MAGiC: A Multimodal Framework for Analysing Gaze in Dyadic Communication
Abstract
:Introduction
Gaze Data Analysis in Dynamical Scenes
A Technical Overview of the MAGiC Framework
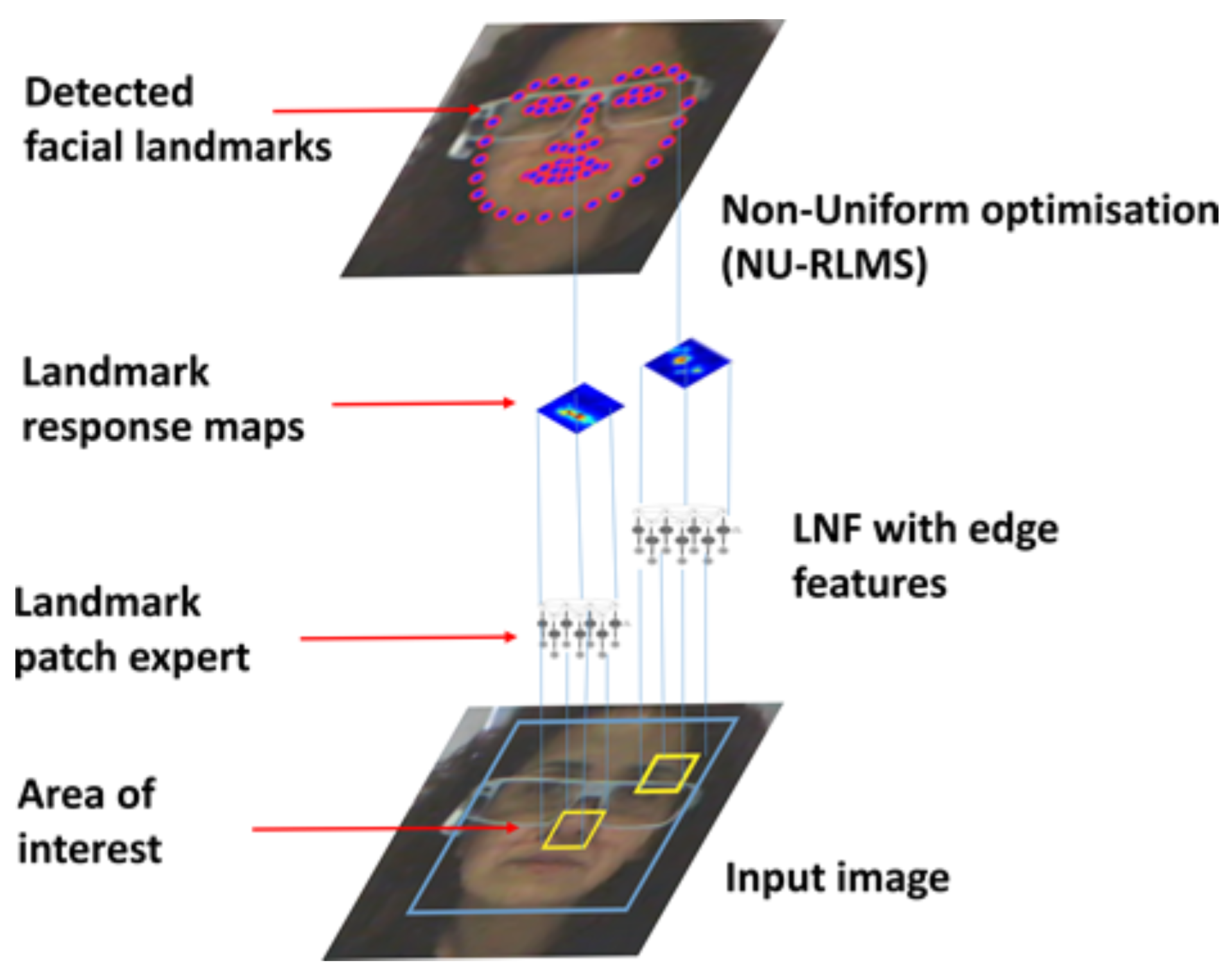
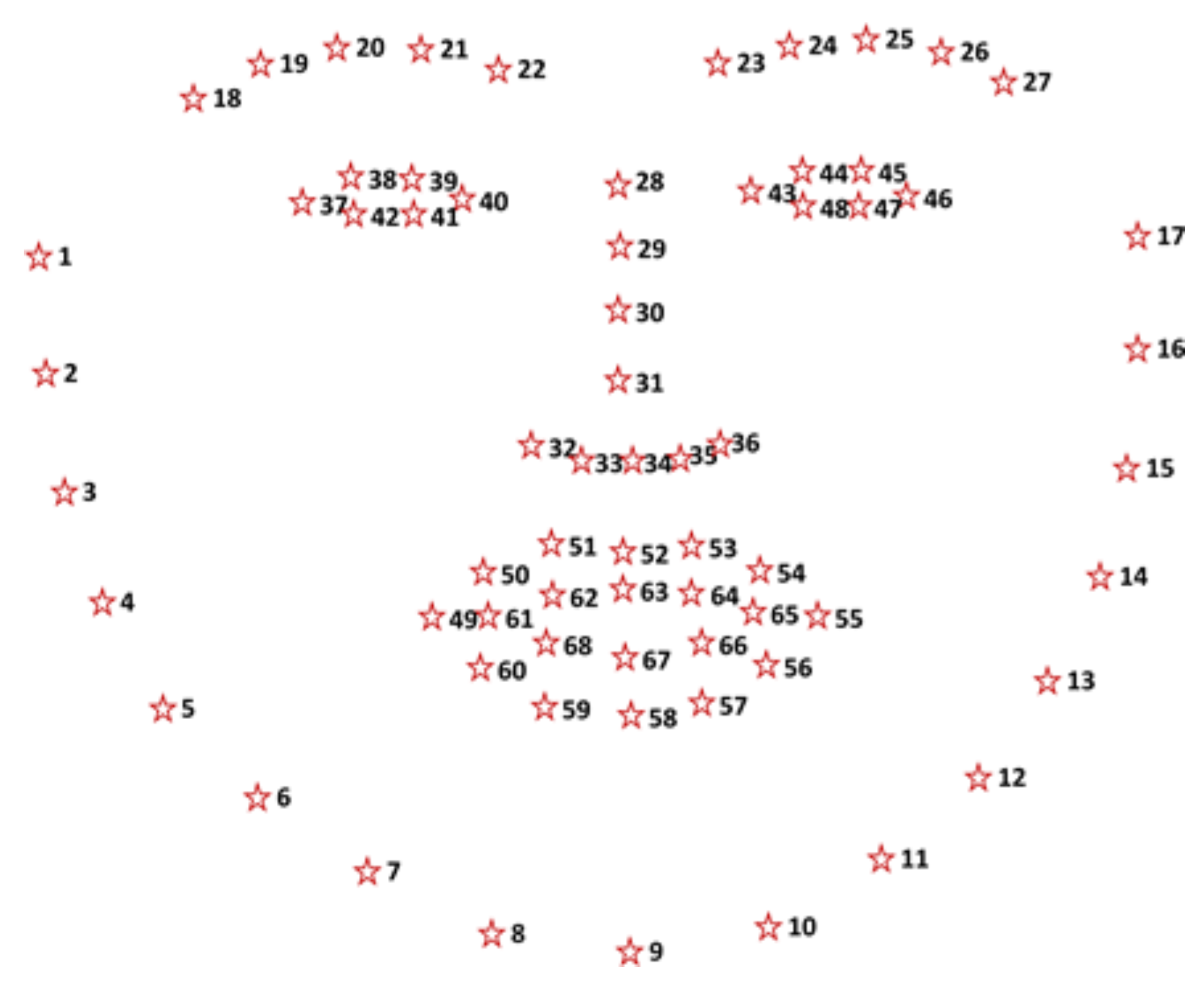
Face Tracking
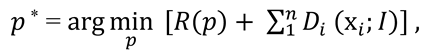
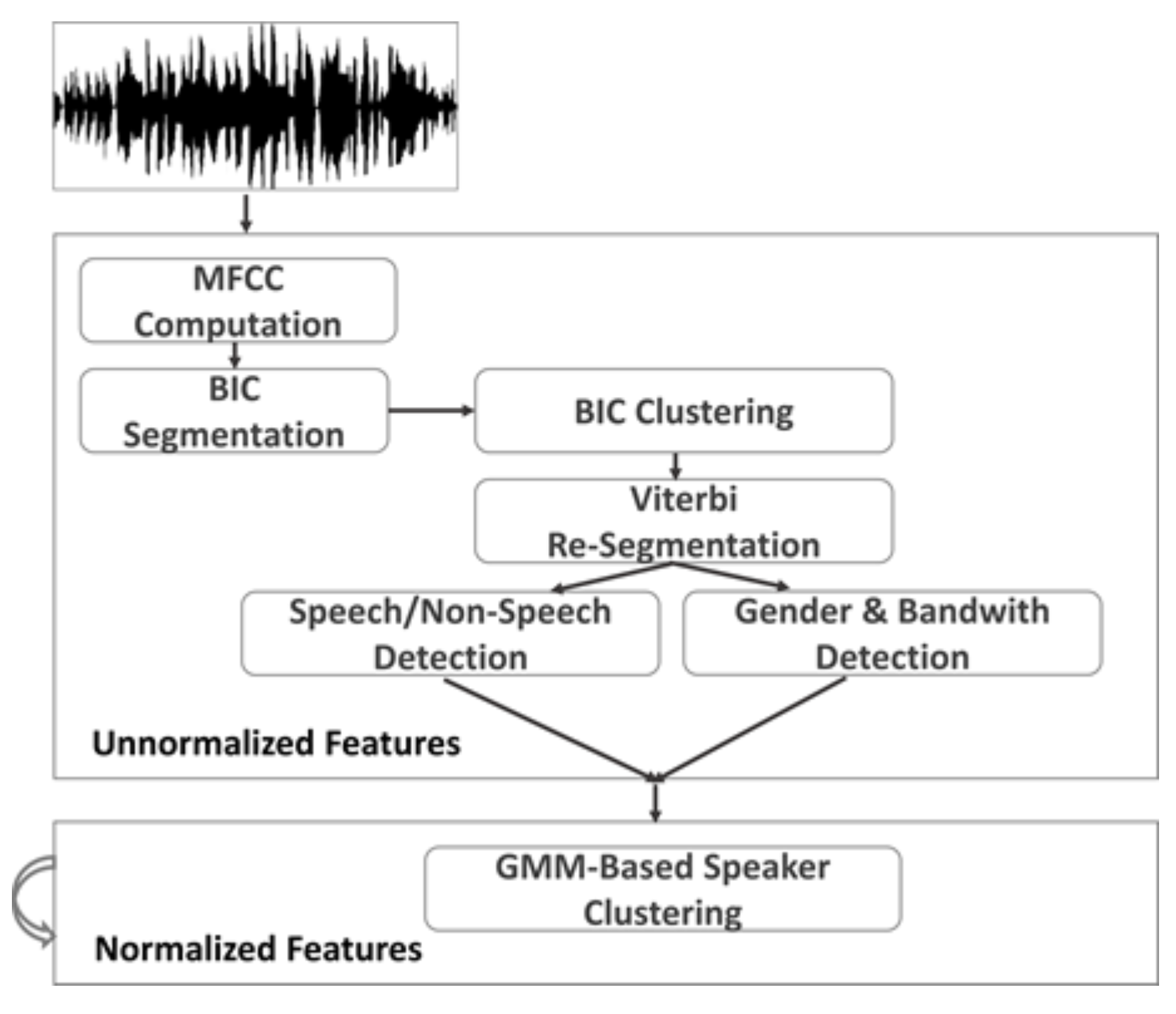
Speech Segmentation

Demonstration of the MAGiC Framework: A Pilot Study
Participants, Materials and Design
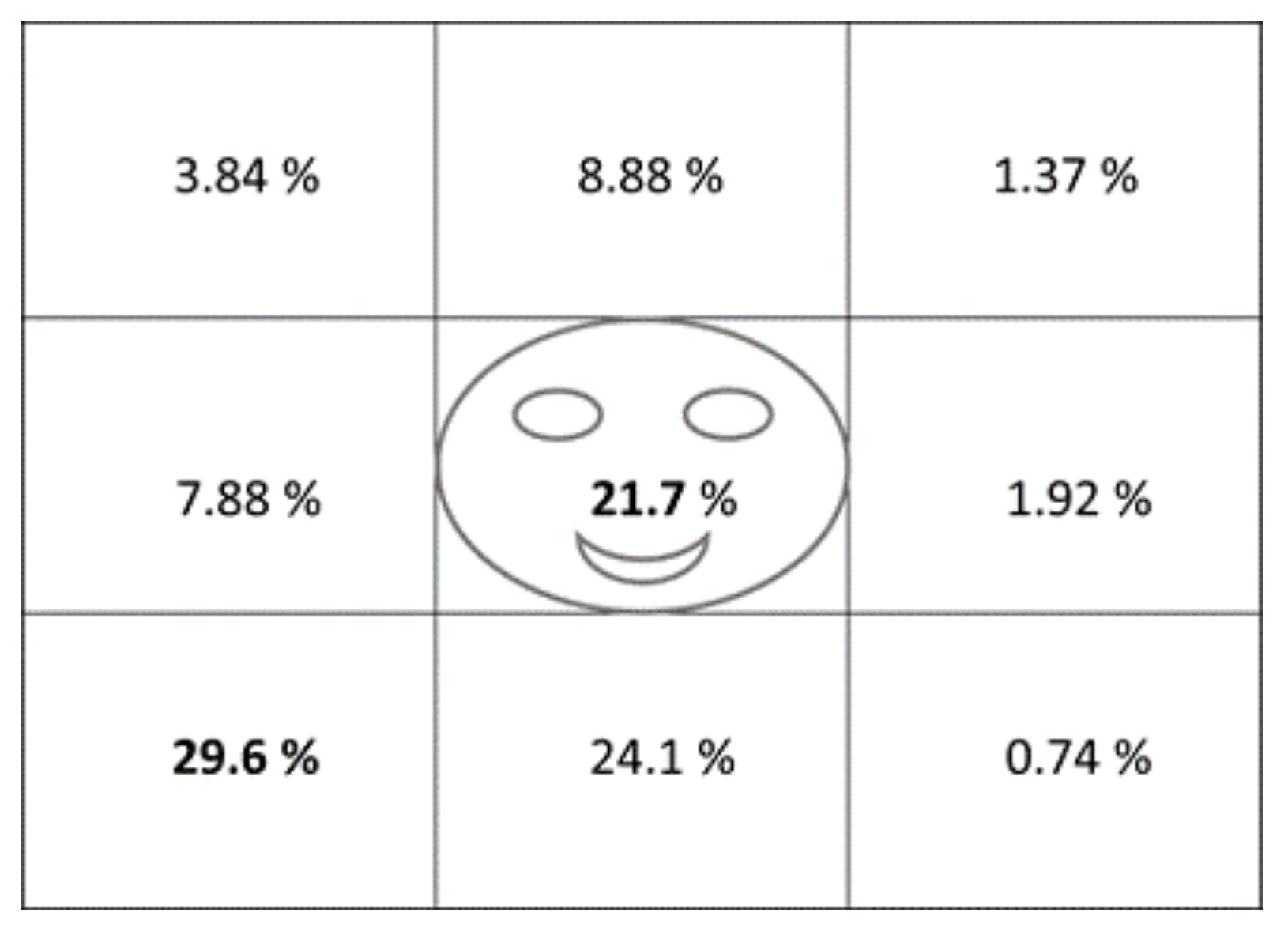
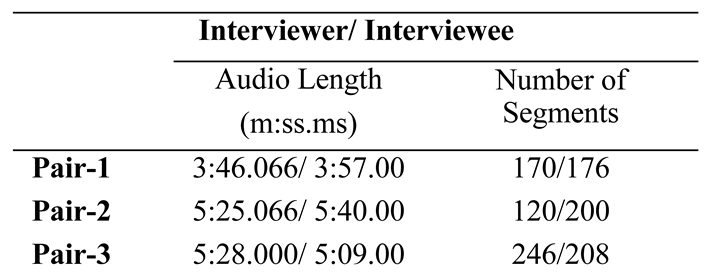
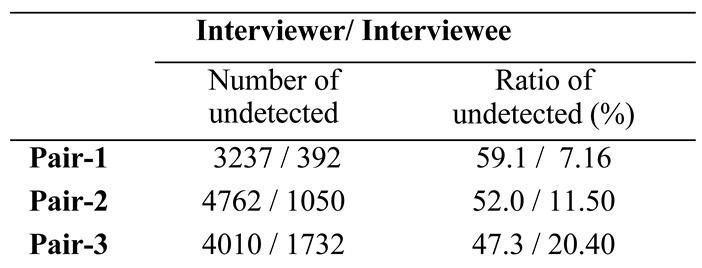
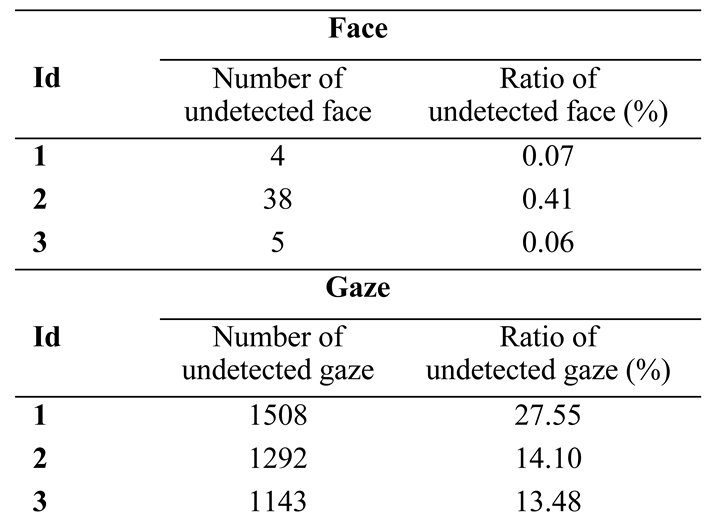
Data Analysis
An Evaluation of the Contributions of the MAGiC Framework
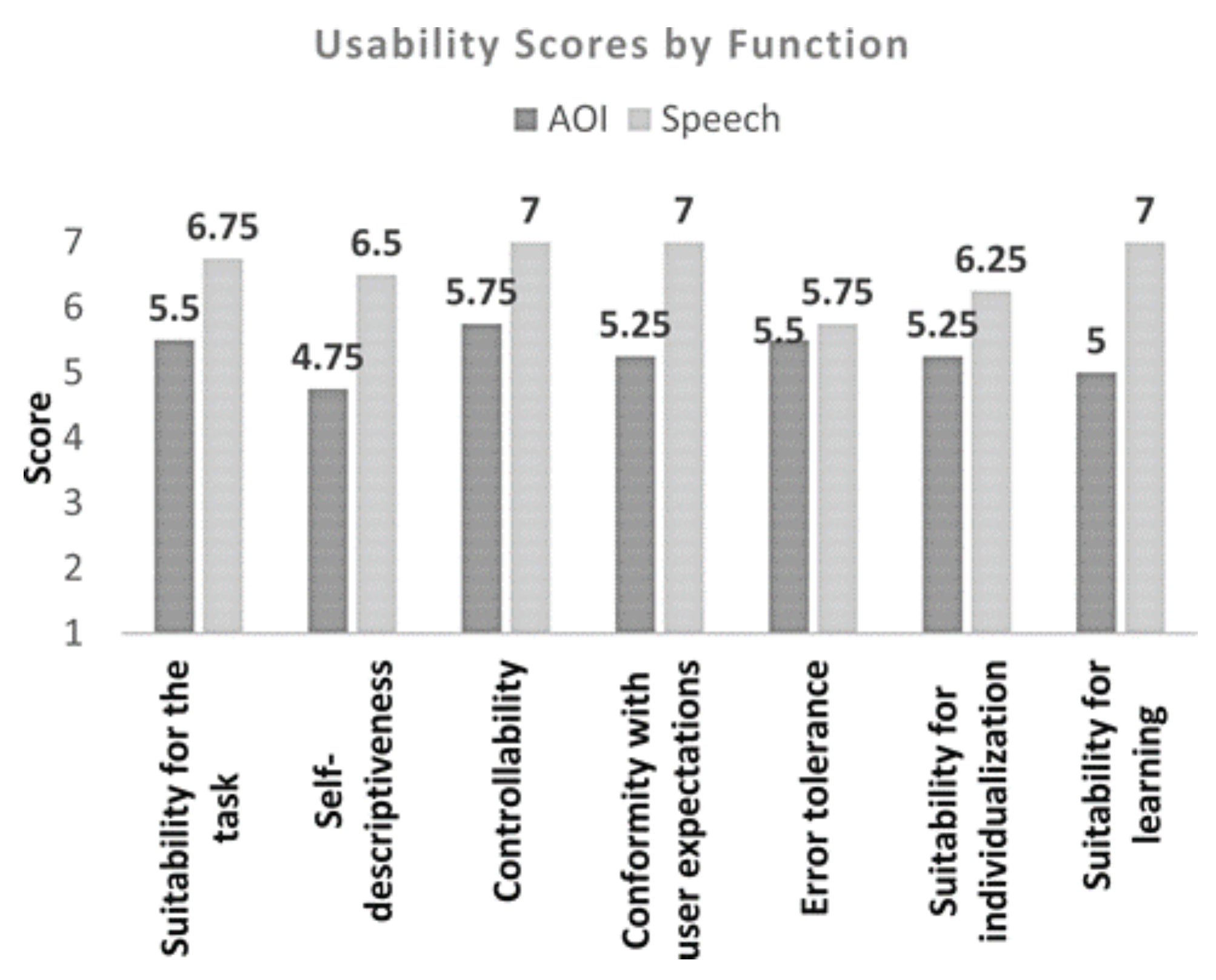
Usability Analysis of MAGiC
- (1)
- Perform the analysis manually,
- (2)
- Perform the analysis by using MAGiC,
- (3)
- Asses the usability of MAGiC using 7-point scale ISO 9241/10 questionnaire.
Discussion and Conclusion
Ethics and Conflict of Interest
References
- Abele, A. 1986. Functions of gaze in social interaction: Communication and monitoring. Journal of Nonverbal Behavior 10, 2: 83–101. [Google Scholar] [CrossRef]
- Archer, D., and R. M. Akert. 1977. Words and everything else: Verbal and nonverbal cues in social interpretation. Journal of Personality and Social Psychology 35: 443–449. [Google Scholar] [CrossRef]
- Argyle, M., and M. Cook. 1976. Gaze and mutual gaze. Cambridge University Press. [Google Scholar] [CrossRef]
- Austin, J. L. 1962. How to do things with words. Oxford University Press. [Google Scholar] [CrossRef]
- Bales, R., F. Strodtbeck, T. Mills, and M. Roseborough. 1951. Channels of communication in small groups. American Sociological Review 16, 4: 461–468. [Google Scholar] [CrossRef]
- Baltrušaitis, T., M. Mahmoud, and P. Robinson. 2015. Cross-dataset learning and person-specific normalisation for automatic Action Unit detection, in Facial Expression Recognition and Analysis Challenge. In Proceeding of the 11th IEEE International Conference Automatic Face and Gesture Recognition. IEEE: Vol. 6, pp. 1–6. [Google Scholar] [CrossRef]
- Baltrušaitis, T., P. Robinson, and L. P. Morency. 2013. Constrained local neural fields for robust facial landmark detection in the wild. In Proceedings of the IEEE International Conference on Computer Vision. IEEE: pp. 354–361. [Google Scholar] [CrossRef]
- Baltrušaitis, T., P. Robinson, and L. P. Morency. 2016. OpenFace: An open source facial behavior analysis toolkit. In Proceedings of IEEE Winter Conference on Applications of Computer Vision. IEEE: pp. 1–10. [Google Scholar] [CrossRef]
- Baron-Cohen, S., S. Wheelwright, and T. Jolliffe. 1997. Is there a ‘language of the eyes’? Evidence from normal adults, and adults with autism or Asperger syndrome. Visual Cognition 4, 3: 311–331. [Google Scholar] [CrossRef]
- Barras, C., X. Zhu, S. Meignier, and J. L. Gauvain. 2006. Multi-stage speaker diarization of broadcast news. IEEE Transactions on Audio, Speech and Language Processing 14, 5: 1505–1512. [Google Scholar] [CrossRef]
- Brône, G., B. Oben, and T. Goedemé. 2011. Towards a more effective method for analyzing mobile eye-tracking data: integrating gaze data with object recognition algorithms. In Proceedings of the 1st international workshop on pervasive eye tracking & mobile eye-based interaction, ACM. September; pp. 53–56. [Google Scholar] [CrossRef]
- Cassell, J., T. Bickmore, M. Billinghurst, L. Campbell, K. Chang, H. Vilhjalmsson, and H. Yan. 1999. Embodiment in conversational interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM: pp. 520–527. [Google Scholar] [CrossRef]
- Chen, S., and P. Gopalakrishnan. 1998. Speaker, environment and channel change detection and clustering via the Bayesian information criterion. In DARPA Broadcast News Transcription and Understanding Workshop. Landsdowne, VA, USA. [Google Scholar]
- De Beugher, S., G. Brône, and T. Goedemé. 2014. Automatic analysis of in-the-wild mobile eye-tracking experiments using object, face and person detection. In Computer Vision Theory and Applications (VISAPP), 2014 International Conference on, IEEE. January, Vol. 1, pp. 625–633. [Google Scholar] [CrossRef]
- Duncan, S. 1972. Some signals and rules for taking speaking turns in conversations. Journal of Personality and Social Psychology 23, 2: 283–292. [Google Scholar] [CrossRef]
- Ehrlichman, H., and D. Micic. 2012. Why Do People Move Their Eyes When They Think? Current Directions in Psychological Science 21, 2: 96–100. [Google Scholar] [CrossRef]
- Elman, J. L. 1995. Edited by R. F. Port and T. van Gelder. Language as a dynamical system. In Mind as motion: Explorations in the dynamics of cognition. MIT Press: pp. 195–226. [Google Scholar]
- Fasola, J., and M. J. Mataric. 2012. Using socially assistive human-robot interaction to motivate physical exercise for older adults. Proceedings of the IEEE 100, 8: 2512–2526. [Google Scholar] [CrossRef]
- Ford, M., and V. M. Holmes. 1978. Planning units and syntax in sentence production. Cognition 6: 35–53. [Google Scholar] [CrossRef]
- Goldman-Eisler, F. 1968. Psycho-linguistics: Experiments in spontaneous speech. New York, NY: Academic Press. [Google Scholar]
- Goodwin, C. 1981. Conversational Organization: Interaction between Speakers and Hearers. New York, NY: Academic Press. [Google Scholar]
- Grosjean, F., and H. Lane. 1976. How the listener integrates the components of speaking rate. Journal of Experimental Psychology 2, 4: 538–543. [Google Scholar] [CrossRef] [PubMed]
- Grosz, B., and C. Sidner. 1986. Attention, intentions, and the structure of discourse. Computational Linguistics 12, 3: 175–204. [Google Scholar]
- Hieke, A. E., S. Kowal, and D. C. O’Connell. 1983. The trouble with “articulatory” pauses. Language and Speech 26: 203–215. [Google Scholar] [CrossRef]
- Hietanen, J. K., J. M. Leppänen, M. J. Peltola, K. Linna-Aho, and H. J. Ruuhiala. 2008. Seeing direct and averted gaze activates the approach-avoidance motivational brain systems. Neuropsychologia 46, 9: 2423–2430. [Google Scholar] [CrossRef] [PubMed]
- Hird, K., R. Brown, and K. Kirsner. 2006. Stability of lexical deficits in primary progressive aphasia: Evidence from natural language. Brain and Language 99: 137–138. [Google Scholar] [CrossRef]
- Holmqvist, K., N. Nyström, R. Andersson, R. Dewhurst, H. Jarodzka, and J. Van de Weijer, eds. 2011. Eye tracking: a comprehensive guide to methods and measures. Oxford University Press. [Google Scholar]
- Kendon, A. 1967. Some functions of gaze-direction in social interaction. Acta Psychologica 26, 1: 22–63. [Google Scholar] [CrossRef] [PubMed]
- King, D. E. 2009. Dlib-ml: A Machine Learning Toolkit. Journal of Machine Learning Research 10: 1755–1758. Retrieved from http://jmlr.csail.mit.edu/papers/v10/king09a.html.
- King, D. E. 2015. Max-Margin Object Detection. arXiv preprint arXiv:1502.00046. Retrieved from http://arxiv.org/abs/1502.00046.
- Kirsner, K., J. Dunn, and K. Hird. 2005. Language productions: A complex dynamic system with a chronometric footprint. Paper presented at the 2005 International Conference on Computational Science, Atlanta, GA. [Google Scholar]
- Kleinke, C. L. 1986. Gaze and eye contact: a research review. Psychological Bulletin 100, 1: 78–100. [Google Scholar] [CrossRef]
- Krivokapić, J. 2007. Prosodic planning: Effects of phrasal length and complexity on pause duration. Journal of Phonetics 35: 162–179. [Google Scholar] [CrossRef]
- Kocel, K., D. Galin, R. Ornstein, and E. Merrin. 1972. Lateral eye movement and cognitive mode. Psychonomic Science 27, 4: 223–224. [Google Scholar] [CrossRef]
- Lamere, P., P. Kwok, E. Gouvea, B. Raj, R. Singh, W. Walker, and P. Wolf. 2003. The CMU SPHINX-4 speech recognition system. In Proceedings of the IEEE Intl. Conf. on Acoustics, Speech and Signal Processing, Hong Kong. [Google Scholar]
- Mason, M. F., E. P. Tatkow, and C. N. Macrae. 2005. The look of love: Gaze shifts and person perception. Psychological Science 16: 236–239. [Google Scholar] [CrossRef] [PubMed]
- Mehrabian, A., and M. Wiener. 1967. Decoding of inconsistent communications. Journal of Personality and Social Psychology 6: 109–114. [Google Scholar] [CrossRef] [PubMed]
- Meignier, S., and T. Merlin. 2010. LIUM SpkDiarization: an open source toolkit for diarization. In Proceedings of the CMU SPUD Workshop. pp. 1–6. Retrieved from http://www-gth.die.upm.es/research/documentation/referencias/Meignier_Lium.pdf.
- Munn, S. M., L. Stefano, and J. B. Pelz. 2008. Fixation identification in dynamic scenes. In Proceedings of the 5th Symposium on Applied Perception in Graphics and Visualization - APGV ’08. ACM: pp. 33–42. [Google Scholar] [CrossRef]
- Pfeiffer, U. J., B. Timmermans, G. Bente, K. Vogeley, and L. Schilbach. 2011. A non-verbal Turing test: differentiating mind from machine in gaze-based social interaction. PLoS One. [Google Scholar] [CrossRef] [PubMed]
- Power, M. J. 1985. Sentence Production and Working Memory. The Quarterly Journal of Experimental Psychology Section A 37, 3: 367–385. [Google Scholar] [CrossRef]
- Quek, F., D. Mcneill, R. Bryll, S. Duncan, X. Ma, C. Kirbas, and R. Ansari. 2002. Multimodal human discourse: gesture and speech. ACM Transactions of Computer-Human Interaction 9, 3: 171–193. [Google Scholar] [CrossRef]
- Quek, F., D. Mcneill, R. Bryll, C. Kirbas, H. Arslan, K. Mccullough, and R. Ansari. 2000. Gesture, speech, and gaze cues for discourse segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Vol. 2, pp. 247–254. [Google Scholar] [CrossRef]
- Sacks, H., E. Schegloff, and G. Jefferson. 1974. A simplest systematics for the organization of turn-taking for conversation. Language 50, 4: 696–735. [Google Scholar] [CrossRef]
- Schegloff, E. 1968. Sequencing in Conversational Openings. American Anthropological 70, 6: 1075–1095. [Google Scholar] [CrossRef]
- Searle, J. R. 1969. Speech Acts: An Essay in the Philosophy of Language. Cambridge, UK: Cambridge University Press. [Google Scholar]
- Stuart, S., B. Galna, S. Lord, L. Rochester, and A. Godfrey. 2014. Quantifying saccades while walking: Validity of a novel velocity-based algorithm for mobile eye tracking. In Proceedings of the IEEE 36th Annual International Conference Engineering of the Medicine and Biology Society, EMBC. IEEE: pp. 5739–5742. [Google Scholar] [CrossRef]
- Stuart, S., D. Hunt, J. Nell, A. Godfrey, J. M. Hausdorff, L. Rochester, and L. Alcock. 2017. Do you see what I see? Mobile eye-tracker contextual analysis and inter-rater reliability. Medical & Biological Engineering & Computing 56, 2: 289–296. [Google Scholar] [CrossRef]
- Villani, D., C. Repetto, P. Cipresso, and G. Riva. 2012. May I experience more presence in doing the same thing in virtual reality than in reality? An answer from a simulated job interview. Interacting with Computers 24, 4: 265–272. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
 |
 |
 |
 |
 |
Copyright © 2018. This article is licensed under a Creative Commons Attribution 4.0 International License.
Share and Cite
Arslan Aydın, Ü.; Kalkan, S.; Acartürk, C. MAGiC: A Multimodal Framework for Analysing Gaze in Dyadic Communication. J. Eye Mov. Res. 2018, 11, 1-13. https://doi.org/10.16910/jemr.11.6.2
Arslan Aydın Ü, Kalkan S, Acartürk C. MAGiC: A Multimodal Framework for Analysing Gaze in Dyadic Communication. Journal of Eye Movement Research. 2018; 11(6):1-13. https://doi.org/10.16910/jemr.11.6.2
Chicago/Turabian StyleArslan Aydın, Ülkü, Sinan Kalkan, and Cengiz Acartürk. 2018. "MAGiC: A Multimodal Framework for Analysing Gaze in Dyadic Communication" Journal of Eye Movement Research 11, no. 6: 1-13. https://doi.org/10.16910/jemr.11.6.2
APA StyleArslan Aydın, Ü., Kalkan, S., & Acartürk, C. (2018). MAGiC: A Multimodal Framework for Analysing Gaze in Dyadic Communication. Journal of Eye Movement Research, 11(6), 1-13. https://doi.org/10.16910/jemr.11.6.2