Interaction Between Image and Text During the Process of Biblical Art Reception
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Introduction
The Present Study
Methods
Participants
Apparatus
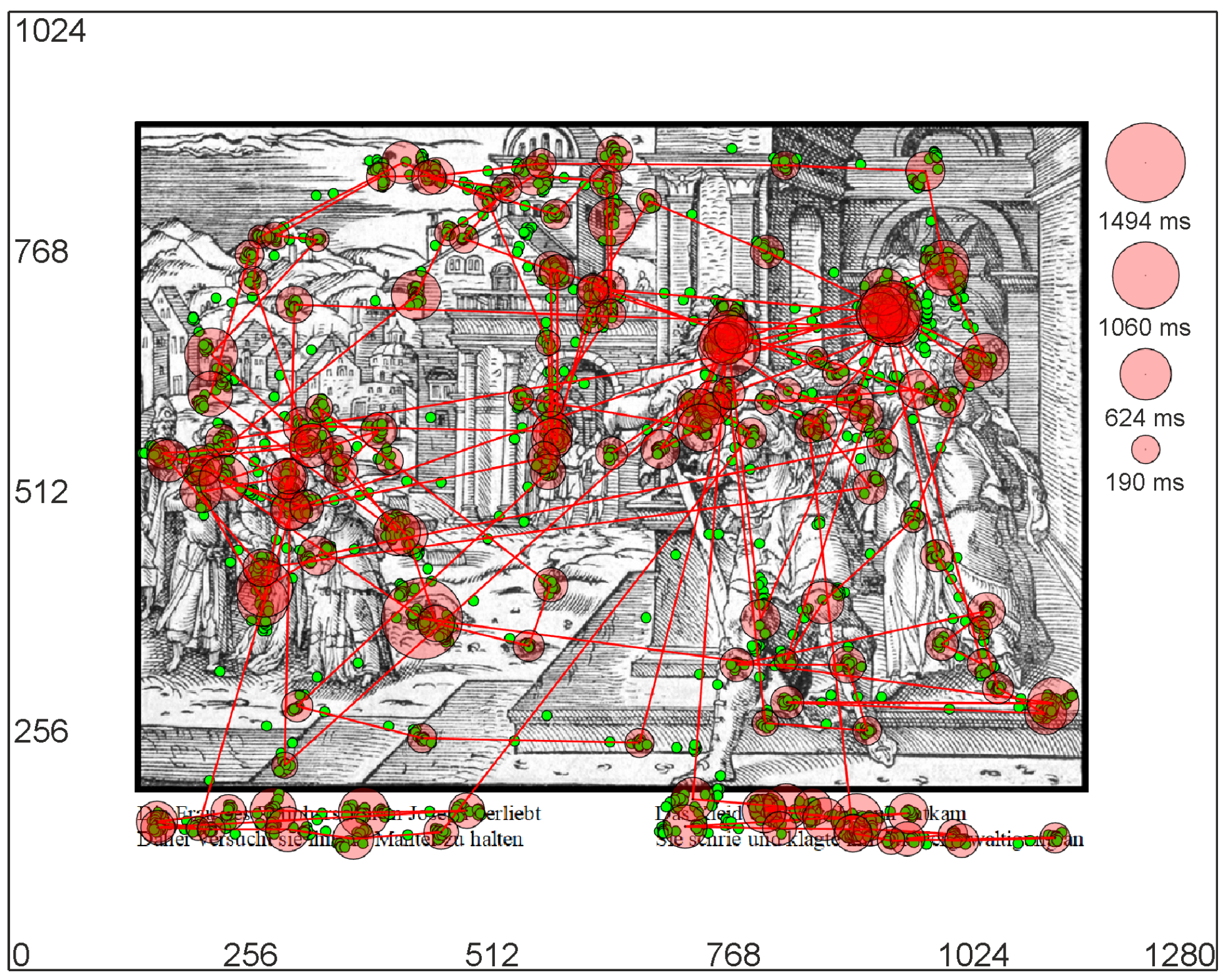
Material
Procedure
Design
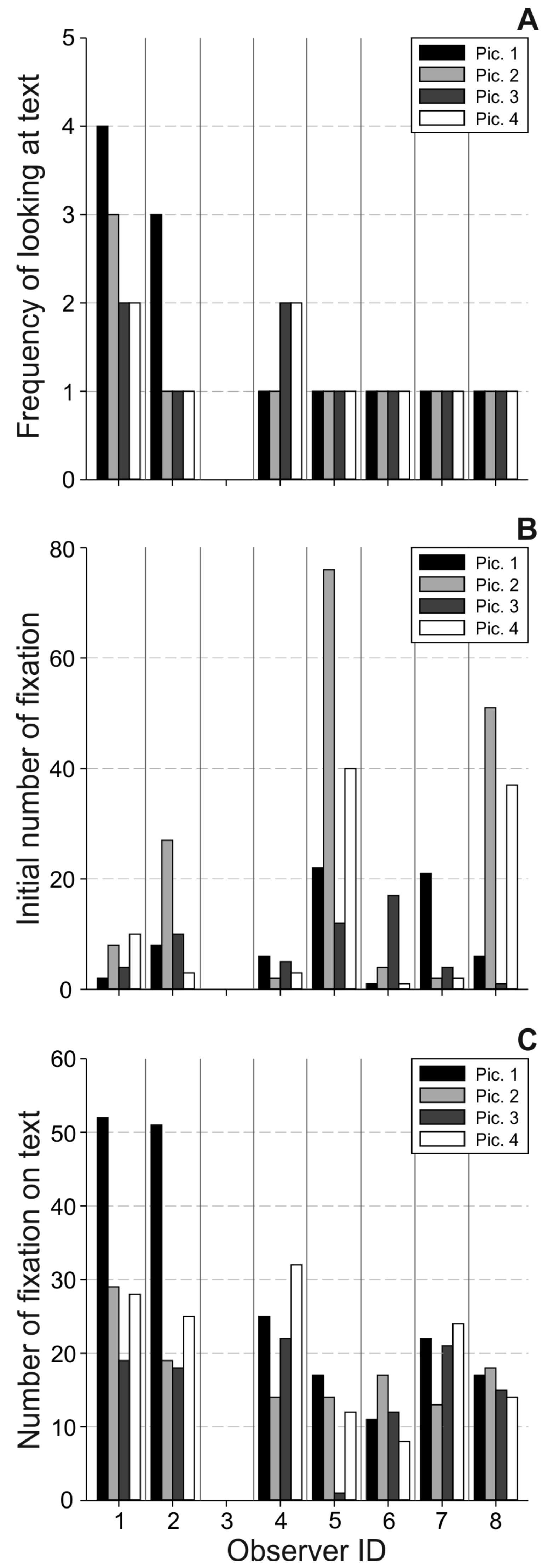
Results
Overall use of text
Relevance of ROIs & text interaction
Discussion
Stimulus saliencies
Overall attraction of texts
Interaction between image and text
Ethics and Conflict of Interest
Acknowledgements
References
- Altmann, G. T. M. 2011. Edited by S.P. Liversedge, Gilchrsit and S. Everling. The mediation of eye movements by spoken language. In The Oxford handbook of eye movements. Oxford 2011: pp. 979–1003. [Google Scholar]
- Andersson, R., F. Ferreira, and J. M. Henderson. 2011. I see what you're saying: The integration of complex speech and scenes during language comprehension. Acta Psychologica 137, 2: 208–216. [Google Scholar] [CrossRef] [PubMed]
- Andresen, A. 1973. Jost Amman, 1539-1591; Graphiker und Buchillustrator der Renaissance. Beschreibender Katalog seiner Holzschnitte, Radierungen und der von ihm illustrierten Bücher. Mit einer biographischen Skizze und mit Registern seines Werkes und der Autoren illustrierten Bücher. Amsterdam 1973. (first published in 1864). [Google Scholar]
- Augustin, M. D., H. Leder, F. Hutzler, and C.-C. Carbon. 2008. Style follows content: On the microgenesis of art perception. Acta Psychologica 128, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Birmingham, E., W. F. Bischof, and A. Kingstone. 2008. Social attention and real-world scenes: The roles of action, competition and social content. Quarterly Journal of Experimental Psychology 61, 7: 986–998. [Google Scholar] [CrossRef]
- Bocksberger, J. M., and J. Amman. 1569. Neuwe Biblische Figuren, deß Alten vnd Neuwen Testaments. Frankfurt am Main. G. Rabe, S. Feyerabend, & W. H. Erben. [Google Scholar]
- Borji, A., and L. Itti. 2014. Defending Yarbus: Eye movements reveal observers' task. Journal of Vision 14, 3: 1–22. [Google Scholar] [CrossRef] [PubMed]
- Brainard, D. H. 1997. The psychophysics toolbox. Spatial vision 10, 4: 433–436. [Google Scholar] [CrossRef]
- Bruce, N. D. B., and J. K. Tsotsos. 2006. Saliency based on information maximization. Advances in Neural Information Processing Systems 18: 155–162. [Google Scholar]
- Brusati, C., K. A. E. Enenkel, and W. Melion, eds. 2012. The Authority of the Word. Reflecting on Image and Text in Northern Europe, 1400-1700. (Intersection 20), Leiden/Boston 2012. [Google Scholar]
- Cavanagh, P., B. R. Conway, R. Bevil, D. Freedberg, R. Rosenberg, and E. Jollet. 2013. Cognitive sciences and art history, an evolving cooperation. Perspective–La Revue de l’. INHA 1: 101–118. [Google Scholar]
- Cerf, M., E. P. Frady, and C. Koch. 2009. Faces and text attract gaze independent of the task: Experimental data and computer model. Journal of Vision 9, 12: 101–105. [Google Scholar] [CrossRef]
- Cipolla, C. 1969. Literacy and Development in the West. London 1969. [Google Scholar]
- Commare, L., R. Rosenberg, and H. Leder. 2018. More than the sum of its parts: Perceiving complexity in painting. Psychology of Aesthetics, Creativity, and the Arts 12, 4: 380–391. [Google Scholar] [CrossRef]
- DeAngelus, M., and J. B. Pelz. 2009. Top-down control of eye movements: Yarbus revisited. Visual Cognition 17, 6-7: 790–811. [Google Scholar] [CrossRef]
- De Munck, B., and H. de Ridder-Symoens. 2018. Education and Knowledge: Theory and Practice in an Urban Context. In City and Society in the Low Countries, 1100-1600. Edited by B. Blondé, M. Boone and A.-L. Van Bruaene. Cambridge: Cambridge University Press, pp. 220–254. [Google Scholar]
- Findlay, J. M., and I. D. Gilchrist. 2003. Active vision: The psychology of looking and seeing (No. 37). Oxford University Press. [Google Scholar]
- Freedberg, D., and V. Gallese. 2007. Motion, emotion and empathy in esthetic experience. Trends in Cognitive Sciences 11, 5: 197–203. [Google Scholar] [CrossRef]
- Gauthier, I., T. W. James, K. M. Curby, and M. J. Tarr. 2003. The influence of conceptual knowledge on visual discrimination. Cognitive Neuropsychology 20: 507–523. [Google Scholar] [CrossRef] [PubMed]
- Greene, M. R., and A. Oliva. 2009. Recognition of natural scenes from global properties: Seeing the forest without representing the trees. Cognitive Psychology 58, 2: 137–176. [Google Scholar] [CrossRef] [PubMed]
- Harland, B., J. Gillett, C. M. Mann, J. Kass, H. J. Godwin, S. P. Liversedge, and N. Donnelly. 2014. Modes of address in pictorial art: An eye movement study of Manet's Bar at the Folies-Bergère. Leonardo 47, 3: 241–248. [Google Scholar] [CrossRef]
- Hayhoe, M., and D. Ballard. 2005. Eye movements in natural behavior. Trends in Cognitive Sciences 9, 4: 188–194. [Google Scholar] [CrossRef]
- Henderson, J. M., G. L. Malcolm, and C. Schandl. 2009. Searching in the dark: Cognitive relevance drives attention in real-world scenes. Psychonomic Bulletin & Review 16, 5: 850–856. [Google Scholar] [CrossRef]
- Horváth, G. 2018. Visual imagination and the narrative image. Parallelisms between art history and neuroscience. Cortex 105: 144–154. [Google Scholar] [CrossRef]
- Hwang, A. D., E. C. Higgins, and M. Pomplun. 2009. A model of top-down attentional control during visual search in complex scenes. Journal of Vision 9, 5: 1–18. [Google Scholar] [CrossRef]
- Kaeppele, S. 2003. Die Malerfamilie Bocksberger aus Salzburg: Malerei zwischen Reformation und italienischer Renaissance. Salzburg 2003. [Google Scholar]
- Jakesch, M., and H. Leder. 2015. The qualitative side of complexity: Testing effects of ambiguity on complexity judgments. Psychology of Aesthetics, Creativity, and the Arts 9, 200–205. [Google Scholar] [CrossRef]
- Kastner, S., and L. G. Ungerleider. 2000. Mechanisms of visual attention in the human cortex. Annual Review of Neuroscience 23, 1: 315–341. [Google Scholar] [CrossRef]
- Kirtley, C. 2018. How Images Draw the Eye: An EyeTracking Study of Composition. Empirical Studies of the Arts 36, 1: 41–70. [Google Scholar] [CrossRef]
- Kummerer, M., T. S. Wallis, L. A. Gatys, and M. Bethge. 2017. Understanding lowand high-level contributions to fixation prediction. In Proceedings of the IEEE International Conference on Computer Vision. pp. 4789–4798. [Google Scholar]
- Kummerer, M., T. S. Wallis, and M. Bethge. 2018. Saliency benchmarking made easy: Separating models, maps and metrics. In Proceedings of the European Conference on Computer Vision (ECCV). p. 770787. [Google Scholar]
- Kurzhals, K., E. Cetinkaya, Y. Hu, W. Wang, and D. Weiskopf. 2017. Close to the Action: Eye-Tracking Evaluation of Speaker-Following Subtitles. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems. ACM: pp. 6559–6568. [Google Scholar]
- Lamberigts, M., and A.A. den Hollander, eds. 2006. Lay Bibles in Europe 1450-1800, (Bibliotheca Ephemeridum Theologicarum Lovaniensium 198). Leuven 2006. [Google Scholar]
- Leder, H., B. Belke, A. Oeberst, and D. Augustin. 2004. A model of aesthetic appreciation and aesthetic judgments. British Journal of Psychology 95: 489–508. [Google Scholar] [CrossRef]
- Leder, H., C. C. Carbon, and A. L. Ripsas. 2006. Entitling art: Influence of title information on understanding and appreciation of paintings. Acta Psychologica 121: 176–198. [Google Scholar] [CrossRef] [PubMed]
- Münch, B. U. 2009. Geteiltes Leid. Die Passion Christi in Bildern und Texten der Konfessionalisierung. Druckgraphik von der Reformation bis zu den jesuitischen Großprojekten um 1600. Regensburg 2009. [Google Scholar]
- Massaro, D., F. Savazzi, C. Di Dio, D. Freedberg, V. Gallese, G. Gilli, and A. Marchetti. 2012. When art moves the eyes: a behavioral and eye-tracking study. PloS One 7, 5: e37285. [Google Scholar] [CrossRef] [PubMed]
- Neider, M. B., and G. J. Zelinsky. 2006. Scene context guides eye movements during visual search. Vision Research 46, 5: 614–621. [Google Scholar] [CrossRef]
- O’Dell, I. 1993. Jost Ammans Buchschmuck-Holzschnitte für Sigmund Feyerabend. Zur Technik der Verwendung von Bild-Holzstöcken in den Drucken von 1563-1599. Wiesbaden 1993. [Google Scholar]
- Pelowski, M., and F. Akiba. 2011. A model of art perception, evaluation and emotion in transformative aesthetic experience. New Ideas in Psychology 29, 2: 80–97. [Google Scholar] [CrossRef]
- Pelowski, M., P. S. Markey, M. Forster, G. Gerger, and H. Leder. 2017. Move me, astonish me... delight my eyes and brain: The Vienna integrated model of top-down and bottom-up processes in art perception (VIMAP) and corresponding affective, evaluative, and neurophysiological correlates. Physics of Life Reviews 21: 80–125. [Google Scholar] [CrossRef]
- Panofsky, E. 1994. Ikonographie und Ikonologie. In Bildende Kunst als Zeichensystem. Ikonographie und Ikonologie. Band 1: Theorien-Entwicklung-Probleme. Cologne, Germany: DuMont: pp. 207–225. [Google Scholar]
- Parker, G. 1977. The Dutch Revolt. Ithaca, NY: Cornell University Press. [Google Scholar]
- Parkhurst, D. J., K. Law, and E. Niebur. 2002. Modeling the role of salience in the allocation of overt visual selective attention. Vision Research 42, 1: 107–123. [Google Scholar] [CrossRef]
- Rayner, K. 1998. Eye movements in reading and information processing: 20 years of research. Psychological Bulletin 124, 3: 372–422. [Google Scholar] [CrossRef]
- Rosenberg, R. 2016. Bridging Art History, Computer Science and Cognitive Science: A Call for Interdisciplinary Collaboration. Zeitschrift für Kunstgeschichte 79, 3: 305–314. [Google Scholar] [CrossRef]
- Ross, N. M., and E. Kowler. 2013. Eye movements while viewing narrated, captioned, and silent videos. Journal of Vision 13, 4: 1–19. [Google Scholar] [CrossRef]
- Russell, P. A., and S. Milne. 1997. Meaningfulness and hedonic value of paintings: Effects of titles. Empirical Studies of the Arts 15: 61–73. [Google Scholar] [CrossRef]
- Sarter, M., B. Givens, and J. P. Bruno. 2001. The cognitive neuroscience of sustained attention: where topdown meets bottom-up. Brain Research Reviews 35, 2: 146–160. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, P. 1962. Die Illustrationen der Lutherbibel 1522-1700. Ein Stück abendländischer Kulturund Kirchengeschichte. Mit Verzeichnis der Bibeln, Bilder und Künstler. Basel 1962. [Google Scholar]
- Simonyan, K., and A. Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv arXiv:1409.1556. [Google Scholar]
- Swami, V. 2013. Context matters: Investigating the impact of contextual information on aesthetic appreciation of paintings by Max Ernst and Pablo Picasso. Psychology of Aesthetics, Creativity, and the Arts 7, 3: 285. [Google Scholar] [CrossRef]
- Tatler, B. W., N. J. Wade, H. Kwan, J. M. Findlay, and B. M. Velichkovsky. 2010. Yarbus, eye movements, and vision. i-Perception 1, 1: 7–27. [Google Scholar] [CrossRef]
- Tessari, A., G. Ottoboni, A. Mazzatenta, A. Merla, and R. Nicoletti. 2012. Please Don't! The Automatic Extrapolation of Dangerous Intentions. PloS One 7, 11: e49011. [Google Scholar] [CrossRef]
- Tinio, P. P. 2013. From artistic creation to aesthetic reception: The mirror model of art. Psychology of Aesthetics, Creativity, and the Arts 7, 3: 265–275. [Google Scholar] [CrossRef]
- Torralba, A., A. Oliva, M. S. Castelhano, and J. M. Henderson. 2006. Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search. Psychological Review 113, 4: 766–786. [Google Scholar] [CrossRef]
- Trawiński, T., N. Mestry, B. Harland, S. P. Liversedge, H. J. Godwin, and N. Donnelly. 2019. The spectatorship of portraits by naïve beholders. Psychology of Aesthetics, Creativity, and the Arts. [Google Scholar]
- Villani, D., F. Morganti, P. Cipresso, S. Ruggi, G. Riva, and G. Gilli. 2015. Visual exploration patterns of human figures in action: an eye tracker study with art paintings. Frontiers in Psychology 6: 1636. [Google Scholar] [CrossRef]
- Walker, F., B. Bucker, N. C. Anderson, D. Schreij, and J. Theeuwes. 2017. Looking at paintings in the Vincent Van Gogh Museum: Eye movement patterns of children and adults. PloS One 12, 6: e0178912. [Google Scholar] [CrossRef] [PubMed]
- Wallraven, C., D. W. Cunningham, J. Rigau, M. Feixas, and M. Sbert. 2009. Aesthetic appraisal of art: from eye movements to computers. In Proceedings of the Eurographics Workshop on Computational Aesthetics in Graphics, Visualization and Imaging. p. 137144. [Google Scholar]
- Wang, H. C., and M. Pomplun. 2012. The attraction of visual attention to texts in real-world scenes. Journal of Vision 12, 6: 1–17. [Google Scholar] [CrossRef] [PubMed]
- Wu, C. C., F. A. Wick, and M. Pomplun. 2014. Guidance of visual attention by semantic information in real-world scenes. Frontiers in Psychology 5, 54: 1–13. [Google Scholar] [CrossRef] [PubMed]
- Yarbus, A. L. 1967. Eye Movement and Vision. New York, NY: Plenum Press. [Google Scholar]
- Zaidel, D. W. 2013. Cognition and art: the current interdisciplinary approach. Wiley Interdisciplinary Reviews: Cognitive Science 4, 4: 431–439. [Google Scholar] [CrossRef]
- Zhao, Z. Q., P. Zheng, S. T. Xu, and X. Wu. 2019. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems 30, 11: 3212–3232. [Google Scholar] [CrossRef]





Copyright © 2021. This article is licensed under a Creative Commons Attribution 4.0 International License.
Share and Cite
Hardiess, G.; Weissert, C. Interaction Between Image and Text During the Process of Biblical Art Reception. J. Eye Mov. Res. 2020, 13, 1-17. https://doi.org/10.16910/jemr.13.2.14
Hardiess G, Weissert C. Interaction Between Image and Text During the Process of Biblical Art Reception. Journal of Eye Movement Research. 2020; 13(2):1-17. https://doi.org/10.16910/jemr.13.2.14
Chicago/Turabian StyleHardiess, Gregor, and Caecilie Weissert. 2020. "Interaction Between Image and Text During the Process of Biblical Art Reception" Journal of Eye Movement Research 13, no. 2: 1-17. https://doi.org/10.16910/jemr.13.2.14
APA StyleHardiess, G., & Weissert, C. (2020). Interaction Between Image and Text During the Process of Biblical Art Reception. Journal of Eye Movement Research, 13(2), 1-17. https://doi.org/10.16910/jemr.13.2.14