
Large Language Models for Synthetic Dataset Generation of Cybersecurity Indicators of Compromise


Abstract
1. Introduction
- By fine-tuning the LLM on the curated social media datasets, our model becomes adept at identifying the distinct patterns, linguistic features, and communication styles present in such discourse. We argue this includes the detection of malicious behaviour, activities, or content within user interactions, which could otherwise go unnoticed by traditional threat detection models and systems.
- The generation of a synthetic dataset that emulates the style of social media content and IoC knowledge, which can be used to simulate a wide range of attack scenarios and behaviours. This dataset can be used to test cybersecurity systems and methodologies in a controlled, privacy-conscious manner while maintaining high relevance to real-world situations.
- When trained on this synthetic data, ML and DL models can learn to identify and classify IoCs more effectively, improving their performance across different types of attack vectors and threat patterns. This approach enhances the generalization and adaptability of these models, enabling them to detect previously unseen or emerging threats with greater accuracy and speed.
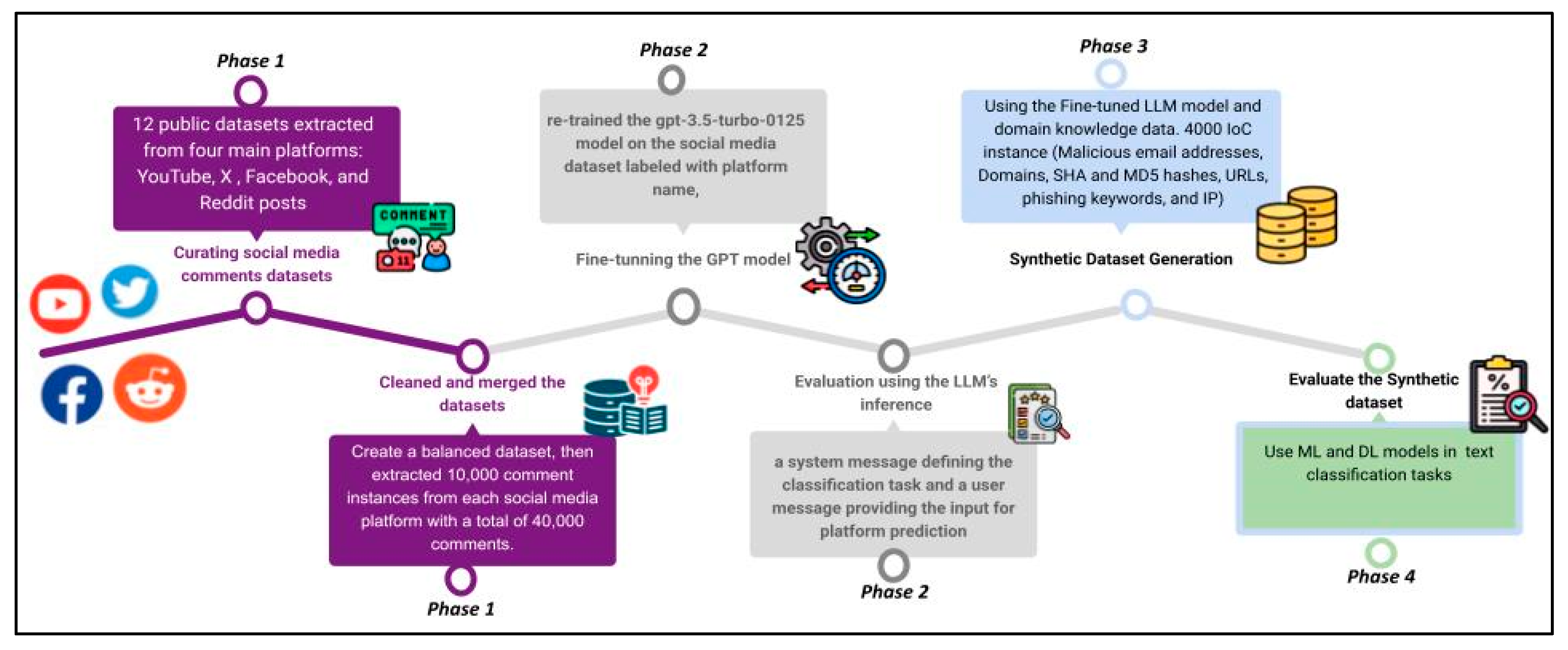
- Curate public social media comments datasets, clean and pre-process them, then label the comments in each dataset using the platform name,
- Fine-tune and evaluate ChatGPT 3.5 on the dataset to classify the comments by platform,
- Use a curated IoC domain knowledge and the previously fine-tuned GPT model to generate a synthetic dataset labelled by both social media platform name and IoC type,
- Evaluate the performance of selected ML and DL models on the generated dataset to classify comments using IoC types.
2. Related Works
2.1. Cybersecurity Threat Detection
2.2. IoC Detection
2.3. Synthetic Dataset Generation
3. Implementation and Results
3.1. Phase 1: Curating Social Media Comments Datasets and Labeling Them
3.2. Phase 2: Fine-Tuning the LLM (GPT 3.5-Turbo) Model on the Merged Dataset
3.3. Phase 3: Synthetic Dataset Generation Using the Fine-Tuned LLM and IoC Domain Knowledge
3.4. Phase 4: Evaluating ML and DL Models on the Generated Dataset to Classify Comments by IoCs
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Shareeda, M.A.; Ali, A.M.; Hammoud, M.A.; Kazem, Z.H.M.; Hussein, M.A. Secure IoT-Based Real-Time Water Level Monitoring System Using ESP32 for Critical Infrastructure. J. Cyber Secur. Risk Audit. 2025, 2, 43–52. [Google Scholar] [CrossRef]
- Aljumaiah; Jiang, W.; Addula, S.R.; Almaiah, M.A. Analyzing Cybersecurity Risks and Threats in IT Infrastructure based on NIST Framework. J. Cyber Secur. Risk Audit. 2025, 2, 12–26. [Google Scholar] [CrossRef]
- Abu, M.S.; Selamat, S.R.; Ariffin, A.; Yusof, R. Cyber threat intelligence–issue and challenges. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 371–379. [Google Scholar]
- Sun, N.; Ding, M.; Jiang, J.; Xu, W.; Mo, X.; Tai, Y.; Zhang, J. Cyber threat intelligence mining for proactive cybersecurity defense: A survey and new perspectives. IEEE Commun. Surv. Tutor. 2023, 25, 1748–1774. [Google Scholar] [CrossRef]
- Tang, B.; Li, X.; Wang, J.; Ge, W.; Yu, Z.; Lin, T. STIOCS: Active learning-based semi-supervised training framework for IOC extraction. Comput. Electr. Eng. 2023, 112, 108981. [Google Scholar] [CrossRef]
- Tang, B.; Qiu, H. Indicators of Compromise Automatic Identification Model Based on Cyberthreat Intelligence and Deep Learning. In Proceedings of the 2022 5th International Conference Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 282–287. [Google Scholar]
- Liu, J.; Yan, J.; Jiang, J.; He, Y.; Wang, X.; Jiang, Z.; Yang, P.; Li, N. TriCTI: An actionable cyber threat intelligence discovery system via trigger-enhanced neural network. Cybersecurity 2022, 5, 8. [Google Scholar] [CrossRef]
- Long, L.; Wang, R.; Xiao, R.; Zhao, J.; Ding, X.; Chen, G.; Wang, H. On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. 2024. Available online: https://arxiv.org/abs/2406.15126 (accessed on 1 December 2024).
- Das, A.; Verma, R. Automated email generation for targeted attacks using natural language. arXiv 2019, arXiv:1908.06893v1. [Google Scholar]
- Zacharis, A.; Patsakis, C. AiCEF: An AI-assisted cyber exercise content generation framework using named entity recognition. Int. J. Inf. Secur. 2023, 22, 1333–1354. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, H.; Lu, Z.; Yin, M. Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations. arXiv 2023, arXiv:2310.07849. [Google Scholar]
- Almanasir, R.; Al-solomon, D.; Indrawes, S.; Almaiah, M.; Islam, U.; Alshar, M. Classification of threats and countermeasures of cloud computing. J. Cyber Secur. Risk Audit. 2025, 2, 27–42. [Google Scholar] [CrossRef]
- Otoom, S. Risk auditing for Digital Twins in cyber physical systems: A systematic review. J. Cyber Secur. Risk Audit. 2025, 2025, 22–35. [Google Scholar] [CrossRef]
- Almuqren, A.A. Cybersecurity threats, countermeasures and mitigation techniques on the IoT: Future research directions. J. Cyber Secur. Risk Audit. 2025, 1, 1–11. [Google Scholar] [CrossRef]
- Mousa, R.S.; Shehab, R. Applying risk analysis for determining threats and countermeasures in workstation domain. J. Cyber Secur. Risk Audit. 2025, 2025, 12–21. [Google Scholar] [CrossRef]
- Alshuaibi, A.; Almaayah, M.; Ali, A. Machine Learning for Cybersecurity Issues: A systematic review. J. Cyber Secur. Risk Audit. 2025, 2025, 36–46. [Google Scholar] [CrossRef]
- Alotaibi, E.; Sulaiman, R.B.; Almaiah, M. Assessment of cybersecurity threats and defense mechanisms in wireless sensor networks. J. Cyber Secur. Risk Audit. 2025, 2025, 47–59. [Google Scholar] [CrossRef]
- Zhou, S.; Long, Z.; Tan, L.; Guo, H. Automatic Identification of Indicators of Compromise using Neural-Based Sequence Labelling. arXiv 2018, arXiv:1810.10156. [Google Scholar]
- Long, Z.; Tan, L.; Zhou, S.; He, C.; Liu, X. Collecting Indicators of Compromise from Unstructured Text of Cybersecurity Articles using Neural-Based Sequence Labelling. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. Available online: https://arxiv.org/abs/1907.02636 (accessed on 19 January 2024).
- Arikkat, D.R.; Sorbo, A.D.; Visaggio, C.A.; Conti, M. Can Twitter be Used to Acquire Reliable Alerts against Novel Cyber Attacks? arXiv 2023, arXiv:2306.16087v1. Available online: https://paperswithcode.com/paper/can-twitter-be-used-to-acquire-reliable (accessed on 19 January 2024).
- Dionisio, N.; Alves, F.; Ferreira, P.M.; Bessani, A. Towards end-to-end Cyberthreat Detection from Twitter using Multi-Task Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Niakanlahiji, A.; Safarnejad, L.; Harper, R.; Chu, B.T. IoCMiner: Automatic Extraction of Indicators of Compromise from Twitter. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: New york, NY, USA, 2019; pp. 4747–4754. [Google Scholar] [CrossRef]
- Murty, C.A.; Rughani, P.H. Dark Web Text Classification by Learning through SVM Optimization. J. Adv. Inf. Technol. 2022, 13, 624–631. [Google Scholar] [CrossRef]
- Mulwad, V.; Li, W.; Joshi, A.; Finin, T.; Viswanathan, K. Extracting Information about Security Vulnerabilities from Web Text. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; IEEE: New York, NY, USA, 2011; Volume 3, pp. 257–260. [Google Scholar]
- Atluri, V.; Horne, J. A Machine Learning based Threat Intelligence Framework for Industrial Control System Network Traffic Indicators of Compromise. In SoutheastCon 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Li, M.; Zheng, R.; Liu, L.; Yang, P. Extraction of Threat Actions from Threat-related Articles using Multi-Label Machine Learning Classification Method. In Proceedings of the 2019 2nd International Conference on Safety Produce Informatization (IICSPI), Chongqing, China, 28–30 November 2019; IEEE: New York, NY, USA, 2019; pp. 428–431. [Google Scholar] [CrossRef]
- Preuveneers, D.; Joosen, W. Sharing Machine Learning Models as Indicators of Compromise for Cyber Threat Intelligence. J. Cybersecur. Priv. 2021, 1, 140–163. [Google Scholar] [CrossRef]
- Stilinski, D.; Potter, K. Adversarial Text Generation in Cybersecurity: Exploring the Potential of Synthetic Cyber Threats for Evaluating NLP-based Anomaly Detection Systems. No. 13059. EasyChair. 2024; pp. 1–11. Available online: https://easychair.org/publications/preprint/87Dz (accessed on 1 December 2024).
- Kholgh, D.K.; Kostakos, P. PAC-GPT: A Novel Approach to Generating Synthetic Network Traffic with GPT-3. IEEE Access 2023, 11, 114936–114951. [Google Scholar] [CrossRef]
- Houston, R. Transformer-Enhanced Text Classification in Cybersecurity: GPT-Augmented Synthetic Data Generation, BERT-Based Semantic Encoding, and Multiclass Analysis. Ph.D. Thesis, The School of Engineering and Applied Science, The George Washington University, Washington, DC, USA, January 2024. [Google Scholar]
- Xu, H.; Wang, S.; Li, N.; Zhao, Y.; Chen, K.; Wang, K.; Liu, Y.; Yu, T.; Wang, H. Large language models for cyber security: A systematic literature review. arXiv 2024, arXiv:2405.04760v3. [Google Scholar]
- Ćirković, S.; Mladenović, V.; Tomić, S.; Drljača, D.; Ristić, O. Utilizing fine-tuning of large language models for generating synthetic payloads: Enhancing web application cybersecurity through innovative penetration testing techniques. Comput. Mater. Continua 2025, 82, 4409–4430. [Google Scholar] [CrossRef]
- ElZemity, A.; Arief, B.; Li, S. CyberLLMInstruct: A new dataset for analysing safety of fine-tuned LLMs using cyber security data. arXiv 2025, arXiv:2503.09334. [Google Scholar]
- Levi, M.; Alluouche, Y.; Ohayon, D.; Puzanov, A.; Gozlan, Y. CyberPal.AI: Empowering LLMs with expert-driven cybersecurity instructions. arXiv 2024, arXiv:2408.09304. [Google Scholar] [CrossRef]
- OpenAI. Fine-Tuning Guide. OpenAI. Available online: https://platform.openai.com/docs/guides/fine-tuning (accessed on 9 January 2025).
- Chae, Y.; Davidson, T. Large language models for text classification: From zero-shot learning to fine-tuning. Open Sci. Found. 2023, 10, 2–46. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Domain | Objective | Models | Results |
|---|---|---|---|---|
| [13] | DT in Cyber–Physical Systems | Review risk auditing frameworks for DTs | Threat Classification | Cyber attacks and data integrity are the main risks |
| [14] | IoT | Classify threats and countermeasures in IoT | Layer-wise threat classification and mitigation | DoS and phishing dominate; need for layered defenses |
| [15] | Workstation Environments | Detect threats and mitigation in workstation domains | Risk Analysis—Content Classification | Malware and MitM attacks are popular access control critical |
| [16] | ML in Cybersecurity | Review ML models for threat detection | Supervised ML, Unsupervised, and Anomaly Detection | SVMs, Decision Trees are effective; ML for detection |
| [17] | WSNs | Evaluate threats and lightweight protections for WSNs | Qualitative Analysis and Energy-efficient defenses | DoS, Sybil attacks are prominent and required for lightweight security |
| Ref. | Model/Approach | Features Used | IoC Types | Data Sources | Evaluation Result |
|---|---|---|---|---|---|
| [18] | Neural-based sequence labeling (LSTM + CRF) | Spelling, Contextual Features | Emails, IPv4, Domain, Malware, URL, Vulnerability, File Hashes, File Info, Attacker, Attack Method, Attack Target | Report | 90.40% |
| [19] | Neural network with multi-head self-attention | Contextual Features from Unstructured Text | Emails, IPv4, Domain, Malware, URL, Vulnerability, File Hashes, File Info, Attacker, Attack Method, Attack Target | Report | 93.1% (English), 83% (Chinese) |
| [20] | Convolutional Neural Network (CNN) | For evaluation used correctness, timeliness, and overlap | IP addresses, URLs, file hashes, domain addresses, and CVE IDs | URLs most frequently traded; 48.67% malicious. | |
| [21] | CNN for Classification and BiLSTM for NER | Multi-task learning approach | Security-related information | 94% | |
| [22] | combination of graph theory, ML, and text mining techniques | Malicious URL | 90% of URLs | ||
| [23] | SVM | Text-based keywords | URL | Dark web | Precision 83%, recall 90%, and F-measure 96% |
| [24] | SVM | Developed a framework using Wikitology | Vulnerabilities and attacks | Web text | evaluated against descriptions from the National Vulnerability Database 89.47% |
| [25] | Bagging Decision Tree: NB, KNN, DT, BDT, RF, ET, ABC, GB, VE | Shared ML Model Features | Five different simulated cyber-attacks: Man-in-the- Middle Change attack (MITM_C), Man-in-the-Middle Read attack (MITM_R), Modbus Query Flooding, Ping Flood DDoS, TCP SYN Flooding DDoS. | Industrial Control System (ICS) testbed, | BDT accuracy 94.24%, precision 95%, recall 93% and F1-score 94% |
| [26] | Topic extraction, semantic similarity computation and multi-label machine learning classification | latent semantic indexing method, semantic similarities | Threat Action | Threat-related articles. | precision59.50%, recall 69.86% and F1 56.96%. |
| [27] | Sharing ML models as IoCs | Network Traffic Data Contextual Information | Integrated with existing CTI platforms such as MISP, TheHive, and Cortex. | Network Traffic—CTI data | - |
| Ref. | Model/Approach | IoCs Type | Evaluation Result |
|---|---|---|---|
| [9] | Natural Language Generation (NLG) | Malicious emails | Among SVM, (NB), and (LR). (LR) achieved the highest accuracy at 91%. |
| [10] | Named entity recognition (NER) and topic extraction are used to structure the information based on a novel ontology called the Cyber Exercise Scenario Ontology (CESO) | Create new exercise scenarios | 80% was achieved in the F1 Score |
| [28] | evaluated NLP-based anomaly detection systems | Creating synthetic cyber threats | Identify the benefits and limits of these methodologies |
| [29] | Used LLM-based packet generator and evaluated its performance using metrics like loss, accuracy, and success rate. | Synthetic network traffic | Transformers are effective for synthetic packet generation with minimal fine-tuning. |
| [30] | combined GPT and BERT models to enhance text classification in cybersecurity | Cybersecurity-related text | Not provided |
| [31] | Literature review of the application of LLMs | threat detection, vulnerability assessment | Not provided |
| [32] | Fine-tuned GPT-2 for payload generation | Synthetic payloads: XSS, SQL, Command Injection | Evaluation loss: 1.42‚ Äì1.58; successful generation of realistic payloads |
| [33] | Fine-tuned multiple LLMs (Llama 3.1 8B, Gemma 2 9B, etc.) using CyberLLMInstruct | Safety analysis: Prompt injection, data exposure, unauthorized actions | Llama 3.1 8B‚ and safety score dropped from 0.95 to 0.15. performance improved to 92.5% on CyberMetric |
| [34] | Expert-driven instruction dataset (SecKnowledge) for fine-tuning LLMs (CyberPal.AI) | Instruction-following tasks for incident response, threat hunting | Performance improved up to 24% over standard models |
| Platform | Sources | Datasets | Columns Count | Size | Total |
|---|---|---|---|---|---|
| YouTube | Hugging face |
| 1 | 180,000 | 180,000 |
| X | Kaggle(K) Data.world (D) |
| 14 12 1 | 1,048,576 3886 10,752 | 1,063,214 |
| Kaggle |
| 18 12 8 8 10 | 2450 7650 1198 957 1527 | 13,782 | |
| Kaggle |
| 24 12 3 | 72,787 458 5573 | 78,818 |
| Platform | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|
| 85.5572 | 74.210551 | 2 | 63 | 1868 | |
| 976.3268 | 1815.243355 | 1 | 373 | 32,575 | |
| X | 115.3024 | 55.121442 | 5 | 115 | 372 |
| YouTube | 163.2189 | 329.854037 | 1 | 76 | 9017 |
| Platform | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|
| 16.4207 | 13.21138 | 1 | 13 | 273 | |
| 170.7618 | 294.032278 | 1 | 70 | 5632 | |
| X | 19.5842 | 10.041852 | 1 | 19 | 66 |
| YouTube | 27.8229 | 56.015892 | 1 | 13 | 1760 |
| IoCs | Description | Size | Type | Example |
|---|---|---|---|---|
| Malicious email addresses | It contains a public email associated with malicious or suspicious activity | 500 | string | 4dminone@gmail.com 56465sdfsd@kksdfs.com 567f27df@opayq.com |
| Domains | It contains domains, which are associated with malware, phishing, or other malicious activity which can be used in a variety of cyber attacks, including virus distribution, phishing website hosting…etc. | 500 | Text string | 0.0.0.winrar.fileplanet.com bestdove.in.ua sus.nieuwmoer.info |
| SHA-1, SHA-256, and MD5 hashes | They are susceptible to collision and attacks, which may compromise data integrity, allow password cracking, and enable digital signature forging, posing serious security issues. | 500 per hash type | hexadecimal strings | SHA-1 “18b0e41e2835c92572d5 99e6e4e0db63e396cf7f” SHA-256 “83d1e736a793ba5d 14b51f8ef8310bf13a2591fc40ad 34d1fa3e74a cf5d40c70” MD5 “fed87b42561dafe8a9ee8c5ffa2e434e” |
| URLs | It includes domains and subdomains, some of which appear suspicious and could be linked to phishing, malware distribution, or other harmful activity. | 500 | Text strings | http://gbdgs.blogspot.bg/ http://fwgnu.blogspot.fi/ http://fwsbf.blogspot.hr/ |
| IP addresses | It consists of IPv4 addresses, which are required for network communication, device identification, and geolocation. | 500 | dotted-decimal | 190.89.103.40 190.173.76.130 190.216.227.18 |
| Phishing keywords | It consists of terms and phrases commonly associated with phishing attempts to lure victims into taking actions that compromise their security | 500 | text | Reserves the right for only information you requested |
| Platform | Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| 1000 | 70.059 | 27.64156 | 13 | 51 | 67 | 86 | 212 | |
| 1000 | 637.689 | 126.8704 | 216 | 554.25 | 664.5 | 733 | 912 | |
| X | 1000 | 65.207 | 22.07336 | 10 | 50.75 | 65 | 79 | 150 |
| YouTube | 1000 | 223.657 | 50.84705 | 88 | 190 | 220 | 254 | 455 |
| Platform | Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| 3000 | 70.082 | 27.23251 | 13 | 51 | 67 | 86 | 212 | |
| 3000 | 641.0153 | 125.6913 | 61 | 562 | 671 | 734.25 | 921 | |
| X | 3000 | 64.61267 | 21.34391 | 10 | 51 | 64 | 78 | 150 |
| YouTube | 3000 | 223.897 | 52.68712 | 84 | 189 | 220 | 254 | 492 |
| Model | Training Duration (s) | CPU Usage (%) | Memory Usage (%) | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|
| ML models | |||||||
| Logistic Regression | 5.11 | 99.9 | 10.9 | 0.7675 | 0.769 | 0.7675 | 0.7667 |
| SVM | 4.17 | 15.3 | 10.9 | 0.7575 | 0.7628 | 0.7575 | 0.7581 |
| DL models | |||||||
| MLPClassifier | 55.76 | 99.9 | 10.7 | 0.72625 | 0.735 | 0.72625 | 0.7298 |
| DenseNN | 3.99 | 22.2 | 8.5 | 0.7725 | 0.7788 | 0.7725 | 0.7743 |
| Model | Metric | URL | sha256 | sha1 | md5 | Keyword | Ip | Domain | |
|---|---|---|---|---|---|---|---|---|---|
| Logistic Regression | Precision | 0.85 | 0.98 | 0.95 | 0.83 | 0.5 | 0.48 | 0.58 | 0.98 |
| Recall | 0.93 | 0.85 | 0.93 | 0.91 | 0.52 | 0.41 | 0.64 | 0.95 | |
| SVC | Precision | 0.83 | 0.98 | 0.99 | 0.78 | 0.5 | 0.45 | 0.59 | 0.98 |
| Recall | 0.91 | 0.84 | 0.91 | 0.9 | 0.53 | 0.4 | 0.64 | 0.93 | |
| MLPClassifier | Precision | 0.84 | 0.9 | 0.98 | 0.87 | 0.45 | 0.41 | 0.47 | 0.97 |
| Recall | 0.9 | 0.86 | 0.95 | 0.79 | 0.43 | 0.43 | 0.53 | 0.92 | |
| DenseNN | Precision | 0.87 | 0.98 | 1 | 0.88 | 0.53 | 0.44 | 0.55 | 0.98 |
| Recall | 0.95 | 0.89 | 0.95 | 0.9 | 0.45 | 0.51 | 0.57 | 0.96 |
| Model | Training Duration (s) | CPU Usage (%) | Memory Usage (%) | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|
| ML models | |||||||
| Logistic Regression | 10.86 | 99.9 | 5.1 | 0.8183 | 0.8169 | 0.8183 | 0.8167 |
| SVM | 26.68 | 15 | 5.2 | 0.8158 | 0.8164 | 0.8158 | 0.8146 |
| DL models | |||||||
| MLPClassifier | 108.53 | 99.9 | 5.2 | 0.7954 | 0.8008 | 0.7954 | 0.7978 |
| DenseNN | 8.23 | 22.1 | 6.3 | 0.8029 | 0.8064 | 0.8029 | 0.8044 |
| Model | Metric | URL | sha256 | sha1 | md5 | Keyword | Ip | Domain | |
|---|---|---|---|---|---|---|---|---|---|
| Logistic Regression | Precision | 0.92 | 0.97 | 0.98 | 0.84 | 0.6 | 0.58 | 0.66 | 0.98 |
| Recall | 0.93 | 0.96 | 0.99 | 0.91 | 0.63 | 0.49 | 0.72 | 0.93 | |
| SVM | Precision | 0.91 | 0.98 | 0.99 | 0.84 | 0.58 | 0.58 | 0.66 | 0.99 |
| Recall | 0.94 | 0.94 | 0.98 | 0.91 | 0.65 | 0.47 | 0.71 | 0.92 | |
| MLPClassifier | Precision | 0.91 | 0.96 | 1 | 0.9 | 0.53 | 0.52 | 0.61 | 0.98 |
| Recall | 0.92 | 0.96 | 0.97 | 0.86 | 0.58 | 0.5 | 0.65 | 0.93 | |
| DenseNN | Precision | 0.9 | 0.96 | 0.99 | 0.91 | 0.57 | 0.5 | 0.63 | 0.99 |
| Recall | 0.93 | 0.96 | 1 | 0.87 | 0.58 | 0.51 | 0.65 | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almorjan, A.; Basheri, M.; Almasre, M. Large Language Models for Synthetic Dataset Generation of Cybersecurity Indicators of Compromise. Sensors 2025, 25, 2825. https://doi.org/10.3390/s25092825
Almorjan A, Basheri M, Almasre M. Large Language Models for Synthetic Dataset Generation of Cybersecurity Indicators of Compromise. Sensors. 2025; 25(9):2825. https://doi.org/10.3390/s25092825
Chicago/Turabian StyleAlmorjan, Ashwaq, Mohammed Basheri, and Miada Almasre. 2025. "Large Language Models for Synthetic Dataset Generation of Cybersecurity Indicators of Compromise" Sensors 25, no. 9: 2825. https://doi.org/10.3390/s25092825
APA StyleAlmorjan, A., Basheri, M., & Almasre, M. (2025). Large Language Models for Synthetic Dataset Generation of Cybersecurity Indicators of Compromise. Sensors, 25(9), 2825. https://doi.org/10.3390/s25092825