1. Introduction
A frequently used clinical trial design is to directly compare a new treatment against a standard therapeutic compound. However, many years may have passed since the standard compound was originally approved. During this time, variations in the disease process, manufacturing changes, or practice deviations may have occurred, such that the standard treatment is no longer efficacious, or is effective to a much lesser degree than originally marketed.
Observing a statistically significant absolute effect (risk) reduction (i.e., the standard minus new therapy event rate) may not necessarily prove the clinical usefulness of the new treatment unless the clinical trial design includes a common comparison group as a referent-control. This contrast allows for the side-by-side evaluation of the new and standard agents in the context of relative effect reduction on the log-difference scale. Importantly, the use of a shared referent-control arm minimizes bias and threats to internal validity compared with assessing the absolute risk difference.
Power and sample size are important components in the planning of a clinical trial. However, the literature is largely silent on the topic of a conditionally independent shared comparison arm when assessing risk reduction on the log-difference, relative effect scale.
2. Preliminaries
2.1. Conditionally Independent, Large-Sample Distribution
Consider a test to compare two relative effect estimates (REEs), denoted as on the log-difference scale, with respect to a common referent-control group. Approximate log-normally distributed REEs include relative risks (RR), odds ratios (OR), and hazard ratios (HR). A variance-stabilizing, logarithmic transformation tends to make the difference of REEs closer to a normal distribution by reducing any potential relationship between the variance and mean. The application of this transformation is especially useful when dealing with probabilities near 0 or 1.
Assuming that (a) the standard error (
) for the logarithm of
does not differ considerably from that for
, (b) corresponding sample sizes
are reasonably large, (c)
and
with a common referent-control arm are asymptotically consistent, but not necessarily unbiased, estimates of the true parameters, and (d) the large-sample distribution for the logarithm of
is approximately Gaussian, with estimated event rates for both groups not being too close to 0 or 1, it follows from the Le Cam–Lévy–Ferguson “Conditional Martingale Limit Theorem” that we obtain the following equation:
where
represents the expectation, and
is the standard normal distribution [
1]. The single tilde, “~”, indicates asymptotic equivalence of the same magnitude, under the assumption that the underlying Martingale processes are stationary, ergodic, and F-measurable [
2], with finite variance.
The cumulative distribution function for divided by that for a standard normal curve approaches unity for large sample sizes. Under asymptotic regularity conditions, is conditionally independent of , given a common referent-control group. That is, the probability (A) for an observation in the numerator of is not affected by the probability (B) for an observation in the numerator of given the probability (C) for a shared observation in the denominators of Mathematically stated, it follows that (⫫ is equivalent to (⫫
The denominator of the limit described above, denoted as
yields the square root of the sample variance estimate of
which may be approximated as follows [
3]:
2.2. Confidence Interval Method for Estimating the Sample Variance
Lower and upper
–level confidence intervals (CIs) for the indicated REEs are given as
and
. That is, for
we obtain the following expression:
where
refers to the probability of rejecting the null hypothesis when it is true, and
corresponds to the
percentile of
[e.g.,
]. Using the above bounds and rearranging, it readily follows that we obtain the following equation:
2.3. Alternative Computational Formula for
Let
denote the
cell sizes for a contingency table with corresponding probabilities of
. Here, the row exposures and column outcomes are indexed by
and
The relative risk estimate
also known as the risk ratio, is defined as follows:
where
and
follow a binomial distribution. By applying the delta method (Taylor series approximation for large sample sizes), we obtain the following equations:
Accordingly, we obtain the following equation:
The advantage of this direct formula is the increased computational speed gained by foregoing the CI method for estimating . In the case of ORs and HRs, one can derive similar computational approximations using the delta method.
2.4. Percentage Relative Effect (Risk) Reduction
When , the percentage relative effect reduction is computed as and vice versa when i.e., If , a null result is obtained for the For example, if and , then = .
2.5. Null Hypothesis and p-Value
In the case of a null hypothesis (H
0),
are deemed to be equal, versus the alterative scenario in which they differ [
3]. That is, H
0:
which is equivalent to a null
compared with H
1:
In the case of (H
0), both
equal zero.
A
p-value for the log-difference of two REEs is estimated as follows:
where
and
2.6. Confidence Interval Decision Criteria
The disjoint CI percentage corresponding to an equivalent
-level test is computed as follows:
This yields slightly wider regions to compensate for the pooled (versus non-pooled) sample variance [
4]. For example, given that
= 0.01, 0.05, and 0.10, the difference between the estimates
is declared as statistically significant if the 93.1452%, 83.4224%, and 75.5206% CIs for
do not overlap.
Analogously, the difference between the estimates
may be declared as statistically significant when the following equation excludes unity:
3. Power and Sample Size
3.1. Power
The power of a study indicates how frequently a statistical test will detect the falsehood of an underlying null hypothesis when it is false (i.e.,
. Let
denote the probability of failing to reject the null the hypothesis when it is false (i.e.,
). It follows that we obtain the following equation:
The area to the left of under a standard normal distribution yields the desired power at the -level of statistical significance for a two-sided test. When use of a one-tailed test is desired, , rather than , is used in this formula.
3.2. Sample Size and Variability
The confidence interval method may be used to approximate the standard error for the logarithm of the respective relative effect estimates () corresponding to an initial rxc (row by column) = (n) contingency table, where (n) denotes the total sample size (i.e., combined rows). Cell frequencies of the pilot sample table are increased multiplicatively (in an iterative fashion) to obtain the corresponding standard errors for different sample sizes and corresponding power.
Using this method, it is important that the initial 3 × 2 contingency table be sufficiently large to accurately estimate the sample variability within a specified fraction of the population variance [
5]. As a rule of thumb, the proportional width of the α-level CI for the population variance of a continuous variable is defined as follows:
This value should be as large as the sample variance, where is the percentile of the chi-squared distribution with degrees of freedom. When α = 0.05, this corresponds to a minimum sample size of 38. However, in practice, a more conservative sample size of 90 (30 per treatment row) is typically chosen as the starting point to account for the binary outcomes.
3.3. Simulation of Observations from a Multinomial Distribution
Given (n) distinct trials, the probability that a mutually exclusive set of (
) non-negative random variates (
) takes on a particular value (
) is given as follows:
where
This probability is known as a multinomial distribution because of the following expression:
where the latter is a multinomial series.
The multinomial distribution, as illustrated in Example 2, plays an important role in validating the asymptotic normality of the conditional test statistic.
4. Computational Methods
Analyses were performed and validated in SAS 9.4 (Cary, NC).
5. Example 1—Comparison of Potassium and Sodium Salts
Potassium salt substitutes can be helpful for lowering sodium intake and controlling high blood pressure. Among a cohort of borderline hypertensive (but otherwise healthy) patients, a team of clinical epidemiologists aimed to determine if randomization to a potassium salt substitute (1500 mg/d) reduces the 24-month risk of major adverse cardiovascular outcomes and non-cancer death compared with a formulary of sodium salt (1500 mg/d), with a common referent-control arm of 2300 mg/d sodium salt.
In a 1:1:1 pilot clinical trial, a 9.52% relative effect (risk) reduction on the log-difference scale was observed at 24 months post-randomization (
Table 1). Based on this promising result, the team decided to conduct a larger population-based phase III clinical trial. To achieve at least 80% power for a similar %RLD (discounting dropouts), the new pivotal trial would need to randomize 36,835 patients per study arm at the α = 0.05 level of statistical significance (
Table 2; see
Appendix A for SAS code).
6. Example 2—Monte Carlo Simulation of the Conditional Martingale Limit Theorem
While a theoretical basis exists for the asymptotic normality and conditional independence of the test statistic [
1,
2], Monte Carlo methods can be used to validate the large- sample properties of this method.
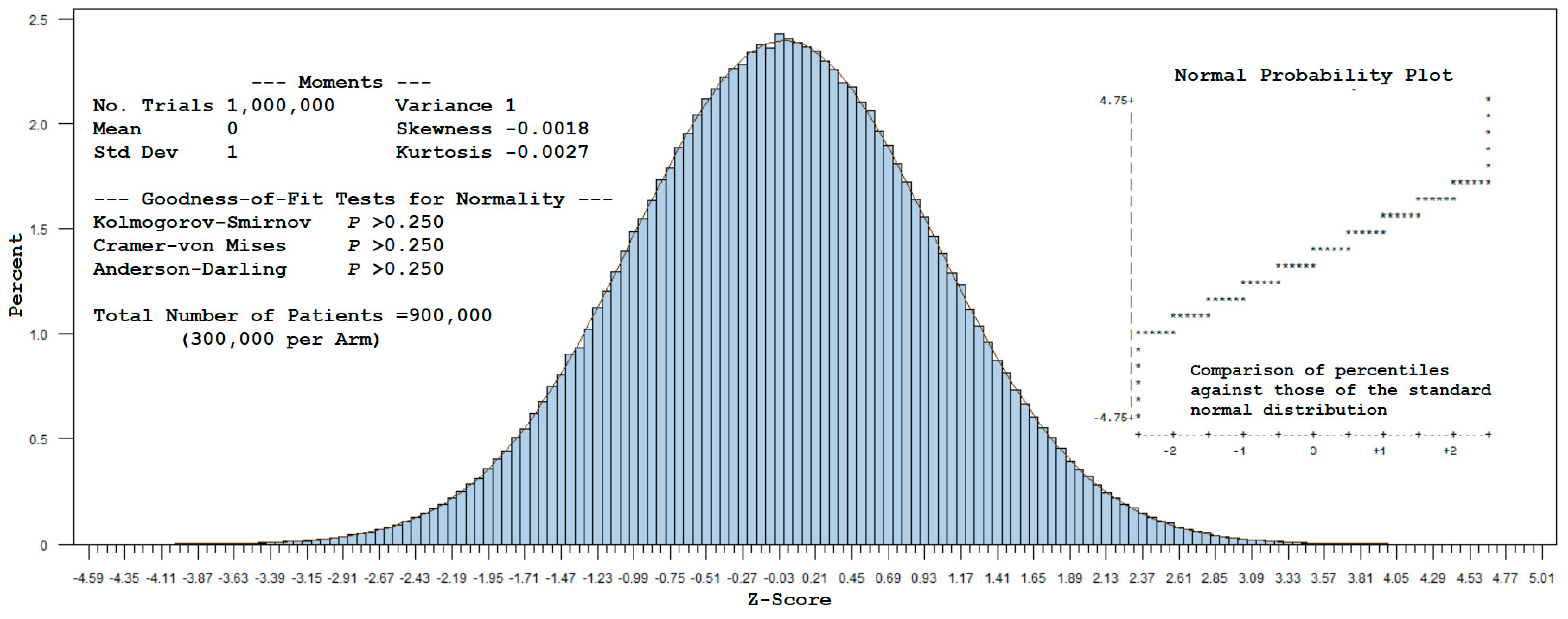
A total of 1,000,000 trials, repeated for each sample of 900,000 patients (300,000 per arm), were drawn from a multinomial distribution using the cell probabilities given in Example 1 (with
T0 denoting the common referent-control group). A standardized value was computed for each simulated observation for
by subtracting
from this estimate and dividing it by
. Plotting these values as a histogram yields
Figure 1. The corresponding statistics (mean = 0, standard deviation = 1, and approximate zero values for skewness and kurtosis) indicate that the z-scores follow a standard normal distribution, as visually confirmed by the Normal (0,1) curve overlay. Furthermore, normality was not rejected by the Kolmogorov–Smirnov, Cramer–von Mises, or Anderson–Darling tests (see
Appendix B for SAS code).
For large samples, this example supports the use of normal-theory methods to estimate power for a 1:1:1 randomized design with a common referent-control arm. In effect, the covariance of can be disregarded as the sample size increases toward infinity, allowing one to assume an independent, identically distributed (i.i.d.) standard normal test statistic.
7. Discussion
7.1. Overview
The comparison of two drugs with respect to a common comparator (referent-control) group is a powerful and efficient approach for conducting a clinical trial. Importantly, this method preserves the randomization of the originally assigned patient groups [
6]. Additionally, it allows for determining risk reduction on the log-difference scale. The current manuscript presents a novel, computer-based technique for estimating the power of the latter by multiplicatively increasing the cell sizes of an initial pilot sample. This yields the inflated variances needed to compute power for larger sample sizes while still allowing the use of traditional normal-theory methods. As reasoned below, the common referent-control design does not require multiplicity adjustment.
7.2. Multiplicity Adjustment
The family-wise type I error rate, which is the probability of at least one false positive test among all hypotheses being tested, is not increased with respect to a common referent-control group [
7]. The associated false positive comparison-wise error rate at the individual level is also not inflated, as the “expected proportion of incorrectly rejected hypotheses will not exceed the significance level used in the individual tests” [
7,
8].
While a treatment is the “family” over which one typically judges the need for multiplicity, there is indistinctness regarding how this entity is defined. Multiplicity control is not required if the underlying therapies have distinct mechanisms of action [
9]. That is, “if each decision to reject each individual null hypothesis depends on no more than one significance test, then none of the individual tests constitute a family”, such that an
-level adjustment for any single hypothesis is unnecessary (except if one performs “disjunction testing of a joint intersection null hypothesis”) [
10]. While cases exist wherein “the decision on the omnibus null will seem to contradict decisions on individual nulls”, it is important to remember that “rejecting or not rejecting a null is not certain proof that the null is false or true” [
10]. Therefore, multiplicity correction for CIs) is needed when the omnibus null can only be evaluated through “a set of surrogate nulls” and cannot be “generalized to testing any diversity of unconnected nulls over the course of a study” [
11].
Adjustment is counterintuitive in the case of conjunctive (intersection–union) testing, in which all tests must be significant for the joint null hypothesis to be rejected [
9]. However, multiplicity adjustment for CIs is advisable if the comparative therapies are related, as is the case when evaluating “different dosages or regimens of a treatment compared with the same control arm” [
12]. This includes trials with collective conditions “if there are no less than two primary hypotheses, unless one assumes that there is an explicit hierarchy in the multiple hypotheses” [
12].
Multiplicity adjustment of CIs in the denominator of a relative-effects (log-difference) test of two compounds is generally not performed in practice, as this is equivalent to a stand-alone interaction test with a pooled variance structure [
3]. If requested by a regulatory agency, the intervals can be easily adjusted for multiplicity using the Hochberg step-up procedure [
13]. However, when “such adjustments are applied unnecessarily, potentially effective treatments may be discarded prematurely” [
9].
7.3. Limitations
A limitation of REEs is that they are ratios and tend to have a slightly skewed log-normal distribution, which creates issues when the parameters of a test statistic are estimated from the sample. According to Jensen’s inequality, the expectation will be less than or equal to its true value. To some degree, this bias is an advantage because it helps to offset the Cauchy infinite variance problem that may result from taking the ratio of two normally distributed variables [
1]. Barring extreme degenerate examples, it is noted that
asymptotically assumes a moderately well-behaved, normal shape in the limit.
The literature offers little consistent advice regarding the lower limit for the sample size needed to satisfy the underlying large-sample assumptions of the test statistic. It is also unclear what level of inaccuracy is incurred when estimating a z-score test statistic when the sample size is small and the observations are not fully independent. By treating the logarithmic transformation of
as a mean difference and applying Gauss’ hypergeometric series, one may heuristically conclude that the small-sample test statistic follows a pseudo Behrens–Fisher distribution with
degrees of freedom [
14], as follows:
An alternative, albeit lower-power, approach is the Lepage test, which treats the problem as a nonparametric test for central tendency and dispersion [
15]. In certain situations, nonparametric methods are better suited (less sensitive) for handling violations of independence.
Addressing the exact convergence rates for a conditional Martingale-type central limit theorem, which are ostensibly slower than
is a complex topic beyond the scope of the current manuscript and is best deferred to future research [
16]. Nonetheless, it is common practice in many applied scenarios to accept that the underlying data are “close enough” to normal to move forward with normal-theory methods.
Imprecise rounding is also a concern. As REEs are expressed on a logarithmic scale, with significant departures from linearity occurring near unity, it is best to avoid intermediate rounding when computing the test statistic. Fortunately, this rarely poses a problem when the operations are performed by a computer rather than by manual means.
In theory, power for a given sample size may be estimated by simulating datasets from a conditional multinomial distribution, with prescribed cell probabilities being reflective of the underlying hypothesized parameters. Power is then defined as the proportion of the simulated test statistics that fall within the “a priori” alpha rejection region. However, the simulation method is computationally intensive and introduces uncertainty in the values at the distribution tails. As large sample sizes are often needed to detect small effect sizes for risk reduction, the process may be resource-prohibitive or prone to computational errors, in which case normal-theory methods may be the better choice for computing power. While robust estimation methods are available in most standard statistical packages to simulate the covariance of REEs and corresponding test statistics involving correlated data, boundary issues regularly result in algorithmic non-convergence. The simulation of power also is problematic for heavy-tailed, Cauchy-like distributions, which may require sample sizes on the order of millions to properly characterize outlying values. Furthermore, multinomial-type power computations are predicated on the observed pilot sample effect size. Thus, simulation cannot be used to determine power for a range of minimally detectable ) values based on a single effect size estimate. In such cases, separate pilot samples will be needed to determine the desired range of values.
7.4. Future Directions
Future investigations are directed at estimating power when sample sizes are small and the assumption of conditional independence is questionable. This will include cases where it is difficult to establish the consistency, stability, and normality of underlying data estimates and parameters. Innovative research efforts focusing on nonparametric, two-sample conditional tests and Bayesian methods also may be useful [
17,
18].
8. Conclusions
The use of a common reference-control arm is an important tool for minimizing bias in a randomized clinical trial. Assuming conditional independence, a large-sample method is presented to estimate power for risk reduction on the log-difference scale. This computationally straightforward approach offsets the uncertainty and potential bias associated with tests of absolute risk reduction.
Funding
The author reports that there is no external funding associated with the work featured in this article. The opinions presented in this manuscript do not necessarily represent those of the VA or the United States Federal Government. All examples provided herein are hypothetical and not intended to reflect any real individuals, communities, or non-profit/corporate/governmental entities.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The insightful comments from Genevieve Dupuis, Kaitlin Cassidy, and Janet M. Grubber during the writing and revision of this manuscript are greatly appreciated. SAS programming was validated by Maria Androsenko.
Conflicts of Interest
The author declares no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ASCVD | Atherosclerotic cardiovascular disease |
| CI | Confidence interval |
| LCI | Lower confidence interval |
| Log | Logarithm |
| Mg/day | Milligrams per day |
| P | p-value |
| REE | Relative effect estimate |
| RLD | Relative effect reduction on the log-difference scale |
| SD | Standard deviation |
| SE | Standard error |
| UCI | Upper confidence interval |
Appendix A. SAS Code for Determining Power and Sample Size, as Shown in Table 2
Appendix B. SAS Code for Simulating the Conditional Central Limit Theorem (Example 2)
References
- Le Cam, L. Asymptotic Methods in Statistical Decision Theory; Springer: New York, NY, USA, 1986. [Google Scholar]
- Peligrad, M. Conditional central limit theorem via Martingale approximation. arXiv 2011. [Google Scholar] [CrossRef]
- Altman, D.; Bland, J. Interaction revisited: The difference between two estimates. Br. Med. J. 2003, 326, 219. [Google Scholar] [CrossRef] [PubMed]
- Knol, M.; Pestmen, W.; Grobbee, D. The (mis)use of overlap of confidence intervals to assess effect modification. Eur. J. Epidemiol. 2011, 26, 253–254. [Google Scholar] [CrossRef] [PubMed]
- Teare, M.; Dimairo, M.; Shephard, N.; Hayman, A.; Whitehead, A.; Walters, J. Sample size requirements to estimate key design parameters from external pilot randomized controlled trials: A simulation study. Trials 2014, 15, 264–277. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Gurrin, L.; Ademi, Z.; Liew, D. Overview of methods for comparing the efficacies of drugs in absence of head-to-head clinical trial data. B.J.C.P 2013, 77, 116–121. [Google Scholar] [CrossRef] [PubMed]
- Parker, R.; Weir, C. Non-adjustment for multiple testing in multi-arm trials of distinct treatments: Rationale and justification. Clin. Trials 2020, 17, 562–566. [Google Scholar] [CrossRef] [PubMed]
- Bender, R.; Lange, S. Adjusting for multiple testing—When and how? J. Clin. Epidemiol. 2001, 54, 343–349. [Google Scholar] [CrossRef] [PubMed]
- Molloy, S.; White, I.; Nunn, A.; Hayes, R.; Wang, D.; Harrison, S. Multiplicity adjustments in parallel-group multi-arm trials sharing a control group: Clear guidance is needed. Contemp. Clin. Trials 2022, 113, 106656. [Google Scholar] [CrossRef] [PubMed]
- Rubin, M. When to adjust alpha during multiple testing: A consideration of disjunction, conjunction, and individual testing. Synthese 2021, 199, 10969–11000. [Google Scholar] [CrossRef]
- García-Pérez, A. Use and misuse of correction for multiple testing. Meth. Psych. B 2023, 8, 100120. [Google Scholar] [CrossRef]
- Li, G.; Taljaard, M.; Van den Heuvel, E.; Levine, M.; Cook, D.; Wells, G.; Deveraux, P.; Thabane, L. An introduction to multiplicity issues in clinical trials: The what, why, when and how. Int. J. Epidemiol. 2017, 46, 746–755. [Google Scholar] [CrossRef] [PubMed]
- Hochberg, Y. A sharper Bonferroni procedure for multiple tests of significance. Biometrika 1988, 75, 800–802. [Google Scholar] [CrossRef]
- Kabe, D. On the exact distribution of the Fisher-Behren’s-Welch statistic. Metrika 1996, 10, 13–15. [Google Scholar] [CrossRef]
- Lepage, Y. A combination Wilcoxon’s and Ansari-Bradley’s statistics. Biometrika 1971, 58, 213–217. [Google Scholar] [CrossRef]
- Bolthauser, E. Exact convergence rates in some Martingale central limit theorems. Ann. Prob. 1982, 3, 672–688. [Google Scholar]
- Lee, S.; Cha, S.; Kim, I. General framework for conditional two-sample testing. arXiv 2024. [Google Scholar] [CrossRef]
- Yan, J.; Li, Z.; Zhang, X. Distance and kernel measures for global and local two-sample conditional distribution testing. arXiv 2024. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}