Forecasting Flu Activity in the United States: Benchmarking an Endemic-Epidemic Beta Model


Abstract
1. Introduction
2. Materials and Methods
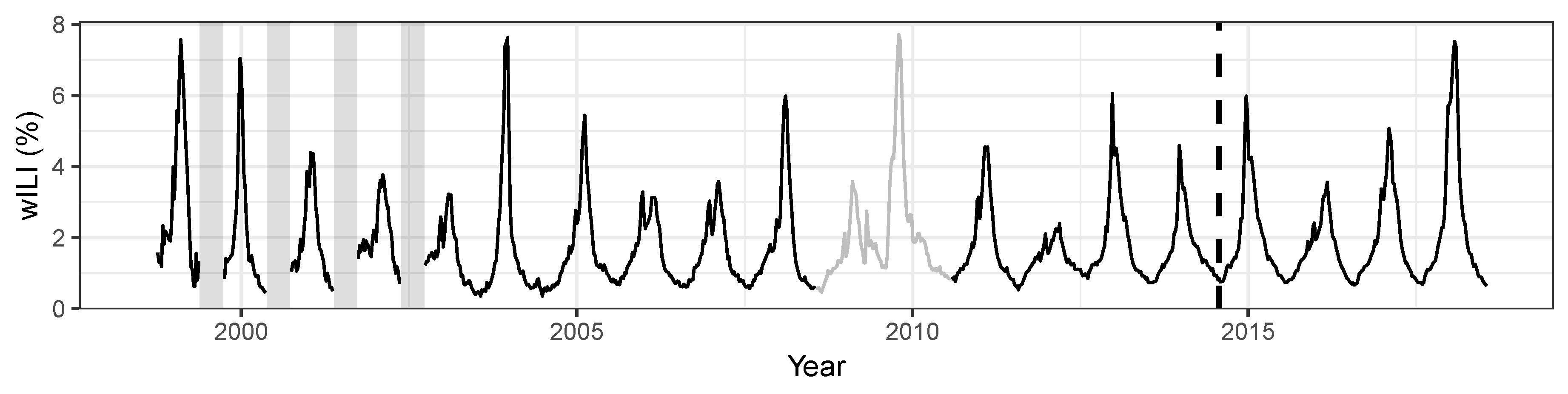
2.1. Data
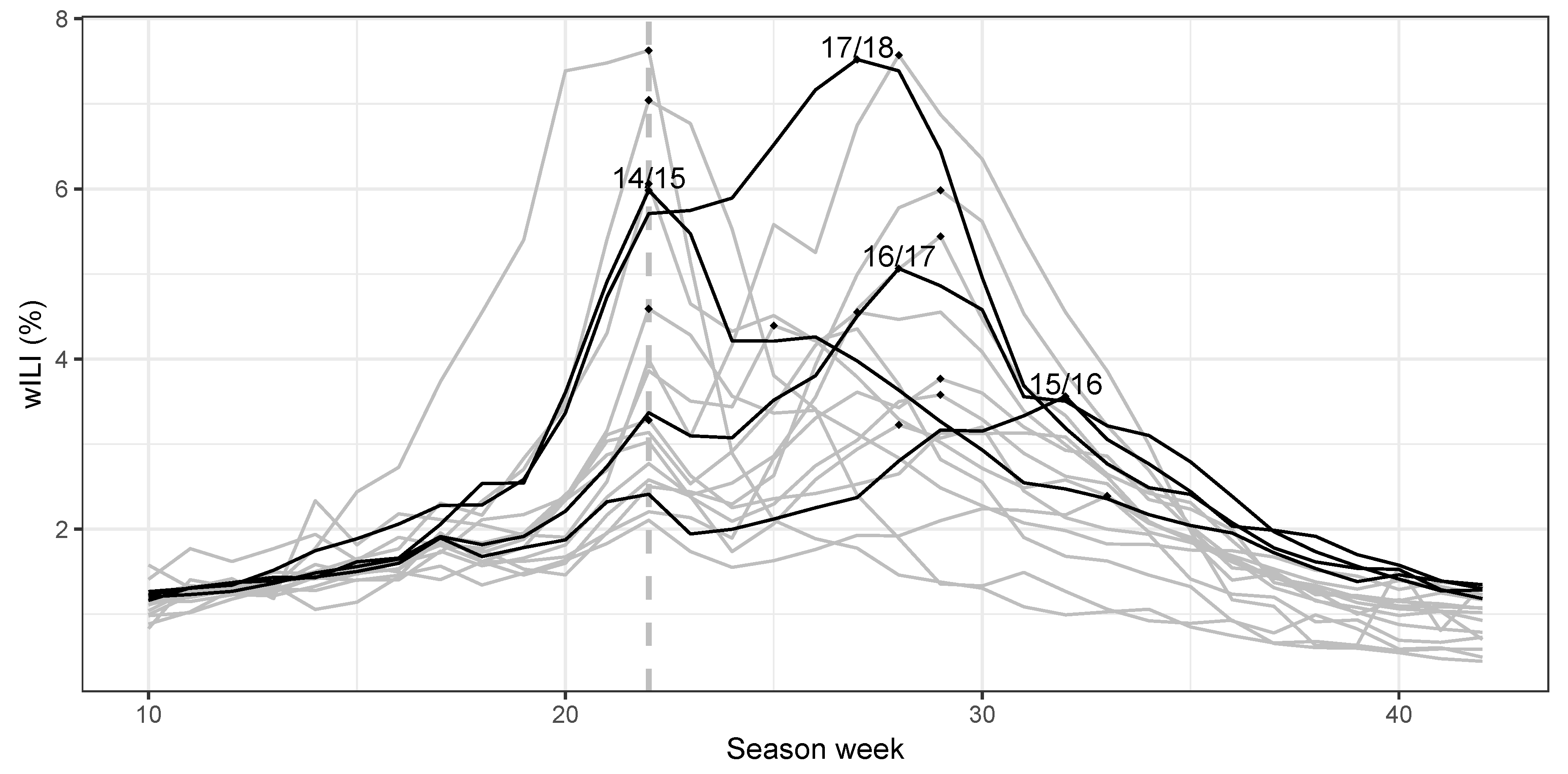
2.2. Prediction Targets and Evaluation Criteria
2.3. Endemic-Epidemic Beta Model
2.4. Baseline Models
3. Results
3.1. Model Selection
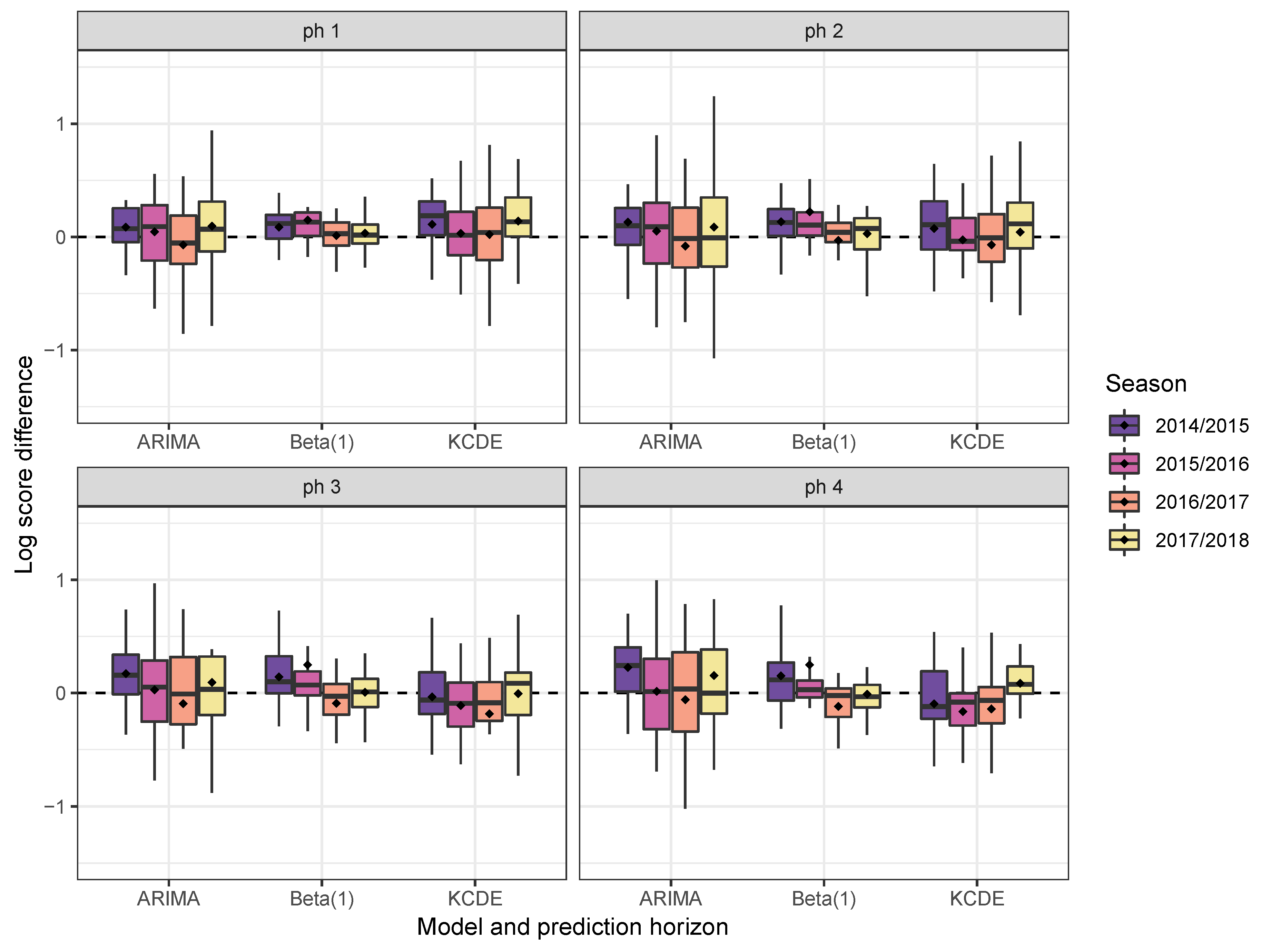
3.2. Short-Term Targets
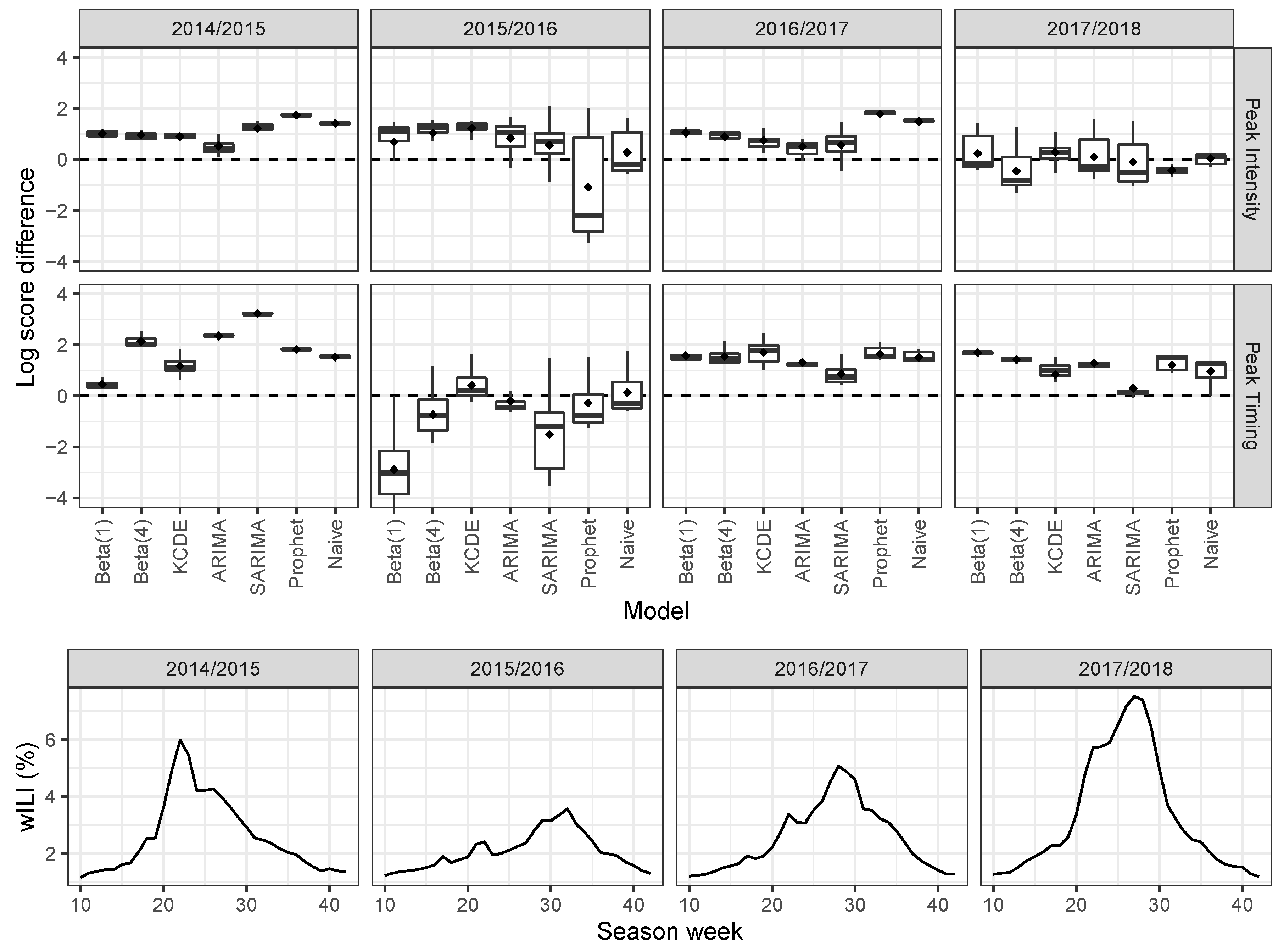
3.3. Seasonal Targets
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tokars, J.I.; Olsen, S.J.; Reed, C. Seasonal Incidence of Symptomatic Influenza in the United States. Clin. Infect. Dis. 2017, 66, 1511–1518. [Google Scholar] [CrossRef]
- Biggerstaff, M.; Johansson, M.; Alper, D.; Brooks, L.C.; Chakraborty, P.; Farrow, D.C.; Hyun, S.; Kandula, S.; McGowan, C.; Ramakrishnan, N.; et al. Results from the second year of a collaborative effort to forecast influenza seasons in the United States. Epidemics 2018, 24, 26–33. [Google Scholar] [CrossRef]
- Reich, N.G.; Brooks, L.C.; Fox, S.J.; Kandula, S.; McGowan, C.J.; Moore, E.; Osthus, D.; Ray, E.L.; Tushar, A.; Yamana, T.K.; et al. A collaborative multiyear, multimodel assessment of seasonal influenza forecasting in the United States. Proc. Natl. Acad. Sci. USA 2019, 116, 3146–3154. [Google Scholar] [CrossRef]
- Nsoesie, E.O.; Brownstein, J.S.; Ramakrishnan, N.; Marathe, M.V. A systematic review of studies on forecasting the dynamics of influenza outbreaks. Influenza Other Respir. Viruses 2014, 8, 309–316. [Google Scholar] [CrossRef]
- Chretien, J.P.; George, D.; Shaman, J.; Chitale, R.A.; McKenzie, F.E. Influenza forecasting in human populations: A scoping review. PLoS ONE 2014, 9, e94130. [Google Scholar] [CrossRef] [PubMed]
- Brooks, L.C.; Farrow, D.C.; Hyun, S.; Tibshirani, R.J.; Rosenfeld, R. Nonmechanistic forecasts of seasonal influenza with iterative one-week-ahead distributions. PLoS Comput. Biol. 2018, 14, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Shaman, J.; Karspeck, A. Forecasting seasonal outbreaks of influenza. Proc. Natl. Acad. Sci. USA 2012, 109, 20425–20430. [Google Scholar] [CrossRef] [PubMed]
- Hickmann, K.S.; Fairchild, G.; Priedhorsky, R.; Generous, N.; Hyman, J.M.; Deshpande, A.; Del Valle, S.Y. Forecasting the 2013–2014 influenza season using Wikipedia. PLoS Comput. Biol. 2015, 11, 1–29. [Google Scholar] [CrossRef]
- Ray, E.L.; Sakrejda, K.; Lauer, S.A.; Johansson, M.A.; Reich, N.G. Infectious disease prediction with kernel conditional density estimation. Stat. Med. 2017, 36, 4908–4929. [Google Scholar] [CrossRef]
- Brooks, L.C.; Farrow, D.C.; Hyun, S.; Tibshirani, R.J.; Rosenfeld, R. Flexible modeling of epidemics with an Empirical Bayes framework. PLOS Comput. Biol. 2015, 11, 1–18. [Google Scholar] [CrossRef]
- Hyndman, R.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Dunsmuir, W.; Scott, D. The glarma package for observation-driven time series regression of counts. J. Stat. Softw. 2015, 67, 1–36. [Google Scholar] [CrossRef]
- Held, L.; Höhle, M.; Hofmann, M. A statistical framework for the analysis of multivariate infectious disease surveillance counts. Stat. Model. 2005, 5, 187–199. [Google Scholar] [CrossRef]
- Meyer, S.; Held, L.; Höhle, M. Spatio-temporal analysis of epidemic phenomena using the R package surveillance. J. Stat. Softw. 2017, 77, 1–55. [Google Scholar] [CrossRef]
- Held, L.; Meyer, S. Forecasting Based on Surveillance Data. In Handbook of Infectious Disease Data Analysis; Held, L., Hens, N., O’Neill, P.D., Wallinga, J., Eds.; Chapman & Hall/CRC Handbooks of Modern Statistical Methods; Chapman & Hall/CRC: Boca Raton, FL, USA, 2019; Chapter 25. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Zeileis, A. Beta regression in R. J. Stat. Softw. 2010, 34, 1–24. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Gneiting, T.; Katzfuss, M. Probabilistic forecasting. Annu. Rev. Stat. Appl. 2014, 1, 125–151. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- U.S. Influenza Surveillance System: Purpose and Methods. Available online: https://www.cdc.gov/flu/weekly/overview.htm (accessed on 6 February 2020).
- Rudis, B. cdcfluview: Retrieve flu season data from the United States Centers for Disease Control and Prevention (CDC) ’FluView’ portal. 2019. Available online: https://CRAN.R-project.org/package=cdcfluview (accessed on 18 February 2020).
- Osthus, D.; Daughton, A.R.; Priedhorsky, R. Even a good influenza forecasting model can benefit from internet-based nowcasts, but those benefits are limited. PLoS Comput. Biol. 2019, 15, 1–19. [Google Scholar] [CrossRef]
- Why CDC Supports Flu Forecasting. Available online: https://www.cdc.gov/flu/weekly/flusight/why-flu-forecasting.htm (accessed on 6 February 2020).
- Held, L.; Meyer, S.; Bracher, J. Probabilistic forecasting in infectious disease epidemiology: The 13th Armitage lecture. Stat. Med. 2017, 36, 3443–3460. [Google Scholar] [CrossRef]
- Funk, S.; Camacho, A.; Kucharski, A.J.; Lowe, R.; Eggo, R.M.; Edmunds, W.J. Assessing the performance of real-time epidemic forecasts: A case study of Ebola in the Western Area region of Sierra Leone, 2014–15. PLOS Comput. Biol. 2019, 15, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. 2007, 69, 243–268. [Google Scholar] [CrossRef]
- Dawid, A.P.; Sebastiani, P. Coherent dispersion criteria for optimal experimental design. Ann. Stat. 1999, 27, 65–81. [Google Scholar] [CrossRef]
- Paul, M.; Held, L. Predictive assessment of a non-linear random effects model for multivariate time series of infectious disease counts. Stat. Med. 2011, 30, 1118–1136. [Google Scholar] [CrossRef]
- Ray, E.L.; Reich, N.G. Prediction of infectious disease epidemics via weighted density ensembles. PLoS Comput. Biol. 2018, 14, e1005910. [Google Scholar] [CrossRef]
- Lu, J.; Meyer, S. An endemic-epidemic beta model for time series of infectious disease proportions. Manuscript in preparation.
- Held, L.; Paul, M. Modeling seasonality in space-time infectious disease surveillance data. Biom. J. 2012, 54, 824–843. [Google Scholar] [CrossRef]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Hurvich, C.M.; Tsai, C.L. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar] [CrossRef]
- Hens, N.; Ayele, G.; Goeyvaerts, N.; Aerts, M.; Mossong, J.; Edmunds, J.; Beutels, P. Estimating the impact of school closure on social mixing behaviour and the transmission of close contact infections in eight European countries. BMC Infect. Dis. 2009, 9, 187. [Google Scholar] [CrossRef]
- Osthus, D.; Gattiker, J.; Priedhorsky, R.; Valle, S.Y.D. Dynamic Bayesian influenza forecasting in the United States with hierarchical discrepancy (with discussion). Bayesian Anal. 2019, 14, 261–312. [Google Scholar] [CrossRef]
- Rocha, A.V.; Cribari-Neto, F. Beta autoregressive moving average models. TEST 2008, 18, 529–545. [Google Scholar] [CrossRef]
- Guolo, A.; Varin, C. Beta regression for time series analysis of bounded data, with application to Canada Google® Flu Trends. Ann. Appl. Stat. 2014, 8, 74–88. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and machine learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Subset | LS | p-Value | maxLS | DSS | AE | Time | npar |
|---|---|---|---|---|---|---|---|---|
| Beta(1) | All weeks | –0.11 (3) | 0.1862 | 5.59 (7) | –2.02 (3) | 0.25 (3) | 2.91 (3) | 19 (3) |
| Beta(4) | –0.12 (1) | 4.34 (2) | –2.07 (2) | 0.25 (2) | 2.64 (2) | 20 (4) | ||
| KCDE | –0.12 (2) | 0.8076 | 4.08 (1) | –2.29 (1) | 0.24 (1) | 266.63 (7) | 28 (5) | |
| ARIMA | –0.02 (4) | 0.0001 | 5.24 (5) | –1.81 (4) | 0.28 (5) | 6.22 (4) | 16 (2) | |
| SARIMA | 0.04 (5) | 0.0001 | 4.92 (3) | –1.69 (5) | 0.27 (4) | 110.37 (6) | 3 (1) | |
| Prophet | 0.48 (7) | 0.0001 | 5.04 (4) | –0.75 (7) | 0.44 (6) | 11.75 (5) | 50 (6) | |
| Naive | 0.42 (6) | 0.0001 | 5.29 (6) | –1.13 (6) | 0.46 (7) | 0.07 (1) | 106 (7) | |
| Beta(1) | weeks 40–20 | 0.43 (4) | 0.0001 | 5.59 (7) | –0.94 (4) | 0.37 (3) | ||
| Beta(4) | 0.35 (2) | 4.34 (2) | –1.10 (2) | 0.35 (2) | ||||
| KCDE | 0.33 (1) | 0.3160 | 4.08 (1) | –1.28 (1) | 0.34 (1) | |||
| ARIMA | 0.41 (3) | 0.0186 | 5.24 (5) | –0.98 (3) | 0.39 (4) | |||
| SARIMA | 0.50 (5) | 0.0001 | 4.92 (3) | –0.77 (5) | 0.39 (5) | |||
| Prophet | 0.97 (7) | 0.0001 | 5.04 (4) | 0.19 (7) | 0.64 (6) | |||
| Naive | 0.97 (6) | 0.0001 | 5.29 (6) | 0.02 (6) | 0.67 (7) |
| Model | Subset | ph1 | ph2 | ph3 | ph4 | ||||
|---|---|---|---|---|---|---|---|---|---|
| LS | DSS | LS | DSS | LS | DSS | LS | DSS | ||
| Beta(1) | All weeks | –0.53 (2) | –2.90 (2) | –0.15 (3) | –2.10 (3) | 0.06 (3) | –1.68 (3) | 0.18 (2) | –1.41 (3) |
| Beta(4) | –0.55 (1) | –2.96 (1) | –0.18 (1) | –2.19 (2) | 0.05 (2) | –1.71 (2) | 0.19 (3) | –1.42 (2) | |
| KCDE | –0.42 (4) | –2.89 (3) | –0.16 (2) | –2.33 (1) | –0.02 (1) | –2.11 (1) | 0.12 (1) | –1.83 (1) | |
| ARIMA | –0.47 (3) | –2.76 (4) | –0.09 (4) | –1.96 (4) | 0.15 (4) | –1.46 (4) | 0.33 (4) | –1.07 (5) | |
| SARIMA | –0.39 (5) | –2.61 (5) | –0.02 (5) | –1.82 (5) | 0.21 (5) | –1.34 (5) | 0.36 (5) | –0.98 (6) | |
| Prophet | 0.46 (7) | –0.78 (7) | 0.47 (7) | –0.76 (7) | 0.48 (7) | –0.73 (7) | 0.49 (7) | –0.72 (7) | |
| Naive | 0.42 (6) | –1.13 (6) | 0.42 (6) | –1.13 (6) | 0.42 (6) | –1.13 (6) | 0.42 (6) | –1.13 (4) | |
| Beta(1) | weeks 40–20 | –0.03 (3) | –1.91 (4) | 0.38 (4) | –1.05 (4) | 0.62 (4) | –0.56 (4) | 0.76 (3) | –0.24 (3) |
| Beta(4) | –0.10 (1) | –2.07 (1) | 0.29 (1) | –1.24 (2) | 0.54 (2) | –0.72 (2) | 0.69 (2) | –0.39 (2) | |
| KCDE | –0.03 (4) | –2.05 (2) | 0.30 (2) | –1.33 (1) | 0.46 (1) | –1.05 (1) | 0.61 (1) | –0.70 (1) | |
| ARIMA | –0.06 (2) | –1.95 (3) | 0.34 (3) | –1.12 (3) | 0.59 (3) | –0.63 (3) | 0.77 (4) | –0.23 (4) | |
| SARIMA | 0.00 (5) | –1.82 (5) | 0.43 (5) | –0.94 (5) | 0.70 (5) | –0.37 (5) | 0.88 (5) | 0.07 (6) | |
| Prophet | 0.95 (6) | 0.14 (7) | 0.97 (6) | 0.17 (7) | 0.98 (7) | 0.21 (7) | 0.99 (7) | 0.23 (7) | |
| Naive | 0.97 (7) | 0.02 (6) | 0.97 (7) | 0.02 (6) | 0.97 (6) | 0.02 (6) | 0.97 (6) | 0.02 (5) | |
| Model | Subset | Peak Intensity | Peak Timing | ||||
|---|---|---|---|---|---|---|---|
| LS | p-Value | maxLS | LS | p-Value | maxLS | ||
| Beta(1) | All weeks | 1.46 (3) | 0.2647 | 5.26 (7) | 1.99 (7) | 0.0001 | 8.11 (8) |
| Beta(4) | 1.51 (4) | 0.0305 | 4.60 (6) | 1.47 (5) | 0.4714 | 5.32 (6) | |
| KCDE | 1.41 (1) | 4.03 (3) | 1.43 (1) | 4.87 (5) | |||
| ARIMA | 1.59 (6) | 0.0001 | 4.06 (4) | 1.44 (3) | 0.8248 | 4.12 (3) | |
| SARIMA | 1.57 (5) | 0.0053 | 4.34 (5) | 1.78 (6) | 0.0017 | 7.01 (7) | |
| Prophet | 1.68 (7) | 0.0338 | 6.57 (8) | 1.44 (2) | 0.8870 | 4.76 (4) | |
| Naive | 1.46 (2) | 0.4184 | 3.87 (2) | 1.46 (4) | 0.5251 | 4.10 (2) | |
| Equal bin | 3.30 (8) | 0.0001 | 3.30 (1) | 3.50 (8) | 0.0001 | 3.50 (1) | |
| Beta(1) | Before peak | 1.69 (3) | 0.2971 | 5.26 (7) | 2.31 (7) | 0.0003 | 8.11 (8) |
| Beta(4) | 1.76 (4) | 0.0784 | 4.60 (6) | 1.71 (5) | 0.6756 | 5.32 (6) | |
| KCDE | 1.63 (1) | 4.03 (3) | 1.65 (2) | 4.87 (5) | |||
| ARIMA | 1.83 (6) | 0.0006 | 4.06 (4) | 1.64 (1) | 0.6116 | 4.12 (3) | |
| SARIMA | 1.83 (5) | 0.0058 | 4.34 (5) | 2.05 (6) | 0.0033 | 7.01 (7) | |
| Prophet | 1.96 (7) | 0.0178 | 6.57 (8) | 1.67 (3) | 0.5846 | 4.76 (4) | |
| Naive | 1.69 (2) | 0.3297 | 3.87 (2) | 1.68 (4) | 0.4014 | 4.10 (2) | |
| Equal bin | 3.30 (8) | 0.0001 | 3.30 (1) | 3.50 (8) | 0.0001 | 3.50 (1) | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Meyer, S. Forecasting Flu Activity in the United States: Benchmarking an Endemic-Epidemic Beta Model. Int. J. Environ. Res. Public Health 2020, 17, 1381. https://doi.org/10.3390/ijerph17041381
Lu J, Meyer S. Forecasting Flu Activity in the United States: Benchmarking an Endemic-Epidemic Beta Model. International Journal of Environmental Research and Public Health. 2020; 17(4):1381. https://doi.org/10.3390/ijerph17041381
Chicago/Turabian StyleLu, Junyi, and Sebastian Meyer. 2020. "Forecasting Flu Activity in the United States: Benchmarking an Endemic-Epidemic Beta Model" International Journal of Environmental Research and Public Health 17, no. 4: 1381. https://doi.org/10.3390/ijerph17041381
APA StyleLu, J., & Meyer, S. (2020). Forecasting Flu Activity in the United States: Benchmarking an Endemic-Epidemic Beta Model. International Journal of Environmental Research and Public Health, 17(4), 1381. https://doi.org/10.3390/ijerph17041381