

Multi-Variable Transformer-Based Meta-Learning for Few-Shot Fault Diagnosis of Large-Scale Systems



Abstract
1. Introduction
2. Related Work
2.1. Transformers in Fault Diagnosis
- Data Scarcity: Although Transformer models excel on large-scale datasets, acquiring sufficient labeled data remains a major challenge in complex system fault diagnosis, particularly in few-shot learning scenarios. In many industrial applications, system failures are rare, leading to a severe shortage of samples for each fault type. Despite its powerful feature extraction capabilities, Transformer typically relies on a vast amount of labeled data for effective training, which is often impractical in real-world settings. While some unsupervised learning methods have been proposed, they still require a large number of unlabeled samples and fail to fundamentally overcome the limitations imposed by sample scarcity on model performance.
- Multivariate Issues: As observed in previous studies, nearly all research relies on publicly available bearing datasets to benchmark against state-of-the-art methods. While this approach intuitively evaluates the performance of proposed methods, bearing datasets inherently consist of single-variable time series data collected from vibration sensors. In contrast, data in complex systems often comprise multivariate time series, making it challenging for bearing datasets to accurately reflect the effectiveness of Transformer-based fault diagnosis methods in more diverse and realistic application scenarios.
- Time Series Nature: Since bearing datasets typically consist of high-frequency sampled time series data, researchers often tokenize or transform them into the frequency domain for processing. However, in large and complex systems—such as process industries and spacecraft—the sampling frequency is usually much lower. Due to limited sampling rates and fewer data points, conventional operations like segmentation or tokenization may fail to effectively extract meaningful features. Consequently, determining how to process these measurement variables and efficiently input them into Transformer models remains an urgent challenge that needs to be addressed.
- State Variables: Similar to the previous issues, bearing datasets primarily collect vibration signals, which are analog data. However, in complex systems, measurement data often include crucial state variables, such as switch states and operating modes, which significantly impact system behavior. Despite their importance, these state variables have not been adequately considered in model inputs. Effectively processing these state variables and seamlessly integrating their features with analog data remains a critical challenge in fault diagnosis.
2.2. Advancements of Meta-Learning in Fault Diagnosis
3. Methodology
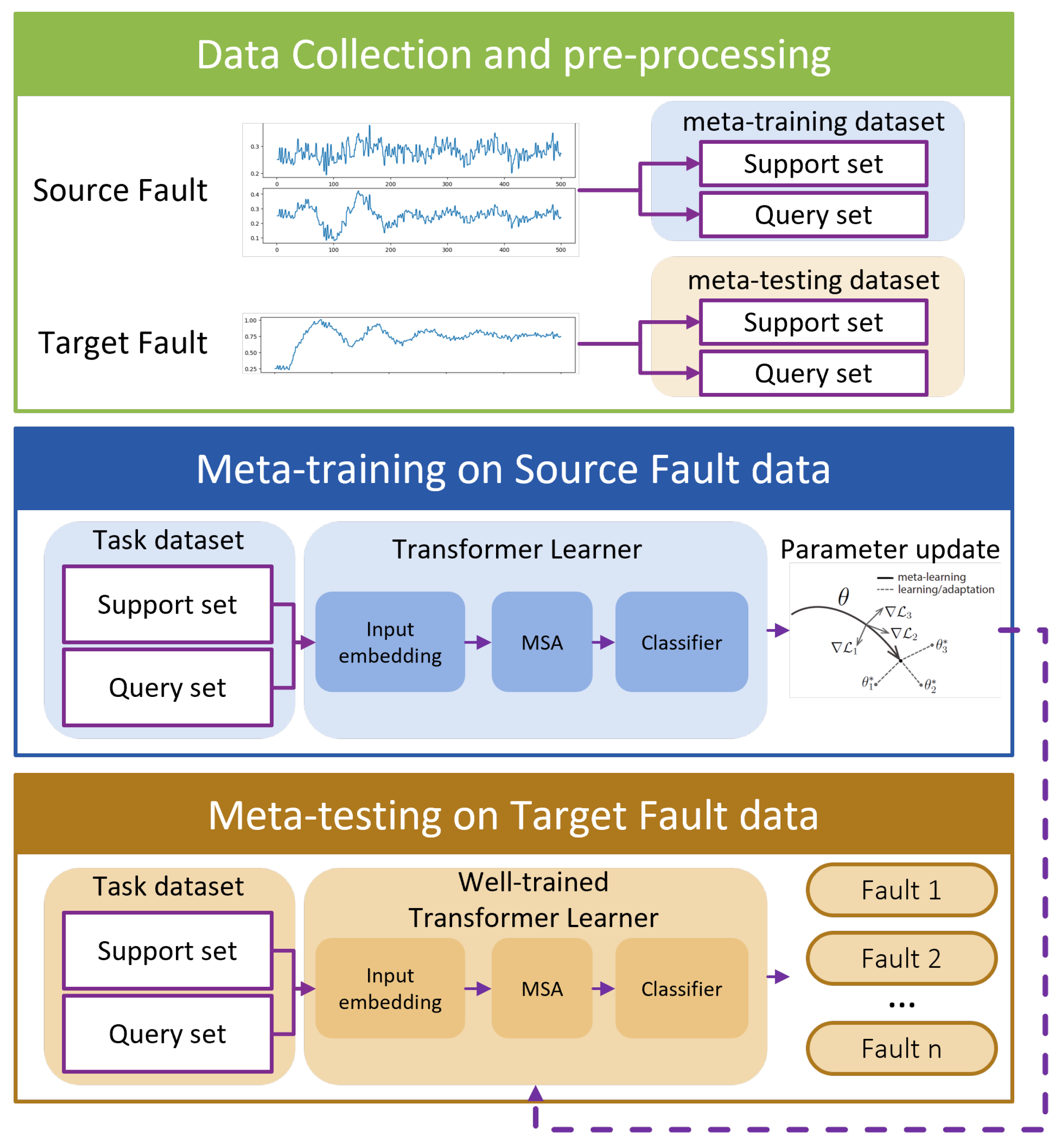
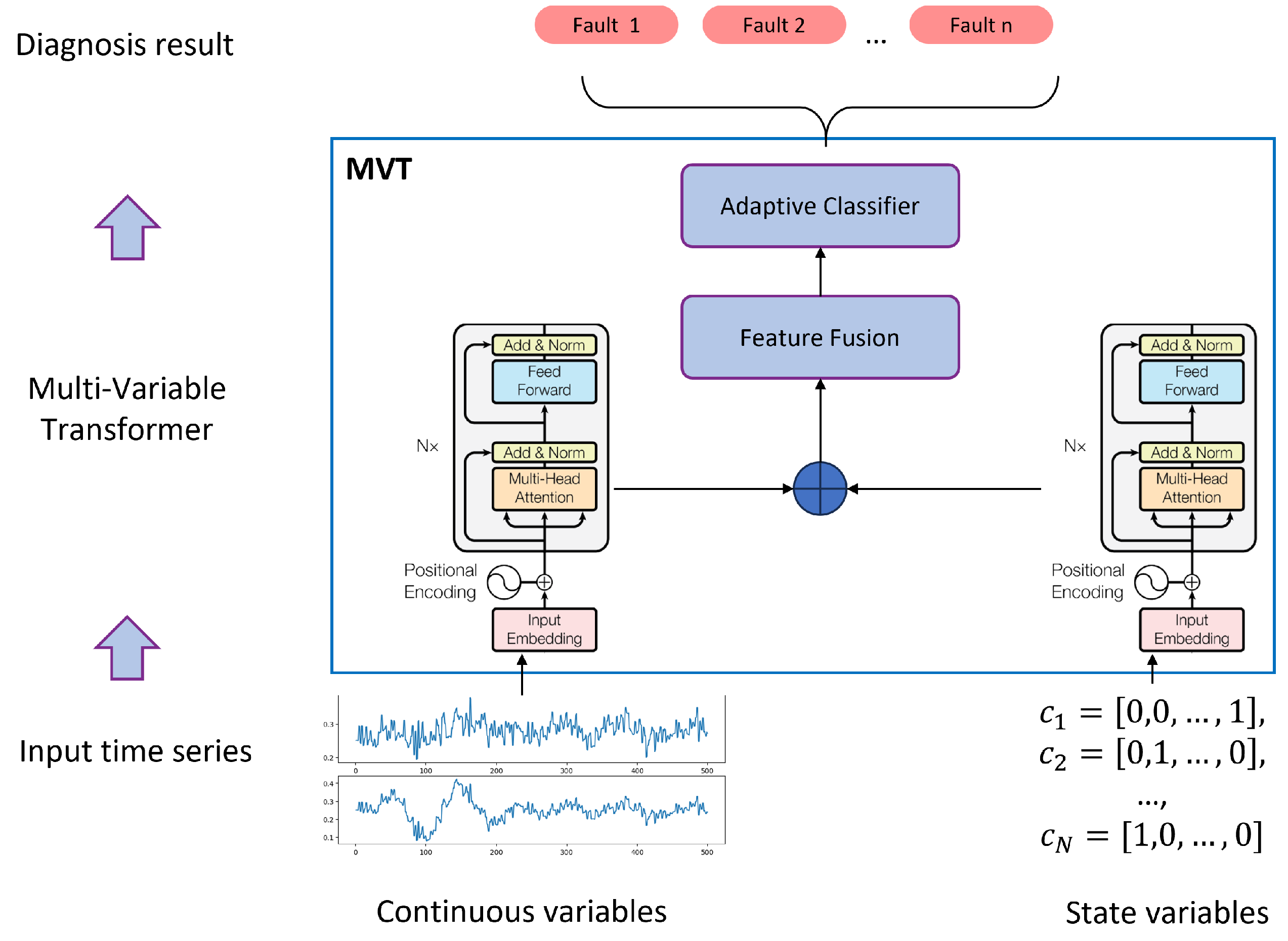
3.1. Overall Framework of the Multi-Variable Meta-Transformer (MVMT)
- Data Collection and Pre-processing: Faults are classified as either source faults or target faults based on the number of available samples. Source faults, being common, have a sufficient number of samples, whereas target faults are rare and have only a limited number of samples. These faults are then allocated to a meta-training task set and a meta-testing task set, respectively. Notably, the faults in the meta-testing set are entirely distinct from those in the meta-training set. Unlike conventional train–test splits, fault types included in the meta-training set do not reappear in the meta-testing set.
- Meta-Training Phase: In this stage, a MAML strategy is employed to train the multi-variable Transformer model, optimizing its initial parameters. This process yields a well-initialized multi-variable Transformer encoder, which serves as the foundation for the subsequent meta-testing phase.
- Meta-Testing Phase: Here, the pre-trained multi-variable Transformer model is fine-tuned using the limited samples of rare faults, enabling it to effectively perform the final few-shot fault diagnosis task.
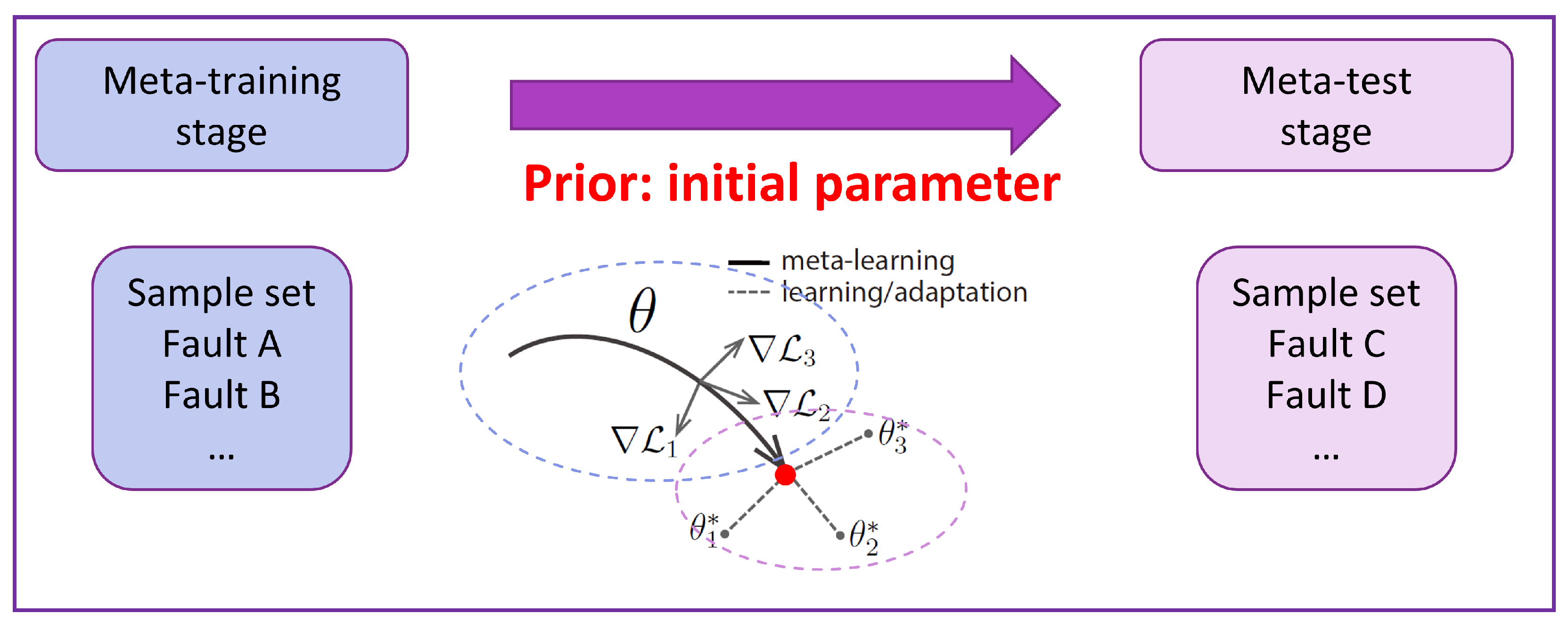
3.2. Meta-Learning Framework
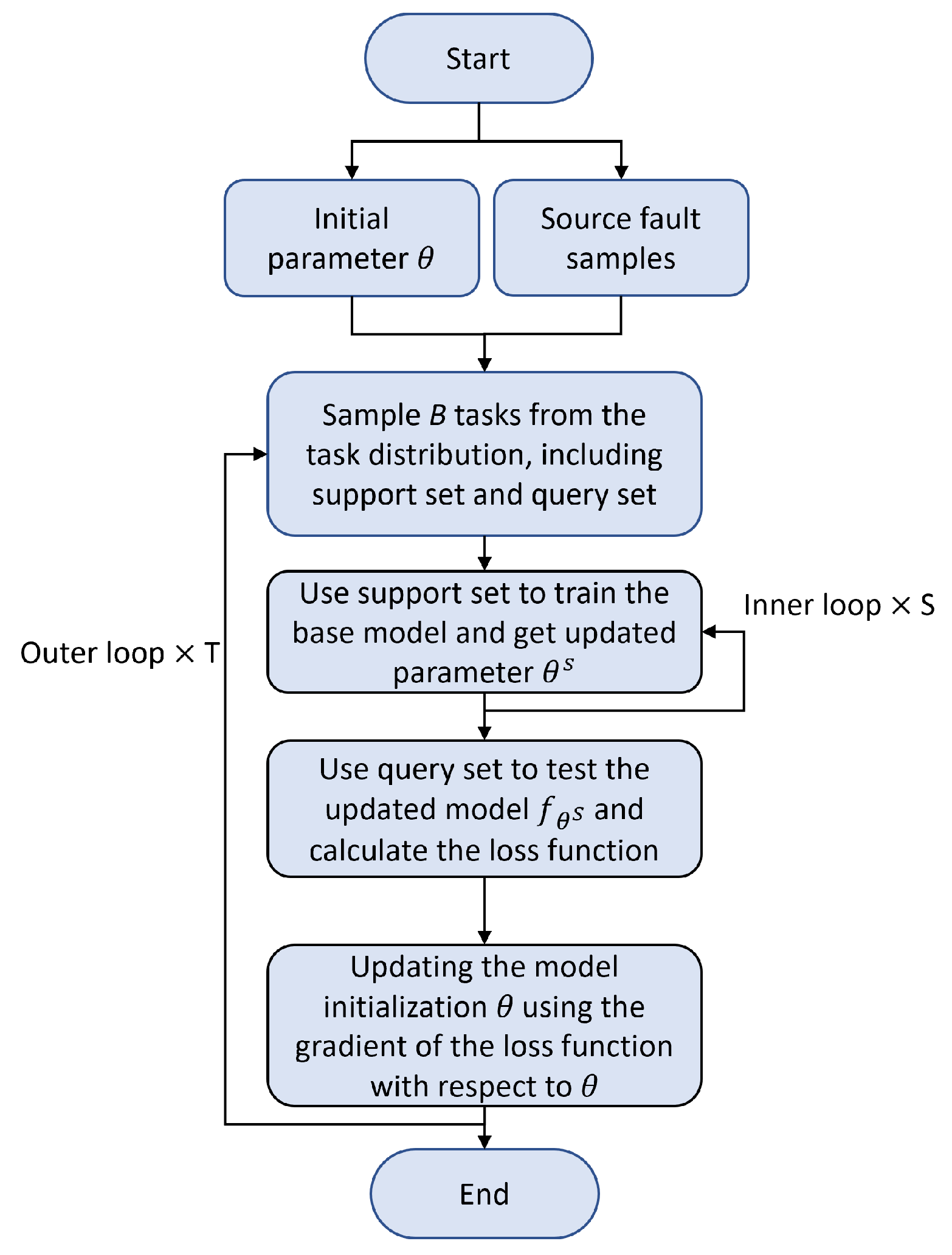
- Sample B tasks from the task distribution . Each task consists of N fault types, with K support samples for task-specific training and Q query samples for task-specific validation.
- For each task , use the support samples to compute the updated parameters through S iterations of inner-loop training:where is the inner-loop learning rate.
- Evaluate the updated model using the query sets from all B tasks. The task-specific loss function is used to compute the overall meta-objective:
- Update the model parameters using the meta-gradient:where is the meta-learning rate (outer-loop learning rate).
| Algorithm 1 MAML for Classification |
| Input:
: learning rate for inner updates : learning rate for meta-update : distribution over tasks |
| Output: Model parameters |
| 1: Initialize model parameters 2: while not done do 3: Sample batch of tasks 4: for all do 5: Sample K datapoints 6: Evaluate using 7: Compute adapted parameters with gradient descent: 8: end for 9: Sample new datapoints 10: Compute meta-objective: 11: end while |
| Algorithm 2 Meta-SGD for Classification |
| Input: : learning rates for inner updates (learned) : learning rate for meta-update : distribution over tasks |
| Output: Model parameters and learning rates |
| 1: Initialize model parameters and learning rates 2: while not done do 3: Sample batch of tasks 4: for all do 5: Sample K datapoints 6: Evaluate using 7: Compute adapted parameters with learned gradient descent: 8: end for 9: Sample new datapoints 10: Compute meta-objective: 11: end while |
| Algorithm 3 MAML with adaptive classifier. |
| Input : Inner-loop learning rate : Meta-learning rate : Task distribution |
| Output Optimized model parameters |
| 1: Initialize model parameters 2: while not converged do 3: Sample a batch of tasks from task distribution 4: for each task do 5: Sample support set and query set 6: Construct the adaptive classifier using 7: Compute task-specific loss: 8: Compute task-specific parameter updates: 9: end for 10: Compute meta-loss on the query set: 11: Update meta-parameters: 12: end while |
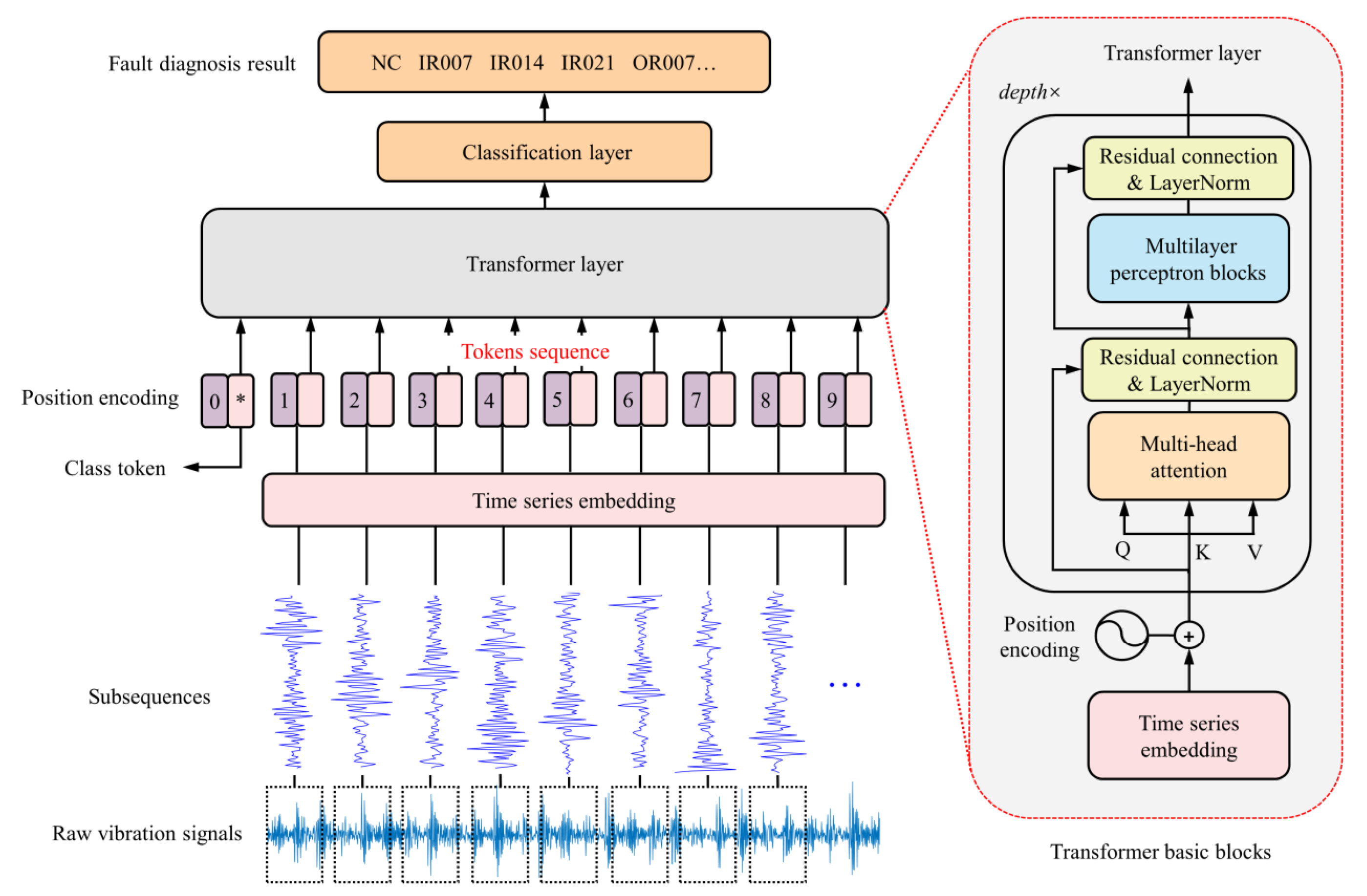
3.3. Multi-Variable Transformer
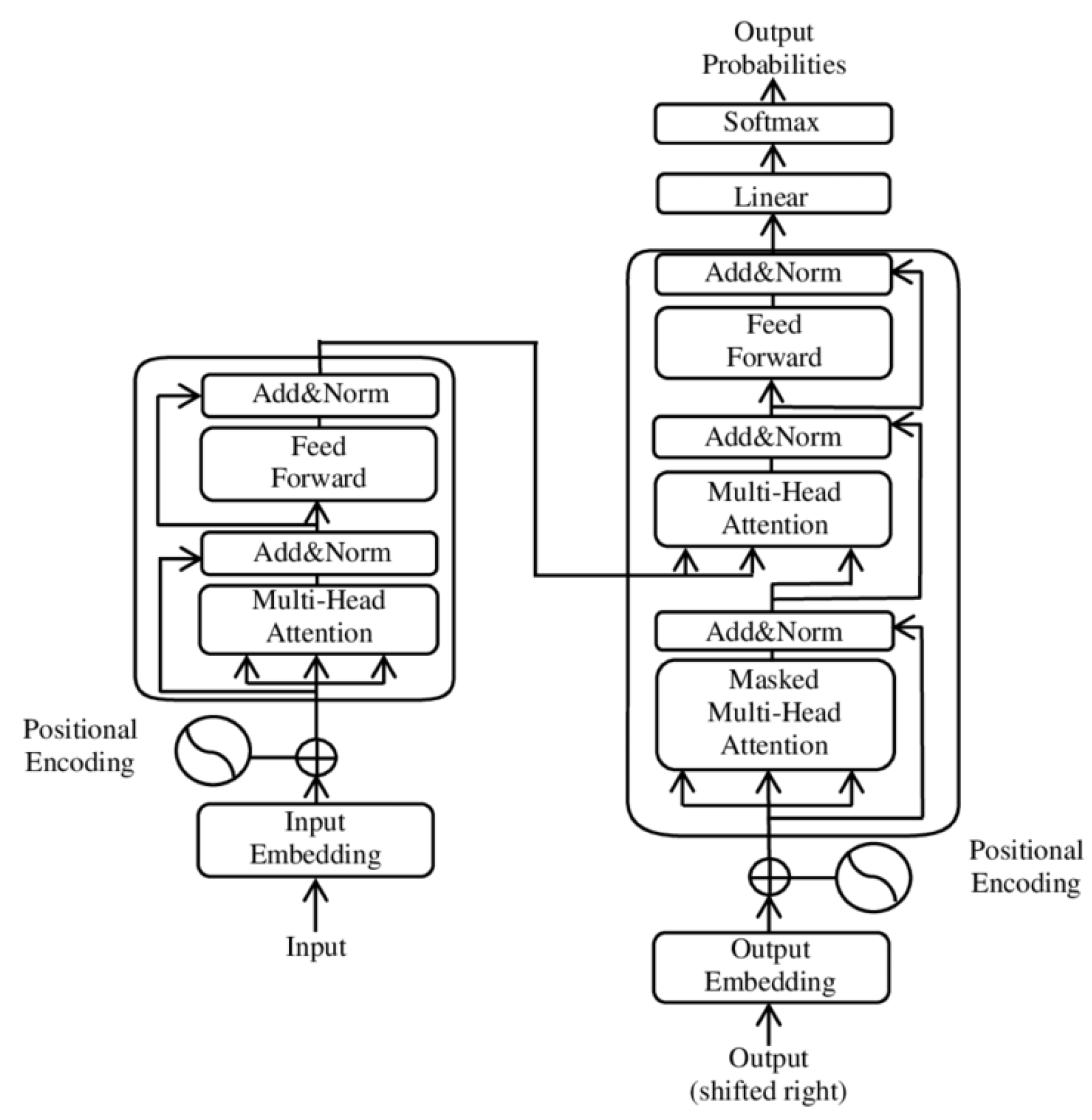
3.3.1. Overall Structure of Transformer
- Multi-Head Self-Attention Mechanism
- Feed-Forward Network (FFN)
- -
- is the representation at layer l.
- -
- Multi-head attention allows the model to learn various time dependencies.
- -
- The Feed-Forward Network (FFN) applies nonlinear transformations to enhance feature representations.
- -
- is the decoder representation at layer l.
- -
- The cross-attention mechanism allows the decoder to access encoder representations , improving prediction performance.
- -
- and are learnable parameters.
- -
- For classification tasks, Softmax outputs a probability distribution over classes.
- -
- For regression tasks, the model directly outputs the predicted values.
3.3.2. Self-Attention Mechanism
- -
- Q (Query): Represents the current time step information.
- -
- K (Key): Stores information about the entire input sequence.
- -
- V (Value): Stores the feature representations of the input sequence.
- -
- is the dimensionality of the key vectors.
- Computing similarity: Performing the dot product .
- Scaling: Dividing by to prevent gradient explosion.
- Softmax normalization: Generating attention weights.
- Weighted sum: Computing the final attention output.
- -
- h is the number of attention heads.
- -
- Each represents an independent attention mechanism.
- -
- is a learnable linear transformation matrix.
- Enables the model to capture different levels of features, improving representation capability.
- Avoids local optima that may arise from a single attention head.
3.3.3. Positional Encoding
- -
- is the position index.
- -
- i is the dimension index.
- -
- is the embedding dimension.
- Ensures temporally close time steps have similar representations.
- Enables the Transformer to recognize sequence order, improving time series modeling.
3.3.4. Multi-Variable Transformer Architecture
3.4. Discussion on Time Complexity
- 1D CNN: Convolution operations exhibit high parallelism, especially on GPU, allowing for more efficient acceleration compared to LSTM and Transformer models. This advantage is particularly evident when processing long sequences and large batches.
- LSTM: While LSTM can leverage GPU for batch computations, its inherently sequential nature limits parallel efficiency. Since each time step must be computed before the next one begins, LSTM computations remain fundamentally serial, resulting in a complexity of even on GPU.
- Transformer: Owing to its fully parallelizable self-attention mechanism, Transformer models benefit significantly from GPU acceleration. Since attention computations at each position are independent, Transformers generally outperform LSTMs in terms of efficiency, particularly as sequence length N increases.
4. Experimental Setup
4.1. Datasets
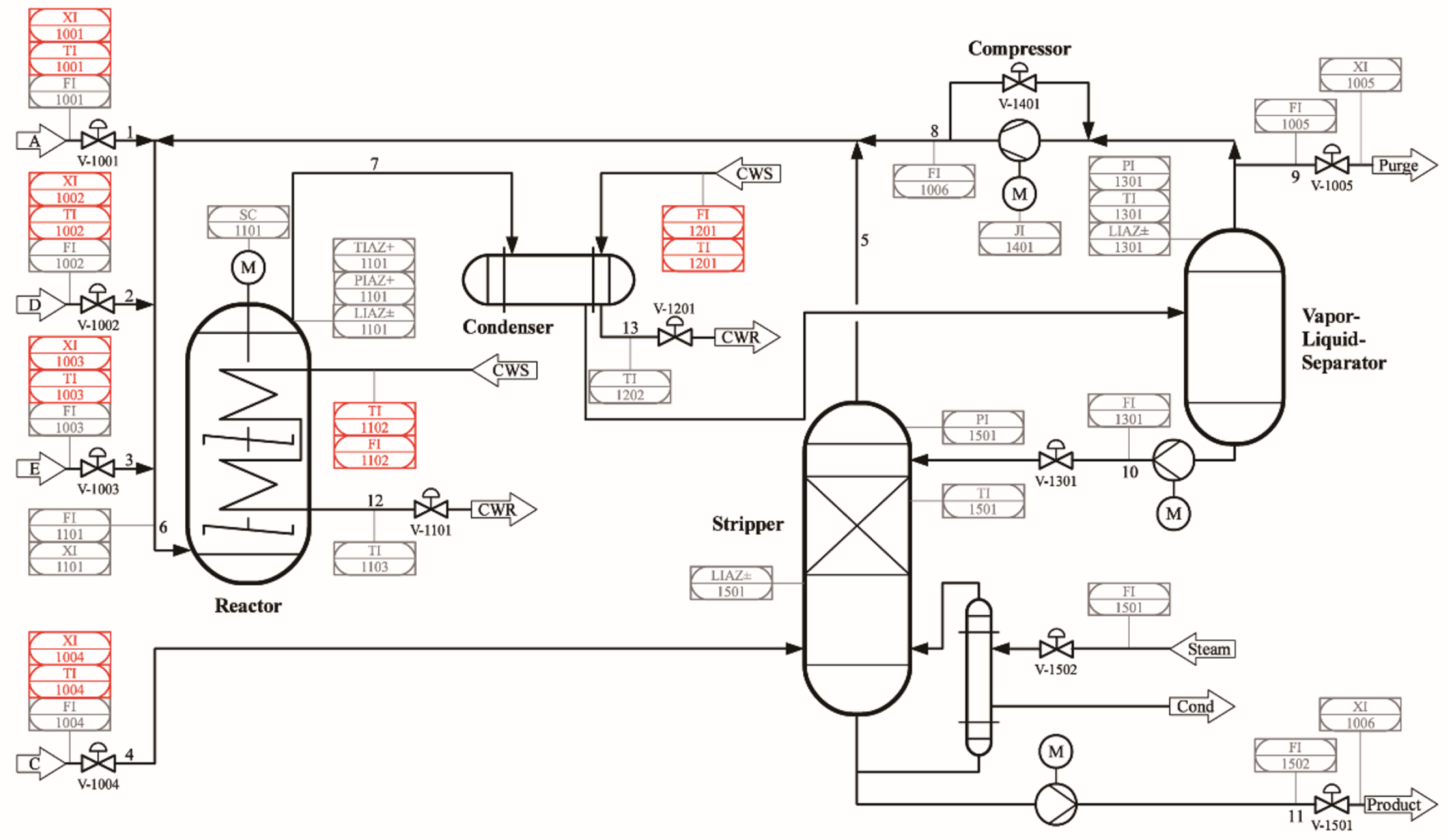
4.1.1. Dataset 1: TEP
- Training Set: The training set for each fault mode contains 480 samples.
- Testing Set: The testing set for each fault mode contains 960 samples.
- 40 Process Variables
- 13 Manipulated Variables
- Task 1: Each task contains 5 fault types. In the meta-training set, each fault type includes 1 support sample and 5 query samples, whereas in the meta-testing set, each fault type includes 1 support sample and 30 query samples. The length of each sample is 50.
- Task 2: Each task contains 5 fault types. In the meta-training set, each fault type includes 3 support samples and 10 query samples, whereas in the meta-testing set, each fault type includes 3 support samples and 30 query samples. The length of each sample is 30.
4.1.2. Dataset 2: Power-Supply System
- Task Setting 1: Each task in both the meta-training and meta-testing sets contains 5 fault types. The meta-training set includes 5 support samples and 10 query samples per task, while the meta-testing set includes 5 support samples and 30 query samples per task. The length of each sample is 30.
- Task Setting 2: The meta-training set contains 5 fault types per task, whereas the meta-testing set contains 7 fault types per task. In the meta-training set, each task consists of 5 support samples and 10 query samples, while in the meta-testing set, each task consists of 5 support samples and 30 query samples. The length of each sample is 30.
- Task Setting 3: Each task in both the meta-training and meta-testing sets contains 5 fault types. The meta-training set includes 3 support samples and 10 query samples per task, while the meta-testing set includes 3 support samples and 30 query samples per task. The length of each sample is 50.
4.2. Evaluation Metrics
4.3. Hardware Platform
4.4. Comparison Methods
4.5. Hyperparameter Settings
5. Results and Discussion
5.1. Experimental Results on Dataset 1 (TEP)
5.2. Experimental Results on Dataset 2 (Power-Supply System)
6. Conclusions
- MVMT demonstrates exceptional feature extraction capabilities, particularly for time series data, and benefits from GPU-accelerated parallel computation, making it more computationally efficient compared to traditional RNNs and LSTMs.
- The model excels in rapidly adapting to new fault tasks with minimal data, addressing the challenge of fault categories with limited samples, which is crucial for complex systems.
- MVMT successfully integrates various types of variables (e.g., analog and status variables), offering high flexibility for deployment in diverse, multi-variable complex systems.
- The introduction of an adaptive classifier solves the issue of varying numbers of fault categories across tasks, overcoming a limitation in the original MAML approach.
- Comparative experiments conducted on the TE chemical process dataset and spacecraft telemetry dataset demonstrate that MVMT outperforms existing methods in multi-variable, small-sample fault diagnosis tasks for complex systems.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Dataset Detail

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault | Description |
|---|---|
| IDV(1) | A/C Feed Ratio, B Composition Constant (Stream 4) Step |
| IDV(2) | B Composition, A/C Ratio Constant (Stream 4) Step |
| IDV(3) | D Feed Temperature (Stream 2) Step |
| IDV(4) | Reactor Cooling Water Inlet Temperature Step |
| IDV(5) | Condenser Cooling Water Inlet Temperature Step |
| IDV(6) | A Feed Loss (Stream 1) Step |
| IDV(7) | C Header Pressure Loss - Reduced Availability (Stream 4) Step |
| IDV(8) | A, B, C Feed Composition (Stream 4) Random Variation |
| IDV(9) | D Feed Temperature (Stream 2) Random Variation |
| IDV(10) | C Feed Temperature (Stream 4) Random Variation |
| IDV(11) | Reactor Cooling Water Inlet Temperature Random Variation |
| IDV(12) | Condenser Cooling Water Inlet Temperature Random Variation |
| IDV(13) | Reaction Kinetics Slow Drift |
| IDV(14) | Reactor Cooling Water Valve Sticking |
| IDV(15) | Condenser Cooling Water Valve Sticking |
| IDV(16) | Unknown |
| IDV(17) | Unknown |
| IDV(18) | Unknown |
| IDV(19) | Unknown |
| IDV(20) | Unknown |
| Variable | Description | Variable | Description |
|---|---|---|---|
| XMV(1) | D Feed Flow (stream 2) (Corrected Order) | XMEAS(15) | Stripper Level |
| XMV(2) | E Feed Flow (stream 3) (Corrected Order) | XMEAS(16) | Stripper Pressure |
| XMV(3) | A Feed Flow (stream 1) (Corrected Order) | XMEAS(17) | Stripper Underflow (stream 11) |
| XMV(4) | A and C Feed Flow (stream 4) | XMEAS(18) | Stripper Temperature |
| XMV(5) | Compressor Recycle Valve | XMEAS(19) | Stripper Steam Flow |
| XMV(6) | Purge Valve (stream 9) | XMEAS(20) | Compressor Work |
| XMV(7) | Separator Pot Liquid Flow (stream 10) | XMEAS(21) | Reactor Cooling Water Outlet Temp |
| XMV(8) | Stripper Liquid Product Flow (stream 11) | XMEAS(22) | Separator Cooling Water Outlet Temp |
| XMV(9) | Stripper Steam Valve | XMEAS(23) | Component A |
| XMV(10) | Reactor Cooling Water Flow | XMEAS(24) | Component B |
| XMV(11) | Condenser Cooling Water Flow | XMEAS(25) | Component C |
| XMV(12) | Agitator Speed | XMEAS(26) | Component D |
| XMEAS(1) | A Feed (stream 1) | XMEAS(27) | Component E |
| XMEAS(2) | D Feed (stream 2) | XMEAS(28) | Component F |
| XMEAS(3) | E Feed (stream 3) | XMEAS(29) | Component A |
| XMEAS(4) | A and C Feed (stream 4) | XMEAS(30) | Component B |
| XMEAS(5) | Recycle Flow (stream 8) | XMEAS(31) | Component C |
| XMEAS(6) | Reactor Feed Rate (stream 6) | XMEAS(32) | Component D |
| XMEAS(7) | Reactor Pressure | XMEAS(33) | Component E |
| XMEAS(8) | Reactor Level | XMEAS(34) | Component F |
| XMEAS(9) | Reactor Temperature | XMEAS(35) | Component G |
| XMEAS(10) | Purge Rate (stream 9) | XMEAS(36) | Component H |
| XMEAS(11) | Product Sep Temp | XMEAS(37) | Component D |
| XMEAS(12) | Product Sep Level | XMEAS(38) | Component E |
| XMEAS(13) | Prod Sep Pressure | XMEAS(39) | Component F |
| XMEAS(14) | Prod Sep Underflow (stream 10) | XMEAS(40) | Component G |
| XMEAS(41) | Component H |
| Number | Device | Unit | Fault Description |
|---|---|---|---|
| 0 | Power Controller | BCRB Module | Single Drive Transistor Open or Short in MEA Circuit |
| 1 | Power Controller | BCRB Module | Single Operational Amplifier Open or Short in MEA Circuit |
| 2 | Power Controller | BCRB Module | Incorrect Battery Charging Voltage Command |
| 3 | Power Controller | Power Lower Machine | CDM Module Current Telemetry Circuit Fault |
| 4 | Power Controller | Power Lower Machine | POWER Module Bus Current Measurement Circuit Fault |
| 5 | Power Controller | Power Lower Machine | Solar Array Current Measurement Circuit Fault |
| 6 | Power Controller | Power Lower Machine | Communication Fault |
| 7 | Power Controller | Global | Load Short Circuit |
| 8 | Power Controller | Power Module | S3R Circuit Diode Short Circuit |
| 9 | Power Controller | Power Module | S3R Circuit Shunt MOSFET Open Circuit |
| 10 | Power Controller | Power Module | Abnormal S3R Shunt Status |
| 11 | Power Controller | Distribution (Heater) Module | Y Board Heater Incorrectly On |
| 12 | Power Controller | Distribution (Heater) Module | Battery Heater Band Incorrectly Off |
| 13 | Power Controller | Distribution (Heater) Module | Battery Heater Band Incorrectly On |
| 14 | Solar Array | Isolation Diode | Short Circuit |
| 15 | Solar Array | Isolation Diode | Open Circuit |
| 16 | Solar Array | Interconnect Ribbon | Open Circuit |
| 17 | Solar Array | Bus Bar | Solder Joint Open Circuit |
| 18 | Solar Array | Solar Cell | Single Cell Short Circuit |
| 19 | Solar Array | Solar Cell | Single Cell Open Circuit |
| 20 | Solar Array | Solar Cell | Solar Cell Performance Degradation |
| 21 | Solar Array | Solar Wing | Single Subarray Open Circuit |
| 22 | Solar Array | Solar Wing | Single Wing Open Circuit |
| 23 | Solar Array | Solar Wing | Solar Wing Single Subarray Open Circuit |
References
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Jin, Y.; Hou, L.; Chen, Y. A time series transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Hou, S.; Lian, A.; Chu, Y. Bearing fault diagnosis method using the joint feature extraction of Transformer and ResNet. Meas. Sci. Technol. 2023, 34, 075108. [Google Scholar] [CrossRef]
- Fang, H.; Deng, J.; Bai, Y.; Feng, B.; Li, S.; Shao, S.; Chen, D. CLFormer: A lightweight transformer based on convolutional embedding and linear self-attention with strong robustness for bearing fault diagnosis under limited sample conditions. IEEE Trans. Instrum. Meas. 2021, 71, 1–8. [Google Scholar] [CrossRef]
- Hou, Y.; Wang, J.; Chen, Z.; Ma, J.; Li, T. Diagnosisformer: An efficient rolling bearing fault diagnosis method based on improved Transformer. Eng. Appl. Artif. Intell. 2023, 124, 106507. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, J.; Ma, X.; Pirttikangas, S.; Yang, C. TSViT: A Time Series Vision Transformer for Fault Diagnosis of Rotating Machinery. Appl. Sci. 2024, 14, 10781. [Google Scholar] [CrossRef]
- Nascimento, E.G.S.; Liang, J.S.; Figueiredo, I.S.; Guarieiro, L.L.N. T4PdM: A deep neural network based on the transformer architecture for fault diagnosis of rotating machinery. arXiv 2022, arXiv:2204.03725. [Google Scholar]
- Yang, Z.; Cen, J.; Liu, X.; Xiong, J.; Chen, H. Research on bearing fault diagnosis method based on transformer neural network. Meas. Sci. Technol. 2022, 33, 085111. [Google Scholar] [CrossRef]
- Kong, X.; Cai, B.; Zou, Z.; Wu, Q.; Wang, C.; Yang, J.; Wang, B.; Liu, Y. Three-model-driven fault diagnosis method for complex hydraulic control system: Subsea blowout preventer system as a case study. Expert Syst. Appl. 2024, 247, 123297. [Google Scholar] [CrossRef]
- Kong, X.; Cai, B.; Liu, Y.; Zhu, H.; Yang, C.; Gao, C.; Liu, Y.; Liu, Z.; Ji, R. Fault diagnosis methodology of redundant closed-loop feedback control systems: Subsea blowout preventer system as a case study. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 1618–1629. [Google Scholar] [CrossRef]
- Li, C.; Li, S.; Zhang, A.; He, Q.; Liao, Z.; Hu, J. Meta-learning for few-shot bearing fault diagnosis under complex working conditions. Neurocomputing 2021, 439, 197–211. [Google Scholar] [CrossRef]
- Chang, L.; Lin, Y.H. Meta-Learning With Adaptive Learning Rates for Few-Shot Fault Diagnosis. IEEE/ASME Trans. Mechatron. 2022, 27, 5948–5958. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Li, S.; Zhou, X.; Jin, L. Small sample-based new modality fault diagnosis based on meta-learning and neural architecture search. Control Decis. 2023, 38, 3175–3183. [Google Scholar]
- Ren, L.; Mo, T.; Cheng, X. Meta-learning based domain generalization framework for fault diagnosis with gradient aligning and semantic matching. IEEE Trans. Ind. Inform. 2023, 20, 754–764. [Google Scholar] [CrossRef]
- Wikimedia Commons, the Free Media Repository. File:The-Transformer-model-architecture.png. 2025. Available online: https://commons.wikimedia.org/wiki/File:The-Transformer-model-architecture.png (accessed on 25 March 2025).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995; p. 3361. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
| Task Set | Selected Fault Types |
|---|---|
| Meta-Training Set | 3, 5, 6, 7, 8, 9, 10, 11, 15, 16, 18, 19, 20 |
| Meta-Testing Set | 1, 2, 4, 12, 13, 14, 17 |
| Task Type | Dataset | Number of Fault Types | Support Samples | Query Samples | Sample Length |
|---|---|---|---|---|---|
| Task 1 | Meta-Training Set | 5 | 1 | 5 | 50 |
| Meta-Testing Set | 5 | 1 | 30 | 50 | |
| Task 2 | Meta-Training Set | 5 | 3 | 10 | 30 |
| Meta-Testing Set | 5 | 3 | 30 | 30 |
| Dataset | Selected Fault Types |
|---|---|
| Meta-Training Set | 0, 1, 5, 8, 9, 11, 12, 14, 16, 17, 18, 19, 20, 22 |
| Meta-Testing Set | 2, 3, 4, 6, 7, 10, 13, 15, 21, 23 |
| Task Setting | Dataset | Number of Fault Types | Support Samples | Query Samples | Sample Length |
|---|---|---|---|---|---|
| Task Setting 1 | Meta-Training Set | 5 | 5 | 10 | 30 |
| Meta-Testing Set | 5 | 5 | 30 | 30 | |
| Task Setting 2 | Meta-Training Set | 5 | 5 | 10 | 30 |
| Meta-Testing Set | 7 | 5 | 30 | 30 | |
| Task Setting 3 | Meta-Training Set | 5 | 3 | 10 | 50 |
| Meta-Testing Set | 5 | 3 | 30 | 50 |
| Hardware Component | Specification |
|---|---|
| CPU | AMD Ryzen 9 9800X3D |
| GPU | NVIDIA RTX 3090 24GB |
| RAM | 48 GB DDR5 |
| Storage | 1 TB SSD |
| Operating System | Windows 11 Version 24H2 |
| Model | Hidden Size | Feature Size | Attention Heads | Encoder Layers | Kernel Size |
|---|---|---|---|---|---|
| MVMT | 128 | 256 | 3 | 2 | – |
| LSTM | 32 | 224 | – | – | – |
| 1DCNN | 96 | 256 | – | – | 5 |
| ViT | 96 | 96 | 4 | 2 | – |
| Model | Hidden Size | Feature Size | Attention Heads | Encoder Layers | Kernel Size |
|---|---|---|---|---|---|
| MVMT | 256 | 256 | 8 | 4 | – |
| LSTM | 128 | 196 | – | – | – |
| 1DCNN | 128 | 256 | – | – | 7 |
| ViT | 96 | 96 | 4 | 2 | – |
| Task Setting Method | Setting 1 Accuracy | Setting 2 Accuracy |
|---|---|---|
| 1DCNN | 33.67% | 38.00% |
| LSTM | 30.14% | 39.67% |
| ViT | 43.55% | 44.53% |
| MVT (proposed) | 44.15% | 43.76% |
| Task Setting | Setting 1 | Setting 2 | ||
|---|---|---|---|---|
| Method | Accuracy | Training Time (s) | Accuracy | Training Time (s) |
| 1DCNN + MAML | 52.73% | 706 | 60.94% | 903 |
| LSTM + MAML | 50.05% | 7749 | 61.33% | 7670 |
| ViT + MAML | 53.47% | 2826 | 63.80% | 3172 |
| MVMT (proposed) | 56.70% | 2867 | 68.00% | 3165 |
| Task Setting | Setting 1 | Setting 2 | Setting 3 | |||
|---|---|---|---|---|---|---|
| Method | Accuracy | Training Time | Accuracy | Training Time | Accuracy | Training Time |
| 1DCNN | 16.30% | NaN | 14.50% | NaN | 19.52% | NaN |
| LSTM | 31.40% | NaN | 33.74% | NaN | 32.86% | NaN |
| ViT | 36.73% | NaN | 26.67% | NaN | 22.86% | NaN |
| MVT (proposed) | 31.67% | NaN | 41.33% | NaN | 33.64% | NaN |
| 1DCNN + MAML | 64.45% | 1353 | 43.63% | 1464 | 65.53% | 1814 |
| LSTM + MAML | 67.87% | 5258 | 60.00% | 5216 | 70.10% | 8750 |
| ViT + MAML | 78.40% | 2955 | 64.45% | 2778 | 80.20% | 3322 |
| MVMT (proposed) | 83.20% | 2652 | 72.10% | 2787 | 80.86% | 3001 |
| 1DCNN + meta-SGD | 68.9% | 1282 | 47.92% | 1550 | 69.87% | 1923 |
| LSTM + meta-SGD | 73.34% | 5250 | 60.00% | 5640 | 79.05% | 8917 |
| ViT + meta-SGD | 72.66% | 2821 | 67.14% | 2775 | 73.30% | 3174 |
| MVMT + meta-SGD (proposed) | 81.15% | 2542 | 73.00% | 2918 | 79.25% | 3111 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Nie, Y.; Yang, F. Multi-Variable Transformer-Based Meta-Learning for Few-Shot Fault Diagnosis of Large-Scale Systems. Sensors 2025, 25, 2941. https://doi.org/10.3390/s25092941
Li W, Nie Y, Yang F. Multi-Variable Transformer-Based Meta-Learning for Few-Shot Fault Diagnosis of Large-Scale Systems. Sensors. 2025; 25(9):2941. https://doi.org/10.3390/s25092941
Chicago/Turabian StyleLi, Weiyang, Yixin Nie, and Fan Yang. 2025. "Multi-Variable Transformer-Based Meta-Learning for Few-Shot Fault Diagnosis of Large-Scale Systems" Sensors 25, no. 9: 2941. https://doi.org/10.3390/s25092941
APA StyleLi, W., Nie, Y., & Yang, F. (2025). Multi-Variable Transformer-Based Meta-Learning for Few-Shot Fault Diagnosis of Large-Scale Systems. Sensors, 25(9), 2941. https://doi.org/10.3390/s25092941