Introduction
Eye gaze estimation has been an active research area for a long time due to its numerous applications. Early systems used techniques like electrooculography, whereas recent systems employed infrared imaging and computer vision techniques to obtain accurate gaze estimates. These infrared-based eye gaze trackers brought eye gaze tracking into the commercial realm and helped realize applications such as gaze-based human-computer interaction in automotive (
Poitschke et al., 2011;
Prabhakar, Ramakrishnan, et al., 2020), aviation (
Murthy et al., 2020) and assistive technology (
Borgestig et al., 2017;
Sharma et al., 2020) domains. Researchers also made progress to utilize gaze estimates for non-interactive purposes like visual scan path analysis (
Eraslan et al., 2016), cognitive load estimation of drivers in automotive domain (
Palinko et al., 2010;
Prabhakar, Mukhopadhyay, et al., 2020). Recently, various efforts were being made to achieve similar performance using commodity hardware like built-in cameras present in laptops and smartphones as this can expand the reach of this technology. With the help of large datasets and advancements in deep-learning techniques, recent appearance-based approaches trumped model-based methods in terms of accuracy.
However, it was observed that appearance-based systems which reported state-of-the-art accuracy on one dataset do not achieve the same degree of accuracy on a different dataset. Spatial weights CNN model proposed by (
Zhang et al., 2017b) reported 42 mm error on MPIIGaze dataset (
Zhang et al., 2017a) whereas the same architecture reported 85.6 mm error on EYEDIAP dataset (
Funes Mora et al., 2014). Further, models which performed well during with-in dataset validation reported a higher error on cross-dataset validation. Diff-NN proposed in (
Liu et al., 2019) used 9 reference samples and reported a 4.64° error on MPIIGaze during with-in dataset validation but reported an error of 9.8° mean angle error when trained on UT-Multiview (
Sugano et al., 2014) dataset and tested on MPII-Gaze. A similar trend can be observed for the MeNet proposed by (
Xiong et al., 2019) which achieved 4.9° during with-in dataset validation but reported 9.51° error during the above mentioned cross-dataset validation setting. Researchers (
Liu et al., 2019) believed that this is due to the discrepancies during pre-processing and variation in head pose and gaze data distributions. It may also be noted that both Diff-NN and MeNet utilized UT-Multiview dataset for training, which is collected in controlled lab conditions and tested on the MPIIGaze dataset, which is recorded in real-world conditions. Even though appearance variations across participants and inherent offset between visual axis and optical axis for each person do exist, high error during cross-dataset validation raises the question of how appearance-based approaches perform on unseen users under real-world conditions.
Appearance-based methods predict gaze angles in normalized space and transforming this to millimeters is not trivial as this also depends on the head pose of the user. Hence, most appearance-based systems reported their performance in terms of mean angle error, but not in pixels or millimeters. Thus, it is unclear how well the existing state-of-the-art appearance-based systems perform in an interactive context like an eye gaze controlled interface. (
Zhang et al., 2019) evaluated Spatial weights CNN in off-line mode under two lighting conditions for its accuracy and the evaluation presented in (
Gudi et al., 2020) focused on accuracy and latency. Both these evaluation works did not evaluate appearance-based systems in the context of interaction and usability.
Infra-red based commercial eye gaze trackers have much higher accuracy than current state-of-the-art appearance-based approaches. Yet, appearance-based gaze estimation systems have several use cases like webcam based gaze controlled interfaces as they do not require any additional hardware. Further, people with severe speech and motor impairment often use gaze controlled interface with limited number of screen elements (
Jeevithashree et al., 2019;
Sharma et al., 2020). Appearance-based gaze estimation systems can be used to build such gaze controlled interfaces on smartphones and tablet PCs using their front cameras.
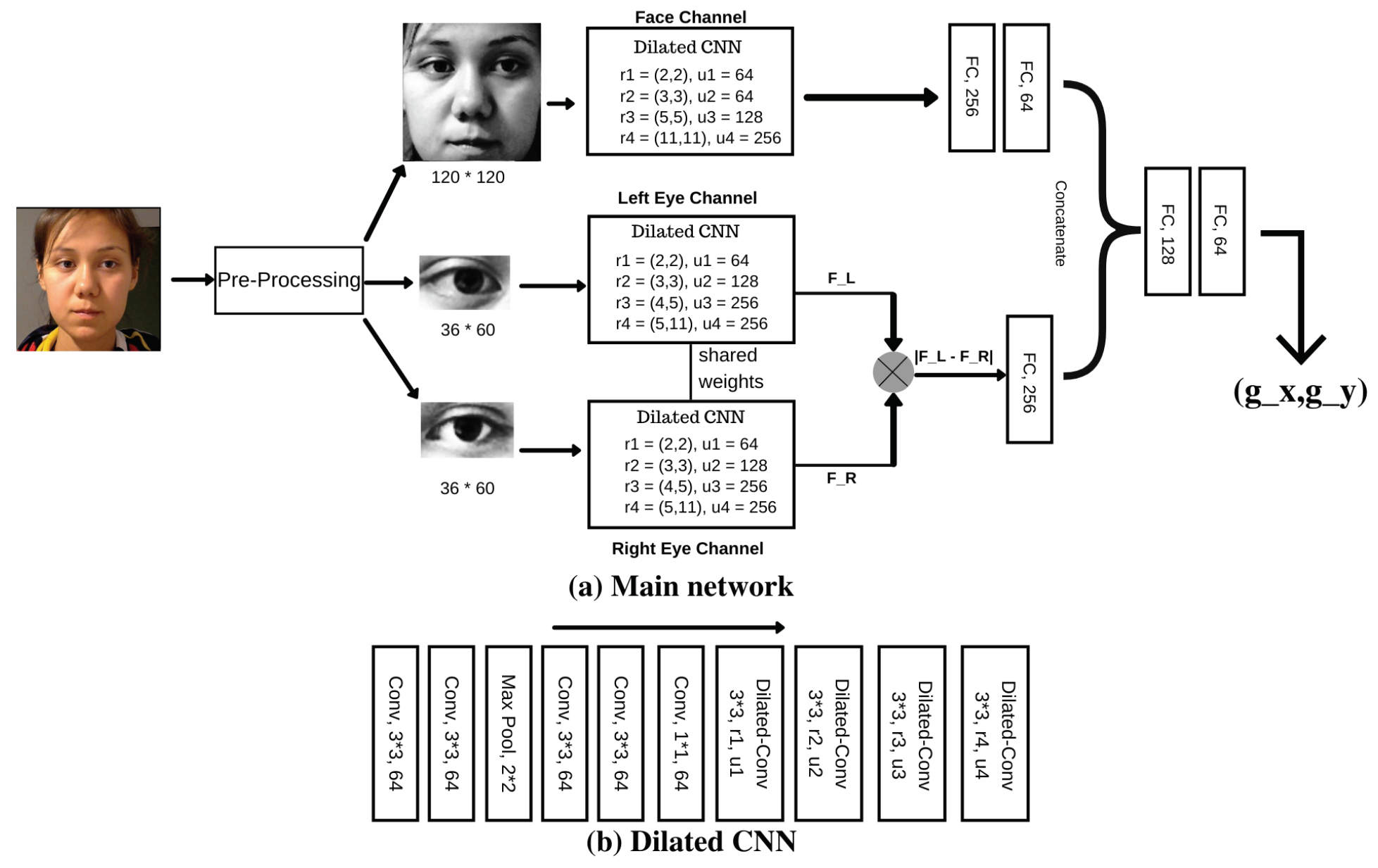
This paper proposes a novel architecture that focuses on overcoming appearance-related variations across users to improve accuracy. We propose I2DNet: I-gaze estimation using dilated differential network which achieved a state-of-the-art 4.3 and 8.4 degree mean angle error during the evaluation on MPIIGaze and RT-Gene respectively. Further, to understand how the proposed system performs for unseen users in real-time, we conducted a user study. We compared its performance for a 9-block pointing and selection task with WebGazer.js (
Papoutsaki et al., 2016) and OpenFace 2.0 (
Baltrusaitis et al., 2018).
This paper is structured as follows. The next section presents literature review of various gaze estimation methods and their evaluation methods. Sections 3 and 4 present the methodology of our proposed model and experiments conducted on MPIIGaze and RT-Gene using our proposed architecture. Section 5 presents the design of our user study. Section 6 presents the results and analysis. Section 7 presents the discussion and future work followed by conclusion in Section 8.
Related work
In this section, we discussed various gaze estimation approaches followed by works which evaluated gaze tracking interfaces.
Infrared imaging-based eye trackers used feature-based methods for gaze estimation which extract features from the eye images. Numerous approaches were proposed for Point of Gaze (PoG) estimation for desktop and mobile settings based on the well-established theory of gaze estimation using the pupil centers and corneal reflections. Guestrin and Eizenman (
Guestrin & Eizenman, 2006) reported to have obtained a PoG accuracy of 0.9° in a desktop setting based on an evaluation on 4 subjects. Further, Brousseau et al. (
Brousseau et al., 2018) proposed a system for gaze estimation for mobile devices compensating for the relative roll between the system and subject’s eyes. They evaluated their system on 4 subjects and reported around 1° of gaze estimation error. Even though these results were promising, it was unclear how these systems will perform on wider population under real-world usage conditions with wider gaze angles and head poses. Recent reports of the commercial IR-based gaze trackers claim to provide gaze accuracy of <1.9° error across 95% of population under real-world usage conditions (
https://www.to-biidynavox.com/devices/eye-gaze-devices/pceye-mini-access-windows-control/#Specifications).
In addition to the desktop setting, head-mounted video-based eye trackers are becoming increasingly more popular. Morimoto and Mimica (
Morimoto & Mimica, 2005) stated that gaze estimation approaches based on pupil tracking techniques have better accuracy since they are not covered by eyelids. They reported that the pupil tracking based gaze estimation systems can achieve an accuracy of ~1°, but they also commented that it is hard to detect the pupil. Since then, several approaches like (
Fuhl et al., 2015,
2016;
Santini et al., 2018a,
2018b) were proposed for robust real-time pupil detection in challenging natural environments like driving and walking. Current state-of-the-art approach (
Eivazi et al., 2019) reported a pupil detection rate of ~85% on PupilNet (
Fuhl et al., 2017) and LPW (
Tonsen et al., 2016) datasets and a detection rate of ~74% on Swirski (
Świrski et al., 2012) dataset. Yet, the performance of these approaches in terms of gaze estimation in similar challenging environments with such pupil detection accuracies is still unknown.
Researchers also approached the problem of gaze estimation without using IR-illuminators. Such model-based approaches rely on the detection of visual features such as pupil, eyeball center and eye corners. These features are then used to fit a geometric model of the 3D eyeball to obtain eye gaze estimates. Early model-based methods such as (
Cristina & Camilleri, 2016), (
Alberto Funes Mora & Odobez, 2014) and (
Jianfeng & Shigang, 2014) relied on high-resolution cameras to detect such visual features with high accuracy, but these methods were not robust to variation in illumination conditions. Recent model-based methods like GazeML (
Park et al., 2018) and OpenFace 2.0 attempted to overcome these limitations by using only commodity web cameras and empowering their feature detectors using machine learning techniques. OpenFace 2.0 reported a state-of-the-art performance on the task of cross-dataset eye gaze estimation with an error of 9.1° on MPIIGaze. Webgazer.js proposed a feature-based method for gaze interaction for web-based platforms. The authors of Webgazer.js proposed to use left and right eye images to train a ridge-regression model and used cursor activity for fine-tuning of the predictions. They conducted an online evaluation with 82 participants and reported a best mean error of around 175 pixels across various tasks, which equates to around 35mm as per present display configurations. This error of 35mm is less than 42mm, which is achieved by Spatial weights CNN on MPIIGaze dataset. Even though we cannot make a direct comparison due to the different datasets used for evaluation, it may be noted that the WebGazer.js reported their performance across 82 participants while MPIIGaze dataset contains 15 participants.
In contrast to feature-based and model-based methods, appearance-based methods rely only on the images captured from off-the-shelf cameras and do not attempt to create handcrafted features from eye images. Instead, these methods utilize machine learning techniques to directly obtain the gaze estimates from eyes or face images. These appearance-based methods are strongly supported by the creation of large datasets and advancements in deep learning techniques. In terms of model architecture, appearance-based gaze estimation can be classified broadly into Multi-channel networks and Single-channel networks. We are aware of the gaze estimation datasets and approaches like Gaze 360 (
Kellnhofer et al., 2019) which focused on 3D gaze estimation across 360° but for this literature review, we have focused on the approaches that worked on MPIIGaze, which is designed exclusively for laptop/desktop setting.
One of the first attempts of appearance-based gaze estimation was GazeNet (
Zhang et al., 2017a), which is a single channel approach where a single eye image is used as the input to an architecture based on 16-layer VGG deep CNN. Head pose information was concatenated to the first fully connected layer after convolutional layers. GazeNet reported a 5.4° mean angle error on the evaluation subset of MPIIGaze, termed as MPIIGaze+. This work was followed by another single-channel approach, by (
Zhang et al., 2017b) where full face images were provided as input instead of eye crops. Authors of this work used the spatial weights approach to provide more weightage to the regions of face which were significant for gaze estimation. (
Ranjan et al., 2018) proposed a branched architecture where a single eye image and head pose were used with a switch condition imposed on the head pose branch.
As an alternative to single-channel approaches, numerous multi-channel approaches were proposed. (
Krafka et al., 2016) proposed one such multi-channel convolutional neural network called iTracker. They used left eye image, right eye image, face crop image and face grid information as inputs. The face grid contained the location of face in the captured image. Subsequent multi-channel approaches did not use face grid as input. Our work is closely related to Multi-Region Dilated-Net proposed in (
Chen & Shi, 2018) which used dilated convolutions instead of several maxpooling layers in their CNN architecture. This approach also reported the same result of 4.8° mean angle error as (
Zhang et al., 2017b) did on MPIIGaze+. As an extension of this work, they utilized gaze decomposition (
Chen & Shi, 2020) in addition to dilated convolutions and achieved 4.5° error on MPIIGaze. Further, most recent work by (
Cheng et al., 2020) proposed face-based asymmetric regression-evaluation network which utilized the asymmetry between two eyes of same person to obtain gaze estimates. In this work, they evaluated the confidence score for gaze estimate obtained from each eye image and relied on the stronger prediction. This work presented two versions of the method: FARE Net and FAR-Net* which reported state-of-the-art performance of 4.41 and 4.3° error on MPIIGaze dataset, respectively.
As mentioned in the Introduction section, several of these approaches with high accuracy during within-dataset validation did not report same degree of accuracy under cross-dataset validation. Most of these cross-dataset validation experiments were conducted with UT-Multiview as training set and MPIIGaze as test set. It may be noted that the former was collected in controlled laboratory setting whereas the latter was recorded in real-world condition with variations in appearance, illumination, and inter-eye illumination difference. Due to the unavailability of such large datasets collected in real-world conditions apart from MPIIGaze, it is unclear how these models would perform under real world conditions when trained on MPIIGaze. Further, most of these works had little focus on the usability of these networks for real-time gaze interaction.
(
Zhang et al., 2019) attempted to evaluate the network’s performance proposed in (
Zhang et al., 2017b) against another model based method GazeML and commercial Tobii EyeX eye tracker. They evaluated these three systems in off-line mode on 20 participants under two illumination conditions and at 8 different distances between user and the camera. They recorded 80 samples under each of these 16 conditions and used 60 of these as calibration samples for fine tuning the gaze predictions and reported accuracy on remaining 20 samples. They used third-order polynomial fitting to map 2D gaze predictions to actual screen coordinates. Even though this study attempted to study the accuracy of various gaze estimation approaches, no emphasis was made on the usability aspect. Further, fine tuning of network for each distance may not be applicable for practical applications.
Summarizing our literature review, we believe that there is still a lack of clarity regarding the performance of existing appearance-based gaze estimation models for dayto-day gaze interaction for unseen users and little evidence is available on their usability. We also believe that an architecture that is robust to appearance-related variations is imperative. In this direction, we propose a novel architecture that attempts to overcome appearance-based variations. Further, we have conducted one of the first real-time user study to evaluate the usability of an appearance-based gaze estimation system.
Design of user study for gaze controlled interface
We investigated and analyzed the performance of our proposed I2DNet in terms of angle error on MPIIGaze and RT-Gene datasets. Since we wanted to study its performance in an interactive setting like a gaze controlled interface, we evaluated the proposed system on a 9-block selection task (
Sharma et al., 2020). From our literature review, OpenFace, a model-based approach, reported least cross-dataset validation error of 9.1° on MPIIGaze, lower than other appearance-based approaches like Diff-NN or MeNet. Further, as we mentioned earlier, WebGazer.js reported an average error of 175 pixels i.e., ~35 mm in a user study which involved 82 participants. Hence, we compared the proposed system’s performance with OpenFace and WebGazer.js.
Task
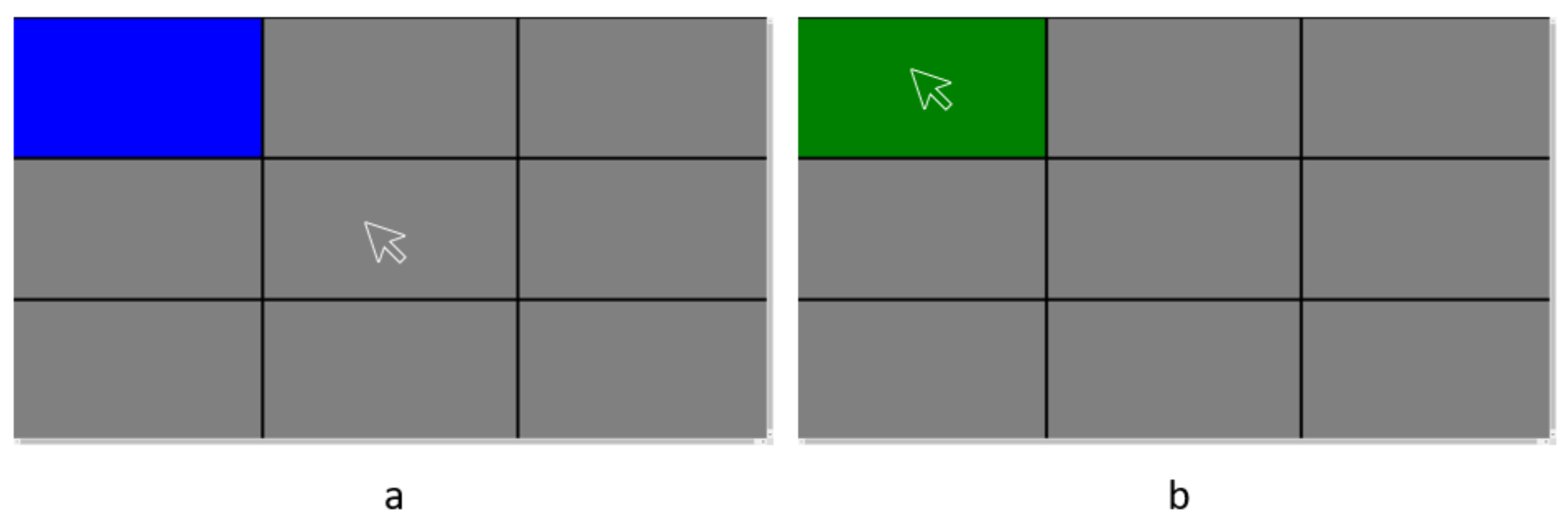
We divided the entire screen into 9 blocks of equal area. At first, we displayed these nine blocks on screen in gray color. We mapped the above mentioned three gaze prediction systems’ outputs to a marker on screen. As illustrated in
Figure 3a, we provided a stimulus to the user by randomly changing one of these nine blocks to blue color. The user was instructed to fixate attention at the block whichever turns blue and press space bar on keyboard. The blue block turned green when the user pressed spacebar while the marker was present inside its boundary as illustrated in
Figure 3b. We defined “
selection time” as the time between the instance a block turned blue and the instance the block turned green. If the user could not make selection with in 10000 milliseconds, we counted it as “
miss click” and stimulus was moved on to a different block.
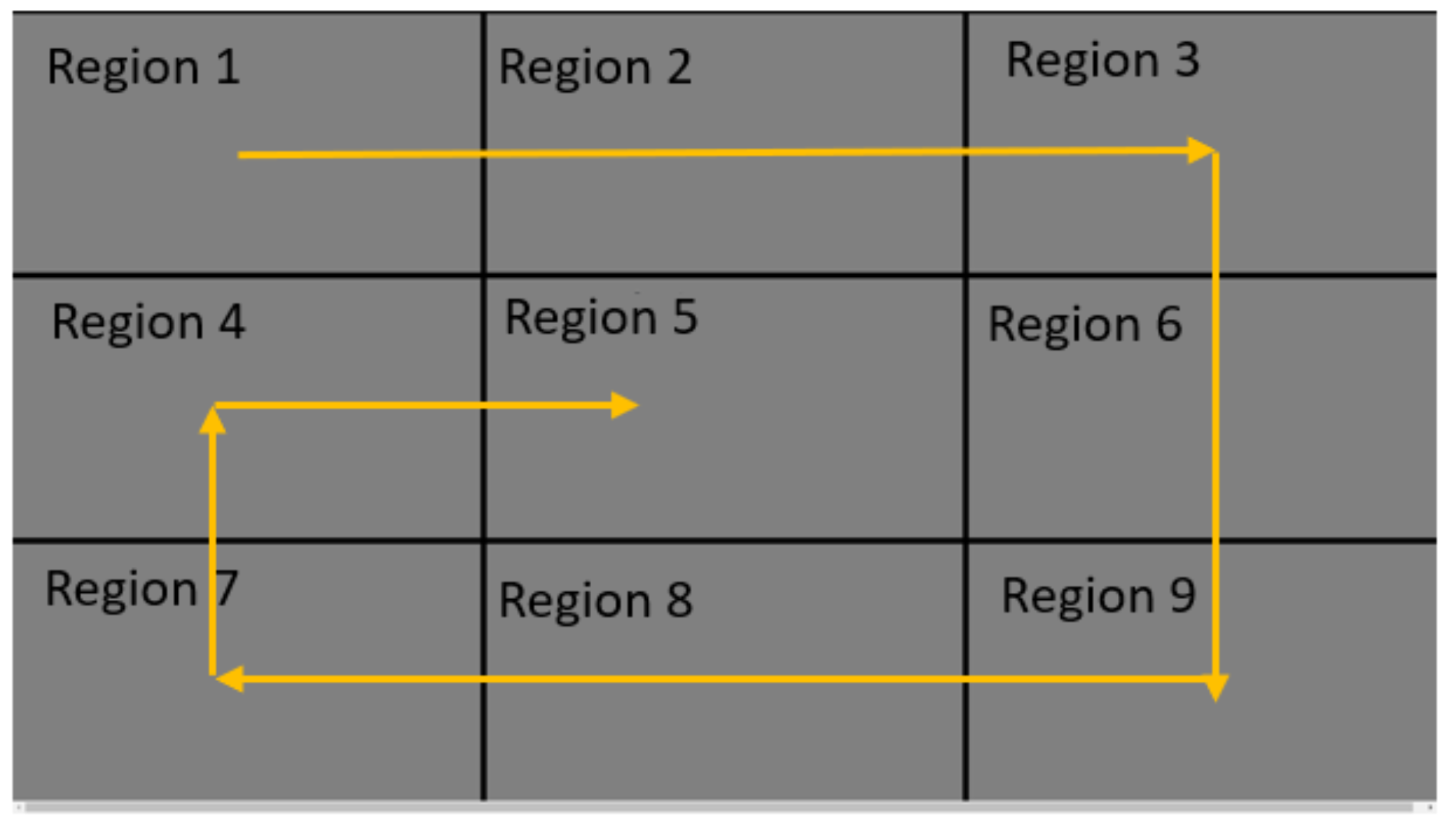
Figure 4 represents the annotations for the 9 blocks which we shall use for the rest of our paper.
WebGazer.js
We setup WebGazer.js software using the provided library at this hyperlink. We enabled Kalman filter provided along with the library to filter noise present in gaze predictions and to make the trajectory of predicted points smooth. This system required user to calibrate before they can start interacting. The calibration step required user to click on 9 dots, 5 times on each placed at different locations on screen. WebGazer.js reported that their system self-calibrates using the clicks and cursor movement. At the end of calibration process, WebGazer.js asked users to stare at a point and reported calibration accuracy. Participants who obtained low calibration accuracy had to repeat the calibration process. We set the minimum value of calibration accuracy as 80% for the participant to proceed to the task. We mapped gaze predictions to a red marker as discussed in previous section. For clear visibility of the marker, we set its size same as the mouse cursor. We ensured that the participants’ head lies in the pre-defined bounding box prescribed by WebGazer for proper tracking throughout the experiment.
OpenFace
During our preliminary studies, 3 participants used OpenFace 2.0 and reported off-set between actual gaze and cursor position with noticeable noise. They also said that they could not reach certain portions of the screen. Hence, we designed a custom calibration routine based on smooth pursuit principle. We asked users to follow a circle which traverses across the screen. We recorded gaze predictions from OpenFace during the smooth pursuit. We trained a classifier network which took gaze angles as inputs and block prediction the user is gazing at as the output.
The circle moved from top-left block (Region 1) to left bottom block (Region 7) through right top block (Region 3) and right bottom block (Region 9). From left bottom block, the circle reached the center block of screen (Region 5). We represented this trajectory in
Figure 4 in yellow lines. Throughout its trajectory, the circle moved at constant pace and halted at the center of each of these nine blocks for 2 seconds. Our calibration routine received these gaze angle predictions from OpenFace through UDP socket. We accounted for latency caused by both system and user and prepared our training data accordingly.
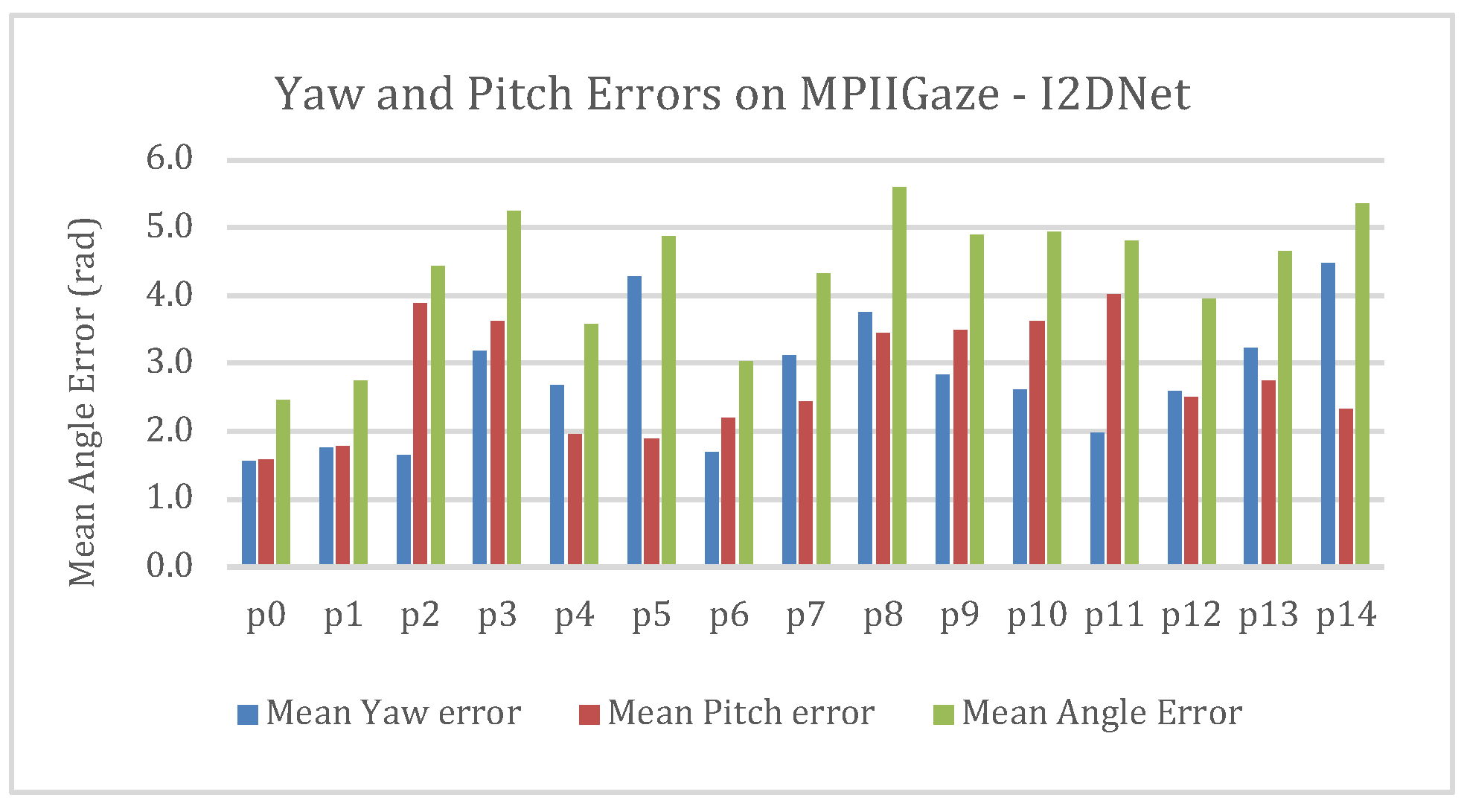
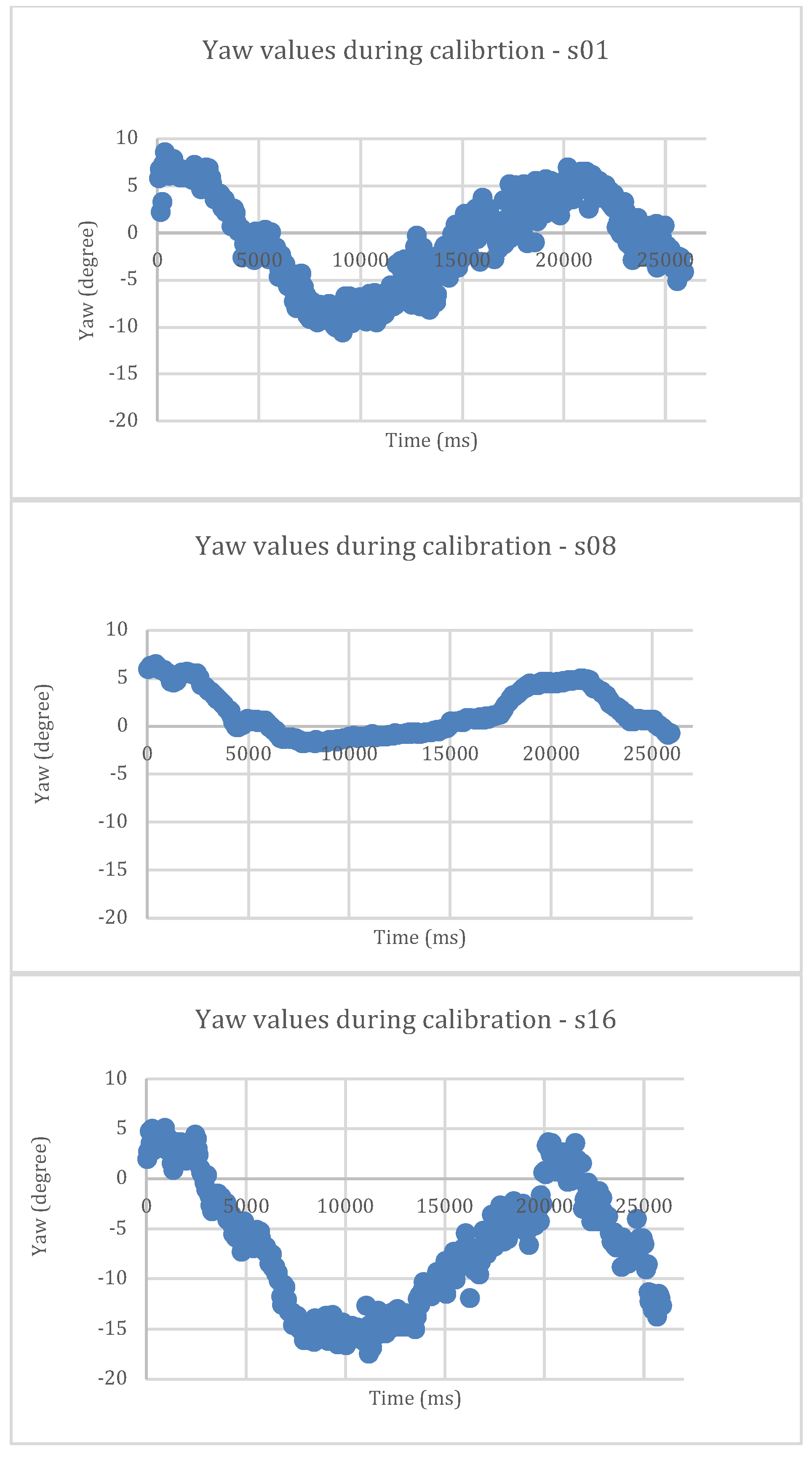
Figure 5 illustrates the raw yaw predictions obtained from OpenFace when three of our participants undertook the above explained calibration routine during the pilot study. The scatter plot indicated that the raw yaw predictions contained noise. We observed difference in minimum and maximum yaw values among participants for the same gaze positions on screen. Hence our calibration routine not only maps gaze predictions to respective blocks, but it also smoothens the noise present in the predictions. We used a 3-layer fully connected neural network which takes gaze yaw and pitch as inputs and predicts one of the 9 blocks as output. Similar to WebGazer.js, we monitored the classification accuracy during training. Participants were allowed to proceed for the task only if the classification accuracy on test set exceeded 75%. We observed that the classification accuracy for participants who used only eye movements with their head fixed was poor. Hence, we suggested our users to use head movement along with eye movement while using this interface. The mouse cursor is placed at the center of the predicted block. We named this interface which uses OpenFace 2.0 and our calibration procedure as OpenFace_NN and used the same for the rest of the paper.
I2DNet - Tracker
We used the same architecture presented in section 4. For real-time evaluation, we trained the network using the entire MPIIGaze dataset. To ensure proper training and to prevent overfitting, we utilized 15% of the dataset as validation set and observed training and validation losses over the training process of 25 epochs.
For each frame from webcam, we obtained 3D facial landmarks and head pose using OpenFace 2.0. We used these 3D landmarks of two corners of both eyes and two mouth corner points to obtain face center. In the same fashion, we used 3D landmarks of two corners of each eye to obtain corresponding eye center. We used these centers, ds and fv and the process explained in previous section to obtain normalized face and eye images. These images were fed to the trained I2DNet to obtain gaze predictions. We computed the screen dimensions, camera intrinsic parameters and performed extrinsic camera calibration to obtain screen-camera pose using the method described in (
Takahashi et al., 2012). For this purpose, we captured the images of checkerboard pattern displayed on screen by the webcam using a planar mirror. Using these images, we performed the screen-camera pose estimation. We obtained gaze vector from I2DNet and face center, face rotation matrix from OpenFace for each frame captured through webcam. We then used these metrics to obtain gaze point on screen using the method described in (
Zhang et al., 2019). For our proposed system, we did not utilize any calibration or filtering techniques, rather we directly map the predicted gaze points on screen to mouse cursor. We named our real-time gaze interface built using I2DNet predictions as I2DNet-tracker.
Experiment Design
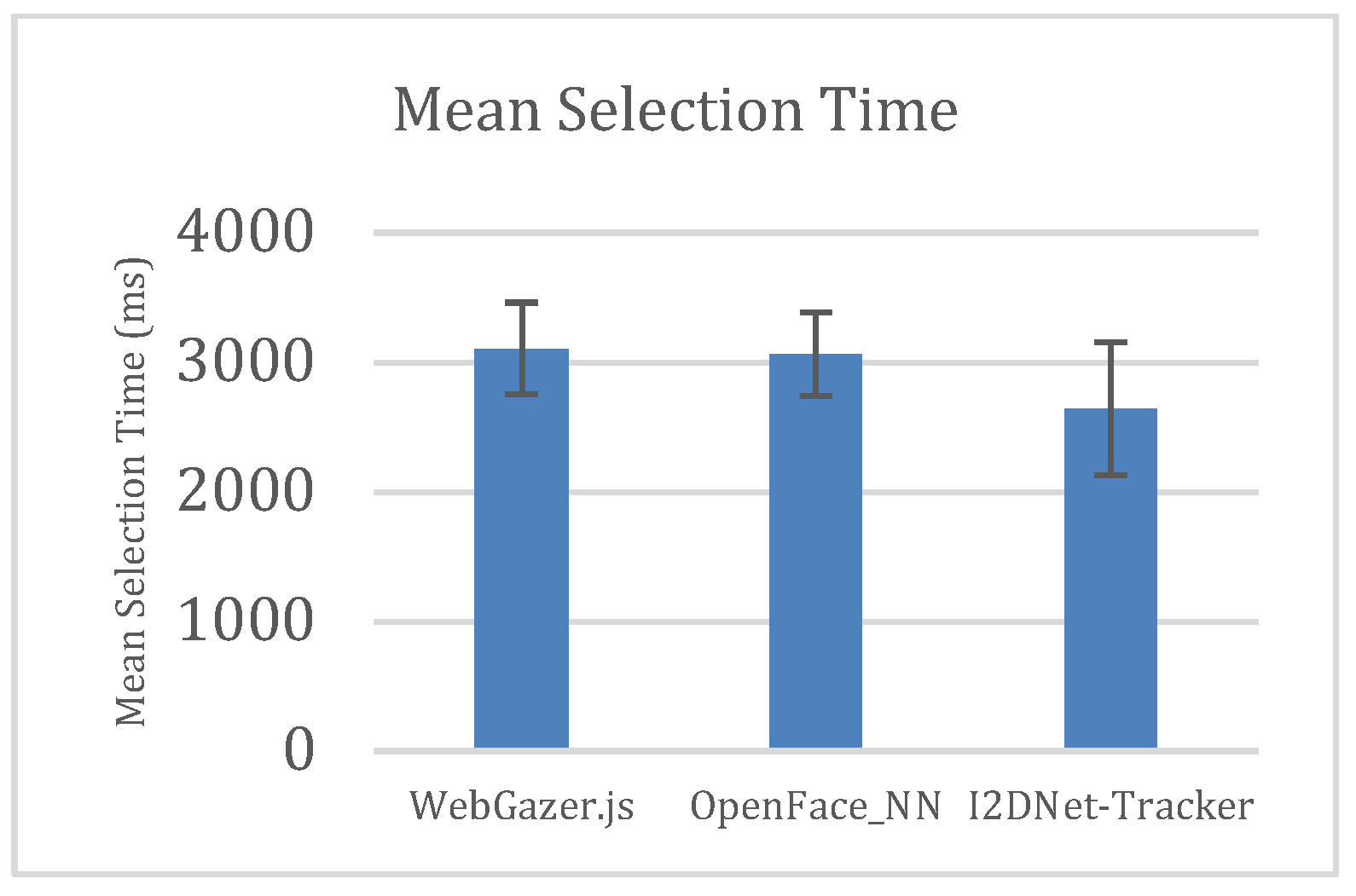
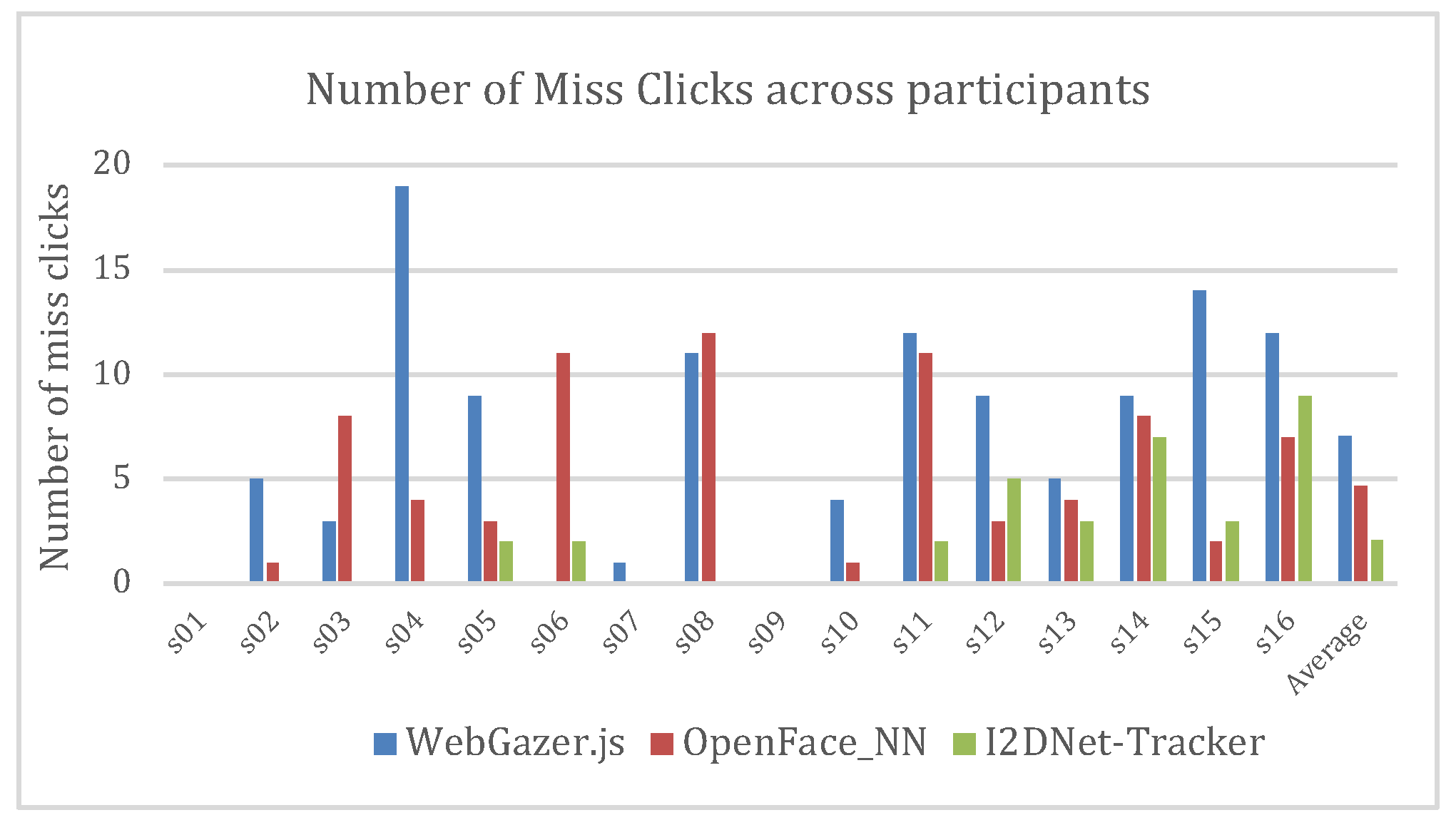
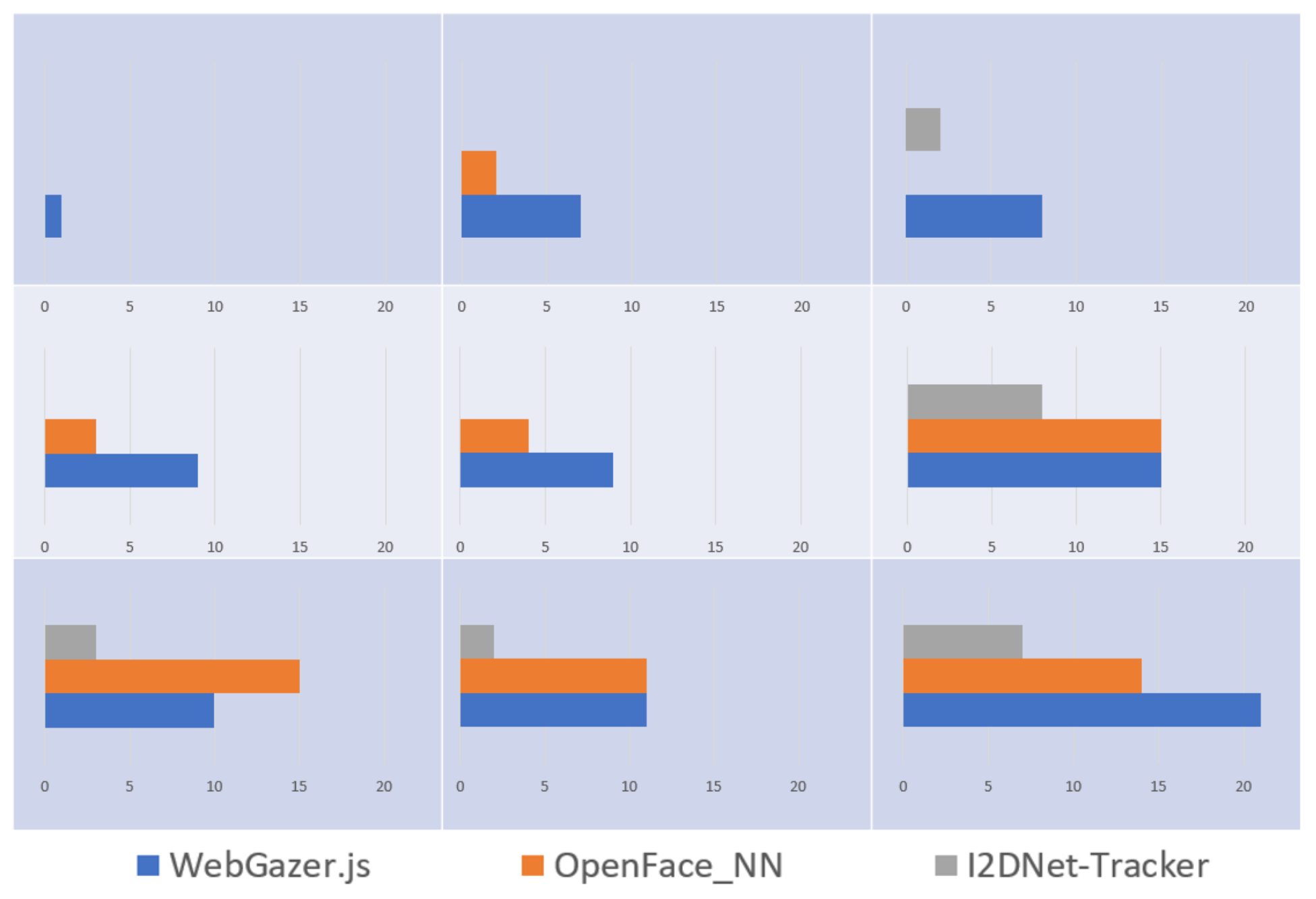
We used repeated measures approach and enrolled 16 users to participate in our user study (Age range from 19 to 51 years). Out of 16, 4 were female and 7 users wore spectacles while performing the task. We conducted our experiment in a closed room under artificial illumination. We used MSI GE75 Raider 9SG laptop with intel-i7 processor, GeForce RTX 2080 graphics card and a webcam of 1280x720 resolution. We used the same resolution for all the three systems. No user had any exposure to eye tracking technology prior to our experiment. Users performed the task elaborated in section 5.1 using three systems. Under each trial, each user got 25 stimuli and hence we recorded 1200 (25x3x16) selections in total and 400 selections using each system. We randomized the order of three systems for each participant to minimize the learning effect. We instructed users to perform the selection as soon as they can. In this experiment, we recorded selection time for each click and block locations for miss clicks. We did not pose any limitations on the head pose user can have during the task. Each of these systems may have various degrees of error for different users. Hence, we instructed users that systems may contain offset, and they can look anywhere inside the blue-colored block. After each session, we instructed users to answer the NASA TLX and SUS questionnaires for qualitative estimation of perceived cognitive load and system usability. We also recorded subjective feedback apart from these questionnaires.
Discussion and Future work
We aimed to achieve similar degree of gaze estimation accuracy during both with-in dataset validations and realworld usage conditions. In this regard, we proposed I2DNet that aimed to circumvent any appearance-related artifacts in appearance-based gaze estimation task which hinders the generalization ability of the network.
Our I2DNet achieved 4.3° and 8.4° mean angle error on MPIIGaze and RT-Gene datasets respectively. We retained face channel which brings in significant appearance-related artifacts into the learning process. We did not feed head pose information into the network separately as the head pose information obtained during real-time using OpenFace 2.0 reported a mean error of 3° for head orientation. We shall investigate whether the present error obtained is due to the inherent offset between visual axis and optical axis of the individual or due to any other appearance-related or illumination-related factors. Further, we shall carry investigation on the effect of accuracy and latency with reduced size of face images.
We conducted our evaluation in a single illumination condition. We believed that such real-time evaluations of state-of-the-art models needs to be performed in various illumination conditions to comprehensively understand the usability of such systems in real-time. Even though OpenFace 2.0 reported state-of-the-art cross validation accuracy on MPIIGaze dataset, its precision is poor as illustrated in
Figure 5. As demonstrated in (
Feit et al., 2017), precision of gaze estimates also need to be studied along with accuracy since poor precision significantly affects the usability. (
Zhang et al., 2019) used third-order polynomial fitting to adapt the gaze predictions for each participant. Studies on efficacy of such calibration and filtering techniques applied on gaze-predictions in the context of appearance-based estimation during real-time is also imperative.
We observed that more stimuli could not be selected during our study when they appeared in Region 6 and Region 9. We inferred that this might be due to the occlusion of eye region with brows while gazing bottom portions of the screen. Further work needs to be done to overcome this ubiquitous challenge as most of the commercially available laptops contain web cameras above the display. We plan to conduct evaluation for finer level of tasks like 25-block selection task to understand the breaking point of such systems. Further investigations are yet to be performed under various illumination conditions for 16 and 25-block selection task. We believe that such evaluations are not only critical to understand the limitations of these systems but also to understand the bounds of usability.
Even though our evaluation indicated superiority of our approach both quantitatively and qualitatively over other two methods, we noted that the other two methods can run on CPU alone while our method requires a GPU. We evaluated our method on a laptop with i5 CPU alone and found that the prediction rate is around 3 fps which is lower than other two systems. This requirement of GPU is an inherent requirement for all appearance-based gaze estimation systems, yet it is a limitation when compared to feature-based methods. We intend to overcome this by applying principles of dark knowledge (
Hinton et al., 2015) to train a smaller and faster network with a minimal loss in accuracy as (
Krafka et al., 2016) did to achieve real-time performance on a mobile device.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}