
MC-ASFF-ShipYOLO: Improved Algorithm for Small-Target and Multi-Scale Ship Detection for Synthetic Aperture Radar (SAR) Images



Abstract
:1. Introduction
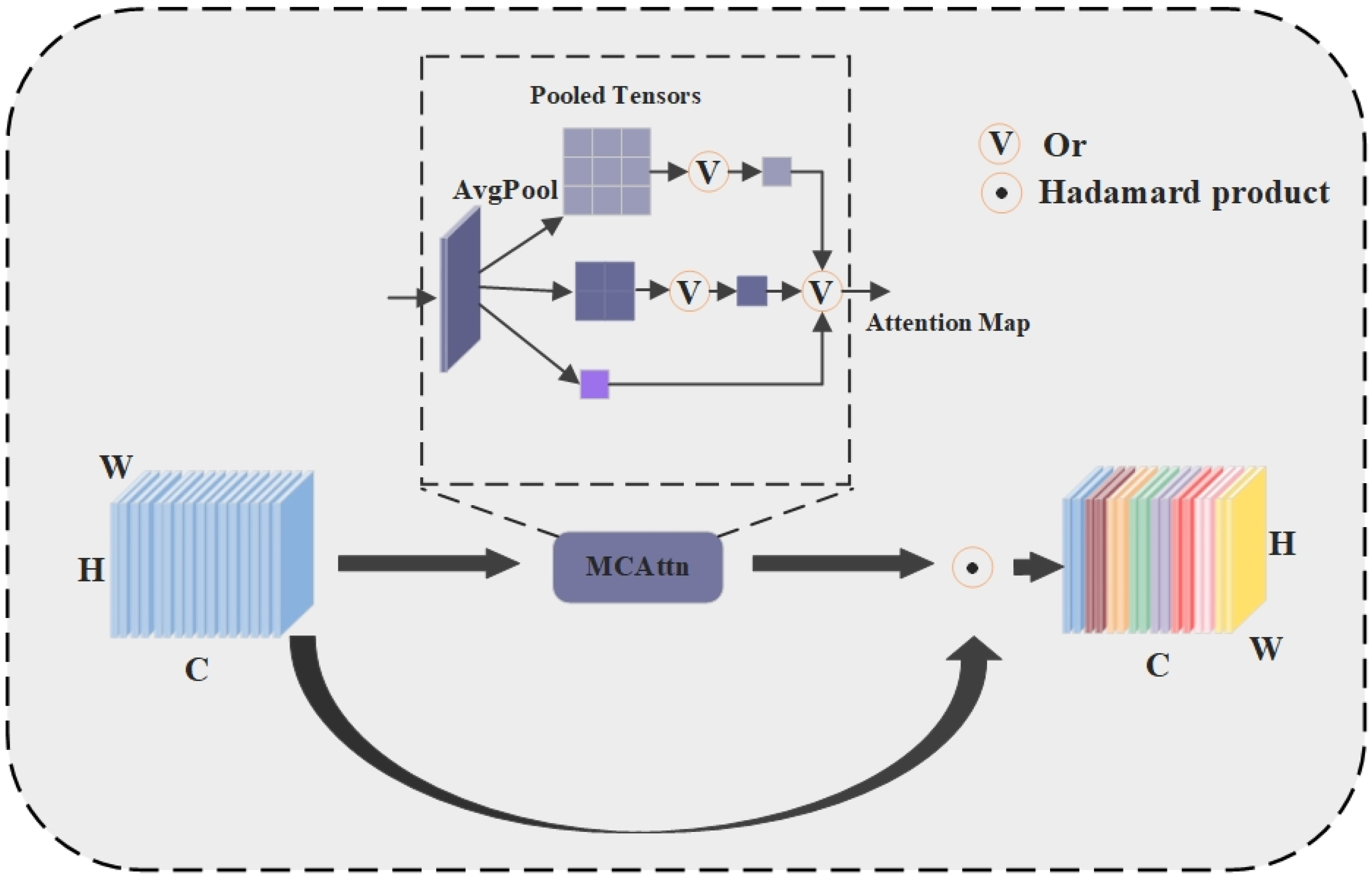
- We introduce the MCAttn module to enhance backbone network performance. This module randomly selects one attention map from three different scales through stochastic sampling pooling operations for the weighting of feature maps. By capturing multi-scale information, the MCAttn module improves the backbone network’s ability to discriminate small ship morphology and position, enhances focus on small targets, prevents information loss during network deepening, and strengthens contextual relationship learning. The module effectively enhances the feature representation of small ships, thereby improving the model’s detection capability for small ship targets.
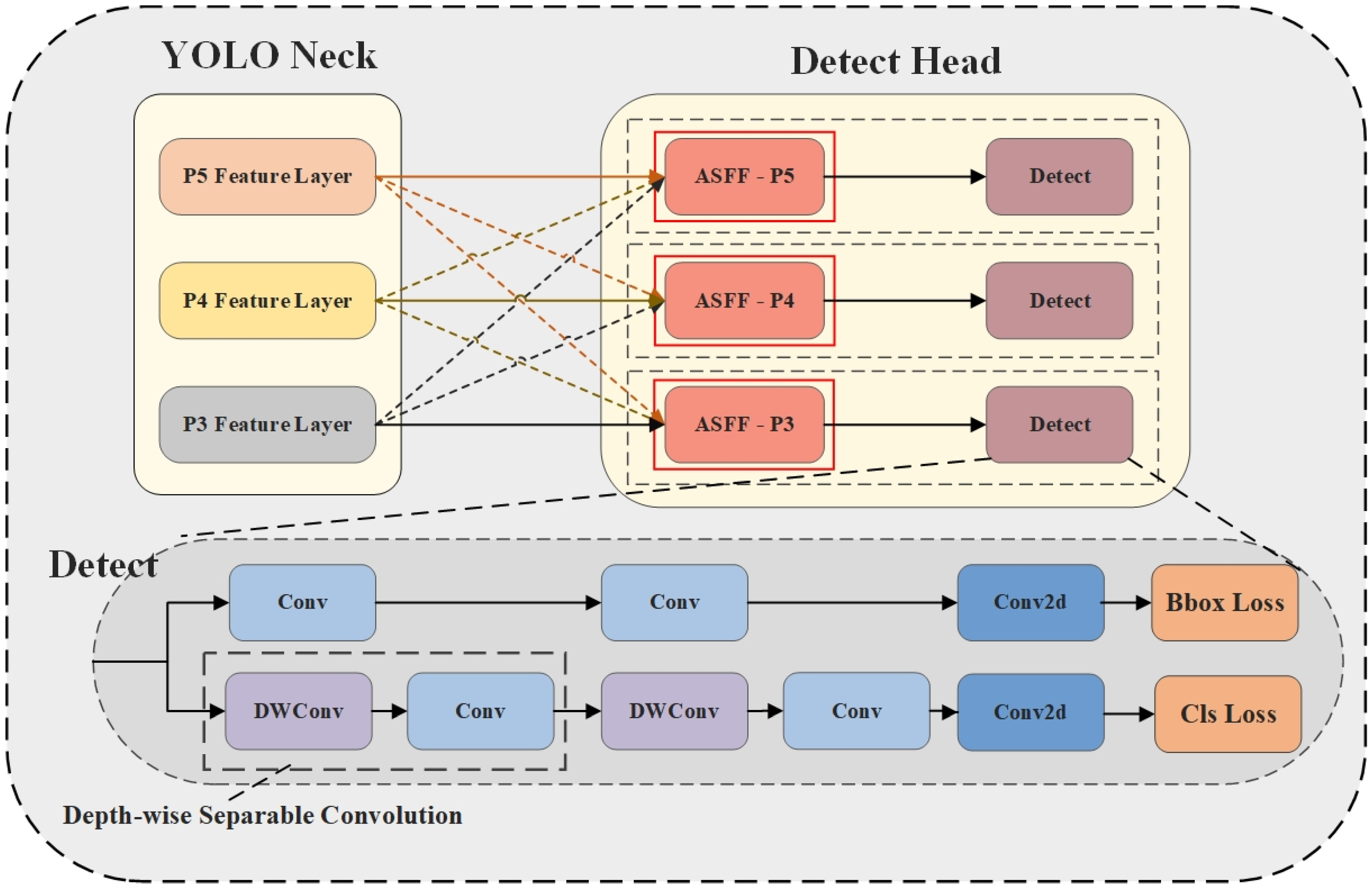
- We incorporated the ASFF module into the detection head, which adaptively learns spatial fusion weights across multi-scale feature layers and performs dynamic feature integration. This approach ensures the consistency of ship feature representations across different scales, effectively mitigating the problem of feature conflicts between varying feature layers. Consequently, the model’s multi-scale ship detection capability is enhanced.
- We propose MC-ASFF-ShipYOLO, an improved deep-learning ship detection model that demonstrates superior precision compared to other baseline models when evaluated on the mixed HRSID and SSDD datasets. Our detection framework effectively improves the critical challenges arising from small target recognition and multi-scale feature representation in SAR ship detection tasks. The experimental results validate the efficacy of our approach and provide valuable methodological guidance for future research in maritime target detection.
2. Materials and Methods
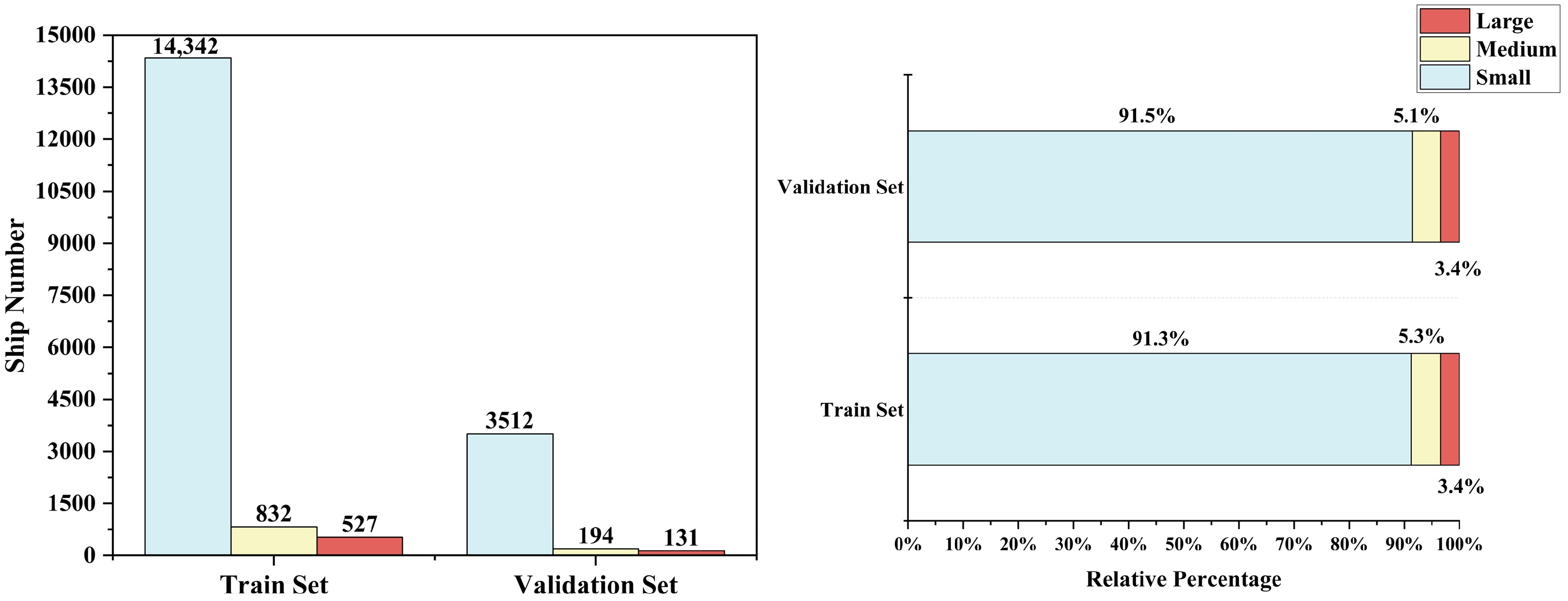
2.1. Dataset Introduction
2.2. Implementation Details
2.3. Evaluation Metrics
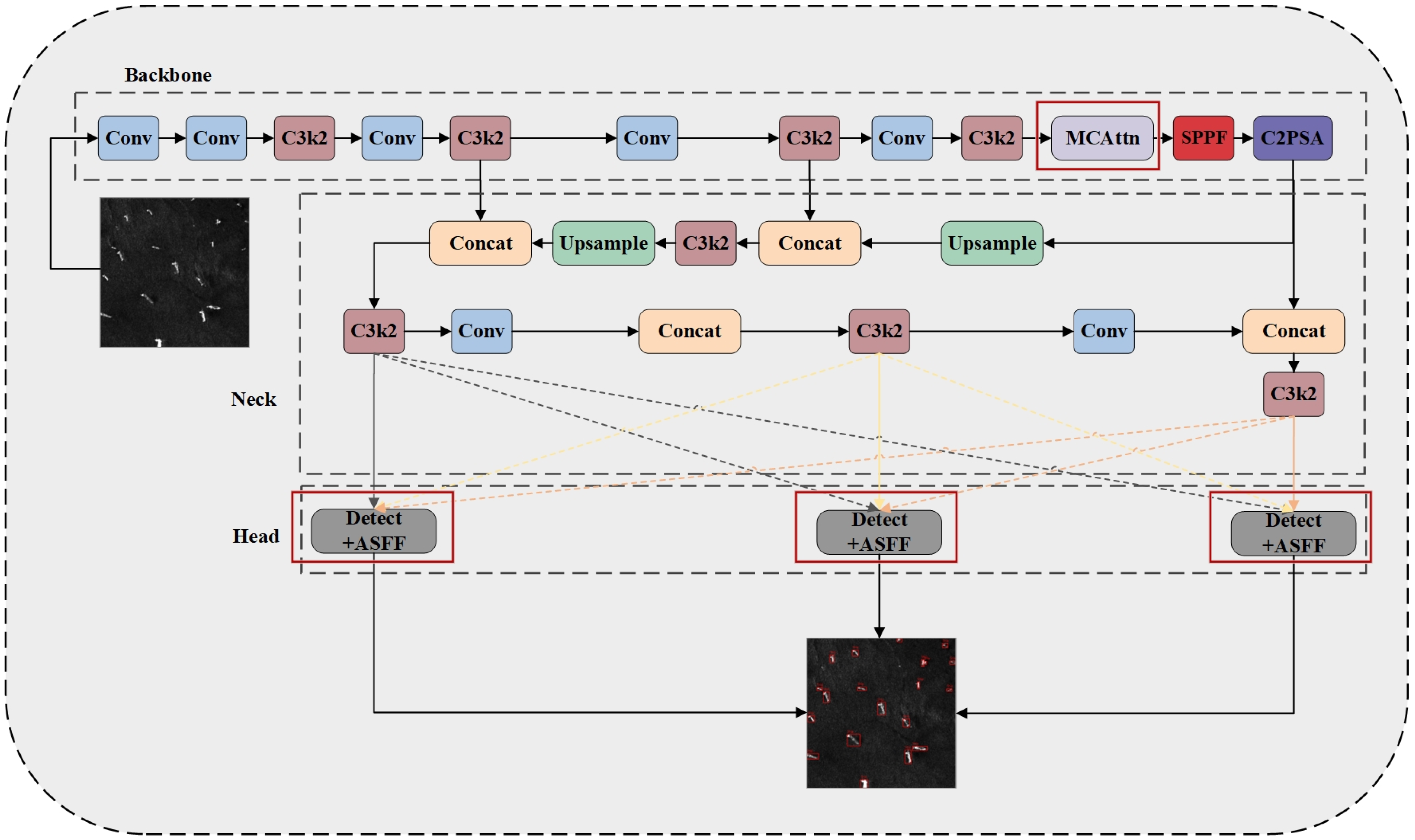
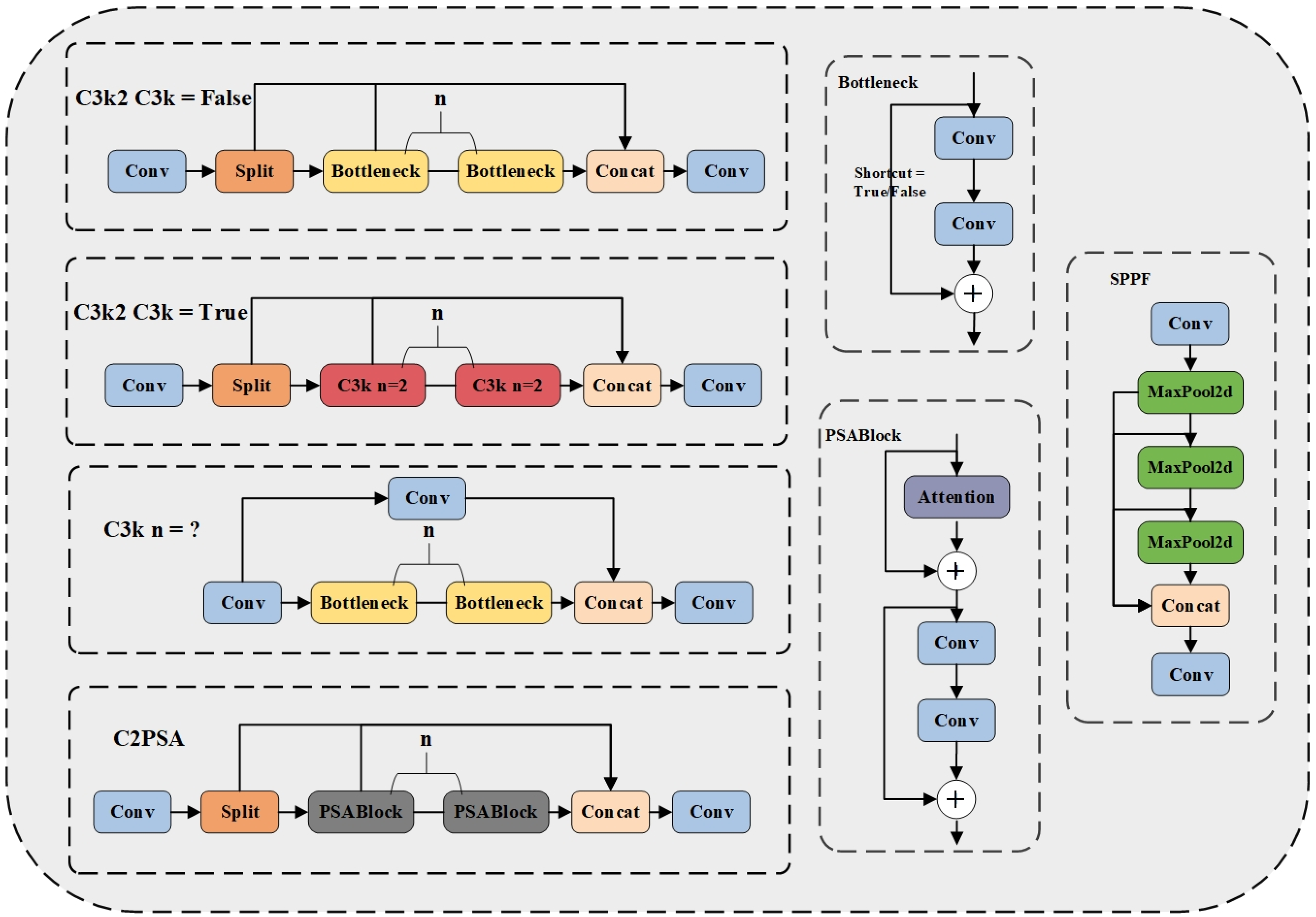
2.4. The MC-ASFF-ShipYOLO Model
2.4.1. Monte Carlo Attention (MCAttn)
2.4.2. Adaptively Spatial Feature Fusion (ASFF)
- Feature Resizing
- 2.
- Adaptive Fusion
2.4.3. Loss Function
3. Results
3.1. Comparison Experiment
3.2. Qualitative Analysis of Ship Detection Results
4. Discussion
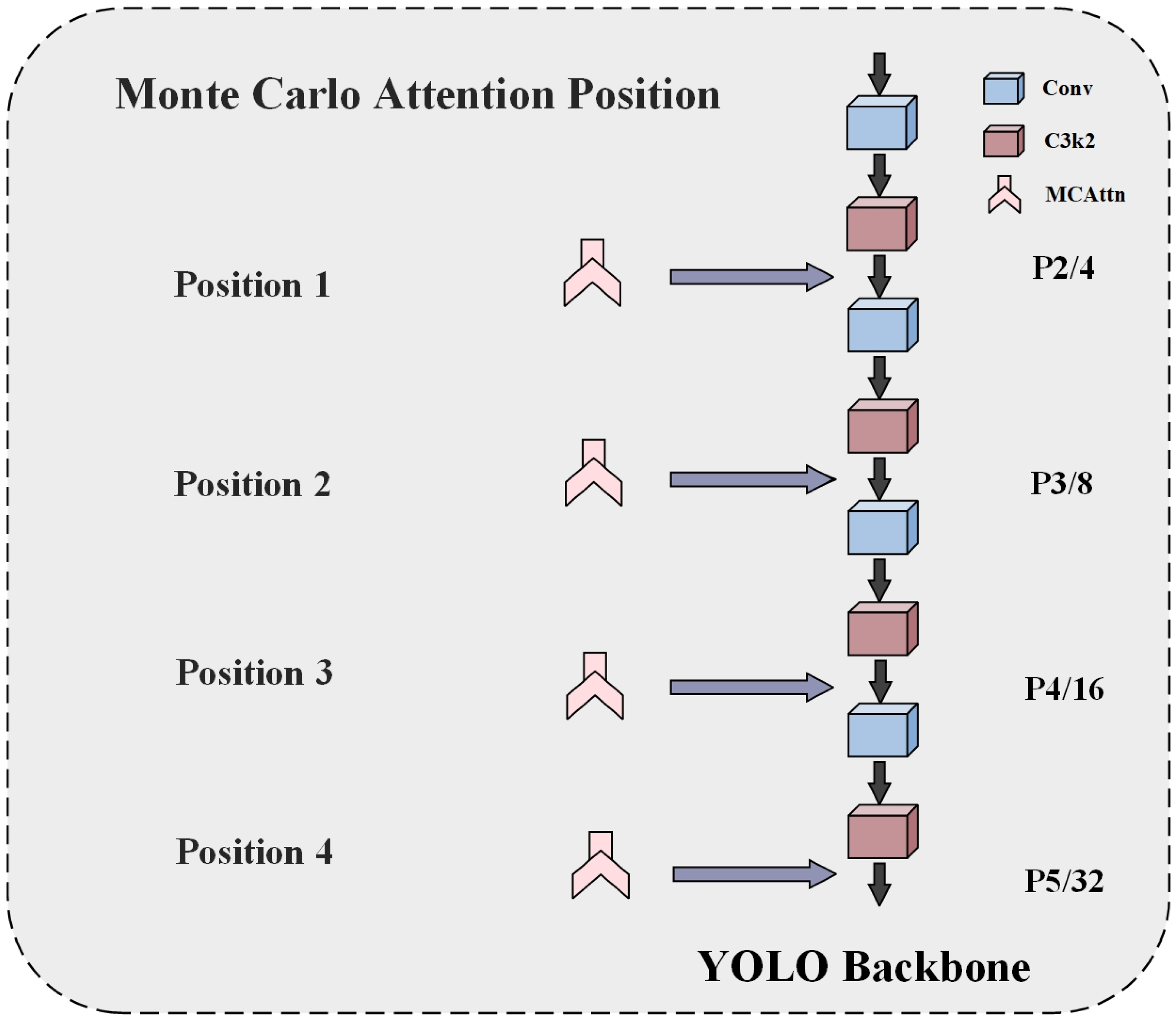
4.1. Effectiveness of the MCAttn and Its Optimal Placement
4.2. Comparative Evaluation of Similar Approaches
4.3. Ablation Experiment
4.4. Analyze the Contribution of the Improvement Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paolo, F.S.; Kroodsma, D.; Raynor, J.; Hochberg, T.; Davis, P.; Cleary, J.; Marsaglia, L.; Orofino, S.; Thomas, C.; Halpin, P. Satellite mapping reveals extensive industrial activity at sea. Nature 2024, 625, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Min, L.; Dou, F.; Zhang, Y.; Shao, D.; Li, L.; Wang, B. CM-YOLO: Context Modulated Representation Learning for Ship Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4202414. [Google Scholar] [CrossRef]
- Alexandre, C.; Devillers, R.; Mouillot, D.; Seguin, R.; Catry, T. Ship detection with SAR C-Band satellite images: A systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14353–14367. [Google Scholar] [CrossRef]
- Er, M.J.; Zhang, Y.; Chen, J.; Gao, W. Ship detection with deep learning: A survey. Artif. Intell. Rev. 2023, 56, 11825–11865. [Google Scholar] [CrossRef]
- Sharma, R.; Saqib, M.; Lin, C.; Blumenstein, M. MASSNet: Multiscale attention for single-stage ship instance segmentation. Neurocomputing 2024, 594, 127830. [Google Scholar] [CrossRef]
- Owda, A.; Dall, J.; Badger, M.; Cavar, D. Improving SAR wind retrieval through automatic anomalous pixel detection. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103444. [Google Scholar] [CrossRef]
- Tsokas, A.; Rysz, M.; Pardalos, P.M.; Dipple, K. SAR data applications in earth observation: An overview. Expert Syst. Appl. 2022, 205, 117342. [Google Scholar] [CrossRef]
- Chen, X.; Tao, H.; Zhou, H.; Zhou, P.; Deng, Y. Hierarchical and progressive learning with key point sensitive loss for sonar image classification. Multimed. Syst. 2024, 30, 380. [Google Scholar] [CrossRef]
- Muhammad, Y.; Liu, S.; Xu, M.; Wan, J.; Sheng, H.; Shah, N.; Xin, Z.; Arife Tugsan, I.C. YOLOv8-BYTE: Ship tracking algorithm using short-time sequence SAR images for disaster response leveraging GeoAI. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103771. [Google Scholar]
- Pappas, O.; Achim, A.; Bull, D. Superpixel-level CFAR detectors for ship detection in SAR imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1397–1401. [Google Scholar] [CrossRef]
- Rihan, M.Y.; Nossair, Z.B.; Mubarak, R.I. An improved CFAR algorithm for multiple environmental conditions. Signal Image Video Process. 2024, 18, 3383–3393. [Google Scholar] [CrossRef]
- Ponsford, A.; McKerracher, R.; Ding, Z.; Moo, P.; Yee, D. Towards a Cognitive Radar: Canada’s Third-Generation High Frequency Surface Wave Radar (HFSWR) for Surveillance of the 200 Nautical Mile Exclusive Economic Zone. Sensors 2017, 17, 1588. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Yu, C.; Shin, Y. SAR ship detection based on improved YOLOv5 and BiFPN. ICT Express 2024, 10, 28–33. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Cheng, P.; Yu, Z.; Yu, L.; Chi, C. A survey on deep-learning-based real-time SAR ship detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3218–3247. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Ke, X.; Zhang, X.; Zhang, T.; Shi, J.; Wei, S. SAR ship detection based on an improved faster R-CNN using deformable convolution. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3565–3568. [Google Scholar]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Wang, Z.; Du, L.; Mao, J.; Liu, B.; Yang, D. SAR target detection based on SSD with data augmentation and transfer learning. IEEE Geosci. Remote Sens. Lett. 2018, 16, 150–154. [Google Scholar] [CrossRef]
- Miao, T.; Zeng, H.; Yang, W.; Chu, B.; Zou, F.; Ren, W.; Chen, J. An improved lightweight RetinaNet for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4667–4679. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Li, S.; Zhou, H.; Wang, S.; Feng, Z. A novel anchor-free method based on FCOS + ATSS for ship detection in SAR images. Remote Sens. 2022, 14, 2034. [Google Scholar] [CrossRef]
- Yu, C.; Shin, Y. SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions. Remote Sens. 2025, 17, 953. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, L.; Wang, X.; Li, G.; He, Y.; Liu, Y. RDB-DINO: An Improved End-to-End Transformer with Refined De-Noising and Boxes for Small-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2024, 63, 5200517. [Google Scholar] [CrossRef]
- Khan, A.; Rauf, Z.; Sohail, A.; Khan, A.R.; Asif, H.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56, 2917–2970. [Google Scholar] [CrossRef]
- Zhao, C.; Fu, X.; Dong, J.; Cao, S.; Zhang, C. Enhancing, Refining, and Fusing: Towards Robust Multi-Scale and Dense Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 9919–9933. [Google Scholar] [CrossRef]
- Yasir, M.; Shanwei, L.; Mingming, X.; Jianhua, W.; Nazir, S.; Islam, Q.U.; Dang, K.B. SwinYOLOv7: Robust ship detection in complex synthetic aperture radar images. Appl. Soft Comput. 2024, 160, 111704. [Google Scholar] [CrossRef]
- Zhou, R.; Gu, M.; Hong, Z.; Pan, H.; Zhang, Y.; Han, Y.; Wang, J.; Yang, S. SIDE-YOLO: A Highly Adaptable Deep Learning Model for Ship Detection and Recognition in Multisource Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2025, 22, 1501405. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Y.; Chen, F.; Shang, E.; Yao, W.; Zhang, S.; Yang, J. YOLOv7oSAR: A Lightweight High-Precision Ship Detection Model for SAR Images Based on the YOLOv7 Algorithm. Remote Sens. 2024, 16, 913. [Google Scholar] [CrossRef]
- Gong, Y.; Zhang, Z.; Wen, J.; Lan, G.; Xiao, S. Small ship detection of SAR images based on optimized feature pyramid and sample augmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7385–7392. [Google Scholar] [CrossRef]
- Yue, T.; Zhang, Y.; Liu, P.; Xu, Y.; Yu, C. A generating-anchor network for small ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7665–7676. [Google Scholar] [CrossRef]
- Gao, S.; Liu, J.M.; Miao, Y.H.; He, Z.J. A high-effective implementation of ship detector for SAR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4019005. [Google Scholar] [CrossRef]
- Chen, P.; Li, Y.; Zhou, H.; Liu, B.; Liu, P. Detection of small ship objects using anchor boxes cluster and feature pyramid network model for SAR imagery. J. Mar. Sci. Eng. 2020, 8, 112. [Google Scholar] [CrossRef]
- Li, X.; Duan, W.; Fu, X.; Lv, X. R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation. Remote Sens. 2025, 17, 551. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Wang, N.; Gao, X. A robust one-stage detector for multiscale ship detection with complex background in massive SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5217712. [Google Scholar] [CrossRef]
- Zhou, L.; Wan, Z.; Zhao, S.; Han, H.; Liu, Y. BFEA: A SAR Ship Detection model based on Attention mechanism and Multi-scale Feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11163–11177. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, J.; Xia, Y.; Xiao, H. DBW-YOLO: A high-precision SAR ship detection method for complex environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7029–7039. [Google Scholar] [CrossRef]
- Wang, X.; Xu, W.; Huang, P.; Tan, W. MSSD-Net: Multi-Scale SAR Ship Detection Network. Remote Sens. 2024, 16, 2233. [Google Scholar] [CrossRef]
- Fan, X.; Hu, Z.; Zhao, Y.; Chen, J.; Wei, T.; Huang, Z. A small ship object detection method for satellite remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11886–11898. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Dai, W.; Liu, R.; Wu, Z.; Wu, T.; Wang, M.; Zhou, J.; Yuan, Y.; Liu, J. Exploiting Scale-Variant Attention for Segmenting Small Medical Objects. arXiv 2024, arXiv:2407.07720. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y.; et al. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef]
- Yamauchi, T. Spatial Sensitive Grad-CAM++: Improved visual explanation for object detectors via weighted combination of gradient map. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 8164–8168. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Model/Parameter |
|---|---|
| Operation system | Windows 11 |
| CPU | Intel(R) Xeon(R) Gold 6430 @2.10 GHz |
| GPU | NVIDIA GeForce RTX 4090 (24,564 MiB) |
| RAM | 120 GB |
| Compiler | Python3.11.11 |
| Framework | CUDA12.4/cudnn9.1.0/torch2.6.0 |
| Models | Backbone | Batch Size | lr0 | lrf | NMS |
|---|---|---|---|---|---|
| Faster R-CNN | R50 | 16 | 0.01 | 0.0001 | 0.6 |
| R101 | 12 | 0.01 | 0.0001 | 0.7 | |
| Cascade R-CNN | R50 | 16 | 0.01 | 0.0001 | 0.6 |
| R101 | 16 | 0.01 | 0.0001 | 0.7 | |
| EfficientNet | Eff-b3 | 6 | 0.01 | 0.0001 | - |
| Models | Backbone or Size | /% | /% | /% | /% | Params (M) | FPS (img/s) |
|---|---|---|---|---|---|---|---|
| YOLOv8 | n | 90.85 | 82.83 | 90.67 | 64.05 | 3.01 | 666.67 |
| s | 90.74 | 84.75 | 91.81 | 65.24 | 11.13 | 370.37 | |
| YOLOv9 | t | 91.11 | 83.82 | 91.55 | 65.76 | 1.97 | 555.57 |
| s | 90.90 | 84.94 | 91.97 | 67.53 | 7.17 | 333.33 | |
| YOLOv10 | n | 88.90 | 81.55 | 90.11 | 65.20 | 2.70 | 666.67 |
| s | 91.09 | 83.40 | 91.76 | 66.77 | 8.04 | 384.62 | |
| YOLO11 | n | 90.41 | 81.56 | 89.20 | 63.92 | 2.58 | 555.57 |
| s | 92.48 | 84.21 | 92.78 | 67.40 | 9.41 | 370.37 | |
| YOLO12 | n | 90.93 | 81.08 | 90.43 | 66.04 | 2.56 | 416.67 |
| s | 91.39 | 82.21 | 91.59 | 66.24 | 9.23 | 243.90 | |
| EfficientNet | Eff-b3 | 74.91 | 89.29 | 88.00 | 61.30 | 18.34 | 306.30 |
| Faster R-CNN | R50 | 84.18 | 82.87 | 83.40 | 60.80 | 41.35 | 308.10 |
| R101 | 84.18 | 83.08 | 83.20 | 60.50 | 60.34 | 324.00 | |
| Cascade R-CNN | R50 | 84.51 | 83.98 | 84.50 | 63.10 | 69.15 | 317.50 |
| R101 | 84.97 | 84.13 | 83.80 | 62.80 | 88.14 | 317.10 | |
| MS-ASFF- ShipYOLO (Ours) | - | 93.87 | 86.84 | 94.56 | 70.44 | 60.28 | 232.56 |
| Models | /% | /% | /% | /% |
|---|---|---|---|---|
| Baseline | 92.48 | 84.21 | 92.28 | 67.40 |
| Posi-1 | 90.53 | 84.44 | 92.44 | 66.66 |
| Posi-2 | 90.55 | 86.42 | 93.20 | 68.28 |
| Posi-3 | 92.37 | 85.28 | 93.45 | 69.17 |
| Posi-4 | 92.62 | 85.56 | 93.46 | 69.34 |
| Model | /% | /% | /% | /% | FPS (img/s) |
|---|---|---|---|---|---|
| Baseline | 92.48 | 84.21 | 92.28 | 67.40 | 370.37 |
| +SimAM | 92.11 | 74.20 | 82.26 | 57.12 | 434.78 |
| +CBAM | 92.55 | 85.07 | 93.32 | 68.27 | 263.16 |
| +MCAttn | 92.62 | 85.56 | 93.46 | 69.34 | 270.27 |
| +HS-FPN | 91.31 | 82.20 | 89.56 | 61.94 | 500.00 |
| +BiFPN | 91.45 | 83.37 | 91.94 | 66.50 | 526.32 |
| +ASFF | 93.23 | 84.62 | 93.10 | 68.39 | 303.03 |
| Different YOLO11s Models | MCAttn | ASFF | /% | /% | /% | /% | FPS (img/s) |
|---|---|---|---|---|---|---|---|
| Experiment 1 (Baseline) | 🗶 | 🗶 | 92.48 | 84.21 | 92.28 | 67.40 | 370.37 |
| Experiment 2 | 🗸 | 🗶 | 92.62 | 85.56 | 93.46 | 69.34 | 270.27 |
| Experiment 3 | 🗶 | 🗸 | 93.23 | 84.62 | 93.10 | 68.39 | 303.03 |
| Experiment 4 | 🗸 | 🗸 | 93.87 | 86.84 | 94.56 | 70.44 | 232.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Pan, H.; Wang, L.; Zou, R. MC-ASFF-ShipYOLO: Improved Algorithm for Small-Target and Multi-Scale Ship Detection for Synthetic Aperture Radar (SAR) Images. Sensors 2025, 25, 2940. https://doi.org/10.3390/s25092940
Xu Y, Pan H, Wang L, Zou R. MC-ASFF-ShipYOLO: Improved Algorithm for Small-Target and Multi-Scale Ship Detection for Synthetic Aperture Radar (SAR) Images. Sensors. 2025; 25(9):2940. https://doi.org/10.3390/s25092940
Chicago/Turabian StyleXu, Yubin, Haiyan Pan, Lingqun Wang, and Ran Zou. 2025. "MC-ASFF-ShipYOLO: Improved Algorithm for Small-Target and Multi-Scale Ship Detection for Synthetic Aperture Radar (SAR) Images" Sensors 25, no. 9: 2940. https://doi.org/10.3390/s25092940
APA StyleXu, Y., Pan, H., Wang, L., & Zou, R. (2025). MC-ASFF-ShipYOLO: Improved Algorithm for Small-Target and Multi-Scale Ship Detection for Synthetic Aperture Radar (SAR) Images. Sensors, 25(9), 2940. https://doi.org/10.3390/s25092940