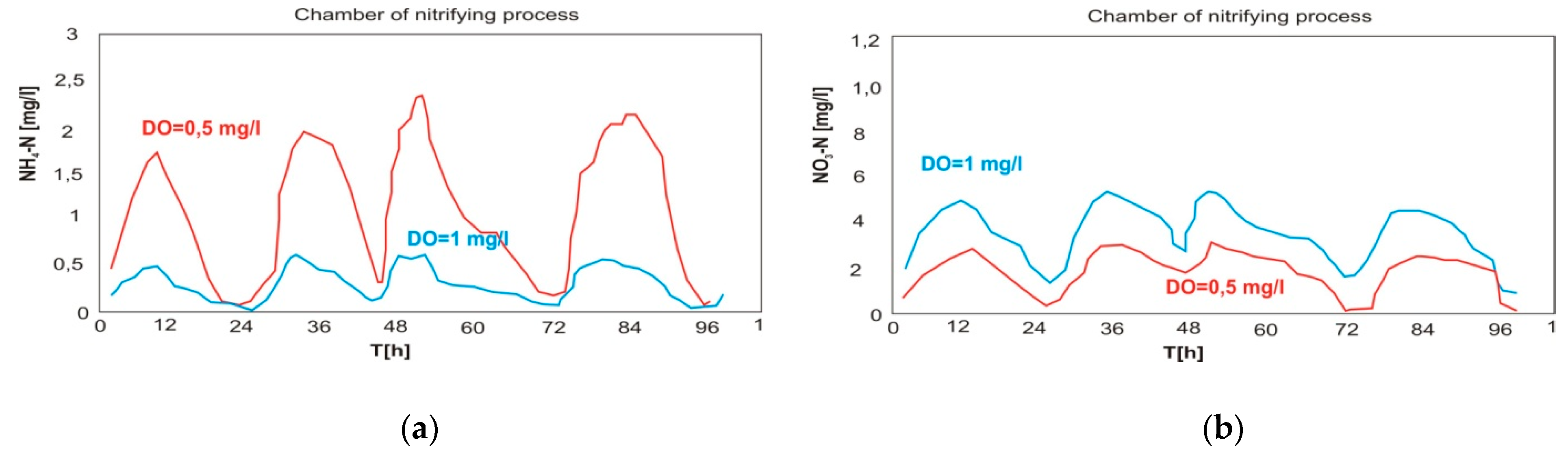
Model of the Subsystem for Oxygen Concentration Control—Thread A
Model of the Subsystem for Internal Recirculation Control—Thread B
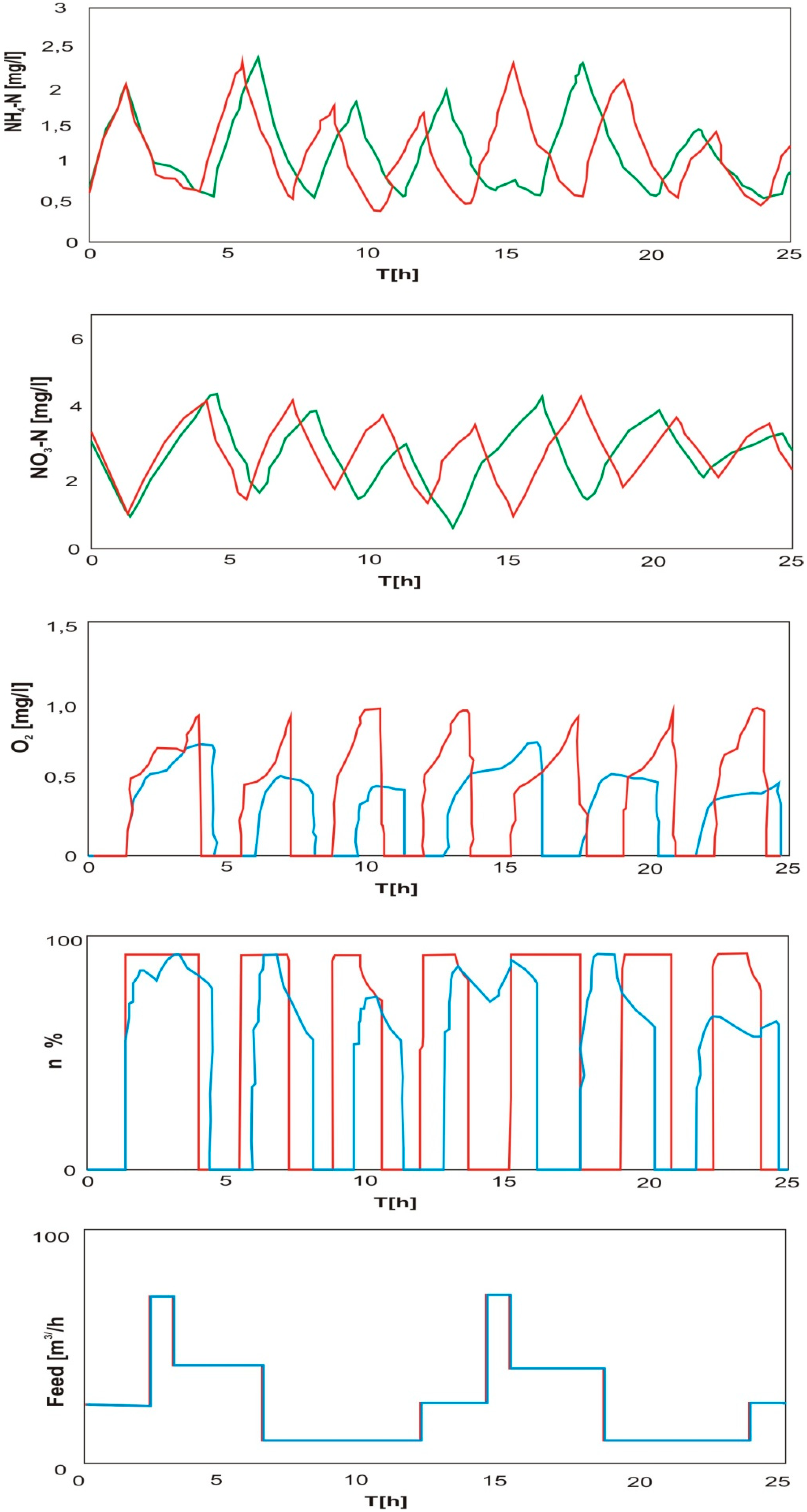
3.2.2. Simulation of the Operation of Biological Reactor-Classic Closed-Loop Control Versus MPC
4. Results and Discussion
4.1. A Case Study—Energy Economics of Waste-Based Fuel Production Processes
- Optimization of the light fraction production process with preset physicochemical, combustion and emission properties (the Algorithm 1 MCSVM classifying waste fractions in the optical separator, based on the SVM network and the master algorithm greedy set cover).
- Optimization of the production process of hybrid fuel components, by mixing the light fraction with fossil fuels, while maximizing the objective function (Wd—calorific value) and constraints imposed on the decision variables of the optimization tasks (modified simplex algorithm).
4.2. A Case Study—Energy Economics of Wastewater Treatment Plant Processes
- Maximum growth rates of autotrophs, heterotrophs and phosphorus accumulating heterotrophs.
- Decomposition rates of autotrophs, heterotrophs and phosphorus accumulating heterotrophs.
- Appropriate saturation constants and other coefficients, describing, e.g., the hydrolysis process, yields of growth of individual groups of microorganisms and other, with slightly less importance for the course of purification processes.
- Growth rate of autotrophs: μA = 0.69
- Growth rate of heterotrophs: μH = 4.8
- Growth rate of phosphorus accumulating heterotrophs: μPH = 3.9
- Autotroph decomposition rate: bA = 0.039
- Heterotroph decomposition rate: bH = 0.49
- Decomposition rate of phosphorus accumulating heterotrophs: bPH = 0.011
5. Conclusions
- Dedicated tool—Diagnostics and optimization of electricity consumption in network objects (pumps rooms, pumping stations, hydrophore rooms).
- Dedicated tool—Validation and reconstruction of process data (Sensor Data Validation and Reconstruction).
- Dedicated tool—Identification and diagnostics of errors (in real time) of measurement parameters in the hydraulic model and in the monitoring and control systems.
- Dedicated tool—Current (in real time) control of the performance characteristics and load profile of pump units.
- Dedicated tool—Diagnostics (in real time) of the operating point of pump units.
- Dedicated tool—Optimization (in real time) of the efficiency of pump units, including motors, inverters, regulation systems.
- Dedicated tool—Diagnostics (in real time) of error detection in the measuring paths of SCADA system.
- Dedicated tool—Diagnostics and optimization of the control quality indicator.
- Dedicated tool—Diagnostics and updating of pipeline characteristics.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ICT | Information and communications technology |
| SCADA | Supervisory Control And Data Acquisition |
| FTC | Fault Tolerant Control |
| HPC | High Performance Computing |
| MPC | Model Predictive Control |
| iRTDS | intelligent Diagnostic System in Real Time |
| CEP | Complex Event Processing |
| OPC UA | Open Platform Communications—Unified Architecture |
| PLC | Programmable Logic Controller |
| PADO | Performance Analysis Diagnostics & Optimization |
| SVM | Support Vector Machine |
| MCSVM | Multi-Class Support Vector Machine |
| FPGA | Field Programmable Gate Arrays |
| ASIC | Application-specific Integrated Circuit |
References
- Nitivattananon, V.; Sadowsky, E.; Quimpo, R.G. Optimization of water supply system operation. J. Water Resour. Plan. Manag. 1996, 122, 374–384. [Google Scholar] [CrossRef]
- Tu, M.Y.; Tsai, F.T.C.; Yeh, W.W.G. Optimization of water distribution and water quality by hybrid genetic algorithm. J. Water Resour. Plan. Manag. 2005, 131, 431–440. [Google Scholar] [CrossRef]
- Westphal, K.S.; Vogel, R.M.; Kirschen, P.; Chapra, S.C. Decision support system for adaptive water supply management. J. Water Resour. Plan. Manag. 2003, 129, 165–177. [Google Scholar] [CrossRef] [Green Version]
- Brdys, M.A.; Ulanicki, B. Operational Control of Water Systems: Structures, Algorithms and Applications; Prentice-Hall International: New York, NY, USA, 1994. [Google Scholar]
- Butler, D.; Memon, F.A. Water Demand Management; IWA Publishing: London, UK, 2006. [Google Scholar]
- Cembrano, G.; Wells, G.; Quevedo, J.; Pérez, R.; Argelaguet, R. Optimal control of a water distribution network in a supervisory control system. Control Eng. Pract. 2000, 8, 1177–1188. [Google Scholar] [CrossRef] [Green Version]
- Maksimović, C.; Butler, D.; Memon, A.F.A.K. Advances in Water Supply Management. In Proceedings of the International Conference on Computing and Control for Water Industry, London, UK, 15–17 September 2003. [Google Scholar]
- Brdys, M.A.; Grochowski, M.; Gminski, T.; Konarczak, K.; Drewa, M. Hierarchical predictive control of integrated wastewater treatment systems. Control Eng. Pract. 2008, 16, 751–767. [Google Scholar] [CrossRef]
- Ocampo-Martínez, C. Model Predictive Control of Wastewater Systems; Springer: London, UK, 2010. [Google Scholar]
- Ocampo-Martínez, C.; Ingimundarson, A.; Puig, V.; Quevedo, J. Objective prioritization using lexicographic minimizers for MPC of sewer networks. IEEE Trans. Control Syst. Technol. 2008, 16, 113–121. [Google Scholar] [CrossRef]
- Pascual, J.; Romera, J.; Puig, V.; Creus, R.; Minoves, M. Operational predictive optimal control of Barcelona water transport network. In Proceedings of the 18th world congress of the International Federation of Automatic Control, IFAC’2011, Milano, Italy, 28 August–2 September 2011; pp. 10571–10578. [Google Scholar]
- Gaska, K.; Generowicz, A.; Zimoch, I. A high-performance computing (HPC) based integrated multithreaded model predictive control (MPC) for water supply networks. Arch. Civ. Eng. Environ. 2017, 10, 141–151. [Google Scholar] [CrossRef] [Green Version]
- Koseki, H. Evaluation of Various Solid Biomass Fuels Using Thermal Analysis and Gas Emission Tests. Energies 2011, 4, 616–627. [Google Scholar] [CrossRef] [Green Version]
- Guerrero, L.A.; Maas, G.; Hogland, W. Solid waste management challenges for cities in developing countries. Waste Manag. 2013, 33, 220–232. [Google Scholar] [CrossRef]
- Jewiarz, M.; Mudryk, K.; Wróbel, M.; Frączek, J.; Dziedzic, K. Parameters Affecting RDF-Based Pellet Quality. Energies 2020, 13, 910. [Google Scholar] [CrossRef] [Green Version]
- Antizar-Ladislao, B.; Turrion-Gomez, J.L. Decentralized Energy from Waste Systems. Energies 2010, 3, 194. [Google Scholar] [CrossRef] [Green Version]
- Brunner, P.; Rechberger, H. Waste to energy—Key element for sustainable waste management. Waste Manag. 2014, 1, 1–10. [Google Scholar] [CrossRef]
- Czop, M.; Poranek, N.; Czajkowski, A. Energetic usability and nuisance to the environment of selected fuels made of wastes. Przem. Chem. 2018, 97, 1460–1462. [Google Scholar]
- Gaska, K.; Generowicz, A.; Lobur, M.; Jaworski, N.; Ciuła, J.; Vovk, M. Advanced algorithmic model for poly-optimization of biomass fuel production from separate combustible fractions of municipal wastes as a progress in improving energy efficiency of waste utilization. E3S Web Conf. 2019, 122, 01004. [Google Scholar] [CrossRef]
- Gaska, K.; Wandrasz, A.J. Mathematical modeling of biomass fuels formation process. Waste Manag. 2008, 28, 973–985. [Google Scholar] [CrossRef] [PubMed]
- Longo, S.; d’Antoni, B.M.; Bongards, M.; Chaparro, A.; Cronrath, A.; Fatone, F. Monitoring and diagnosis of energy consumption in wastewater treatment plants. A state of the art and proposals for improvement. Appl. Energy 2016, 179, 1251–1268. [Google Scholar] [CrossRef]
- Daw, J.; Hallett, K.; Dewolfe, J.; Venner, I. Energy Efficiency Strategies for Municipal Wastewater Treatment Facilities; National Renewable Energy Laboratory: Golden, CO, USA, 2012. [Google Scholar]
- Di Matteo, U.; Nastasi, B.; Albo, A.; Astiaso Garcia, D. Energy Contribution of OFMSW (Organic Fraction of Municipal Solid Waste) to Energy-Environmental Sustainability in Urban Areas at Small Scale. Energies 2017, 10, 229. [Google Scholar] [CrossRef] [Green Version]
- Brdyś, M.A.; Chang, T.; Konarczak, K. Estimation of wastewater treatment plant state for model predictive control of N-P removal at medium time scale. In Proceedings of the IFAC 10th Symposium Large Scale Systems: Theoryand Applications, Osaka, Japan, 26–28 July 2004. [Google Scholar]
- Suchodolski, T.; Brdys, M.A.; Piotrowski, R. Respiration rate estimation for model predictive control of dissolved oxygen in wastewater treatment plant. In Proceedings of the 11th IFAC Symposium on Large Scale Systems: Theory and Applications, Gdansk, Poland, 23–25 July 2007; Elsevier: Laxenburg, Austria, 2008; Volume 11. [Google Scholar]
- Gaska, K.; Generowicz, A.; Lobur, M.; Jaworski, N.; Ciuła, J.; Mzyk, T. Optimization of Biological Wastewater Treatment Process by Hierarchical Adaptive Control. In Proceedings of the IEEE XVth International Conference on the Perspective Technologies and Methods in MEMS Design (MEMSTECH), Polyana, Ukraine, 22–26 May 2019; pp. 119–122. [Google Scholar] [CrossRef]
- Dellana, S.; West, D. Predictive modeling for wastewater applications: Linear and nonlinear approaches. Environ. Model. Softw. 2009, 24, 96–106. [Google Scholar] [CrossRef]
- Dudley, J.; Buck, G.; Ashley, R.; Jack, A. Experience and extensions to the ASM2 family of models. Water Sci. Technol. 2002, 45, 177–186. [Google Scholar] [CrossRef]
- Rosen, C.; Larsson, M.; Jeppsson, U.; Yuan, Z. A framework for extreme-event control in wastewater treatment. Water Sci. Technol. 2002, 45, 299–308. [Google Scholar] [CrossRef]
- Yamashita, T.; Shiraishi, M.; Yokoyama, H.; Ogino, A.; Yamamoto-Ikemoto, R.; Osada, T. Evaluation of the Nitrous Oxide Emission Reduction Potential of an Aerobic Bioreactor Packed with Carbon Fibres for Swine Wastewater Treatment. Energies 2019, 12, 1013. [Google Scholar] [CrossRef] [Green Version]
- Smol, M.; Włodarczyk-Makuła, M. Effectiveness in the Removal of Polycyclic Aromatic Hydrocarbons FromIndustrial Wastewater by Ultrafiltration Technique. Arch. Environ. Prot. 2013, 38, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Drewnowski, J.; Remiszewska-Skwarek, A.; Duda, S.; Łagód, G. Aeration Process in Bioreactors as the Main Energy Consumer in a Wastewater Treatment Plant. Review of Solutions and Methods of Process Optimization. Processes 2019, 7, 311. [Google Scholar] [CrossRef] [Green Version]
- Santos-Clotas, E.; Cabrera-Codony, A.; Castillo, A.; Martín, M.J.; Poch, M.; Monclús, H. Environmental Decision Support System for Biogas Upgrading to Feasible Fuel. Energies 2019, 12, 1546. [Google Scholar] [CrossRef] [Green Version]
- Godo-Pla, L.; Emiliano, P.; Valero, F.; Poch, M.; Sin, G.; Monclús, H. Predicting the oxidant demand in full-scale drinking water treatment using an artificial neural network: Uncertainty and sensitivity analysis. Process Saf. Environ. 2019, 125, 317–327. [Google Scholar] [CrossRef]
- Garrido-Baserba, M.; Reif, R.; Hernández, F.; Poch, M. Implementation of a knowledge-based methodology in a decision support system for the design of suitable wastewater treatment process flow diagrams. J. Environ. Manag. 2012, 112, 384–391. [Google Scholar] [CrossRef]
- Drewnowski, J. Advanced supervisory control system implemented at full-scale WWTP—A case study of optimization and energy balance improvement. Water 2019, 11, 121. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Parameter | Required Value |
|---|---|---|
| 1. | Calorific value | ≥15 000 kJ/kg |
| 2. | Ash content | ≤20.0% |
| 3. | Total sulfur content | ≤2.0% |
| 4. | Chlorine content | ≤1.0% |
| 5. | Granulation | ≤40 mm |
| 6. | Moisture content | ≤30% |
| 7. | Average bulk density | 0.2 Mg/m3–0.6 Mg/m3 |
| 8. | Scrap content | ≤0.5% |
| Parameter | Permissible Value [ppm] |
|---|---|
| Total (As, Co, Ni, Sb, Pb, Cr, Cu, Mn, V) | 1000 |
| Item | Fraction | Test A [Mg] | Test B [Mg] |
|---|---|---|---|
| 1 | Undersize fraction | 3.7 (20.33%) | 1.79 (9.84%) |
| 2 | Oversize fraction | 2.42(13.30%) | 3.1 (17.03%) |
| 3 | RDF fuel | 10.74 (59.01%) | 13.3 (73.08%) |
| 4 | Loss | 1.34 (7.36%) | 0.01 (0.05%) |
| Item | Parameter | Required Value |
|---|---|---|
| 1. | Calorific value | 24.31 MJ/kg |
| 2. | Ash content | 8% |
| 3. | Total sulfur content | 1.4% |
| 4. | Chlorine content | 0.21% |
| 5. | Granulation | 30–38 mm |
| 6. | Moisture content | 24% |
| 7. | Average bulk density | 0.48 Mg/m3 |
| 8. | Scrap content | 0.32% |
| Fuel Components | Mass Fractions in Components C1 and C2 (kg i/kg) | |||||||
|---|---|---|---|---|---|---|---|---|
| c | s | h | o | n | w | p | cl | |
| C1 (dark coal) | 0.60350 | 0.00270 | 0.04100 | 0.08970 | 0.00010 | 0.07140 | 0.18420 | 0.00740 |
| C2 (light-caloric fraction) | 0.50010 | 0.00920 | 0.06760 | 0.21860 | 0.13580 | 0.02000 | 0.04710 | 0.00160 |
| Mass Fraction in Formed Fuel (kg i/kg) | ||||||||
|---|---|---|---|---|---|---|---|---|
| c | s | h | o | n | w | p | cl | |
| Criterium | <0.016 | <0.0024 | ||||||
| MPC—Parameters | Root Mean Square Error RMSE | ||
|---|---|---|---|
| Prediction Horizon Hp | Time T [min] | Oxygen Chamber 1 | Oxygen Chamber 2 |
| 5 | 5 | 0.041 | 0.037 |
| 10 | 10 | 0.047 | 0.042 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaska, K.; Generowicz, A. SMART Computational Solutions for the Optimization of Selected Technology Processes as an Innovation and Progress in Improving Energy Efficiency of Smart Cities—A Case Study. Energies 2020, 13, 3338. https://doi.org/10.3390/en13133338
Gaska K, Generowicz A. SMART Computational Solutions for the Optimization of Selected Technology Processes as an Innovation and Progress in Improving Energy Efficiency of Smart Cities—A Case Study. Energies. 2020; 13(13):3338. https://doi.org/10.3390/en13133338
Chicago/Turabian StyleGaska, Krzysztof, and Agnieszka Generowicz. 2020. "SMART Computational Solutions for the Optimization of Selected Technology Processes as an Innovation and Progress in Improving Energy Efficiency of Smart Cities—A Case Study" Energies 13, no. 13: 3338. https://doi.org/10.3390/en13133338
APA StyleGaska, K., & Generowicz, A. (2020). SMART Computational Solutions for the Optimization of Selected Technology Processes as an Innovation and Progress in Improving Energy Efficiency of Smart Cities—A Case Study. Energies, 13(13), 3338. https://doi.org/10.3390/en13133338