1. Introduction
Reservoir engineering comprises one of the more important segments of the petroleum and natural-gas-related exploration and production technologies. By analyzing the field data, structuring mathematical models, and conducting experimental measurements, significant insights in terms of reservoir characterization, reservoir behavior, and hence, production forecasting and field development planning can be drawn from a reservoir engineer’s perspective. However, conventional reservoir engineering approaches have encountered challenges in many facets of reservoir analysis. For instance, processing, cleaning and analyzing the raw field data can be laborious and computationally intensive. Reservoir engineers most of the time must follow a trial and error protocol to convert data, such as seismic survey data, well logs, core analysis data, production history, etc. into a format for more practical engineering uses. Numerical simulation models employing black oil and compositional formulations are broadly employed to study the fluid transport dynamics in porous media. Such high-fidelity numerical models are structured to assess the fluid production and pressure responses by imposing a project development strategy. However, when the size of the problem becomes considerably large, executing numerical simulations would be increasingly and sometimes prohibitively slow. If complex physical, thermodynamical and chemical effects are coupled into the numerical simulation model, the computational cost would turn to be even more expensive. Moreover, there are reservoir engineering applications that demand multiple simulation runs for the purposes of history-matching, sensitivity analysis, project design optimization, etc. Thus, it could be computationally ineffective and costly to completely rely on the high-fidelity numerical models to work on problems of this class.
Artificial intelligence (AI) technologies have been gaining increasingly more attention for their fast response speeds and vigorous generalization capabilities. The AI technology exhibits promising potentials to assist and improve the conventional reservoir engineering approaches in a large spectrum of reservoir engineering problems [
1,
2,
3,
4]. Advanced machine-learning algorithms such as fuzzy logic (FL), artificial neural networks (ANN), support vector machines (SVM), response surface model (RSM) are employed by numerous studies as regression and classification tools [
5,
6,
7,
8]. Most of the machine-learning algorithms used in the reservoir engineering area belong to the category of supervised learning. The evolutionary optimization protocols, such as genetic algorithm (GA) and particle swarm optimization (PSO) are also utilized in many reservoir engineering applications [
9,
10,
11].
In this paper, we briefly review the state-of-art research works related to artificial intelligence applications in reservoir engineering. One of the primary goals of this study is to summarize the merits and demerits of the AI models comparing against the conventional reservoir engineering approaches. Based on the knowledge gained from the literature survey, we systematically present the workflows that utilize the intelligent systems to effectively realize computationally intensive processes such as field development optimization, history-matching, project uncertainty analysis, etc. Moreover, the ‘hand-shaking’ protocol that synergistically employs the conventional numerical simulator and intelligent systems is foreseen to be the trend of structuring more advanced models, which have the capabilities of processing big data and comprehending complex thermodynamical, physical and chemical effects behind the reservoir engineering problems.
The discussion in this article will start with the forward and inverse looking versions of intelligent models. Case studies regarding forecasting of the response function, history-matching, and project design AI models will be discussed. Then, we will explore the currently deployed approaches to structure field-specific and universally intelligent models using representative developments. Last but not least, we will discuss the handshaking protocols that comprehensively utilize AI and conventional reservoir engineering tools to enhance the computational efficacies to solve reservoir engineering problems. The experiences and lessons gained from the current research and applications indicate that intelligent models can not completely replace the conventional reservoir engineering models, such as high-fidelity numerical simulator and analytical tools. The reservoir engineering problems would bring in more concept related questions for AI technologies. However, the most robust solution could possibly be found by taking advantages of both AI and conventional reservoir engineering approaches.
2. Forward and Inverse Looking Models of Artificial Intelligence
In the reservoir engineering applications, artificial-intelligence-based models are deployed to solve a large spectrum of problems in both forward and inverse-looking manners. In
Table 1, the three categories of data to be processed are listed, which include reservoir characteristics, project design parameters, and field response data [
4].
Figure 1 illustrates how the forward and inverse-looking models treat various type of data as input and output.
A forward-looking model utilizes the reservoir characteristic and project design parameter as input, to predict the field response. A well-developed forward-looking model can be employed as an AI-based predictor to obtain quick assessments of certain project development strategies. Instead of rigorously solving the system of flow transportation equations, the forward-looking AI models generate predictions by interpolating the data structures exhibited by the input and output data. Therefore, the computational cost would be much less intensive comparing against the high-fidelity numerical models. Current developments have demonstrated that forward-looking AI models act effectively as proxies of high-fidelity numerical models to solve reservoir engineering problems that require an extensive volume of simulation runs, such as field development optimization [
12] and project uncertainty analysis [
13].
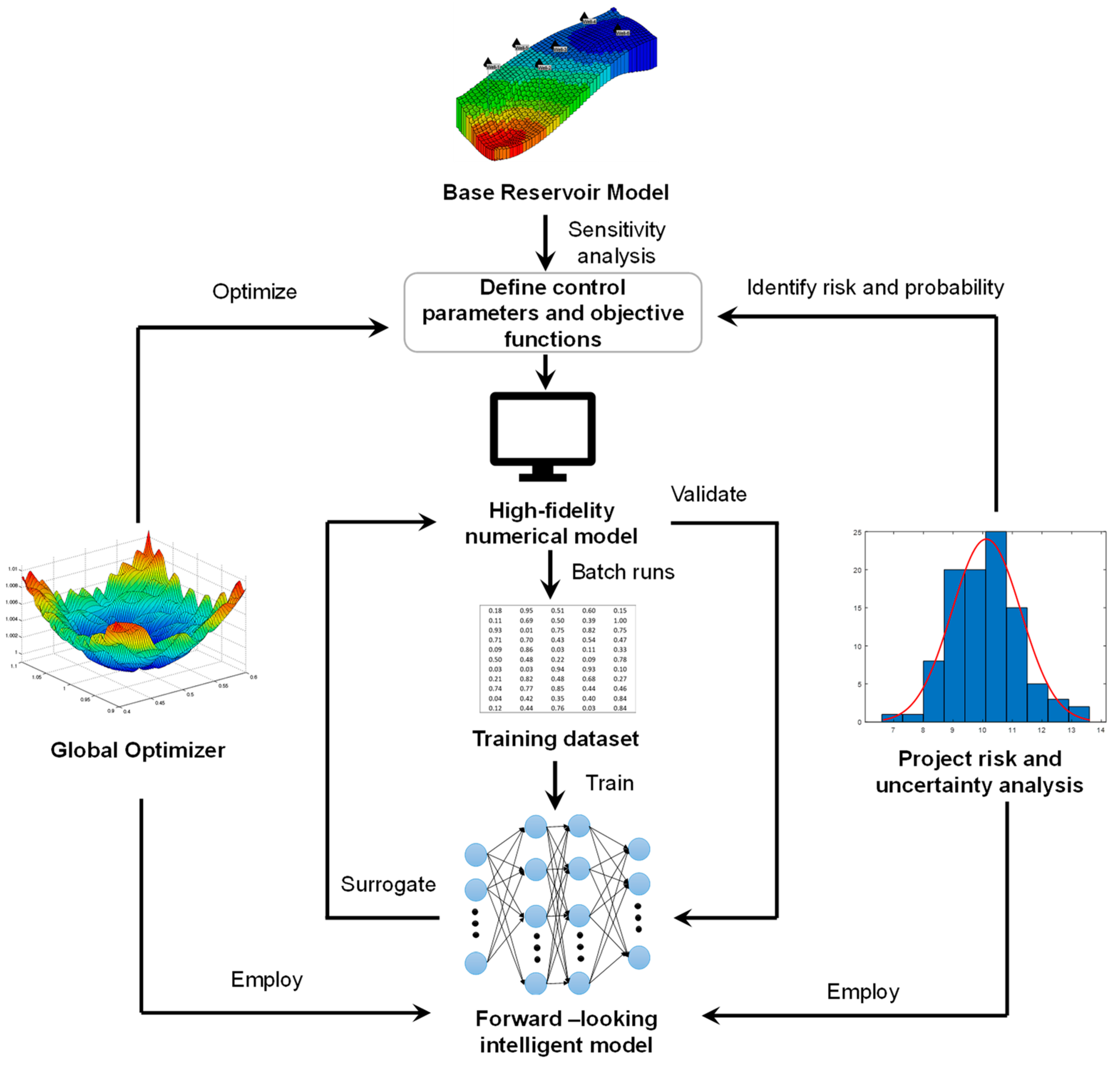
Figure 2 illustrates the general workflow that employs forward-looking intelligent systems to solve the aforementioned reservoir engineering problems. Typically, a base case reservoir model needs to be structured to capture the geological and petrophysical characteristics of the study area. If field historical data is available, the base case model has to be validated via a rigorous history matching process. Based on the goal of the project, the critical control parameters and objective functions can be defined. By varying the control parameters within a prescribed range, one can send batch simulation runs to establish a dataset exhibiting the one-to-one relationship between the control parameters (input) and objective functions (output). Such a dataset can serve as the knowledge to train the forward-looking AI model. The AI models can be validated via blind testing applications against the high-fidelity numerical simulator. More importantly, a well-trained forward-looking AI model can act as proxies of the numerical model. Global optimization algorithm and project uncertainty and risk analysis protocol can utilize the proxy models to accomplish the time-consuming analysis processes in a much shorter period of time.
For instance, forward-looking AI models have been successfully coupled with GA and PSO to co-optimize CO
2 water-alternative-gas (WAG) injection project considering multiple objective functions including oil recovery, project net present values (NPV) and CO
2 storage efficacies [
14,
15]. Quadratic response surface and artificial neural network (ANN) models are developed to mimic a history matched numerical simulation model and forecast long-term project responses. In such studies, the project design parameters such as water and gas cycle durations, well bottom-hole pressure constraints, and fluid injection rates are considered as input of the forward-looking model. The GA and PSO algorithms are coupled with the AI-models that evaluate the fitness of the individuals and particles during the evolutionary process. In this type of work, forward-looking proxies play vital roles in finding the optimum solution by achieving enough volume of simulation runs in a short period of time.
Moreover, Sun and Ertekin [
16] established computational workflows driven by forward-looking ANN models to carry project uncertainty analysis for cyclic steam injection projects. In this work, ANN models are employed by Monte Carlo simulation protocol to calculate p90, p50, and p10 recovery numbers in the presence of uncertainties from the reservoir characteristics. In this study, 10,000 random samples of permeability and porosity values are prepared, all of which are located within the range of uncertainty. The expert ANN model assists the Monte Carlo simulation to finish the desired volume of runs using 127 s of CPU time, which is several orders of magnitude faster than that of the high-fidelity numerical simulation model.
Meanwhile, the AI-models can be structured with two inverse versions. Unlike the forward-looking models, the inverse AI-models always use the field response data (for example, fluid production and pressure measurement data) as input. The first version of the inverse model is called history-matching model, which uses project design parameter and field historical data as input to characterize the reservoir properties. Extensive research efforts have been put forward to develop inverse history matching models. For instance, Ramgulam [
17] established an inverse ANN model to characterize the permeability, porosity and thickness distributions of an oil reservoir. This work utilized field historical data, including oil (q
o), water (q
w), gas (q
g) production, and producing gas-oil-ratio (GOR) data. Ramgulam prepared 50 simulation runs by varying the aforementioned reservoir properties to serve as the training dataset. The inverse history-matching ANN model is structured in such a way that the disparities between the numerical model prediction and the field historical data (Δq
o, Δq
w, Δq
g, and ΔGOR) are considered as the input. Namely, when the inverse history-matching model is trained and validated, small Δq
o, Δq
w, Δq
g, and ΔGOR will feed into the ANN model. Accordingly, the predicted reservoir property distributions would indicate a satisfactory matching quality against the field historical data. Ramgulam’s work provides a successful case of using inverse history-matching AI-model to obtain a well-tuned reservoir model.
The second version of the inverse AI model aims at finding the engineering design strategy that fulfills the desired project outcome, such as the hydrocarbon recovery, project NPV, etc. For projects with considerable capital and operational cost, for instance, drilling of maximum reservoir contact (MRC) wells and large-scale chemical flooding, implementation of inverse design model would reasonably guide and place the project strategy on the right trajectory and significantly reduce the project risks. More recent research studies have focused on developing inverse ANN models to design MRC wells in liquid-rich shale gas reservoirs [
18,
19]. The inverse-design ANN uses reservoir characteristics and the hydrocarbon production profile as input and predicts the MRC well architecture that is competent to achieve the desired oil and gas recoveries. The output of inverse well design model includes the lateral spacing, lateral length, lateral directions, mother-well length, and the producing bottom-hole pressure. In these works, good agreements are observed from a large volume of testing cases that check the hydrocarbon production using the predicted MRC architecture with the desired project outcome, which confirms the robustness of the inverse MRC well design model. AI models are also employed to design slanted wells for black oil reservoirs [
20].
Notably, the solutions to history matching and project design problems exhibit strong non-uniqueness characteristics. For the history-matching problem, there is more than one combination of reservoir property distributions that can make a numerical model match a set of the field historical data. In the meantime, a project can go through various development strategies to achieve a desired outcome. The inverse AI models are trained to adapt to the existing one-to-one relationship between the input and output parameters. Therefore, the prediction of the inverse AI-models provides one of the solutions to inverse problems. To obtain more robust solutions to the inverse problems, research works are done to establish computational workflows by coupling the forward and inverse-looking AI models.
For example, Rana et al. [
21] structured AI-assisted history matching workflows employing forward-looking Gaussian processes proxy models, Bayesian optimization and high-fidelity numerical models. The developed methodology is deployed to solve a history-matching problem of a coal seam degasification project. Multiple solutions of reservoir property distributions can be found by Bayesian optimization to fit the field historical data. Esmaili and Mohaghegh [
22] developed an ANN-based expert system using field data collected from a section of Marcellus shale gas reservoir, which is competent to assist the history-matching process considering various hydraulic fracturing design. Costa et al. [
23] employed ANN models and genetic algorithms to solve a history matching problem of an oil field. In this application, forward-looking ANN expert systems are trained to mimic the high-fidelity numerical models to predict the production data during the field historical period. ANN models collaborate with genetic algorithm in the optimization process to minimize the history-matching errors. In these applications, the forward-looking models are widely used as an alternative of a high-fidelity numerical simulator to assess the history matching errors of different sets of reservoir characteristics. The prediction from the inverse history matching model would act as an educated guess to initialize the process.
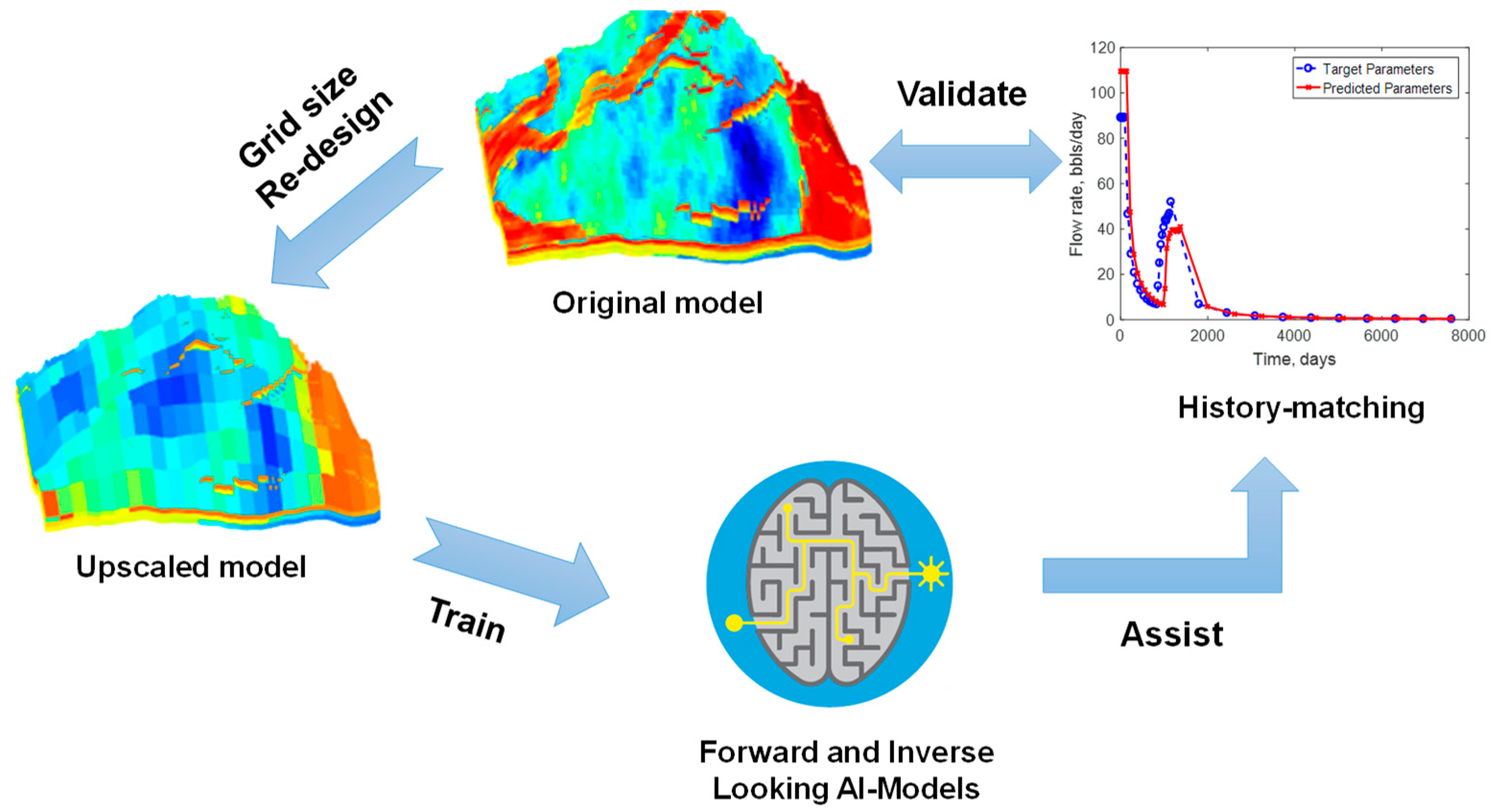
However, some concerns have been rising in the AI-assisted history matching studies. When large or extra-large scale field models come into the picture, preparing the dataset to train the intelligence systems could be a computationally intensive process. More importantly, the error margins exhibited in the forward and inverse-looking AI models may introduce negative effects to the history matching study. To address those issues, a more robust AI-assisted history-matching workflow is proposed by comprehensively employing the forward-looking, inverse-looking intelligent systems and the high-fidelity numerical models. As displayed in
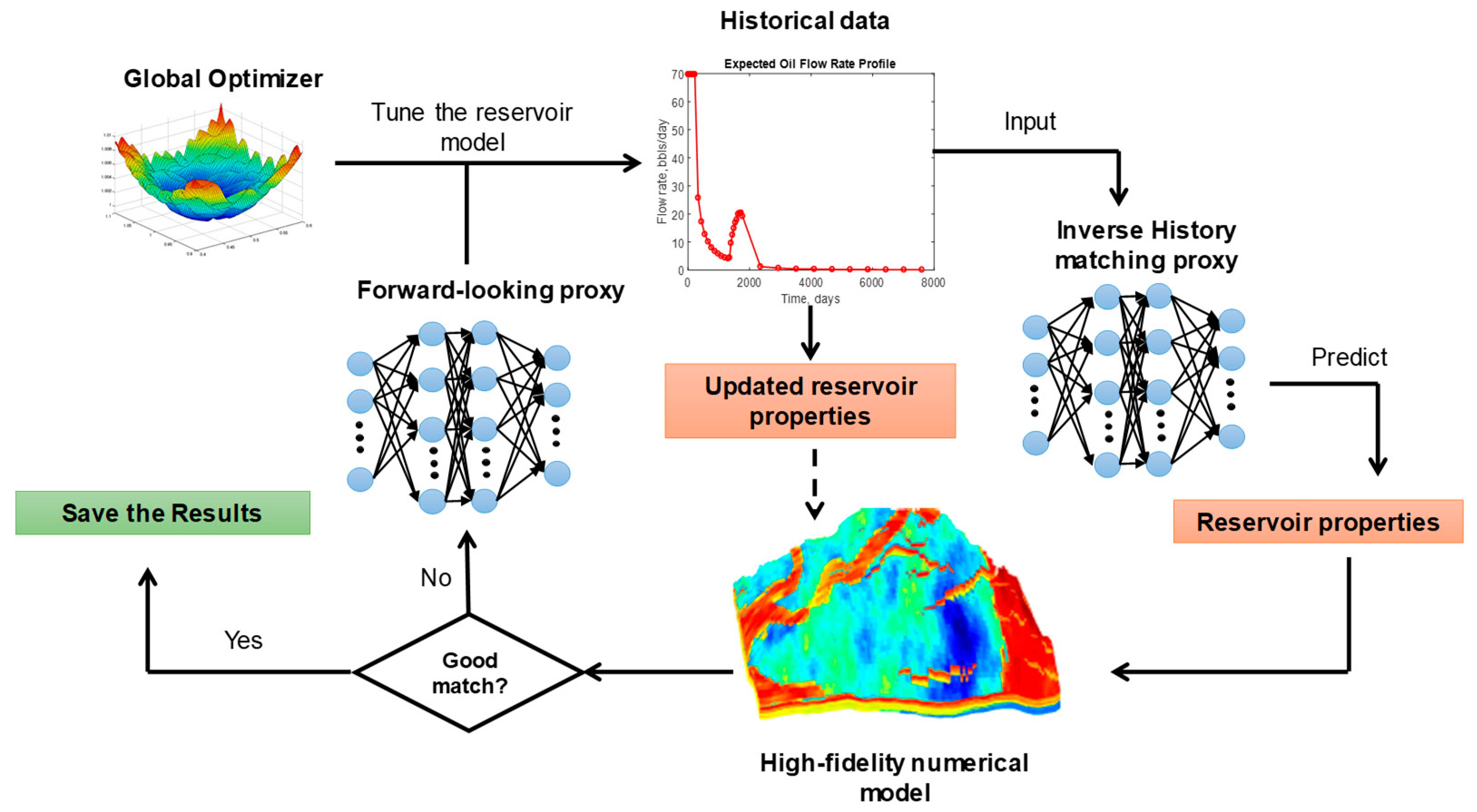
Figure 3, an upscaled numerical reservoir model is employed to generate the dataset to train the AI-models to assist the history matching study. Since the upscaled numerical model is computationally much less intensive than the original model, it can be used to establish a data-enriched knowledgebase to train the intelligent systems. Once the AI models are successfully trained, they will be deployed to the workflow illustrated in
Figure 4 to tune the reservoir properties. In this process, the field historical data will first go through the inverse history-matching model to obtain a preliminary prediction of the reservoir properties. The high-fidelity numerical model is called to test the matching quality using the predicted reservoir properties. If a good match is observed, the result will be saved. Otherwise, the forward-looking would be employed to further tune the reservoir properties. In this case, global optimization algorithms can be coupled with the intelligent systems to minimize the history matching error. It is worth to emphasize that the solution found by the workflow has to be validated by the original reservoir model before upscaling. The proposed workflow can be considered as a general AI-numerical hybrid approach to solve history-matching problems.
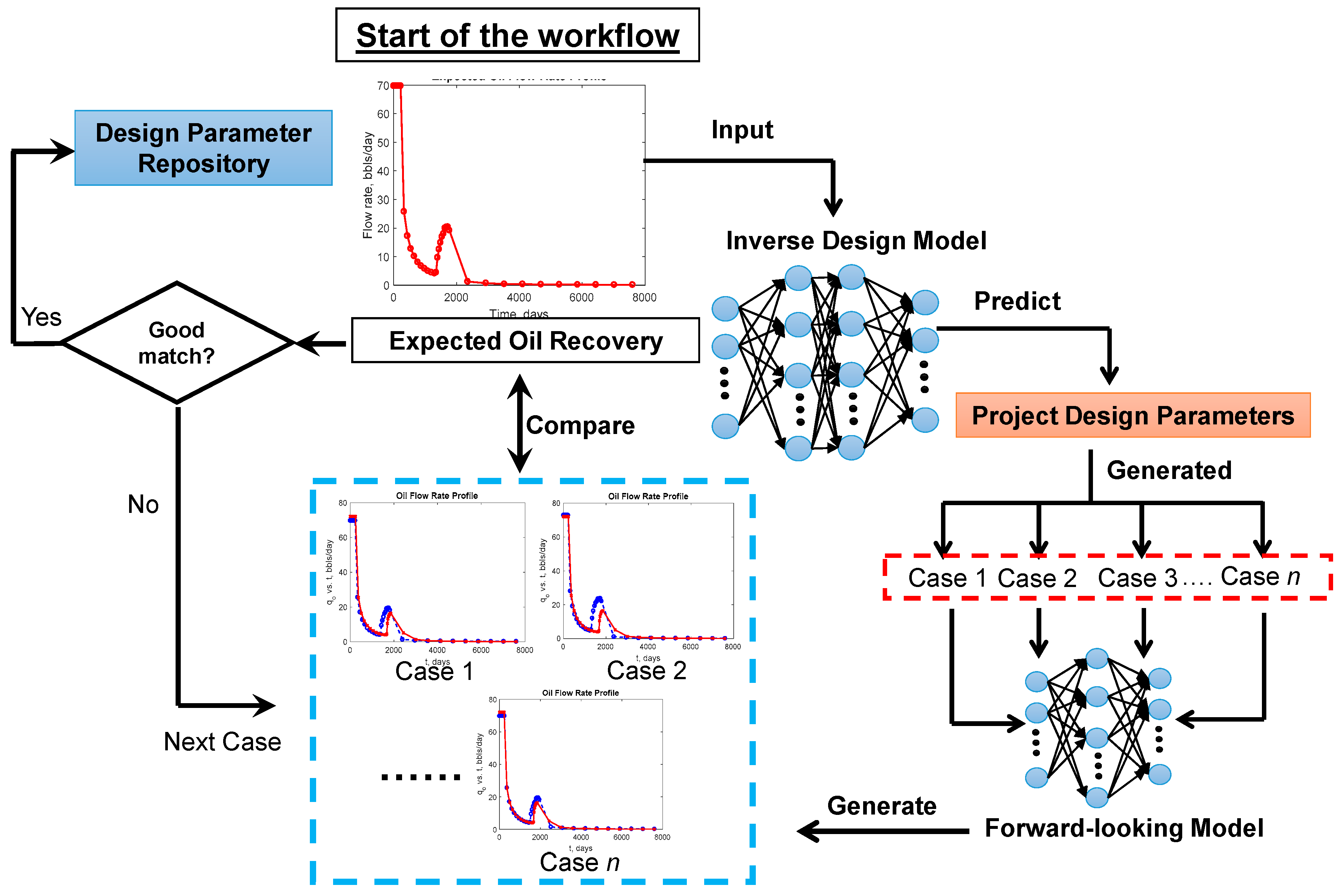
An example regarding project design can be found in Sun and Ertekin’s work [
24], which proposed project design workflow (
Figure 5) that is competent to find multiple polymer slug designs to fulfill the expected production increments of a polymer injection project. The forward and inverse-looking ANN models are employed in this work. Based on the prediction from the inverse project design model, a robust search protocol is proposed to find multiple polymer slug designs that could achieve the desired enhanced oil recovery outcome. Considering the polymer slug design predicted by the inverse-looking model as an educated initial guess, the workflow employs the forward-looking model to examine numerous polymer slug formulations to find the ones which would achieve the expected oil recovery. In this case, the forward-looking ANN plays a significant role in enabling the workflow to test a large spectrum of polymer injection schemes and establish a solution repository to fulfill the targeted oil recovery.
Moreover, recent research works have developed more advanced intelligent systems to address issues related to non-unique solutions using multiple-objective optimization (MOO) protocols. Such applications can be deployed to minimize multiple history matching errors [
25] and optimize various field development objectives [
26]. Typically, global optimization algorithms coupled with Pareto frontier theory [
27] are employed to establish a repository storing the dominating solutions. In this case, the forward-looking intelligent systems would play an even more significant role since the MOO protocols are naturally computationally intensive. Coimbra et al. [
28] recently developed a Pareto-based optimization workflow coupling genetic algorithm and response surface proxies to optimize steam alternative solvent project considering seven objective functions. Negash et al. [
29] employed a multiple-objective genetic algorithm and response surface proxies to solve a history-matching problem considering the historical data collected from multiple wells. The Pareto fronts include multiple solutions that co-optimize all the objective functions, which provide multiple choices for the engineers to make the decisions by applying various constraints considering the field practices.
3. Field-Specific and Generalized (Universal) Intelligent Models
Based on the application objectives and the data availabilities, developments of AI model can target specific field cases or can be presented in a generic form (universal models).
Field-specific intelligent models are trained using realistic data such as seismic survey, well log, core analysis, well completion, production data, and pressure data. Thararoop et al. [
30] developed a virtual intelligence system to characterize the prolific infill drilling locations of a tight sand gas field in the US. In this work, ANN models are trained to correlate the seismic survey data, well completion data against the gas production. The developed expert system is capable to predict the gas production at an arbitrary location in the field where the seismic data is available. A high-resolution production potential surface map can be generated to visualize the sweet spot of gas recovery, which guides the selection of infill drilling locations. Later, Bansal et al. [
31], Ketineni et al. [
32] and Ozdemir [
33] have extended the workflow to characterize onshore and offshore oil reservoirs. Along with seismic survey data, various types of well log data are also utilized as the input of the AI model to predict the well production performance. These intelligence systems are developed in two stages for deployment in these locations where well log data are not available:
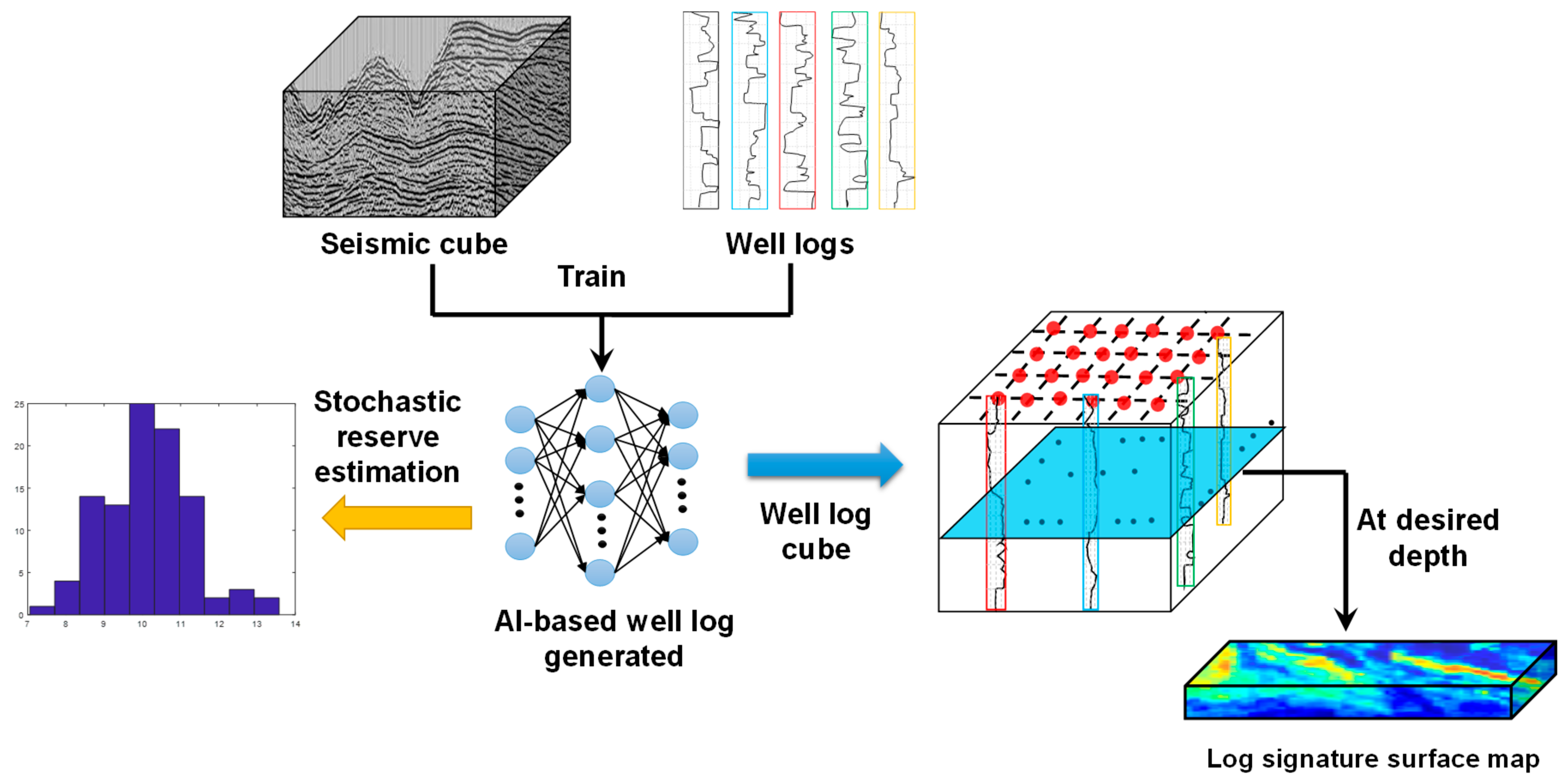
(1) A virtual well log generator is first trained to structure artificial well logs using the seismic data as input.
Figure 6 illustrates the structure of the AI-based synthetic well log generator. The AI models are trained to adapt to the data structure presented by the seismic data, well completion data and various types of well logs. The seismic cube is upscaled using a prescribed areal and vertical resolution. Meanwhile, well logs are discretized vertically using a certain depth interval. Each data sample includes a seismic attributes vector and a well completion vector as input, and the well log vector as output. Such an AI system can be employed to generate virtual well logs at arbitrary locations in the seismic surveyed area. Field engineers could characterize a new area using artificial logs without drilling and logging any wells, which would considerably reduce the project cost and risk. Moreover, one can deploy the virtual well log generator to sweep the entire seismic surveyed area to structure a three-dimensional well-log-cube. One can view the well log surface map by slicing the synthetic well log cube at desired depths, and obtain critical reservoir property distributions (saturation, porosity, shale content, etc.) to find out prolific regions for future development. Notably, Ozdemir [
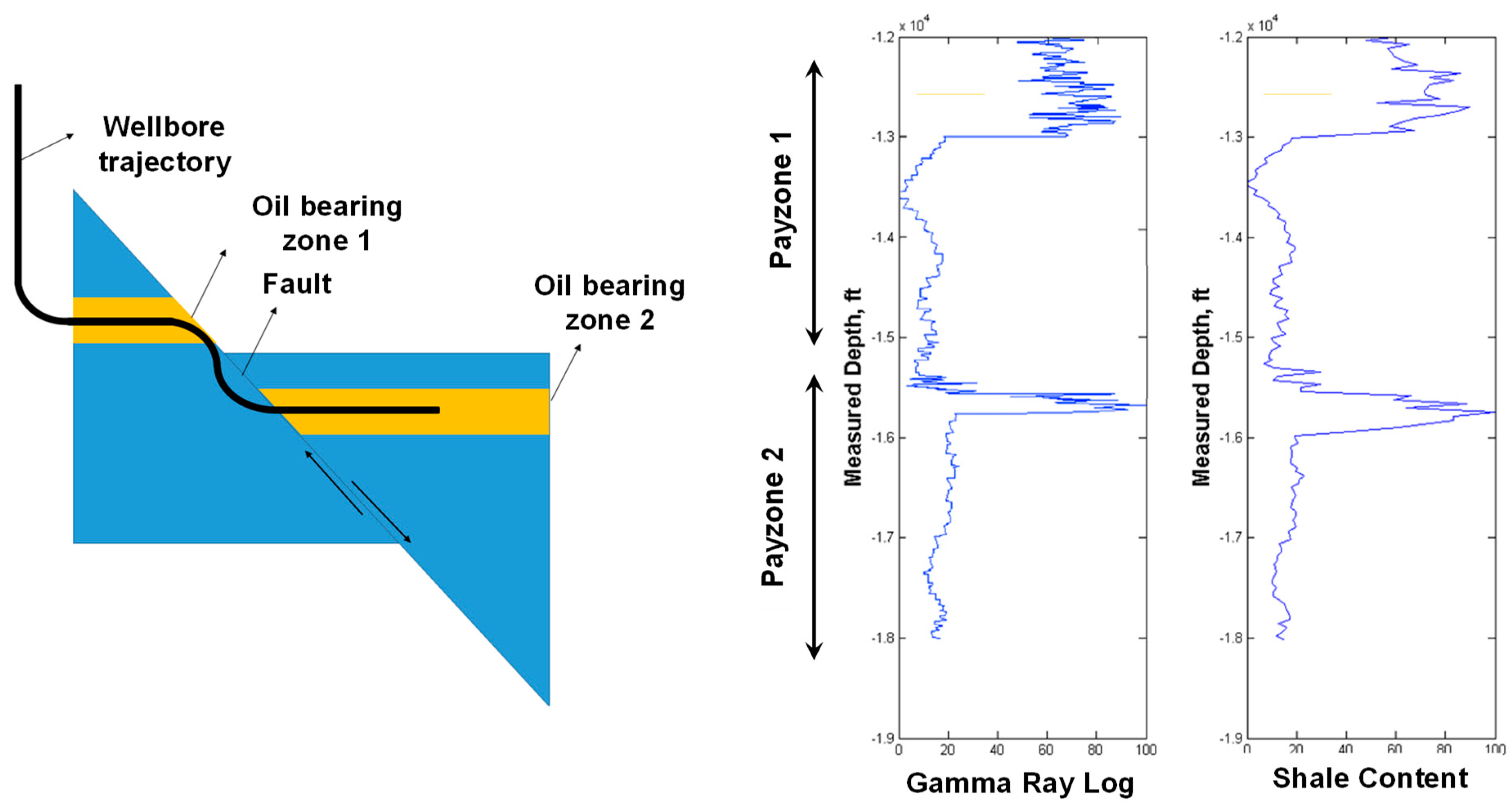
33] further implemented the virtual well log model to generate logs for wells completed with complex architectures. He developed an interpolation algorithm to construct artificial logs along the borehole measured depth using the virtual log values passed through by the wellbore trajectory. An example well log of a well penetrating two pay zones is displayed in
Figure 7. This application of the virtual well log model is expedient since logging of long lateral wells is rather expensive. More importantly, the virtual well log models enable the intelligent system to consider the well log data as an input to forecast the production performance, even at the infill drilling locations where real well logs are not available.
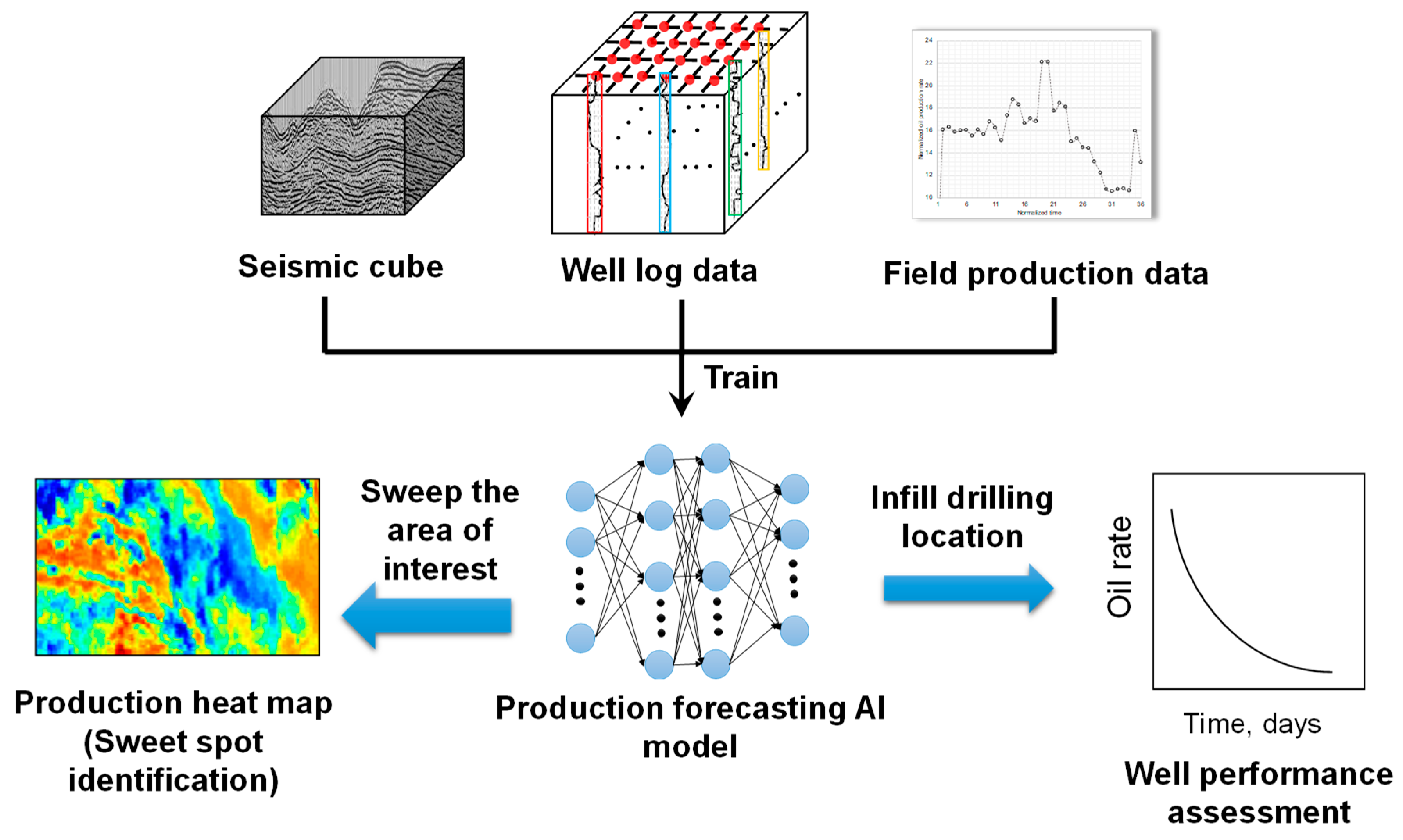
(2) The second stage of the intelligence system is trained using seismic data, well logs as input to predict the well production performance. As indicated in
Figure 8, the production performance intelligent systems are trained utilizing the seismic data and well logs as input, and the well historical production data as output. Notably, at these locations where the real well logs are not available, the virtual log model will be called to generate artificial logs to keep the consistency of the input data. The well-trained intelligent system can quickly assess numerous what-if infill drilling scenarios to optimize field development strategies.
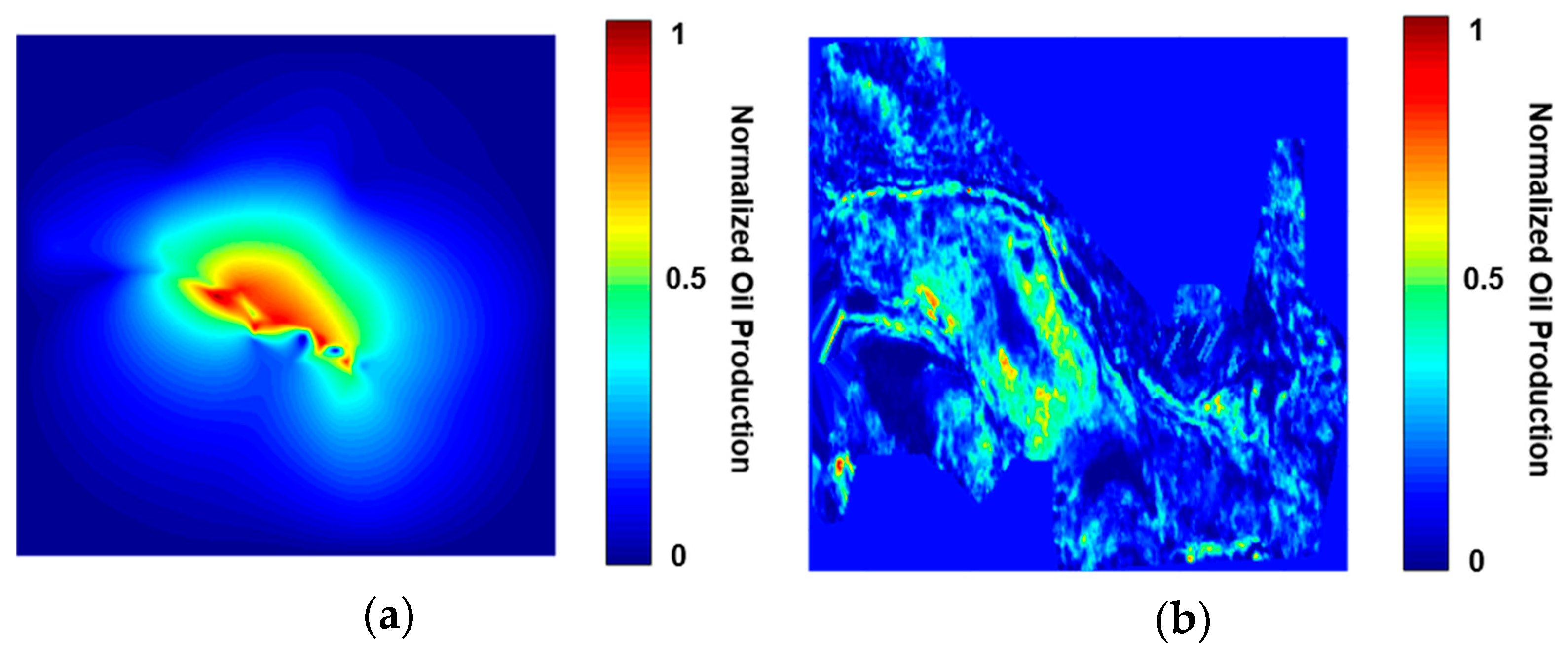
Figure 9 displays an example of the productivity heat map generated using the conventional Kriging algorithm and the production performance AI model.
Research works also compared the productivity heat map generated using the intelligence system against that from the conventional interpolation approaches. In
Figure 9, one can observe that the virtual intelligent approach generates a more robust solution than Kriging algorithm. Interpolations from Kriging algorithm are more constrained in the area where the existing wells are drilled (
Figure 9a), while the high permeability channels and versatile high productivity regions can be observed from the heat map generated by the intelligent model (
Figure 9b). This is because the AI models are trained to understand the relationship between geophysical data and field production data, while conventional geostatistical algorithms employ mathematical interpolations based only on the production data from the existing wells.
The aforementioned examples are representative cases that solve the infill drilling optimization and reservoir characterization problems of specific field case. These developments confirm the strength of the intelligent models to process big data collected from the field. More importantly, the promising results indicate that AI models can be employed to extract valuable information using data that cannot even be formulated using physical or mathematical equations. For instance, the seismic and well log data cannot be used by either conventional numerical or analytical model to predict the production performance. Moreover, since the field-specific intelligence systems are trained and validated directly using the field data, their applications would skip the cumbersome process of establishing numerical simulation models, such as treatment of raw data, gridding, and history-matching.
Generalized (universal) intelligent systems are developed to solve a category of problems regardless of the variation of reservoir rock and fluid properties. Unlike the field-specific applications, universal intelligent systems focus more on well-drainage-area or injection-pattern-scale problems. This type of intelligent systems is trained using the synthetic data generated with the help of the high-fidelity numerical models. A certain volume of batch simulation runs need to be prepared by varying the input parameters within the prescribed ranges.
Table 2 and
Table 3 summarize the typical reservoir models covered by the current research studies using generalized intelligent systems regarding well-drainage-area and injection-pattern scales, respectively.
The use of drainage-area scale models emphasizes fluid transportation dynamics around the wellbore, which helps intelligent systems learn the physical and thermodynamical signatures that exist within the data. Research works have structured well-drainage-area based AI models as general hydrocarbon production forecasting tool for gas condensate [
34], coal seam degasification [
35] and shale gas reservoirs [
36] using machine-learning algorithms such as ANN, SVM, and RSM models. Moreover, advanced models are developed to study enhanced oil recovery projects. For example, radial cylindrical reservoir models have been employed to develop universal ANN models for cyclic gas injection [
37] and cyclic steam injection processes [
38]. Proxy models are also developed as qualitative screen tools for steam-assisted gravity drainage (SAGD) process, which utilizes two horizontal wells to develop heavy oil reservoirs [
39]. Siripatrachai [
40] developed ANN expert system to characterize the stimulated reservoir volume (SRV) of horizontal gas wells with multi-stage hydraulic fractures.
Another important category of research work in this area is the AI-based pressure transient (PTA) and rate transient analysis (RTA) tools for reservoirs developed using wells with complex architecture such as slanted well, horizontal well, multi-lateral well, etc. Current analytical solution cannot be deployed to these systems due to the complex borehole trajectories and boundary conditions. To develop universal AI-based PTA and/or RTA models, numerical reservoir simulation models are employed to generate synthetic flow rate or pressure transient data by varying the reservoir rock and fluid properties, wellbore trajectory and internal constraints applied to the well. Successful developments are accomplished to train ANN models as RTA tools for horizontal wells in gas condensate reservoirs [
41], multilateral horizontal wells in gas reservoirs [
42], fishbone wells in shale gas reservoir [
43]. Zhang and Ertekin [
44] developed an AI-based RTA approach to characterize the relative permeability and capillary pressure data for multiphase reservoir systems. In the meantime, AI-based PTA tools are structured for naturally fractured tight gas reservoirs developed with multilateral wells [
45], and gas reservoir recovered using dual lateral wells [
46]. In these studies, universal intelligent systems act as robust data-driven RTA and/or PTA tools applicable for various types of reservoirs. Graphical user interfaces (GUI) are built in these tools to analyze field production and pressure data, which are particularly useful for the systems lacking mature analytical solutions.
It is noted that considerable research efforts have been extended to study improved oil recovery (IOR) processes using advanced intelligence systems. This type of study typically focuses on generalized injection pattern scaled reservoir models as summarized in
Table 3. Utilizing the existing symmetry, numerical reservoir simulation models can be structured to study the minimum unit of the patterns to reduce the computational overheads. Literature surveys indicate that generalized intelligence systems are developed to study water flooding [
47], steam injection [
48], in-situ combustion [
49], chemical flooding [
50], miscible gas injection [
51] and CO
2 sequestration in brine formations [
52]. Machine learning algorithms such as ANN and SVM models serve as regression tools to study various types of reservoirs developed using different injection patterns.
Notably, the generalized AI models discussed in this paper may include three modules which forecast the fluid production and pressure response functions (forward-looking model), design injection schemes (inverse project design model) and characterize the reservoir properties (inverse history-matching model).
One of the more challenging aspects of developing universally applicable intelligence systems is the generalization of the rock and fluid properties that are typically obtained via laboratory measurements and field investigations. One needs to ensure that data patterns are prepared considering various rock and fluid samples to train the universal proxies when preparing the training dataset. However, it would be expensive to run a large volume of lab experiments or field tests to establish a dataset containing sufficient amount of information to train the generalized intelligent system. Thus, it is important to find suitable mathematical models (expressions) that could predict the rock and fluid property data with the help of some key parameters. For instance, Corey’s formulation [
53] is widely used to calculate oil phase relative permeability of oil-water curve (
krow), water relative permeability (
krw), oil phase relative permeability of gas-liquid curve (
krog) and gas relative permeability (
krgo) via Equations (1) through (4), respectively:
Note that krwro is the end-point water relative permeability at residual oil saturation, kroiw is the end-point oil relative permeability at irreducible water saturation, Siw is the irreducible water saturation, Sorw is the residual oil saturation of the oil-water interaction, krgro is the end-point relative gas permeability at the residual liquid saturation, Sgc is the critical gas saturation, Sorg is the residual oil saturation of the gas-liquid interaction, nw and now are the exponents for water and oil phases in the oil-water interaction, respectively, ng and nog are the exponents for gas and liquid phases in the gas-liquid interaction, respectively.
In this case, the relative permeability curves can be captured by 11 Corey’s coefficients:
krwro,
kroiw,
Siw,
Sorw,
nw,
now,
krgro,
Sgc,
Sorg,
ng,
nog. By setting the ranges of the 11 parameters, one can establish a library of three-phase relative permeability curves. The intelligence system will use Corey’s coefficients as input to generalize in terms of the relative permeability [
54]. Another example would be the utilization of Andrade’s viscosity correlation [
55] to calculate the temperature-dependent viscosity (
µ) depicted by Equation (5):
where
T is the temperature,
AVIS is the oil viscosity at a reference temperature,
BVIS is the temperature-dependent exponent.
This equation describes the variation of oil viscosity change as a function of temperature using two parameters, which are
AVIS and
BVIS. It has been broadly employed to generalize intelligent systems for heavy oil EOR projects [
56].
The major objective of employing the empirical and semi-empirical models is to establish a data-enriched knowledgebase, which includes a large volume of synthetic rock and fluid properties curves/tables to train the intelligent systems. Taking the relative permeability curve as an example, suppose developing a well-generalized AI model in terms of relative permeability requires 100 sets of data. Corey’s formulation can be employed to generate 100 synthetic relative permeability curves by varying the parameters without running any physical experiments. The intelligent system will comprehend the relationship between the relative permeability against the output by learning the data structure presented by the synthetic data. When deploying the trained AI system, the model would use a real relative permeability curve (such data can be obtained via experiment measurements) as input and interpolate in data space created by the synthetic dataset to make a prediction. The generalized AI models can use either Corey’s coefficient or the discretized data (presented as saturation-to-relative permeability relationship) in the training stage. When the discretized data is used in the development stage, the tabulated relative permeability data can be used directly as input variables of the intelligent model. If the AI models use Corey’s coefficients as input, the relative permeability curve needs to be fitted into Corey’s model via a regression process to find the suitable coefficient combination. The advantage of this approach is that the dimensionality of the problem could be reduced considerably. However, there are uncertainties introduced by the regression process. For instance, if the fitting results of the field data are poor, the coefficient cannot represent the real data effectively. Thus, it is vital to select proper models and the range of the parameters when generating the synthetic rock and fluid property dataset.
There are other empirical and semi-empirical correlations and physical models that characterize the reservoir rock and fluid properties, which have been employed by the studies to develop generalized intelligence systems.
Black oil pressure-volume-temperature (PVT) data. When black oil formulation is employed to model the phase behavior of hydrocarbon fluid system, universal AI models need to be generalized in terms of the PVT data. In this way, the intelligent system can be implemented to different reservoirs with various types of petroleum fluid. Accordingly, such intelligent systems must be exposed to a library of PVT data during the training stage to learn its impact on the response function.
Table 4 summarizes the commonly used correlations of black oil PVT data. This approach generalizes the intelligence system in terms of PVT data using only a few oil and gas properties (for example, the specific gravity of oil and gas) and reservoir temperature as inputs.
Phase equilibria. Generalization of the intelligent systems emphasizing the phase behavior of the fluid components is more challenging, because the intelligent systems need to be trained using datasets that consider the variation of component partition-ratio in different phases at various pressure values. Typically, compositional formulation coupled with Peng-Robinson [
63] or Soave-Redlich-Kwong [
64] equation of state (EOS) are employed to model the phase behaviors of hydrocarbon fluids. To generalize this type of problem, the intelligent systems use the fluid compositions as input and the output would be the partition ratio of the component to different phases [
65]. Langmuir isotherms are employed by proxy models to generalize the phase equilibria of coalbed methane reservoirs [
66]. In these applications, one pressure (
pL) and one volumetric constant (
VL) is used to capture the partition ratios between the adsorbed and free phase gases.
For the chemical EOR projects injecting surfactants, more advanced EOS are employed to model the phase behavior of aqueous, oleic and microemulsion phases. Ramakrishnan and Wasan [
67] proposed a thermodynamically based EOS calculate the reduction of interfacial tension (IFT) between oleic and aqueous phases as a function of alkali concentration. A monolayer model is employed to capture the chemical equilibria established in the system since the presence of alkali creates a weak microemulsion phase. This EOS has been successfully coupled to develop universal ANN proxies to study alkali-polymer injection projects [
68]. The expert system is trained using a series of IFT versus alkali concentration curves for generalization purposes. Moreover, a physical EOS, Hydrophilic-Lipophilic-Difference-Net-Average-Curvature (HLD-NAC) equation, proposed by Ghosh and Johns [
69] is employed by an ANN-based EOR screening tool [
68] to generalize the phase behavior of surfactant/polymer and alkaline/surfactant/polymer flooding processes. HLD-NAC equation calculates the partitioning ratios of oil/brine/surfactant components in the oleic/aqueous/micelle phases via a non-iterative flash calculation. By varying the input of HLD-NAC equation including the crude oil properties (e.g., the equivalent alkane carbon number, total acid number, etc.), surfactant properties (e.g., optimum salinity, maximum chain length of surfactant tail, etc.), one can establish a dataset containing large number of phase behavior data of the surfactant/brine/crude oil systems. Furthermore, Chun-Huh’s equation [
70] is employed to calculate the IFT between different phases using the output of the HLD-NAC equation.
4. Establishing Effective Handshaking Protocols between Conventional and AI-Based Reservoir Engineering Practices
In this paper, we have reviewed extensive successful cases using robust intelligent systems to solve reservoir engineering problems. The AI-models exhibit their advantages in terms of fast computational efficacy and strong adaptability. However, the intelligent system cannot completely replace conventional reservoir engineering practices such as high-fidelity numerical simulation models and analytical tools. We have summarized the criteria and situations which could potentially limit the application of AI-models in reservoir engineering:
Although the computational speed of the AI models is much faster than that of the high-fidelity numerical models, the intelligent systems have to be trained in advance before being applied to solve a reservoir engineering problem.
To develop robust AI models, a project group needs to hire additional personnel with expert knowledge to treat the dataset and calibrate the internal parameter of the AI models.
There always exist error margins even for well-developed expert systems. Thus, it is difficult to use the AI models to solve problems that are sensitive to numerical errors and dispersions (for instance, flash calculations in the compositional simulation model).
Based on the complexity of the problem, training and validations of the AI models need a certain volume of data. Therefore, the reliability of AI models could become questionable if the available dataset contains little amount of data.
Most of the current developments are focusing on interpolation applications. When the input data falls out of the range of the training dataset, the validity of the extrapolation results would become attenuated.
Also, it is not suitable to apply intelligent systems to solve problems if the computational overhead of the physical model is not intensive. For example, the calculation of gas compressibility factor, and well testing analysis of conventional dry gas wells.
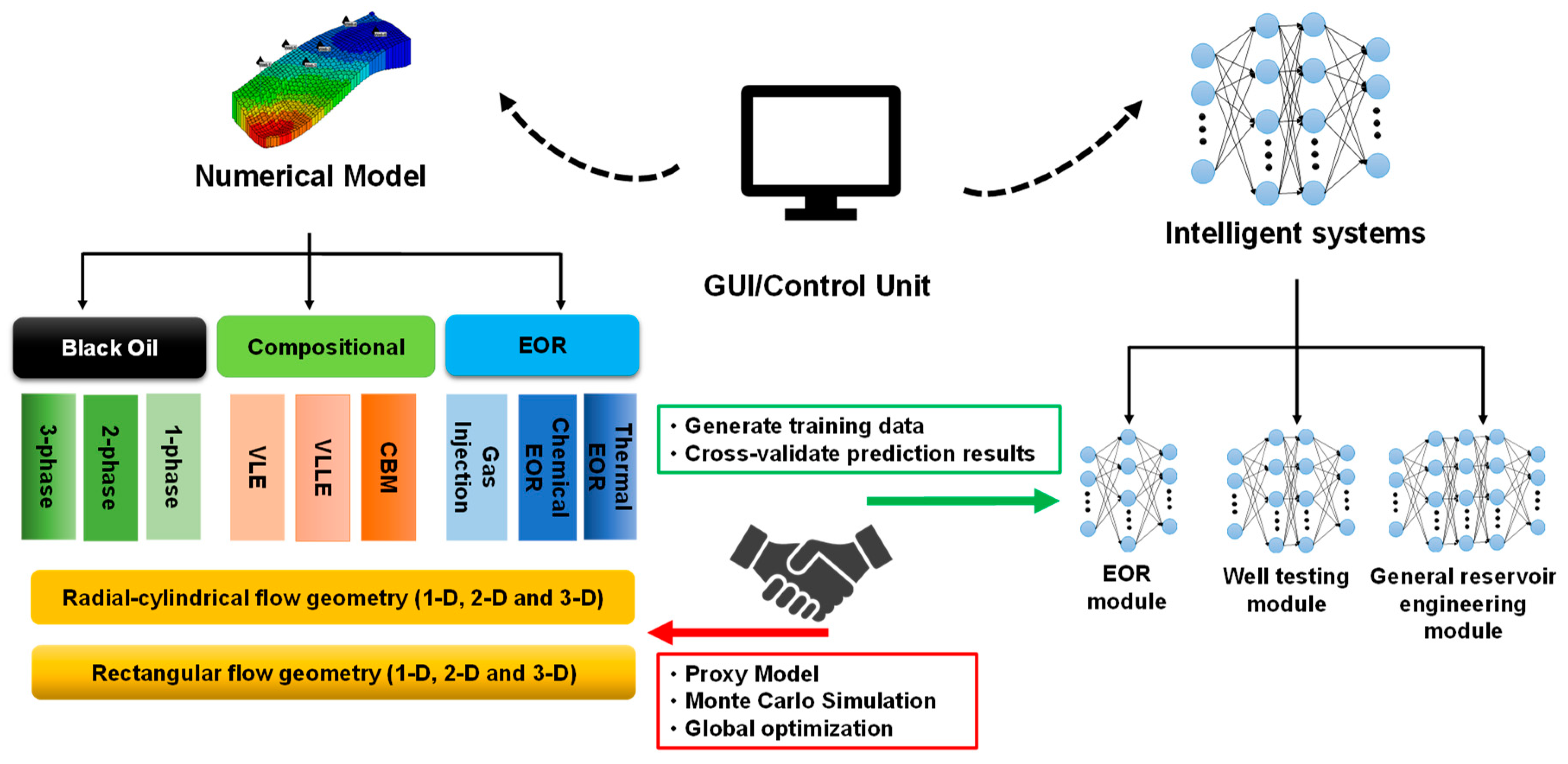
Notably, the use of AI models could assist the high-fidelity numerical model to achieve reservoir engineering analysis more effectively. Therefore, the importance of establishing a “handshaking protocol” to exploit the advantages offered by the numerical and AI models cannot be over-emphasized. In
Figure 10, the architecture bridging high-fidelity numerical model and the intelligence system is illustrated. Advanced numerical models are developed to simulate the underground fluid transportation dynamics using various gridding schemes and fluid models, which enables the high-fidelity numerical simulator to mimic a large spectrum of hydrocarbon extraction processes. The numerical models could establish or enrich the knowledgebase to train intelligent systems by generating synthetic field data for various reservoir engineering processes, which includes well testing analysis, rate transient analysis, history matching, and EOR projects design. Moreover, the validities of the intelligent systems can be confirmed by the cross-checking with the high-fidelity numerical models. Then, the intelligence systems could mimic the high-fidelity model and act as proxies of the numerical models to accomplish fast and accurate engineering analysis results. More importantly, the deployment of the proxy models could realize the computationally intensive protocols such as Monte Carlo analysis, history matching and optimization in a much shorter period of time. The collaborative framework illustrated in
Figure 8 take advantages of both numerical simulation and data-driven approaches and establish a high-efficacy reservoir engineering analysis tool.
A representative example can be found in Zhang’s work [
71] that develops a neuro-simulation protocol coupling an in-house numerical simulation package and ANN-based expert systems. The neuro-simulation workflow is established to allow the expert system to update its knowledge automatically using data generated from the numerical simulation model. Such a connection is done via a GUI which transfers data and training responses between the numerical and AI models.
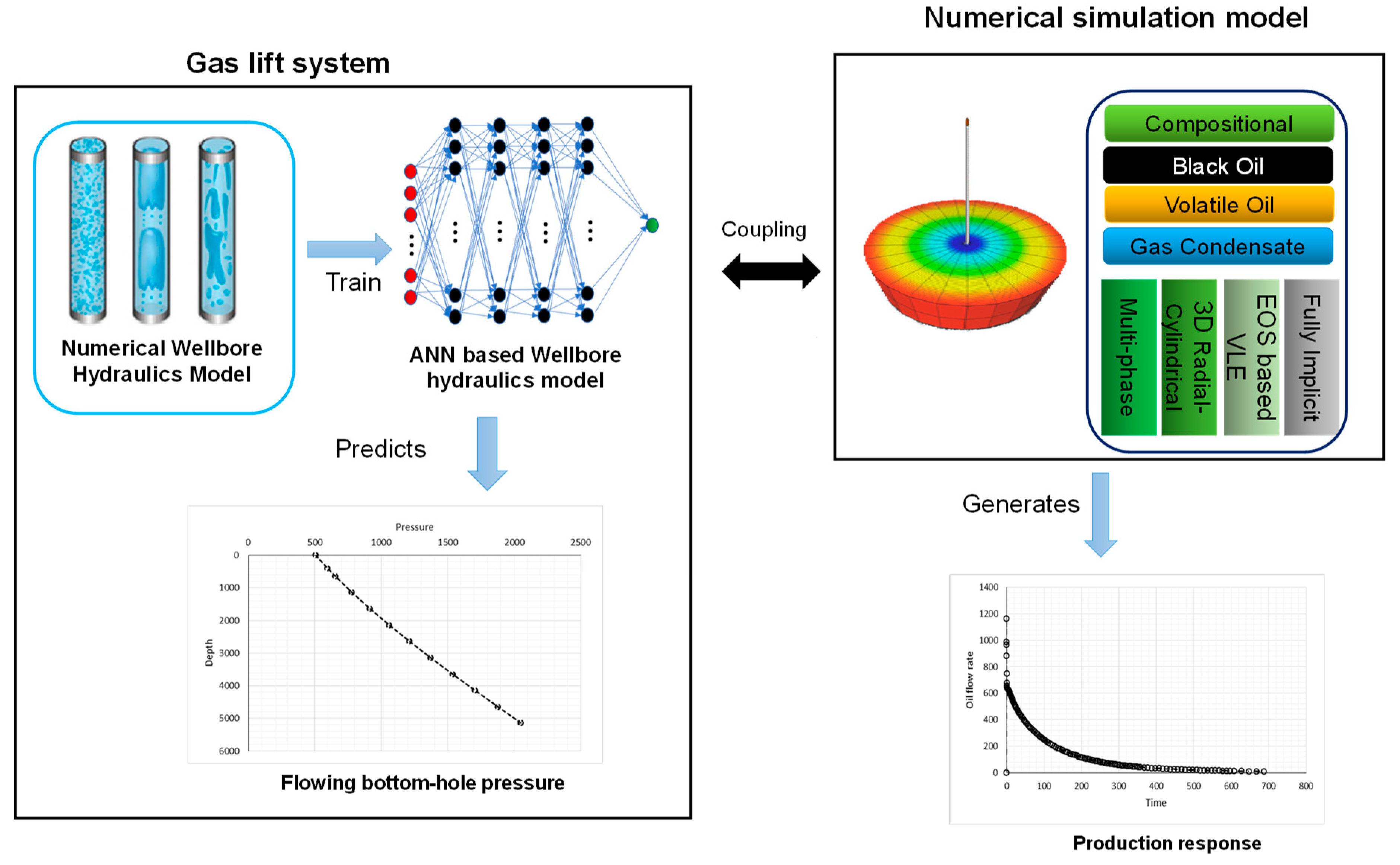
Moreover, Putcha and Ertekin [
72] proposed a coupled computational protocol that comprehensively employs intelligent models and high-fidelity numerical models to solve a gas lift problem. An ANN expert system is developed to solve the wellbore hydraulic dynamics of the gas lift injection operation [
73], while the fluid inflow performance from the reservoir is calculated using a compositional numerical simulator. As shown in
Figure 11, the intelligent gas lifting model calculates the flowing bottom-hole pressure for every iteration level using the producing fluid composition from the numerical simulator, while the numerical reservoir simulator employs the bottom-hole pressure as an internal boundary condition to update the pressure and in-situ composition distributions. Putcha and Ertekin observed that the entire calculation is accelerated by two to three orders of magnitude as compared to a full numerical model at the same level of accuracy, which effectively addresses the computational overhead issues associated with the application of an integrated wellbore-reservoir model.
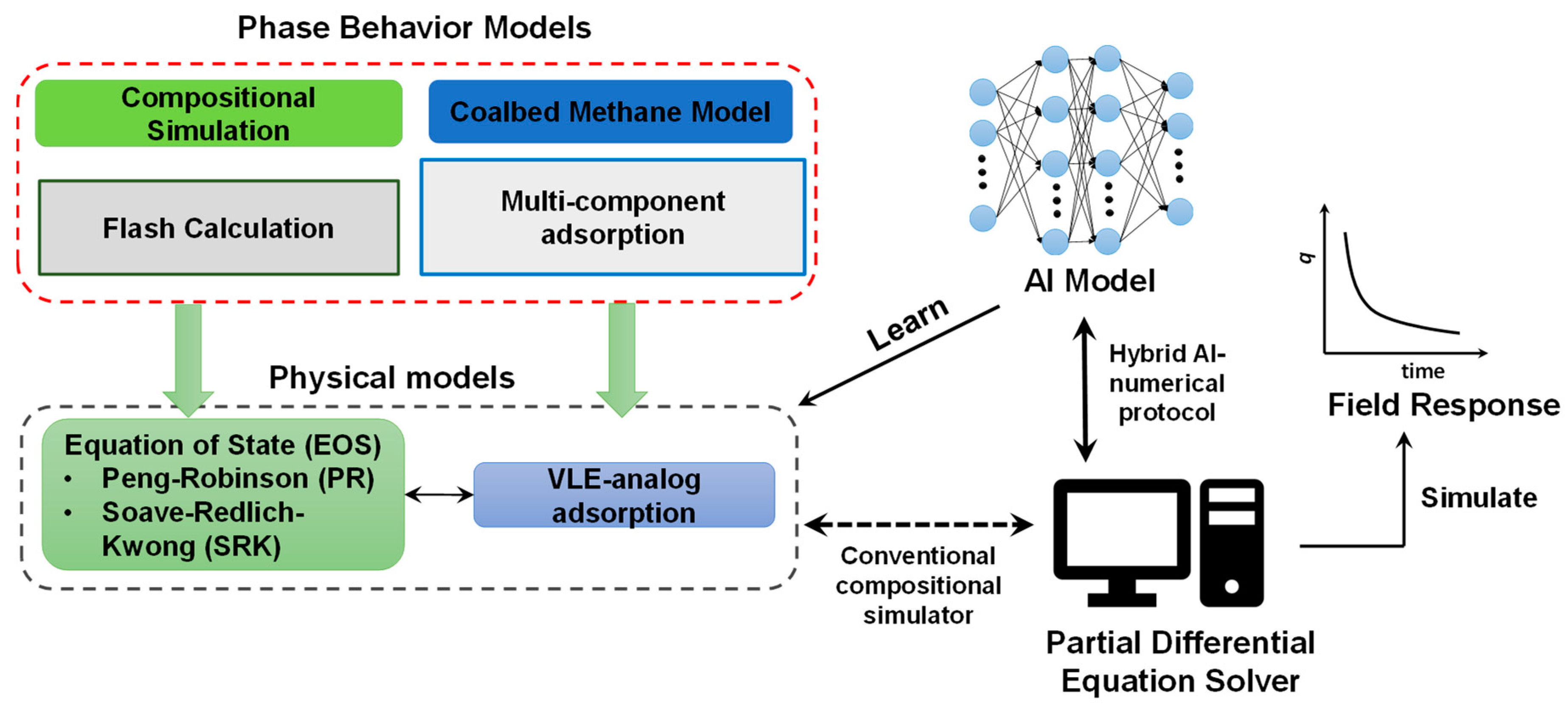
It is reasonable to expect more fully coupled models that are capable of accelerating the compositional simulator by employing AI-based flash calculation modules. Promising developments have been accomplished by Li et al., which employs deep neural network models to accelerate the flash calculation [
74].
Figure 12 conceptually illustrates the hybrid compositional simulation protocol which uses the AI models to mimic the phase behavior of hydrocarbon fluid, and partial differential equation solver to solve the fluid transportation equations in the porous media. However, this type of internal coupling could be a difficult procedure, since the error margins introduced by the intelligent model may bring additional numerical dispersions to numerical solvers. Still, the flash calculation model can use the result from the AI model as an educated initial guess to reduce the number of iterations. These are the main reasons why we foresee that developing advanced coupled models using numerical and artificial intelligent models would lead the trend in reservoir simulation area in the near future.
The intelligent reservoir engineering models would play a critical role in the next generation of smart field management protocols. Coupled with the AI models, the advances of information and computer sciences enable the subsurface engineers to process and analyze the real-time field data more effectively. For example, Mohaghegh highlighted the capability of the intelligent model to analyze the real-time field production data and calibrate the reservoir model to make more accurate forecasting results [
75]. He also pointed out the importance of AI system by analyzing the real-time pressure and production data for the purpose of monitoring the well performance and diagnosing the inter-well connectivity [
76]. In the unconventional reservoir development area, literature surveys indicate that the importance of analyzing the real-time pressure data during the hydraulic fracture treatment cannot be overemphasized since such data would provide significant information regarding the petrophysical and geomechanical characteristics of the near-wellbore regions [
77,
78]. We can foresee potentials of establishing intelligent systems to quickly analyze the real-time pressure measurement during the fracking treatment job and provide a better understanding of the near-wellbore environment [
79]. Such an outcome can be used by a geomechanical model to structure the fracture network propagation and a reservoir model to forecast the hydrocarbon production. The process described here also agrees with the hand-shaking concept proposed in the paper.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






