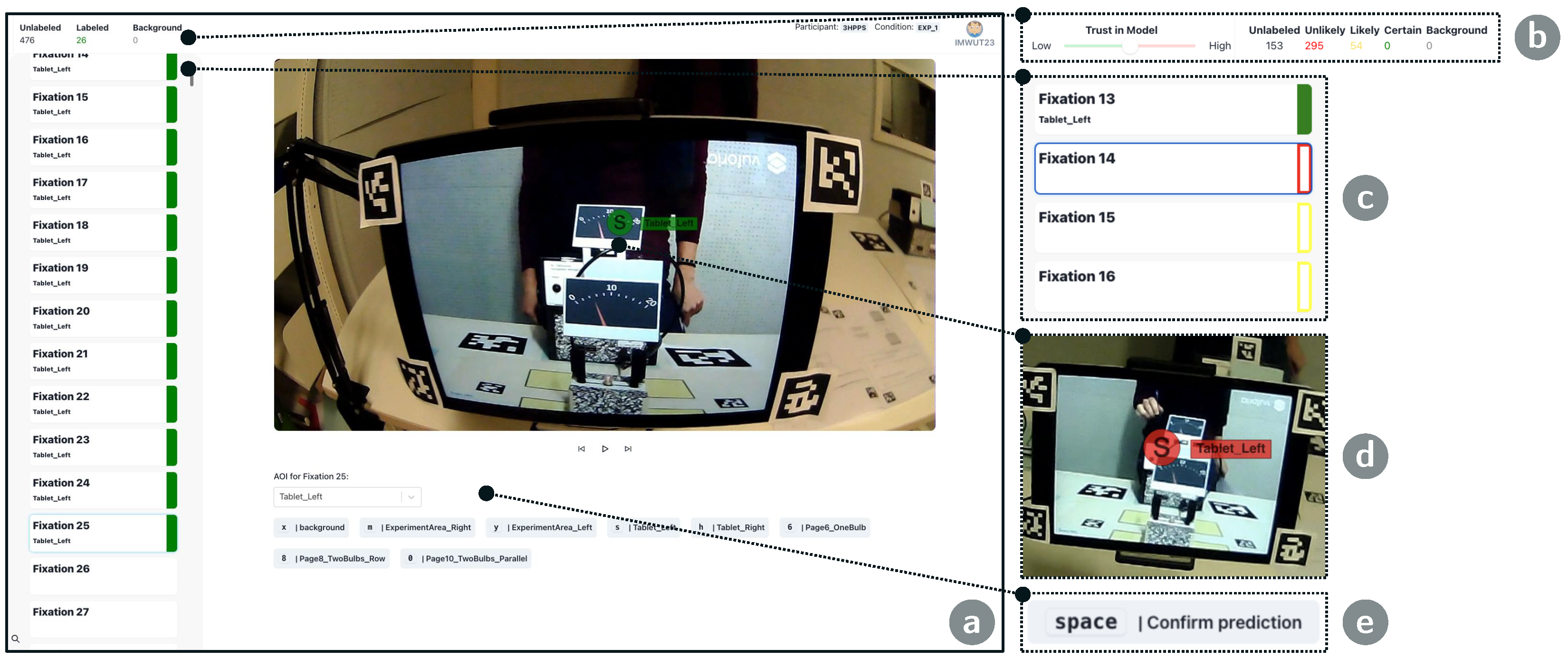
With eyeNotate, we present a tool for annotating mobile eye tracking data. Our goal is to create a tool that allows researchers to more effectively and efficiently annotate recordings from mobile eye trackers while providing a high usability. In the following, we discuss the results of our evaluation, including a case study with three trained annotators and a post hoc machine learning experiment.
5.2. Efficiency
On average, task completion times for both tool versions were similar: annotators were 3.44% (48 s) slower when using the IML-support version. Likewise, the difference in task completion times between versions per participant is small. On the other hand, the differences between participants are large. A1 required around 2000 s to solve the task per tool, while B1 and B2 required around 1200 s and below 1000 s, respectively. This is almost twice as fast without compromising accuracy, which indicates that B1 and B2 had a more efficient strategy in using our tools. Analyzing the task completion times over time, we observe that A1 is consistently slower than B1 and B2 with annotation times of 250–300 s/100 annotations. B1 and B2 require only around 150 s/100 annotations. During the study, we observed that all participants used shortcuts for annotation and confirmation, but A1 did not use the multi-select feature, which could explain the high difference to B1 and B2 in terms of task completion time. Another indicator for the high effectiveness of the multi-select feature is that B1 and B2 had the lowest task completion times (50–100 s/100 annotations) at the end of
exp_1, which includes many consecutive occurrences of P_6 and P_8 (see also the low class-wise annotation times in
Table 3). Overall, given the 870 fixations in the annotation task, our eyeNotate achieves a worst-case annotation rate of 2.41 s/fixation for user A1 when using the IML-support version and a best-case annotation rate of 1.11 s/fixation for user B2 when using the IML-support version. This means, using an automatic annotation method to map the remaining 230k fixations in the full dataset, there is a time-saving potential between 70 and 150 h for this use case.
However, we could not confirm our hypothesis that providing label suggestions would accelerate the labeling process. This is likely because all annotators tended to manually check and confirm label suggestions in the IML-support version (cf.
Section 5.3). We observed corresponding annotation behavior during the study, and theme (b) of our SSI analysis concerning the constrained model performance confirms this: annotators did not trust the model sufficiently and felt highly responsible for performing the job well. Hence, they did not benefit from automatic label suggestions as found in Desmond et al. [
23]. The differences in interaction design between the baseline and the IML-support version of our tool seemingly played no role in this context. Our findings from the SSI analysis relating to theme (a) suggest that participants, in principle, liked the interaction design of the IML-support version, but due to the low model performance, these features were not effective. Our findings suggest that future investigations should include more effective computer vision models that can better cope with the challenges of mobile eye tracking data like differentiating classes with similar appearance. This could, for instance, be achieved using a classification model that takes the position of a fixated object into account [
86] or by tracking objects once they have been annotated once using 3D scene reconstruction and object tracking algorithms [
87]. Follow-up work could also investigate how lay users, in contrast to the trained annotators in our case study, perform in the annotation task, following the questions whether lay users could achieve the same validity as trained annotators and whether lay users would benefit more from label suggestions in terms of efficiency.
5.3. Usability
The usability of our tool’s baseline version was consistently rated as excellent: the basic features and general interaction design of our annotation tool were perceived very positively, which is supported by theme (a) of our thematic analysis concerning the tool’s interaction design: “the tool’s design facilitates the annotation of mobile eye tracking data.” However, B1 and B2 rated the IML-supported version drastically lower, which contradicts our assumption that both tools achieve a similar usability rating. Looking into individual SUS items, B1 and B2 majorly penalized an increased inconsistency of the IML-support version and indicated that it was more cumbersome to use. Both felt less confident using the IML-support version and thought it was less easy to use. Particularly, B1, who rated the usability of the IML-support version as “poor”, reported that the system provided many wrong label suggestions and seemed uncertain in many cases, which caused confusion and deteriorated trust. B1 reports that, as a consequence, they fell back to a manual annotation strategy. B2 and A1 reported similar issues with the model performance despite rating usability higher. We observed that B2 and A1 favored manual annotation, similar to B1. These usability issues can be attributed to the integration of IML-support features and relate to theme (b) of our thematic analysis concerning the constrained model performance: “the constrained model performance limits IML-based benefits.” The two themes, originating from a reflexive thematic analysis of the SSI, are detailed below.
5.3.1. (a) The Tool’s Design Facilitates the Annotation of Mobile Eye Tracking Data
Our case study participants liked our tool’s basic functionality and interaction design. In particular, they highlighted the clean design that allowed them to focus on the annotation task throughout the study. They reported high usability and learnability. Quick reaction times and visual feedback were highly appreciated. Particularly, the video overlay immediately displaying updates after manual annotation or confirmation was considered very helpful because they had to check the video frame to decide on the AOI class anyway. All participants reported a high perceived performance due to the clean, focused interaction design and the ability to use shortcuts for navigation and annotation. Also, the multi-select feature for annotation and confirmation seems to impact annotation efficiency positively. The video playback function was not used by our participants but might have supported understanding the video-editing-like interface metaphor. Upon asking them, participants reported they understood the trust-level slider but did not use it often, although it was considered useful. High-certainty suggestions (green highlight) were also considered helpful. However, certain but wrong label suggestions were frustrating as they could lead to wrong confirmations. Also, the red color of uncertain suggestions was reported to interrupt the interaction flow in the case the predictions were correct. In summary, color-coding of the model certainty for label suggestions might cause frustration in the case of certain but wrong predictions and can interrupt the interaction flow in the case of uncertain but correct predictions. An implication could be to restrict label suggestions to highly certain suggestions. Our participants suggested two interesting features that will be considered in future versions of our tool. They proposed a feature that enables jumping to non-annotated fixations or uncertain suggestions. Further, they proposed a feature to batch-accept all certain predictions, which would be dependent on the state of the trust-level slider and could be restricted to classes with good classification performance.
5.3.2. (b) The Constrained Model Performance Limits IML-Based Benefits
All participants reported a perceived model performance of 30–40% accuracy, although the true value is higher (62%). This indicates that our participants had low trust in the underlying model generating the AOI label suggestions and could explain why they checked all suggestions manually. This is also in line with their reports on problems with certainty-based color coding. All participants specified that the model suffered from a left/right weakness: Some AOIs with the same appearance were present on the left and right sides of the experiment scene, but the model could not properly differentiate between them. We intentionally investigated this challenge by including experiment phase 2. One example is
T_L and
T_R, referring to two instances of the same tablet mounted on the left or right side of the experiment scene. This is evident in the confusion matrix for FRNet in
Figure 7:
T_L is wrongly classified as
T_R in 12.38% of the cases. The false-negative errors concerning all other classes besides
BG sum up to 0.31%. We observe similar problems for the
experiment area and
workbook page AOIs. If objects look very much alike, our IML-support version has limitations. Addressing the left/right weakness is essential because AOIs with similar appearances are common. Future research should investigate whether object-tracking or position-aware models can help to address this challenge. Another option can be found in meta-models that iteratively learn for which classes a model performs well and activate suggestions for those only.
5.4. Post Hoc ML Experiment
We observed the best average f1 scores and accuracy scores when using the FRNet model architecture in the final setting, i.e., when using the 870 annotated fixations for training (see
Table 4 and
Table 5). However, using more training data for the FRNet model only slightly increases the performance, e.g., +1.21% in accuracy and +0.015 concerning the weighted average f1 score. With +11.78% for accuracy and +0.062 for the weighted f1 score, ResNet showed the greatest improvement when more training samples were added. MobileNet performs slightly worse for all metrics. However, the results show that the models are not good enough for most applications such as automatic or semi-automatic annotation with humans-in-the-loop. This is in line with the user’s feedback from the SSI as summarized in theme (b).
The best f1 score of 0.687 was observed for the
T_L class for the FRNet model in the
final setting, followed by an f1 score of 0.681 for the
BG class. The precision is highest for
BG with 0.765 (see
Table 6), so labeling support only for the
BG class could have been effective. Since almost 60% of all labels belong to this class, this could already save a lot of time without raising usability issues like the ones mentioned in theme (b). The high ratio of
BG samples in the test set also means that summary statistics like accuracy and the weighted f1 score are biased through the relatively high performance for this class. This is visible in the large deviation between the weighted and macro-average f1 scores for all models. Overall, FRNet shows the most balanced performance across all classes: it performs best for all classes besides
P_10. This also explains the greater relative difference in the macro-average values and the weighted average values for f1 for MobileNet and ResNet.
The confusion matrix in
Figure 7 shows the strengths and weaknesses of the FRNet model (final) on the class level in more detail. As counts are normalized over the true condition, i.e., over rows, the diagonal shows the recall scores for the true condition or class of that row, while the remaining values of that row sum up to the corresponding miss rate. For
BG, we observed a recall of 61.33% with a precision of 76.53%. This means that, when limiting suggestions to the
BG class, labels for more than one-third of all instances (61.33% of 59.88% of all 230.3k instances) could have been provided, of which around three-quarters would have been correct. Still, one-quarter would have been wrong. So, limiting suggestions to
BG alone would likely not solve the usability issues mentioned in theme (b). These scores were observed for the default setting when
BG is assigned if the model’s classification probability for an AOI class is lower than
. Lowering
would increase the precision for the
BG class but at the cost of a lower recall. Likewise, increasing the threshold for assigning one of the seven AOI classes, we call it
, would increase the precision for these classes. Eventually, a class-specific batch-accept feature for accepting label suggestions for a certain class with manually tuned
and
could be useful. The user should be able to configure the probability threshold
and the classification thresholds
for each class, which would allow annotators to accept labels based on their own experiences of how the model performs per class. However, most f1 scores and all precision scores for AOI classes are lower than the scores for the
BG class (see
Table 6), which indicates that tuning the thresholds for a batch-accept feature might be difficult. We conduct and report on a follow-up experiment that investigates how changes in
and
affect the classification performance and relate to the number of fixations without a label suggestion. By that, we aim to estimate the potential of a class-wise batch-accept feature.
The confusion matrix also indicates that a reason for the low f1 scores is the similar appearance of the AOI classes, including the two experiment areas
E_*, the two tablets
T_*, and the three workbook pages
P_*. These three groups can be clearly identified along the diagonal as three squares based on the high number of false-negative errors within each group. Further, it shows that many AOI classes are frequently misclassified as belonging to the background class
BG, particularly the three workbook AOIs. Confusion of AOI classes with the
BG class could be reduced by increasing the classification threshold
. This could be realized, e.g., through a class-based trust-level slider. Confusion of similar-looking AOI classes can only be solved by using more suitable approaches like multi-object tracking; i.e., once an AOI was manually labeled or confirmed by a user, the system could track this instance to reveal wrong classifications or auto-confirm true classification, or graph neural networks that consider the spatial location of an object for classification [
86]. An option to increase the utility of the FRNet model would be to provide label suggestions at a higher semantic level. For instance, eyeNotate could identify all tablets and ask the user which instances belong to the left (
T_L) or right (
T_R) class. Similarly, this could be performed for the two experiment areas and the three workbook pages. Classification performance would likely be higher for this four-class problem because it is a less complex classification problem. We investigate this aspect in another follow-up experiment. Further, a two-level decision task (left vs. right) or three-level decision task in the case of the workbook pages is less difficult for users than the eight-level decision task, which includes all AOIs and the separate background class.
Next, we report on the the two mentioned follow-up experiments: one for estimating the utility of a class-wise batch-accept feature and one for investigating how the model would perform for the four-class classification problem.
5.4.1. Estimating the Utility of a Class-Wise Batch-Accept Feature
To estimate the utility of a class-wise batch-accept feature, we investigate the impact of adjusting the classification thresholds and on the model performance in an additional experiment. In the current setting, eyeNotate suggested BG as a label when the probability was below a threshold of and the highest-ranked AOI class otherwise. In this post hoc experiment, we add a second threshold that determines the minimum classification probability p before we assign an AOI class. The higher the gap between these two thresholds, the higher the number of instances without a label suggestion will be. Hence, there will be a trade-off between the number of instances with a label suggestion and the precision of those.
In the first step, we assess whether the default threshold for classifying the background class
was a good choice. For this, we plot an ROC curve that illustrates the trade-off between the true-positive rate (recall) and the false-positive rate for classifying the
BG class (versus all other AOI classes) depending on
(see
Figure 8). Note that in the default setting,
. The ROC curve shows that false-positive rate for
is quite high: 28.07% of non-
BG instances are wrongly classified as
BG. Reducing
to 0.35 or 0.30 improves the false-positive rate: only 10.92% or 3.06% are wrongly classified as background. The recall would drop to 44.83% and 29.96%, respectively. A recall of 29.96% still corresponds to 17.94% of all samples (41.3k) because 59.88% of all 230.3k samples belong to the
BG class.
However, simultaneously reducing
and
optimizes the false-positive rate for the background class but will also lead to an increase in false-positive rates for all other classes. Hence, we investigate the impact of increasing
in 5% steps on accuracy with constant
for
. At the same time, we investigate the impact on the number of samples that will not be annotated. The results are presented in
Figure 9a. It shows the model accuracy and the annotation ratio, i.e., the portion of samples that received an annotation suggestion, as a function of
. Using the default parameters
, we observe an accuracy of 58.78% as reported in
Table 4 for FRNet in the
final setting. The annotation ratio is 100% because
. For
, the curve starts with an accuracy of 45.15%. For
, accuracy starts with 52.58%. In all three cases, the accuracy increases and the annotation ratio decreases with increasing
. Setting
means, we do not consider annotations for any class besides
BG. For
, the accuracy reaches 76.53% and the annotation ratio 57.96% in this setting. We observe that the lower
, the lower the accuracy, and the higher the annotation ratio. Consequently, the maximum accuracy is reached for
with 93.54% as well as the minimum annotation ratio of 18.97%. However, for
, prediction labels would be limited to
BG. This indicates that a batch-accept feature for
BG could be effective. For a batch-accept feature that includes other classes than
BG,
must be smaller than 1. To assess how well the model would perform for AOI classes only, i.e., for all classes besides the background class
BG, we ran the experiment for
and
. The corresponding diagram is shown in
Figure 9b. Up to
, all samples are classified as one of the AOI classes. This means that the minimum model certainty lies between 0.15 and 0.2. With increasing
the accuracy also increases until it reaches its maximum for
with 64.75%. However, with these parameters, only 1.24% of all samples would be annotated.
Overall, the results of this additional experiment indicate that a batch-accept feature for the background class BG could add value to eyeNotate. Since the parameters are optimized over the test set, the results can only serve as an upper bound of the performance. In a realistic scenario, the performance with a human optimizing the parameters would lie below this upper bound, but it would, in theory, be reachable for the considered use case, dataset, and model. However, the results also show that the classifier is not good enough for providing label suggestions for AOI classes, even under the assumption that users could tune the decision thresholds. A reason is likely the high similarity between some of the AOI classes.
5.4.2. Simulating Model Performance in a Four-Class Classification Setting
Another option to increase the utility of eyeNotate using the FRNet model is to treat the classification as a four-class problem, i.e., to only differentiate between the background class BG and three further AOI classes: experiment area E, tablet T, and workbook pages P. For our use case, the human annotator would still need to decide whether, e.g., the identified tablet is the left or right version. But this decision is less complex than assigning one out of all eight classes. Also, this investigation can reveal the potential benefit of eyeNotate for other, more simple use cases. Hence, we assess the overall accuracy and the precision, recall, and f1 scores under the assumption that only four target classes exist, i.e., E, T, P, BG, using the FRNet model in the final setting. For this, we replace the true and predicted class labels with the corresponding summary class; e.g., E_L and E_R are replaced with E before computing scores. The BG labels do not change.
In the four-class setting, FRNet achieves an accuracy of 65.30%, which is 6.52% better than in the original eight-class setting.
Table 7 shows the corresponding precision, recall, and f1 scores. As expected, the scores for summary classes are better compared to the original classes. For instance, for
E, we observe an f1 score of 0.524, while the f1 scores for
E_L and
E_R are 0.384 and 0.463, respectively. This also holds for
T and
P. The results do not change for
BG because there were no changes concerning the background class. Consequently, the macro-average and weighted average f1 scores are also higher. The macro-average f1 score increases by 0.167 and the weighted average f1 score by 0.063.
In summary, reducing the complexity of the classification problem has a positive effect on all observed scores. However, to enable effective annotation support we will need to further improve the model performance. Promising directions that should be investigated include methods like multi-object tracking and graph neural network models.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}