

Scalable Semantic Adaptive Communication for Task Requirements in WSNs


Abstract
1. Introduction
1.1. Backgrounds
1.2. Motivation and Contributions
- (1)
- Reducing the task-independent semantic noise during feature extraction, thereby improving task accuracy;
- (2)
- Reducing the number of training sessions under different channel conditions in the presence of limited computing;
- (3)
- Improving the frequency band utilization of semantic communication systems.
- (1)
- An Attention Mechanism-based Joint Source Channel Coding (AMJSCC) is designed in order to adapt to the dynamically changing channel conditions in practical communication scenarios, on the basis of task and semantic relationships.
- (2)
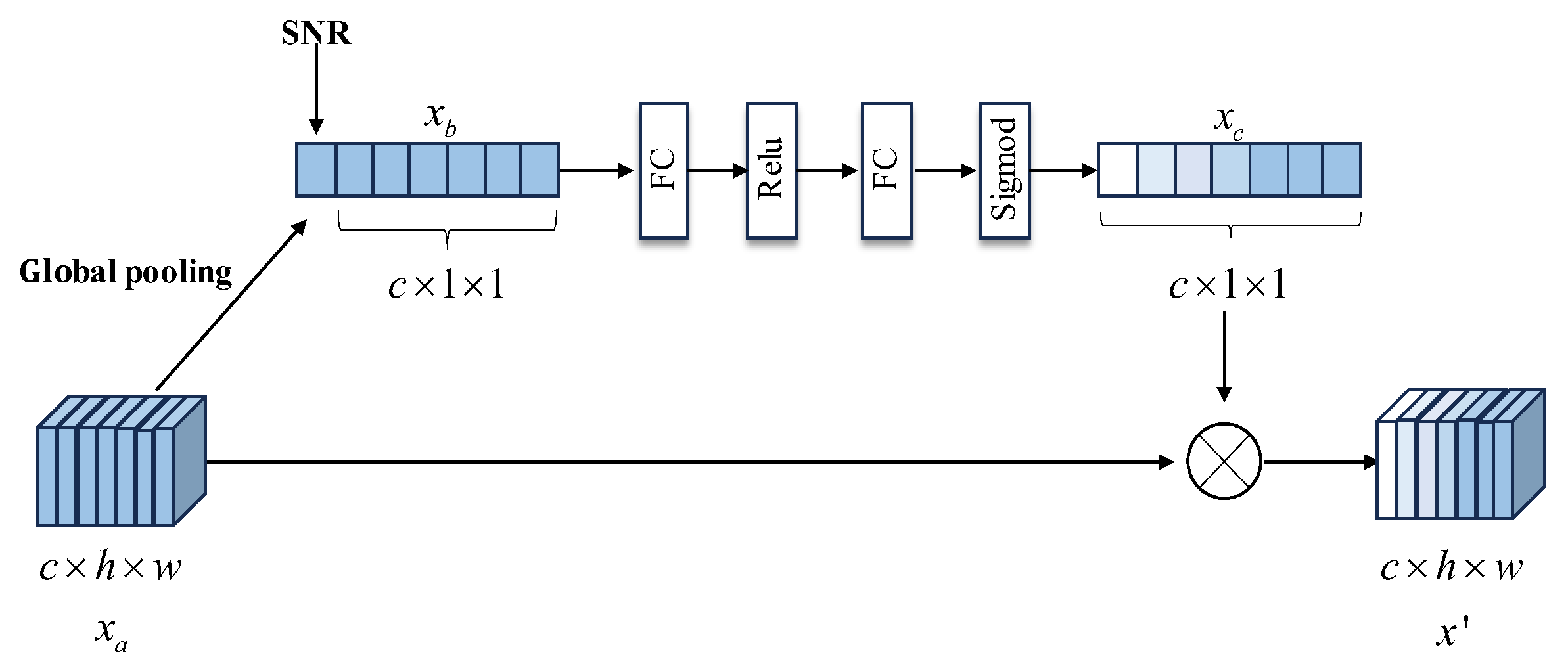
- An adaptive channel condition (ACC) module is designed to dynamically adjust the weights and encoding sequence of semantic features, leading to improved robustness in semantic communication and consistent accuracy in classification tasks under channel condition.
- (3)
- In order to generate the multi-scale semantic feature and achieve communication efficiency under bandwidth constraints, a Prediction Scalable Semantic Generator (PSSG) is designed, which includes variable compression ratio, Pre-Net, the optimizer of compression rate, and the loss function. Additionally, the PSSG incorporates attention mechanisms [29] and mask operations [30] to dynamically adapt the length of generated semantic features and could improve system bandwidth utilization without compromising classification performance.
1.3. Structure
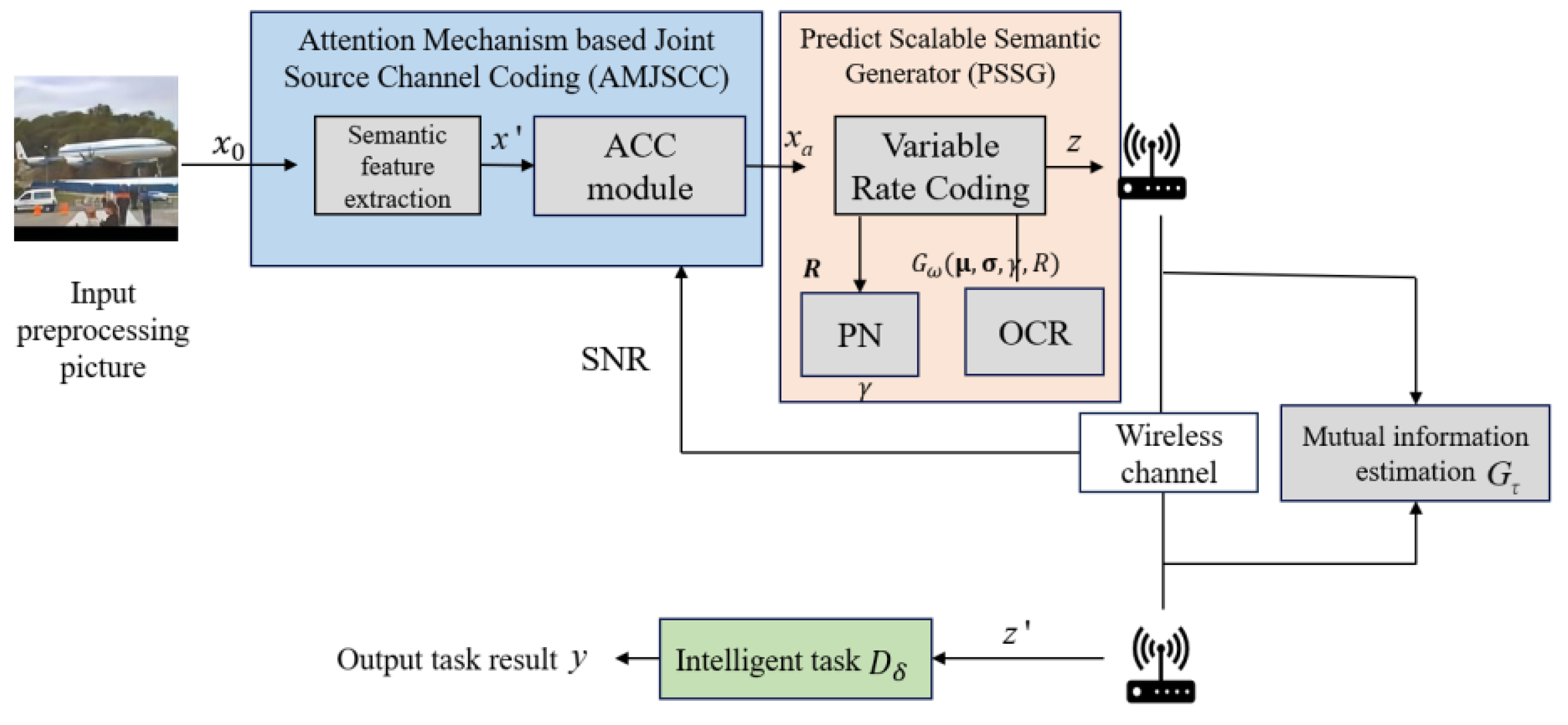
2. Scalable Semantic Adaptive Communication Framework for Task Requirements
3. Attention Mechanic Based Joint Semantic Channel Coding
3.1. Joint Semantic Channel Coder
3.2. Adaptive Channel Condition
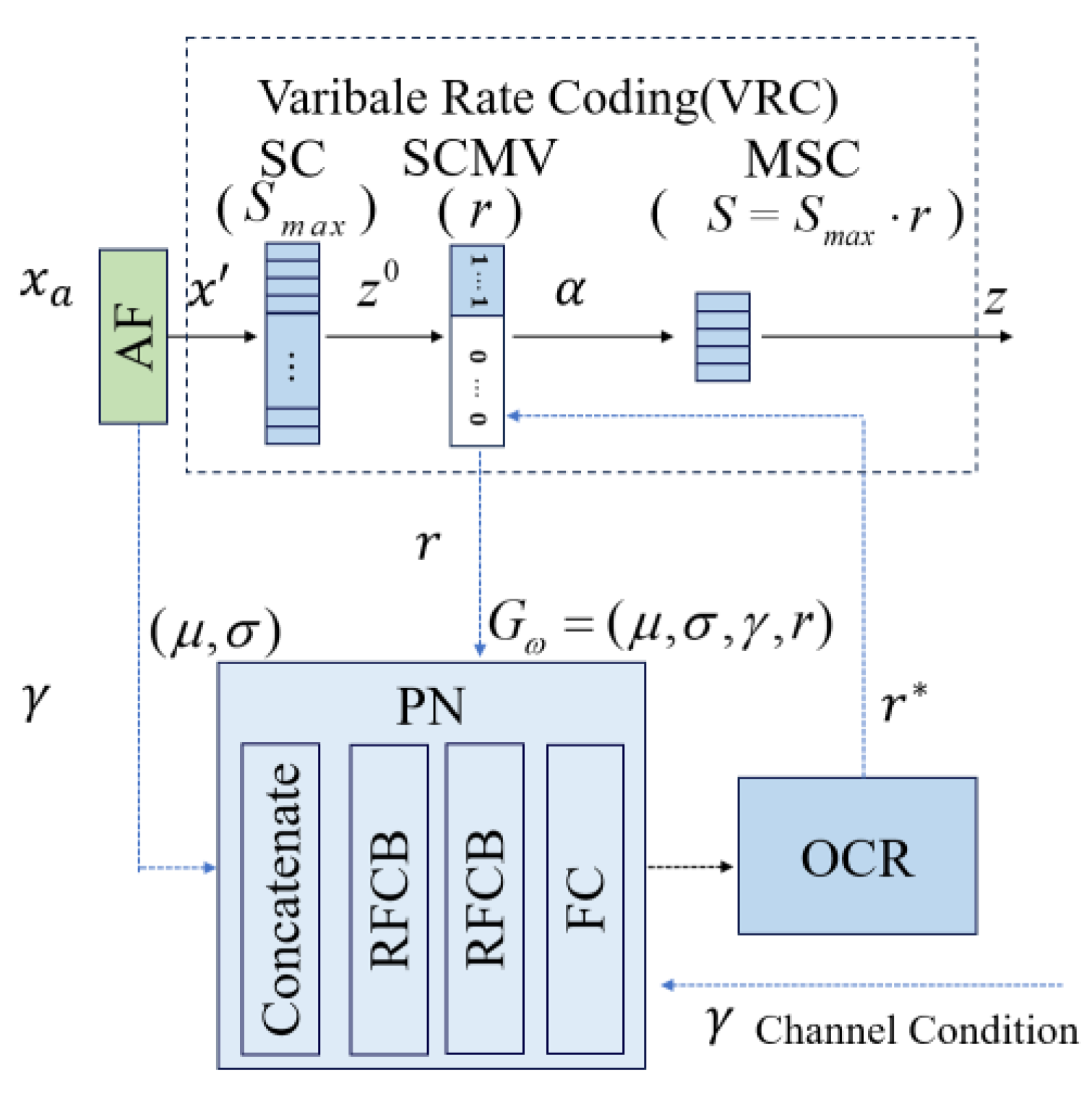
4. Prediction Based on Scalable Semantic Generator
4.1. Variable Compression Ratio
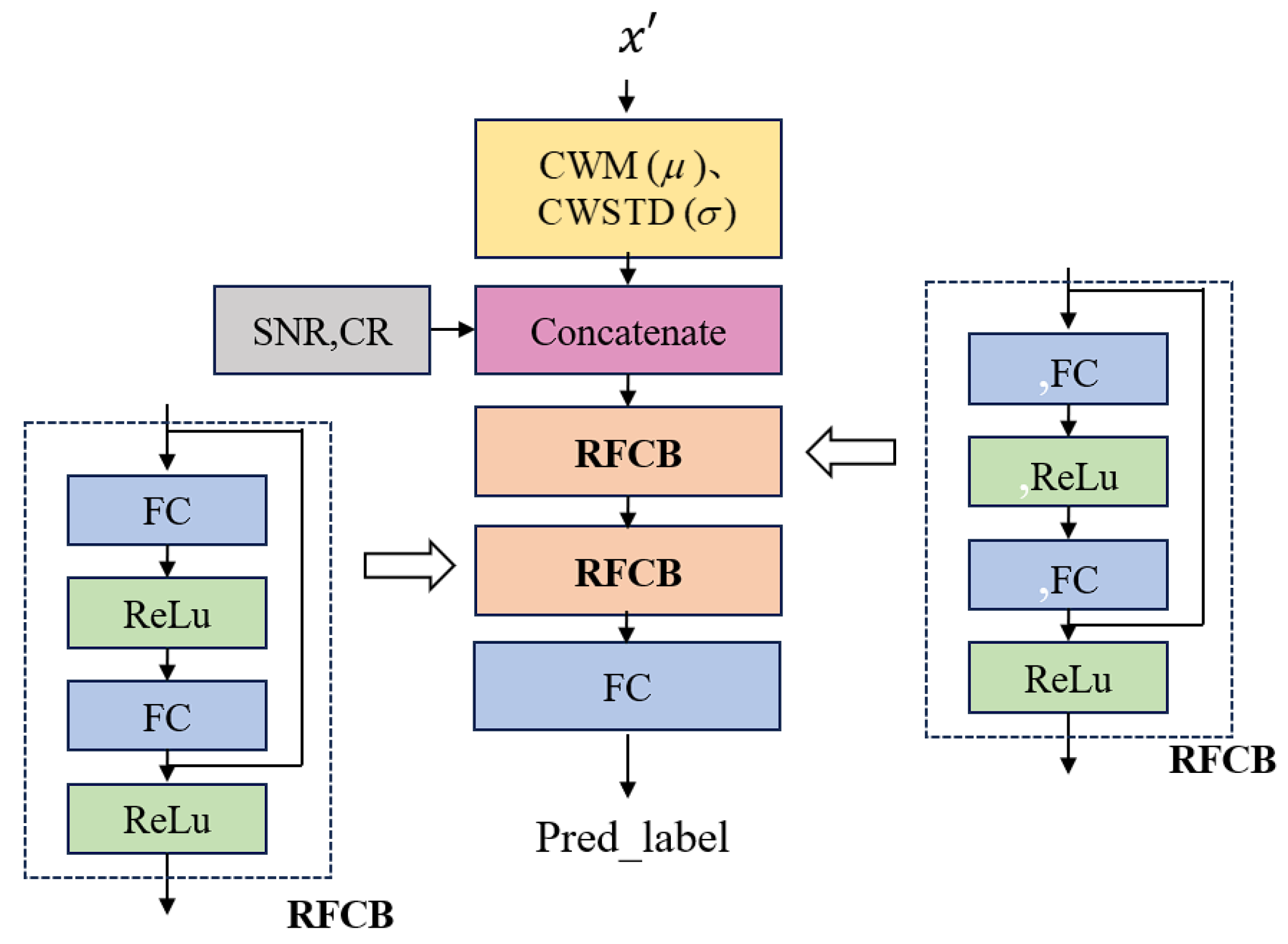
4.2. Pre-Net
4.3. The Optimizer of Compression Rate
4.4. The Loss Function
5. Experiments
5.1. Experimental Data and Settings
5.2. The Analysis and Comparison of Experimental Results
5.2.1. Subsection
5.2.2. The PSSG Result Analysis
- (1)
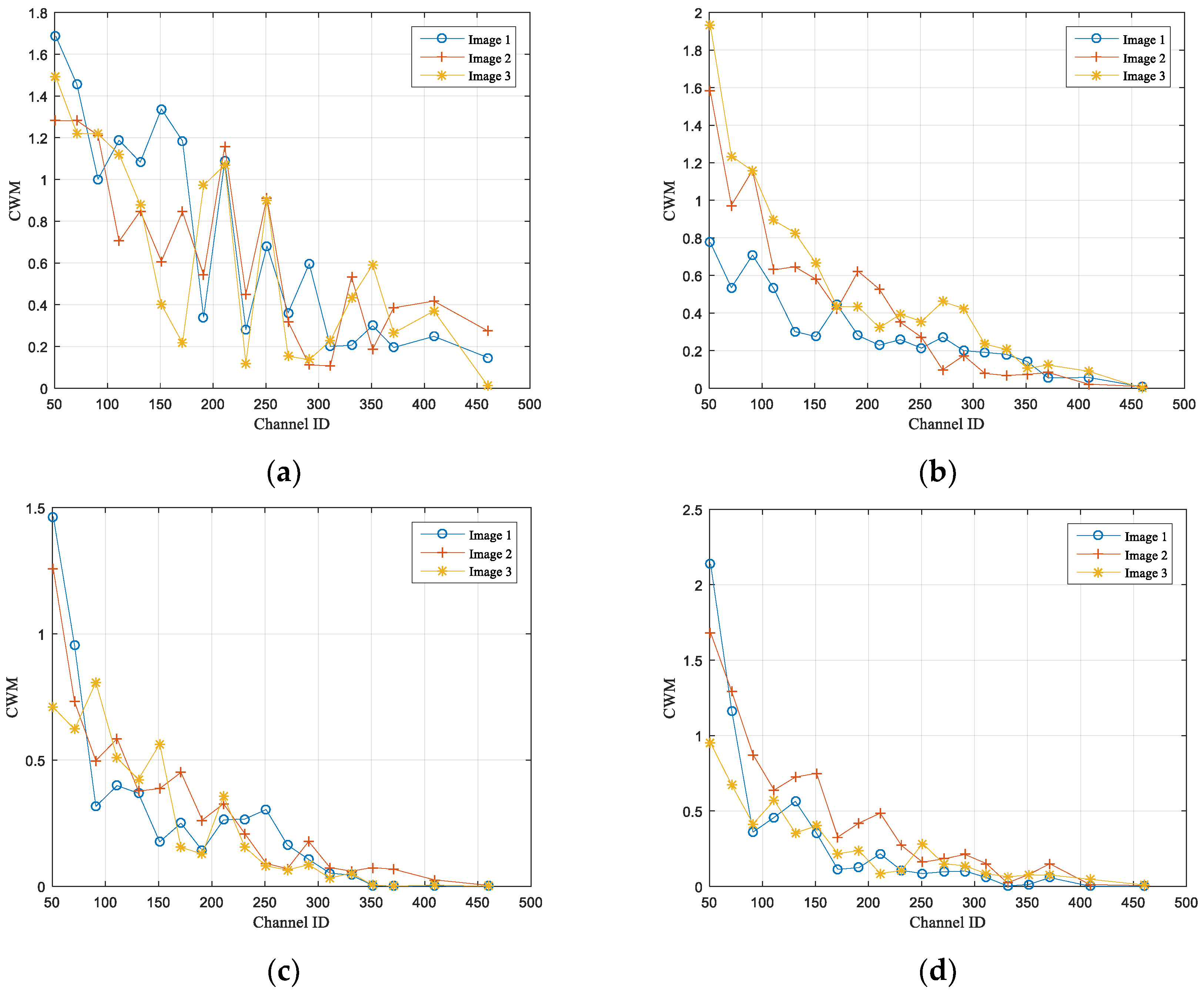
- Performance Analysis of Pre-Net Prediction
- (2)
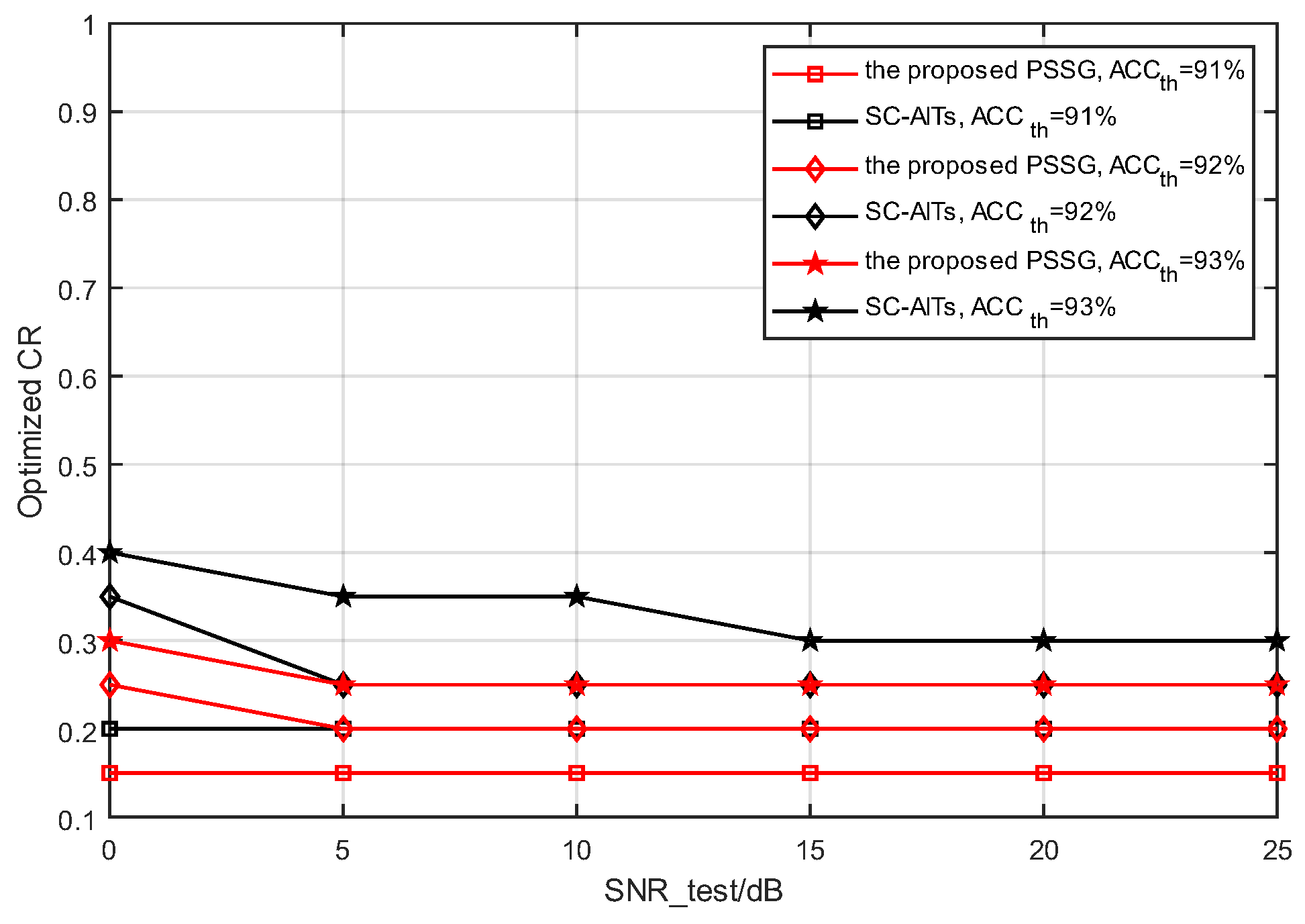
- Compression ratio optimization OCR results
5.2.3. The Analysis of Classification Performance of SSAC
- (1)
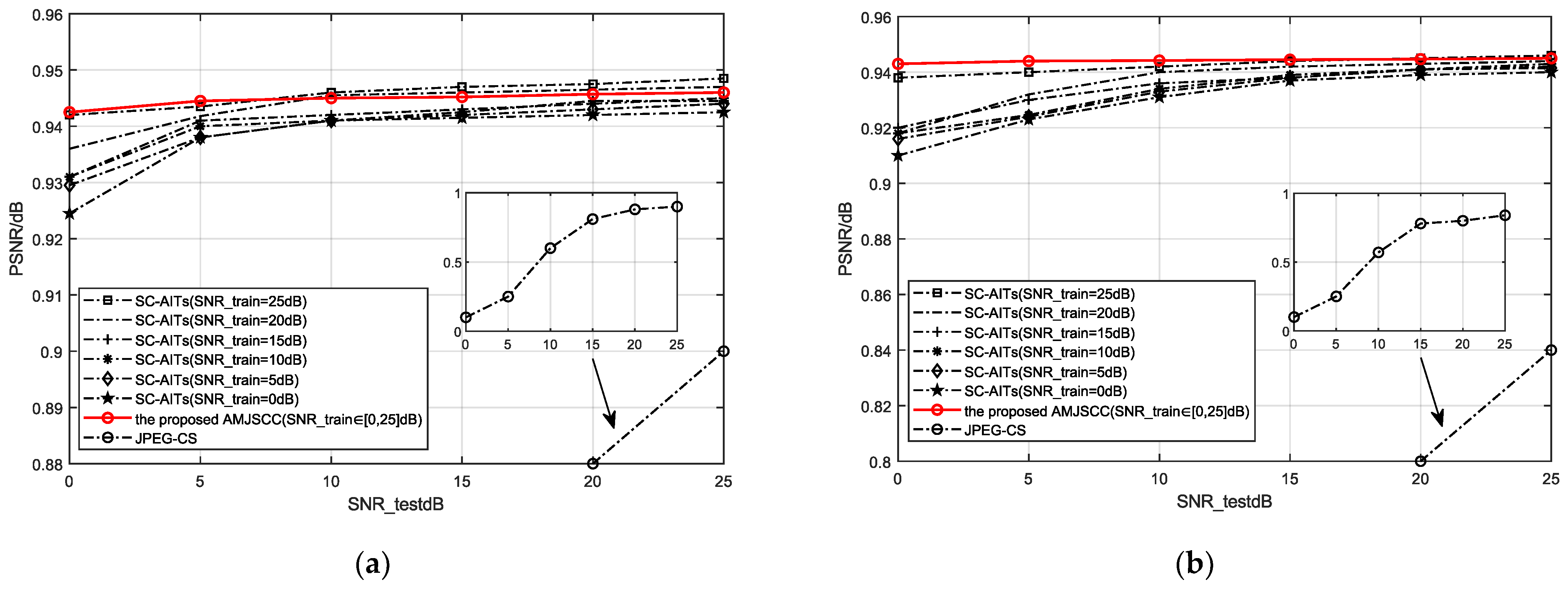
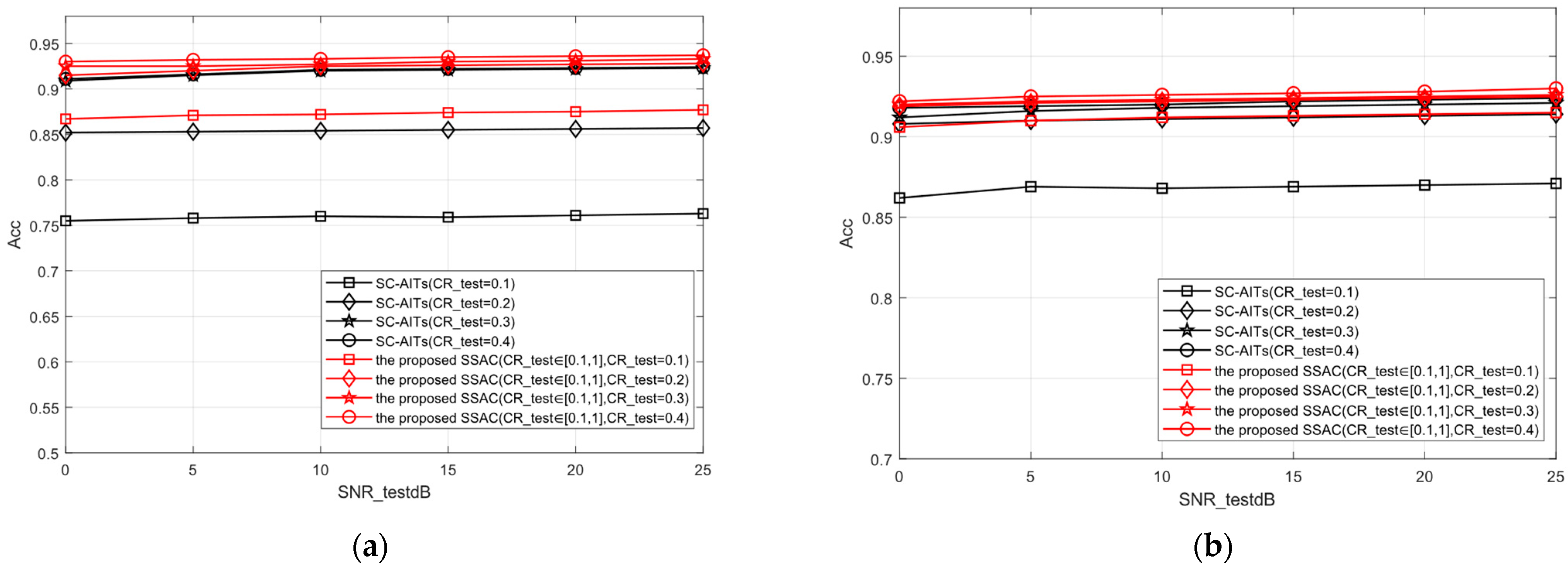
- Whether under high or low SNR conditions, the SSAC proposed in this paper can achieve classification accuracy similar to SC-AITs [19] at the same compression rate (such as CR = 0.3). This indicates that SSAC can maintain good stability and robustness in high dynamic range channels.
- (2)
- At lower compression rates (such as CR = 0.1), the SSAC method proposed in this paper significantly outperforms the SC-AIT [19] method in terms of classification accuracy after compression. Taking the STL-10 dataset as an example, when using SC mask for semantic feature compression with a compression rate of 0.1, the classification accuracy of the SSAC method is about 11% higher than SC-AITs [19]. This indicates that the SSAC classification performance proposed in this paper is better at lower compression rates, which means it has the advantage of preserving important features of classification tasks.
- (3)
- In the case of a single model, the overall performance of the proposed SSAC model is equivalent to or even better than that of multiple models trained by SC-AITs [19] using different compression rates. This indicates that SSAC can achieve scalable semantic features by adapting to different compression requirements through a single training session, thereby helping to reduce the resource consumption of training and deployment. This is highly attractive for application scenarios that require the deployment of efficient semantic communication systems in resource constrained environments.
5.2.4. The Analysis of the Complexity of SSAC
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Huang, Z.; Zhang, Y.; Jia, Y.; Wen, W. CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs. Sensors 2024, 24, 957. [Google Scholar] [CrossRef] [PubMed]
- Sharma, B.; Koundal, D.; Ramadan, R.A.; Corchado, J.M. Emerging Sensor Communication Network-Based AI/ML Driven Intelligent IoT. Sensors 2023, 23, 7814. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Zhou, Y.; Wen, D.; Wu, Y.; Jiang, C.; Letaief, K.B. Task-Oriented Communications for 6G: Vision, Principles, and Technologies. IEEE Wirel. Commun. 2023, 30, 78–85. [Google Scholar] [CrossRef]
- Yang, W.; Du, H.; Liew, Z.Q.; Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Chi, X.; Shen, X.S.; Miao, C. Semantic communications for future internet: Fundamentals, applications, and challenges. IEEE Commun. Surv. Tutorials 2022, 25, 213–250. [Google Scholar] [CrossRef]
- Fu, Q.; Xie, H.; Qin, Z.; Slabaugh, G.; Tao, X. Vector Quantized Semantic Communication System. IEEE Wirel. Commun. Lett. 2023, 12, 982–986. [Google Scholar] [CrossRef]
- Luo, X.; Gao, R.; Chen, H.H.; Chen, S.; Guo, Q.; Suganthan, P.N. Suganthan. Multimodal and Multiuser Semantic Communications for Channel-Level Information Fusion. IEEE Wirel. Commun. Lett. 2024, 31, 117–125. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.H. Deep learning based semantic communications: An initial investigation. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.H. Deep learning enabled semantic communication systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Jiang, P.; Wen, C.K.; Jin, S.; Li, G.Y. Wireless semantic communications for video conferencing. IEEE J. Sel. Areas Commun. 2023, 41, 230–244. [Google Scholar] [CrossRef]
- Wang, S.; Dai, J.; Liang, Z.; Niu, K.; Si, Z.; Dong, C.; Qin, X.; Zhang, P. Wireless deep video semantic transmission. IEEE J. Sel. Areas Commun. 2023, 41, 214–229. [Google Scholar] [CrossRef]
- Lan, Q.; Wen, D.; Zhang, Z.; Zeng, Q.; Chen, X.; Popovski, P.; Huang, K. What is semantic communication? A view on conveying meaning in the era of machine intelligence. J. Commun. Inf. Netw. 2021, 6, 336–371. [Google Scholar] [CrossRef]
- Lokumarambage, M.U.; Gowrisetty, V.S.S.; Rezaei, H.; Sivalingam, T.; Rajatheva, N.; Fernando, A. Wireless end-to-end image transmission system using semantic communications. IEEE Access 2023, 11, 37149–37163. [Google Scholar] [CrossRef]
- Güler, B.; Yener, A.; Swami, A. The semantic communication game. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 787–802. [Google Scholar] [CrossRef]
- Fu, Y.; Cheng, W.; Zhang, W. Content-aware semantic communication for goal-oriented wireless communications. In Proceedings of the IEEE INFOCOM 2023-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 17–20 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Luo, X.; Chen, H.H.; Guo, Q. Semantic communications: Overview, open issues, and future research directions. IEEE Wirel. Commun. 2022, 29, 210–219. [Google Scholar] [CrossRef]
- Dinh, N.T.; Van, T.T.; Le, T.M. Semantic relationship-based image retrieval using kd-tree structure. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Ho Chi Minh City, Vietnam, 28–30 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 455–468. [Google Scholar]
- Kang, X.; Song, B.; Guo, J.; Qin, Z.; Yu, F.R. Task-oriented image transmission for scene classification in unmanned aerial systems. IEEE Trans. Commun. 2022, 70, 5181–5192. [Google Scholar] [CrossRef]
- Pan, Q.; Tong, H.; Lv, J.; Luo, T.; Zhang, Z.; Yin, C.; Li, J. Image segmentation semantic communication over internet of vehicles. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Yang, Y.; Guo, C.; Liu, F.; Sun, L.; Liu, C.; Sun, Q. Semantic Communications With Artificial Intelligence Tasks: Reducing Bandwidth Requirements and Improving Artificial Intelligence Task Performance. IEEE Ind. Electron. Mag. 2023, 17, 4–13. [Google Scholar] [CrossRef]
- Mingkai, C.; Minghao, L.; Zhe, Z.; Zhiping, X.; Lei, W. Task-oriented semantic communication with foundation models. China Commun. 2024, 21, 65–77. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, W.; Zhou, K.; Song, X.; Shen, Y.; Liu, S. Weighted Pseudo-Labels and Bounding Boxes for Semisupervised SAR Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2024, 17, 5193–5203. [Google Scholar] [CrossRef]
- Deng, J.; Wang, W.; Zhang, H.; Zhang, T.; Zhang, J. PolSAR Ship Detection Based on Superpixel-Level Contrast Enhancement. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Gündüz, D.; Qin, Z.; Aguerri, I.E.; Dhillon, H.S.; Yang, Z.; Yener, A.; Wong, K.K.; Chae, C.B. Beyond transmitting bits: Context, semantics, and task-oriented communications. IEEE J. Sel. Areas Commun. 2023, 41, 5–41. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust semantic communications against semantic noise. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Sun, Z.; Liu, F.; Yang, Y.; Tong, W.; Guo, C. Multi-task semantic communications: An extended rate-distortion theory based scheme. In Proceedings of the 2023 IEEE International Conference on Communications Workshops (ICC Workshops), Rome, Italy, 28 May–1 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1380–1385. [Google Scholar]
- Zhang, G.; Hu, Q.; Qin, Z.; Cai, Y.; Yu, G. A unified multi-task semantic communication system with domain adaptation. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3971–3976. [Google Scholar]
- Zhang, G.; Hu, Q.; Qin, Z.; Cai, Y.; Yu, G.; Tao, X. A unified multi-task semantic communication system for multimodal data. IEEE Trans. Commun. 2024, 72, 4101–4116. [Google Scholar] [CrossRef]
- Tian, Z.; Vo, H.; Zhang, C.; Min, G.; Yu, S. An asynchronous multi-task semantic communication method. IEEE Netw. 2023, 38, 275–283. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, H.; Ma, H.; Shao, H.; Wang, N.; Leung, V.C. Predictive and adaptive deep coding for wireless image transmission in semantic communication. IEEE Trans. Wirel. Commun. 2023, 22, 5486–5501. [Google Scholar] [CrossRef]
- Greenacre, M.; Groenen, P.J.; Hastie, T.; d’Enza, A.I.; Markos, A.; Tuzhilina, E. Principal component analysis. Nat. Rev. Methods Primers 2022, 2, 100. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x0 | The input image | z | The transmitted SF | σ | The Channel Wise Standard Deviation |
| x′ | The extracted SF | z′ | The received SF | γ | The compression ratio value |
| xa | The compressed SF | μ | The Channel Wise Mean | R | The bandwidth compression rate of SF |
| Hardware and Dataset | Description |
|---|---|
| CPU | Intel(R) Core(TM) i7-9700 |
| GPU | NVIDIA GeForce RTX 4060 Ti (x2) |
| Memory capacity | 32 GB |
| GPU driver version | 535.146.02 |
| CUDA version | 11.7 |
| Operating system | Ubuntu 18.04.6 LTS |
| Network conditions | 1000 Mbps |
| Dataset 1 | Self-Taught Learning 10 (STL-10) |
| Dataset 1 size | Training set: 5000 images; Test set: 8000 images |
| Dataset 1 image Size | |
| Dataset 2 | Canadian Institute for Advanced Research 10 (CIFAR-10) |
| Dataset 2 size | Training set: 5000 images; Test set: 10,000 images |
| Dataset 2 image size |
| The Name of Parameter | The Value of Parameter |
|---|---|
| Loop_num | 10 |
| Epochs | 30 |
| Batch size | 64 |
| Weight decay | SGD |
| Learning rate (lr) | 0.001 |
| Momentum factor (Momentum) | 0.9 |
| Weight_decay | 0 |
| Learning rate decay period (step_size) | 7 |
| Multiplicative factor for learning rate decay | 0.1 |
| 0.0001 | |
| SNR | [0, 25] |
| Communication Methods | Experimental Process of Communication Framework |
|---|---|
| JPEG-CS [19] | 1. First, perform traditional JPEG compression encoding; 2. Adopting LDPC encoding with a code rate of 2/3 and 16QAM modulation; 3. And then transmitted through the channel to the receiving end; 4. The receiving end decodes and restores the image; 5. Then classify and process the restored images. |
| SC-AITs [19] | 1. Firstly, the image is subjected to a joint semantic encoder to extract semantic feaures; 2. Transmitting semantic features to the receiving end under fixed SNR; 3. The receiving end performs classification tasks based on the received features. |
| Our SSAC | 1. Adjust the semantic feature weights of the extracted semantic features through a SNR adaptation module; 2. Send the sorted semantic features to the semantic channel joint encoder (AMJSCC) for processing, achieving the semantic encoding characteristics of adaptive channel conditions; 3. Then it is fed into a prediction based scalable semantic generator (PSSG) to achieve scalable semantic features with variable compression rates; 4. Finally, under channel conditions within the SNR range, semantic features are transmitted to the receiving end to complete the classification task. |
| Model | FLOPs | Params | Memory |
|---|---|---|---|
| SC-AITs [19] | 1.73 G | 11.64 M | 65.63 MB |
| The proposed SSAC | 1.63 G | 11.09 M | 65.24 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Zhu, X.; Yang, J.; Li, J.; Qing, L.; He, X.; Wang, P. Scalable Semantic Adaptive Communication for Task Requirements in WSNs. Sensors 2025, 25, 2823. https://doi.org/10.3390/s25092823
Yang H, Zhu X, Yang J, Li J, Qing L, He X, Wang P. Scalable Semantic Adaptive Communication for Task Requirements in WSNs. Sensors. 2025; 25(9):2823. https://doi.org/10.3390/s25092823
Chicago/Turabian StyleYang, Hong, Xiaoqing Zhu, Jia Yang, Ji Li, Linbo Qing, Xiaohai He, and Pingyu Wang. 2025. "Scalable Semantic Adaptive Communication for Task Requirements in WSNs" Sensors 25, no. 9: 2823. https://doi.org/10.3390/s25092823
APA StyleYang, H., Zhu, X., Yang, J., Li, J., Qing, L., He, X., & Wang, P. (2025). Scalable Semantic Adaptive Communication for Task Requirements in WSNs. Sensors, 25(9), 2823. https://doi.org/10.3390/s25092823