1. Introduction
Load forecasting is an essential part for energy management and distribution management in power grids. With the continuous development of the power grids and the increasing complexity of grid management, accurate load forecasting is a challenge [
1,
2]. High-accuracy power load forecasting for customers can make the reasonable arrangements of power generation to maintain the safety and stability of power supply and reduce electricity costs so that the economic and social benefit is improved. Moreover, forecasting at individual customer level can optimize power usage and help to balance the load and make detailed grid plans. Load forecasting is the process of estimating the future load value at a certain time with historical related data, which can be divided into long-term load forecasting, medium-term load forecasting and short-term load forecasting according to the forecasting time interval. Short-term load forecasting, which this paper focuses on, is the daily or weekly forecasting [
3,
4]. It is used for the daily or weekly schedule including generator unit control, load allocation and hydropower dispatching. With the increasing penetration of renewable energies, short-term load forecasting is fundamental for the reliability and economy of power systems.
Models of short-term load forecasting can be classified into two categories consisting of tradition statistic models and artificial intelligent models. Statistic models, such as regression analysis models and time sequence models, are researched and used frequently were previously limited by computing capability. Taylor et al. [
5] proposed an autoregressive integrated moving average (ARIMA) model with an extension of Holt–Winters exponential smoothing for short-term load forecasting. Then, an power autoregressive conditional heteroskedasticity (PARCH) method was presented for better performance [
6]. These statistic models need fewer historical data and have a small amount of calculation. However, they require a higher stability of the original time sequences and do not consider the uncertain factors such as weather and holidays. Therefore, artificial intelligent models about forecasting, such as neural networks [
7,
8], fuzzy logic method [
9] and support vector regression [
10], were proposed with the development of computer science and smart grids. Recently, neural networks are becoming an active research topic in the area of artificial intelligence for its self-learning and fault tolerant ability. Some effective methodologies for load forecasting based on neural networks have been proposed in recent years. A neural network based method for the construction of prediction intervals was proposed by Quan et al. [
7]. Lower upper bound estimation was applied and extended to develop prediction intervals using neural network models. The method resulted in higher quality for different types of prediction tasks. Ding [
8] used separate predictive models based on neural networks for the daily average power and the day power variation forecasting in distribution systems. The prediction accuracy was improved with respect to naive models and time sequence models. The improvement of forecasting accuracy cannot be ignored, but, with the increasing complexity and scale of power grids, high-accuracy load forecasting with advanced network model and multi-source information is required.
Deep learning, proposed by Hinton [
11,
12], made a great impact on many research areas including fault diagnosis [
13,
14] and load forecasting [
15,
16,
17] by its strong learning ability. Recurrent neural network (RNNs), a deep learning framework, are good at dealing with temporal data because of its interconnected hidden units. It has proven successful in applications for speech recognition [
18,
19], image captioning [
20,
21], and natural language processing [
22,
23]. Similarly, during the process of load forecasting, we need to mine and analyse large quantities of temporal data to make a prediction of time sequences. Therefore, RNNs are an effective method for load forecasting in power grids [
24,
25]. However, the vanishing gradient problem limits the performance of original RNNs. The later time nodes’ perception of the previous ones decreases when RNNs become deep. To solve this problem, an improved network architecture called long short-term memory (LSTM) networks [
26] were proposed, and have proven successful in dealing with time sequences for power grids faults [
27,
28]. Research on short-term load forecasting based on LSTM networks was put forward. Gensler et al. [
29] showed the compared results for solar power forecasting about physical photovoltaic forecasting model, multi-layer perception, deep belief networks and auto-LSTM networks. It proved the LSTM networks with autoencoder had the lowest error. Zheng et al. [
30] tackled the challenge of short-term load forecasting with proposing a novel scheme based on LSTM networks. The results showed that LSTM-based forecasting method can outperform traditional forecasting methods. Aiming at short-term load forecasting for both individual and aggregated residential loads, Kong et al. [
31] proposed an LSTM recurrent neural network based framework with the input of day indices and holiday marks. Multiple benchmarks were tested in the real-world dataset and the proposed LSTM framework achieved the best performance. The research works mentioned above indicate the successful application of LSTM for load forecasting in power grids. However, load forecasting needs to be fast and accurate. The principle and structure of LSTM are complex with input gate, output gate, forget gate and cell, so the calculation is heavy for forecasting in a large scale grid. Gated recurrent unit (GRU) neural networks was proposed in 2014 [
32], which combined the input gate and forget gate to a single gate called update gate. The model of a GRU is simpler compared with an LSTM block. It was proved on music datasets and ubisolf datasets that GRU’s performance is better with less parameters about convergence time and required training epoches [
33]. Lu et al. [
34] proposed a multi-layer self-normalizing GRU model for short-term electricity load forecasting to overcome the exploding and vanishing gradient problem. However, short-term load forecasting for customers is influenced by factors including date, weather and temperature, which previous research did not consider seriously. People may need more energy when the day is cold or hot. Enterprises or factories may reduce their power consumption on holidays.
In this paper, a method based on GRU neural networks with multi-source input data is proposed for short-term load forecasting in power grids. Moreover, this paper focuses on the load forecasting for individual customers, which is an important and tough problem because of the high volatility and uncertainty [
30]. Therefore, before training the networks, we preprocess the customers’ load data with clustering analysis to reduce the interference of the electricity use characteristics. Then, the customers are classified into three categories to form the training and test samples by K-means clustering algorithm. To obtain not only the load measurement data but also the important factors including date, weather and temperature, the input of the network are set as two parts. The temporal features of load measurement data are extracted by GRU neural networks. The merge layer is built to fuse the multi-source features. Then, we can get the forecasting results by training the whole network. The methodologies are described in detail in
Section 2. The main contributions of this paper are as follows.
Trained samples are formed by clustering to reduce the interference of different characteristics of customers.
Multi-source data including date, weather and temperature are quantified for input so that the networks obtain more information for load forecasting.
The GRU units are introduced for more accurate and faster load forecasting of individual customers.
In general, the proposed method uses the clustering algorithm, quantified multi-source information and GRU neural network for short-term load forecasting, which past research did not consider comprehensively. The independent experiments in the paper verify the advantages of the proposed method. The rest of the paper is organized as follows. The methodology based on GRU Neural Networks for short-term load forecasting is proposed in
Section 2. Then, the results and discussion of the simulation experiments are described to prove the availability and superiority of the proposed method in
Section 3. Finally, the conclusion is made in
Section 4.
2. Methodology Based on GRU Neural Networks
In this section, the methodology is proposed for short-term load forecasting with multi-source data using GRU Neural Networks. First, the basic model of GRU neural networks are introduced [
32]. Then, data description and processing are elaborated. The load data are clustered by K-means clustering algorithm so that the load samples with similar characteristics in a few categories are obtained. This helps improve the performance of load forecasting for individual customers. In the last subsection, the whole proposed model based on GRU neural networks is shown in detail.
2.1. Model of GRU Neural Networks
Gated recurrent unit neural networks are the improvement framework based on RNNs. RNNs are improved artificial neural networks with the temporal input and output. Original neural networks only have connections between the units in different layers. However, in RNNs, there are connections between hidden units forming a directed cycle in the same layer. The network transmits the temporal information through these connections. Therefore, the RNNs outperform conventional neural networks in extracting the temporal features by these connections. A simple structure for an RNN is shown in
Figure 1. The input and output are time sequences, which is different from original neural networks. The process of forward propagation is shown in
Figure 1 and given by Equations (
1)–(
3).
where
w is the weight;
a is the sum calculated through weights;
f is the activation function;
s is the value after calculation by the activation function;
t represents the current time of the network;
i is the number of input vectors;
h is the number of hidden vectors in
t is time;
is the number of hidden vectors in
time; and
o is the number of output vectors.
Similar to conventional neural networks, RNNs can be trained by back-propagation through time [
35] with the gradient descent method. As shown in
Figure 1, each hidden layer unit receives not only the data input but also the output of the hidden layer in the last time step. The temporal information can be recorded and put into the calculation of the current output so that the dynamic changing process can be learned with this architecture. Therefore, RNNs are reasonable to predict the customer load curves in power grids. However, when the time sequence is longer, the information will reduce and disappear gradually through transferring in hidden units. The original RNNs have the vanishing gradient problem and the performance declines when dealing with long time sequences.
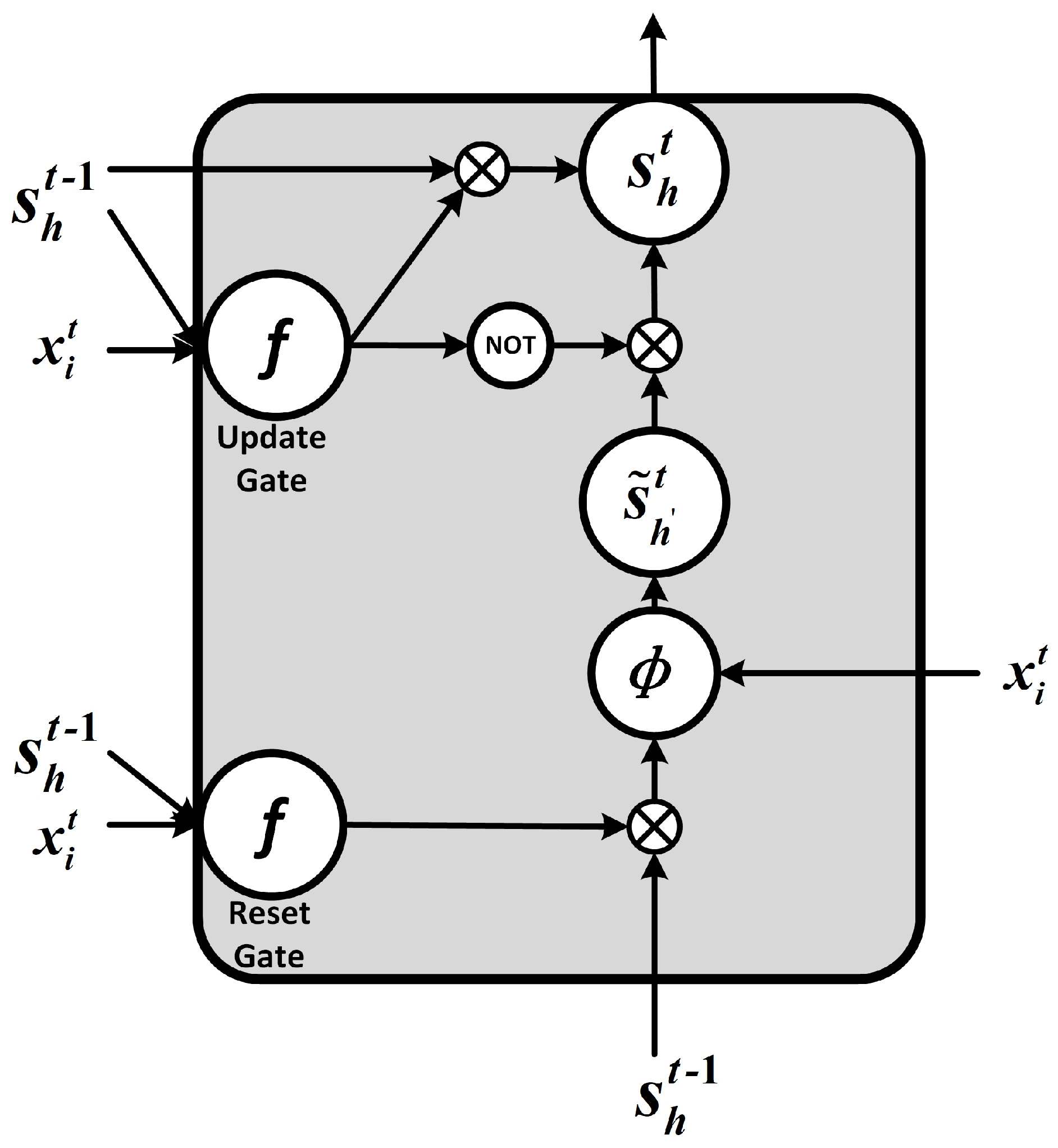
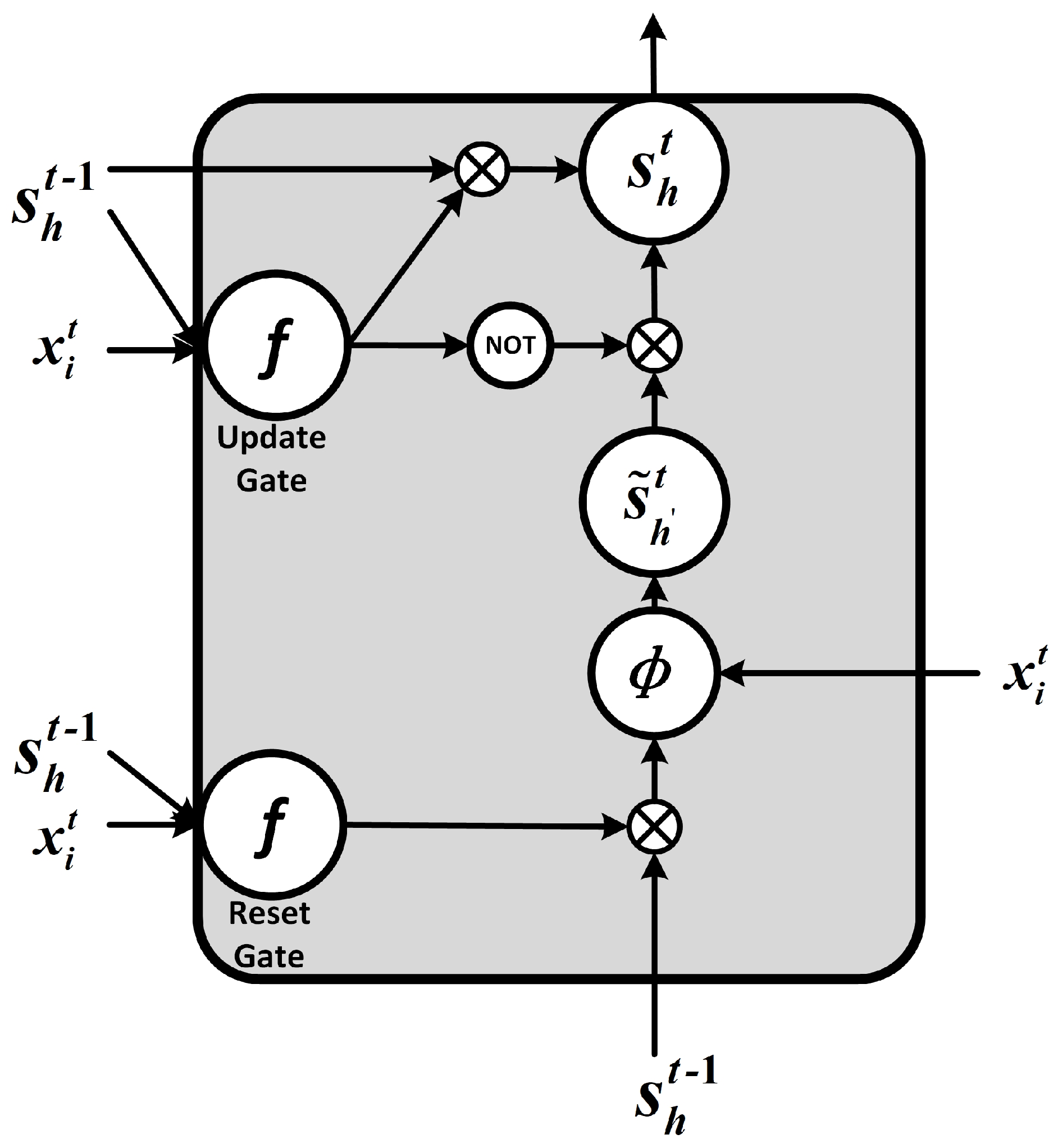
The vanishing gradient problem can be solved by adding control gates for remembering information in the process of data transfer. In LSTM networks, the hidden units of RNNs are replaced with LSTM blocks consisting of cell, input gate, output gate and forget gate. Moreover, the forget gate and input gate are combined into a single update gate in GRU neural network. The structure of GRU is shown in
Figure 2.
The feedforward deduction process for GRU units is shown in
Figure 2 and given by Equations (
4)–(
10).
where
u is the number of update gate vector;
r is the number of reset gate vector;
h is the number of hidden vectors at
t time step;
is the number of hidden vectors at
time step;
f and
are the activation functions;
f is the sigmoid function and
is the tanh function generally; and
means the new memory of hidden units at
t time step.
According to
Figure 2, the new memory
is generated by the input
at the current time step and the hidden unit state
at the last time step, which means the new memory can combine the new information and the historical information. The reset gate determines the importance of
to
. If the historical information
is not related to new memory, the reset gate can completely eliminate the information in the past. The update gate determines the degree of transfer from
to
. If
,
is almost completely passed to
. If
,
is passed to
. The structure shown in
Figure 2 results in a long memory in GRU neural networks. The memory mechanism solves the vanishing gradient problem of original RNNs. Moreover, compared to LSTM networks, GRU neural networks merge the input gate and forget gate, and fuse the cell units and hidden units in LSTM block. It maintains the performance with simpler architecture, less parameters and less convergence time [
33]. Correspondingly, GRU neural networks are trained by back-propagation through time as RNNs [
35].
2.2. Data Description
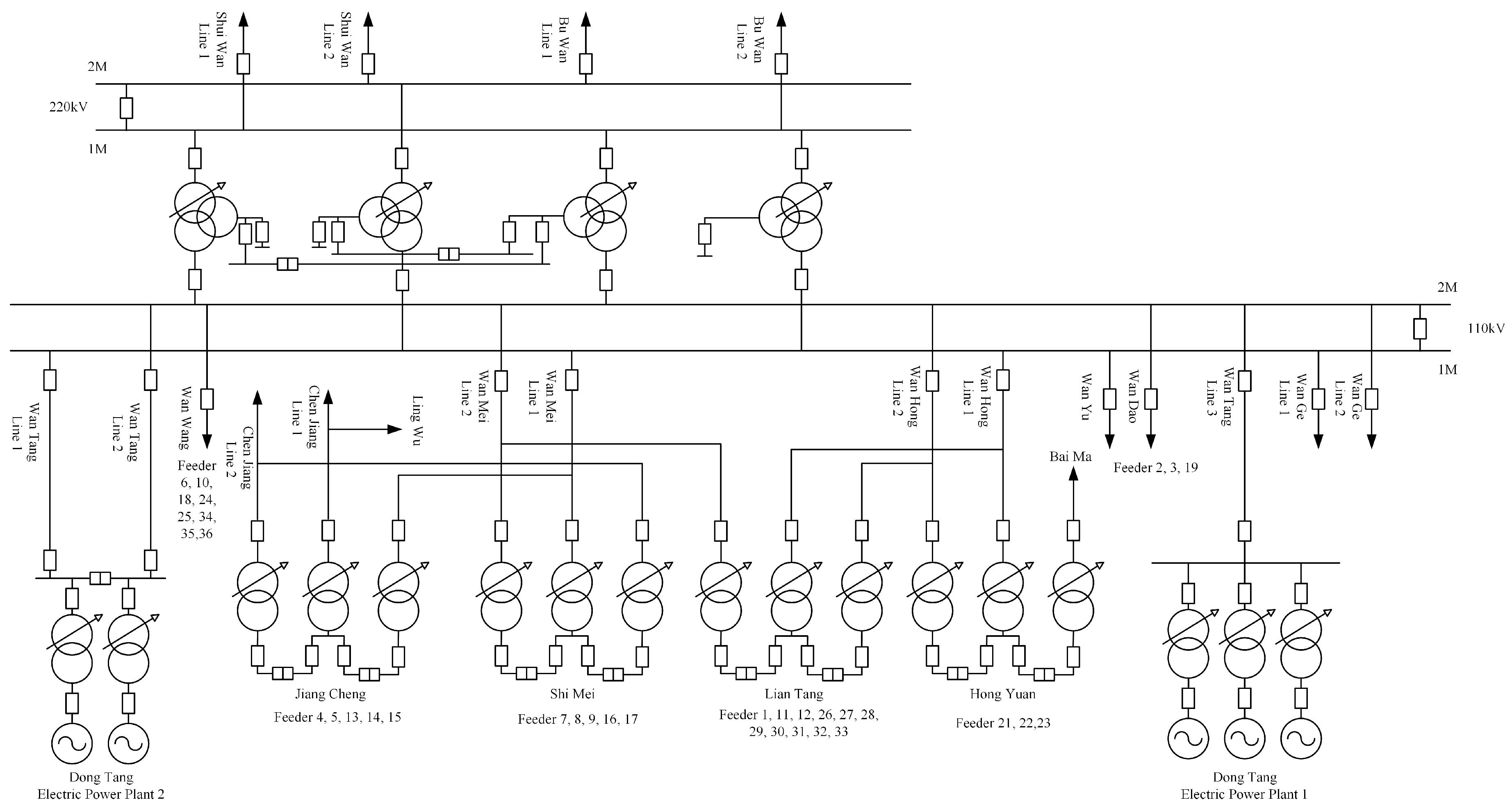
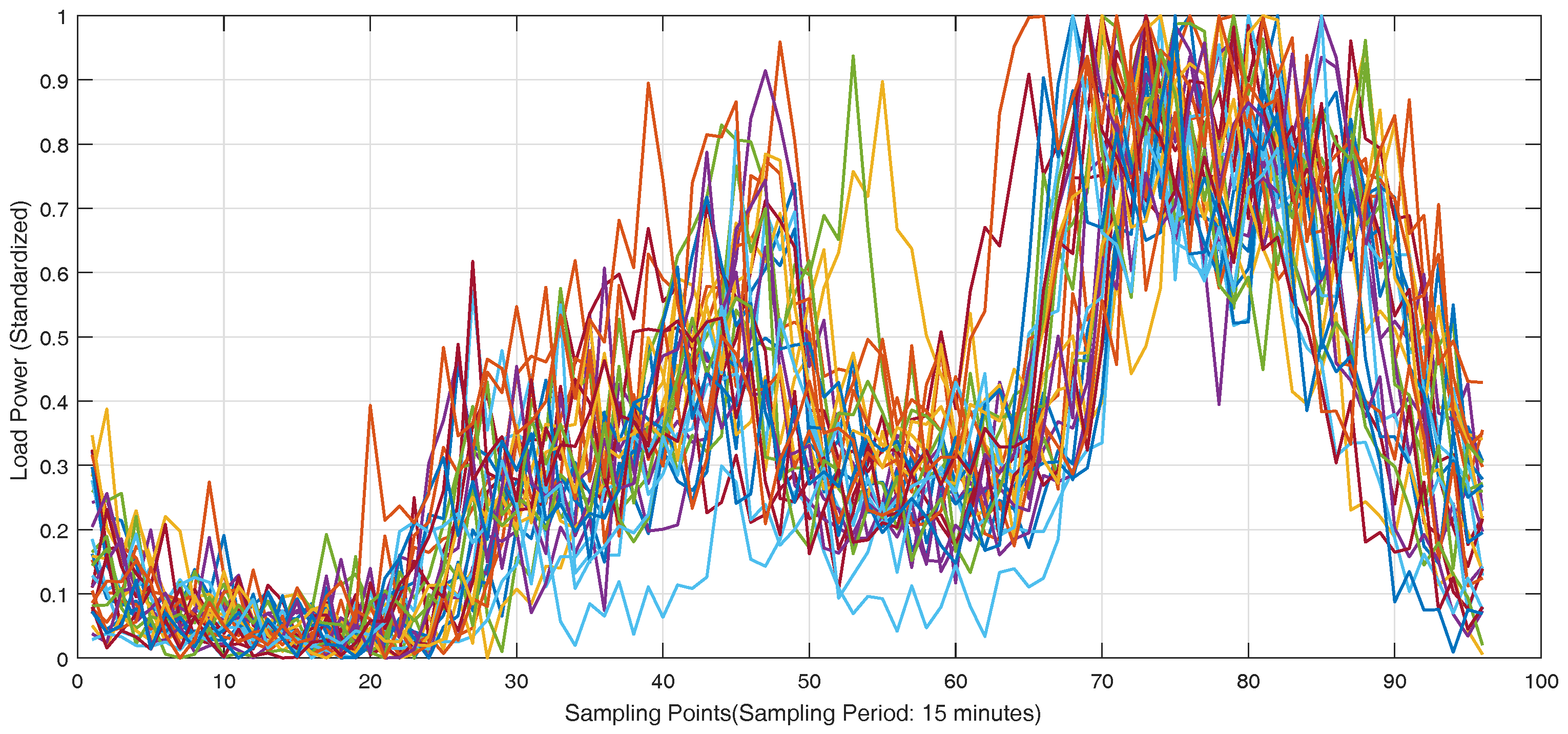
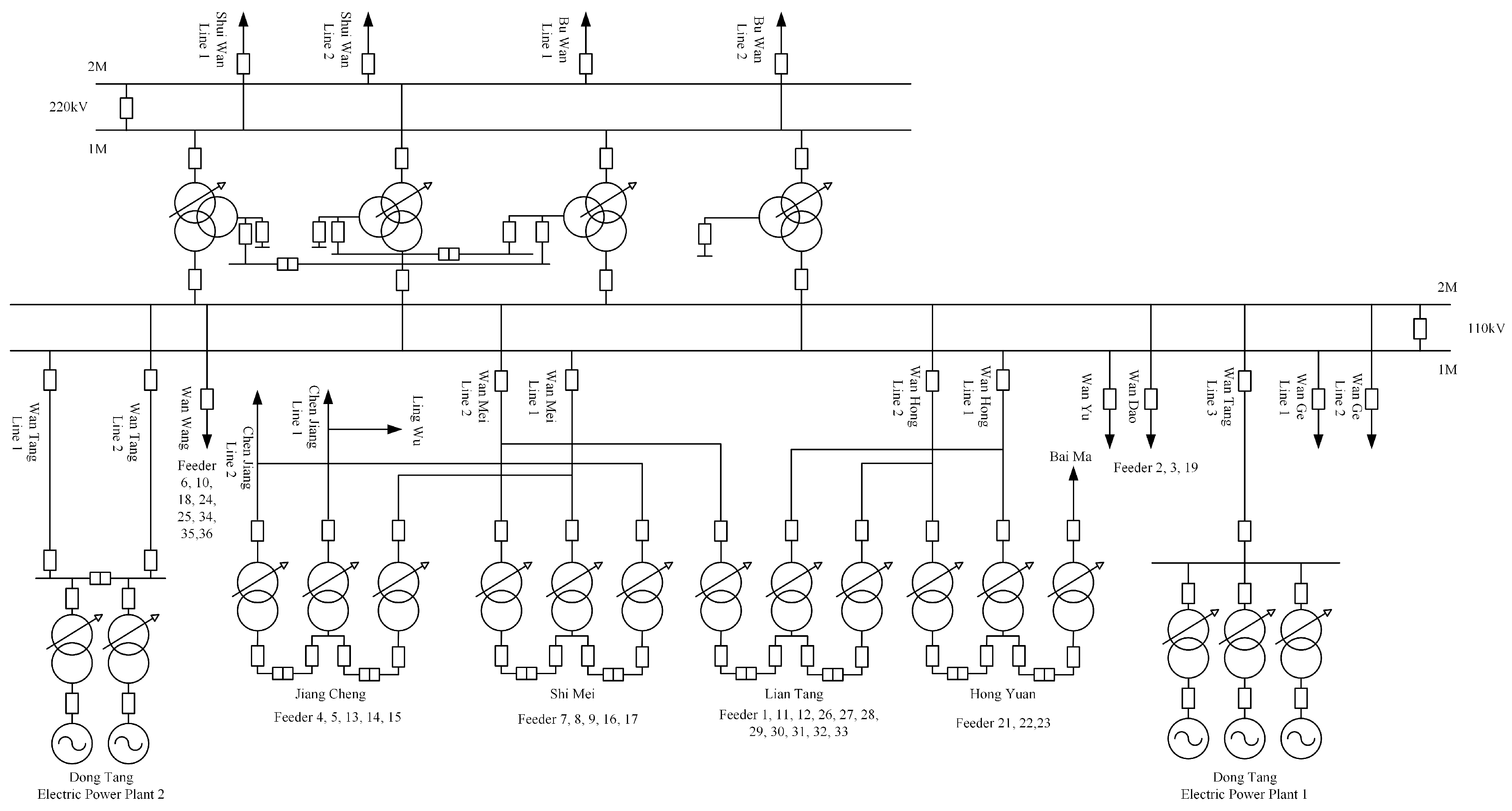
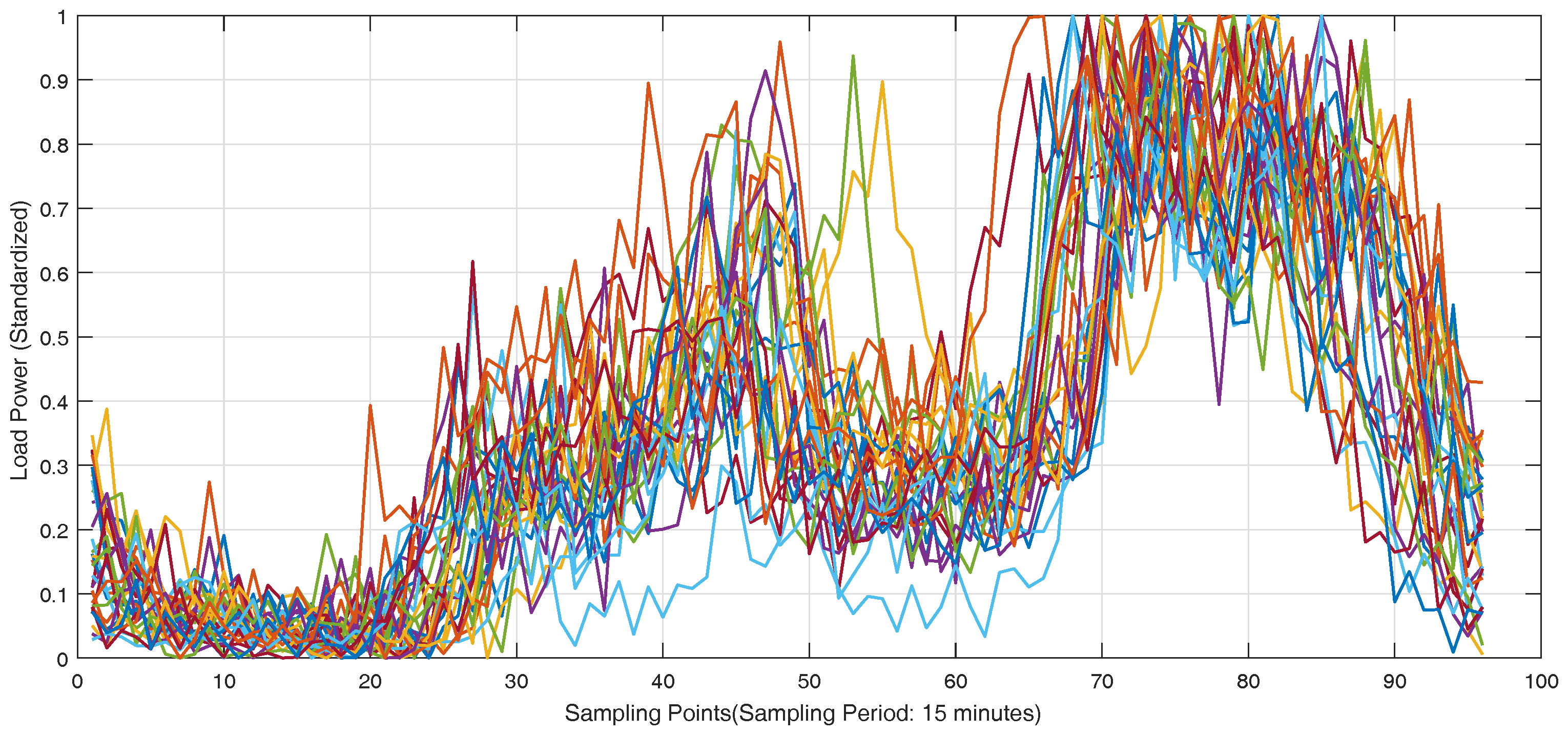
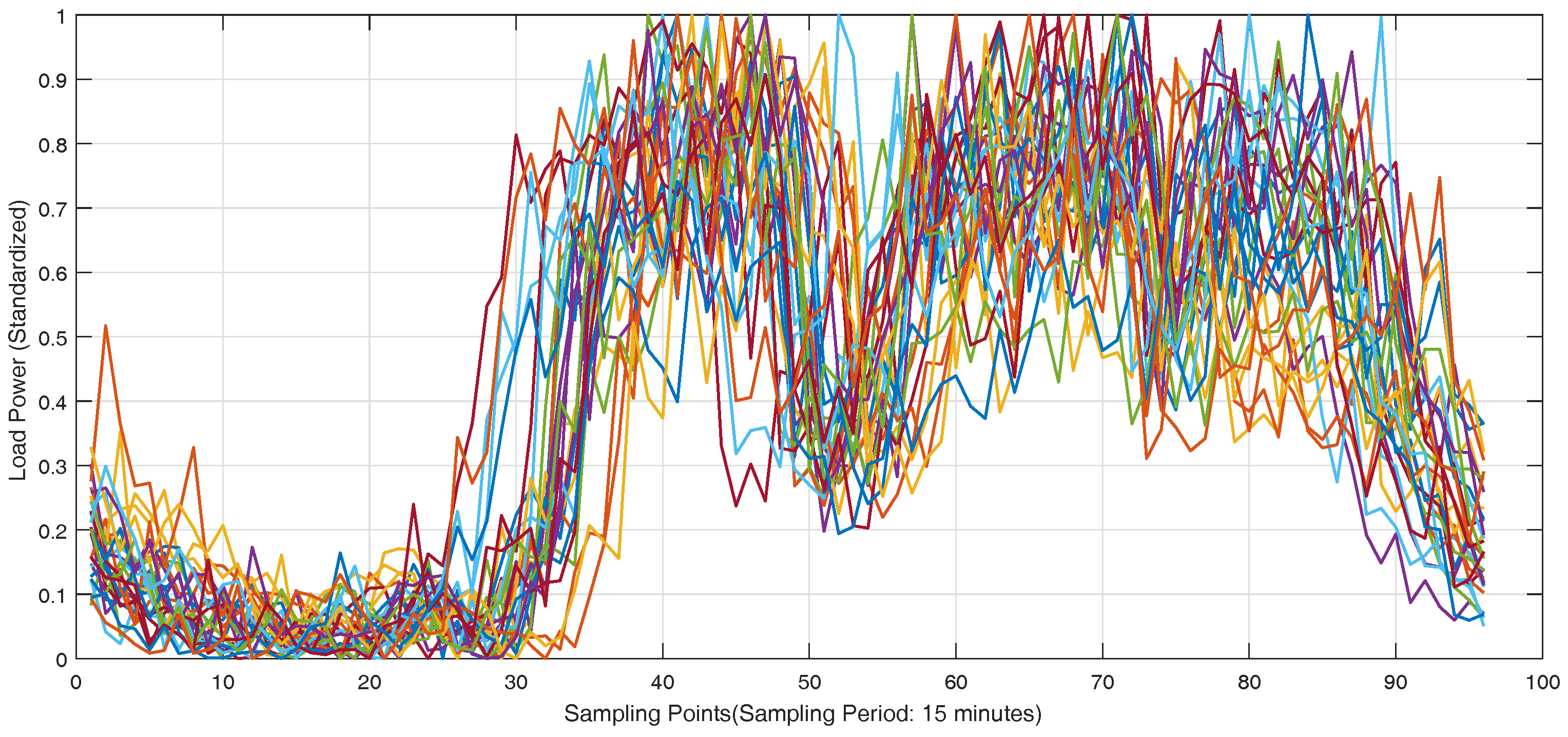
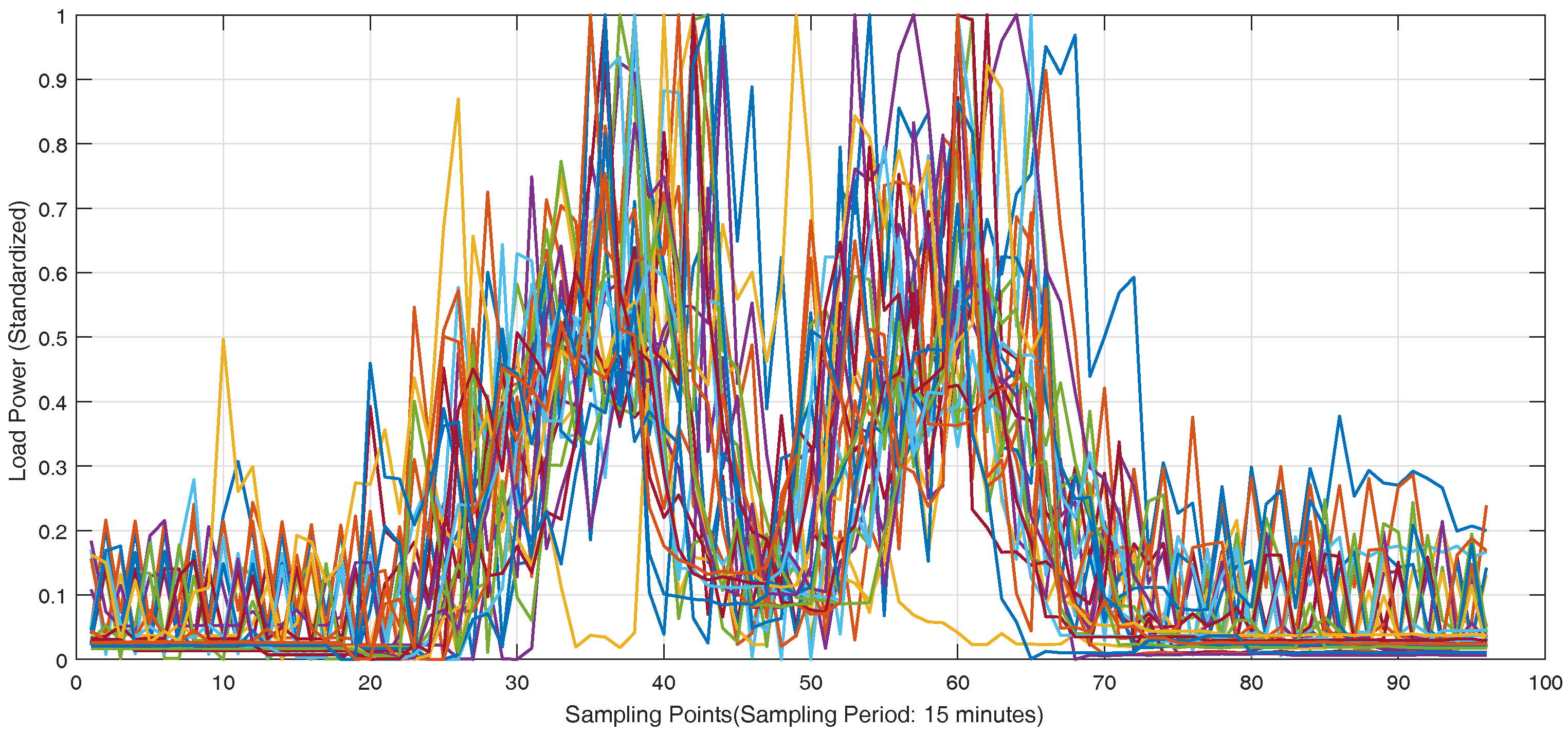
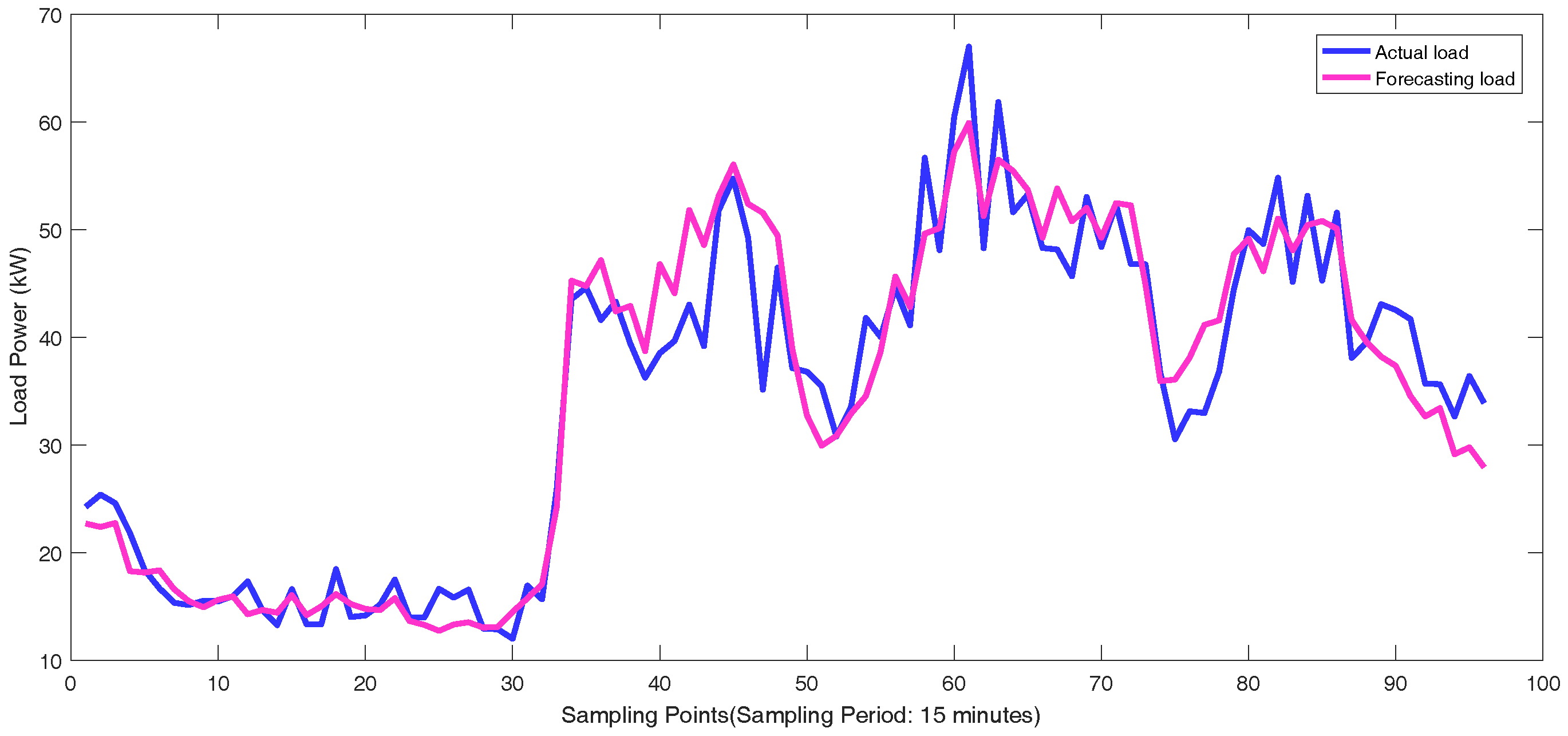
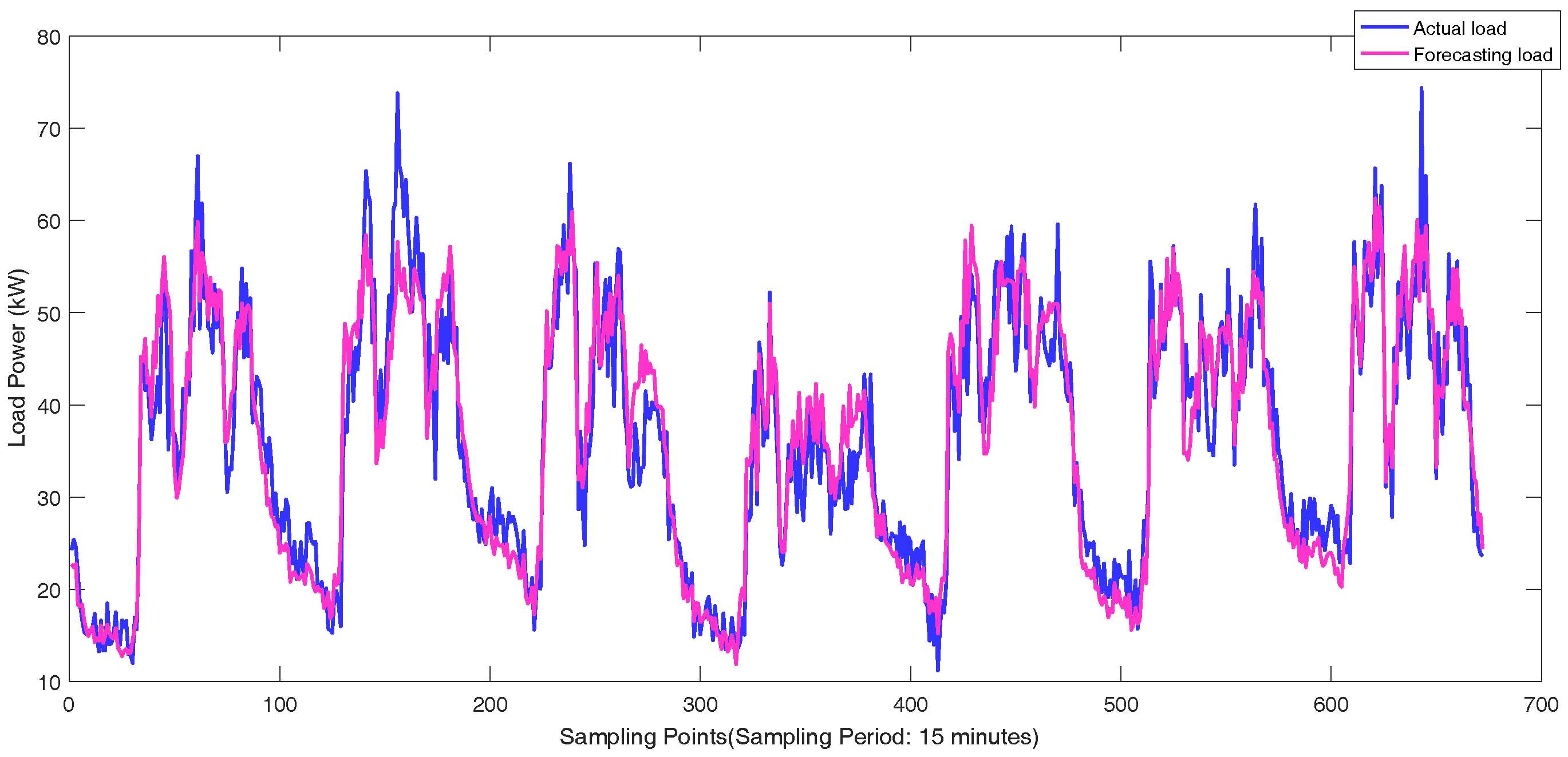
The real-world load data of individual customers in Wanjiang area is recorded from Dongguan Power Supply Bureau of China Southern Power Grid in Guangdong Province, China during 2012–2014. The topology structure of Wanjiang area is shown in
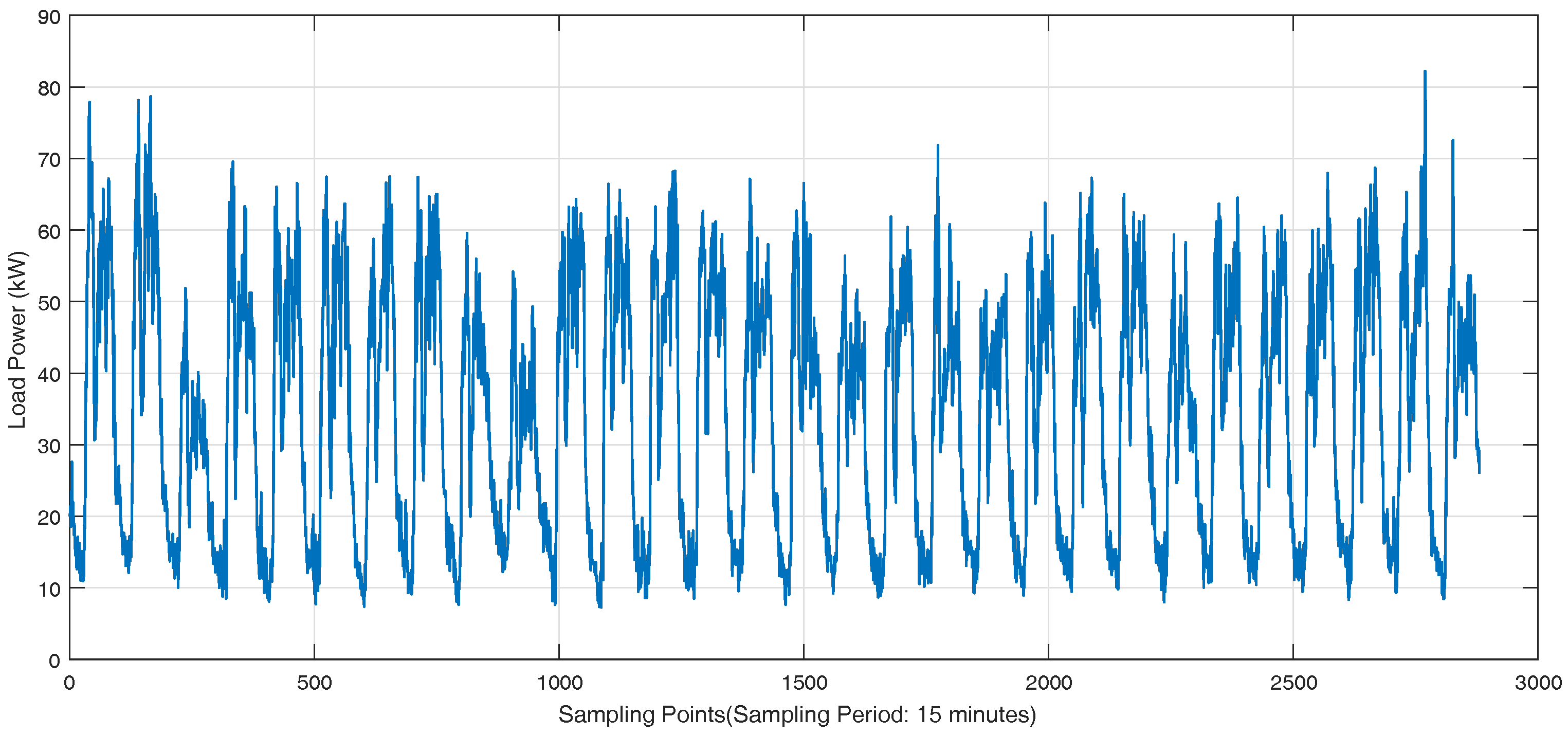
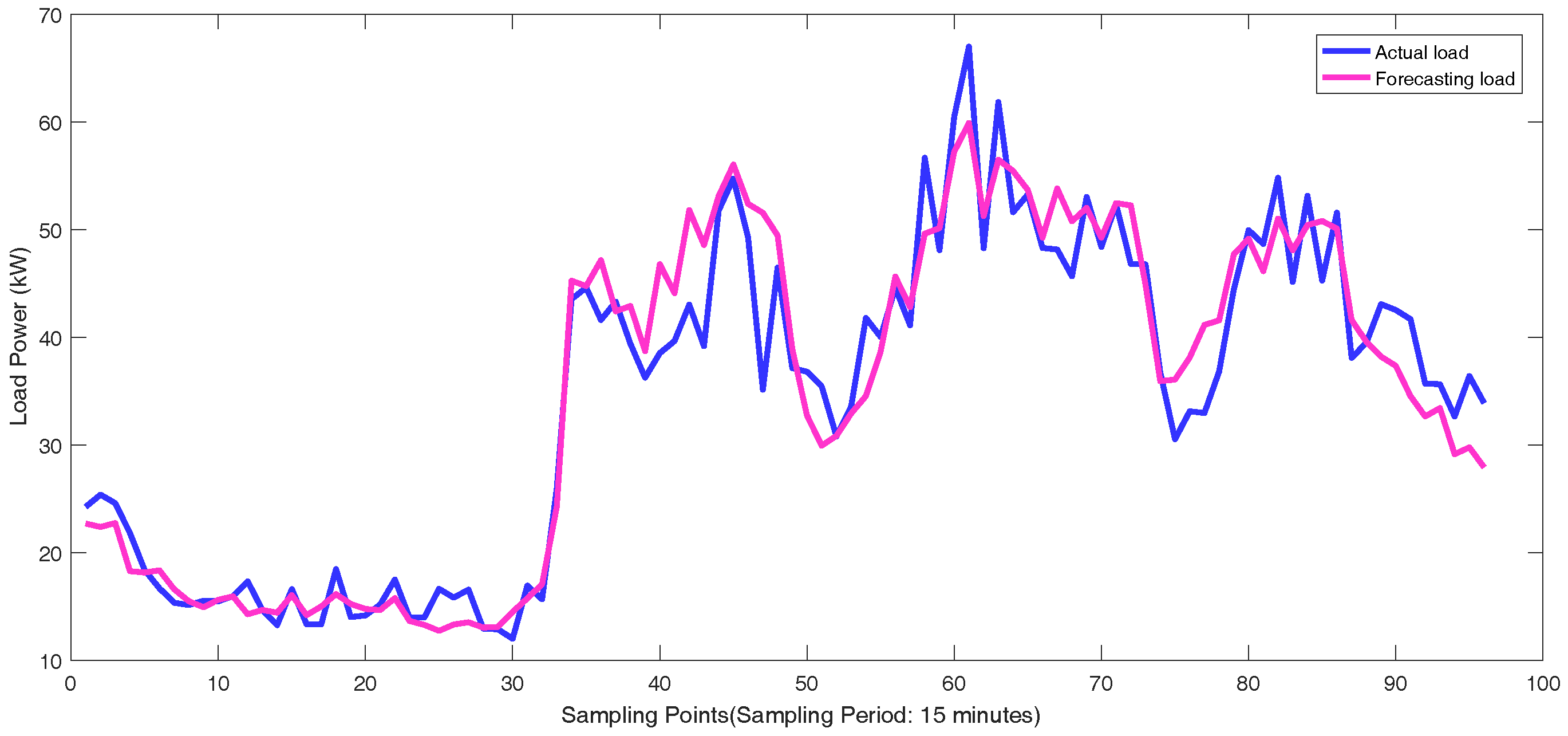
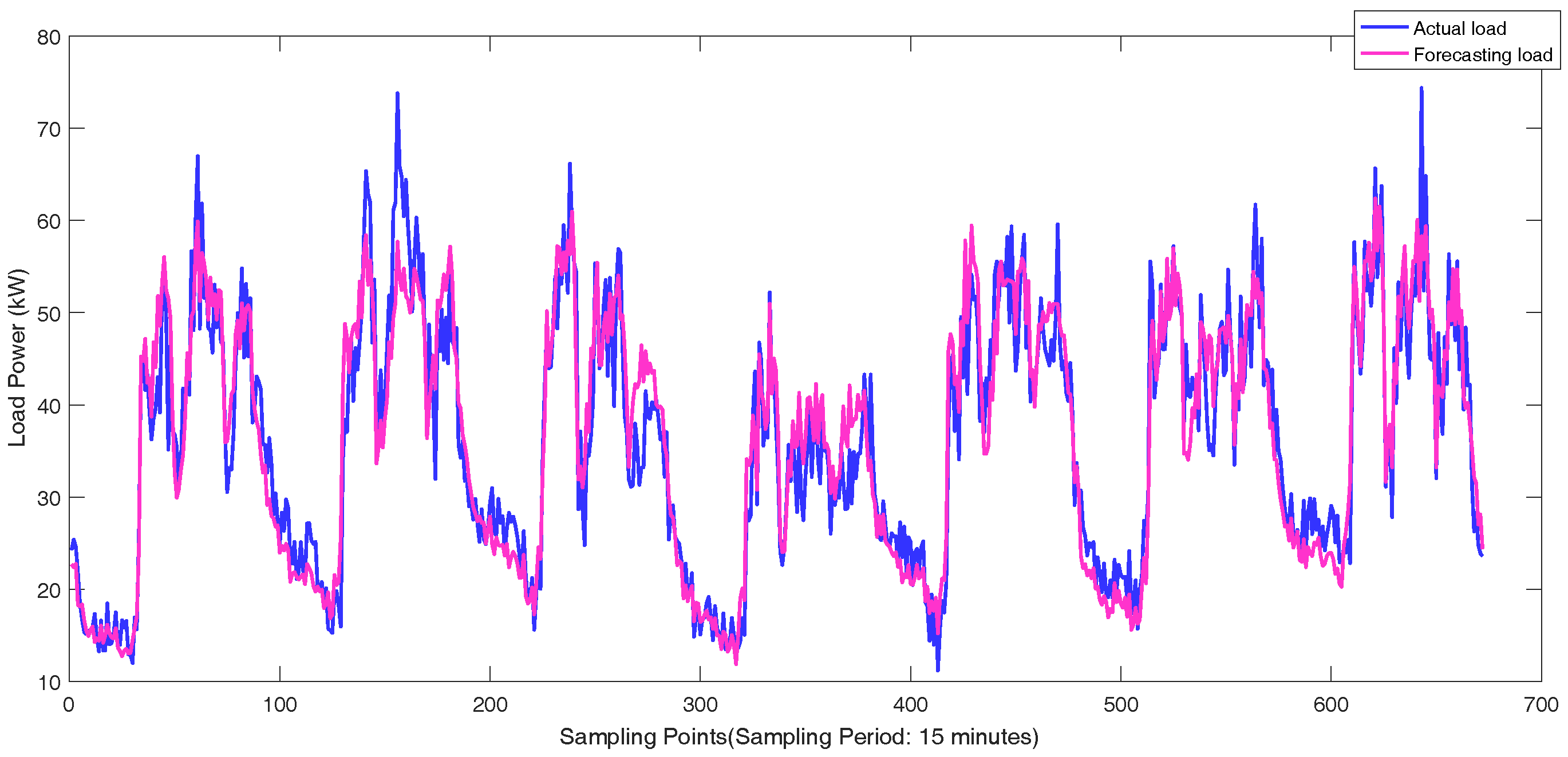
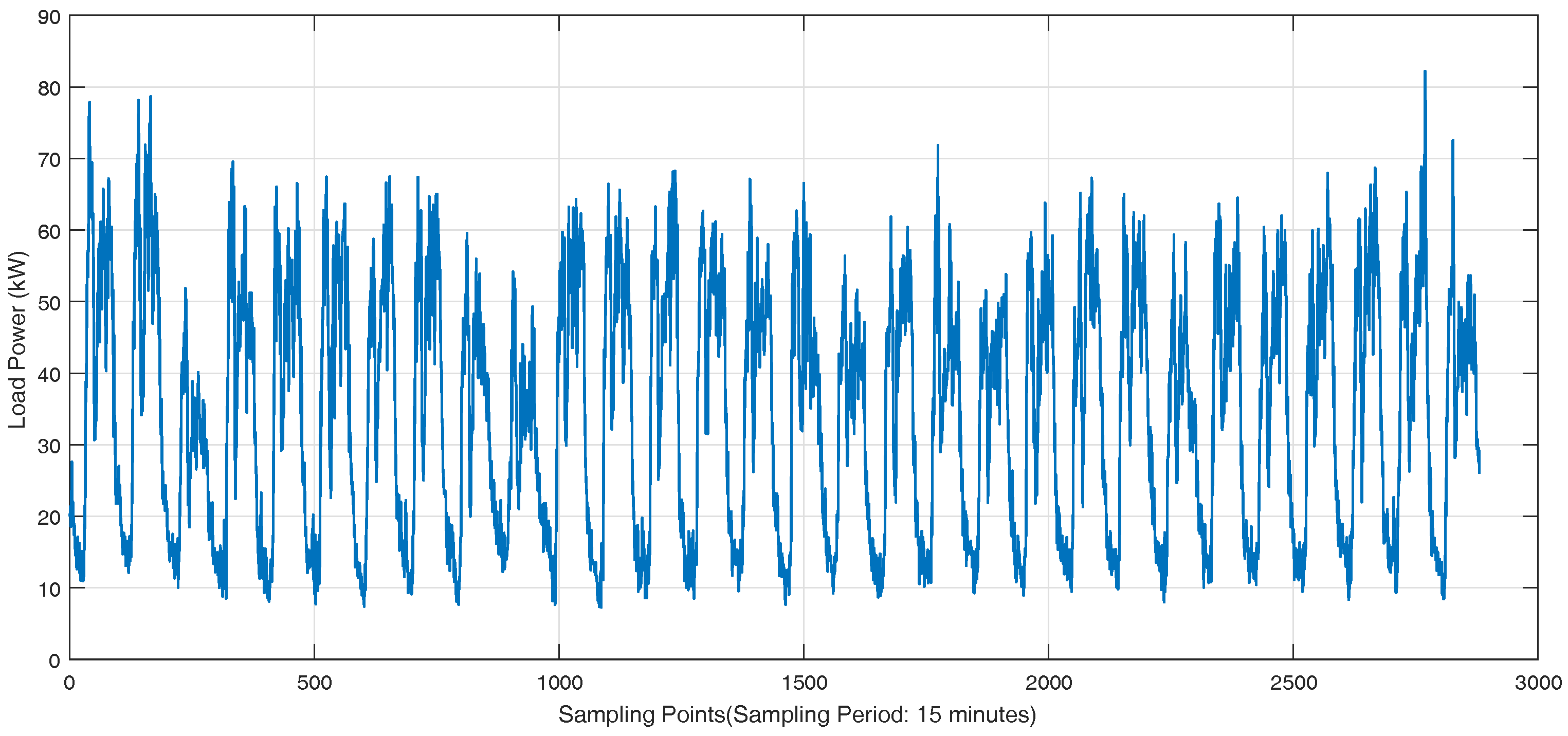
Figure 3. There are 36 feeders connecting to the load sides in the Wanjiang area, i.e., Feeders 1—36. The active power is extracted for load forecasting from these feeders. The sampling period is 15 min as the meter record data. The load curve of a customer, No. 53990001, from Feeder 2 during a month is shown in
Figure 4, where the different load characteristics of the customer on each day can be concluded.
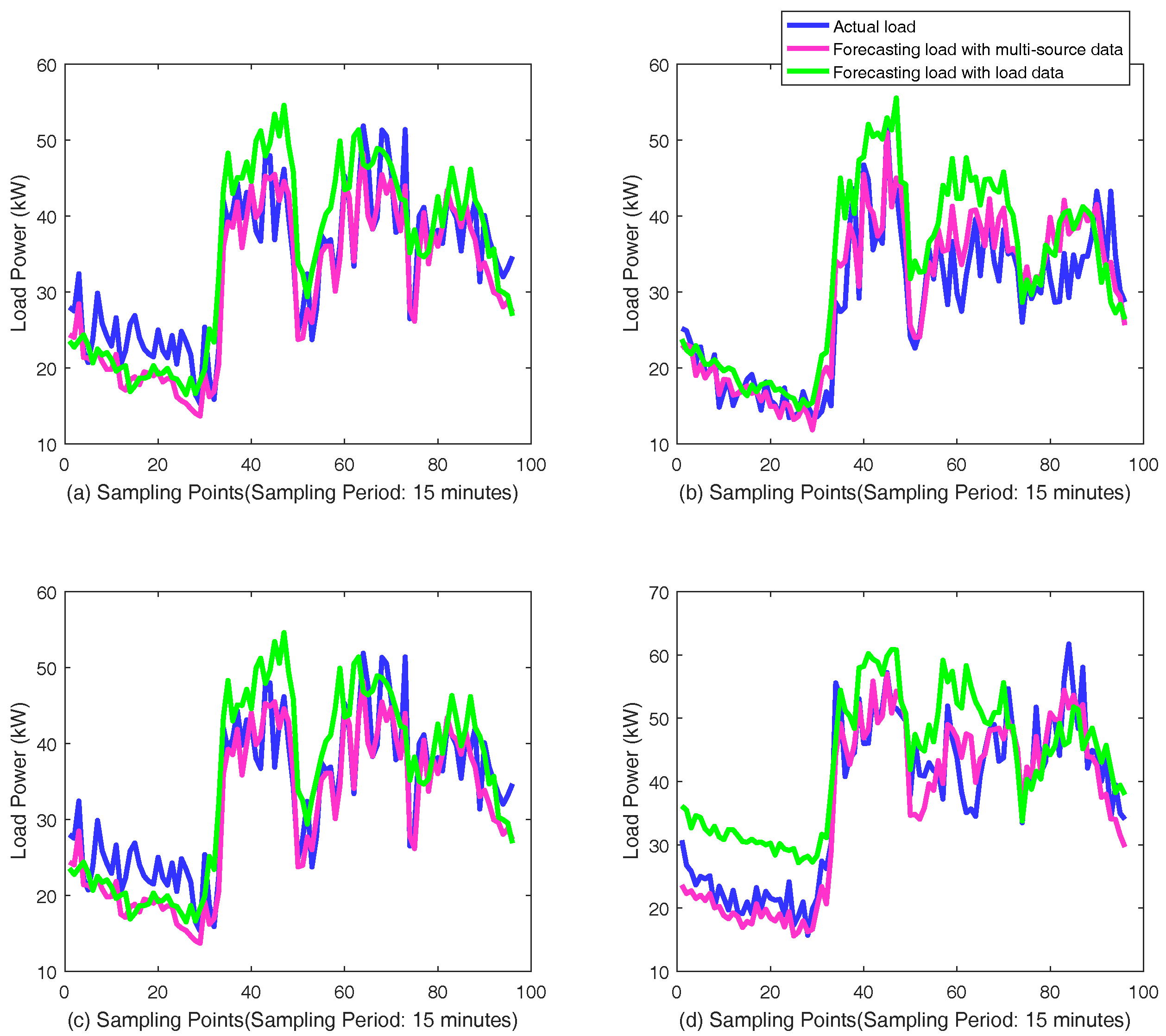
Besides the historical load curves, short-term load forecasting is influenced by the factors of date, weather and temperature. The real historical data of weather and temperature in the corresponding area in Dongguan City were obtained online from the weather forecast websites. The categories of weather include sunny, cloud, overcast, light rain, shower, heavy rain, typhoon and snow. The date features can be found in calendars.
2.3. Clustering and Quantization
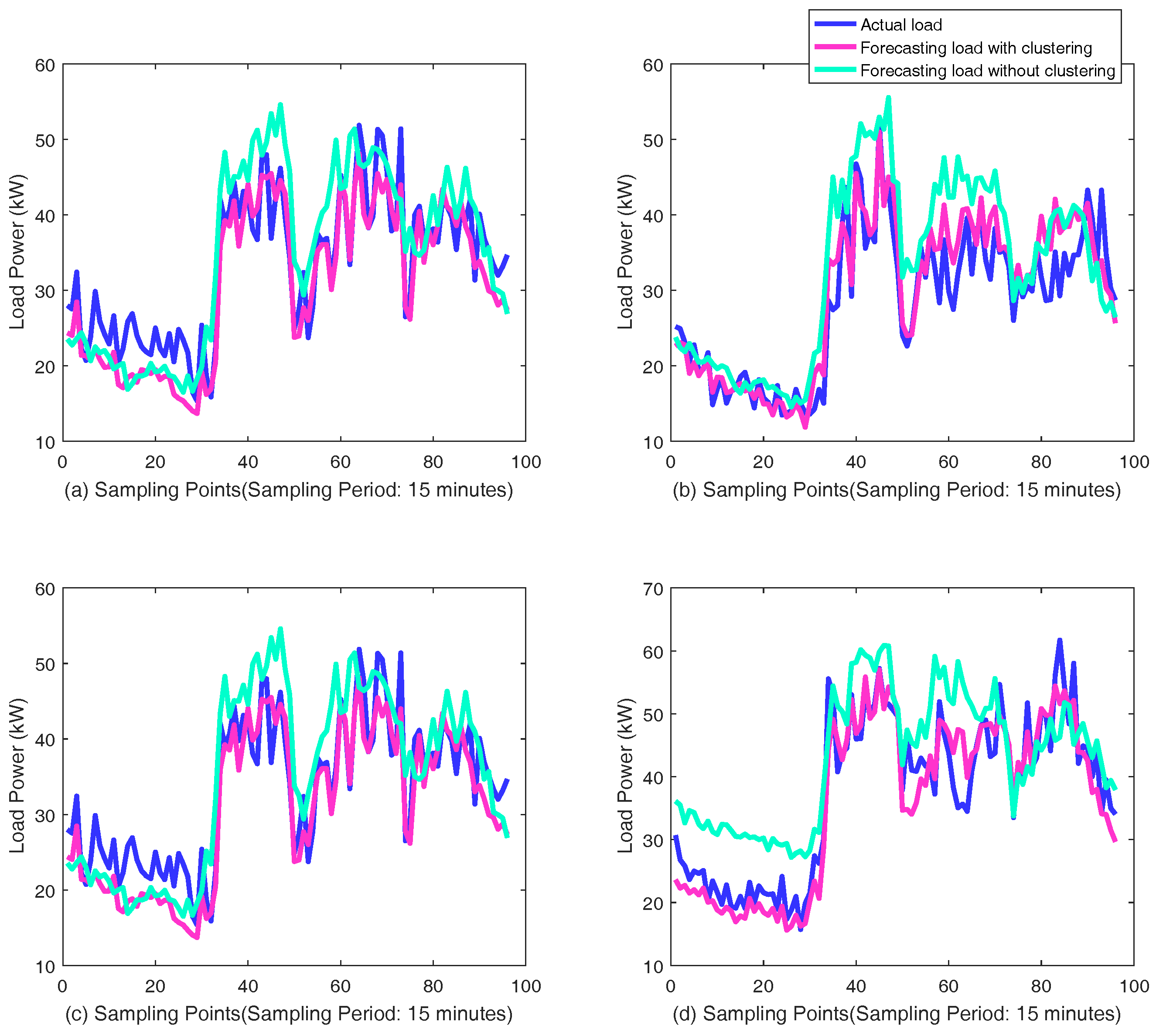
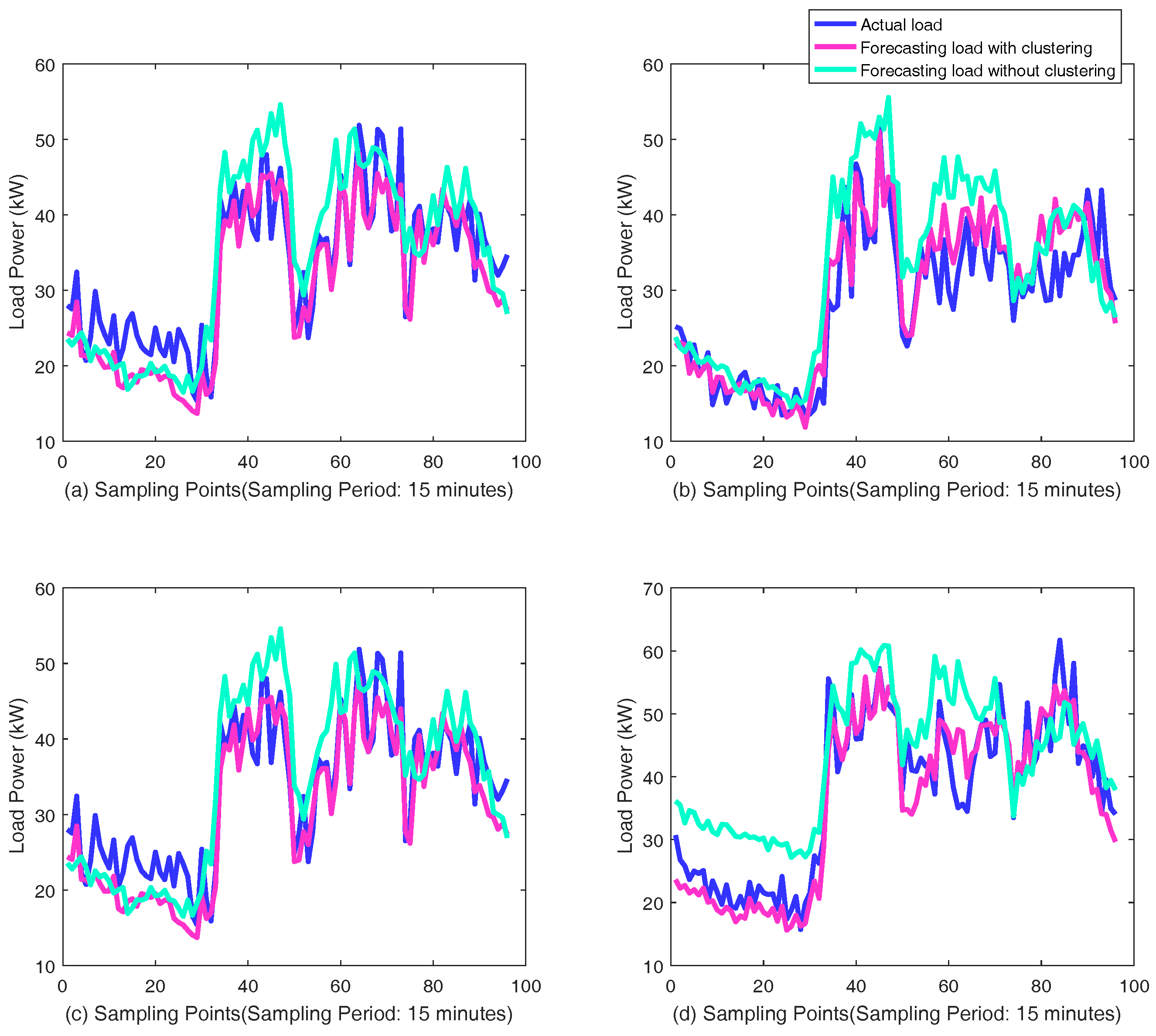
The custom of electricity use and characteristics of load curve are different among the different categories of customers such as industrial customers, residential customers and institution customers. The different characteristics would affect the performance of forecasting. Training forecasting networks with each customer separately would be a huge computation and storage problem. Therefore, in the proposed method, the load curve samples are divided into certain categories using K-means clustering algorithm. Samples with similar characteristics form a certain category, which form the input of GRU neural networks for the corresponding customers. K-means clustering algorithm is a simple and available method for clustering through unsupervised learning with fast convergence and less parameters. The only parameter, K, number of clustering category, can be determined by Elbow method with the turning point of loss function curve.
Suppose the input sample is . The algorithm is shown as follows.
Moreover, the factors of date, weather and temperature should be added into input with quantization. First, the power consumption should be different between weekdays and weekends. The official holidays are also an important factor, so we quantify the date index as shown in
Table 1, where the index of official holidays is 1 no matter what day it is. Similarly, the weather and temperature are quantified according to their inner relations, as shown in
Table 2 and
Table 3.
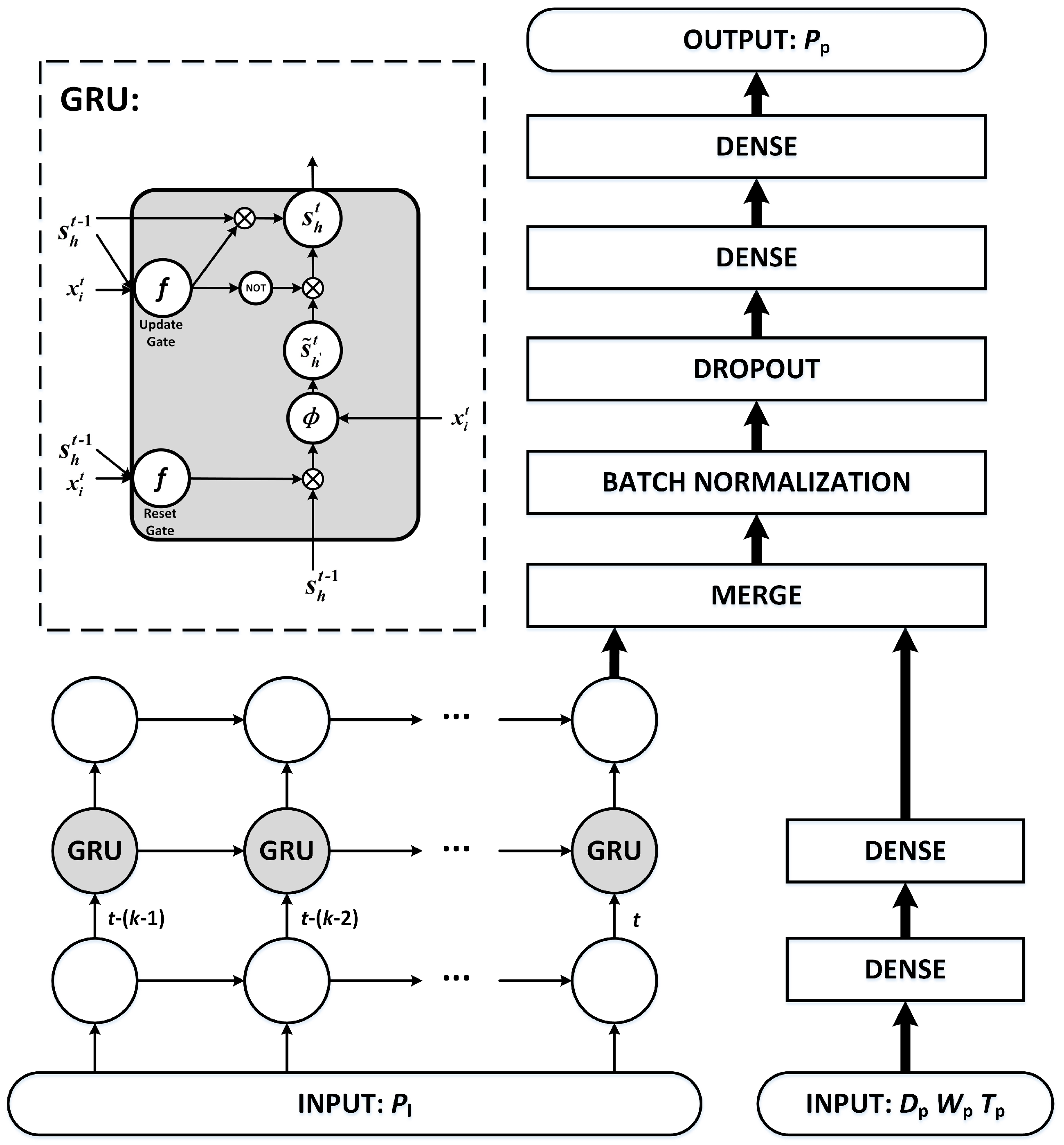
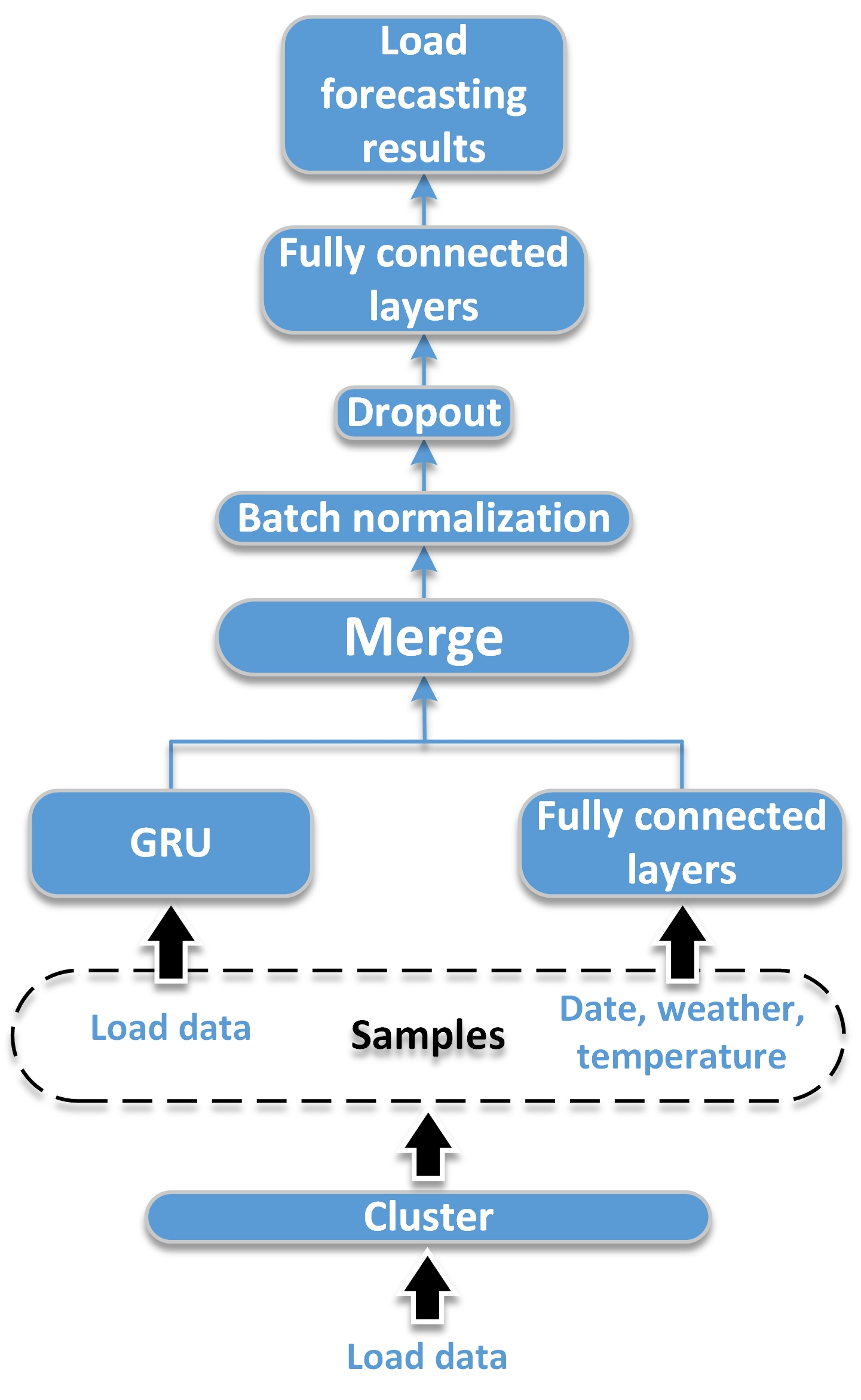
2.4. The Proposed Framework Based on GRU Neural Networks
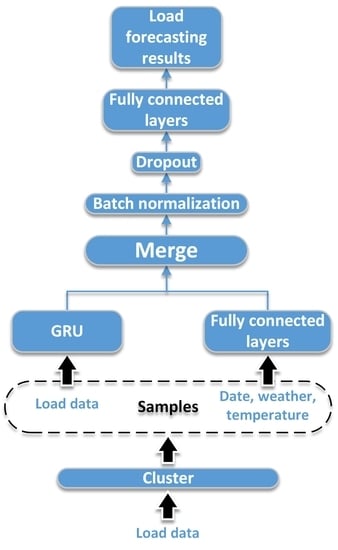
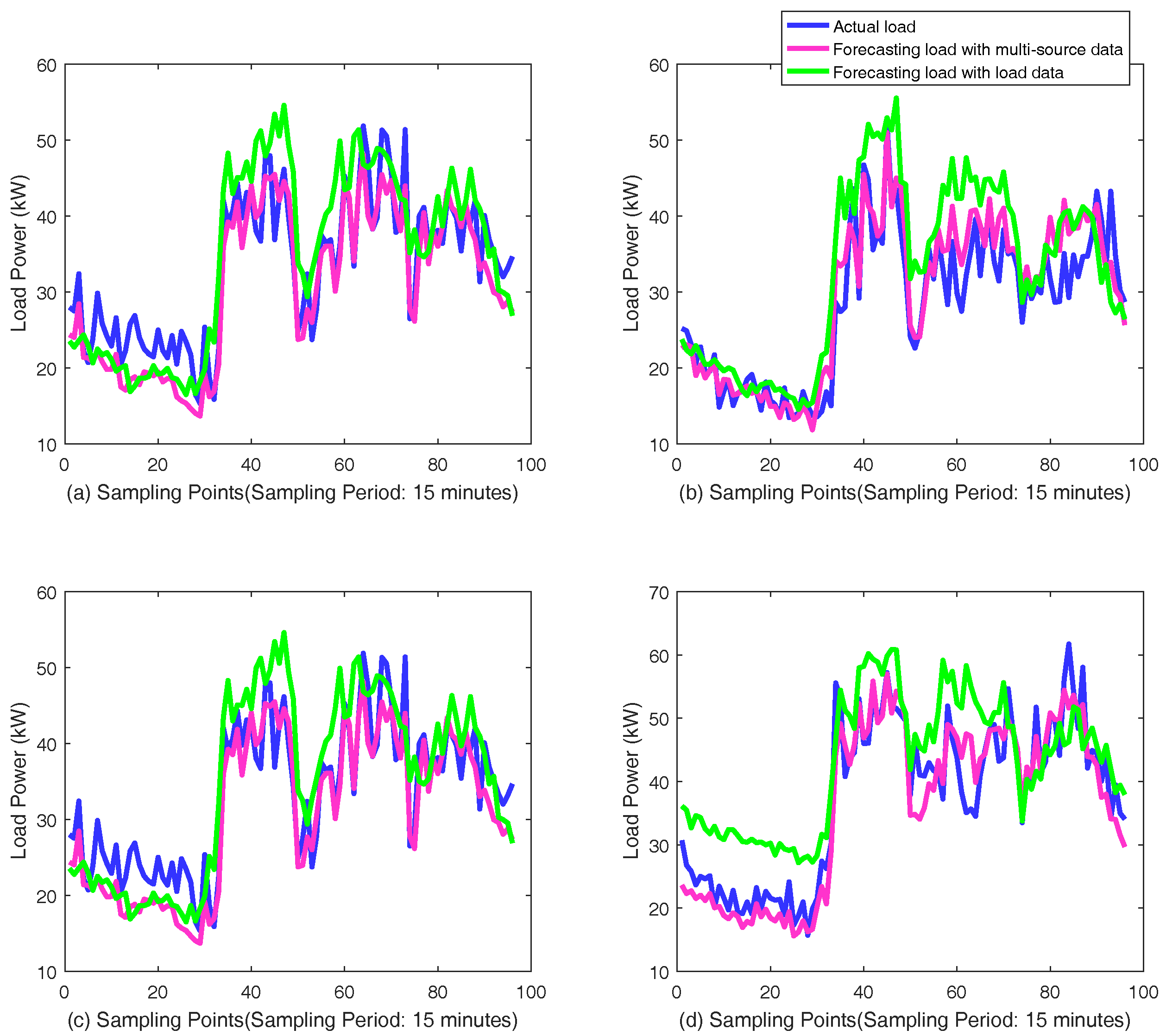
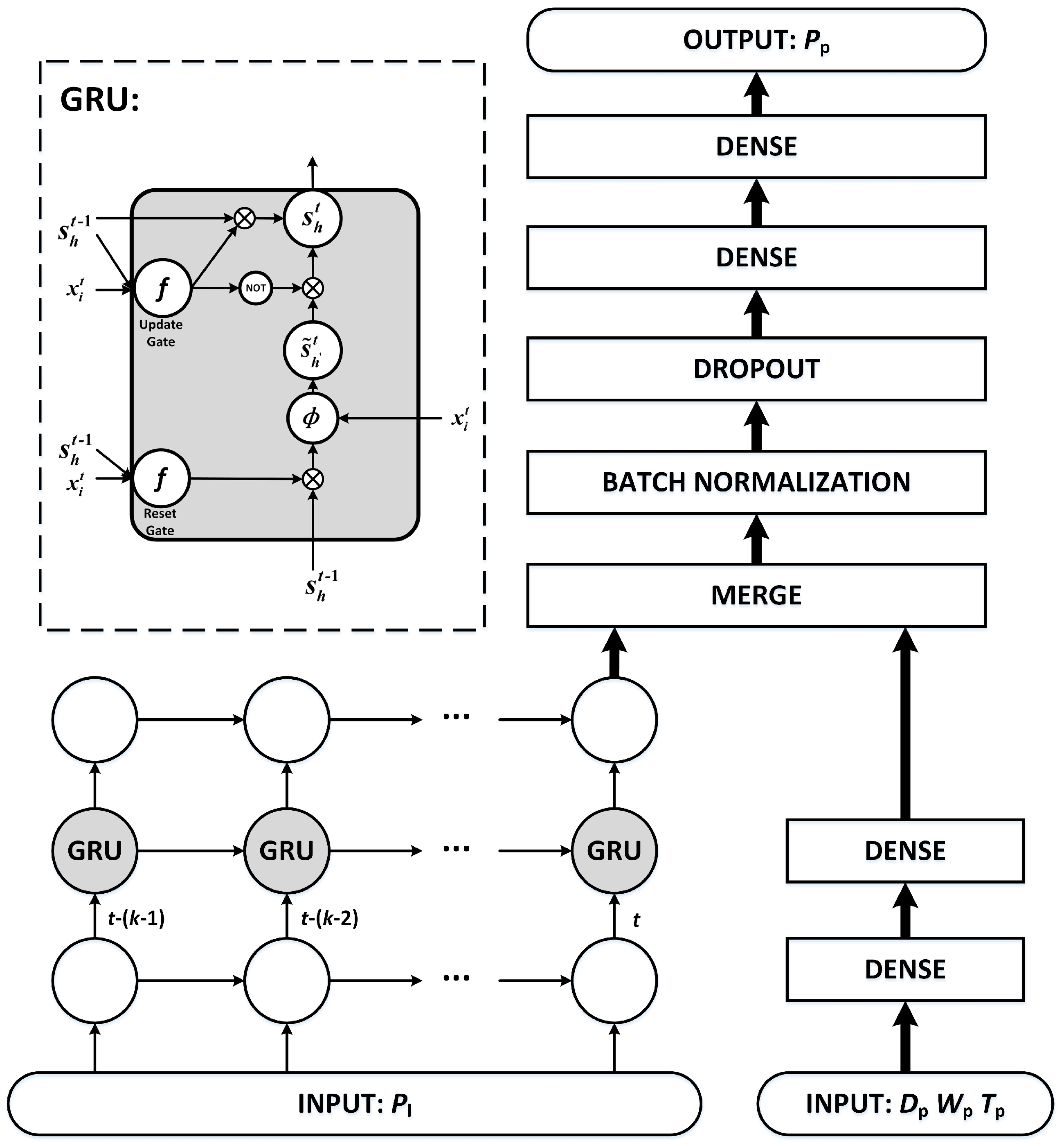
The schematic diagram of proposed framework based on GRU neural networks for short-term load forecasting is shown in
Figure 5. The individual customers are clustered into a few categories for more accurate forecasting. The samples are recorded from the categories where the customer to be predicted locates in. The load measurement data of individual customers in one day is extracted as a sample for short-term load forecasting, noted by
. The dimension of
is 96 with the 15 min sampling period. Then, the samples are reshaped into two-dimension for the input of GRU neural networks. Considering the influencing factors date
, weather
and temperature
, date
, weather
and temperature
on the forecasting day are added to the another input of the GRU neural networks. Considering the general factor of date, the prediction interval is set to seven days. Therefore, the load measurement data
on the day in the last week from the forecasting day,
,
and
, are recorded as the overall input. The load measurement data
on the forecasting day are recorded as the output, whose dimension is 96. Therefore, the input
and output
of samples are given by Equations (
14) and (
15).
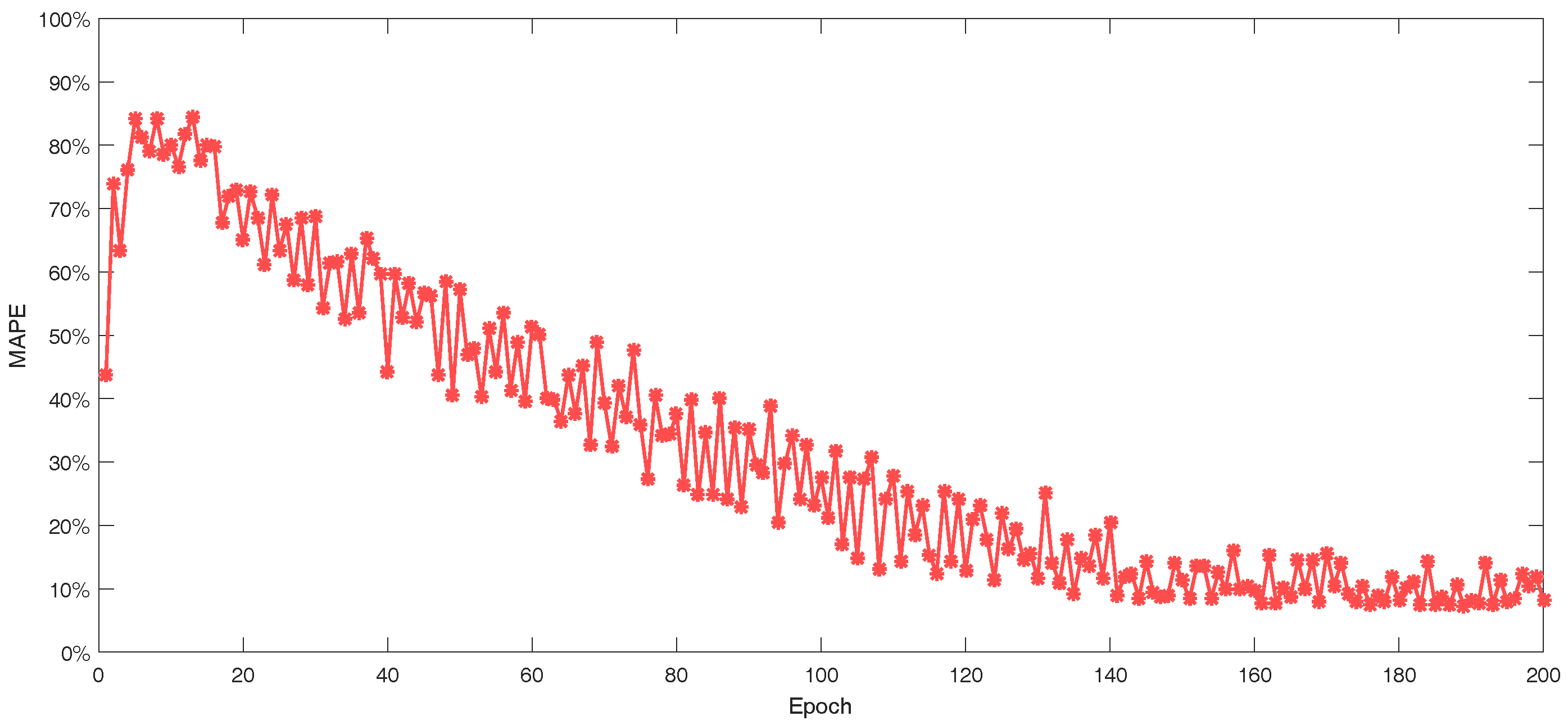
The features from GRU neural networks and fully connected neural network are merged with the concatenating mode and passes through batch normalization and dropout layer to avoid overfitting and increase the learning efficiency. The principle is that batch normalization can avoid the gradient vanishing of falling into the saturated zone, and that the better performance in fixed combination is avoided when random neurons do not work in a dropout layer. Then, two-layer fully connected neural network are added before the output for learning and generalization ability. With training by back-propagation through time, the whole network implements the short-term load forecasting for individual customers. The structure can be extended if there is more information in the practical situation. The basic theory is also acceptable for medium-term load forecasting and long-term load forecasting, but different influence factors should be considered and the model should be changed with different input, output, and inner structure for good performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
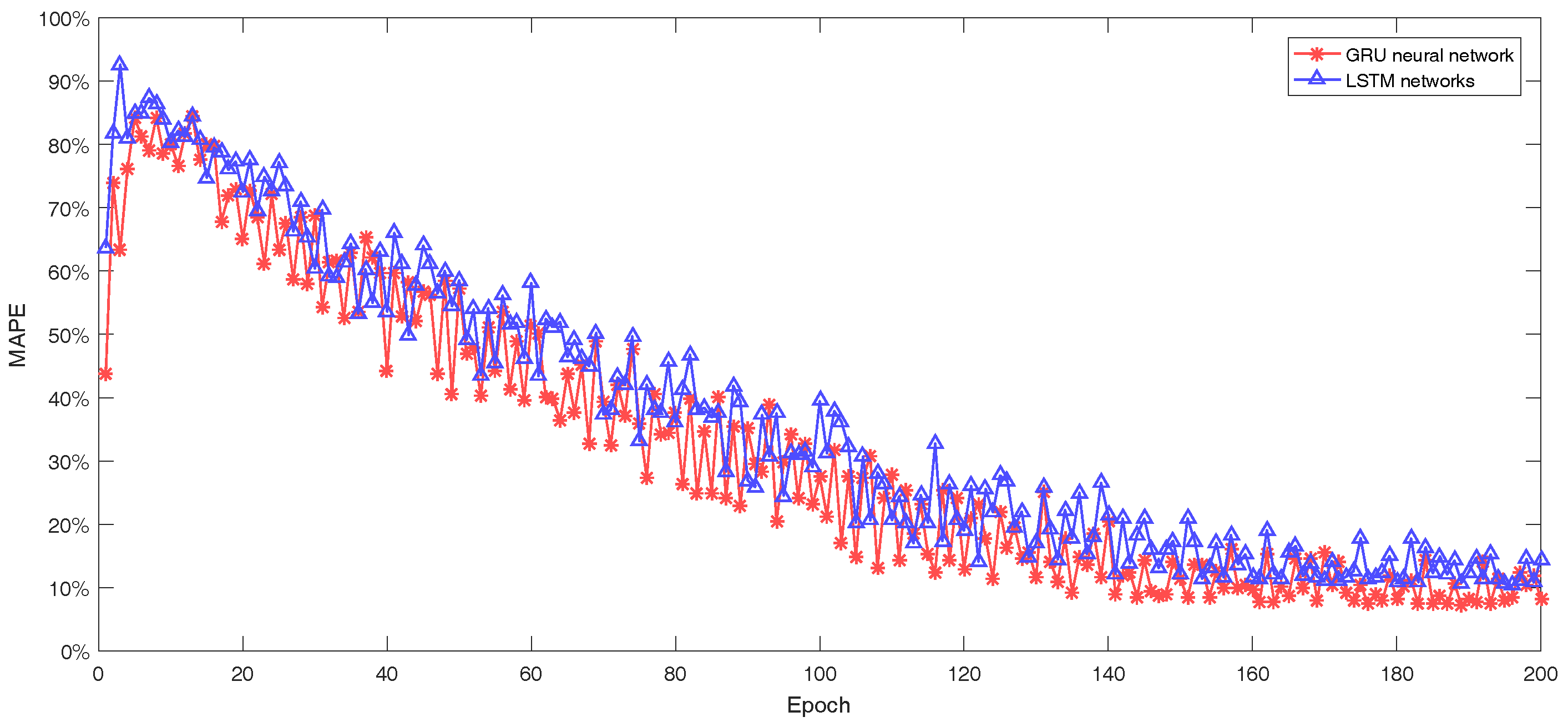{kind=link}
{kind=link}
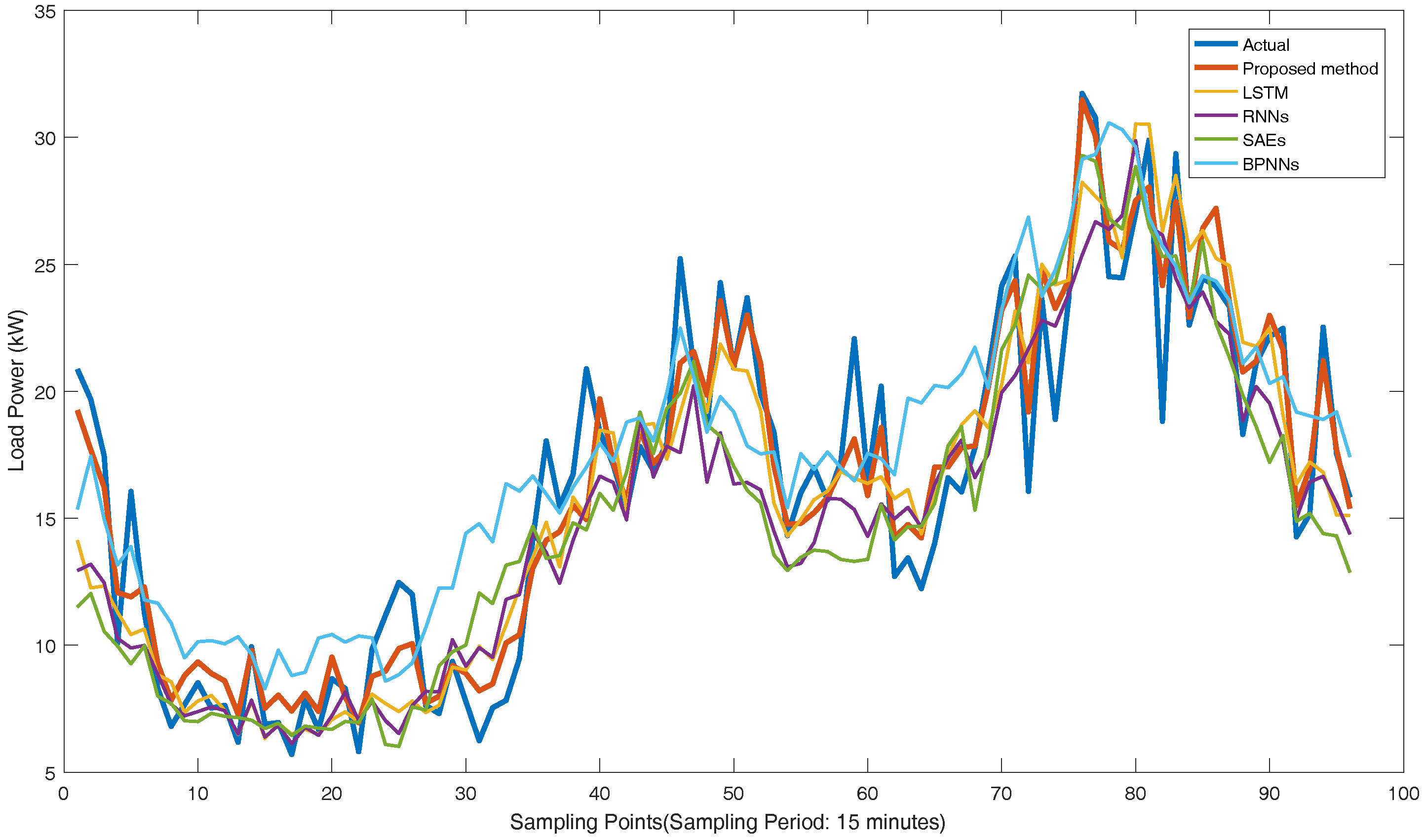{kind=link}
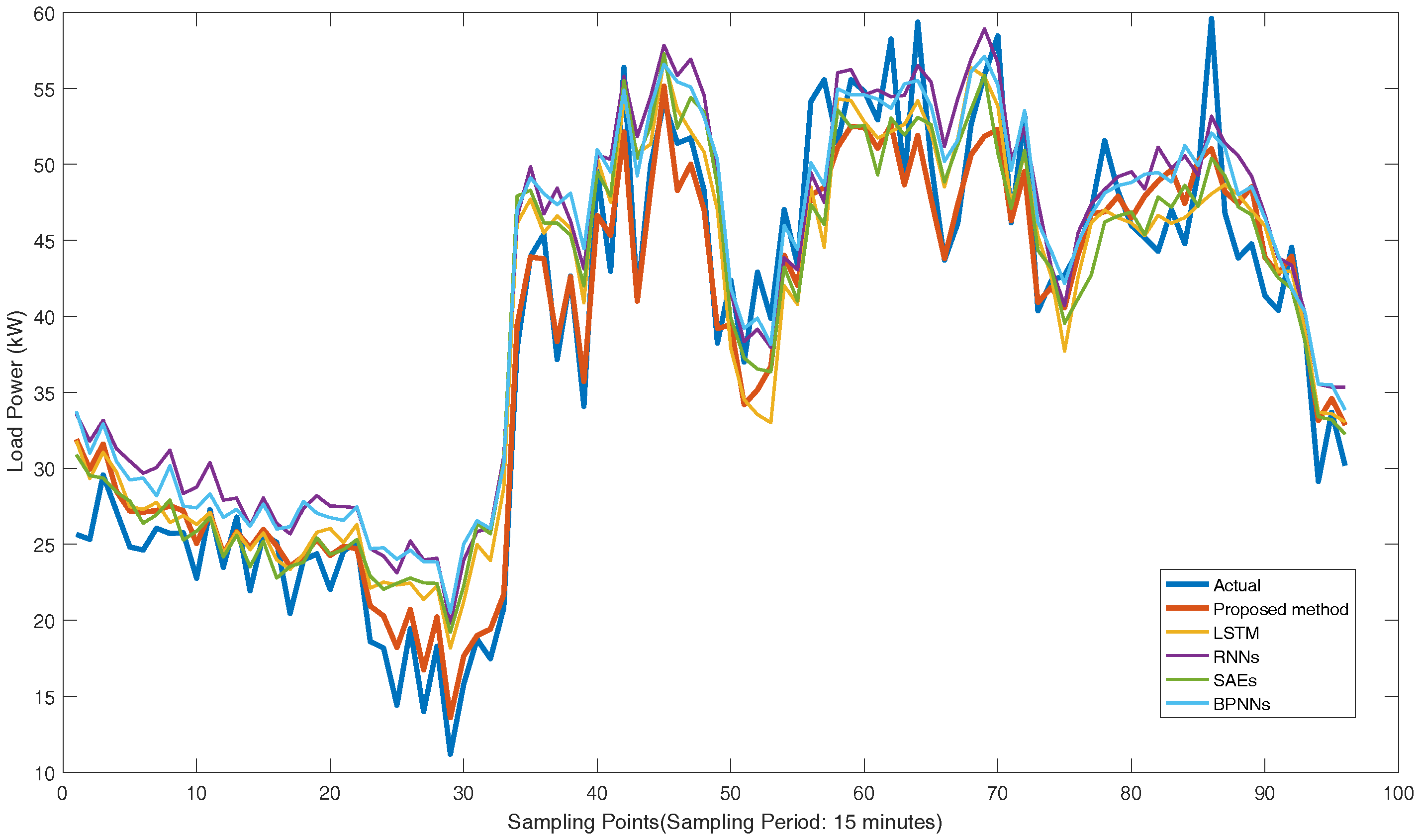{kind=link}