A Skeleton-Based Approach to Analyzing Oculomotor Behavior When Viewing Animated Characters
Abstract
:Introduction
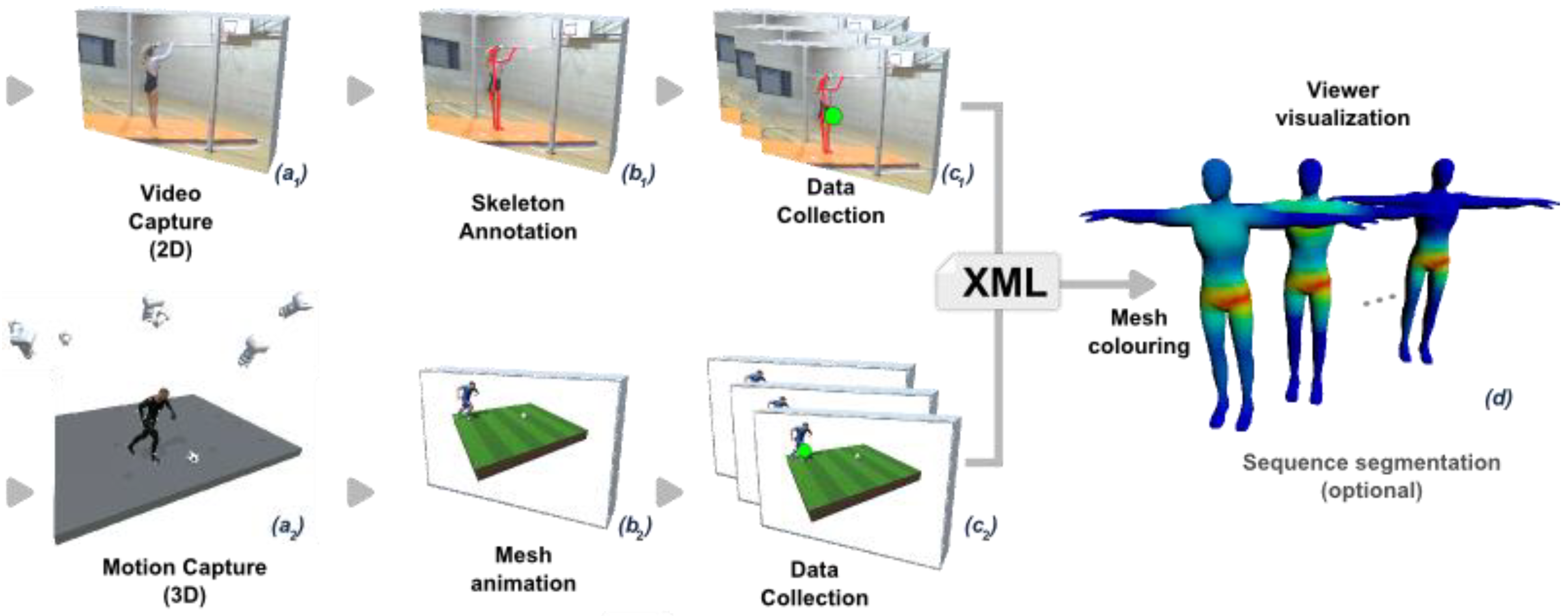
Gaze Visualization on Animated Characters
Related Techniques
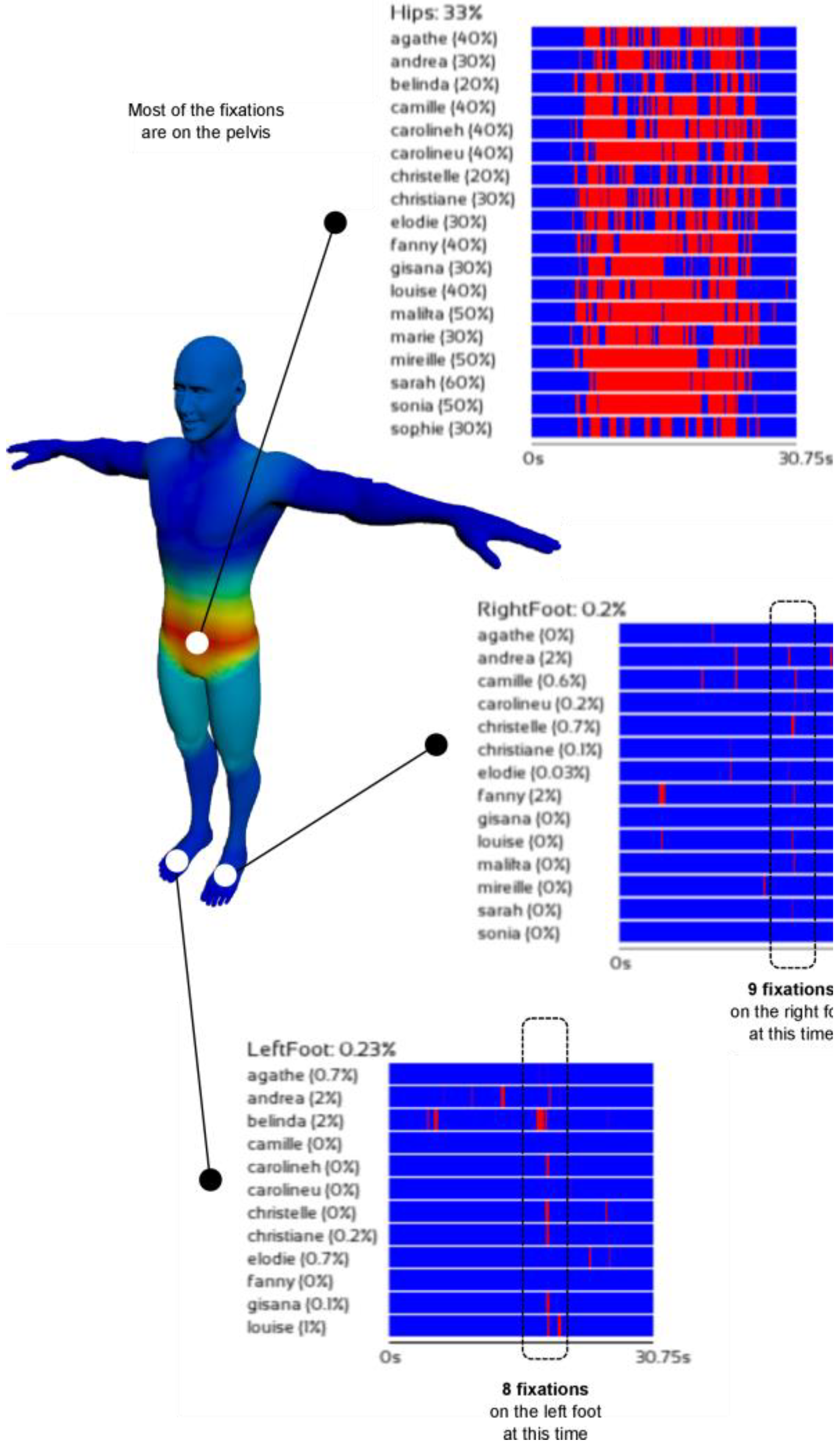
- a heat mesh (i.e., the colored mesh illustrated by the Figure 1d) is used to provide qualitative information about the gaze distribution of one or more viewers;
- a viewer timeline is used to specifically compare the synchronization between viewers.
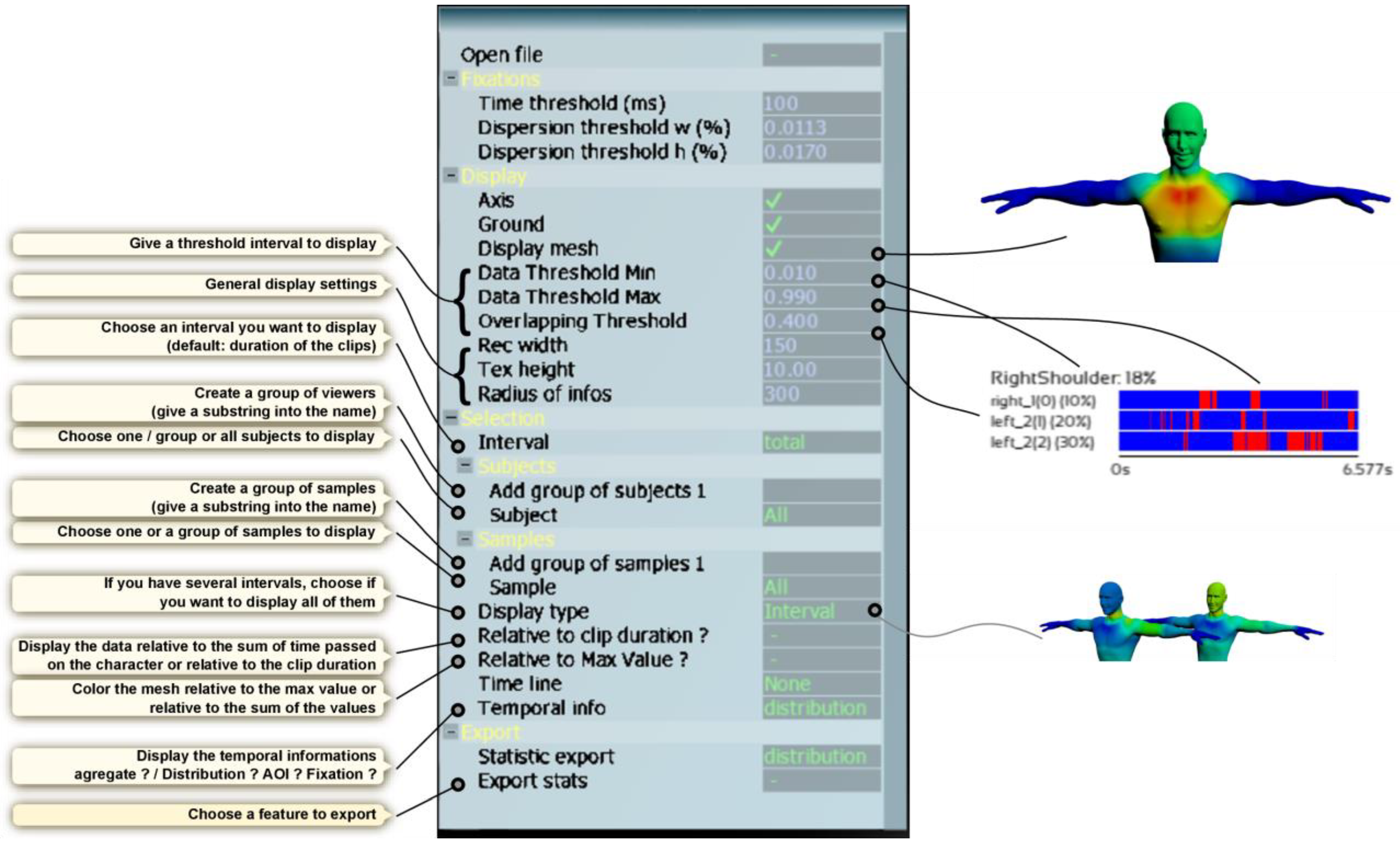
Our Visualization System
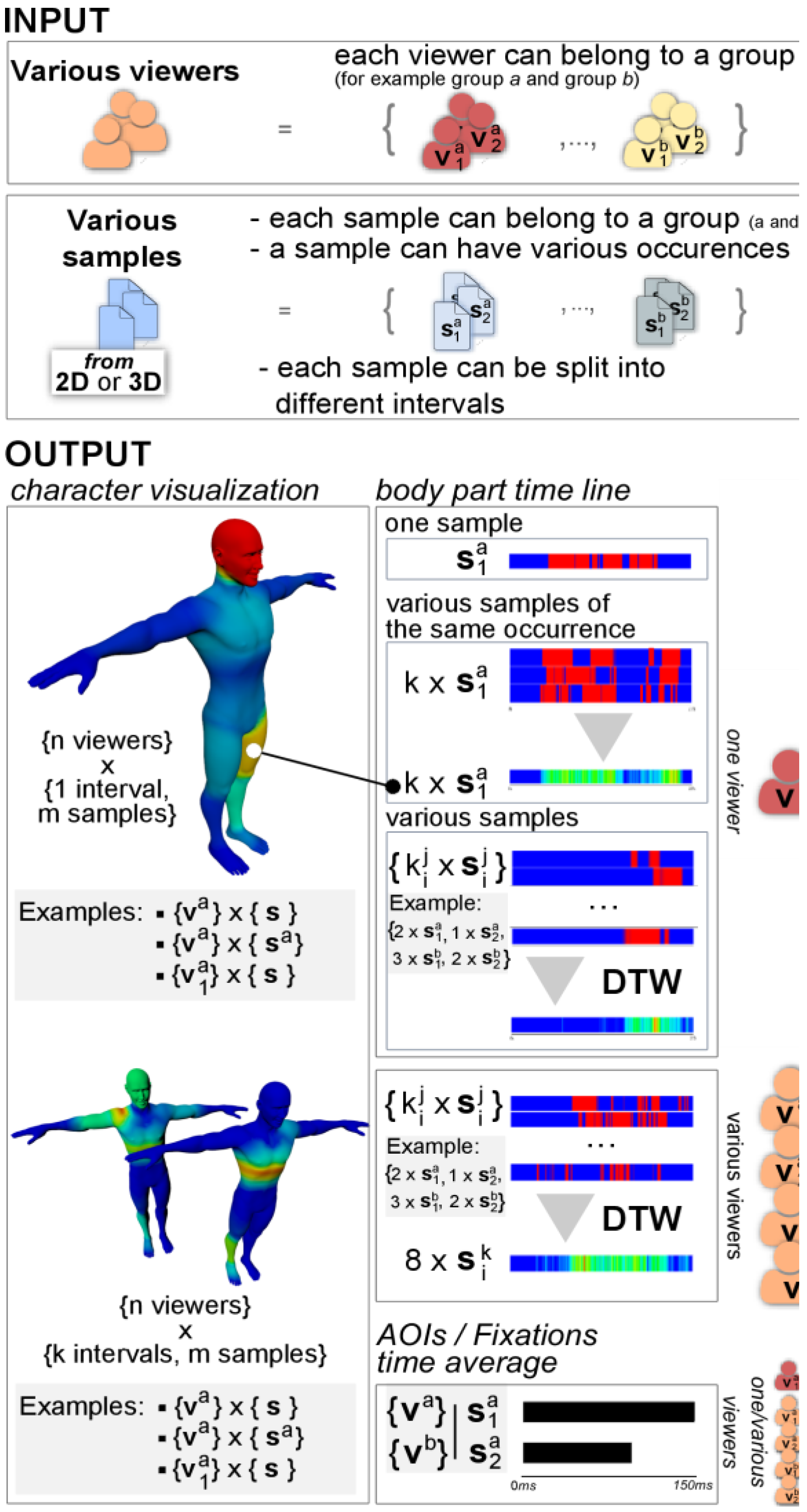
- Basic information. Name and duration of the media source; Note that the name is important since the user will be able to compare different media source by class, by associating one or various parts of the name to different classes.
- Intervals (optional). The user has the possibility to define specific intervals. In most cases, the movements that we want to analyze can be segmented into temporal sub-sequences. Specifically, a movement can be semantically or technically viewed as a concatenation of different phases, each of which can be analyzed separately. For example, whether for interpersonal communication or in sport situations, each ‘phase’ can be analyzed separately. The resulting sub-sequences are defined manually by the user according to the more general context of the analyzed gesture. The result of this partitioning is illustrated in Figure 1d.
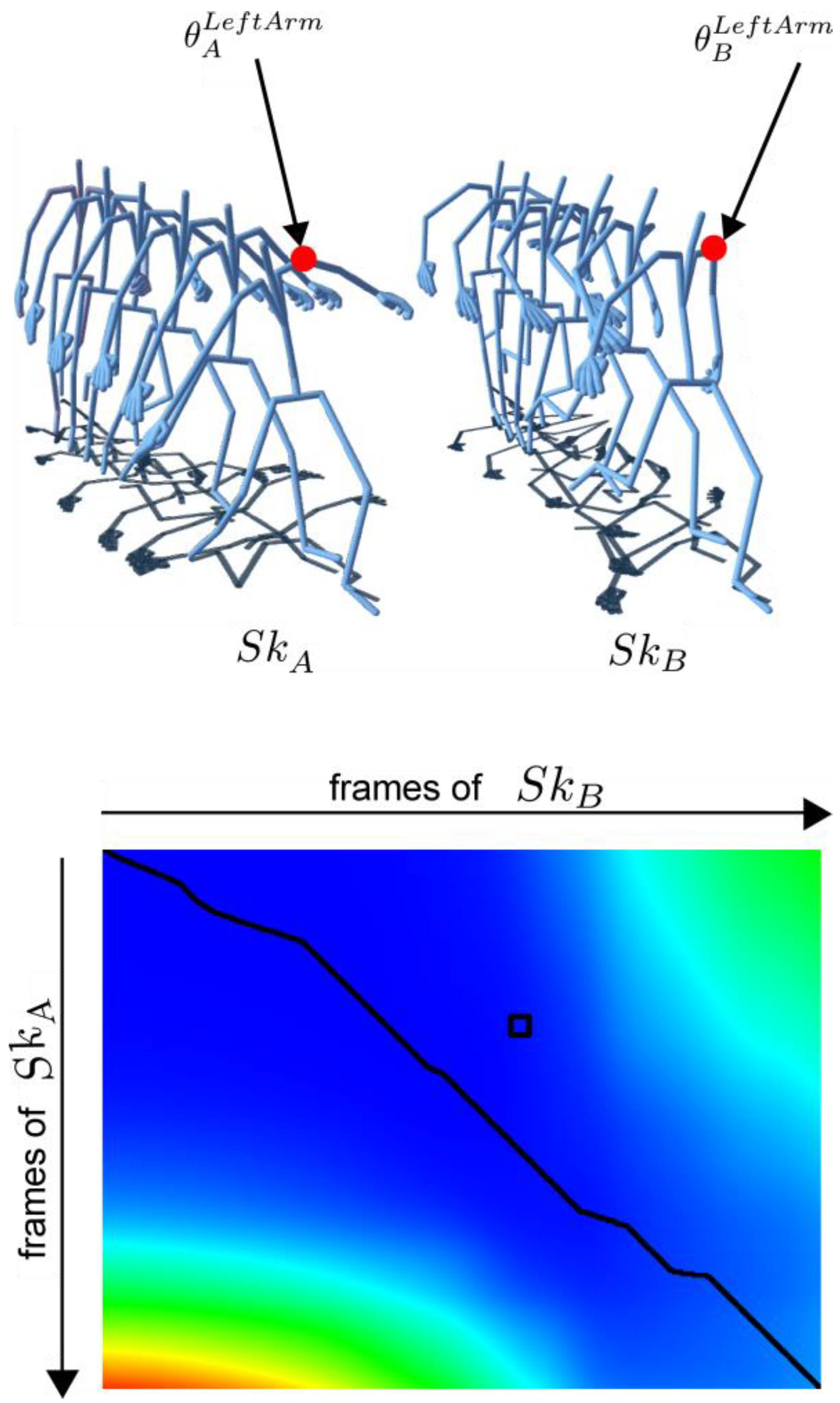
- Temporal mapping between media sources (optional). The user can add a temporal mapping between media sources. As mentioned before, one of the features of our system is the ability to compare the gaze distribution of various viewers on different semantically equivalent gestures. Segmentation is a first step in this direction. However, for any given piece of semantic information, the gestures present different kinematic features (in particular regarding speed and acceleration, or the beginning and the end of movements). To overcome this problem, our tool gives the user the possibility to create a temporal correspondence between any chosen reference sequence of movement and any other selected sequences. This temporal correspondence is performed by the dynamic time warping algorithm. This process is explained in detail in the third section.
- Basic information. The name and the index of the capture order during the experiment. Note that the name is important since the user will be able to compare different media sources by groups, by associating one or various parts of the name to different groups;
- Eye tracking samples. This is a list of eye tracking samples. Each sample is defined by the coordinates of the eyes onto the screen and its corresponding time;
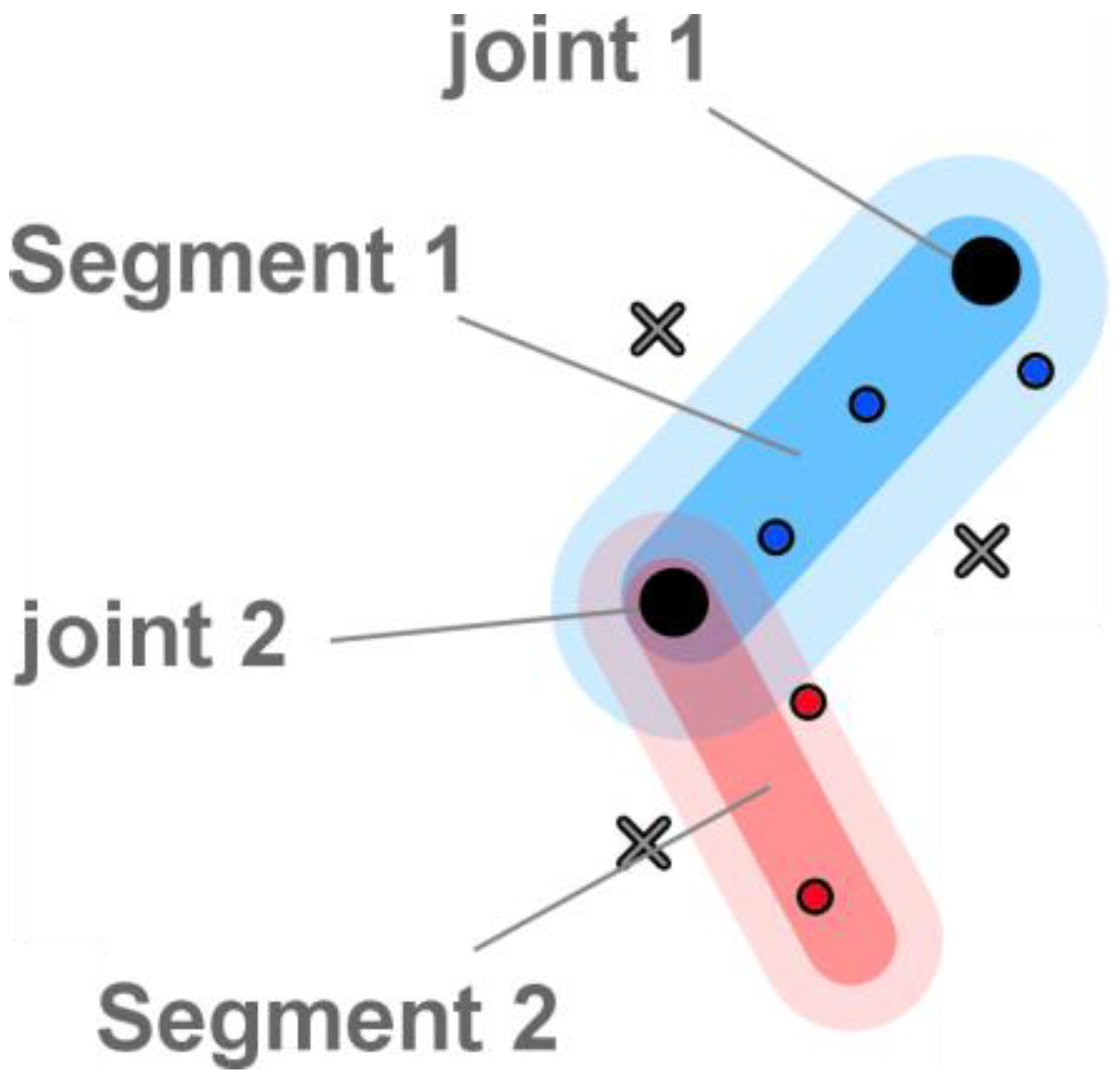
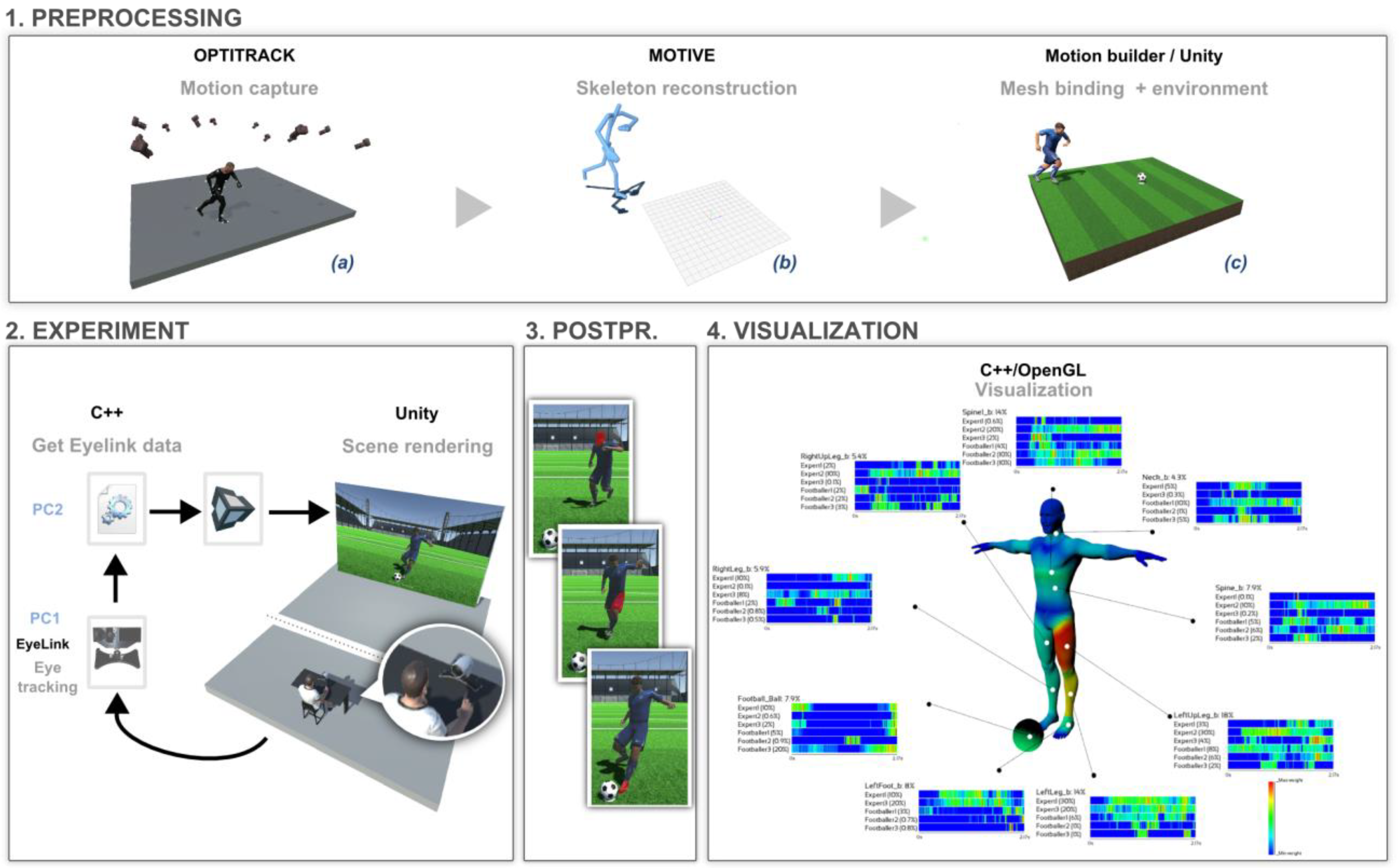
- Sample joint mapping. For each sample, an AOI is defined either by the name of the body part of the viewed character, or by an empty string. The list contains n values. Regarding the naming of body parts (i.e., joints of the skeleton), our system accepts the classical nomenclatures used by the major software products such as motion builder, mixamo, unity or kinect. In the next sections, we will explain how we calculate this sample body part mapping in 2D and 3D.
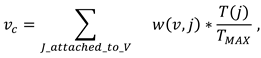
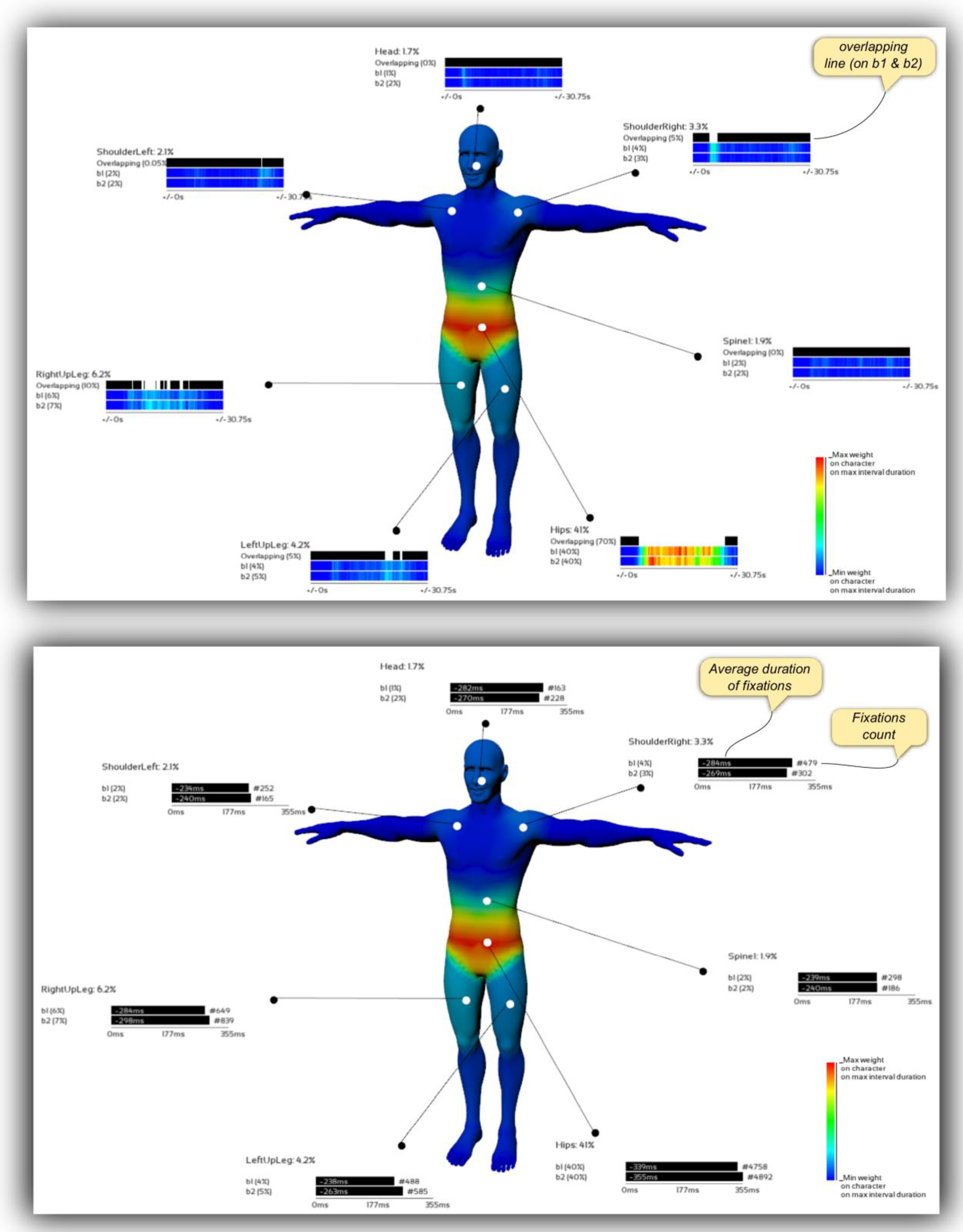
2D Use Case: Evaluation of Gymnastics judges
Material Preparation
Experiment
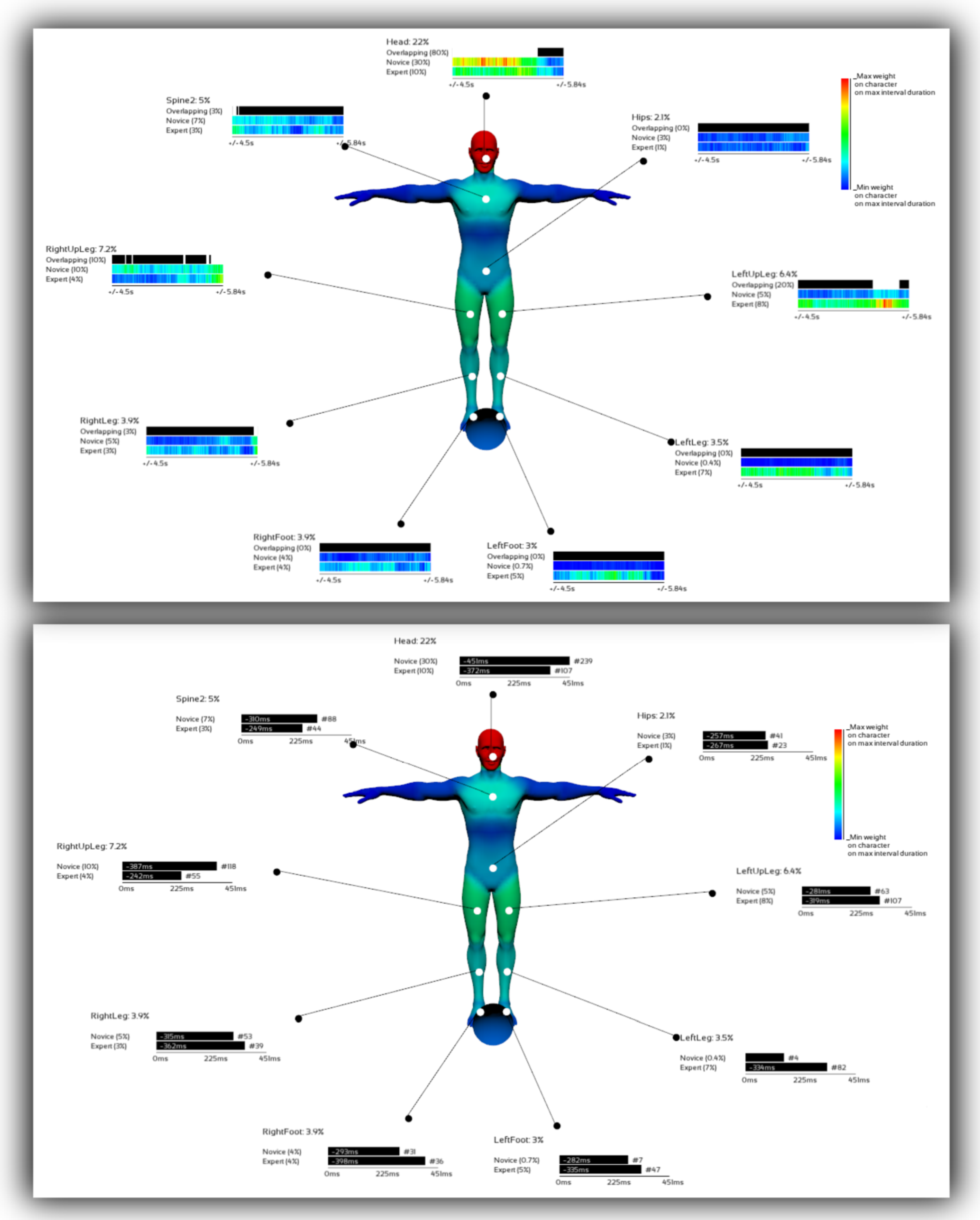
3D Use Case: Prediction of the Direction of a Penalty Kick
Experiment
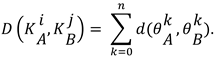
Results
Conclusion and Discussion
Ethics and Conflict of Interest
Appendix A

References
- Bard, C., M. Fleury, L. Carriere, and M. Halle. 1980. Analysis of Gymnastics Judges Visual Search. Research Quarterly for Exercise and Sport 51: 267–273. [Google Scholar] [CrossRef] [PubMed]
- Bente, G., F. Eschenburg, and N. Krämer. 2007. Virtual Gaze. A Pilot Study on the Effects of Computer Simulated Gaze in Avatar-Based Conversations. Virtual Reality, 185–194. [Google Scholar] [CrossRef]
- Bente, G., A. Petersen, N. Krämer, and J. P. de Ruiter. 2001. Transcript-based computer animation of movement: Evaluating a new tool for nonverbal behavior research. Behavior Research Methods, Instruments, & Computers 33: 303–310. [Google Scholar] [CrossRef]
- Berndt, D. J., and J. Clifford. 1994. Using dynamic time warping to find patterns in time series. KDD workshop. [Google Scholar]
- Bideau, B., R. Kulpa, N. Vignais, S. Brault, F. Multon, and C. Craig. 2010. Using Virtual Reality to Analyze Sports Performance. IEEE Computer Graphics and Applications 30: 14–21. [Google Scholar] [CrossRef]
- Blascheck, T., K. Kurzhals, M. Raschke, M. Burch, D. Weiskopf, and T. Ertl. 2014. State-of-the-Art of Visualization for Eye Tracking Data. EuroVis—STARs: The Eurographics Association. [Google Scholar] [CrossRef]
- Bruderlin, A., and L. Williams. 1995. Motion Signal Processing. In Proceedings of the 22Nd Annual Conference on Computer Graphics and Interactive Techniques. ACM. [Google Scholar] [CrossRef]
- Buss, S. R., and J. P. Fillmore. 2001. Spherical Averages and Applications to Spherical Splines and Interpolation. ACM Trans. Graph. 20: 95–126. [Google Scholar] [CrossRef]
- Goulet, C., C. Bard, and M. Fleury. 1989. Expertise Differences in Preparing to Return a Tennis Serve: A Visual Information Processing Approach. Journal of Sport and Exercise Psychology 11: 382–398. [Google Scholar] [CrossRef]
- Hancock, D. J., and D. M. Ste-marie. 2013. Gaze behaviors and decision making accuracy of higher-and lower-level ice hockey referees. Psychology of Sport & Exercise 14: 66–71. [Google Scholar] [CrossRef]
- Huang, Y., L. Churches, and B. Reilly. 2015. A Case Study on Virtual Reality American Football Training. In Proceedings of the 2015 Virtual Reality International Conference. ACM. [Google Scholar] [CrossRef]
- Jacob, R. J., and K. S. Karn. 2003. Eye tracking in human-computer interaction and usability research: Ready to deliver the promises. Mind 2: 4. [Google Scholar] [CrossRef]
- Korda, A., C. Siettos, A. D. I. Cagno, I. Evdokimidis, and N. Smyrnis. 2015. Judging the Judges’ Performance in Rhythmic Gymnastics. 640–648. 640–648. [Google Scholar] [CrossRef]
- Kurzhals, K., F. Heimerl, and D. Weiskopf. 2014. ISeeCube: Visual Analysis of Gaze Data for Video. In Proceedings of the Symposium on Eye Tracking Research and Applications. ACM. [Google Scholar] [CrossRef]
- Kurzhals, K., and D. Weiskopf. 2013. Space-time visual analytics of eye-tracking data for dynamic stimuli. IEEE Transactions on Visualization and Computer Graphics 19: 2129–2138. [Google Scholar] [CrossRef] [PubMed]
- Lahiri, U., A. Trewyn, Z. Warren, and N. Sarkar. 2011. Dynamic eye gaze and its potential in virtual reality based applications for children with autism spectrum disorders. Autism-Open Access 1. [Google Scholar] [CrossRef]
- Lewis, J. P., M. Cordner, and N. Fong. 2000. Pose Space Deformation: A Unified Approach to Shape Interpolation and Skeleton-driven Deformation. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques. ACM Press/Addison-Wesley Publishing Co. [Google Scholar] [CrossRef]
- Mackworth, J. F., and N. H. Mackworth. 1958. Eye Fixations Recorded on Changing Visual Scenes by the Television Eye-Marker. J. Opt. Soc. Am. 48: 439–445. [Google Scholar] [CrossRef] [PubMed]
- Mann, D. T. Y., A. M. Williams, P. Ward, and C. M. Janelle. 2007. Perceptual-Cognitive Expertise in Sport: A Meta-Analysis. Journal of Sport and Exercise Psychology 29: 457–478. [Google Scholar] [CrossRef]
- Maurus, M., J. H. Hammer, and J. Beyerer. 2014. Realistic Heatmap Visualization for Interactive Analysis of 3D Gaze Data. In Proceedings of the Symposium on Eye Tracking Research and Applications. ACM. [Google Scholar] [CrossRef]
- Page, J. 2009. The development and effectiveness of perceptual training programme for coaches and judges in gymnastics. University of Liverpool (University of Chester). [Google Scholar]
- Papenmeier, F., and M. Huff. 2010. DynAOI: A tool for matching eye-movement data with dynamic areas of interest in animations and movies. Beh3Dor Research Methods 42: 179–187. [Google Scholar] [CrossRef]
- Poole, A., and L. J. Ball. 2006. Eye tracking in HCI and usability research. Encyclopedia of Human Computer Interaction 1: 211–219. [Google Scholar]
- Rodrigues, R., A. Veloso, and O. Mealha. 2012. A television news graphical layout analysis method using eye tracking. In 16th International Conference on Information Visualisation (IV). pp. 357–362. [Google Scholar] [CrossRef]
- Roth, D., C. Bloch, A.-K. Wilbers, M. E. Latoschik, K. Kaspar, and G. Bente. 2016. What You See is What You Get: Channel Dominance in the Decoding of Affective Nonverbal Behavior Displayed by Avatars. 66th Annual Conference of the International Communication Association (ICA), Fukuoka, Japan, June 9–13. [Google Scholar]
- Salvucci, D. D., and J. H. Goldberg. 2000. Identifying Fixations and Saccades in Eye-tracking Protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications. ACM. [Google Scholar] [CrossRef]
- Savelsbergh, G. J. P., J. V. der Kamp, A. M. Williams, and P. Ward. 2005. Anticipation and visual search behaviour in expert soccer goalkeepers. Ergonomics 48: 1686–1697. [Google Scholar] [CrossRef] [PubMed]
- Stark, L.W., and S.R. Ellis. 1981. Scanpaths revisited: Cognitive models direct active looking 193–226. Lawrence Erlbaum Associates. [Google Scholar]
- Stellmach, S., L. E. Nacke, and R. Dachselt. 2010. Advanced Gaze Visualizations for Three-Dimensional Virtual Environments. In Proceedings of ETRA 2010. pp. 109–112. [Google Scholar] [CrossRef]
- Widdel, H. 1984. Operational Problems in Analysing Eye Movements. Advances in Psychology 22: 21–29. [Google Scholar]
- Williams, A. M., K. Davids, L. Burwitz, and J. G. Williams. 1994. Visual Search Strategies in Experienced and Inexperienced Soccer Players. Research Quarterly for Exercise and Sport 65: 127–135. [Google Scholar] [CrossRef]
- Wilms, M., L. Schilbach, U. Pfeiffer, G. Bente, G. R. Fink, and K. Vogeley. 2010. It’s in your eyes-using gaze-contingent stimuli to create truly interactive paradigms for social cognitive and affective neuroscience. Social Cognitive and Affective Neuroscience 5: 98–107. [Google Scholar] [CrossRef]
- Woo, M., J. Neider, T. D3Ds, and D. Shreiner. 1999. OpenGL Programming Guide: The Official Guide to Learning OpenGL, Version 1.2. [Google Scholar]
- Woolley, T. L., R. G. Crowther, K. Doma, and J.D. Connor. 2015. The use of spatial manipulation to examine goalkeepers anticipation. Journal of Sports Sciences 33: 1766–1774. [Google Scholar] [CrossRef] [PubMed]
- Wu, M. 2016. SEQIT: Visualizing Sequences of Interest in Eye Tracking Data. IEEE Transactions on Visualization and Computer Graphics (TVCG, Proceedings of InfoVis 2015) 22: 449–458. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Display features | stimuli | |||||||
| spatial distribution | time-lines | Synchro overlapping | scanpath | type | AOI | Comparing Several users | Comparing Several media | |
| Maurus | Yes | No | No | No | 3D | no | No | No |
| Stellmach (Tobii 1750) | Yes | Yes | No | Yes | 3D | Automatic (vertex based) | No | No |
| Kurzhal (Tobii T60 XL) | No | Yes | Yes | Yes | 2D | rectangles | Yes | No |
| Roth (SMI RED-500) | Yes(2D) | No | No | No | 3D | rectangles | No | No |
| Maurus | Yes | Yes | Yes | No | 2D/3D | 2D: rectangles 3D:automatic (vertex based) | Yes | Yes |
Copyright © 2017. This article is licensed under a Creative Commons Attribution 4.0 International License.
Share and Cite
Le Naour, T.; Bresciani, J.-P. A Skeleton-Based Approach to Analyzing Oculomotor Behavior When Viewing Animated Characters. J. Eye Mov. Res. 2017, 10, 1-19. https://doi.org/10.16910/jemr.10.5.7
Le Naour T, Bresciani J-P. A Skeleton-Based Approach to Analyzing Oculomotor Behavior When Viewing Animated Characters. Journal of Eye Movement Research. 2017; 10(5):1-19. https://doi.org/10.16910/jemr.10.5.7
Chicago/Turabian StyleLe Naour, Thibaut, and Jean-Pierre Bresciani. 2017. "A Skeleton-Based Approach to Analyzing Oculomotor Behavior When Viewing Animated Characters" Journal of Eye Movement Research 10, no. 5: 1-19. https://doi.org/10.16910/jemr.10.5.7
APA StyleLe Naour, T., & Bresciani, J.-P. (2017). A Skeleton-Based Approach to Analyzing Oculomotor Behavior When Viewing Animated Characters. Journal of Eye Movement Research, 10(5), 1-19. https://doi.org/10.16910/jemr.10.5.7