An Investigation of Feed-Forward and Feedback Eye Movement Training in Immersive Virtual Reality
Abstract
:Introduction
Hypotheses
Methods
Participant and public involvement and engagement
Design
Participants
Materials
VR equipment
VR Room Clearance Assessment Task
VR Training Conditions
Measures
Performance
- Failures to inhibit fire – number of instances where shots landed on non-threatening targets, which was automatically detected by the VR simulation (calculated as a proportion of non-threat targets);
- Time to shoot all hostiles – the time from entering the room until all hostile targets had been shot, as calculated by the VR software (in seconds); and
- Missed hostiles – whether there were any threatening targets left in the room that were not successfully shot, as calculated by the VR software (as a proportion of all hostile targets).
Eye movement measures


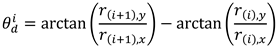
Data Analysis
Results
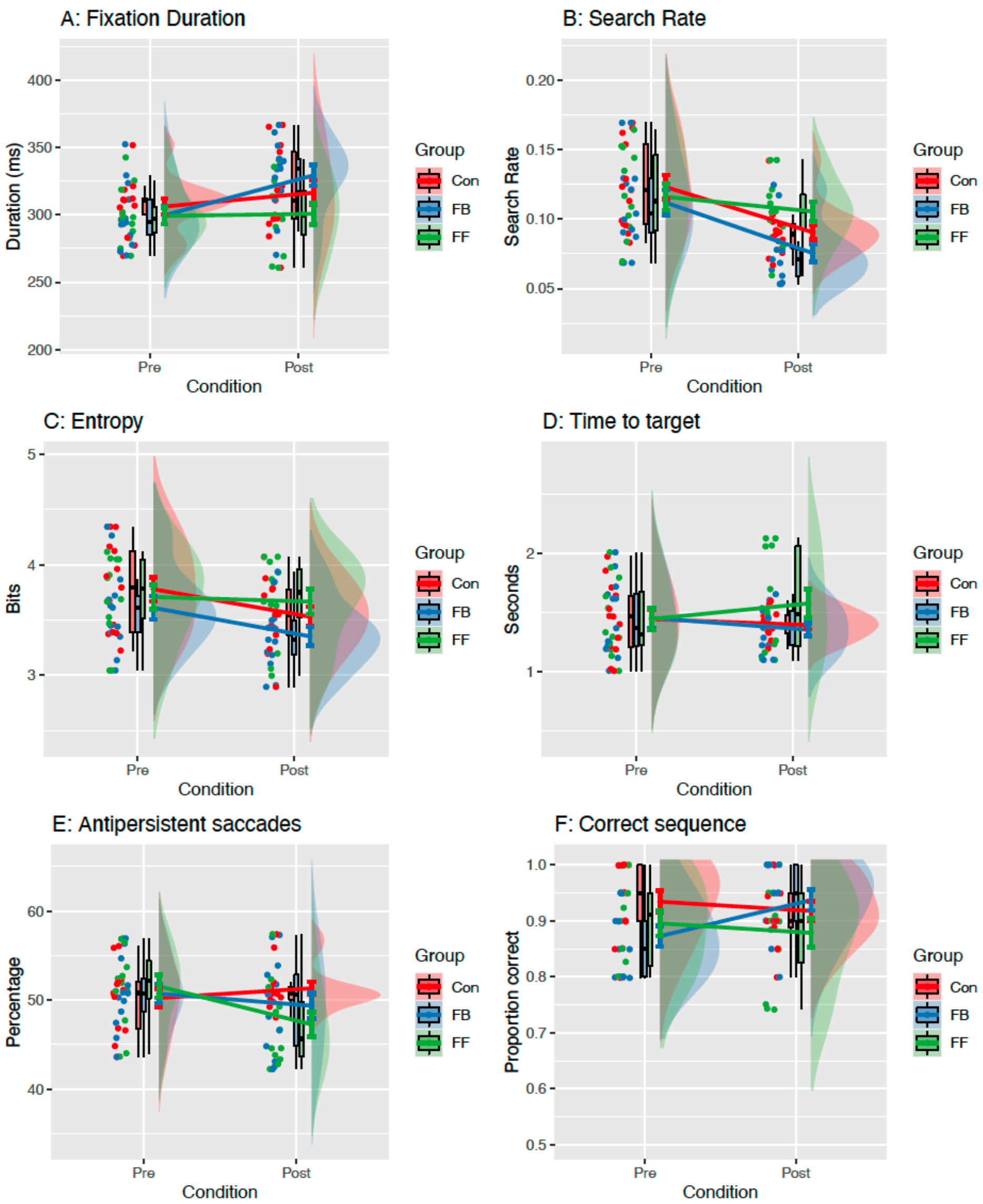
Pre to Post Changes in Eye Movement Metrics in VR
Fixation Duration
Search Rate
Gaze Transition Entropy
Time to Fixate First Target
Percentage of Antipersistent Saccades
Search Order Compliance
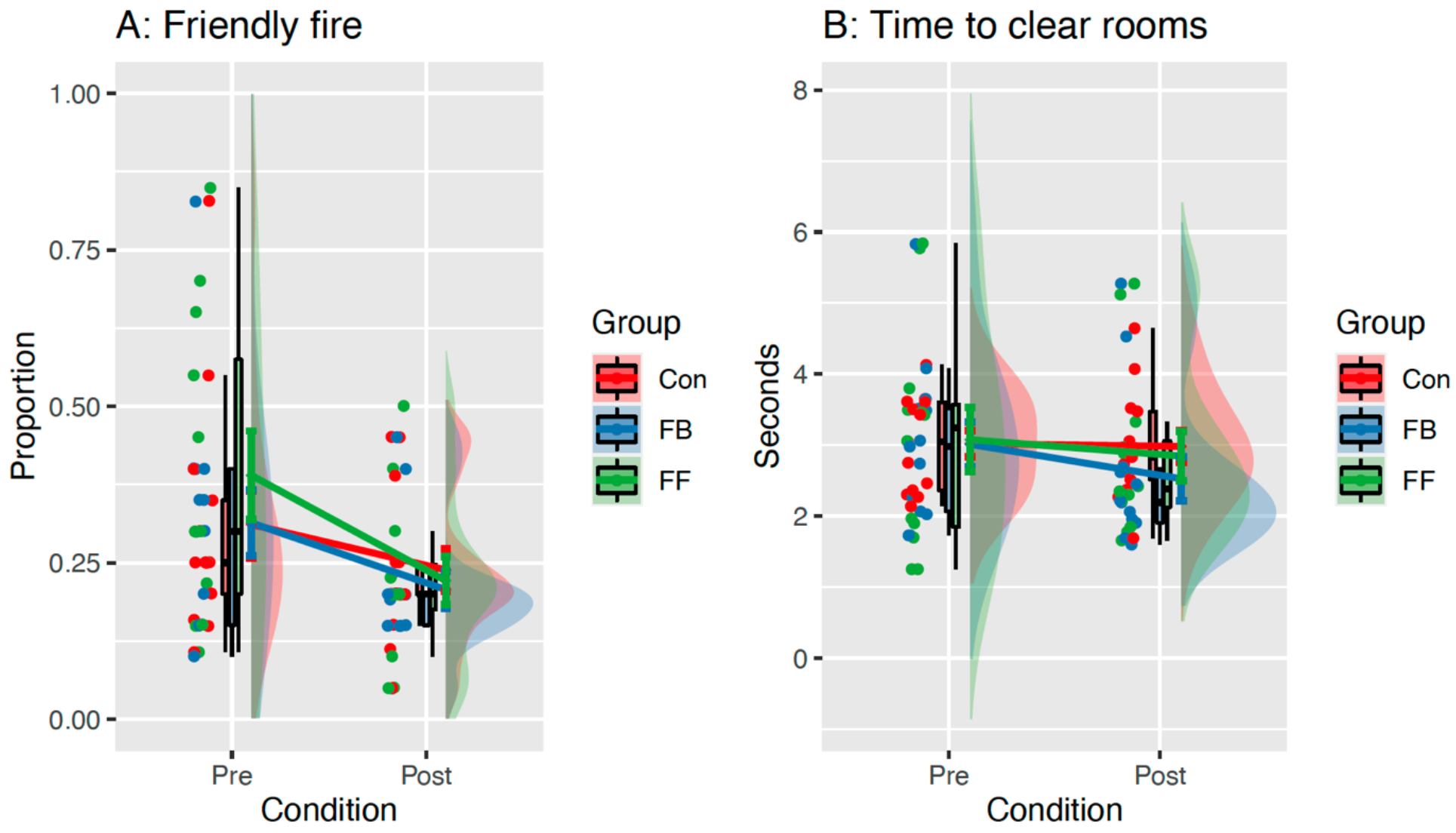
Changes in Performance Within the VR Environment
Failures to Inhibit Fire
Time to Shoot All Hostiles
Proportion of Hostiles Cleared
Discussion
Conclusions
Ethics and Conflict of Interest
Acknowledgements
Data
References
- Adamovich, S. V., G. G. Fluet, E. Tunik, and A. S. Merians. 2009. Sensorimotor training in virtual reality: A review. NeuroRehabilitation 25, 1: 29–44. [Google Scholar] [CrossRef] [PubMed]
- Allsop, J., and R. Gray. 2014. Flying under pressure: Effects of anxiety on attention and gaze behavior in aviation. Journal of Applied Research in Memory and Cognition 3, 2: 63–71. [Google Scholar] [CrossRef]
- Amor, T. A., S. D. S. Reis, D. Campos, H. J. Herrmann, and J. S. Andrade. 2016. Persistence in eye movement during visual search. Scientific Reports 6, 1: 20815. [Google Scholar] [CrossRef]
- Arthur, T., D. Harris, G. Buckingham, M. Brosnan, M. Wilson, G. Williams, and S. Vine. 2021. An examination of active inference in autistic adults using immersive virtual reality. Scientific Reports 11, 1: 20377. [Google Scholar] [CrossRef]
- Blandin, Y., and L. Proteau. 2000. On the cognitive basis of observational learning: Development of mechanisms for the detection and correction of errors. The Quarterly Journal of Experimental Psychology Section A 53, 3: 846–867. [Google Scholar] [CrossRef] [PubMed]
- Brams, S., G. Ziv, O. Levin, J. Spitz, J. Wagemans, A. M. Williams, and W. F. Helsen. 2019. The relationship between gaze behavior, expertise, and performance: A systematic review. Psychological Bulletin 145, 10: 980–1027. [Google Scholar] [CrossRef]
- Buckingham, G., J. D. Wong, M. Tang, P. L. Gribble, and M. A. Goodale. 2014. Observing object lifting errors modulates cortico-spinal excitability and improves object lifting performance. Cortex 50: 115–124. [Google Scholar] [CrossRef]
- Causer, J., P. S. Holmes, and A. M. Williams. 2011. Quiet Eye Training in a Visuomotor Control Task. Medicine and Science in Sports and Exercise 43, 6: 1042–1049. [Google Scholar] [CrossRef]
- Cesqui, B., M. Mezzetti, F. Lacquaniti, and A. d’Avella. 2015. Gaze Behavior in One-Handed Catching and Its Relation with Interceptive Performance: What the Eyes Can’t Tell. PLOS One 10, 3: e0119445. [Google Scholar] [CrossRef]
- Cheung, O. S., and M. Bar. 2012. Visual prediction and perceptual expertise. International Journal of Psychophysiology 83, 2: 156–163. [Google Scholar] [CrossRef]
- de Brouwer, A. J., J. R. Flanagan, and M. Spering. 2021. Functional Use of Eye Movements for an Acting System. Trends in Cognitive Sciences. [Google Scholar] [CrossRef]
- de Koning, B. B., H. K. Tabbers, R. M. J. P. Rikers, and F. Paas. 2009. Towards a Framework for Attention Cueing in Instructional Animations: Guidelines for Research and Design. Educational Psychology Review 21, 2: 113–140. [Google Scholar] [CrossRef]
- Fooken, J., and M. Spering. 2020. Eye movements as a readout of sensorimotor decision processes. Journal of Neurophysiology 123, 4: 1439–1447. [Google Scholar] [CrossRef]
- Gegenfurtner, A., E. Lehtinen, H. Jarodzka, and R. Säljö. 2017. Effects of eye movement modeling examples on adaptive expertise in medical image diagnosis. Computers & Education 113: 212–225. [Google Scholar] [CrossRef]
- Grant, E. R., and M. J. Spivey. 2003. Eye Movements and Problem Solving: Guiding Attention Guides Thought. Psychological Science 14, 5: 462–466. [Google Scholar] [CrossRef]
- Hagita, K., Y. Kodama, and M. Takada. 2020. Simplified virtual reality training system for radiation shielding and measurement in nuclear engineering. Progress in Nuclear Energy 118: 103127. [Google Scholar] [CrossRef]
- Harle, S. K., and J. N. Vickers. 2001. Training Quiet Eye Improves Accuracy in the Basketball Free Throw. The Sport Psychologist 15, 3: 289–305. [Google Scholar] [CrossRef]
- Harris, D. J., G. Buckingham, M. R. Wilson, J. Brookes, F. Mushtaq, M. Mon-Williams, and S. J. Vine. 2020. The effect of a virtual reality environment on gaze behaviour and motor skill learning. Psychology of Sport and Exercise, 101721. [Google Scholar] [CrossRef]
- Harris, D. J., K. J. Hardcastle, M. R. Wilson, and S. J. Vine. 2021. Assessing the learning and transfer of gaze behaviours in immersive virtual reality. Virtual Reality 25, 4: 961–973. [Google Scholar] [CrossRef]
- Harris, D. J., S. J. Vine, M. R. Wilson, J. S. McGrath, M.-E. LeBel, and G. Buckingham. 2017. The effect of observing novice and expert performance on acquisition of surgical skills on a robotic platform. PLOS One 12, 11: e0188233. [Google Scholar] [CrossRef]
- Harris, D., M. Wilson, T. Holmes, T. de Burgh, and S. Vine. 2020. Eye movements in sports research and practice: Immersive technologies as optimal environments for the study of gaze behaviour. In Eye Tracking: Background, Methods, and Applications. New York, NY: Springer US: pp. 207–221. [Google Scholar]
- Hayhoe, M. M. 2017. Vision and Action. Annual Review of Vision Science 3, 1: 389–413. [Google Scholar] [CrossRef]
- Henderson, J. M. 2017. Gaze control as prediction. Trends in Cognitive Sciences 21, 1: 15–23. [Google Scholar] [CrossRef] [PubMed]
- Janelle, C. M. 2002. Anxiety, arousal and visual attention: A mechanistic account of performance variability. Journal of Sports Sciences 20, 3: 237–251. [Google Scholar] [CrossRef] [PubMed]
- Janelle, C. M., and B. D. Hatfield. 2008. Visual Attention and Brain Processes That Underlie Expert Performance: Implications for Sport and Military Psychology. Military Psychology 20, sup1: S39–S69. [Google Scholar] [CrossRef]
- Jarodzka, H., T. Balslev, K. Holmqvist, M. Nyström, K. Scheiter, P. Gerjets, and B. Eika. 2012. Conveying clinical reasoning based on visual observation via eye-movement modelling examples. Instructional Science 40, 5: 813–827. [Google Scholar] [CrossRef]
- Jarodzka, H., T. van Gog, M. Dorr, K. Scheiter, and P. Gerjets. 2013. Learning to see: Guiding students’ attention via a Model’s eye movements fosters learning. Learning and Instruction 25: 62–70. [Google Scholar] [CrossRef]
- Karlsson, P., and A. Bergmark. 2015. Compared with what? An analysis of control-group types in Cochrane and Campbell reviews of psychosocial treatment efficacy with substance use disorders. Addiction (Abingdon, England) 110, 3: 420–428. [Google Scholar] [CrossRef]
- Krassanakis, V., V. Filippakopoulou, and B. Nakos. 2014. EyeMMV toolbox: An eye movement post-analysis tool based on a two-step spatial dispersion threshold for fixation identification. Journal of Eye Movement Research 7, 1. [Google Scholar] [CrossRef]
- Land, M. F. 2006. Eye movements and the control of actions in everyday life. Progress in Retinal and Eye Research 25, 3: 296–324. [Google Scholar] [CrossRef]
- Land, M. F. 2009. Vision, eye movements, and natural behavior. Visual Neuroscience 26, 1: 51–62. [Google Scholar] [CrossRef]
- Lebeau, J.-C., S. Liu, C. Sáenz-Moncaleano, S. Sanduvete-Chaves, S. Chacón-Moscoso, B. J. Becker, and G. Tenenbaum. 2016. Quiet Eye and performance in sport: A meta-analysis. Journal of Sport and Exercise Psychology 38, 5: 441–457. [Google Scholar] [CrossRef] [PubMed]
- Lefrançois, O., N. Matton, and M. Causse. 2021. Improving Airline Pilots’ Visual Scanning and Manual Flight Performance through Training on Skilled Eye Gaze Strategies. Safety 7, 4: Article 4. [Google Scholar] [CrossRef]
- Lele, A. 2013. Virtual reality and its military utility. Journal of Ambient Intelligence and Humanized Computing 4, 1: 17–26. [Google Scholar] [CrossRef]
- Lounis, C., V. Peysakhovich, and M. Causse. 2021. Visual scanning strategies in the cockpit are modulated by pilots’ expertise: A flight simulator study. PLOS One 16, 2: e0247061. [Google Scholar] [CrossRef] [PubMed]
- Mann, D. L., H. Nakamoto, N. Logt, L. Sikkink, and E. Brenner. 2019. Predictive eye movements when hitting a bouncing ball. Journal of Vision 19, 14: 28–28. [Google Scholar] [CrossRef] [PubMed]
- Mann, A. M. Williams, P. Ward, and C. M. Janelle. 2007. Perceptual-Cognitive Expertise in Sport: A MetaAnalysis. Journal of Sport and Exercise Psychology 29, 4: 457–478. [Google Scholar] [CrossRef]
- Marteniuk, R. G. 1976. Information processing in motor skills. Holt, Rinehart and Winston. [Google Scholar]
- Miles, C. A. L., S. J. Vine, G. Wood, J. N. Vickers, and M. R. Wilson. 2014. Quiet eye training improves throw and catch performance in children. Psychology of Sport and Exercise 15, 5: 511–515. [Google Scholar] [CrossRef]
- Moore, L. J., D. J. Harris, B. T. Sharpe, S. J. Vine, and M. R. Wilson. 2019. Perceptual-cognitive expertise when refereeing the scrum in rugby union. Journal of Sports Sciences 37, 15: 1778–1786. [Google Scholar] [CrossRef]
- Moore, L. J., S. J. Vine, P. Freeman, and M. R. Wilson. 2013. Quiet eye training promotes challenge appraisals and aids performance under elevated anxiety. International Journal of Sport and Exercise Psychology 11, 2: 169–183. [Google Scholar] [CrossRef]
- Moore, L. J., S. J. Vine, A. N. Smith, S. J. Smith, and M. R. Wilson. 2014. Quiet Eye Training Improves Small Arms Maritime Marksmanship. Military Psychology 26, 5–6: 355–365. [Google Scholar] [CrossRef]
- Nalanagula, D., J. S. Greenstein, and A. K. Gramopadhye. 2006. Evaluation of the effect of feedforward training displays of search strategy on visual search performance. International Journal of Industrial Ergonomics 36, 4: 289–300. [Google Scholar] [CrossRef]
- Norman, G. 2010. Likert scales, levels of measurement and the “laws” of statistics. Advances in Health Sciences Education 15, 5: 625–632. [Google Scholar] [CrossRef] [PubMed]
- Parr, T., N. Sajid, L. Da Costa, M. B. Mirza, and K. J. Friston. 2021. Generative Models for Active Vision. Frontiers in Neurorobotics 15. [Google Scholar] [CrossRef]
- Salvucci, D. D., and J. H. Goldberg. 2000. Identifying fixations and saccades in eye-tracking protocols. Proceedings of the Symposium on Eye Tracking Research & Applications ETRA ’00, 71–78. [Google Scholar] [CrossRef]
- Shannon, C. E. 1948. A Mathematical Theory of Communication. Bell System Technical Journal 27, 3: 379–423. [Google Scholar] [CrossRef]
- Shannon, C. E., and W. Weaver. 1949. The Mathematical Theory of Communication. UoI Press. [Google Scholar]
- Szulewski, A., H. Braund, R. Egan, A. Gegenfurtner, A. K. Hall, D. Howes, D. Dagnone, and J. J. G. van Merrienboer. 2019. Starting to Think Like an Expert: An Analysis of Resident Cognitive Processes During Simulation-Based Resuscitation Examinations. Annals of Emergency Medicine 74, 5: 647–659. [Google Scholar] [CrossRef]
- Szulewski, A., H. Braund, R. Egan, A. K. Hall, J. D. Dagnone, A. Gegenfurtner, and J. J. G. van Merrienboer. 2018. Through the Learner’s Lens: Eye-Tracking Augmented Debriefing in Medical Simulation. Journal of Graduate Medical Education 10, 3: 340–341. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B. W., M. M. Hayhoe, M. F. Land, and D. H. Ballard. 2011. Eye guidance in natural vision: Reinterpreting salience. Journal of Vision 11, 5: 5. [Google Scholar] [CrossRef]
- Vine, S. J., L. J. Moore, A. Cooke, C. Ring, and M. R. Wilson. 2013. Quiet eye training: A means to implicit motor learning. International Journal of Sport Psychology 44, 4: 367–386. [Google Scholar]
- Vine, S. J., L. J. Moore, and M. R. Wilson. 2014. Quiet eye training: The acquisition, refinement and resilient performance of targeting skills. European Journal of Sport Science 14, 1: S235–S242. [Google Scholar] [CrossRef]
- Vine, S. J., L. Moore, and M. R. Wilson. 2011. Quiet Eye Training Facilitates Competitive Putting Performance in Elite Golfers. Frontiers in Psychology 2. [Google Scholar] [CrossRef]
- Vine, S. J., L. Uiga, A. Lavric, L. J. Moore, K. Tsaneva-Atanasova, and M. R. Wilson. 2015. Individual reactions to stress predict performance during a critical aviation incident. Anxiety, Stress, & Coping 28, 4: 467–477. [Google Scholar] [CrossRef]
- Vine, S. J., and M. R. Wilson. 2011. The influence of quiet eye training and pressure on attention and visuomotor control. Acta Psychologica 136, 3: 340–346. [Google Scholar] [CrossRef] [PubMed]
- Williams, A. M., K. Davids, L. Burwitz, and J. G. Williams. 1994. Visual Search Strategies in Experienced and Inexperienced Soccer Players. Research Quarterly for Exercise and Sport 65, 2: 127–135. [Google Scholar] [CrossRef] [PubMed]
- Wilson, M., M. Coleman, and J. McGrath. 2010. Developing basic hand-eye coordination skills for laparoscopic surgery using gaze training. BJU International 105, 10: 1356–1358. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. This article is licensed under a Creative Commons Attribution 4.0 International License.
Share and Cite
Harris, D.J.; Wilson, M.R.; Jones, M.I.; de Burgh, T.; Mundy, D.; Arthur, T.; Olonilua, M.; Vine, S.J. An Investigation of Feed-Forward and Feedback Eye Movement Training in Immersive Virtual Reality. J. Eye Mov. Res. 2022, 15, 1-14. https://doi.org/10.16910/jemr.15.3.7
Harris DJ, Wilson MR, Jones MI, de Burgh T, Mundy D, Arthur T, Olonilua M, Vine SJ. An Investigation of Feed-Forward and Feedback Eye Movement Training in Immersive Virtual Reality. Journal of Eye Movement Research. 2022; 15(3):1-14. https://doi.org/10.16910/jemr.15.3.7
Chicago/Turabian StyleHarris, David J., Mark R. Wilson, Martin I. Jones, Toby de Burgh, Daisy Mundy, Tom Arthur, Mayowa Olonilua, and Samuel J. Vine. 2022. "An Investigation of Feed-Forward and Feedback Eye Movement Training in Immersive Virtual Reality" Journal of Eye Movement Research 15, no. 3: 1-14. https://doi.org/10.16910/jemr.15.3.7
APA StyleHarris, D. J., Wilson, M. R., Jones, M. I., de Burgh, T., Mundy, D., Arthur, T., Olonilua, M., & Vine, S. J. (2022). An Investigation of Feed-Forward and Feedback Eye Movement Training in Immersive Virtual Reality. Journal of Eye Movement Research, 15(3), 1-14. https://doi.org/10.16910/jemr.15.3.7