
TF-LIME : Interpretation Method for Time-Series Models Based on Time–Frequency Features

Abstract
1. Introduction
- Proposal of the time–frequency homogeneous segmentation (TFHS) algorithm. This paper designs a segmentation algorithm for the time–frequency matrix (TFHS), which integrates techniques such as frequency peak detection, spatiotemporal continuity clustering, and dynamic boundary expansion to divide the time–frequency matrix into several homogeneous regions, each corresponding to relatively consistent time–frequency signal characteristics. This method effectively addresses the limitations of traditional LIME in capturing complete homogeneous regions in the time–frequency domain. Compared to methods that treat each time–frequency element as an independent perturbation unit, TFHS significantly reduces the number of perturbations and improves computational efficiency.
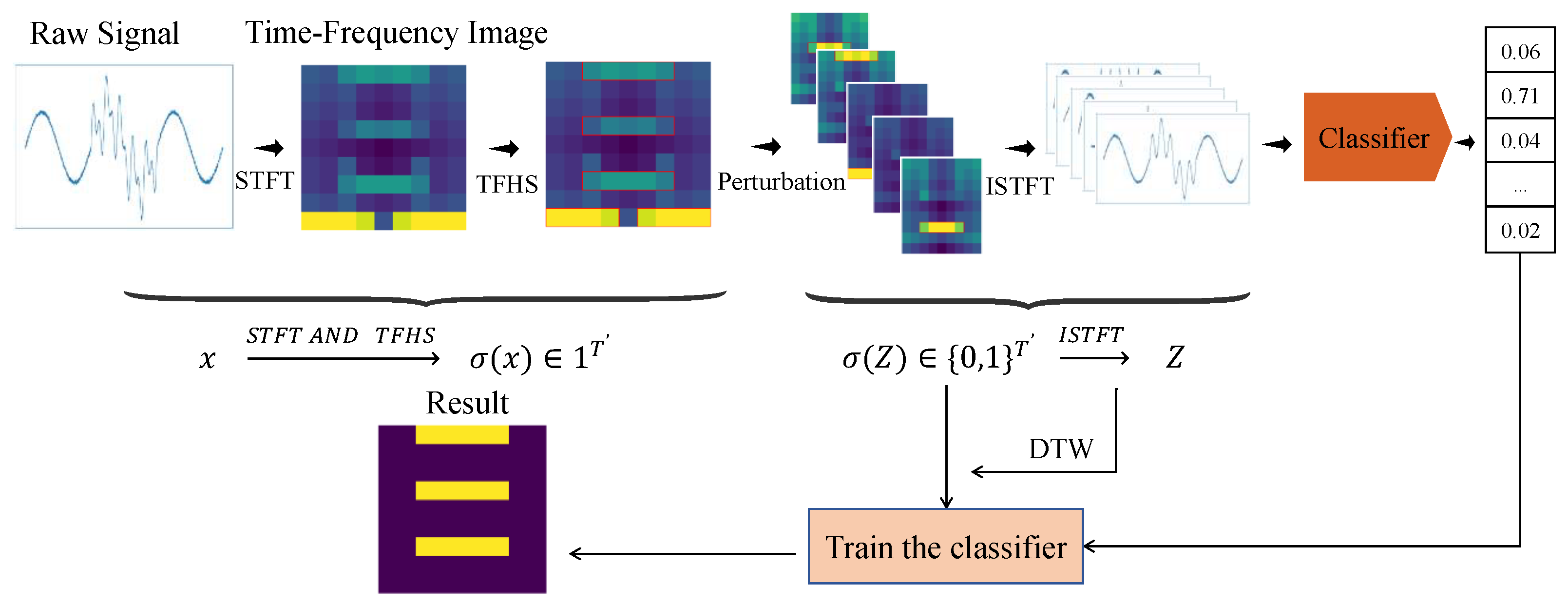
- Proposal of the TF-LIME algorithm integrating multiple techniques. This paper integrates key technologies such as the short-time Fourier transform (STFT) [27], the TFHS segmentation algorithm, LIME, and Inverse STFT (ISTFT) to propose the TF-LIME algorithm, constructing an efficient time–frequency domain explanation framework for time series. This method not only retains the model-agnostic advantages of LIME but also enhances its interpretability and semantic consistency in time–frequency analysis scenarios.
- Construction of synthetic datasets for algorithm evaluation. This paper designs and constructs two synthetic datasets (Synthetic Dataset 1 and Synthetic Dataset 2) to evaluate the performance of the TFHS segmentation algorithm and the TF-LIME explanation algorithm, respectively. Each dataset is annotated with clear Ground Truth to ensure the objectivity and reproducibility of the evaluation process.
- Comprehensive Evaluation of Algorithm Performance. The performance of the TFHS segmentation algorithm is quantitatively and qualitatively analyzed on Synthetic Dataset 1. The interpretability of the TF-LIME algorithm is evaluated on Synthetic Dataset 2 and real-world datasets, verifying its effectiveness and robustness in different scenarios.
2. Methods
2.1. Interpretable Data Representation of Features
2.1.1. The Short-Time Fourier Transform
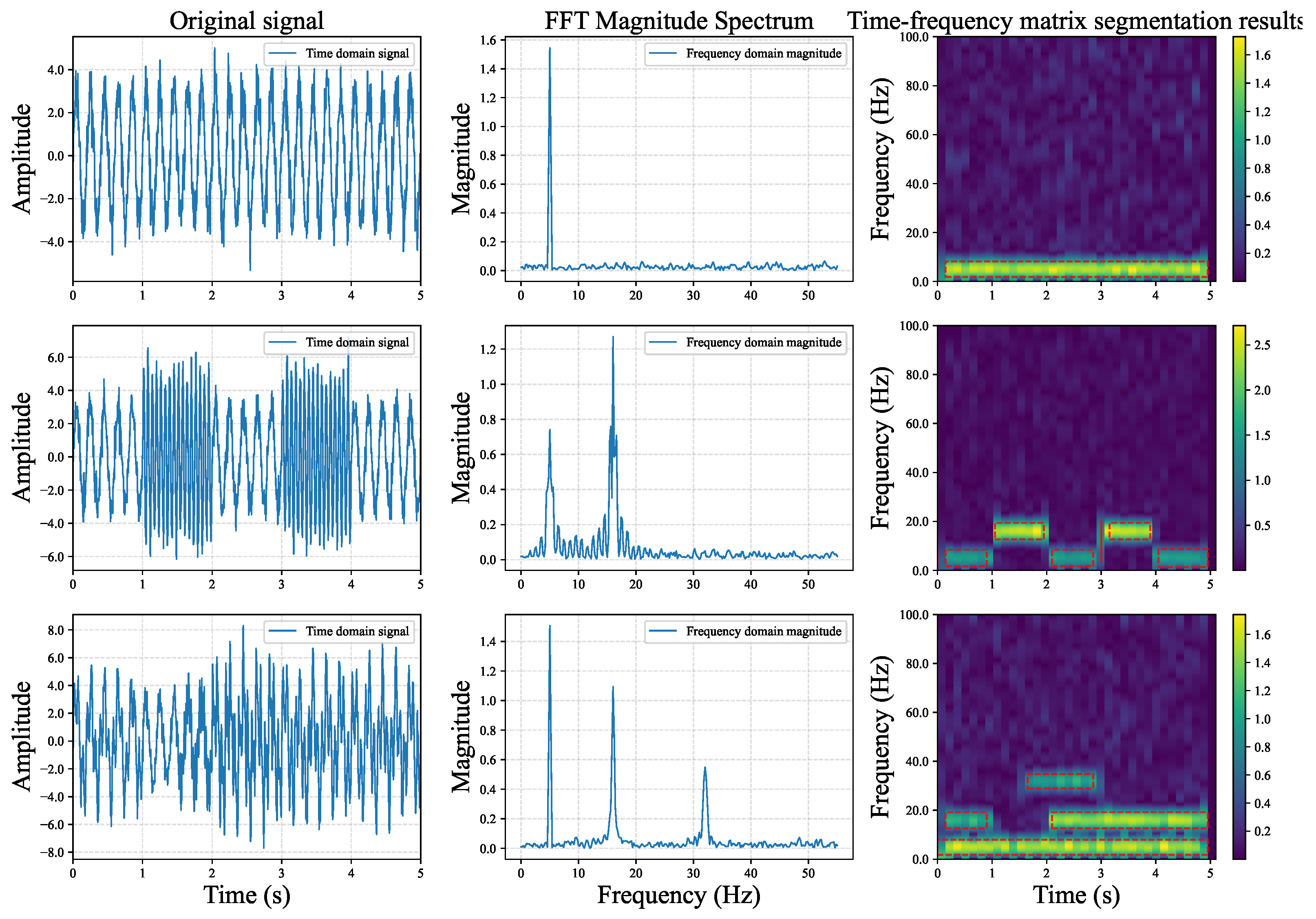
2.1.2. Time–Frequency Matrix Segmentation
2.1.3. Vector Representation
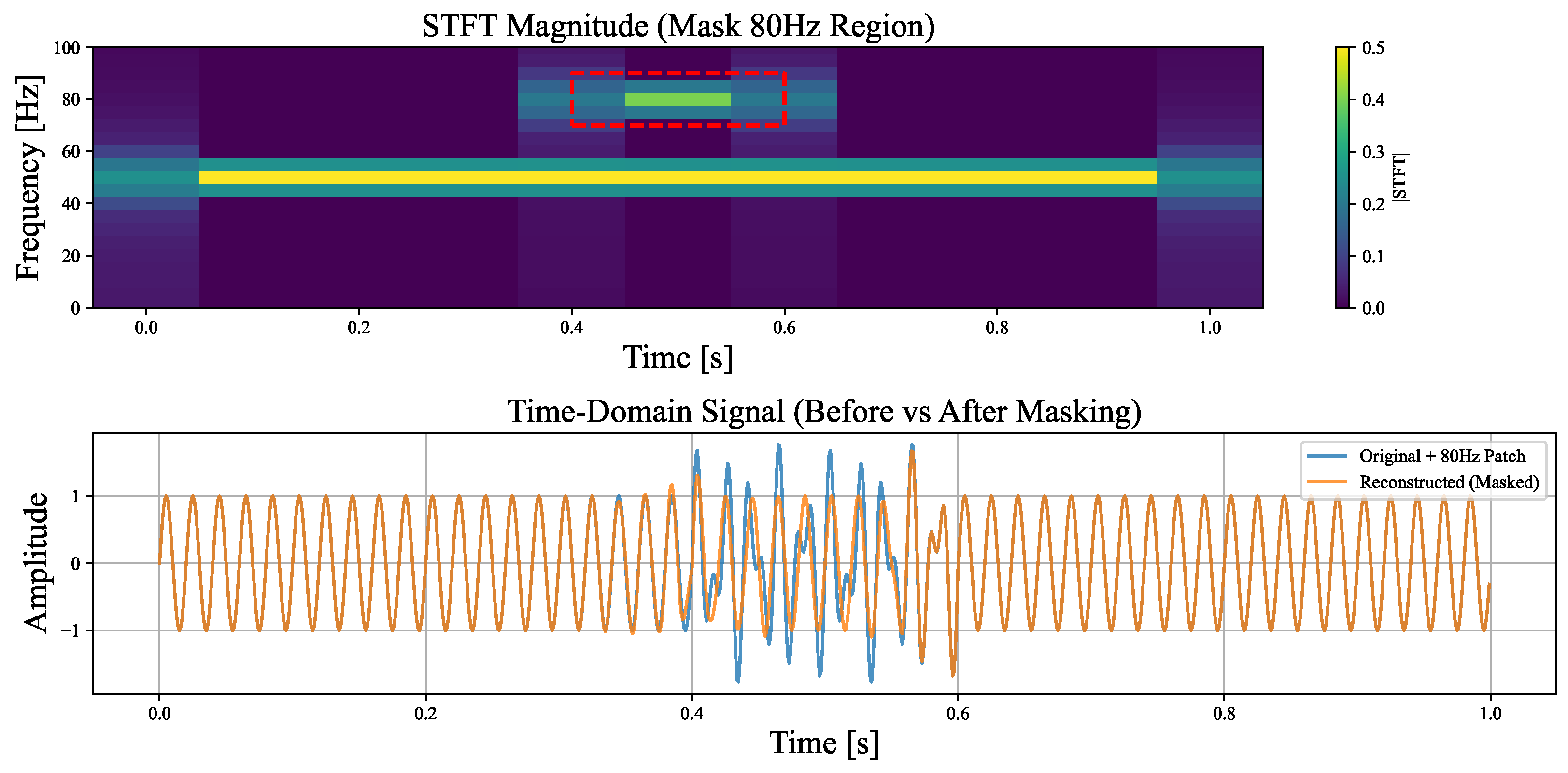
2.2. Local Perturbation
2.3. Defining the Neighborhood
2.4. Constructing a Surrogate Model
3. Experimental Results
3.1. Dataset and Model Introduction
3.1.1. Synthetic Dataset 1
3.1.2. Synthetic Dataset 2
3.1.3. MIT-BIH Dataset
3.2. Baselines
3.3. Parameter Settings
3.4. Metrics
- Intersection over union (IoU) [42]: Measures the overlap between the predicted segmentation region and the ground truth segmentation region, defined as follows:where P represents the predicted segmentation region, G represents the ground truth segmentation region. For multi-class segmentation problems, the mean IoU (mIoU) is calculated by averaging the IoU values across all classes:where N is the number of classes, and is the IoU value for class X.
- False positive rate (FPR): Measures the proportion of incorrectly extracted regions in the algorithm’s output, i.e., regions that are not part of the ground truth but are mistakenly identified by the algorithm:where represents the regions in the predicted segmentation that are not marked as signals in the ground truth. A higher FPR indicates more false detections, leading to increased noise impact.
- Energy retention ratio (ERR): Calculates the proportion of energy in the overlapping region between the predicted segmentation and the ground truth relative to the total energy in the ground truth. This metric evaluates whether the segmentation accurately captures the signal energy:where is the signal energy value at position in the matrix. If , it indicates that the segmentation region fully covers the high-energy regions of the ground truth; if , it indicates that some signal energy is not captured.
3.5. Evaluation of the TFHS Algorithm
3.5.1. Quantitative Evaluation
3.5.2. Visualization
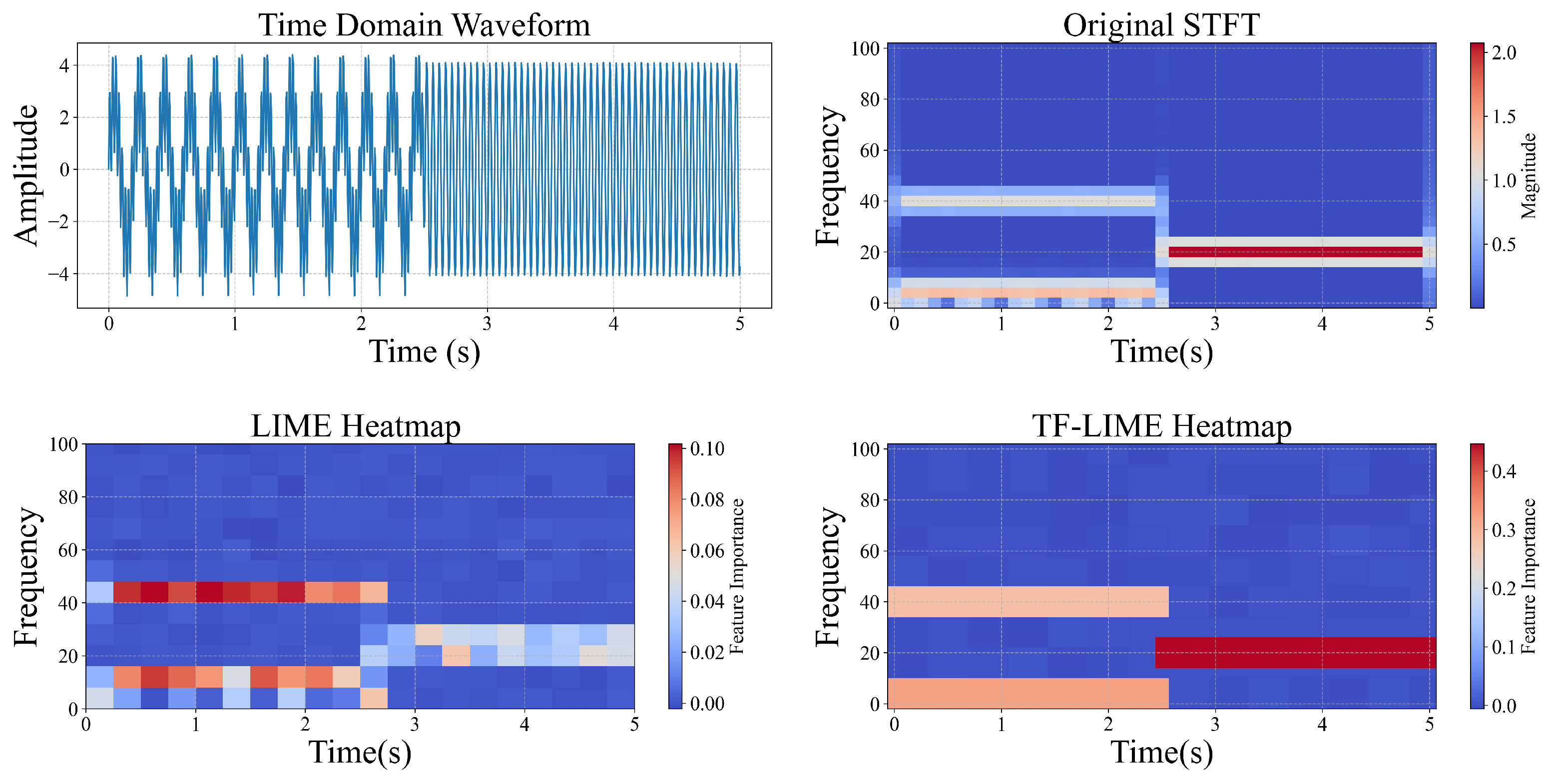
3.6. Evaluation of the TF-LIME Algorithm on Synthetic Datasets
3.6.1. Quantitative Evaluation
3.6.2. Visualization
3.7. Evaluation of the TF-LIME Algorithm on Real-World Datasets
3.7.1. Quantitative Evaluation
3.7.2. Visualization
4. Conclusions
- Multidimensional dynamic correlation modeling: There is a need to develop interpretative tools that can simultaneously capture temporal dimensions and interactions between variables, breaking through the limitations of traditional univariate analysis. This will provide new possibilities for a deeper understanding of complex time series data.
- Construction of a general interpretative framework: The goal is to establish a model-agnostic standardized interpretative interface that is compatible with mainstream time series models such as RNNs and Transformers. This will significantly improve the applicability and transferability of the method.
- Validation in multidisciplinary applications: Research will test the proposed method in typical scenarios such as medical monitoring (e.g., multi-parameter physiological signals) and industrial sensing (e.g., multi-sensor data from equipment) to verify its reliability and robustness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Toy Numerical Example of the Proposed Method
Appendix A.1. Time–Frequency Matrix Construction
Appendix A.2. Peak Detection
- (1)
- Local Peak Identification
- (2)
- Global Statistical Filtering
Appendix A.3. Peak Clustering via DBSCAN
Appendix A.4. Temporal Continuity Processing
- Subset 1:
- Subset 2:
Appendix A.5. Dynamic Boundary Expansion
- Energy decay threshold:
- Global energy threshold:
- Global mean magnitude of the matrix:
Appendix A.6. Time–Frequency Block Generation and Optimization
- and have no overlap in the temporal domain, so their overlap is 0.
- and share the same time range , but their frequency ranges do not intersect, so the overlap is also 0.
Appendix B. Explanation of Algorithm Parameters
Appendix B.1. STFT Algorithm Parameter Settings
- (1)
- Window Length N
- (2)
- Frameshift H
- (3)
- Frequency Resolution Trade-off
- For low-frequency detection tasks, ensure that , where is the smallest frequency component of interest;
- For signals with dynamic variations, select a small H so that each change is captured by multiple overlapping frames, avoiding information loss.
- (4)
- Window Function
Appendix B.2. TF-LIME Algorithm Parameter Settings
- (1)
- Energy Threshold Factor
- For signals with dominant frequency components, consider increasing (e.g., 0.6–0.7) to improve peak purity;
- For flat-spectrum or weak-signal cases, reducing (e.g., 0.3–0.4) improves sensitivity.
- (2)
- Noise Suppression Coefficient
- For signals with strong background noise or low signal-to-noise ratios (SNR), increase (e.g., 1.5–2.0) to enhance detection robustness;
- For cleaner signals or weaker spectral peaks, reduce (e.g., 0.5–0.8) to avoid missing informative components.
- (3)
- DBSCAN Clustering Radius
- For signals with dense and finely spaced peaks, use a smaller (e.g., 0.3–0.4);
- For signals with sparse peak patterns or high amplitude variation, use a larger (e.g., 0.6–0.8).
- (4)
- Scaling Factor
- (5)
- Maximum Time Gap
- Increase (e.g., 2–3) when the signal exhibits strong temporal continuity in its spectral features, or when the TFHS algorithm tends to excessively fragment a single-frequency band across adjacent time frames;
- Keep or smaller to enforce high temporal discrimination during clustering.
- (6)
- Energy Decay Constraint and Global Energy Threshold
- To enforce sharper boundary constraints, increase to 0.7–0.8;
- For simpler signals or when strict boundary conditions are not required, keep low (e.g., 0.3–0.4) to allow more flexible frequency expansion;
- Increase (e.g., to 1.5) to suppress noise and exclude weak frequencies;
- For smooth signals or low SNR scenarios, lowering both parameters can help enhance robustness and tolerance.
- (7)
- Overlap Threshold
- Decrease (e.g., to 0.1) for finer segmentation and stricter overlap control;
- Increase (e.g., to 0.3 or above) when some level of overlap is acceptable or useful for representing continuous signal structures.
- (8)
- Segmentation Window window
- Use larger windows (e.g., or ) to reduce the number of interpretable units and compress the representation;
- Use smaller windows (e.g., or ) when local structure preservation is important;
- Use the minimum window if extremely fine-grained interpretability is desired, such as per-bin attribution analysis. Note that this significantly increases the computational cost.
- (9)
- Number of Generated Perturbation Samples u
- If the explanation region is simple and the model response is stable, u can be reduced to below 500 to improve efficiency;
- For deep neural models or when the time–frequency blocks exhibit complex nonlinear patterns, u should be increased above 500 to enhance surrogate model fitting;
- When setting u, it is crucial to consider the dimensionality of the interpretability space—i.e., the total number of blocks to be explained.
References
- Kaushik, S.; Choudhury, A.; Sheron, P.K.; Dasgupta, N.; Natarajan, S.; Pickett, L.A.; Dutt, V. AI in healthcare: Time-series forecasting using statistical, neural, and ensemble architectures. Front. Big Data 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed]
- Bento, J.; Saleiro, P.; Cruz, A.F.; Figueiredo, M.A.; Bizarro, P. Timeshap: Explaining recurrent models through sequence perturbations. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, 14–18 August 2021; pp. 2565–2573. [Google Scholar] [CrossRef]
- Adebayo, T.S.; Awosusi, A.A.; Kirikkaleli, D.; Akinsola, G.D.; Mwamba, M.N. Can CO2 emissions and energy consumption determine the economic performance of South Korea? A time series analysis. Environ. Sci. Pollut. Res. 2021, 28, 38969–38984. [Google Scholar] [CrossRef] [PubMed]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: London, UK, 2017; pp. 3319–3328. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html (accessed on 23 March 2025).
- Schlegel, U.; Arnout, H.; El-Assady, M.; Oelke, D.; Keim, D.A. Towards a rigorous evaluation of XAI methods on time series. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; IEEE: New York, NY, USA, 2019; pp. 4197–4201. [Google Scholar] [CrossRef]
- Rooke, C.; Smith, J.; Leung, K.K.; Volkovs, M.; Zuberi, S. Temporal dependencies in feature importance for time series predictions. arXiv 2021, arXiv:2107.14317. [Google Scholar] [CrossRef]
- Chuang, Y.N.; Wang, G.; Yang, F.; Zhou, Q.; Tripathi, P.; Cai, X.; Hu, X. Cortx: Contrastive framework for real-time explanation. arXiv 2023, arXiv:2303.02794. [Google Scholar] [CrossRef]
- Ismail, A.A.; Corrada Bravo, H.; Feizi, S. Improving deep learning interpretability by saliency guided training. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 26726–26739. Available online: https://proceedings.neurips.cc/paper/2021/hash/e0cd3f16f9e883ca91c2a4c24f47b3d9-Abstract.html (accessed on 23 March 2025).
- Sivill, T.; Flach, P. Limesegment: Meaningful, realistic time series explanations. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 28–30 March 2022; PMLR: London, UK; pp. 3418–3433. Available online: https://proceedings.mlr.press/v151/sivill22a.html (accessed on 23 March 2025).
- Crabbé, J.; Van Der Schaar, M. Explaining time series predictions with dynamic masks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: London, UK; pp. 2166–2177. Available online: https://proceedings.mlr.press/v139/crabbe21a.html?ref=https://githubhelp.com (accessed on 23 March 2025).
- Queen, O.; Hartvigsen, T.; Koker, T.; He, H.; Tsiligkaridis, T.; Zitnik, M. Encoding time-series explanations through self-supervised model behavior consistency. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 32129–32159. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/65ea878cb90b440e8b4cd34fe0959914-Paper-Conference.pdf (accessed on 23 March 2025).
- Liu, Z.; Wang, T.; Shi, J.; Zheng, X.; Chen, Z.; Song, L.; Dong, W.; Obeysekera, J.; Shirani, F.; Luo, D. Timex++: Learning time-series explanations with information bottleneck. arXiv 2024, arXiv:2405.09308. [Google Scholar] [CrossRef]
- Keil, A.; Bernat, E.M.; Cohen, M.X.; Ding, M.; Fabiani, M.; Gratton, G.; Kappenman, E.S.; Maris, E.; Mathewson, K.E.; Ward, R.T.; et al. Recommendations and publication guidelines for studies using frequency domain and time-frequency domain analyses of neural time series. Psychophysiology 2022, 59, e14052. [Google Scholar] [CrossRef]
- Yan, K.; Long, C.; Wu, H.; Wen, Z. Multi-resolution expansion of analysis in time-frequency domain for time series forecasting. IEEE Trans. Knowl. Data Eng. 2024, 36, 6667–6680. [Google Scholar] [CrossRef]
- Decker, T.; Lebacher, M.; Tresp, V. Explaining Deep Neural Networks for Bearing Fault Detection with Vibration Concepts. In Proceedings of the 2023 IEEE 21st International Conference on Industrial Informatics (INDIN), Lemgo, Germany, 18–20 July 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Vielhaben, J.; Lapuschkin, S.; Montavon, G.; Samek, W. Explainable AI for time series via virtual inspection layers. Pattern Recognit. 2024, 150, 110309. [Google Scholar] [CrossRef]
- Chung, H.; Jo, S.; Kwon, Y.; Choi, E. Time is Not Enough: Time-Frequency based Explanation for Time-Series Black-Box Models. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 394–403. [Google Scholar] [CrossRef]
- Shi, J.; Stebliankin, V.; Narasimhan, G. The power of explainability in forecast-informed deep learning models for flood mitigation. arXiv 2023, arXiv:2310.19166. [Google Scholar] [CrossRef]
- Chowdhury, T.; Rahimi, R.; Allan, J. Rank-lime: Local model-agnostic feature attribution for learning to rank. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, Taipei, Taiwan, 23 July 2023; pp. 33–37. [Google Scholar] [CrossRef]
- Zhou, Z.; Hooker, G.; Wang, F. S-lime: Stabilized-lime for model explanation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, 14–18 August 2021; pp. 2429–2438. [Google Scholar] [CrossRef]
- Gabor, D. Theory of communication. Part 3: Frequency compression and expansion. J. Inst. Electr. Eng. Part III Radio Commun. Eng. 1946, 93, 445–457. [Google Scholar] [CrossRef]
- Kemp, B.; Zwinderman, A.H.; Tuk, B.; Kamphuisen, H.A.; Oberye, J.J. Analysis of a sleep-dependent neuronal feedback loop: The slow-wave microcontinuity of the EEG. IEEE Trans. Biomed. Eng. 2000, 47, 1185–1194. [Google Scholar] [CrossRef]
- Moody, G. A new method for detecting atrial fibrillation using RR intervals. Proc. Comput. Cardiol. 1983, 10, 227–230. [Google Scholar]
- Qian, S.; Chen, D. Joint time-frequency analysis. IEEE Signal Process. Mag. 1999, 16, 52–67. [Google Scholar] [CrossRef]
- Mallat, S. A Wavelet Tour of Signal Processing; Elsevier: Amsterdam, The Netherlands, 1999; Chapter 4; pp. 63–69. [Google Scholar]
- Boashash, B. Estimating and interpreting the instantaneous frequency of a signal. I. Fundamentals. Proc. IEEE 1992, 80, 520–538. [Google Scholar] [CrossRef]
- Fang-Ming, B.; Wei-Kui, W.; Long, C. DBSCAN: Density-based spatial clustering of applications with noise. J. Nanjing Univ. Nat. Sci. 2012, 48, 491–498. Available online: https://cdn.aaai.org/KDD/1996/KDD96-037.pdf?source=post_page (accessed on 23 March 2025).
- Yadav, M.; Alam, M.A. Dynamic time warping (dtw) algorithm in speech: A review. Int. J. Res. Electron. Comput. Eng. 2018, 6, 524–528. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. In Advances in Neural Information Processing Systems; Cambridge University Press: Cambridge, UK, 2021; Volume 34, pp. 24261–24272. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings; pp. 315–323. Available online: https://proceedings.mlr.press/v15/glorot11a (accessed on 23 March 2025).
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Kachuee, M.; Fazeli, S.; Sarrafzadeh, M. Ecg heartbeat classification: A deep transferable representation. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; IEEE: New York, NY, USA, 2018; pp. 443–444. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Morch, N.J.; Kjems, U.; Hansen, L.K.; Svarer, C.; Law, I.; Lautrup, B.; Strother, S.; Rehm, K. Visualization of neural networks using saliency maps. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: New York, NY, USA, 1995; Volume 4, pp. 2085–2090. [Google Scholar] [CrossRef]
- Anders, C.J.; Neumann, D.; Samek, W.; Müller, K.R.; Lapuschkin, S. Software for dataset-wide XAI: From local explanations to global insights with Zennit, CoRelAy, and ViRelAy. arXiv 2021, arXiv:2106.13200. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 658–666. [Google Scholar]
- Gottlieb, D.; Shu, C.W. On the Gibbs phenomenon and its resolution. SIAM Rev. 1997, 39, 644–668. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Szecowka, P.M. Limitations of sensitivity analysis for neural networks in cases with dependent inputs. In Proceedings of the 2006 IEEE International Conference on Computational Cybernetics, Talinn, Estonia, 20–22 August 2006; IEEE: New York, NY, USA, 2006; pp. 1–5. [Google Scholar] [CrossRef]
- Christopher Frey, H.; Patil, S.R. Identification and review of sensitivity analysis methods. Risk Anal. 2002, 22, 553–578. [Google Scholar] [CrossRef]
- Leiber, M.; Barrau, A.; Marnissi, Y.; Abboud, D. A differentiable short-time Fourier transform with respect to the window length. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; IEEE: New York, NY, USA, 2022; pp. 1392–1396. [Google Scholar] [CrossRef]
- Leiber, M.; Marnissi, Y.; Barrau, A.; El Badaoui, M. Differentiable short-time Fourier transform with respect to the hop length. In Proceedings of the 2023 IEEE Statistical Signal Processing Workshop (SSP), Hanoi, Vietnam, 2–5 July 2023; IEEE: New York, NY, USA, 2023; pp. 230–234. [Google Scholar] [CrossRef]
- Leiber, M.; Marnissi, Y.; Barrau, A.; El Badaoui, M. Differentiable adaptive short-time Fourier transform with respect to the window length. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Energy threshold factor | |
| Noise suppression coefficient | |
| DBSCAN clustering radius | |
| Scaling factor | 1 |
| Maximum time gap | 1 |
| Energy decay constraint | |
| Global energy threshold | |
| Overlap threshold | |
| Segmentation window window | 2 |
| Number of generated perturbation samples u | 500 |
| Sample Type | IoU (%) | FPR (%) | ERR (%) |
|---|---|---|---|
| Single-frequency () | 93.1 | 2.3 | 94.7 |
| Single-frequency () | 85.5 | 3.3 | 92.5 |
| Multi-frequency () | 83.1 | 6.2 | 89.2 |
| Multi-frequency () | 79.3 | 8.6 | 84.3 |
| Method | AUPRC | AUP | AUR |
|---|---|---|---|
| Sensitivity | 0.34 | 0.43 | 0.32 |
| IG | 0.56 | 0.62 | 0.44 |
| LRP | 0.57 | 0.61 | 0.45 |
| FIA-Insertion | 0.42 | 0.41 | 0.35 |
| FIA-Deletion | 0.58 | 0.57 | 0.37 |
| FIA-Combined | 0.52 | 0.56 | 0.36 |
| LIME | 0.64 | 0.61 | 0.54 |
| TF-LIME | 0.83 | 0.78 | 0.64 |
| Method | AUPRC | AUP | AUR |
|---|---|---|---|
| Sensitivity | 0.30 | 0.38 | 0.28 |
| IG | 0.52 | 0.55 | 0.41 |
| LRP | 0.50 | 0.54 | 0.40 |
| FIA-Insertion | 0.41 | 0.38 | 0.33 |
| FIA-Deletion | 0.53 | 0.51 | 0.34 |
| FIA-Combined | 0.49 | 0.49 | 0.34 |
| LIME | 0.59 | 0.52 | 0.47 |
| TF-LIME | 0.75 | 0.72 | 0.60 |
| Method | AUPRC | AUP | AUR |
|---|---|---|---|
| IG | 0.42 | 0.59 | 0.39 |
| LRP | 0.47 | 0.61 | 0.41 |
| FIA-Insertion | 0.31 | 0.42 | 0.29 |
| FIA-Deletion | 0.43 | 0.57 | 0.40 |
| FIA-Combined | 0.39 | 0.49 | 0.37 |
| LIME | 0.38 | 0.49 | 0.36 |
| TF-LIME | 0.49 | 0.60 | 0.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, R.; Li, Q. TF-LIME : Interpretation Method for Time-Series Models Based on Time–Frequency Features. Sensors 2025, 25, 2845. https://doi.org/10.3390/s25092845
Wang J, Zhang R, Li Q. TF-LIME : Interpretation Method for Time-Series Models Based on Time–Frequency Features. Sensors. 2025; 25(9):2845. https://doi.org/10.3390/s25092845
Chicago/Turabian StyleWang, Jiazhan, Ruifeng Zhang, and Qiang Li. 2025. "TF-LIME : Interpretation Method for Time-Series Models Based on Time–Frequency Features" Sensors 25, no. 9: 2845. https://doi.org/10.3390/s25092845
APA StyleWang, J., Zhang, R., & Li, Q. (2025). TF-LIME : Interpretation Method for Time-Series Models Based on Time–Frequency Features. Sensors, 25(9), 2845. https://doi.org/10.3390/s25092845