
Non-Intrusive Load Monitoring Applied to AC Railways


Abstract
:1. Introduction
2. AC Railway System and Electrical Quantities
3. Signal Features and Clustering
3.1. Signal Features and Quantities
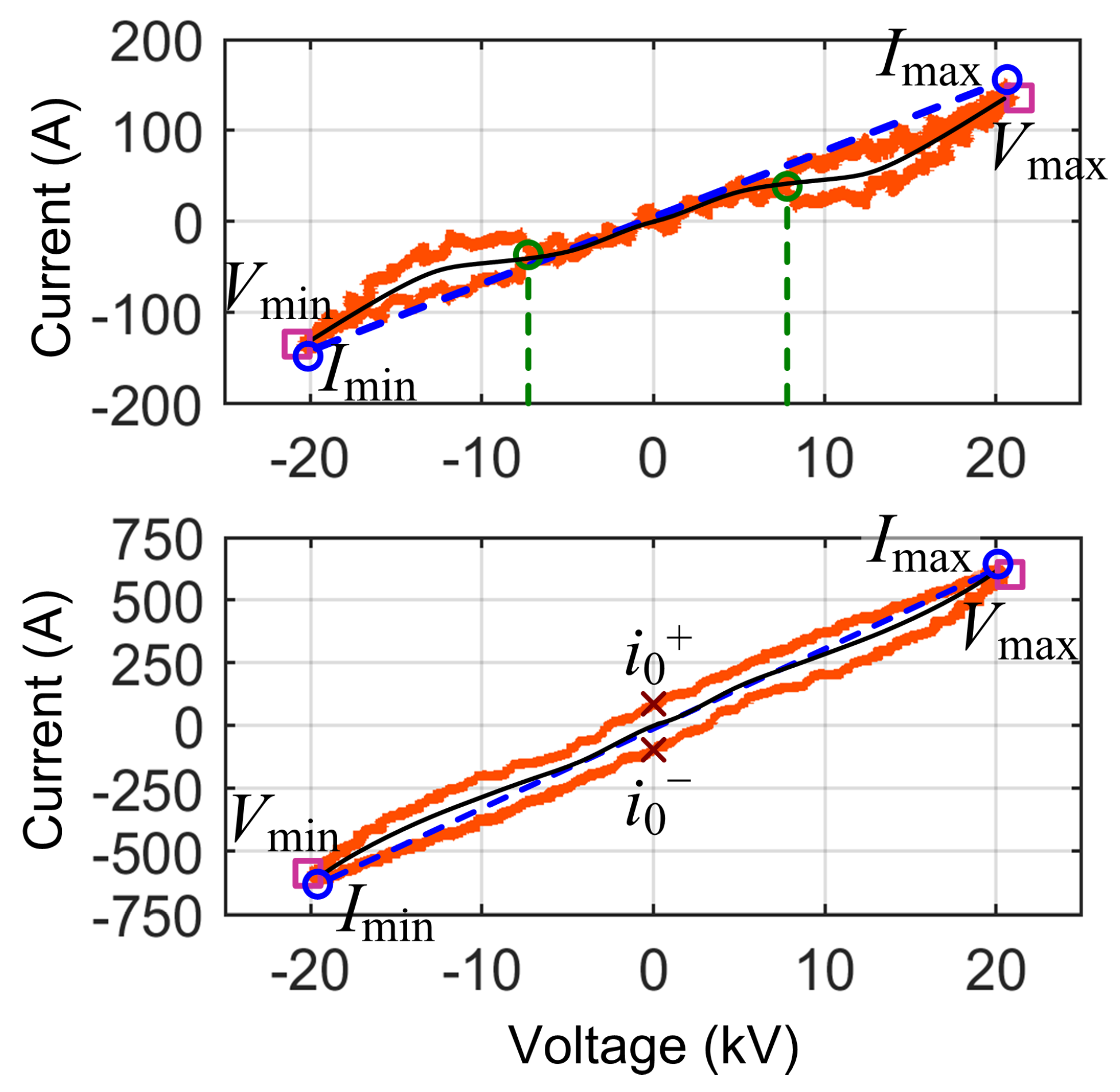
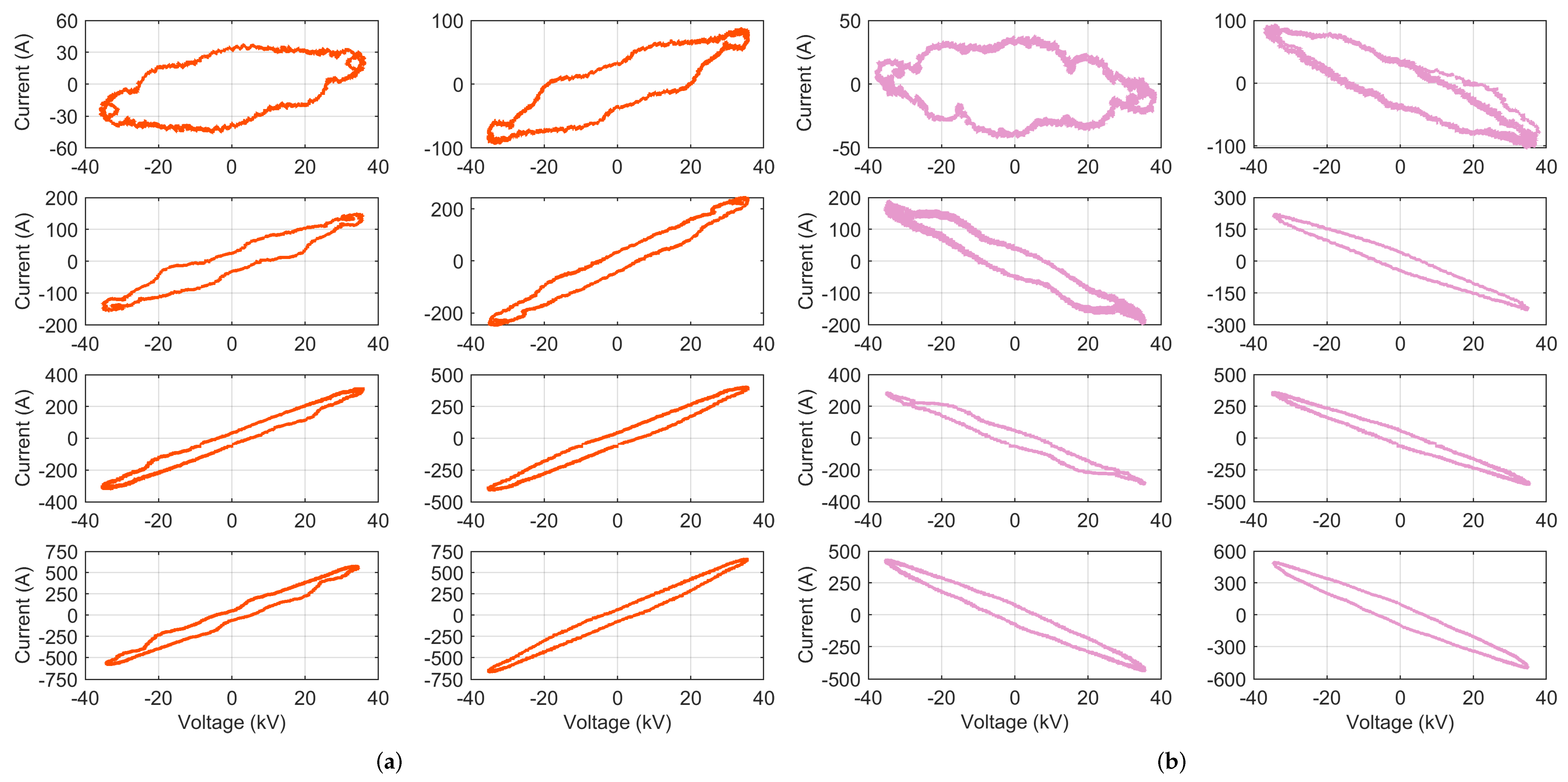
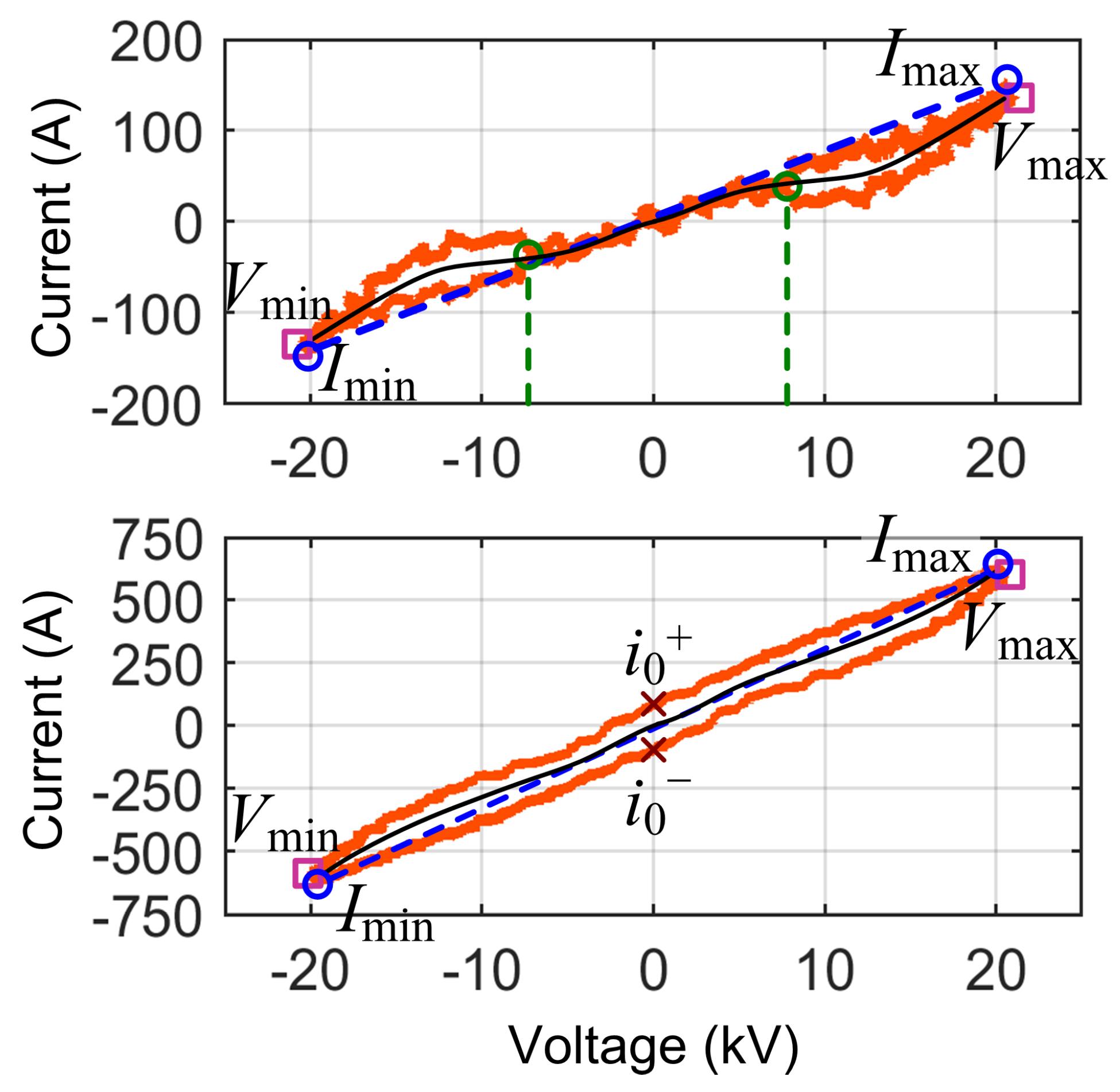
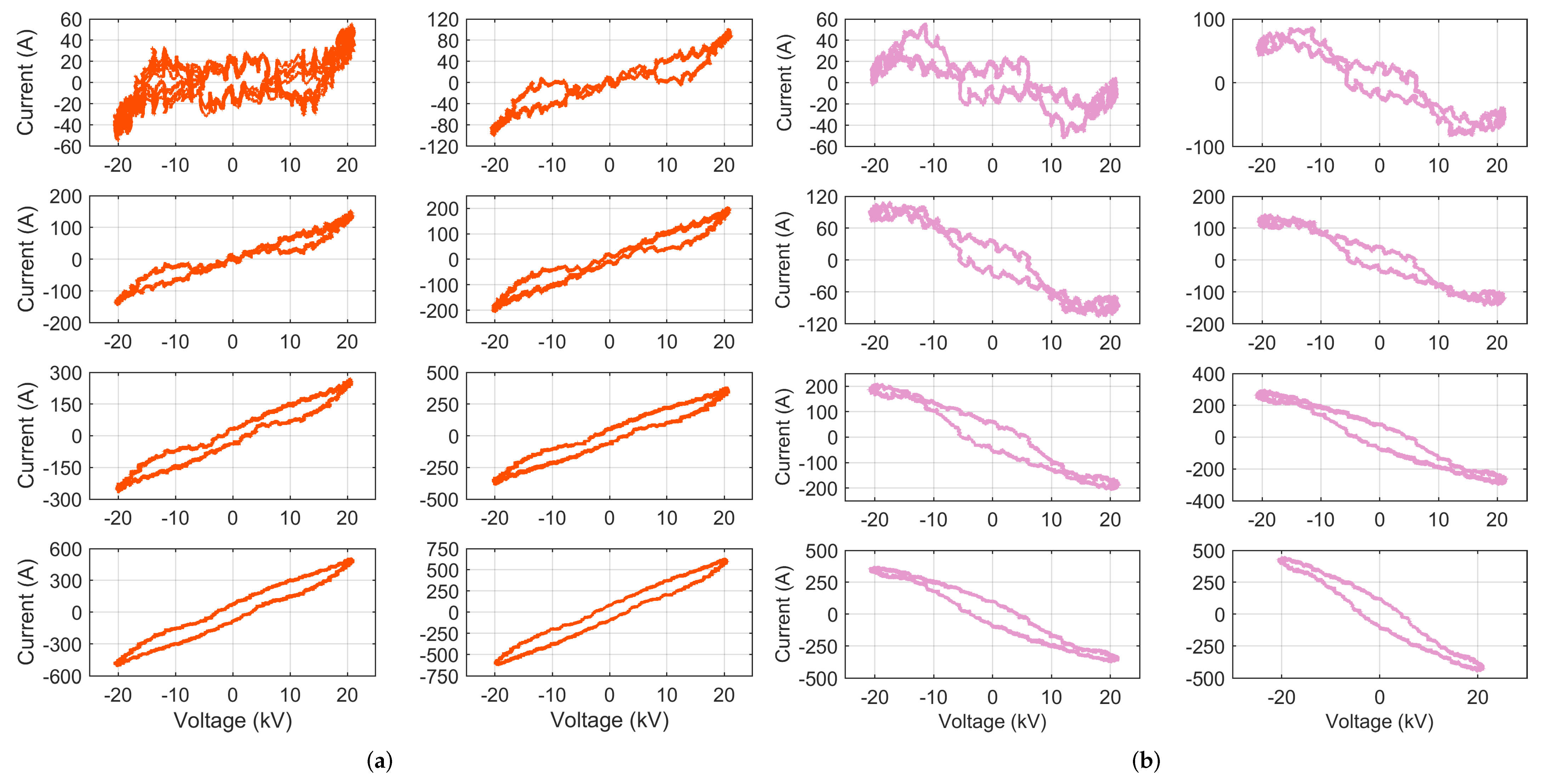
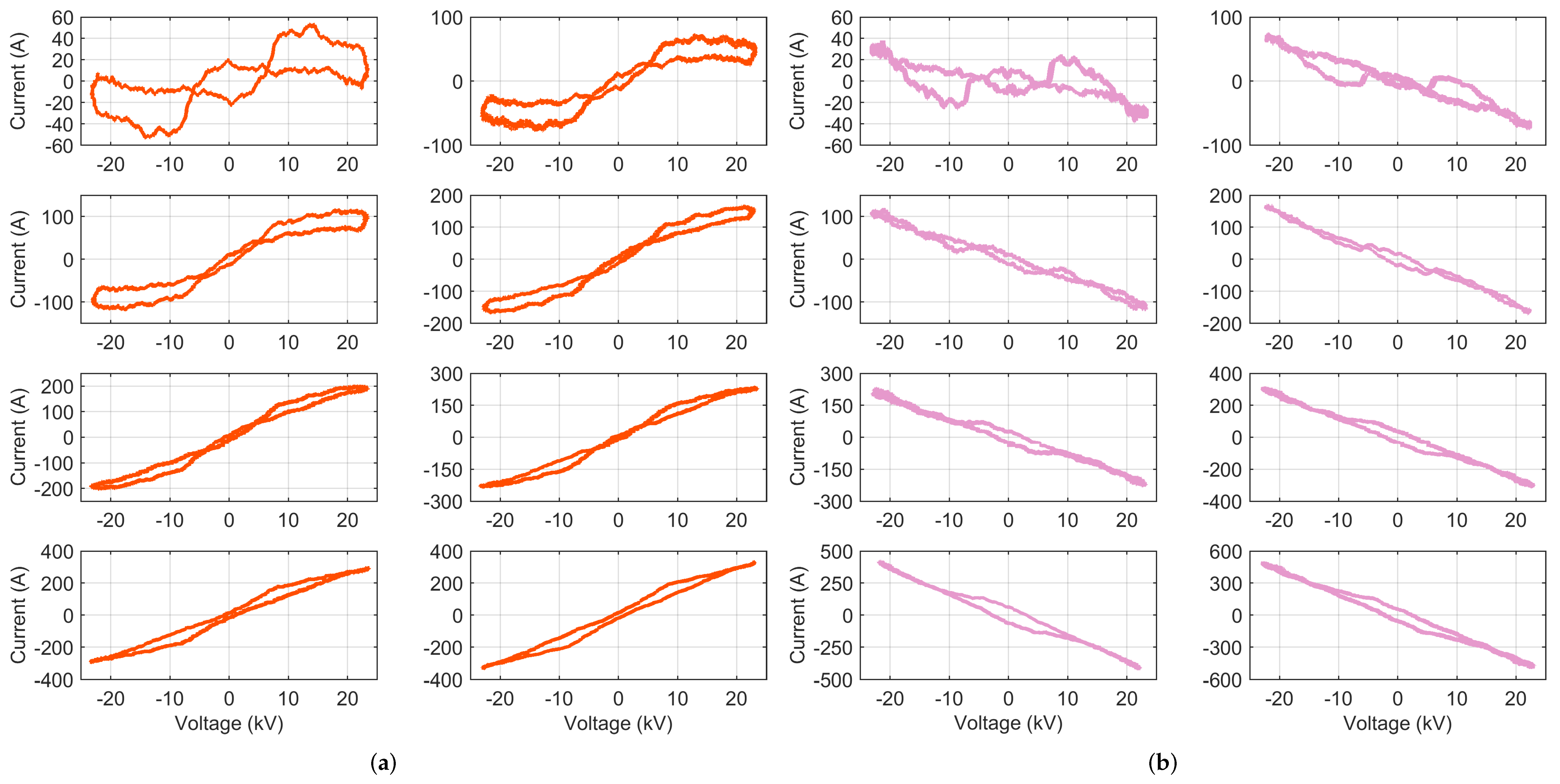
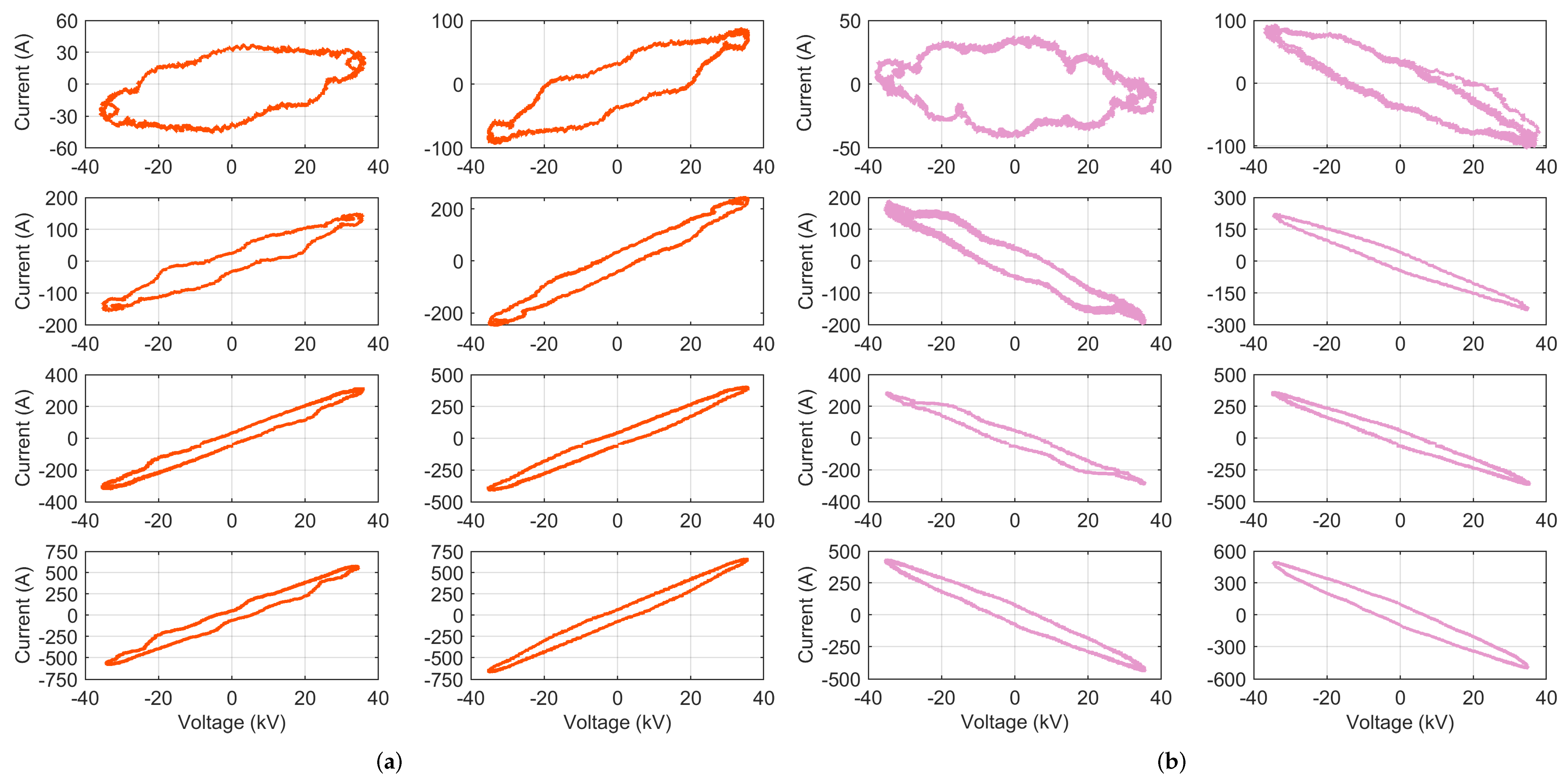
3.1.1. VI Diagrams
- Loop direction of the VI locus, where the clockwise direction indicates capacitive behavior (which is quite uncommon in railways, being almost prohibited by the EN 50388 [46]), but also regenerative braking; the sign of current entering or exiting the pantograph provides clarification.
- Maximum and minimum points for the current (to compare with the total rms current ) and voltage (less significant, as it depends on the line supply condition, rather than the rolling stock itself); the slope of the line joining the current extreme points (opposed vertices of the curve) is commonly used as an indicator.
- Mean curve traversing the locus in the middle of the closed shape and joining the two vertices; the most meaningful index that can be extracted from it is its slope at some predetermined point, such as near the origin; in the following, the average slope in the first 30% of the x-axis voltage points will be used.
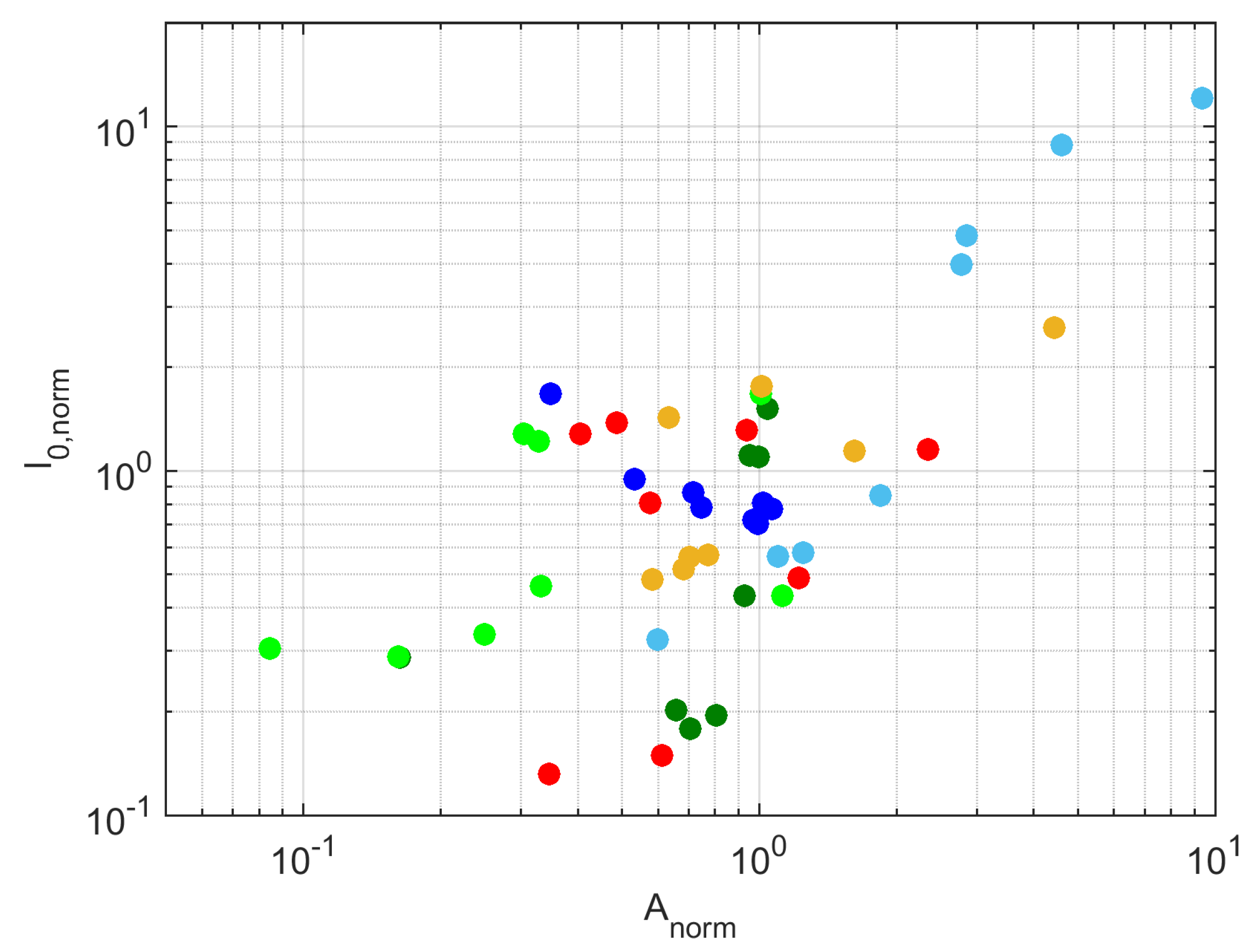
- Area A enclosed by the locus, measuring at the same time current intensity and loop aperture; this value should be normalized by the voltage intensity (to make the comparison of different systems possible, as well as different catenary voltage conditions) and by the current intensity (to compare different power absorption levels).
- Intersection points of the vertical i axis at ( and ) and related span .
- Presence of self intersections and their numbers .
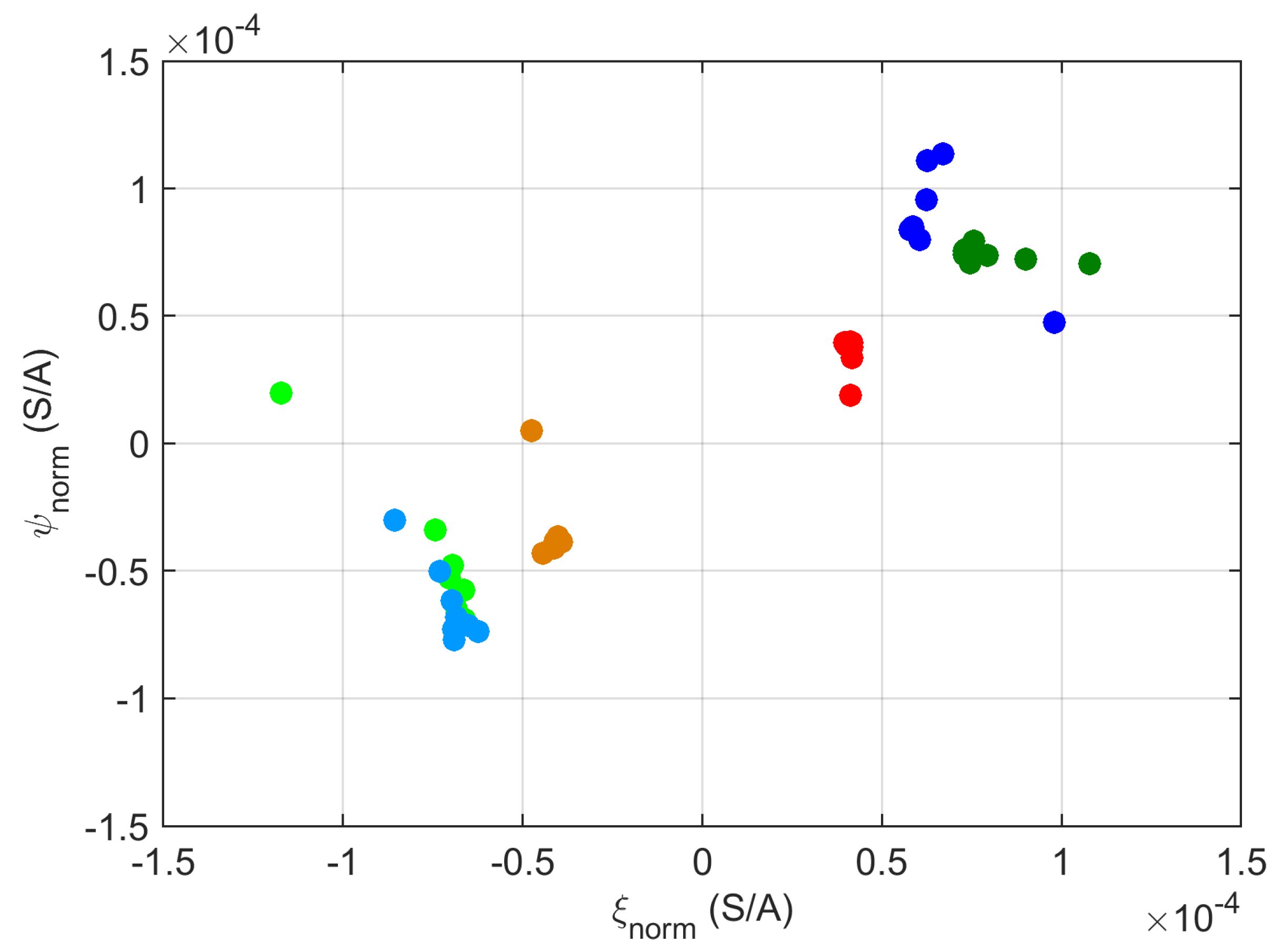
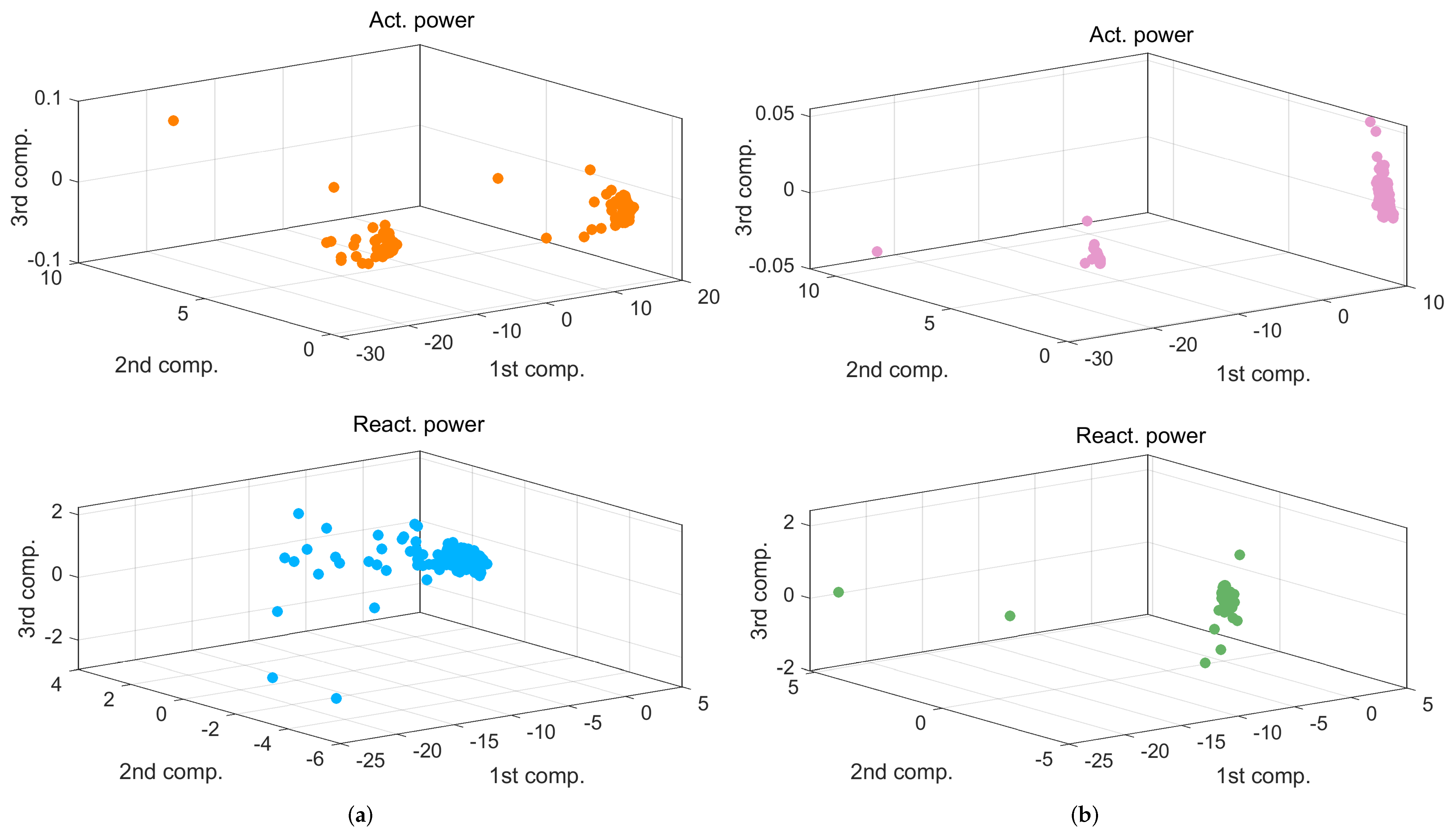
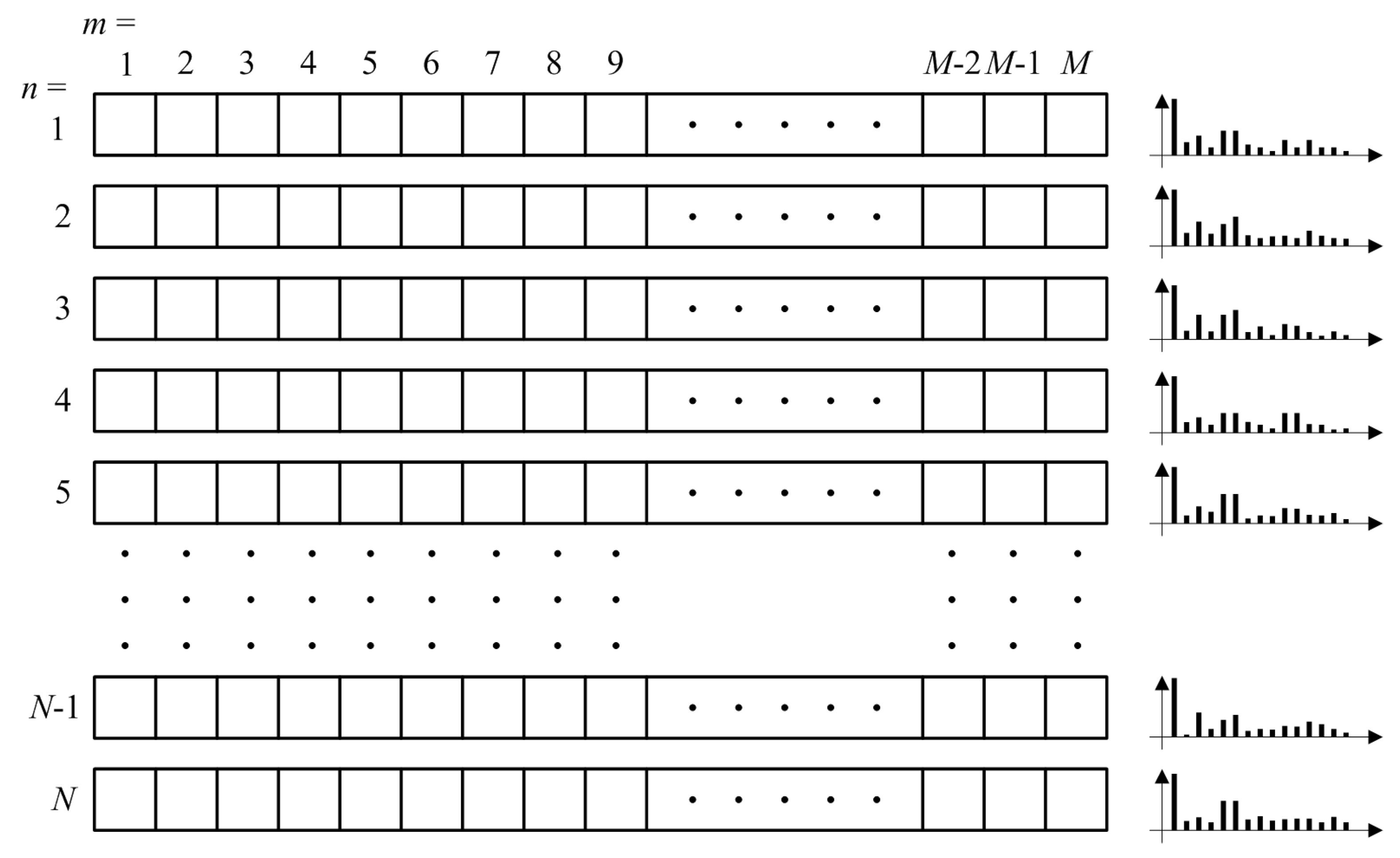
3.1.2. PCA and SVD Analysis
3.1.3. Partial Least Squares Regression
- It requires a smaller number of PCs to achieve the same quality of representation;
- PLSR includes the information of the second vector of responses y and it is more suitable to the wide class of classification problems.
3.2. Cluster Analysis
- Density-based algorithms: grouping is carried out, identifying areas of high concentrations of points, separated by areas of low concentrations;
- Distribution-based algorithms: make some kind of assumption on the distribution of points around the supposed centroids, the probability reducing with distance indicates to which cluster a data point belongs;
- Centroid-based algorithms: similarly, the simple distance from centroids instructs how to separate data points;
- Hierarchical-based algorithms: it attempts to create a hierarchy of data by either an agglomerative approach (bottom-up, combining smaller clusters) or divisive approach (top-down, splitting into smaller clusters starting from one large cluster of all data).
- The predictive performance of a classifier decreases as the number of features increases, while keeping the number of training instances constant [50]; in other words, training should be augmented in terms of the number of instances, at least proportionally to the increase in the number of features;
- The metric based on distance tends to lose significance as dimensionality grows [51].
3.2.1. K-Means
3.2.2. Density-Based Spatial Clustering of Applications with Noise
- It does not fix the number of clusters a priori;
- It has the ability of separating outliers labeling them as “noisy points”, possibly reinserting them into a cluster during the process;
- It works effectively with non-convex data points.
- Performance is impaired by data groups featuring varying density, as the distance threshold and minimum point required to form a cluster should be continuously adapted;
- It may face a similar problem for high-dimensional data, which is, in any case, alleviated by pre-processing data with feature extraction techniques, such as the autoencoder.
3.2.3. Mean Shift
3.2.4. Gaussian Mixture Model
- During the estimation phase, the probability is calculated for each datum point, , belonging to each cluster, given the distribution and the actually assigned point (number for each cluster):
- Data point is assigned to cluster k following the indication of the largest values;
- During the maximization phase, parameters are updated, calculating as the fraction of the number of data points effectively assigned to cluster k, and quantities updated as follows with similarity with mean shift for (referred to , with ):
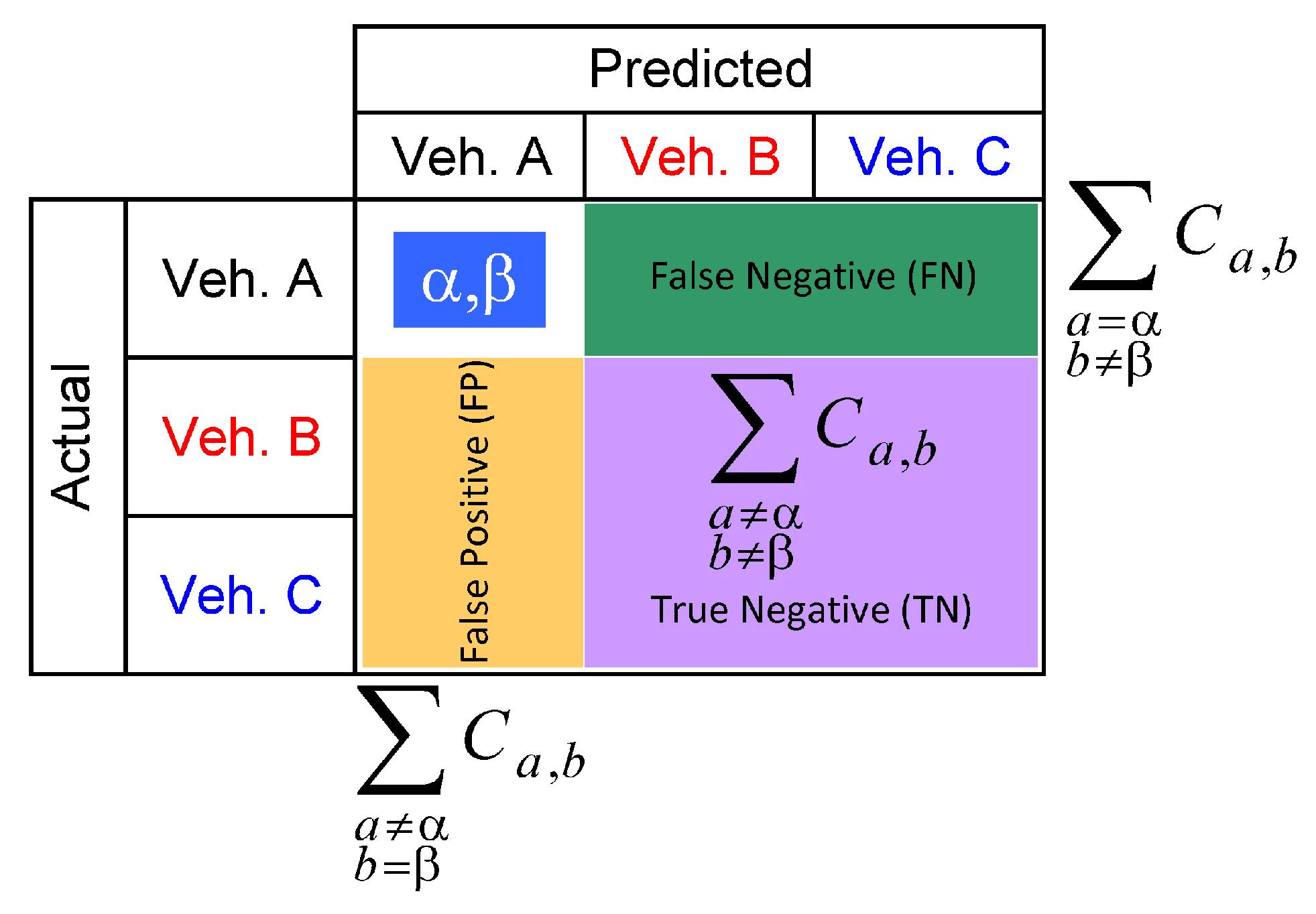
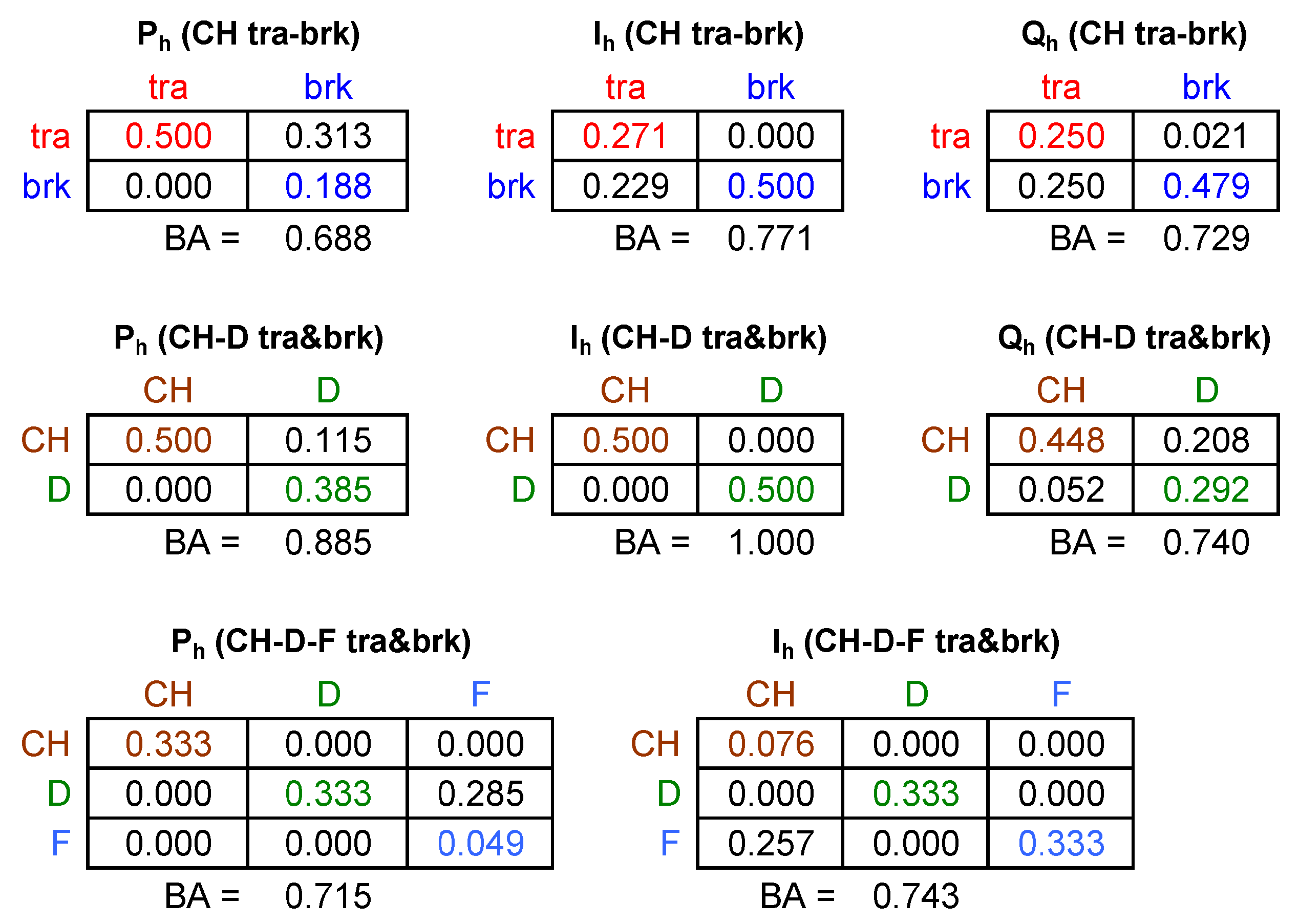
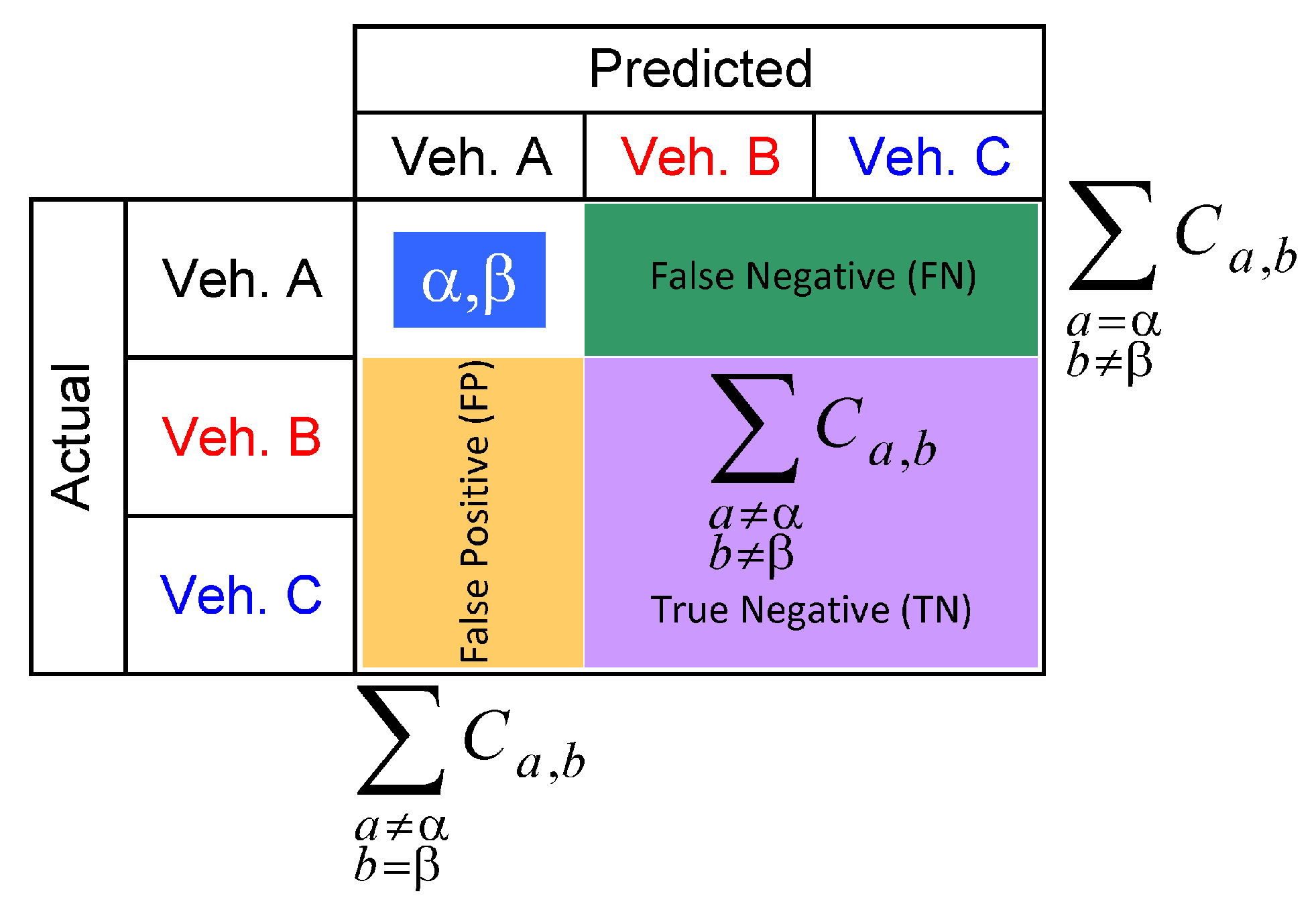
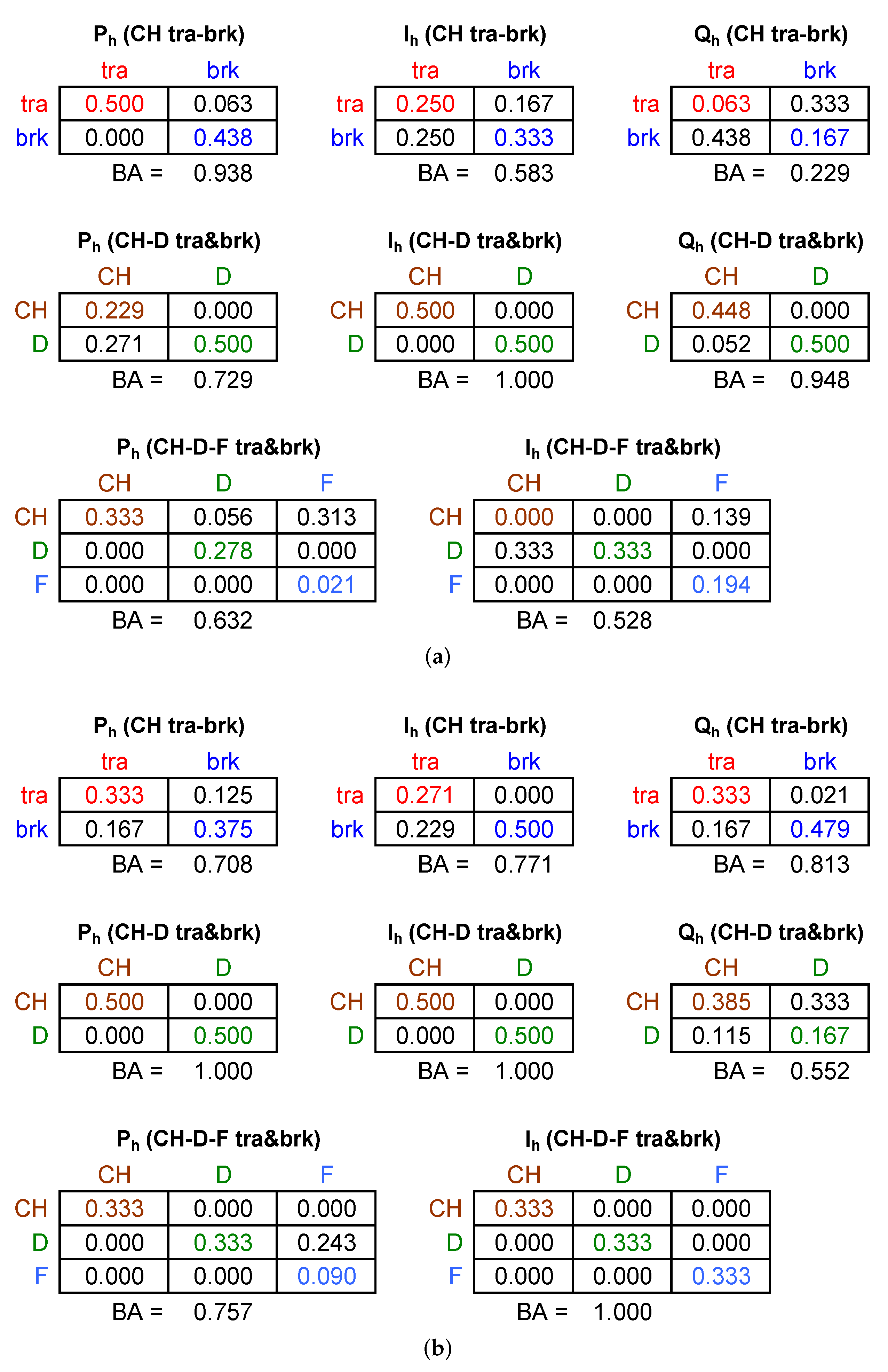
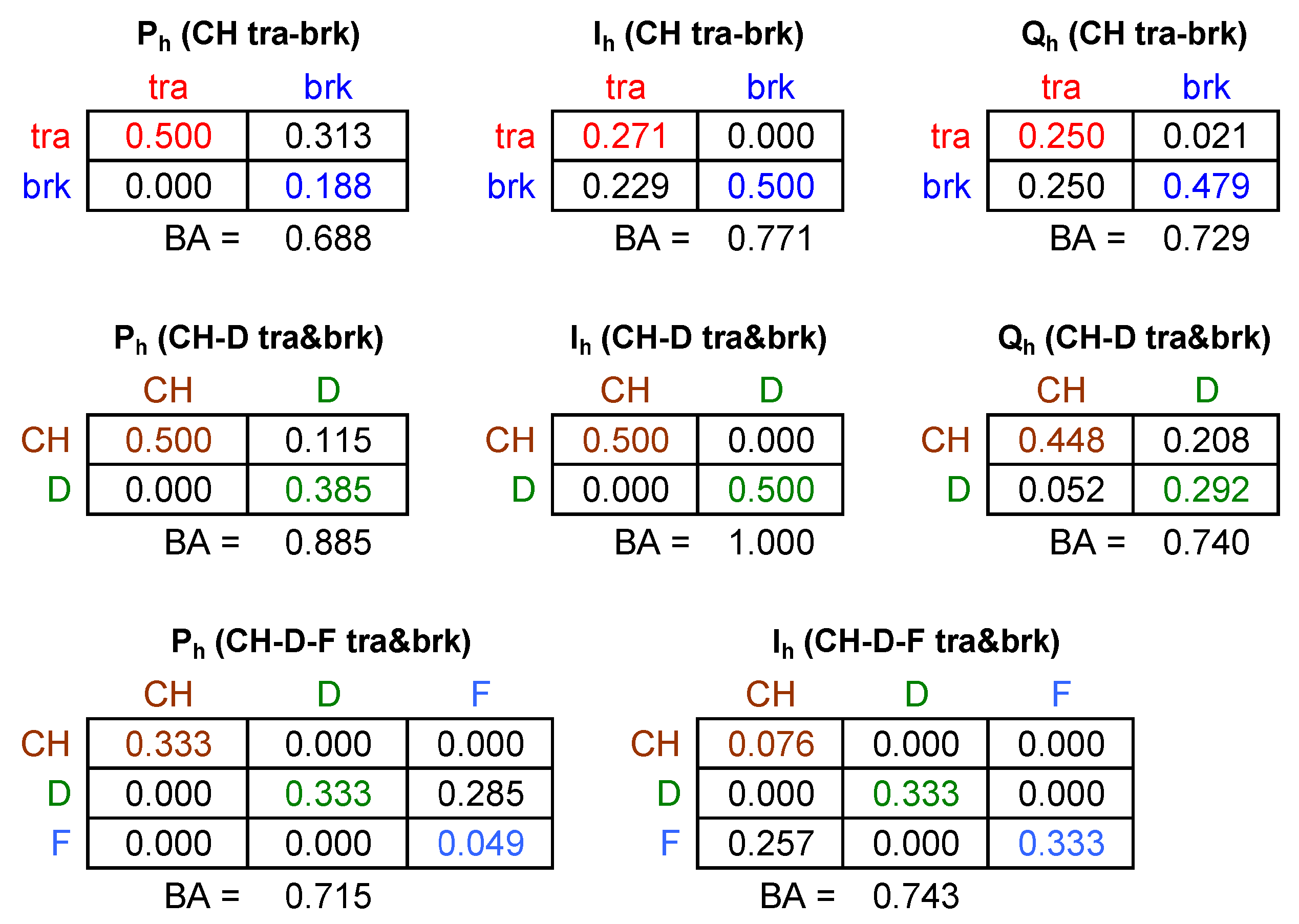
3.3. Verification of Performance
4. Exemplification and Results of Classification
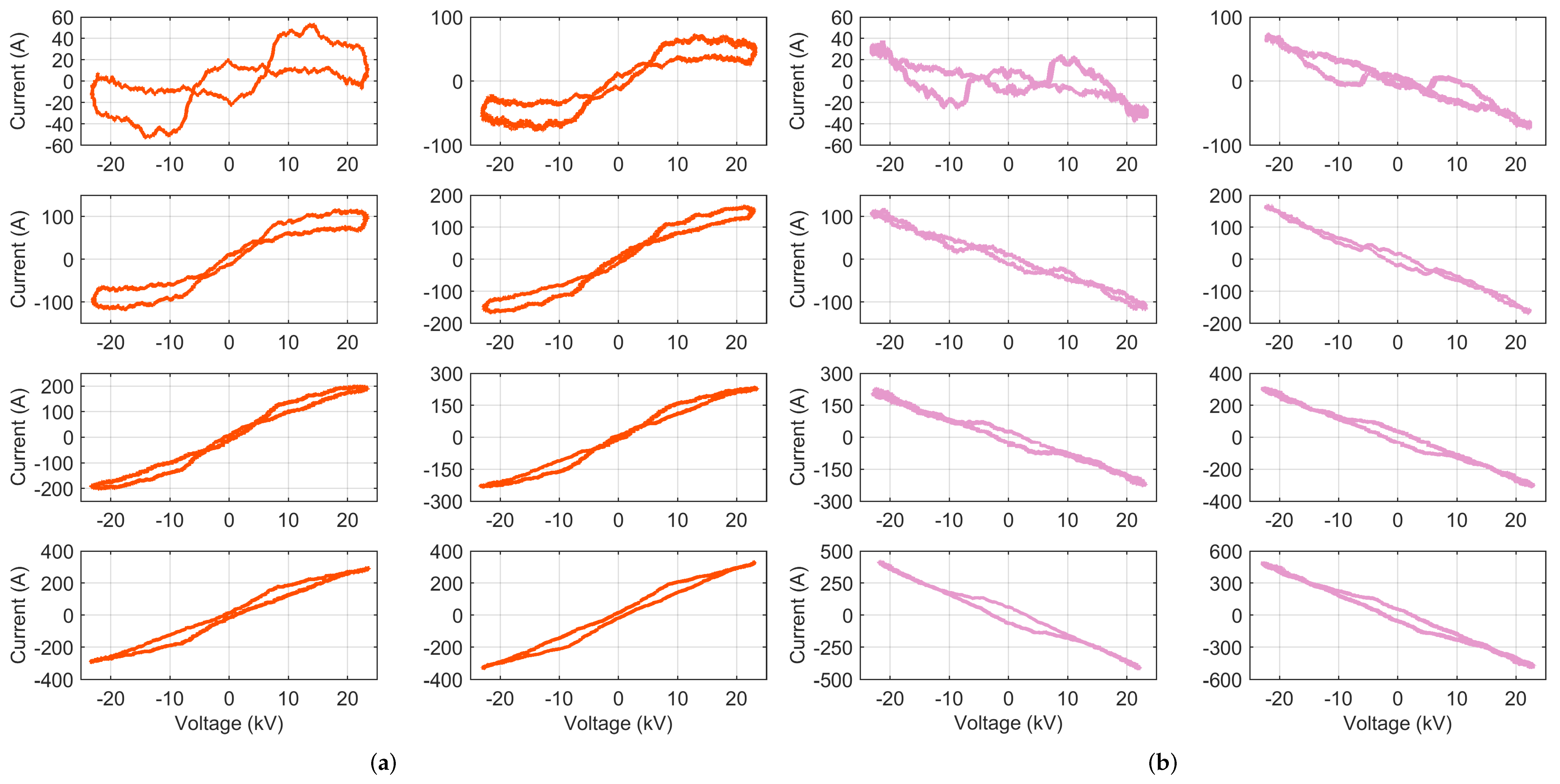
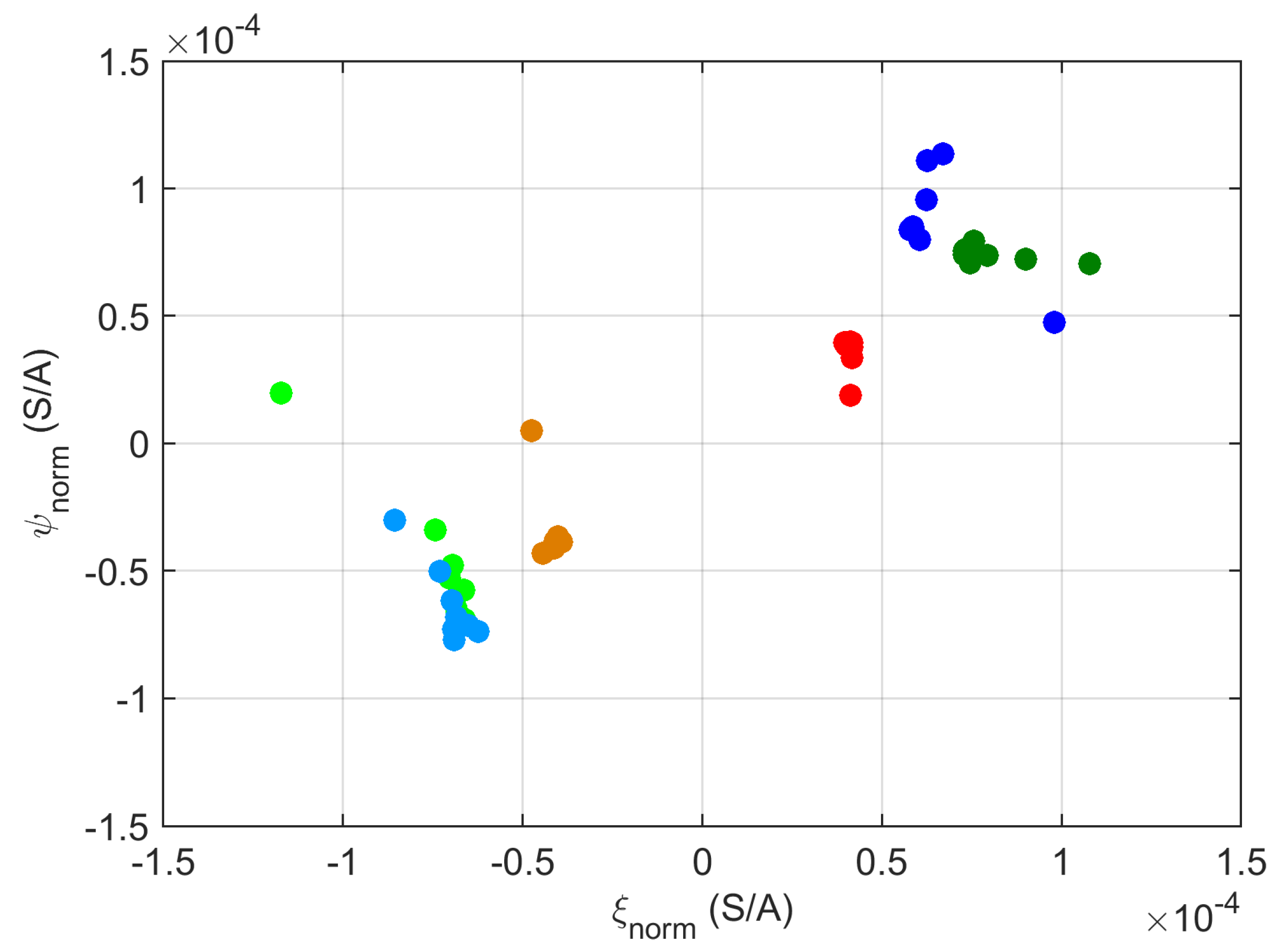
4.1. VI Diagrams
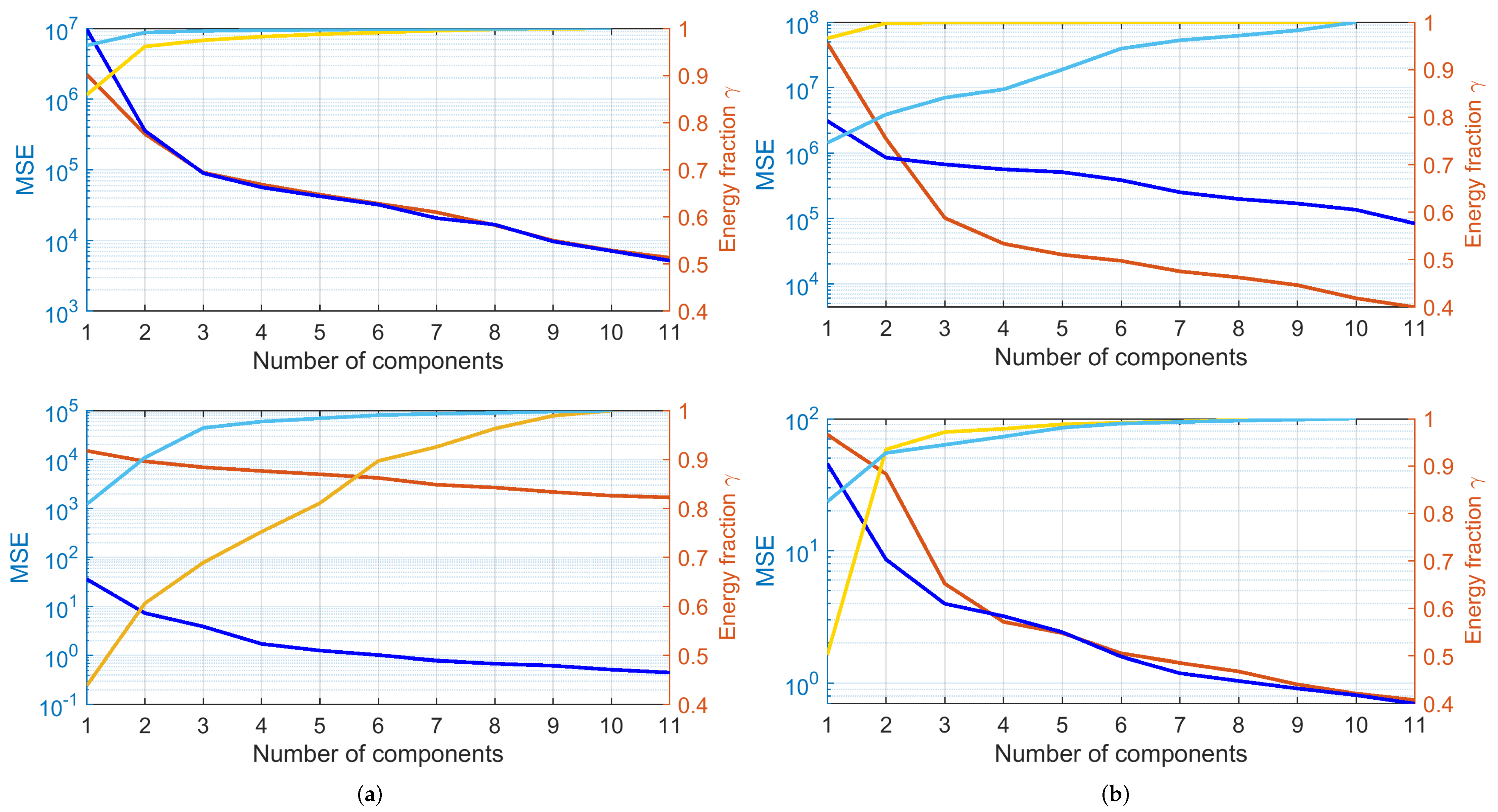
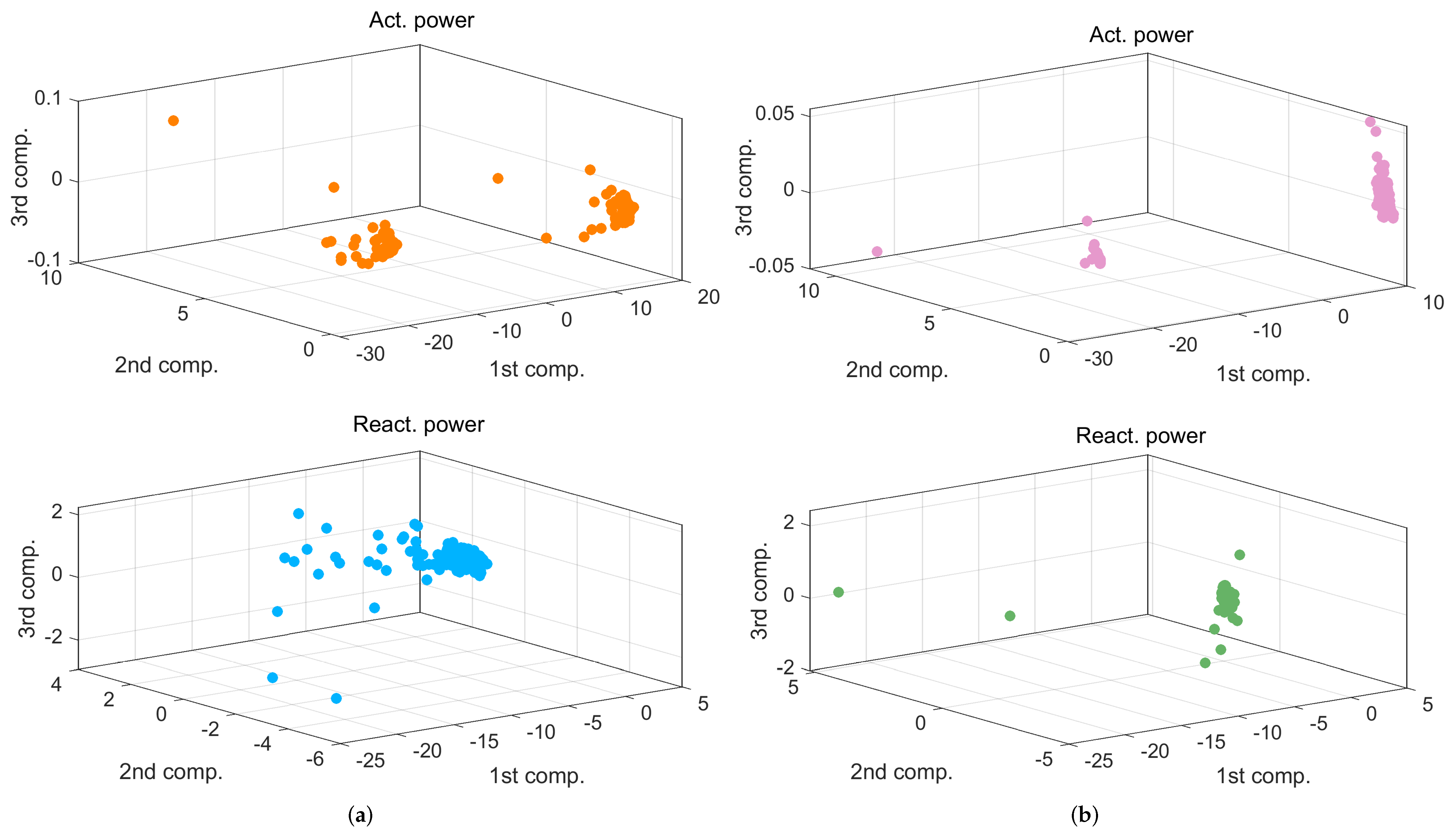
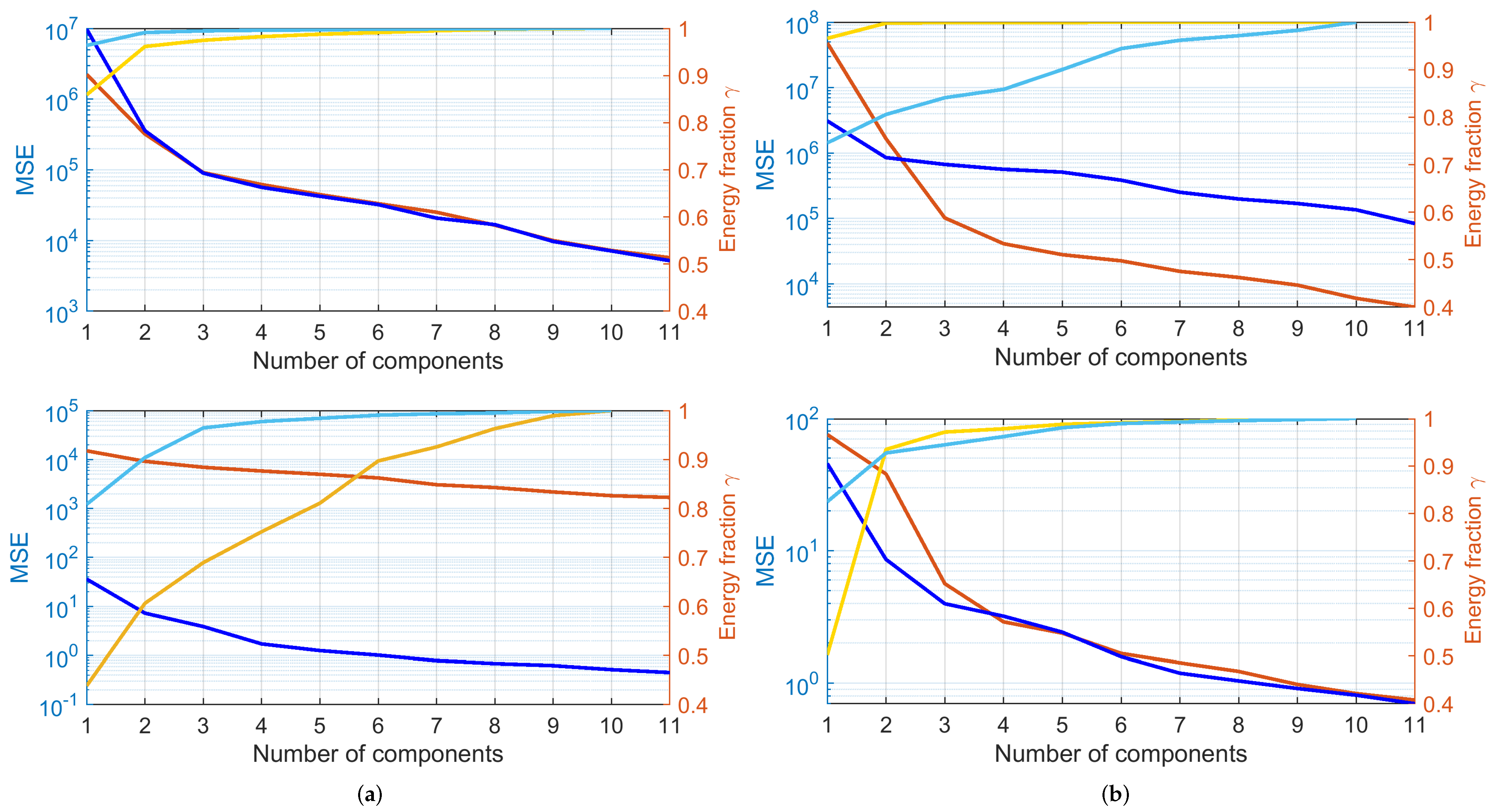
4.2. PCA Analysis and Spectra Regularity
- was described by only one main component, accounting for 99.86% of energy in tractioning and 99.90% in braking; adding the second one indicates 100% within four decimal digits;
- For , the same accuracy is reached with three components (99.88% of energy), but energy increase by adding successive components was much slower; the same performance of within four digits was reached at the 28th and 20th components for tractioning and braking conditions, respectively.
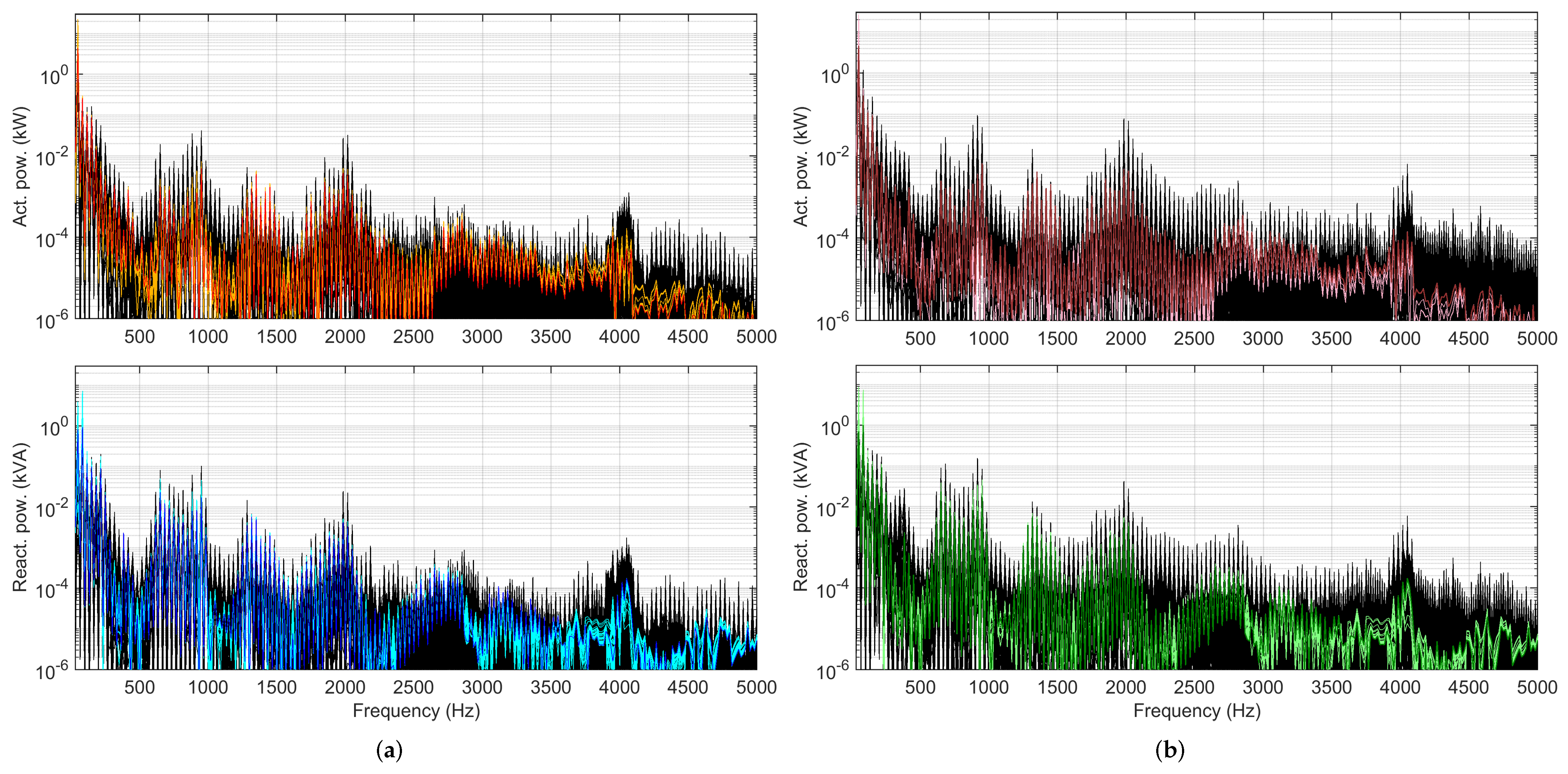
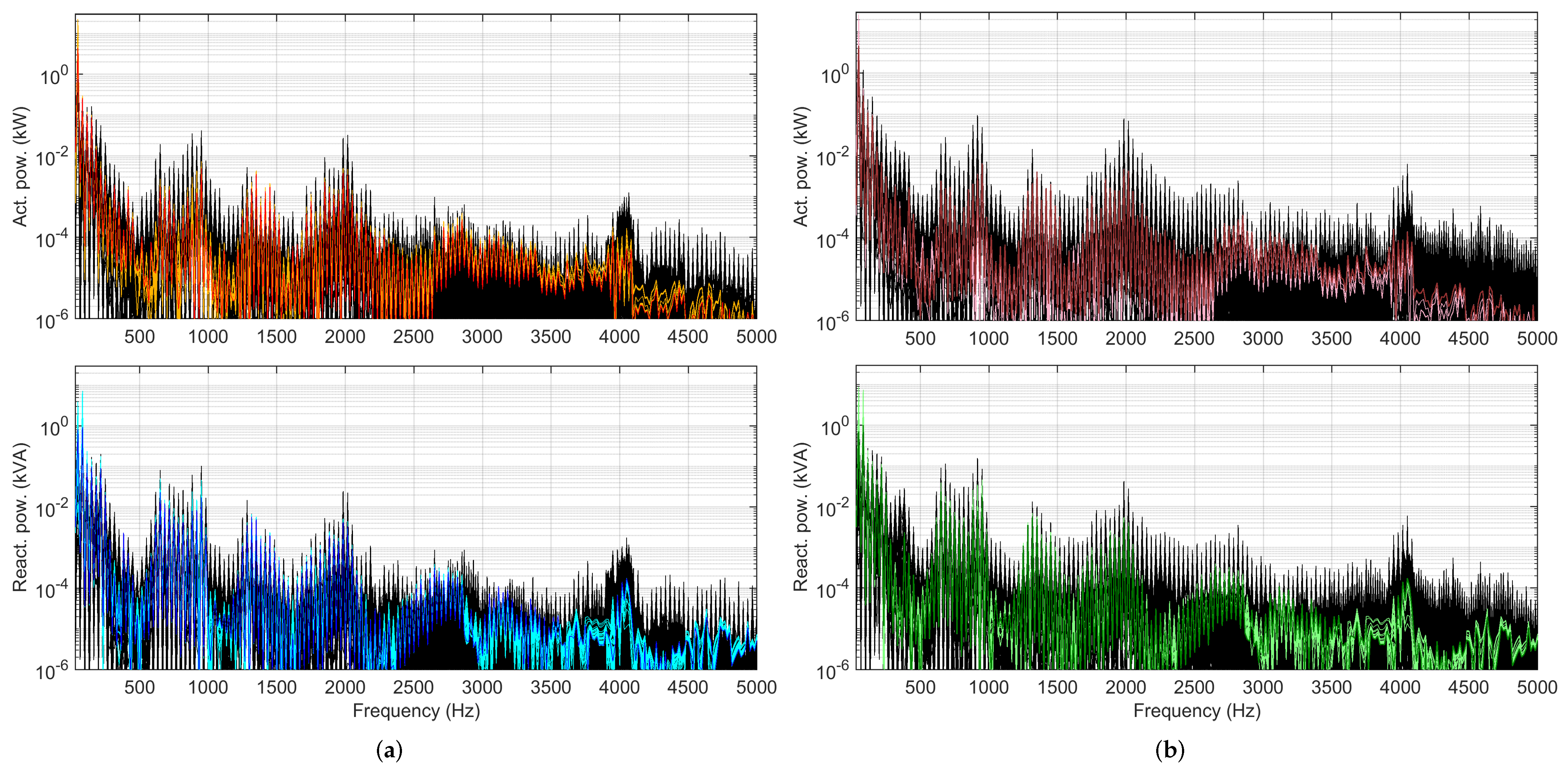
4.3. Selection of Spectral Components as Features
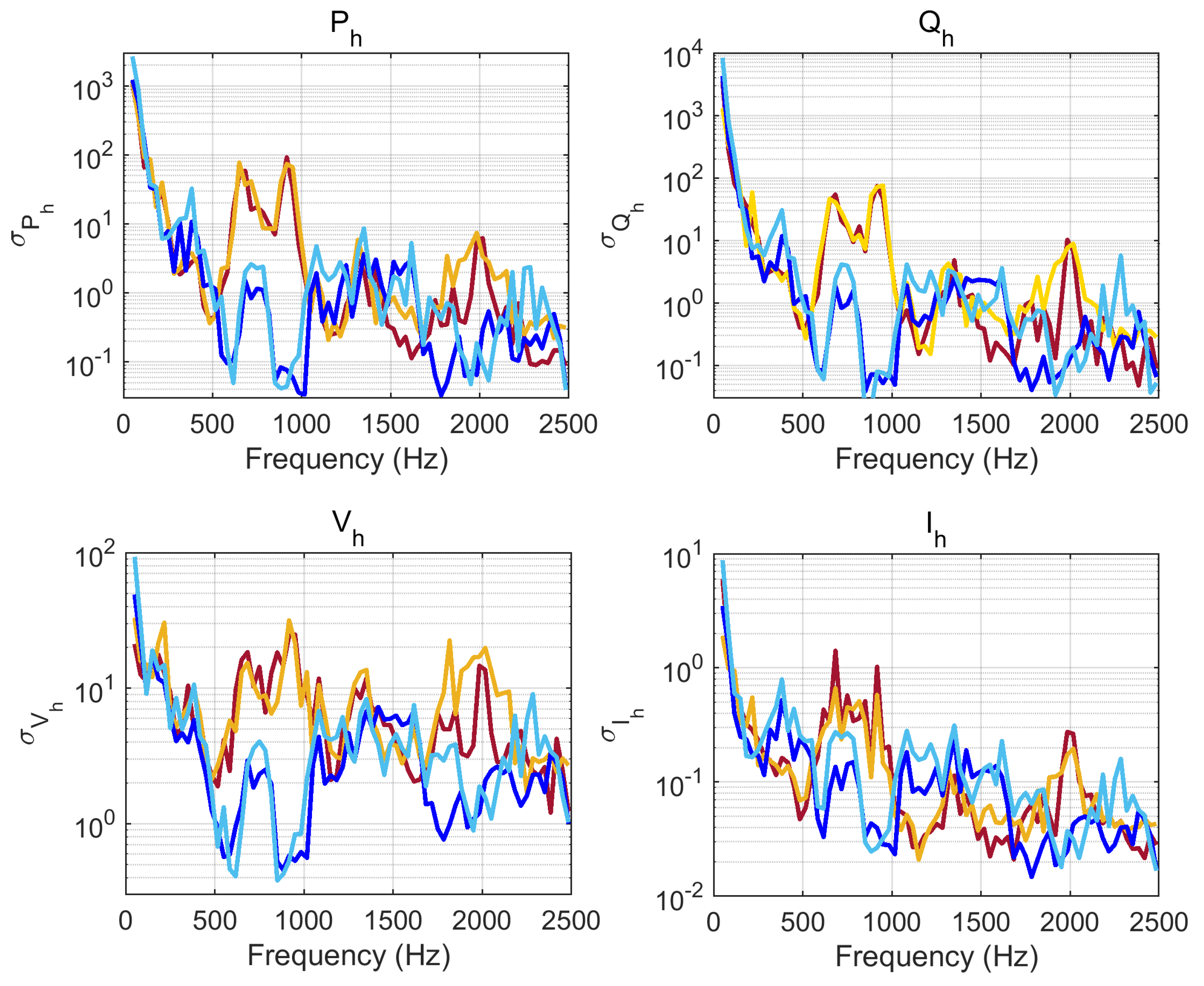
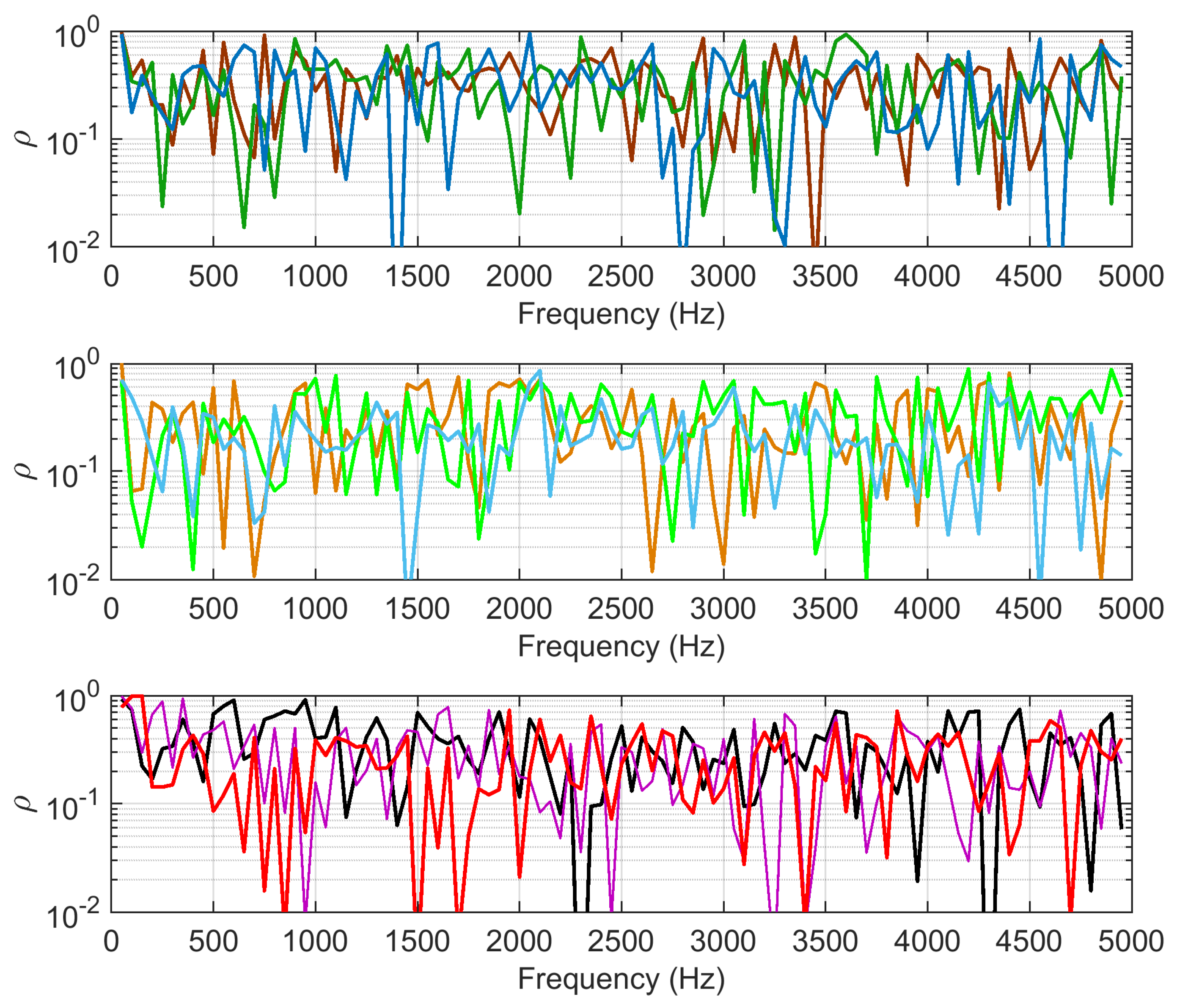
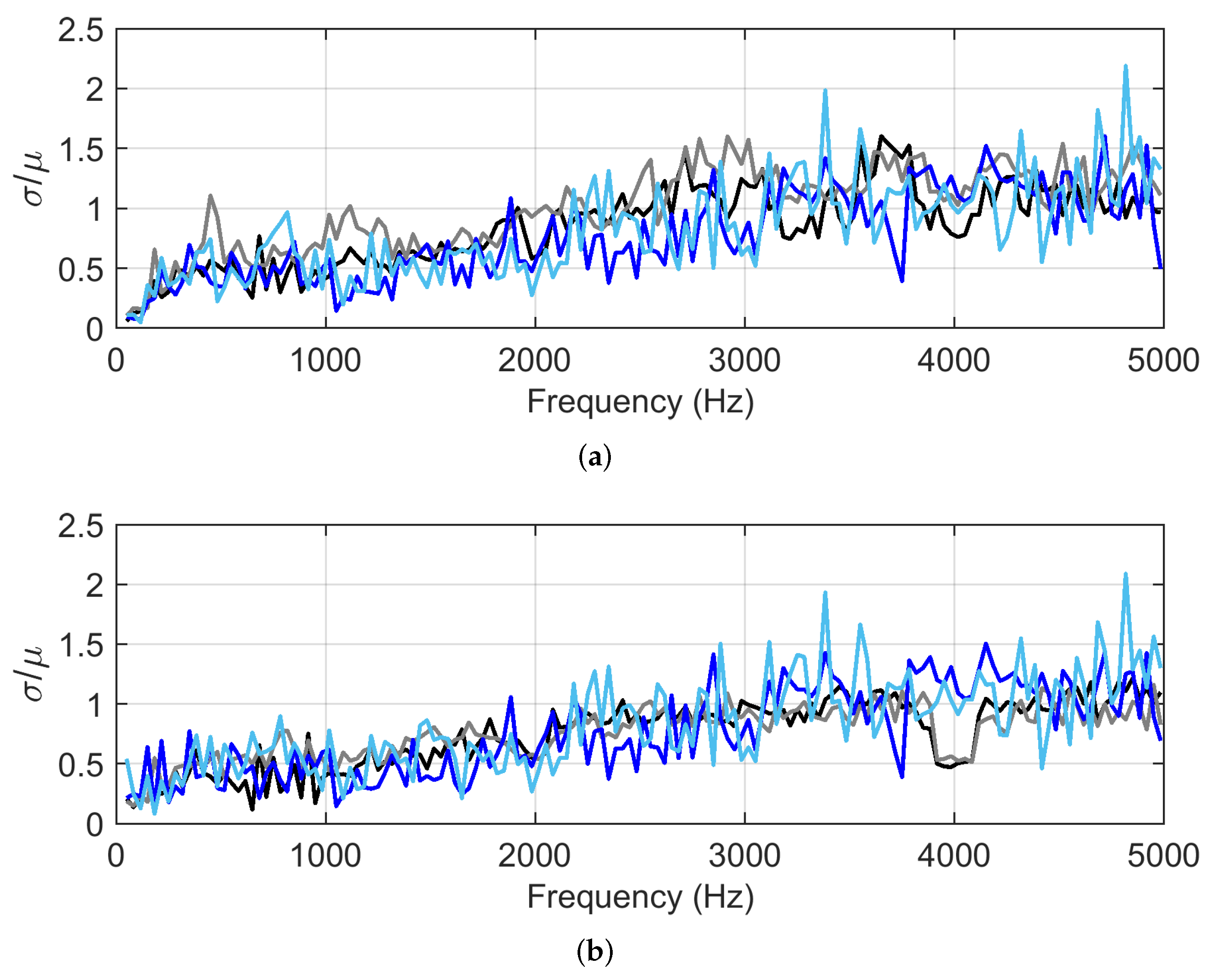
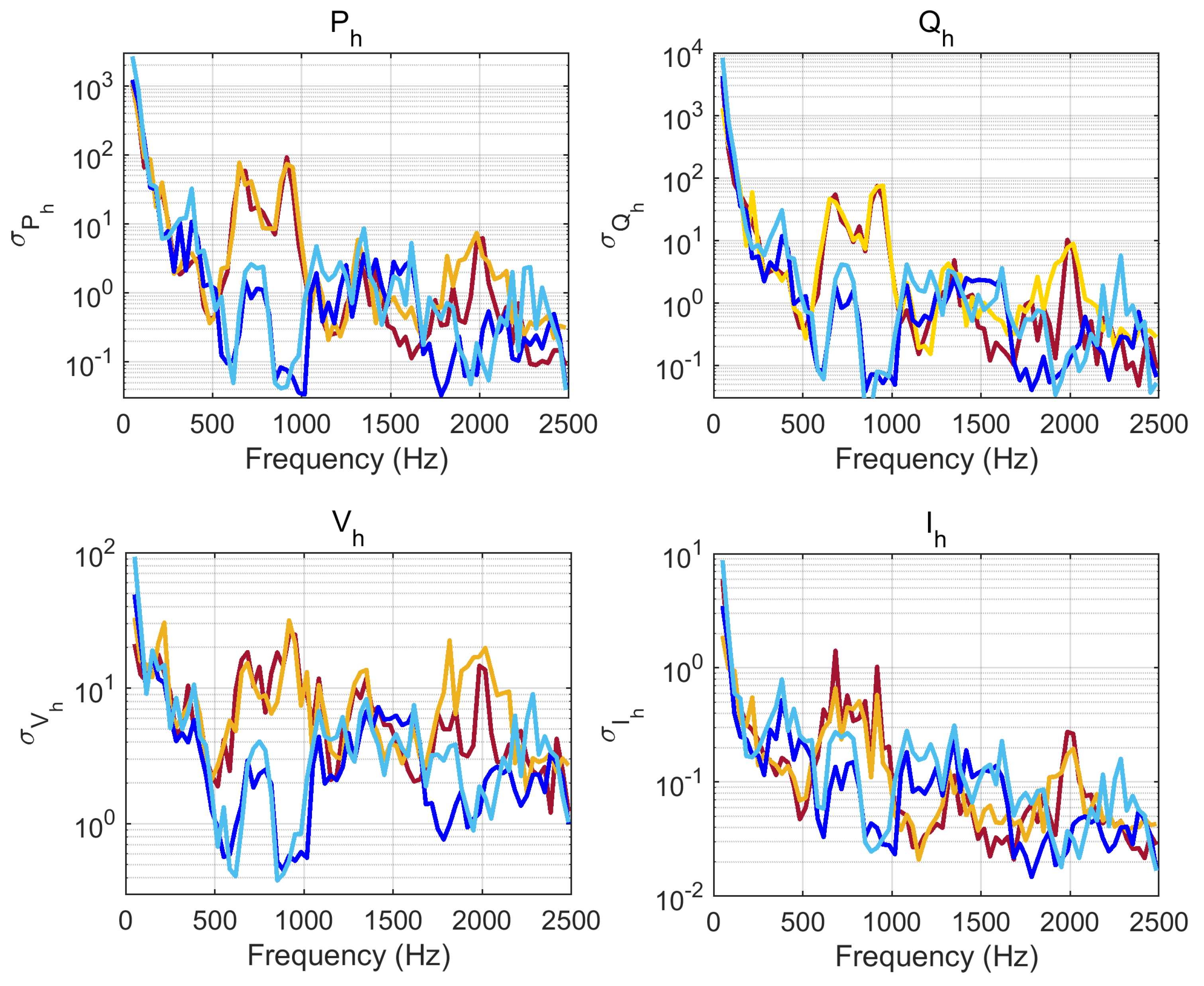
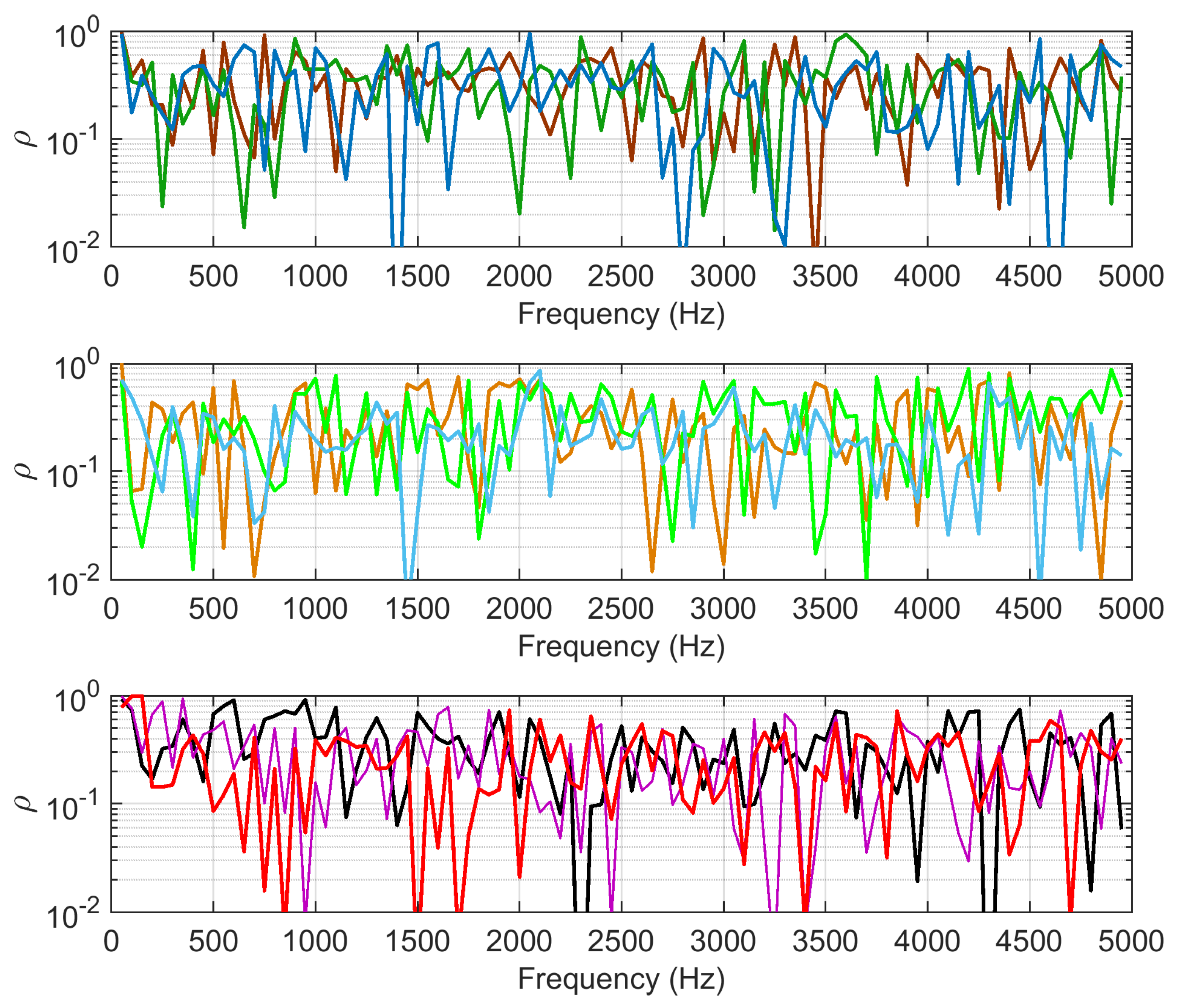
4.3.1. Dispersion and Correlation
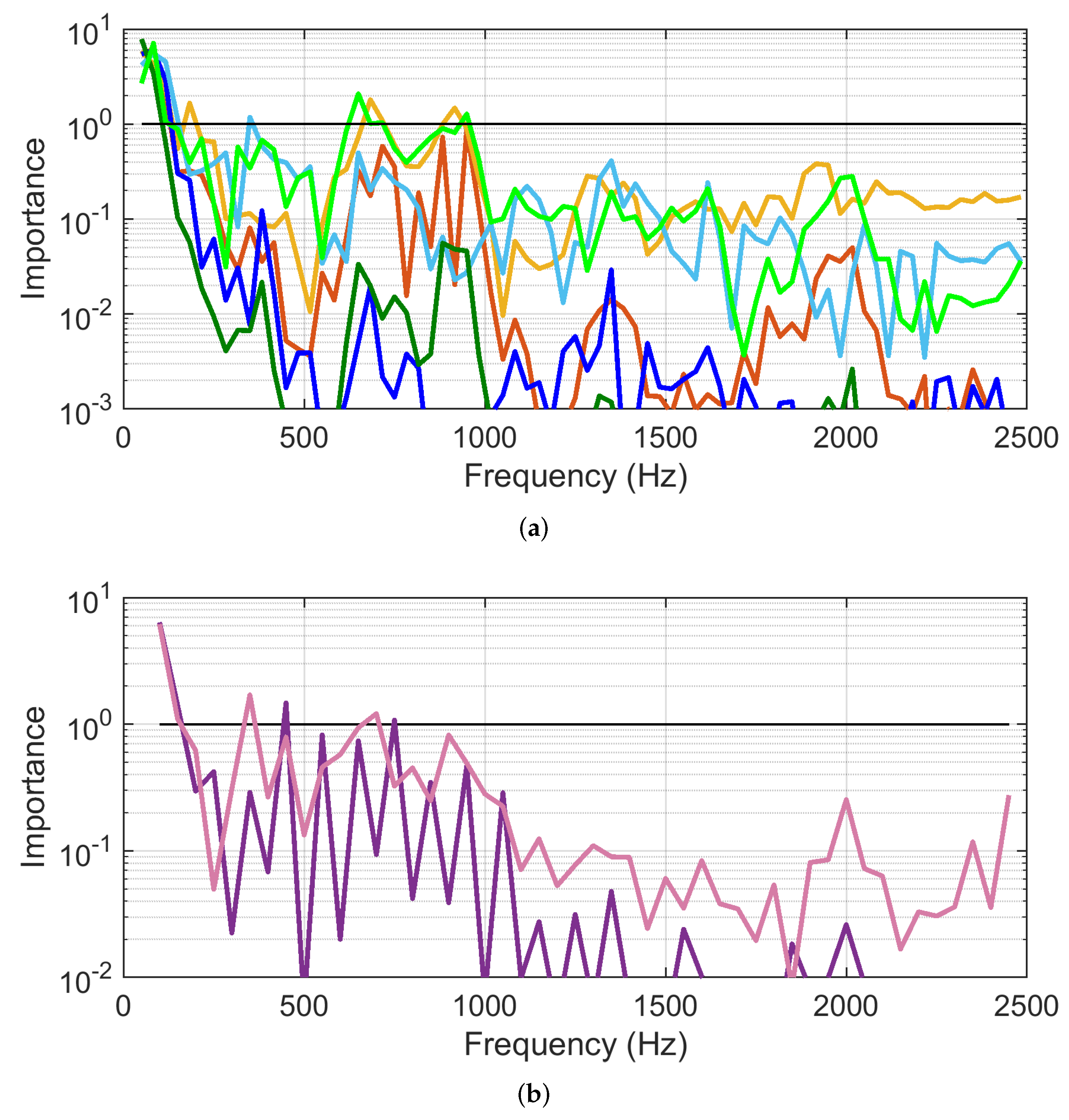
4.3.2. PLSR Analysis
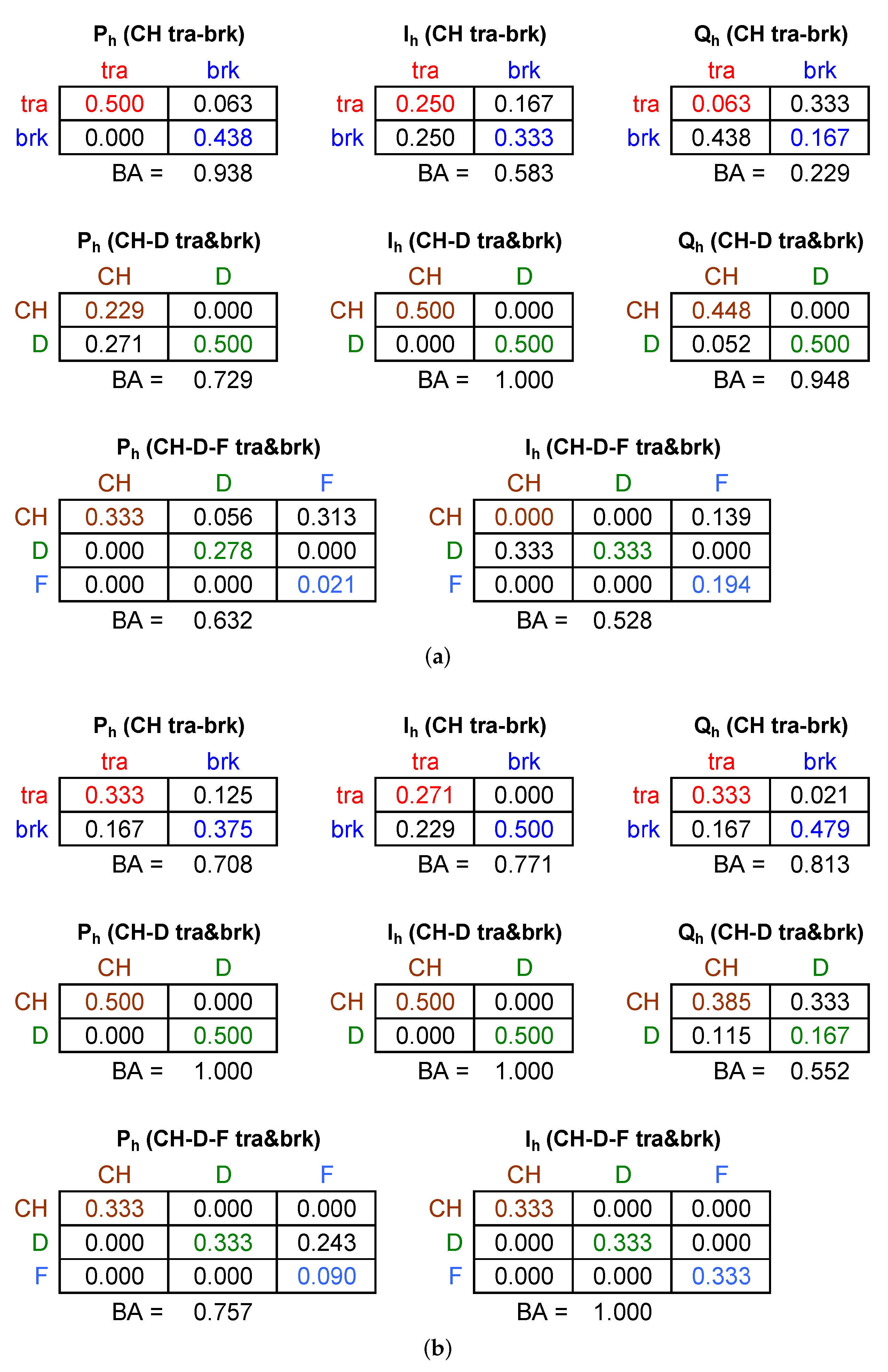
4.4. Classification Performance
- Anticipated and demonstrated by other means, active power and current are the most effective indices; reactive power also has good performance.
- The size of the problem is not an indicator of its complexity, as when systems are different, so their spectral signatures are; for the problem of separation of traction and braking for the same train, we saw the worst performance (the quantities are provided as absolute values, so removing the most relevant, but trivial, piece of information, i.e., the direction of flow).
- The current has a good understandable performance and is the best candidate to carry out NILM at the TPS.
- PLSR has a better performance than PCA, likely due to the dimensionality reduction.
5. Conclusions
- Voltage–current time domain trajectories provided poor performances because in the AC railway context, rolling stock has a strictly regulated displacement factor dictated by standards, so it does not represent a feature bearing relevant information for household NILM.
- Converter emissions are located at low-order harmonics and for more modern rolling stocks at the switching frequency of four-quadrant converters (4QCs), providing a feature-rich pattern of emissions up to about some kHz. For the analyzed case, the relevant frequency range extended up to 1 kHz, but there was evidence of an extraneous emission (explained by the presence of other trains in the same supply section) at 2 kHz, found relevant in one case at 4 kHz.
- Power and current harmonic spectra (, , and ) were analyzed for significance with identification and classification purposes. The used methods spanned simple harmonic component tracking by means of sample dispersion and correlation, as well as principal component analysis (PCA) and partial least squares regression (PLSR) for extraction of more compact/better representations, aimed at clustering techniques.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zoha, A.; Gluhak, A.; Imran, M.; Rajasegarar, S. Non-Intrusive Load Monitoring Approaches for Disaggregated Energy Sensing: A Survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [Green Version]
- Hassan, T.; Javed, F.; Arshad, N. An Empirical Investigation of V-I Trajectory Based Load Signatures for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2014, 5, 870–878. [Google Scholar] [CrossRef] [Green Version]
- Herrero, J.R.; Murciego, Á.L.; Barriuso, A.L.; de la Iglesia, D.H.; González, G.V.; Rodríguez, J.M.C.; Carreira, R. Non Intrusive Load Monitoring (NILM): A State of the Art. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 125–138. [Google Scholar] [CrossRef]
- Alqahtani, A.; Ali, M.; Xie, X.; Jones, M.W. Deep Time-Series Clustering: A Review. Electronics 2021, 10, 3001. [Google Scholar] [CrossRef]
- Hosseini, S.S.; Agbossou, K.; Kelouwani, S.; Cardenas, A. Non-intrusive load monitoring through home energy management systems: A comprehensive review. Renew. Sustain. Energy Rev. 2017, 79, 1266–1274. [Google Scholar] [CrossRef]
- Klemenjak, C.; Kovatsch, C.; Herold, M.; Elmenreich, W. A synthetic energy dataset for non-intrusive load monitoring in households. Sci. Data 2020, 7. [Google Scholar] [CrossRef] [Green Version]
- Raygani, S.; Tahavorgar, A.; Fazel, S.; Moaveni, B. Load flow analysis and future development study for an AC electric railway. IET Electr. Syst. Transp. 2012, 2, 139. [Google Scholar] [CrossRef]
- Mariscotti, A. Results on the power quality of French and Italian 2 × 25 kV 50 Hz railways. In Proceedings of the 2012 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Graz, Austria, 13–16 May 2012; pp. 400–1405. [Google Scholar] [CrossRef]
- Bongiorno, J.; Mariscotti, A. Recent results on the power quality of Italian 2 × 25 kV 50 Hz railways. In Proceedings of the 20th IMEKO TC4 Symposium on Measurements of Electrical Quantities, Benevento, Italy, 15–17 September 2014. [Google Scholar] [CrossRef]
- Gazafrudi, S.M.M.; Langerudy, A.T.; Fuchs, E.F.; Al-Haddad, K. Power Quality Issues in Railway Electrification: A Comprehensive Perspective. IEEE Trans. Ind. Electron. 2015, 62, 3081–3090. [Google Scholar] [CrossRef]
- Kaleybar, H.J.; Brenna, M.; Foiadelli, F.; Fazel, S.S.; Zaninelli, D. Power Quality Phenomena in Electric Railway Power Supply Systems: An Exhaustive Framework and Classification. Energies 2020, 13, 6662. [Google Scholar] [CrossRef]
- Hanafy, A.M.; Hebala, O.M.; Hamad, M.S. Power Quality Issues in Traction Power Systems. In Proceedings of the 2021 22nd International Middle East Power Systems Conference (MEPCON), Luxor City, Egypt, 14–16 December 2021. [Google Scholar] [CrossRef]
- Seferi, Y.; Blair, S.M.; Mester, C.; Stewart, B.G. Power Quality Measurement and Active Harmonic Power in 25 kV 50 Hz AC Railway Systems. Energies 2020, 13, 5698. [Google Scholar] [CrossRef]
- Mariscotti, A. Experimental characterisation of active and non-active harmonic power flow of AC rolling stock and interaction with the supply network. IET Electr. Syst. Transp. 2021, 11, 109–120. [Google Scholar] [CrossRef]
- Lam, H.; Fung, G.; Lee, W. A Novel Method to Construct Taxonomy Electrical Appliances Based on Load Signaturesof. IEEE Trans. Consum. Electron. 2007, 53, 653–660. [Google Scholar] [CrossRef] [Green Version]
- Kosarev, A.P.; Volkov, A.G.; Zinoviev, G.S. Analysis of new multizone rectifier for electric locomotives of V185 type. In Proceedings of the 2010 11th International Conference and Seminar on Micro/Nanotechnologies and Electron Devices, Novosibirsk, Russia, 30 June–4 July 2010. [Google Scholar] [CrossRef]
- Chang, G.; Lin, H.W.; Chen, S.K. Modeling Characteristics of Harmonic Currents Generated by High-Speed Railway Traction Drive Converters. IEEE Trans. Power Deliv. 2004, 19, 766–773. [Google Scholar] [CrossRef]
- Van der Weem, J.; Bolln, H. Measurement and analysis of line interference currents generated by an IGBT four quadrant converter. In Proceedings of the 2005 European Conference on Power Electronics and Applications, Dresden, Germany, 11–14 September 2005. [Google Scholar] [CrossRef]
- He, Z.; Zheng, Z.; Hu, H. Power quality in high-speed railway systems. Int. J. Rail Transp. 2016, 4, 71–97. [Google Scholar] [CrossRef] [Green Version]
- Florio, A.; Mariscotti, A.; Mazzucchelli, M. Voltage Sag Detection Based on Rectified Voltage Processing. IEEE Trans. Power Deliv. 2004, 19, 1962–1967. [Google Scholar] [CrossRef]
- Kamble, S.; Thorat, C. Voltage Sag Characterization in a Distribution Systems: A Case Study. J. Power Energy Eng. 2014, 2, 546–553. [Google Scholar] [CrossRef]
- Santis, M.D.; Noce, C.; Varilone, P.; Verde, P. Analysis of the origin of measured voltage sags in interconnected networks. Electr. Power Syst. Res. 2018, 154, 391–400. [Google Scholar] [CrossRef]
- Liang, J.; Ng, S.K.K.; Kendall, G.; Cheng, J.W.M. Load Signature Study — Part I: Basic Concept, Structure, and Methodology. IEEE Trans. Power Deliv. 2010, 25, 551–560. [Google Scholar] [CrossRef]
- Cardenas, A.; Agbossou, K.; Guzman, C. Development of real-time admittance analysis system for residential load monitoring. In Proceedings of the 2016 IEEE 25th International Symposium on Industrial Electronics (ISIE), Santa Clara, CA, USA, 8–10 June 2016. [Google Scholar] [CrossRef]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM Techniques for Intelligent Home Energy Management and Ambient Assisted Living: A Review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Zhang, J.; Shang, J.; Zhang, Z. Optimization and Control on High Frequency Resonance of Train-Network Coupling Systems. Math. Probl. Eng. 2019, 2019, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Mariscotti, A.; Ruscelli, M.; Vanti, M. Modeling of audiofrequency track circuits for validation, tuning, and conducted interference prediction. IEEE Trans. Intell. Transp. Syst. 2009, 11, 52–60. [Google Scholar] [CrossRef]
- Dolara, A.; Gualdoni, M.; Leva, S. EMC disturbances on track circuits in the 2 × 25 kV high speed AC railways systems. In Proceedings of the 2011 IEEE Trondheim PowerTech, Trondheim, Norway, 19–23 June 2011. [Google Scholar] [CrossRef]
- Mariscotti, A. Induced Voltage Calculation in Electric Traction Systems: Simplified Methods, Screening Factors, and Accuracy. IEEE Trans. Intell. Transp. Syst. 2011, 12, 201–210. [Google Scholar] [CrossRef]
- Milesevic, B.; Haddad, N. Estimation of current through human body in case of contact with pipeline in the vicinity of a 50 Hz electrified railway. In Proceedings of the 2013 International Symposium on Electromagnetic Compatibility, Brugge, Belgium, 2–6 September 2013. [Google Scholar]
- Gao, S.; Li, X.; Ma, X.; Hu, H.; He, Z.; Yang, J. Measurement-Based Compartmental Modeling of Harmonic Sources in Traction Power-Supply System. IEEE Trans. Power Deliv. 2017, 32, 900–909. [Google Scholar] [CrossRef]
- Yang, R.; Zhou, F.; Zhong, K. A Harmonic Impedance Identification Method of Traction Network Based on Data Evolution Mechanism. Energies 2020, 13, 1904. [Google Scholar] [CrossRef] [Green Version]
- Mariscotti, A.; Sandrolini, L. Detection of harmonic overvoltage and resonance in AC railways using measured pantograph electrical quantities. Energies 2021, 14, 5645. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Z.; Lin, F.; Cao, J. Harmonic Loss Analysis of the Traction Transformer of High-Speed Trains Considering Pantograph-OCS Electrical Contact Properties. Energies 2013, 6, 5826–5846. [Google Scholar] [CrossRef] [Green Version]
- EN 50463-2; Railway Applications—Energy Measurement on Board Trains. Technical report; CENELEC: Brussels, Belgium, 2017.
- Mariscotti, A. Impact of Harmonic Power Terms on the Energy Measurement in AC Railways. IEEE Trans. Instrum. Meas. 2020, 69, 6731–6738. [Google Scholar] [CrossRef]
- Giordano, D.; Clarkson, P.; Gamacho, F.; van den Brom, H.; Donadio, L.; Fernandez-Cardador, A.; Spalvieri, C.; Gallo, D.; Istrate, D.; Laporte, A.D.S.; et al. Accurate Measurements of Energy, Efficiency and Power Quality in the Electric Railway System. In Proceedings of the 2018 Conference on Precision Electromagnetic Measurements (CPEM 2018), Paris, France, 8–13 July 2018. [Google Scholar] [CrossRef]
- Hasegawa, D.; Nicholson, G.L.; Roberts, C.; Schmid, F. Standardised approach to energy consumption calculations for high-speed rail. IET Electr. Syst. Transp. 2016, 6, 179–189. [Google Scholar] [CrossRef]
- Hemmer, B.; Mariscotti, A.; Wuergler, D. Recommendations for the calculation of the total disturbing return current from electric traction vehicles. IEEE Trans. Power Deliv. 2004, 19, 1190–1197. [Google Scholar] [CrossRef]
- IEEE Std. 1459; IEEE Standard Definitions for the Measurement of Electric Power Quantities Under Sinusoidal, Nonsinusoidal, Balanced, or Unbalanced Conditions. IEEE: Piscataway, NJ, USA, 2010.
- Mariscotti, A. Behavior of single-point harmonic producer indicators in electrified ac railways. Metrol. Meas. Syst. 2020, 27, 641–657. [Google Scholar] [CrossRef]
- Tenti, P.; Mattavelli, P. A Time-Domain Approach to Power Term Definitions under Non-Sinusoidal Conditions. In Proceedings of the Sixth International Workshop on Power Definitions and Measurements under Non-Sinusoidal Conditions, Milano, Italy, 13–15 October 2003. [Google Scholar]
- Mariscotti, A. Harmonic and Supraharmonic Emissions of Plug-In Electric Vehicle Chargers. Smart Cities 2022, 5, 496–521. [Google Scholar] [CrossRef]
- EN 50388; Railway Applications—Power Supply and Rolling Stock—Technical Criteria for the Coordination between Power Supply (Substation) and Rolling Stock to Achieve Interoperability. Technical report; CENELEC: Brussels, Belgium, 2012.
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H. Encyclopedia of Social Sciences Research Methods; Chapter Partial Least Squares (PLS) Regression; Sage: Newbury Park, CA, USA, 2003. [Google Scholar]
- De Jong, S. SIMPLS: An alternative approach to partial least squares regression. Chemom. Intell. Lab. Syst. 1993, 18, 251–263. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-Based Learning Algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Mariscotti, A. Data sets of measured pantograph voltage and current of European AC railways. Data Brief 2020, 30, 105477. [Google Scholar] [CrossRef] [PubMed]
- Mariscotti, A. Direct measurement of power quality over railway networks with results of a 16.7-Hz network. IEEE Trans. Instrum. Meas. 2010, 60, 1604–1612. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Irms (A) | A (MVA) | Vmin (kV) | Vmax (kV) | Imin (A) | Imax (A) | (mS) | (mS) |
|---|---|---|---|---|---|---|---|---|
| Tra1 | 24.3 | 0.0593 | 21.10 | −20.58 | 54.49 | −54.65 | 2.62 | 1.72 |
| Tra2 | 53.6 | 0.5680 | 21.18 | −20.68 | 101.84 | −100.02 | 4.82 | 3.87 |
| Tra3 | 83.9 | 0.8287 | 21.10 | −20.45 | 138.05 | −138.36 | 6.65 | 6.18 |
| Tra4 | 122.0 | 1.4746 | 20.93 | −20.44 | 187.60 | −188.12 | 9.08 | 8.65 |
| Tra5 | 165.4 | 2.3639 | 20.89 | −20.40 | 258.55 | −258.08 | 12.51 | 13.14 |
| Tra6 | 240.4 | 3.5886 | 21.03 | −20.50 | 362.53 | −369.02 | 17.61 | 18.30 |
| Tra7 | 328.8 | 5.1505 | 20.88 | −20.63 | 495.86 | −497.66 | 23.93 | 24.83 |
| Tra8 | 412.5 | 5.7500 | 20.61 | −20.07 | 613.71 | −610.52 | 30.09 | 30.55 |
| Brk1 | 21.3 | 0.1114 | 21.21 | −20.60 | 54.64 | −49.79 | −2.50 | 0.42 |
| Brk2 | 52.5 | 0.4189 | 21.13 | −20.72 | 85.70 | −78.10 | −3.90 | −1.77 |
| Brk3 | 72.9 | 0.7821 | 21.47 | −20.90 | 108.38 | −106.42 | −5.07 | −3.49 |
| Brk4 | 96.2 | 1.0762 | 21.14 | −20.77 | 141.41 | −142.27 | −6.76 | −5.09 |
| Brk5 | 144.1 | 2.2006 | 21.45 | −21.10 | 204.76 | −202.55 | −9.57 | −8.29 |
| Brk6 | 202.4 | 3.2431 | 21.63 | −21.03 | 295.41 | −296.26 | −13.87 | −13.14 |
| Brk7 | 262.8 | 3.8325 | 21.47 | −20.94 | 368.65 | −367.51 | −17.36 | −18.15 |
| Brk8 | 311.8 | 4.6487 | 21.31 | −20.82 | 443.19 | −437.03 | −20.90 | −22.02 |
| Case | Irms (A) | A (MVA) | Vmin (kV) | Vmax (kV) | Imin (A) | Imax (A) | (mS) | (mS) |
|---|---|---|---|---|---|---|---|---|
| Tra1 | 23.3 | 0.8209 | 23.44 | −23.27 | 53.49 | −53.06 | 2.28 | 1.11 |
| Tra2 | 44.8 | 0.8197 | 23.23 | −23.03 | 68.14 | −70.73 | 3.00 | 5.09 |
| Tra3 | 79.0 | 1.1113 | 23.23 | −23.06 | 113.60 | −115.47 | 4.95 | 8.76 |
| Tra4 | 116.9 | 1.0105 | 22.45 | −22.98 | 165.39 | −165.60 | 7.29 | 11.18 |
| Tra5 | 148.6 | 0.7708 | 23.07 | −22.86 | 197.81 | −202.32 | 8.71 | 12.61 |
| Tra6 | 174.6 | 1.0620 | 23.26 | −23.04 | 234.60 | −232.98 | 10.10 | 14.64 |
| Tra7 | 214.2 | 1.9642 | 23.41 | −23.19 | 291.60 | −293.99 | 12.57 | 18.04 |
| Tra8 | 238.7 | 1.7447 | 23.05 | −22.76 | 332.51 | −329.66 | 14.46 | 19.06 |
| Brk1 | 19.3 | 0.3256 | 23.06 | −23.20 | 37.95 | −38.42 | −1.65 | −0.58 |
| Brk2 | 45.3 | 0.6861 | 22.05 | −22.22 | 72.43 | −73.92 | −3.30 | −2.28 |
| Brk3 | 73.9 | 0.1791 | 22.94 | −22.75 | 117.07 | −117.15 | −5.13 | −5.38 |
| Brk4 | 109.1 | 0.1381 | 22.30 | −22.07 | 168.13 | −168.98 | −7.60 | −6.73 |
| Brk5 | 145.1 | 0.6629 | 22.87 | −22.72 | 229.39 | −228.16 | −10.03 | −11.18 |
| Brk6 | 206.0 | 0.7705 | 22.99 | −24.00 | 308.06 | −310.56 | −13.42 | −14.68 |
| Brk7 | 278.3 | 1.3882 | 22.15 | −21.97 | 422.08 | −417.77 | −19.04 | −18.97 |
| Brk8 | 330.1 | 1.6285 | 23.00 | −22.87 | 474.03 | −469.78 | −20.58 | −24.38 |
| Case | Irms (A) | A (MVA) | Vmin (kV) | Vmax (kV) | Imin (A) | Imax (A) | (mS) | (mS) |
|---|---|---|---|---|---|---|---|---|
| Tra1 | 27.4 | 3.4812 | 36.31 | −35.92 | 37.16 | −44.37 | 1.13 | 0.52 |
| Tra2 | 61.1 | 4.0156 | 35.72 | −35.34 | 87.62 | −93.28 | 2.55 | 2.06 |
| Tra3 | 102.6 | 4.0501 | 35.76 | −35.33 | 149.11 | −154.93 | 4.28 | 3.87 |
| Tra4 | 164.7 | 4.3928 | 35.70 | −35.19 | 241.20 | −245.99 | 6.87 | 6.53 |
| Tra5 | 216.7 | 4.7573 | 35.95 | −35.75 | 304.73 | −309.54 | 8.57 | 8.55 |
| Tra6 | 282.7 | 6.1352 | 36.00 | −35.17 | 401.04 | −405.61 | 11.33 | 10.90 |
| Tra7 | 403.7 | 8.2298 | 34.84 | −34.22 | 574.20 | −578.20 | 16.69 | 16.12 |
| Tra8 | 460.0 | 8.6922 | 35.82 | −35.44 | 657.54 | −662.02 | 18.5 | 17.67 |
| Brk1 | 21.9 | 3.4022 | 38.52 | −37.95 | 37.49 | −42.26 | −1.04 | 0.11 |
| Brk2 | 63.4 | 3.5954 | 37.29 | −36.88 | 89.07 | −95.23 | −2.48 | −2.45 |
| Brk3 | 122.5 | 4.3329 | 35.75 | −35.02 | 188.67 | −196.15 | −5.44 | −5.27 |
| Brk4 | 156.6 | 3.8601 | 34.90 | −34.69 | 219.77 | −228.41 | −6.44 | −6.24 |
| Brk5 | 197.0 | 4.3599 | 35.60 | −35.28 | 284.69 | −290.28 | −8.11 | −8.08 |
| Brk6 | 253.1 | 5.1692 | 35.41 | −35.20 | 359.28 | −364.93 | −10.26 | −9.60 |
| Brk7 | 303.0 | 7.2288 | 35.56 | −35.68 | 430.61 | −436.41 | −12.17 | −11.04 |
| Brk8 | 347.5 | 9.4055 | 34.92 | −34.77 | 494.98 | −500.58 | −14.29 | −13.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariscotti, A. Non-Intrusive Load Monitoring Applied to AC Railways. Energies 2022, 15, 4141. https://doi.org/10.3390/en15114141
Mariscotti A. Non-Intrusive Load Monitoring Applied to AC Railways. Energies. 2022; 15(11):4141. https://doi.org/10.3390/en15114141
Chicago/Turabian StyleMariscotti, Andrea. 2022. "Non-Intrusive Load Monitoring Applied to AC Railways" Energies 15, no. 11: 4141. https://doi.org/10.3390/en15114141
APA StyleMariscotti, A. (2022). Non-Intrusive Load Monitoring Applied to AC Railways. Energies, 15(11), 4141. https://doi.org/10.3390/en15114141