1. Introduction
Autonomous visual–inertial integrated navigation systems (VINS) have gained widespread adoption, especially in Global Navigation Satellite System (GNSS)-denied environments, such as indoors, underwater, in urban canyons, and in space [
1]. Most inertial navigation systems (INS) rely on inertial measurement units (IMU) to measure the platform’s local linear acceleration and angular velocity. However, high-end tactical-grade IMUs are commercially unviable; thus, low-cost, lightweight micro-electromechanical (MEMS) inertial measurement units (IMUs) are utilized. The MEMS-based IMUs are affected by noise and bias, making the simple integration of IMU measurements to estimate the 6DOF pose (position and orientation) unreliable for long-term navigation. When GNSS signals are available, the motion drift accumulated over time due to IMU manufacturing imperfections can be corrected using the global information from GNSS [
2]. However, in GNSS-denied environments, a monocular camera that is lightweight, small in size, and energy-efficient, and provides substantial environmental data, can be utilized to correct the drift accumulated in the navigation solution, yielding visual–inertial integrated navigation systems (VINS) [
3].
Theoretically, visual–inertial navigation can be classified as either visual–inertial simultaneous localization and mapping (VI-SLAM) or visual–inertial odometry (VIO) [
3]. VI-SLAM performs localization and environmental mapping simultaneously, which makes it computationally expensive. In contrast, VIO is a localization method that does not perform environmental mapping; instead, it utilizes environmental features such as points, lines, and planes to correct the navigation solution affected by IMU imperfections. Since VIO does not perform environmental mapping, it estimates only a limited number of environmental features to refine the navigation solution, making it computationally efficient compared to VI-SLAM; however, this efficiency comes at the cost of losing mapping information.
Like SLAM systems, all visual–inertial navigation systems, including VIO and VI-SLAM, can be divided into front-end and back-end components. The front end processes the visual information, and the back end serves as the estimation engine [
4]. In short, we can say that the front end performs image processing or computer vision tasks, such as the extraction and tracking of environmental features. The back end deals with the estimation process, which is performed in various ways, primarily through loosely coupled and tightly coupled estimation methods. The loosely coupled methods independently process the visual and inertial measurements [
5]. In contrast, the tightly coupled methods derive constraints between the visual and inertial measurements to obtain the motion and observation models [
6]. The loosely coupled and tightly coupled methods are further classified as filtering-based [
5,
6] or optimization-based [
7]. The optimization approach is more efficient but computationally expensive because it solves a non-linear least squares problem over a set of measurements through re-linearization. Research in this area is also progressing with the emergence of several optimized, computationally efficient, and open-source libraries, such as Ceres [
8] and g2o [
9]. On the other hand, filtering-based back ends are still popular among researchers because of their computational efficiency [
3,
4].
Among the tightly coupled filtering methods of VIO, the multi-state constrained Kalman filter (MSCKF) [
10] developed by Mourikis and Roumeliotis is a masterpiece based on the extended Kalman filter (EKF) [
11], which maintains a sliding window of IMU/camera poses and does not estimate environmental features in the state vector, as opposed to SLAM. Instead, a static environmental feature observed by multiple camera poses is triangulated and used for measurement updates. State propagation is performed using quaternion-based inertial dynamics with the IMU measurements, and state updates are performed by projecting the visual bearing measurements onto the left null space of the feature Jacobian, constraining the motion to the cloned IMU/camera poses. Thus, the computational cost associated with estimating thousands of feature points is eliminated.
The MSCKF algorithm has been extended in several directions, notably the stereo cameras in the fast UAV autonomous flight [
12], LARVIO [
13], have extended MSCKF to include zero-velocity updates, and OpenVINS [
14] has combined the MSCKF with a VIO and SLAM framework, incorporating online camera calibration, zero velocity detection, static and dynamic state initialization, etc. All three studies have open-sourced their implementations and tested them on several open-source public datasets, such as EuRoC [
15].
All these studies have focused on VIO [
12,
13,
14], specifically localization. A complete and robust visual–inertial navigation system must offer adequate information for applications like path planning, collision avoidance, and obstacle detection in a cost-effective, compact, lightweight, and computationally efficient manner while utilizing limited resources. The MSCKF algorithm typically tracks the uniformly distributed FAST [
16] features in the environment using either optical flow [
17,
18] or descriptors [
19] and performs measurement updates when the tracked features are either lost in the current frame (i.e., could not be tracked) or when the IMU/camera pose corresponding to the observed feature is marginalized from the state vector.
Once the MSCKF update is performed and the IMU/camera poses in the state vector are corrected, the MSCKF can triangulate the tracked features in real time, provided they have been observed more than once and the tracking accuracy is reliable. However, applications such as path planning, collision avoidance, and obstacle detection require a dense or sparsely dense depth map of the environment. Traditional optical flow and descriptor techniques are susceptible to noise and changing lighting conditions. Furthermore, feature points cannot be extracted from textureless surfaces. While the MSCKF can triangulate points (not just features) in real time, the lack of features in the environment (such as textureless surfaces like walls and the sky), the limitation of optical flow and descriptor tracking methods to features only, and the limitation of computational resources like GPUs on smaller agile platforms restrict the application of the MSCKF to localization only. Although several efforts have been made recently to address the highlighted issues, such as Zibin Wu’s proposed feature point mismatch removal method [
20], which complements RANSAC, Chao Feng Yuan proposed a combined point and line SLAM in dynamic environments [
21], Cong Zhang proposed a monocular depth estimation network [
22], and Jiale Liu proposed enhanced visual SLAM leveraging point-line features [
23]. However, none of these methods addressed the following issues:
Limitations of feature point extraction and tracking techniques in environments with limited features;
Depth map without estimating features and featureless pixel points in the state vector, given limited computational resources.
To address these problems, we propose a visual–inertial odometry system based on pixel point tracking using reference features from the OpenVINS framework, which simultaneously performs localization and depth estimation of the environment. The main contributions are as follows:
To achieve a dense or sparsely dense depth map of the environment, where feature points could not be extracted across the entire image, especially in regions such as walls or planes, an adaptive reference features-based tracking algorithm is proposed. This algorithm can track featureless pixel points across sequential images. The depth of the tracked pixel points is estimated using the MSCKF triangulation method;
The traditional VIO tracking methods rely on feature points based on optical flow or descriptors, both of which are susceptible to lighting conditions and camera motion. When feature points cannot be tracked using either of these techniques, such as optical flow or descriptors, even if they remain visible in the image, our pixel point tracking method, which utilizes reference features, can still track any pixel point by using the reference features in the broader vicinity.
After applying the proposed technique, we can estimate the depth of nearly all pixels in the image, except in situations like the sky, where no reference features are available in the vicinity. The remainder of this article, in
Section 2, outlines the architecture of the proposed algorithm.
Section 3 provides a detailed description of our grid-based pixel point extraction method.
Section 4 elaborates on our pixel point tracking algorithm.
Section 5 describes the depth estimation and representation methodology.
Section 6 presents the experimental results using open-source visual–inertial datasets supported by OpenVINS. Finally,
Section 7 concludes and discusses future work.
2. System Overview
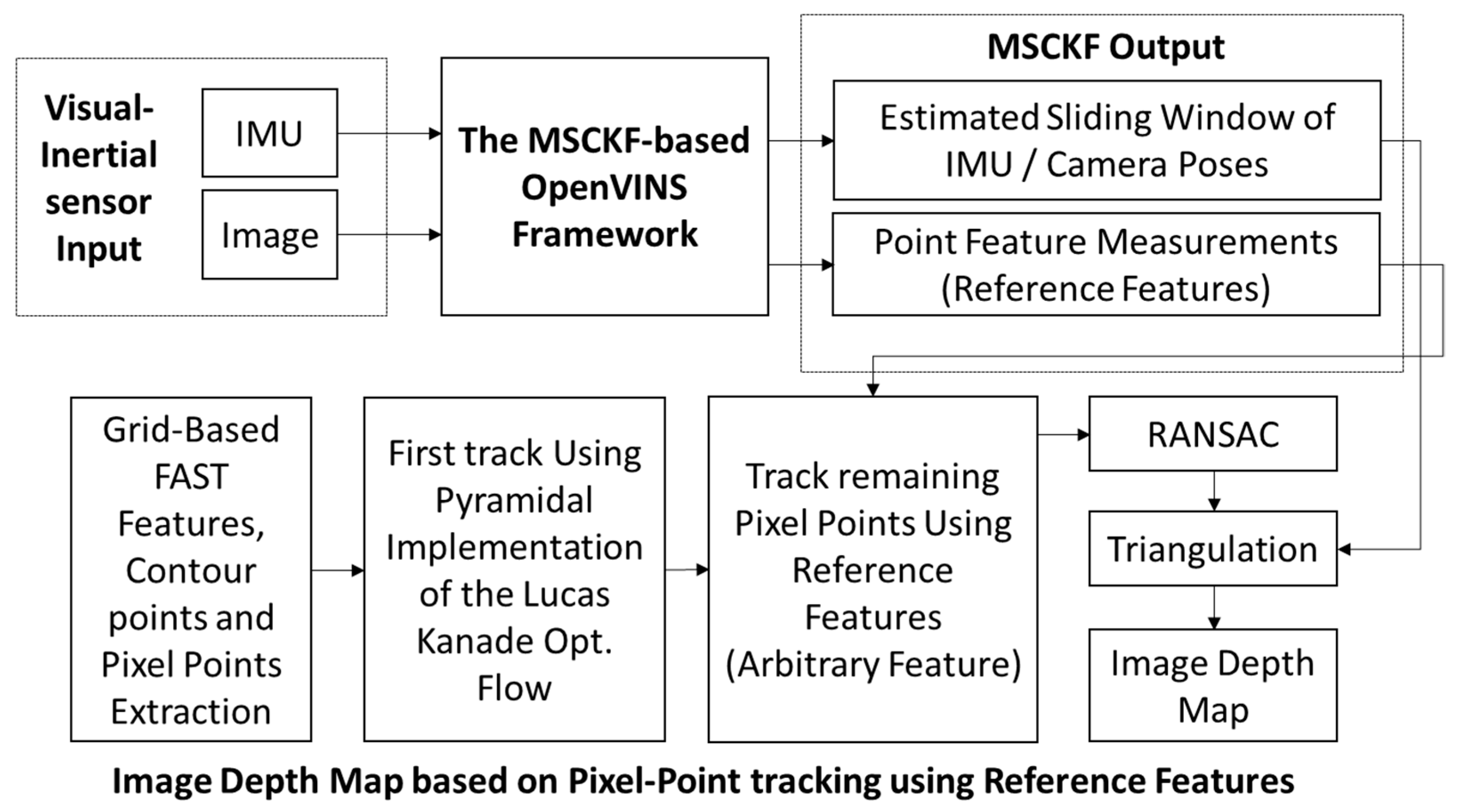
The method proposed in this paper is mainly an improvement based on the OpenVINS framework [
14]. The designed system block diagram is shown in
Figure 1, which is primarily divided into the MSCKF-VIO framework, grid-based pixel point extraction, tracking, and triangulation for depth map estimation. The MSCKF-VIO framework employs the same strategy as OpenVINS, mainly including initialization, state propagation, and MSCKF measurement updates. The FAST feature tracker in OpenVINS is initialized by extracting FAST features through a grid-based methodology to ensure a minimum pixel distance between the features. These features are tracked using either pyramidal LK optical flow [
24] or ORB descriptors [
25]. After being observed more than once, the tracked features can be triangulated using the corresponding camera poses. These tracked features are then sorted according to the number of tracks. The features observed from all camera poses in the state vector are treated as SLAM features and are estimated in the state vector alongside the IMU poses and calibration parameters. The remaining features are treated as MSCKF features, which are only used to correct the IMU pose after triangulation and are not estimated in the state vector.
Our tracking algorithm considers the MSCKF and SLAM features as reference features. After estimating the sliding window of IMU/camera poses from the FAST features (i.e., MSCKF and SLAM features), pixel points are extracted in a grid-based structure, similar to OpenVINS. It is ensured that every grid contains at least one pixel point, which can be a feature point, a point on the contour (i.e., contour points), or a featureless pixel point that is arbitrarily selected as the grid’s center. The grids are kept smaller (5 × 5 pixels) near the center of the image to create a dense depth map, while larger grids are used in other areas. The grid size determines the number of grids in the image, dictating the density of pixel points used to represent the depth map.
The pixel points are tracked using a pyramidal implementation of LK optical flow. The pixel points that are not successfully tracked with optical flow are then tracked using reference features. Finally, Random Sample Consensus (RANSAC) [
26,
27,
28] is applied to remove any outliers. After successful tracking, each tracked point is assigned an ID similar to that used in OpenVINS, and the feature database is updated. Pixel point triangulation is performed using measurements from consecutive images and the corresponding camera poses, thus resulting in a real-time depth map of the image.
The MSCKF-based VINS framework, shown in
Figure 1, has already been implemented in several open-source systems, such as MSCKF-VIO [
29] and OpenVINS [
30], which are publicly available online. This research is developed using the existing framework of OpenVINS, an open platform based on MSCKF and Extended Kalman Filtering, developed by the Robot Perception and Navigation Group (RPNG) laboratory. OpenVINS offers modular management of state vectors and feature databases to facilitate user expansion. A detailed description of the methods and algorithms of the OpenVINS framework can be found in [
31]. The MSCKF-VIO framework’s output includes the estimated sliding window of N camera poses and reference features.
Our significant contribution in this paper is the design of a tracking algorithm that uses reference features to track both features and featureless pixel points across sequential images. This approach enables depth estimation for the entire image, except in regions where reference features are unavailable in the vicinity, such as the sky.
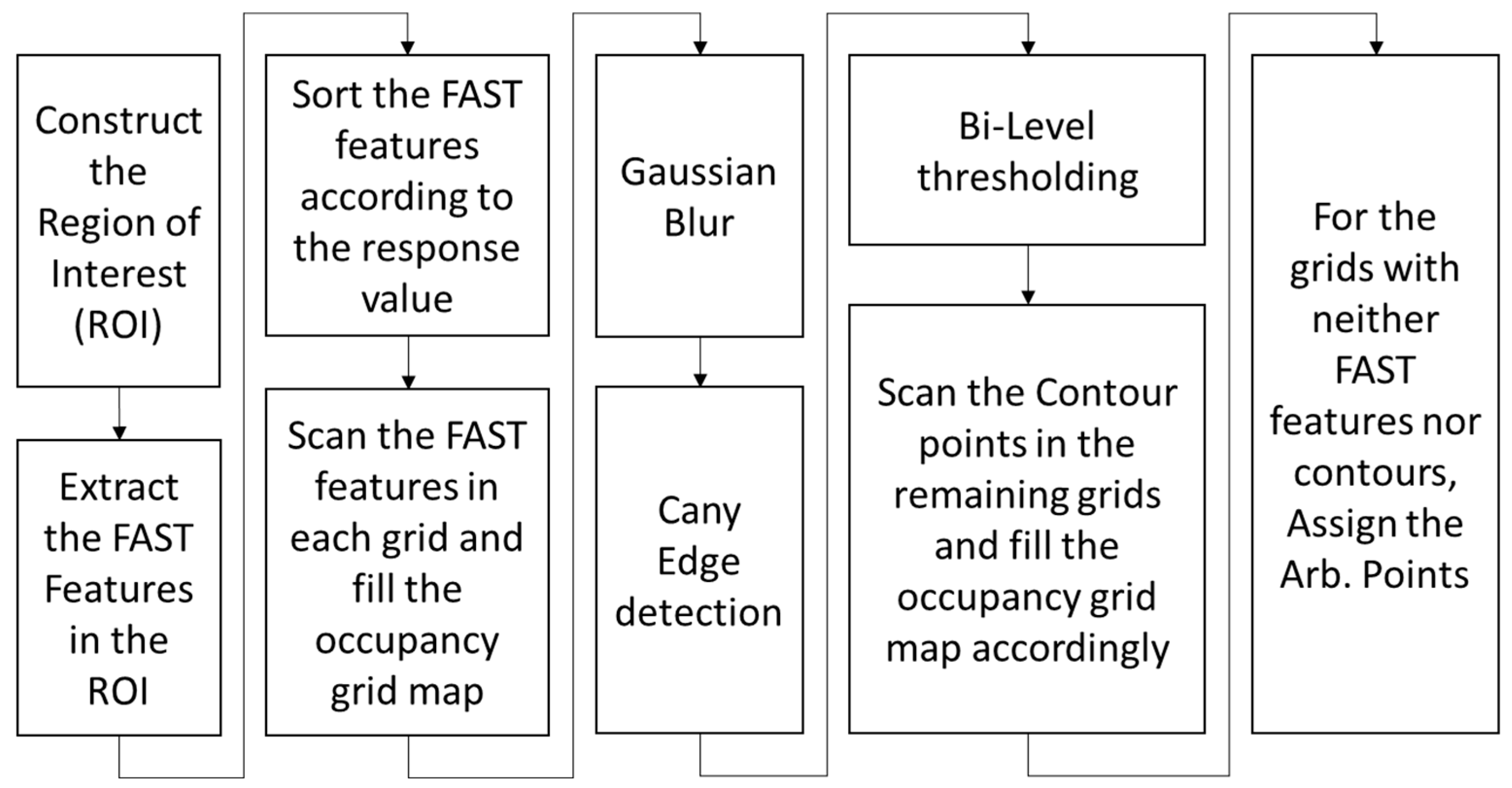
3. Gridded Pixel Point Extraction Algorithm
The extraction of pixel points is the first phase in estimating the depth of gridded sparse pixel points in the image. As the camera moves, some pixel points move out of the image, and new pixel points must be extracted from the newly observed space. Therefore, the extraction and initialization of pixel points is a continuous process in VIO. Furthermore, an image consists of tens of thousands of pixels, and depth estimation for all pixel points is extremely computationally expensive in real time, especially with limited computational resources, such as in the absence of GPUs.
The image is divided into several grids to restrict the computational load, with one pixel point selected in each grid. Usually, the direction of motion is toward the center of the image. Thus, the density of extracted pixel points is kept higher around the center of the image and lower outside this region. Therefore, the size of the grids around the image center is kept smaller, while it is bigger elsewhere. Grid-based extraction also ensures a uniform distribution of pixel points in the depth map of the image. Since the required density of pixel points differs in the two image regions, we define two distinct areas within each image and utilize two different trackers for this purpose. The number of feature points alone is insufficient to meet the constraint of one pixel point per grid in the occupancy grid map. Therefore, other methods to extract pixel points are considered.
The contours in the image are extracted as a continuum of pixel points, all of which exhibit similar properties, preventing us from characterizing these pixels as features. These points on the contours can also serve as candidate pixel points to be tracked when there is no FAST feature in a grid. Grids containing neither features nor contours can be categorized as textureless planes. All the pixels in these grids exhibit similar properties, and any pixel could be chosen as a candidate pixel point for the depth map.
In the first stage, FAST corner point features above a certain threshold are extracted from the two regions using the FAST [
16] corner detection algorithm from OpenCV [
32]. The FAST features are refined and sorted according to the maximum response value, from which the strongest FAST feature is selected. Each grid is scanned for these FAST features. If one or more FAST features are present in a grid, the one with the maximum response is selected as a candidate point for tracking, and the occupancy grid map is updated. Since it is extremely unlikely to extract FAST feature pixel points in each grid, as shown in
Figure 2a, given that the grid size is very small, i.e., in the range of 5 to 10 pixels in both directions, the points on the contours serve as a convenient choice for the unoccupied grids in the occupancy grid map.
To extract contours, the image is convolved with a Gaussian kernel for blurring, the Canny edge detector is applied to detect the edges, binary image thresholding is performed to obtain a bi-level image, and lastly, OpenCV is used to extract the coordinates of the pixel points on the edges of the bi-level image, as shown in
Figure 2b. These contour points are then scanned for each unoccupied grid in the occupancy grid map. Next, we update our tracker by choosing at least one contour point for the unoccupied grids that contain a contour point.
For grids without any features or contours, i.e., textureless or noisy patches in the image, any pixel can be taken as a candidate point to be tracked, i.e., arbitrary points. To ensure uniformity of pixel distribution in the depth map, we select the center of the grid as an arbitrary point to be tracked and initialized in the tracker.
Figure 2c shows the extraction of pixel points around the image center with a grid size of 5 × 5 pixels from the image taken from the EuRoC dataset V1_01_easy, showing the three different types of pixel points and the count of the different kinds of pixel points extracted around the image center. Similarly,
Figure 2d shows the extraction of pixel points outside the ROI (region of interest) defined around the image center with a grid size of 8 × 8 pixels, showing the three different types of pixel points and their counts. As mentioned earlier, the density requirement for pixel points far from the image center is lower.
In
Figure 2, neither the FAST features nor the contour points can be found in several grids corresponding to textureless surfaces, such as carpeted floors, windows, or walls. Consequently, several pixel points (1855 points around the center and 1941 points outside the ROI around the center) are assigned as arbitrary points. The pixel point extraction process is illustrated as a flowchart in
Figure 3. Additionally, the number of pixel points (pixel density) chosen within the ROI around the center is significantly higher than in other areas, even though it is four times larger. The reason is apparent: the grid size defines the pixel density.
4. An Adaptive Threshold-Based Pixel Point Tracking Algorithm Using Reference Features
To estimate the depth of pixel points in the image, both the newly extracted pixel points and those tracked from the previous image must be tracked with sufficient accuracy, allowing for triangulation for depth estimation. For this purpose, the pyramidal LK optical flow is a convenient choice. Since the optical flow is calculated for pixel points with distinct characteristics, namely features, many points, including the three types of points, i.e., features, contour points, and arbitrary featureless pixel points, cannot be tracked using optical flow.
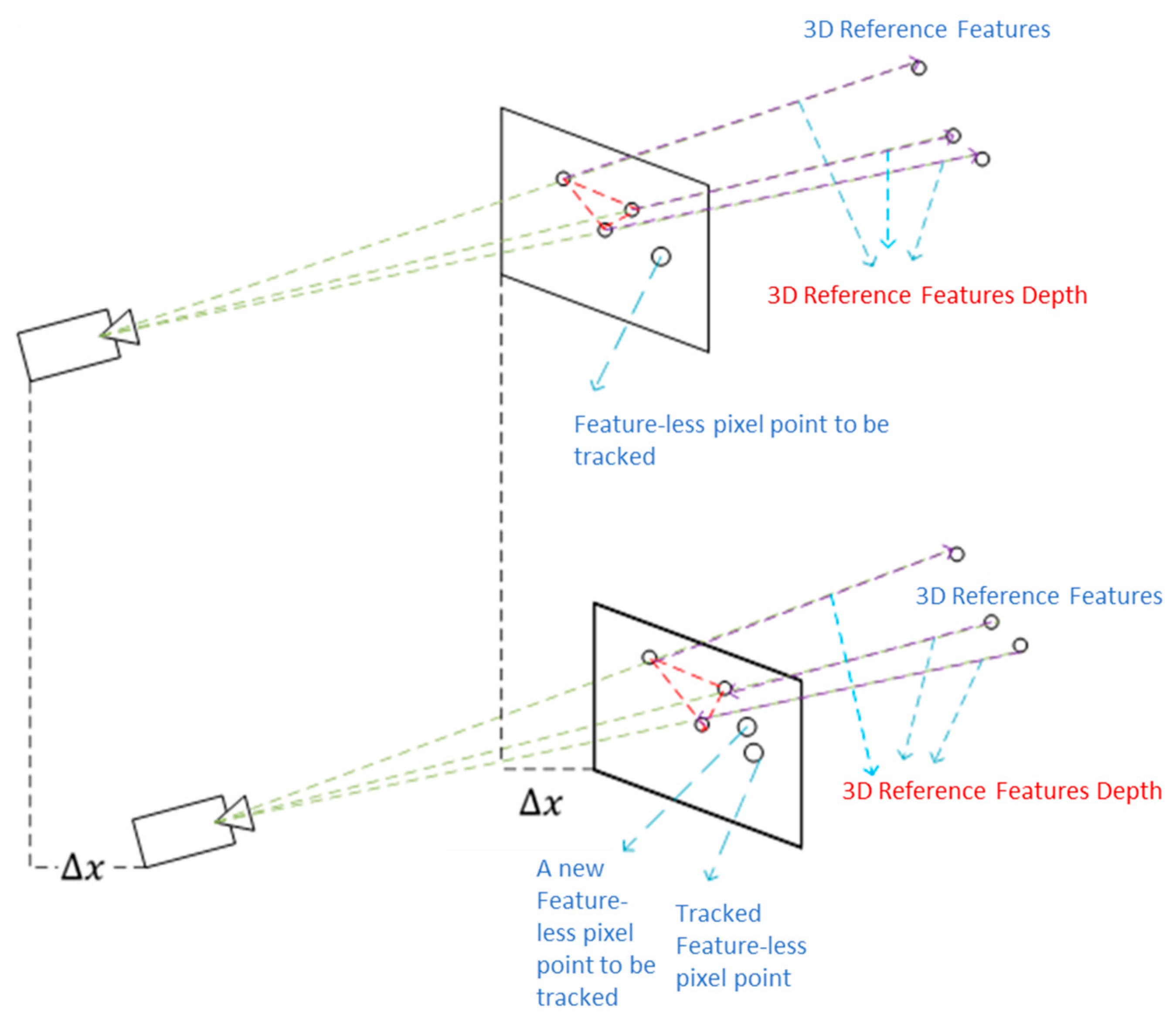
To determine the corresponding positions of untracked pixel points in the image, the feature points from the VIO framework, whose depths have been estimated in adjacent images, serve as reference features. The invariance of the relative positions between the points to be matched and the reference feature points in adjacent image frames is utilized to estimate the matching position of the pixel points in subsequent image frames. However, due to the differing observation positions of points in space, the relative positions of the points in various frames will change. To effectively match featureless points in adjacent frames, selecting a reference position relative to the point to be estimated that does not change with camera motion is essential.
To address this problem, we propose an adaptive threshold-based reference feature selection algorithm for tracking featureless pixel points, which adaptively selects the set of reference features for a given point while satisfying the aforementioned constraint. Once the set of reference features is known, the depth range of a given point can be calculated using the reference features in the neighborhood. Given the reference features that satisfy the positional invariance constraint concerning the point to be tracked and the depth range around that point, we can track the position of the pixel point in the image using the geometry of the selected reference features in the two images. After tracking all the given pixel points, the 8-point RANSAC outlier rejection algorithm is applied to remove any outliers. The detailed tracking process is explained below.
4.1. An Adaptive Threshold-Based Reference Feature Selection Algorithm for Tracking Featureless Pixel Points
Consider the projected coordinates of a pixel point,
, in an image, 0, with depth
and the camera intrinsics matrix, K, as follows:
where
represent the projected coordinates of a pixel point,
. The distance between the two points,
(point to be matched) and
(reference point), in image 0, without considering rotation and translation, is given as follows:
After the camera pose changes, the position of
in the image plane is given as follows:
where
is the depth of
after the camera pose changes. By solving Equation (3) after camera displacement and rotation, the image plane coordinates are obtained as follows:
Therefore, the corresponding depths of points
and
after camera rotation and translation are given as follows:
After the camera pose changes, the distance between the two points in space in the image plane is given as follows:
The first part, i.e., , refers to the distance within the image plane without the effect of translation, while the second part, , refers to the effect of translation on the distance within the image plane. The following conclusions can be drawn from the analysis above:
Camera rotation will cause changes in the relative position of points in space on the imaging plane;
Camera displacement will cause changes in the relative position of points in space on the imaging plane.
The interval between consecutive frames is small, i.e.,
, then
,
. Therefore, the effect of camera rotation on depth can be ignored. If the camera displacement is smaller relative to the depth, we can formulate a constraint equation for selecting reference features as follows:
Hence, it can be considered that changes in the relative positional relationship between spatial points in the space within the imaging plane can be ignored if the ratio, , is less than a certain threshold. If the reference feature, , and the point to be matched, , satisfy this constraint, we can select as a reference feature with sufficient invariance that can be used to estimate the position of in the adjacent frame, i.e., .
4.2. Depth Range Estimation
If we can select at least three reference features that form a triangle in both images, and the interior angle values of the triangles in the imaging planes remain unchanged at different times after the camera pose changes (i.e., within a threshold), we can approximately conclude that the change in the camera pose does not affect the relative relationship between the reference features and the pixel point to be matched in the imaging plane.
In practical applications, the depth of the point to be estimated, i.e., both and , is unknown. Therefore, the reference feature points around the point to be estimated are used to define the depth range. In cases in which reference features are unavailable in the broader neighborhood, a pixel point may not be successfully tracked, which can occur situations such as the sky, where no reference depths are available in the vicinity. The translation in Equations (3)–(7) is calculated using the estimated sliding window of IMU/Camera poses from the VIO framework.
Given the normalized coordinates of
, i.e.,
, and the depths of reference features around
, the minimum and maximum depths in the neighborhood around
are known, i.e., (
). Given the depth range around
, the position of
corresponding to the minimum and maximum depths (
) in the camera coordinate frame can be calculated as follows:
Using the same reference features, we can find the minimum and maximum depths around in the next frame, i.e., . However, we still do not know the position of in the next frame, i.e., .
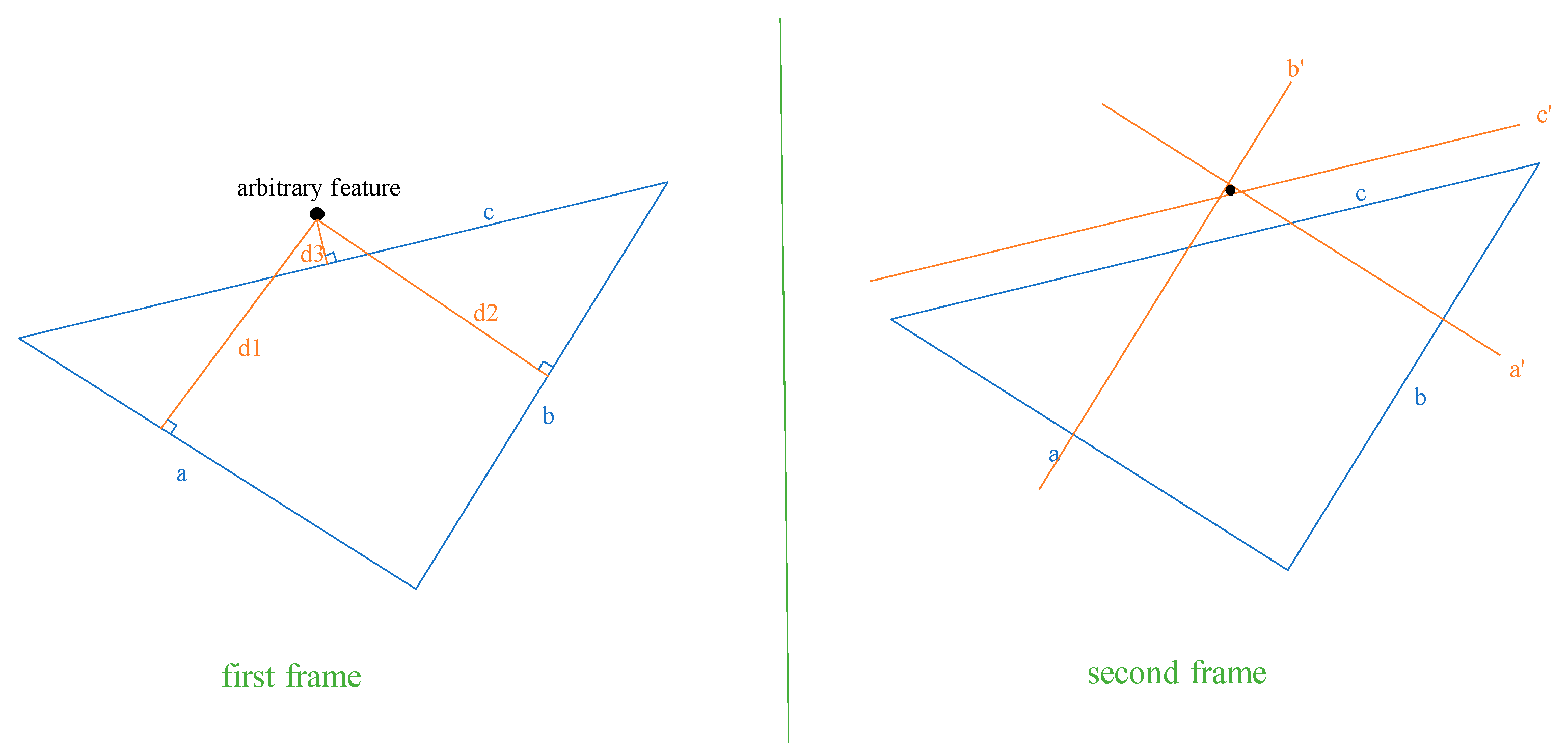
4.3. Threshold-Based Pixel Point Tracking Algorithm Based on Three Reference Points
After establishing the constraint in Equation (7) for selecting reference features in the adjacent images for a given point to be matched, sets of three reference features are selected individually in the adjacent image frames using the feature ID, forming a triangle, as shown in
Figure 4. It is essential to impose the following geometrical constraints, in addition to Equation (7), on the triangles formed by the three reference features in the adjacent images:
First, the lengths and interior angles of the triangles should be greater than a certain threshold, such as 10 pixels and 15 degrees;
To ensure the similarity of the triangles, the difference in the ratios of the three lengths of the two triangles should be less than a certain threshold, which depends on the accuracy requirement of the depth map. A lower threshold value, such as 0.1, indicates higher similarity than any value greater than 0.1;
Given the translation, t, depth of the reference feature, , after the camera movement, minimum depth, , around the point, , in image 1, i.e., , after camera movement, the position of the reference feature in image 0, i.e., , and the position of the point to be tracked in the camera frame in image 0, i.e., , calculated with minimum depth , we can apply the constraint Equation (7) to find the ratio, ;
Again, calculate the ratio, , using the maximum depth, , around the point, , in image 1, i.e., after camera movement and the position of the point to be tracked in the camera frame in image 0, i.e., , calculated with the maximum depth, ;
Apply the same process to the remaining two reference features and find the threshold ratios. If the six ratios are within the pre-defined threshold limit, , such as 0.1 or 0.05, the three reference features can be used to find the matching position of .
Given the positions of the three reference features in the two images and the position of
in image 0, the distance from the point,
, in the first frame to each side of the virtual triangle can be used to establish the constraints on its position, as shown in
Figure 5.
Figure 4.
Featureless pixel point tracking algorithm using reference features.
Figure 4.
Featureless pixel point tracking algorithm using reference features.
Firstly, the equations of the straight lines satisfying the three sides
of the feature triangle in the previous frame are calculated. For example, knowing the two reference feature points on the edge
, the general formula
for the straight line on which
is located can be calculated as follows:
where
and
are the two-dimensional image coordinates of the two reference features. Then, calculate the distances,
, from the arbitrary pixel point to be tracked (from the last image) to the three lines of the triangle from the previous image, respectively, as follows:
where
is the position of the arbitrary point in the previous frame. These distances,
, define other equations of lines that are perpendicular to the three sides,
, of the feature triangle. The lines perpendicular to the three sides,
, of the feature triangle can be calculated as follows:
Let us denote the perpendicular lines given by Equation (11) as
. The intersection of lines
is the arbitrary feature point, represented by the coordinates (x
0, y
0). Similar to finding the equations of the lines of the triangle formed by the three selected reference features in the last frame, calculate the parameters
of the three lines in the new frame using the reference feature’s position in the new image frame, as given by Equation (9). Calculate the parameter,
, for the perpendicular lines in the new image using the distances,
, from the arbitrary feature (from the last image) to the three lines of the triangle from the previous image as follows:
Depending on whether
in the last frame or
, the sign of D in the new frame is positive or negative. Finally, the intersection of any two out of three of these perpendicular lines is the predicted position of the arbitrary feature, as shown in
Figure 5. Let us say that the two perpendicular lines are given by
and
; the predicted position of the pixel point in the new image frame,
, can be calculated as follows:
Depending on the computational resources and the required accuracy,
, multiple sets of reference features satisfying the above constraints can be used to track the pixel point
. The estimate can be further refined by taking the arithmetic mean of all the estimates, as shown in Equation (14).
4.4. RANSAC Outlier Rejection Algorithm
Once all the pixel points are tracked using either optical flow or reference features, only the pixel points tracked within the image are considered, and the eight-point RANSAC [
27,
28] outlier rejection is applied based on the fundamental matrix derived from the corresponding points in two images. The main idea is that the matching points in the two images should satisfy the following constraint:
where
and
are the homogeneous coordinates of the pixel points in the two image frames,
is the antisymmetric matrix of the displacement vector t, and R is the rotation matrix of the two frames. Due to matching errors, not all matching points can satisfy the abovementioned constraints.
Finally, pixel point extraction is performed in the newly observed or empty image grids, according to
Section 3, and the database is updated based on the tracked and newly observed pixel points.
6. Experimental Results and Discussion
To verify the effectiveness of the proposed method based on pixel point tracking using reference features, experiments are conducted in an indoor environment using the publicly available EuRoC visual–inertial dataset [
15]. This approach is instrumental when featureless pixel points and feature points cannot be tracked using traditional techniques, such as optical flow or descriptors. The EuRoC dataset contains 11 sequences of stereo images, each with a size of 752 × 480 pixels, synchronized IMU information at 200 Hz, ground truth, and calibration information for the sensors’ external and internal parameters.
This research focuses on monocular VIO, considering only one IMU/camera pair. The experiments are conducted on three sequences from the EuRoC dataset. The experimental platform is a Xiaomi Redmi G 2022 laptop purchased from Beijing, China, with an Intel I7-12650H @ 2.3GHz, 16 GB of RAM, no GPU acceleration, and the 64-bit Ubuntu 20.04 WSL operating system.
When matching is performed reasonably accurately, the MSCKF triangulation algorithm can successfully triangulate the tracked points. The greater the number of tracks for a point, the higher the depth estimation accuracy. The depth of every selected tracked pixel point cannot be estimated successfully in real time because of several constraints, such as RANSAC, the availability of reference features in the neighborhood, and the calculation of depth with fewer tracks. For these reasons, the grid size should be selected carefully, as it affects the density of the depth map and the computational cost. To ensure that the depth map is useful for applications such as obstacle detection, collision avoidance, or path planning, the image is divided into several grids, each containing several triangulated pixel points. When there are more than N triangulated pixel points in a grid, we can estimate the average depth of that grid, provided the grid size is small enough to be represented by N pixel points.
6.1. V1_01_Easy Sequence
The V1_01_easy sequence comprises 2912 timestamped monocular images with IMU measurements at 200 Hz.
Figure 7a shows the depth map at the beginning of the sequence when sufficient measurements are unavailable.
Figure 7b shows the average depth of each grid, where less than 50% of the grids could be estimated. This is because reference features are not available around the remaining grids. However, the depth of most of the grids in
Figure 7c,d, especially around the center, could be estimated. Moreover, it can also be seen that the highlighted grids in
Figure 7 do not have any reference features in the neighborhood, which also restricts the tracking of pixel points in these grids. Moreover, the camera motion in
Figure 7 is rightward. Hence, the pixel points in the rightmost grids do not have sufficient tracks for triangulation. However, for all the grids in which reference features are available in the neighborhood, the depth of the grids could be estimated.
It can further be seen in
Figure 7 that our reference feature-based tracking algorithm was applied 5520 times to obtain the image in
Figure 7c and 11,958 times to obtain the image in
Figure 7d, when the optical flow technique was not successful. Furthermore, triangulation is performed based on camera translation; if the translation is too small or the camera motion only consists of pure rotation, triangulation cannot be performed successfully. Moreover, the EuRoC V1_01_easy dataset consists of 2912 image frames, from which we can estimate more than 90% of grids in 736 frames when the image is divided into 15 × 15 grids. Feature extraction around the image center is performed with 5 × 5 grids and 8 × 8 grids elsewhere, with one feature in each grid.
Another experiment was conducted to compare the proposed method with the pyramidal LK optical flow method. First, the extracted FAST features are tracked using pyramidal LK optical flow and triangulated using the MSCKF feature point triangulation method. These data serve as the ground truth. The same FAST features are also tracked and triangulated using the proposed method. It can be seen in
Table 1 and
Table 2 that the depths calculated from the two methods differ by only a few centimeters. Due to space limitations, the estimated depths of only a few features tracked with both methods are shown in
Table 1 and
Table 2 for adjacent frames of the EuRoC dataset v1_01_easy.
In another experiment on the v1_01_easy sequence, the pixel points were tracked 30,000 times using the proposed method. The average time to track a pixel point successfully using reference features is 0.001034 s, without using any parallel programming techniques, and the minimum time to track a pixel point is 0.000038523 s.
6.2. V1_02_Medium Sequence
A similar experiment was performed on the v1_02_medium sequence, which consisted of 1710 monocular images. It can be seen in
Figure 8 that we can estimate the average depth of most of the grids in the entire sequence, especially toward the center of the image. The following constraints were observed:
Insufficient translation at the beginning to triangulate the observed points due to the initialization phase of MSCKF-VIO;
The unavailability of reference features in the neighborhood of pixel points to be tracked leads to a reduced density of triangulated pixel points;
Triangulation is performed when a point is observed for at least five measurements. Thus, points with fewer than five measurements were not triangulated, which reduced the density of triangulated pixel points.
Depending on the accuracy requirements and the density of the depth map, the constraints of five measurements for triangulation or the number of triangulated pixel points necessary for calculating the average depth of the grid can be adjusted. Under the current parameters, i.e., five measurements of three estimated points, we can estimate the depths of most of the grids in each image. It is also important to note that during the sequence of 1710 image frames, the optical flow technique was applied 11,291,373 times, while the proposed technique was successfully applied 174,680 times, proving its usefulness.
As shown in
Figure 8, we cannot estimate the depths of around 25% of the grids in several images of this sequence. This is because the MSCKF algorithm is sensitive to camera translation. Both very small and very large translations affect the MSCKF triangulation capabilities. Additionally, the lack of distinct characteristics within the grid or in the vicinity also affects the estimation results.
Figure 8.
(a–d) A 15 × 15 gridded depth map of the images at different timestamps from the v1_02_medium sequence of the EuRoC dataset. The pixel points are extracted using a grid size of 5 × 5 pixels around the center and 8 × 8 pixels elsewhere. Triangulation is performed when a pixel point is tracked across five frames. The various colors of the pixel points represent different depth ranges. The average depth of each grid is calculated when the number of triangulated pixels in that grid is three or more.
Figure 8.
(a–d) A 15 × 15 gridded depth map of the images at different timestamps from the v1_02_medium sequence of the EuRoC dataset. The pixel points are extracted using a grid size of 5 × 5 pixels around the center and 8 × 8 pixels elsewhere. Triangulation is performed when a pixel point is tracked across five frames. The various colors of the pixel points represent different depth ranges. The average depth of each grid is calculated when the number of triangulated pixels in that grid is three or more.
Similar to
Table 1 and
Table 2, we tracked the known feature points using two methods, i.e., pyramidal LK optical flow and the proposed tracking method using reference features. Due to space limitations, the estimated depths of the points tracked with the two methods are shown in
Table 3 and
Table 4 for two random images. This supports our assertion that the proposed method can track pixel points with adequate accuracy based on the reference features in the neighborhood. Furthermore, the depths estimated after tracking with the two methods differ by only a few centimeters.
For the v1_02_medium sequence, the proposed technique was applied 337,004 times and was successful 174,680 times. It was determined that the average time to track a pixel point using reference features successfully is 0.0003769 s, without utilizing any parallel programming techniques, and the minimum time to track a pixel point is 0.0000102 s.
6.3. MH_01_Easy Sequence
The MH_01_easy dataset comprises 3682 monocular images. Consistent with our previous findings, the proposed algorithm can track and estimate the depth of most grids in the image that possess distinct characteristics either within or nearby, as illustrated in
Figure 9. The algorithm was applied successfully 153,785 times during the sequence when the optical flow method could not track pixel points. The minimum and average times to successfully track a pixel point are 0.00002972 and 0.002932774 s, respectively. As shown in
Figure 9, we can estimate over 75% of the grids in most images within this sequence.
6.4. Comparison and Timing Details
A detailed comparison of the proposed method for the sequences mentioned above with the generated ground truth is available on Google Drive, as stated in the Data Availability Statement for all three sequences. For the v1_01_easy sequence, each feature ID is accompanied by the depth estimated using pyramidal Optical Flow tracking and the depth estimated by the proposed method. For the other sequences, the feature ID is followed by its timestamp and the estimated depths from both methods. The time taken to track a single pixel, the average time spent tracking pixels up to the specified timestamp, and the total number of tracked pixels are provided, along with videos of each sequence displaying the estimated grid depths.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}