5.1. Intelligent Firmware Analysis
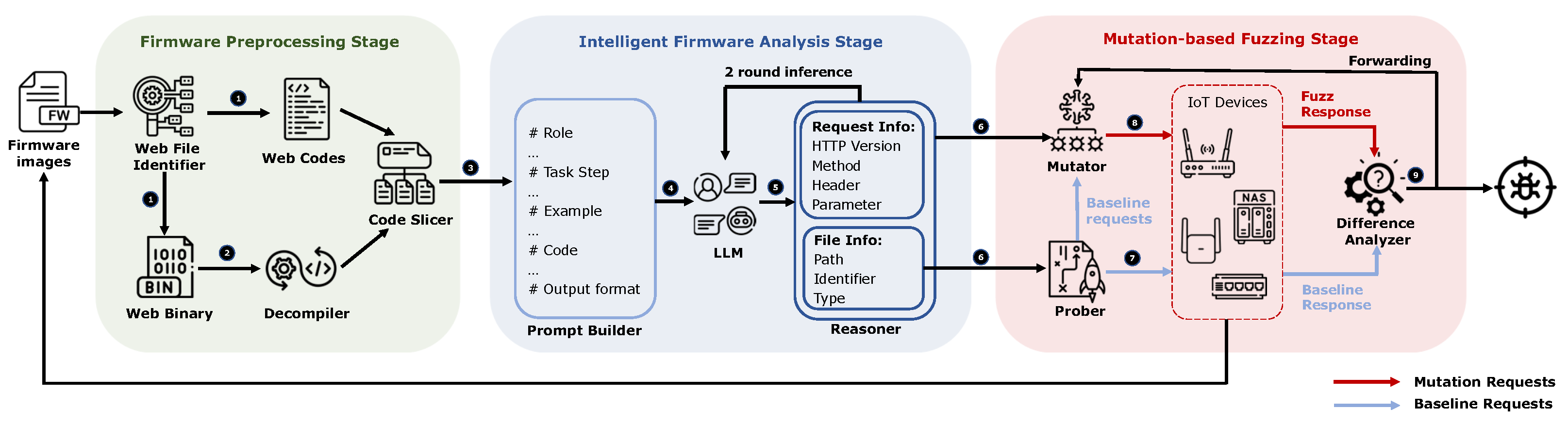
In the firmware preprocessing stage, we extracted 1,274,646 lines of web-related code from 11 IoT device firmware images, including script files (PHP, JavaScript, Lua, etc.) and decompiled binaries (HTTP servers, CGI programs, etc.). We then employed a code slicer to transform these into semantically complete code snippets that comply with the LLM’s context length limitations. In this stage, we developed an intelligent firmware analysis technique based on the code-understanding and -reasoning capabilities of the LLM, as illustrated in
Figure 7. This technique employs a chain-of-thought method to construct analysis prompts and utilizes a two-round LLM inference mechanism to extract key information from heterogeneous code: In the first round, the LLM identifies the structural elements for information extraction and marks portions requiring in-depth analysis. In contrast, it infers the specific constraints and values of these marked items in the second round. The final output includes file information of web interfaces and valid input values, which guide subsequent fuzzing. The following figure details our approach.
5.1.1. Information Extraction
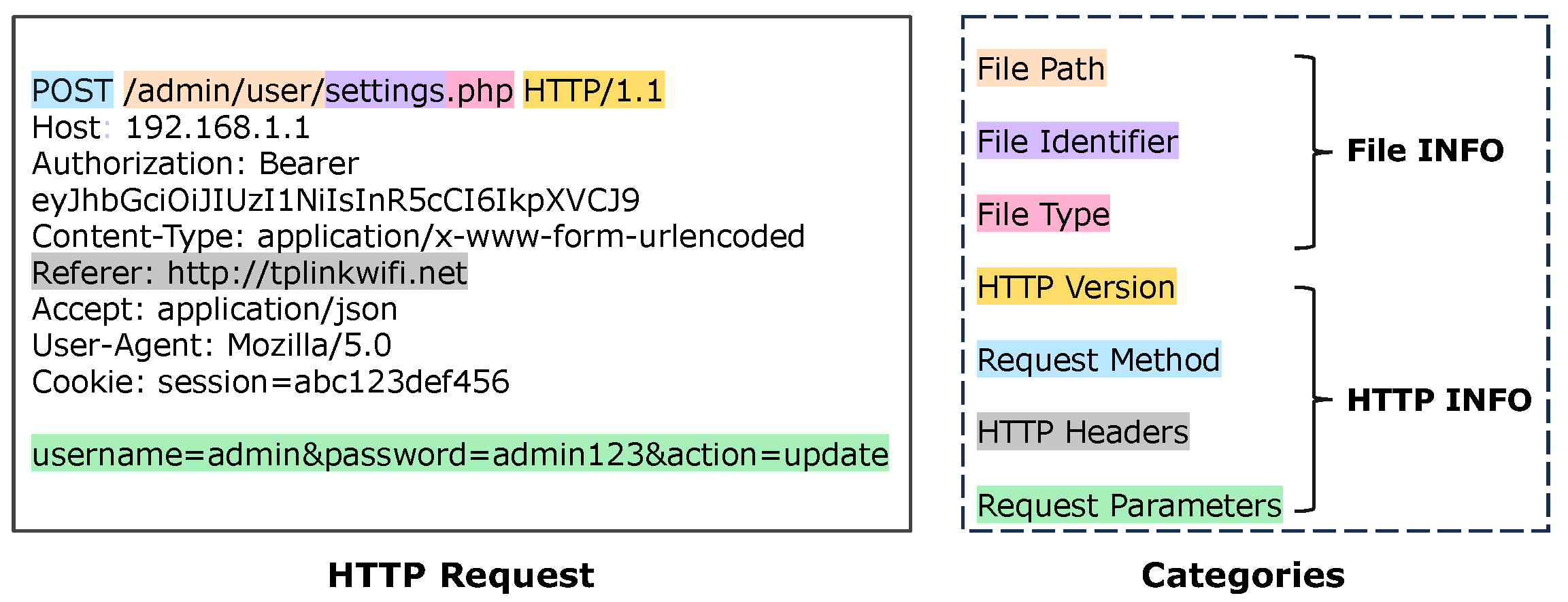
As shown in
Figure 1, we extract two categories of key information from the IoT firmware code: file information and HTTP information. This categorization enables the model to focus on extraction tasks in specific dimensions, providing valid input values for subsequent fuzzing, thereby enhancing fuzzing effectiveness.
In the file information dimension, we extract three elements for constructing web interfaces: file path (e.g., “/admin/user/”) specifies the interface access path, file identifier (e.g., “settings”) determines the specific interface, and file type (e.g., “.php”) determines the processing method. In the HTTP information dimension, we extract four elements required for constructing requests: HTTP version and request method are used for constructing the request line; HTTP headers (such as Content-Type, Authorization, etc.) are used to control the behavior of request processing; and request parameters (such as “username=admin&password=admin123”) contain specific values required for business operators.
5.1.2. Four Steps for Analysis
Extracting device-specific information from firmware is a complex analytical task. We decompose it into four steps and employ chain-of-thought prompting to guide the LLM in a step-by-step analysis, thereby enhancing accuracy. This method applies to the extraction of both file information and HTTP information. This section provides a detailed explanation of these four steps using HTTP information extraction as an example.
Step 1: Programming Language Identification. T firmware typically employs multi-language hybrid development, including scripting languages such as PHP, JavaScript, Lua, and compiled languages like C/C++. Each language has its specific patterns for handling web interfaces, such as PHP using superglobal variables ($_GET, $_POST) for HTTP request handling, while C/C++ relies on structures and function parameters. We first instruct the LLM to accurately identify the language type of the code being analyzed, enabling it to tailor its analysis strategy accordingly and improve extraction accuracy.
Step 2: HTTP Request Information Extraction. In this step, we instruct the LLM to identify HTTP protocol information, primarily including (1) protocol version identifiers (such as HTTP/1.0, HTTP/1.1), (2) HTTP request method declarations, and (3) HTTP header information. To enhance analysis quality, we provide typical HTTP information definition examples, such as headers = {“Content-Type”: “application/json”}, to help the model better recognize this information.
Step 3: Parameter Analysis. Parameter analysis comprises three key tasks: (1) Conditional statement analysis; this involves extracting parameter value range constraints by parsing control structures (such as if-else, switch-case) and generating values covering different execution paths, for example, after extracting constraints from “if ($RoleID < 0)”, thereby generating values -1 and 1 to cover different branches. (2) Default value extraction; this comprises obtaining parameter initialization or default values based on variable definitions. (3) Constraint analysis; this consists of generating feasible values that satisfy all explicit constraint conditions related to the parameters.
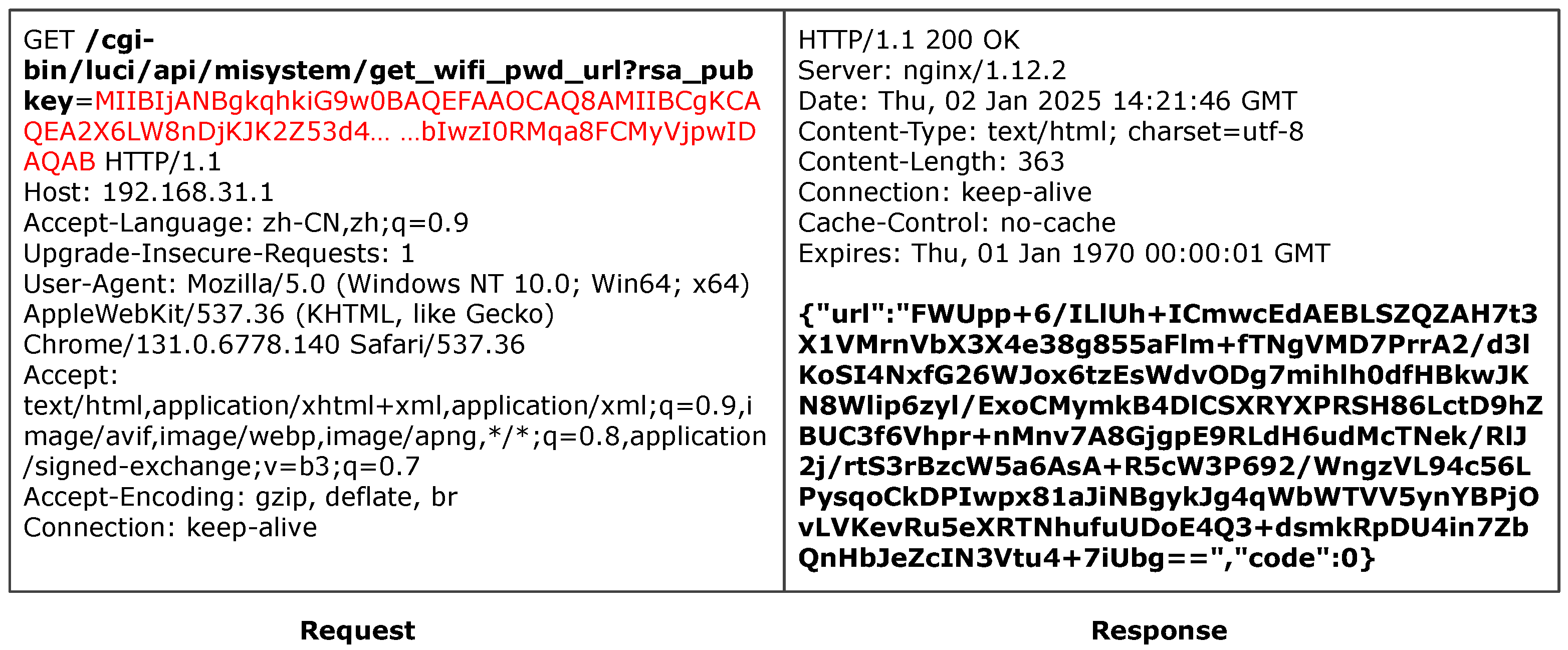
Step 4: Dynamic Value Generation. Dynamic value generation specifically handles parameter values that require computation, primarily involving the generation of session tokens, timestamps, and cryptographic hashes. The LLM infers values that meet constraints by analyzing value generation algorithms (such as specific hash functions) and usage scenarios (such as time format requirements). For instance, for MD5-based token generation logic, the LLM can derive hash values in the correct format.
Finally, we require the LLM to combine the analysis results from the above four steps to provide the final structured information. This multi-step chain-of-thought analysis enables us to obtain accurate and complete file and HTTP information, providing effective values for subsequent mutation-based fuzzing.
5.1.3. Prompt Builder
The design of prompts directly determines the quality of the answer output by the LLM, so we carefully constructed a structured prompt template consisting of five core components to enhance understanding, as shown in
Figure 7.
Role Definition: We instruct the LLM as an “IoT firmware code analysis expert”. This explicit role constraint enables the LLM to maintain a professional perspective and focus on analyzing IoT device code.
Analysis Steps: We begin by instructing the LLM to reason step by step using a chain-of-thought approach [
47]. Then, we briefly list and explain the four analytical steps described in
Section 5.1.2, accompanied by illustrative examples.
Examples: We employ a few-shot learning method, manually designing three real-world examples: HTTP request analysis, parameter analysis, and dynamic value inference. Each example includes input code and corresponding analysis results in JSON format, guiding the LLM in understanding the analysis task and standardizing the output format through specific examples.
Input Code: We use XML tags to encapsulate the code obtained from the firmware preprocessing stage for the LLM to analyze.
Output Format: We instruct the LLM to output final results in a structured JSON format to ensure result parsability.
We combine the above five components—role definition, analysis steps, few-shot examples, input code, and output format—into a single structured prompt. This complete prompt is submitted as a whole to the LLM, rather than in separate parts, to ensure contextual consistency. We regenerate the complete prompt for each new code analysis task by replacing the “Input Code” component with the new code snippet while keeping the other components unchanged. This ensures that every query provides the LLM with the full analytical context, thereby enhancing extraction accuracy and consistency across multiple tasks.
5.1.4. Reasoner
We designed a Reasoner using a two-round inference strategy to overcome the limitations of single-round LLM analysis, particularly when handling dynamically generated values and complex conditional constraints.
In the first round, using a breadth-first strategy [
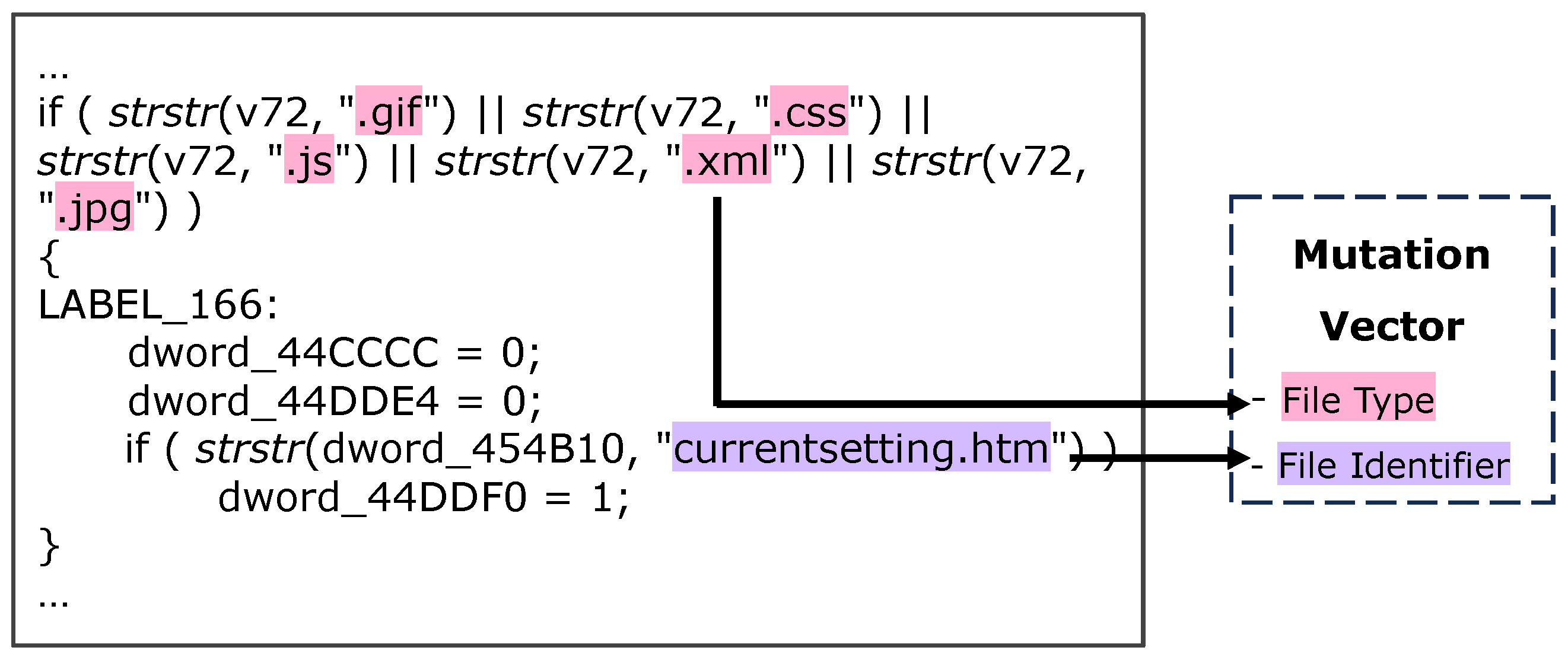
48], the LLM systematically extracts basic information from the firmware code, including interface paths and HTTP basic parameters. When it encounters complex parameters that require in-depth analysis—such as values derived from encryption functions or conditional logic—it marks them with placeholders or natural language descriptions for further inference.
The second round of inference focuses on processing these marked items. The Reasoner identifies the fields to be analyzed by parsing the JSON output from the first round and performs targeted reasoning to infer valid input values. For example, when analyzing a Lua script that dynamically constructs a parameter like md5_param = md5(seed ...), the Reasoner recognizes the MD5-based generation logic and infers a valid hash-formatted value to satisfy the request constraint. These in-depth analysis results provide valid input values for subsequent fuzzing and are crucial for triggering access control evasion that depends on correctly formatted dynamic inputs.
5.2. Mutation-Based Fuzzing
ACBreaker employs mutation-based fuzzing to detect broken access control vulnerabilities in protected interfaces. This approach performs mutations on HTTP requests while preserving their semantic integrity, aiming to evade access control mechanisms and obtain unauthorized access. To achieve this, we designed a fuzzing framework that integrates mutation chain coordination and effective mutation prioritization strategy, as shown in Algorithm 1.
| Algorithm 1 Mutation-based Fuzzing |
| Require: |
| 1: : {Path Information, File Identifier, File Type} |
| 2: : {Protocol Information, Request Methods, HTTP Headers, Request Parameters} |
| Ensure: |
| 3: Vulnerability Report: {Interface of evasion, Mutation Chain, Mutation Request, Mutation Response} |
| 4: function Fuzzing(, ) |
| 5: | ▹ Initialize interface set |
| 6: | ▹ Initialize mutation set |
| 7: | ▹ Initialize vulnerability report |
| 8: | ▹ Priority queue for mutation chains |
| 9: for all do |
| 10: for all do |
| 11: for all do |
| 12: CombineInterface(, , ) |
| 13: ConstructRequest() |
| 14: SendRequest() |
| 15: if then |
| 16: |
| 17: |
| 18: |
| 19: if then |
| 20: ExtractMutationInfo()) |
| 21: end if |
| 22: end if |
| 23: end for |
| 24: end for |
| 25: end for |
| 26: InitializeMutators(, ) |
| 27: | ▹ Initialize pending interface set |
| 28: for all do |
| 29: GenerateMutationChains() |
| 30: RemoveConflicts() |
| 31: while do |
| 32: if then |
| 33: |
| 34: | ▹ Reset pending interfaces |
| 35: while do |
| 36: |
| 37: ApplyMutationChain(, ) |
| 38: SendRequest() |
| 39: DifferenceAnalyzer(, ) |
| 40: if then |
| 41: |
| 42: end if |
| 43: end while |
| 44: else |
| 45: |
| 46: ApplyMutationChain(, ) |
| 47: SendRequest() |
| 48: DifferenceAnalyzer(, ) |
| 49: if then |
| 50: |
| 51: | ▹ Prioritize effective chain |
| 52: end if |
| 53: end if |
| 54: end while |
| 55: end for |
| return |
| 56: end function |
The algorithm accepts two inputs: (1) FileINFO, containing path information, file identifiers, and file types extracted from firmware, and (2) HTTPINFO, containing protocol information, request methods, HTTP headers, and request parameters. The algorithm outputs vulnerability reports documenting discovered broken access control vulnerabilities, including protected interfaces of evasion, successful mutation chains, mutation requests, and the corresponding responses. Its execution process consists of three main phases:
Phase 1: Interface Detection (Lines 5–25). ACBreaker first constructs web interfaces by combining path information, file identifiers, and file types from FileINFO. It sends initial HTTP requests to each interface, storing interfaces with response status codes other than 404 and corresponding HTTP response information as baseline data in the interface set for differential analysis. Notably, when the baseline response status code is 200, ACBreaker extracts path and file identifier information from that interface through the ExtractMutationInfo function, which mutation operators will use.
Phase 2: Mutation Generation and Execution (Lines 26–47). ACBreaker first initializes the mutation operator set by invoking the InitializeMutators function based on FileINFO and HTTPINFO, and maintains the pendingInterfaces set to track interfaces pending testing. For each valid interface, the GenerateMutationChains function generates mutation chain coordination, and the RemoveConflicts function subsequently removes conflicting mutation chains. During fuzzing, ACBreaker employs an “effective mutation prioritization” scheduling strategy. When a mutation chain successfully triggers a vulnerability, it is immediately added to the priorityQueue, and the current fuzz sequence is paused to apply this mutation chain to all interfaces in pendingInterfaces.
Phase 3: Differential Analysis. The DifferenceAnalyzer function (show in Algorithm 2) analyzes mutation responses through a three-layer filtering mechanism: first filtering invalid responses, then checking for significant status code changes (e.g., from 401/403 to 200/202), and finally verifying whether access control has been successfully evaded through response body analysis.
The following sections will detail the specific implementation of mutation algorithms, mutation operators, and differential analysis strategies.
5.2.1. Mutation Algorithm
We designed a mutation algorithm that integrates mutation chain coordination and effective mutation prioritization to enhance the efficiency of discovering broken access control vulnerabilities.
Mutation Chain Coordination. The mutation chain coordination strategy generates fuzzing sequences by combining multiple mutation operators. For each baseline request, the Mutator constructs a complete list of mutation chains in the form of {M1, M2, M3, M1M2, M1M3, M2M3, M1M2M3…}, where each element represents a mutation chain, consisting of a specific combination of mutation operators. To optimize the generation and execution efficiency of mutation chains, this strategy implements two key dynamic optimization mechanisms: (1) Conflict Detection: analyzes interactions between operators within mutation chains and automatically removes conflicting combinations, such as those that mutually modify the same HTTP header field; and the (2) Minimization Principle: when a shorter mutation chain successfully triggers a vulnerability, ACBreaker automatically eliminates all longer mutation chains containing this successful chain to ensure the simplest vulnerability triggering conditions.
Effective Mutation Prioritization. The effective mutation prioritization strategy optimizes fuzzing sequences through dynamic scheduling. The Mutator suspends the current fuzzing sequence when the differential analyzer confirms that a mutation chain successfully evades access control for a protected interface. It prioritizes testing all pending interfaces using this effective mutation chain. This strategy is based on the observation that different web interfaces within the same device often implement similar access control mechanisms, thereby accelerating vulnerability discovery by reusing verified effective mutation chains.
5.2.2. Mutation Operators
The design of mutation operators directly affects the effectiveness and efficiency of discovering broken access control vulnerabilities. We developed a systematic set of mutation operators based on the key components of HTTP requests to create a fuzzer that effectively identifies vulnerabilities in protected interfaces. These mutation operators are categorized into four dimensions: request line (M1–M8), headers (M9–M11), body (M12), and byte level (M13–M17). As shown in
Table 1, we designed 17 mutation operators, 12 of which are novel methods introduced in this study (operators not marked with an asterisk). These operators systematically uncover security flaws in protected interfaces, enabling us to identify and classify three common types of broken access control vulnerabilities: path manipulation, header manipulation, and parameter manipulation.
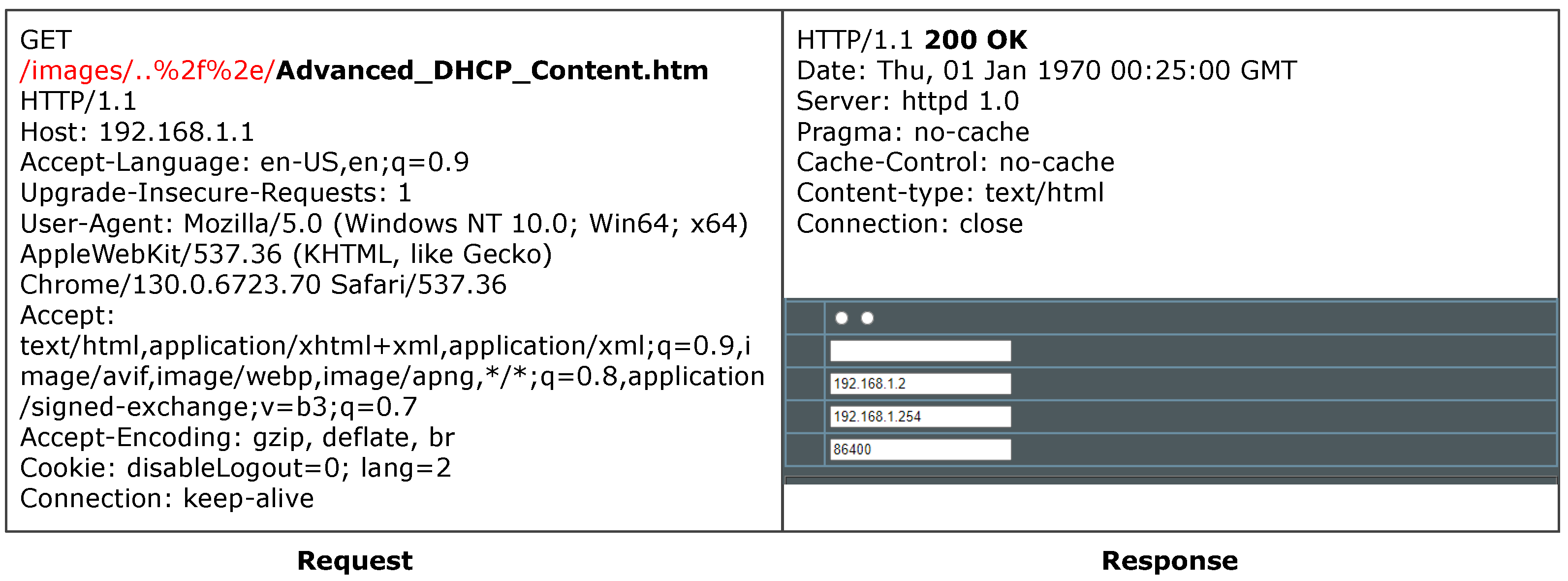
Request Line Mutation Operators explore access control evasion based on HTTP request lines. M1 and M2 implement basic mutations of HTTP request methods and protocol versions, respectively. M3 to M5 focus on path mutation designed based on URL parsing features from RFC 3986, including Matrix Parameters (such as transforming /admin/ to /;/admin/), suffix addition, and path hierarchy insertion. M6 and M7 are designed based on relative URI parsing rules from RFC 3986 [
49], employing directory traversal sequences (e.g., /static/../admin) to test the server’s path normalization handling. These fuzzing sequences are constructed by combining path and file identifiers through the
ExtractMutationInfo function. M8 specifically leverages ASP.NET’s cookieless feature for fuzzing.
Header Mutation Operators explore access control evasion based on HTTP headers. M9 tests source address verification by injecting IP-related headers (such as X-Remote-IP: 127.0.0.1). M10 probes parsing vulnerabilities by adding URL rewriting-related headers. M11 constructs requests using header information extracted from firmware (e.g., specific Referer values).
Body Mutation Operators explore access control evasion based on parameter processing logic. They extract parameter names and values from firmware to create valid parameter combinations, thereby identifying flaws in parameter validation.
Byte-level Mutation Operators provide more fine-grained request modifications. These include special character injection (M13), case conversion (M14), Unicode homograph replacement (M15), URL encoding (M16), and control character replacement (M17). These low-level operations probe for parsing implementation flaws by altering character encoding and representation methods, such as mutating /system.php?public.cgi to /system.php%00public.cgi to test for parameter delimiter processing flaws.
In summary, the choice of mutation operators is aimed at simulating a wide range of potential evasion techniques based on attack patterns observed in real-world scenarios, such as the CVE-2024-0204 vulnerability found in Fortra GoAnywhere MFT. This vulnerability exploits a flaw in a URL path parser, allowing an unauthenticated attacker to bypass authentication by manipulating the request path and access interfaces that are supposed to be protected, such as those for creating administrator accounts.
5.2.3. Difference Analyzer
The Difference Analyzer identifies broken access control vulnerabilities by comparing baseline and mutation responses. As shown in Algorithm 2, we designed three complementary detection strategies to accurately capture protected interface evasion characteristics: preprocessing strategy, status code transition-based detection, and response body difference-based detection.
| Algorithm 2 Difference Analysis for Vulnerability Detection |
| Require: |
| 1: : Response from baseline request |
| 2: : Response from mutation request |
| 3: : A queue or dictionary to store the frequency of response body hashes |
| Ensure: |
| 4: : Boolean indicating if a vulnerability is detected |
| 5: function DifferenceAnalyzer(, , ) |
| 6: if or then return |
| 7: end if |
| 8: if then return |
| 9: end if |
| 10: if and then |
| 11: FNV1aHash() |
| 12: GetHashFrequency(, ) |
| 13: if then |
| return |
| 14: end if |
| 15: FilterDynamicContent() |
| 16: CalculateSimilarity(, ) |
| 17: if then |
| return |
| 18: end if |
| 19: end if |
| return |
| 20: end function |
Preprocessing Strategy (Lines 5–8). This strategy first filters out invalid responses, including responses with status codes 400, 404, 501, and empty response bodies. Subsequently, ACBreaker compares the content of mutation response bodies with baseline response bodies. Even if the status code changes, identical response content generally indicates that the server’s error-handling mechanism was activated, rather than a successful evasion of the protected interface. For example, we often encounter cases where mutating the request method to HEAD results in a 200 status code but with an empty response body. Status Code Transition-based Detection Strategy (Line 10). This strategy determines whether access permissions have changed by alterations in response status codes. When protected interface evasion is successful, status codes typically transition from 401 (Unauthorized) or 403 (Forbidden), indicating restricted access, to 200 (OK) or 202 (Accepted), indicating successful requests. ACBreaker identifies potentially protected interface evasion by monitoring these characteristic status code transitions.
Response Body Difference-based Detection Strategy (Lines 11–18). This strategy employs two complementary techniques: (1) Page similarity analysis based on hash value statistics uses the FNV-1a hashing algorithm to calculate feature values of the response body and filters out frequently occurring non-sensitive page content, such as login-redirect pages or generic error messages, through a frequency threshold, and (2) page comparison with dynamic content filtering identifies and filters dynamic content in responses (such as timestamps, session IDs) through the
FilterDynamicContent function, then calculates the similarity of static content. When similarity falls below 0.9 (this threshold is set to minimize errors in identifying different strings as identical and maintain consistency with existing SOTA research [
50]), the strategy determines whether there is a valid protected interface evasion.
5.3. ACBreaker Prototype
We implemented the ACBreaker prototype to discover access control vulnerabilities in protected interfaces automatically. ACBreaker uses a modular architecture designed for seamless integration with existing security tools and frameworks. Written in Python, it comprises 11,990 lines of code and covers the entire workflow from firmware analysis to vulnerability detection.
In the firmware preprocessing stage, ACBreaker integrates three core modules. The Web File Identifier uses regular expressions and heuristic rules to detect web-related files in the firmware. It can work with existing firmware analysis tools, such as Binwalk and Firmadyne, for firmware extraction and analysis. The decompiler converts binary files into pseudo-C code and can interface with existing decompilation tools like Ghidra and IDA Pro to enhance the accuracy and readability of decompilation outputs. The code slicer analyzes call relationships, breaking down code files with over 100 K tokens into semantic blocks, ensuring compatibility with large language models (LLMs).
In the intelligent firmware analysis stage, ACBreaker uses LangChain, which includes a prompt builder and a Reasoner. The prompt builder creates prompt templates for information extraction by combining role definitions, chain-of-thought strategies, and few-shot learning. The Reasoner employs two rounds of reasoning to ensure the completeness and accuracy of the extracted information. LangChain integrates with other AI-based models, such as OpenAI’s GPT models or Google’s Gemini, enhancing the system’s information extraction capabilities. Users can easily connect their own models via API, ensuring flexibility and scalability.
In the fuzzing stage, ACBreaker operates through three collaborative modules: the Prober, the Mutator, and the Difference Analyzer. The Prober uses the requests [
51] library to identify valid web interfaces. The Mutator generates mutation requests based on 17 specialized mutation operators to fuzz-protected interfaces. The differential analyzer examines baseline requests and mutated requests to detect vulnerabilities. All request data are managed using an SQLite database. All components communicate via JSON, maintaining a consistent and coherent workflow.
The modular design and open interfaces of ACBreaker ensure its adaptability and ease of integration into different environments, enhancing reproducibility by allowing users to customize components and workflows based on their specific needs.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}