Partial Discharge Data Matching Method for GIS Case-Based Reasoning

 ,
, 
Abstract
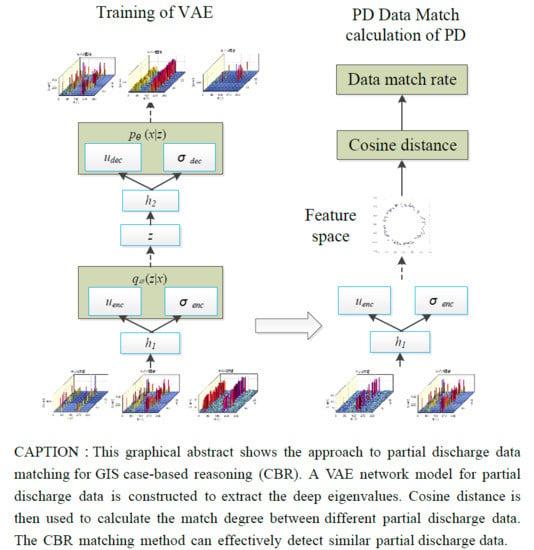
1. Introduction
2. Variational Autoencoder
3. Data Matching Method of Partial Discharge Based on VAE
4. Dataset
4.1. Laboratory Experiment
4.2. Substation On-Site Detection
5. Experiment and Results Analysis
5.1. Experiment Setup
5.2. The Comparison between Different Feature Extraction Methods
5.3. The Comparison between Different Match Degree Calculation Methods
5.4. The Comparison between Different Threshold
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Schichler, U.; Koltunowicz, W.; Endo, F.; Feser, K.; Giboulet, A.; Girodet, A.; Girodet, A.; Hama, H.; Hampton, B.; Kranz, H.G.; et al. Risk assessment on defects in GIS based on PD diagnostics. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 2165–2172. [Google Scholar] [CrossRef]
- Kang, Y.B.; Krishnaswamy, S.; Zaslavsky, A. A retrieval strategy for case-based reasoning using similarity and association knowledge. IEEE Trans. Cybern. 2014, 44, 473–478. [Google Scholar] [CrossRef] [PubMed]
- Jeong, M.; Morrison, J.R.; Suh, H. Approximate life cycle assessment via case-based reasoning for eco-design. IEEE Trans. Autom. Sci. Eng. 2015, 12, 716–728. [Google Scholar] [CrossRef]
- Platon, R.; Dehkordi, V.R.; Martel, J. Hourly prediction of a building’s electricity consumption using case-based reasoning, artificial neural networks and principal component analysis. Energy Build. 2015, 92, 10–18. [Google Scholar] [CrossRef]
- De la Rosa, J.J.G.; Agüera-Pérez, A.; Palomares-Salas, J.C.; Sierra-Fernández, J.M.; Moreno-Muñoz, A. A novel virtual instrument for power quality surveillance based in higher-order statistics and case-based reasoning. Measurement 2012, 45, 1824–1835. [Google Scholar] [CrossRef]
- Nandanwar, S.R.; Warkad, S.B. Application of case based reasoning in voltage security assessment. In Proceedings of the Computational Intelligence on Power, Energy and Controls with their Impact on Humanity (CIPECH), Ghaziabad, India, 18–19 November 2016; pp. 19–22. [Google Scholar]
- Tiako, R.; Jayaweera, D.; Islam, S. Real-time dynamic security assessment of power systems with large amount of wind power using Case-Based Reasoning methodology. In Proceedings of the Power and Energy Society General Meeting (PESGM), San Diego, CA, USA, 22–26 July 2012; pp. 1–7. [Google Scholar]
- Qian, Z.; Gao, W.S.; Yan, Z. Application of case-based reasoning theory in fault diagnosis of power transformer. In Proceedings of the 8th International Conference on Properties and Applications of Dielectric Materials, Bali, Indonesia, 26–30 June 2006; pp. 242–245. [Google Scholar]
- Alekhin, R.; Varshavsky, P.; Eremeev, A.; Kozhevnikov, A. Application of the case-based reasoning approach for identification of acoustic-emission control signals of complex technical objects. In Proceedings of the 2018 3rd Russian-Pacific Conference on Computer Technology and Applications (RPC), Vladivostok, Russia, 18–25 August 2018; pp. 1–4. [Google Scholar]
- Truong, L.H.; Lewin, P.L. Phase resolved analysis of partial discharges in liquid nitrogen under AC voltages. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 2179–2187. [Google Scholar] [CrossRef]
- Florkowski, M.; Florkowska, B. Phase-resolved rise-time-based discrimination of partial discharges. IET Gener. Transm. Distrib. 2009, 3, 115–124. [Google Scholar] [CrossRef]
- Sahoo, N.C.; Salama, M.M.A.; Bartnikas, R. Trends in partial discharge pattern classification: A survey. IEEE Trans. Dielectr. Electr. Insul. 2005, 12, 248–264. [Google Scholar] [CrossRef]
- Wong, J.K.; Illias, H.A.; Bakar, A.H.A. A novel high noise tolerance feature extraction for partial discharge classification in XLPE cable joints. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 66–74. [Google Scholar]
- Evagorou, D.; Kyprianous, A.; Lewin, P.; Stavrou, A.; Efthymiou, V.; Metaxas, A.C.; Georghiou, G.E. Feature extraction of partial discharge signals using the wavelet packet transform and classification with a probabilistic neural network. IET Sci. Meas. Technol. 2010, 4, 177–192. [Google Scholar] [CrossRef]
- Majidi, M.; Fadali, M.S.; Etezadi-Amoli, M.; Oskuoee, M. Partial discharge pattern recognition via sparse representation and ANN. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 1061–1070. [Google Scholar] [CrossRef]
- Majidi, M.; Oskuoee, M. Improving pattern recognition accuracy of partial discharges by new data preprocessing methods. Electr. Power Syst. Res. 2015, 119, 100–110. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Science 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Garcia, C.; Delakis, M. Convolutional face finder: A neural architecture for fast and robust face detection. IEEE Trans. Patt. Anal. Mach. Int. 2004, 26, 1408–1423. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Catterson, V.M.; Sheng, B. Deep neural networks for understanding and diagnosing partial discharge data. In Proceedings of the IEEE Electrical Insulation Conference, Seattle, WA, USA, 7–10 June 2015; pp. 218–221. [Google Scholar]
- Li, G.; Rong, M.; Wang, X.; Li, X.; Li, Y. Partial discharge patterns recognition with deep Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Condition Monitoring and Diagnosis (CMD), Xi’an, China, 25–28 September 2016; pp. 324–327. [Google Scholar]
- Chen, Z.; Li, W. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. Available online: https://arxiv.org/abs/1312.6114 (accessed on 20 December 2013).
- Woolrich, M.W.; Behrens, T.E. Variational bayes inference of spatial mixture models for segmentation. IEEE Trans. Med. Imaging 2006, 25, 1380–1391. [Google Scholar] [CrossRef]
- Tjandra, A.; Sakti, S.; Nakamura, S.; Adriani, M. Stochastic gradient variational bayes for deep learning-based ASR. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 175–180. [Google Scholar]
- Xu, W.; Sun, H.; Deng, C.; Tan, Y. Variational autoencoder for semi-supervised text classification. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence and The Twenty-Ninth Innovative Applications of Artificial Intelligence Conference, San Francisco, CA, USA, 4–9 February 2017; pp. 3358–3364. [Google Scholar]
- Li, L.; Tang, J.; Liu, Y. Partial discharge recognition in gas insulation switchgear based on multi-information fusion. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 1080–1087. [Google Scholar] [CrossRef]
- Zhang, X.; Tang, J.; Pan, C.; Zhang, X.; Jin, M.; Yang, D.; Zheng, J.; Wang, T. Research of partial discharge recognition based on deep belief nets. Power Syst. Technol. 2016, 40, 3272–3278. (In Chinese) [Google Scholar]
- Nguyen, C.; Lovering, C.; Neamtu, R. Ranked time series matching by interleaving similarity distances. In Proceedings of the IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 1–14 December 2017; pp. 3530–3539. [Google Scholar]
- Wang, X.; Song, G.; Chang, Z.; Luo, J.; Gao, J.; Wei, X.; Wei, Y. Faulty feeder detection based on mixed atom dictionary and energy spectrum energy for distribution network. IET Gener. Transm. Distrib. 2018, 12, 596–606. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PD Type | PDIV (kV) | PDEV (kV) |
|---|---|---|
| Floating electrode discharge | 128 | 112 |
| Metallic protrusion discharge | 67 | 60 |
| Insulation void discharge | 110 | 102 |
| Free metal partial discharge | 84 | 70 |
| Instrument Type | Key Parameter |
|---|---|
| IEC60270 Digital partial discharge detector | Sensitivity: <0.1 pC System bandwidth: 30 kHz–1.5 MHz |
| Oscilloscope | Sampling rate: single channel 10 GS/s Analog bandwidth: 2 GHz |
| PD Type | Number of Cases | Defect Reason | Number of Cases |
|---|---|---|---|
| Floating Electrode Discharge | 24 | Poor contact in disconnector | 6 |
| Loose connection in equipotential leaf spring | 10 | ||
| The build in sensors is not effectively grounded | 5 | ||
| Other reasons | 3 | ||
| Metallic Protrusion Discharge | 2 | Quality defects in conductor | 2 |
| Insulation Void Discharge | 14 | Quality defects in supporting insulator | 4 |
| Aging of insulation | 3 | ||
| Installation defects | 2 | ||
| Other reasons | 5 | ||
| Free Metal Particle Discharge | 2 | Installation defects | 2 |
| Layer Number | Layer Type | Number of Neurons | Activation Function |
|---|---|---|---|
| 1 | Input layer | 3600 | - |
| 2 | Hidden layer | 1000 | ReLU |
| 3 | Hidden layer | 500 | ReLU |
| 4 | Latent variables layer | 2 | Gaussian distribution |
| 5 | Hidden layer | 500 | ReLU |
| 6 | Hidden layer | 1000 | ReLU |
| 7 | Output layer | 3600 | Sigmoid |
| Case Number | PD Type | PD Location |
|---|---|---|
| 1 | Floating discharge | Joint of insulation tension pole and transmission gear in disconnector |
| 2 | Floating discharge | Joint of insulation tension pole and transmission gear in disconnector |
| 3 | Floating discharge | Built-in sensor connector |
| 4 | Insulation discharge | Cable terminal damaged in GIS |
| Case Number | VAE | Statistical | DBN | CNN |
|---|---|---|---|---|
| 1-2 | 96.87% | 66.42% | 90.41% | 88.62% |
| 1-3 | 73.78% | 59.33% | 85.38% | 88.46% |
| 1-4 | 6.93% | 40.41% | 9.28% | 7.41% |
| 2-3 | 61.75% | 60.27% | 86.50% | 89.15% |
| 2-4 | 1.92% | 39.53% | 5.74% | 6.46% |
| 3-4 | 9.51% | 26.98% | 11.72% | 11.96% |
| Case Number | Cosine Distance | Euclidean Distance | Correlation Coefficient |
|---|---|---|---|
| 1-2 | 96.87% | 93.03% | 95.70% |
| 1-3 | 73.78% | 75.23% | 77.64% |
| 1-4 | 6.93% | 8.31% | 12.67% |
| 2-3 | 61.75% | 60.84% | 79.14% |
| 2-4 | 1.92% | 6.80% | 18.22% |
| 3-4 | 9.51% | 7.18% | 13.95% |
| PD Type | Floating Discharge | Metallic Protrusion Discharge | Insulation Discharge | Particle Discharge |
|---|---|---|---|---|
| Cosine distance | 82.6% | 79.3% | 85.7% | 89.6% |
| Euclidean distance | 63.6% | 53.5% | 75.3% | 40.4% |
| Correlation coefficient | 77.5% | 48.5% | 70.9% | 39.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, J.; Teng, Y.; Zhang, Z.; Yu, Z.; Sheng, G.; Jiang, X. Partial Discharge Data Matching Method for GIS Case-Based Reasoning. Energies 2019, 12, 3677. https://doi.org/10.3390/en12193677
Dai J, Teng Y, Zhang Z, Yu Z, Sheng G, Jiang X. Partial Discharge Data Matching Method for GIS Case-Based Reasoning. Energies. 2019; 12(19):3677. https://doi.org/10.3390/en12193677
Chicago/Turabian StyleDai, Jiejie, Yingbing Teng, Zhaoqi Zhang, Zhongmin Yu, Gehao Sheng, and Xiuchen Jiang. 2019. "Partial Discharge Data Matching Method for GIS Case-Based Reasoning" Energies 12, no. 19: 3677. https://doi.org/10.3390/en12193677
APA StyleDai, J., Teng, Y., Zhang, Z., Yu, Z., Sheng, G., & Jiang, X. (2019). Partial Discharge Data Matching Method for GIS Case-Based Reasoning. Energies, 12(19), 3677. https://doi.org/10.3390/en12193677