1. Introduction
Energy is a vital input for social and economic development [
1]. The energy crisis has been proven to be one of the major factors that limit the development of the economy, and this has been increasingly emphasized by the increasing energy demands for rapid economic development [
2]. With the continuous increase in energy demand, the consumption of non-renewable energy sources, such as coal and oil, has become alarmingly serious, resulting in an ever-growing energy crisis. This is due to the fact that fossil fuels, such as coal and oil, are slowly drying up, and non-renewable energy will become history in the near future [
3]. In view of this present situation, people have gradually turned their attention to the development and utilization of new energy sources and have tried to change the trend in energy consumption to relieve, to some extent, the double pressure caused by the dry up of conventional energy and worsening of the global ecological environment [
4].
Wind energy, one of the most important renewable energy resources, is drawing increasing attention by virtue of its prominent characteristics. such as wide distribution and prodigious reserves [
5]. The development of wind energy, as an efficient and clean energy resource, is well known and establishes a good base for the strategic transformation of economic development from relying on traditional fossil fuels to utilization of renewable energy sources [
6]. Wind energy utilization has been around for than a century, and wind power generation has also been substantially explored by humans in the past. Wind power generation technology has been developed through a long process has become increasingly mature [
7]. Moreover, there is a huge amount of wind energy in the world [
8]. By the end of 2016, the worldwide wind capacity reached 486,661 MW, of which, 54,846 MW of energy were added in 2016. This represents a growth rate of 11.8% (17.2% in 2015). All wind turbines installed around the globe by the end of 2016 can generate around 5% of the world’s total electricity demand [
9].
As we all recognize, China has a large population, and its economy has been predicted to maintain good momentum of development. Thus, the above problems become more prominent due to the amazing energy consumption and the growth speed of traditional fossil fuel exploitation. In the near future, the supply of fossil fuel will not keep up with the demand which may hold back economic development. At the same time, the pressure of environmental degradation is also a problem that people have to face. Therefore, it is urgent to rationally adjust the energy structure for the sustainable development of the economy. In view of these reasons, the research about new energy, especially the wind power industry becomes more necessary. The wind power industry in China, through the government’s great attention, is playing a positive role in optimizing the energy structure, promoting changes in energy production methods, and promoting transformation in the energy consumption of modern industrial systems [
10].
Moreover, in wind data, it is necessary to consider and discuss the frequency of data sampling. According to State Grid Dispatching arrangement and plan in China, 144 wind speed datapoints should be obtained per day (24 h). In other words, the sampling interval is supposed to be 10 min. Ten minute wind speed forecasting has contributed to scientific and rational arrangements for the shut-down and start-up of the generators in the net so that the system can maintain a rotational reserve capacity within a reasonable and safe range [
11]. Moreover, the minimum time interval recorded by the anemometer is 10 min at present. Thus, the sampling interval is set to 10 min and sampling frequency is 144 times per day in most researches [
12] to meet the requirement of power grid scheduling in China.
While the potential of wind power as an energy resource is fully ascertained, its controllability needs to be improved. This controllability of wind power can be improved if the wind speed and the power output of a wind farm can be forecasted as accurately as possible and changes in wind speed can be predicted well in advance [
13]. This would also help mitigate a series of adverse effects that result from wind power grid integration. Wind speed is influenced by several factors, such as air pressure, temperature, and humidity, which lead to randomness and volatility in wind speed prediction [
14]. Wind speed forecasting has been an important link in the planning and working of power grid system; this is a heavy and high repetitive work. Moreover, wind speed forecasting is the basis of wind power and an important prerequisite for wind-power generation capacity forecasting. Thus, wind speed forecasting is a significant task and establishing a high accuracy of the wind speed forecasting model becomes a pressing concern [
15].
The rest of this paper is organized as follows:
Section 2 reviews and discusses the extant studies on wind speed forecasting. The methods used in this study are introduced in
Section 3.
Section 4 describes the datasets and setup.
Section 5 describes the experimental results obtained from the datasets, while
Section 6 analyses and discusses the forecasting results.
Section 7 discusses parameters of the hybrid forecasting system.
Section 8 further carries out the experiment for hourly time-horizon wind speed forecasting, and
Section 9 gives the conclusion.
Figure 1 clearly explains this structure.
2. Review and Discussion for Previous Works
Based on the discussion presented in
Section 1 above, it can be appreciated that wind speed forecasting is a challenging yet crucial task. The accuracy and stability of such a forecasting is, perhaps, the single most significant issue, and as such, numerous extant researches have been targeted at addressing this concern.
Two prominent models used at present for wind speed forecasting include the single model [
16,
17,
18] and hybrid model. The single model mainly comprises of a physical model, statistical model and an artificial neural network model. The physical model essentially utilizes a dynamic atmosphere model to simulate and forecast the wind speed. In the real-world scenario, hydrodynamic and thermodynamic equations that model changes in the weather pattern are used along with specified initial and boundary conditions to model the exact situation to be simulated by a megacomputer [
19].
Time series is a set of values wherein all values of one index are arranged in chronological order. The main utility of the time series model is to forecast the future based on historical data. The traditional statistical models, such as Autoregressive (AR) [
20,
21], Autoregressive Moving Average (ARMA) [
22], Autoregressive Integrated Moving Average (ARIMA) [
23], and exponential smoothing (ES) [
24], have widely used and reported in literature for their utility in wind speed forecasting, which was originally developed by Kendall and Ord [
25].
Artificial neural network models have attracted extensive attention of scholars in various fields as they are capable of modeling linear as well as nonlinear functions arbitrarily. The use of artificial neural networks is a popular method for wind speed forecasting. Li et al. [
26] compared three different neural networks for wind forecasting, including the adaptive linear element, back propagation, and radial basis function, and demonstrated that no single model is superior to others for all evaluation metrics. Hervás-Martínez et al. [
27] proposed the hyperbolic tangent basis function neural network for wind forecasting, and the results demonstrate that their model improved the performance of the previous multilayer perceptron. Salcedo-Sanz et al. [
28] forecasted the short-term wind speed by applying the Coral Reefs Optimization (CRO) algorithm and an Extreme Learning Machine (ELM). A Feature Selection Problem (FSP) was carried out to prove that the CRO-ELM approach had an excellent performance in wind speed forecasting. A further study showed that better results could be obtained by using ELM in conjunction with a CRO-Harmony Search (HS) optimization algorithm [
29]. In addition to these above-stated models, other popular models employed in wind forecasting include support vector regression [
30,
31,
32,
33], Bayesian mode [
34], and regression trees [
35].
As mentioned above, no single model can obtain optimum results under all situations and perform better than others on all fronts. Therefore, some hybrid models have been proposed to remedy some of the weaknesses [
36,
37,
38,
39]. A hybridization of the fifth generation mesoscale model with neural networks was employed to address the short-term wind speed forecasting issue [
40]. Similarly, the hybridization of global and mesoscale weather forecasting models with neural networks was also employed for short-term wind speed forecasting. The results prove that the hybrid weather forecast model’s neural network approach can achieve great forecasting results for short-term wind speeds under specific situations [
41]. Hervas-Martinez et al. proposed a hybrid model that combines the physical, statistical, and artificial neural networks, and achieves great forecasting accuracy [
42]. Zhang et al. [
43] developed a novel wavelet transform technique (WTT)-seasonal adjustment method (SAM)-radial basis function neural network (RBFNN) for short-term wind speed forecasting, which was proved to be an effective approach to improve the forecasting performance. Compared to the single model, the hybrid model was found to effectively improve the forecasting accuracy.
In addition to the choice of the forecasting model, de-noising of raw data also makes a significant contribution to the prediction accuracy. Wind signal de-noising methods, such as empirical mode decomposition [
44,
45], secondary decomposition [
46], and fast ensemble empirical mode decomposition [
47] algorithms, can effectively reduce noise in the wind speed time series signal and greatly improve the prediction accuracy.
Additionally, in the physical model, results of the numerical simulation greatly influence forecasting accuracy. The physical model is based on a large amount of historical data and requires specific and accurate physical information, such as pressure, temperature, and terrain, which may result in the systematic errors [
48].
As for the time series methods, they, too, often require a large amount of historical data and face restrictions imposed by assumptions, such as normality postulates [
49]. At the same time, models based on artificial intelligence often suffer from over-fitting or the difficulty of parameter setting. Moreover, over a long period, the existing forecasting models forecast wind speed by mostly using the original wind speed data recorded directly from wind farms, and as such, the high volatility of this data and outliers, which are not accounted for in the model, seriously influence the forecasting accuracy [
50,
51].
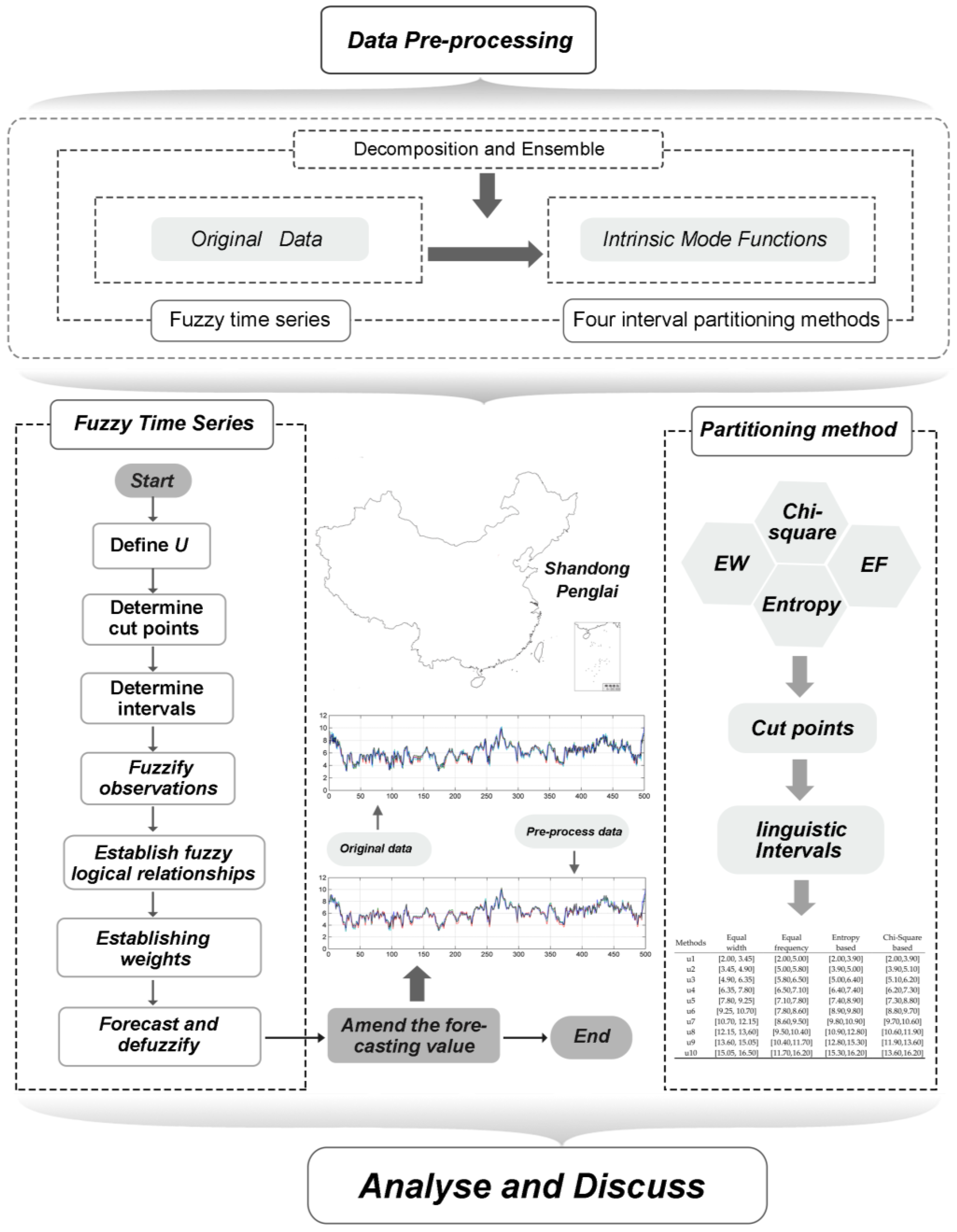
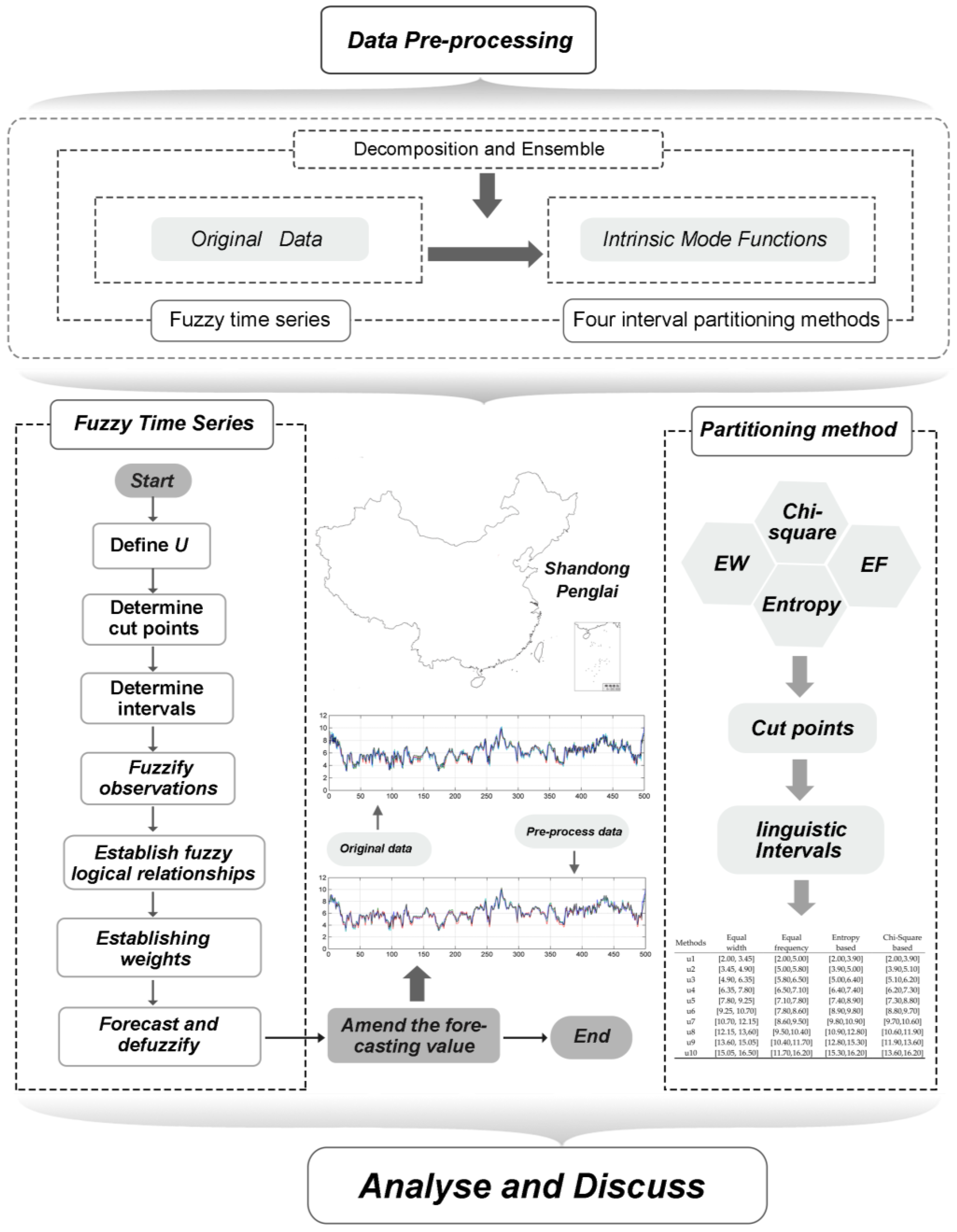
Hence, for the more accurate and stable forecasting results, a hybrid forecasting system, which combines a ‘decomposition and ensemble’ strategy and fuzzy time series model, is proposed in this paper. The proposed system includes two modules—data pre-processing and forecasting—to achieve better forecasting performance. In the data pre-processing module, ensemble empirical mode decomposition is employed to decompose the time series into finite number of intrinsic mode functions and reconstruct the raw wind data to overcome any non-stationary features. Next, in the forecasting module, a fuzzy time series, constructed by fuzzy sets, is developed to carry out wind speed forecasting. In fuzzy time series algorithm, a set of continuous numbers are assigned with linguistic value according to different interval partitioning methods which will also be discussed and compared in this paper. Furthermore, a set of comprehensive evaluating indicator system are established to compare different models’ performance. Accordingly, features of the developed hybrid forecasting system and our main contributions through this study are as follows:
A hybrid forecasting system is developed including two modules—data pre-processing and forecasting. Unlike previous time series models that dealt with continuous numbers, the fuzzy time series model is handled by fuzzy sets, which solve the weakness of traditional models requiring extensive historical data and assumptions. The effectiveness of this hybrid system is tested and is found to significantly enhance forecasting performance.
The pre-processing of raw data for wind speed forecasting makes significant contribution to forecasting accuracy. However, in most extant studies, the forecasting was often based on original data, which was not pre-processed. The volatility of and noise in unprocessed data seriously influence the forecasting accuracy and stability. The proposed hybrid system employs the ‘decomposition and ensemble’ strategy to effectively reduce noise in the wind speed time series signal. The results prove that eliminating the noise and uncertainty components from the original chaotic time series by pre-processing the raw data can remarkably improve the forecasting performance.
The forecasting performance of the fuzzy time series model is always influenced by the interval length, which in turn, depends on the discretization method. Therefore, to search for the most suitable discretization method for wind speed forecasting, four different interval partitioning methods of fuzzy time series have been discussed and compared. The results indicate that supervised discretization methods outperform unsupervised methods in most cases.
To obtain the best settings of the system, sensitivity analysis of the parameters of the hybrid system is performed, which demonstrates that by appropriately selecting the ensemble number, the white noise amplitude is found to increase forecasting accuracy.
The Diebold–Mariano (DM) test and forecasting effectiveness (FE) have been selected as testing methods, and the variance in the error is used to measure the stability of the forecasting results in addition to common evaluation metrics thereby enabling a more thorough evaluation of the proposed hybrid system.
4. Data Description and Setup
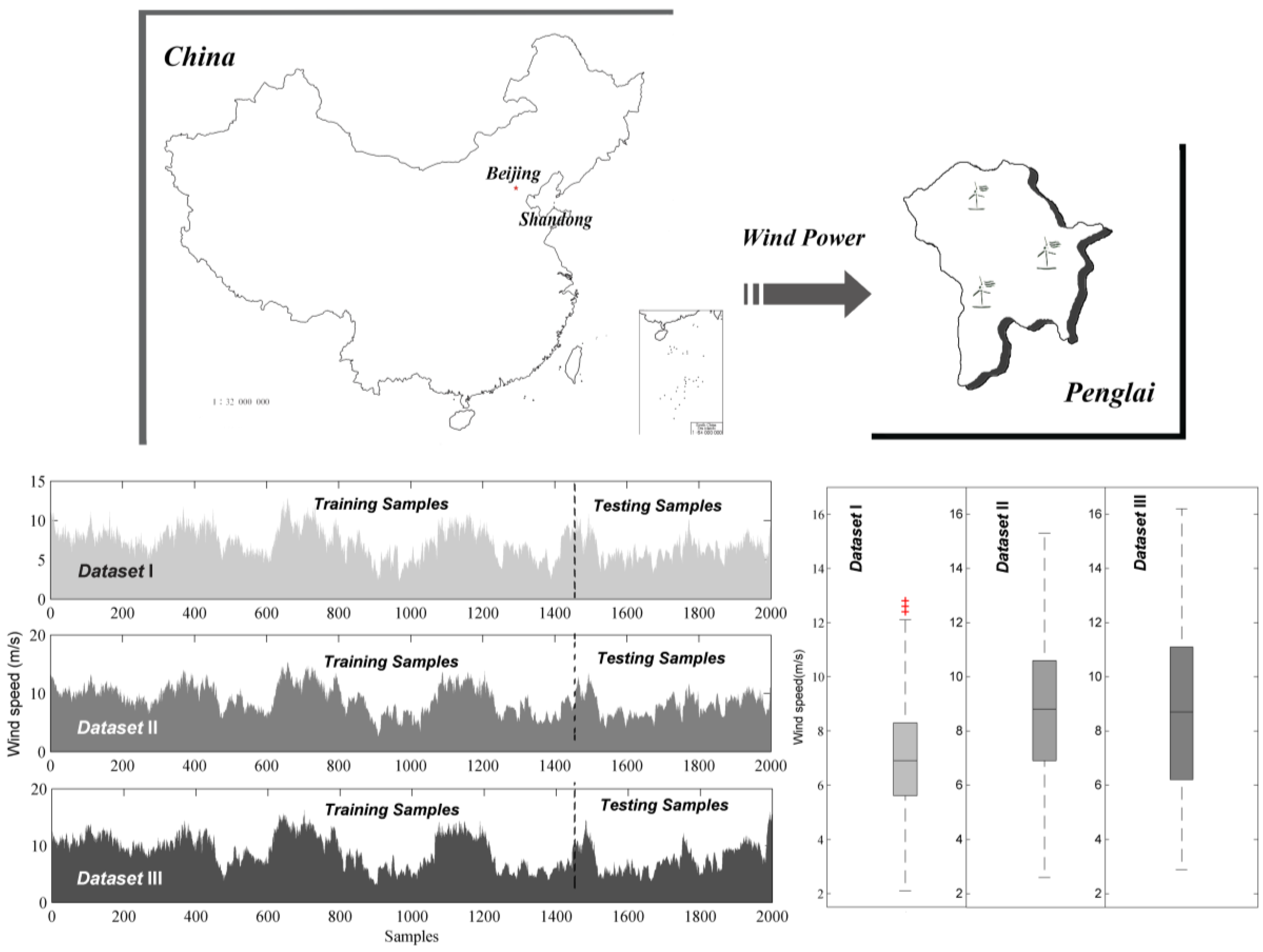
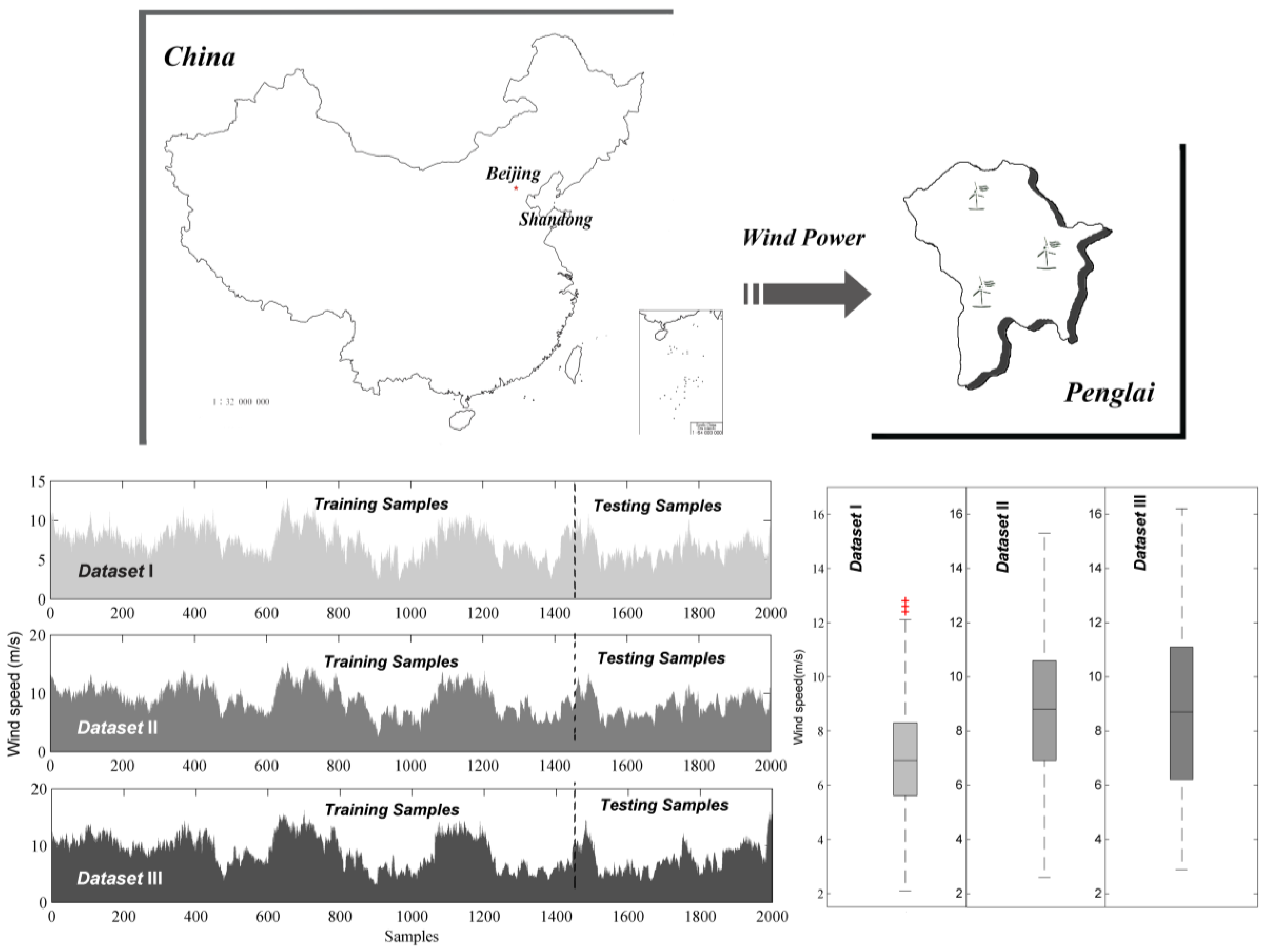
To specifically evaluate and compare the ability and performance of the fuzzy time series models under different interval partitioning methods, three primary different wind speed time series datasets obtained from a wind farm located at Penglai in Shandong Province of China are selected. Shandong is surrounded by the sea on three sides, and is located in China’s coastal wind belt, where wind resources are very rich. As such, prospects of wind power development in this region are extremely broad. The installed wind energy capacity of this region is about 67 million KW. Penglai, a part of Yantai, Shandong Province, located at 37°48′ N and 129°45′ E, belongs to the Northern temperate East Asian monsoon region continental climate and hilly area, which is south-high and north-low, possessing rich wind resources and many wind farms. The installed wind capacity of Yantai was 2104.15 MW in July 2016, and the wind power scale is the largest among power grids in the Shandong peninsula. Thus, it is crucial to accurately forecast the wind speed in this region. Accordingly, two thousand data points with the sampling interval is 10 min and sampling frequency is 144 times per day were selected from each dataset recoded from 10:00, 1 January 2011 to 7:10, 15 January 2011 including training set (1500 samples) and the testing set (500 samples).
Features of the three wind speed datasets are listed in
Table 2 and are visualized via the box and line charts in
Figure 2. As described, all three datasets possess large fluctuations and are divided into training and testing samples. From the box chart, it is seen that Dataset III possesses the maximum degree of dispersion and the opposite is true for Dataset I.
Table 2 presents numerical values of some statistical indicators; the standard deviations are approximately 2 m/s, and the interquartile ranges are mostly above 3 m/s. Both these values indicate significant fluctuations in the wind speed. This evident fluctuation in the wind speed datasets verifies the challenges involved in wind speed forecasting.
For the fuzzy time series model and subsequent interval partitioning methods, the universe of discourse for wind data is defined as (2, 16.5). Wind-data intervals corresponding to four different interval partitioning methods are listed in
Table 3.
The continuous values are transformed into 10 linguistic values
A1–
A10. Taking the Chi-square-based discretization of Dataset III, the fuzzy relationship groups are summarized in
Table 4. Each number in the matrix indicates the occurrence of a fuzzy logic relationship. Based on this matrix and Equation (1), the weight matrix can be calculated, as presented in
Table 4 and
Table 5. Ultimately, forecasting values can be calculated by Equations (2) and (3). After repeated tests, the weight in Equation (3) was set as 0.5.
6. Analysis and Discussion
In this section, the performance of the different methods from computational aspect is discussed. Moreover, the frequency of data sampling plays a vital role in wind data. According to State Grid Dispatching scheduling and the energy industry standard NB/T31046-2013 which was formulated by National energy administration in China, 144 wind speed data should be obtained per day (24 h). And the wind energy measurement rule was set in 2013. The time interval of wind speed data obtained from wind farm is supposed to be no less than ten minute. Due to the non-storage of wind energy, short wind speed forecasting can warn dispatchers to carry out some necessary operation in a critical state to avoid economic losses and safety accidents as much as possible for the stable operation of power system. Accordingly, in this section, ten min wind speed data from three sites is selected to evaluate the performance of the models.
Several metrics have been employed by researchers in extant studies for error evaluation. However, there is no common standard to evaluate the forecasting performance of different methods. Therefore, various criteria are utilized to compare the forecasting performance. These criteria are defined in
Table 6. MAE measures the difference between the forecasting values and observations; RMSE measures the deviation between observations and forecasted values, and it is more easily affected by extreme values than MAE; MAPE is the average of absolute percentage error to evaluate the forecasting accuracy in statistics; IA is a dimensionless index to compare different models and is selected as a substitutes for
R or
R2; and VAR measures the stability of the methods. Furthermore, MAE, RMSE, MAPE, and VAR are negative indicators; i.e., the lower the better, while IA is a positive indicator.
6.1. Experiment I: The Data Pre-Processing for Fuzzy Time Series Forecasting
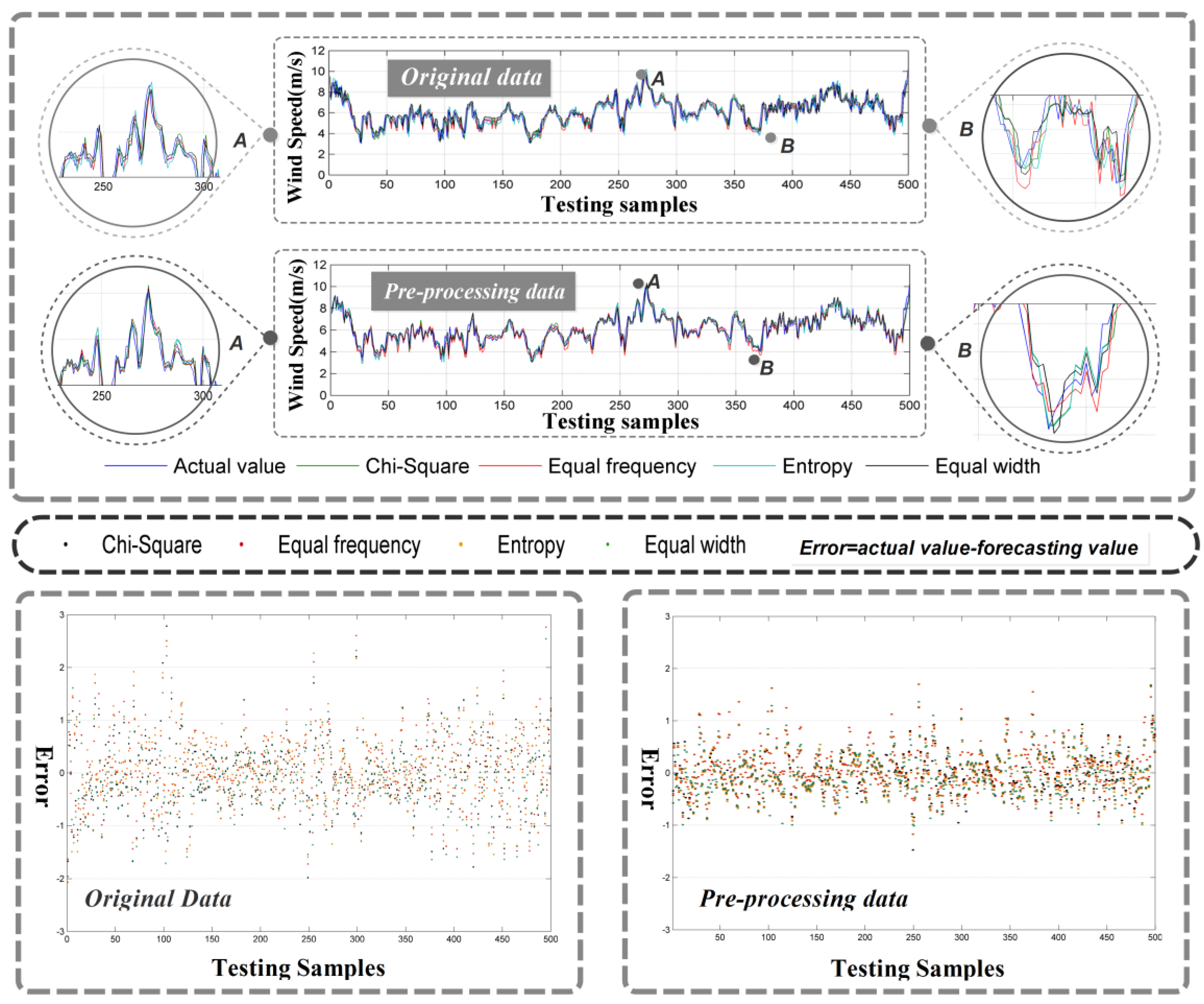
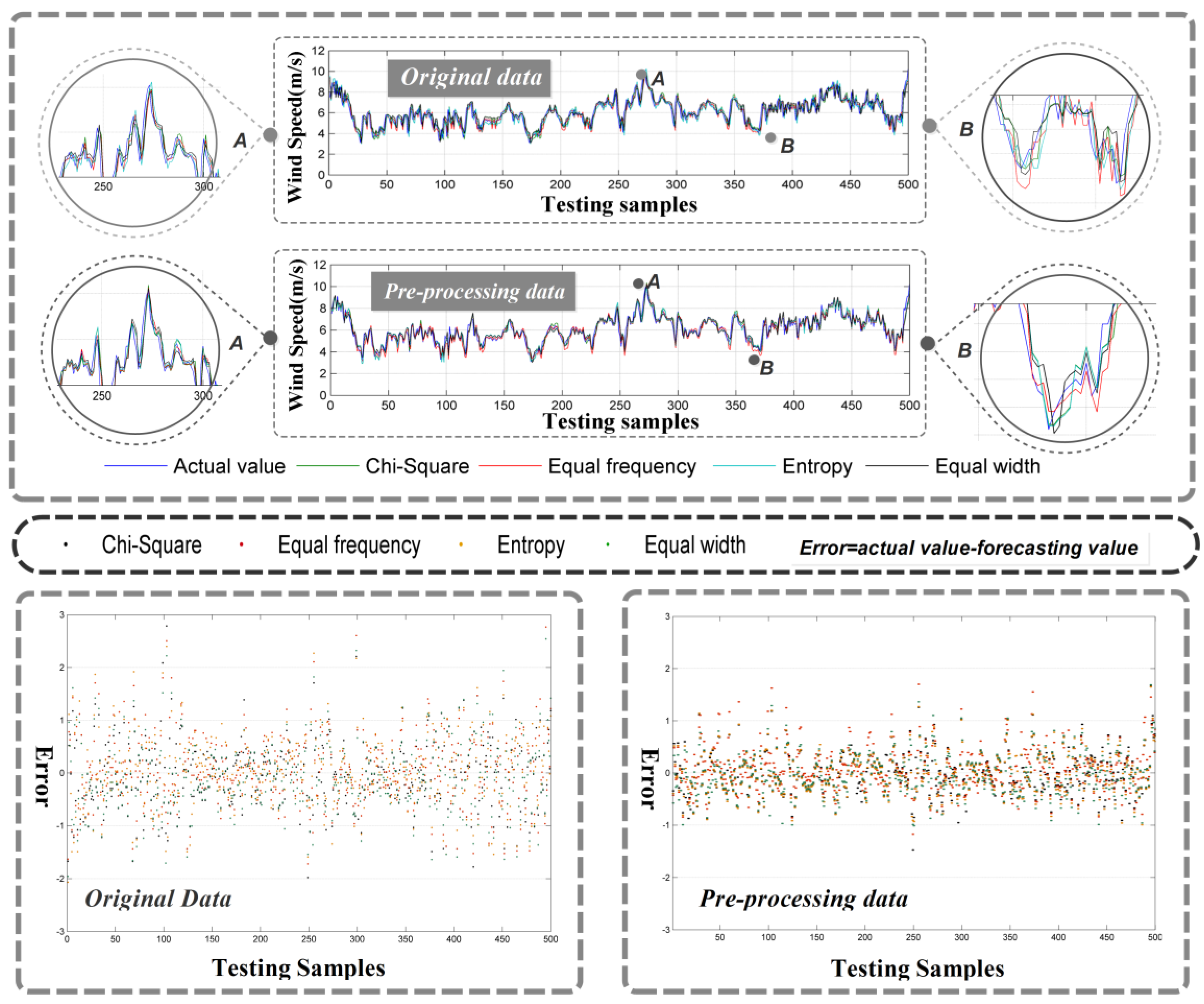
The high volatility and instability of wind speed data undoubtedly increases the challenge in accurate forecasting. As a consequence, in the process of data analysis, it is necessary to process the original data according to specific analysis requirements. In this study, the ensemble empirical mode decomposition is utilized to pre-process original data thereby effectively reducing the influence of instability and noise. We set the ensemble number as 100 and noise amplitude as 0.2. As can be seen in
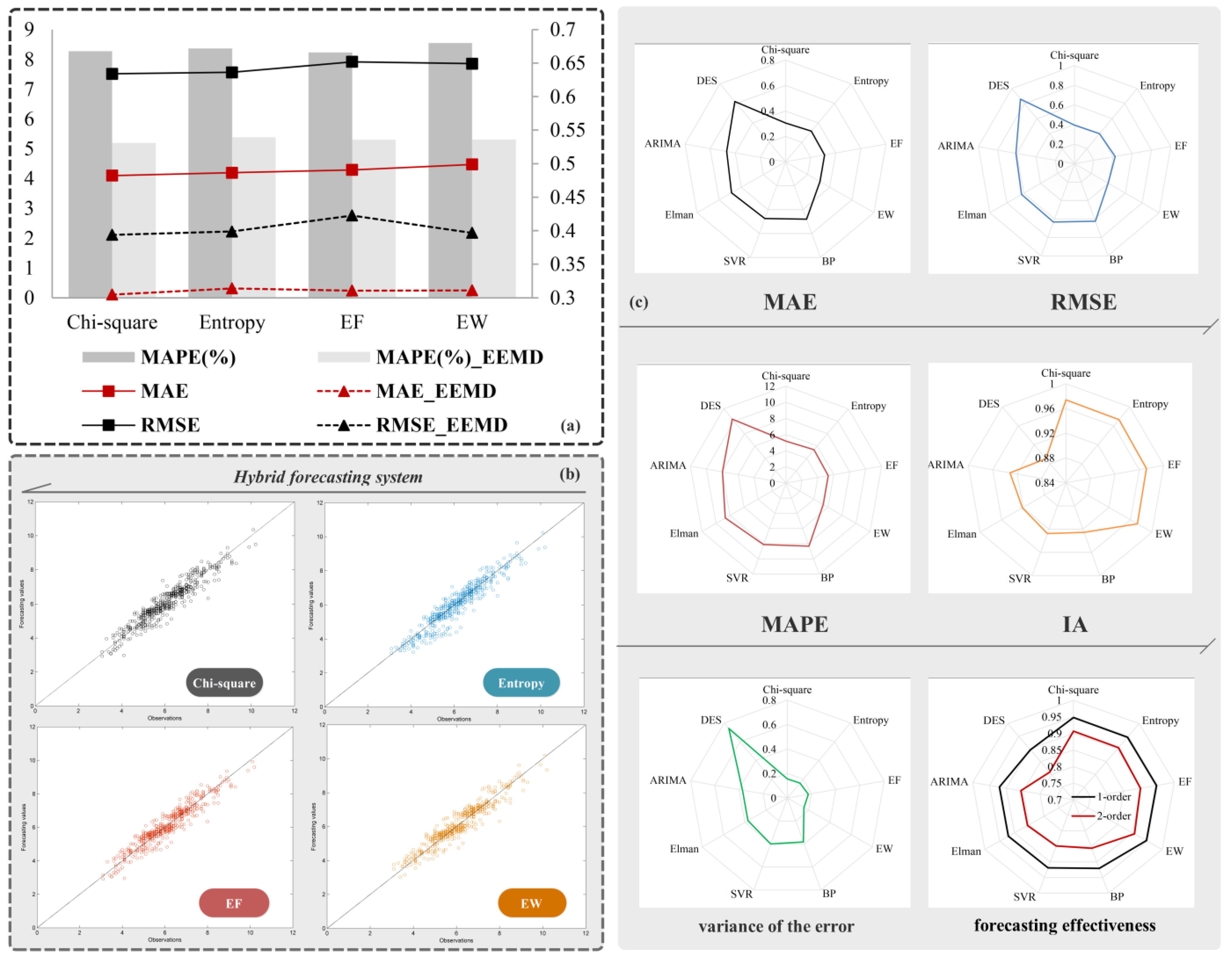
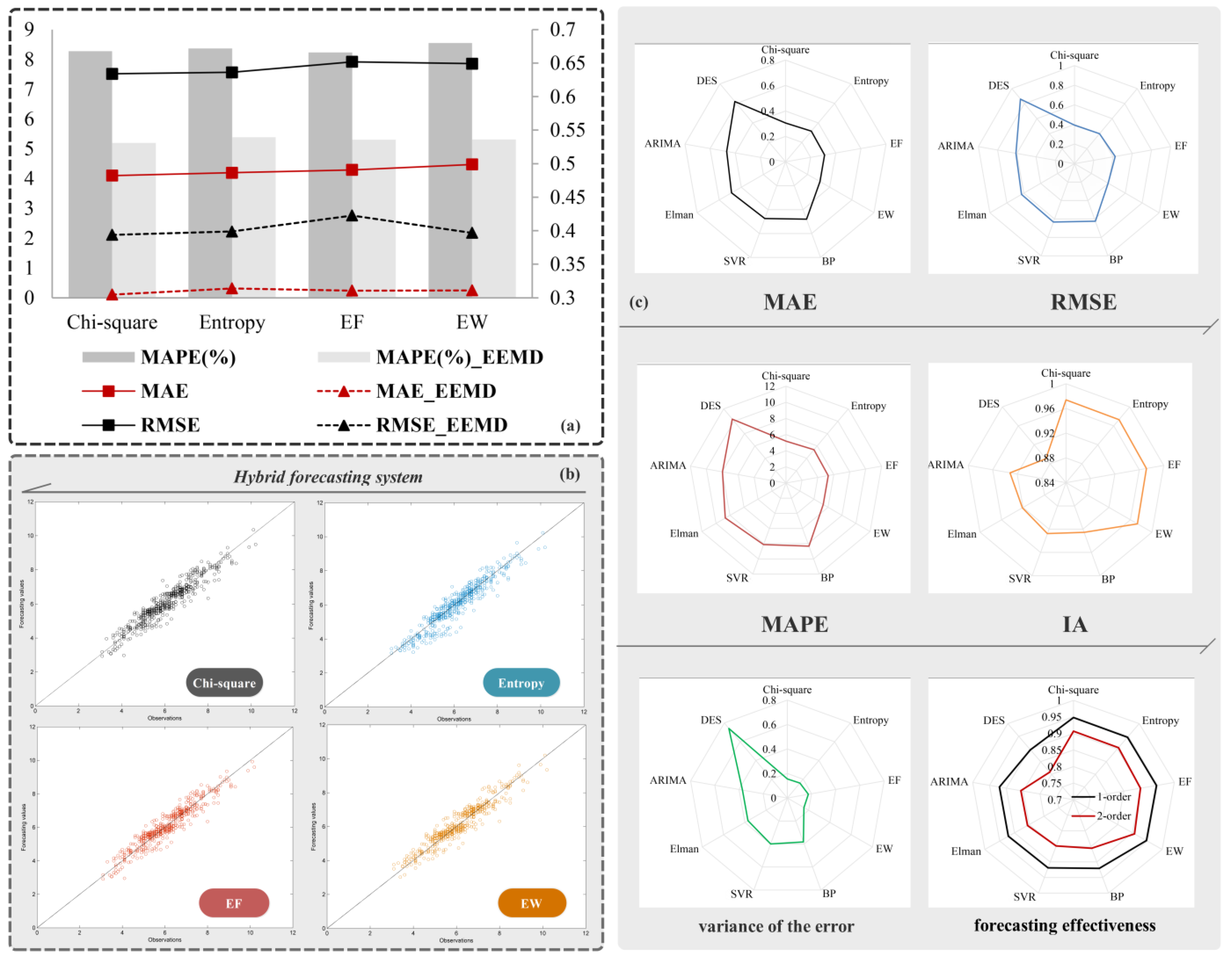
Figure 4a, it is obvious that pre-processing data achieves better forecasting performance, and the variance in forecasting errors drops significantly. For a more direct and clear cognition, the improvement ratio of the indexes can be calculated using Equation (7):
Table 7 quantitatively summarizes the improvement in forecasting performance through data pre-processing. In terms of MAE, RMSE, and MAPE, the average improvement ratio is about 30–40%, the highest being 38.86%, which is achieved under equal width interval discretization. In terms of IA, the average improvement ratio is relatively low—about 2% for Datasets II and III and 5% for Dataset I. This may be due to values of this index being large originally. Variance (VAR) demonstrates the highest average improvement ratio (about 60%) with the highest individual value being 62.43%. This proves that data pre-processing significantly improves the forecasting stability.
Remark 1: The high volatility and instability of wind speed data affects the forecasting results significantly. Thus, suitable data pre-processing method can improve the forecasting performance greatly especially the stability of the forecasting results.
6.2. Experiment II: The Comparison of Fuzzy Time Series, Artificial Neural Network, Statistical Models and Support Vector Regression
Owing to the widespread popularity of artificial intelligence, statistical models, and Support Vector Regression (SVR), this experiment was designed to compare the performance of the proposed hybrid forecasting system against artificial intelligence (Back Propagation Neural Network (BPNN), Extreme Learning Machine (ELM), and Elman) and statistical (Double Exponential Smoothing (DES) and Autoregressive Integrated Moving Average (ARIMA) models. In all artificial intelligence models, the node-point numbers of input and output layers are set as 5 and 1, respectively. For hidden layers in BPNN, ELM, and Elman, the node-point numbers are, respectively, set as 2, 20, and 14. For the ARIMA (
p,
d,
q) model, values of
p,
d, and
q are set as 4, 1, and 5, respectively, in confirmation with the A-Information Criterion (AIC) and the stationary test. In SVR, the radial basis function (RBF) is selected as kernel function. The precise parameter settings are listed in
Table 8 and other parameters use the default setting.
Results of the abovementioned comparison are presented in
Table 9. Considering Dataset I, the proposed hybrid forecasting system achieves the optimum MAPE value amongst the models compared. As shown in
Figure 4c, we can easily see that DES demonstrates the worst performance and its corresponding MAPE increases by about 5% when compared to the proposed hybrid forecasting system. The proposed system betters the performance of all models in terms of other indexes too. Amongst artificial neural networks, ELM achieves better forecasting accuracy and stability, while Elman performs relatively poorly. DES also exhibits the largest variance of the forecasting error indicating that the forecasting accuracy of the DES is unstable when compared to, both, the proposed forecasting system as well as artificial neural networks.
In real world forecasting applications, the conventional statistical model may not be suitable owing to its inherent nonlinearity and instability. The use of artificial neural networks usually requires setting of many parameter values which significantly affects the forecasting performance; also, the forecasting results are different for several experiments conducted using the same sample. Additionally, in certain complex networks, the response time of the model substantially long. This may be considered as a drawback, since the timeliness of forecasting results is of critical importance in modern economic and industrial applications, especially in the energy sector.
To further demonstrate the performance of the proposed forecasting system, the persistence model, one of the most popular and frequently utilized benchmark methods, has been used as the benchmark test in our study. The persistence model simply assumes that forecasted value at any time
t is identical to the last observation. The model does not require any parameter setting nor does it involve exogenous variables. Nonetheless, it usually demonstrates great performance [
76,
77]. Comparison results presented in
Table 9 indicate that the proposed hybrid forecasting system demonstrates better forecasting performance in terms of all five model evaluation criteria. It can, thus, be concluded that the proposed hybrid forecasting system performs better than the benchmark persistence model.
Remark 2: Comparing with the artificial neural network, statistical models, Support Vector Regression and persistence model, the proposed hybrid forecasting system possesses the better forecasting accuracy and stability than others. Moreover, unlike the traditional time series models which need a large amount of historical data and have restrictions of linear or normality postulates assumptions, and artificial neural network which have many parameters and complex structure, the proposed hybrid forecasting system has the advantage of the simple calculation and stable result ensuring the timeliness and reliability of the forecasting results.
6.3. Experiment III: Forecasting Performance of the Fuzzy Time Series with Different Interval Partitioning Methods
Table 10 enlists the forecasting results in terms of MAE, RMSE, MAPE, VAR, and IA for original as well as pre-processed data using the four previously described discretization algorithms—Chi-square-based discretization (
χ2), entropy based discretization, equal frequency interval discretization, and equal width interval discretization. Most of the metrics indicate that the Chi-square-based discretization performs the best for Datasets I and III. For dataset II, the entropy-based discretization method demonstrates the best forecasting performance for original data, while the equal frequency interval discretization rules the roost in handling pre-processed data.
Figure 4 shows the forecasting results graphic of the three datasets. From
Table 10 and
Figure 4a, it can be concluded that supervised discretization methods possess better stability and forecasting accuracy compared to unsupervised methods. In
Figure 4b, scatter plot of the observations and values forecasted by the proposed hybrid forecasting system indicates that the proposed system demonstrates great performance.
Remark 3: The forecasting results of the fuzzy time series with four different interval partitioning methods do not have large difference but the supervised discretization methods outperform than unsupervised discretization methods and the equal frequency interval discretization has the worst performance in general.
6.4. Experiment IV: Testing Based on the DM Test and Forecasting Effectiveness
Although the evaluation metrics presented in experiment II have been well compared to evaluate the forecasting performance of the different forecasting models, the performance of these models has been further studied using statistical testing methods based on the DM test and forecasting effectiveness (FE). This section discusses these methods thereby enabling a more comprehensive test and comparison of the models’ performance.
6.4.1. DM Test
The Diebold–Mariano test, which focuses on forecasting accuracy, is used to test the difference between the proposed system’s forecasting accuracy and that of other methods [
78].
The test is described as follows:
Statistic values of the DM test are described by:
denotes the forecasting error
S2 denotes the estimation value for the variance of
denotes a loss function that is utilized to represent the forecasting accuracy of the model.
Absolute deviation error loss and square error loss are two popular loss functions, which are widely employed.
When there is no significant difference between forecasting performance of the compared models, we will reject the null hypothesis given by
where
Zα/2 is the critical value of the standard normal distribution when the significance level is
α.
In our analysis, we used the DM test to investigate significant differences in performance between the proposed hybrid system and traditional models. The results of the DM test on the basis of the square error loss function are presented in
Table 11, which indicate that the DM statistical values for all models far exceed the critical value at 1% significance level. As obvious, the proposed hybrid system performs differently when compared to the traditional models at 1% significance level. Combining this with the evaluation criteria in Experiment II, the proposed hybrid system is outright better than the traditional models and potentially meets the requirements of wind speed forecasting.
6.4.2. Forecasting Effectiveness
In this section, forecasting effectiveness is introduced, which evaluates the performance of models by using the sum of the squared errors as well as the mean and mean squared deviation of the forecasting accuracy. Furthermore, the skewness and kurtosis of the forecasting accuracy distribution need to be considered in practical circumstances. The general form of forecasting effectiveness is described as follows [
79].
The
kth-order forecasting effectiveness unit is described as:
where
Qn denotes the discrete probability distribution at time
n. As any prior information of the discrete probability distribution is unknown,
Qn is defined as 1/
N.
An is the forecasting accuracy defined as:
The
k-order forecasting effectiveness is defined as:
When is a continuous function in one-variable, the first-order forecasting effectiveness is the expected forecasting accuracy sequence defined as . Similarly, when is a continuous function in two variables, the second-order forecasting effectiveness is the difference between the standard deviation and expectation, which can be described as
In this study, forecasting effectiveness was also used to evaluate the performance of different models. The model which possesses greater forecasting effectiveness is said to perform better. The first-order forecasting effectiveness is based on the expected value of the forecasting accuracy sequence, while the second-order forecasting effectiveness is related to the difference between the standard deviation and expectation of the forecasting accuracy sequence. Detailed results of the first- and second-order forecasting effectiveness are presented in
Table 12. It can be easily seen that the proposed hybrid forecasting system outperforms the other models, for the value of the forecasting effectiveness of the proposed system far exceeds that corresponding to other models in all cases. Take dataset I for example, the first-order forecasting effectiveness of BPNN, ELM, Elman, SVR, ARIMA, and DES models are, respectively, 0.9209, 0.922, 0.9205, 0.9189, 0.9203, and 0.8967. At the same time, corresponding values of the proposed hybrid forecasting system with four different discretization methods are 0.9480, 0.9462, 0.9470, and 0.9469. Further, the second-order forecasting effectiveness values for the above methods and the proposed hybrid system are 0.8558, 0.8563, 0.8557, 0.8487, 0.8565, and 0.8086 and 0.9069, 0.9049, 0.8994, 0.9063, respectively.
Remark 4: The results obtained from the DM test and forecasting effectiveness indicate that the forecasting accuracy of the proposed system is remarkably higher than the BPNN, ELM, Elman, SVR, ARIMA, and DES models, and the developed hybrid forecasting system is more viable and significantly superior to the traditional forecasting models.
8. Further Experiments for Hourly Time Horizon
In order to support the merits of the proposed hybrid system in comparison to other forecasting models, we performed a further experiment comprising the hourly time-horizon wind speed forecasting. The results of this experiment, in terms of evaluation criteria, are presented in
Table 14, and the results of the DM test and forecasting effectiveness are listed in
Table 15 and
Table 16, respectively. It is easily recognized that MAPE of the proposed system is about 7%, while for the compared models, this value varies in the range of 15–20%. Corresponding VAR values are about 0.3 and above 1, respectively, indicating that forecasting results of the proposed system have better accuracy and stability. The performance of artificial neural networks is only slightly different from each other, while DES is evidently poor compared to ARIMA amongst statistical models.
The DM statistical values of all models are about 5, which is higher than the critical value at the 1% significance level. We can, thus, conclude that the proposed hybrid system is obviously different and performs better compared to other models at the 1% significance level. Combining this with the results based on evaluation criteria, the proposed hybrid system can be seen to outperform traditional models.
It can be inferred from
Table 16 that the forecasting effectiveness of the proposed system exceeds that of the compared models under all cases. The first-order forecasting effectiveness offered by BPNN, ELM, Elman, SVR, ARIMA, and DES is about 0.85, while that corresponding to the proposed hybrid forecasting system with four different interval partitioning methods is about 0.93. The respective second-order values are about 0.88 and 0.75. Amongst the models being compared, DES has the worst performance with respective first- and second-order forecasting effectiveness values of 0.799 and 0.6614.
Remark 5: As for the hourly time-horizon wind speed forecasting, the evaluation criteria and testing results which are obtained by DM test the forecasting effectiveness all show that the level of forecasting accuracy of the proposed system is remarkably higher than the compared model. But, the forecasting performance for the 10 min-horizon wind speed are overall superior to the hourly time-horizon wind speed for the same model. Based on the above analysis, we can conclude that the proposed system has general applicability and great performance.
9. Conclusions
Data pre-processing and future forecasting are crucial tasks in modern national and regional economic development, especially in the energy sector. Poor energy forecasting may lead to wastage of the already scarce energy sources. As such, both accuracy and stability are important objectives to be achieved in energy forecasting. Nevertheless, accurate energy forecasting is considered to be a challenging task because of various influencing factors, such as noise and high data volatility. Conventional statistical models require a large amount of historical data and face restrictions, such as linear or normality postulates. On the other hand, use of artificial neural networks involves several parameters and requires substantial response time. To overcome the limitations and challenges in these methods, we proposed the hybrid forecasting system with four different interval partitioning methods.
By comparing the forecasting accuracy, stability, and effectiveness of the proposed system against conventional statistical models and artificial neural networks via the data from three sites, it is concluded that the proposed system significantly outperforms the other models. Especially, the variance criterion (VAR) for the DES model is significantly larger compared to that for the proposed hybrid forecasting system thereby reducing the stability and reliability of DES forecasting results. Also, because the proposed system involves simple calculations and results do not change with time for the same sample, the forecasting efficiency and stability is evidently improved.
The volatility and instability of raw data increase the difficulties involved in wind speed forecasting; thus, the pre-processing the data prior to forecasting is essential. Experiments performed in this study indicate that the ‘decomposition and ensemble’ strategy for raw data remarkably improves the forecasting performance. The comparison of forecasting results obtained using four different interval partitioning methods indicate that although forecasting accuracy does vary significantly between them, the supervised discretization methods are superior to unsupervised methods.
Additionally, sensitivity analysis of parameters used in the proposed forecasting system indicates that by appropriately setting the ensemble number and white noise amplitude, the forecasting accuracy can be greatly improved. In order to prove the superiority of the proposed hybrid system over other forecasting models, the hourly time-horizon wind speed was further simulated. Results of this simulation indicate that the proposed system has better performance compared to all other models for different time-horizon datasets. Further, forecasting performance of the proposed system for the 10 min-horizon wind speed is superior to the forecasting performance for the hourly time-horizon wind speed. In conclusion, the proposed hybrid forecasting system demonstrates better forecasting accuracy, effectiveness, and stability while handling noisy and insufficient datasets in the wind energy system.



{kind=link}
{kind=link}
{kind=link}
{kind=link}