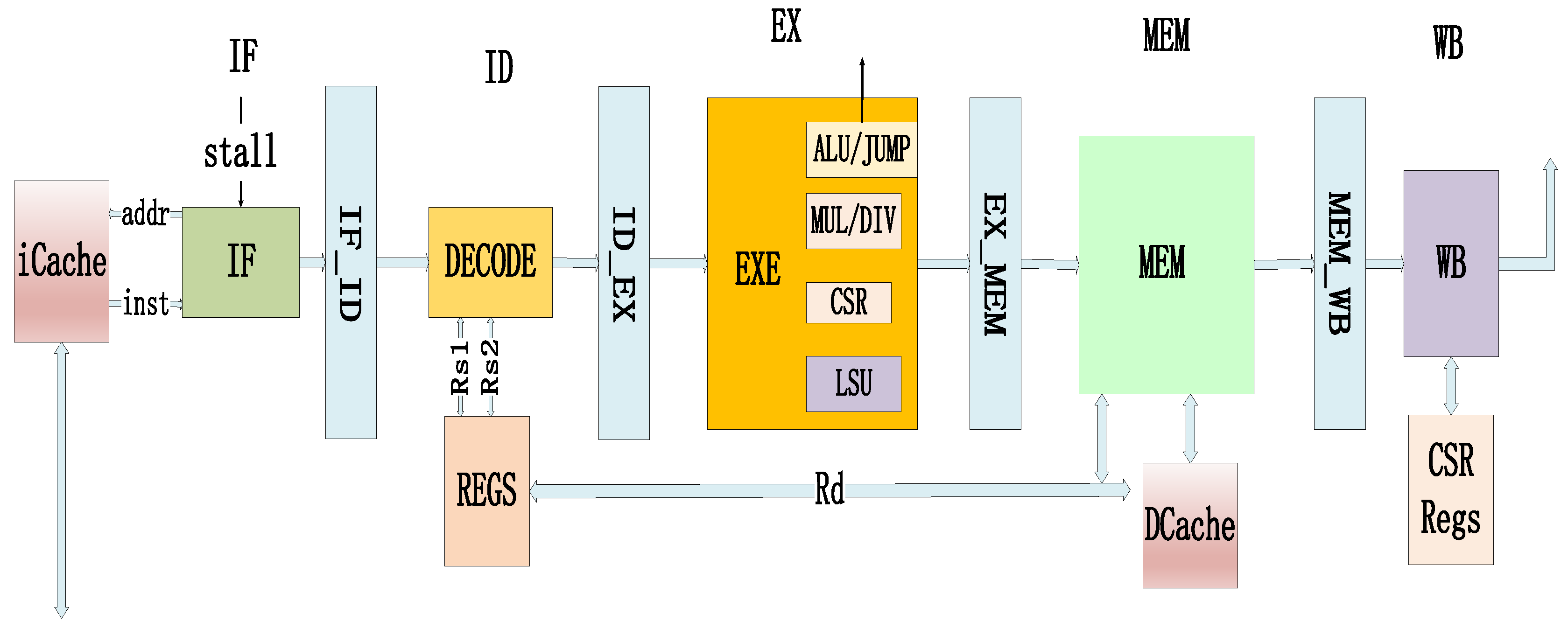
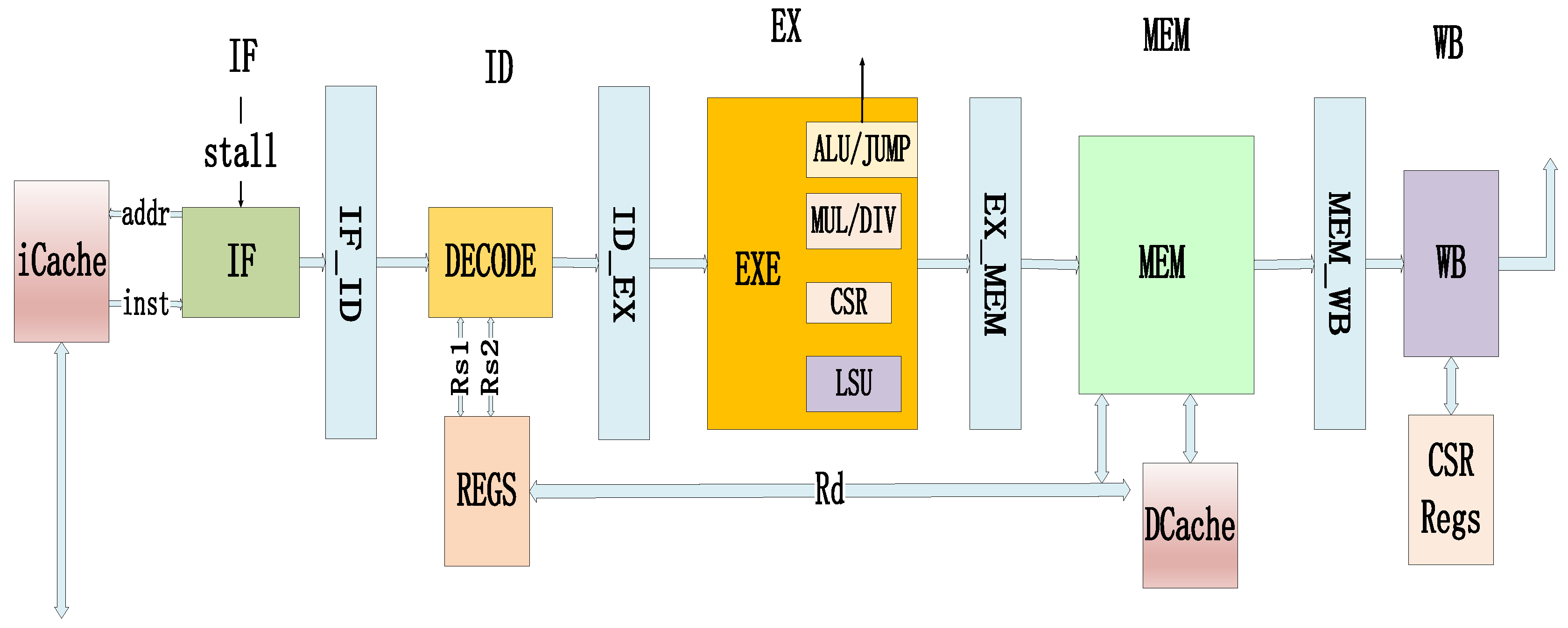
Figure 1.
Rv32IM processor core architecture.
Figure 1.
Rv32IM processor core architecture.
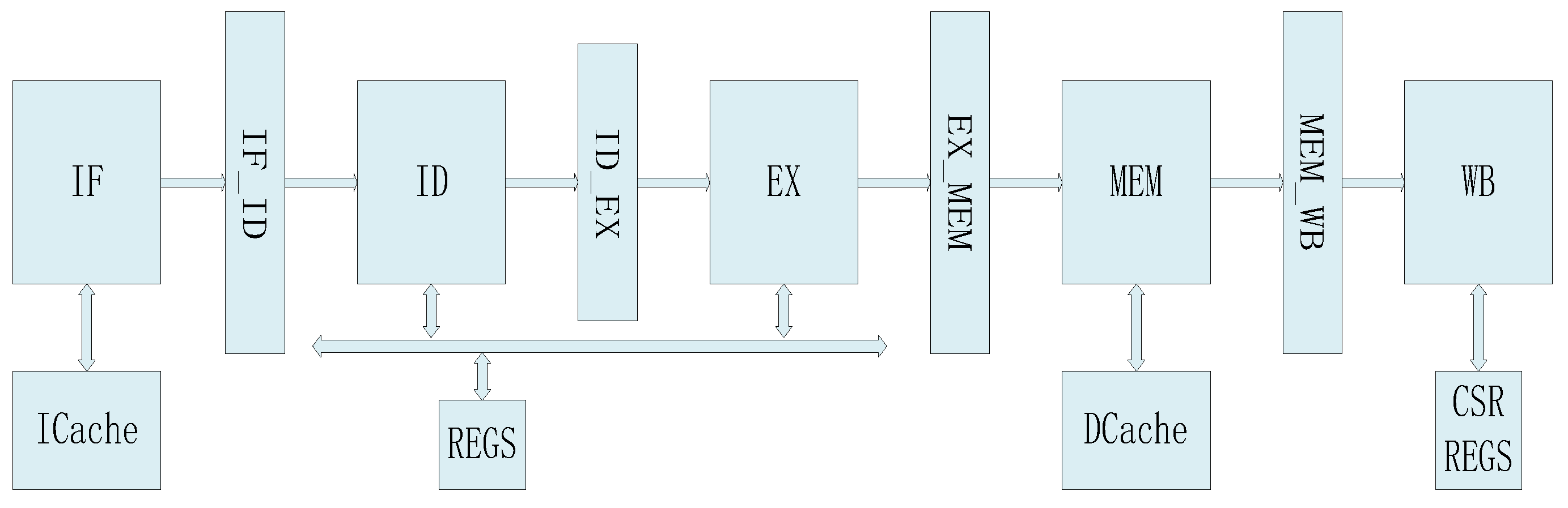
Figure 2.
Simple model of the processor core (5-stage).
Figure 2.
Simple model of the processor core (5-stage).
Figure 3.
Simple model of the processor core (3-stage).
Figure 3.
Simple model of the processor core (3-stage).
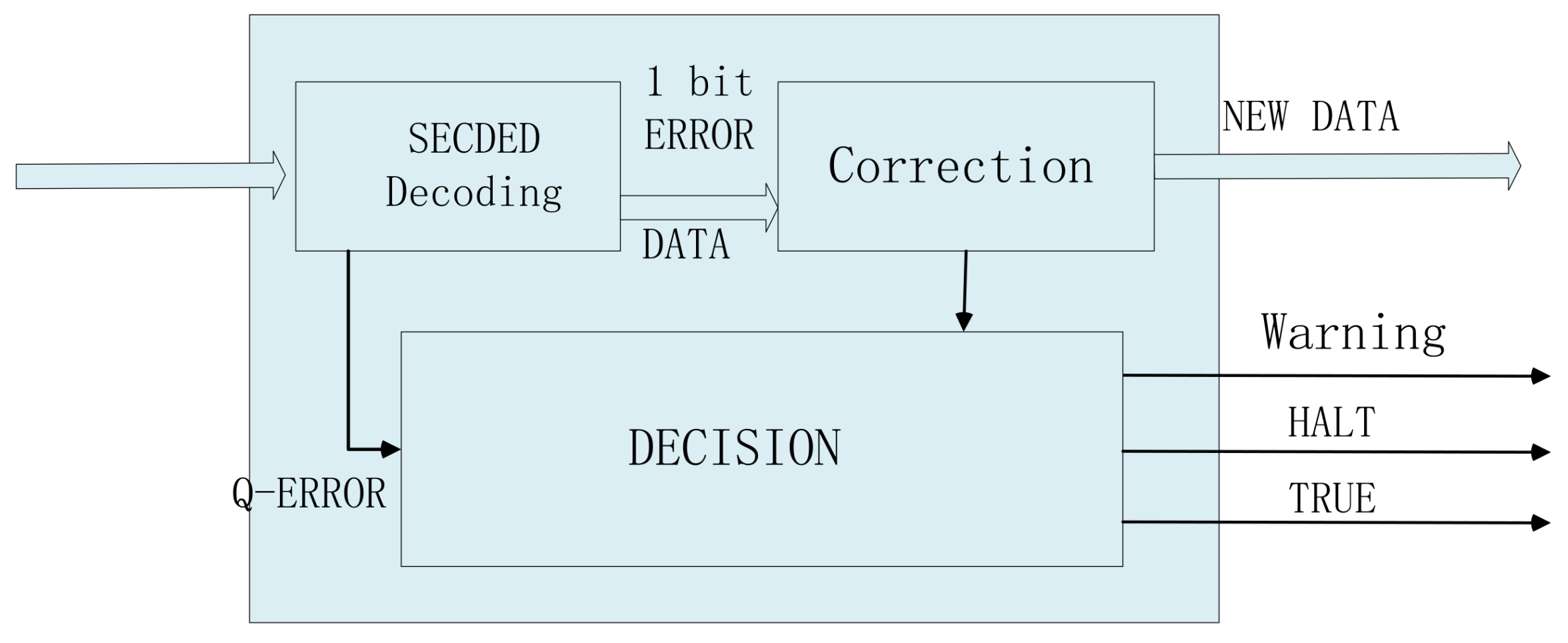
Figure 4.
Improved SECDED code encoding and verification scheme.
Figure 4.
Improved SECDED code encoding and verification scheme.
Figure 5.
Data encoding module.
Figure 5.
Data encoding module.
Figure 6.
Embedded data decoding module. It is embedded in a combinational logic module to realize the SECDED decoding function and correct errors in time. It will generate an alarm signal in case of a multi-bit error.
Figure 6.
Embedded data decoding module. It is embedded in a combinational logic module to realize the SECDED decoding function and correct errors in time. It will generate an alarm signal in case of a multi-bit error.
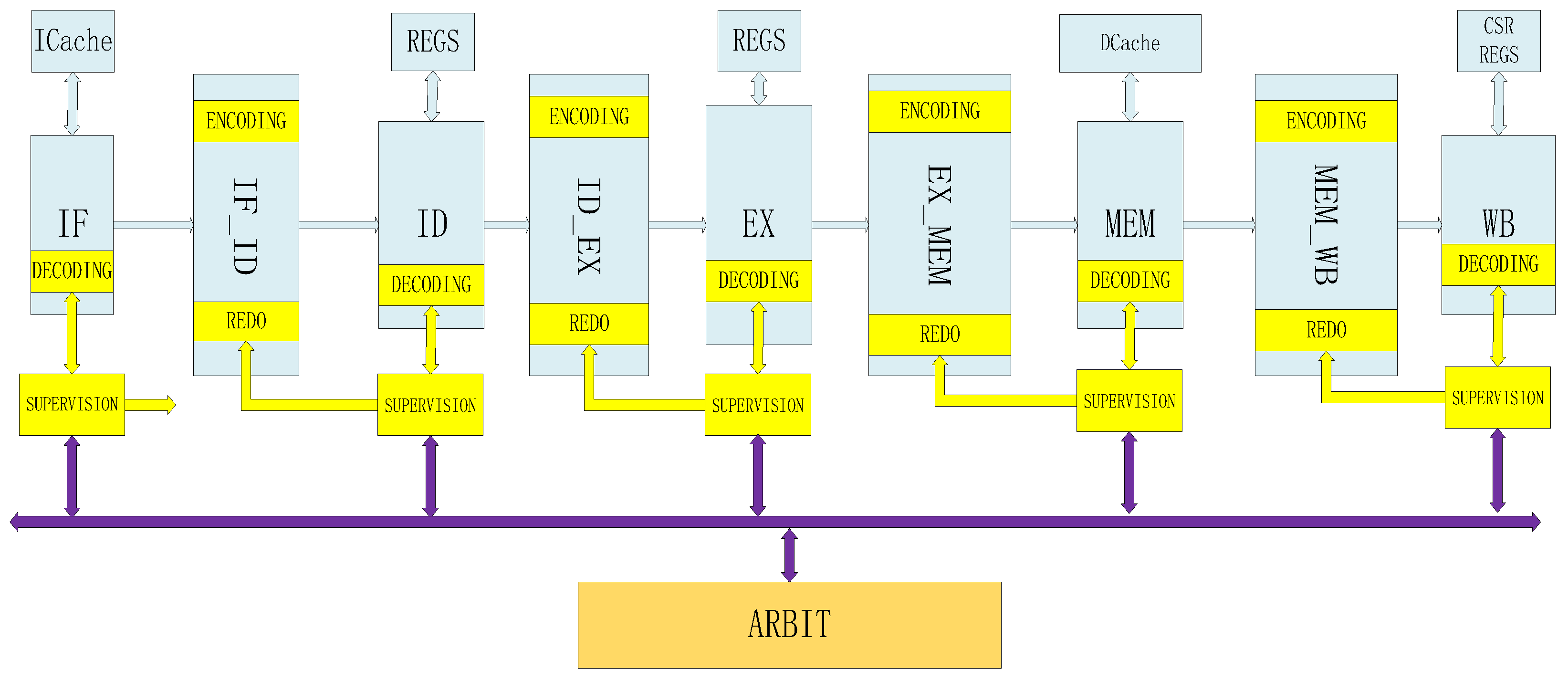
Figure 7.
Processor fault-tolerant architecture based on pipeline rollback.
Figure 7.
Processor fault-tolerant architecture based on pipeline rollback.
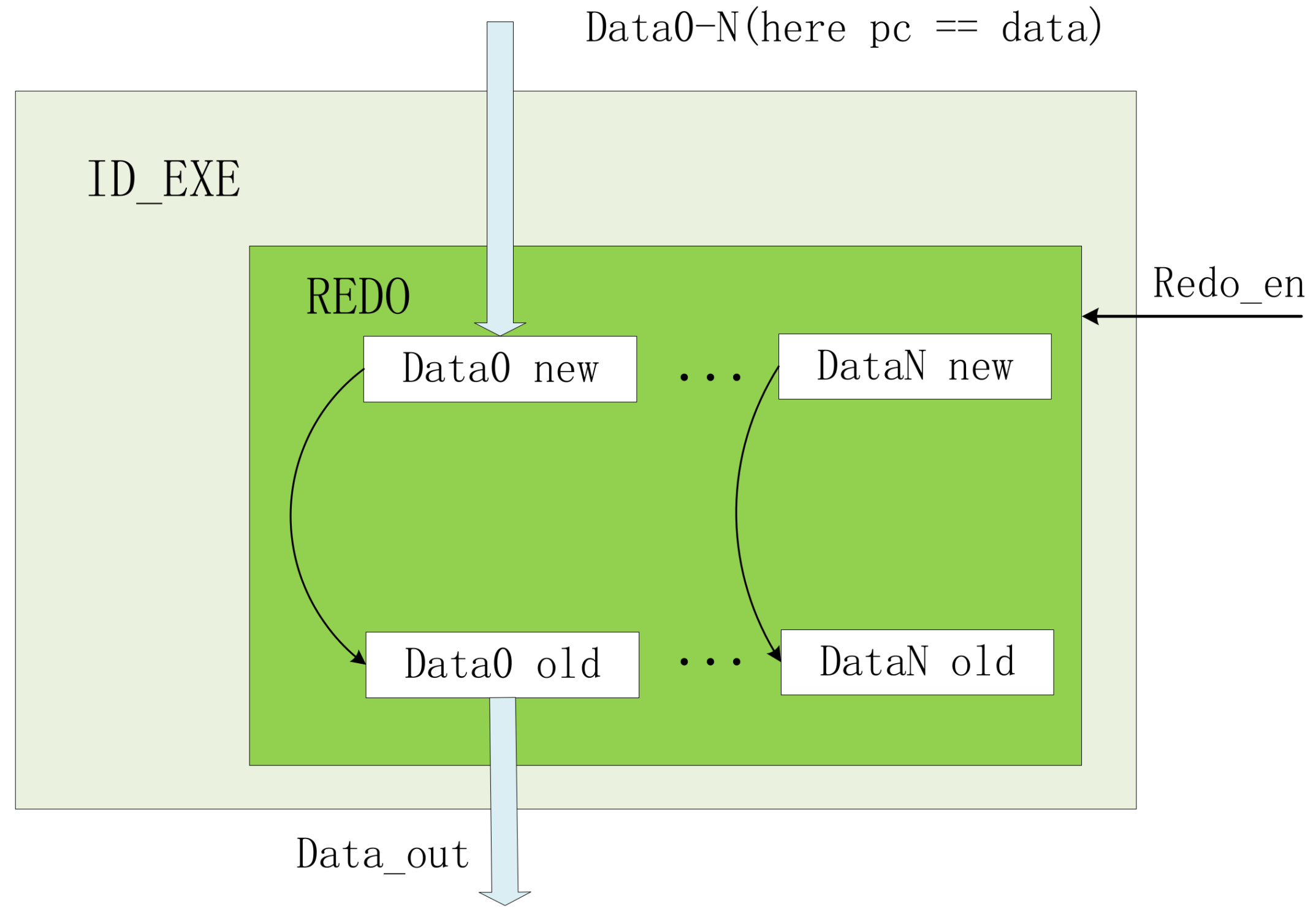
Figure 8.
REDO module: It is embedded in the timing logic module to store temporary data in real-time. When the REDO operation is performed, it realizes the function of data replacement.
Figure 8.
REDO module: It is embedded in the timing logic module to store temporary data in real-time. When the REDO operation is performed, it realizes the function of data replacement.
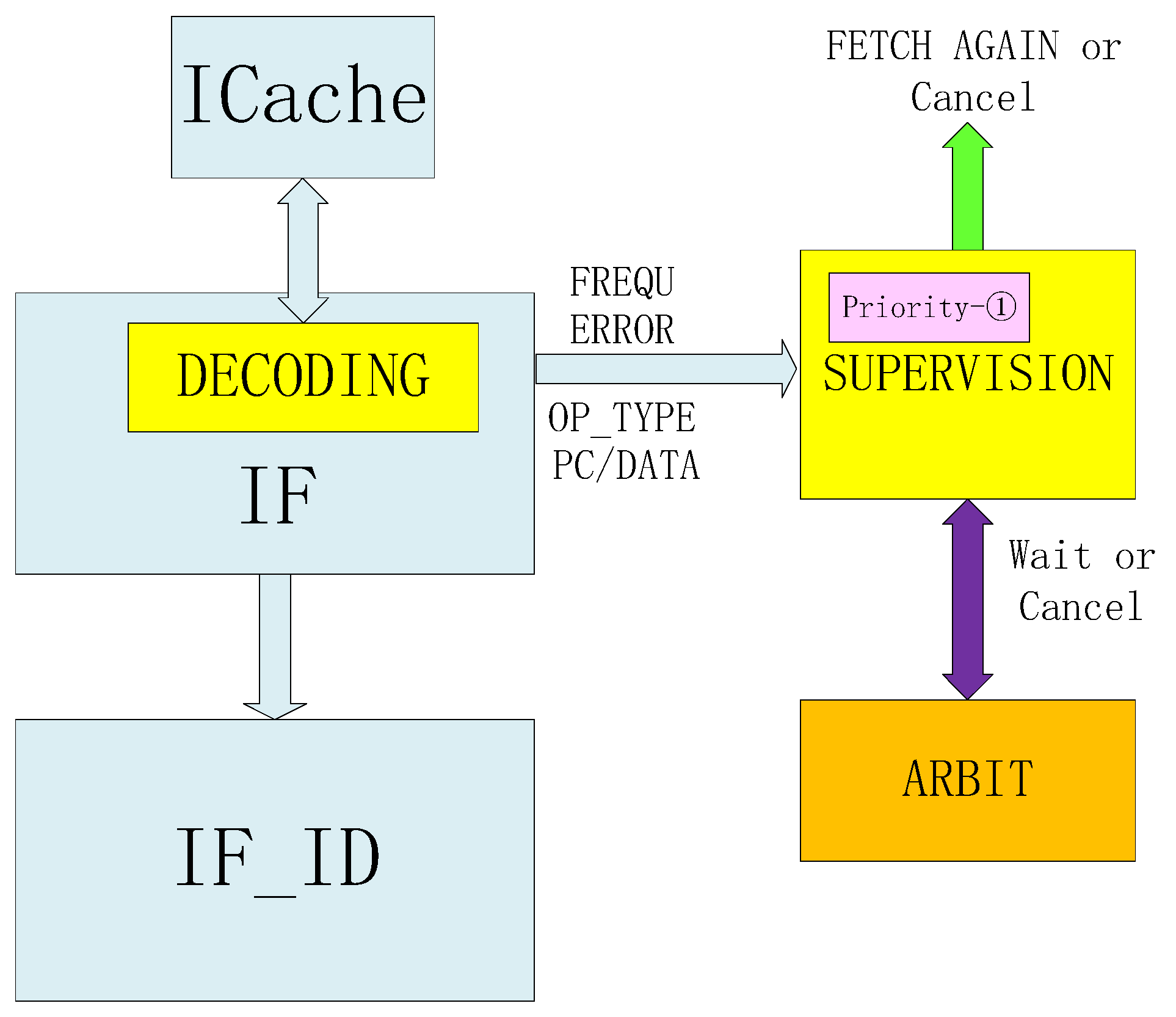
Figure 9.
Fetching rollback process. The fetching refers to fetching data from the ICache. After decoding, if there is no exception, the data will enter the next timing logic. After the exception occurs, the relevant data will be sent to the SUPERVISION module. The SUPERVISION module performs re-fetching or cancels fetching according to the processing given by the ARBIT module.
Figure 9.
Fetching rollback process. The fetching refers to fetching data from the ICache. After decoding, if there is no exception, the data will enter the next timing logic. After the exception occurs, the relevant data will be sent to the SUPERVISION module. The SUPERVISION module performs re-fetching or cancels fetching according to the processing given by the ARBIT module.
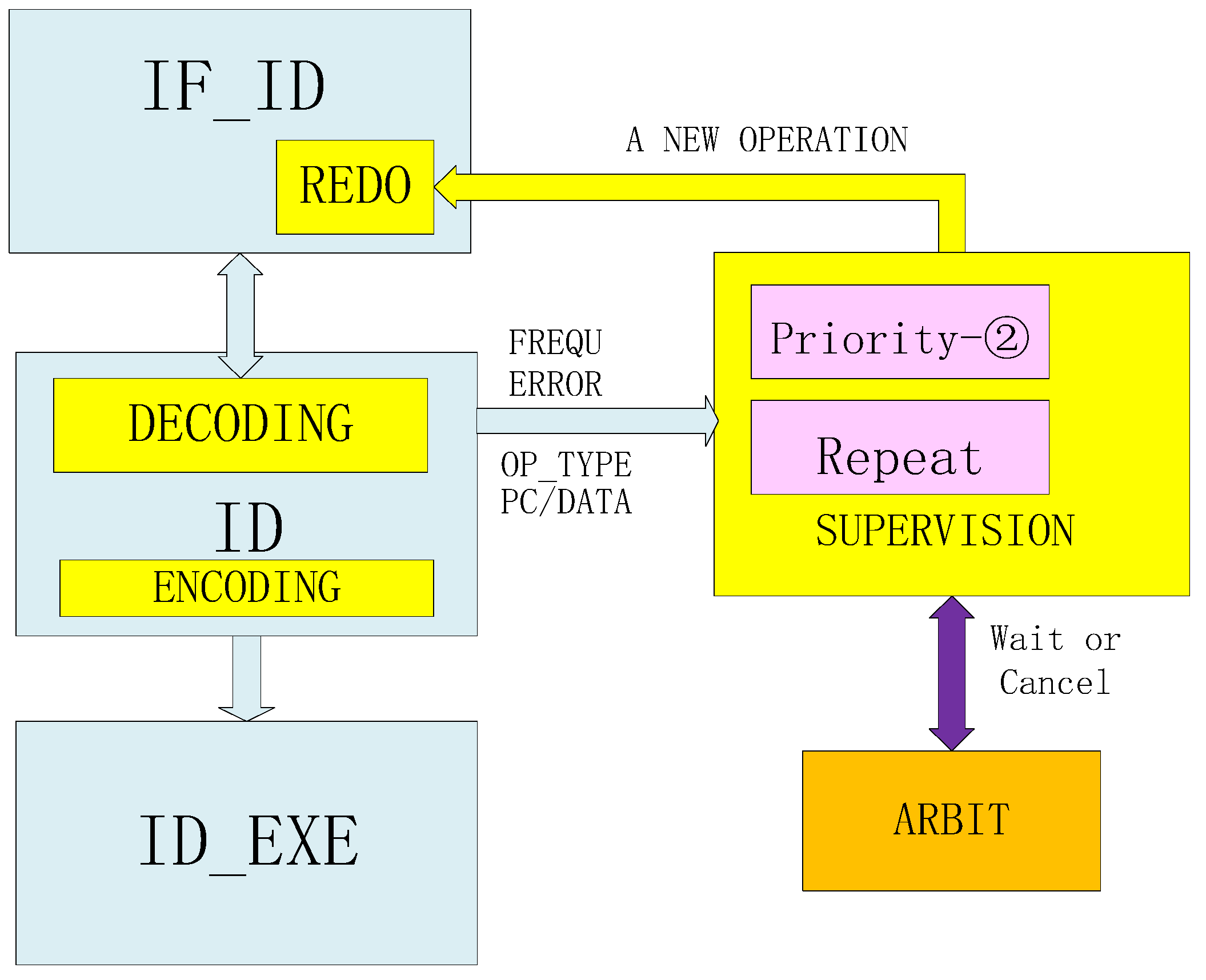
Figure 10.
Fetching-decoding rollback process. After the data from the fetching module enters the timing logic, the data without error is sent to the decoding module. If there is an exception, the REDO operation will be executed at this stage to return the original data. The REDO operation is arbitrated by the ARBIT module, and then the SUPERVISION module is notified to give feedback.
Figure 10.
Fetching-decoding rollback process. After the data from the fetching module enters the timing logic, the data without error is sent to the decoding module. If there is an exception, the REDO operation will be executed at this stage to return the original data. The REDO operation is arbitrated by the ARBIT module, and then the SUPERVISION module is notified to give feedback.
Figure 11.
Decoding Rollback Process. The execution of this module is similar to that of the fetching module, but the data does not come from the ICache. This stage also detects whether there is a decoding error and reports the data to the SUPERVISION module.
Figure 11.
Decoding Rollback Process. The execution of this module is similar to that of the fetching module, but the data does not come from the ICache. This stage also detects whether there is a decoding error and reports the data to the SUPERVISION module.
Figure 12.
Execution rollback process. The operation in this stage is similar to that in
Figure 9, but the instruction type needs to be determined in this stage. Therefore, the Jump module is embedded in this module to determine whether the current execution type is a Control Transfer Instruction and report the information to the ARBIT module.
Figure 12.
Execution rollback process. The operation in this stage is similar to that in
Figure 9, but the instruction type needs to be determined in this stage. Therefore, the Jump module is embedded in this module to determine whether the current execution type is a Control Transfer Instruction and report the information to the ARBIT module.
Figure 13.
Rv32IM instruction classification.
Figure 13.
Rv32IM instruction classification.
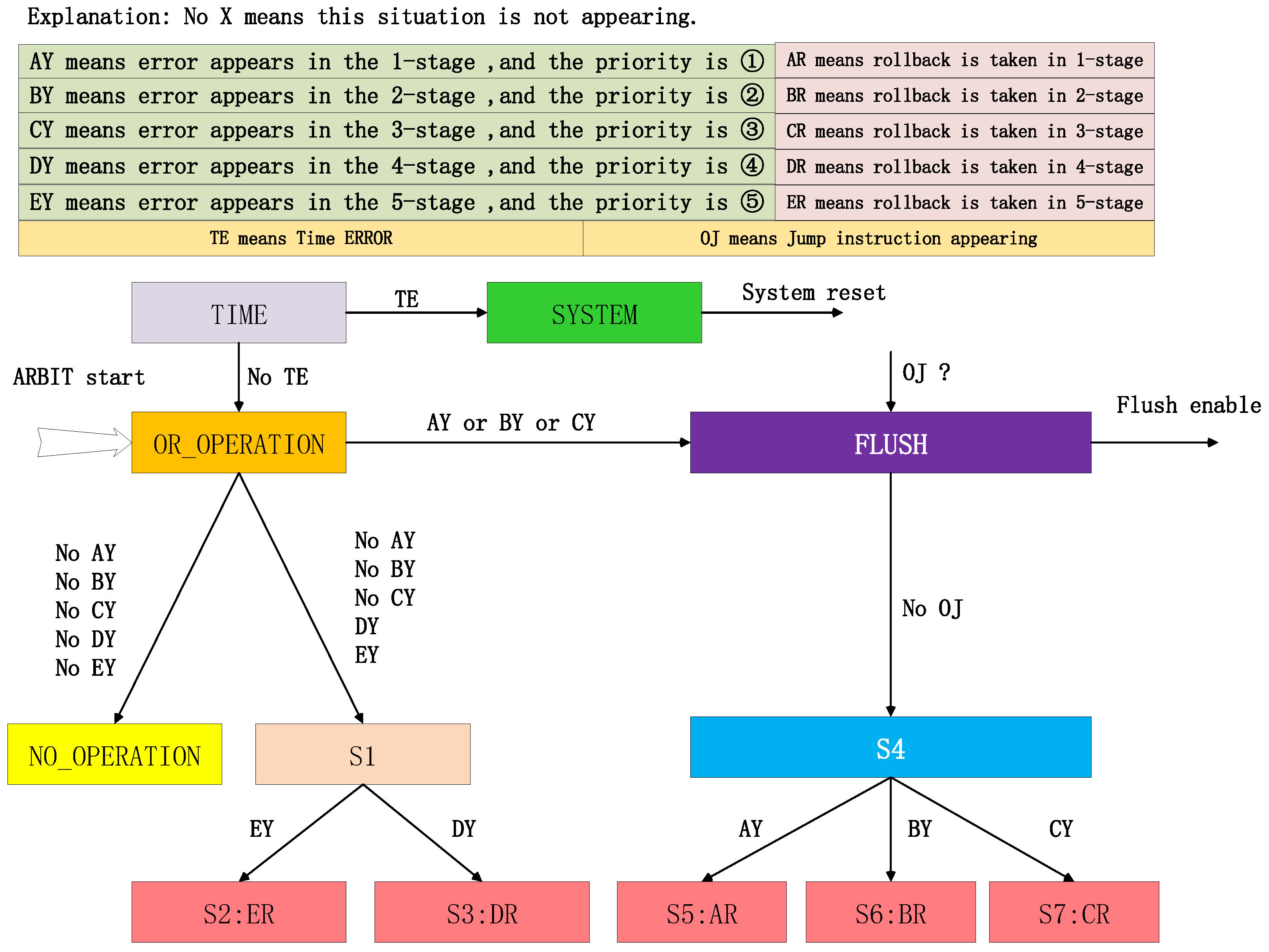
Figure 14.
Flush module: The module is embedded in the ARBIT module to determine whether the current instruction needs to be refreshed according to the received error type, priority, and instruction type. If there is an error appearing in the levels of the first–third stage, the jump situation needs to be determined.
Figure 14.
Flush module: The module is embedded in the ARBIT module to determine whether the current instruction needs to be refreshed according to the received error type, priority, and instruction type. If there is an error appearing in the levels of the first–third stage, the jump situation needs to be determined.
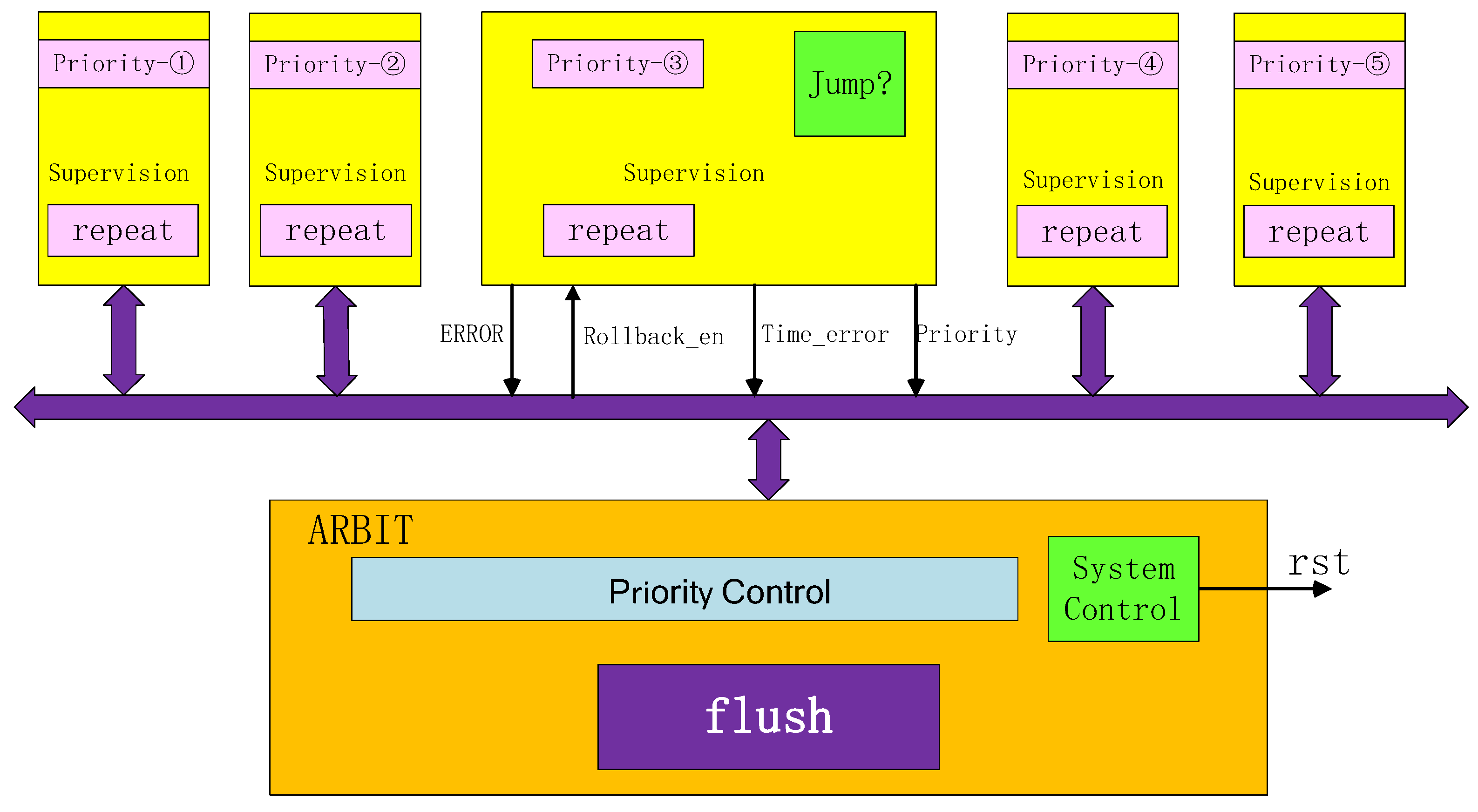
Figure 15.
The relationship between the arbiter and the supervisory module. The yellow part of the figure shows the SUPERVISION modules distributed between the 1–5 stages of the pipeline, which are distributed from left to right to monitor the error conditions of the 1–5 stages of the pipeline in turn. The SUPERVISION module summarizes the collected error signal, priority, and instruction type to the ARBIT module. The ARBIT module determines the rollback strategy through internal judgment and sends the rollback command back to each SUPERVISION module.
Figure 15.
The relationship between the arbiter and the supervisory module. The yellow part of the figure shows the SUPERVISION modules distributed between the 1–5 stages of the pipeline, which are distributed from left to right to monitor the error conditions of the 1–5 stages of the pipeline in turn. The SUPERVISION module summarizes the collected error signal, priority, and instruction type to the ARBIT module. The ARBIT module determines the rollback strategy through internal judgment and sends the rollback command back to each SUPERVISION module.
Figure 16.
Internal operation diagram of the ARBIT module.
Figure 16.
Internal operation diagram of the ARBIT module.
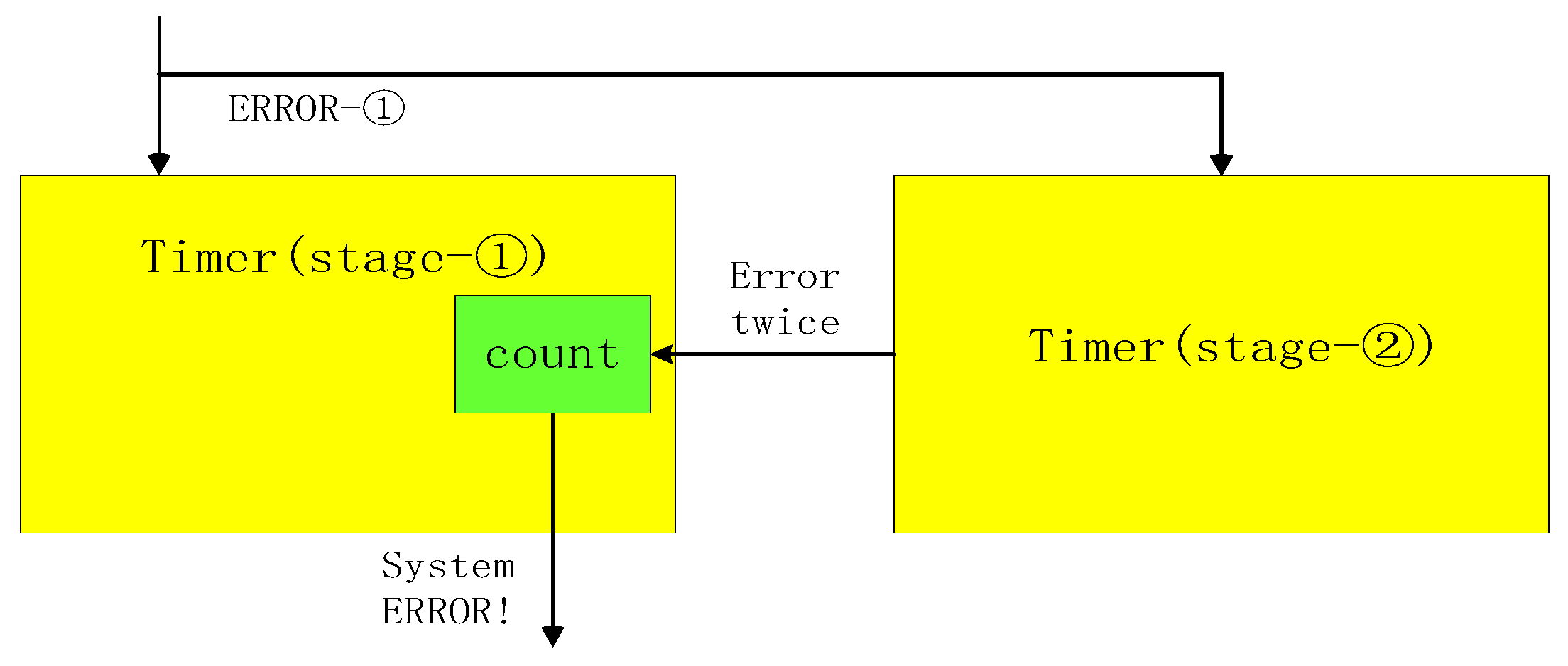
Figure 17.
Fatal error abnormal monitoring. The module is embedded between 1 to 5 stages of the pipeline and is placed at every two stages of the pipeline to monitor whether the errors between two adjacent decoding modules occur repeatedly. If the interval period is one cycle, the count will increase by 1, and a fatal information alarm will be sent after the count reaches the threshold. Then, the system generates a system ERROR.
Figure 17.
Fatal error abnormal monitoring. The module is embedded between 1 to 5 stages of the pipeline and is placed at every two stages of the pipeline to monitor whether the errors between two adjacent decoding modules occur repeatedly. If the interval period is one cycle, the count will increase by 1, and a fatal information alarm will be sent after the count reaches the threshold. Then, the system generates a system ERROR.
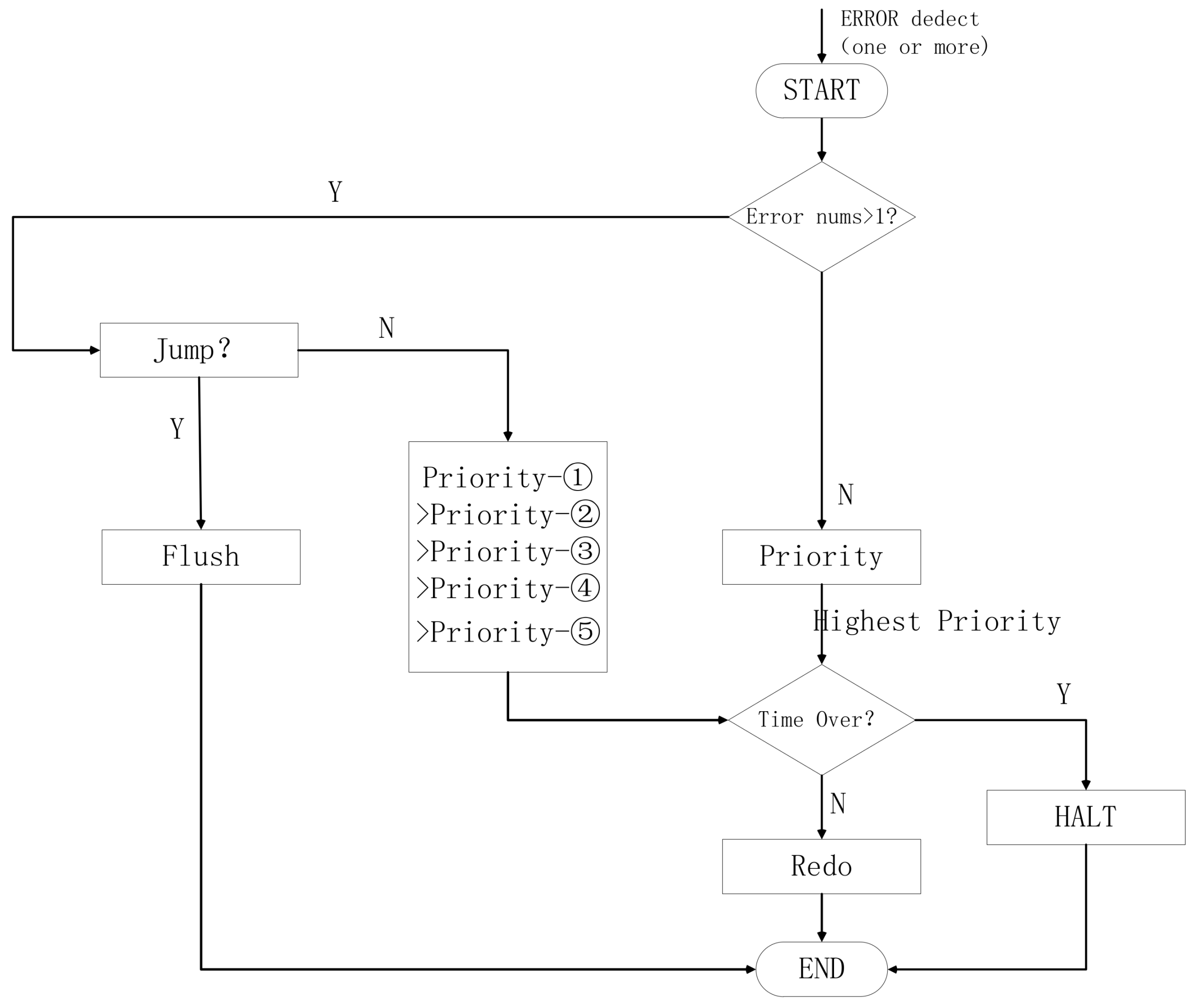
Figure 18.
Flowchart of fault-tolerant rollback operation.
Figure 18.
Flowchart of fault-tolerant rollback operation.
Figure 19.
Program operation abnormal data flow 1.
Figure 19.
Program operation abnormal data flow 1.
Figure 20.
Program operation abnormal data flow 2.
Figure 20.
Program operation abnormal data flow 2.
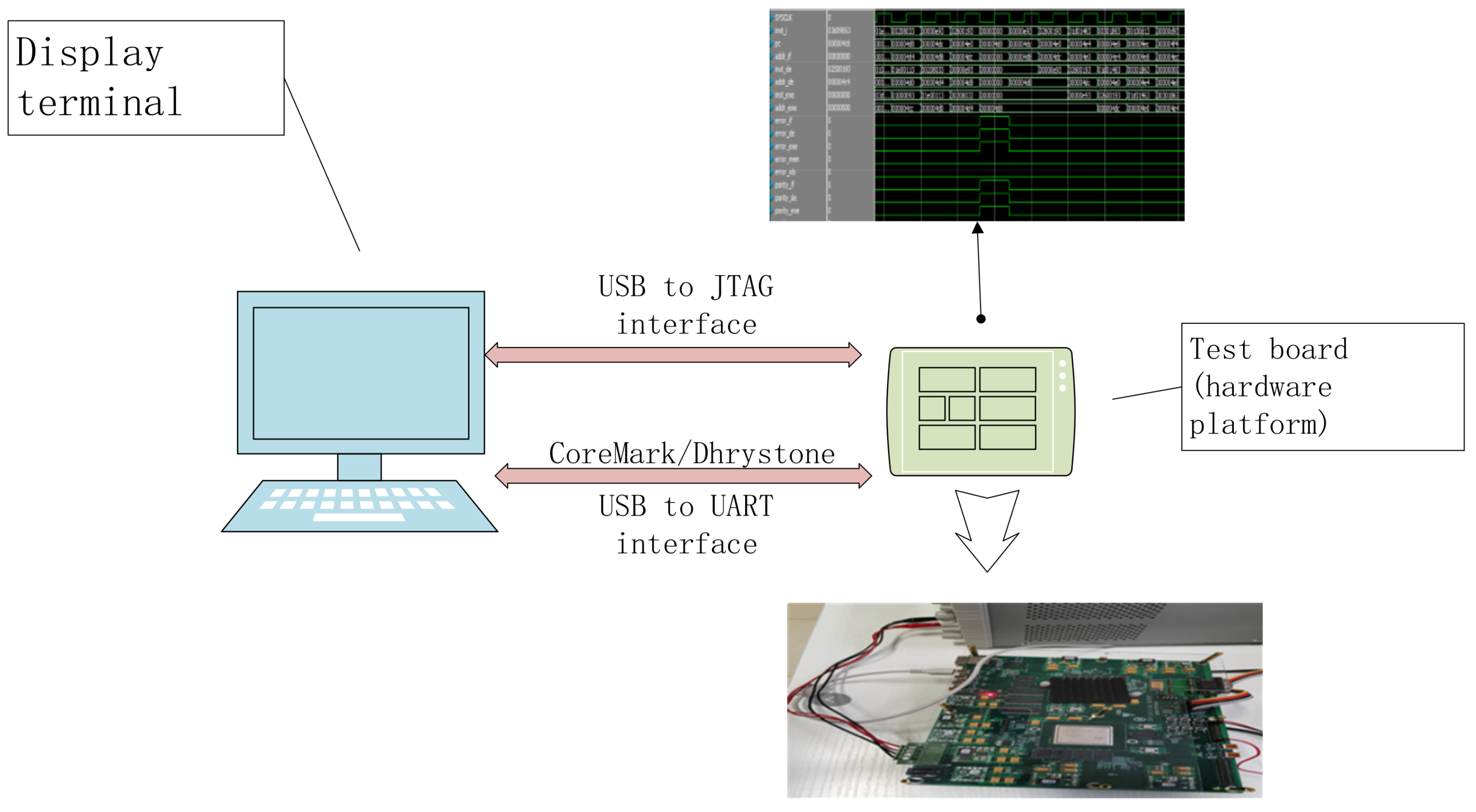
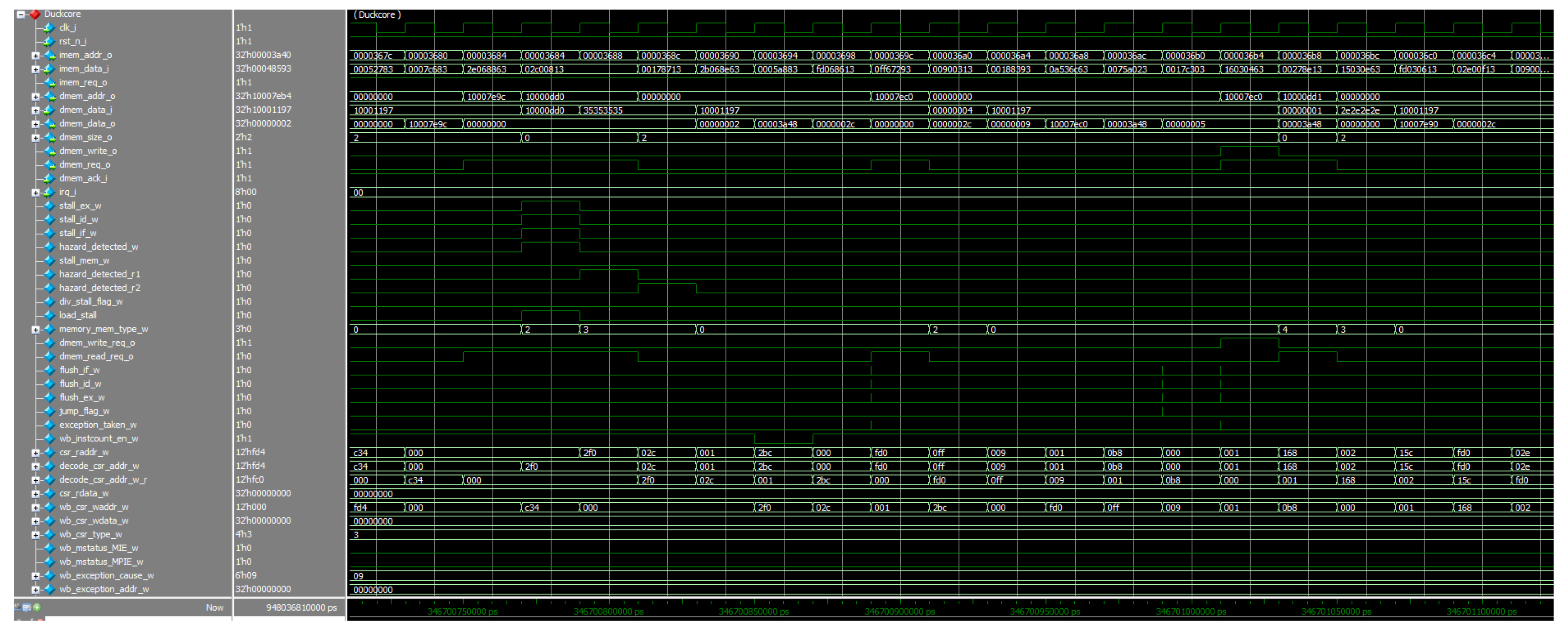
Figure 21.
Hardware interaction platform.
Figure 21.
Hardware interaction platform.
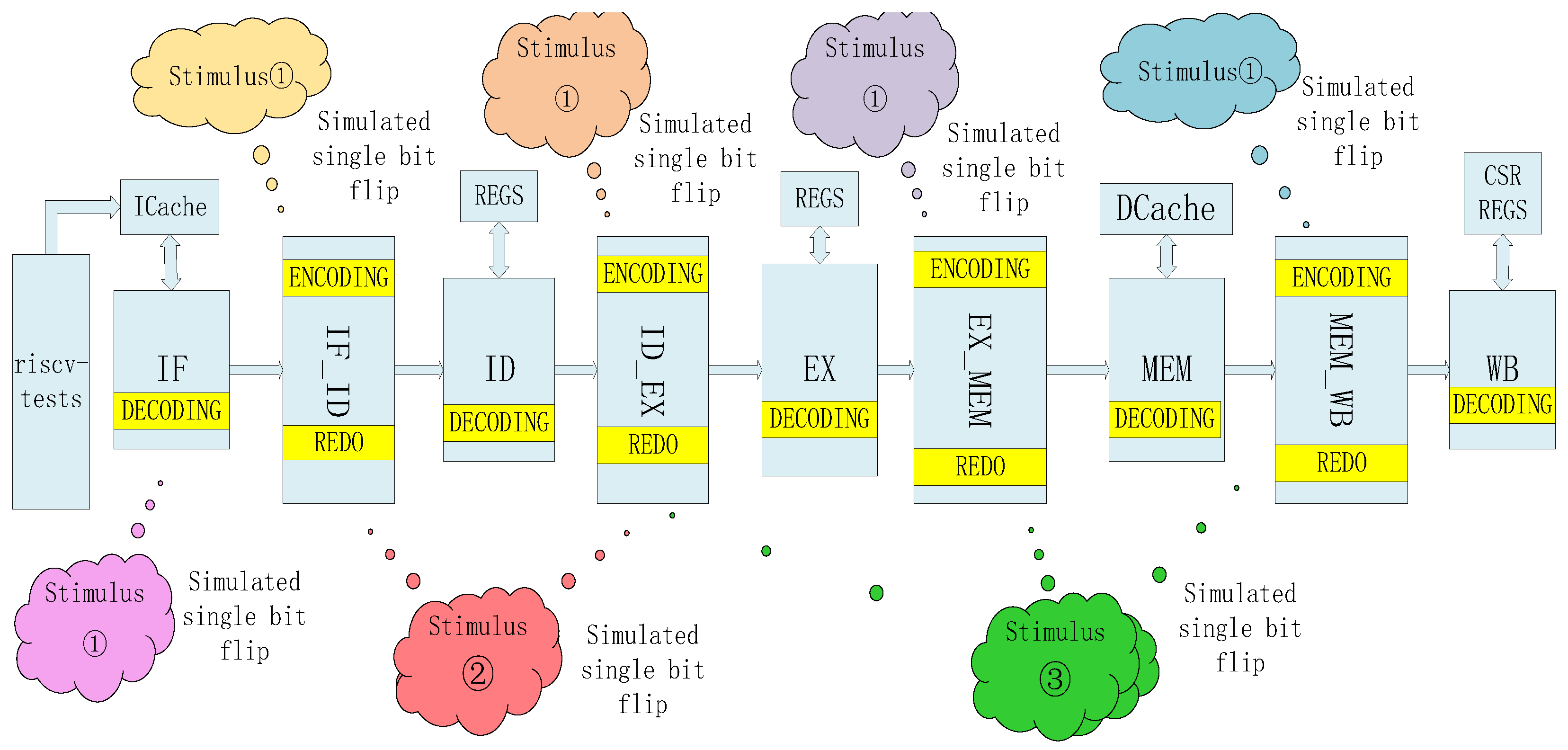
Figure 22.
Simulation test excitation diagram.
Figure 22.
Simulation test excitation diagram.
Figure 23.
Encoding embedded in the CSR control module.
Figure 23.
Encoding embedded in the CSR control module.
Figure 24.
CSR instruction test incentive flow chart.
Figure 24.
CSR instruction test incentive flow chart.
Figure 25.
Decoding-stage error rollback strategy.
Figure 25.
Decoding-stage error rollback strategy.
Figure 26.
Decoding-stage error is flushed by jump instruction.
Figure 26.
Decoding-stage error is flushed by jump instruction.
Figure 27.
Exception handling in the case of multiple errors in a single cycle.
Figure 27.
Exception handling in the case of multiple errors in a single cycle.
Figure 28.
Fatal error handling diagram.
Figure 28.
Fatal error handling diagram.
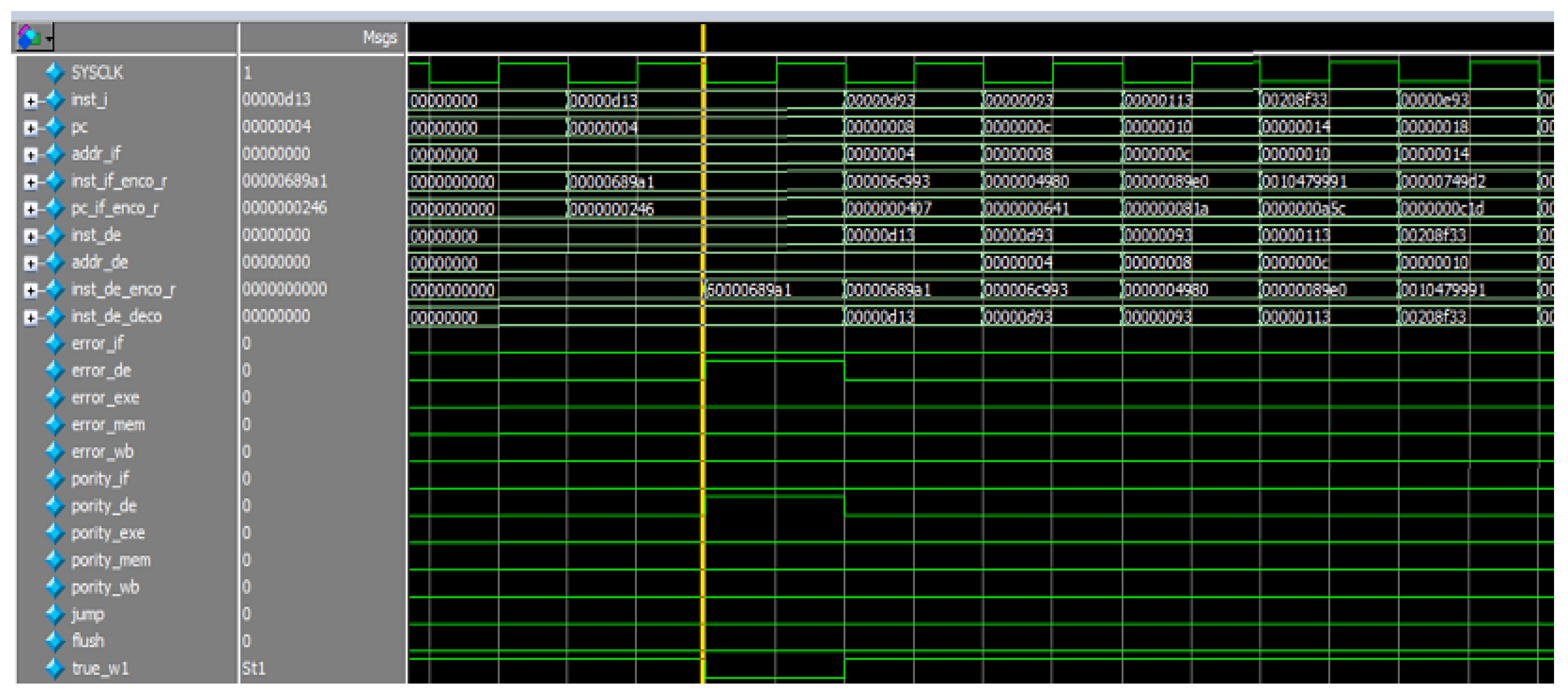
Figure 29.
CoreMark operation waveform.
Figure 29.
CoreMark operation waveform.
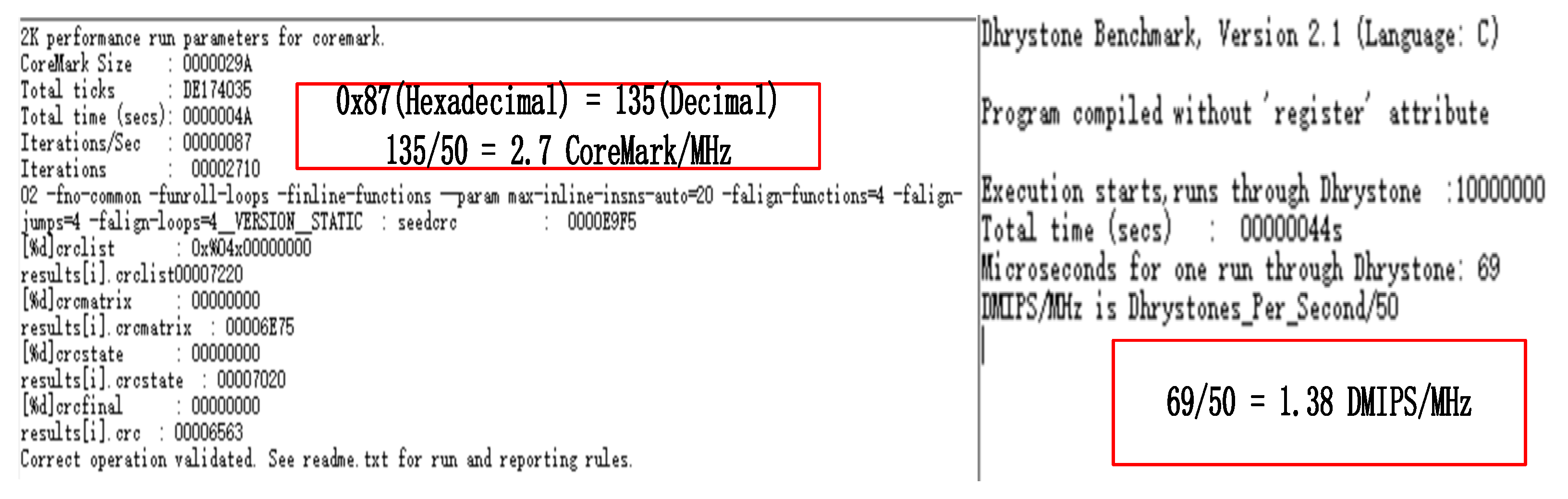
Figure 30.
Operation result display diagram of CoreMark and Dhrystone.
Figure 30.
Operation result display diagram of CoreMark and Dhrystone.
Figure 31.
Dhrystone running scores under different error injection frequencies.
Figure 31.
Dhrystone running scores under different error injection frequencies.
Figure 32.
CoreMark running scores under different error injection frequencies.
Figure 32.
CoreMark running scores under different error injection frequencies.
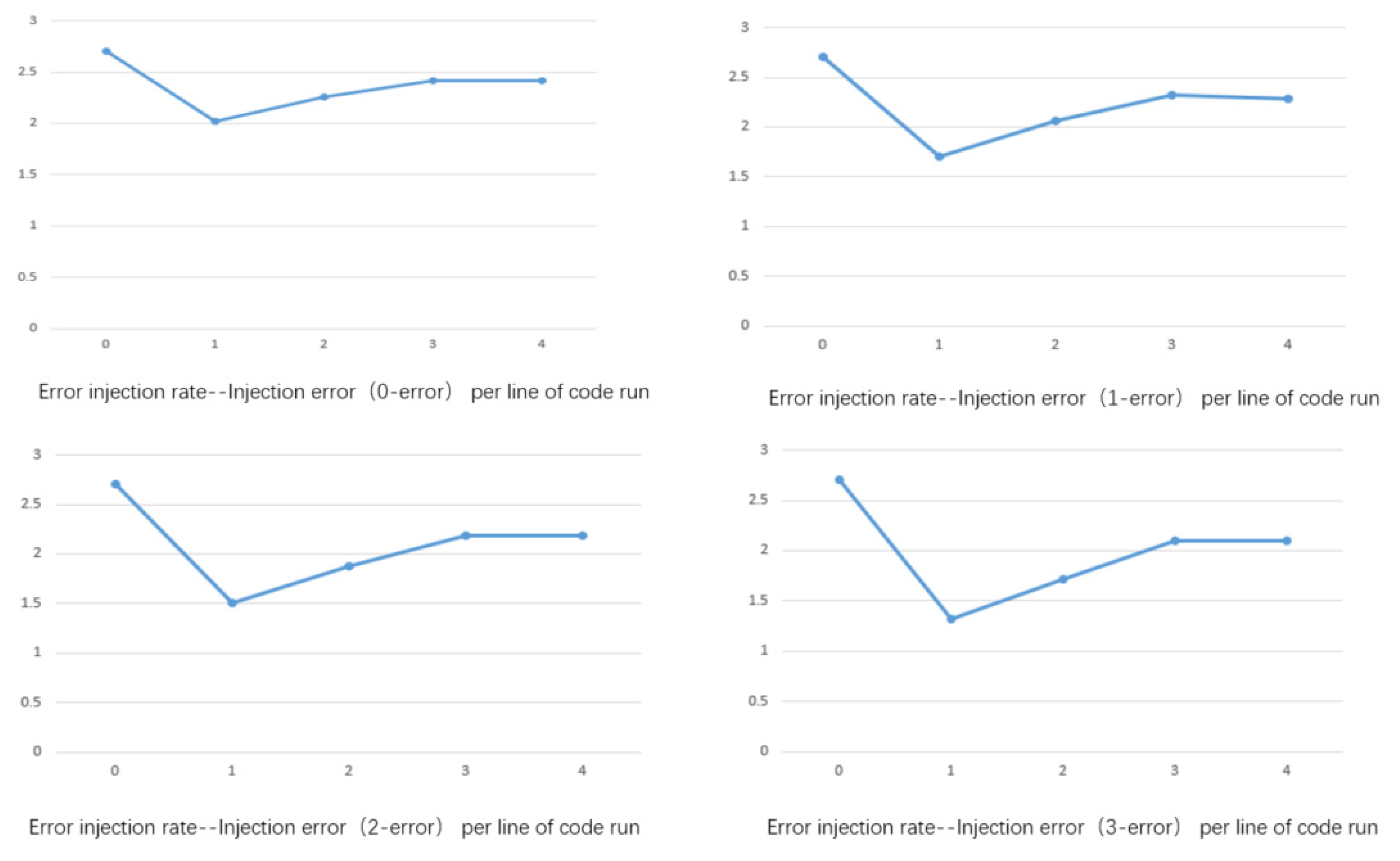
Table 1.
Running results of CoreMark and Dhrystone under different error injections.
Table 1.
Running results of CoreMark and Dhrystone under different error injections.
| X-Errors | Abscissa | CoreMark | Dhrystone |
|---|
| 0 | 1 | 2.02 | 0.92 |
| 0 | 2 | 2.26 | 1.1 |
| 0 | 3 | 2.40 | 1.18 |
| 0 | 4 | 2.42 | 1.2 |
| 1 | 1 | 1.7 | 0.68 |
| 1 | 2 | 2.06 | 0.96 |
| 1 | 3 | 2.27 | 1.08 |
| 1 | 4 | 2.28 | 1.14 |
| 2 | 1 | 1.5 | 0.6 |
| 2 | 2 | 1.88 | 0.78 |
| 2 | 3 | 2.16 | 1 |
| 2 | 4 | 2.18 | 1.06 |
| 3 | 1 | 1.32 | 0.68 |
| 3 | 2 | 1.72 | 0.72 |
| 3 | 3 | 2.1 | 0.92 |
| 3 | 4 | 2.12 | 1.01 |
Table 2.
Comparison of resources occupied by fault-tolerant solutions of different open-source cores.
Table 2.
Comparison of resources occupied by fault-tolerant solutions of different open-source cores.
| Processor Core | ISA | Slice LUTs | Slice | LUT as Logic |
|---|
| DuckCore | Rv32IM | 2916(1.43%) | 266 | 2916 |
| DuckCore (change Architecture) | Rv32IM | 3073(1.5%) | 2093 | 3073 |
| V-scale | Rv32IM | 2700(1.32%) | 1003 | 2700 |
| V-scale (change Architecture) | Rv32IM | 2700(1.32%) | 1904 | 2700 |
| Ultrascale | Rv32IM | 3598(1.77%) | 2706 | 3598 |
| Ultrascale (change Architecture) | Rv32IM | 4223(2.07%) | 4223 | 3598 |
| Tinyriscv | Rv32IM | 5754(2.82%) | 1984 | 5754 |
| Tinyriscv (change Architecture) | Rv32IM | 5754(2.82%) | 2637 | 5754 |
Table 3.
Comparison of resource occupation under different codes.
Table 3.
Comparison of resource occupation under different codes.
| Processor Core | Slice LUTs |
|---|
| Ultrascale | 3598(1.77%) |
| Ultrascale (use Classic SECDED) | 4877(1.77%) |
| Ultrascale (use improved SECDED) | 4223(2.07%) |
| DuckCore | 2916(1.43%) |
| DuckCore (use Classic SECDED) | 3621(1.78%) |
| DuckCore (use improved SECDED) | 3073(1.5%) |
Table 4.
Comparison of power consumption under different codes.
Table 4.
Comparison of power consumption under different codes.
| Processor Core | Total on-Chip Power |
|---|
| DuckCore | 0.214 W |
| DuckCore (change Architecture with Classic SECDED) | 0.244 W |
| DuckCore (change Architecture with improved SECDED) | 0.227 W |
Table 5.
Comparison of different processor core indicators.
Table 5.
Comparison of different processor core indicators.
| Processor Core | ISA | Core | One-Bit Error | Two-Bit Error | M-Bit Error |
|---|
| DuckCore | RV32IM | 1 | Y | Y—support 1–5piple | Part support |
| SHAKTI-F | Rv32I | 1 | Y | Y—support 3piple | No support |
| DIVA | SPARC | 2 | Part support | Part support | Part support |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}